MRMS-Net and LMRMS-Net: Scalable Multi-Representation Multi-Scale Networks for Time Series Classification
Time series classification (TSC) performance depends not only on architectural design but also on the diversity of input representations. In this work, we propose a scalable multi-scale convolutional framework that systematically integrates structure…
Authors: Celal Alagöz, Mehmet Kurnaz, Farhan Aadil
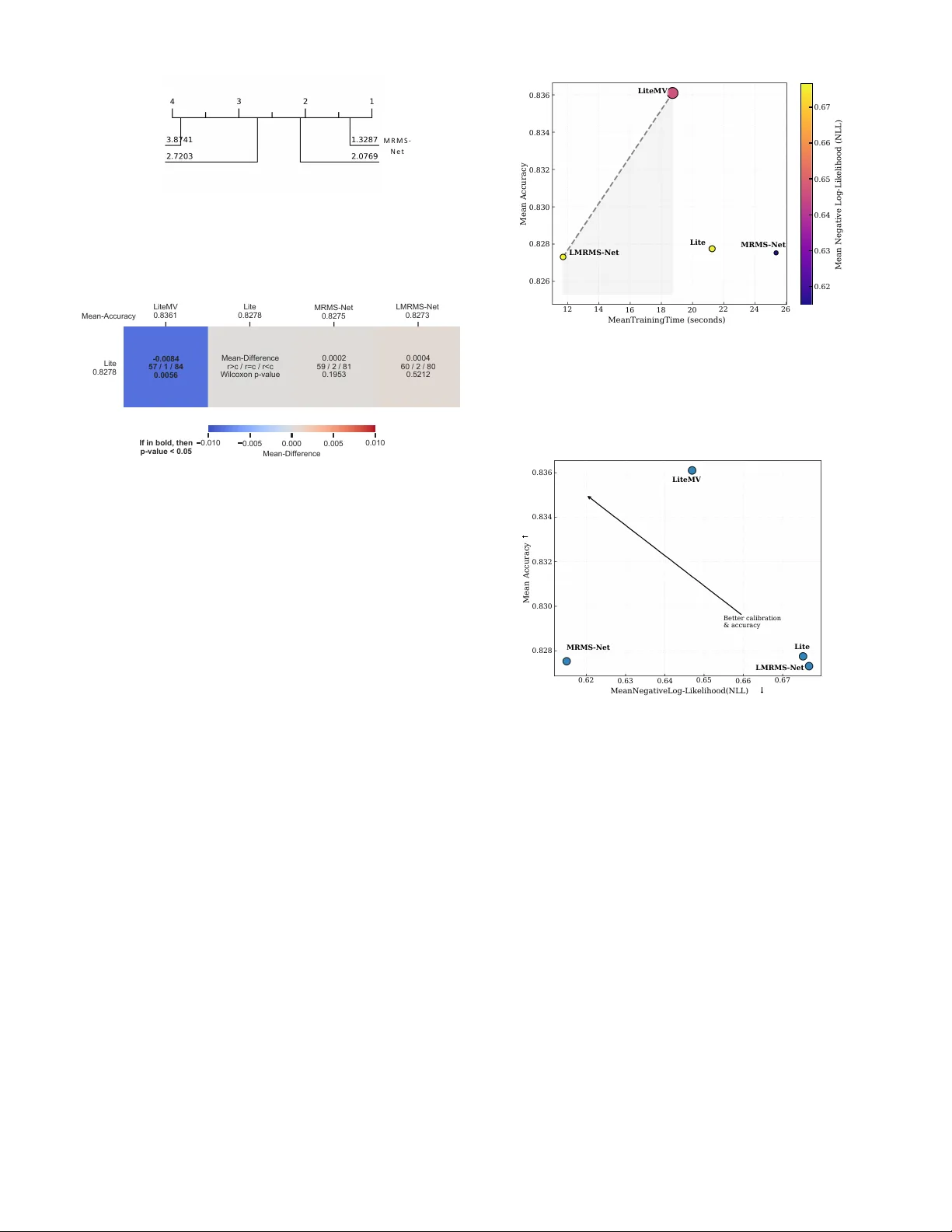
MRMS-Net and LMRMS-Net: Scalable Multi-Representation Multi-Scale Networks for T ime Series Classification 1 st Celal Alag ¨ oz Computer Engineering Sivas Bilim ve T eknoloji ¨ Universitesi Siv as, T ¨ urkiye 0000-0001-9812-1473 2 nd Mehmet Kurnaz Computer Engineering Sivas Bilim ve T eknoloji ¨ Universitesi Siv as, T ¨ urkiye 0009-0003-1303-1623 3 rd Farhan Aadil Computer Engineering Sivas Bilim ve T eknoloji ¨ Universitesi Siv as, T ¨ urkiye 0000-0001-8737-2154 Abstract —Time series classification (TSC) performance de- pends not only on architectural design but also on the diversity of input repr esentations. In this work, we propose a scalable multi- scale con volutional framework that systematically integrates structured multi-representation inputs for univariate time series. W e introduce two architectures: MRMS-Net, a hierarchi- cal multi-scale con volutional network optimized for robustness and calibration, and LMRMS-Net, a lightweight variant de- signed for efficiency-aware deployment. In addition, we adapt LiteMV—originally developed f or multivariate inputs—to oper - ate on multi-repr esentation univariate signals, enabling cross- repr esentation interaction. W e evaluate all models across 142 benchmark datasets under a unified experimental protocol. Critical Difference (CD) analysis confirms statistically significant performance differences among the top models. Results show that LiteMV achieves the high- est mean accuracy , MRMS-Net provides superior probabilistic calibration (lowest NLL), and LMRMS-Net offers the best effi- ciency–accuracy tradeoff . Pareto analysis further demonstrates that multi-repr esentation multi-scale modeling yields a flexible design space that can be tuned for accuracy-oriented, calibration- oriented, or resource-constrained settings. These findings establish scalable multi-representation multi- scale learning as a principled and practical direction for modern TSC. Reference implementation of MRMS-Net and LMRMS-Net is available at: https://github .com/alagoz/mrmsnet- tsc Index T erms —Time Series Classification, Multi-Scale CNN, Multi-Representation Learning, Lightweight Deep Neural Net- works, Computational Efficiency I . I N T RO D U C T I O N TSC has witnessed substantial progress with the emergence of deep conv olutional and transformer -based architectures. Despite these advances, two fundamental aspects remain un- derexplored in a unified manner: (i) the role of structured rep- resentation div ersity , and (ii) the trade-of f between accuracy , calibration, and computational efficienc y at scale. Most existing deep TSC models operate on ra w time- domain inputs, implicitly expecting the network to learn all relev ant transformations internally . Howe ver , classical signal processing suggests that complementary representations—such as deriv atives, frequency-domain projections, and autocorrela- tion structures—encode discriminativ e information that may not be easily recoverable from raw signals alone. While prior studies have explored representation ensembles or feature concatenation, systematic multi-representation learning within scalable deep architectures remains limited. In parallel, multi-scale con volutional networks have proven effecti ve for capturing temporal dependencies across v arying receptiv e fields. Y et, current multi-scale models are typi- cally optimized purely for predictiv e accuracy , with limited analysis of calibration quality and efficienc y trade-offs. For large benchmark collections, such as the 142-dataset UCR archiv e [1], scalability and robustness become critical design considerations. In this work, we propose a principled multi-representation multi-scale learning framework for TSC. Our contributions are threefold: • Scalable Multi-Scale Architecture (MRMS-Net). W e introduce MRMS-Net, a hierarchical multi-scale con vo- lutional network designed to integrate structured rep- resentation groups while maintaining stable calibration performance. • Lightweight Efficiency-Oriented V ariant (LMRMS- Net). W e design LMRMS-Net as a computationally efficient alternative that preserv es competiti ve predic- tiv e performance while significantly reducing train- ing cost.LMRMS-Net incorporates a dynamic inference mechanism inspired by early-exit architectures [2]. Un- like static models that apply uniform computation to all samples, LMRMS-Net employs a confidence-based gating strategy . By prioritizing shallow feature extraction for high-confidence samples and reserving the deeper fusion block for ambiguous cases, LMRMS-Net achieves a fa vorable trade-off between predictiv e latency and clas- sification accuracy . • Multi-Representation Adaptation of LiteMV . W e re- purpose LiteMV -originally dev eloped for multi variate time series- to operate on structured multi-representation inputs of uni variate signals, enabling cross-representation interaction through multiv ariate-style modeling. W e ev aluate our models across 142 benchmark datasets under a unified experimental protocol with Monte Carlo re- sampling. Beyond reporting accuracy , we analyze macro-F1, Area Under the R OC Curve (A UC), negati ve log-likelihood (NLL), and runtime. Statistical v alidation using CD analysis confirms significant differences among the top-performing models. Our results re veal three ke y findings. First, structured multi-representation learning consistently improves perfor - mance ov er raw inputs. Second, MRMS-Net achieves superior calibration performance, while LiteMV attains the highest ov erall accuracy . Third, LMRMS-Net establishes a strong effi- ciency–accurac y Pareto frontier , demonstrating that multi-scale modeling can be adapted to resource-constrained scenarios. These findings establish scalable multi-representation multi- scale learning as a flexible and statistically v alidated paradigm for modern TSC. I I . R E L A T E D W O R K A. Deep Learning for T ime Series Classification Early TSC methods relied on distance-based approaches such as nearest neighbor classifiers [3] with elastic similarity measures. The introduction of deep learning shifted focus tow ard conv olutional neural networks (CNNs), which demon- strated strong performance by automatically learning hierar- chical temporal features from ra w inputs. Architectures such as fully con volutional networks and residual networks became competitiv e baselines across large benchmark collections [4], [5]. More recently , attention-based [6] transformer architectures [7] have further advanced TSC performance. Ho wever , many of these approaches prioritize predictiv e accurac y without explicitly addressing calibration quality or computational scal- ability across div erse dataset characteristics. B. Multi-Scale Modeling Early multi-scale approaches, such as the Multi-Scale Con- volutional Neural Network (MCNN) [8] , introduced a trans- formation stage to extract multi-resolution features through down-sampling and smoothing. More recent multi-scale con- volutional architectures [9] aim to capture temporal depen- dencies at different resolutions through parallel con volutional branches or hierarchical receptiv e fields. These designs hav e prov en effecti ve in modeling both short-term and long-term dynamics. Other CNN models [10] similarly stack dilated or multi-size filters to capture patterns of varying receptiv e fields. These architectures excel at accuracy , but rarely analyze their calibration or ef ficiency . Nonetheless, existing multi- scale networks generally operate on a single raw represen- tation, implicitly assuming that scale di versity alone suf fices to capture signal complexity . Beyond complex designs, Fully Con volutional Networks (FCNs) hav e demonstrated that supe- rior performance can be achiev ed through relatively simple, parameter-ef ficient architectures that bypass pooling layers to preserve temporal resolution [11]. In contrast, our work combines scale diversity with rep- resentation diversity , enabling complementary information sources (e.g., time-domain deriv atives, frequency magnitudes, autocorrelation) to be jointly modeled within a unified frame- work. C. Representation Learning and Multi-V iew Appr oaches Feature-based TSC approaches [12]–[14] have long lev er- aged handcrafted transformations such as wa velets [15], Fourier coefficients [16], and autocorrelation features to cap- ture diverse temporal characteristics. Ensemble-based methods [17], [18] further combine heterogeneous representations at the classifier lev el to improve robustness and accuracy . Beyond individual feature sets, recent work has explored systematic integration of features extracted from multiple signal representations. For example, Crossfire [19] integrates features derived from deriv ativ e, autocorrelation, Fourier , co- sine, wav elet, and Hilbert representations within a unified feature extraction framework. Ev aluated on the 142 datasets of the UCR archi ve, this approach demonstrated that combin- ing complementary representations can improve classification robustness while maintaining strong computational ef ficiency and scalability . In parallel, con volutional kernel-based methods such as R OCKET and its v ariants [20], [21] have shown that generat- ing large stochastic representation spaces using thousands of random conv olutional kernels can effecti vely capture complex temporal patterns. Deep learning approaches hav e also been widely applied to TSC, often relying on ensembles of identi- cal architectures trained independently to impro ve predicti ve performance [22]. While ensembling improves accuracy , these models typically rely on random initialization to introduce div ersity , which may lead to redundant feature representations. More recently , representation learning paradigms ha ve emerged to learn robust embeddings directly from time series data. Self-supervised methods such as TS2V ec [23] and TF- C [24] aim to capture temporal and spectral dependencies through contrastiv e learning objectives. In parallel, multi-view learning frameworks hav e been explored in other domains to integrate complementary data sources and improve generaliza- tion. Despite these advances, systematic integration of multiple signal representations within deep con volutional architectures remains relativ ely undere xplored. In this work, we introduce multiple representation regimes and ev aluate their impact across 142 datasets, providing large-scale empirical evidence that carefully designed representation combinations can yield consistent performance improv ements. D. Multivariate Modeling and LiteMV LiteMV [25] was originally proposed for multiv ariate TSC, modeling interactions across channels. In this work, we rein- terpret distinct signal representations as structured channels, allowing LiteMV to operate in a multi-representation setting. This adaptation enables cross-representation interaction with- out requiring inherently multiv ariate input signals, extending the applicability of multi variate architectures to representation- enhanced univ ariate problems. E. Calibration and Efficiency in TSC While accuracy remains the dominant ev aluation metric in TSC, probabilistic calibration has gained increasing attention due to its importance in risk-sensitiv e applications. NLL provides a principled measure of predictiv e confidence quality . T o this end, MRMS-Net is designed as a high-capacity , hierar- chical architecture that leverages full representation di versity to achiev e superior calibration and robustness across complex signal domains. Furthermore, large-scale empirical ev aluations necessitate careful analysis of training and inference cost. The LITE model [26] that accuracy-competitiv e CNN architectures for TSC can be achie ved with significantly reduced parameter counts. Similarly , Omni-Scale architectures like OS-CNN [27] emphasize the importance of capturing univ ersal patterns through diverse kernel sizes. Inspired by these efficienc y- oriented design principles and neural scaling laws, LMRMS- Net incorporates lightweight conv olutional strategies, such as reduced filter sizes and computationally ef ficient feature ex- traction, to maintain competitive performance while lowering computational cost. Our study e xplicitly analyzes accuracy , macro-F1, A UC, NLL, and runtime, and visualizes trade-offs using P areto analysis. T o our kno wledge, this is among the first works to jointly e valuate multi-scale, multi-representation architectures with statistical significance testing and ef ficiency–calibration tradeoff analysis across the full 142-dataset benchmark suite. I I I . M E T H O D O L O G Y A. Multi-Representation F ramework Rather than relying solely on raw time-domain signals, we construct structured representation sets designed to capture complementary temporal characteristics. F or each univ ari- ate time series x ( t ) , we consider following representations: T I M E , D T 1 , D T 2 , H LB M AG , D W T A , F F T M AG , D C T , and AC F . Here, D T 1 and DT 2 denote first and second deriv atives, H LB M AG and F F T M AG correspond to frequency mag- nitude projections, D W T A represents wa velet approxima- tion coefficients, DC T denotes discrete cosine transform coefficients, and AC F represents autocorrelation features. Each representation is treated as an input channel, enabling structured multi-representation learning within con volutional architectures. This formulation allows controlled analysis of representation impact across datasets. B. Arc hitectural Overview Figure 1 provides a visual comparison between MRMS- Net and LMRMS-Net architectures. Both architectures process multi-representation inputs with shape ( R × L ) , where R is the number of representations and L is the time series length. C. MRMS-Net: Multi-Scale Representation Network MRMS-Net is designed to capture temporal dependencies at multiple recepti ve field scales while inte grating structured representations. Giv en an input tensor of shape ( R, L ) , where R is the number of representations and L is the series length, MRMS- Net applies parallel conv olutional branches with dif ferent kernel sizes. These branches capture short-term and long-term temporal patterns simultaneously . Branch outputs are concatenated and passed through hier- archical con volutional fusion blocks consisting of: • Batch normalization • ReLU activ ation • Stacked 1 D con volutions • Dropout regularization Global average pooling aggreg ates temporal information before classification. The architecture is optimized for stable training, controlled capacity gro wth, and robust calibration performance. D. LMRMS-Net: Lightweight Multi-Scale Network with Early Exit T o address computational ef ficiency , we introduce LMRMS- Net (implemented as FastMultiScaleCNN ), a lightweight multi-scale architecture with conditional early exit. 1) Ultra-Light Multi-Scale F eature Extraction: LMRMS- Net uses two shallow con volutional branches with kernel sizes 3 and 5 : b 3 = Conv1d ( R, 16 , k = 3) , b 5 = Conv1d ( R, 16 , k = 5) The branch outputs are concatenated to form a compact 32- channel representation. 2) Early Exit Classifier: An early classifier operates di- rectly on pooled branch features: • Adaptiv e average pooling • Fully connected layer (32 → 64) • ReLU activ ation • Output layer (64 → C ) During inference, prediction confidence is computed via softmax probabilities. If the mean maximum class probability exceeds a threshold τ = 0 . 8 , the early prediction is returned. 3) Main P athway (F allback): If confidence is below thresh- old, features are processed through a deeper fusion block: • BatchNorm + ReLU • Con v1d(32 → 64) • Con v1d(64 → 128) • Dropout (0.3) After global average pooling, a final linear classifier pro- duces predictions. During training, only the main pathway is used to ensure stable gradient flow . Early exit is activ ated only during infer- ence. This design enables LMRMS-Net to reduce inference cost on “easy” samples while maintaining competitiv e accuracy . Input ( R × L ) Con v1D k = 3 Con v1D k = 5 Con v1D k = 7 Short Medium Long Concatenate Feature Fusion BN → ReLU → Conv → Dropout Global A vg Pool + FC (a) MRMS-Net architecture Input ( R × L ) Con v1D k = 3 Con v1D k = 5 Concatenate (32 ch) conf ≥ τ Early Exit Pool + FC Main Path Con v → Pool → FC Y es No Training: main path only (b) LMRMS-Net architecture Fig. 1: Architecture comparison of the proposed models. MRMS-Net employs three multi-scale con volution branches ( k = 3 , 5 , 7 ) followed by a feature fusion block. LMRMS-Net uses a lightweight two-branch design and incorporates a confidence- based early-exit mechanism to reduce inference cost. E. LiteMV Multi-Representation Adaptation LiteMV was originally designed for multiv ariate TSC. W e reinterpret representation channels as structured pseudo- variables, enabling cross-representation interaction modeling. Formally , for a representation set of size R , the input tensor is treated as multiv ariate with R channels. LiteMV thus models: F : R R × L → R C This adaptation allows structured interaction between time- domain and frequency-domain signals without requiring inher- ently multiv ariate datasets. I V . E X P E R I M E N T A L P R OT O C O L A. Datasets and Evaluation W e ev aluate all models on 142 benchmark TSC datasets. For each dataset, we employ Monte Carlo resampling with R repeated train/test splits. Predefined resampling indices are used when av ailable to ensure strict comparability with prior state-of-the-art (SOT A) studies. Performance is reported as: • Mean across resamples (per dataset), • Then macro-averaged across datasets. This a voids dataset-size bias and follows established large- scale ev aluation protocols. B. T raining Configuration All models are trained using the Adam optimizer with cross- entropy loss for a maximum of 1500 epochs. Early stopping is applied based on training loss with a fixed patience parameter . The best model state is restored before ev aluation. Batch size is automatically selected as a function of dataset workload ( N × L ), with dynamic adjustment to pre vent GPU out-of-memory failures. C. Evaluation Metrics For each resample, we compute Accuracy , Macro F1-score, A UC (computed for both binary and multi-class cases), NLL, and training and test time. Final rankings and statistical comparisons are conducted using the Friedman test with Nemenyi post-hoc analysis. V . R E S U LT S W e ev aluate four primary architectures across 142 UCR/UEA datasets using 30 Monte-Carlo resamples per dataset. Performance is measured using accuracy , macro-F1, A UC, and NLL. T raining and test times are also recorded to assess computational efficienc y . L M R M S - N e t L i t e M V M R M S - N e t L i t e Fig. 2: CD diagram based on accuracy rankings across 142 datasets. Lower ranks indicate better performance. Methods connected by a horizontal bar are not significantly different according to the Nemenyi test. L i t e 0 . 8 2 7 8 M e a n - A c c u r a c y L i t e M V 0 . 8 3 6 1 0 . 0 1 0 L i t e 0 . 8 2 7 8 M e a n - D i f f e r e n c e r > c / r = c / r < c W i l c o x o n p - v a l u e 0 . 0 0 5 0 . 0 0 0 0 . 0 0 5 M e a n - D i f f e r e n c e M R M S - N e t 0 . 8 2 7 5 0 . 0 0 0 2 5 9 / 2 / 8 1 0 . 1 9 5 3 0 . 0 1 0 L M R M S - N e t 0 . 8 2 7 3 0 . 0 0 0 4 6 0 / 2 / 8 0 0 . 5 2 1 2 - 0 . 0 0 8 4 5 7 / 1 / 8 4 0 . 0 0 5 6 I f i n b o l d , t h e n p - v a l u e < 0 . 0 5 Fig. 3: Multi comparision matrix. The four architectures compared in detail are: • Lite (baseline) • LiteMV (multi-view adaptation) • LMRMS-Net (Lightweight Scale Network) • MRMS-Net (Multi-Scale Network) All statistical comparisons are performed using the Fried- man test follo wed by Nemenyi post-hoc analysis across 142 datasets. A. Overall P erformance Comparison T able I reports mean performance across all datasets. LiteMV achieves the highest mean accuracy and macro-F1, while MRMS-Net achiev es the best calibration (lo west NLL). LMRMS-Net provides competitive accuracy with significantly reduced computational cost. B. Statistical Significance Acr oss 142 Datasets Figure 2 presents the CD diagram based on accuracy rankings across 142 datasets. The Friedman test indicates statistically significant dif- ferences among methods ( p < 0 . 05 ). The Nemenyi post- hoc test shows: (i) LiteMV ranks first overall, (ii) Lite and MRMS-Net are statistically indistinguishable from LiteMV , and (iii) LMRMS-Net remains competiti ve but slightly lower in av erage rank. Importantly , no architecture dominates all others across ev ery dataset, confirming that improvements are dataset- dependent. C. Efficiency–P erformance T radeof f Figure 4 shows the Pareto tradeoff between mean training time and accuracy . Marker size represents A UC, and color 0 . 8 3 6 0 . 8 3 4 0 . 8 3 2 0 . 8 3 0 0 . 8 2 8 0 . 8 2 6 1 2 L M R M S - N e t 1 4 1 6 L i t e M V 1 8 2 0 L i t e 2 2 2 4 M R M S - N e t 2 6 0 . 6 7 0 . 6 6 0 . 6 5 0 . 6 4 0 . 6 3 0 . 6 2 MeanTrainingTime (seconds) Mean Accuracy Mean Negative Log-Likelihood (NLL) Fig. 4: Pareto tradeoff between mean training time and clas- sification accuracy . Marker size represents mean A UC, while color encodes mean NLL. The dashed curve denotes the P areto frontier , identifying models that achie ve optimal tradeof fs between predictiv e performance and computational cost. 0 . 8 3 6 0 . 8 3 4 0 . 8 3 2 0 . 8 3 0 0 . 8 2 8 M R M S - N e t 0 . 6 2 0 . 6 3 0 . 6 4 L i t e M V 0 . 6 5 0 . 6 6 0 . 6 7 L i t e L M R M S - N e t MeanNegativeLog-Likelihood(NLL) Mean Accuracy B e t t e r c a l i b r a t i o n & a c c u r a c y Fig. 5: Accuracy versus mean NLL across ev aluated architec- tures. encodes NLL. LMRMS-Net lies near the Pareto frontier, achieving near-SO T A accuracy with substantially reduced training time. LiteMV provides the strongest accuracy while maintaining moderate training cost. MRMS-Net achiev es su- perior calibration but at increased computational expense. This demonstrates that scalable multi-scale modeling can be adapted to different operating regimes: • Accuracy-oriented regime: LiteMV • Efficiency-oriented regime: LMRMS-Net • Calibration-oriented regime: MRMS-Net D. Calibration Analysis Figure 5 plots accuracy versus NLL. While several models achiev e similar accuracy , MRMS-Net consistently achiev es lower NLL values, indicating better probabilistic calibration. This suggests that multi-scale feature aggregation contributes not only to classification accuracy b ut also to improv ed uncer- tainty estimation. T ABLE I: Mean performance across 142 datasets (best values in bold). Architecture Accuracy F1 A UC NLL ↓ T rain Time (s) T est Time (s) Lite 0.828 0.802 0.936 0.675 21.26 0.059 LiteMV 0.836 0.812 0.938 0.647 18.72 0.088 LMRMS-Net 0.827 0.801 0.939 0.677 11.70 0.027 MRMS-Net 0.828 0.799 0.938 0.615 25.35 0.088 E. Impact of Representations 1) Arc hitecture–Repr esentation Interaction: The benefit of representation expansion varies across architectures: • LiteMV benefits most strongly , likely due to cross- channel interaction. • MRMS-Net shows stable improvements, indicating inher- ent robustness to representation div ersity . • LMRMS-Net achieves optimal efficiency under the Min- imal setting. These findings demonstrate that representation div ersity interacts with architectural design in non-trivial ways. 2) Efficiency Considerations: Although the Default repre- sentation often yields the highest accurac y , it increases training time. The Minimal set captures most gains at significantly lower computational cost, offering a strong tradeoff point. F . Summary of Findings Across 142 datasets, the results support three main conclu- sions: 1) Multi-view representation expansion significantly im- prov es performance over raw time-domain inputs. 2) Scalable multi-scale con volution provides strong calibra- tion benefits. 3) Lightweight variants can achieve near state-of-the-art performance with substantially reduced computational cost. Overall, combining structured representation div ersity with scalable multi-scale architectures forms a robust and efficient framew ork for TSC. V I . D I S C U S S I O N This study provides large-scale empirical evidence across 142 datasets that performance in TSC is gov erned by three interacting factors: architectural capacity , representation diver - sity , and computational scalability . A. Arc hitecture vs. Representation A key finding is that representation div ersity consistently improv es performance across all architectures. Moving from raw time-domain inputs to the Minimal representation set yields substantial gains in both accuracy and macro-F1. Ex- panding further to the Default set provides smaller but con- sistent improv ements, suggesting diminishing returns be yond a compact, informativ e transformation core. Interestingly , the magnitude of improv ement depends on architectural design. LiteMV benefits the most from repre- sentation expansion, indicating that cross-view interactions effecti vely exploit complementary feature domains. In con- trast, MRMS-Net exhibits more stable performance across representation regimes, suggesting inherent robustness due to multi-scale aggregation. LMRMS-Net achie ves its best ef fi- ciency–accurac y balance under the Minimal setting, indicating that lightweight models benefit most from carefully curated representation subsets. These results highlight that representation engineering and architectural design should not be treated independently; their interaction is central to scalable TSC performance. B. Accuracy vs. Calibration While LiteMV achiev es the highest mean accuracy , MRMS- Net consistently attains the lowest NLL, indicating superior probabilistic calibration. This suggests that multi-scale hier- archical aggregation impro ves uncertainty estimation beyond pure classification accuracy . This distinction is important for applications requiring re- liable confidence estimates, such as medical diagnosis or anomaly detection. The results imply that architectural depth and multi-scale structure contribute differently to discrimina- tion and calibration. C. Efficiency Considerations From an ef ficiency standpoint, LMRMS-Net demonstrates that competitive accuracy can be achiev ed with substantially reduced training and inference cost. The Pareto analysis shows that LMRMS-Net lies near the efficiency frontier , making it attractiv e for large-scale or resource-constrained deployments. Importantly , the representation expansion strategy does not break scalability . The Minimal representation captures most performance gains while preserving computational ef ficiency , making it a strong default configuration for practical applica- tions. D. Statistical Robustness The Friedman and Nemenyi analyses confirm statistically significant differences among architectures. Howe ver , no sin- gle model dominates across all datasets. This reinforces the importance of reporting average ranks and performing multi- dataset statistical testing rather than relying solely on mean accuracy . Overall, the results demonstrate that scalable multi-scale con volution combined with structured multi-representation in- puts forms a robust and adaptable TSC framework. V I I . C O N C L U S I O N W e introduced a scalable multi-scale con volutional frame- work for TSC and systematically ev aluated its beha vior across 142 benchmark datasets. Our contributions can be summarized as follows: 1) W e demonstrated that structured representation expan- sion (Raw → Minimal → Def ault) consistently improves classification performance. 2) W e showed that adapting LiteMV to multi- representation univ ariate inputs provides strong accuracy gains. 3) W e proposed MRMS-Net and LMRMS-Net, scalable multi-scale architectures that balance accuracy , calibra- tion, and computational efficienc y . 4) W e provided statistically rigorous comparisons using CD analysis and Pareto tradeoff e valuation. The results rev eal that: • LiteMV achieves the highest mean accuracy across 142 datasets. • MRMS-Net provides superior calibration performance. • LMRMS-Net achieves competitive accuracy with signif- icantly reduced training cost. These findings suggest that combining representation di ver- sity with scalable multi-scale modeling offers a flexible design space that can be tuned for accuracy-oriented, calibration- oriented, or efficienc y-oriented regimes. Future work will inv estigate adaptive representation selec- tion, dynamic multi-scale attention mechanisms, and extension to large-scale multiv ariate benchmarks. Overall, this study establishes that scalable multi- representation multi-scale learning is a principled and practical direction for modern TSC. R E F E R E N C E S [1] H. A. Dau, A. Bagnall, K. Kamgar , C.-C. M. Y eh, Y . Zhu, S. Gharghabi, C. A. Ratanamahatana, and E. Keogh, “The ucr time series archiv e, ” IEEE/CAA Journal of Automatica Sinica , vol. 6, no. 6, pp. 1293–1305, 2019. [2] S. T eerapittayanon, B. McDanel, and H.-T . Kung, “Branchynet: Fast inference via early exiting from deep neural networks, ” in 2016 23rd international conference on pattern r ecognition (ICPR) . IEEE, 2016, pp. 2464–2469. [3] Y .-H. Lee, C.-P . W ei, T .-H. Cheng, and C.-T . Y ang, “Nearest-neighbor- based approach to time-series classification, ” Decision Support Systems , vol. 53, no. 1, pp. 207–217, 2012. [4] B. Dhariyal, T . Le Nguyen, and G. Ifrim, “Back to basics: A sanity check on modern time series classification algorithms, ” in International W orkshop on Advanced Analytics and Learning on T emporal Data . Springer , 2023, pp. 205–229. [5] A. Shifaz, C. Pelletier , F . Petitjean, and G. I. W ebb, “Elastic similarity and distance measures for multiv ariate time series, ” Knowledge and Information Systems , vol. 65, no. 6, pp. 2665–2698, 2023. [6] Y . W ang, Z. Zhang, L. Feng, Y . Ma, and Q. Du, “ A ne w attention-based cnn approach for crop mapping using time series sentinel-2 images, ” Computers and electr onics in agricultur e , vol. 184, p. 106090, 2021. [7] X.-M. Le, L. Luo, U. Aickelin, and M.-T . T ran, “Shapeformer: Shapelet transformer for multivariate time series classification, ” in Proceedings of the 30th A CM SIGKDD Conference on Knowledge Discovery and Data Mining , 2024, pp. 1484–1494. [8] Z. Cui, W . Chen, and Y . Chen, “Multi-scale con volutional neural net- works for time series classification, ” arXiv preprint , 2016. [9] H. Ismail Fa waz, B. Lucas, G. Forestier , C. Pelletier, D. F . Schmidt, J. W eber, G. I. W ebb, L. Idoumghar , P .-A. Muller, and F . Petitjean, “Inceptiontime: Finding alexnet for time series classification, ” Data mining and knowledge discovery , vol. 34, no. 6, pp. 1936–1962, 2020. [10] W . X. Cheng, P . N. Suganthan, and R. Katuwal, “Time series classifica- tion using div ersified ensemble deep random vector functional link and resnet features, ” Applied Soft Computing , vol. 112, p. 107826, 2021. [11] Z. W ang, W . Y an, and T . Oates, “Time series classification from scratch with deep neural networks: A strong baseline, ” in 2017 International joint conference on neural networks (IJCNN) . IEEE, 2017, pp. 1578– 1585. [12] C. H. Lubba, S. S. Sethi, P . Knaute, S. R. Schultz, B. D. Fulcher, and N. S. Jones, “catch22: Canonical time-series characteristics: Selected through highly comparative time-series analysis, ” Data mining and knowledge discovery , vol. 33, no. 6, pp. 1821–1852, 2019. [13] M. Middlehurst and A. Bagnall, “The freshprince: A simple transforma- tion based pipeline time series classifier, ” in International Confer ence on P attern Recognition and Artificial Intelligence . Springer , 2022, pp. 150–161. [14] M. Christ, N. Braun, J. Neuffer , and A. W . Kempa-Liehr , “Time series feature extraction on basis of scalable hypothesis tests (tsfresh–a python package), ” Neurocomputing , vol. 307, pp. 72–77, 2018. [15] D. Li, T . F . Bissyande, J. Klein, and Y . L. Traon, “T ime series classifi- cation with discrete wa velet transformed data, ” International Journal of Softwar e Engineering and Knowledge Engineering , vol. 26, no. 09n10, pp. 1361–1377, 2016. [16] P . Sch ¨ afer , “Scalable time series classification, ” Data Mining and Knowledge Discovery , vol. 30, no. 5, pp. 1273–1298, 2016. [17] V . M. Souza, P . S. V eiga, and A. G. Ribeiro, “V isemble: A fast ensemble approach for time series classification with multiple visual representations, ” Knowledge-Based Systems , vol. 309, p. 112864, 2025. [18] M. Middlehurst, J. Large, M. Flynn, J. Lines, A. Bostrom, and A. Bag- nall, “Hive-cote 2.0: a new meta ensemble for time series classification, ” Machine Learning , vol. 110, no. 11, pp. 3211–3243, 2021. [19] C. Alag ¨ oz, “Crossfire: cross-domain feature integration for robust time series classification, ” P eerJ Computer Science , vol. 11, p. e3328, 2025. [20] A. Dempster, F . Petitjean, and G. I. W ebb, “Rocket: exceptionally fast and accurate time series classification using random conv olutional kernels, ” Data Mining and Knowledge Discovery , vol. 34, no. 5, pp. 1454–1495, 2020. [21] C. W . T an, A. Dempster , C. Bergmeir , and G. I. W ebb, “Multirocket: multiple pooling operators and transformations for f ast and effecti ve time series classification: Cw tan, ” Data Mining and Knowledge Discovery , vol. 36, no. 5, pp. 1623–1646, 2022. [22] J. Abdullayev , M. Dev anne, C. Meyer , A. Ismail-Fawaz, J. W eber , and G. Forestier , “Enhancing time series classification with div ersity-driven neural network ensembles, ” in 2025 International Joint Conference on Neural Networks (IJCNN) . IEEE, 2025, pp. 1–10. [23] Z. Y ue, Y . W ang, J. Duan, T . Y ang, C. Huang, Y . T ong, and B. Xu, “Ts2vec: T owards univ ersal representation of time series, ” in Proceed- ings of the AAAI confer ence on artificial intelligence , vol. 36, no. 8, 2022, pp. 8980–8987. [24] X. Zhang, Z. Zhao, T . Tsiligkaridis, and M. Zitnik, “Self-supervised contrastiv e pre-training for time series via time-frequency consistency , ” Advances in neural information pr ocessing systems , vol. 35, pp. 3988– 4003, 2022. [25] A. Ismail-Fawaz, M. Devanne, S. Berretti, J. W eber , and G. Forestier, “Look into the lite in deep learning for time series classification, ” International Journal of Data Science and Analytics , vol. 20, no. 4, pp. 4029–4049, 2025. [26] A. Ismail Fawaz, M. Dev anne, S. Berretti, J. W eber, and G. Forestier , “Lite: Light inception with boosting techniques for time series classifi- cation, ” in 2023 IEEE 10th International Conference on Data Science and Advanced Analytics (DSAA) . IEEE, 2023, pp. 1–10. [27] W . T ang, G. Long, L. Liu, T . Zhou, M. Blumenstein, and J. Jiang, “Omni-scale cnns: a simple and effecti ve kernel size configuration for time series classification, ” arXiv preprint , 2020.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment