Enhancing Online Support Group Formation Using Topic Modeling Techniques
Online health communities (OHCs) are vital for fostering peer support and improving health outcomes. Support groups within these platforms can provide more personalized and cohesive peer support, yet traditional support group formation methods face c…
Authors: Pronob Kumar Barman, Tera L. Reynolds, James Foulds
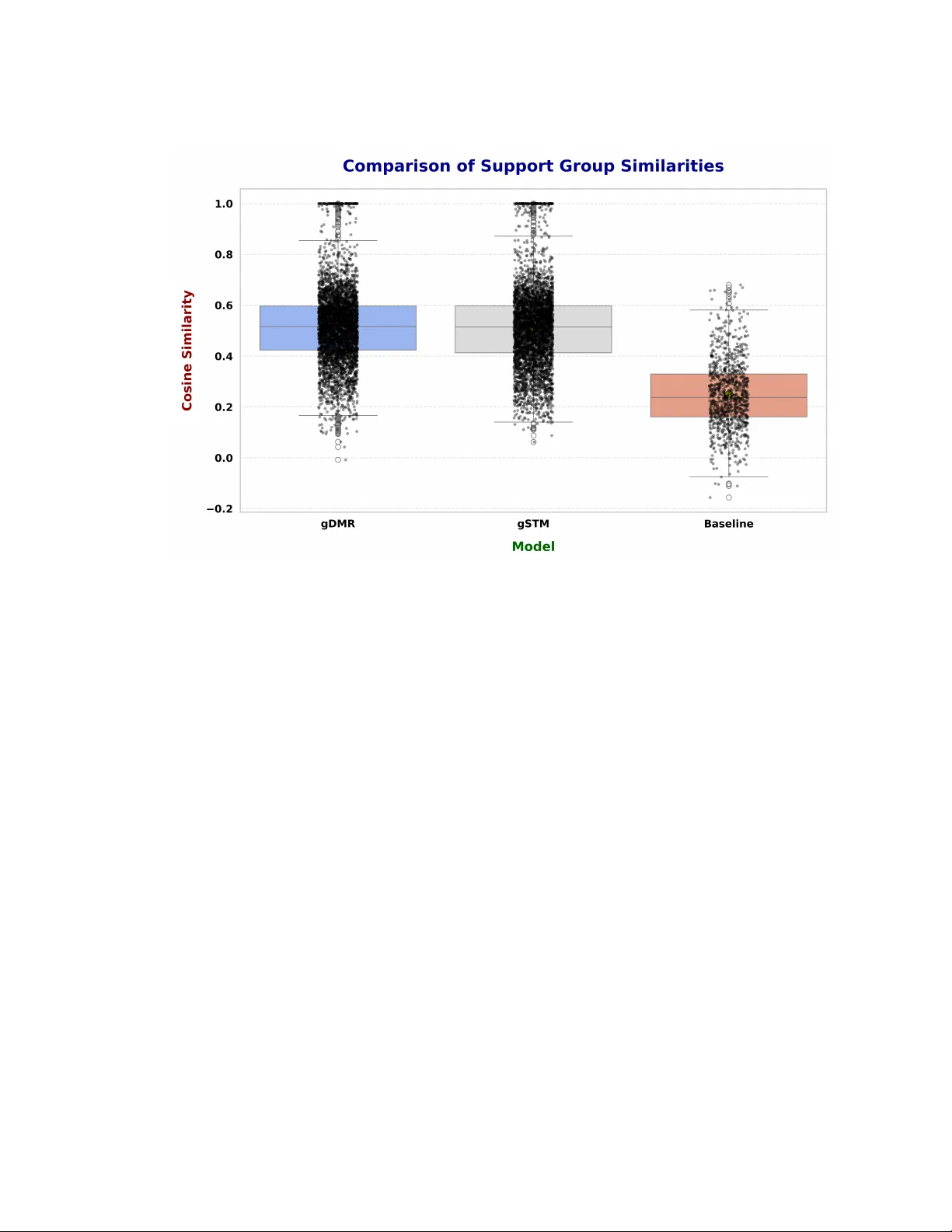
Enhancing Online Support Group Formation Using T opic Modeling T echniques PRONOB K UMAR BARMAN, University of Maryland, Baltimore County, USA TERA L. REYNOLDS, University of Maryland, Baltimore County, USA JAMES FOULDS, University of Maryland, Baltimore County, USA Online health communities (OHCs) are vital for fostering peer support and improving health outcomes. Support groups within these platforms can provide more personalized and cohesive peer supp ort, yet traditional support group formation methods face challenges related to scalability , static categorization, and insucient personalization. T o overcome these limitations, we propose two novel machine learning models for automated support group formation: the Group-specic Dirichlet Multinomial Regression (gDMR) and the Group-specic Structured T opic Model (gSTM). These mo dels integrate user-generated textual content, demographic proles, and interaction data represented through node embeddings derived from user networks to systematically automate personalize d, semantically coherent support group formation. W e evaluate the models on a large-scale dataset from MedHelp.org, comprising ov er 2 million user posts. Both models substantially outperform baseline methods—including LDA, DMR, and STM—in predictive accuracy (held-out log-likelihood), semantic coherence (UMass metric), and internal group consistency . The gDMR model yields group covariates that facilitate practical implementation by leveraging relational patterns fr om network structures and demographic data. In contrast, gSTM emphasizes sparsity constraints to generate more distinct and thematically specic groups. Qualitativ e analysis further validates the alignment between model-generated groups and manually coded themes, showing the practical r elevance of the models in informing groups that address div erse health concerns such as chronic illness management, diagnostic uncertainty , and mental health. By reducing reliance on manual curation, these frameworks provide scalable solutions that enhance peer interactions within OHCs, with implications for patient engagement, community resilience, and health outcomes. Additional Key W ords and Phrases: automated support groups, health informatics, node embeddings, online health forums, personalized support systems, semantic coherence, topic modeling A CM Reference Format: Pronob Kumar Barman, T era L. Reynolds, and James Foulds. 2026. Enhancing Online Support Group Formation Using T opic Mo deling T e chniques. 1, 1 (March 2026), 34 pages. https://doi.org/10.1145/nnnnnnn.nnnnnnn 1 Introduction Online health communities (OHCs), such as PatientsLikeMe and MedHelp , have emerged as vital platforms enabling patients to access emotional, informational, and social support, particularly in managing chronic illnesses and mental health conditions [ 35 , 47 , 51 ]. The proliferation of digital health forums, ranging from disease-specic discussion boards to expansive social me dia groups, underscores their signicance as accessible resources for patients seeking peer Authors’ Contact Information: Pronob Kumar Barman, Department of Information Systems, University of Maryland, Baltimore County, Baltimore, Maryland, USA, pbarman1@umbc.edu; T era L. Reynolds, Department of Information Systems, University of Maryland, Baltimore County, Baltimore, Maryland, USA, reynoter@umbc.edu; James Foulds, Department of Information Systems, University of Maryland, Baltimore County, Baltimore, Maryland, USA, jfoulds@umbc.edu. Permission to make digital or hard copies of all or part of this work for personal or classr oom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is p ermitted. T o copy other wise, or republish, to p ost on servers or to redistribute to lists, requires prior specic permission and /or a fee. Request permissions from permissions@acm.org. © 2026 Copyright held by the owner/author( s). Publication rights licensed to ACM. Manuscript submitted to ACM Manuscript submitted to ACM 1 2 Barman et al. interaction and shared understanding [ 20 , 42 , 48 ]. Empirical evidence consistently demonstrates that active engagement within these communities correlates positively with improved emotional well-being, better self-management practices, and enhanced health outcomes [ 2 , 27 , 30 ]. Despite these benets, signicant challenges persist in harnessing the full therapeutic potential of OHCs. Organically formed communities often experience rapid growth, resulting in large, heterogeneous groups where active engagement remains limited and lurking behavior predominates [ 26 ]. The sheer volume of participants complicates users’ ability to identify groups aligning precisely with their emotional and informational ne eds, thereby limiting the ecacy of peer support [ 25 ]. Traditional manual approaches to forming smaller , structured support groups often rely on simple heuristics such as self-selection, symptom-based categorization, or clinician-led grouping. These approaches typically overlook existing user connections, interaction patterns, and complex social relationships within broader communities, leading to suboptimal group cohesion and limited personalization [ 11 , 17 ]. Consequently , patients may not fully reap the benets intended by these supp ort environments, such as increased treatment adherence and improv ed psychological resilience [ 2 , 27 ]. T o address these limitations, computational methodologies for automating supp ort group formation have attracted considerable interest. Graph-based methods utilizing person-generated health data (PGHD) hav e shown promise in constructing semantically coherent and personalized groups by leveraging latent user interaction patterns [ 18 , 19 , 23 ]. Furthermore, hybrid approaches integrating textual content, demographic data, and r elational patterns have signicantly advanced the eectiveness and scalability of group formation te chniques [ 29 , 43 , 44 ]. However , critical challenges such as ensuring fairness in group assignments, safeguarding user privacy , and maintaining interpretability in large-scale environments remain largely unresolv ed [ 24 , 28 , 50 ]. Motivated by these persistent gaps, this paper introduces two innovative and complementary models explicitly de- signed to automate the formation of personalized support groups within OHCs: the Group-specic Dirichlet Multinomial Regression (gDMR) model and the Group-specic Structured T opic Mo del (gSTM). The gDMR model extends the founda- tional Dirichlet Multinomial Regression (DMR) framework [ 32 ] by incorporating node embe ddings derived from user interaction networks and group-specic parameters. This enables nuanced capture of demographic characteristics and relational context, signicantly enhancing the personalization and relevance of gr oup assignments. Complementarily , the gSTM builds upon the Structured T opic Model (STM) [ 40 ], introducing sparsity-inducing priors and structured covariates alongside group-specic deviations to enhance topic coherence and interpretability within gr oups. Our empirical evaluations demonstrate that these models substantially outperform baseline approaches, such as standard Latent Dirichlet Allocation (LD A) [ 9 ], traditional DMR, and conventional STM, in critical metrics including held-out log-likelihood and topic coherence [ 32 , 40 ]. The integration of relational data in gDMR notably improves the accuracy and personalization of group formation, while gSTM excels in generating semantically rich and interpretable thematic structures, thus supporting meaningful p eer interactions. W e acknowledge that challenges regarding fairness in gr oup allocation and robust privacy preservation remain partially addressed, highlighting avenues for futur e research. This research provides a scalable, data-driven paradigm for automating p ersonalized support group formation, signicantly advancing the state-of-the-art in OHC management. By mitigating the limitations inherent to manual group formation methods, the gDMR and gSTM models have the potential to enhance patient engagement, facilitate more cohesiv e peer support networks, and ultimately contribute to impro ved health outcomes and more resilient online communities. Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 3 2 Background and Related W ork 2.1 Role and Challenges of Online Health Communities and Support Groups OHCs are broad digital platforms where patients and caregiv ers engage in discussions, share experiences, and seek emotional and informational support related to a wide range of health concerns [ 36 , 38 , 52 ]. Examples include disease- specic forums like Diabetes Daily or expansive social media groups center e d on mental health. These communities often comprise thousands to millions of users and provide open spaces for interaction. Within these expansive OHCs, support groups refer to smaller , more focuse d sub-communities formed around specic conditions, experiences, or ne eds. Support groups typically oer a more intimate setting that facilitates deeper connections and tailored pe er support, often resulting in improved participant engagement and better health outcomes [ 3 , 11 , 17 ]. Support groups can form in various ways: - Manual formation through user self-selection or facilitation by moderators or healthcare professionals, often based on criteria such as diagnosis or tr eatment phase; - Algorithmic or automated formation leveraging computational te chniques that consider user-generated data and interaction patterns. Manual methods may rely primarily on demographic or diagnostic information, sometimes overlooking complex social interactions and evolving user needs. While straightforward, such methods may pr o duce groups with limited cohesion and inadequate personalization, failing to capture the nuanced social relationships that inuence peer support eectiveness. 2.2 Computational Approaches to Support Group Formation Recent computational approaches aim to automate support group formation by exploiting rich data sources and advanced modeling techniques. Approaches such as those utilizing PGHD—including user posts, activity logs, and symptom reports—have shown promise in aligning peer matches based on shared health experiences, thereby promoting meaningful connections [ 23 , 49 ]. Graph-based algorithms, particularly those employing embe dding techniques like Node2V ec [ 22 ], capture latent interaction structures between users, enabling clustering methods that consider b oth social ties and content similarities [ 18 , 19 ]. Hybrid frameworks that combine textual content analysis, demographic attributes, and interaction data have emerged as comprehensive solutions addressing the dual challenges of scalability and personalization in group formation [ 29 , 43 , 51 ]. 2.3 Current Limitations and Gaps Despite promising progress, several critical limitations remain. Many existing metho dologies rely on static categorizations , where users are assigned to groups based on xed attributes or pre-dened labels that do not r ee ct evolving behaviors, changing health statuses, or shifting social connections [ 5 ]. This rigidity limits the adaptability of support groups to meet users’ interaction and complex needs. Moreover , ethical challenges such as bias and fairness in group assignment frequently remain under-addressed, risking the marginalization of vulnerable populations [ 24 ]. Scalability and interpretability also present ongoing obstacles, especially when applying models to large-scale, continuously growing online communities. Robust privacy protections are essential but often dicult to integrate eectively [ 28 , 50 ]. Manuscript submitted to ACM 4 Barman et al. Our work addresses these limitations by developing novel e xtensions of probabilistic topic modeling frameworks. T opic modeling enables simultaneous extraction of latent thematic structures from te xtual data while incorporating user features and interaction patterns. This integrated approach facilitates exible , data-driven group formation that adapts to users’ evolving communication and engagement patterns. Furthermore, topic modeling inherently supports interpretability through semantically coherent topics, making gr oup assignments more transparent and actionable. 3 Methods 3.1 Dataset Overview The dataset utilized in this study was sourced from MedHelp.org , a widely known OHC that operated for nearly three decades before ceasing on May 31, 2024 [ 31 ]. MedHelp served as a platform where users engaged in discussions on a wide range of health-related topics. The dataset comprises over 2 million user-generated questions and 8 million corresponding answers, contributed by more than 2 million users. These discussions cover an extensive variety of health conditions and concerns, ranging from chronic diseases such as diabetes and asthma to general health advice, including tness routines and dietary suggestions. Each post is enriched with user metadata, which includes: • Gender and Age : Facilitates demographic analyses to discern trends in health-related discussions across dierent user groups. • Membership Y ear : Enables examination of user engagement patterns over time, oering insights into the evolution of community participation. • Location : Allows for regional analysis of health discussions, aiding in the identication of geographically specic health concerns and trends. The richness of this dataset provides a valuable resource for analyzing user interactions and information dissemination within online health communities. The inclusion of demographic and temporal metadata enhances the potential for conducting comprehensive studies on health communication patterns, user engagement relationships, and the impact of regional factors on health-related discussions. Data Preprocessing. W e b egin by cleaning, standardizing, and tokenizing the textual data to prepare it for analysis. Demographic features are normalized for consistency , and interaction data is used to generate node embe ddings, which capture latent relationships between users. 3.2 Model Overview W e propose two complementary models, the gDMR and the gSTM, to automate the formation of personalize d support groups within online healthcare forums. Both models integrate user-generated content, demographic information, and interaction data to identify nuanced user relationships and generate contextually relevant support groups. While gDMR extends the DMR framew ork, gSTM builds upon the STM to further enhance exibility and interpretability in group-level topic modeling. 3.2.1 Group-specific Dirichlet Multinomial Regression (gDMR). The gDMR mo del builds upon the DMR framework introduced by Mimno et al. [ 32 ]. It incorporates group-specic parameters and node embeddings to capture intricate patterns in user behavior , demographics, and textual content, enabling the formation of highly personalized support groups [ 4 ]. Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 5 Fig. 1. The gDMR Model Plate Diagram. Generative Process: (1) For each group 𝑔 : (a) Draw wor d distribution 𝜙 𝑔 ∼ Dirichlet ( 𝛽 ) . (b) Draw group-specic pseudocounts 𝛾 𝑔 ∼ Gamma ( 1 , 1 ) . (c) Draw regr ession coecients 𝜆 𝑔 ∼ N ( 𝜇 , 𝜎 2 𝐼 ) . (2) For each user 𝑢 : (a) Compute group membership weight: 𝛼 𝑢𝑔 = exp ( 𝑥 𝑇 𝑢 𝜆 𝑔 ) + 𝛾 𝑔 . (b) Draw group membership proportions 𝜃 𝑢 ∼ Dirichlet ( 𝛼 𝑢 ) . (3) For each word 𝑤 𝑢,𝑛 of user 𝑢 : (a) Draw group assignment 𝑧 𝑢,𝑛 ∼ Categorical ( 𝜃 𝑢 ) . (b) Draw word 𝑤 𝑢,𝑛 ∼ Categorical ( 𝜙 𝑧 𝑢,𝑛 ) . In this model, the regression co ecients 𝜆 𝑔 control the inuence of user demographic covariates 𝑥 𝑢 on group memberships, while the node embe ddings capture latent interaction structures. This combination allows gDMR to identify contextually relevant and demographically aligned support groups. 3.2.2 Group-specific Structured T opic Model ( gSTM). The gSTM model e xtends the STM framework [ 40 ] by introducing group-specic deviations, sparsity-inducing priors, and structured covariates to model ne-grained variations in group-level topics. Unlike gDMR, which employs a Dirichlet distribution for group memberships, gSTM lev erages a Logistic-Normal distribution to provide greater e xibility in capturing correlations between group memberships. Generative Process: (1) For each group 𝑔 : (a) Draw group-specic deviations 𝜅 𝑔 𝑥 , 𝑤 ∼ Laplace ( 0 , 𝜏 𝑔 𝑥 , 𝑤 ) . (b) Draw sparsity parameter 𝜏 𝑔 𝑥 , 𝑤 ∼ Gamma ( 1 , 1 ) . (c) Draw group-specic prior 𝛾 𝑔 ∼ Gamma ( 1 , 1 ) . (d) Draw regr ession coecients 𝜆 𝑔 ∼ N ( 0 , 𝜎 2 𝐼 ) . Manuscript submitted to ACM 6 Barman et al. Fig. 2. The gSTM Model Plate Diagram. (e) Compute the group-specic wor d distribution: 𝛽 𝑤 𝑔 ∝ exp ( 𝑚 𝑤 + 𝜅 𝑔 𝑥 , 𝑤 ) . (2) For each user 𝑢 : (a) Compute the group membership mean: 𝜇 𝑢,𝑔 = 𝑋 𝑇 𝑢 𝜆 𝑔 + 𝛾 𝑔 . (b) Draw group membership proportions 𝜃 𝑢 ∼ Logistic Normal ( 𝜇 𝑢 , Σ ) . (3) For each word 𝑤 𝑢,𝑛 of user 𝑢 : (a) Draw group assignment 𝑧 𝑢,𝑛 ∼ Categorical ( 𝜃 𝑢 ) . (b) Draw word 𝑤 𝑢,𝑛 ∼ Categorical ( 𝛽 𝑧 𝑢,𝑛 ) . In gSTM, group-specic word distributions 𝛽 𝑤 𝑔 are modele d using group-level deviations 𝜅 𝑔 𝑥 , 𝑤 , which are drawn from a sparsity-inducing Laplace prior . This enables gSTM to capture ne-grained group variations while maintaining semantic coherence. The use of a Logistic-Normal distribution for group memberships 𝜃 𝑢 allows gSTM to account for correlations between group assignments, oering greater exibility compar e d to the Dirichlet-based gDMR model. Both gDMR and gSTM are designed to automate support group formation by leveraging textual, demographic, and interaction data. While gDMR extends the DMR framework with node embeddings to improve gr oup alignment and relevance, gSTM builds upon STM with additional sparsity controls and group-specic deviations to improve topic coherence and interpretability . These models provide complementary solutions for creating personalized and scalable support groups in online healthcare forums. 3.3 Incorporating Node Embe ddings A key innovation in our proposed models, gDMR and gSTM, is the integration of node embeddings derived from user interaction data. These embeddings capture latent relationships between users by modeling their interactions within the online forum, such as replies, posts, and mentions. This allows the models to move beyond basic demographic and textual similarities, incorporating deeper , graph-based relational data that enhances support group formation. Graph Construction. W e begin by constructing a directed graph 𝐺 to represent user interactions, wher e each node corresponds to a user . The edges between nodes represent interactions, such as comments or replies, extracted from the dataset. The weight of each edge reects the frequency of interactions between users, with the edge weight increasing Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 7 by 1 for each additional interaction. W e also store the post_id as an attribute of the edge, allowing us to track the context of each interaction. Node Embedding via No de2V ec. T o generate no de embeddings, we employ the Node2V ec algorithm [ 22 ], which has also b een used in previous computational group formation work [ 18 , 19 ]. Node2V ec learns low-dimensional representations of nodes in a graph by simulating random walks. It explores both the local and global structures of the graph by sampling random walks of length 30 for each no de and repeating this process 200 times. Each node is embedded into a 64-dimensional space, capturing its relative position and interaction patterns in the network. • Graph Input: The directed graph 𝐺 serves as input to Node2V ec, where each node represents a user and each edge represents an interaction between users. • Ke y Parameters: – Dimensions: The node embeddings are 64-dimensional vectors, capturing detailed interaction-based informa- tion about users in the graph. – Random W alks: For each user , 200 random walks of length 30 are performed, enabling the algorithm to capture both local and broader structural information. – Window Size: The context window size is set to 10, which controls the range of neighboring nodes considered when learning the embedding of a given node. Embedding Usage in gDMR. In the gDMR model , the learned node embeddings are integrated as additional covariate features into the regression component. Specically , the embeddings complement the demographic and textual data by providing graph-based relational insights. These enhanced featur es allow gDMR to better model group membership weights 𝛼 𝑢𝑔 , improving its ability to form contextually coher ent and demographically relevant support groups. Embedding Usage in gSTM. In the gSTM model , node emb eddings are incorporated as structured covariates into the group membership mean 𝜇 𝑢,𝑔 . The embeddings interact with the regression coecients 𝜆 𝑔 to inform gr oup assignments, ensuring that both interaction-based relationships and demographic features inuence user membership proportions 𝜃 𝑢 . By leveraging these embeddings, gSTM improves its capacity to model ne-grained group-level topic deviations, resulting in enhanced topic coherence and interpretability . The integration of node embeddings in both gDMR and gSTM models enables the incorporation of structural infor- mation derived from user interactions. While gDMR uses the embeddings to rene group membership weights through exponential regression, gSTM leverages them to inform group membership means and deviations, enhancing exibility in topic modeling. T ogether , these models provide a robust solution for automating the formation of personalized and contextually coherent support groups. 3.4 Training Pr o cedure In this research, we experiment separately with two distinct topic modeling frameworks—the gDMR and the gSTM—to automate the formation of personalized support groups. Each model independently lev erages textual content, demo- graphic characteristics, and user interaction data to identify contextually relevant and coherent user groups within online health forums. The overall methodological approach is depicted in Figures 3 and 4 . T o ensure robustness and stability in gr oup discovery and topic coherence, distinct training strategies tailored to the specic assumptions and computational requirements of each model are employed. Although both models utilize the same underlying features, their parameter initialization, inference methods, and optimization procedures dier Manuscript submitted to ACM 8 Barman et al. Fig. 3. Model Methodology Flowchart. signicantly . The performance and outcomes of the two models are subsequently compared through comprehensive evaluations, highlighting their relative str engths and applicability in forming personalize d support groups. 3.4.1 gDMR T raining Proce dure. The training procedure for the gDMR model integrates topic modeling with user- specic metadata to form personalized and interpretable support groups. This process adopts a multi-phase strategy , leveraging a warm-start initialization followed by iterative optimization, with hyperparameters carefully tuned to ensure robust performance. Specically , the model was congured with the following hyperparameters: number of groups 𝐺 = 20 , Dirichlet prior for group-word distributions 𝛽 = 0 . 01 , and regression variance parameter 𝜎 = 1 . 0 . The training spanned a total of 1000 Gibbs iterations, divided into distinct phases to balance semantic coher ence and user-specic renement. W arm-Start Initialization. The training commenced with a warm-start phase, employing standard Latent Dirichlet Allocation (LDA ) [ 9 ] for the rst 700 iterations. This initialization relied solely on document-level word co-occurrence patterns to establish coherent initial topic assignments. By providing a stable foundation, this phase facilitated the Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 9 Fig. 4. Support Group Formation Flowchart. subsequent integration of demographic and interaction-based features, enhancing convergence speed and mo del stability . Further details on the warm-start implementation are provided in Appendix A . Iterative Optimization Phase. Following the warm-start, the training transitioned to an iterative optimization phase from iteration 701 to 1000. During these 300 iterations, the model alternated every 10 Gibbs iterations between two key processes: collapsed Gibbs sampling for updating group assignments and Broyden–Fletcher–Goldfarb–Shanno (BFGS) optimization for rening regression parameters [ 21 ]. • Collapsed Gibbs Sampling : Group assignments 𝑍 ( 𝑖 ) were updated according to the posterior probability: 𝑃 ( 𝑍 ( 𝑖 ) = 𝑔 | 𝑍 ( − 𝑖 ) , 𝑊 ) ∝ ( 𝑛 ( − 𝑖 ) 𝑔,𝑤 + 𝛽 𝑤 ) ( 𝑛 ( − 𝑖 ) 𝑢,𝑔 + 𝛼 𝑢𝑔 ) ( 𝑛 ( − 𝑖 ) 𝑔 + 𝑊 𝛽 ) where 𝑛 ( − 𝑖 ) 𝑔,𝑤 denotes the count of word 𝑤 in group 𝑔 (excluding the current w ord), 𝑛 ( − 𝑖 ) 𝑢,𝑔 represents the number of words from user 𝑢 assigned to group 𝑔 (excluding the current word), 𝛽 𝑤 is the Dirichlet prior for word distributions, and 𝛼 𝑢𝑔 is the regression parameter linking users to groups. Manuscript submitted to ACM 10 Barman et al. • BFGS Optimization : Concurrently , regression parameters 𝜆 and 𝛾 were optimized using BFGS to maximize the log-posterior objective function: 𝑙 ( 𝜆, 𝛾 ) ∝ 𝑢 log Γ 𝑖 exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 ! − log Γ 𝑖 exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 + 𝑛 𝑢 ! ! + 𝑢 𝑖 log Γ exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 + 𝑛 𝑖 | 𝑢 − log Γ exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 − 𝑖 , 𝑑 𝜆 2 𝑖𝑑 2 𝜎 2 − 𝑖 𝛾 𝑔 𝑖 Here, x 𝑢 encapsulates user-spe cic features (e.g., demographics or node emb eddings), 𝜆 𝑖 are regression coecients for the 𝑖 -th feature, 𝛾 𝑔 𝑖 are group-specic adjustments, and 𝜎 2 regularizes the regr ession coecients. The full derivation and implementation details are elaborated in Appendix B . This dual approach ensured that the gDMR model eectively captured user-group associations while preserving topic coherence, iteratively r ening the model to reect b oth semantic and metadata-driven structures. Parameter Stabilization and Convergence. T o achieve parameter stability , a burn-in perio d was incorporated during the latter stages of training. Although the exact duration varied slightly in prior descriptions, the nal iterations (approximately the last 300) allo wed the group assignments and regression parameters to stabilize. Convergence was rigorously assessed using log-likelihood metrics and the held-out likelihood, estimated via Anneale d Importance Sampling (AIS) [ 34 ]. This evaluation conrme d the mo del’s pr edictive performance on unseen data, with compr ehensive details provided in Appendix B . 3.4.2 gSTM Training Procedure. The gSTM model leverages a variational Expectation-Maximization (EM) algorithm [ 1 , 8 , 46 ] to infer latent topics while incorp orating group-specic structures and metadata. This training procedure iteratively estimates the posterior distributions of latent variables and optimizes model parameters to maximize the Evidence Lower Bound (ELBO ). Below , we outline the gSTM training process in a comprehensiv e and academically rigorous manner . V ariational EM Algorithm. The gSTM employs a fast variant of the variational EM algorithm to t the model to textual data. This algorithm alternates between two steps to maximize the ELBO , dened as: L = E 𝑞 [ log 𝑃 ( 𝑊 , 𝑍 , 𝜂 , 𝜅 | 𝛾 , Σ ) ] − E 𝑞 [ log 𝑞 ( 𝑍 , 𝜂, 𝜅 ) ] The variables and parameters are: • 𝑊 : Observed word data from documents. • 𝑍 : Latent topic assignments for individual words. • 𝜂 : Latent variables representing document-level topic pr oportions, mo deled via a logistic normal distribution. • 𝜅 : Group-specic deviations in topic content, inuenced by covariates, treated as latent variables with priors. • 𝛾 : Parameters mapping document metadata to topic prevalences. Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 11 • Σ : Covariance matrix capturing topic correlations. The ELBO balances the expected log-likelihood of the data and the Kullback-Leibler (KL) divergence between the variational distribution 𝑞 ( 𝑍 , 𝜂, 𝜅 ) and the true posterior . Here, 𝛾 and Σ are parameters optimized during training, while 𝑍 , 𝜂 , and 𝜅 are latent variables with approximated posteriors. (1) E-Step : The variational distribution 𝑞 ( 𝑍 , 𝜂, 𝜅 ) is optimized to approximate the posterior 𝑃 ( 𝑍 , 𝜂, 𝜅 | 𝑊 , 𝛾 , Σ ) by minimizing the KL divergence, updating variational parameters based on current 𝛾 and Σ estimates. (2) M-Step : The parameters 𝛾 and Σ are update d to maximize the ELBO, rening metadata’s inuence on topic prevalences ( 𝛾 ) and topic correlations ( Σ ). This process iterates until convergence, determined by a maximum iteration limit or ELBO stabilization. Enhancing Interpretability . T o improve interpretability , the gSTM model incorporates sparsity-inducing priors, ensuring that group-lev el deviations are meaningful and semantically coherent. A dditionally , the model summarizes topics using FREX scoring [ 39 ], which balances word fr equency and exclusivity to provide intuitive repr esentations. FREX labels topics based on the harmonic mean of wor d probability under the topic and exclusivity to the topic, producing semantically insightful summaries [ 6 ]. This iterative process ensures that gSTM captures ne-grained variations in group-level topics while maintaining high topic coherence and interpretability , making it particularly well-suited for analyzing p ersonalized support groups in online health forums. Practical Implementation. The gSTM training was implemented with: • Number of Groups ( 𝐺 ) : 20, setting topic granularity . • Initialization : Spectral initialization for robust starting values. • Maximum EM Iterations : 75, balancing eciency and convergence. 3.5 alitative Analysis and Sampling For each support group generated by our models (gDMR and gSTM), we performe d stratied random sampling of 20 users (total group user counts range from appr oximately 20 to 80). This sample size was chosen to balance representativeness with manual coding feasibility . Data Extraction. All posts authored by the selected users wer e compiled into datasets serving as the basis for qualitative thematic analysis. Coding Proce dure. Qualitative coding was conducted through a rigorous thematic analysis approach [ 10 , 16 ], involving: (1) Codebook Development: W e constructe d an initial codeb ook based on establishe d health-related themes (deductive codes) drawn from prior literatur e [ 14 ], augmented by emergent themes (inductive codes) identied during preliminary data exploration. (2) Independent Coding: A primar y coder systematically applied the co ding framework to the p osts, rening codes iteratively as new themes emerged. (3) Interrater Reliability: T o ensure rigor , a se cond coder independently coded a randomly selected 10% subset of the data. Interrater agreement was quantied using Cohen’s Kappa, yielding a substantial agreement of 0.78. (4) Thematic Aggregation: Co des were aggregated to identify dominant themes, which were then compared with model-derived keywords and representative posts to assess semantic coherence and r elevance. Manuscript submitted to ACM 12 Barman et al. 4 Evaluation Methods 4.1 antitative Evaluation and Refinement W e comprehensively evaluated both the gDMR and gSTM models using quantitative and qualitative methods to ensure robust assessment of topic quality and support group coherence. Log-Likelihood Estimation. T o quantitatively assess predictive performance and model t, we employed Annealed Importance Sampling ( AIS) [ 34 ] to estimate the log-likelihood of held-out data. AIS provides reliable estimates by transi- tioning thr ough intermediate distributions to approximate the posterior accurately , reecting the models’ generalization capabilities. T opic Coherence. Semantic interpretability and coherence of generated topics were assessed using the UMass coher- ence metric [ 33 , 41 ]. This metric calculates coherence based on the co-o ccurrence statistics of top representative wor ds within each topic from a reference corpus, wher e higher scores indicate better topic quality . Within-Group Similarity . Semantic coherence within groups was quantied by calculating the cosine similarity among textual embeddings (e.g., BERT emb eddings) [ 37 ] of group memb ers’ p osts. Higher within-group similarity scores reect greater internal semantic consistency , validating the interpretability of automatically generated support groups. 4.2 alitative Coding Procedure T o complement the quantitative evaluation, we conducted a qualitative analysis to assess the interpretability of topics and automatic support group formation. For each support group generate d by our models (gDMR and gSTM), we randomly selected 20 users. All posts from these selected users wer e then extracted for detailed manual review and coding. 4.2.1 Selection and Data Extraction. For each supp ort group, a stratied random sampling approach was employed to select 20 users, ensuring that the sample was representative of the group ’s overall composition. All posts authored by these selected users were compiled into datasets that served as the foundation for qualitative analysis. 4.2.2 Coding Methodology . Qualitative coding was performed systematically by a single expert coder through the following structured approach: (1) Codebook Development: An initial coding framework was established base d on a thorough review of relevant literature and a preliminary examination of the data. This frame work integrated deductive codes derived from established health themes, as well as inductiv e codes that emerged organically during initial data exploration [ 16 ]. (2) Independent Coding: The coder independently reviewed each user’s posts in full, meticulously applying the initial coding scheme. During this phase, emergent themes identied, documented, and integrated into the evolving codebook. (3) Thematic Aggregation: After coding all posts, co des were aggregated to identify dominant themes within each support group. These emergent themes were systematically compared with the top keywords and representative posts generated by the models to assess semantic coherence and practical relevance. Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 13 5 Experimental Results 5.1 Support Group Formation In addition to the probabilistic topic models ( gDMR and gSTM), we implemented a multi-stage p ost-processing approach to form coherent and practical support groups by combining textual content and user attribute data. This procedure is designed to rene the raw model outputs into well-balanced, actionable pe er groups suitable for online health forums. 5.1.1 Initial Group A ssignment via gDMR. The initial step leverages the gDMR model to generate high-level group assignments for users. This model integrates demographic information, node emb eddings from user interaction networks, and textual content similarity to produce personalized cluster memberships. Similarity Computation. T extual similarity was quantied using TF-IDF vectorization of user posts, capturing semantic relationships around ke y health themes (e.g., chronic illness, mental health). Simultaneously , feature similarity was calculated from user embeddings (derived from interaction data) and one-hot encoded demographic features such as gender , age group, country , and membership status. A weighted combination scheme was applied: 70% weight was assigne d to textual similarity and 30% to feature similarity , generating a composite similarity score for each user-group pairing. Users were assigned to the gr oup for which this combined similarity was maximal, aligning both content and demographic anities. 5.1.2 Refinement via Constrained K-Means Clustering. T o improve internal group coherence and achie ve manageable group sizes for r eal-world application, we applied a constrained K -Means clustering algorithm to users within each initial group. Constraints and Rationale. Clusters were constrained to sizes between 10 and 30 members, balancing the trade-o between group cohesion and feasibility for meaningful peer interaction. These size constraints are informe d by literature on optimal support group sizes for engagement and manageability [ 15 ]. Features used in clustering were standardized with StandardScaler to ensure consistent scaling across heterogeneous attributes. 5.1.3 Evaluation Framework. Comparison Baselines. T o rigor ously evaluate the semantic coherence of the formed groups, we compar e d the support groups generated by our models against a baseline of randomly assigned groupings. Although the dataset contains organic MedHelp forums and user-created groups, these were not use d as baselines due to data availability and structural dierences. Incorporating such organic groupings in future work w ould provide valuable comparative insight. Semantic Similarity A nalysis. Within-group semantic coherence was measured using cosine similarity of TF-IDF vectors representing user posts. Figure 5 illustrates the distribution of these similarities across groups formed by gDMR, gSTM, and the random baseline. 5.1.4 Results and Interpretation. • gDMR: Achieved a median cosine similarity of appro ximately 0.55 with an interquartile range (IQR) of 0.42 to 0.6, indicating generally strong thematic alignment, though with some variability . • gSTM: Exhibited comparable median similarity ( 0.55) but with a tighter IQR and fewer low-similarity outliers. Notably , gSTM produce d groups with exceptionally high similarity ( > 0 . 85 ), reecting highly coherent clusters. Manuscript submitted to ACM 14 Barman et al. Fig. 5. Comparison of Within-Group and Random Baseline Similarities, highlighting enhanced semantic coher ence within groups formed by gDMR and gSTM models. • Random Baseline: Displayed signicantly lower median similarity ( 0.27) and br oader variability , conrming the robustness of the model-based groupings. These results highlight that both gDMR and gSTM generate support groups with substantially greater semantic coherence than random assignment, validating their practical utility . 5.1.5 Key Insights. Despite comparable median p erformances, gSTM exhibits greater internal consistency and reduced variability , indicating stronger reliability and coherence. Given its superior consistency and interpretability , gSTM is particularly suited to real-world applications demanding precise thematic grouping and meaningful peer interactions. W e evaluated the proposed gDMR and gSTM models by comparing their performance against several baseline models: LD A, DMR, and STM. T o comprehensively assess the quality of the generated support gr oups and topics, we report three primary p erformance metrics: perplexity , held-out log-likelihood, and topic coherence. These metrics collectively evaluate the models’ predictive capability on unseen data and the semantic interpretability of the derived topics. 5.2 Experimental Setup For all experiments, we partitioned the dataset into training and testing sets using an 80/20 split. This approach allows us to evaluate the models’ ability to generalize beyond the training data, which is critical for applications such as support group formation where new user data continuously emerges. Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 15 Model Held-out Log-Likelihood Coherence Score LD A Mo del -606.874 -4.488 DMR Model -465.230 -4.789 gDMR Model (without node embeddings) -463.778 -5.048 gDMR Model (with node embeddings) -403.350 -2.401 STM Model -7.669 -4.499 gSTM Model -7.314 -2.165 T able 1. Comparison of held-out log-likelihood and coherence scores across models. The 80/20 split balances sucient training data for model learning with an adequate hold-out set for reliable performance estimation. 5.3 antitative Performance Evaluation T able 1 summarizes the comparative performance of all models in terms of held-out log-likelihood and topic coherence. 5.3.1 Held-out Log-Likelihood. Held-out log-likelihood evaluates each mo del’s ability to predict unse en data, with higher (less negative) values indicating better predictive p erformance. W e estimated this metric using Anneale d Importance Sampling (AIS) [ 45 ], a robust technique that approximates the partition function for complex probabilistic models. The gDMR model incorporating node emb eddings achieved a held-out log-likelihood of -403.350, which represents an improvement ov er its variant without no de embeddings (-463.778). Although this numerical dierence may appear moderate, in the context of log-likelihood metrics for large datasets, such impro vements are meaningful and statistically signicant given the scale of data and model complexity . Similarly , the gSTM model outperforme d the STM baseline (-7.669 vs. -7.314), demonstrating the benets of incorpo- rating group-specic structures and sparsity priors. It is important to note that STM and gSTM log-likelihood values are on a dierent scale due to their model structures and likelihood formulations. Baseline models such as LD A and DMR showed lower log-likelihoo ds, reecting their limitations in capturing complex user interactions and demographic heterogeneity that the proposed models address. 5.3.2 T opic Coherence. T opic coherence measures the semantic interpr etability of generated topics by assessing the degree of semantic relatedness among top w ords within each topic. This is critical for ensuring that support gr oups correspond to meaningful and engaging themes. As shown in T able 1 , gDMR with node embeddings achieved a coherence score of -2.401, outperforming both the no-embedding variant (-5.048) and the DMR baseline (-4.789). This underscores the value of incorporating graph-based user interaction features to enhance semantic consistency . The gSTM model attained the best coherence score ( -2.165), exceeding that of STM (-4.499). This improvement reects gSTM’s ability to model ne-grained group-level topic de viations and enforce sparsity , which promotes topic distinctiveness and interpretability . 5.3.3 Summary of antitative Results. Both gDMR and gSTM demonstrate clear advantages over traditional models in terms of predictive accuracy and topic coherence. Manuscript submitted to ACM 16 Barman et al. • gDMR: Node embeddings enrich the model with relational context, enhancing predictive and interpretative quality . • gSTM: Group-specic sparsity and structured covariates improve thematic clarity and topic quality . These complementary strengths highlight the potential of integrating te xtual, demographic, and interaction data to support scalable, personalized group formation in online health communities. 5.4 alitative Performance Evaluation W e conducte d a qualitative analysis comparing mo del-generated support groups to thematic codes derived from independent qualitative analysis. 5.4.1 Overview . For each support group produced by gDMR and gSTM, T able 2 and T able 3 (Appendix C ) present the model’s top keywords alongside repr esentative posts and their corresponding qualitative codes. This comparison provides insight into the alignment between computational clusters and nuance d, context-rich themes identied through qualitative analysis. 5.4.2 gDMR-Forme d Support Gr oups. The gDMR model identied 20 distinct groups, each characterized by a dominant theme corresponding closely with qualitative coding. For example: • Group 0 focuses on gastrointestinal issues, with ke y words such as “stomach, ” “eat, ” and “bowel. ” The majority of posts were coded as relating to digestive disorders, encompassing conditions like diverticulitis and related symptom management. • Group 1 centers on cardiac health concerns, with terms like “heart, ” “rate, ” and “ chest. ” Posts often addressed symptoms such as palpitations and chest pain, coded under cardiac conditions or health anxiety specic to cardiac symptoms. (Note: health anxiety diers from cardiac health in that it reects psychological concern about symptoms rather than medically diagnosed conditions.) • Group 5 primarily includes dermatological terms (e.g., “skin, ” “red, ” “bump”) but also captures overlapping respiratory concerns and anxiety symptoms. This group illustrates how the model clusters users experiencing somatic symptoms that span multiple health areas, such as respiratory discomfort accompanied by anxiety about physical sensations. These examples demonstrate that the gDMR model clusters posts by the dominant health concern or symptom focus, aligning with how r eal-world support groups form around shar ed experiences. For instance, users describing post-nasal drip and shortness of breath (initially coded under respiratory issues) clustered with others experiencing somatic health anxieties, suggesting meaningful grouping by user concern rather than strictly clinical categories. Moreover , demographic attributes played a signicant role: - The W omen’s Health group (Group 8) predominantly comprised women discussing menstruation and pregnancy-related topics, supporte d by high gender covariate weights. - The HIV risk anxiety group (Group 7) ske wed toward male users, reecting the gendered nature of the content and user base. - Age-related patterns emerged in groups addressing parenting and sleep disturbances, mirroring real-world demographic trends. 5.4.3 gSTM-Formed Support Groups. The gSTM model generated groups with strong thematic coher ence and clear alignment to qualitative codes: Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 17 • Group 0 (Parenting & Behavioral Issues) featured keywords like “child, ” “son, ” and “baby , ” matching posts code d as behavioral concerns in children. • Group 5 (Car diac Health) clustered posts focused on heart symptoms and diagnostics, reecting precise thematic grouping. • Group 14 (Forum Meta-Discussion) clustered posts related to community management rather than health topics, showcasing the model’s ability to capture meta-lev el themes. Demographic and geographic covariates further enriched group characterization, revealing age and country-sp ecic participation patterns consistent with health topics. 5.5 Forum-Level Analysis: From Large Forums to Personalized Support Groups In online health communities, a forum typically refers to a broad topical community wher e all users discuss a shared health condition or concern (e .g., “Stroke Help” or “STDs Help ”). In contrast, a support group denotes a smaller , more focused cluster of users grouped according to highly similar ne eds, experiences, or contexts, as discovered by our computational models. T o evaluate the practical eectiveness of our approach, we conducte d a comparative analysis of ve randomly selected MedHelp forums: Stroke Help , Back & Neck Help , STDs Help , Ovarian Cancer Help , and Orthopedics Help . Each of these forums originally consiste d of a large, heterogeneous user base—for instance, the Stroke Help forum containe d 52 unique users with a forum-level median semantic similarity of 0.407, while Back & Ne ck Help included 1459 users (similarity 0.356). Both the gDMR and gSTM models automatically partitioned these broad forums into multiple, smaller support groups, each exhibiting substantially higher within-group semantic similarity and incr ease d thematic specicity . For example, in the Stroke Help forum, gDMR identied support groups such as “Supp ort_group19-431” (2 users, median similarity 0.569), “Support_group14-140” (2 users, 0.560), and “Support_group2-25” (3 users, 0.461), grouping users with shared experiences such as caregiver concerns or p ost-stroke rehabilitation. The gSTM model produced groups such as “Support_group11-10” (4 users, 0.513) and “Support_group11-142” (2 users, 0.566), achieving similar or higher thematic coherence. This trend was consistent across all forums. In Back & Neck Help (1459 users, forum similarity 0.356), b oth models formed support gr oups with internal median similarities often above 0.60, signicantly surpassing the baseline similarity of the full forum. In the STDs Help forum (3376 users, similarity 0.430), gDMR identied groups like “Support_group11- 4” (35 users, 0.556) and “Support_group5-434” (30 users, 0.598), while gSTM generated “Support_group2-120” (28 users, 0.606) and “Support_group12-68” (28 users, 0.547), each with high thematic cohesion focused on specic aspects such as recent diagnoses or risk assessment. Similarly , in O varian Cancer Help (564 users, similarity 0.391) and Orthopedics Help (319 users, 0.273), b oth models produced numerous support groups with within-group median similarities up to 0.590 (Ovarian Cancer Help, gDMR) and 0.479 (Orthopedics Help, gSTM), with group sizes ranging from small dyads to larger , thematically consistent clusters. In summary , both quantitative (semantic similarity) and qualitative (thematic focus) analyses demonstrate that our model-generated support groups are markedly more cohesive, personalize d, and eective than the original, broad forums. These results underscore the value of automated support group formation for enhancing the granularity and relevance of peer support in large-scale online health communities. Manuscript submitted to ACM 18 Barman et al. 6 Discussion This study introduces two complementar y models, the Group-specic Dirichlet Multinomial Regression (gDMR) and the Group-specic Structured T opic Model (gSTM), designe d to enhance automated support group formation within online health communities (OHCs). Both models signicantly advance curr ent methodologies by integrating demographic metadata, user interaction features, and user-generated textual content. Colle ctively , these models address critical limitations identied in traditional, manually created support groups, which typically lack personalization, scalability , and interpretability [ 11 , 17 ]. The gDMR model extends the Dirichlet Multinomial Regression framework by incorporating node embeddings and group-specic parameters, eectively capturing latent relational structures among users. Our experiments demonstrate that this extension signicantly impro ves predictive accuracy (held-out log-likelihood) and semantic coherence compared to baseline models such as DMR, STM, and LDA. Specically , the incorporation of interaction-based no de embeddings enables gDMR to accurately identify and lev erage complex relational patterns and demographic nuances, enhancing the formation of personalized and contextually relevant support groups. Complementarily , the gSTM model pro vides a rigorous framework for ne-grained thematic analysis through structured covariates, sparsity-inducing priors, and group-spe cic deviations. Our results indicate that gSTM surpasses baseline models in generating semantically coherent and interpretable topics. The hierarchical nature of gSTM allows it to capture subtle thematic variations across groups, particularly benecial when clear topic interpretability is essential for practical applications such as targeted health interventions or personalize d information dissemination [ 40 ]. 6.1 Comparative Insights This work oers valuable advances for multiple stakeholders involved in managing and participating in OHCs, including platform designers, healthcare practitioners, patient advocacy groups, and researchers in digital health informatics. These audiences stand to benet from impr oved methods for fostering personalized, dynamic, and meaningful peer support that better reect the complex realities of users’ health experiences. Both gDMR and gSTM substantially outperform traditional static categorization appr oaches, which remain pre valent in p opular platforms such as Reddit and Faceb ook. These conventional methods typically rely on predened, rigid categories or community labels—for example, subreddits organized strictly around specic diagnoses (e.g., r/diabetes, r/depression) or Facebook groups manually created for discrete hea lth conditions. Such static structures inherently limit adaptability , failing to capture the heterogeneity of individual user journe ys, the evolving nature of health concerns, and the nuanced social interactions occurring within these communities [ 12 , 20 ]. In practice, static categorization manifests as rigid forum sections or xed group memberships that do not adjust to changing user needs or intersecting health issues. Users with overlapping or multiple conditions may be forced to engage in multiple disjointed groups, hindering holistic support. Moreover , these categories rarely incorporate user interaction patterns or demographic context, limiting their capacity to foster meaningful connections or personalize support. In contrast, gDMR and gSTM dynamically integrate demographic metadata and user interaction networks with textual content, enabling adaptive, nuanced support group formation that better aligns with individual and collective experiences. gDMR excels at relational clustering through node embeddings, eectively capturing social connectivity and fostering peer groups that mirror natural interaction patterns. Meanwhile, gSTM enhances thematic specicity and Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 19 interpretability by modeling ne-grained topic variations, enabling the formation of gr oups with clearly distinguishable and relevant health concerns. T ogether , these models provide a comprehensive framework addressing both social and thematic dimensions critical to eective support in OHCs. For platform developers and healthcare facilitators, this translates into the ability to deliver tailored peer support networks that evolve with users’ health trajectories, promote sustained engagement, and ultimately improve patient outcomes thr ough b etter community cohesion and information relevance. 6.2 Addressing Bias and Fairness A utomated supp ort group formation, while oering scalability and personalization, raises important ethical concerns around bias and fairness due to its r eliance on demographic attributes and interaction-based features [ 24 ]. Attributes such as age, gender , and geographic lo cation are critical for tailoring support, yet overr eliance on these factors risks perpetuating existing so cial inequities. For instance, underrepresented groups—such as racial minorities or socioeconomically disadvantage d populations—may be systematically marginalize d if the models preferentially cluster users based on dominant demographic patterns, thereby limiting their access to eective peer support. Moreover , node embeddings employed in gDMR, which encapsulate user interaction patterns, may inadvertently reect biases present in the underlying social netw orks. For example, if certain groups engage less fr equently or are socially isolated within the online community , their sparse connections can result in lower-quality embeddings, and consequently , less favorable group assignments. T o concretely illustrate, consider a hypothetical online health forum where younger users dominate discussions and form tightly connected clusters, while older adults participate less frequently and have weaker interaction networks. Without fairness-aware adjustments, the model might consistently assign older adults to less coherent or smaller gr oups, diminishing their access to supportive peer networks. Addressing such biases r equires explicitly integrating fairness constraints into the group formation pr ocess. This could involve ensuring demographic parity—where each protected group (e .g., age, gender , ethnicity) receives equitable representation across formed gr oups—or optimizing for equality of opp ortunity by guaranteeing comparable support quality metrics for all user segments. Practically , this necessitates developing fairness-aware extensions of gDMR and gSTM that incorporate such con- straints during optimization or as post-processing corrections. Additionally , ongoing evaluation using fairness metrics should accompany traditional performance measures to monitor and mitigate disparate impacts. Finally , transparent decision-making frameworks that allow users and community managers to understand and contest group assignments can further promote inclusivity and trust. By embedding fairness considerations into the technical and op erational pipeline of automated support group formation, future models can b etter uphold ethical standards and ensure that digital health communities serve the diverse needs of all users eectively . 7 Limitations, Ethical Considerations, and Future Directions While the proposed gDMR and gSTM frameworks advance automated support group formation, several important limitations and ethical considerations warrant attention in future research to ensure robust, fair , and scalable deployment. Manuscript submitted to ACM 20 Barman et al. 7.1 Data ality and Representation The models’ eectiveness critically depends on the quality , diversity , and representativ eness of input data. Imbalances in demographic groups or limited variability in health conditions can reduce generalizability and unintentionally r einforce systemic biases. Ensuring equitable outcomes—in this context, fair and unbiased representation and access to supportiv e peer groups across all demographic and social segments—is essential. Future work should emphasize comprehensiv e, balanced data curation and incorporate fairness-aware modeling strategies to mitigate disparities. 7.2 Computational Scalability and Real- Time Adaptation gSTM’s complexity , due to structured priors and topic correlations, poses computational challenges for training and inference, particularly on large-scale or resour ce-constraine d platforms. Enhancing computational eciency through algorithmic optimization, approximate inference methods, or distribute d computing will b e critical for real-time or near-real-time gr oup adaptation. Incorporating user fee dback and evolving behavioral patterns dynamically will further improve gr oup relevance and engagement. 7.3 Evaluation Beyond antitative Metrics Traditional evaluation metrics such as log-likelihoo d and topic coherence eectively measure predictive accuracy and semantic quality but fall short of capturing user experience and real-world impact. Incorporating user-centric evaluations—such as satisfaction sur veys, longitudinal engagement analysis, and qualitative fe edback—is vital for assessing practical utility and informing iterative model improvements. 7.4 Privacy Protections Given the sensitive nature of health data, maintaining rigorous privacy safeguards is paramount. Although this study utilized anonymized and de-identie d datasets compliant with existing ethical standards, future deployments must adhere to e volving global privacy frame works ( e.g., GDPR). T echniques such as dier ential privacy or federated learning could be explored to enhance data security and user trust without compromising model performance. 7.5 Mitigating Bias and Ensuring Inclusivity A utomated group formation systems must continuously monitor and addr ess potential biases stemming from demo- graphic attributes and interaction patterns. Equitable access here means that users from all backgrounds—regardless of age, gender , ethnicity , or social connectivity—should have fair opportunities to be assigned to supportive and coher- ent groups. A chieving this requires embedding fairness constraints into model training and evaluation, transparent decision-making mechanisms to explain group assignments, and ongoing assessment of group composition relative to inclusivity benchmarks. 7.6 Broader Applicability and Future Research Beyond healthcare , the exible nature of gDMR and gSTM suggests applicability in diverse domains such as education (personalized study groups), customer support (dynamic client clustering), and social networking. Future work should explore these contexts while addr essing the challenges ab ove. Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 21 In summary , by proactively integrating fairness, privacy , scalability , and user-centered evaluation into the dev elop- ment pipeline, future iterations of these models hold promise for transforming how personalize d support communities are created and sustained across digital platforms. A Appendix A: Justification for Using LDA as a Baseline In this study , LD A was chosen as the baseline model due to its established role as a standar d topic modeling algorithm in the literature [ 7 , 9 ]. LD A ’s widespread use in uncovering latent topics within large text corpora makes it an appropriate reference point for evaluating the performance of more complex models, such as gDMR. A.1 Rationale for Using LD A in Initial Iterations W e initiated the training process with 700 iterations of LD A to provide a stable foundation for topic discovery before introducing the demographic features and regression parameters in gDMR. The use of LDA during the initial phase serves several purposes: • Robust Initialization: LD A eectively identies coherent topics based solely on textual data, providing a robust starting point for the more sophisticated gDMR model. This ensures that the initial topics are meaningful and reduces the computational burden when transitioning to gDMR. • Ecient Training: Introducing gDMR from the start would r e quire the model to simultaneously learn both topic distributions and the inuence of demographic features, potentially leading to slower convergence. By allowing LD A to rst converge on the text data, the subsequent introduction of gDMR results in more ecient training and more stable results. A.2 LD A as a Benchmark for gDMR LD A ser ves as an essential b enchmark for evaluating the enhancements oered by gDMR. By comparing the perplexity and log-likeliho od metrics, we can quantitatively assess the improvements brought by incorporating demographic features into the topic modeling process. The observed reductions in perplexity and impro vements in log-likelihood underscore the gDMR model’s ability to provide a more nuanced understanding of the data, particularly in capturing user-specic topics informed by demographic variables. B Appendix B: Collapsed Gibbs Sampling and Evaluation Methods B.1 Mathematical Framework and Derivations W e present the mathematical foundations for the gradient derivations used in the gDMR model’s optimization pro- cess [ 13 ]. The posterior function 𝑃 ( z , 𝜆, 𝛾 ) leads to the following log-posterior function: Manuscript submitted to ACM 22 Barman et al. 𝑙 ( 𝜆, 𝛾 ) ∝ 𝑢 " log Γ 𝑖 exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 ! − log Γ 𝑖 exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 + 𝑛 𝑢 ! # + 𝑖 h log Γ exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 + 𝑛 𝑖 | 𝑢 − log Γ exp ( x 𝑇 𝑢 𝜆 𝑖 ) + 𝛾 𝑔 𝑖 i − 𝑖 ,𝑑 𝜆 2 𝑖𝑑 2 𝜎 2 + log 1 √ 2 𝜋 𝜎 2 ! − 𝑖 𝛾 𝑔 𝑖 . The digamma function Ψ ( 𝑥 ) , as the logarithmic derivative of the gamma function, is used in the gradient calculations: Ψ ( 𝑥 ) = Γ ′ ( 𝑥 ) Γ ( 𝑥 ) . B.2 Partial Derivatives for Optimization W e derive the gradients with respect to the mo del parameters 𝜆 and 𝛾 as follows, which guide the optimization process using BFGS. B.2.1 Gradient with respect to 𝜆 𝑖𝑢 . 𝜕𝑙 𝜕𝜆 𝑖𝑢 = 𝑢 𝑥 𝑖𝑢 exp ( 𝑥 𝑇 𝑢 𝜆 𝑖 ) " Ψ 𝑖 𝛼 𝑖 ! − Ψ 𝑖 𝛼 𝑖 + 𝑛 𝑢 ! + Ψ 𝛼 𝑖 + 𝑛 𝑖 | 𝑢 − Ψ ( 𝛼 𝑖 ) # − 𝜆 𝑖𝑢 𝜎 2 . B.2.2 Gradient with respect to 𝛾 𝑔 𝑖 . 𝜕𝑙 𝜕𝛾 𝑔 𝑖 = 𝑢 Ψ 𝑖 𝛼 𝑖 ! − Ψ 𝑖 𝛼 𝑖 + 𝑛 𝑢 ! + Ψ 𝛼 𝑖 + 𝑛 𝑖 | 𝑢 − Ψ ( 𝛼 𝑖 ) − 𝐺 . These gradients help optimize the parameters to improve the formation of group-specic distributions and enhance topic coherence. B.3 Annealed Importance Sampling for Log-Likelihoo d Estimation W e employed AIS to estimate the log-likelihoo d on held-out data [ 45 ], approximating the partition function between a simple prior and the complex posterior . This method provides a reliable means to evaluate the model’s performance in probabilistic frameworks such as gDMR. W e dened intermediate distributions { 𝑃 𝑠 ( 𝑧 ) } 𝑆 𝑠 = 0 with: 𝑃 𝑠 ( 𝑧 ) ∝ 𝑃 ( 𝑧 | 𝛼 ) · 𝑃 ( 𝑤 | 𝑧, Φ ) 𝜏 𝑠 , Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 23 where 𝜏 𝑠 is a temperature schedule, gradually transitioning from prior 𝑃 0 ( 𝑧 ) to posterior 𝑃 𝑆 ( 𝑧 ) . Markov chain Monte Carlo (MCMC) sampling is employ e d at each temperature 𝜏 𝑠 , and the importance weight for each sample sequence is computed as: 𝑤 𝐴𝐼 𝑆 = 𝑆 Ö 𝑠 = 1 𝑃 ( 𝑤 | 𝑧 ( 𝑠 ) , Φ ) 𝜏 𝑠 − 𝜏 𝑠 − 1 𝑇 𝑠 ( 𝑧 ( 𝑠 − 1 ) → 𝑧 ( 𝑠 ) ) , where 𝑇 𝑠 ( 𝑧 ( 𝑠 − 1 ) → 𝑧 ( 𝑠 ) ) represents the transition probability between states in the Markov chain. The log-likelihood estimate for the held-out data is derived by averaging the importance weights across sev eral runs: log 𝑃 ( 𝑤 | Φ , 𝛼 ) ≈ log 1 𝑀 𝑀 𝑚 = 1 𝑤 ( 𝑚 ) 𝐴𝐼 𝑆 ! . This process allows us to evaluate how well the model generalizes to unseen data, ensuring r obustness in performance assessment. C Appendix C: Thematic Insights from gDMR and gSTM Models T able 2. gDMR Model Support Groups with T op W ords and Example Posts Support Group T op W ords Representative Post Qualitative Code Covariates Group 0 Gastrointestinal Disorders eat, stomach, problem, drink, food “I was diagnosed with diverticulitis about 10 days ago... lower left side pain... ” Grenada, Kiribati, France Group 1 Heart Disease and Symptoms heart, stress, exercise , rate, normal “There is a histor y of heart disease in my family ... For the last 6 months I have been experiencing episodes... ” Lithuania, Vietnam Group 2 Joint Pain and Swelling Syndrome problem, diagnosis, physical, increase, episode “I am trying to nd out why occasion- ally my wrists, n- gers and one foot will swell up for no obvious reason... ” Male Continued on next page Manuscript submitted to ACM 24 Barman et al. T able 2 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 3 HPV T esting question, possible, concern, point, con- cerned “Does anyone know whether gyn’s au- tomatically do the HPV test when they do a pap?” Malaysia Group 4 Post- Treatment Side Eects see, body , begin, dierent, treat “My father , 77, has had GERD for years with increasing severity . A biopsy ... [we are seeking] relief from post-radiation therapy . ” Macau Group 5 Respiratory Issues area, skin, red, small, bump “Six weeks ago I started having post- nasal drip and then it felt like it was all in my chest... short of breath... ” Greece, Female Group 6 CT Scan surgery , cancer , remove , cyst, breast “I had a CA T scan of the abdomen and I wanted to know if it would show a tumor in my stom- ach... ” Sri Lanka, A ustralia Group 7 Unprotected Oral Sex sex, hiv , sore, oral, risk “I’ve read many threads about oral sex, but none discuss if brushing your teeth after can increase the risk of HIV . ” Netherlands, United Kingdom Continued on next page Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 25 T able 2 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 8 Pregnancy Anxiety perio d, stop, bad, wonder , go “I started bleeding just twelve days af- ter my last period... me and my hubby are trying to get pregnant... ” Age 30-39, Female, Germany Group 9 Chest Pain throat, cough, chest, ear , lung “My chest felt like it was exploding... They diagnosed [me with acute bronchitis after I collapsed]. ” Germany , Australia Group 10 Thyroid Levels Con- fusion normal, high, blood, level, low “These numbers still confuse me. I’m still b eing adjusted for my hypothy- roid... What are normal T4, T3, TSH levels?” Age 50-59, Ukraine, Netherlands Group 11 Genital Health Con- cerns penis, herpe, burn, touch, genital “This summer I went to the gyno for the rst time with what I thought was a bad infec- tion... [could it be herpes]?” Hong Kong, A us- tralia, Poland Group 12 Muscle Fascicula- tions leg, arm, MRI, neck, muscle “I am a 40-year-old female... I had surgery last May and no w I have muscle twitching (fasciculations). Is it benign or ALS?” Mauritius, Lithua- nia, Brazil Continued on next page Manuscript submitted to ACM 26 Barman et al. T able 2 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 13 Recurrent Pain pain, right, left, severe , low “I am 31 years old and have had multi- ple areas of discom- fort/pain for several months with no an- swers... ” Singapore, Djibouti Group 14 Health Anxiety me, sometimes, night, eye , head “I have had headaches for months and I’m worried it might be an aneurysm. I NEED answers...!” China, Vietnam, Fe- male Group 15 Diagnostic Uncer- tainty doctor , cause, diagnose, giv e, long “My main question at this point: can a sinus infe ction (that I had on and o ) cause these strange neurological symp- toms?” Mexico, Age 60-69, Iraq Group 16 STI T est Results test, symptom, result, negative, blood “My doctor called yesterday with my blood test results. I tested positive for HSV -1 (which I al- ready knew ) and... ” Portugal, Jordan Group 17 Behavioral Aggres- sion child, son, home, daughter , school “My 4-year-old son has started having severe anger ts that turn violent... ” Hong Kong, Lithua- nia, Age 50-59 Continued on next page Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 27 T able 2 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 18 Nutritional Supple- ments treatment, state, medical, patient, rec- ommend “I’ve be en on lipotropic injec- tions with my doctor ... they have worked, but I’ve seen he has B1/B6 injections. What’s the dierence?” Thailand, China, T aiwan Group 19 Forum Usability post, life, people, hear , answer “Thank you for being open with your thoughts on the new look and feel of the forum. W e are looking to... ” Canada, France, Dji- bouti T able 3. gSTM Model Support Groups with T op W ords and Example Posts Support Group T op W ords Representative Post Qualitative Code Covariates Group 0 Behavioral Issues child, son, baby , daughter , school, home “I have two young daughters and lately my 3-year- old has been saying disturbing things. I’m frustrated and worried. . . ” Djibouti, Nepal, T urkey Group 1 T esting Proce- dures/Results test, negativ e, result, positive, hiv , symptom “I know it’s a little early to worry , but my period is late and the pregnancy test is still negative. I’m anxious. . . ” Costa Rica, Grenada, Mace do- nia Continued on next page Manuscript submitted to ACM 28 Barman et al. T able 3 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 2 Sexual Health Con- cern herpes, sex, hsv , penis, genital, wart, partner “I have genital warts and starte d using Aldara cream. My husband has been patient but I would like to have a normal sex life. . . ” Croatia, Lithuania, Poland Group 3 Joint Pain pain, leg, arm, leave, right, muscle, neck, hand “I have numbness and tingling in hands and feet. Also e xperienc- ing bouts of bad painful gas and constipation. ” Trinidad and T o- bago, Kuwait, Bul- garia Group 4 Bypass Surgery Complications surgery , treatment, remove , doctor , cancer “My dad had six by- pass surgeries, now experiencing burn- ing in his chest. What tests should be done?” Indonesia, Chile, Macedonia Group 5 Cardiac T esting heart, normal, rate, beat, stress, chest “I am 38 female. I exercise r egularly but experience pain, shortness of breath, and dizziness. What tests should I ask for?” Portugal, Hong Kong, Malta Group 6 Cancer Risk Con- cerns cyst, right, leave, show , ultrasound, scan “I had my ovaries removed due to cysts. Can I still get ovarian cancer with just remnants left?” Vietnam, Malta, Greece Continued on next page Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 29 T able 3 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 7 Psychiatric Drug Side Eects anxiety , bad, life, sleep, drug, med “Depakote caused anger issues, aecting my mar- riage. Should I discontinue the medication?” Mexico, Brazil, Macau Group 8 Liver and Enzymes blood, liver , normal, high, test, count “I have Hepatitis C, my blood work was slightly elevated, but I feel ne. Should I go for treatment or wait?” Chile, Oman, Mau- ritius Group 9 Chest and Respira- tory Issues pain, chest, stomach, cough, throat, doctor “I have been expe- riencing excessive burping, atulence, and chest pain. Doc- tors susp ect GERD or anxiety . . . ” Iraq, Mauritius, Do- minican Republic Group 10 Maternal Health period, night, happ en, pregnant, morning, bad “I’m 31 weeks preg- nant and having trouble sleep- ing. My stomach cramps when I lie on my side. Should I be concerned?” Kiribati, Nigeria, Netherlands, Age 0-9 Group 11 Vision Problems eye, head, headache , symptom, brain, ear “I have worsening myopia and some oaters. Is my high myopia likely to progress into a serious condition?” Y ugoslavia, Malaysia, Bel- gium Continued on next page Manuscript submitted to ACM 30 Barman et al. T able 3 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 12 Sexual Health sex, hiv , protect, condom, risk, sore “I had protected sex, but the condom slipped slightly . I later saw a panty liner with a stain. How risky was this?” T anzania, Latvia, Ukraine, Thailand, Age 10-19 Group 13 Diet and Nutrition eat, drink, food, diet, water , vitamin “I experience extreme gas, stom- ach cramps, and irregular bowel movements. Could I have a gluten allergy or other issue?” Oman, Kiribati, China Group 14 Community and Support post, people, question, hear , forum, answer “W e are working on splitting the forum into two—one for medical weight loss and one for natural methods. . . ” Age 0-9, Croatia, Namibia Group 15 W eight Manage- ment weight, lose, loss, lbs, doctor , pound “I am pregnant, but my husband insists I should continue di- eting. Is it safe to lose weight during the rst trimester?” Afghanistan, Spain, Poland, Age 0-9 Continued on next page Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 31 T able 3 – Continued from previous page Support Group Qualitative Code T op W ords Representative Post Covariates Group 16 Skin Conditions and Symptoms skin, red, area, bump, small, rash “I have red bumps on my arm that don’t respond to treatment. Do ctors ruled out shingles. What else could it be?” Namibia, Afghanistan, U AE Group 17 Thyroid Function and T esting thyroid, level, normal, tsh, test, symptom “I have hypothy- roidism and uctuating TSH levels. What symp- toms should I watch out for? Should my dosage be adjusted?” Uganda, Germany , Egypt Group 18 Symptoms and Con- ditions infection, symptom, pain, doctor , antibiotic “I had kidney stones removed but still feel soreness. How long does recovery usually take?” Ukraine, T aiwan, Botswana Group 19 Medical Treatment and Professional Care pain, test, cd, right, symptom, doctor “My wife suers from cervical pain extending to her hands. She had MRI results indicating compression at C5-C6. . . ” India, Lithuania, Iraq, Age 80-89 Appendix D: alitative Coding Codebo ok Manuscript submitted to ACM 32 Barman et al. T able 4. alitative Codebook for Thematic Analysis of Online Health Community Posts Code Name Denition/Description Example Quotation Chronic Disease Manage- ment Discussion of ongoing, long-term conditions (e .g., dia- betes, heart disease, asthma, hypothyroidism) and their management. “I was diagnosed with diabetes last y ear and struggle to keep my sugar under control. ” Acute Symptom or Flare Description of sudden or short-term physical symptoms, illness are-ups, or episodic health issues. “I started having chest pain and short- ness of breath last night. ” Diagnostic Uncertainty Expressions of confusion or seeking clarity about symp- toms, medical diagnoses, or test results. “My test results still don’t explain why I’m having these headaches. ” Treatment and Medica- tion Discussion of treatments, medication regimens, pr oce- dures, or medical advice (including adherence, changes, or concerns). “My doctor prescribed a new antidepres- sant, but I’m not sure about the side ef- fects. ” Side Ee cts / Complica- tions Reference to negativ e eects or complications following treatment, medication, or medical intervention. “Since starting radiation, I’ve had trou- ble sleeping and more fatigue. ” Health Anxiety / Psycho- logical Distress Expressions of anxiety , worry , or emotional distress related to health, symptoms, or uncertainty . “I’m worried this headache is something serious like a tumor . ” Peer Support Request Request for information, advice, shared experiences, or emotional support from other forum members. “Has anyone else experience d this? I could use some advice. ” Parenting / Family Care Concerns related to caring for children, family members, or parenting in the context of health. “My 4-year-old son has been having trouble sleeping at night. ” Gender-Specic / Repro- ductive Health T opics spe cic to gendered health or reproductive con- cerns (e.g., pr egnancy , menstruation, menopause, male sexual health). “I’m anxious ab out my misse d p eriod and whether I might be pregnant. ” Diet / Nutrition / Supple- ments Discussion of dietar y habits, nutrition, food allergies, or use of supplements. “I started taking vitamin D and changed to a gluten-free diet. ” Exercise / Physical Activ- ity References to exercise routines, physical activity , or rehabilitation. “I began walking every morning after my surgery to help with recovery . ” Preventiv e Health / Screening Mention of health screenings, preventive measur es, or proactive health behaviors. “I had my annual mammogram last week as part of a regular checkup. ” Community / Forum Meta Discussion about the forum itself, community rules, structure, or requests for technical help. “Does anyone know when the forum layout will be updated?” Stigma / Privacy Concerns Expressed concerns about privacy , stigma, or fear of being judged for sharing personal information online. “I’m hesitant to talk about my diagnosis here because I worry about privacy . ” (Continued on next page) Manuscript submitted to ACM Enhancing Online Support Group Formation Using T opic Modeling T echniques 33 (Continued from previous page) Code Name Denition/Description Example Quotation Age-Specic Concerns Issues specic to certain age groups ( e.g., elderly , ado- lescents, pediatric topics). “My elderly mother has been losing her memory lately and I’m not sure what to do. ” Geographic / Cultural Context Mentions of location, cultural dierences, or healthcare access as relevant to the user’s situation. “Is this treatment available in Canada? My doctor wasn’t sure. ” Emergent / Other New or unexpected themes not covered by the above codes (to be dened during co ding). “I found humor really helps me cope with this illness. ” References [1] Amr Ahmed and Eric P Xing. 2007. Seeking the truly correlated topic posterior-on tight approximate inference of logistic-normal admixture model. In A rticial Intelligence and Statistics . PMLR, 19–26. [2] Azy Barak, Meyran Boniel-Nissim, and John Suler . 2008. Fostering empowerment in online support groups. Computers in human b ehavior 24, 5 (2008), 1867–1883. [3] Pronob Kumar Barman, James R Foulds, and T era L Reynolds. 2026. Understanding User Perceptions of Human-centered AI-Enhanced Support Group Formation in Online Healthcare Communities. arXiv preprint arXiv:2603.11237 (2026). [4] P. K. Barman, T . L. Reynolds, and J. Foulds. 2025. Facilitating Online Healthcare Support Group Formation using T opic Modeling. In Proceedings of the MedInfo 2025: The 20th W orld Congress on Medical and Health Informatics . International Medical Informatics Association (IMIA), Taipei, T aiwan. Accepted as a Full Paper . [5] Jason S Bergtold and Aleksan Shanoyan. 2024. Assessment of group formation methods on performance in group-based learning activities. In Frontiers in Education , V ol. 9. Frontiers Media SA, 1362211. [6] Jonathan Bischof and Edoardo M. Airoldi. 2012. Summarizing T opical Content with W ord Frequency and Exclusivity . In Proceedings of the 29th International Conference on Machine Learning (ICML-12) . 201–208. [7] David M. Blei. 2012. Probabilistic topic models. Commun. A CM 55, 4 (2012), 77–84. https://www .cs.columbia.edu/~blei/pap ers/Blei2012.pdf [8] David M Blei and John D Laerty . 2007. A correlated topic model of science. The annals of applied statistics (2007), 17–35. [9] David M. Blei, Andrew Y . Ng, and Michael I. Jordan. 2003. Latent Dirichlet Allo cation. Journal of Machine Learning Research 3 (2003), 993–1022. [10] Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology . Qualitative research in psychology 3, 2 (2006), 77–101. [11] Louise Breuer and Chris Barker . 2015. Online supp ort groups for depression: Benets and barriers. Sage Open 5, 2 (2015), 2158244015574936. [12] G. M. Burlingame, A. Fuhriman, and J. E. Johnson. 2004. Cohesion in group psychotherapy . In Handbo ok of Group Counseling and Psychotherapy . Sage Publications, 114–127. [13] Bob Carp enter . 2010. Integrating Out Multinomial Parameters in Latent Dirichlet Allocation and Naive Bayes for Collapse d Gibbs Sampling. https://api.semanticscholar .org/CorpusID:2104516 [14] AL Chapman, M Hadeld, and CJ Chapman. 2015. Qualitative research in healthcare: an intr oduction to grounded the ory using thematic analysis. Journal of the Royal College of Physicians of Edinburgh 45, 3 (2015), 201–205. [15] Annie T Chen. 2012. Exploring online support spaces: using cluster analysis to examine breast cancer , diab etes and bromyalgia support groups. Patient education and counseling 87, 2 (2012), 250–257. [16] Victoria Clarke and Virginia Braun. 2017. Thematic analysis. The journal of positive psychology 12, 3 (2017), 297–298. [17] Gunther Eysenbach, John Powell, Marina Englesakis, Carlos Rizo, and Anita Stern. 2004. Health related virtual communities and ele ctronic support groups: systematic review of the eects of online peer to peer interactions. Bmj 328, 7449 (2004), 1166. [18] Anna Fang and Haiyi Zhu. 2022. Matching for Peer Support: Exploring Algorithmic Matching for Online Mental Health Communities. In Proceedings of the ACM on Human-Computer Interaction , V ol. 6. 1–37. [19] X. Fang et al. 2022. Graph-Based Peer Matching in Online Health Communities. Health Informatics Journal (2022). [20] Jeremy A Gr eene, Niteesh K Choudhry , Elaine Kilabuk, and William H Shrank. 2011. Online social networking by patients with diabetes: a qualitativ e evaluation of communication with Facebook. Journal of general internal medicine 26 (2011), 287–292. [21] Thomas L. Griths and Mark Ste y vers. 2004. Finding scientic topics. Proceedings of the National Academy of Sciences 101, suppl. 1 (2004), 5228–5235. [22] Aditya Grover and Jur e Leskovec. 2016. Node2V ec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) . 855–864. Manuscript submitted to ACM 34 Barman et al. [23] Andrea L. Hartzler et al . 2016. Leveraging cues from person-generate d health data for p eer matching in online communities. Journal of the American Medical Informatics Association 23, 3 (2016), 496–507. [24] Razi Hashmi and Yichen W ang. 2022. Is bigger better? A study of the ee ct of group size on collective intelligence in online groups. Computers in Human Behavior 131 (2022), 107231. [25] Sohyeon Hwang and Jeremy D Foote. 2021. Why do people participate in small online communities? Proce e dings of the ACM on Human-Computer Interaction 5, CSCW2 (2021), 1–25. [26] Mareile Kaufmann and Meropi T zanetakis. 2020. Doing Internet research with hard-to-reach communities: Methodological reections on gaining meaningful access. Qualitative Research 20, 6 (2020), 927–944. [27] Laurel J Kiser . 2001. So cial Support Measurement and Intervention: A Guide for Health and Social Scientists. 801–802 pages. [28] Y vonne W . Leung et al . 2021. Natural Language Processing–Based Virtual Cofacilitator for Online Cancer Supp ort Groups: Protocol for an Algorithm Development and V alidation Study. BMC Health Ser vices Research 21, e745 (2021). [29] Changhao Liang, Rwitajit Majumdar, and Hiroaki Ogata. 2021. Learning log-based automatic group formation: system design and classroom implementation study . Research and Practice in T echnology Enhanced Learning 16, 1 (2021), 14. [30] W enlong Liu, Xiucheng Fan, Rongrong Ji, and Yi Jiang. 2020. Perceived community support, users’ interactions, and value co-creation in online health community: The moderating eect of social exclusion. International journal of environmental research and public health 17, 1 (2020), 204. [31] MedHelp.org. 2024. Online Health Community. https://ww w .medhelp.org [32] David Mimno and Andrew McCallum. 2012. T opic models conditioned on arbitrary features with Dirichlet-multinomial regression. https: //arxiv .org/abs/1206.3278 [33] David Mimno, Hanna W allach, Edmund T alley , Miriam Leenders, and Andrew McCallum. 2011. Optimizing Semantic Coherence in T opic Models. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing . 262–272. [34] Radford M. Neal. 2001. Annealed Imp ortance Sampling. Statistics and Computing 11, 2 (2001), 125–139. [35] Aaron Necaise and Mary Jean Amon. 2024. Peer Supp ort for Chronic Pain in Online Health Communities: Quantitative Study on the Dynamics of Social Interactions in a Chronic Pain Forum. Journal of Medical Internet Research 26 (2024), e45858. [36] M. W . Newman, D. Lauterbach, S. A. Munson, P . Resnick, and M. E. Morris. 2011. It’s not that I don’t have problems, I’m just not putting them on Facebook: challenges and opportunities in using online social netw orks for health. In Proceedings of the A CM 2011 Conference on Computer Supported Cooperative W ork . 341–350. [37] Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence emb eddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019). [38] P. K. Ressler, Y. S. Bradshaw , L. Gualtieri, and K. K. Chui. 2012. Communicating the experience of chronic pain and illness through patient narratives. Journal of Health Communication 17, 9 (2012), 929–943. [39] Margaret E. Roberts, Brandon M. Stewart, and Edoar do M. Airoldi. 2016. A Model of T ext for Experimentation in the Social Sciences. J. A mer . Statist. Assoc. 111, 515 (2016), 988–1003. [40] Margaret E. Roberts, Brandon M. Stewart, Dustin Tingley , Edoardo M. Airoldi, et al . 2013. The Structural T opic Model and Applied Social Science. In Advances in Neural Information Processing Systems W orkshop on T opic Models: Computation, A pplication, and Evaluation , V ol. 4. 1–20. [41] Frank Rosner, Alexander Hinneburg, Michael Röder, Martin Nettling, and Andreas Both. 2014. Evaluating T opic Coherence Measures. https: //arxiv .org/abs/1403.6397 [42] Mayo Clinic Sta. 2023. Support groups: Make connections, get help. https://w ww.may oclinic.org/healthy- lifestyle/support- groups/in- depth/ support- groups/art- 20044655 [43] Florence R Sullivan and P Kevin K eith. 2019. Exploring the potential of natural language processing to support micr ogenetic analysis of collaborative learning discussions. British Journal of Educational T echnology 50, 6 (2019), 3047–3063. [44] T oni V allès-Català and Ramon Palau. 2023. Minimum entropy collaborative groupings: A to ol for an automatic heterogeneous learning group formation. Plos one 18, 3 (2023), e0280604. [45] Hanna M. W allach, Iain Murray , Ruslan Salakhutdinov , and David Mimno. 2009. Evaluation methods for topic models. In Proceedings of the 26th A nnual International Conference on Machine Learning . 1105–1112. [46] Chong W ang and David M Blei. 2013. V ariational inference in nonconjugate models. The Journal of Machine Learning Research 14, 1 (2013), 1005–1031. [47] Xi W ang, Kang Zhao, Nick Street, et al . 2017. Analyzing and predicting user participations in online health communities: a social support perspective. Journal of medical Internet research 19, 4 (2017), e6834. [48] Hugh W orrall, Richard Schweizer , Ellen Marks, Lin Y uan, Chris Lloyd, and Rob Ramjan. 2018. The Eectiveness of Support Groups: A Literature Review . Mental Health and So cial Inclusion 22, 2 (2018), 85–93. doi:10.1108/MHSI- 12- 2017- 0055 [49] S. Y e o et al. 2023. Enhancing W ell-Being through Personalized Digital Peer Supp ort. International Journal of Medical Informatics (2023). [50] Y . Zhao et al. 2022. Privacy-Preserving Algorithms for Online Support Group Formation. Journal of Medical Internet Research (2022). [51] Y uxiang Chris Zhao et al . 2022. Online Health Information Seeking Among Patients With Chronic Conditions: Integrating the Health Belief Model and Social Support Theor y . Journal of Medical Internet Research 24, e36056 (2022). [52] S. Ziebland and S. W yke. 2012. Health and illness in a connecte d world: how might sharing experiences on the internet aect pe ople’s health? The Milbank Quarterly 90, 2 (2012), 219–249. Manuscript submitted to ACM
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment