Elements of Conformal Prediction for Statisticians
Predictive inference is a fundamental task in statistics, traditionally addressed using parametric assumptions about the data distribution and detailed analyses of how models learn from data. In recent years, conformal prediction has emerged as a rap…
Authors: Matteo Sesia, Stefano Favaro
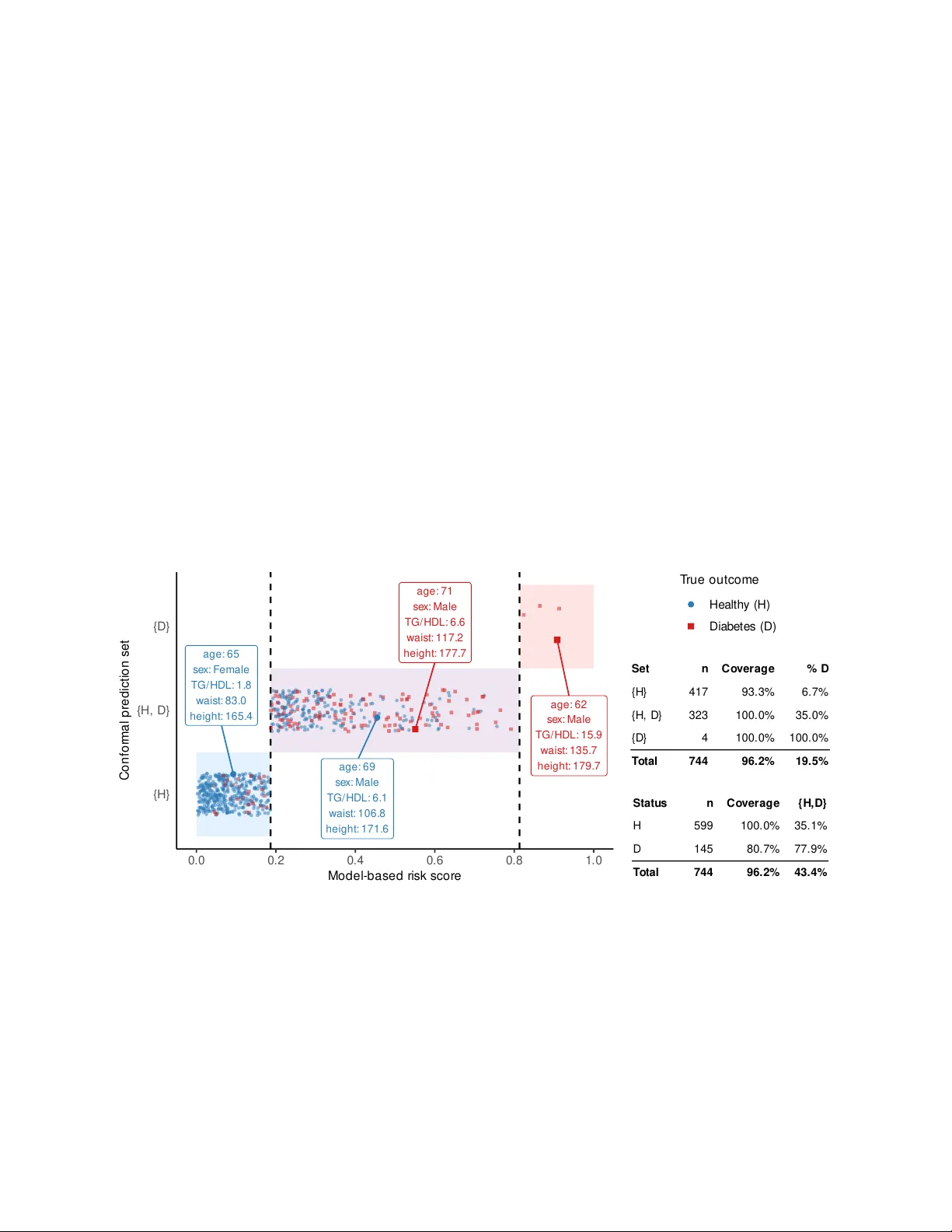
Elemen ts of Conformal Prediction for Statisticians Matteo Sesia ∗ Stefano F a v aro † Marc h 26, 2026 Abstract Predictiv e inference is a fundamental task in statistics, traditionally addressed using para- metric assumptions ab out the data distribution and detailed analyses of how mo dels learn from data. In recen t years, conformal prediction has emerged as a rapidly growing alternative frame- w ork that is particularly w ell suited to modern applications in v olving high-dimensional data an d complex mac hine learning models. Its appeal stems from being b oth distribution-free—relying mainly on symmetry assumptions such as exchangeabilit y—and mo del-agnostic, treating the learning algorithm as a blac k b ox. Even under such limited assumptions, conformal prediction pro vides exact finite-sample guarantees, though these are t ypically of a marginal nature that requires careful in terpretation. This pap er explains the core ideas of conformal prediction and reviews selected metho ds. Rather than offering an exhaustiv e survey , it aims to provide a clear conceptual entry p oint and a p edagogical ov erview of the field. Keyw ords: Exchangeabilit y , distribution-free metho ds, exact inference, machine learning, predic- tiv e inference. 1 In tro duction A pioneering work in conformal prediction (V ovk et al., 1999) op ens with: “two imp ortant differ enc es of most mo dern metho ds of machine le arning fr om classic al statistic al metho ds ar e that: (1) machine le arning metho ds pr o duc e b ar e pr e dictions, without estimating c onfidenc e in those pr e dictions; and (2) many machine le arning metho ds ar e designe d to work under the gener al i.i.d. assumption and they ar e able to de al with extr emely high-dimensional hyp otheses sp ac es.” This observ ation remains relev ant to da y and explains the growth of conformal prediction, a v ersatile statistical framework developed to quantify uncertain ty in the predictions of complex mo dels while pro viding exact statistical guaran tees under limited assumptions. The ro ots of conformal prediction can b e traced bac k at least to foundational statistical w ork from the 1940s (Wilks, 1941, W ald, 1943, Sc heffe and T uk ey, 1945, T uk ey, 1947, 1948). Remark ably , its core ideas ha ve remained largely unc hanged, even as metho dology and the scop e of mac hine learning applications hav e expanded dramatically . This stability reflects the reliance of conformal prediction on fundamental statistical principles: it requires neither parametric assumptions on the ∗ Departmen t of Data Sciences and Op erations, and Thomas Lord Department of Computer Science, Univ ersity of Southern California, Los Angeles, CA 90089, USA. Email: sesia@marshall.usc.edu † Dipartimen to di Scienze Economico-So ciali e Matematico-Statistiche, Universit` a di T orino and Collegio Carlo Alb erto, T orino, Italy . 1 data distribution nor knowledge of the internal mechanics of the predictive mo dels it accompanies. As a result, conformal prediction is well positioned to remain relev an t as data sets gro w and mo dels con tinue to ev olve. Man y high-quality exp ository resources on conformal prediction already exist, including b o oks (V ovk et al., 2005, 2022a, Angelop oulos et al., 2024), literature surveys (Shafer and V o vk, 2008, Tian et al., 2022, F ontana et al., 2023, Zhou et al., 2025), and practitioner-oriented tutorials (An- gelop oulos and Bates, 2023). Moreo v er, research in this area is still expanding rapidly , so that a new comprehensiv e survey of recent adv ances would risk b ecoming quickly outdated. Accordingly , the goal of this review is to complement existing resources b y offering a concise and p edagogical in tro duction to some of the key ideas, starting from the b eginning and adopting a p ersp ective that should resonate with statisticians. 2 F oundations 2.1 Exc hangeabilit y , Conformal Prediction Sets and p -V alues 2.1.1 Exc hangeable data W e consider data that can b e represen ted as n + 1 pairs Z i = ( X i , Y i ), with X i ∈ X and Y i ∈ Y , for all i ∈ [ n + 1] := { 1 , . . . , n + 1 } , where X , Y are measurable spaces such that Z = X × Y . In tuitively , Y is the outcome (or lab el) to predict and X are features (or cov ariates) that may b e relev ant. Giv en observed data Z 1: n := ( Z 1 , . . . , Z n ) and new features X n +1 , the goal is to predict, with confidence, the outcome Y n +1 , b efore observing it. The main assumption is that Z 1 , . . . , Z n +1 are exchangeable random samples from some p opulation. Throughout the pap er, w e often refer to unordered sets allowing rep etitions of random v ariables as multisets or bags, H Z 1:( n +1) I := { Z 1 , . . . , Z n +1 } , consistent with the notation of V ovk et al. (2005). 2.1.2 Uncertain t y quan tification via prediction sets Conformal methods quantify uncertain t y ab out Y n +1 b y constructing a prediction set. This, denoted as C α ( X n +1 ; Z 1: n ) ⊆ Y , may dep end on the features X n +1 , the data Z 1: n , and a significance level α ∈ (0 , 1). In practice, C α ( X n +1 ; Z 1: n ) is often designed to guarantee marginal cov erage: 1 P [ Y n +1 ∈ C α ( X n +1 ; Z 1: n )] ≥ 1 − α. (1) Crucially , this guarantee is finite-sample and distribution-free, meaning it holds exactly for an y data distribution under whic h Z 1:( n +1) are exc hangeable. The probabilit y is tak en o v er ( X n +1 , Y n +1 ) and Z 1: n , all of which are random—hence the term “marginal”. Therefore, Eq. 1 do es not imply cov erage conditional on any particular v alue of X n +1 , Y n +1 , or Z 1: n . Marginal co verage is a reasonable ob jectiv e b ecause it is easy to achiev e in finite samples under limited assumptions. How ev er, it is rarely fully satisfactory on its own, and that is why practical conformal prediction metho ds are typically designed to not only satisfy Eq. 1 but also pro duce prediction sets that are as informative as p ossible. Although differen t applications ma y call for differen t measures of informativ eness, a broadly app ealing ideal goal w ould be to minimize the av erage size of the prediction sets while ac hieving feature-conditional cov erage, P [ Y n +1 ∈ C α ( X n +1 ; Z 1: n ) | X n +1 = x ] ≥ 1 − α, ∀ x ∈ X . (2) 1 This prop erty is also equiv alent to one of the cov erage requirements for tolerance regions (Wilks, 1941), which w ere, how ever, traditionally studied in the case without features (no X ). 2 Prediction sets satisfying Eq. 2 with minimal size would b e highly informative, with uncertain t y tailored to the inheren t difficulty of predicting Y n +1 giv en X n +1 . Unfortunately , achieving exact conditional cov erage with reasonably-sized prediction sets is often imp ossible, esp ecially when the feature space X is large (e.g., V ovk, 2012, Lei and W asserman, 2014, Barb er et al., 2021b, etc). Consequen tly , conformal metho ds are typically designed to seek informative and feature-adaptiv e prediction sets, while guaran teeing marginal cov erage. 2.1.3 Prediction sets from tests of exchangeabilit y Conformal prediction op erates by building a test for the n ull hypothesis H n +1 that the full dataset Z 1 , . . . , Z n +1 is exc hangeable. Since the lab el Y n +1 is unobserv ed and th us plays a distinguished role, it is helpful to emphasize the dep endence of v arious quantities of in terest on its h yp othetical v alue y ∈ Y . W e introduce a function p : ( y ; Z 1: n , X n +1 ) 7→ [0 , 1] whose role is to quan tify the evidence against H n +1 con tained in the h yp othesized unordered dataset D ( y ) := { Z 1 , . . . , Z n , ( X n +1 , y ) } . This p -function is designed, as detailed b elo w, in suc h a w ay that ev aluating it at the true (random) test lab el Y n +1 giv es a conformal p -v alue p ( Y n +1 ; Z 1: n , X n +1 ): a statistic that is marginally sup er- uniform under H n +1 ; that is, if the full data are exc hangeable, P [ p ( Y n +1 ; Z 1: n , X n +1 ) ≤ α ] ≤ α, ∀ α ∈ (0 , 1) . (3) The α -lev el conformal prediction set for Y n +1 is the set of labels y ∈ Y for which the evidence con tained in D ( y ) would b e insufficient to reject H n +1 at level α ; i.e., C α ( X n +1 ; Z 1: n ) := { y ∈ Y : p ( y ; Z 1: n , X n +1 ) > α } . (4) In other words, C α ( X n +1 ; Z 1: n ) is the acceptance region for this test of H n +1 . 2 T esting H n +1 is a theoretical device in this con text; we compute the critical region but w e nev er truly apply the test, for tw o reasons. Firstly , the test’s decision dep ends on the unobserved Y n +1 ; secondly , the null h yp othesis H n +1 is assumed true from the momen t one decides to apply conformal prediction, and the goal is not to dispro ve it. 3 Nonetheless, this imaginary hypothesis test is useful to pro ve that C α ( X n +1 ; Z 1: n ) has v alid 1 − α marginal cov erage for Y n +1 . In fact, marginal cov erage follo ws directly from Eq. 3–4, since Y n +1 / ∈ C α ( X n +1 ; Z 1: n ) if and only if p ( Y n +1 ; Z 1: n , X n +1 ) ≤ α . If the outcome space Y is finite, C α ( X n +1 ; Z 1: n ) can b e constructed in practice by ev aluating the p -function explicitly for each hypothetical v alue y . Analytical simplifications are in many cases p ossible and sometimes necessary , for example if Y is uncoun table. 2.1.4 Nonconformit y scores and conformal p -functions The p -function is generally constructed by comparing how unusual, or non-conforming, the hy- p othesized case ( X n +1 , y ) lo oks relativ e to the reference dataset D ( y ), against the corresp onding non-conformit y of all other observ ations Z i ∈ D ( y ), for i ∈ [ n ]. In each case, conformity is quan- tified b y a non-conformit y score function s : Z × Z n +1 7→ R , so that s ( z , D ) aims to assign larger v alues to observ ations z ∈ Z that are more atypical relative to the reference set D ∈ Z n +1 . 2 Sometimes, conformal prediction is explained as testing “random hypotheses” of the type H n +1 ( y ) : Y n +1 = y , using p ( y ; Z 1: n , X n +1 ) as a “ p -v alue” for H n +1 ( y ). Ho wev er, that in terpretation is not entirely rigorous because p ( y ; Z 1: n , X n +1 ) is not sup er-uniform for any fixed y . 3 Using the conformal p -v alue p ( Y n +1 ; Z 1: n , X n +1 ) to dispro ve H n +1 is the goal in a differen t, related class of outlier detection problems, discussed in Section 3.3. 3 The conformal p -function at y is then defined as the relative rank of the hypothesized test score s (( X n +1 , y ); D ( y )) among the scores s (( X i , Y i ); D ( y )) of all reference observ ations: p ( y ; Z 1: n , X n +1 ) = 1 + P n i =1 I s ( X n +1 , y ); D ( y ) ≤ s Z i ; D ( y ) 1 + n . (5) This tak es v alues in { 1 / ( n + 1) , 2 / ( n + 1) , . . . , 1 } , with smaller v alues for more unusual hypothesized test cases ( X n +1 , y ). It is readily v erified that this construction yields v alid conformal p -v alues. Theorem 1. If Z 1:( n +1) ar e exchange able, P [ p ( Y n +1 ; Z 1: n , X n +1 ) ≤ α ] ≤ α , ∀ α ∈ (0 , 1) . Pr o of. Because D ( Y n +1 ) is in v arian t to p erm utations, under H n +1 the scores s ( Z 1 ; D ( Y n +1 )) , . . . , s ( Z n ; D ( Y n +1 )) , s (( X n +1 , Y n +1 ); D ( Y n +1 )) are exchangeable. Consequen tly , if the scores are almost-surely distinct, the rank of the last one among the n + 1 v alues is uniformly distributed on { 1 , . . . , n + 1 } , which implies Eq. 3. In general, a careful definition of the rank is needed to ensure exact uniformit y in the presence of ties. Ho wev er, conditional on the bag of scores, the distribution of s (( X n +1 , Y n +1 ); D ( Y n +1 )) is still uniform ov er the bag, which implies the p -v alue is v alid. 2.1.5 Connection to pivots Exc hangeability connects conformal prediction to the classical notion of piv ots; and sp ecifically also to rank and p ermutation tests (Kuc hibhotla, 2020). In general, pivots are useful b ecause they can b e inv erted to construct confidence s ets, and this forms the basis of man y common interv als, suc h as the t -interv al. In conformal prediction, the v ector Z 1:( n +1) is a conditional pivot, whose distribution given the bag H Z 1:( n +1) I do es not dep end on an y p opulation parameters and is fully known: it is uniform o ver all p erm utations of the scores. The inv ersion of this conditional pivot, which dep ends on the unkno wn outcome Y n +1 through Z n +1 , is precisely what giv es the conformal prediction set for Y n +1 . This p ersp ec tiv e can b e pushed further to construct join t cov erage regions sim ultaneously for b oth parameters and outcomes (Dobriban and Lin, 2023). 2.1.6 Marginal co v erage: strengths and limitations W e ha v e seen how the marginal co verage of conformal prediction generally enjo ys an exact lo w er b ound. There is also an (almost) matching upp er b ound, as long as the nonconformit y scores are almost-surely distinct. The latter is a v ery mild assumption b ecause any ties can alwa ys b e broken at random, indep endent of the data. This result has a long history and v arious versions of it ha ve app eared throughout the y ears, including in Wilks (1941), V o vk et al. (1999, 2005), Lei et al. (2013). Theorem 2. If Z 1 , . . . , Z n +1 ar e exchange able, for any sc or e function s and any α ∈ [0 , 1] , the c onformal pr e diction sets given by Eq. 4–5 have mar ginal c over age ab ove 1 − α . Mor e over, if the sc or es s ( Z 1 ; D ( Y n +1 )) , . . . , s ( Z n +1 ; D ( Y n +1 )) ar e almost-sur ely distinct, 1 − α ≤ P [ Y n +1 ∈ C α ( X n +1 ; Z 1: n )] ≤ 1 − α + 1 n + 1 . (6) The upp er b ound in Theorem 2 shows that co verage conv erges to 1 − α at the fast rate O (1 /n ). This is v ery efficient relative to most estimation tasks, for whic h t ypically the error conv erges no faster than O (1 / √ n ) due to the cen tral limit theorem. 4 Ho wev er, not all prediction sets satisfying Eq. 6 are equally informativ e. F or instance, marginal co verage can be ac hieved by a trivial prediction set defined as: C trivial α ( X n +1 ; Z 1: n ) = ( Y , if U n +1 ≤ 1 − α, ∅ , otherwise , (7) where the features X are augmented with indep endent noise U ∼ Uniform(0 , 1), to enable random- ization. Despite ha ving exact 1 − α cov erage, this set is uninformative. This counterexample shows wh y marginal co verage alone is not the ultimate goal of conformal prediction. It is rather a basic sanity c heck, while the real challenge is to construct informativ e pre- diction sets. Achieving this often requires careful design of the nonconformity score and, sometimes, more sophisticated metho ds. W e return to this topic later. 2.2 Illustration: Predicting a Con tin uous Scalar V ariable T o build intuition, w e begin b y studying a simple problem where the goal is to construct a one-sided prediction interv al for a con tinuous outcome without using feature information. Supp ose the distribution of Y is supp orted on Y = R without p oint masses, and X = 1 almost surely , so the features can b e ignored. W e focus on constructing a one-sided prediction in terv al C α ( X n +1 ; Z 1: n ) = ( −∞ , U α ( Y 1: n )], with upp er b ound U α ( Y 1: n ). The marginal co verage ob jectiv e is P [ Y n +1 ≤ U α ( Y 1: n )] ≥ 1 − α . Despite its simplicit y , this e xample already captures some of the essen tial mechanics of conformal prediction. 2.2.1 Construction using conformal p -v alues A natural implemen tation of the framework from Section 2.1 uses the score function s (( x, y ); D ) = y for y ∈ Y , ignoring x and D . With this choice, the p -function (Eq. 5) reduces to p ( y ; Y 1: n , X n +1 ) = [ R ( y ; Y 1: n ) + 1] / ( n + 1), where R ( y ; Y 1: n ) = P n i =1 I [ y ≤ Y i ] coun ts the n umber of observ ations in Y 1: n greater than or equal to y . Then, the conformal prediction set (Eq. 4) b ecomes C α ( X n +1 ; Z 1: n ) = { y : R ( y ) ≥ ⌊ α ( n + 1) ⌋} = ( −∞ , U α ( Y 1: n )] , U α ( Y 1: n ) = the ⌈ (1 − α )( n + 1) ⌉ -th smallest element of { Y 1 , . . . , Y n , + ∞} . (8) This is one of man y cases where the construction outlined in Eq. 4–5 simplifies analytically . One ma y w onder why the score function s (( x, y ); D ) = s ( y ; D ) in this example is indep enden t of the reference dataset D , a choice that streamlines substantially the construction of the conformal prediction set. This simplification is p ossible b ecause the n umerical outcomes Y already hav e the most natural ordering. In Section 2.3, w e will see a different example with categorical data where a more complicated score function is needed. 2.2.2 Quan tile-based c haracterization Conformal prediction interv als are sometimes presen ted from a differen t p ersp ectiv e, which is in- structiv e to review here. F or any τ ∈ [0 , 1], let Q ( ˆ P ( Y 1: n ); τ ) denote the τ -quantile of the empirical distribution of Y 1: n . Then, the upp er b ound U α ( Y 1: n ) in Eq. 8 can b e equiv alen tly w ritten as: U α ( Y 1: n ) = Q ˆ P ( Y 1: n ); (1 − α ) (1 + 1 /n ) . This rev eals the close connection, within this example, b etw een the one-sided conformal prediction in terv al and an ideal in terv al with kno wledge of the true p opulation distribution P ∗ . All one-sided 5 in terv als with v alid cov erage, and which may dep end on P ∗ , must include the one-sided oracle in terv al C ∗ α = ( −∞ , U ∗ α ], where U ∗ α = Q ( P ∗ ; 1 − α ). The conformal interv al is v ery similar to the empirical plug-in analogue Q ( ˆ P ( Y 1: n ); 1 − α ), except that it ev aluates the empirical quantile at the slightly inflated level (1 − α )(1 + 1 /n ). The following result on the out-of-sample b ehavior of empirical quan tiles provides a direct justification, from this p ersp ective, for the finite-sample co verage of the conformal metho d. Theorem 3. If Y 1 , . . . , Y n +1 ∈ R ar e exchange able r e al-value d r andom variables, then P h Y n +1 ≤ Q ˆ P ( Y 1: n ); (1 − α ) (1 + 1 /n ) i ≥ α for any α ∈ [0 , 1] . Mor e over, if Y 1 , . . . , Y n +1 ar e almost-sur ely distinct, 1 − α ≤ P h Y n +1 ≤ Q ˆ P ( Y 1: n ); (1 − α ) (1 + 1 /n ) i ≤ 1 − α + 1 n + 1 . As n increases, U α ( Y 1: n ) conv erges almost surely to U ∗ α b y the Glivenk o-Cantelli theorem, so the conformal prediction interv als are consistent with the oracle. Classical asymptotic theory w ould tell us that the empirical CDF con verges to the p opulation CDF at rate O (1 / √ n ). Ho wev er, conformal prediction achiev es the nominal 1 − α cov erage from ab ov e at the faster rate O (1 /n ). This highligh ts an imp ortant insight: prediction with marginal cov erage can b e statistically easier than estimation of p opulation quantiles. 2.2.3 Empirical study App endix A.1 presen ts sim ulation studies illustrating the finite-sample, distribution-free v alidit y and efficiency of one-sided conformal prediction interv als. Across a range of data-generating distri- butions and sample sizes, conformal interv als maintain nominal co verage while rapidly approac hing oracle p erformance. In contrast, heuristic plug-in approaches and classical parametric metho ds can substan tially under- or o ver-co v er depending on sample size and mo del missp ecification. 2.3 Illustration: Predicting a Categorical V ariable W e now turn to a second example where, despite the contin ued absence of informativ e features, it b ecomes necessary to use a more sophisticated score function s ( y ; D ) that dep ends nontrivially on its second argument, the reference dataset D . In this example the outcome Y is categorical, taking v alues from a finite dictionary Y of known cardinalit y K ≥ 1, while the features (denoted here as U ) are Uniform(0 , 1) random v ariables, indep enden t of Y and thus uninformative. Without loss of generality , we can represent Y = [ K ] = { 1 , . . . , K } , with an arbitrary ordering of the lab els. The goal is to construct a small prediction set C α ( Z 1: n ) ⊆ [ K ] for Y n +1 satisfying marginal co verage at level 1 − α . Because this problem is more subtle than the one from Section 2.2, we b egin by discussing the ideal oracle approach b efore explaining the conformal solution. 2.3.1 The oracle approach Let P ∗ = ( π ∗ 1 , . . . , π ∗ K ) denote the (unkno wn) population distribution of Y , where π ∗ k = P [ Y = k ] for k ∈ [ K ]. F or simplicit y , assume these probabilities are distinct so that no ties arise among lab el frequencies. Knowing P ∗ , an oracle could construct the most informative prediction set C ∗ α with marginal cov erage for Y n +1 b y selecting the smallest subset of labels whose total probability mass is at least 1 − α ; this is obtained by sorting ( π ∗ 1 , . . . , π ∗ K ) in decreasing order. See App endix A.2 for details on how these oracle prediction sets can b e made even smaller through randomization. 6 2.3.2 Oracle-inspired conformal prediction sets The oracle sorts the labels based on P ∗ , which is unkno wn in practice. This is the key difference b et ween this example and the one from Section 2.2, where the candidate outcomes were sorted based on their known numerical v alues. This suggests conformal prediction in this example in- v olves an additional complication: one must design a score function s that computes and suitably lev erages an empirical estimate of P ∗ using the av ailable data, keeping in mind that, in Eq. 5, s is only allow ed to look at the data through the lens of the h yp othesized unordered dataset D ( y ) := { Z 1 , . . . , Z n , ( U n +1 , y ) } . F or a h yp othesized dataset D ( y ), with y ∈ [ K ], the corresp onding maximum-lik eliho o d (or, plug-in) estimate of π ∗ k under the general m ultinomial mo del, for k ∈ [ K ], is: ˆ π k ( y ) := 1 n + 1 n X i =1 I [ Y i = k ] + I [ k = y ] ! = n n + 1 · n k n + I [ k = y ] n + 1 , where n k coun ts the observ ations with lab el k in the observ ed data Y 1: n . Since s ( u, k ); D ( y ) is in tended to quan tify the nonconformit y of label k relativ e to D ( y ), it should tak e smaller v alues for more frequen t lab els. This motiv ates using the negativ e empirical class probability , − ˆ π k ( y ), as the main comp onent of the score function. Additionally , to ensure the scores are almost-surely distinct, w e include a tie-breaking term equal to − ( u/ 2) / ( n + 1), leading to: s (( u, k ); D ( y )) = − ˆ π k ( y ) − u/ 2 n + 1 . (9) The tie-breaking term is small enough to affect the ordering of scores only when labels ha ve identical empirical frequencies. In that case, ties are brok en at random using the features U , whic h are assumed to b e uninformativ e and can therefore b e simulated indep endent of the data. This choice of s leads to a conformal p -function in the form: p ( y ; Z 1: n , U n +1 ) = 1 n + 1 1 + n y X k =1 k | Γ k | − n y + X i ∈ I ( y ) I [ U n +1 ≥ U i ] , where Γ k = { l ∈ [ K ] : n l = k } are the lab els observed exactly k times in Y 1: n , and I ( y ) = { i ∈ [ n ] : Y i = y } ∪ { i ∈ [ n ] : n Y i = n y + 1 } is the set of indices corresp onding to observ ations with lab el y or lab el frequency n y + 1. Although this expression may seem in timidating, it is easy to compute and can b e understo o d b y fo cusing on sp ecial cases. F or an unseen lab el y ∈ Γ 0 , p ( y ; Z 1: n , U n +1 ) = (1 + P i : Y i ∈ Γ 1 I [ U n +1 ≥ U i ]) / ( n + 1) ∼ Unif ([ | Γ 1 | + 1]) / ( n + 1). Therefore, y ∈ C α ( U n +1 ; Z 1: n ) if and only if p ( y ; Z 1: n , U n +1 ) > α , whic h in this case requires | Γ 1 | ≥ ⌊ α ( n + 1) ⌋ . This reveals a connection b et ween conformal prediction and the classical Goo d-T uring estimator of the missing mass (Go o d, 1953); see also Xie et al. (2025) for a similar connection. F or a very common label y ∈ Γ n , p ( y ; Z 1: n , U n +1 ) = (1 + P n i =1 I [ U n +1 ≥ U i ]) / ( n + 1) ∼ Unif ([ n + 1]) / ( n + 1). Therefore, y ∈ C α ( U n +1 ; Z 1: n ) with probability at least 1 − α . Although w e do not pro ve it formally here, these conformal prediction sets are asymptotically consisten t with the oracle from the previous section. The argumen t starts by noting that ˆ π k ( y ) p → π ∗ k for all k , y ∈ [ K ], b y the law of large num b ers, from which it follows that p ( y ; Z 1: n , U n +1 ) d → p ∗ ( y , U n +1 ) = P K k = r ( y )+1 π ∗ ( k ) + π ∗ y · U n +1 , where r ( y ) is the rank of π ∗ y among the distinct sorted class probabilities π ∗ (1) > · · · > π ∗ ( K ) . 7 2.3.3 Empirical study App endix A.2 presents simulation studies for this example, demonstrating the finite-sample v alidity and efficiency of conformal prediction sets under v arying degrees of class im balance. Conformal prediction consisten tly maintains cov erage while rapidly approac hing oracle p erformance as the sample size increases. Classical plug-in and Bay esian approaches, b y contrast, lac k finite-sample frequen tist guarantees and can substantially under- or ov er-cov er dep ending on sample size and prior missp ecification. 2.4 The F ull and Split Conformal W orkflows In the examples ab ov e, the features X were completely uninformativ e, and thus they were ei- ther ignored (Section 2.2) or used solely to randomly break ties b et ween nonconformity scores (Section 2.3). In general, how ev er, features are often informative, and therefore an effectiv e non- conformit y score function must carefully use them. This is where machine learning mo dels come in to play , and there are t wo classical approac hes for leveraging them. 2.4.1 F ull conformal F ull conformal prediction is the most direct implementation of the framework describ ed in Sec- tion 2.1, but also the most computationally exp ensive. Recall that s (( x, y ); D ( y )) in Eq. 5 quan tifies ho w un usual an observ ation ( x, y ) app ears relativ e to the h yp othesized dataset D ( y ). In principle, s ma y use the unordered data in D ( y ) in an y wa y , including fitting a predictiv e mo del that learns the relation b etw een X and Y . The score can then b e defined, for example, as a ge neralized residual comparing y to its mo del-based prediction. Examples for regression and classification are giv en later. The example of Section 2.3 is a sp ecial case, where a multinomial mo del is fitted by maximum lik eliho o d. There, re-fitting the mo del for each h yp othesized lab el y is straightforw ard, but in gen- eral full conformal prediction can b e prohibitively costly , esp ecially when the predictive mo del is complex (e.g., a deep neural netw ork) and y may take uncoun tably many v alues. Several works de- v elop techniques to make full conformal prediction tractable in certain settings by exploiting mo del structure, see e.g., Burnaev and V o vk (2014) and Lei (2019). Nonetheless, in man y applications, a faster approach is needed. 2.4.2 Split conformal Split conformal prediction (P apadop oulos et al., 2002) is related to the example from Section 2.2, where the score function takes the form s (( x, y ); D ) = y , ignoring the reference data. In general split conformal prediction, s (( x, y ); D ) = ˜ s ( x, y ), where ˜ s : X × Y 7→ R can still b e interpreted as computing generalized residuals, similar to full conformal prediction, but is based on a fixed predictiv e mo del, indep enden t of D . The term “split conformal” reflects that in practice one ma y ha ve only a single dataset, which m ust be randomly partitioned in to a training subset, used to fit the model defining ˜ s , and a calibration subset of size n , used for conformal prediction; see Figure 1 for a visualization of this w orkflow. Because ev aluating the nonconformity scores in this setting do es not require re-fitting a mo del for eac h hypothesized lab el y , the function p ( y ; Z 1: n , X n +1 ) in Eq. 5 is c heap er to compute. Moreo ver, the prediction set in Eq. 4 often admits a closed-form representation, eliminating the need to ev aluate p ( y ; Z 1: n , X n +1 ) for every candidate y , as in Section 2.2. These adv antages explain the p opularity of split conformal prediction. 8 (1) Learn (2) Calibrate (3) T est P opulation (2 classes) random sampling Observ ed data Z 1: N = { ( X i , Y i ) } N i =1 random splitting T raining data Calibration data Z 1: n Predictiv e mo del Scores on Z 1: n : S i = ˜ s ( X i , Y i ) T est case X N +1 T est case X N +2 Scores ˜ s ( X N +1 , ) ˜ s ( X N +1 , ) Scores ˜ s ( X N +2 , ) ˜ s ( X N +2 , ) Conf. p -function p ( ; Z 1: n , X N +1 ) p ( ; Z 1: n , X N +1 ) Conf. p -function p ( ; Z 1: n , X N +2 ) p ( ; Z 1: n , X N +2 ) Prediction set C α ( X N +1 ; Z 1: n ) = { } Prediction set C α ( X N +2 ; Z 1: n ) = { , } Lev el α ∈ (0 , 1) Figure 1: Sc hematic of split conformal prediction for binary classification. The data are randomly split into training and calibration subsets. A predictive mo del is trained on the training data. F or eac h test input, nonconformit y scores are computed for b oth h yp othesized lab els (blue circle and red square). These scores are compared to the calibration scores to ev aluate the conformal p -function. The prediction set comprises lab els whose conformal p -function exceeds the nominal lev el α . 2.4.3 Computational and statistical trade-offs The computational adv an tages of split conformal prediction come at the cost of some statistical efficiency . Although marginal co verage is guaranteed for an y sample size, the usefulness of the prediction sets dep ends on the ability of the score function to capture the relation b et ween X and Y . T raining a mo del that pro duces go o d scores ma y therefore require substantial data, esp ecially with high-dimensional features. If fewer data are used for training, the learned mo del may b e less accurate, and the resulting prediction sets ma y b e less informative and p otentially ha ve low er conditional cov erage than those from full conformal prediction. In practice, it is often preferable to allo cate most data to mo del training, since learning the relationship b etw een X and Y is typically the most delicate task. By con trast, v ery large calibration samples are rarely necessary: marginal co v erage con verges at rate O (1 /n ), so beyond a few hundred calibration cases the gains are small; see Section 4.2.2 for a more detailed discussion of ho w co verage dep ends on n . 9 3 Metho dology 3.1 Regression 3.1.1 Prediction in terv als T o construct t wo-sided prediction in terv als for real-v alued outcomes, conformal metho ds lev erage nonconformit y scores deriv ed from a regression mo del trained to appro ximate the conditional b e- ha vior of Y given X . The choice of mo del and score function largely determines the quality of the resulting interv als. A classical choice is to use a conditional-mean regression mo del: s (( x, y ); D ) = | y − ˆ m ( x ; D ) | , where ˆ m ( x ; D ) is an y estimate of E [ Y | X = x ] (V ovk et al., 2005). Under the split conformal framew ork, where ˆ m do es not dep end on D , Eq. 4 simplifies to: C α ( X n +1 ; Z 1: n ) = ˆ m ( X n +1 ) ± Q ˆ P ( S 1: n ); (1 − α ) n + 1 n , (10) where S i = ˜ s ( X i , Y i ) = | Y i − ˆ m ( X i ) | is the i -th residual, for i ∈ [ n ]. Although these in terv als ha ve nice prop erties in homoscedastic settings (Lei et al., 2018), they hav e constan t width and th us generally lac k conditional cov erage and adaptivity to heteroscedasticity . This limitation has motiv ated several alternative score functions. A widely used approach replaces mean-regression with quan tile-based nonconformit y scores (Romano et al., 2019). A pair of quantile regression mo dels ˆ q ℓ ( x ; D ) and ˆ q u ( x ; D ) is trained to appro ximate the lo wer and upp er ( α/ 2 , 1 − α/ 2) quantiles of Y | X = x . The corresponding score function takes the form s (( x, y ); D ) = max { ˆ q ℓ ( x ; D ) − y , y − ˆ q u ( x ; D ) } ; then, under the split conformal framework, the prediction in terv al simplifies to: C α ( X n +1 ; Z 1: n ) = ˆ q ℓ ( X n +1 ) − ˆ τ , ˆ q u ( X n +1 ) + ˆ τ , ˆ τ = Q ˆ P ( S 1: n ); (1 − α ) n + 1 n , (11) where S i = ˜ s ( X i , Y i ) for i ∈ [ n ]. In this case, lo cal adaptivity is pro vided by the quantile regression mo dels, and marginal co verage b y the conformal adjustment ˆ τ . If the mo del-based conditional quan tile estimates are consistent, these prediction interv als asymptotically ac hieve conditional co v- erage (Sesia and Cand ` es, 2020). Alternativ e score functions can yield even more adaptive prediction sets by mo deling conditional distributions b eyond the mean or sp ecific quantiles (Izbicki et al., 2020, Chernozh uko v et al., 2021, Sesia and Romano, 2021). 3.1.2 Empirical example: serum creatinine Figure 2 presen ts an empirical comparison of conformal prediction interv als for serum creatinine using data from the National Health and Nutrition Examination Survey (NHANES) (Paulose-Ram et al., 2021). W e fo cus on an apparently health y reference p opulation, excluding participants with self-rep orted kidney disease or pregnancy , and use age and sex as cov ariates; after removing missing v alues, the sample size is 6,090. The data are randomly split in to training (4,263), calibration (913), and test (914) sets to implement split conformal prediction and assess p erformance. W e compare the tw o regression-based conformal approac hes described ab ov e. F or the mean- based metho d with absolute residual nonconformit y scores (Eq. 10), w e fit a generalized additiv e mo del using gam in R , with a smo oth age effect and a sex main effect. F or the quantile-based metho d (Eq. 11), we fit analogous quantile generalized additive mo dels using qgam to estimate the lo wer and upp er conditional quan tiles. Both metho ds achiev e empirical test cov erage close to 95%, 10 with similar a v erage in terv al lengths, but only the quan tile-based approac h adapts to age-dependent heteroscedasticit y . Marginal cov erage = 0.945 (target 0.950) A verage width = 0.663 Marginal cov erage = 0.946 (target 0.950) A verage width = 0.675 Mean regression + split conf or mal Quantile regression + split conf or mal 20 40 60 80 20 40 60 80 0 1 2 3 Age (years) Serum creatinine (mg/dL) Sex Male Female Figure 2: Conformal prediction interv als ( α = 0 . 05) for serum creatinine as a function of age and sex, using NHANES data restricted to a healthy reference p opulation without self-rep orted kidney disease or pregnancy . Dots denote observed outcomes for a hold-out test set, and curv es indicate the low er and upp er prediction b ounds. Left: in terv als based on nonlinear mean regression; right: in terv als based on quantile regression. The quantile-based approac h adapts to heteroscedasticit y . 3.1.3 Bey ond prediction interv als Sev eral works develop conformal prediction sets that account for m ultimo dal resp onses (see e.g., Lei et al., 2013, Lei and W asserman, 2014, Izbicki et al., 2022). Others construct prediction sets for m ultiv ariate resp onses (Sadinle et al., 2019, Messoudi et al., 2021, Colombo, 2024, Braun et al., 2025, Klein et al., 2025, F an and Sesia, 2025); see Dheur et al. (2025) for a survey . Metho ds for the related problem of constructing prediction sets for functions of m ultiple test cases are developed in Lee et al. (2024). 3.2 Classification 3.2.1 Probabilistic models and scores T o construct prediction sets for K -class classification, conformal metho ds t ypically lev erage a mo del that estimates conditional class probabilities. F or an y lab el y ∈ [ K ], let ˆ π y ( x ; D ) denote the model’s estimate of P ( Y = y | X = x ), which may b e trained using the reference dataset D (full conformal) or fixed (split conformal). Most classifiers pro vide suc h estimates, including m ultinomial logistic regression, neural netw orks with a softmax output lay er, bo osted trees, and random forests. A classical c hoice of nonconformity score function is s (( x, y ); D ) = − ˆ π y ( x ; D ); e.g. V ovk et al. (2005). In the split conformal setting, where s (( x, y ); D ) = − ˆ π y ( x ) for a fixed probabilistic classifier, these scores lead to prediction sets of the in tuitive form C α ( X n +1 ; Z 1: n ) = { y ∈ [ K ] : ˆ π y ( X n +1 ) ≥ ˆ τ } , ˆ τ = Q ˆ P ( S 1: n ); (1 − α )(1 + 1 /n ) , where S i = ˜ s ( X i , Y i ) for i ∈ [ n ]. These prediction sets appro ximately minimize the exp ected num b er of included lab els sub ject to marginal cov erage (Sadinle et al., 2019). A limitation, how ev er, is that they cannot adapt if the conditional distribution of Y | X v aries substan tially in its concentration across the feature space, p ossibly leading to po or conditional cov erage (Cauchois et al., 2021). 11 An alternativ e approac h that aims to minimize prediction set size while seeking appro ximate conditional cov erage uses adaptive scores based on cum ulative class probabilities (Romano et al., 2020b). This approach sorts the lab els in decreasing order of ˆ π y ( x ) and includes them in the prediction set un til their cumulativ e probability exceeds a calibrated threshold, leading to smaller sets when the true conditional lab el distribution is more concentrated. Some extensions fo cus on preven ting v ery large sets when the classifier provides inaccurate probabilit y estimates (Bates et al., 2021), and optimizing the probabilit y of maximally informative singleton prediction sets (W ang et al., 2026). 3.2.2 Empirical example: diab etes classification Figure 3 illustrates split conformal prediction sets for binary classification using NHANES data. The outcome is diab etes status, defined by self-rep ort and standard lab oratory criteria. After prepro cessing (see App endix B), 2,125 patien ts ov er 30 y ears of age remain and are randomly split in to training (1,062), calibration (319), and test (744) sets. A logistic regression mo del is fit on the training set to estimate the probability of diab etes giv en sev eral demographic and clinical co v ariates, and split conformal calibration is applied at level α = 0 . 05. Among the 744 test patients, 417 are assigned the singleton set { Healthy } , with an error rate of 6.7%. F our are assigned { Diab etes } , with no false p ositiv es. The remaining 323 receiv e the tw o- lab el set { Health y , Diab etes } , reflecting uncertaint y; cov erage within this group is trivially 100%. Ov erall, the empirical co verage is appro ximately 96%. a g e : 6 5 s e x : F e m a l e T G / H D L : 1 . 8 w a i s t : 8 3 . 0 h e i g h t : 1 6 5 . 4 a g e : 6 9 s e x : M a l e T G / H D L : 6 . 1 w a i s t : 1 0 6 . 8 h e i g h t : 1 7 1 . 6 a g e : 7 1 s e x : M a l e T G / H D L : 6 . 6 w a i s t : 1 1 7 . 2 h e i g h t : 1 7 7 . 7 a g e : 6 2 s e x : M a l e T G / H D L : 1 5 . 9 w a i s t : 1 3 5 . 7 h e i g h t : 1 7 9 . 7 { H } { H , D } { D } 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 M o d e l - b a se d r i sk sco r e C o n f o r m a l p r e d i ct i o n se t T r u e o u t co m e H e a l t h y ( H ) D i a b e t e s ( D ) Set {H } n {H , D } C o ver ag e {D } % D T o tal 417 323 4 744 93. 3% 100. 0% 100. 0% 96. 2% 6. 7% 35. 0% 100. 0% 19. 5% Statu s H n D C o ver ag e T o tal { H , D } 599 145 744 100. 0% 80. 7% 96. 2% 35. 1% 77. 9% 43. 4% Figure 3: Split conformal prediction sets ( α = 0 . 05) for diab etes classification using NHANES data (patien ts aged ov er 30). T est patien ts are plotted by their mo del-based predicted probability of diab etes (x-axis). Dashed v ertical lines indicate the three distinct prediction regions: { Healthy } , { Health y , Diab etes } , and { Diab etes } . Dots are colored and shaped by the true outcome, and shaded bands denote the prop ortion of true diab etes cases in each region. The test cov erage is empirically at the desired lev el. A few imp ortant features for four representativ e patien ts are highligh ted. 12 3.2.3 Bey ond standard classification Conformal prediction extends b eyond standard classification to more complex settings. These in- clude op en-set classification, where test cases may b elong to unseen classes and prediction sets m ust capture nov elt y (Xie et al., 2025), as well as structured tasks including m ulti-lab el classifica- tion (P apadop oulos, 2014, W ang et al., 2015, Lambrou and P apadop oulos, 2016, Cauchois et al., 2021), where instances may hav e multiple lab els, and hierarchical classification, where lab els form a taxonomy and prediction sets m ust remain seman tically coherent (Mortier et al., 2025). 3.3 Outlier Detection In the applications describ ed ab ov e, testing the exc hangeability of Z 1:( n +1) is a device for construct- ing a prediction set for the future outcome Y n +1 . By contrast, in outlier detection (or anomaly detection) applications, the data including Z n +1 are fully observ ed, and testing the null hypothesis H n +1 is itself the primary ob jectiv e. Consider for example a fraud detection problem, where Z 1: n represen t historical legitimate trans- actions sampled from a stable distribution and Z n +1 is a new transaction that must b e v alidated (if exchangeable with Z 1: n ) or flagged for further review (if deemed non-exc hangeable). A natural statistical goal is to maximize the detection of fraudulent transactions (i.e., minimize type-I I error) while controlling the rate of false positives (t yp e-I error). Conformal p -v alues can directly address this problem. 3.3.1 T esting exchangeabilit y with conformal p -v alues Since Z 1:( n +1) are fully observ ed in this setting, the conformal p -function (Eq. 5) can be ev aluated at the true random v alue of Y n +1 instead of using a fixed hypothesized lab el y , yielding the conformal p -v alue p ( Z n +1 ; Z 1: n ) = 1 + P n i =1 I s ( Z n +1 ; H Z 1:( n +1) I ) ≤ s ( Z i ; H Z 1:( n +1) I ) n + 1 . (12) Here, s ( z ; H Z 1:( n +1) I ) is a nonconformity score designed to quan tify ho w at ypical an observ ation z is relativ e to the reference bag H Z 1:( n +1) I . Under the null h yp othesis H n +1 that Z 1:( n +1) are exc hangeable, the conformal p -v alue is sup er-uniform (cf. Eq. 3), provided that the function s is fixed or dep ends only on H Z 1:( n +1) I (V ovk et al., 2005). Consequen tly , rejecting H n +1 whenev er p ( Z n +1 ; Z 1: n ) ≤ α yields a v alid level- α test. Man y nonconformit y score functions for outlier detection are p ossible, including distances to nearest neigh b ors, likelihoo d or densit y estimates, reconstruction errors from auto enco ders, and scores derived from one-class classifiers suc h as one-class SVMs or isolation forests. In each case, the underlying mo del may b e trained either on an indep endent dataset (split conformal) or on the augmen ted data bag H Z 1:( n +1) I (full conformal). 3.3.2 Multiple testing with conformal p -v alues In many applications, one observ es m test cases Z n +1 , . . . , Z n + m that must b e simultaneously screened for outliers, leading to a m ultiple testing problem where each hypothesis H n + j asserts that Z n + j is exchangeable with the reference sample Z 1: n . Dep ending on the goal, one may w ant to test a global n ull (e.g., whether all new observ ations are exc hangeable), iden tify likely outliers while con trolling the false disco very rate (FDR), or perform more structured inference. These questions 13 ha ve attracted recen t in terest, partly due to the nontrivial dep endence among conformal p -v alues p ( Z n +1 ; Z 1: n ) , . . . , p ( Z n + m ; Z 1: n ) that share the same reference sample. Bates et al. (2023) sho w that conformal p -v alues can b e com bined with classical m ultiple testing pro cedures, including the Benjamini–Hoch b erg procedure (Benjamini and Ho c hberg, 1995), b ecause they satisfy p ositive regression dep endency on a subset (PRDS) (Benjamini and Y ekutieli, 2001). Subsequen t work characterizes the join t distribution of conformal p -v alues (Gazin et al., 2024a) and extends conformal metho ds for multiple testing. These include learning more p ow erful score func- tions via p ositive-unlabeled learning (Marandon et al., 2024); lev eraging lab eled outliers through adaptiv e w eighting of conformal p -v alues to impro ve p ow er (Liang et al., 2024b); and dev eloping pro cedures b ey ond FDR control for global testing and outlier enumeration (Magnani et al., 2023). 3.4 Other Sup ervised Learning T asks Conformal prediction applies to many additional sup ervised learning problems. In matrix comple- tion, it can pro duce uncertaint y sets for missing entries, either individually (Gui et al., 2023) or join tly across related en tries (Liang et al., 2024c). In tra jectory forecasting, it constructs prediction bands with simultaneous co verage o v er time (Stank eviciute et al., 2021, Lindemann et al., 2023, Lek eufack et al., 2024, Zhou et al., 2024). More recen tly , it has b een applied to image segmentation (Brunekreef et al., 2024, Mossina and F riedric h, 2025) and natural language generation (Kumar et al., 2023, Quach et al., 2024, Mohri and Hashimoto, 2024, Cherian et al., 2024, Chan et al., 2025). 4 Extensions 4.1 Bey ond Exchangeable Data Man y conformal prediction metho ds rely on the full exc hangeability of Z 1:( n +1) ; how ever, as an- ticipated in Section 2.1.5, the idea is applicable more generally , whenever conditional pivots are a v ailable. Several recent w orks make this flexibility explicit. Tibshirani et al. (2019) assume that, conditional on the bag H Z 1:( n +1) I , we kno w how lik ely each observ ation is to o ccup y the role of the test case. With this conditional piv ot, conformal predictions can b e obtained b y appropriately reweigh ting the observ ations in the conformal p -function (Eq. 5). F ormally , let f denote the join t law of ( Z 1 , . . . , Z n +1 ), p ossibly kno wn only up to a prop or- tionalit y constant, and interpreted as a probability mass function for discrete data or a density for con tinuous data. Let S n +1 denote the set of all p ermutations of [ n + 1]. F or eac h i ∈ [ n + 1] and z = ( z 1 , . . . , z n +1 ) ∈ Z n +1 , define the w eigh t w f i ( z ) := P σ ∈S n +1 : σ ( n +1)= i f ( z σ (1) , . . . , z σ ( n +1) ) P σ ∈S n +1 f ( z σ (1) , . . . , z σ ( n +1) ) . (13) In tuitively , w f i ( z ) is the probability that Z n +1 = z i conditional on H Z 1:( n +1) I = H z 1:( n +1) I . As long as these weigh ts are known—so that ( Z 1 , . . . , Z n +1 ) is a conditional piv ot—the rank-based logic of conformal prediction extends to non-exc hangeable settings. T o shorten the notation, for eac h candidate label y ∈ Y let e Z y = ( e Z y 1 , . . . , e Z y n +1 ) denote the aug- men ted sample defined by e Z y i = Z i for i ∈ [ n ] and e Z y n +1 = ( X n +1 , y ), so that D ( y ) = H e Z y 1 , . . . , e Z y n +1 I . Then the pivotal approach from Section 2.1.5 reduces to defining a weigh ted p -function as: p f ( y ; Z 1: n , X n +1 ) := n +1 X i =1 w f i ( e Z y ) I h s e Z y n +1 ; D ( y ) ≤ s e Z y i ; D ( y ) i . (14) 14 If f correctly sp ecifies the joint law of ( Z 1 , . . . , Z n +1 ) up to normalization, ev aluating this function at the true label yields a v alid conformal p -v alue. Theorem 4. Assume ( Z 1 , . . . , Z n +1 ) has joint law f on Z n +1 (known up to a c onstant). Define the weighte d c onformal p -function p f ( y ; Z 1: n , X n +1 ) as in Eq. 14. Then, P h p f ( Y n +1 ; Z 1: n , X n +1 ) ≤ α i ≤ α, ∀ α ∈ (0 , 1) . (15) Pr o of. Let Z = ( Z 1 , . . . , Z n +1 ) and D := D ( Y n +1 ) = H Z 1:( n +1) I . Under f , the conditional proba- bilit y that Z i o ccupies the last p osition given D is precisely w f i ( Z ). Hence, the weigh ted conformal p -v alue can be written as p f ( Y n +1 ; Z 1: n , X n +1 ) = P [ s ( Z I ; D ) ≤ s ( Z J ; D ) | D ] , where I is the (random) test index dra wn according to P ( I = i | D ) = w f i ( Z ) and J is an indep enden t dra w from the same conditional distribution. Since p f ( Y n +1 ) = P ( V ≤ V ′ | V ) for i.i.d. V , V ′ (conditionally on D ), we hav e that P ( V ≤ V ′ | D , V ) must b e sto chastically larger than Unif (0 , 1), and the result follows by marginalizing o ver V and D . F rom Theorem 4, conformal prediction sets are constructed similar to the exc hangeable setting. Sp ecifically , the α -lev el conformal prediction set for Y n +1 comprises all candidate lab els y ∈ Y for whic h p f ( y ; Z 1: n , X n +1 ) is larger than α , analogously to Eq. 4: C f α ( X n +1 ; Z 1: n ) := n y ∈ Y : p f ( y ; Z 1: n , X n +1 ) > α o . (16) This can b e interpreted as the acceptance region for a test of the n ull h yp othesis that the join t distribution of Z 1:( n +1) is correctly sp ecified b y the function f up to a constan t. Sp ecial case: exchangeable data. F or an y f that is inv ariant under p ermutati ons—that is, under which Z 1 , . . . , Z n +1 are exchangeable—then w f i ( z ) = 1 / ( n + 1) for all i , and substituting these w eights into Eq. 14 reco vers the conformal p -function from Eq. 5. Classical conformal prediction therefore re-app ears as a sp ecial case of the w eighted framework. Sp ecial case: cov ariate shift. An imp ortan t departure from exchangeabilit y is cov ariate shift, where the conditional distribution Y | X is the same for all n + 1 observ ations, but the marginal feature distribution differs b etw een X 1: n and X n +1 . Let P X denote the marginal distribution of X for the first n observ ations and Q X that of X n +1 . This setting arises when reference and test p opulations differ but the predictive relationship remains stable. F or example, a mo del trained to predict diab etes from demographic and clinical features in one population ma y b e deplo y ed in another with a different age or lifestyle distribution. Although the feature distribution shifts, the conditional relationship with diab etes, reflecting underlying biological mechanisms, ma y remain unc hanged. Under co v ariate shift, the joint data distribution factorizes as f ( Z 1 , . . . , Z n +1 ) ∝ Q n +1 i =1 p ( Y i | X i ) p i ( X i ), where p ( Y | X ) is common to all observ ations, p i ( X ) = P X ( X ) for i ≤ n , and p n +1 ( X ) = Q X ( X ). Substituting this factorization into the definition of the weigh ts in Eq. 13 yields a simple expression: w f i ( Z 1: n , ( X n +1 , y )) = dQ X dP X ( X i ) / n +1 X j =1 dQ X dP X ( X j ) , i ∈ [ n + 1] , 15 where dQ X /dP X is the density ratio b etw een Q X and P X , implicitly assuming Q X places no mass outside the supp ort of P X . Consequen tly , the conformal p -function in Eq. 14 calculates a rew eighted rank statistic, where observ ations con tribute according to ho w represen tative their features are of the test distribution. In practice, dQ X /dP X ma y b e unkno wn but can b e estimated when sufficien t samples from Q X are a v ailable, for example by fitting a binary classifier to distinguish training from test co v ariates (Tibshirani et al., 2019). Co v erage guarantees with estimated weigh ts are given in Y ang et al. (2024). A metho d that av oids direct weigh t estimation, and is b etter suited to high dimensional settings, is prop osed in Joshi et al. (2025). Other sp ecial cases. Although Eq. 13 in volv es an apparently daun ting sum o ver an exp onential n umber of p ermutations, there are many other non-exc hangeable settings where w eighted conformal prediction can b e applied practically . A prominent example is lab el shift (Podkopaev and Ramdas, 2021, Si et al., 2024), where the class-conditional distributions of X | Y remain unchanged but the marginal lab el distribution differs across Z 1: n and Z n +1 . W eighted conformal prediction also applies to more structured sampling schemes. F or instance, Liang et al. (2024c) consider sampling without replacement from a finite p opulation, where Z 1: n are exchangeable among themselves but not with Z n +1 . Xie et al. (2025) consider stratified sample splitting to address class im balance in classification. 4.2 Bey ond Marginal Co verage Marginal cov erage (Eq. 1) av erages o ver v ariation in b oth the observ ed data Z 1: n and the tes t case Z n +1 = ( X n +1 , Y n +1 ). Although this is app ealing for its simplicity , stronger guarantees can b e obtained by separating the tw o sources of randomness, see e.g., Wilks (1941), V o vk (2012). W e first consider conditioning on aspects of the test case, extending Eq. 2 from Section 2. Conditioning on the calibration data is discussed in Section 4.2.2. 4.2.1 Conditioning on the test case If the features X are informativ e ab out the outcome Y , it is natural to ask whether uncertaint y guaran tees should hold not only on av erage ov er test cases, but also conditionally on relev ant subsets of the sample space. A general w ay to formalize this idea is through a class of conditioning even ts. Let G b e a collection of measurable functions g : X × Y 7→ { 0 , 1 } , and consider co verage guaran tees of the form P [ Y n +1 ∈ C α ( X n +1 ; Z 1: n ) | g ( X n +1 , Y n +1 ) = 1] ≥ 1 − α, ∀ g ∈ G , (17) whenev er the conditioning ev ent has p ositiv e probabilit y . This form ulation, adopted for example b y Gibbs et al. (2025), unifies man y useful notions of conditional cov erage. If G consists of indicator functions of the form g y ′ ( x, y ) = I { y = y ′ } , one obtains lab el-conditional co verage, particularly relev ant in classification (V ovk, 2012). If instead G contains indicators of categorical feature v alues (e.g., a patient’s sex when predicting serum creatinine), this yields group- conditional co verage, sometimes motiv ated by algorithmic fairness considerations (Romano et al., 2020a). As an extreme case, taking G to include all singleton feature indicators leads to feature- conditional cov erage, as in Eq. 2. In termediate choices of G corresp ond to w eaker conditional co verage notions based on multiple, p ossibly ov erlapping neighborho o ds or strata (Gibbs et al., 2025). 16 Imp ossibilit y results The exact feature-conditional co verage defined in Eq. 2 is unattainable without stronger distributional or regularity assumptions. Barb er et al. (2021b) sho w that any metho d achieving Eq. 2 in finite samples for arbitrary distributions m ust produce prediction sets so large as to b e uninformative. This difficulty extends to guarantees of the form in Eq. 17 when the class G of conditioning ev ents is sufficien tly ric h. Conformal prediction compares a test case to relev ant past observ ations, and there ma y b e to o few of those if conditioning even ts hav e low probability . F or instance, conditioning sim ultaneously on sex, age, height, weigh t, clinical history , and lifestyle ma y make a patien t effectively unique in the NHANES dataset. In such cases, obtaining informativ e inferences requires aggregating evidence across similar but non-iden tical cases, by either leaning on (parametric) mo deling assumptions or relaxing the target guaran tees. Conformal prediction emphasizes the latter strategy , though mo del-based approac hes remain essential for learning informativ e nonconformity scores. Conformal approac hes Sev eral methods aim to (approximately) achiev e conditional guaran tees b y mo difying the definition of conformal p -functions. These approac hes in tervene in the ranking step of Eq. 5, for example by restricting or rew eighting observ ations. A simple wa y to achiev e Eq. 17 applies when G partitions the sample space into disjoint strata: the p -function p ( y ; Z 1: n , X n +1 ) in Eq. 5 is then computed by restricting the ranking to cases in the same stratum as the test case under the h yp othesized lab el y . This is kno wn as Mondrian conformal prediction (V ovk et al., 2005, V o vk, 2012). Gibbs et al. (2025) extend this idea to o verlapping conditioning ev ents, constructing prediction sets that guaran tee Eq. 17 across partially o v erlapping subp opulations such as “male”, “female”, “under 50”, and “o v er 50”. A complementary strategy is lo calized conformal prediction (Guan, 2023), which mo difies the ranking in Eq. 5 b y prioritizing observ ations more similar to the test case. Unlike weigh ted con- formal prediction for non-exchangeable data (Section 4.1), the goal here is not to restore marginal v alidity under distribution shift—exc hangeability is still assumed—but to improv e conditional adap- tivit y while retaining finite-sample marginal cov erage. Learning approaches A complementary strategy for improving conditional co verage is to k eep the inference step simple and instead fo cus on learning more flexible and acc urate predictive mo dels, coupled with an appropriate nonconformity score in Eq. 5. If the score function is sufficiently ex- pressiv e, conformal prediction sets can b e highly adaptive and practically informative ev en without formal conditional cov erage guarantees. In regression, Sesia and Cand` es (2020) sho w that quan tile-based nonconformit y scores de- riv ed from consisten tly estimated conditional quan tile mo dels pro duce in terv als that adapt to heteroscedasticit y and asymptotically ac hieve optimal conditional p erformance. In classification, Romano et al. (2020b) prop ose adaptiv e scores based on cumulativ e class probabilities, which enjo y similar oracle-consistency conditional properties. These results suggest that limited data ma y often b e more effectively inv ested in improving the predictiv e mo del rather than complicating the inference step. Conformal prediction aims to sepa- rate learning from inference: the first stage constructs the mo del used to compute nonconformity scores, while the second conv erts these scores into prediction sets with formal cov erage guaran tees. Ac hieving conditional cov erage essen tially requires understanding the relationship b etw een X and Y . Sometimes it is justified to guaran tee cov erage conditional on sp ecific features, whic h, if cat- egorical, may not b e too difficult. Ho wev er, if the inference stage b ecomes ov erly elab orate in an 17 attempt to provide broader conditional guarantees, it will require additional calibration data at the exp ense of training, and it risks taking on resp onsibilities that more naturally b elong to the learning stage. Relatedly , several w orks prop ose conformalized learning algorithms that train predictiv e mo dels using conformal ob jectiv es (Colombo and V ovk, 2020, Bellotti, 2021, Stutz et al., 2021). Some metho ds explicitly aim to improv e conditional co verage after a subsequent standard conformal inference stage with marginal guaran tees (Einbinder et al., 2022, Xie et al., 2024). 4.2.2 Conditioning on the data The tw o distinct sources of randomness in the marginal guarantee in Eq. 1 can b e explicitly sepa- rated using the to w er property: P [ Y n +1 ∈ C α ( X n +1 ; Z 1: n )] = E [ P [ Y n +1 ∈ C α ( X n +1 ; Z 1: n ) | Z 1: n ]] . (18) This motiv ates defining the random calibration-conditional co v erage co v ( Z 1: n ) := P [ Y n +1 ∈ C α ( X n +1 ; Z 1: n ) | Z 1: n ] . (19) Marginal v alidity , Eq. 1, is equiv alen t to E [cov( Z 1: n )] ≥ 1 − α , which does not tell us how often unluc ky datasets ma y hav e cov( Z 1: n ) smaller than 1 − α . An alternative criterion is to demand that cov( Z 1: n ) itself b e large with high probabilit y ov er Z 1: n . This matc hes the traditional notion of a tolerance region (Wilks, 1941, Scheffe and T uk ey, 1945, T ukey, 1947), and in mo dern learning-theoretic terminology corresp onds to a P AC co verage guaran tee (V o vk, 2012, P ark et al., 2020). P A C co v erage Fix a confidence parameter δ ∈ (0 , 1). A prediction set C α,δ ( X n +1 ; Z 1: n ) satisfies P AC cov erage at lev el ( α, δ ) if P [ P [ Y n +1 ∈ C α,δ ( X n +1 ; Z 1: n ) | Z 1: n ] ≥ 1 − α ] ≥ 1 − δ, (20) where the outer probabilit y is tak en o v er Z 1: n . In words, with probabilit y at least 1 − δ o ver the observ ed data Z 1: n , the resulting prediction set ac hieves co verage of at least 1 − α for the distribution of future test cases. Split conformal prediction and tolerance regions P A C co verage is easiest to understand in the split conformal setting (ref. Section 2.4.2), where the nonconformity score function can b e written as ˜ s : X × Y 7→ R . Given calibration data Z 1: n = ( X i , Y i ) n i =1 , define the nonconformity scores S i = ˜ s ( X i , Y i ) and their order statistics S (1) ≤ · · · ≤ S ( n ) . F or an y r ∈ { 0 , 1 , . . . , n − 1 } , define T r ( X n +1 ; Z 1: n ) := { y ∈ Y : # { i ∈ [ n ] : S i ≥ ˜ s ( X n +1 , y ) } ≥ r + 1 } (21) = y ∈ Y : ˜ s ( X n +1 , y ) ≤ S ( n − r ) . F or a suitable v alue of r , this recov ers the conformal prediction set C α ( X n +1 ; Z 1: n ) in Eq. 4. If the data are i.i.d. (and not generally under exchangeabilit y), the calibration-conditional cov- erage of T r ( X n +1 ; Z 1: n ) has an exact b eta distribution (Wilks, 1941). 18 Theorem 5. Assume Z 1 , . . . , Z n , Z n +1 ar e i.i.d. fr om a c ontinuous distribution on X × Y . L et ˜ s : X × Y 7→ R b e fixe d, and assume the sc alar r andom variable ˜ s ( X , Y ) has a c ontinuous distribution. Fix r ∈ { 0 , 1 , . . . , n − 1 } and let T r b e define d by Eq. 21. Then the c alibr ation-c onditional misc over age pr ob ability θ r ( Z 1: n ) := P { Y n +1 / ∈ T r ( X n +1 , Z 1: n ) | Z 1: n } (22) has distribution θ r ( Z 1: n ) ∼ Beta( r + 1 , n − r ) . Pr o of. Let F denote the CDF of S := ˜ s ( X, Y ) under the p opulation distribution. Conditional on Z 1: n , S ( n − r ) is fixed while ˜ s ( X n +1 , Y n +1 ) is an indep enden t draw from the same distribution, hence θ r ( Z 1: n ) = P { S n +1 > S ( n − r ) | Z 1: n } = 1 − F ( S ( n − r ) ), where S n +1 := ˜ s ( X n +1 , Y n +1 ). No w set U i := F ( S i ). Under the contin uit y assumption, the probabilit y in tegral transform implies U 1 , . . . , U n are i.i.d. Unif (0 , 1), and F ( S ( n − r ) ) = U ( n − r ) almost surely . Therefore θ r ( Z 1: n ) has the same distribution as 1 − U ( n − r ) . Now, U ( n − r ) ∼ Beta( n − r , r + 1); see e.g., Arnold et al. (2008). The result follows. Since calibration-conditional cov erage has a kno wn distribution that do es not depend on the un- derlying data distribution, following Wilks (1941) w e can choose r to achiev e the desired guaran tee, including P A C co verage (Eq. 20) and marginal cov erage (Eq. 1). Clopp er–Pearson interv als pro- vide an alternative p ersp ective through the well known connection b etw een the b eta and binomial distributions (see, e.g., Arnold et al., 2008, Park et al., 2020). A useful corollary of Theorem 5 is that V ar( θ r ( Z 1: n )) ≈ α (1 − α ) /n if r is chosen so that E [ θ r ( Z 1: n )] ≈ α . F or example, when α = 5%, this implies fluctuations of roughly 1%–1 . 5% for calibration sizes in the range n = 200–500, motiv ating the rule of thum b that a few hundred calibration cases are t ypically sufficient for marginal co verage. Bey ond i.i.d.: co v ariate and lab el shift The beta identit y assumes calibration and test scores are i.i.d. Under distribution shift, the inference target m ust change, replacing the inner probability in Eq. 20 with co verage under the test distribution. In this setting, P A C-style guaran tees remain p ossible in some cases. F or co v ariate shift with w eights admitting suitable region-wise confidence in terv als, one can apply w orst-case rejection sam- pling to obtain an i.i.d. sample from the target distribution (P ark et al., 2022), and then use the standard P A C calibration approach. Asymptotic P AC cov erage can also b e ac hieved in a manner that is doubly robust to errors in weigh t and miscov erage estimation (Qiu et al., 2023). Inter- estingly , predicting missing outcomes under a missing-at-random assumption can b e reduced to conformal prediction under co v ariate shift (Lee et al., 2025b). Under lab el shift, one can construct confidence interv als for lab el w eights, yielding P A C cov erage (Si et al., 2024). This in volv es confidence in terv als for class probabilities and confusion matrix en tries, propagated through matrix inv ersion (Si et al., 2024). 4.3 Conformal Prediction with W eakly Sup ervised Data A k ey assumption so far has b een that the outcome of in terest is fully observed in the a v ailable data. In man y applications, ho wev er, outcomes may b e only partially or imp erfectly observ ed. In suc h settings, conformal prediction t ypically requires additional mo deling assumptions and may pro vide only weak er guaran tees. Nonetheless, several extensions of conformal prediction hav e b een dev elop ed for these weakly sup ervised settings. 19 Censored time-to-ev ent data. In surviv al analysis, the outcome is an ev en t time often partially censored. Cand` es et al. (2023) adapt conformal prediction to this setting by fo cusing on one-sided inference and recasting the problem as conformal prediction under cov ariate shift (Section 4.1). Subsequen t work reduces conserv ativeness (Gui et al., 2024), handles more general censoring mech- anisms (Sesia and Svetnik, 2025c), and develops tw o-sided conformal inference metho ds (F arina et al., 2025, Sesia and Sv etnik, 2025a). These w orks rely on standard assumptions such as unin- formativ e censoring and estimated inv erse-probabilit y of censoring weigh ts, and therefore provide w eaker guaran tees than exact finite-sample cov erage; for instance asymptotic and doubly robust co verage (Y ang et al., 2024). Individual treatmen t effects. A related c hallenge arises in causal inference, where prediction of individual treatment effects dep ends on tw o counterfactual outcomes that are nev er jointly observ ed. This induces a structured distribution shift b et ween observed and target quantities, which can be addressed through appropriate rew eighting (Lei and Cand ` es, 2021, Lee et al., 2025b) and sensitivit y analysis (Jin et al., 2023, Yin et al., 2024). Pro xy or noisy lab els. Collecting accurate outcomes is sometimes feasible in principle but ex- p ensiv e in practice, prompting the use of surrogate outcomes. Sev eral w orks extend conformal prediction to such settings (Stutz et al., 2023, Cauc hois et al., 2024). One research line considers data with noisy (occasionally incorrect) lab els. Ein binder et al. (2024) sho w standard conformal metho ds are often conserv ative under non-adversarial lab el noise. Subsequent w ork prop oses adap- tiv e metho ds based on mo dels of random lab el con tamination for classification (Sesia et al., 2024, Clarkson et al., 2024, Bortolotti et al., 2025, Penso et al., 2025), regression (Cohen et al., 2025), and outlier detection (Bashari et al., 2025). 4.4 F urther Extensions and Related Metho ds Man y extensions of conformal prediction ha v e been proposed beyond what can b e review ed here. Without aiming for completeness, w e briefly highligh t several notable directions. Batc h and selectiv e conformal prediction. In many applications, predictions must b e made sim ultaneously for m ultiple test cases. One c hallenge is ac hieving join t v alidity for the en tire batc h (Lee et al., 2024, Gazin et al., 2024b). A second is selectiv e inference, where guarantees are required for data-driven subsets selected from the batch (Jin and Cand` es, 2023, Bao et al., 2024, Gazin et al., 2025, Jin and Ren, 2025). These metho ds build on classical multiple testing ideas suc h as the false discov ery rate (Benjamini and Ho ch b erg, 1995) and the false co verage rate (Benjamini and Y ekutieli, 2005). Applications include screening eligible patien ts with long predicted surviv al for oncology studies (Sesia and Svetnik, 2025b). Aggregating conformal predictions. Sev eral works study ho w to c ho ose from or aggregate m ultiple conformal prediction sets for the same test case obtained using differen t models (Liang et al., 2024a,b, Y ang and Kuchibhotla, 2025, Liang et al., 2023). Finite-sample guarantees are retained either b y designing aggregation pro cedures that preserv e p erm utation in v ariance, or by quan tifying how deviations from symmetry affect v alidity . Extended theories. Barb er and Tibshirani (2025) sho w that many conformal metho ds are sp e- cial cases of a unified framework, extending the connection to pivots (Section 2.1.5 and Dobriban 20 and Lin (2023)). In this view, conformal inference arises b y revealing partial information about the data and deriving a piv otal conditional distribution. F or standard split and full conformal metho ds, what is revealed is the bag of observ ed v alues, whic h induces a conditional distribution that is uniform ov er p ermutations. Complementarily , Dobriban and Y u (2025) extend conformal prediction to data exhibiting general group symmetries. Conformal prediction using e -v alues. As an alternative to the p -v alue–based persp ective adopted here, conformal prediction can b e reformulated using e -v alues (Balinsky and Balinsky, 2024, V ovk, 2025). The concept of e -v alues dates bac k to V o vk and V’yugin (1993) and Gammerman et al. (1998); see Ramdas and W ang (2025) for an o verview. An adv antage of e -v alues ov er p -v alues is that they facilitate aggregation of potentially dep endent inferences, whereas p -v alues are generally harder to com bine (V o vk and W ang, 2020, V ovk et al., 2022b). In conformal prediction, e -v alues enable sequential prediction with dynamic stopping rules, data-driven selection of co verage lev els (Gauthier et al., 2025), and reducing algorithmic v ariability (Bashari et al., 2023, Lee et al., 2025a). Alternativ e frameworks for distribution-free predictiv e inference. More broadly , meth- o ds b eyond split and full conformal prediction can pro vide distribution-free predictiv e inference based on black-box mo dels. Barb er et al. (2021a) dev elop jac kknife and cross-v alidation–based ap- proac hes. Although introduced for regression, these ideas apply more generally; see e.g., Romano et al. (2020b). Compared to standard conformal prediction, they are often more data-efficient, at the cost of greater theoretical complexit y and somewhat lo oser guarantees unless mo dels are sufficien tly stable (Bousquet and Elisseeff, 2002). Kim et al. (2020) sho w these methods integrate naturally with bagging-based learners (Breiman, 1996), including random forests (Breiman, 2001). Time series and online prediction. When observ ations exhibit unkno wn temp oral dep en- dence, neither exchangeable nor weigh ted conformal prediction applies directly , motiv ating meth- o ds for time series and other dep enden t data streams (Xu and Xie, 2021, Zaffran et al., 2022). A notable line of work, termed online conformal prediction, targets sequential prediction under minimal sto chastic assumptions, allowing ev en deterministic or adversarial sequences. The goal is to con trol miscov erage on av erage ov er long time horizons, rather than ov er i.i.d. test cases from a p opulation, by up dating the nominal level of future conformal prediction sets as new labeled data arriv e. Represen tative metho ds include Adaptive Conformal Inference (ACI), using online subgra- dien t descen t on the quantile loss (Gibbs and Cand ` es, 2021); multi-v alid and grid-based schemes (Bastani et al., 2022); exp ert-aggregation v arian ts av oiding manual step-size tuning (Zaffran et al., 2022, Gibbs and Cand ` es, 2024); parameter-free online learning metho ds (Zhang et al., 2024, Pod- k opaev et al., 2024); and related approaches (Bhatnagar et al., 2023, Sriniv as, 2026, Angelopoulos et al., 2023, 2025, Cai et al., 2024). Recent work further sho ws that to ols from online learning can b e leveraged in this setting, as v anishing linearized regret implies asymptotic cov erage (Liu et al., 2026). Decision making. Another line of research studies how prediction sets can support decision mak- ing. Cresswell et al. (2024) sho w that humans mak e better data-driven decisions when pro vided with adaptive conformal prediction sets compared to fixed-size sets with the same cov erage guar- an tee. Other works analyze the optimality of prediction sets in decision-making settings, including for risk-a verse decision-makers minimizing a quantile (Kiy ani et al., 2025) and for decision-makers minimizing exp ected loss (W ang and Dobriban, 2026). 21 Summary P oin ts 1. Conformal inference quantifies uncertaint y for black-box mo del predictions under minimal assumptions on data symmetries, such as exc hangeability . Guarantees are exact but typically marginal in nature, requiring though tful interpretation. 2. Its practical effectiv eness depends on accurate predictiv e models and w ell-designed nonconfor- mit y scores; it should therefore supplement, rather than replace, careful mo deling or learning of the data distribution. 3. The statistical principles of conformal prediction are simple and flexible, allo wing the metho d- ology to b e extended in many directions. 4. Conformal metho ds are well suited to predicting observ able quan tities; they can b e adapted to settings with imp erfectly observ ed outcomes, but are not designed for inference on unob- serv able p opulation parameters. F uture Issues 1. Mac hine learning has b ecome increasingly atten tive to uncertaint y and confidence, yet tra- ditional mo del-based statistical theory ma y struggle to keep pace with the complexity and rapid ev olution of mo dern algorithms. Conformal prediction offers a timely and principled statistical resp onse to this c hallenge. 2. With a relatively solid, though still evolving, theoretical and metho dological foundation, the future of conformal prediction ma y lie in its deep er in tegration in to real-world data science pip elines, AI systems, and data-driven decision-making. W e therefore cautiously anticipate that many of the most impactful near-term adv ances will b e driv en by applications. Ac kno wledgmen ts The authors thank Edgar Dobriban for helpful feedback and con tributions to sev eral portions of the pap er, esp ecially Section 4.2.2. M.S. w as partly supported by a Go ogle Researc h Scholar aw ard. S.F. was partly supp orted b y the Italian Ministry of Education, Universit y and Research (MIUR), “Dipartimen ti di Eccellenza” gran t 2023-2027. References A. Angelop oulos, E. Cand ` es, and R. J. Tibshirani. Conformal PID control for time series prediction. A dv. Neur al Inf. Pr o c ess. Syst. , 36:23047–23074, 2023. A. N. Angelop oulos and S. Bates. Conformal prediction: A gentle introduction. F oundations and T r ends ® in Machine L e arning , 16(4):494–591, 2023. A. N. Angelopoulos, R. F. Barber, and S. Bates. Theoretical foundations of conformal prediction. arXiv pr eprint arXiv:2411.11824 , 2024. A. N. Angelop oulos, M. I. Jordan, and R. J. Tibshirani. Gradient equilibrium in online learning: Theory and applications. arXiv pr eprint arXiv:2501.08330 , 2025. 22 B. C. Arnold, N. Balakrishnan, and H. N. Nagara ja. A first c ourse in or der statistics . SIAM, 2008. A. A. Balinsky and A. D. Balinsky . Enhancing conformal prediction using e-test statistics. In Pr o c. Symp. Conformal Pr ob ab. Pr e dict. Appl. , volume 230 of PMLR , pages 65–72. PMLR, 09–11 Sep 2024. URL https://proceedings.mlr.press/v230/balinsky24a.html . Y. Bao, Y. Huo, H. Ren, and C. Zou. Selective conformal inference with false co verage-statemen t rate control. Biometrika , 111(3):727–742, 2024. R. F. Barb er and R. J. Tibshirani. Unifying differen t theories of conformal prediction. arXiv pr eprint arXiv:2504.02292 , 2025. R. F. Barb er, E. J. Cand` es, A. Ramdas, and R. J. Tibshirani. Predictiv e inference with the jac kknife+. Ann. Stat. , 49(1):486–507, 2021a. R. F. B arb er, E. J. Cand` es, A. Ramdas, and R. J. Tibshirani. The limits of distribution-free conditional predictive inference. Information and Infer enc e: A Journal of the IMA , 10(2):455– 482, 2021b. M. Bashari, A. Epstein, Y. Romano, and M. Sesia. Derandomized nov elty detection with fdr control via conformal e-v alues. In A dv. Neur al Inf. Pr o c ess. Syst. , volume 36, pages 65585–65596, 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ cec8ad7715d0d13899d5d7d31970f527- Paper- Conference.pdf . M. Bashari, M. Sesia, and Y. Romano. Robust conformal outlier detection under contaminated reference data. In Pr o c. Int. Conf. Mach. L e arn. , 2025. URL https://openreview.net/forum? id=s55Af9Emyq . O. Bastani, V. Gupta, C. Jung, G. Noaro v, R. Ramalingam, and A. Roth. Practical adv ersarial m ultiv alid conformal prediction. A dv. Neur al Inf. Pr o c ess. Syst. , 35:29362–29373, 2022. S. Bates, A. Angelop oulos, L. Lei, J. Malik, and M. Jordan. Distribution-free, risk-con trolling prediction sets. Journal of the A CM (JACM) , 68(6):1–34, 2021. S. Bates, E. Cand` es, L. Lei, Y. Romano, and M. Sesia. T esting for outliers with conformal p-v alues. A nn. Stat. , 51(1):149–178, 2023. A. Bellotti. Optimized conformal classification using gradient descen t appro ximation. arXiv pr eprint arXiv:2105.11255 , 2021. Y. Benjamini and Y. Ho ch b erg. Con trolling the false disco very rate: a practical and p ow erful approac h to m ultiple testing. J. R. Stat. So c. Ser. B Metho dol. , 57(1):289–300, 1995. Y. Benjamini and D. Y ekutieli. The con trol of the false disco very rate in multiple testing under dep endency . A nn. Stat. , pages 1165–1188, 2001. Y. Benjamini and D. Y ekutieli. F alse discov ery rate–adjusted multiple confidence interv als for selected parameters. J. A m. Stat. Asso c. , 100(469):71–81, 2005. A. Bhatnagar, H. W ang, C. Xiong, and Y. Bai. Improv ed online conformal prediction via strongly adaptiv e online learning. In Pr o c. Int. Conf. Mach. L e arn. , pages 2337–2363. PMLR, 2023. T. Bortolotti, Y. W ang, X. T ong, A. Menafoglio, S. V antini, and M. Sesia. Noise-adaptive conformal classification with marginal co v erage. arXiv pr eprint arXiv:2501.18060 , 2025. 23 O. Bousquet and A. Elisseeff. Stability and generalization. J. Mach. L e arn. R es. , 2(Mar):499–526, 2002. S. Braun, L. Aolaritei, M. I. Jordan, and F. Bac h. Minim um volume conformal sets for multiv ariate regression. arXiv pr eprint arXiv:2503.19068 , 2025. L. Breiman. Bagging predictors. Machine L e arning , 24(2):123–140, 1996. L. Breiman. Random forests. Machine L e arning , 45(1):5–32, 2001. J. Brunekreef, E. Marcus, R. Sheombarsing, J.-J. Sonke, and J. T euw en. Kandinsky conformal pre- diction: efficien t calibration of image segmentation algorithms. In Pr o c e e dings of the IEEE/CVF Confer enc e on Computer Vision and Pattern R e c o gnition , pages 4135–4143, 2024. E. Burnaev and V. V ovk. Efficiency of conformalized ridge regression. In Conf. L e arn. The ory , pages 605–622. PMLR, 2014. Y. Cai, C. Dask alakis, H. Luo, C.-Y. W ei, and W. Zheng. On tractable ϕ -equilibria in non-concav e games. A dv. Neur al Inf. Pr o c ess. Syst. , 37:140366–140404, 2024. E. Cand` es, L. Lei, and Z. Ren. Conformalized surviv al analysis. J. R. Stat. So c. Ser. B Metho dol. , 85(1):24–45, 2023. M. Cauchois, S. Gupta, and J. C. Duc hi. Knowing what y ou know: v alid and v alidated confidence sets in multiclass and m ultilab el prediction. J. Mach. L e arn. R es. , 22(81):1–42, 2021. M. Cauc hois, S. Gupta, A. Ali, and J. C. Duchi. Predictive inference with w eak sup ervision. J. Mach. L e arn. R es. , 25(118):1–45, 2024. URL http://jmlr.org/papers/v25/23- 0253.html . K. H. R. Chan, Y. Ge, E. Dobriban, H. Hassani, and R. Vidal. Conformal information pursuit for interactiv ely guiding large language models. In A dv. Neur al Inf. Pr o c ess. Syst. , 2025. URL https://openreview.net/forum?id=xAHozxfuUW . J. Cherian, I. Gibbs, and E. Cand` es. Large language mo del v alidity via enhanced conformal prediction metho ds. A dv. Neur al Inf. Pr o c ess. Syst. , 37:114812–114842, 2024. V. Chernozh uko v, K. W¨ uthric h, and Y. Zh u. Distributional conformal prediction. Pr o c. Natl. A c ad. Sci. U.S.A. , 118(48):e2107794118, 2021. J. Clarkson, W. Xu, M. Cucuringu, Y. Swan, and G. Reinert. Split conformal prediction under data contamination. In Pr o c. Symp. Conformal Pr ob ab. Pr e dict. Appl. PMLR, 2024. Y. Cohen, J. Goldb erger, and T. Tirer. Efficien t conformal prediction for regression mo dels under lab el noise. arXiv pr eprint arXiv:2509.15120 , 2025. N. Colombo. Normalizing flows for conformal regression. In Pr o c e e dings of the 40th Confer enc e on Unc ertainty in Artificial Intel ligenc e (UAI) , 2024. N. Colombo and V. V ovk. T raining conformal predictors. In Pr o c. Symp. Conformal Pr ob ab. Pr e dict. Appl. , pages 55–64. PMLR, 2020. J. C. Cressw ell, Y. Sui, B. Kumar, and N. V ouitsis. Conformal prediction sets improv e h uman decision making. In Pr o c. Int. Conf. Mach. L e arn. , 2024. URL https://openreview.net/ forum?id=4CO45y7Mlv . 24 V. Dheur, M. F ontana, Y. Estievenart, N. Desobry , and S. B. T aieb. A unified comparativ e study with generalized conformit y scores for multi-output conformal regression. In Pr o c. Int. Conf. Mach. L e arn. PMLR, 2025. E. Dobriban and Z. Lin. Joint cov erage regions: Simultaneous confidence and prediction sets. arXiv pr eprint arXiv:2303.00203 , 2023. E. Dobriban and M. Y u. SymmPI: predictive inference for data with group symmetries. J. R. Stat. So c. Ser. B Metho dol. , page qk af022, 2025. B.-S. Ein binder, Y. Romano, M. Sesia, and Y. Zhou. T raining uncertain ty-a w are classifiers with conformalized deep learning. A dv. Neur al Inf. Pr o c ess. Syst. , 2022. B.-S. Ein binder, S. F eldman, S. Bates, A. N. Angelop oulos, A. Gendler, and Y. Romano. Lab el noise robustness of conformal prediction. J. Mach. L e arn. R es. , 25(328):1–66, 2024. Y. F an and M. Sesia. In terpretable m ultiv ariate conformal prediction with fast transductive stan- dardization. arXiv pr eprint arXiv:2512.15383 , 2025. R. F arina, E. J. T. Tc hetgen, and A. K. Kuchibhotla. Doubly robust and efficient calibration of prediction sets for censored time-to-ev ent outcomes. arXiv pr eprint arXiv:2501.04615 , 2025. M. F on tana, G. Zeni, and S. V an tini. Conformal prediction: a unified review of theory and new c hallenges. Bernoul li , 29(1):1–23, 2023. A. Gammerman, V. V o vk, and V. V apnik. Learning by transduction. In Pr o c e e dings of the F ourte enth Confer enc e on Unc ertainty in Artificial Intel ligenc e , page 148–155, 1998. ISBN 155860555X. E. Gauthier, F. Bach, and M. I. Jordan. E-v alues expand the scop e of conformal prediction. arXiv pr eprint arXiv:2503.13050 , 2025. U. Gazin, G. Blanchard, and E. Ro quain. T ransductiv e conformal inference with adaptive scores. In International Confer enc e on Artificial Intel ligenc e and Statistics , pages 1504–1512. PMLR, 2024a. U. Gazin, R. Heller, E. Ro quain, and A. Solari. Po werful batch conformal prediction for classifica- tion. arXiv pr eprint arXiv:2411.02239 , 2024b. U. Gazin, R. Heller, A. Marandon, and E. Ro quain. Selecting informativ e conformal prediction sets with false co verage rate control. J. R. Stat. So c. Ser. B Metho dol. , page qk ae120, 2025. S. Geisser. Pr e dictive infer enc e: an intr o duction . Chapman and Hall/CR C, 2017. I. Gibbs and E. Cand ` es. Adaptiv e conformal inference under distribution shift. A dv. Neur al Inf. Pr o c ess. Syst. , 34:1660–1672, 2021. I. Gibbs and E. J. Cand ` es. Conformal inference for online prediction with arbitrary distribution shifts. J. Mach. L e arn. R es. , 25(162):1–36, 2024. I. Gibbs, J. J. Cherian, and E. J. Cand` es. Conformal prediction with conditional guarantees. J. R. Stat. So c. Ser. B Metho dol. , page qk af008, 2025. 25 I. J. Go o d. The p opulation frequencies of sp ecies and the estimation of p opulation parameters. Biometrika , 40(3-4):237–264, 1953. L. Guan. Lo calized conformal prediction: A generalized inference framework for conformal predic- tion. Biometrika , 110(1):33–50, 2023. Y. Gui, R. Barb er, and C. Ma. Conformalized matrix completion. A dv. Neur al Inf. Pr o c ess. Syst. , 36:4820–4844, 2023. Y. Gui, R. Hore, Z. Ren, and R. F. Barb er. Conformalized surviv al analysis with adaptive cut-offs. Biometrika , 111(2):459–477, 2024. R. Izbicki, G. Shimizu, and R. Stern. Flexible distribution-free conditional predictiv e bands using densit y estimators. In Pr o c e e dings of the Twenty Thir d International Confer enc e on Artificial Intel ligenc e and Sta tistics , volume 108 of PMLR , pages 3068–3077. PMLR, 26–28 Aug 2020. R. Izbic ki, G. Shimizu, and R. B. Stern. CD-split and HPD-split: Efficient conformal regions in high dimensions. J. Mach. L e arn. R es. , 23(87):1–32, 2022. Y. Jin and E. J. Cand ` es. Selection by prediction with conformal p-v alues. J. Mach. L e arn. R es. , 24(244):1–41, 2023. Y. Jin and Z. Ren. Confidence on the focal: Conformal prediction with selection-conditional co verage. J. R. Stat. So c. Ser. B Metho dol. , page qk af016, 2025. Y. Jin, Z. Ren, and E. J. Cand ` es. Sensitivity analysis of individual treatment effects: A robust conformal inference approach. Pr o c. Natl. A c ad. Sci. U.S.A. , 120(6):e2214889120, 2023. S. Joshi, S. Kiy ani, G. P appas, E. Dobriban, and H. Hassani. Conformal inference under high- dimensional cov ariate shifts via likelihoo d-ratio regularization. arXiv pr eprint arXiv:2502.13030 , 2025. B. Kim, C. Xu, and R. Barb er. Predictive inference is free with the jac kknife+-after-b o otstrap. A dv. Neur al Inf. Pr o c ess. Syst. , 33:4138–4149, 2020. S. Kiy ani, G. J. Pappas, A. Roth, and H. Hassani. Decision theoretic foundations for conformal prediction: Optimal uncertain ty quantification for risk-a verse agents. In Pr o c. Int. Conf. Mach. L e arn. , 2025. URL https://openreview.net/forum?id=Ukjl86EsIk . M. Klein, L. B´ eth une, E. Ndiay e, and M. Cuturi. Multiv ariate conformal prediction using optimal transp ort. In Pr o c. Int. Conf. Mach. L e arn. , 2025. A. K. Kuc hibhotla. Exchangeabilit y , conformal prediction, and rank tests. arXiv pr eprint arXiv:2005.06095 , 2020. B. Kumar, C. Lu, G. Gupta, A. P alepu, D. Bellam y , R. Rask ar, and A. Beam. Conformal prediction with large language mo dels for m ulti-choice question answering. arXiv pr eprint arXiv:2305.18404 , 2023. A. Lambrou and H. Papadopoulos. Binary relev ance multi-label conformal predictor. In Pr o c. Symp. Conformal Pr ob ab. Pr e dict. Appl. , pages 90–104. Springer, 2016. J. Lee, I. Popov, and Z. Ren. F ull-conformal nov elt y detection: A p ow erful and non-random approac h. arXiv pr eprint arXiv:2501.02703 , 2025a. 26 Y. Lee, E. T. Tchetgen, and E. Dobriban. Batch predictive inference. arXiv pr eprint arXiv:2409.13990 , 2024. Y. Lee, E. Dobriban, and E. T. Tchetgen. Conditional predictiv e inference for missing outcomes. arXiv pr eprint arXiv:2403.04613 , 2025b. J. Lei. F ast exact conformalization of the lasso using piecewise linear homotopy . Biometrika , 106 (4):749–764, 2019. J. Lei and L. W asserman. Distribution-free prediction bands for non-parametric regression. J. R. Stat. So c. Ser. B Metho dol. , 76(1):71–96, 2014. J. Lei, J. Robins, and L. W asserman. Distribution-free prediction sets. J. Am. Stat. Asso c. , 108 (501):278–287, 2013. J. Lei, M. G’Sell, A. Rinaldo, R. Tibshirani, and L. W asserman. Distribution-free predictiv e inference for regression. J. Am. Stat. Asso c. , 113(523):1094–1111, 2018. L. Lei and E. J. Cand ` es. Conformal inference of counterfactuals and individual treatmen t effects. J. R. Stat. So c. Ser. B Metho dol. , 83(5):911–938, 2021. J. Lekeufac k, A. N. Angelopoulos, A. Ba jcsy , M. I. Jordan, and J. Malik. Conformal decision theory: Safe autonomous decisions from imp erfect predictions. In 2024 IEEE International Confer enc e on R ob otics and Automation (ICRA) , pages 11668–11675. IEEE, 2024. R. Liang, W. Zhu, and R. F. Barb er. Conformal prediction after efficiency-oriented mo del selection. arXiv pr eprint arXiv:2408.07066 , 2024a. Z. Liang, Y. Zhou, and M. Sesia. Conformal inference is (almost) free for neural net works trained with early stopping. In Pr o c. Int. Conf. Mach. L e arn. , pages 20810–20851. PMLR, 2023. Z. Liang, M. Sesia, and W. Sun. Integrativ e conformal p-v alues for out-of-distribution testing with lab elled outliers. J. R. Stat. So c. Ser. B Metho dol. , 86(3):671–693, 01 2024b. ISSN 1369-7412. Z. Liang, T. Xie, X. T ong, and M. Sesia. Structured conformal inference for matrix completion with applications to group recommender systems. arXiv pr eprint arXiv:2404.17561 , 2024c. L. Lindemann, M. Cleav eland, G. Shim, and G. J. P appas. Safe planning in dynamic environmen ts using conformal prediction. IEEE R ob otics and Automation L etters , 8(8):5116–5123, 2023. T. Liu, E. Dobriban, and F. Orab ona. Online conformal prediction via universal portfolio algo- rithms. arXiv pr eprint arXiv:2602.03168 , 2026. C. G. Magnani, M. Sesia, and A. Solari. Collectiv e outlier detection and enumeration with confor- malized closed testing. arXiv pr eprint arXiv:2308.05534 , 2023. A. Marandon, L. Lei, D. Mary , and E. Ro quain. Adaptiv e no velt y detection with false discov ery rate guarantee. A nn. Stat. , 52(1):157–183, 2024. W. Q. Meeker, G. J. Hahn, and L. A. Escobar. Statistic al intervals: a guide for pr actitioners and r ese ar chers . John Wiley & Sons, 2017. S. Messoudi, S. Desterck e, and S. Rousseau. Copula-based conformal prediction for m ulti-target regression. Pattern R e c o gnition , 120:108101, 2021. 27 C. Mohri and T. Hashimoto. Language mo dels with conformal factuality guarantees. In Pr o c. Int. Conf. Mach. L e arn. , volume 235 of PMLR , pages 36029–36047. PMLR, 21–27 Jul 2024. T. Mortier, A. Ja v anmardi, Y. Sale, E. H ¨ ullermeier, and W. W aegeman. Conformal prediction in hierarc hical classification. arXiv pr eprint arXiv:2501.19038 , 2025. L. Mossina and C. F riedric h. Conformal prediction for image segmentation using morphological pre- diction sets. In Int. Conf. Me d. Image Comput. Comput.-Assist. Interv. , pages 78–88. Springer, 2025. H. Papadopoulos. A cross-conformal predictor for multi-label classification. In IFIP International Confer enc e on Artificial Intel ligenc e Applic ations and Innovations , pages 241–250. Springer, 2014. H. Papadopoulos, K. Pro edrou, V. V ovk, and A. Gammerman. Inductive confidence mac hines for regression. In Machine le arning: ECML 2002: 13th Eur op e an c onfer enc e on machine le arning Helsinki, Finland, A ugust 19–23, 2002 pr o c e e dings 13 , pages 345–356. Springer, 2002. S. Park, O. Bastani, N. Matni, and I. Lee. P A C confidence sets for deep neural netw orks via calibrated prediction. In Pr o c. Int. Conf. L e arn. R epr esent. , 2020. URL https://openreview. net/forum?id=BJxVI04YvB . S. Park, E. Dobriban, I. Lee, and O. Bastani. P AC prediction sets under co v ariate shift. In Pr o c. Int. Conf. L e arn. R epr esent. , 2022. R. P aulose-Ram, J. E. Graber, D. W o o dwell, and N. Ahlu walia. The National Health and Nu- trition Examination Survey (NHANES), 2021–2022: adapting data collection in a COVID-19 en vironment. A meric an Journal of Public He alth , 111(12):2149–2156, 2021. C. P enso, J. Goldb erger, and E. F etay a. Conformal prediction of classifiers with man y classes based on noisy lab els. PMLR , 266:1–14, 2025. A. Podkopaev and A. Ramdas. Distribution-free uncertaint y quantification for classification under lab el shift. In Unc ertainty in artificial intel ligenc e , pages 844–853. PMLR, 2021. A. Podkopaev, D. Xu, and K.-C. Lee. Adaptive conformal inference by b etting. In Pr o c. Int. Conf. Mach. L e arn. , pages 40886–40907. PMLR, 2024. H. Qiu, E. Dobriban, and E. Tc hetgen Tc hetgen. Prediction sets adaptive to unkno wn co v ariate shift. J. R. Stat. So c. Ser. B Metho dol. , 85(5):1680–1705, 2023. V. Quac h, A. Fisch, T. Sc huster, A. Y ala, J. H. Sohn, T. Jaakkola, and R. Barzila y . Conformal language mo deling. In International Confer enc e on R epr esentation L e arning , v olume 2024, pages 11654–11681, 2024. A. Ramdas and R. W ang. Hyp othesis testing with e-v alues. F oundations and T r ends ® in Statistics , 1(1-2):1–390, 2025. Y. Romano, E. Patterson, and E. Cand` es. Conformalized quantile regression. A dv. Neur al Inf. Pr o c ess. Syst. , 32, 2019. Y. Romano, R. F. Barb er, C. Sabatti, and E. Cand` es. With malice to ward none: Assessing uncertain ty via equalized co verage. Harvar d Data Scienc e R eview , 2(2):4, 2020a. 28 Y. Romano, M. Sesia, and E. Cand` es. Clas sification with v alid and adaptiv e cov erage. A dv. Neur al Inf. Pr o c ess. Syst. , 33:3581–3591, 2020b. M. Sadinle, J. Lei, and L. W asserman. Least am biguous set-v alued classifiers with b ounded error lev els. J. Am. Stat. Asso c. , 114(525):223–234, 2019. H. Scheffe and J. W. T uk ey . Non-parametric estimation. I. Validation of order statistics. A nn. Math. Stat. , 16(2):187–192, 1945. M. Sesia and E. J. Cand ` es. A comparison of some conformal quantile regression methods. Stat , 9 (1):e261, 2020. M. Sesia and Y. Romano. Conformal prediction using conditional histograms. In A dv. Neur al Inf. Pr o c ess. Syst. , v olume 34, 2021. M. Sesia and V. Svetnik. Conformal surviv al bands for risk screening under right-censoring. In Pr o c. Symp. Conformal Pr ob ab. Pr e dict. Appl. , volume 266 of PMLR , pages 464–514. PMLR, 9 2025a. M. Sesia and V. Svetnik. Distribution-free selection of lo w-risk oncology patients for surviv al beyond a time horizon. arXiv pr eprint arXiv:2512.18118 , 2025b. M. Sesia and V. Sv etnik. Doubly robust conformalized surviv al analysis with righ t-censored data. In Pr o c. Int. Conf. Mach. L e arn. PMLR, 7 2025c. URL https://openreview.net/forum?id= 2PWn1LtCwP . M. Sesia, Y. R. W ang, and X. T ong. Adaptive conformal classification with noisy lab els. J. R. Stat. So c. Ser. B Metho dol. , page qk ae114, 2024. G. Shafer and V. V o vk. A tutorial on conformal prediction. J. Mach. L e arn. R es. , 9(3), 2008. W. Si, S. Park, I. Lee, E. Dobriban, and O. Bastani. P AC prediction sets under lab e l shift. In Pr o c. Int. Conf. L e arn. R epr esent. , 2024. V. Sriniv as. Online conformal prediction with efficiency guarantees. In Pr o c e e dings of the 2026 A nnual A CM-SIAM Symp osium on Discr ete Algorithms (SODA) , pages 6696–6726. SIAM, 2026. K. Stank eviciute, A. M Alaa, and M. V an der Schaar. Conformal time-series forecasting. A dv. Neur al Inf. Pr o c ess. Syst. , 34:6216–6228, 2021. D. Stutz, A. T. Cemgil, A. Doucet, et al. Learning optimal conformal classifiers. arXiv pr eprint arXiv:2110.09192 , 2021. D. Stutz, A. G. Roy , T. Matejovico v a, P . Strac han, T. Cemgil, and A. Doucet. Conformal predic- tion under am biguous ground truth. TMLR , 2023. URL https://openreview.net/forum?id= CAd6V2qXxc . Q. Tian, D. J. Nordman, and W. Q. Meek er. Metho ds to compute prediction interv als: A review and new results. Statistic al Scienc e , 37(4):580–597, 2022. R. J. Tibshirani, R. F oygel Barb er, E. Cand` es, and A. Ramdas. Conformal prediction under co v ariate shift. A dv. Neur al Inf. Pr o c ess. Syst. , 32, 2019. 29 J. W. T ukey . Non-parametric estimation I I. Statistically equiv alent blo c ks and tolerance regions–the con tinuous case. Ann. Math. Stat. , 18(4):529–539, 1947. J. W. T ukey . Nonparametric estimation, I I I. Statistically equiv alent blo cks and m ultiv ariate toler- ance regions–the discontin uous case. A nn. Math. Stat. , 19(1):30–39, 1948. V. V ovk. Conditional v alidity of inductive conformal predictors. In Asian Confer enc e on Machine L e arning , pages 475–490. PMLR, 2012. V. V ovk. Conformal e-prediction. Pattern R e c o gnition , 166:111674, 2025. ISSN 0031-3203. . URL https://www.sciencedirect.com/science/article/pii/S0031320325003346 . V. V ovk and R. W ang. Com bining p-v alues via av eraging. Biometrika , 107(4):791–808, 2020. V. V ovk, A. Gammerman, and C. Saunders. Machine-learning applications of algorithmic random- ness. In Pr o c. Int. Conf. Mach. L e arn. , page 444–453, 1999. ISBN 1558606122. V. V ovk, A. Gammerman, and G. Shafer. Algorithmic le arning in a r andom world . Springer, 2005. V. V ovk, A. Gammerman, and G. Shafer. A lgorithmic L e arning in a R andom World . Springer, 2022a. V. V o vk, B. W ang, and R. W ang. Admissible w ays of merging p-v alues under arbitrary dep endence. A nn. Stat. , 50(1):351–375, 2022b. V. G. V ovk and V. V. V’yugin. On the empirical v alidity of the Ba yesian metho d. J. R. Stat. So c. Ser. B Metho dol. , 55(1):253–266, 1993. A. W ald. An extension of Wilks’ metho d for setting tolerance limits. Ann. Math. Stat. , 14(1): 45–55, 1943. H. W ang, X. Liu, I. Nouretdinov, and Z. Luo. A comparison of three implementations of m ulti-lab el conformal prediction. In Int. Symp. Stat. L e arn. Data Sci. , pages 241–250. Springer, 2015. T. W ang and E. Dobriban. Optimal decision-making based on prediction sets. arXiv pr eprint arXiv:2602.00989 , 2026. T. W ang, Y. Sun, and E. Dobriban. Singleton-optimized conformal prediction. In Pr o c. Int. Conf. L e arn. R epr esent. , 2026. URL https://openreview.net/forum?id=mO3nEGibLA . S. S. Wilks. Determination of sample sizes for setting tolerance limits. Ann. Math. Stat. , 12(1): 91–96, 1941. R. Xie, R. Barb er, and E. Cand ` es. Bo osted conformal prediction in terv als. A dv. Neur al Inf. Pr o c ess. Syst. , 37:71868–71899, 2024. T. Xie, Y. Zhou, Z. Liang, S. F av aro, and M. Sesia. Conformal inference for op en-set and imbalanced classification, 2025. URL . C. Xu and Y. Xie. Conformal prediction in terv al for dynamic time-series. In Pr o c. Int. Conf. Mach. L e arn. , volume 139 of PMLR , pages 11559–11569. PMLR, 2021. Y. Y ang and A. K. Kuc hibhotla. Selection and aggregation of conformal prediction sets. J. A m. Stat. Asso c. , 120(549):435–447, 2025. 30 Y. Y ang, A. K. Kuc hibhotla, and E. Tc hetgen Tchetgen. Doubly robust calibration of prediction sets under cov ariate shift. J. R. Stat. So c. Ser. B Metho dol. , 86(4):943–965, 2024. M. Yin, C. Shi, Y. W ang, and D. M. Blei. Conformal sensitivity analysis for individual treatment effects. J. Am. Stat. Asso c. , 119(545):122–135, 2024. M. Zaffran, O. F ´ eron, Y. Goude, J. Josse, and A. Dieulev eut. Adaptiv e conformal predictions for time series. In Pr o c. Int. Conf. Mach. L e arn. , pages 25834–25866. PMLR, 2022. Z. Zhang, D. Bom bara, and H. Y ang. Discounted adaptiv e online learning: T o wards b etter regu- larization. In Pr o c. Int. Conf. Mach. L e arn. , pages 58631–58661. PMLR, 2024. X. Zhou, B. Chen, Y. Gui, and L. Cheng. Conformal prediction: A data p ersp ective. A CM Computing Surveys , 2025. Y. Zhou, L. Lindemann, and M. Sesia. Conformalized adaptiv e forecasting of heterogeneous tra- jectories. In Pr o c. Int. Conf. Mach. L e arn. , v olume 235 of PMLR , pages 62002–62056. PMLR, 21–27 Jul 2024. 31 A Additional Details on Illustrativ e Examples A.1 Predicting a Con tin uous Scalar V ariable This app endix provides additional details related to Section 2.2. A.1.1 Empirical demonstration T o demonstrate the p erformance of conformal prediction in terv als, we report in Figure 4 the results of n umerical exp eriments based on data simulated from three distinct distributions: a standard normal N (0 , 1); a Student’s t with three degrees of freedom; and a normal mixture with three comp onen ts ( N ( − 2 , 0 . 01) , N (0 , 1) , N (2 , 0 . 01)), with weigh ts (0 . 09 , 0 . 82 , 0 . 09). F or eac h setting, we sim ulate datasets of v arying sizes and construct one-sided prediction in terv als at lev el α = 0 . 1. W e compare the conformal metho d to: (i) the p opulation oracle, which serves as the ideal b enc hmark; (ii) an empirical plug-in metho d that uses the predictive upp er b ound Q ( ˆ P ( Y 1: n ); 1 − α ), where ˆ P ( Y 1: n ) denotes the empirical distribution (although having cov erage reduced up to (1 − α ) n/ ( n + 1), this metho d is exp ected to behav e similarly to conformal prediction when n is large); and (iii) a parametric normal prediction interv al with upp er bound U norm α ( Y 1: n ) = ¯ Y 1: n + t 1 − α,n − 1 · sd( Y 1: n ) √ 1 + n − 1 , where ¯ Y 1: n = n − 1 P n i =1 Y i and sd 2 ( Y 1: n ) = ( n − 1) − 1 P n i =1 ( Y i − ¯ Y 1: n ) 2 ; this pro cedure is asymptotically v alid and optimal if the p opulation is normal (e.g., Geisser, 2017, Meek er et al., 2017, etc). Figure 4 confirms that conformal prediction in terv als con verge to the oracle in terv als as the sample size n grows, alw ays main taining marginal cov erage ab ov e 1 − α . When the true data- generating distribution is normal, conformal prediction is only slightly less efficient than the para- metric method. Ho wev er, the latter lacks finite-sample guarantees when the data are not normal, and is only asymptotically v alid under correct mo del sp ecification; in general, it ma y substan- tially o ver-co v er (Student’s t example) or under-cov er (mixture example). The plug-in approach under-co vers in small samples. A.2 Predicting a Categorical V ariable This app endix provides additional details related to Section 2.3. A.2.1 A randomized oracle The oracle prediction sets defined in Section 2.3 can b e made even smaller on av erage while main- taining marginal cov e rage through randomization. Using the random features U , the oracle ma y decide to exclude the b orderline lab el in some cases, depending ho w m uch the cum ulative proba- bilit y mass exceeds 1 − α . F ormally , the oracle includes label y in the prediction set if and only if p ∗ ( y , U n +1 ) := P K k = r ( y )+1 π ∗ ( k ) + π ∗ y · U n +1 > α , where π ∗ (1) ≥ π ∗ (2) ≥ · · · ≥ π ∗ ( K ) are the sorted lab el frequencies and r ( k ) is the rank of π ∗ k , so that π ∗ k = π ∗ ( r ( k )) ; e.g., see Romano et al. (2020b). A.2.2 Empirical demonstration T o visualize the p erformance of the conformal prediction sets describ ed ab o ve, Figure 5 re- p orts the results of numerical exp eriments based on syn thetic data generated from three multi- nomial distributions ov er K = 5 lab els. Specifically , w e consider: a b alanc e d distribu- tion assigning equal probabilit y 1 / 5 to each label; a mo der ately imb alanc e d distribution with probabilities (0 . 4 , 0 . 25 , 0 . 15 , 0 . 12 , 0 . 08); and a highly imb alanc e d distribution with probabilities 32 Normal Student's t (df = 3) Normal Mixture Cov erage Excess UB 10 100 1000 10 100 1000 10 100 1000 0.80 0.85 0.90 0.95 1.00 −0.2 0.0 0.2 Sample size Method Oracle Plug−in Conformal P arametric (nor mal) Figure 4: Illustrative simulation of one-sided prediction upp er b ounds for a con tinuous random v ariable at lev el α = 0 . 1, under three differen t data-generating distributions. Tw o p erformance metrics are shown as a function of the sample size: marginal co verage (top) and excess upp er b ound relativ e to the ideal p opulation oracle (b ottom). The metho ds compared are conformal prediction, an empirical plug-in approach, and a normal asymptotic prediction interv al. Each curv e represents av erages ov er 10 , 000 indep endent sim ulations. Conformal prediction guarantees exact cov erage and p erforms similarly to the oracle as the sample size grows. (0 . 75 , 0 . 15 , 0 . 09 , 0 . 01 , 0). F or each setting we generate training samples of v arying sizes and con- struct prediction sets at lev el α = 0 . 1. W e compare conformal prediction with three b enchmarks: (i) the p opulation oracle, which uses kno wledge of the true distribution P ∗ ; (ii) an empirical plug-in approach, which replaces P ∗ b y its m ultinomial maximum-lik eliho o d estimate based on the observ ed sample Y 1: n ; and (iii) a Bay esian approac h using a uniform Dirichlet prior. In the Bay esian method, we place a Dirichlet(1 , . . . , 1) prior on the class probabilities π = ( π 1 , . . . , π K ), yielding a Dirichlet(1 + n 1 , . . . , 1 + n K ) p osterior after observing lab el counts ( n 1 , . . . , n K ). W e then apply the oracle construction using the predictiv e distribution P Bay es [ Y n +1 = k | Y 1: n ] = (1 + n k ) / ( K + n ) instead of the true data-generating distribution P ∗ . Figure 5 sho ws that conformal prediction sets conv erge quickly to the oracle sets as the sample size increases, while consistently ac hieving marginal cov erage at the desired level 1 − α . The plug-in approac h, lac king an y finite-sample guarantees, under-cov ers substan tially in small samples. The Ba yesian predictor, although more conserv ative due to the prior, still do es not satisfy finite-sample frequen tist cov erage guarantees and may either under-co ver (balanced and mo derately im balanced cases) or ov er-cov er (highly imbalanced case), dep ending on how well the prior aligns with the true p opulation distribution. 33 Balanced Moderately imbalanced Highly imbalanced Cov erage Excess Size 10 100 1000 10 100 1000 10 100 1000 0.8 0.9 1.0 −0.25 0.00 0.25 0.50 0.75 Sample size Method Oracle Plug−in Conformal Bay esian (Dirichlet pr ior) Figure 5: Illustration of prediction sets for a categorical outcome at target lev el α = 0 . 1 under three differen t data-generating distributions. The top panel sho ws the marginal co v erage as a function of the sample size, and the b ottom panel shows the excess size of each metho d relative to the p opulation oracle. The metho ds compared are conformal prediction, a plug-in estimator, and a Ba yesian approach with a uniform Diric hlet prior. Results are av eraged o ver 10 , 000 independent rep etitions. Conformal prediction maintains finite-sample marginal co verage guaran tees and ap- proac hes the oracle p erformance rapidly as the sample size grows. B F urther Details on Diab etes Classification Example using NHANES Data This app endix describ es the data prepro cessing, v ariable construction, mo del sp ecification, and con- formal calibration steps for the diab etes classification example using NHANES (08/2021–08/2023) data (Figure 3), obtained from P aulose-Ram et al. (2021). W e merge demographic, examination, lab oratory , and questionnaire comp onen ts using the resp ondent identifier (SEQN). All prepro cess- ing is p erformed prior to sample splitting. Outcome definition and prepro cessing. An individual is classified as having diab etes ( Y = 1) if they rep ort a ph ysician diagnosis of diab etes or meet standard lab oratory criteria (fasting plasma glucose ≥ 126 mg/dL or HbA1c ≥ 6 . 5%). Individuals rep orting no diagnosis and b elo w b oth lab oratory thresholds are classified as healthy ( Y = 0); observ ations with missing or indeterminate outcome information are excluded. W e restrict the analysis to participants o v er 30 years of age and exclude pregnan t individuals. After additionally removing observ ations with missing cov ariates, 2,125 individuals remain. Risk mo deling. W e fit a logistic regression mo del including demographic v ariables (age, sex, race/ethnicit y , pov erty-income ratio), an throp ometric measures (waist circumference and heigh t), cardiometab olic markers (systolic blo o d pressure, triglyceride-to-HDL ratio, AL T, uric acid, and GGT), and b ehavioral v ariables (sleep duration and self-rep orted physical activit y). Con tinuous v ariables are used on their natural scales. Age is mo deled flexibly using a natural cubic spline with three degrees of freedom, while the remaining co v ariates enter as linear or categorical main effects. 34 Split-conformal metho dology . The data are randomly partitioned in to training (1,062), cal- ibration (319), and test (744) sets. The logistic mo del is fit on the training set to estimate ˆ p 1 ( x ) = P ( Y = y | X = x ), with ˆ p 0 ( x ) = 1 − ˆ p 1 ( x ). On the calibration set, w e compute probabilit y-based nonconformity scores and determine the empirical (1 − α ) quan tile with α = 0 . 05, yielding a threshold τ . F or a new individual, the conformal prediction set is b C ( x ) = { y ∈ { 0 , 1 } : ˆ p y ( x ) ≥ 1 − τ } , whic h in the binary setting pro duces one of three p ossible outputs: { Health y } , { Diab etes } , or { Health y , Diab etes } . Under exc hangeabilit y , this guaran tees marginal co verage P Y ∈ b C ( X ) ≥ 1 − α = 0 . 95, where the probability is taken ov er the join t distribution of ( X , Y ). Co verage is ev aluated on the indep endent test set as the prop ortion of individuals whose true lab el lies in the reported prediction set. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment