LLM 정보 감수성 이론: 고예산 환경에서 고정 LLM의 한계와 중첩 구조의 가능성
본 논문은 대규모 언어 모델(LLM)을 최적화 모듈로 활용하는 에이전트 시스템에서, 계산 자원이 충분히 클 때 고정된 LLM이 전략 집합의 성능 감수성을 예산에 대해 향상시킬 수 없다는 ‘감수성 가설’을 제시한다. 다변량 효용 함수와 선형 응답 이론을 이용해 이 가설을 일반화하고, 다중 예산 채널이 공동 확장(co‑scaling)될 경우 경계 초과가 가능함을 보인다. 테트리스, 0/1 배낭, 순위 평가, AIME 수학 문제 등 네 분야와 1‑2…
저자: Zhuo-Yang Song, Hua Xing Zhu
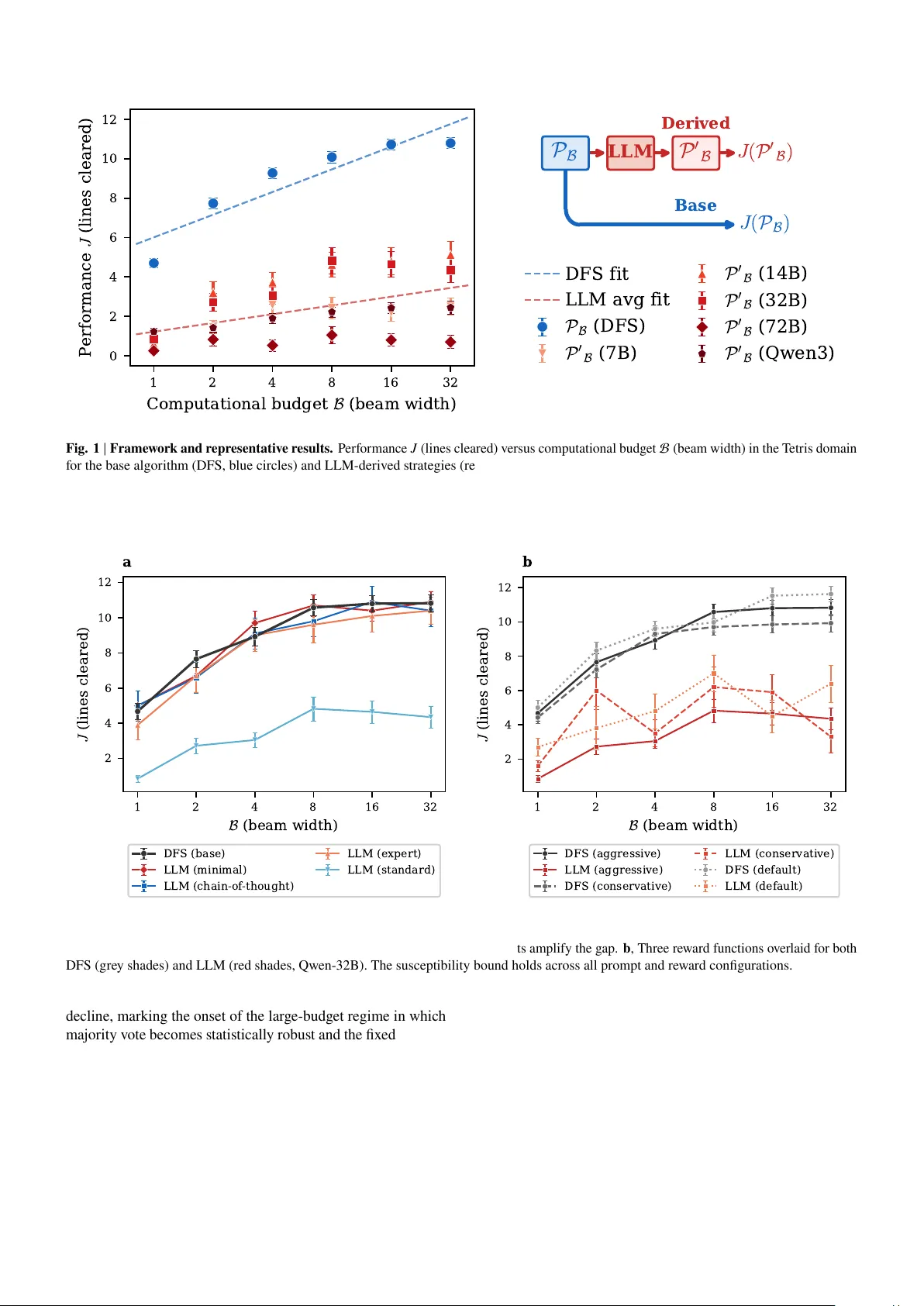
본 연구는 최근 에이전트 시스템에서 LLM을 최적화 모듈로 활용하는 사례가 급증함에 따라, 이러한 LLM‑중재 최적화가 근본적으로 어떤 한계에 묶이는지를 이론적으로 규명하고자 한다. 저자들은 “LLM 정보 감수성”이라는 개념을 정의하고, 핵심 가설인 **감수성 가설**을 제시한다. 이 가설은 “계산 자원이 충분히 클 때, 고정된 LLM이 전략 집합 P_B 를 변환해 만든 파생 전략 집합 P′_B 의 성능 감수성(∂J/∂B)은 원본 P_B 의 감수성을 초과하지 않는다”는 내용이다. 여기서 J는 전략 집합에 대한 효용(점수, 정확도 등)이며, B는 빔 폭, 샘플 수, 모델 크기 등 에이전트가 제어할 수 있는 계산 예산을 의미한다.
가설을 수식화하면
lim_{B→∞}⟨∂J(P_B)/∂B⟩ ≥ lim_{B→∞}⟨∂J(P′_B)/∂B⟩,
또는 단일 예산 변수 경우 상대 감수성 α(B)= (∂J(P′_B)/∂B)/(∂J(P_B)/∂B) ≤ 1 (B→∞) 로 표현된다. 이 식은 LLM이 고정 파라미터와 제한된 컨텍스트 창을 가진 ‘채널’로 작동한다는 데이터 처리 불등식에 기반한다. 즉, 파생 전략과 최적 전략 사이의 상호 정보는 원본 전략과 최적 전략 사이의 상호 정보를 초과할 수 없으며, 따라서 추가 예산이 가져오는 정보 이득을 LLM이 증폭시킬 수 없다는 논리다.
**실험 설계**
1. **도메인 및 모델**: 테트리스(조합 게임), 0/1 배낭(조합 최적화), 순위 평가(사실 회수 + 노이즈), AIME 수학 문제(다단계 추론) 네 가지 도메인. 모델은 Qwen‑3 시리즈(7B, 14B, 32B, 72B, 200B) 등 약 1‑2 오더 규모를 포함한다.
2. **베이스 전략**: 각 도메인마다 전통적인 탐색·검색 알고리즘(DFS, 빔 서치, 다수결 등)을 사용해 P_B 를 생성한다.
3. **LLM 파생 전략**: 고정된 LLM이 P_B 를 입력받아 재처리·재구성해 P′_B 를 만든다. 프롬프트는 최소형(JSON), 표준형, 체인‑오브‑쓰, 전문가형 네 종류를 테스트했다.
4. **평가 지표**: 효용 J는 도메인에 따라 라인 클리어 수, 정확도, 순위 점수 등으로 정의하고, 각 B 에 대해 평균값과 표준오차를 구했다.
**핵심 결과**
- **테트리스**: 빔 폭 B 가 증가함에 따라 베이스 DFS 전략은 선형에 가까운 상승을 보였으며, LLM 파생 전략은 전반적으로 낮은 기울기(≈0.5)와 α≈0.35 를 나타냈다. 모델 규모가 7B에서 200B까지 변해도 패턴은 일관적이었다.
- **프롬프트·보상 함수 강건성**: 최소형 프롬프트조차도 베이스와 거의 동일한 성능을 보였으며, 복잡한 프롬프트는 오히려 격차를 확대했다. 보상 함수(점수, 정확도, 순위 등)를 바꾸어도 LLM 파생 전략이 베이스를 초과하지 못하는 현상이 유지되었다.
- **AIME 수학**: 생성 LLM B_gen 과 선택 LLM B_sel 두 예산 변수를 도입해 k(샘플 수) 를 늘렸다. k≤5에서는 선택 LLM이 다수결을 능가해 α>1 이었지만, k≈12를 넘는 순간 α가 1 이하로 떨어져 대규모 샘플 집계가 LLM의 판단을 압도함을 확인했다. 이는 “충분히 큰” 예산이 실제로는 k≈12 정도에서 도달한다는 실증적 기준을 제공한다.
- **배낭 문제**: 베이스와 LLM 파생 전략 간 성능 차이가 거의 없으며, 이는 LLM이 입력 후보를 거의 그대로 전달하는 “패스‑스루” 현상으로 해석된다. 즉, LLM이 구조적 정보를 충분히 활용하지 못하는 경우에도 감수성 경계는 유지된다.
**다변량 확장**
효용 J를 J(B₁,…,B_n) 로 일반화하고, 각 예산 채널에 대한 감수성 벡터 ∇_B J 를 정의한다. 공동 확장(co‑scaling) 상황에서는 전체 상대 감수성 α_total = Σ_i (∂J/∂B_i)/(∂J_base/∂B_ref)·(dB_i/dB_ref) 로 계산한다. 실험에서는 생성‑선택 구조가 두 채널을 동시에 확장함으로써 α_total>1 인 경우가 관찰되었으며, 이는 고정 LLM만을 반복 적용하는 단순 자기‑향상 에이전트가 감수성 한계에 봉착한다는 이론적 주장과 일치한다.
**이론적·실용적 함의**
- 고정 LLM은 제한된 정보 처리 용량 때문에, 계산 예산이 충분히 클 때는 성능 향상의 한계점에 도달한다. 따라서 에이전트 설계자는 LLM을 삽입하기 전에 예산 규모와 기대 감수성을 평가해야 한다.
- 감수성 경계를 넘어서는 성능 향상을 원한다면, **중첩 구조**(예: 생성‑선택, 탐색‑검증, 도구‑피드백 등)와 **다중 예산 채널의 공동 확장**이 필요하다. 이는 LLM이 서로 다른 역할을 수행하면서 서로 보완적인 정보를 제공할 수 있기 때문이다.
- 통계 물리학의 선형 응답 이론을 AI 시스템에 적용함으로써, 사전 예측 가능한 설계 원칙을 도출할 수 있다. 이는 향후 오픈‑엔드 자기‑향상 에이전트, 자동화된 연구 도구, 복합 의사결정 시스템 등에 중요한 설계 가이드라인을 제공한다.
**결론**
논문은 “LLM 정보 감수성”이라는 새로운 이론적 프레임워크를 제시하고, 고정 LLM이 대규모 예산 상황에서 성능 감수성을 초과할 수 없다는 가설을 다변량 효용 함수와 실험적 검증을 통해 뒷받침한다. 또한, 중첩·공동 확장 구조가 이 한계를 극복할 수 있음을 보이며, 향후 에이전트 설계에서 구조적 다양성과 예산 채널의 동시 확장이 핵심 전략이 될 것임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기