How Open is Open TTS? A Practical Evaluation of Open Source TTS Tools for Romanian
Open-source text-to-speech (TTS) frameworks have emerged as highly adaptable platforms for developing speech synthesis systems across a wide range of languages. However, their applicability is not uniform -- particularly when the target language is u…
Authors: Teodora Răgman, Adrian Bogdan Stânea, Horia Cucu
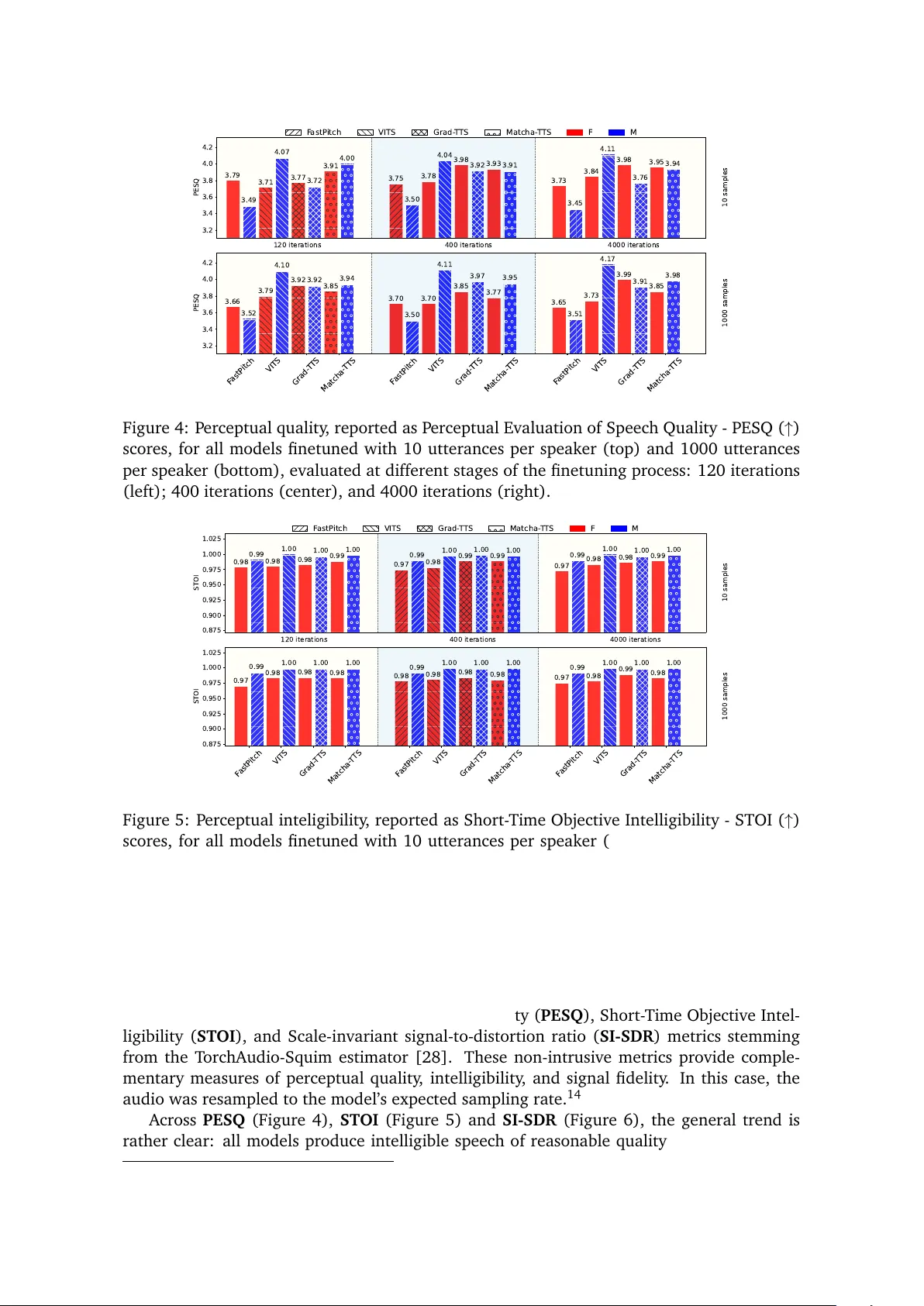
How Open is Open T TS? A Practical Evaluation of Open Source TTS T ools for Romanian T eodora R ˘ agman 1 , Adrian Bogdan Stânea 2 , Horia Cucu 1 , and Adriana Stan 1,2 1 National University of Science and T echnology POLITEHNICA Bucharest, R omania 2 T echnical University of Cluj-Napoca, R omania adriana.stan@com.utcluj.ro Published in IEEE Access https://ieeexplore.ieee.org/document/11269795 Abstract Open-source text-to-speech (TTS) frameworks have emerged as highly adaptable platforms for developing speech synthesis systems across a wide range of languages. However , their applicability is not uniform – particularly when the target language is under-resourced or when computational resources are constrained. In this study , we sys- tematically assess the feasibility of building novel T TS models using four widely adopted open-source architectures: F astPitch, VITS, Grad- TTS, and Matcha- T TS. Our evaluation spans multiple dimensions, including qualitative aspects such as ease of installation, dataset preparation, and hardware requirements, as well as quantitative assessments of synthesis quality for Romanian. W e employ both objective metrics and subjective lis- tening tests to evaluate intelligibility , speaker similarity , and naturalness of the generated speech. The results reveal significant challenges in tool chain setup, data preprocessing, and computational efficiency , which can hinder adoption in low-resource contexts. By grounding the analysis in reproducible protocols and accessible evaluation criteria, this work aims to inform best practices and promote more inclusive, language-diverse T TS development. All information needed to reproduce this study (i.e. code and data) are available in our git repository 1 . 1 Introduction Large-capacity deep neural networks play a crucial role in advancing speech generation be- cause they can model the complex, high-dimensional relationships between linguistic, acous- tic, and prosodic features required for natural-sounding speech. Speech is not only about producing correct words—it involves capturing subtle variations in tone, rhythm, emotion, and speaker identity . Larger models, with their greater number of parameters and deeper architectures, have the representational power to learn these intricate patterns from vast datasets, enabling them to produce more human-like intonation, smoother transitions be- tween phonemes, and more consistent voice quality . This capacity also allows for better generalization across diverse speakers, languages, and styles, making them suitable for ap- plications like conversational AI, dubbing, assistive technologies, and creative content gen- eration. In essence, the size and depth of these networks directly translate into their ability to synthesize speech that is both intelligible and expressive. Despite their impressive capabilities, large-capacity deep neural networks present notable challenges when applied to underserved languages . 2 These networks typically require massive 1 https://gitlab.com/opentts_ragman/OpenTTS 2 W e note here that underserved does not equate to low-resource. Underserved means that speech and text data are available, but the research and commercial communities have not yet focused on developing the tech- nology for the respective language. 1 amounts of high-quality , annotated speech data to achieve their full potential. As a result, the models risk overfitting to limited datasets or inheriting biases from dominant languages present in multilingual training corpora, leading to mispronunciations, unnatural prosody , or the erosion of language-specific nuances. Furthermore, training and fine-tuning such large networks demand substantial computational resources, which can be cost-prohibitive for research teams or communities working on less spoken languages. This creates a techno- ical gap where high-performing speech generation is disproportionately accessible for well- resourced languages, while those with smaller speaker populations remain underserved in generative AI-driven applications. Problem . While open-source text-to-speech (T TS) frameworks offer substantial flexibil- ity for building speech synthesis systems, their performance and usability are not consistent across all languages or computational environments. Underserved languages, such as R o- manian, face a dual challenge: limited availability of high-quality training data and the high computational demands of state-of-the-art architectures. Motivation . As generative speech technologies mature, ensuring equitable access to high-quality synthesis capabilities across diverse language families becomes increasingly im- portant. Open-source models hold the promise of lowering entry barriers for research and development, but practical obstacles in installation, dataset preparation, and compute effi- ciency can prevent their effective adoption for less widely spoken languages. A systematic, comparative assessment is needed to identify these obstacles and to guide practitioners to- ward workable, reproducible solutions. Unlike previous studies that primarily compare TTS models based on reported results, our study takes a hands-on, experimental approach to evaluating open-source systems. While current research focuses on speech quality , controllability or architecture improvements, many surveys lack practical validation. F or instance, [1] provides an overview of speech syn- thesis techniques and open-source implementations, but relies solely on documented results, making direct comparisons difficult due to different training and evaluation setups. Other studies focus on specific aspects, such as controllable speech synthesis [2] or diffusion-based models [3]. Although valuable, these works evaluate isolated categories of models, with performance results mainly derived from English-based checkpoints and little exploration of underserved languages. A study with a related approach to this one is that of P atole et al. [4] which evaluates the selected T TS models using MOS (Mean Opinion Score). However , details on the experimental setup, including the evaluation language, are not fully provided. Contributions . This study evaluates the feasibility of developing novel TTS systems for R omanian using four popular open-source architectures. W e conduct qualitative assessments in terms of ease of installation, dataset preparation complexity , as well as quantitative eval- uations of intelligibility , speaker similarity , and naturalness using objective and subjective metrics. Our findings highlight key technical and procedural bottlenecks while outlining best practices for low-resource TTS development. By grounding the analysis in reproducible workflows and accessible evaluation criteria, we aim to support more inclusive, scalable, and language-diverse TTS research. 2 The speech generation landscape Nowadays, generative speech or more traditionally speech synthesis is a stack of complemen- tary advances: neural codecs that compress and represent waveforms, acoustic and wave- form generators based on diffusion/flow/normalizing-flow/variational families, and highly engineered commercial systems that package these models into APIs and products. T ogether they enable near-human naturalness, low-latency serving, and flexible voice-style control, but they also bring compute, data and safety trade-offs. 2 Neural audio codecs such as SoundStream [5], EnCodec [6] and follow-ups learn com- pact, high-fidelity latent representations of raw waveforms using end-to-end encoder-decoder architectures with vector quantization and adversarial or perceptual losses. These codecs serve two important roles: (i) they let generative models work in a discrete or low-rate la- tent space — drastically reducing compute and sample time compared with operating at raw waveform resolution — and (ii) they enable codec-level editing, compression, and stream- ing for production use. SoundStream demonstrated real-time, low-bitrate speech and mu- sic compression with human-rated quality , and Meta’s EnCodec is now widely used as the latent front-end for downstream audio generation. F or example, P arlerT TS [7] combines descriptive prompts with the Descript Audio Codec [8] to elicit controllable, expressive text- to-speech synthesis. In terms of more standard approaches to the task of speech synthesis or generation, re- cent work has shown that diffusion [9] and normalising flow [10] methods produce highly natural mel-spectrograms or latents when used as decoders. Some of the most notable ar- chitectures are: W aveGrad [11], Guided- TTS [12], F astDiff [13], DiffW ave [14] or Grad- TTS [15] which introduced score-based diffusion decoders for TTS, showing strong subjec- tive quality while offering explicit control over the quality/speed tradeoff; Flowtron [16], FlowTTS [17], P ortaSpeech [18], Glow-TTS [19], and Matcha- T TS [20] applied conditional flow matching, an ODE-based (Ordinary Differential Equation) approach related to recti- fied flows, to achieve fast sampling with competitive quality; and flow/ODE or score-based decoders have been combined with alignment modules to remove dependence on external aligners. These methods have become central in recent papers and codebases because they balance probabilistic expressivity (to model variability and prosody) with mechanisms to speed up inference (fewer iterative steps, distillation, ODE samplers). A previous generation of speech synthesis architecture, yet one that still achieves high quality output is that based also on variational inference. F or example VITS [21] combines variational inference, normalizing flows and adversarial training to produce single-stage, end-to-end T TS systems that avoid separate spectrogram-to-waveform stages while achiev- ing state-of-the-art naturalness. Such models integrate alignment, acoustic modelling and waveform synthesis into one network, simplifying pipelines and improving prosody and ex- pressiveness when trained on adequate data. W e note here that for most of these systems, the authors have also released their source code, and associated inference and/or training recipes. This, at least hypothetically , should make the architectures readily available for direct use, reproduction or adaptation to other domains, speakers or languages. As a result, major companies operationalize all these re- search advances into production-grade APIs for voice cloning, multi-style T TS, and speech- to-speech. The research allows them to obtain ultra-realistic, low-latency voice synthesis and enterprise SDKs for dozens of languages. Ethics, safety and accessibility concerns . The same systems that enable high-fidelity cloning and style transfer raise misuse risks (unauthorized voice cloning, deepfake audio). Commercial vendors increasingly add watermarking/detectors and human-in-the-loop poli- cies, but robust provenance and detection remain active research and policy areas. More- over , the compute/data demands of SotA models can widen access gaps for underserved languages and smaller labs — reinforcing the need for efficient codecs, transfer learning, limited-resource adaptation, and community datasets. 3 Methodology Evaluating the complete landscape of open source TTS architectures is definitely unfeasi- ble. W e, therefore, select four of the most representative and referenced tools in the recent 3 scientific literature. The tools have shown their flexibility across application domains and languages, and constitute a relevant starting point for the type of analysis we aim to per- form. F or each system, we used the official or widely-adopted implementations in an effort to ensure reproducibility and consistency across experiments, as well as for future reference. This section details the selected models’ architecture, the speech data used for training and evaluation, as well as the text processing module and training environment setup. 3.1 TTS systems selection F astPitch 3 [22] is a fully non-autoregressive text-to-speech model designed for fast, high- quality speech synthesis with explicit prosody control. It builds on the F astSpeech 2 frame- work by incorporating a feed-forward T ransformer-based encoder–decoder that predicts Mel- spectrograms in parallel, eliminating the sequential dependencies of autoregressive models and thus enabling low-latency synthesis. A central innovation is the explicit prediction of the fundamental frequency (F0) contour at the phoneme level, which is then added to the encoder output as a conditioning signal for the decoder . This mechanism allows fine-grained control over pitch, enabling prosody manipulation without retraining. The architecture uses a duration predictor to align phoneme sequences with Mel frames, removing the need for attention-based aligners and improving robustness against alignment errors. In evaluations, F astPitch demonstrated substantial speedups compared to autoregressive baselines while maintaining competitive naturalness, making it well suited for large-scale and interactive applications. VITS 4 [21] is an end-to-end text-to-speech model that unifies text–speech alignment, acoustic modelling, and waveform synthesis in a single architecture. It integrates a condi- tional variational autoencoder (V AE) with normalizing flows and adversarial training, allow- ing it to directly generate waveforms without an intermediate vocoder stage. T ext inputs are processed through a phoneme encoder , and monotonic alignment search is employed to align them with latent speech representations, eliminating the need for precomputed align- ments. The decoder uses a HiFi-GAN–style adversarial waveform generator conditioned on latent variables sampled from the flow-based prior , enabling both high fidelity and control- lable variation in speech output. By merging the traditionally separate stages of spectrogram generation and vocoding, VITS reduces pipeline complexity , improves prosody modelling, and achieves state-of-the-art naturalness in both objective and subjective evaluations. Grad- TTS 5 [15] is a diffusion probabilistic model for text-to-speech synthesis that formu- lates Mel-spectrogram generation as a denoising process. Conditioned on text embeddings and predicted phoneme durations, the model iteratively refines Gaussian noise into a target spectrogram using a score-based model parametrised by a non-causal convolutional U-Net. The architecture employs monotonic alignment search for unsupervised text–speech align- ment, avoiding the need for external aligners or attention mechanisms. A key advantage of Grad- TTS is the ability to control the trade-off between synthesis quality and inference speed by adjusting the number of denoising steps. This iterative refinement process allows for modelling fine-grained prosodic details and produces speech with high naturalness and expressiveness, rivalling both autoregressive and GAN-based systems, while retaining flexi- bility in controlling output characteristics. Matcha- TTS 6 [20] is a conditional flow-matching text-to-speech architecture that com- bines alignment learning, prosody modelling, and efficient generative modelling in a unified, 3 https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/ FastPitch 4 https://github.com/jaywalnut310/vits 5 https://github.com/huawei- noah/Speech- Backbones/tree/main/Grad- TTS 6 https://github.com/shivammehta25/Matcha- TTS 4 end-to-end framework. The system learns to map text-conditioned latent representations to target Mel-spectrograms using conditional flow matching, an ODE-based generative process related to diffusion models but optimized for fast sampling. The architecture integrates a monotonic alignment search mechanism, enabling it to learn text–speech correspondences without external aligners, and uses a stochastic duration predictor to model prosodic vari- ability . Compared to traditional diffusion-based T TS, Matcha-TTS achieves competitive per- ceptual quality with significantly fewer sampling steps, making it more suitable for low- latency scenarios. Its design offers a balance between the probabilistic expressiveness of iterative generative models and the efficiency demands of real-time deployment. T able 1 shows an overview of the selected text-to-speech synthesis tools and their contri- butions. F or all TTS systems, except VITS, we relied on the HiF i-GAN vocoder 7 [23] to transform the Mel-spectrograms into waveforms. T able 1: Comparison of selected open-source T TS architectures. Model Architecture Alignment Prosody Output Main contributions F astPitch F eed- forward T rans- former (non- autoregressive) Duration predictor Explicit F0 prediction Mel- spectrogram P arallel spectrogram prediction with explicit pitch conditioning for control- lable prosody and fast inference. VITS V AE + normaliz- ing flows + GAN vocoder Monotonic alignment search Latent variable sampling W aveform End-to-end architecture unifying align- ment, acoustic modeling, and vocod- ing; high-fidelity direct waveform gen- eration with controllable variation. Grad- TTS Diffusion probabilis- tic model (score- based) Monotonic alignment search Duration- based prosody control Mel- spectrogram Iterative denoising process enabling quality–speed trade-off; fine-grained prosody modeling without external aligners. Matcha- TTS Conditional flow matching (ODE- based) Monotonic alignment search Stochastic duration modeling Mel- spectrogram Efficient iterative generation with flow matching, combining probabilistic ex- pressiveness with fewer sampling steps for low-latency TTS. 3.2 T ext processing The selected speech generation systems rely on distinct text processing procedures and sym- bol sets. VITS and Matcha- TTS include phoneme conversion using the Phonemizer package 8 with the eSpeak-NG backend 9 in their text cleaners. F astPitch and Grad- T TS use code-based cleaners which simply lowercase text, expand abbreviations and convert characters to the ASCII counterparts, but do not include any phonetic processing. Their default symbol sets are limited to standard English alphabet. T o ensure consistency across our trained models, we standardized the text processing pipeline by applying phonetic transcription with Phonemizer and eSpeak-NG and adapting 7 The universal V1 checkpoint was used: https://github.com/jik876/hifi- gan?tab=readme- ov- file# pretrained- model 8 https://github.com/bootphon/phonemizer 9 https://github.com/espeak- ng/espeak- ng 5 the symbol sets to R omanian. F or all TTS systems, this step was integrated directly into the text pipelines. As the transcripts from training and evaluation datasets were manually checked and normalised, no additional text pre-processing was carried out with the excep- tion of lower-casing. 3.3 Speech Data F or TTS systems’ training we selected the R omanian SW ARA Speech Corpus [24]. 10 SW ARA comprises 21 hours of high-quality R omanian read speech recordings, contributed by 17 non- professional speakers. Each speaker read aloud between 921 and 1493 prompts randomly selected from newspaper articles. The recordings were conducted in a semi-professional stu- dio environment, utilizing a sound-proof booth and high-quality microphones. The audio data is sampled at 44.1 kHz with 16-bit resolution, and each utterance was manually seg- mented and checked for transcription errors. A significant subset of SW ARA, i.e. 16 hours, comprises 880 unique utterances read aloud by all the 17 speakers . This subset represents a valuable parallel spoken dataset, enabling cross-speaker analysis and controlled data selec- tion, and we therefore use it as the core training data. Compared to the original release of SW ARA, an updated version of it added two new speakers (BEA and MAR) and removed a very noisy one, TIM. So our baseline SW ARA dataset comprises 18 speakers. The common set of text prompts was retained from all speakers, making the training data parallel. This is not a necessary step, but it can alleviate imbalanced datasets with respect to the speaker representation. W e use 16 speakers to train our baseline models. W e refer to these models as eigen-voice models . This terminology was very common in the HMM-based TTS era, and it refers to models which are trained on multiple speakers, but in which the speaker identity is not explicitly provided at the system’s input. This, in theory , enables the system to extract relevant acoustic information without the need to specialise in the discrimination of the speaker identities. Nowadays, most of the speech generation architectures are trained on a wide range of speaker and acoustic conditions data, making the eigen-voices somewhat implicit. The other two speakers–BAS (female) and SGS (male)–were reserved for speaker adapta- tion and finetuning. T o ensure a more realistic test of the systems’ robustness, these speakers were selected based on automatically estimated naturalness scores using UTMOS [25], and obtained from a batch of randomly selected utterances. Both of them exhibited rather low recordings’ quality , which would make them representative of real-world data. F or each speaker , we construct two subsets of samples: one with 10 samples and one with 1000 samples. The 10-sample subset is designed to simulate extremely low-resource finetuning scenarios (47.82 seconds of speech for BAS and 39.73 seconds for SGS). The 1000-sample subset (approximately 60 minutes for BAS and 50 minutes for SGS), while much larger , still reflects a realistic amount of data that could be acquired or selected in practice. Given the parallel nature of the SW ARA corpus, the two speaker subsets contain the same set of prompts–this minimizes the impact of the linguistic coverage in the adaptation process’s direct comparison. 3.4 T raining Environment and Setup Each of the four TTS tools was trained from scratch using the default hyperparameters listed in their code repositories. T o ensure consistency across models, all audio was resampled to 22 , 050 Hz and the same phoneme-based text processing pipeline was applied. Each baseline eigen-voice model was trained for 1 . 125 mln iterations with a batch size of 16. No speaker 10 https://zenodo.org/records/15736789 6 identity was used to condition the output of these baseline models. Grad- T TS and Matcha- TTS were trained on a single T esla V100-SXM2 GP U with 32GB VRAM. VITS and F astPitch were trained on a single T esla T4 GPU with 16GB of VRAM. F or finetuning we used the two subsets of 10 and 1000 samples from each of the two held-out speakers, BAS and SGS. W e sampled the finetuning process at three iteration counts: 120, 400 and 1000. F or the 10 sample finetuning we used a batch size of 4, and a batch size of 16 was used for the 1000 sample subset. 4 Evaluation The evaluation methodology assesses the selected TTS tools from two major perspectives: usability and output quality . F or usability we focus on setup complexity , documentation quality and community support. While the quality of the synthesised speech is evaluated objectively and subjectively across several dimensions. W e should note that we did not run the English baseline training recipes because our fo- cus was not on benchmarking performance in high-resource languages, but rather on adapt- ing the framework to low-/mid-resource settings. English baselines are already extensively documented in the original recipe, and replicating them would not provide additional in- sights beyond what is already established in the literature. 4.1 Usability assessment When developing a novel TTS system, the final selection of the adopted tool is also based on its ease of use. As a result, we first rate the T TS tools according to the following criteria: • installation and dependencies: the ease of setting up each model, including the li- brary dependency complexity and the availability of setup scripts (such as Docker or requirements files); • documentation quality: the clarity and completeness of available instructions, includ- ing troubleshooting guides and example usage; • reproducibility: the ease of replicating and adapting the setup, training and inference processes, including the necessary language-dependent modifications; • training and finetuning experience: the ease of training/finetuning the model with custom datasets and the amount of effort mandated by data preprocessing; • community support: the level of support available from the maintainers and the com- munity , based on the number of open/closed GitHub issues, responsiveness and issue resolution rates. T able 2 summarises our findings and a detailed description is provided next: F astPitch has a detailed setup process with structured documentation, especially when using the Docker container . The current version requires additional tools like Apex for mixed precision training, which can cause conflicts with some modules (CUDA, PyT orch). Addi- tionally , specific GPU requirements (V olta, T uring and Ampere architectures) are needed for optimal performance. As a result we resorted to an older version (commit ID: 72a15ee ), which eliminates the Apex dependency . T o ensure reproducibility on modern infrastructure, we established a stable environment using Python 3.12.3, PyT orch 2.6.0 and CUDA 12.4, running on NVIDIA T uring Architecture GPUs. This older version also includes lighter and simpler training scripts. Adaptations for Romanian included modifying the text cleaner and 7 T able 2: Setup and usability assessment of the selected T TS systems. Criteria VITS F astPitch Grad- TTS Matcha- TTS Setup difficulty Simple Moderate Simple Simple Step-by-step examples ✓ ✓ ✓ ✓ Pretrained checkpoints ✓ ✓ ✓ ✓ Manual fixes needed Minor Moderate Moderate Minor Adaptations for R omanian T ext processor T ext processor , T raining pipeline T ext processor T ext processor Community support Moderate Active Moderate Active phoneme processing pipeline, as mentioned in section 3.2. Setup was challenging initially , but after reverting to the aforementioned version, the training and finetuning proved intu- itive. Community support seems to be active, with 289 open issues and 575 closed issues on GitHub, although recent maintenance involvement has been minimal. VITS is easy to set up, with very brief instructions for installation and dependency man- agement. However , it lacks a clear documentation on dataset format and training config- uration files. This makes the adaptation process difficult for less experienced users. VITS allows for straightforward finetuning, but community support is limited, with 156 open and 57 closed issues, and maintainer engagement being minimal. It works out-of -the-box for En- glish, but adapting it for languages like R omanian requires adjustments particularly in text preprocessing, which in this case is a separate preliminary step that cleans the original text before training. The setup of Grad- TTS requires addressing specific implementation gaps to achieve full reproducibility . While the repository exhibits moderate official maintenance, evidenced by only 23 open and 11 closed issues, necessary solutions are readily available through com- munity contributions. First, the compilation of the monotonic_align module initially failed due to a missing directory in the source tree. Second, we integrated unmerged patches to stabilize training: the text encoder was updated to ensure proper usage of embedding in- formation for the multi-speaker configuration, and the mel-spectrogram cropping logic was corrected to prevent shape mismatch failures when processing short utterances. Finally , adapting the model to Romanian required replacing the original CMUDICT -based phoneme extraction with eSpeak to generate compatible phoneme IDs. Matcha- TTS offers a straightforward setup process accompanied by comprehensive doc- umentation and numerous command line tools for interaction. Its design facilitates easy adaptation to new datasets through clear , detailed instructions covering configuration and feature extraction pipelines. It includes readily available example configurations for both single and multi-speaker systems, alongside flexible training options such as multi-GP U sup- port and neatly organized experiments’ configurations. Adapting it to R omanian primarily involved executing the feature extraction script, adjusting the text processing pipeline for the language, and modifying the experiment configuration to utilize our specific dataset and ex- tracted features. The project’s GitHub repository indicates active community support with 18 open and 93 closed issues. User queries are timely addressed, although active development appears to have slowed down lately . Among the evaluated systems, Matcha-TTS stands out as the most user-friendly , provid- ing the most comprehensive documentation, a structured setup process and flexible adapta- tion pipeline. VITS is lightweight and simple to install, yet its limited documentation and separate text processing step may represent an obstacle for less experienced users. F ast- Pitch can seem less accessible due to its heavier setup requirements and more involved text processing adaptations. Grad-TTS is one of the least favoured options, as the repository required fixes and introduced additional overhead when running experiments for languages 8 0 10 20 30 WER [%] 3.6 3.1 3.1 2.8 4.5 4.6 13.0 9.8 6.5 16.4 13.4 11.3 32.5 15.0 14.8 16.8 10.2 12.7 6.3 4.6 4.2 3.8 4.4 4.4 10 samples 120 iterations 400 iterations 4000 iterations F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 0 10 20 30 WER [%] 2.6 2.1 2.4 6.2 5.9 6.2 11.9 10.4 8.6 17.9 17.5 19.8 10.4 9.6 11.6 11.1 9.2 10.3 4.3 4.0 4.0 5.3 5.4 5.5 1000 samples Figure 1: Pronunciation accuracy and intelligibility , reported as W ord Error Rate - WER ( ↓ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). other than English. 4.2 Objective Assessment of TTS Output Quality Objective measures of TTS quality have recently gained more academic and commercial interest as complementary assessments of a system’s output. They can, to some extend, estimate the intelligibility , naturalness and speaker similarity without relying on subjective listening tests. On top of tool-level evaluation, we employ a finer-grained analysis of speech quality influencing factors, like adaptation data size and compute time, or speaker characteristics (here, male vs female). Each metric is computed per utterance, and the average over the 42 synthesized evaluation samples (held-out set) is reported. Results for the the speaker adap- tation using 10 or 1000 speech samples, and varying the number of adaptation iterations (120, 400 or 4000) for the male and female speakers are also discussed. In order to perform this objective assessment, we resort to the extended set of mea- sures described in the following subsections. Although not always in line with the results obtained using listening tests, this extended set of metrics allows for a comprehensive and reproducible assessment of TTS performance. 4.2.1 Pronunciation accuracy and intelligibility assessment W ord Error Rate ( WER ) and Character Error Rate ( CER ) are used to assess pronunciation accuracy and intelligibility . Both metrics were computed by comparing Whisper-transcribed [26] outputs with the corresponding reference transcripts using the Jiwer 11 library . The same text normalization process was applied to both transcriptions, including lowercasing, removing punctuation, mapping common abbreviations to their full forms, and converting numbers into words. 11 https://jitsi.github.io/jiwer/usage/ 9 2.2 2.4 2.6 2.8 3.0 3.2 UTMOS 2.91 2.81 2.78 2.95 2.91 2.93 2.82 2.85 2.97 2.64 2.44 2.92 2.28 2.75 2.71 2.59 2.68 2.78 2.98 2.99 3.12 2.99 3.07 3.00 120 iterations 400 iterations 4000 iterations 10 samples F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 2.2 2.4 2.6 2.8 3.0 3.2 UTMOS 2.76 2.83 2.72 3.00 3.04 3.02 2.81 2.91 2.94 2.86 3.08 3.00 2.74 2.63 2.71 2.62 2.82 2.72 2.69 2.58 2.69 2.95 3.00 2.91 1000 samples Figure 2: P erceived naturalness, reported as Mean Opinion Score - UTMOS ( ↑ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). Figure 1 reveals clear differences among the intelligibility of the models. F astPitch achieved the lowest error rates across all finetuning conditions, with the best result of 2.1% WER for the female speaker using 1000 training samples. Matcha-TTS followed closely and maintained a stable performance across both low and high resource scenarios–its WER con- sistently remained below 6% for both speakers, suggesting robustness to data volumes. In contrast, VITS and Grad- T TS showed weaker performances. Grad- TTS produced the highest WERs, although its accuracy improved substantially with more training (from 32% to 14% for the female speaker). VITS displayed instability for the male speaker , where additional training led to a slight degradation (from 17% to 19% WER). Manual inspection confirmed that VITS often generated truncated utterances, which contributed to the high WER. Across all systems, adaptation to the female voice resulted in lower WER. Y et, this is correlated to the natural speech samples, where the female speaker yielded a 3% WER compared to 7% for the male. 4.2.2 Naturalness assessment Mean Opinion Score ( MOS ) based on the UTMOS automatic prediction system [25] is used to assess perceived naturalness. This was evaluated with the implementation provided in the Discrete Speech Metrics package. 12 T est waveforms were resampled to 16 kHz before applying the predictor to obtain a non-intrusive MOS estimate. This automatic approach was selected as a scalable and reproducible alternative to subjective listening tests. UTMOS scores (shown in Figure 2 are automatic evaluations of the perceived naturalness of speech, with higher values indicating more natural-sounding synthesis. Baseline scores from the original recordings were 3 . 07 for the female speaker and 2 . 92 for the male speaker . These values provide a reference for the assessment of the model performance. Across all systems, UTMOS scores ranged from 2 . 28 to 3 . 12 , with the male speaker generally perceived as slightly more natural, despite the female speaker achieving lower WER and better speaker similarity . Matcha-TTS and F astPitch consistently delivered the best results, while VITS per- formed competitively in the 1000-sample scenarios, occasionally surpassing both. However , 12 https://github.com/Takaaki- Saeki/DiscreteSpeechMetrics 10 0.70 0.75 0.80 0.85 0.90 0.95 1.00 SECS 0.84 0.88 0.88 0.73 0.81 0.83 0.89 0.89 0.9 0.84 0.85 0.84 0.85 0.87 0.87 0.8 0.84 0.84 0.87 0.89 0.89 0.84 0.86 0.87 120 iterations 400 iterations 4000 iterations F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 0.70 0.75 0.80 0.85 0.90 0.95 1.00 SECS 0.92 0.92 0.92 0.87 0.88 0.88 0.91 0.91 0.92 0.89 0.9 0.9 0.91 0.91 0.91 0.87 0.87 0.87 0.91 0.92 0.92 0.88 0.88 0.89 Figure 3: Speaker similarity , reported as Speaker Encoder Cosine Similarity - SECS ( ↑ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). VITS lacked stability: in the 10-sample case, its scores fluctuated thus reflecting instability in its generation process. F astPitch remained steady across training conditions, peaking at 3 . 02 in the 1000-sample setup. Matcha-TTS consistently scored high but showed an unexpected dip for the female speaker in the 1000-sample scenario. Grad- TTS, while improving with more training data, generally remained below the other models, achieving competitive re- sults only in the high-resource scenario. It should be noted that this objective assessment of naturalness is not always correlated with the subjective assessment, performed with listening tests (see section 4.3). 4.2.3 Speaker similarity assessment Speaker Encoder Cosine Similarity ( SEC S ) using the V oice Encoder [27] from the Resem- blyzer 13 package quantifies speaker identity preservation by computing the cosine similarity between embeddings extracted from each synthesized utterance and its paired reference recording. Prior to embedding, audio was converted to mono and resampled to 16 kHz. High SEC S scores are desirable, indicating better replication of speaker identity . Figure 3 shows the results for the four architectures, and we can draw the following insights: speaker cosine similarity increases consistently with more training data: models trained on 1000 samples outperform those trained on only 10, while additional finetuning iterations have a lower impact. Across all systems, the female speaker yields higher similarity scores than the male one. VITS achieves the highest speaker similarity overall (peaking at 0 . 92 ), preserving identity even in low-data settings, while F astPitch improves with more samples, particularly for the male speaker . Matcha- TTS delivers competitive and stable results across all training scenarios, though slightly below VITS. Grad- TTS shows the lowest similarity scores, improv- ing with data but remaining weaker than the other models. T aken together , these results suggest a trade-off between intelligibility and identity preservation: F astPitch leads in WER, but VITS more faithfully captures speaker characteristics. Matcha- TTS seemingly provides a 13 https://github.com/resemble- ai/Resemblyzer 11 3.2 3.4 3.6 3.8 4.0 4.2 PESQ 3.79 3.75 3.73 3.49 3.50 3.45 3.71 3.78 3.84 4.07 4.04 4.11 3.77 3.98 3.98 3.72 3.92 3.76 3.91 3.93 3.95 4.00 3.91 3.94 120 iterations 400 iterations 4000 iterations 10 samples F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 3.2 3.4 3.6 3.8 4.0 4.2 PESQ 3.66 3.70 3.65 3.52 3.50 3.51 3.79 3.70 3.73 4.10 4.11 4.17 3.92 3.85 3.99 3.92 3.97 3.91 3.85 3.77 3.85 3.94 3.95 3.98 1000 samples Figure 4: P erceptual quality , reported as P erceptual Evaluation of Speech Quality - PESQ ( ↑ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). 0.875 0.900 0.925 0.950 0.975 1.000 1.025 STOI 0.98 0.97 0.97 0.99 0.99 0.99 0.98 0.98 0.98 1.00 1.00 1.00 0.98 0.99 0.98 1.00 1.00 1.00 0.99 0.99 0.99 1.00 1.00 1.00 120 iterations 400 iterations 4000 iterations 10 samples F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 0.875 0.900 0.925 0.950 0.975 1.000 1.025 STOI 0.97 0.98 0.97 0.99 0.99 0.99 0.98 0.98 0.98 1.00 1.00 1.00 0.98 0.98 0.99 1.00 1.00 1.00 0.98 0.98 0.98 1.00 1.00 1.00 1000 samples Figure 5: P erceptual inteligibility , reported as Short- T ime Objective Intelligibility - STOI ( ↑ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). more balanced performance. 4.2.4 P erceptual quality , intelligibility , and signal fidelity assessment W e also adopt P erceptual Evaluation of Speech Quality ( PESQ ), Short- T ime Objective Intel- ligibility ( STOI ), and Scale-invariant signal-to-distortion ratio ( SI-SDR ) metrics stemming from the T orchAudio-Squim estimator [28]. These non-intrusive metrics provide comple- mentary measures of perceptual quality , intelligibility , and signal fidelity . In this case, the audio was resampled to the model’s expected sampling rate. 14 Across PESQ (Figure 4), STOI (Figure 5) and SI-SDR (Figure 6), the general trend is rather clear: all models produce intelligible speech of reasonable quality , but some handle 14 https://docs.pytorch.org/audio/2.6.0/generated/torchaudio.pipelines.SQUIM_OBJECTIVE.html 12 24 26 28 30 SI-SDR 25 25 25 25 25 24 25 25 27 27 26 29 25 27 26 25 26 25 24 25 26 28 27 27 120 iterations 400 iterations 4000 iterations 10 samples F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 24 26 28 30 SI-SDR 24 25 25 25 25 25 26 24 24 27 28 28 26 25 26 26 27 26 25 24 25 27 27 27 1000 samples Figure 6: Signal fidelity , reported as Scale-invariant signal-to-distortion ratio - SI-SDR ( ↑ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). perceptual fidelity better than others. Increasing training data from 10 to 1000 samples and extending iterations had only minor effects. VITS and Matcha- TTS consistently lead, meaning they generate speech that sounds more natural and less distorted. F astPitch and Grad- TTS are slightly weaker , indicating that perceptual quality and signal fidelity do not always align with improvements in WER or speaker similarity: a model can produce accu- rate pronunciations or succeed in preserving speaker identity while being perceptually less convincing. Slight advantages for the male speaker show that speaker characteristics can influence perceptual and distortion-sensitive metrics, but differences are small. 4.2.5 Prosodic and spectral deviation assessment Prosodic and spectral aspects were evaluated through the root mean squared error ( RMSE ) of the log F0 patterns and Mel Cepstral Distortion ( MCD ). Log F0 RMSE measures aver- age differences in pitch contour between generated and reference speech extracted with a WORLD -based procedure over 40 − 800 H z search range. T rajectories are converted to the logarithmic scale and aligned frame-wise before computing the per-utterance RMSE. On the other hand, MCD quantifies spectral deviation of the synthesised waveform through Mel- frequency cepstral coefficients of order 25. Both metrics were evaluated with the Discrete- SpeechMetrics package using a window size of 512 and a hop of 256 samples. MCD (shown in Figure 7) quantifies spectral differences between natural and synthe- sized speech, with lower values indicating closer alignment. Across all models, MCD was consistently better for the male speaker , contrasting with other metrics like WER or Log F0 RMSE where the female speaker typically performed better . Increasing training data had the largest impact: the 10-sample scenario yielded a minimum of 4 . 22 , while 1000 samples reduced it to 3 . 83 . Additional training iterations contributed only marginal improvements. Model-wise, Matcha- T TS consistently achieved the best scores, peaking at 3 . 83 , while VITS excelled in the 10-sample scenario and remained competitive at higher resources. F astPitch struggled under little adaptation data conditions but improved with more data, and Grad- TTS remained the weakest overall. Overall, spectral fidelity benefits primarily from larger datasets, with Matcha- TTS and VITS showing the strongest ability to reproduce the natural spectrum. 13 4 5 6 7 8 9 MCD 7.91 7.41 7.40 6.16 5.30 5.22 6.83 6.74 6.66 4.76 4.40 4.45 7.42 7.31 7.39 4.63 4.42 4.48 7.54 7.17 7.23 4.30 4.29 4.22 120 iterations 400 iterations 4000 iterations 10 samples F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 4 5 6 7 8 9 MCD 5.73 5.71 5.84 4.62 4.59 4.60 5.53 5.49 5.36 4.07 3.94 3.99 6.13 6.13 6.25 4.05 4.01 4.04 5.63 5.54 5.54 3.83 3.86 3.84 1000 samples Figure 7: Spectral deviation of the synthesised waveform, reported as Mel Cepstral Distortion - MCD ( ↓ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). 0.20 0.25 0.30 0.35 0.40 0.45 L ogF0 RMSE 0.32 0.21 0.23 0.41 0.3 0.27 0.19 0.19 0.18 0.22 0.24 0.2 0.2 0.2 0.2 0.21 0.22 0.2 0.24 0.2 0.22 0.2 0.2 0.21 120 iterations 400 iterations 4000 iterations F astP itch VITS Grad- T TS Matcha- T TS F M F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS F astP itch VITS Grad- T TS Matcha- T TS 0.125 0.150 0.175 0.200 0.225 0.250 L ogF0 RMSE 0.16 0.18 0.17 0.25 0.21 0.21 0.14 0.15 0.14 0.2 0.17 0.2 0.15 0.16 0.16 0.23 0.22 0.22 0.16 0.17 0.15 0.21 0.2 0.21 Figure 8: Differences in pitch contour , reported as Log F0 RMSE ( ↓ ) scores, for all models finetuned with 10 utterances per speaker (top) and 1000 utterances per speaker (bottom), evaluated at different stages of the finetuning process: 120 iterations (left); 400 iterations (center), and 4000 iterations (right). Log F0 RMSE quantifies deviations in pitch contour between synthesized and reference speech, with lower values indicating closer alignment and more accurate pitch reproduction. The results are summarized in Figure 8 with scores ranging from 0 . 14 to 0 . 41 . All models achieved their best performance for the female speaker in the 1000-sample scenario, with minimum RMSE values at 0 . 14 , demonstrating that ample training data allows models to capture fine-grained pitch variations. F or the male speaker , however , additional training data did not improve pitch accuracy , suggesting that male pitch contours were inherently more challenging to model under these settings. Across iterations, log F0 RMSE was generally stable in both the 10 and 1000 samples scenarios, except for F astPitch in the 10-sample scenario, which improved substantially with more training iterations (from 0 . 41 to 0 . 27 for the male speaker). F astPitch struggled under little adaptation data conditions but improved 14 steadily with more data, Matcha- T TS was consistently stable, VITS achieved the overall best score, and Grad-TTS showed relative strength in pitch despite weaker WER and speaker similarity . Overall, pitch reproduction benefits from sufficient training data, female voices are easier to model, and F astPitch is the least stable under limited resources. 4.2.6 Summary of objective assessment Overall, the objective results highlight that once a model has enough data to capture a speaker’s style, further training contributes only marginally to improvements in perceptual quality . Instead, choosing the right architecture has a larger impact than simply adding training data or allowing the model to learn for more iterations. F astPitch and Matcha-TTS perform well even in little data conditions. F or instance, F astPitch achieves a WER of 0 . 03 , a SECS of 0 . 72 and an UTMOS of 2 . 94 for the male speaker using only 10 training samples and 120 finetuning steps, matching or surpassing baseline scores. Similarly , Matcha- TTS reaches a WER of 0 . 05 , a SEC S score of 0 . 87 and a UTMOS of 2 . 98 for the female speaker under comparable conditions. In contrast, Grad-TTS and VITS require more data and training to achieve competitive performance. 4.3 Subjective Evaluation of TTS Output Quality A clearer picture of the synthesis quality can be obtained through subjective listening tests. W e opt for naturalness and speaker similarity evaluations for the two target speaker voices, BAS and SGS. A group of 31 listeners were asked to rate the TTS models finetuned with 1000 samples for 4000 iterations. Separate listening tests were set up for the two speakers. The samples were rated on a 0-unnatural to 100-natural scale, and all systems were presented to the listeners in parallel. The corresponding natural sample was mixed among the synthetic samples. F or the speaker similarity test, the natural sample was clearly marked in the page. The test was carried out by the listeners in their home environments, but they were asked to listen over headphones. The instructions were: • “ Assign a score from 0-bad to 100-excelent to evaluate the overall quality of the voice. F ocus on how natural and intelligible each sample sounds” and • “ Assign a score from 0-bad to 100-excellent to evaluate the similarity of the synthesized voice to the original speaker . The original speaker sample can be accessed by pressing the ’Reference’ button located on the left side of the test page.” R esults of the listening test are shown in Figures 9 and 10. T wo listeners were dropped due to high score variance and flat rating. W e can notice that VITS exhibits best performance in naturalness and speaker similarity , for both speakers, with F astPitch being consistently rated as second-best option. The listener ratings were also analysed using one-way ANOV A followed by T ukey HSD post-hoc tests to assess statistical differences among the speech synthesis systems. F or nat- uralness ratings, F astPitch and Matcha- TTS achieved comparable scores, showing no signif- icant difference from each other (p > 0.05). Natural, Grad- TTS, and VITS each differed significantly from the other systems, indicating substantial variability in perceived natural- ness. Speaker similarity ratings showed a similar pattern. F astPitch and Matcha- TTS were again comparable, with no significant difference between them. 15 Figure 9: P erceived Naturalness score statistics obtained in the listening test for the models finetuned with 1000 utterances per speaker for 4000 iterations. Figure 10: P erceived Speaker Similarity score statistics obtained in the listening test for the models finetuned with 1000 utterances per speaker for 4000 iterations. 5 Discussions and Conclusions This study explored the adaptability of four open-source TTS models to a new language. T o bridge compatibility with English-oriented models, we adopted a language-agnostic text 16 processing pipeline. Unlike other surveys on speech synthesis systems that focus primarily on reported results, we approached these models from a practical user perspective. W e evaluated not only their output quality , but also the ease of setup and training in uncovered languages, including speaker adaptation experiments to test generalization. Across our evaluations, F astPitch consistently demonstrated strong intelligibility , achiev- ing the lowest WER in all experimental conditions. R egarding naturalness, F astPitch ranked second in the listening tests and placed first or second in most objective evaluation scenarios. F or speaker similarity , both the objective and subjective assessments positioned F astPitch as the second-best system, following VITS. VITS achieved the highest scores in all subjective evaluations, indicating clear listener preference. However , its objective intelligibility performance was substantially weaker , con- sistently ranking third or fourth among the tested systems, with word error rates frequently exceeding 10%. Notably , none of the 31 listeners explicitly reported intelligibility issues, although our protocol did not directly solicit such feedback. W e hypothesize that VITS- generated speech may contain artifacts that interfere with Whisper-based transcription, thereby inflating its WER. In terms of speaker similarity , VITS consistently ranked first, performing comparably to F astPitch and Matcha- TTS in the objective assessment and outperforming all systems in the subjective evaluations. Matcha- TTS achieved the highest naturalness scores in the objective evaluation according to UTMOS. However , human listeners did not concur , ranking Matcha- TTS third in both naturalness and speaker similarity . This discrepancy illustrates a clear limitation of objective naturalness metrics such as UTMOS, whose predictions did not align with human perceptual judgments. Nevertheless, Matcha- T TS showed strong robustness in the objective evaluation, maintaining competitive performance even with minimal finetuning data. In contrast, VITS and Grad-TTS generally required larger amounts of data and additional training effort to reach similar performance levels. Grad- TTS typically ranked last in naturalness across both objective and subjective evalu- ations. Its intelligibility performance was similarly limited, with WER values often exceeding 10% and placing it third or fourth among the systems. As with VITS, it is plausible that Grad- TTS outputs contain artifacts that Whisper struggles to transcribe reliably . From a user experience perspective, Matcha- T TS was the most accessible T TS system, offering clear instructions and tooling for customization. F astPitch, while powerful and well documented, required careful requirement setup due to module incompatibilities, which could be a barrier for some users. Grad- TTS and VITS offered less guidance, with Grad-TTS depending heavily on community fixes. In preparation for this study , we also explored the adaptation of P arler- TTS [7], which incorporates not only text prompts, but also structured descriptions of speech attributes and recording conditions. P arler- T TS proved difficult to adapt, revealing the fragility of state-of- the-art T TS pipelines when used with non-English data. Even after implementing a multi- stage workaround for generating R omanian speech attribute descriptors, the model failed to train from scratch and produced only silence. Although fine-tuning an existing checkpoint worked, it diverged from our intended protocol (i.e. train from scratch), so P arler- T TS was ultimately excluded. W e believe that this work serves as a practical reference for researchers and practitioners aiming to adapt T TS models to languages beyond their original design, and contributes to the development of more inclusive and accessible speech technologies. 17 Acknowledgment This work was co-funded by EU Horizon project AI4TRUST (No. 101070190) and by a grant of the Ministry of R esearch, Innovation and Digitization, CCCDI - UEFISCDI, project number PN-IV -P7-7.1-PTE-2024-0546, within PNCDI IV . R eferences [1] X. T an, T. Qin, F . Soong, and T .- Y . Liu, “A Survey on Neural Speech Synthesis,” 2021. [2] T . Xie, Y . R ong, P . Zhang, and L. Liu, “T owards Controllable Speech Synthesis in the Era of Large Language Models: A Survey,” 2024, accepted at EMNLP 2025. [3] C. Zhang, C. Zhang, S. Zheng, M. Zhang, M. Qamar , S.-H. Bae, and I. S. Kweon, “A Survey on Audio Diffusion Models: T ext T o Speech Synthesis and Enhancement in Generative AI,” 2023. [4] P . P atole, A. P andey , K. Bhagwat, M. V aishnav , and S. Chadar , “A Survey on T ext-to- Speech Systems for R eal- Time Audio Synthesis,” International Journal of Advanced Re- search in Science, Communication and T echnology , pp. 375–379, 06 2021. [5] N. Zeghidour , A. Luebs, A. Omran, J. Skoglund, and M. T agliasacchi, “SoundStream: An End-to-End Neural Audio Codec,” IEEE/ACM T ransactions on Audio, Speech, and Language Processing , vol. 30, pp. 495–507, 2022. [6] A. Défossez, J. Copet, G. Synnaeve, and Y . Adi, “High Fidelity Neural Audio Compres- sion,” in Proceedings of the International Conference on Learning Representations (ICLR) , 2023. [7] D. Lyth and S. King, “Natural language guidance of high-fidelity text-to-speech with synthetic annotations,” 2024. [Online]. A vailable: https://arxiv .org/abs/2402.01912 [8] R. K umar , P . Seetharaman, A. Luebs, I. K umar , and K. Kumar , “High-Fidelity Audio Compression with Improved R VQGAN,” in Advances in Neural Information Processing Systems , A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 27 980–27 993. [9] J. Sohl-Dickstein, E. W eiss, N. Maheswaranathan, and S. Ganguli, “Deep Unsupervised Learning using Nonequilibrium Thermodynamics,” in Proceedings of the 32nd Interna- tional Conference on Machine Learning , ser . Proceedings of Machine Learning R esearch, F . Bach and D. Blei, Eds., vol. 37. Lille, France: PMLR, 07–09 Jul 2015, pp. 2256– 2265. [10] D. Rezende and S. Mohamed, “V ariational Inference with Normalizing Flows,” in Pro- ceedings of the 32nd International Conference on Machine Learning , ser . Proceedings of Machine Learning R esearch, F . Bach and D. Blei, Eds., vol. 37. Lille, France: PMLR, 07–09 Jul 2015, pp. 1530–1538. [11] N. Chen, Y . Zhang, H. Zen, R. J. W eiss, M. Norouzi, and W . Chan, “W aveGrad: Esti- mating Gradients for W aveform Generation,” in International Conference on Learning Representations (ICLR) , 2021. 18 [12] H. Kim, S. Kim, and S. Y oon, “Guided-TTS: A diffusion model for text-to-speech via classifier guidance,” in Proceedings of the 39th International Conference on Machine Learning , ser . Proceedings of Machine Learning R esearch, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, Eds., vol. 162. PMLR, 17–23 Jul 2022, pp. 11 119–11 133. [13] R. Huang, M. W . Y . Lam, J. W ang, D . Su, D. Y u, Y . R en, and Z. Zhao, “F astdiff: A fast conditional diffusion model for high-quality speech synthesis,” in International Joint Conference on Artificial Intelligence , 2022. [Online]. A vailable: https://api.semanticscholar .org/CorpusID:248300058 [14] Z. Kong, W . Ping, J. Huang, K. Zhao, and B. Catanzaro, “DiffW ave: A V ersatile Diffusion Model for Audio Synthesis,” in International Conference on Learning R epresentations (ICLR) , 2021. [15] V . P opov , I. V ovk, V . Gogoryan, T. Sadekova, and M. Kudinov , “Grad- T TS: A Diffusion Probabilistic Model for T ext-to-Speech,” pp. 8599–8608, 18–24 Jul 2021. [16] R. V alle, K. Shih, R. Prenger , and B. Catanzaro, “Flowtron: An Autoregres- sive Flow-Based Generative Network for T ext-to-Speech Synthesis,” arXiv preprint arXiv:2005.05957 , 2020. [17] C. Miao, S. Liang, M. Chen, J. Ma, S. W ang, and J. Xiao, “Flow-TTS: A Non- Autoregressive Network for T ext to Speech Based on Flow,” in Proc of ICA S SP , 2020, pp. 7209–7213. [18] Y . R en, J. Liu, and Z. Zhao, “P ortaSpeech: P ortable and High-Quality Generative T ext-to-Speech,” in Advances in Neural Information Processing Systems , M. Ranzato, A. Beygelzimer , Y . Dauphin, P . Liang, and J. W . V aughan, Eds., vol. 34. Curran Asso- ciates, Inc., 2021, pp. 13 963–13 974. [19] J. Kim, J. S. Kong, S. Kim, H. Seo, J. Kim, H. Kang, and B. Y oon, “Glow-tts: A gen- erative flow for text-to-speech via monotonic alignment search,” Advances in Neural Information Processing Systems , vol. 33, pp. 15 829–15 840, 2020. [20] S. Mehta, R. T u, J. Beskow , É. Székely , and G. E. Henter , “Matcha-TTS: A fast TTS architecture with conditional flow matching,” in Proc. of ICAS SP , 2024. [21] J. Kim, J. S. Kong, B. Y oon, S. Kim, and D . Choi, “Vits: V ariational inference with ad- versarial learning for end-to-end text-to-speech,” Advances in Neural Information Pro- cessing Systems , vol. 34, pp. 6879–6895, 2021. [22] A. Ła ´ ncucki, “F astpitch: P arallel T ext-to-Speech with Pitch Prediction,” in Proc. of ICAS SP , 2021, pp. 6588–6592. [23] J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,” in Advances in Neural Information Processing Sys- tems , H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 17 022–17 033. [24] A. Stan, F . Dinescu, C. Tiple, S. Meza, B. Orza, M. Chirila, and M. Giurgiu, “The SW ARA Speech Corpus: A Large P arallel R omanian R ead Speech Dataset,” in Proceedings of the 9th Conference on Speech T echnology and Human-Computer Dialogue (SpeD) , Bucharest, R omania, July , 6-9 2017. 19 [25] T akaaki Saeki and Detai Xin and W ataru Nakata and T omoki Koriyama and Shinnosuke T akamichi and Hiroshi Saruwatari, “UTMOS: UT okyo-SaruLab System for V oiceMOS Challenge 2022,” in Proc. of Interspeech , 2022, pp. 4521–4525. [26] A. Radford, J. W . Kim, T . Xu, G . Brockman, C. Mcleavey , and I. Sutskever , “R obust Speech R ecognition via Large-Scale W eak Supervision,” in Proceedings of the 40th In- ternational Conference on Machine Learning , ser . Proceedings of Machine Learning Re- search, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23–29 Jul 2023, pp. 28 492–28 518. [27] L. W an, Q. W ang, A. P apir , and I. L. Moreno, “Generalized End-to-End Loss for Speaker V erification,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICAS SP) , 2018, pp. 4879–4883. [28] A. Kumar , K. T an, Z. Ni, P . Manocha, X. Zhang, E. Henderson, and B. Xu, “T orchaudio- Squim: R eference-Less Speech Quality and Intelligibility Measures in T orchaudio,” in Proc. of ICAS SP) , 2023, pp. 1–5. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment