A Deep Dive into Scaling RL for Code Generation with Synthetic Data and Curricula
Reinforcement learning (RL) has emerged as a powerful paradigm for improving large language models beyond supervised fine-tuning, yet sustaining performance gains at scale remains an open challenge, as data diversity and structure, rather than volume…
Authors: Cansu Sancaktar, David Zhang, Gabriel Synnaeve
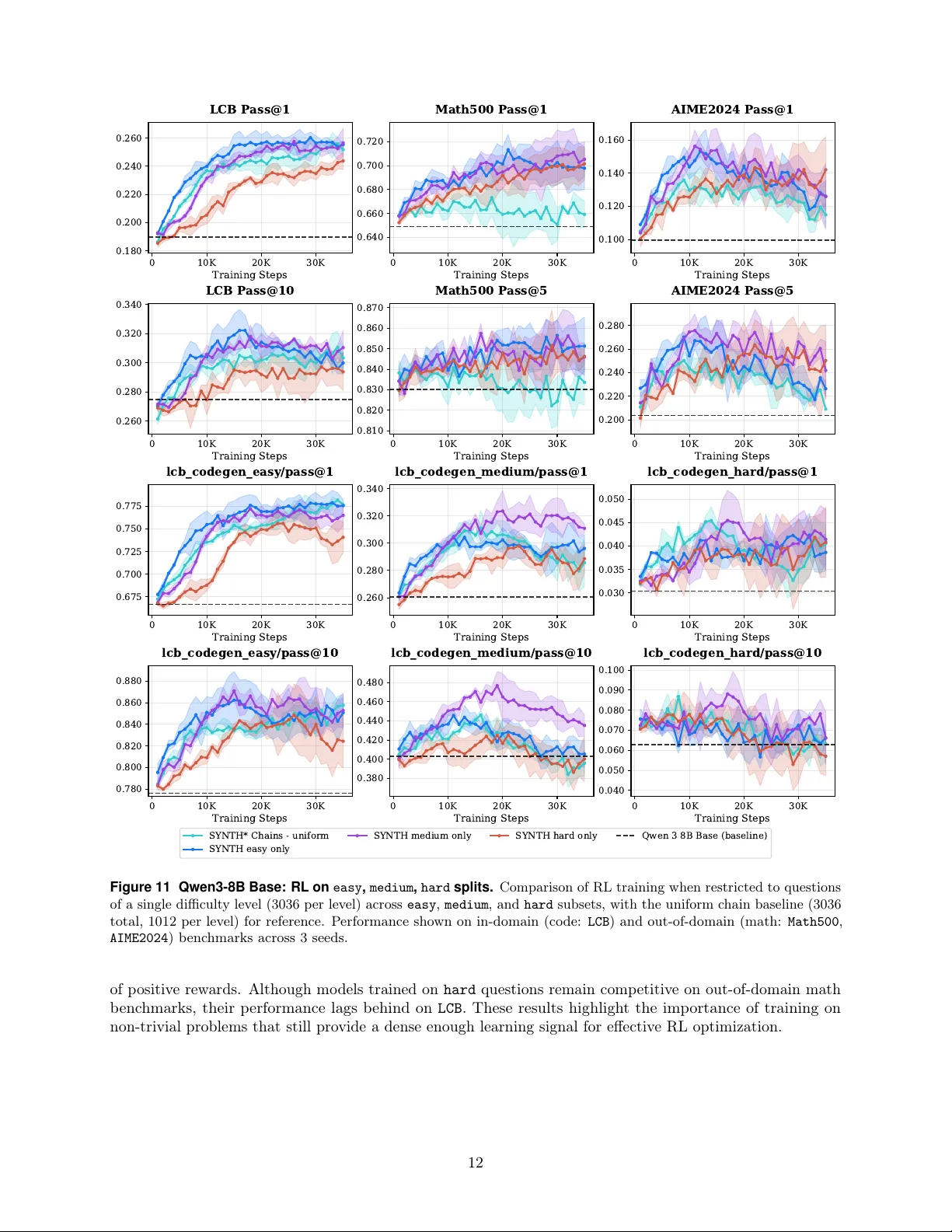
A Deep Dive into Scaling RL for Code Generation with Synthetic Data and Curricula Cansu Sancaktar 1 , 2 , ∗ , David Zhang 3 , Gabriel Synnaeve 3 , T aco Cohen 3 1 Univ ersit y of Tübingen, 2 Max Planc k Institute for In telligen t Systems, 3 Meta F AIR ∗ W ork done during an internship at Meta Reinforcemen t learning (RL) has emerged as a pow erful paradigm for impro ving large language mo dels b ey ond sup ervised fine-tuning, yet sustaining p erformance gains at scale remains an op en c hallenge, as data diversit y and structure, rather than volume alone, b ecome the limiting factor. W e address this by introducing a scalable multi-turn synthetic data generation pip eline in which a teacher mo del iterativ ely refines problems based on in-con text student p erformance summaries, pro ducing structured difficulty progressions without any teac her fine-tuning. Compared to single-turn generation, this multi-turn approac h substan tially impro v es the yield of v alid syn thetic problems and naturally pro duces stepping stones, i.e. easier and harder v ariants of the same core task, that support curriculum-based training. W e systematically study ho w task difficult y , curriculum scheduling, and en vironmen t div ersit y in teract during RL training across the Llama3.1-8B Instruct and Qwen3-8B Base mo del families, with additional scaling exp eriments on Qw en2.5-32B. Our results sho w that syn thetic augmentation consistently improv es in-domain co de and in most cases out-of-domain math p erformance, and we provide empirical insights in to ho w curriculum design and data diversit y join tly shap e RL training dynamics. Date: March 26, 2026 Correspondence: Cansu Sancaktar at cansu.sancaktar@tuebingen.mpg.de Random Code Snippets T eacher generates initial problem Real C oding Puzzles [Student attempts to solv e problem] x k Inspiration seed F ra me T eacher iterates on probl em based on student success/failure summary T urn = 1 def is_lig(atom): # Non-hydrogen if atom.residue.name == "UNL" and atom.atomic_number > 1: return True def find_atom(res_atom=None, prot_file=None, combined_pmd=None): # Parse the input data like this -> "A_LYS_311_N" chain = res_atom.split("_")[0] res_name = res_atom.split("_")[1] res_number = int(res_atom.split("_")[2]) atom_name = res_atom.split("_")[3] T urn > 1 Synthetic Data Generation Pipeline Filter & Deduplicate Error when running code Formatting errors Input-output pairs are not diverse enough Student never solved Given an array arr of n positive integers lesser than 1000, check if there exists at least one subarray, the product of whose elements is a power of 2. Input format: n arr Output format: boolean Note: 1. 1 <= n <= 99 S tudent Summar y ## Task: Mutate Python Code Snippet Based on Student Responses to Previous Challenge and Create a New Challenge ### Previous Code, input-output pairs and message: [....] Previous message: [....] ### Student answers summary: Pass rate for the student over 8 attempts was: Example solved: [....] Example failed: [....] ### Progression Strategy: The student almost always solved the previous task with a pass rate of 0.875. Either the input- output relationship was too trivial (maybe not diverse enough or incomplete such that a much easier function also passes the tests), or the function was relatively easy to implement. Try to mutate this problem into a medium problem: student should have a pass rate of 0.35-0.65. 0.875. R andom C ode Snippe ts T eacher gener at es init ial pr obl em R eal C oding P uzzl es [S tudent at t emp ts t o sol v e pr obl em] x k Inspir at ion seed F ra me T eacher it er at es on pr obl em based on s tudent suc c ess/f ailur e summar y T urn = 1 def is_lig(atom): # Non-hydrogen if atom.residue.name == "UNL" and atom.atomic_number > 1: return True def find_atom(res_atom=None, prot_file=None, combined_pmd=None): # Parse the input data like this -> "A_LYS_311_N" chain = res_atom.split("_")[0] res_name = res_atom.split("_")[1] res_number = int(res_atom.split("_")[2]) atom_name = res_atom.split("_")[3] T urn > 1 S ynt he t ic Data Gener at ion Pipeline F il t er & Deduplic at e Err or when running c ode F ormat t ing err or s Input - output pair s ar e no t div er se enough S tudent ne v er sol v ed Given an array arr of n positive integers lesser than 1000, check if there exists at least one subarray, the product of whose elements is a power of 2. Input format: n arr Output format: boolean Note: 1. 1 <= n <= 99 S tudent Summar y ## Task: Mutate Python Code Snippet Based on Student Responses to Previous Challenge and Create a New Challenge ### Previous Code, input-output pairs and message: [....] Previous message: [....] ### Student answers summary: Pass rate for the student over 8 attempts was: Example solved: [....] Example failed: [....] ### Progression Strategy: The student almost always solved the previous task with a pass rate of 0.875. Either the input- output relationship was too trivial (maybe not diverse enough or incomplete such that a much easier function also passes the tests), or the function was relatively easy to implement. Try to mutate this problem into a medium problem: student should have a pass rate of 0.35-0.65. 0.875. R andom C ode Snippe ts T eacher gener at es init ial pr obl em R eal C oding P uzzl es [S tudent at t emp ts t o sol v e pr obl em] x k Inspir at ion seed F ra me T eacher it er at es on pr obl em based on s tudent suc c ess/f ailur e summar y T urn = 1 def is_lig(atom): # Non-hydrogen if atom.residue.name == "UNL" and atom.atomic_number > 1: return True def find_atom(res_atom=None, prot_file=None, combined_pmd=None): # Parse the input data like this -> "A_LYS_311_N" chain = res_atom.split("_")[0] res_name = res_atom.split("_")[1] res_number = int(res_atom.split("_")[2]) atom_name = res_atom.split("_")[3] T urn > 1 S ynt he t ic Data Gener at ion Pipeline F il t er & Deduplic at e Err or when running c ode F ormat t ing err or s Input - output pair s ar e no t div er se enough S tudent ne v er sol v ed Given an array arr of n positive integers lesser than 1000, check if there exists at least one subarray, the product of whose elements is a power of 2. Input format: n arr Output format: boolean Note: 1. 1 <= n <= 99 S tudent Summar y ## Task: Mutate Python Code Snippet Based on Student Responses to Previous Challenge and Create a New Challenge ### Previous Code, input-output pairs and message: [....] Previous message: [....] ### Student answers summary: Pass rate for the student over 8 attempts was: Example solved: [....] Example failed: [....] ### Progression Strategy: The student almost always solved the previous task with a pass rate of 0.875. Either the input- output relationship was too trivial (maybe not diverse enough or incomplete such that a much easier function also passes the tests), or the function was relatively easy to implement. Try to mutate this problem into a medium problem: student should have a pass rate of 0.35-0.65. 0.875. R andom C ode Snippe ts T eacher gener at es init ial pr obl em R eal C oding P uzzl es [S tudent at t emp ts t o sol v e pr obl em] x k Inspir at ion seed F ra me T eacher it er at es on pr obl em based on s tudent suc c ess/f ailur e summar y T urn = 1 def is_lig(atom): # Non-hydrogen if atom.residue.name == "UNL" and atom.atomic_number > 1: return True def find_atom(res_atom=None, prot_file=None, combined_pmd=None): # Parse the input data like this -> "A_LYS_311_N" chain = res_atom.split("_")[0] res_name = res_atom.split("_")[1] res_number = int(res_atom.split("_")[2]) atom_name = res_atom.split("_")[3] T urn > 1 S ynt he t ic Data Gener at ion Pipeline F il t er & Deduplic at e Err or when running c ode F ormat t ing err or s Input - output pair s ar e no t div er se enough S tudent ne v er sol v ed Given an array arr of n positive integers lesser than 1000, check if there exists at least one subarray, the product of whose elements is a power of 2. Input format: n arr Output format: boolean Note: 1. 1 <= n <= 99 S tudent Summar y ## Task: Mutate Python Code Snippet Based on Student Responses to Previous Challenge and Create a New Challenge ### Previous Code, input-output pairs and message: [....] Previous message: [....] ### Student answers summary: Pass rate for the student over 8 attempts was: Example solved: [....] Example failed: [....] ### Progression Strategy: The student almost always solved the previous task with a pass rate of 0.875. Either the input- output relationship was too trivial (maybe not diverse enough or incomplete such that a much easier function also passes the tests), or the function was relatively easy to implement. Try to mutate this problem into a medium problem: student should have a pass rate of 0.35-0.65. 0.875. Figure 1 Overview of the m ulti-turn synthetic data pipeline. A seed snipp et, sampled from random co de or real co ding puzzles, serves as inspiration for the teacher. In the first turn, the teacher generates an initial problem according to the current environmen t’s rules, and the student attempts to solve it multiple times. In later turns, the teacher receiv es a summary of the studen t’s p erformance (pass rate and representativ e solutions) and adapts the problem accordingly . Inv alid or redundant generations are filtered and deduplicated b efore inclusion in the dataset. 1 1 Intr oduction Reinforcemen t learning (RL) has b ecome a centr al paradigm for improving large language mo dels (LLMs) b ey ond sup ervised fine-tuning. Y et as RL scales, a key challenge emerges: how can we sustain p erformance gains, and where should new training data come from? Addressing this question requires understanding what defines an effective RL task and environmen t. Recen t works explore asymmetric play in the LLM p ost-training era, where a teacher dynamically generates data tailored to the student mo del’s learning progress, aiming for op en-ended RL at scale. Ho w ev er, effectiv ely training suc h a teacher remains elusive. As shown in Zhao et al. ( 2025 ), training the teacher do es not result in substantial improv emen ts o v er training only the student. Although there are p ositive gains from dynamically generating syn thetic tasks, we are still b ottleneck ed by a limited teac her suc h that initial p erformance gains plateau. RL with real data is not easy to scale. One fundamen tal c hallenge with RL p ost-training is that naively increasing th e num ber of problems do es not guarantee further p erformance gains, as results are confounded b y RL dynamics as well as the difficult y distribution of the problem set at hand. Typically , each problem set has a mix of easy and medium-level problems, accompanied by very hard problems. The latter split p oses a hard exploration challenge that cannot b e solved by the initial mo del, such that the computation sp ent on these samples early on in training hurts efficiency . How ev er, on the other end of the sp ectrum, the very easy questions giv e early gradien t up dates, but dominate training while the mo del’s entrop y collapses. A common strategy prop osed in the literature is curriculum sampling, where the mo del is first trained on easier problems, gradually shifting to w ards the hard ones ( Kimi T eam et al. , 2025 ). How ev er, in the case of real data, there is often no guarantee that the hard problems build up on the easy ones in a meaningful wa y . Moreo v er, since mo del entrop y naturally decreases during RL training ( Cui et al. , 2025 ), sp ending too muc h of the exploration budget on easy problems can reduce the mo del’s capacity to learn from more challenging ones later. These factors limit the effectiveness of naive curriculum-based sampling in practice. T aking inspiration from the idea of stepping stones in goal-based exploration ( F orestier et al. , 2022 ), we incorp orate e asier v arian ts of hard problems to help alleviate the hard exploration challenge. W e prop ose a m ulti-turn approach to generate synthetic data (Fig. 1 ). Similar to Magico der ( W ei et al. , 2023 ), we make use of actual co de snipp ets to ground the problem generation and ensure diversit y and cov erage. Unlik e standard single-turn generation, where multiple problem instances are indep endently sampled from a seed snipp et and later filtered for solv abilit y , formatting, and div ersit y , our metho d introduces an additional iteration axis. The teac her revisits and mutates the initially generated problem ov er m ultiple turns, adjusting its difficulty at each step. This pro cess pro duces structured v ariants of the same core task, yielding easier and harder counterparts that serve as targeted augmentations. Crucially , this adaptation happ ens purely through in-con text learning, requiring no gradient up dates to the teacher. Multi-turn data generation provides a practical pip eline for pro ducing high-quality synthetic data at scale, reducing inv alid generations and naturally in tro ducing problem v arian ts of v arying difficulty . Augmen ting real co de-con test questions with such synthetic data results in consisten t p erformance gains on b oth in-domain (co de) and out-of-domain (math) b enchmarks. T o b etter understand the individual factors contributing to RL improv ements, we systematically isolate the effects of differen t design c hoices. In particular, we address the following research questions: • Do stepping stones , i.e. intermediate problems of v arying difficult y , improv e downstream generalization? • Ho w do es the difficult y level of RL problems influence training dynamics and conv ergence? • T o what extent do es the c h oice of curriculum sc hedule matter? • Giv en a limited compute budget, is it more effective to scale the num b er of problems within a single en vironmen t, or to scale across m ultiple environmen ts; and can environmen t div ersit y serv e as an indep enden t axis of impro v ement? Our main contributions are a scalable multi-turn framework for synthetic data creation and a systematic exp erimen tal study of how task difficult y , curriculum design, and environmen t diversit y affect RL for code generation. Through extensive exp eriments across mo del families (Llama3.1-8B Instruct, Qwen3-8B Base, and 2 Qw en2.5-32B Base), we analyze conv ergence and generalization under different data generation and training setups. 2 Related W ork Synthetic Data. Syn thetic data generation has b ecome a p ow erful to ol both in sup ervised fine-tuning (SFT) and reinforcement learning (RL) for large language mo dels (LLMs). Magicoder ( W ei et al. , 2023 ) demonstrates that large-scale syn thetic co de data can substan tially enhance co de generation capabilities of a mo del in an SFT setting, motiv ating the use of automatically generated problem instances for RL. Similarly , Havrilla et al. ( 2025 ) present SP ARQ, which generates o v er 20 million synthetic math problems using quality–div ersity algorithms and studies how problem difficulty and diversit y affect generalization in fine-tuning. Jiang et al. ( 2025 ) explore generative data refinement, transforming noisy real-data corp ora in to higher-utilit y training data for mo del adaptation. A t the RL stage, Guo et al. ( 2025 ) propose a framew ork for RL using only syn thetic question-answ er pairs deriv ed from task definitions and retrieved do cuments, rep orting large improv ements across reasoning b enc hmarks. Liang et al. ( 2025 ) introduce SwS , which identifies mo del weakness areas and synthesizes targeted problems to improv e reasoning p erformance. Goldie et al. ( 2025 ) further address multi-step reasoning and to ol-use tasks via synthetic data generation in a multi-step RL pip eline. T ogether, these works highlight the increasing role of syn thetic data in scaling adaptation and reasoning for LLMs. Our approach builds on this line of work by combining structured RL environmen ts with teacher–studen t generation and curriculum con trol to optimize b oth in-domain p erformance and out-of-domain generalization. Asymmetric Self-Play. Asymmetric self-pla y in LLMs has b een explored across several domains, including co ding and verification ( Zhao et al. , 2025 ; Lin et al. , 2025 ), to ol use ( Zhou et al. , 2025 ), alignmen t ( Y e et al. , 2025 ), and theorem pro ving ( Dong and Ma , 2025 ; Poesia et al. , 2024 ). These works leverage the interaction b et w een a generator (teacher) and a solver (student) to create adaptiv e task distributions, an idea closely related to our teac her–studen t setup for multi-t urn data generation. Curriculum L e arning. Curriculum learning remains an active area of research in RL for LLM p ost-training. W ang et al. ( 2025 ) prop ose a distribution-level curriculum learning framew ork, where the sampling probabilities are dynamically adjusted, prioritizing either distributions with high av erage adv antage (exploitation) or low sample count (exploration). Bae et al. ( 2025 ) introduce adaptive sampling strategies that remov e ov erly easy or hard examples to fo cus on intermediate difficult y . In the context of alignment, Pattnaik et al. ( 2024 ) in tro duce curricula that gradually increase task difficulty , while Kimi T eam et al. ( 2025 ) employ manually defined heuristic curriculum stages, starting with easy problems and gradually progressing to harder ones. They also use a prioritized sampling strategy , where problems with low er success rates receiv e higher sampling probabilities. Xie et al. ( 2025 ) study the effectiveness of reasoning with RL on synthetic logic puzzles, showing that under a fixed data budget, well-designed curricula consistently outp erform random sh uffling. Finally , rev erse curricula hav e b een sho w n to improv e exploration, where the start state of reasoning progressively slides from a demonstration’s end to its b eginning ( Xi et al. , 2024 ). 3 Synthetic Data Generation Pipeline 3.1 En vironments Eac h en vironment is framed as a teacher–studen t interaction: the teacher generates task instances, and the studen t attempts to solve them. The RL environmen ts used throughout this work are: Induction , Abduction , Deduction (inspired b y Zhao et al. ( 2025 )) and Fuzzing . Induction Program syn thesis environmen t. This can b e seen as a v ariant of classical co de puzzle environmen ts used for RL p ost-training. 3 A b duction Input prediction environmen t. Given a function f() and an output o , the task is to predict the input i that pro duced o . De duction Output prediction environmen t. Given a function f() and an input i , the task is to predict the output o obtained up on execution. F uzzing F uzzing en vironment inspired by prop erty-based testing. Giv en f() , pre_test_f() , and test_f() , the task is to find an input such that test_f() fails while pre_test_f() passes. The function pre_test_f() acts as a type chec ker, e.g. verifying correct input t yp es to ensure that test_f() fails for non-trivial reasons. The corresp onding teacher–studen t sp ecifications and reward definitions for eac h environmen t are summarized in T able 1 . T able 1 Overview of RL en vironments. The teacher column sp ecifies how each task instance is generated, while the studen t column describes the corresp onding RL problem to b e solved. The final column shows the reward function used for ev aluation. Here, ˆ · denotes the student’s prediction, and I [ · ] is the indicator function. En vironment T eacher: Generator Student: Solver Rewar d Induction Generates function f() , a natural language message , and k input cases i 1 , ..., i k . The corresponding gold outputs o 1 , ..., o k are computed by execution: o k = f ( i k ) . Given k ′ < k input-output pairs { i 1 , o 1 } ..., { i ′ k , o ′ k } (the remaining k − k ′ are held out as private test cases) and the message , student syn- thesizes f() . r = I h ∀ k, ˆ f ( i k ) = o k i Abduction Generates function f() and one in- put case i . The gold output is com- puted as o = f ( i ) . Given f() and the output o , infers the input i that pro duced the giv en output. r = I [ f ( ˆ i ) = o ] Deduction Generates function f() and one in- put case i . The gold output is com- puted as o = f ( i ) . Given f() and the input i , infers the output o to b e obtained when executing f(i) . r = I [ ˆ o = o ] Fuzzing Generates a function f() , which con- tains a subtle bug to b e exploited, and tests pre_test_f() and test_- f() . Given f() , pre_test_f() and test_f() , finds an input test case such that test_f() fails while pass- ing pre_test_f() . r = I [ pre_test_f ( ˆ i ) ∧ ¬ test_f ( ˆ i )] 3.2 Inspiration seeds W e use seed data as inspiration for synthetic data generation to ensure diversit y and grounding. W e use tw o differen t classes of seed data: (1) we extract successful solutions to real co ding problems solved during an initial RL training run, and (2) random op en source co de snipp ets collected from the wild. F or (2), similar to W ei et al. ( 2023 ), w e adopt starcoderdata as our seed corpus. In order to generate a syn thetic question, we randomly select 25–50 consecutive lines to be our seed snipp et for inspiration, and the teac her mo del is ask ed to try to incorp orate the core logic of this example snipp et for data generation. 3.3 Generating Multi-T urn Synthetic Data W e p erform multi-turn data generation, where the teacher iteratively adapts task difficulty based on the studen t’s p erformance (Fig. 2 ). In the first turn, given a seed snipp et (see Sec. 3.2 ) and a task description, the teacher is prompted to generate a v alid problem instance following the rules of the current RL environmen t. The res ulting problem t 1 is then presen ted to the studen t, who attempts to solve it M times (e.g. M = 32 ). 1 1 In practice, we use M = 32 . W e also exp erimented with M = 8 , but found that studen t pass rate estimates b ecome noisy for small M . 4 t = int(input()) for _ in range(t): x = int(input()) # The minimum number of rolls is 1 (since minimum face is 2) # The maximum number of rolls is x // 2 (since each roll is at least 2) # We can return any number of rolls between 1 and x//2 # For simplicity, we return x // 2 print(x // 2) from typing import List def f(total: int) -> int: """ Return the number of unordered combinations of dice rolls that sum to `total`, where each die can show a value from 2 to 6 (inclusive). The algorithm is a classic unbounded-knapsack / coin-change DP: - `dp[s]` holds the count of ways to obtain sum `s`. - We iterate over the allowed face values first, then over increasing sums, which guarantees that the order of faces does not create duplicate permutations. """ if total < 2: # cannot reach a sum smaller than the smallest face return 0 faces: List[int] = [2, 3, 4, 5, 6] dp = [0] * (total + 1) dp[0] = 1 # one way to reach sum 0 – choose no dice for face in faces: for s in range(face, total + 1): dp[s] += dp[s - face] return dp[total] T urn 1 T urn 1 → 2 Seed Figure 2 Example of multi-turn data generation. The top-left panel shows the seed snipp et provided to the teacher, tak en from a real co ding puzzle. In turn 1, the teacher generates a puzzle with a student pass rate of 0.875 ( M = 8 ). In turn 2, after observing the student’s p erformance, the teacher pro duces a harder v ariant with a pass rate of 0.25. In the second turn, the studen t’s attempts from turn 1 are summarized as the pass rate p = 1 M P M m =1 r m , together with representativ e examples of b oth successful and failed solutions (if av ailable). The teacher then receiv es the original question and this performance summary , and is prompted to adapt the problem accordingly for the next iteration. The adaptation follows a progression strategy that adjusts task difficulty based on the observed pass rate (e.g. increasing complexity if p > 0 . 65 , or decreasing complexity if p = 0 ). Subsequen t turns follow the same iterative structure, with each turn conditioned on the immediately preceding question and student summary rather than the full history (in practice, we use 6 turns p er seed). A full example of this in-con text adaptation, including the teacher prompt and reasoning, is provided in Sec. F . Curren tly , the data generation pip eline is decoupled from the RL runs and the actual student. During m ulti-turn generation, the same mo del used as teacher takes on the role of the student. In our exp eriments, w e use GPT-OSS 120B high reasoning mo de as our teac her and the same mo del is used in low reasoning mo de as the student. W e exp ect further p erformance gains from having the teacher in the lo op and learning from the mistak es of the studen t on-the-go, resulting in more effective augmentations. 3.4 Reinforcement Learning with V erifiable Rewar ds W e employ an asynchronous v ariant of Group Relative P olicy Optimization (GRPO) ( Shao et al. , 2024 ) as our reinforcemen t learning algorithm. GRPO replaces the v alue function with a Monte Carlo–based estimation, sampling G outputs from the mo del and computing the adv antage of each o i ( i ∈ { 1 , . . . , G } ) by normalizing its rew ard relative to others within the group. In our implementation, we omit b oth the standard-deviation normalization in the adv antage computation and the KL-regularization term (see Sec. E for more details). 5 4 Results W e train Llama3.1-8B Instruct ( Grattafiori et al. , 2024 ), Qw en3-8B Base (non-thinking mo de) ( Y ang et al. , 2025 ), and Qw en2.5-32B Base ( Y ang et al. , 2024 ) with reinforcement learning on co de tasks without explicit reasoning traces, and ev aluate b oth in-domain (co de) and out-of-domain (math) p erformance to analyze p erformance across mo del families and scales. F or co de, we use LiveCodeBench (LCB) ( Jain et al. , 2024 ), aggregating queries b et w een 08.2024 and 05.2025 (454 problems), as w ell as the LCBv5 splits ( easy , medium , hard ; 05.2023–01.2025). F or math, w e ev aluate on the Math500 ( Hendryc ks et al. , 2021 ) and AIME2024 b enc hmarks. 4.1 Scaling and A ugmenting RL with Synthetic Data W e b egin by examining whether scaling reinforcement learning with additional real co ding problems alone leads to sustained p erformance gains. Figure 3 compares RL training on 25K and 81K real co ding problems in Qw en3-8B Base. 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.280 0.300 0.320 0.340 0.360 LCB P ass@10 0 10K 20K 30K Training Steps 0.660 0.680 0.700 0.720 0.740 0.760 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 REAL 25K REAL 81K Qwen 3 8B Base (baseline) Figure 3 Scaling with real data in Qwen3-8B Base . W e compare RL training on 25K and 81K real co ding problems using GRPO (3 seeds). Performance is trac ked on in-domain ( LCB ) and out-of-domain ( Math500 and AIME2024 ) b enc hmarks throughout training. P erformance gains plateau early , indicating limited b enefit from scaling real data alone. During RL training, p erformance impro vemen ts plateau early as p olicy entrop y decreases. Increasing the n um b er of RL problems does not yield prop ortional gains (Figure 3 ), suggesting that data div ersity or structure, rather than v olume alone, b ecomes the limiting factor. 4.1.1 Does augmenting real coding problems with synthetic problems help boost performance? W e show that augmenting real co ding questions with synthetic problems leads to faster and more stable con v ergence in-domain (co de) for Llama3.1-8B Instruct (Fig. 4 ), Qwen3-8B Base (Fig. 5 ), and Qwen2.5-32B Base (Fig. 6 ), and improv es out-of-domain (math) p erformance for Llama3.1-8B Instruct and Qwen2.5-32B. F or RL runs with augmented data, the total num b er of training problems is increased b y 20K, while k eeping the o verall training budget fixed. Consequen tly , each problem is encoun tered fewer times within the same n um b er of RL steps sho w n in the plots. Notably , synthetic augmentation also outp erforms the larger 81K real-data baseline on most in-domain LCB metrics, underscoring the efficiency of diverse synthetic additions ev en under a fixed compute budget (see Fig. 19 ). T o test whether the choice of seed affects these gains, we p erform an ablation comparing synthetic problems seeded with answ ers to real questions versus random co de snippets from starcoderdata (see Fig. 5 ). W e matc h dataset difficulty across conditions to ensure that observed trends are not driven by easier questions. T raining on synthetic problems seeded with starcoderdata increases data diversit y compared to augmenting real problems with their own v ariations. Consequently , we observe higher pass@1 and pass@10 in-domain, indicating that greater diversit y b o osts p erformance and that random-co de seeding can b e comp etitiv e with real data for synthetic augmentation. Next, we analyze p erformance when training exclusively on synthetic problems. 6 0 10K 20K 30K Training Steps 0.050 0.075 0.100 0.125 0.150 0.175 0.200 LCB P ass@1 0 10K 20K 30K Training Steps 0.420 0.440 0.460 0.480 0.500 Math500 P ass@1 0 10K 20K 30K Training Steps 0.060 0.080 0.100 0.120 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.120 0.140 0.160 0.180 0.200 0.220 0.240 LCB P ass@10 0 10K 20K 30K Training Steps 0.630 0.640 0.650 0.660 0.670 Math500 P ass@5 0 10K 20K 30K Training Steps 0.120 0.140 0.160 0.180 0.200 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.300 0.400 0.500 0.600 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.040 0.050 0.060 0.070 0.080 0.090 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.005 0.010 0.015 0.020 0.025 0.030 lcb_codegen_hard/pass@1 REAL 25K REAL 25K + SYNTH-AUG 20K Solved Llama 3.1 8B Instruct (baseline) Figure 4 Synthetic data augmentations in Llama3.1-8B Instruct. RL training on 25K real co de-contest problems (baseline) versus 25K real plus 20K syn thetic problem augmentations seeded from solved real questions (3 seeds). Syn thetic augmentation improv es p erformance across b oth in-domain (co de: LCB ) and out-of-domain (math: Math500 , AIME2024 ) b enchmarks. 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 LCB P ass@1 0 10K 20K 30K Training Steps 0.280 0.300 0.320 0.340 0.360 LCB P ass@10 0 10K 20K 30K Training Steps 0.625 0.650 0.675 0.700 0.725 0.750 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 REAL 25K REAL 25K + SYNTH-Real-Aug 20K REAL 25K + SYNTH*-Aug 20K Qwen 3 8B Base (baseline) Figure 5 Synthetic data augmentations in Qwen3-8B Base . RL training on real co de-contest problems (baseline) v ersus with synthetic problem augmentation (3 seeds). Syn thetic data are seeded either with answers to real questions ( SYNTH-Real-Aug ) or with random co de snipp ets from starcoderdata ( SYNTH*-Aug ). Performance improv es primarily on in-domain (co de: LCB ), while out-of-domain (math: Math500 , AIME2024 ) b enchmark performance remains comparable or slightly low er. 4.1.2 Are synthetic RL problems alone sufficient, and does seeding matter? Figure 16 and Figure 17 show that RL training on fully synthetic problems can matc h the LCB scores achiev ed with real data. As seen in Fig. 5 , the difference b etw een using real code-contest questions and random starcoderdata snipp ets as seeds for synthetic data generation is minimal. In the in-domain co de setting ( LCB ), we observe slightly faster conv ergence when syn thetic problems are seeded with real data. F or all 7 0 10K 20K 30K 40K 50K Training Steps 0.22 0.24 0.26 0.28 0.30 0.32 LCB P ass@1 0 10K 20K 30K 40K 50K Training Steps 0.30 0.32 0.34 0.36 0.38 LCB P ass@10 0 10K 20K 30K 40K 50K Training Steps 0.55 0.60 0.65 0.70 Math500 P ass@1 0 10K 20K 30K 40K 50K Training Steps 0.06 0.08 0.10 0.12 0.14 AIME2024 P ass@1 REAL 25K REAL 25K + SYNTH-AUG 20K Induction Qwen 2.5 32B Base (baseline) Figure 6 Synthetic data augmentations in Qwen2.5-32B Base . RL training on 25K real co de-contest problems (baseline) versus 25K real plus 20K syn thetic problem augmentations seeded from solved real questions (2 seeds). Syn thetic augmentation shows improv ed p erformance trends for b oth in-domain (co de: LCB ) and out-of-domain (math: Math500 , AIME2024 ) b enchmarks. exp erimen ts, w e matc h the difficulty histograms (based on student pass rates) b etw een the starcoderdata - and real-seeded datasets to ensure a fair comparison. Closer insp ection reveals that most of the LCB gains are correlated with p erformance on the LCBv5-easy split, while p erformance on medium decreases. W e hypothesize that this stems from the distribution of generated question difficulties: during filtering, we include all questions with pass rates b etw een 0.01 and 0.97 without explicitly flattening the difficulty distribution. In practice, this results in a dataset dominated by easier questions, leading to ov erfitting on simpler tasks. W e further analyze the effects of difficult y filtering and curriculum strategies in the follo wing sections. 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.280 0.300 0.320 LCB P ass@10 0 10K 20K 30K Training Steps 0.640 0.660 0.680 0.700 0.720 Math500 P ass@1 0 10K 20K 30K Training Steps 0.090 0.100 0.110 0.120 0.130 0.140 AIME2024 P ass@1 SYNTH* Induction 20K SYNTH-Real-Aug 20K Qwen 3 8B Base (baseline) Figure 7 RL with pure synthetic data in Qwen3-8B Base . Instead of augmenting the 25K real co de-con test questions, RL is p erformed solely on synthetic induction problems generated with tw o seeding strategies: (1) real questions as inspiration seeds ( SYNTH-Real-Aug ), and (2) random co de snipp ets from starcoderdata ( SYNTH*-Aug ). Results shown for 3 seeds. P erformance is comparable across b oth setups, with slightly faster in-domain conv ergence ( LCB ) when seeding with real data. T akeawa y • Augmen ting real co de-contest questions with synthetic RL problems from a custom induction en vironmen t helps obtain b etter and faster con vergence in-domain across mo del families, while also sho wing gains out-of-domain on Math b enchmarks with Llama3.1-8B Instruct and Qwen2.5-32B Base. • Div ersifying inspiration snipp ets and using starcoderdata instead of the real data itself for augmen tation sho ws impro v ed trends in LCB . • Syn thetic RL problems alone are comp etitive; how ever, the difficulty distribution of the generated data migh t need explicit curation to a v oid ov erfitting on easy problems. • Seeding with real co de-contest questions instead of starcoderdata pro vides slightly faster conv er- gence on LCB . 8 Chain Example 1 hard Y our task is to write an algorithm that, giv en a set of geographic no des and directed edges b etw een them, determines for each no de the smallest angular sector that con tains all b earings of its outgoing edges. The challenge lies in handling circular wrap-around (e.g., bearings near 0 ° and 359 ° ) and producing exact degree spans efficiently . medium Y our challenge is to write a function that, given a list of compass b earings (in degrees), finds the smallest angular sector that cov ers them all. The sector may need to wrap around the 0 ° /360 ° b oundary , so careful handling of circular wrap-around is required. Return the sector size rounded to one decimal place. easy Y our task is to write a function that, given tw o compass b earings (in degrees), returns the smallest angular distance b etw een them. The distance must b e b etw een 0 ° and 180 ° , and you should round the answer to one decimal place. Think carefully ab out the circular nature of a compass when the tw o b earings lie on opposite sides of the 0 ° /360 ° line. Chain Example 2 hard Y our task is to implement f that computes the minimum num b er of node insertions and deletions needed to transform one ordered tree into another. Both trees are encoded as strings consisting solely of ‘(’ and ‘)’, where each pair represents a no de. The challenge lies in handling arbitrary tree shap es, deriving the correct post-order indices, left-most leaf descendants, and keyroots, and then applying the Zhang-Shasha dynamic programming recurrence. Think carefully ab out the 1-based indexing used by the algorithm and ensure your implementation runs efficiently for the provided test cases. medium Y our challenge is to implemen t f that, given t wo strings consisting only of ‘(’ and ‘)’, builds the corresp onding ordered trees and returns the size (num ber of no des) of the biggest r o ote d sub-tree that app ears identically at the top of b oth trees. In other words, start from the tw o ro ots and walk down the left-most children as long as the sub-trees match p erfectly; sum the no des you encounter. Think about how to parse the parenthesis representation into a tree and how to compare tw o sub-trees for exact structural equality . No randomisation or I/O is inv olved—just careful recursion and tree trav ersal. easy Y our challenge is to write f that takes a single string made only of ‘(’ and ‘)’, builds the ordered tree enco ded by that parenthesis representation, and returns the total num b er of no des in the tree. Think about how each ‘(’ creates a new node and each ‘)’ finishes the current no de, then recursively count the no des. No I/O, randomness, or date/time operations are needed—just careful parsing and a simple recursion. Figure 8 Examples of easy – medium – hard question chains. Each chain illustrates a progression in task complexity within the same conceptual domain, derived by starting from a hard question and generating simpler v ariants that capture its core subproblems. This reverse construction ensures that easy and medium questions corresp ond to meaningful comp onents of the original hard task rather than trivial simplifications. 0 5720 11436 17152 22856 28572 34288 39996 RL T raining Step 0 20 40 60 80 Cumulative Solve R ate (%) Solve R ate Progress During RL T raining by Difficulty (Mean ± Std) Complete Chains Disjoint Chains (a) Hard curriculum 0 5724 11440 17156 22872 28588 34292 39996 RL T raining Step 0 20 40 60 80 Cumulative Solve R ate (%) Solve R ate Progress During RL T raining by Difficulty (Mean ± Std) Complete Chains Disjoint Chains (b) Soft curriculum Figure 9 Qwen3-8B Base: Solve rates across easy–medium–hard splits under different curriculum strategies. (a) Hard curriculum with abrupt transitions b etw een difficulty levels. (b) Soft curriculum with gradual transitions b et w een difficulty levels. Curv es depict cumulativ e solve rates for easy , medium , and hard questions during RL training. Solid lines corresp ond to training on complete easy–medium–hard c hains, while dashed lines show the disjoint-c hain ablation. 4.2 Does multi-turn data generation help over single-turn data g eneration? Multi-turn data generation improv es b oth the quality and retention of synthetic problems. By allowing the teac her mo del to iterativ ely refine previous outputs, we reduce inv alid generations caused by formatting 9 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K 40K Training Steps 0.260 0.270 0.280 0.290 0.300 0.310 0.320 LCB P ass@10 0 10K 20K 30K 40K Training Steps 0.660 0.680 0.700 0.720 Math500 P ass@1 0 10K 20K 30K 40K Training Steps 0.100 0.120 0.140 0.160 AIME2024 P ass@1 SYNTH* Chains curriculum -- hard SYNTH* Disjoint curriculum -- hard Qwen 3 8B Base (baseline) (a) Hard curriculum: hard transitions b etw een easy – medium – hard splits. 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K 40K Training Steps 0.260 0.270 0.280 0.290 0.300 0.310 0.320 LCB P ass@10 0 10K 20K 30K 40K Training Steps 0.660 0.680 0.700 0.720 0.740 Math500 P ass@1 0 10K 20K 30K 40K Training Steps 0.080 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 SYNTH* Chains curriculum -- soft SYNTH* Disjoint curriculum -- soft Qwen 3 8B Base (baseline) (b) Soft curriculum: soft transitions b etw een easy – medium – hard splits. 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.260 0.280 0.300 0.320 LCB P ass@10 0 10K 20K 30K Training Steps 0.640 0.660 0.680 0.700 0.720 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.110 0.120 0.130 0.140 0.150 AIME2024 P ass@1 SYNTH* Chains - uniform SYNTH* Disjoint - uniform Qwen 3 8B Base (baseline) (c) No curriculum: uniform sampling from easy – medium – hard splits throughout RL training. Figure 10 Qwen3-8B Base: RL on chains of easy–medium–hard questions with different curriculum strategies. Eac h row shows a different curriculum setup: (a) hard transitions b etw een difficulty levels, (b) soft transitions, and (c) no curriculum (uniform sampling). Results are shown for LCB (in-domain) and Math500 , AIME2024 (out-of-domain) with pass@1 and pass@10 metrics plotted ov er RL training steps. errors or o verly difficult tasks, increasing the fraction of viable problems by appro ximately fourfold after filtering compared to the same num b er of indep endent single-turn samples p er seed. Beyond this practical impro v ement, m ulti-turn generation introduces a second, conceptual adv an tage: it naturally pro duces stepping stones, i.e. progressiv ely refined task v arian ts that can act as in termediate challenges during RL training. Hard problems p ose a significant exploration challenge under binary rewards, where p ositive feedback is only obtained for fully correct solutions. W e therefore test whether the stepping-stone structure induced by m ulti-turn generation helps mitigate this c hallenge and facilitates more effective learning for RL. Building complete chains of easy - medium - hard questions. T o ev aluate whether stepping stones help mitigate the hard-exploration challenge, we compare RL training on problem sets with and without explicit stepping-stone structure. This pro cess builds on the m ulti-turn generation pip eline (Sec. 3.3 ), but reverses the direction: rather than generating problems across turns and filtering p ost-ho c, we start from hard questions and explicitly prompt the teacher to pro duce progressively easier v ariants, filtering b etw een turns to ensure v alid difficulty transitions (see Sec. B for details on the filte ring). This yields 1012 coheren t easy–medium–hard question c hains (3036 problems total) built around the same underlying task. Some examples are shown in Fig. 8 . Starting from hard questions ensures that we do not obtain artificially inflated difficulties (e.g. by trivially mo difying easy questions), and that the generated v ariants reflect meaningful v ariations in problem 10 complexit y . In order to isolate the effect of explicit stepping-stone structure, we construct a base line consisting of disjoint easy–medium–hard problems that share the same difficulty distribution as the c hained data but are not deriv ed from one another. Note that this is a strong baseline, as disjoint problems are drawn from indep endent seeds and thus offer greater ov erall div ersity . In this baseline, the easy , medium , and hard splits are matched b y their empirical student pass-rate histograms, ensuring comparable difficulty levels across datasets. While these problems do not form explicit c hains, some implicit skill ov erlap ma y still o ccur, as certain questions ma y target similar problem t yp es. T o ensure that the easy and medium coun terparts are sufficiently reinforced b efore attempting harder v ariants, w e replace uniform sampling across difficulty levels with curriculum-based scheduling. W e design tw o v ariants: (1) Hard curriculum, where transitions b etw een difficulty levels are sharp, i.e. training b egins almost exclusively on easy tasks, shifts predominantly to medium , and finally fo cuses on hard tasks. (2) Soft curriculum, where easy and medium problems contin ue to app ear throughout training, allowing for smo other transitions and mixed exp osure. The exact sampling weigh ts for b oth curricula are provided in App endix B.1 . As shown in Fig. 9 , training on full c hains with explicit stepping stones improv es the mo del’s ability to solv e medium and hard questions for b oth curriculum strategies. How ev er, when insp ecting do wnstream b enc hmark p erformance, w e observ e n uanced differences across curricula (Fig. 10 ). Although ov erall differences remain marginal, training with explicit stepping stones yields mo dest impro v emen ts under the hard curriculum, while effects under the soft and uniform setups are less consistent, particularly on out-of-domain b enc hmarks. Zhang and Zuo ( 2025 ) show that for GRPO, if rewards are applied uniformly across problems regardless of their difficulty , mo dels end up excessively optimizing simpler tasks while neglecting more challenging problems that require deep er reasoning. Similarly , Qu et al. ( 2026 ) s ho w that optimization on easier, already-solv able problems can actively inhibit progress on harder ones. Ec hoing their findings, w e also find that p erformance is often dominated by the easy split in our exp eriments, and mixing the splits throughout training hurts p erformance gains. In the context of stepping stones, how ever, this trade-off b ecomes a double-edged sword. Ideally , the mo del should con tin ue to see the easy and medium v ariants of hard problems often enough to learn the underlying structure b efore attempting the hardest instances. This effect is eviden t in Fig. 9 , where the soft curriculum, whic h maintains exp osure to the easy split later in to training, achiev es higher solve rates. Y et, mixing gradien ts from problems of v arying difficulty can reduce the effectiveness of gradien t updates across difficult y lev els, resulting in solv e-rate improv ements that do not translate in to downstream gains. Overall, these results suggest that while explicit stepping stones offer mild b enefits, their effectiveness dep ends strongly on curriculum design and the balance of rew ards across difficulty levels. T akeawa y Multi-turn generation introduces intermediate problem v ariants that can marginally improv e learning under structured curricula. Their b enefit is most evident with hard curricula, while mixed-difficulty training can limit these gains b y creating interference across tasks. 4.3 How muc h does the difficulty of questions matter for RL? So far, we hav e operated under the assumption that solving harder questions provides a more v aluable learning signal than solving easier ones. W e test this hypothesis by examining how question difficulty shap es RL dynamics. Instead of using mixed chains of 3036 questions across difficulty levels ( easy , medium , hard ; 1012 each), we train mo dels exclusively on questions from a single difficulty level (3036 p er difficult y level) (Fig. 11 ). T raining on easy questions yields early gains and faster conv ergence, as exp ected. How ever, training on medium questions ac hieves comparable or b etter ov erall p erformance despite slightly slow er conv ergence. Notably , mo dels trained on medium -lev el questions p erform b etter on the LCBv5-medium and LCBv5-hard splits. This suggests that the apparent early gains from easy questions ma y reflect ov erfitting to simpler problem types. T raining on the hard split, in contrast, results in muc h slow er conv ergence due to the sparsity 11 0 10K 20K 30K Training Steps 0.180 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.640 0.660 0.680 0.700 0.720 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.260 0.280 0.300 0.320 0.340 LCB P ass@10 0 10K 20K 30K Training Steps 0.810 0.820 0.830 0.840 0.850 0.860 0.870 Math500 P ass@5 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.675 0.700 0.725 0.750 0.775 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.260 0.280 0.300 0.320 0.340 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.030 0.035 0.040 0.045 0.050 lcb_codegen_hard/pass@1 0 10K 20K 30K Training Steps 0.780 0.800 0.820 0.840 0.860 0.880 lcb_codegen_easy/pass@10 0 10K 20K 30K Training Steps 0.380 0.400 0.420 0.440 0.460 0.480 lcb_codegen_medium/pass@10 0 10K 20K 30K Training Steps 0.040 0.050 0.060 0.070 0.080 0.090 0.100 lcb_codegen_hard/pass@10 SYNTH* Chains - uniform SYNTH easy only SYNTH medium only SYNTH hard only Qwen 3 8B Base (baseline) Figure 11 Qwen3-8B Base: RL on easy , medium , hard splits. Comparison of RL training when restricted to questions of a single difficulty level (3036 p er lev el) across easy , medium , and hard subsets, with the uniform chain baseline (3036 total, 1012 p er level) for reference. P erformance shown on in-domain (co de: LCB ) and out-of-domain (math: Math500 , AIME2024 ) b enchmarks across 3 seeds. of p ositiv e rewards. Although mo dels trained on hard questions remain comp etitive on out-of-domain math b enc hmarks, their p erformance lags behind on LCB . These results highligh t the imp ortance of training on non-trivial problems that still pro vide a dense enough learning signal for effective RL optimization. 12 T akeawa y T raining on medium -lev el questions offers the b est balance b et w een conv ergence sp eed and generalization, while easy questions risk o v erfitting and hard ones suffer from sparse rewards. 4.4 Does the curriculum matter? 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 0.280 LCB P ass@1 0 10K 20K 30K 40K Training Steps 0.640 0.660 0.680 0.700 0.720 0.740 Math500 P ass@1 0 10K 20K 30K 40K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 0 10K 20K 30K 40K Training Steps 0.260 0.280 0.300 0.320 0.340 LCB P ass@10 0 10K 20K 30K 40K Training Steps 0.830 0.840 0.850 0.860 0.870 Math500 P ass@5 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 0 10K 20K 30K 40K Training Steps 0.675 0.700 0.725 0.750 0.775 0.800 0.825 lcb_codegen_easy/pass@1 0 10K 20K 30K 40K Training Steps 0.225 0.250 0.275 0.300 0.325 0.350 lcb_codegen_medium/pass@1 0 10K 20K 30K 40K Training Steps 0.030 0.035 0.040 0.045 0.050 0.055 lcb_codegen_hard/pass@1 0 10K 20K 30K 40K Training Steps 0.775 0.800 0.825 0.850 0.875 0.900 lcb_codegen_easy/pass@10 0 10K 20K 30K 40K Training Steps 0.300 0.350 0.400 0.450 0.500 lcb_codegen_medium/pass@10 0 10K 20K 30K 40K Training Steps 0.060 0.070 0.080 0.090 0.100 lcb_codegen_hard/pass@10 REAL 25K Classic curriculum Uniform Reverse curriculum [medium start] Qwen 3 8B Base (baseline) Figure 12 Comparing different curriculum strategies in Qwen3-8B Base . The figure compares RL training with differen t curriculum strategies o ver extended difficulty splits ( easy , easy–medium , medium , hard ). Curves show pass@1 and pass@10 on the in-domain b enchmark ( LCB , including LCBv5 - easy , medium , and hard splits) and pass@1 and pass@5 on the out-of-domain b enchmarks ( Math500 , AIME2024 ), av eraged across three seeds. Rev erse curricula starting from medium -level questions mitigate ov erfitting to easy tasks and maintain stronger p erformance on harder splits. 13 As observ ed in our earlier experiments with stepping-stones, the c hoic e of curriculum can influence RL dynamics, although the p erformance differences were not alwa ys significant. Here, we further inv estigate the exten t to whic h the curriculum sc hedule affects training outcomes. In these exp eriments, we expand the dataset by adopting a broader binning for easy , medium , and hard questions. T o retain more data, we do not homogenize the num b er of examples p er split. 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 0.280 LCB P ass@1 0 10K 20K 30K 40K Training Steps 0.660 0.680 0.700 0.720 0.740 Math500 P ass@1 0 10K 20K 30K 40K Training Steps 0.100 0.120 0.140 0.160 AIME2024 P ass@1 0 10K 20K 30K 40K Training Steps 0.260 0.280 0.300 0.320 0.340 LCB P ass@10 0 10K 20K 30K 40K Training Steps 0.830 0.840 0.850 0.860 0.870 Math500 P ass@5 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 AIME2024 P ass@5 0 10K 20K 30K 40K Training Steps 0.675 0.700 0.725 0.750 0.775 0.800 0.825 lcb_codegen_easy/pass@1 0 10K 20K 30K 40K Training Steps 0.220 0.240 0.260 0.280 0.300 lcb_codegen_medium/pass@1 0 10K 20K 30K 40K Training Steps 0.030 0.035 0.040 0.045 0.050 0.055 lcb_codegen_hard/pass@1 0 10K 20K 30K 40K Training Steps 0.775 0.800 0.825 0.850 0.875 0.900 0.925 lcb_codegen_easy/pass@10 0 10K 20K 30K 40K Training Steps 0.300 0.350 0.400 0.450 lcb_codegen_medium/pass@10 0 10K 20K 30K 40K Training Steps 0.060 0.070 0.080 0.090 0.100 lcb_codegen_hard/pass@10 Classic curriculum Reverse curriculum [hard start] Reverse curriculum [medium start] Qwen 3 8B Base (baseline) Figure 13 Rever sed curriculum experiments in Qwen3-8B Base. The figure compares RL training with different rev erse curriculum strategies o ver extended difficulty splits ( easy , easy–medium , medium , hard ). W e ev aluate tw o v ariants: starting with the medium split (“medium-start”) and starting with the hard split (“hard-start”). Curv es show pass@1 and pass@10 on the in-domain b enchmark ( LCB , including LCBv5 - easy , medium , and hard splits) and pass@1 and pass@5 on the out-of-domain b enchmarks ( Math500 , AIME2024 ), av eraged across three seeds. The medium-start rev erse curriculum shows faster conv ergence and lo w er v ariance across seeds compared to the hard-start v ariant. 14 W e test the following hypothesis: con ven tional curricula typically progress from easier to harder problems ( easy → medium → hard ). How ever, as the mo del’s en tropy naturally decreases during RL training, starting with easy problems may waste exploration capacity on tasks that the mo del can already solve, p otentially reducing its abilit y to solve harder questions later. Motiv ated b y this intuition, w e ev aluate a r everse curriculum , in which training pro ceeds from harder to easier problems ( hard → medium → easy ). Given that medium -lev el questions previously show ed strong generalization performance (Fig. 11 ), we also exp eriment with a me dium-start r everse curriculum ( medium → easy - medium ). Exact sampling sc hedules for all curricula are provided in T able 4 . The difficulty bins and corresp onding data sizes are summarized in T able 3 (see App endix Sec. C ). Results in Fig. 12 show that: (1) uniform sampling across difficulty levels is sub optimal, as p erformance is largely driv en by the easy split; (2) the classic curriculum yields faster conv ergence and stronger p erformance on easier problems, but tends to underp erform on more c hallenging splits; and (3) the rev erse curriculum ac hiev es a more balanced outcome, improving stability and yielding higher scores on LCBv5-medium , though gains on LCBv5-hard remain limited. These findings suggest that reversing the curriculum order can help main tain exploration and prev en t o v erfitting to trivial cases without sacrificing con v ergence sp eed. Notably , in the medium -start rev erse curriculum: once the training transitions tow ards the easy–medium split (after ∼ 20K steps), b oth medium and hard p erformance b egin to plateau, and in some cases degrade sligh tly . This suggests that while rev erse curricula help maintain exploration early on, contin ued exp osure to easier tasks later in training ma y again bias optimization to ward simpler problems. W e also ev aluate a reverse curriculum that starts directly from the hard split, which p oses a challenging exploration problem early in training (Fig. 13 ). This setup leads to slightly slo wer con v ergence compared to the medium-start v ariant, as the mo del initially struggles to obtain p ositive rewards on the hardest problems. More notably , we observe substantially higher v ariance across random seeds, reflecting the sensitivity of early learning to rare successful samples when rewards are sparse. These results suggest that while reverse curricula can encourage exploration, b eginning from excessively difficult tasks may destabilize optimization. T akeawa y Uniform and classic curricula tend to ov erfit to easy -lev el questions. Reverse curricula that b egin from medium tasks encourage broader exploration and more stable learning, though their adv antage ov er training solely on medium -lev el data requires further in v estigation. 4.5 How does en vironment diversity affect RL performance? So far, we hav e seen that increasing data diversit y improv es p erformance. The gains observed from synthetic data augmentation can also b e viewed as a form of diversit y injection: although the induction en vironmen t shares the core principles of typical co ding puzzles, it differs in input–output structure and question templates. W e no w ask: giv en a fixed RL problem budget, is it more b eneficial to allo cate it entirely to one environmen t with sufficient internal div ersity , or to distribute it across multiple environmen ts to in tro duce structural v ariation? T o test this, w e compare t wo settings: (1) RL training on 20K problems from the induction en vironmen t, and (2) training on 5K problems eac h from four distinct environmen ts: induction , abduction , deduction , and fuzzing . As shown in Fig. 14 , distributing the data budget across en vironmen ts yields significant improv ements on out-of-domain b enchmarks. Ev en in in-domain ev aluations, where pass@1 slightly lags b ehind the single- en vironmen t baseline, the multi-en vironment setup surpasses it in pass@10. Notably , unlik e pure induction training, we observe no ov erfitting on the easy split, which otherwise harms p erformance on medium . The same trends hold when compared to RL training on 25K real co de-contest questions (Fig. 23 ). Fig. 15 shows a similar trend for Llama3.1-8B Instruct: training on 20K problems distributed across the four environmen ts outp erforms RL on 25K real co de-con test questions, with higher out-of-domain generalization and impro ved pass@10 scores on LCB . 15 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.660 0.680 0.700 0.720 0.740 0.760 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.260 0.280 0.300 0.320 0.340 LCB P ass@10 0 10K 20K 30K Training Steps 0.820 0.840 0.860 0.880 Math500 P ass@5 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 0.300 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.675 0.700 0.725 0.750 0.775 0.800 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.240 0.260 0.280 0.300 0.320 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.030 0.035 0.040 0.045 0.050 lcb_codegen_hard/pass@1 0 10K 20K 30K Training Steps 0.775 0.800 0.825 0.850 0.875 0.900 lcb_codegen_easy/pass@10 0 10K 20K 30K Training Steps 0.350 0.400 0.450 lcb_codegen_medium/pass@10 0 10K 20K 30K Training Steps 0.060 0.070 0.080 0.090 0.100 lcb_codegen_hard/pass@10 SYNTH* Induction 20K SYNTH* Envs[x4] 20K Qwen 3 8B Base (baseline) Figure 14 Scaling the number of RL envir onments in Qwen3-8B Base . The figure compares RL traini ng on 20K syn thetic problems from a single environmen t ( induction ) with training on an equal total of 20K synthetic problems distributed across four environmen ts: induction , abduction , deduction , and fuzzing . Curves show pass@1 and pass@10 on in-domain ( LCB ) and pass@1 and pass@5 out-of-domain ( Math500 , AIME2024 ) b enchmarks throughout RL training. Distributing the data budget across environmen ts improv es out-of-domain generalization and yields higher pass@10 scores in-domain, while reducing ov erfitting on the easy split. T akeawa y The n um b er of RL environmen ts can b e viewed as an additional scaling axis: • Our exp eriments show that the diversit y injected via increasing the num b er of RL environmen ts leads to p erformance gains in pass@k scores, with less ov erfitting on easy tasks in LCBv5 . • Differen t environmen ts can target/aid different skill sets, as shown in our improv ed p erformance on out-of-domain math b enc hmarks when training across multiple environmen ts. 16 0 10K 20K 30K Training Steps 0.060 0.080 0.100 0.120 0.140 0.160 0.180 LCB P ass@1 0 10K 20K 30K Training Steps 0.420 0.440 0.460 0.480 0.500 Math500 P ass@1 0 10K 20K 30K Training Steps 0.060 0.080 0.100 0.120 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.120 0.140 0.160 0.180 0.200 LCB P ass@10 0 10K 20K 30K Training Steps 0.630 0.640 0.650 0.660 0.670 Math500 P ass@5 0 10K 20K 30K Training Steps 0.120 0.140 0.160 0.180 0.200 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.250 0.300 0.350 0.400 0.450 0.500 0.550 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.040 0.050 0.060 0.070 0.080 0.090 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.010 0.015 0.020 0.025 lcb_codegen_hard/pass@1 0 10K 20K 30K Training Steps 0.350 0.400 0.450 0.500 0.550 0.600 lcb_codegen_easy/pass@10 0 10K 20K 30K Training Steps 0.080 0.090 0.100 0.110 0.120 0.130 lcb_codegen_medium/pass@10 0 10K 20K 30K Training Steps 0.015 0.020 0.025 0.030 lcb_codegen_hard/pass@10 REAL 25K SYNTH* Envs[x4] 20K Llama 3.1 8B Instruct (baseline) Figure 15 Scaling the number of RL en vironments in Llama3.1-8B Instruct compared to real data. The figure compares RL training on 25K real co de-contest problems with training on a total of 20K synthetic problems distributed across four environmen ts: induction , abduction , deduction , and fuzzing . Curves show pass@1 and pass@10 on the in-domain b enchmark ( LCB ) and pass@1 and pass@5 on out-of-domain b enchmarks ( Math500 , AIME2024 ) throughout RL training. Despite using less data, training across multiple synthetic en vironments improv es out-of-domain generalization and yields higher in-domain pass@10 scores compared to real-only training. 5 Discussion Our exp eriments highlight several factors that influence the effectiveness of RL fine-tuning in the co ding domain. First, synthetic augmen tation of real co ding problems consistently improv es b oth con vergence sp eed and final p erformance. The gains stem not merely from additional data but from the diversit y introduced 17 b y v arying input–output structures and templates. Synthetic data generated from random starcoderdata snipp ets p erform comparably to those seeded with real questions, underscoring the imp ortance of div ersity . When used alone, synthetic RL problems remain comp etitive, though their difficulty distribution requires explicit con trol to a v oid o v erfitting on easy problems. Second, multi-turn data generation pro vides an additional adv antage b y increasing the prop ortion of v alid problems generated and implicitly introducing intermediate problem v ariants that can serv e as stepping stones during RL. While these stepping stones offer mo dest b enefits under structured curricula, their impact dep ends strongly on how difficulty levels are mixed during training. Hard curricula b enefit most, whereas excessive in terlea ving of easy and hard problems in tro duces interference that weak ens the b enefits of stepping stones. Third, our results show that problem difficulty and curriculum design join tly determine the efficiency of RL optimization: training on medium -lev el problems offers the b est balance b etw een conv ergence sp eed and generalization, while easy problems lead to ov erfitting and hard ones suffer from sparse rew ards. Results indicate that the apparent early gains from easy problems in RL data mixes provide limited long-term b enefit and may even hinder generalization. Rev erse curricula that b egin from medium tasks mitigate early ov erfitting, though their adv antage ov er training solely on medium -level data requires further inv estigation. Finally , w e find that scaling the n umber of RL environmen ts serves as a complemen tary axis of improv ement. Distributing the data budget across diverse enviro nments ( induction , abduction , deduction , fuzzing ) impro v es out-of-domain generalization and reduces ov erfitting on easy in-domain splits. These results suggest that en vironmen t div ersit y can pla y a role comparable to data scale in shaping robust RL b ehavior. References Sangh wan Bae, Jiwoo Hong, Min Y oung Lee, Hanb yul Kim, JeongY eon Nam, and Dongh yun Kw ak. Online difficult y filtering for reasoning oriented reinforcement learning. arXiv pr eprint arXiv:2504.03380 , 2025. Jade Copet, Quen tin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, F elix Kreuk, Emily McMilin, Michel Meyer, Y uxiang W ei, et al. Cwm: An op en-weigh ts llm for research on co de generation with world mo dels. arXiv pr eprint arXiv:2510.02387 , 2025. Ganqu Cui, Y uchen Zhang, Jiacheng Chen, Lifan Y uan, Zhi W ang, Y uxin Zuo, Haozhan Li, Y uchen F an, Huayu Chen, W eize Chen, et al. The en trop y mechanism of reinforcement learning for reasoning language mo dels. arXiv pr eprint arXiv:2505.22617 , 2025. Kefan Dong and T engyu Ma. Stp: Self-play llm theorem prov ers with iterative conjecturing and proving. arXiv pr eprint arXiv:2502.00212 , 2025. Sébastien F orestier, Rémy Portelas, Y oan Mollard, and Pierre-Y ves Oudeyer. Intrinsically motiv ated goal exploration pro cesses with automatic curriculum learning. Journal of Machine L e arning R ese arch , 23(152):1–41, 2022. http: //jmlr.org/papers/v23/21- 0808.html . Anna Goldie, Azalia Mirhoseini, Hao Zhou, Irene Cai, and Christopher D Manning. Synthetic data generation & m ulti-step rl for reasoning & to ol use. arXiv preprint , 2025. Aaron Grattafiori, Abhimanyu Dub ey , Abhinav Jauhri, Abhina v Pandey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Sc helten, Alex V aughan, et al. The llama 3 herd of models. arXiv pr eprint arXiv:2407.21783 , 2024. Yiduo Guo, Zhen Guo, Chuan wei Huang, Zi-Ang W ang, Zek ai Zhang, Haofei Y u, Huishuai Zhang, and Yik ang Shen. Syn thetic data rl: T ask definition is all you need. arXiv pr eprint arXiv:2505.17063 , 2025. Alex Havrilla, Edward Hughes, Mik ay el Samv elyan, and Jacob D Ab ernethy . Sparq: Synthetic problem generation for reasoning via quality-div ersity algorithms. CoRR , 2025. Dan Hendryc ks, Collin Burns, Saurav Kada v ath, Akul Arora, Steven Basart, Eric T ang, Dawn Song, and Ja- cob Steinhardt. Measurin g mathematical problem solving with the math dataset. In J. V anschoren and S. Y eung, editors, Pro c e e dings of the Neur al Information Pr o c essi ng Systems T r ack on Datasets and Bench- marks , v olume 1, 2021. https://datasets- benchmarks- proceedings.neurips.cc/paper_files/paper/2021/ file/be83ab3ecd0db773eb2dc1b0a17836a1- Paper- round2.pdf . 18 Naman Jain, King Han, Alex Gu, W en-Ding Li, F anjia Y an, Tianjun Zhang, Sida W ang, Armando Solar-Lezama, K oushik Sen, and Ion Stoica. Liv eco deb ench: Holistic and contamination free ev aluation of large language models for co de. arXiv pr eprint arXiv:2403.07974 , 2024. Minqi Jiang, João GM Araújo, Will Ellsworth, Sian Go o ding, and Edward Grefenstette. Generativ e data refinement: Just ask for b etter data. arXiv pr eprint arXiv:2509.08653 , 2025. Kimi T eam, Angang Du, Bofei Gao, Bow ei Xing, Chang jiu Jiang, C Chen, C Li, C Xiao, C Du, C Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms, 2025. URL https://arxiv. or g/abs/2501.12599 , 2025. Xiao Liang, Zhong-Zhi Li, Y eyun Gong, Y ang W ang, Hengyuan Zhang, Y elong Shen, Ying Nian W u, and W eizhu Chen. Sws: Self-aw are weakness-driv en problem synthesis in reinforcement learning for llm reasoning. arXiv pr eprint arXiv:2506.08989 , 2025. Zi Lin, Sheng Shen, Jingb o Shang, Jason W eston, and Yixin Nie. Learning to solve and v erify: A self-play framework for co de and test generation. arXiv pr eprint arXiv:2502.14948 , 2025. Pulkit Pattnaik, Rishabh Maheshw ary , Kelec hi Ogueji, Vik as Y adav, and Sathwik T ejaswi Madhusudhan. Curry-dp o: Enhancing alignment using curriculum learning & ranked preferences. arXiv pr eprint arXiv:2403.07230 , 2024. Gabriel Poesia, Da vid Broman, Nick Hab er, and Noah Goo dman. Learning formal mathematics from intrinsic motiv ation. A dvanc es in Neur al Information Pr o c essing Systems , 37:43032–43057, 2024. Y uxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdino v, and A viral Kumar. P op e: Learning to reason on hard problems via privileged on-p olicy exploration. arXiv pr eprint arXiv:2601.18779 , 2026. Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haow ei Zhang, Mingch uan Zhang, YK Li, Y ang W u, et al. Deepseekmath: Pushing the limits of mathematical reasoning in op en language mo dels. arXiv pr eprint arXiv:2402.03300 , 2024. Zhen ting W ang, Guofeng Cui, Y u-Jhe Li, Kun W an, and W entian Zhao. Dump: Automated distribution-level curriculum learning for rl-based llm p ost-training. arXiv pr eprint arXiv:2504.09710 , 2025. Y uxiang W ei, Zhe W ang, Jiaw ei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Emp o wering code generation with oss-instruct. arXiv pr eprint arXiv:2312.02120 , 2023. Zhiheng Xi, W enxiang Chen, Boy ang Hong, Senjie Jin, Rui Zheng, W ei He, Yiwen Ding, Shich un Liu, Xin Guo, Junzhe W ang, et al. T raining large language mo dels for reasoning through reverse curriculum reinforcemen t learning. arXiv pr eprint arXiv:2402.05808 , 2024. Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Y uqian Hong, Bryan Dai, Jo ey Zhou, Kai Qiu, Zhirong W u, and Chong Luo. Logic-rl: Unleashing llm reasoning with rule-based reinforcemen t learning. arXiv pr eprint arXiv:2502.14768 , 2025. An Y ang, Baosong Y ang, Beic hen Zhang, Binyuan Hui, Bo Zheng, Bow en Y u, Chengyuan Li, Dayiheng Liu, F ei Huang, et al. Qwen2.5 technical rep ort. , 2024. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bow en Y u, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qw en3 technical rep ort. arXiv preprint , 2025. Ziyu Y e, Rishabh Agarwal, Tianqi Liu, Rishabh Joshi, Sarmishta V elury , Qijun T an, and Y uan Liu. Ev olving alignment via asymmetric self-play , 2025. https://openreview.net/forum?id=TMYe4rUuTc . Qiying Y u, Zheng Zhang, Ruofei Zhu, Y ufeng Y uan, Xiao chen Zuo, Y u Y ue, W einan Dai, Tiantian F an, Gaohong Liu, Ling jun Liu, et al. Dapo: An op en-source llm reinforcement learning system at scale. arXiv pr eprint arXiv:2503.14476 , 2025. Jixiao Zhang and Chunsheng Zuo. Grpo-lead: A difficulty-a ware reinforcement learning approach for concise mathe- matical reasoning in language mo dels. arXiv pr eprint arXiv:2504.09696 , 2025. Andrew Zhao, Yiran W u, Y ang Y ue, T ong W u, Quentin Xu, Matthieu Lin, Shenzhi W ang, Qingyun W u, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data. arXiv pr eprint arXiv:2505.03335 , 2025. Yifei Zhou, Sergey Levine, Jason W eston, Xian Li, and Sain ba yar Sukhbaatar. Self-challenging language mo del agents. arXiv pr eprint arXiv:2506.01716 , 2025. 19 A Extended Results for RL with Synthetic Data Here, we provide extended results for the syn thetic data exp eriments discussed in Section 4.1 . Figure 16 –Fig- ure 17 show detailed in-domain and out-of-domain p erformance for augmen tations seeded with real questions and random co de snipp ets, resp ectively , while Figure 18 compares RL training using purely synthetic datasets. Figure 19 further contrasts scaling real data (25K vs. 81K problems) with augmenting real data using 20K syn thetic problems, sho wing that syn thetic augmentation can outp erform even the larger real-data baseline. 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 LCB P ass@1 0 10K 20K 30K Training Steps 0.640 0.660 0.680 0.700 0.720 0.740 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.280 0.300 0.320 0.340 LCB P ass@10 0 10K 20K 30K Training Steps 0.820 0.830 0.840 0.850 0.860 0.870 Math500 P ass@5 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.700 0.750 0.800 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.200 0.250 0.300 0.350 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.030 0.035 0.040 0.045 0.050 0.055 lcb_codegen_hard/pass@1 0 10K 20K 30K Training Steps 0.775 0.800 0.825 0.850 0.875 0.900 lcb_codegen_easy/pass@10 0 10K 20K 30K Training Steps 0.300 0.350 0.400 0.450 0.500 lcb_codegen_medium/pass@10 0 10K 20K 30K Training Steps 0.060 0.070 0.080 0.090 0.100 lcb_codegen_hard/pass@10 REAL 25K REAL 25K + SYNTH-Real-Aug 20K SYNTH-Real-Aug 20K Qwen 3 8B Base (baseline) Figure 16 RL with synthetic data augmentation seeded from real problems in Qwen3-8B Base . RL training on 25K real co de-con test questions (baseline) versus the same data augmented with 20K synthetic induction problems generated using real questions as inspiration seeds ( Real 25K + SYNTH-Real-Aug 20K ), as well as training solely on the synthetic partition ( SYNTH-Real-Aug 20K ). Performance shown on in-domain ( LCB ) and out-of-domain ( Math500 , AIME2024 ) b enchmarks. 20 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 LCB P ass@1 0 10K 20K 30K Training Steps 0.625 0.650 0.675 0.700 0.725 0.750 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.800 0.820 0.840 0.860 Math500 P ass@5 0 10K 20K 30K Training Steps 0.180 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.700 0.750 0.800 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.240 0.260 0.280 0.300 0.320 0.340 0.360 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.030 0.035 0.040 0.045 0.050 lcb_codegen_hard/pass@1 0 10K 20K 30K Training Steps 0.800 0.825 0.850 0.875 0.900 0.925 lcb_codegen_easy/pass@10 0 10K 20K 30K Training Steps 0.350 0.400 0.450 0.500 lcb_codegen_medium/pass@10 0 10K 20K 30K Training Steps 0.060 0.070 0.080 0.090 0.100 lcb_codegen_hard/pass@10 REAL 25K REAL 25K + SYNTH* Induction 20K SYNTH* Induction 20K Qwen 3 8B Base (baseline) Figure 17 RL with synthetic data augmentation seeded from random code snippets in Qwen3-8B Base . RL training on 25K real co de-contest questions (baseline) versus the same data augmented with 20K synthetic induction problems generated using random snipp ets from starcoderdata ( Real 25K + SYNTH* Induction 20K ), as well as training solely on the synthetic partition ( SYNTH* Induction 20K ). Performance shown on in-domain ( LCB ) and out-of-domain ( Math500 , AIME2024 ) b enchmarks. 21 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.640 0.660 0.680 0.700 0.720 Math500 P ass@1 0 10K 20K 30K Training Steps 0.090 0.100 0.110 0.120 0.130 0.140 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.280 0.300 0.320 LCB P ass@10 0 10K 20K 30K Training Steps 0.820 0.830 0.840 0.850 0.860 Math500 P ass@5 0 10K 20K 30K Training Steps 0.200 0.210 0.220 0.230 0.240 0.250 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.675 0.700 0.725 0.750 0.775 0.800 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 0.300 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.030 0.035 0.040 0.045 0.050 0.055 lcb_codegen_hard/pass@1 0 10K 20K 30K Training Steps 0.775 0.800 0.825 0.850 0.875 0.900 lcb_codegen_easy/pass@10 0 10K 20K 30K Training Steps 0.300 0.350 0.400 0.450 lcb_codegen_medium/pass@10 0 10K 20K 30K Training Steps 0.060 0.070 0.080 0.090 lcb_codegen_hard/pass@10 SYNTH* Induction 20K SYNTH-Real-Aug 20K Qwen 3 8B Base (baseline) Figure 18 RL with pure synthetic data in Qwen3-8B Base . Instead of augmenting the 25K real co de-contest questions, RL is p erformed solely on synthetic induction problems generated with tw o seeding strategies: (1) real questions as inspiration seeds ( SYNTH-Real-Aug ), and (2) random co de snipp ets from starcoderdata ( SYNTH*-Aug , 3 seeds). 22 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 LCB P ass@1 0 10K 20K 30K Training Steps 0.625 0.650 0.675 0.700 0.725 0.750 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.280 0.300 0.320 0.340 0.360 LCB P ass@10 0 10K 20K 30K Training Steps 0.800 0.820 0.840 0.860 Math500 P ass@5 0 10K 20K 30K Training Steps 0.180 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 0 10K 20K 30K Training Steps 0.700 0.750 0.800 lcb_codegen_easy/pass@1 0 10K 20K 30K Training Steps 0.260 0.280 0.300 0.320 0.340 0.360 lcb_codegen_medium/pass@1 0 10K 20K 30K Training Steps 0.030 0.035 0.040 0.045 0.050 lcb_codegen_hard/pass@1 0 10K 20K 30K Training Steps 0.775 0.800 0.825 0.850 0.875 0.900 0.925 lcb_codegen_easy/pass@10 0 10K 20K 30K Training Steps 0.400 0.420 0.440 0.460 0.480 0.500 0.520 lcb_codegen_medium/pass@10 0 10K 20K 30K Training Steps 0.060 0.070 0.080 0.090 0.100 lcb_codegen_hard/pass@10 REAL 25K REAL 81K REAL 25K + SYNTH* Induction 20K Qwen 3 8B Base (baseline) Figure 19 Scaling with real data vs. synthetic augmentation in Qwen3-8B Base . Comparison of RL training on 25K and 81K real co de-contest problems, and on 25K real data augmented with 20K synthetic problems generated from random starcoderdata snipp ets ( Real 25K + SYNTH*-Aug 20K ). Performance is shown on in-domain ( LCB ) and out-of-domain ( Math500 and AIME2024 ) benchmarks throughout training. Syn thetic augmentation yields additional gains ov er the 81K real-data baseline across all LCB splits except medium . 23 B Stepping Stones with Easy-Medium-Hard Chains T o construct the easy , medium , and hard categories used for building question chains, w e bin problems according to their empirical student pass rates, computed ov er 32 solution attempts p er problem. Problems with a verage pass rates in the range 0 . 81 – 0 . 91 are labeled as easy , those be t ween 0 . 41 – 0 . 59 as medium , and those b et w een 0 . 05 – 0 . 16 as hard . These thresholds ensure a clear separation b etw een difficulty levels. B.1 Curriculum Strategies for Easy–Medium–Hard Chains W e provide details of the hard and soft curriculum strategies used in Sec. 4.2 and Fig. 10 . Sampling probabilities for easy , medium , and hard tasks in the soft and hard curricula are listed b elow. T able 2 Sampling weigh ts across training stages for soft and hard curricula. Stage (RL steps) Easy Medium Hard Soft curriculum 0–7,500 0.80 0.15 0.05 7,500–17,500 0.15 0.80 0.05 17,500–30,000 0.15 0.40 0.45 30,000–40,000 0.05 0.15 0.80 Hard curriculum 0–7,500 0.90 0.05 0.05 7,500–17,500 0.05 0.90 0.05 17,500–40,000 0.05 0.05 0.90 B.2 Extended Results W e provide extended results for the curriculum exp eriments in Qwen3-8B Base with the full vs. disjoint chains, sho wing detailed p erformance across in-domain ( LCB ) and out-of-domain ( Math500 , AIME2024 ) b enc hmarks for hard (Fig. 20 ), soft (Fig. 21 ), and uniform sampling (Fig. 22 ) strategies. 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K 40K Training Steps 0.660 0.680 0.700 0.720 Math500 P ass@1 0 10K 20K 30K 40K Training Steps 0.100 0.120 0.140 0.160 AIME2024 P ass@1 0 10K 20K 30K 40K Training Steps 0.260 0.270 0.280 0.290 0.300 0.310 0.320 LCB P ass@10 0 10K 20K 30K 40K Training Steps 0.830 0.840 0.850 0.860 0.870 Math500 P ass@5 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 0 10K 20K 30K 40K Training Steps 0.675 0.700 0.725 0.750 0.775 0.800 lcb_codegen_easy/pass@1 0 10K 20K 30K 40K Training Steps 0.260 0.270 0.280 0.290 0.300 0.310 lcb_codegen_medium/pass@1 0 10K 20K 30K 40K Training Steps 0.025 0.030 0.035 0.040 0.045 0.050 lcb_codegen_hard/pass@1 SYNTH* Chains curriculum -- hard SYNTH* Disjoint curriculum -- hard Qwen 3 8B Base (baseline) Figure 20 Chains with hard curriculum in Qwen3-8B Base . Extended results for RL training on easy–medium–hard question chains using the hard curriculum schedule. Shown are in-domain results ( LCB , including easy , medium, and hard splits) and out-of-domain results ( Math500 , AIME2024 ) with pass@1, pass@5/pass@10 metrics plotted ov er RL training steps. 24 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K 40K Training Steps 0.660 0.680 0.700 0.720 0.740 Math500 P ass@1 0 10K 20K 30K 40K Training Steps 0.080 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 0 10K 20K 30K 40K Training Steps 0.260 0.270 0.280 0.290 0.300 0.310 0.320 LCB P ass@10 0 10K 20K 30K 40K Training Steps 0.820 0.830 0.840 0.850 0.860 Math500 P ass@5 0 10K 20K 30K 40K Training Steps 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 0 10K 20K 30K 40K Training Steps 0.675 0.700 0.725 0.750 0.775 0.800 lcb_codegen_easy/pass@1 0 10K 20K 30K 40K Training Steps 0.260 0.280 0.300 0.320 lcb_codegen_medium/pass@1 0 10K 20K 30K 40K Training Steps 0.030 0.035 0.040 0.045 0.050 lcb_codegen_hard/pass@1 SYNTH* Chains curriculum -- soft SYNTH* Disjoint curriculum -- soft Qwen 3 8B Base (baseline) Figure 21 Chains with soft curriculum in Qwen3-8B Base. Extended results for RL training on easy–medium–hard question chains using the soft curriculum schedule. P erformance is rep orted for LCB (easy , medium, hard splits) and out-of-domain b enchmarks ( Math500 , AIME2024 ) with pass@1, pass@5/pass@10 metrics o v er training steps. 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.640 0.660 0.680 0.700 0.720 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.110 0.120 0.130 0.140 0.150 AIME2024 P ass@1 0 10K 20K 30K Training Steps 0.260 0.280 0.300 0.320 LCB P ass@10 0 10K 20K 30K Training Steps 0.810 0.820 0.830 0.840 0.850 0.860 Math500 P ass@5 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 0.280 AIME2024 P ass@5 SYNTH* Chains - uniform SYNTH* Disjoint - uniform Qwen 3 8B Base (baseline) Figure 22 Chains without curriculum in Qwen3-8B Base . Extended results for RL training on easy–medium–hard question chains under uniform sampling across difficulty levels. Plots sho w in-domain ( LCB ) and out-of-domain ( Math500 , AIME2024 ) p erformance, including easy , medium, and hard splits, with pass@1, pass@5/pass@10 metrics o ver RL training steps. C Curriculum Experiments with Broader Difficulty Bins W e extend our curriculum analysis by adopting broader difficulty bins to retain more data p er split and reduce b oundary effects b etw een difficulty levels. The corresp onding pass-rate thresholds and dataset sizes 25 T able 3 Difficulty bins and data split siz es used in curriculum experiments. Difficulty P ass Rate Rang e Number of Problems easy 0.85–0.97 10000 easy–medium 0.61–0.85 7479 medium 0.26–0.61 5268 hard 0.10–0.26 2220 are summarized in T able 3 . This configuration allows us to test differen t curriculum strategies when difficulty gran ularit y is relaxed, pro viding a more data-efficien t setup for large-scale RL exp eriments. Sampling w eigh ts for the differen t curriculum strategies are shown in T able 4 . T able 4 Sampling weigh ts across training stages for classic and reverse curricula. The reverse (medium → easy) setup uses the easy–medium split instead of the standard easy bin. Stage (RL steps) Easy Medium Hard Easy Split Used Classic curriculum (Easy → Medium → Hard) 0–10,000 1.00 0.00 0.00 easy 10,000–15,000 0.75 0.25 0.00 easy 15,000–25,000 0.00 1.00 0.00 easy 25,000–30,000 0.00 0.75 0.25 easy 30,000–40,000 0.00 0.00 1.00 easy Reverse curriculum (Hard → Medium → Easy) 0–10,000 0.00 0.00 1.00 easy 10,000–15,000 0.00 0.25 0.75 easy 15,000–25,000 0.00 1.00 0.00 easy 25,000–30,000 0.25 0.75 0.00 easy 30,000–40,000 1.00 0.00 0.00 easy Reverse curriculum (Medium → Easy) 0–17,500 0.00 1.00 0.00 easy–medium 17,500–20,000 0.25 0.75 0.00 easy–medium 20,000–40,000 1.00 0.00 0.00 easy–medium D Scaling Number of RL En vironments 0 10K 20K 30K Training Steps 0.200 0.220 0.240 0.260 LCB P ass@1 0 10K 20K 30K Training Steps 0.260 0.280 0.300 0.320 0.340 LCB P ass@10 0 10K 20K 30K Training Steps 0.660 0.680 0.700 0.720 0.740 0.760 Math500 P ass@1 0 10K 20K 30K Training Steps 0.100 0.120 0.140 0.160 0.180 AIME2024 P ass@1 REAL 25K SYNTH* Induction 20K SYNTH* Envs[x4] 20K Qwen 3 8B Base (baseline) Figure 23 Scaling RL envir onments with real-data baseline in Qwen3-8B Base . Comparison of RL training on 20K problems from a single environmen t ( induction ), 20K problems distributed across four environmen ts ( induction , abduction , deduction , fuzzing ), and the 25K real co de-contest baseline. Sho wn are in-domain results ( LCB , pass@1 and pass@10) and out-of-domain results ( Math500 , AIME2024 , pass@1). Distributing the data budget across multiple en vironments impro ves out-of-domain generalization and results in competitive or higher (in terms of pass@10) in-domain p erformance compared to the real-data baseline. 26 E RL T raining Details W e use the same asynchronous RL infrastructure as Copet et al. ( 2025 ). W e use G = 8 samples p er prompt for GRPO with no KL regularization ( β = 0 ) and a sampling temp erature of 1.0 during training (0.2 at ev aluation). After an initial linear warm up ov er 800 steps (400 for Qwen2.5-32B Base), we use a constant learning rate of 6 × 10 − 8 for Llama3.1-8B Instruct and Qwen2.5-32B Base, and 1 . 4 × 10 − 7 for Qwen3-8B Base. W e adopt a higher upp er clipping v alue ( ε low = 0 . 2 , ε high = 0 . 25 ) to mitigate entrop y collapse ( Y u et al. , 2025 ). F or ev aluation, we generate 20 samples p er problem on LCB , 10 on Math500 , and 64 on AIME2024 . All exp erimen ts are run on 4 no des of 8 × NVIDIA H100 GPUs. F Qualitative Example of In-Context Learning The teacher is shown the question generated in the previous round (turn 1), where the student manages to solv e the question in all attempts. F or turn 2, the teacher is asked to pro duce a problem of intermediate difficulty . The newly generated problem in turn 2 no w has a studen t pass rate of 0.625. W e show the prompt for the teacher in turn 2, as well as the teacher’s resp onse including key excerpts from its reasoning. T urn 2 — T eacher Prompt T ask Description ## Task: Mutate Python Code Snippet Based on Student Responses to Previous Challenge and Create a New Challenge You ' ve already created a coding challenge, and students have attempted to solve it. Now, design a new transformed problem that builds upon your previous challenge while addressing the strengths and weaknesses demonstrated in student responses. First, carefully analyze student responses to your previous challenge, then devise a clear plan for your new function with an adjusted level of difficulty. Identify how your proposed inputs have high coverage and why the inputs will be challenging and creative. Then, write the code, inputs, and message. Remember to wrap your inputs in ``` input ``` tags, and your message in ``` message ``` tags. Previous Code, Input-Output Pairs and Message (T urn 1) ``` python def f(resources: dict, timeout: int) -> bool: """ Determine whether there exists **any** sequential execution order of the pending resources that * respects every mandatory dependency, * may benefit from *optional* dependencies (each optional dependency that has been completed before the task starts reduces its run time by a given amount, but the run time never goes below 0), * finishes each resource no later than its individual *deadline*, * and has a total elapsed time <= `` timeout `` . 27 `` resources `` maps a resource name to a 5-tuple: (status, mandatory_deps, optional_deps, run_time, deadline) * `` status `` - `` "Running" `` (already completed at time 0) or `` "Pending" `` . * `` mandatory_deps `` - list of resource names that must be finished before this one can start. * `` optional_deps `` - list of `` (dep_name, reduction) `` tuples; if `` dep_name `` is finished before the task starts, the task ' s run time is reduced by `` reduction `` (but not below 0). * `` run_time `` - base execution time once mandatory (and optional) deps are satisfied. * `` deadline `` - latest absolute time (from start) by which this resource must finish. If any dependency name (mandatory or optional) is unknown the whole problem is unsolvable and the function returns `` False `` . """ # ------------------------------------------------------------ # Normalise data - assign each resource a numeric index. # ------------------------------------------------------------ names = list(resources.keys()) n = len(names) idx = {name: i for i, name in enumerate(names)} status = [None] * n mand = [set() for _ in range(n)] opt = [[] for _ in range(n)] # list of (dep_idx, reduction) base_rt = [0] * n deadline = [0] * n # Validate and fill structures for name, (st, md, od, rt, dl) in resources.items(): i = idx[name] status[i] = st for d in md: if d not in idx: # unknown mandatory dependency return False mand[i].add(idx[d]) for d, red in od: if d not in idx: # unknown optional dependency return False opt[i].append((idx[d], red)) base_rt[i] = rt deadline[i] = dl # -------------------------------------------------------- # Bit-mask DP over subsets of already-finished resources. # dp[mask] = earliest possible finish time after completing # exactly the resources indicated by `` mask `` . # -------------------------------------------------------- INF = 10 ** 18 size = 1 << n dp = [INF] * size # Resources marked "Running" are already done at time 0. start_mask = 0 for i, st in enumerate(status): if st == "Running": if deadline[i] < 0: # a running task already missed its deadline return False start_mask |= 1 << i dp[start_mask] = 0 28 # Helper to compute reduction contributed by optional deps already in mask def optional_reduction(task_idx: int, mask: int) -> int: red = 0 for dep_idx, amount in opt[task_idx]: if mask & (1 << dep_idx): red += amount return red # Iterate over all masks for mask in range(size): cur_time = dp[mask] if cur_time == INF: continue # Try to start any still-pending resource whose mandatory deps are satisfied for i in range(n): bit = 1 << i if mask & bit: continue # already finished # mandatory deps must be in mask if not mand[i].issubset( {j for j in range(n) if mask & (1 << j)}): continue # Compute effective run time after optional reductions reduction = optional_reduction(i, mask) eff_rt = max(0, base_rt[i] - reduction) finish_time = cur_time + eff_rt # Respect deadline and overall timeout (timeout check deferred to final mask) if finish_time > deadline[i]: continue new_mask = mask | bit if finish_time < dp[new_mask]: dp[new_mask] = finish_time full_mask = (1 << n) - 1 return dp[full_mask] <= timeout ``` ``` input { "A": ("Running", [], [], 0, 0), "B": ("Pending", ["A"], [("A", 2)], 5, 10), "C": ("Pending", ["B"], [], 4, 15) }, 15 ``` ``` output True ``` ``` input { "X": ("Pending", [], [], 7, 8), "Y": ("Pending", [], [("X", 3)], 6, 12) }, 13 ``` ``` output True ``` ``` input { 29 "P": ("Pending", [], [("Q", 1)], 4, 10), "Q": ("Pending", [], [], 3, 6) }, 9 ``` ``` output True ``` ``` input { "U": ("Pending", [], [("V", 2)], 5, 9), "V": ("Pending", [], [("U", 2)], 5, 9) }, 10 ``` ``` output True ``` ``` input { "M": ("Running", [], [], 0, 0), "N": ("Pending", ["M"], [("M", 1)], 4, 5), "O": ("Pending", ["N"], [("N", 2)], 3, 8), "P": ("Pending", ["O"], [], 2, 10) }, 9 ``` ``` output True ``` No message found! Make sure to correctly format the message. Student Answer s Summary Pass rate for the student over 8 attempts was: 1.000 Example solved 1: def f(task_dict, limit): """ Returns True if the sum of the fourth element (assumed duration) of each task tuple in ` task_dict ` does not exceed ` limit ` . """ total_duration = sum( info[3] for info in task_dict.values()) return total_duration <= limit Example solved 2: def f(tasks, target): """ Determine whether the given target integer lies within the inclusive range defined by the sum of the lower and upper bounds of all tasks. Parameters ---------- tasks : dict Mapping from a task name to a tuple: (status: str, list1: list, list2: list, low: int, high: int) target : int The integer to test against the aggregated range. Returns ------- bool 30 True if low_sum <= target <= high_sum, otherwise False. """ low_sum = sum(info[3] for info in tasks.values()) high_sum = sum(info[4] for info in tasks.values()) return low_sum <= target <= high_sum Response Instructions Remember that your goal is to create a function that feels like a natural progression from your previous challenge while addressing the specific learning needs revealed by student responses. Your response should include: 1. Your new code snippet must again have the function named ` f ` wrapped in ``` python ``` tags - Build upon your previous challenge by adjusting the complexity or introducing new concepts - Do not include print statements or input/output examples inside the code block! 2. 5 diverse inputs that demonstrate your function ' s behavior - Each input should be individually wrapped in ``` input ``` tags. - For each input, format multiple arguments with commas between them - Remember to add quotes around string arguments. Example: ``` input ' John ' , { ' age ' : 20, ' city ' : ' New York ' } ``` ``` input ' Sammy ' , { ' age ' : 37, ' city ' : ' Los Angeles ' } ``` 3. A message that hints at the function ' s purpose wrapped message in ``` message ``` tags - You cannot provide the code snippet in the message Progression Strategy The student always solved the previous task. Either the input-output relationship was too trivial (maybe not diverse enough or incomplete such that a much easier function also passes the tests), or the function was too easy to implement. Try to mutate this problem into a medium problem: student should have a pass rate of 0.35-0.65. You need to add more complexity to the problem and make sure the inputs you propose lead to diverse outputs to ensure a good learning experience for the student! Last reminder: Remember the question is a standalone question! The message should only reflect the current problem and not assume knowledge of the previous questions. Make sure the problem is interesting and challenging. This problem will be given to a student to solve, and they should learn valuable skills from it, such that they can overall code better and also do better in coding contests type questions. 31 T urn 2 — T eacher Answer (Student Pass Rate: 0.625) T eac her Reasoning [trunc ate d with [. . . ] ] W e need to design a new co ding challenge based on previous one, but more complex; av oid trivial solutions like sum durations. [. . . ] W e need to consider student resp onses: they submitted trivial functions computing sum of elemen t 3 or low/high sum. That indicates they simplified problem to just chec king total duration or range, ignoring dep endencies. So new problem should require handling mandatory dependencies, optional reductions, deadlines, timeout, similarly but maybe add additional constraints such that naiv e sum fails. [. . . ] W e hav e to ensure the new function is more complex: maybe also include “resource weigh t” v alues and allow parallel execution up to a concurrency limit? But that ma y b e to o complex. Simpler: keep same original problem but require that optional reductions can b e applied only if the optional dep endency finishes strictly b efore the task starts, and also mandatory dep endencies can b e “or” (any of list) – more complex. [. . . ] Alternativ ely , we could add a constrain t: resources can ha ve “exclusive groups” meaning only one resource from a group can run (cannot b oth b e selected). Migh t be hea vy . Goal: make harder for studen ts who previously used trivial solution of sum. Th us we can retain mandatory/optional dep endencies and deadlines, but also add “resource cost” and a global “budget” that must not b e exceeded, and optional reductions affect cost. Studen ts may still try to sum something but must consider dep endencies. So we design function f(resources: dict, timeout: int, budget: int) -> bool . It m ust decide if there exists execution order resp ecting dep endencies, deadlines, total time ≤ timeout , and total cost ≤ budget where cost = base_cost − optional reductions, not b elow 0. [. . . ] W e need to implement solution: bitmask DP similar to earlier but with t wo dimensions: time and cost? [. . . ] Simpler: store for each mask the minimal time and minimal cost pair (Pareto frontier). W e’ll compute reachable states list of (time, cost). F or eac h mask, we keep list of non-dominated pairs. Implemen tation: u se dict mapping mask → list of (time, cost). Start with start_mask (running tasks) ha ving time 0, cost 0. [. . . ] New_time = time + run_time_i. If new_time > deadline_i: skip. New_cost = cost + max(0, base_cost_i − sum_reductions_i) where sum_reductions_i = sum of reduction amounts for optional deps already completed (i.e., in mask). Add to frontier if within limits. After pro cessing all masks, chec k any pair for full_mask with time ≤ timeout and cost ≤ budget. [. . . ] No w we need to provide 5 diverse inputs: • Input 1: simple chain with optional cost discounts. • Input 2: t wo parallel tasks with optional mutual discounts. • Input 3: unkno wn dependency → should return F alse. • Input 4: deadline tight preven ts schedule. • Input 5: budget constraint fails. [. . . ] T eacher Output ``` python from typing import Dict, List, Tuple def f(resources: Dict[str, Tuple[str, List[str], List[Tuple[str, int]], int, int, int]], timeout: int, budget: int) -> bool: """ resources maps a name to a 6-tuple: 32 (status, mandatory_deps, optional_deps, run_time, base_cost, deadline) * status - "Running" (already finished at time 0) or "Pending". * mandatory_deps - names that must be completed before this task starts. * optional_deps - list of (dep_name, discount) tuples; if dep_name is already finished when the task starts, the task ' s **cost** is reduced by *discount* (cost never goes below 0). Discounts do **not** affect run time. * run_time - execution time of the task. * base_cost - cost of executing the task before discounts. * deadline - absolute latest time by which the task must finish. The function returns True iff there exists an order of executing all pending tasks such that: * every mandatory dependency is satisfied before a task starts, * each task finishes no later than its deadline, * the total elapsed time after the last task is <= `` timeout `` , * the sum of (discounted) costs of all pending tasks is <= `` budget `` . If any dependency name is unknown the problem is unsolvable and False is returned. """ # ------------------------------------------------------------ # Normalise names to integer indices. # ------------------------------------------------------------ names = list(resources.keys()) n = len(names) idx = {name: i for i, name in enumerate(names)} status = [None] * n mand = [set() for _ in range(n)] opt = [[] for _ in range(n)] # (dep_idx, discount) run = [0] * n base_cost = [0] * n deadline = [0] * n for name, (st, md, od, rt, bc, dl) in resources.items(): i = idx[name] status[i] = st for d in md: if d not in idx: # unknown mandatory dependency return False mand[i].add(idx[d]) for d, disc in od: if d not in idx: # unknown optional dependency return False opt[i].append((idx[d], disc)) run[i] = rt base_cost[i] = bc deadline[i] = dl # ------------------------------------------------------------ # Initial mask - resources already marked "Running". # ------------------------------------------------------------ start_mask = 0 for i, st in enumerate(status): if st == "Running": if deadline[i] < 0: # already missed its deadline return False start_mask |= 1 << i from collections import defaultdict # frontier[mask] = list of (elapsed_time, total_cost) pairs that are # not dominated (i.e., no other pair is both <= in time and <= in cost). frontier = defaultdict(list) frontier[start_mask].append((0, 0)) full_mask = (1 << n) - 1 # ------------------------------------------------------------ 33 # Breadth-first DP over subsets. # ------------------------------------------------------------ for mask in range(1 << n): if mask not in frontier: continue cur_states = frontier[mask] for i in range(n): bit = 1 << i if mask & bit: continue # already finished # mandatory dependencies must be satisfied if not mand[i].issubset({j for j in range(n) if mask & (1 << j)}): continue # total discount from optional dependencies already in mask discount = sum(disc for dep_idx, disc in opt[i] if mask & (1 << dep_idx)) eff_cost = max(0, base_cost[i] - discount) for cur_time, cur_spent in cur_states: finish_time = cur_time + run[i] if finish_time > deadline[i]: continue new_spent = cur_spent + eff_cost if new_spent > budget: continue new_mask = mask | bit # Insert the new pair, keeping only non-dominated pairs. improved = True to_remove = [] for t, c in frontier[new_mask]: if t <= finish_time and c <= new_spent: # existing pair dominates the new one improved = False break if t >= finish_time and c >= new_spent: # new pair dominates existing one to_remove.append((t, c)) if improved: for itm in to_remove: frontier[new_mask].remove(itm) frontier[new_mask].append((finish_time, new_spent)) # ------------------------------------------------------------ # Any feasible final state? # ------------------------------------------------------------ for t, c in frontier[full_mask]: if t <= timeout and c <= budget: return True return False ``` ``` input { "A": ("Running", [], [], 0, 0, 0), "B": ("Pending", ["A"], [("A", 2)], 5, 6, 12), "C": ("Pending", ["B"], [], 4, 5, 20) }, 15, 10 ``` ``` input { "X": ("Pending", [], [("Y", 2)], 3, 5, 10), "Y": ("Pending", [], [("X", 3)], 4, 6, 10) }, 8, 9 ``` 34 ``` input { "P": ("Pending", ["Q"], [], 4, 5, 10) }, 10, 10 ``` ``` input { "A": ("Pending", [], [], 6, 5, 5), "B": ("Pending", [], [], 1, 2, 10) }, 10, 10 ``` ``` input { "A": ("Pending", [], [], 3, 7, 10), "B": ("Pending", [], [], 4, 6, 10) }, 10, 10 ``` ``` message Determine whether all pending resources can be completed within a given overall time limit **and** a total cost budget, while respecting mandatory dependencies, optional cost discounts, and individual deadlines. ``` 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment