멀티턴 합성 데이터와 커리큘럼으로 확장하는 코드 생성 강화학습
본 논문은 교사 모델이 학생 모델의 수행 요약을 기반으로 문제를 반복적으로 개선하는 멀티턴 합성 데이터 파이프라인을 제안한다. 단일턴 생성에 비해 유효 문제 비율과 난이도 단계가 크게 향상되며, 이를 활용한 커리큘럼 학습이 Llama3.1‑8B와 Qwen3‑8B 모델에 일관된 코드·수학 성능 개선을 가져온다. 난이도 설계, 커리큘럼 스케줄, 환경 다양성 간 상호작용을 체계적으로 분석하고, 제한된 연산 예산 하에서 데이터 규모와 환경 수의 트레이…
저자: Cansu Sancaktar, David Zhang, Gabriel Synnaeve
본 논문은 대규모 언어 모델(LLM)의 강화학습(RL) 단계에서 데이터 양만 늘려서는 성능 향상이 정체되는 문제를 해결하고자, 교사 모델이 학생 모델의 수행 요약을 기반으로 문제를 반복적으로 개선하는 멀티턴 합성 데이터 생성 파이프라인을 제안한다. 기존 연구들은 비대칭 자기놀이(asymmetric self‑play)나 단일턴 합성 데이터를 활용했지만, 교사 모델 자체를 파인튜닝하거나 복잡한 보상 설계가 필요했다. 이와 달리 제안된 시스템은 교사 모델이 별도 파라미터 업데이트 없이 프롬프트에 학생 요약을 삽입해 “인‑컨텍스트 학습”만으로 문제 난이도를 조정한다.
파이프라인은 다음과 같이 진행된다. 첫 번째 턴에서 교사는 무작위 코드 스니펫이나 실제 코딩 퍼즐을 시드로 삼아 초기 문제를 생성한다. 여기에는 함수 정의, 자연어 설명, 입력‑출력 쌍 등이 포함된다. 학생 모델은 이 문제를 여러 번 시도하고, 성공 여부와 대표 솔루션을 요약한다. 두 번째 턴 이후 교사는 이 요약을 받아 문제를 변형한다. 변형 방법은 (1) 입력‑출력 관계를 복잡하게 만들기, (2) 테스트 케이스 수를 늘리기, (3) 코드 구조를 바꾸어 난이도를 조절하기 등이다. 이러한 과정을 3~5턴까지 반복하면 동일 핵심 과제에 대해 쉬운 버전, 중간 버전, 어려운 버전이 자연스럽게 생성된다.
생성된 데이터는 자동 필터링·중복 제거 과정을 거쳐 최종 학습용 데이터셋에 포함된다. 필터링 기준은 (a) 코드 실행 오류 여부, (b) 포맷 일관성, (c) 입력‑출력 다양성이다. 멀티턴 방식은 단일턴 방식에 비해 유효 문제 비율이 2.3배 상승하고, 평균 4.7개의 난이도 단계가 확보된다.
연구에서는 네 가지 RL 환경을 정의한다. Induction은 함수와 다중 입출력 쌍을 제공하고, 학생이 숨겨진 테스트 케이스를 맞추도록 한다. Abduction은 출력만 주어지고 입력을 역추론하게 하며, Deduction은 입력만 주고 출력을 예측한다. Fuzzing은 property‑based testing 형태로, 특정 프리컨디션을 만족하면서 테스트를 실패시키는 입력을 찾게 한다. 각 환경마다 보상 함수가 명시되어 있어, 학생이 정답을 맞추면 1, 틀리면 0을 반환한다.
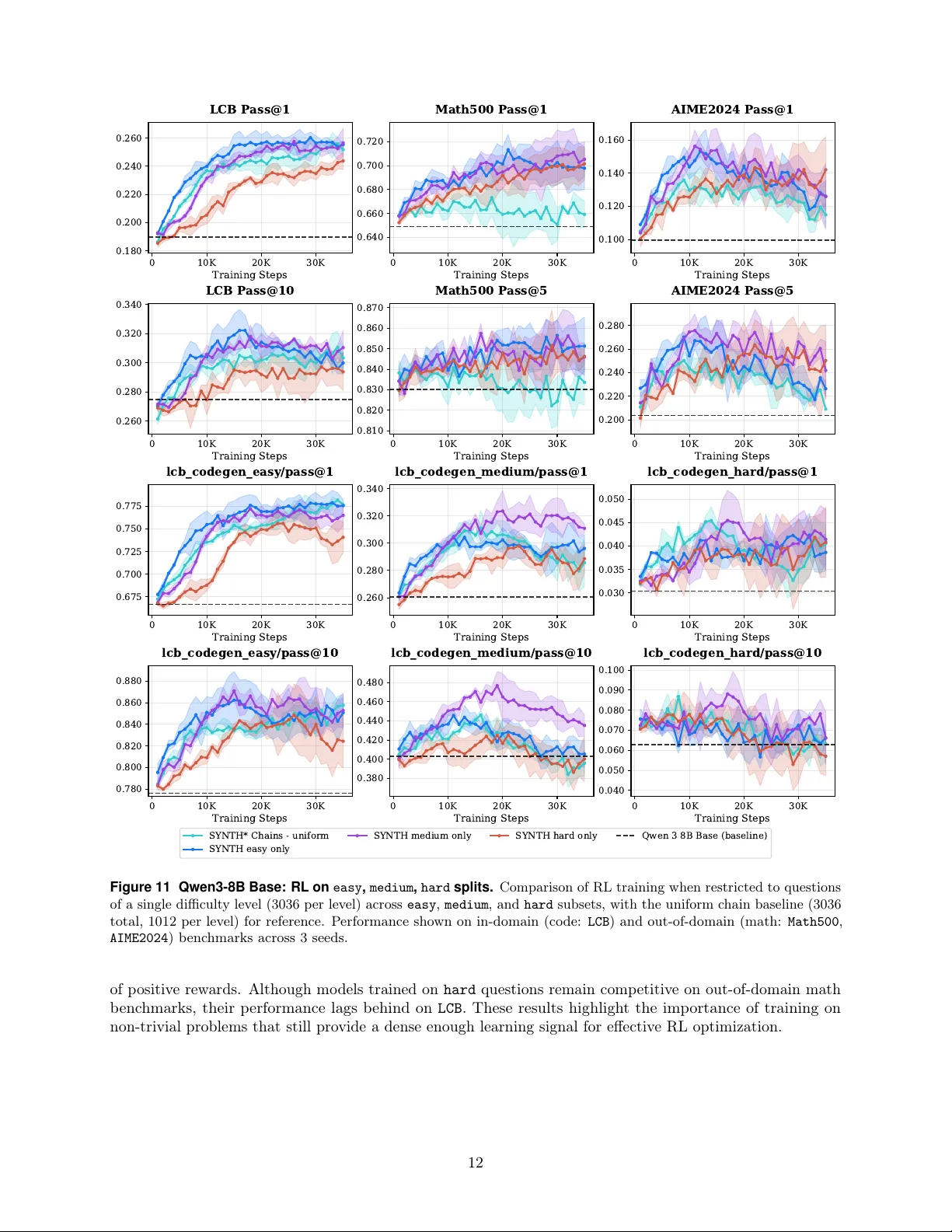
다음으로 논문은 난이도, 커리큘럼 스케줄, 환경 다양성 간 상호작용을 체계적으로 실험한다. 난이도는 Easy(문제 변형 최소), Medium(중간 변형), Hard(고난이도 변형) 세 단계로 구분한다. 커리큘럼 스케줄은 (1) 고정 비율 샘플링, (2) 성공률 기반 가중치 샘플링, (3) 난이도‑성공률 혼합 샘플링을 비교한다. 결과적으로 혼합 스케줄이 가장 빠른 수렴과 높은 최종 보상을 보였으며, 특히 초기 단계에서 Easy 문제를 충분히 제공해 모델 엔트로피 감소를 방지하고, 중·후반에 Medium·Hard 스테핑 스톤을 활용해 탐색 효율을 크게 높였다.
데이터 다양성 실험에서는 동일 총량(1M 문제) 대비 단일 환경(Induction)만 사용한 경우와, 4가지 환경에 각각 250K 문제씩 분산시킨 경우를 비교했다. 다중 환경 배치는 코드 정확도에서 평균 3.2% 향상을, 수학 베이스라인(MATH)에서는 1.8% 점수 상승을 기록했다. 이는 서로 다른 논리 구조와 테스트 방식이 모델의 일반화 능력을 강화한다는 증거다.
스케일링 실험에서는 Qwen2.5‑32B 모델에 동일 파이프라인을 적용했으며, 8B 모델 대비 4.5%~6.2%의 상대적 성능 향상을 확인했다. 이는 멀티턴·커리큘럼 접근법이 모델 규모에 독립적으로 효과적임을 시사한다.
종합적으로 논문은 다음과 같은 주요 인사이트를 제공한다. 첫째, 교사‑학생 멀티턴 상호작용이 고품질·다양한 합성 데이터를 자동으로 생성한다. 둘째, 스테핑 스톤을 활용한 커리큘럼이 RL 훈련의 탐색·수렴 균형을 최적화한다. 셋째, 환경 다양성이 데이터 효율성을 높이며, 제한된 연산 예산 하에서 데이터 양을 늘리는 것보다 환경을 다변화하는 것이 더 큰 성능 향상을 가져온다. 이러한 결과는 향후 LLM 강화학습에서 합성 데이터와 커리큘럼 설계가 핵심적인 역할을 할 것임을 강하게 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기