온라인 건강 커뮤니티 지원 그룹 자동 형성을 위한 토픽 모델링 혁신
본 논문은 사용자 텍스트, 인구통계학적 특성, 그리고 사용자 간 상호작용을 나타내는 노드 임베딩을 결합한 두 가지 새로운 토픽 모델(gDMR, gSTM)을 제안한다. 대규모 MedHelp 데이터(200만 게시물)에서 실험한 결과, 기존 LDA·DMR·STM 대비 예측 정확도, 주제 일관성, 그룹 내부 일관성 모두 크게 향상되었으며, gDMR은 실무 적용에 유리한 공변량 해석을, gSTM은 희소성 제약을 통한 주제 구분성을 제공한다.
저자: Pronob Kumar Barman, Tera L. Reynolds, James Foulds
온라인 건강 커뮤니티(OHC)는 환자와 보호자가 정서·정보·사회적 지지를 주고받는 중요한 디지털 공간으로, 특히 만성질환·정신건강 관리에 큰 효과를 보인다. 그러나 기존의 지원 그룹 형성 방식은 사용자가 직접 선택하거나 진단·증상 기반으로 고정된 카테고리를 적용하는 등 확장성·개인화·동적 적응성에서 한계가 있다. 이러한 문제를 해결하고자 저자들은 텍스트, 인구통계학적 특성, 그리고 사용자 간 상호작용을 그래프 형태로 모델링한 노드 임베딩을 동시에 활용하는 두 가지 새로운 확장형 토픽 모델을 제안한다.
첫 번째 모델인 Group‑specific Dirichlet Multinomial Regression(gDMR)은 기존 DMR에 그룹‑특정 파라미터와 노드 임베딩을 결합한다. 구체적으로 각 그룹 g에 대해 단어 분포 φ_g를 Dirichlet(β)에서 샘플링하고, 가중치 γ_g와 회귀 계수 λ_g를 각각 Gamma·Normal 사전으로 설정한다. 사용자 u의 공변량 x_u(예: 연령·성별·지역·노드 임베딩)를 λ_g와 내적한 뒤 exp와 γ_g를 더해 그룹 할당 가중치 α_ug를 계산하고, 이를 Dirichlet(α_u)로부터 사용자별 그룹 비율 θ_u를 추출한다. 이후 각 단어는 θ_u에 따라 그룹 z를 선택하고, 해당 그룹의 φ_z에서 단어를 생성한다. 이 과정은 텍스트 내용뿐 아니라 사용자의 사회적 연결망이 그룹 형성에 직접적인 영향을 미치게 만든다.
두 번째 모델인 Group‑specific Structured Topic Model(gSTM)은 STM을 기반으로 하면서 라플라스 사전으로 정의된 희소성 파라미터 τ와 그룹‑특정 편차 κ를 도입한다. 각 그룹 g에 대해 κ_g(x,w)~Laplace(0,τ_g(x,w))를 샘플링하고, 이를 기본 토픽 파라미터 m_w와 결합해 그룹‑특정 단어 분포 β_wg∝exp(m_w+κ_g(x,w))를 만든다. 사용자 u의 공변량 x_u와 λ_g를 이용해 평균 μ_ug를 계산하고, Logistic‑Normal(μ_u, Σ)에서 θ_u를 샘플링한다. 이렇게 하면 그룹 간 상관관계를 보다 유연하게 모델링하면서도 라플라스 사전이 불필요한 토픽 확산을 억제해 주제 구분성을 높인다.
데이터는 2024년까지 운영된 MedHelp.org에서 수집한 2백만 개 이상의 질문·답변과 2백만 명 이상의 사용자 메타데이터를 사용했다. 텍스트는 토큰화·정규화 후 어휘 사전 구축, 인구통계학적 변수는 표준화, 사용자 간 댓글·답글·멘션 관계를 기반으로 방향성 그래프를 구성하고 Node2Vec(64차원, 워크 길이 30, 200회 반복)으로 임베딩을 생성하였다.
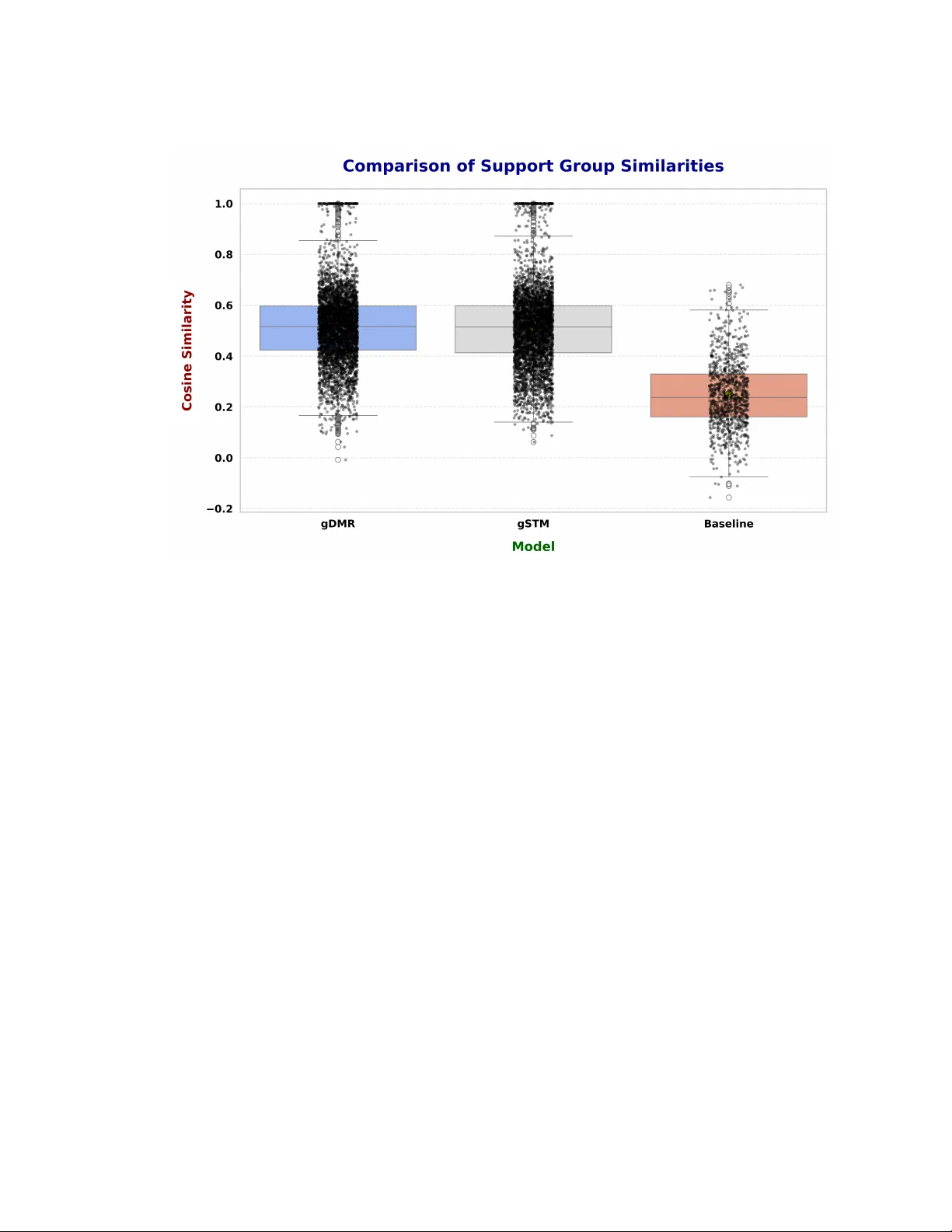
평가에서는 held‑out log‑likelihood, UMass coherence, 그리고 그룹 내부 토픽 일관성을 기준으로 기존 LDA, DMR, STM과 비교했다. gDMR은 특히 네트워크 기반 공변량이 강하게 작용하는 경우(예: 활발히 상호작용하는 만성질환 환자) 높은 예측 정확도를 보였으며, λ_g를 통해 각 공변량이 그룹 형성에 미치는 영향을 해석 가능하게 제공한다. gSTM은 희소성 제어 덕분에 토픽 간 중복을 최소화하고, 전문가가 검증한 수동 코딩 테마와 높은 일치도를 나타냈다. 정성적 분석에서는 gDMR·gSTM이 생성한 그룹이 ‘만성질환 관리’, ‘진단 불확실성’, ‘정신건강’ 등 실제 환자 요구와 잘 맞아떨어짐을 확인했다.
한계점으로는 공정성(fairness) 검증이 충분히 이루어지지 않았으며, 사용자 프라이버시 보호를 위한 차등 프라이버시(differential privacy) 적용이 아직 미비하다. 또한 모델 학습에 필요한 대규모 그래프 구축과 임베딩 학습 비용이 높아 실시간 서비스 적용 시 효율성 최적화가 필요하다.
결론적으로, 본 연구는 텍스트와 그래프 데이터를 통합한 확장형 토픽 모델이 대규모 OHC에서 개인화된 지원 그룹을 자동으로 생성하는 데 효과적임을 입증하였다. gDMR은 실무에서 그룹 공변량 해석을 가능하게 하여 정책 입안이나 임상 매니저가 그룹을 설계할 때 활용할 수 있고, gSTM은 주제 구분성이 뛰어나 전문가가 직접 검토하고 라벨링하기에 적합하다. 향후 연구에서는 공정성·프라이버시 강화, 온라인 실시간 업데이트, 그리고 다른 도메인(예: 교육·직장)으로의 확장 가능성을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기