A Theory of LLM Information Susceptibility
Large language models (LLMs) are increasingly deployed as optimization modules in agentic systems, yet the fundamental limits of such LLM-mediated improvement remain poorly understood. Here we propose a theory of LLM information susceptibility, centr…
Authors: Zhuo-Yang Song, Hua Xing Zhu
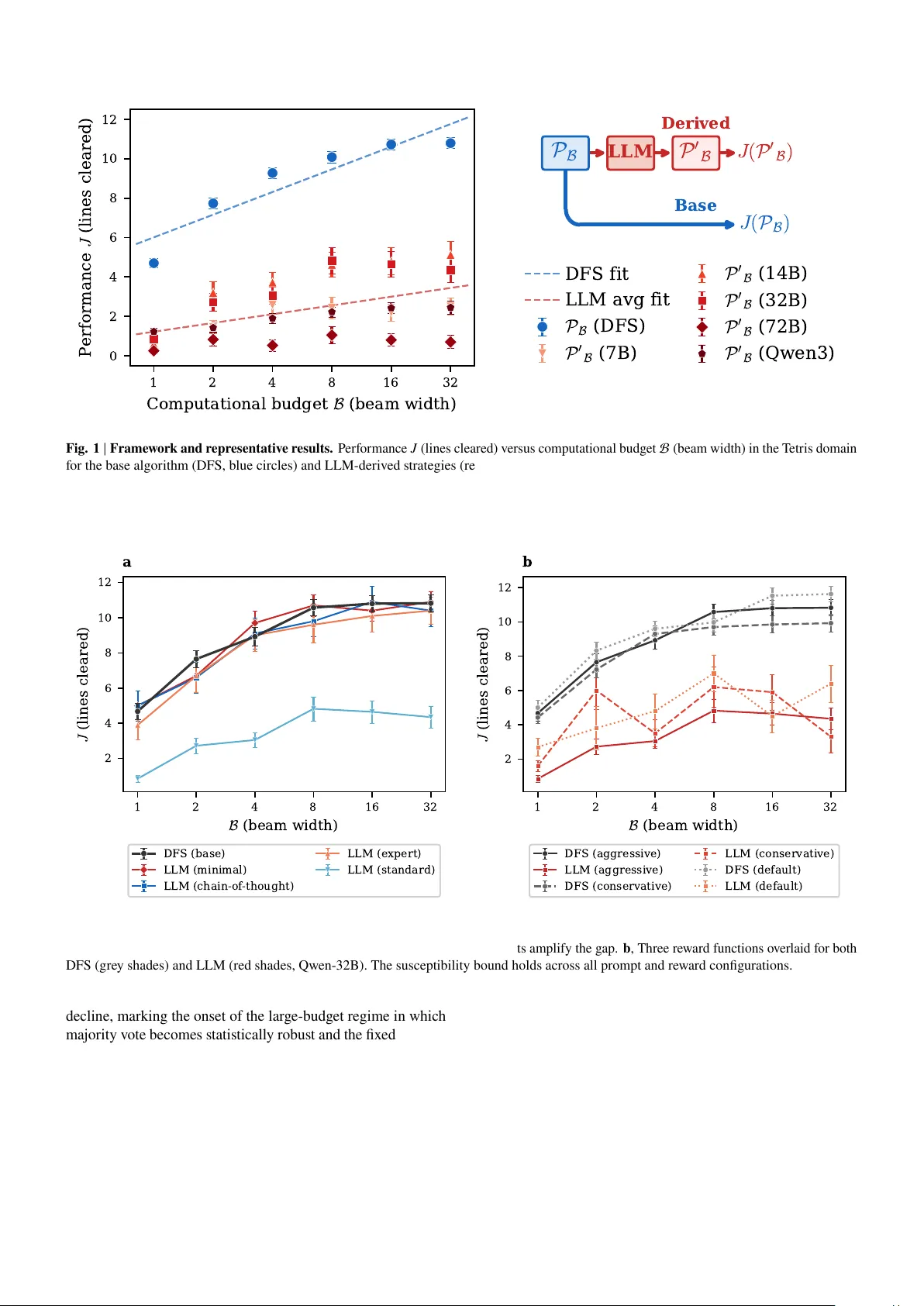
Preprint A Theory of LLM Inf ormation Susceptibility Zhuo- Y ang Song 1, B Hua Xing Zhu 1,2, B 1 School of Ph ysics, P eking U niversity , Bei jing 100871, China 2 Center f or High Energy Ph ysics, P eking Univ ersity , Bei jing 100871, China B e-mail: zhuo yangsong@s tu.pku.edu.cn; zhuhx@pk u.edu.cn Larg e language models (LLMs) are increasingl y deplo y ed as optimization modules in agentic sy stems, y et the fundamental limits of such LLM-mediated impro v ement remain poorly unders tood. Here we propose a theory of LLM information susceptibility , centred on the hypothesis that when computational resources are sufficiently lar ge, the interv ention of a fix ed LLM does not increase the per f ormance susceptibility of a strategy set with respect to budg et. W e dev elop a multi-v ariable utility -function frame work that generalizes this h ypothesis to arc hitectures with multiple co-varying budg et channels, and discuss the conditions under which co-scaling can e xceed the susceptibility bound. W e v alidate the theory empir ically across s tructurally div erse domains and model scales spanning an order of magnitude, and sho w that nested, co-scaling architectures open response channels una vailable to fix ed configurations. These results clarify when LLM intervention helps and when it does not, demonstrating that tools from s tatistical ph ysics can pro vide predictive cons traints f or the design of AI sy stems. If the susceptibility h ypothesis holds generall y , the theory suggests that nes ted architectures ma y be a necessary structural condition for open-ended ag entic self-impro v ement. Introduction Larg e languag e models (LLMs) are rapidl y becoming core components of ag entic sy stems, especiall y when combined with search, planning, v er ification, memory and tool-use modules 1 – 8 . Such sys tems often outperf or m pure language modeling or traditional pipelines alone, motivating g ro wing interes t in agents that iterativ ely impro ve their o wn strategies, modules or internal organization 9 – 15 . Meanwhile, the empir ical success of LLM-mediated optimization has outpaced our theoretical understanding of its limits. Existing w ork has focused pr imar ily on specific prompting, training or inference schemes 16 – 25 , but a general theoretical framew ork for unders tanding the fundamental limits of LLM-mediated optimization remains absent. Here we propose a h ypothesis about the limits of LLM- mediated optimization and, dra wing on linear response the- ory 26 , 27 , dev elop a framew ork to understand its applicability across different agent arc hitectures. W e treat an agent as produc- ing a strategy set tog ether with a utility function 𝐽 defined o v er that set, and study ho w 𝐽 chang es with respect to computational variables that the architecture can control. This viewpoint is inherently broad: depending on the task and agent structure, 𝐽 ma y denote score, accuracy , ranking quality or another op- erational measure of per f ormance, while the relev ant budget v ar iable B ma y denote beam width, searc h depth, sample count, model size, v erification effor t or other architecture-dependent resources. Within this formulation, we h ypothesize that a fix ed LLM-derived mapping cannot increase the perf ormance susceptibility of the strategy set with respect to budg et. When there is onl y a single budg et variable, this hypoth- esis can be equivalentl y e xpressed as a relative sensitivity 𝛼 that has an upper bound of one in the large-budg et regime. This h ypothesis is significant because it separates two ques- tions often conflated in discussions of agentic improv ement: whether LLMs help in finite-budget settings (empir ically , often y es 9 , 10 , 17 , 19 ) and whether a fixed LLM la y er can impro v e the asymptotic response of performance to additional computation. Our e xper iments address the latter ques tion and giv e a negativ e answ er in the fixed-arc hitecture setting. This pro vides a more precise wa y to reason about the design and optimization of high-compute pipelines and self-ev olving agents 4 , 28 – 31 . A self-ev olving agent cannot simpl y be under - stood as a sy stem that repeatedl y applies the same optimization la y er to its o wn outputs; rather , it must be a sy stem whose performance-relev ant components and computational channels chang e as complexity gro w s 7 , 10 , 12 , 13 , 15 . W e ar gue that, if the susceptibility h ypothesis holds generall y , nested architectures ma y be a necessary structural condition for ov ercoming the sus- ceptibility bound imposed b y a fix ed LLM la y er . More broadly , the frame work dev eloped here demonstrates that theoretical tools from statis tical phy sics can pro vide a pr iori constraints and predictiv e structure in the design of comple x agentic sy s- tems 27 – 32 . Results A theory of LLM inf ormation susceptibility Consider a base strategy set P B generated under a compu- tational budget B to maximize a utility function 𝐽 ( P B ) (see Fig. 1 , r ight). As the computational resources increase with- out bound, 𝐽 ( P B →∞ ) approaches its optimal value 𝐽 ∞ . N ow introduce a fix ed LLM that reads the base strategy set P B and outputs a derived s trategy set P ′ B . W e h ypothesize that, when computational resources are sufficientl y larg e, the performance susceptibility of P ′ B does not e x ceed that of P B : lim B →∞ 𝜕 𝐽 ( P B ) 𝜕 B ≥ lim B →∞ 𝜕 𝐽 ( P ′ B ) 𝜕 B , (1) where ⟨·⟩ denotes the a v erage o ver different random seeds or e xperimental repetitions. This is the central h ypothesis of 1 Preprint the theory: the susceptibility 𝜕 𝐽 / 𝜕 B under the LLM-derived strategy cannot e xceed that under the base strategy in the larg e- budget limit. The use of par tial der ivativ es is deliberate: 𝐽 ma y in general depend on multiple budg et v ar iables, and this f ormulation pro vides the basis f or the multi-v ariable gener - alization dev eloped below . As a hypothesis, equation ( 1 ) is empirically testable and carr ies concrete implications for ag ent design: it implies that fixed LLM lay ers cannot impro v e the asymptotic scaling trajectory of the base strategy . Impor tantly , the asymptotic regime sets in at practically rele vant budget lev els: as sho wn in Fig. 3 , the relativ e sensitivity 𝛼 defined in equation ( 2 ) crosses belo w 1 at 𝑘 ∼ 12 independent samples, after which the susceptibility bound is already operativ e. This rapid onset means the bound is not merel y a theoretical limit but a constraint that go verns real-w orld ag ent per formance. The intuition behind this claim rests on tw o arguments. Firs t, as B → ∞ , the performance 𝐽 ( P B ) con v erg es tow ard the global optimum 𝐽 ∞ , so the residual impro v able gap 𝐽 ∞ − 𝐽 ( P B ) shrinks. Any mapping applied to P B , including the LLM, can only redistribute probability mass among strategies already present in or reachable from P B ; it cannot inject strategies that are not computable from the information contained in P B and the LLM’ s fixed parameters. Second, a fix ed LLM can be vie wed as a deterministic (or fix ed-distr ibution) channel with finite capacity 33 : it compresses the input s trategy set through a fix ed-dimensional representation, based on its context windo w and parameters, and outputs a derived set. When the base set already encodes near -optimal information at larg e B , the channel cannot amplify the marginal inf ormation content of additional budget. Since the mutual inf or mation between the der iv ed set and the optimal strategy cannot ex ceed that betw een the base set and the optimal strategy by data-processing- inequality reasoning 34 , the marginal return on budget cannot increase through the LLM intervention. This argument is not a f ormal proof, but it motivates wh y the bound 𝛼 ≤ 1 should hold g ener ically rather than being an artefact of specific tasks. Figure 1 sho ws representativ e results f or the T etris domain (see Methods f or full experimental details). The per f or mance of the base strategy set (beam search with depth-first back - tracking, hereafter DFS) increases monotonically with beam width, while the LLM-derived strategy set exhibits a consis- tently lo w er susceptibility across all fiv e Qwen-series models ranging from 7B to ∼ 200 B parameters. A linear fit yields an a v erage slope of 1.4 f or the base algor ithm versus 0.5 f or the LLM-derived strategies, indicating that the LLM transforms each unit increase in beam width into about one third the perf or - mance gain of the base algorithm. This pattern is remarkably consistent: all five models, despite their order-of-magnitude difference in parameter count, f all within the same narrow performance band at each beam width, sugg esting that the susceptibility bound is not merely a consequence of insufficient model capacity but reflects a structural proper ty of the fixed- LLM inter v ention. W e define the nor malized per f or mance gap as Δ ( B ) = 𝐽 ( P B ) − 𝐽 ( P ′ B ) / 𝐽 ( P B ) , where 𝐽 ( P B ) is the mean of the base per f ormance o v er budget lev els. The per -model breakdown of Δ ( B ) across all f our domains is sho wn in Extended Data Fig. 1 and Extended Data Fig. 2 , confir ming that this pattern holds at the lev el of individual models. When the utility function 𝐽 depends on a single budg et variable B , the hypothesis can equivalentl y be expressed in terms of a relative sensitivity : 𝛼 ( B ) = 𝑑𝐽 ( P ′ B ) 𝑑𝐽 ( P B ) = 𝜕 𝐽 ( P ′ B ) / 𝜕 B ⟨ 𝜕 𝐽 ( P B ) / 𝜕 B ⟩ ≤ 1 ( B → ∞) . (2) Here 𝛼 ( B ) admits a natural interpretation: computational re- sources increase the mutual inf or mation betw een the strategy set and the optimum, while the fixed LLM c hannel cannot am- plify this inf ormation gain (b y the data-processing inequality), so that 𝛼 ≤ 1 when computational resources are sufficientl y larg e. Robustness of the suscep tibility bound A natural concern is whether the observ ed susceptibility g ap is an ar tefact of specific prompt engineering choices or re ward function design. W e tested both sy stematicall y in the T etris domain (Fig. 2 ). Four prompt variants were e v aluated: minimal (JSON-only output), s tandard (full analy sis), chain-of-thought (5-step reasoning) and e xpert (domain-specific strategy). All v ar iants e xhibit the same qualitativ e beha viour: the susceptibil- ity of the LLM-deriv ed strategy does not e x ceed that of the base strategy (Fig. 2 a). The obser vation that the minimal prompt, which pro vides the least guidance to the LLM, nearl y matches the DFS baseline implies that the gap arises from active repro- cessing rather than a passiv e inf ormation bottleneck. Three distinct re ward functions like wise show q ualitative in variance: in all cases the DFS baseline outper f or ms the LLM-der iv ed strategy and the g ap g ro ws with budg et (Fig. 2 b), confirming that the susceptibility bound is a structural property of the fix ed- LLM inter v ention, independent of prompt design or rew ard signal. Empirical c haracterization of the sufficiency condition The theory predicts that the susceptibility bound holds when computational resources are “sufficiently lar g e”, but does not specify the threshold a pr iori. T o characterize this transition empirically , w e designed an e xper iment using 60 mathematics problems from AIME 2024 and 2025 35 , 36 . In this domain the performance depends on three variables: 𝐽 = 𝐽 ( 𝑘 , B gen , B sel ) , where 𝑘 is the number of independent solution attempts, B gen is the generator model size and B sel is the selector model size. A g enerator LLM of size B gen produces 𝑘 independent solution attempts, and the base strategy applies ma jority v ote 17 . A fixed selector LLM of size B sel then reads the candidate answers and selects one, forming the derived strategy set P ′ B . This generate-then-select arc hitecture has been widely adopted in competitiv e programming 37 , mathematical reasoning 38 , 39 and scientific disco v ery 12 , 13 . T o isolate the effect of the sample budget 𝑘 , we a v erage o v er all five selector model sizes B sel and all fiv e g enerator model sizes B gen . This yields an av erage sensitivity ¯ 𝛼 ( 𝑘 ) = ⟨ 𝛼 ( B gen , B sel ; 𝑘 ) ⟩ B gen , B sel that character izes how the relativ e advantag e of the LLM selector ev olv es as the base strategy aggregates more samples. Figure 3 show s ¯ 𝛼 ( 𝑘 ) as a function of 𝑘 . At low 𝑘 ( ≤ 5 ), the selector LLM could outperform ma jor ity v ote ( ¯ 𝛼 > 1 ), reflecting the regime in which the LLM’ s wor ld know ledge and reasoning pro vide a g enuine advantag e ov er a sparse vote distribution. As 𝑘 increases, ¯ 𝛼 crosses belo w 1 and continues to 2 Preprint 1 2 4 8 16 32 C o m p u t a t i o n a l b u d g e t B ( b e a m w i d t h ) 0 2 4 6 8 10 12 P e r f o r m a n c e J ( l i n e s c l e a r e d ) P B LLM P 0 B J ( P 0 B ) Derived J ( P B ) Base DFS fit LLM avg fit P B ( D F S ) P 0 B ( 7 B ) P 0 B ( 1 4 B ) P 0 B ( 3 2 B ) P 0 B ( 7 2 B ) P 0 B ( Q w e n 3 ) Fig. 1 | Frame wor k and r epresentativ e results. Performance 𝐽 (lines cleared) v ersus computational budg et B (beam width) in the T etris domain f or the base algorithm (DFS, blue circles) and LLM-der ived s trategies (red markers; fiv e Qwen models: 7B, 14B, 32B, 72B and Qwen3-Max). Dashed lines sho w linear fits f or DFS and the LLM a v erage. Error bars indicate the standard error of the mean across 40 random seeds. The schematic on the right illustrates the tw o ev aluation paths: the base strategy set P B is e valuated directl y b y the utility function 𝐽 (base path, blue), or first processed b y a fix ed LLM to produce a derived set P ′ B (derived path, red). 1 2 4 8 16 32 B ( b e a m w i d t h ) 2 4 6 8 10 12 J ( l i n e s c l e a r e d ) a DFS (base) LLM (minimal) LLM (chain-of -thought) LLM (expert) LLM (standard) 1 2 4 8 16 32 B ( b e a m w i d t h ) 2 4 6 8 10 12 J ( l i n e s c l e a r e d ) b DFS (aggressive) LLM (aggressive) DFS (conservative) LLM (conservative) DFS (default) LLM (default) Fig. 2 | Robustness of the suscep tibility bound. a , Four prompt v ar iants compared agains t the DFS baseline in the T etris domain (Qw en-32B). The minimal prompt nearl y matches DFS at high B , while more elaborativ e prompts amplify the gap. b , Three re ward functions o ver laid f or both DFS (grey shades) and LLM (red shades, Qw en-32B). The susceptibility bound holds across all prompt and rew ard configurations. decline, marking the onset of the large-budg et regime in which ma jor ity v ote becomes statisticall y robus t and the fix ed selector can no longer improv e upon it. This crosso v er 40 pro vides an empirical operationalization of “sufficiently larg e ”: where the base strategy’ s aggregation of diverse samples begins to dominate the LLM’ s judgement. Cross-domain v alidation T o test the univ ersality of the h ypothesis, w e conducted e xperiments across four task domains that differ subs tantially in their structure and the role of LLM know ledge: T etris (combinatorial game-pla ying), 0/1 Knapsack 41 (combinatorial optimization), w orld-kno wledg e Ranking (factual recall under noise) and AIME mathematics (multi-step reasoning). Full e xperimental configurations are provided in Methods; results are sho wn in Fig. 4 . A cross all domains, the base strategy set’ s perf ormance increases monotonically with computational budg et, while the LLM-derived strategy set ’ s susceptibility is generall y not larg er, validating equation ( 1 ). The Ranking domain is par ticularl y instructiv e: at low budg ets, the LLM significantly outperf or ms the noisy algor ithmic baseline because it can draw on wor ld 3 Preprint 3 5 9 15 17 19 21 k ( n u m b e r o f s a m p l e s ) 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 α ( k ) α = 1 α ( k ) ( l i n e a r f i t ) Fig. 3 | T ransition of the r elative sensitivity 𝛼 . A verag e 𝛼 v ersus the number of samples 𝑘 . For each 𝑘 , 𝛼 is estimated by fitting 𝐽 agent = 𝛼 · 𝐽 MV + 𝛽 across fiv e generator model sizes, where 𝐽 MV is the majority-v ote accuracy , 𝐽 agent is the LLM-selector accuracy and 𝛽 is the regression intercept (see Methods). As 𝑘 increases, 𝛼 decreases and f alls belo w 1 around 𝑘 ∼ 12 , marking the onset of the lar ge-budg et regime where the susceptibility bound takes effect. kno w ledge (f or e xample, identifying China as more populous than Japan regardless of the noisy score estimate). Ho we v er , as the signal-to-noise ratio increases, the algorithmic ranking con v erg es to the ground truth and the LLM advantag e v anishes, consistent with the h ypothesis ’ s prediction that the susceptibility advantag e of the base strategy dominates at large budg et. This pattern, g reater LLM adv antag e at lo w budg et and greater algorithmic advantag e at high budg et, is precisel y the signature predicted b y the theory and is observ ed across all f our domains. These results underscore that the utility function 𝐽 is fle xible and task -dependent: it ma y represent game score, solution qual- ity , ranking performance or answ er accuracy , depending on the domain. Like wise, B should be inter preted as the controllable budg et associated with the underl ying ag ent. The Knapsac k do- main deserves particular comment: the performance gap Δ ( B ) is near ly zero across all budget lev els and model sizes (Extended Data Fig. 1 ). This is consistent with the theor y ( 𝛼 ≤ 1 ) but does not e xhibit the dramatic separation seen in T etris. The lik ely e xplanation is that the LLM acts appro ximately as an identity mapping in this domain: because the beam-search candidates are already sorted by v alue density and the packing s tructure is opaque to the LLM without e xplicit combinatorial reasoning, the model larg ely def ers to the algor ithmic ranking rather than reprocessing it. This “pass-through” regime is similar to the minimal prompt regime in T etris and represents a qualitativ ely different manif estation of the susceptibility bound, one in which the LLM neither helps nor hur ts, because it recognizes the limits of its o wn inter vention. The empir ical e vidence theref ore supports a general s tatement: the h ypothesis applies whenev er one can define a strategy set, a utility function o v er that set and a meaningful computational variable with respect to which susceptibility is measured. Generality : 𝐽 as a multi-variable utility function The e xper iments also clar ify the scope of the frame w ork. The basic f or mulation in equation ( 1 ) concerns a fix ed derivation mapping responsiv e to a single effectiv e budg et v ar iable. More generall y , the utility function 𝐽 depends on all architectural budget variables: 𝐽 = 𝐽 ( B 1 , B 2 , . . . , B 𝑛 ) . By analogy with linear response theory 26 , the gradient ∇ B 𝐽 is the susceptibility v ector; each component 𝜕 𝐽 / 𝜕 B 𝑖 measures ho w efficiently one budget c hannel con v er ts additional compute into per f or mance. Equation ( 2 ) is the 𝑛 = 1 special case in which a single budget variable controls the entire sy stem. When the architecture is extended so that additional com- putational v ar iables become rele vant, the utility function can be cor respondingly generalized. If we wr ite 𝐽 f or the seed- a v eraged deriv ed-strategy performance and 𝐽 base f or that of the base strategy , both as deterministic functions of the budget variables, the generalized total sensitivity f ollo ws b y summing o v er all budg et channels that co-v ar y with a ref erence budget B ref : 𝛼 total = 𝑛 𝑖 = 1 𝜕 𝐽 / 𝜕 B 𝑖 𝜕 𝐽 base / 𝜕 B ref · 𝑑 B 𝑖 𝑑 B ref . (3) As a concrete ex ample, in the AIME domain, if the selector LLM is allow ed to v ary with the generator LLM, then the utility of the derived strategy set becomes 𝐽 ( P ′ B gen , B sel ) . Here the results are a verag ed ov er large v alues of 𝑘 ( 𝑘 ∈ { 15 , 17 , 19 , 21 } ), which is theref ore not treated as a co-v arying budget c hannel. Setting 𝑛 = 2 , B 1 = B gen , B 2 = B sel and B ref = B gen , the relativ e sensitivity reduces to 𝛼 ( B gen , B sel ) = 𝜕 𝐽 ( P ′ B gen , B sel ) / 𝜕 B gen 𝜕 𝐽 ( P B gen ) / 𝜕 B gen + 𝜕 𝐽 ( P ′ B gen , B sel ) / 𝜕 B sel 𝜕 𝐽 ( P B gen ) / 𝜕 B gen · 𝑑 B sel 𝑑 B gen . (4) The first term on the right-hand side is the fixed-arc hitecture contribution constrained b y the h ypothesis ( 𝛼 ≤ 1 ), while the second ter m appears only when the architecture itself is allow ed to vary with budget. Here 𝑑 B sel / 𝑑 B gen is the rate at which the selector’ s budget c hanges when the generator’ s budget is increased: it equals zero in the fix ed-selector configuration and one when generator and selector are co-scaled. Note that equation ( 3 ) has a co v ar iant-contra variant structure: the susceptibility vector 𝜕 𝐽 / 𝜕 B 𝑖 characterizes the local g eome- try of the per f or mance landscape (par tial derivativ es hold other budg et variables fixed), while the scaling protocol 𝑑 B 𝑖 / 𝑑 B ref is a design c hoice specifying ho w budget c hannels co-v ary . Their contraction yields the scalar 𝛼 total , which depends on both the landscape and the chosen scaling path. This viewpoint re v eals three distinct coupling regimes (Fig. 5 ). (i) Decoupled ( 𝑑 B sel / 𝑑 B ref = 0 ): each budg et chan- nel operates independentl y , and the h ypothesis 𝛼 ≤ 1 applies to each channel separately ; this is the regime descr ibed b y equation ( 2 ). (ii) N eg ativ e coupling : In this regime, co-scaling the selector with the generator reduces the marginal return of additional budg et, analogous to Le Chatelier’ s principle 42 , so that the total slope 𝛼 total < 𝛼 gen ≤ 1 falls belo w that of the fix ed-selector cur v e, where 𝛼 gen denotes the first term on the right-hand side of equation ( 4 ), the contribution from the 4 Preprint 1 2 4 8 16 32 B ( b e a m w i d t h ) 2 4 6 8 10 J (a) T etris (lines cleared) J ( P B ) J ( P 0 B ) 1 2 4 8 16 32 64 B ( b e a m w i d t h ) 1550 1560 1570 1580 1590 (b) 0/1 Knapsack (total value) J ( P B ) J ( P 0 B ) 1 2 4 8 16 32 64 128 B ( S N R ) 0.5 0.6 0.7 0.8 0.9 1.0 J (c) R anking (accuracy) J ( P B ) J ( P 0 B ) 7B 14B 32B 72B Qwen3 B ( m o d e l s i z e ) 0.10 0.15 0.20 0.25 (d) AIME Math (accuracy) J ( P B ) J ( P 0 B ) Fig. 4 | Cross-domain v alidation. Performance 𝐽 v ersus computational budget B f or the base strategy set (blue circles) and the LLM-derived strategy set (red squares) across f our domains: T etris, Knapsack, Ranking and AIME mathematics. In the AIME domain, the deriv ed strategy set a verag es ov er all five selector models and o v er 𝑘 ∈ { 15 , 17 , 19 , 21 } . generator c hannel alone (Fig. 5 b). This occurs when 𝜕 𝐽 / 𝜕 B sel and 𝑑 B sel / 𝑑 B ref ha v e opposite signs, so that their product contributes a negativ e term to 𝛼 total . (iii) P ositiv e coupling : co-scaling increases the mar ginal return, so that 𝛼 total can e x- ceed 1 (Fig. 5 c). This occurs when a strong er selector genuinel y complements a strong er generator , as demons trated empirically in the nested AIME configuration (equation ( 4 ) and F ig. 6 ). The sign of the inter-la yer coupling can be estimated em- pirically from ho w the utility function chang es with different budget combinations: positiv e coupling indicates that increas- ing the g enerator’ s capability amplifies the marginal return of the selector, and vice v ersa. When the coupling is positiv e, co-scaling is beneficial and a nes ted architecture is pref er red; when it is near zero or negativ e, independent scaling of in- dividual components may be more efficient. This pro vides a concrete, measurable design cr iterion: before committing to a nested ag ent architecture, e valuate 𝛼 total from a small gr id of budget combinations and chec k whether co-scaling improv es the marginal return. Figure 6 illustrates this in the AIME domain: w e compare a “nested” configuration, in which the g enerator and selector are the same model and thus co-scale, agains t “fixed” configura- tions, in which the selector is held cons tant while the generator varies. The nested cur v e intersects each fixed-selector curve at the model size of the respective fix ed selector, since the tw o configurations coincide at that point. Cr ucially , the nested curve can e x ceed an y individual fix ed-selector curve in the lar ge- generator regime, demonstrating that co-scaling arc hitectural components opens a response c hannel that is not a v ailable to the fix ed-lay er configuration. The fix ed-architecture hypothesis applies to each individual fixed-selector cur v e, but does not constrain the nes ted curve, which can e x ceed the en v elope of the fix ed-selector famil y and thereby e xplore a fundamentally different region of the architectural parameter space. Discussion A theory of LLM inf or mation susceptibility addresses a question that is increasingl y pressing as LLM-based agents are deplo yed in high-compute settings: does inserting a fix ed LLM la y er into an optimization pipeline improv e ho w efficiently additional computation is con v er ted into per f ormance? Our results give a neg ativ e answ er for fixed architectures and a conditionally positiv e answer f or nested, co-scaling ones. This finding has a natural inter pretation in ter ms of the susceptibility frame w ork. The utility function 𝐽 is not defined independently of arc hitecture: the structure of the ag ent deter - mines which budg et variables are a vailable, ho w the y couple to one another and which response channels contribute to per - f or mance 26 – 30 , 43 . The generalized susceptibility (eq uation ( 3 )) makes this dependence explicit: the contraction of the sus- ceptibility v ector 𝜕 𝐽 / 𝜕 B 𝑖 with the scaling protocol 𝑑 B 𝑖 / 𝑑 B ref determines whether co-scaling helps or hur ts (Fig. 5 ). If the agent structure is held fixed and onl y the budget along one response c hannel is increased, then LLM intervention can impro v e constants or finite-budget beha viour , but it does not increase the large-budg et susceptibility . By contrast, nesting chang es the relationship between 𝐽 and its budget variables b y allo wing the capability of one component to scale with the comple xity induced b y another , a regime characterized b y 5 Preprint B r e f Gen Sel B g e n B s e l f i x e d J a 2 4 6 8 10 B r e f 0 10 20 30 40 50 J B r e f Gen Sel B g e n B s e l − J b 2 4 6 8 10 B r e f 0 10 20 30 40 50 J B r e f Gen Sel B g e n B s e l + J c 2 4 6 8 10 B r e f 0 10 20 30 40 50 J Fig. 5 | Inter-la y er coupling regimes. Each panel sho ws an architecture diagram (top) and illus tration of 𝐽 v ersus B ref (bottom). Faded blue lines represent three fixed-selector configurations; solid coloured lines sho w the nes ted (co-scaled) configuration. Dots mark intersection points where configurations coincide. a , Decoupled: only the g enerator scales with B ref ; the selector remains fixed. The nested line coincides with one of the fix ed lines. b , Neg ative coupling: both components scale, but co-scaling reduces marginal return ( 𝛼 total < 1 ). The nested line falls belo w the fix ed line. c , Positiv e coupling: co-scaling amplifies marginal return ( 𝛼 total can e x ceed 1). The nested line e xceeds all fix ed lines, opening a response channel una v ailable to fixed arc hitectures. 7B 14B 32B 72B Qwen3 Generator model size 0.075 0.100 0.125 0.150 0.175 0.200 0.225 0.250 J ® k ( a c c u r a c y ) MV (each model) Agent (nested derived) Agent (sel=7B) Agent (sel=14B) Agent (sel=32B) Agent (sel=72B) Agent (sel=Qwen3) Fig. 6 | Nested v ersus fixed ar chitectures in the AIME domain. Accuracy 𝐽 (a verag ed ov er 𝑘 ∈ { 15 , 17 , 19 , 21 } ) v ersus model size f or the nested derived strategy set (generator and selector co-scaled) and fixed derived strategy sets (fixed selector , varying generator). The curves intersect at the model size of the respective fix ed selector , showing that co-scaling arc hitectural components can ex ceed the susceptibility bound. 6 Preprint positiv e inter -lay er coupling. This perspective is consistent with the potential-landscape analy sis of Song et al. 31 , which sho ws that within a fixed LLM-driven ag ent, optimization is constrained b y an intr insic landscape. Our results complement that picture at the sy stem lev el: repeated optimization b y a fixed la y er is fundamentally limited both b y internal model structure and b y e xter nal response structure. These findings car ry practical implications f or agent design. Firs t, when the targ et application operates in a large-budg et regime, in v esting computation in the base s trategy-g eneration process, like s tronger search, better proposal generation or more reliable v erification, ma y be more effective than rel ying on a fix ed LLM wrapper to amplify gains 28 – 30 , 40 , 43 . Second, static LLM selection modules are most useful in lo w- or inter mediate- budget regimes, where w orld know ledge and heur istic com- pression still provide noticeable impro v ements 9 , 10 , 17 . Third, if the goal is to build sy stems capable of open-ended im- pro v ement, designers should allocate budget so that g enerator, selector , verifier , memory and tool-use components can co- scale 4 , 7 , 13 , 15 , 30 , 44 , 45 . More broadl y , the susceptibility-based vie wpoint dev eloped here suggests a q uantitativ e language f or comparing ag ent arc hitectures: rather than asking onl y whether an LLM helps, one can ask which architectural variables ap- pear in 𝐽 , how those variables couple through the scaling protocol and which susceptibilities dominate in the regime of interest 30 , 32 . Be y ond these design implications, the results bear directl y on a fundamental ques tion in AI: whether LLMs can ac hiev e open-ended self-e v olution 11 , 46 , 47 (see Extended Data Fig. 3 f or a detailed phenomenological model). Consider a scenar io in which an LLM attempts to impro v e its o wn strategies b y using itself as the optimization la yer . If the LLM mediation cannot increase asymptotic susceptibility ( 𝛼 ≤ 1 ), then self- guided impro v ement is e xpected to saturate once the model’ s capability e xceeds a threshold, because the fix ed LLM la y er cannot increase the rate at which per f ormance responds to additional computation; the feedbac k loop of self-impro v ement is inherently bounded. A related limitation has been obser v ed in unsupervised reinforcement learning, where initial training gains are f ollo w ed by collapse once the self-g enerated rew ard signal diver g es from the true objectiv e at sufficient scale 48 . Con v ersely , if a nes ted architecture enables 𝛼 total > 1 , the LLM can alter its own strategy dis tribution in a wa y that increases marginal return: as the LLM’ s capability g ro ws, its ability to guide its o wn improv ement strengthens in turn, potentially creating a positiv e f eedback loop. Figure 6 provides empirical evidence f or this logic: the nested configuration ’ s accuracy is approaching and poised to e x ceed the ma jority-v ote baseline, indicating that the LLM’ s ability to reshape its o wn dis tribution through nested co-scaling is near ing a cr itical crosso v er . In the cur rent e xper iments, the nested cur v e for Qw en3-Max is close to but has not y et crossed this threshold. Conting ent on the susceptibility hypothesis holding, this sugg ests that nested, co-scaling architectures are not merely sufficient f or ex ceeding the susceptibility bound, but cons titute a necessary structural condition f or open-ended self-ev olution: if fix ed architectures cannot achiev e 𝛼 > 1 , only architectures whose components co-scale can sustain unbounded impro vement. Sev eral directions for future w ork emer ge naturally from this study . First, the theor y is stated as an empir ical h ypothesis supported by experiments; dev eloping a formal proof would place the bound on fir mer theoretical ground. Second, the f our domains tested, though structurally div erse, do not co ver settings with v er y long hor izons, multi-agent interaction or continuous action spaces, where the relationship between bud- get and perf or mance ma y differ qualitativ ely ; e xploring these settings w ould clar ify the boundar y conditions of the frame- w ork. Third, the framew ork sugges ts a practical engineer ing methodology: b y measuring the susceptibility of individual architectural la y ers and combining these measurements with the kno wn compositional structure of the architecture, one could in principle, if the inter -la y er coupling s tructure is kno wn, reconstruct the full utility function 𝐽 across the entire budg et space; this w ould reduce sys tem-le v el per f ormance prediction from costl y end-to-end ev aluation to composable single-la y er characterizations, offering more efficient guidance f or engi- neering design. Finall y , the nested-architecture experiments demonstrate that co-scaling can e xceed the susceptibility bound, but do not y et characterize the rate at whic h it does so; deriving a quantitativ e scaling law f or nested susceptibility is perhaps the most important open question, as it w ould pro vide concrete guidance f or allocating compute across co-scaling components. Be y ond these future directions, the frame w ork offers a con- crete criter ion for e valuating when LLM intervention is w or th the cost: compute the sensitivity 𝛼 in the targ et budget regime. If 𝛼 < 1 , the LLM lay er is consuming resources without pro- portionally improving the scaling trajectory , and the design should either mov e to a nested architecture or redirect com- putation to the base strategy . This criter ion is measurable, domain-agnostic and complementary to standard metrics such as absolute accuracy or win rate that do not dis tinguish between constant offsets and scaling impro v ements. More generall y , the susceptibility-based approac h demonstrates that tools from statis tical ph ysics can provide a predictiv e frame w ork f or the study of AI systems, one that constrains design choices be- y ond post-hoc rationalization of empirical results. Among its concrete, h ypothesis-dependent predictions is that open-ended self-ev olution ma y require nested co-scaling, a claim that is already approaching tes tability with cur rent models. Methods Models and infrastructure All experiments use five Qw en-ser ies models: Qw en-2.5-7B- Instruct (7B), Qw en-2.5-14B-Instruct (14B), Qw en-2.5-32B- Instruct (32B), Qwen-2.5-72B-Ins truct (72B) and Qw en3-Max ( ∼ 200 B) 49 , 50 . Decoding parameters are specified per domain belo w . All domains use the same models and API, ensur ing that the obser v ed effects are not ar tefacts of a par ticular model. T e tris En vironment. A 10 × 20 T etris board with 6 pre-filled garbag e lines. Pieces are dra wn from 18 fix ed orientations (I, O, T , S, Z, L, J variants); no rotation is per f or med dur ing play . Each g ame lasts at mos t 50 steps. The utility function 𝐽 is the number of lines cleared. Base strategy P B . Beam search 51 with depth-first back - tracking and a lookahead depth of 3. A t each s tep, the algor ithm e xpands all legal placements to depth 3, ev aluates terminal states using a heuristic combining agg regate height, hole count, 7 Preprint bumpiness and lines cleared, and retains the top- B candidates (beam width). The top 3 placements are retur ned as candidates. Beam widths tested: B ∈ { 1 , 2 , 4 , 8 , 16 , 32 } . Deriv ed strategy P ′ B . Each LLM receiv es the cur rent board state (ASCII grid), the cur rent piece and the top 3 DFS candidates with their heur istic scores. The LLM selects one placement. Decoding: temperature = 0 . 1 , max tok ens = 500 , timeout = 15 s, max retr ies = 2. Prom pt variants. Four prompt designs were tested: minimal (JSON-only output f or mat), standard (full board analy sis), chain-of-thought (e xplicit 5-s tep reasoning) and e xper t (domain- specific T etr is strategy). The main text repor ts results using the standard prompt with the agg ressiv e rew ard function as the representativ e case sho wing the stronges t susceptibility gap; robus tness across all prompt and rew ard configurations is reported in Fig. 2 . Re ward functions. Three heur istic ev aluation functions w ere tested: agg ressiv e (prior itizing line clear ing with weight 5.0), conservativ e (pr ior itizing hole a voidance with weight 3.0) and def ault (balanced w eights). The qualitativ e patter n of the susceptibility bound is in variant across all three. Statistics. 40 independent random seeds per (model, B ) pair . Er ror bars in Fig. 1 are standard errors of the mean o v er seeds. AIME mathematics Problem set. 60 problems from AIME 2024 (30 problems) and AIME 2025 (30 problems). Each answ er is an integer in [ 0 , 999 ] . Base strategy P B . For each problem, a generator LLM of size B gen produces 𝑘 independent solution attempts at tem- perature 0.7 (max tok ens = 1 , 500 ). The base s trategy applies majority v ote 17 , 52 : answ ers are grouped b y approximate eq ual- ity ( | 𝑎 − 𝑏 | < 0 . 5 ) and the most common group is selected, with random tie-breaking. Here 𝑘 serves as a control parameter that tunes the s tatistical po wer of the ma jor ity v ote, while the generator model size B gen determines the quality of individual attempts. V alues tested: 𝑘 ∈ { 1 , 3 , 5 , 9 , 15 , 17 , 19 , 21 } ; all 21 samples are generated once and subsampled f or each 𝑘 . Deriv ed strategy P ′ B . A selector LLM of size B sel reads the 𝑘 candidate answ ers (deduplicated, without frequency counts) and selects one. The “fix ed deriv ed” configuration uses each of the fiv e models as a fix ed selector while varying the generator model; the repor ted ¯ 𝛼 ( 𝑘 ) a v erages o ver all fiv e generator sizes and all fiv e selectors. Agent selection uses temperature = 0 . 1 . The generation temperature of 0.7 ensures div ersity across the 𝑘 independent attempts, while the lo w selection temperature yields deterministic selector beha viour. The prompt does not strictly adhere to the official AIME f or mat; this is intentional, to minimize w ording differences between the ma jor ity-v ote and LLM-selector conditions. Estimation of 𝛼 . For each 𝑘 and each fix ed selector, five data points ( 𝐽 ( 𝑖 ) MV , 𝐽 ( 𝑖 ) agent ) are obtained, one per generator model size B gen . A linear model 𝐽 agent = 𝛼 · 𝐽 MV + 𝛽 is fitted using ordinary least squares. The slope 𝛼 and its standard error are reported. The a verag e ¯ 𝛼 ( 𝑘 ) sho wn in Fig. 3 is obtained b y first a v eraging the agent ’ s accuracy o v er all fiv e selectors f or each generator size, then fitting a single linear model across the five generator sizes. Statistics. The accuracy f or eac h (model, 𝑘 ) pair is the mean correctness o v er 60 problems. Er ror bars in F igs. 4 and 6 are binomial standard errors 𝑝 ( 1 − 𝑝 ) / 𝑛 , where 𝑝 is the observed accuracy and 𝑛 is the number of independent tr ials. For the majority-v ote baseline, 𝑛 = 60 × | 𝐾 | (60 problems times the number of 𝑘 values av eraged o v er); f or the LLM ag ent, 𝑛 = 60 × 5 × | 𝐾 | (additionally a v eraged o v er fiv e selector configurations). The binomial standard error is used because each problem outcome is a Ber noulli trial (cor rect or incorrect), and the standard error quantifies the uncertainty due to finite sample size. 0/1 Knapsack 50 items with weights 𝑤 𝑖 ∈ [ 1 , 50 ] and v alues 𝑣 𝑖 ∈ [ 1 , 100 ] , capacity = 0 . 3 Í 𝑤 𝑖 . The base s trategy is beam search o v er the item-selection tree, with items sorted b y value density 𝑣 𝑖 / 𝑤 𝑖 41 . The LLM receiv es the top 3 pac kings and selects one. 𝐽 = total value, B = beam width ∈ { 1 , 2 , 4 , 8 , 16 , 32 , 64 } . S tatistics: 50 problem instances; error bars are standard errors of the mean o v er instances. W orld-kno wledg e Ranking Four real-w orld ranking datasets (GDP of 15 countries, population of 15 countries, diameters of 8 planets, w eights of 12 animals). For eac h item, a noisy score es timate is g enerated: ˆ 𝑠 𝑖 = 𝑠 𝑖 + N ( 0 , 𝜎 / √ B ) , where 𝜎 is a dataset-specific baseline noise scale chosen so that the algor ithmic success rate is approximatel y 50% at B = 1 . The top 5 candidates b y noisy score are presented to the LLM, which selects the item it believ es ranks first using wor ld kno w ledge. 𝐽 = fraction correctly identifying the true rank -1 item, B = signal-to-noise ratio ∈ { 1 , 2 , 4 , 8 , 16 , 32 , 64 , 128 } . S tatistics: 100 noise seeds × 4 datasets × 8 SNR lev els. Er ror bars are standard errors of the mean o v er noise seeds and datasets. Data a v ailability All e xperimental data generated in this study are publicl y a vailable on HuggingFace at https: //huggingface.co/datasets/Nondegeneracy/LLM- Susceptibility- theory under the CC B Y 4.0 license. Code a vailability The code used to r un the e xper iments and produce all figures is av ailable on GitHub at https://github.com/ SonnyNondegeneracy/LLM- Susceptibility- theory un- der the MIT license. A ckno wledgements This w ork is suppor ted by N ational Natural Science Founda- tion of China under contract No. 12425505. Compe ting interests The author declares no competing interests. Ref erences [1] W ang, L. et al. A surve y on larg e language model based autonomous agents. F rontier s of Computer Science 18 , 186345 (2024). URL https://link.springer.com/ article/10.1007/s11704- 024- 40231- 1 . 8 Preprint [2] Xi, Z. et al. The r ise and potential of larg e language model based agents: A sur - v e y . Science China Information Sciences 68 , 121101 (2025). URL https://link.springer.com/ article/10.1007/s11432- 024- 4222- 0 . [3] Y ao, S. et al. R eact: Synergizing reasoning and acting in languag e models. In Proceedings of the Eleventh International Conf erence on Lear ning Representations (2023). URL https://openreview.net/forum?id= WE_vluYUL- X . [4] Schic k, T . et al. T oolf ormer: Language models can teach themsel v es to use tools. In Advances in N eur al Informa- tion Processing Systems , v ol. 36 (2023). URL https: //proceedings.neurips.cc/paper_files/paper/ 2023/hash/d842425e4bf79ba039352da0f658a906- Abstract- Conference.html . [5] Park, J. S. et al. Generative agents: Interactive simu- lacra of human behavior . In Proceedings of the 36th Annual A CM Symposium on User Int er face Softwar e and T echnology , UIST ’23 (Association for Comput- ing Machinery , Ne w Y ork, NY , US A, 2023). URL https://doi.org/10.1145/3586183.3606763 . [6] Bran, A. M. e t al. Chemcrow : Augmenting larg e-languag e models with chemistry tools (2023). URL https:// arxiv.org/abs/2304.05376 . 2304.05376 . [7] W ang, G. et al. V oy ager: An open-ended embodied agent with lar ge languag e models (2023). URL https: //arxiv.org/abs/2305.16291 . 2305.16291 . [8] Durante, Z. et al. Agent ai: Surve ying the hor izons of multimodal interaction (2024). URL https://arxiv. org/abs/2401.03568 . 2401.03568 . [9] Madaan, A. et al. Self-refine: Iterativ e refinement with self-feedbac k. In Advances in Neur al Inf ormation Processing Sys tems , vol. 36 (2023). URL https: //proceedings.neurips.cc/paper_files/paper/ 2023/hash/91edff07232fb1b55a505a9e9f6c0ff3- Abstract- Conference.html . [10] Shinn, N., Cassano, F ., Gopinath, A., Narasimhan, K. & Y ao, S. Refle xion: Language agents with v erbal reinf orcement learning. In Adv ances in N eural Inf or ma- tion Processing Systems , v ol. 36 (2023). URL https: //proceedings.neurips.cc/paper_files/paper/ 2023/hash/1b44b878bb782e6954cd888628510e90- Abstract- Conference.html . [11] Zelikman, E., W u, Y ., Mu, J. & Goodman, N . D. ST aR: Bootstrapping reasoning with reasoning. In Advances in N eural Inf or mation Processing Sy stems , v ol. 35 (2022). URL . [12] R omera-Paredes, B. et al. Mathematical disco v er ies from program search with larg e language models. Natur e 625 , 468–475 (2024). URL https://doi.org/10.1038/ s41586- 023- 06924- 6 . [13] Cui, C. et al. Alphaev olv e: A lear ning framew ork to disco v er no v el alphas in quantitativ e inv estment. In Pro- ceedings of the 2021 Int ernational Conf er ence on Manag e- ment of Data , SIGMOD ’21, 2208–2216 (Association f or Computing Machinery , Ne w Y ork, NY , US A, 2021). URL https://doi.org/10.1145/3448016.3457324 . [14] Liu, F . et al. Evolution of heuristics: T o wards efficient automatic algorithm design using large languag e model. In Pr oceedings of the 41st International Conf er ence on Mac hine Learning , v ol. 235 of PMLR , 32201–32223 (2024). URL https://proceedings.mlr.press/ v235/liu24bs.html . [15] Song, Z.- Y . et al. Iterated agent f or symbolic regression (2025). URL . 2510.08317 . [16] W ei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neur al Infor - mation Processing Sy stems , v ol. 35 (2022). URL https: //proceedings.neurips.cc/paper_files/paper/ 2022/hash/9d5609613524ecf4f15af0f7b31abca4- Abstract- Conference.html . [17] W ang, X. e t al. Self-consistency impro ves chain of thought reasoning in language models. In Proceedings of the Elevent h International Conf er ence on Lear ning Repr esentations (2023). URL https://openreview. net/forum?id=1PL1NIMMrw . [18] Ouy ang, L. e t al. T raining language mod- els to f ollo w instructions with human f eed- back. In Advances in Neur al Information Pro- cessing Syst ems , vol. 35 (2022). URL https: //proceedings.neurips.cc/paper_files/paper/ 2022/hash/b1efde53be364a73914f58805a001731- Abstract- Conference.html . [19] Y ao, S. et al. T ree of thoughts: Deliberate problem solving with larg e language models. In Advances in N eural Inf or - mation Processing Sy stems , v ol. 36 (2023). URL https: //proceedings.neurips.cc/paper_files/paper/ 2023/hash/271db9922b8d1f4dd7aaef84ed5ac703- Abstract- Conference.html . [20] W ang, L. et al. Plan-and-solv e prompting: Improving zero- shot chain-of-thought reasoning by larg e language models (2023). URL . 2305.04091 . [21] Chen, W ., Ma, X., W ang, X. & Cohen, W . W . Pro- gram of thoughts prompting: Disentangling compu- tation from reasoning for numerical reasoning tasks (2023). URL . 2211.12588 . [22] Gao, L. et al. P AL: Program-aided languag e mod- els. In Pr oceedings of the 40th International Con- f erence on Machine Learning , v ol. 202 of Proceed- ings of Mac hine Lear ning Researc h , 10764–10799 (PMLR, 2023). URL https://proceedings.mlr. press/v202/gao23f.html . 9 Preprint [23] Besta, M. et al. Graph of thoughts: Sol ving elaborate problems with large language models. Proceedings of the AAAI Confer ence on Artificial Int ellig ence 38 , 17682– 17690 (2024). URL https://ojs.aaai.org/index. php/AAAI/article/view/29720 . [24] OpenAI. OpenAI o1 sys tem card (2024). URL https: //arxiv.org/abs/2412.16720 . 2412.16720 . [25] DeepSeek -AI. DeepSeek -R1: Incentivizing reasoning capability in LLMs via reinf orcement lear ning (2025). URL . 2501. 12948 . [26] Kubo, R. Statistical-mec hanical theory of ir rev ersible processes. I. General theory and simple applications to magnetic and conduction problems. Journal of the Physical Society of Japan 12 , 570–586 (1957). URL https://doi.org/10.1143/JPSJ.12.570 . [27] De Nittis, G. & Lein, M. Linear response theory : an analytic-alg ebraic appr oach (Spring er , 2017). [28] Kaplan, J. et al. Scaling la ws f or neural language models (2020). URL . 2001.08361 . [29] Hoffmann, J. e t al. T raining compute-optimal large language models. In Adv ances in Neur al Informa- tion Processing Systems , v ol. 35 (2022). URL https: //arxiv.org/abs/2203.15556 . [30] Kim, Y . e t al. T o wards a science of scaling ag ent systems (2025). URL . 2512.08296 . [31] Song, Z.- Y ., Cao, Q.-H., xing Luo, M. & Zhu, H. X. Detailed balance in larg e language model-driven ag ents (2025). URL . 2512.10047 . [32] W olper t, D. H. & Macready , W . G. No free lunc h theorems f or optimization. IEEE tr ansactions on evolutionar y com- putation 1 , 67–82 (2002). URL https://ieeexplore. ieee.org/abstract/document/585893 . [33] Shannon, C. E. A mathematical theor y of communi- cation. The Bell Sys tem T echnical Journal 27 , 379– 423 (1948). URL https://ieeexplore.ieee.org/ document/6773024 . [34] Co v er , T . M. & Thomas, J. A. Elements of Inf orma- tion Theor y (Wile y-Interscience, Hoboken, NJ, 2006), 2 edn. URL https://onlinelibrary.wiley.com/ doi/book/10.1002/047174882X . [35] Hendryc ks, D. et al. Measuring mathematical problem sol ving with the math dataset (2021). URL https:// arxiv.org/abs/2103.03874 . 2103.03874 . [36] Hugging F ace H4. Aime 2024 dataset. https: //huggingface.co/datasets/HuggingFaceH4/ aime_2024 (2024). A ccessed: 2025-05-16. [37] Li, Y . et al. Competition-lev el code generation with AlphaCode. Science 378 , 1092–1097 (2022). URL https://arxiv.org/abs/2203.07814 . [38] Cobbe, K. e t al. T raining v er ifiers to solv e math w ord prob- lems (2021). URL 14168 . 2110.14168 . [39] Bro wn, B. et al. Larg e language monke ys: Scal- ing inf erence compute with repeated sampling (2024). URL . 2407. 21787 . [40] Hogg, T ., Huberman, B. A. & Williams, C. P . Phase transi- tions and the search problem. Artificial Int ellig ence 81 , 1– 15 (1996). URL https://www.sciencedirect.com/ science/article/pii/0004370295000445 . Fron- tiers in Problem Solving: Phase T ransitions and Com- ple xity . [41] Kellerer , H., Pfersc hy , U . & Pisinger , D. Knap- sac k Problems (Spr inger , Berlin, 2004). URL https://link.springer.com/book/10.1007/978- 3- 540- 24777- 7 . [42] Le Chatelier , H. L. Sur un ´ enonc ´ e g ´ en ´ eral des lois des ´ equilibres chimiq ues. Compt es rendus de l’ Acad ´ emie des sciences 99 , 786–789 (1884). URL https://gallica. bnf.fr/ark:/12148/bpt6k3055h/f786.item . [43] Snell, C., Lee, J., X u, K. & Kumar , A. Scaling llm test-time compute optimall y can be more effectiv e than scaling model parameters (2024). URL https://arxiv. org/abs/2408.03314 . 2408.03314 . [44] Hu, S., Lu, C. & Clune, J. A utomated design of ag entic sys tems (2025). URL 08435 . 2408.08435 . [45] Hosseini, A. et al. V -star: T raining v er ifiers f or self- taught reasoners (2024). URL abs/2402.06457 . 2402.06457 . [46] Good, I. J. Speculations concer ning the first ultraintelli- gent machine. In Advances in Comput ers , v ol. 6, 31–88 (A cademic Press, 1966). URL https://doi.org/10. 1016/S0065- 2458(08)60418- 0 . [47] Singh, A. et al. Bey ond human data: Scaling self-training f or problem-sol ving with language models. In Advances in N eural Inf ormation Pr ocessing Sy stems , vol. 37 (2024). URL . [48] He, B. et al. How f ar can unsupervised rl vr scale llm train- ing? (2026). URL 08660 . 2603.08660 . [49] T eam, Q. Qwen2.5 tec hnical repor t (2025). URL https: //arxiv.org/abs/2412.15115 . 2412.15115 . [50] Y ang, A. et al. Qw en3 technical repor t (2025). URL . 2505. 09388 . 10 Preprint [51] Russell, S. & Norvig, P . Artificial In- tellig ence: A Modern Approac h (Pearson, Hoboken, NJ, 2021), 4 edn. URL https: //www.pearson.com/en- us/subject- catalog/ p/artificial- intelligence- a- modern- approach/P200000003500/9780137505135 . [52] de Condorcet, M. J. A. N. d. C. Essai sur l’application de l’analyse ` a la pr obabilit ´ e des d ´ ecisions r endues ` a la pluralit ´ e des voix (Impr imer ie R o y ale, Paris, 1785). URL https://gallica.bnf.fr/ark: /12148/bpt6k417181 . R eprinted b y Chelsea, Ne w Y ork, 1972. 11 Preprint Extended Data 12 Preprint 1 2 4 8 16 32 B ( b e a m w i d t h ) 0.0 0.2 0.4 0.6 0.8 ∆ ( B ) (a) T etris 1 2 4 8 16 32 64 B ( b e a m w i d t h ) 0.010 0.005 0.000 0.005 0.010 0.015 (b) 0/1 Knapsack 1 2 4 8 16 32 64 128 B ( S N R ) 0.3 0.2 0.1 0.0 ∆ ( B ) (c) R anking 7B 14B 32B 72B Qwen3 B ( M o d e l s i z e ) 0.0 0.1 0.2 0.3 0.4 (d) AIME Math (fixed derive) Extended Data Fig. 1 | A verag ed performance g ap across domains. The nor malized performance gap Δ ( B ) = 𝐽 ( P B ) − 𝐽 ( P ′ B ) / 𝐽 ( P B ) , a verag ed ov er all five LLMs, as a function of computational budget B f or f our domains. Blue shading indicates the regime where the base algorithm outperforms the LLM-derived strategy ( Δ > 0 ); red shading indicates the opposite. In T etr is, Δ grow s monotonically . In Knapsac k, Δ is negligible. In Ranking, Δ transitions from negativ e (LLM advantag e at lo w SNR) to near zero. In AIME, Δ (a verag ed ov er 𝑘 ∈ { 15 , 17 , 19 , 21 } ) remains positiv e across model sizes. 13 Preprint 1 2 4 8 16 32 B ( b e a m w i d t h ) 0.00 0.25 0.50 0.75 1.00 ∆ ( B ) (a) T etris 7B 14B 32B 72B Qwen3 1 2 4 8 16 32 64 B ( b e a m w i d t h ) 0.01 0.00 0.01 0.02 (b) 0/1 Knapsack 7B 14B 32B 72B Qwen3 1 2 4 8 16 32 64 128 B ( S N R ) 0.4 0.2 0.0 ∆ ( B ) (c) R anking 7B 14B 32B 72B Qwen3 7B 14B 32B 72B Qwen3 B ( M o d e l s i z e ) 0.2 0.0 0.2 0.4 (d) AIME Math k = 3 k = 5 k = 9 k = 1 5 k = 2 1 Extended Data Fig. 2 | P er-model perf ormance gap acr oss domains. The nor malized performance g ap Δ ( B ) broken do wn by individual model size (7B through Qw en3-Max) for eac h domain. In T etris, 72B models show larg est g aps. In Knapsack, all models produce negligible gaps. In Ranking, all models conv erge from neg ativ e to near -zero Δ as SNR increases. In AIME, the gap v aries with both generator model size and number of samples 𝑘 , with larger 𝑘 showing an increasing tendency with model size. 14 Preprint 2 3 4 5 6 7 8 9 10 Data quality b ∗ a p 0 > l 0 : u n s t a b l e f i x e d p o i n t p ( b ) ( p i p e l i n e ) l ( b ) ( m o d e l ) 1 2 3 4 5 6 7 8 9 Data quality b ∗ b p 0 < l 0 : s t a b l e f i x e d p o i n t p ( b ) ( p i p e l i n e ) l ( b ) ( m o d e l ) 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 M o d e l c a p a b i l i t y b 2 1 0 1 2 d b / d r ∝ p ( b ) − l ( b ) Collapse Self -evolution 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 M o d e l c a p a b i l i t y b 2 1 0 1 2 d b / d r ∝ p ( b ) − l ( b ) Bounded improvement Bounded degradation Extended Data Fig. 3 | Illustration of the phenomenological theory of self-ev olution dynamics. T op row : data quality functions 𝑝 ( 𝑏 ) (pipeline, blue) and 𝑙 ( 𝑏 ) (model output, red) v ersus model capability 𝑏 . Bottom ro w : phase portrait 𝑑𝑏 / 𝑑𝑟 ∝ 𝑝 ( 𝑏 ) − 𝑙 ( 𝑏 ) , with arrow s indicating the flo w direction. Open circle: unstable fix ed point; filled circle: stable fix ed point. a , 𝑝 ′ ( 𝑏 ) > 𝑙 ′ ( 𝑏 ) : the fixed point is a repeller , giving rise to a collapse phase ( 𝑏 < 𝑏 ∗ ) and a self-e volution phase ( 𝑏 > 𝑏 ∗ ). b , 𝑝 ′ ( 𝑏 ) < 𝑙 ′ ( 𝑏 ) : the fixed point is an attractor; impro vement and degradation are both bounded. See Supplementar y Note 1 f or the full der ivation. 15 Preprint Supplementary Information Supplementary Note 1: Phenomenological theory of self- e v olution The self-e volution argument in the main text can be for - malized with a minimal dynamical model. Let 𝑏 denote the capability of a model, 𝑝 ( 𝑏 ) the quality of training data pro- duced by a data-g eneration pipeline constructed using a model of capability 𝑏 , and 𝑙 ( 𝑏 ) the quality of output generated directl y b y a model of capability 𝑏 . When the model is trained on its o wn pipeline-generated data, the capability e vol ves according to 𝑑𝑏 𝑑𝑟 = 𝜂 [ 𝑝 ( 𝑏 ) − 𝑙 ( 𝑏 ) ] , (S1) where 𝑟 is the cumulativ e training resource and 𝜂 > 0 is a learning-rate cons tant. The driving ter m 𝑝 ( 𝑏 ) − 𝑙 ( 𝑏 ) represents the gap betw een what the pipeline can produce and what the model currently outputs: when the pipeline g enerates higher - quality data than the model’s o wn output ( 𝑝 > 𝑙 ), training impro v es the model; when the pipeline produces lo wer -quality data ( 𝑝 < 𝑙 ), training degrades it. A fix ed point 𝑏 ∗ satisfies 𝑝 ( 𝑏 ∗ ) = 𝑙 ( 𝑏 ∗ ) : the pipeline output quality matc hes the model’ s own output, so training produces no net chang e in capability . The stability of this fix ed point is determined by the sign of 𝑝 ′ ( 𝑏 ∗ ) − 𝑙 ′ ( 𝑏 ∗ ) . Case 1: 𝑝 ′ ( 𝑏 ) > 𝑙 ′ ( 𝑏 ) (repeller). Since 𝑝 − 𝑙 is an increasing function of 𝑏 , the fixed point 𝑏 ∗ is unstable (Extended Data Fig. 3 a). For 𝑏 < 𝑏 ∗ , 𝑝 ( 𝑏 ) < 𝑙 ( 𝑏 ) and 𝑑𝑏 / 𝑑 𝑟 < 0 : the pipeline produces data of low er quality than the model’ s own output, so training degrades capability , which further widens the g ap (collapse phase with positive f eedback). For 𝑏 > 𝑏 ∗ , 𝑝 ( 𝑏 ) > 𝑙 ( 𝑏 ) and 𝑑𝑏 / 𝑑 𝑟 > 0 : the pipeline data quality e x ceeds the model’ s output, so training continuall y impro ves the model and the impro v ement accelerates as the gap widens (self-ev olution phase). The sy stem thus e xhibits a phase transition: whether the initial capability 𝑏 0 lies abov e or below the cr itical point 𝑏 ∗ determines whether the model undergoes unbounded self- ev olution or ir rev ersible collapse. Case 2: 𝑝 ′ ( 𝑏 ) < 𝑙 ′ ( 𝑏 ) (attractor). Since 𝑝 − 𝑙 is a decreasing function of 𝑏 , the fixed point 𝑏 ∗ is s table (Extended Data Fig. 3 b). For 𝑏 < 𝑏 ∗ , 𝑝 ( 𝑏 ) > 𝑙 ( 𝑏 ) and the model impro v es, but the impro v ement decelerates as 𝑏 approaches 𝑏 ∗ (bounded impro v ement). For 𝑏 > 𝑏 ∗ , 𝑝 ( 𝑏 ) < 𝑙 ( 𝑏 ) and the model degrades, but the degradation likewise decelerates (bounded degradation). In both cases the sy stem con v erg es to 𝑏 ∗ . There is no phase transition; training alwa ys produces a finite, bounded chang e in capability . Marginal case: 𝑝 ′ ( 𝑏 ) = 𝑙 ′ ( 𝑏 ) . When the tw o slopes are equal, 𝑝 ( 𝑏 ) − 𝑙 ( 𝑏 ) is a cons tant independent of 𝑏 . If this constant is positive, the system is in a global self-ev olution phase; if neg ativ e, it collapses globall y . No fix ed point e xists and no phase transition occurs. In the linear model this case is degenerate, as it requires tw o parallel lines whose fate is determined entirely b y the sign of the global offset. Connection to the susceptibility framew ork. In the frame- w ork de v eloped in the main te xt, the pipeline quality 𝑝 ( 𝑏 ) corresponds to the effective perf or mance of a nested arc hitec- ture in which a model of capability 𝑏 serves as both g enerator and selector , while 𝑙 ( 𝑏 ) corresponds to the per f ormance of the base strategy (e.g., majority v ote). The condition 𝑝 ′ ( 𝑏 ) > 𝑙 ′ ( 𝑏 ) is then equiv alent to the nested total sensitivity 𝛼 total > 1 (posi- tiv e coupling regime, equation ( 4 ) in the main text), whereas 𝑝 ′ ( 𝑏 ) < 𝑙 ′ ( 𝑏 ) corresponds to 𝛼 total < 1 (negativ e coupling or decoupled regime). Within the hypothesis frame w ork of the main te xt, the requirement of nested co-scaling to realize 𝛼 total > 1 can thus be restated dynamicall y: self-ev olution is possible only when the pipeline’ s data quality responds to model capability faster than the model’ s own output quality does. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment