통계학자를 위한 컨포멀 예측 입문
** 컨포멀 예측은 교환가능성이라는 최소 가정만으로도 유한표본에서 정확한 마진 커버리지를 제공한다. 모델을 블랙박스로 취급하며, 비정규화·고차원 데이터에도 적용 가능하다. 본 논문은 교환가능성, 비순응 점수, p‑값 기반 예측 집합 구성 등을 설명하고, 연속형·범주형 예시를 통해 실용적 구현 방법과 한계를 조명한다. **
저자: Matteo Sesia, Stefano Favaro
**
본 논문은 최근 통계·머신러닝 분야에서 급부상하고 있는 ‘컨포멀 예측(Conformal Prediction)’의 핵심 개념과 이론적 기반을 통계학자 관점에서 정리한다.
1. **배경 및 동기**
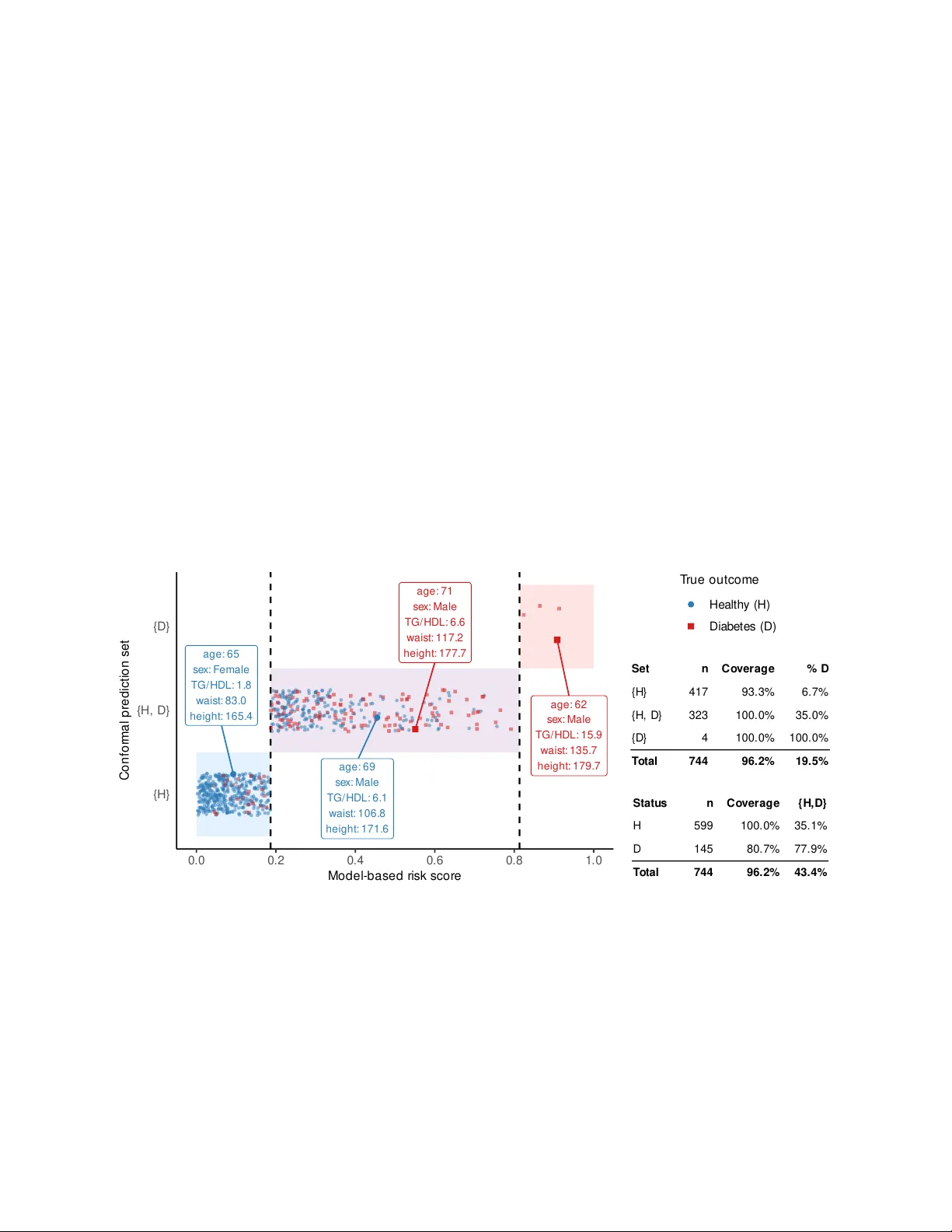
전통적인 예측 구간은 모델 파라미터에 대한 가정(정규성, 선형성 등)과 대규모 표본에 의존한다. 반면, 현대 머신러닝 모델은 고차원·비선형 구조를 가지며, 예측값 자체는 제공하지만 불확실성 추정은 부재한 경우가 많다. 컨포멀 예측은 이러한 ‘블랙박스’ 모델에 대해, 데이터가 교환가능(exchangeable)하다는 최소 가정만으로도 정확한 유한표본 마진 커버리지를 제공한다는 점에서 매력적이다.
2. **교환가능성 및 마진 커버리지**
데이터 \(\{Z_i=(X_i,Y_i)\}_{i=1}^{n+1}\) 가 교환가능하다는 가정은 모든 순열에 대해 동일한 결합분포를 의미한다. 이 가정 하에서, 전체 데이터가 교환가능하다는 영가설 \(H_{n+1}\) 를 검정하는 형태로 컨포멀 예측을 정의한다. 검정 통계는 비순응 점수 \(s(z,D)\) 로 구성되며, 점수들의 순위(rank)를 이용해 p‑값을 계산한다. p‑값은 초균등성을 만족하므로, 임계값 \(\alpha\) 에 대해
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기