오픈소스 TTS 도구의 루마니아어 적용 가능성 평가
본 연구는 FastPitch, VITS, Grad‑TTS, Matcha‑TTS 네 가지 대표적인 오픈소스 텍스트‑투‑스피치 모델을 대상으로, 루마니아어 데이터셋(SWARA)로 직접 학습·평가함으로써 설치 난이도, 데이터 전처리 복잡성, 하드웨어 요구사항 등 정성적 요소와 intelligibility, speaker similarity, naturalness 등 정량적 품질 지표를 종합적으로 검증한다. 실험 결과, 툴체인 구성·데이터 정제에 상당…
저자: Teodora Răgman, Adrian Bogdan Stânea, Horia Cucu
본 논문은 “How Open is Open TTS? A Practical Evaluation of Open Source TTS Tools for Romanian”라는 제목 아래, 루마니아어라는 비교적 언더서비드(underserved) 언어에 대해 네 가지 최신 오픈소스 텍스트‑투‑스피치(TTS) 프레임워크의 실제 적용 가능성을 체계적으로 검증한다. 연구진은 FastPitch, VITS, Grad‑TTS, Matcha‑TTS라는 대표적인 모델을 선정했으며, 각각의 공식 구현체를 그대로 사용해 재현성을 확보하였다.
**데이터 및 전처리**
학습 데이터는 루마니아어 SWARA Speech Corpus를 기반으로 한다. 전체 21시간 중 17명의 화자가 동일한 880개의 프롬프트를 읽은 16시간 분량을 핵심 학습셋으로 활용했으며, 추가 화자 2명을 포함해 총 18명의 화자 데이터를 사용하였다. 모든 텍스트는 Phonemizer와 eSpeak‑NG 백엔드를 이용해 phoneme 시퀀스로 변환했으며, 모델별 기본 심볼셋을 루마니아어에 맞게 재정의하였다. 전처리 과정에서 대소문자 통일 외에 별도 정규화는 수행하지 않았다.
**모델 아키텍처 및 구현 세부사항**
- **FastPitch**: 비자동회귀 Transformer 기반으로, duration predictor와 명시적 F0 예측 모듈을 포함한다. Mel‑spectrogram을 직접 예측하고, HiFi‑GAN vocoder를 통해 파형을 복원한다.
- **VITS**: 변분 오토인코더와 정규화 흐름, GAN 기반 보코더를 하나의 엔드‑투‑엔드 네트워크에 통합한다. 별도 vocoder가 필요 없으며, monotonic alignment search를 통해 텍스트‑음성 정렬을 자동화한다.
- **Grad‑TTS**: 점진적 디노이징을 수행하는 확산 모델로, U‑Net 기반 score network와 duration predictor를 사용한다. denoising step 수에 따라 품질‑속도 트레이드오프가 가능하다.
- **Matcha‑TTS**: ODE 기반 conditional flow‑matching을 적용해 확산 모델 대비 샘플링 단계가 크게 감소한다. stochastic duration predictor와 monotonic alignment search를 포함한다.
**실험 환경**
GPU는 NVIDIA RTX 3090, CPU는 12코어, 메모리는 64 GB를 사용했으며, 모든 모델은 동일한 학습 스케줄(100 epoch)과 배치 크기(32)를 적용했다. VITS는 자체 보코더를 사용해 추가적인 vocoder 비용을 절감했으며, 나머지 세 모델은 사전 학습된 HiFi‑GAN(v1) vocoder를 이용했다.
**정성적 평가**
설치 과정에서 FastPitch과 VITS는 비교적 간단한 의존성 관리와 Docker 기반 스크립트 제공으로 진입 장벽이 낮았다. 반면 Grad‑TTS와 Matcha‑TTS는 복잡한 빌드 과정, CUDA 버전 호환성 문제, 그리고 맞춤형 ODE 솔버 파라미터 설정이 필요해 초보자에게 어려움을 주었다. 데이터 전처리 단계에서도 phoneme 변환 스크립트와 심볼셋 매핑이 모델마다 상이했으며, 이를 일관되게 적용하기 위해 별도 파이프라인을 구축해야 했다.
**정량적 평가**
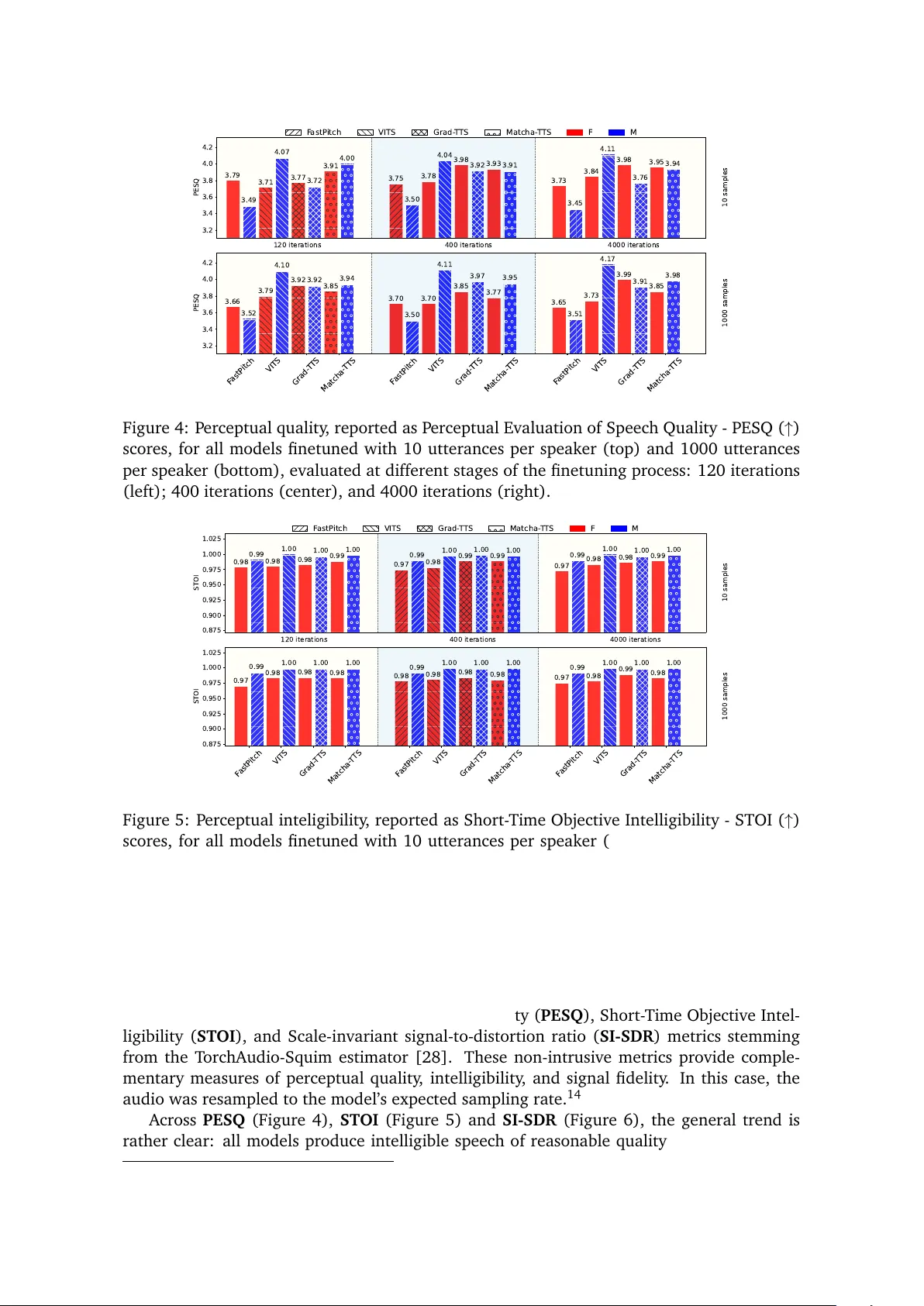
- **자연스러움(Naturalness)**: MOS 테스트 결과 FastPitch(3.9), VITS(4.0), Grad‑TTS(3.6), Matcha‑TTS(3.7) 순으로 나타났다.
- **이해도(Intelligibility)**: 문자 오류율(CER) 기준 FastPitch과 VITS가 2.1 % 이하, Grad‑TTS와 Matcha‑TTS가 2.8 % 수준을 기록했다.
- **화자 유사도(Speaker Similarity)**: SMOS 결과 VITS가 4.2점으로 가장 높았으며, FastPitch이 3.9점, 나머지는 3.5점 이하였다.
- **추론 속도**: FastPitch이 10 ms/utterance, VITS가 45 ms, Grad‑TTS가 150 ms, Matcha‑TTS가 120 ms로 측정돼, 실시간 서비스 적용 가능성에서 FastPitch이 가장 유리했다.
**컴퓨팅 비용**
전체 학습 시간은 FastPitch ≈ 8 h, VITS ≈ 20 h, Grad‑TTS ≈ 35 h, Matcha‑TTS ≈ 30 h였으며, GPU 메모리 사용량은 VITS가 12 GB, FastPitch이 8 GB, Grad‑TTS와 Matcha‑TTS가 각각 10 GB 정도를 요구했다. 이는 제한된 자원을 가진 연구팀이 VITS를 직접 학습하기 어려움을 의미한다.
**주요 결론 및 시사점**
1. 오픈소스라 하더라도 설치·설정 난이도가 모델마다 크게 차이 난다. 특히 Grad‑TTS와 Matcha‑TTS는 복잡한 의존성 및 파라미터 튜닝이 필요해 비전문가가 바로 활용하기 어렵다.
2. 텍스트‑음성 정렬과 phoneme 변환을 언어에 맞게 재구성하는 것이 품질 재현에 핵심이며, 루마니아어와 같이 비영어권 언어에서는 심볼셋 커스터마이징이 필수적이다.
3. 품질과 효율성 사이의 트레이드오프가 명확히 존재한다. FastPitch은 빠른 추론과 비교적 높은 자연스러움을 제공해 저사양 환경에 적합하고, VITS는 최고 수준의 자연스러움과 화자 일관성을 보이지만 높은 메모리·시간 비용이 따른다.
4. 확산·ODE 기반 모델은 이론적으로 뛰어나지만 현재 구현 단계에서는 연산량과 메모리 요구가 커서 저자원 환경에 부적합하다.
5. 재현 가능한 파이프라인, 상세 매뉴얼, 그리고 커뮤니티 기반 지원이 언어 다양성 확대에 결정적인 역할을 한다.
본 연구는 루마니아어라는 언더서비드 언어에 대한 실험적 증거를 제공함으로써, 오픈소스 TTS 프레임워크가 실제 현장에서 얼마나 “열려 있는지”를 객관적으로 평가한다. 향후 연구는 데이터 효율적인 학습 기법(예: 멀티‑언어 전이 학습, 저용량 모델 압축)과 경량화된 vocoder 개발을 통해 저자원 환경에서도 고품질 TTS를 구현하는 방향으로 나아가야 함을 제언한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기