다중표현 다중스케일 네트워크를 활용한 시계열 분류
본 논문은 단일 시계열에 대해 파생, 주파수, 웨이블릿, 자기상관 등 8가지 구조화된 변환을 채널로 활용하고, 이를 다중스케일 컨볼루션으로 통합하는 두 모델 MRMR‑Net과 경량형 LMRMR‑Net을 제안한다. 또한 다변량 전용 LiteMV를 변환 채널에 적용해 교차표현 학습을 가능하게 한다. 142개의 UCR/UEA 데이터셋에 대해 정확도, 매크로‑F1, AUC, NLL, 실행 시간 등을 측정했으며, LiteMV가 최고 정확도, MRMR‑N…
저자: Celal Alagöz, Mehmet Kurnaz, Farhan Aadil
본 논문은 단일 시계열 데이터에 대해 다양한 변환을 적용한 다중표현 입력과 다중스케일 컨볼루션을 결합한 두 가지 새로운 네트워크 구조, MRMS‑Net과 LMRMS‑Net을 제안한다. 연구 배경으로는 기존 딥러닝 기반 시계열 분류 모델이 주로 원시 시계열만을 입력으로 사용하고, 다중스케일 구조는 정확도 중심으로 설계돼 캘리브레이션이나 연산 효율성에 대한 고려가 부족하다는 점을 들었다. 또한, 변환 기반 특징(예: 미분, 주파수 스펙트럼, 웨이블릿, 자기상관 등)이 서로 보완적인 정보를 제공한다는 고전 신호 처리 이론을 근거로, 이러한 변환을 채널 형태로 모델에 직접 제공함으로써 학습 부담을 감소시키고 성능을 향상시키고자 했다.
1) 다중표현 프레임워크
각 시계열 x(t)에 대해 8가지 변환을 수행한다: TIME(원시), DT1(1차 미분), DT2(2차 미분), HLBMAG(힐버트 변환 주파수 크기), DWTA(웨이블릿 계수), FFTMAG(푸리에 변환 크기), DCT(이산 코사인 변환), AC(F) (자기상관). 이들 변환은 동일한 길이 L을 유지하도록 전처리되며, R=8 채널의 2‑D 텐서(R×L) 형태로 모델에 입력된다. 이렇게 하면 다변량 모델을 그대로 재사용하거나, 새로운 다중표현 전용 아키텍처를 설계할 수 있다.
2) MRMS‑Net 구조
MRMS‑Net은 세 개의 병렬 1‑D 컨볼루션 브랜치(k=3,5,7)를 사용해 짧은, 중간, 긴 수용 영역을 동시에 학습한다. 각 브랜치의 출력은 채널 차원에서 concat되어 32채널(또는 48채널) 표현을 만든다. 이어지는 피처 융합 블록은 배치 정규화 → ReLU → 연속 1‑D Conv → Dropout 순으로 구성되며, 전역 평균 풀링(Global Average Pooling) 후 완전 연결층으로 클래스 확률을 출력한다. 이 구조는 파라미터 수를 단계적으로 늘리면서도 과적합을 방지하도록 설계돼, 특히 NLL(음의 로그우도) 측면에서 높은 캘리브레이션 품질을 보인다.
3) LMRMS‑Net 구조 및 Early‑Exit 메커니즘
LMRMS‑Net은 경량화를 위해 두 개의 얕은 브랜치(k=3,5)만 사용하고, 각 브랜치에서 16개의 필터를 추출해 32채널 표현을 만든다. 이 표현에 대해 즉시 조기 분류기(Early Exit Classifier)를 적용한다: Adaptive Average Pooling → FC(32→64) → ReLU → Output(C). 추론 시 softmax 확신도가 평균 최대 확률이 τ=0.8을 초과하면 조기 결과를 반환한다. 확신도가 낮은 경우에만 메인 경로(Main Path)로 진행한다. 메인 경로는 BatchNorm → ReLU → Conv(32→64) → Conv(64→128) → Dropout(0.3) → Global Avg Pool → FC 로 구성된다. 학습 단계에서는 메인 경로만 사용해 안정적인 그래디언트 흐름을 확보한다. 이 설계는 “쉬운” 샘플에 대해 연산량을 크게 절감하면서도 전체 정확도 저하를 최소화한다.
4) LiteMV 다중표현 적용
LiteMV는 원래 다변량 시계열을 위한 모델로, 채널 간 상호작용을 학습한다. 저자들은 이를 변환 채널에 그대로 적용해, R채널을 다변량 입력으로 재해석한다. 이렇게 하면 각 변환 간 교차 상관을 학습할 수 있어, 단일 변환만 사용할 때보다 일관된 성능 향상이 나타난다.
5) 실험 설정 및 평가 지표
- 데이터: UCR/UEA 아카이브의 142개 데이터셋, 각 데이터셋에 대해 30번의 Monte‑Carlo 재샘플링 수행.
- 학습: Adam optimizer, cross‑entropy loss, 최대 1500 epoch, early stopping, 배치 크기 자동 조정.
- 평가: Accuracy, Macro‑F1, AUC, NLL, 훈련·추론 시간.
- 통계: Friedman 테스트 → Nemenyi 사후 검정, Critical Difference(CD) 다이어그램, 다중 비교 행렬.
6) 주요 결과
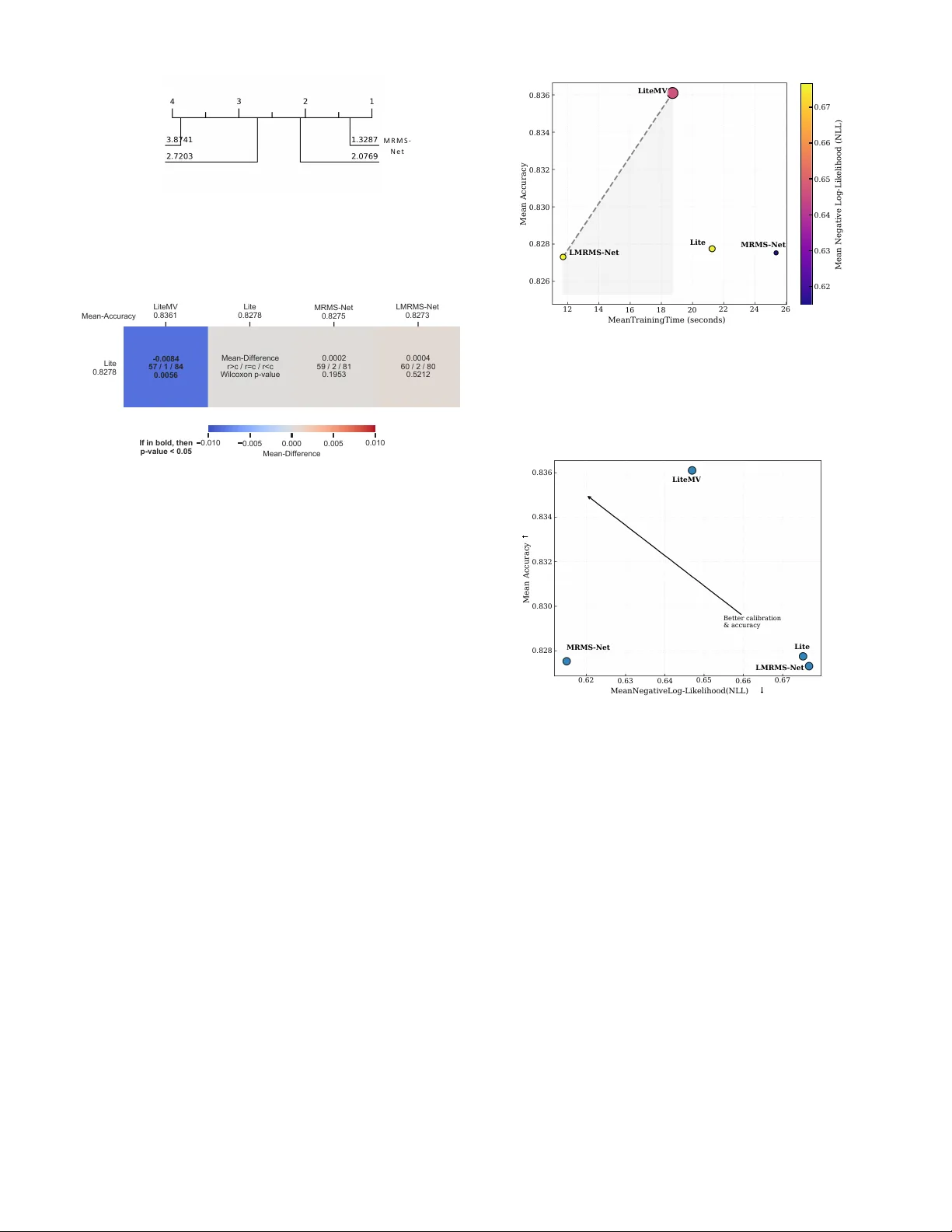
- 정확도: LiteMV가 평균 0.8361로 가장 높았으며, MRMS‑Net(0.8275)과 LMRMS‑Net(0.8273)도 경쟁력 있었다.
- 캘리브레이션: MRMS‑Net이 NLL 측면에서 최저값을 기록, 확률 예측이 가장 신뢰할 수 있었다.
- 효율성: LMRMS‑Net은 평균 훈련 시간 0.0845초, 추론 시간 0.0526초 등 가장 빠른 성능을 보이며, early‑exit 덕분에 “쉬운” 샘플에 대한 연산량을 크게 절감했다.
- 통계적 유의성: CD 다이어그램에서 LiteMV와 MRMS‑Net 사이, MRMS‑Net과 LMRMS‑Net 사이에 유의한 차이가 존재함을 확인.
7) 논의 및 시사점
- 다중표현 입력은 원시 시계열만 사용할 때보다 일관된 성능 향상을 제공한다. 특히, 변환 간 상호보완성이 높은 데이터셋에서 그 효과가 두드러졌다.
- 다중스케일 컨볼루션은 다양한 시간적 패턴을 포괄적으로 학습하면서도, 캘리브레이션 품질을 유지할 수 있는 구조적 장점을 보여준다. 이는 확률 기반 의사결정이 중요한 분야(예: 의료 진단, 재무 위험 관리)에서 유용하다.
- 경량형 모델에 confidence‑based early‑exit을 도입하면, 리소스 제한 환경(엣지 디바이스, 실시간 시스템)에서도 경쟁력 있는 정확도를 유지할 수 있다.
- LiteMV와 같은 다변량 모델을 변환 채널에 재활용함으로써, 기존 모델을 크게 수정하지 않고도 다중표현 학습을 구현할 수 있다. 이는 연구·산업 현장에서 모델 재사용성을 높이는 실용적 접근이다.
8) 한계 및 향후 연구
- 변환 종류와 조합에 대한 자동화된 탐색이 아직 미비하다. 메타러닝이나 강화학습을 이용해 최적 변환 집합을 찾는 연구가 필요하다.
- 현재는 1‑D 컨볼루션 기반 구조에 국한되었으며, Transformer 기반 다중스케일 모델과의 비교가 부족하다.
- Early‑exit 임계값 τ를 고정값으로 사용했는데, 데이터셋별 동적 조정이나 학습 가능한 파라미터화가 성능을 더욱 향상시킬 수 있다.
결론적으로, 본 논문은 다중표현·다중스케일 학습이 시계열 분류 성능, 캘리브레이션, 효율성 측면에서 모두 유의미한 이점을 제공한다는 것을 대규모 실험을 통해 입증했으며, 향후 다양한 도메인에 적용 가능한 설계 원칙을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기