LLM-Based Test Case Generation in DBMS through Monte Carlo Tree Search
Database Management Systems (DBMSs) are fundamental infrastructure for modern data-driven applications, where thorough testing with high-quality SQL test cases is essential for ensuring system reliability. Traditional approaches such as fuzzing can b…
Authors: Yujia Chen, Yingli Zhou, Fangyuan Zhang
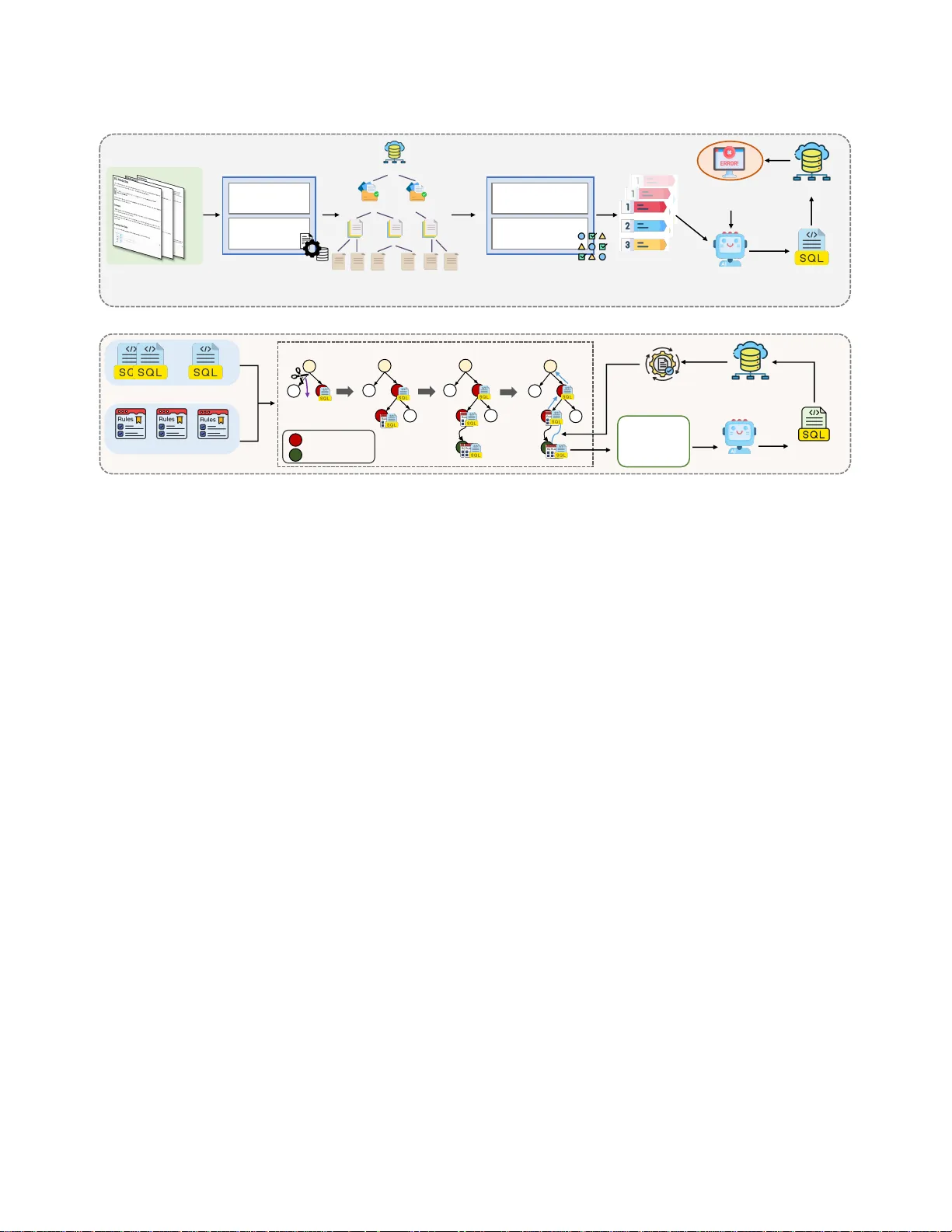
LLM-Based T est Case Generation in DBMS through Monte Carlo T ree Search Y ujia Chen Harbin Institute of T echnology , Shenzhen Shenzhen, China yujiachen@stu.hit.edu.cn Yingli Zhou The Chinese University of Hong K ong, Shenzhen Shenzhen, China yinglizhou@link.cuhk.edu.cn Fangyuan Zhang Huawei Hong K ong Research Center Hongkong, China zhang.fangyuan@huawei.com Cuiyun Gao ∗ Harbin Institute of T echnology , Shenzhen Shenzhen, China gaocuiyun@hit.edu.cn Abstract Database Management Systems (DBMSs) ar e fundamental infras- tructure for modern data-driven applications, where thorough test- ing with high-quality SQL test cases is essential for ensuring system reliability . Traditional approaches such as fuzzing can b e eective for specic DBMSs, but adapting them to dierent proprietary di- alects requires substantial manual eort. Large Language Models (LLMs) present promising opp ortunities for automated SQL test generation, but face critical challenges in industrial environments. First, lightweight models are widely used in organizations due to security and privacy constraints, but they struggle to generate syntactically valid queries for proprietary SQL dialects. Second, LLM-generated queries are often semantically similar and exercise only shallow execution paths, thereby quickly reaching a coverage plateau. T o address these challenges, we pr opose MIST , an LL M -based test case generat I on framework for DBM S through Monte Carlo T ree search. MIST consists of two stages: Feature-Guided Error- Driven T est Case Synthetization , which constructs a hierarchical feature tree and uses error feedback to guide LLM generation, aim- ing to produce syntactically valid and semantically diverse queries for dierent DBMS dialects, and Monte Carlo Tree Sear ch-Based T est Case Mutation , which jointly optimizes see d quer y selection and mutation rule application guide d by coverage fee dback, aiming at b oosting code coverage by exploring deep er execution paths. Experiments on three widely-used DBMSs with four lightweight LLMs show that MIST achieves average improvements of 43.3% in line coverage , 32.3% in function coverage , and 46.4% in branch coverage compared to the baseline approach with the highest line coverage of 69.3% in the Optimizer module. ∗ Corresponding author . This work is licensed under a Creativ e Commons Attribution 4.0 International License. ICSE-Companion ’26, Rio de Janeiro, Brazil © 2026 Copyright held by the owner/author(s). ACM ISBN 978-1-4503-XXXX -X/2018/06 https://doi.org/10.1145/3774748.3793625 CCS Concepts • Computing methodologies → Articial intelligence ; • Soft- ware and its engineering → Software post-development is- sues . Ke ywords DBMSs testing, Large language model, T est case generation A CM Reference Format: Y ujia Chen, Yingli Zhou, Fangyuan Zhang, and Cuiyun Gao. 2026. LLM- Based T est Case Generation in DBMS through Monte Carlo Tree Search. In 2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE-Companion ’26), A pril 12–18, 2026, Rio de Janeiro, Brazil . ACM, Ne w Y ork, N Y , USA, 12 pages. https://doi.org/10.1145/3774748.3793625 1 Introduction Database Management Systems (DBMSs) ar e fundamental infras- tructure for modern data-driven society , underpinning applications across nance, healthcare and e-commerce [ 25 , 29 , 36 ]. Ensuring the correctness and robustness of DBMSs is vital, as even minor faults can lead to sever e consequences, including data corruption, service outages, or security breaches [ 3 , 21 , 26 ]. An essential step toward assuring DBMS r eliability is thorough testing using high- quality SQL test cases, which help uncover subtle defects before deployment and prev ent them from aecting production environ- ments [ 2 , 48 ]. Traditional approaches for generating test cases, such as BuzzBee [ 46 ], SQLsmith [ 34 ], SQLancer [ 32 ], can be eective for a specic DBMS; however , there exist many DBMSs designed for dierent application scenarios, such as DuckDB [ 29 ] for analytical workloads, PostgreSQL [ 36 ] for general-purpose OLTP systems, and SQLite [ 24 ] for lightweight emb edded environments. Adapt- ing these methods to dierent DBMSs requires substantial manual eort, such as crafting grammar rules and maintaining specic operators, which severely limits their scalability [ 48 – 50 ]. Recent advances in Large Language Models (LLMs) present promising opportunities for DBMS test case generation. First, LLMs have already demonstrated success in related data management tasks, including text-to-SQL [ 4 , 17 , 18 ], data cleaning [ 5 , 19 , 22 , 27 ], knob tuning [8, 16], and DBMS diagnosis [35, 47, 52]. Second, LLMs are applied in testing across multiple domains, such as general software testing [ 39 , 43 ], compiler testing [ 10 , 42 ], and embedded testing [ 1 ]. As illustrated in Figure 1, LLMs can directly generate SQL test cases by leveraging their understanding of SQL syntax and semantics ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil Y ujia Chen, Yingli Zhou, Fangyuan Zhang, and Cuiyun Gao Y ou are a professional database testing engineer . Y our task is to generate high - quality and complex SQL test cases for DuckDB . Instruction Prompt LLM Te s t Case for DBMS Data Defin ition Language Data Mani pulation Language Data Query Language CREATE TABLE weather ( city TEXT NOT NULL , temp INTEGER , humidity INTEGER , prcp REAL , date DATE ); INSERT INTO weather VALUES ( ‘ San Francisco ' , 46 , 50 , 0 . 25 , ' 1994 - 11 - 27 ' ), ( ‘ San Francisco ' , 43 , 57 , 0 . 0 , ' 1994 - 11 - 29 ' ), ( ' Hayward ' , 37 , 54 , NULL , ' 1994 - 11 - 29 ’ ); SELECT city, EXTRACT( MONTH FROM date ) as month , SUM ( prcp) as total_precipitation FROM weather WHERE date >= ' 1994 - 11 - 27 ' AND date <= ' 1994 - 12 - 01 ' ; Figure 1: An illustrative example of using Qwen2.5-7B to generate a SQL test case for DBMS. acquired during pre-training. Despite these encouraging develop- ments, deploying LLMs for industrial-scale DBMS testing still faces two critical challenges: • Challenge 1: Limited model adaptability in proprietary and resource-constrained industrial DBMS environments. In- dustrial DBMSs often have proprietary SQL diale cts with unique syntax and features. At the same time, security and privacy re- quirements r estrict organizations to locally deployed lightw eight LLMs (typically 70B parameters or smaller ). The limited model capacity results in generating overly simple queries with insu- cient testing coverage (see Figure 2( a)). Moreover , these models lack sucient training on proprietary SQL variants, often pro- ducing queries that violate dialect-sp ecic rules (see Figure 2(b)). As a result, adapting lightweight LLMs to proprietary industrial DBMSs remains challenging. • Challenge 2: Limited exploration of deep er execution paths in test generation. Ee ctive DBMS testing r equires queries that cover meaningful execution paths beyond syntactic correctness. Howev er , simply generating a large number of test cases do es not translate into high coverage, as many queries are seman- tically similar and exercise only shallow execution paths. As demonstrated in a prior study [ 40 ], the generated test cases may improve co verage initially , but the coverage quickly plateaus as new inputs rarely explore deeper logic. Establishing an eective mechanism to guide test generation toward unexplored code regions remains a critical challenge. Our work. T o address these challenges, we propose MIST , an LL M - based test case generat I on framework for DBM S through Monte Carlo T ree search. MIST consists of two complementary stages: 1) Feature-Guided Error-Driven T est Case Synthetization. This stage constructs a feature tree from ocial do cumentation and hierar- chically samples feature combinations to guide LLM generation. Execution errors are captured and fed back to subse quent prompts, C R E A T E T A B L E p r o d u c t s ( i d I N T E G E R , n a m e T E X T , p r i c e R E A L ) ; I N S E R T I N T O p r o d u c t s V A L U E S ( 1 , ' L a p t o p ' , 9 9 9 . 9 9 ) , ( 2 , ' P h o n e ' , 4 9 9 . 9 9 ) ; S E L E C T n a m e , p r i c e F R O M p r o d u c t s W H E R E p r i c e > 1 0 ; (a) Simple query with limited testing coverage. C R E A T E T A B L E e m p l o y e e s ( i d I N T E G E R , d e t a i l s STRUCT ) ; I N S E R T I N T O e m p l o y e e s V A L U E S ( 1 , 5 ) ; S E L E C T * F R O M p r o d u c t s W H E R E n a m e REGEXP_MATCHES ( ' ^ A ' ) CROSS JOIN c i t i e s c ON c . i d = 1 ; (b) Query violating syntax rules on DuckDB (errors highlighted in red ). Figure 2: Illustrating challenges in LLM-based DBMS test case generation with Qwen2.5-7B. improving syntactic validity and semantic diversity of synthesized test cases. 2) Monte Carlo Tree Search-Based T est Case Mutation. After coverage gro wth plateaus, this stage employs MCTS to iteratively select seed queries and apply mutation rules guide d by coverage feedback from test execution. With elab orate mutation rules cover- ing schema, data, and query operations, this stage systematically explores deeper execution paths to boost code coverage. W e evaluate MIST on three widely-used open-source DBMSs (DuckDB, PostgreSQL, and SQLite) with four LLMs of dierent pa- rameter scales (Qwen2.5-7B [ 28 ], Llama3.1-8B [ 9 ], Qwen2.5-14B [ 28 ], and Qwen2.5-32B [ 28 ]). Experimental results show that MIST im- proves the baseline approach by 23.9% ∼ 69.17% on DuckDB, 18.5% ∼ 54.1% on PostgreSQL, and 18.5% ∼ 92.9% on SQLite in terms of average code coverage . Moreover , MIST achieves the highest line coverage in the Optimizer module, reaching 69.3% in DuckDB and 63.4% in PostgreSQL. These results demonstrate that MIST greatly enhances test eectiveness for industrial DBMS testing using only lightweight, locally deployed LLMs. The source code is released at https://github.com/yujiachen99/DBMST esting. Contributions. The main contributions of our paper are summa- rized below: • W e propose MIST , a novel framework that eectively gener- ates high-quality test cases to improve code coverage for propri- etary DBMSs using only lightweight, locally deployed LLMs in resource-constrained industrial environments. LLM-Based T est Case Generation in DBMS through Monte Carlo Tree Search ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil • W e introduce a hierarchical feature tree with error-driven feed- back and an MCTS-based mutation engine that jointly optimizes test case generation to improve code cov erage. • Extensive experiments on thr ee widely-used DBMSs with four LLMs demonstrate that MIST remarkably outperforms baseline models in code coverage and critical module coverage. Outline. W e pr esent the necessary background in Section 2. Sec- tion 3 presents the overall framework of MIST , followed by detailed introduction. The experimental setup and results are provided in Section 4 and Section 5, respectively . Section 6 oers a case study illustrating why MIST works and discusses threats to validity . Fi- nally , we review related work in Section 7 and conclude the paper in Section 8. 2 Background 2.1 DBMS T esting DBMS testing is a critical process for ensuring the correctness and reliability of database systems, which ser ve as the backbone of modern data-driven applications. The goal of DBMS testing is to systematically generate SQL test cases that exer cise various func- tional components of the system, including the parser , optimizer , executor , and storage engine, to uncover potential bugs before de- ployment. A typical SQL test case consists of three essential components, as illustrated in Figure 1: Data Denition Language (DDL) statements that dene the database schema (e.g., CREATE TABLE to create ta- bles with specic columns and constraints), Data Manipulation Language (DML) statements that p opulate the database with test data (e.g., INSERT to add records), and Data Query Language (DQL) statements that quer y the database to trigger various execution paths (e.g., SELECT with complex predicates, joins, and aggrega- tions). The interplay of these three comp onents enables compr ehen- sive testing of the DBMS under diverse scenarios. The eectiveness of DBMS testing is measured by code coverage , which quanties how thoroughly the test cases exercise dierent execution paths in the system. Higher coverage indicates that more code regions have been tested, thereby increasing the likelihood of discovering bugs hidden in less frequently executed paths. 2.2 Monte Carlo Tr ee Search Monte Carlo Tree Search (MCTS) [ 14 ] is a p owerful heuristic search algorithm for navigating decision-making problems, particularly those characterized by vast and complex search spaces. Its ee c- tiveness has b een demonstrated in a variety of domains [ 13 , 37 , 51 ]. The core of MCTS is an iterative process that asymmetrically grows a search tree by focusing on the most promising regions. Each iteration involves four fundamental steps: • Selection: Starting from the root, the algorithm recursively selects child nodes with the highest utility value until a leaf node is reached. This selection strategy , often guided by the Upper Condence Bound ( UCB) formula, strategically balances the trade-o between exploiting known promising paths and exploring less-visited nodes. • Expansion: Once a leaf node is selected, the tree is expanded by creating one or more child nodes corresponding to new , unexplored actions or states. • Simulation: From a newly expanded node, a lightweight simulation, often called a "rollout, " is execute d. This typically involves making random or semi-random choices until a terminal state is reached, pr oviding an estimated outcome or value. • Backpropagation: The result from the simulation is then propagated back up the tree, updating the statistics (such as visit counts and value estimates) of all nodes along the path from the expanded node to the root. By repeating this cycle, MCTS intelligently allocates computa- tional resources to the most valuable parts of the search space, making it an ideal technique for optimization problems where ex- haustive search is infeasible. 3 Approach In this se ction, we propose MIST , an LLM-based test case generation framework for DBMS through Monte Carlo tree search. W e rst present the ov erview of MIST and then describe its details in the following subsections. 3.1 Overview Given a target DBMS and a lightweight LLM, MIST generates high- quality SQL test cases through a two-stage approach, as shown in Figure 3. In the (1) Feature-Guided Error-Driven T est Case Syn- thetization stage, MIST constructs a hierarchical feature tree from ocial do cumentation and samples feature paths to guide LLM generation. Execution errors are captured and fe d back to rene subsequent generations, progressively impro ving the syntactic va- lidity and semantic diversity of test cases. When coverage growth plateaus, MIST transitions to the (2) Monte Carlo Tr ee Search-Based T est Case Mutation stage, where it treats generated queries as seeds and employs MCTS to iteratively select seeds and apply mutation rules. Coverage feedback from test execution guides the search to- ward unexplored code regions, systematically improving coverage beyond the initial generation plateau. 3.2 Feature-Guided Error-Driven T est Case Synthetization As shown in Stage I of Figure 3, this stage generates SQL test cases by guiding the LLM with DBMS-specic features. MIST rst con- structs a hierar chical feature tr ee from ocial documentation, then samples feature combinations to construct prompts for generation. Execution error memory enables the LLM to learn diale ct-specic constraints and progressively improve the syntactic validity and semantic diversity of generated test cases. 3.2.1 Feature tree construction. W e collect ocial documentation from target DBMSs, where each document describes SQL features with syntax specications and usage examples. These documents cover the full spectrum of SQL dialects, including data types, oper- ators, functions, and query constructs. Feature extraction. The documentation manager parses doc- umentation les to extract feature entries. Each entry contains a ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil Y ujia Chen, Yingli Zhou, Fangyuan Zhang, and Cuiyun Gao … DBMS Document DBMS Feature Extraction Feature Organization Feat ur e Group Feat ur e To p i c Feat ur e Feat ur e … … … Hierarchical Path Sampling Diversity- Awar e Enhancement Parsed Feature Tr e e Composite Feature List Execution Error Memory LLM T est Case Stage I. Feature - Guided Error - Driven Te s t C a s e Synthetization … T est Case Seed Pool Mutation Rules DML Par t DDL Par t DQL Par t Simulation Selection Expansion Backproga tion Selected Nod e Te r m i n a l Node Searched T est Case and Rules Coverage Reward DBMS LLM Mutated T est Case Stage II. Monte Carlo Tr e e S e a r c h - Based Te s t C a s e Mutation DBMS Early Termination ① Feature T re e Construction ② Hierarchical Feature Selection ③ Error - Driven T est Case G eneration Figure 3: The overview of MIST . feature name, its functional description, and repr esentative syntax patterns. For instance, DuckDB’s string concatenation operator || is extracted with its description and usage pattern SELECT ’A’ || ’B’ . Similarly , PostgreSQL’s CONCAT function is extracted as a dis- tinct feature, capturing the syntactic divergence between DBMSs for the same functionality . Feature organization. Extracted features are organized into a three-level hierarchical tr ee, as shown in Figure 3. The rst level represents dierent DBMSs, the second level categorizes features into functional groups ( e.g., String Operations, Aggregation Func- tions), and the third level contains sp ecic feature topics within each group. This parse d feature tree captures the multi-level se- mantic organization of DBMS functionalities, linking each database with its functional categories and concr ete SQL features, thereby enabling ne-grained and context-aware feature sampling. The feature e xtraction pr ocess is performed manually by parsing ocial documentation and organizing features into the hierar chi- cal tree structure. For the three evaluated DBMSs, we extract a total of 143 SQL features for DuckDB (covering basic operations, joins/aggregations, advanced features, and specic functionalities), 167 features for PostgreSQL (including basic operations, advanced queries, transactions/views, and specic extensions), and 62 fea- tures for SQLite (spanning basic syntax, advanced queries, joins, constraints/indexes, transactions/triggers, and advanced features). Each feature entry contains the feature name , functional descrip- tion, and representative syntax patterns extracted from the ocial documentation. The manual construction process for each DBMS takes approximately 6-8 hours, including do cumentation review , feature extraction, and tree organization. Once constructe d, the feature tree can be reused across all experiments and extended incrementally when new DBMS versions introduce additional fea- tures. 3.2.2 Hierarchical feature sele ction. T o guide the LLM in generat- ing diverse and semantically coherent SQL queries, we employ a two-step feature selection strategy that samples feature combina- tions from the hierarchical tree. Hierarchical path sampling. W e rst randomly sele ct a main path from the feature tree, traversing from a specic DBMS through a feature group to individual features. For example, a sampled path might be “DuckDB → String Operations → || operator” . W e then sample additional features within the same path and expand to related paths within the same DBMS to maintain semantic consis- tency . This ensures that selected features are functionally related and can be meaningfully combined in a single SQL quer y . Diversity-aware enhancement. T o increase functional diver- sity , we introduce cross-category features that are not selected in the rst step. For instance, if the main path focuses on string oper- ations, we may add features from aggregation or join operations. This enhancement prevents generated queries from concentrating in a single functional area. The resulting comp osite feature list balances semantic coherence and functional diversity , providing comprehensive guidance for LLM generation. 3.2.3 Error-Driven test case generation. With the selecte d feature combinations, we construct a structured input prompt to guide the LLM in generating SQL test cases. The pr ompt template, illustrated in Figure 4, includes four components: (1) a role denition instruct- ing the LLM to act as a database testing engineer , (2) the selected feature list with descriptions, (3) error memory containing common mistakes from previous generations, and (4) output requirements specifying that the response should contain only executable SQL statements including DDL, DML, and DQL. This structured prompt provides both positive guidance through features to use and nega- tive guidance through errors to avoid. The generated test cases are LLM-Based T est Case Generation in DBMS through Monte Carlo Tree Search ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 Confer ence acr onym ’XX, June 03–05, 2018, W o o dsto ck, N Y Anon. 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 Prompt T emplate for T est Case Synthetization Role De � nition: Y ou are a professional database testing engine er . Generate high-quality SQL test cases for [DBMS_ T YPE] database. En- sure all SQL statements follow [DBMS_ TYPE] conventions. T arget Features: Generate a complete SQL test case that MUST use ALL of the following features: 1. [FEA T URE_1] - Description: [DESC_1] 2. [FEA T URE_2] - Description: [DESC_2] [ ··· ] Error Memory: Common errors to avoid (from previous failures): [ERROR_MEMORY] Please carefully avoid these errors in your generated SQL test case. Output Requirements: Output ONL Y pure SQL statements. NO explanations, NO comments. The output must include DDL, DML and DQL. Figur e 4: The pr ompt template for test case synthetization. [DBMS_ T YPE] is the target DBMS, [FEA T URE_LIST] con- tains sele cte d featur es fr om the hierar chical tr e e , and [ER- ROR_MEMORY] pr o vides fe e dback fr om pr e vious e xe cution failur es. o cial do cumentation and samples featur e paths to guide LLM generation. Exe cution err ors ar e captur e d and fe d back to r e ne subse quent generations, pr ogr essiv ely impr o ving the syntactic va- lidity and semantic div ersity of test cases. When co v erage gr o wth plateaus, MIST transitions to the (2) Monte Carlo T r e e Sear ch-Base d T est Case Mutation stage , wher e it tr eats generate d queries as se e ds and emplo ys MCTS to iterativ ely sele ct se e ds and apply mutation rules. Co v erage fe e dback fr om tes t e xe cution guides the sear ch to- war d une xplor e d co de r egions, systematically impr o ving co v erage b e y ond the initial generation plateau. 3.2 Featur e-Guide d Err or-Driv en T est Case Synthetization A s sho wn in Stage I of Figur e 3, this stage generates SQL test cases by guiding the LLM with DBMS-sp e ci c featur es. MIST rst con- structs a hierar chical featur e tr e e fr om o cial do cumentation, then samples featur e combinations to construct pr ompts for generation. Exe cution err or memor y enables the LLM to learn diale ct-sp e ci c constraints and pr ogr essiv ely impr o v e the syntactic validity and semantic div ersity of generate d test cases. 3.2.1 Featur e tr e e construction. W e colle ct o cial do cumentation fr om target DBMSs, wher e each do cument describ es SQL featur es with syntax sp e ci cations and usage e xamples. T hese do cuments co v er the full sp e ctrum of SQL diale cts, including data typ es, op er- ators, functions, and quer y constructs. Featur e e xtraction. The do cumentation manager parses do c- umentation les to e xtract featur e entries. Each entr y contains a featur e name , its functional description, and r epr esentativ e syntax patterns. For instance , DuckDB’s string concatena tion op erator || is e xtracte d with its description and usage pattern SELECT ’A’ || ’B’ . Similarly , Postgr eSQL’s CONCAT function is e xtracte d as a dis- tinct featur e , capturing the syntactic div ergence b etw e en DBMSs for the same functionality . Featur e organization. Extracte d featur es ar e organize d into a thr e e-le v el hierar chical tr e e , as sho wn in Figur e 3. The rst le v el r epr esents di er ent DBMSs, the se cond le v el categorizes featur es into functional gr oups ( e .g., String Op erations, A ggr egation Func- tions), and the thir d le v el contains sp e ci c featur e topics within each gr oup . This parse d featur e tr e e captur es the multi-le v el se- mantic organization of DBMS functionalities, linking each database with its functional categories and concr ete SQL featur es, ther eby enabling ne-graine d and conte xt-awar e featur e sampling. 3.2.2 Hierar chical featur e sele ction. T o guide the LLM in generat- ing div erse and semantically coher ent SQL queries, w e emplo y a tw o-step featur e sele ction st rategy that samples featur e combina- tions fr om the hierar chical tr e e . Hierar chical path sampling. W e rst randomly sele ct a main path fr om the featur e tr e e , trav ersing fr om a sp e ci c DBMS thr ough a featur e gr oup to individual feat ur es. For e xample , a sample d path might b e “DuckDB ! String Op erations ! || op erator” . W e then sample addition al featur es within the same path and e xpand to r elate d paths within the same DBMS to maintain semantic consis- tency . This ensur es that sele cte d featur es ar e functionally r elate d and can b e meaningfully combine d in a single SQL quer y . Div ersity-awar e enhancement. T o incr ease functional div er- sity , w e intr o duce cr oss-categor y featur es that ar e not sele cte d in the rst step . For instance , if the main path fo cuses on string op er- ations, w e may add featur es fr om aggr egation or join op erations. This enhancement pr e v ents generate d queries fr om concentrating in a single functional ar ea. The r esulting comp osite featur e list balances semantic coher ence and functional div ersity , pr o viding compr ehensiv e guidance for LLM generation. 3.2.3 Err or-Driv en test case generation. With the sele cte d featur e combinations, w e construct a structur e d input pr ompt to guide the LLM in generating SQL test cases. The pr ompt template , illustrate d in Figur e 4, includes four comp onents: (1) a r ole de nition instruct- ing the LLM to act as a database testing engine er , (2) the sele cte d featur e list with descriptions, (3) err or memor y containing common mistakes fr om pr e vious generations, and (4) output r e quir ements sp e cifying that the r esp onse should contain only e xe cutable SQL statements including DDL, DML, and DQL. This structur e d pr ompt pr o vides b oth p ositiv e guidance thr ough featur es to use and nega- tiv e guidance thr ough err ors to av oid. The generate d test cases ar e then e xe cute d on the target DBMS, and any encounter e d err ors ar e captur e d and stor e d in the memor y mo dule . The accumulate d err or fe e dback in this memor y subse quently guides the LLM to r e ne and generate mor e accurate test cases, forming a close d fe e dback lo op 4 Figure 4: The prompt template for test case synthetization. [DBMS_ T YPE] is the target DBMS, [FEA T URE_LIST] con- tains selecte d features from the hierarchical tree, and [ER- ROR_MEMORY] provides fee dback from previous execution failures. then executed on the target DBMS, and any encountered errors are captured and stor ed in the memory module. The accumulated error feedback in this memor y subsequently guides the LLM to r ene and generate more accurate test cases, forming a closed feedback loop that enables MIST to learn from past errors and improv e generation quality continuously . MIST employs an implicit oracle approach wher e test cases are considered to pass if they execute without crashes, runtime excep- tions, or syntax errors. Specically , we dene three types of test failures: (1) syntax errors detecte d during SQL parsing, (2) runtime exceptions raised during quer y execution (e.g., type mismatch, con- straint violations), and (3) system crashes that terminate the DBMS process. When a test case fails, the error message is captured and stored in the error memory module. This accumulated error fee d- back guides subsequent LLM generations to avoid similar mistakes, enabling MIST to progressively impro ve the syntactic validity and semantic correctness of generated test cases. While this implicit oracle approach cannot verify functional correctness (i.e., whether query results are semantically correct), it is highly eective for discovering crashes, parser bugs, and executor errors, which are critical for DBMS reliability . Algorithm 1: MCTS for test case mutation Input: The numb er of iterations 𝑇 Output: Mutated test case with maximum reward 1 Initialize MCTS tree root 𝑣 0 ; 2 foreach 𝑡 ← 1 , 2 , 3 , · · · , 𝑇 do 3 𝑣 𝑡 ← Select ( 𝑣 0 ) ; 4 ( 𝑣 ′ 𝑡 , 𝑎 𝑡 ) ← Expand ( 𝑣 𝑡 ) ; // Complete the mutation trajectory randomly 5 𝜃 𝑡 ← Rollout ( 𝑣 ′ 𝑡 ) ; 6 b 𝑅 ( 𝑣 𝑡 , 𝑎 𝑡 ) ← 𝑓 𝑄 ( 𝜃 𝑡 ) ; 7 Backpropagation via equations (2) - (4); 8 end 3.3 Monte Carlo Tr ee Search-Based T est Case Mutation After the rst stage generates an initial set of test cases, coverage growth typically plateaus as new queries be come repetitive. T o systematically explore deeper execution paths and maximize code coverage, we employ Monte Carlo Tree Search (MCTS) to guide the mutation process, as shown in Stage II of Figure 3. 3.3.1 Mutation rules curation. W e formulate test case mutation as a tree-structured search problem over a directed tree T = ( 𝑉 , 𝐸 ) . In this formulation, each node represents a test case, while each edge corresponds to an action, either sele cting a seed SQL from the test case pool or applying a specic mutation rule. Therefore, each root-to-leaf path represents a mutation trajectory , i.e., a com- plete sequence of selections and transformations that progressively evolve an initial seed test case into a newly mutate d one. By em- ploying MCTS, we can jointly optimize the selection of see d test cases and the application of mutation rules, thereby discovering the most coverage-eective mutations. T o support this search process, we curate a colle ction of 135 dialect-aware mutation rules (45 rules per DBMS) co vering schema, data, and quer y op erations. For each DBMS, the rules are distributed as follo ws: 10 DDL rules that modify database schemas ( e.g., adding columns with complex data types, creating indexes), 10 DML rules that manipulate data ( e.g., inserting boundary values, NULL han- dling), and 25 DQL rules that transform queries (e .g., changing join types, adding subqueries, introducing window functions). T o- gether , these rule categories dene a comprehensive mutation space that allows MIST to systematically transform SQL test cases while preserving syntactic validity . 3.3.2 MCTS-based mutation process. W e employ MCTS to itera- tively explore the mutation search space and discover high-coverage test cases. As detailed in Algorithm 1, MCTS operates through four fundamental steps that work together to balance exploration of new mutations and exploitation of promising trajectories. At each iteration, the algorithm starts from the root node and progressively builds the search tree by selecting actions, expanding nodes, simu- lating complete mutation trajectories, and up dating node statistics based on coverage feedback from the target DBMS. Selection. At each iteration, MCTS traverses the search tree from the root 𝑣 0 to a leaf 𝑣 𝑡 by recursively selecting the child node ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil Y ujia Chen, Yingli Zhou, Fangyuan Zhang, and Cuiyun Gao ① Selectio n ② Expansi on ③ Simulatio n Seed SQL 1. Add new columns to a table, supporting rich data types 2. Create views DDL DML 3 . Insert LIST , STRU CT , MAP and other complex types 4 . Use INNER JOIN to join tables 5. Use Aggregate Functions, like COUNT , SUM, A VG, MIN etc. DQL Figure 5: Illustrating the MCTS for test case mutation. with the highest score (line 3 in Algorithm 1), where the Upper Condence Bound for Trees (UCT) [ 14 ] is used as the scoring p olicy . Specically , for a state 𝑣 and an action 𝑎 ∈ A ( 𝑣 ) , where A ( 𝑣 ) denotes the set of feasible actions from 𝑣 , the UCT score is: 𝑈 ( 𝑣 , 𝑎 ) = 𝑅 ( 𝑣 , 𝑎 ) 𝑁 ( 𝑣 , 𝑎 ) + 𝑐 · ln 𝑁 ( 𝑣 ) 𝑁 ( 𝑣 , 𝑎 ) , (1) where 𝑅 ( 𝑣 , 𝑎 ) is the cumulative rewar d obtained by executing action 𝑎 at state 𝑣 , 𝑁 ( 𝑣 , 𝑎 ) is the number of times action 𝑎 has been taken from 𝑣 , and 𝑁 ( 𝑣 ) is the total number of visits to 𝑣 . The constant 𝑐 balances exploration and exploitation. Expansion. In the 𝑡 -th iteration, if the selected node 𝑣 𝑡 is not at the terminal layer or is not fully expanded (i.e., there exists an action in A ( 𝑣 𝑡 ) that has not yet been executed), we randomly choose one such unexplored action, denoted as 𝑎 𝑡 . Exe cuting 𝑎 𝑡 generates a new child state 𝑣 ′ 𝑡 , which is then added to the search tree (line 4). Simulation. In the simulation phase (lines 5–6), suppose the newly expanded node 𝑣 ′ 𝑡 lies at layer 𝑖 . The algorithm then performs a rollout strategy to complete the remaining mutation trajectory from 𝑣 ′ 𝑡 to a terminal node. A commonly used strategy is random playout, in which the remaining mutation actions are sampled uniformly at random and combined with the already xed actions along the path leading to 𝑣 ′ 𝑡 , ther eby producing a complete mutate d test case for evaluation. Backpropagation. Following the simulation phase, the nal reward b 𝑅 ( 𝑣 𝑡 , 𝑎 𝑡 ) = 𝑓 ( 𝜃 𝑡 ) is propagated back along the search path, where 𝑓 ( 𝜃 𝑡 ) denotes the coverage rate achieved by executing the generated test cases 𝜃 𝑡 on the current DBMS under test. The goal of this backpropagation phase is to up date the value estimates and visit counts for all intermediate state–action pairs encountered during the rollout, thereby rening the search p olicy toward actions that yield higher coverage in subsequent iterations. Spe cically , for each state-action pair ( 𝑣 , 𝑎 ) along the search path, we update three statistics: 𝑅 ( 𝑣 , 𝑎 ) ← 𝑅 ( 𝑣 , 𝑎 ) + b 𝑅 ( 𝑣 , 𝑎 ) (2) 𝑁 ( 𝑣 ) ← 𝑁 ( 𝑣 ) + 1 (3) 𝑁 ( 𝑣 , 𝑎 ) ← 𝑁 ( 𝑣 , 𝑎 ) + 1 (4) where 𝑅 ( 𝑣 , 𝑎 ) is the cumulative r eward, 𝑁 ( 𝑣 ) is the visit count of node 𝑣 , and 𝑁 ( 𝑣 , 𝑎 ) is the visit count of action 𝑎 from node 𝑣 . Example 3.1. Figure 5 illustrates an example of MCTS for test case mutation. Each iteration begins at the root node. The algorithm traverses the tree by repeatedly selecting the no de with the highest UCT score (i.e., selecting a seed SQL) until it reaches an expandable node. From there, the algorithm expands the tree by randomly choosing an untried action, i.e., selecting a DDL mutation rule, to create a new node. Next, a simulation (or rollout) is performed fr om this state, randomly applying additional actions from the DML and DQL rule sets to complete the mutation trajectory . The resulting mutated SQL quer y is then executed on the target DBMS to obtain a reward (i.e., the achieved coverage). Finally , this reward is used to update the statistics of all no des along the path back to the root, which is highlighted the black in this gure. Early termination. T o improve search eciency , we design an early termination strategy that prioritizes see d SQLs with recently high performance while automatically pruning saturated or ov er- complex ones. Specically , the strategy continuously tracks the recent branch coverage improvement of each SQL; once its coverage gain becomes saturated, the corresponding node is excluded from further expansion in subsequent MCTS iterations. 4 Experimental Setup 4.1 Research Questions In this paper , we mainly investigate the following research ques- tions through experiments. • RQ1 : How eective is MIST in improving code coverage for DBMSs compared to baseline approaches? • RQ2 : How does MIST perform across dierent DBMS mod- ules (i.e., Parser , Optimizer , Executor , Storage )? • RQ3 : What are the impacts of the two stages in MIST on code coverage improv ement? 4.2 Studied DBMSs Following prior studies [ 49 , 50 ], we e valuate MIST on three widely- used open-source DBMS representing diverse architectural designs and SQL dialect characteristics. • DuckDB [ 29 ]: An in-process analytical database designed for OLAP workloads with columnar storage and vectorized execution. It supports modern SQL features including win- dow functions and CTEs. • PostgreSQL [ 36 ]: A mature relational database system with a sophisticated quer y optimizer and advanced features such as materialized views and JSON operations. • SQLite [ 24 ]: A lightweight embe dded database engine widely deployed in mobile and emb edded systems. It implements a comprehensive SQL dialect with unique featur es such as virtual tables. These three systems colle ctively cover a broad spectrum of DBMS architectures (in-process analytical, client-server relational, and embedded transactional, respectively), enabling us to comprehen- sively evaluate MIST’s generalizability acr oss dier ent SQL dialects and execution models. LLM-Based T est Case Generation in DBMS through Monte Carlo Tree Search ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil 4.3 Studied LLMs and Baseline T o evaluate MIST’s eectiveness across dierent model capacities, we select four open-source LLMs spanning dierent parameter scales and model families: Qwen2.5-7B, Llama3.1-8B, Qwen2.5-14B, and Qwen2.5-32B. These models represent lightweight to medium- sized LLMs that are practical for local deployment in industrial environments, aligning with the resource constraints commonly faced in real-world DBMS testing scenarios. For baseline comparison, we select Fuzz4All [ 41 ] as our primar y baseline. T o the best of our knowledge, there is currently no existing work that uses LLMs as complete test case generators for DBMS testing. Inspired by ShQ veL [ 50 ], we adopt the state-of-the-art LLM- based framework Fuzz4All for fair comparison. Fuzz4All is the rst universal fuzzer that leverages LLMs to generate test inputs across multiple programming languages and systems. 4.4 Metrics W e evaluate MIST using two categories of coverage metrics to comprehensively assess its eectiveness in exer cising DBMS code. • Code Coverage. W e measure three standard code coverage metrics: (1) Line Coverage , which calculates the percentage of executed source code lines; (2) Function Coverage , which measures the percentage of functions that are invoked at least once; and (3) Branch Coverage , which tracks the per- centage of conditional branches (e .g., if-else statements) that are executed. These metrics pro vide a holistic view of how thoroughly the generated test cases exer cise the DBMS code- base. • Module-Level Coverage. T o understand the ne-grained impact of MIST on dierent DBMS components, we also measure coverage across four critical functional modules: (1) Parser , which handles SQL parsing and syntax validation; (2) Optimizer , which performs query optimization and plan generation; (3) Executor , which executes the quer y plan and produces results; and (4) Storage , which manages data storage and retrieval operations. This module-level analysis rev eals which components benet most from MIST’s test generation strategy . 4.5 Implementation Details All LLMs are downloaded from Hugging Face [ 11 ] and deployed locally using vLLM [ 15 ] as the inference engine on 8 N VIDIA GP Us, with generation parameters congured as follows: maximum token length of 1,024, temperature of 0.2 for stable generation, and batch size of 1 with 3 concurrent workers to balance throughput and re- source utilization. In Stage I, we generate 900 initial SQL test cases for each DBMS, with each test case incorporating 3 to 20 selected features from the hierarchical feature tree to ensure diversity . The range of 3 to 20 features is chosen thr ough preliminary e xperiments to balance semantic richness and syntactic complexity: fewer than 3 features tend to produce overly simple queries with limited cover- age, while more than 20 featur es often r esult in syntactically invalid SQL due to feature conicts. In Stage II, we perform 600 mutation iterations to explore deeper execution paths and improve cover- age incrementally . After generation, we apply post-processing to ensure the generated SQL can be correctly executed, including re- moving Markdown code block markers, stripping explanatory text and comments, extracting only valid SQL statements (DDL, DML, and DQL), and ensuring proper semicolon terminati on following standard practices in LLM-based code generation [ 12 , 20 , 38 ]. For the MCTS mutation, we set the exploration weight 𝑐 in the UCT formula to 1.414 following the standard UCT formula recommen- dation [ 14 ], and dene an early-termination threshold of 50 new branches, which is empirically set to balance exploration eciency and coverage impro vement potential. 5 Result 5.1 Code Coverage of MIST (RQ1) Experimental Design. T o answer this research question, we eval- uate MIST on three DBMSs (DuckDB, PostgreSQL, SQLite) using four LLMs (Qwen2.5-7B, Llama3.1-8B, Qwen2.5-14B, Qwen2.5-32B). Results Analysis. T able 1 shows the coverage comparison be- tween the baseline and MIST . Base d on the results, we make the following observations. (1) MIST consistently improves coverage across all DBMSs and coverage metrics. Across the thr ee DBMSs, MIST achieves substantial coverage improv ements over the baseline. For DuckDB, MIST improves line cov erage by an average of 49.0%, function cov- erage by 33.6%, and branch coverage by 45.8%. For PostgreSQL, the improvements are 34.0% in line coverage, 35.1% in function coverage, and 35.6% in branch co verage. For SQLite, MIST achie ves improvements of 47.0% in line co verage, 28.3% in function cov er- age, and 57.7% in branch coverage. These consistent improvements across diverse DBMS ar chitectures, ranging from in-process analyti- cal (DuckDB) to client-server relational (PostgreSQL) and emb edded transactional (SQLite), demonstrate that MIST is eective regardless of the underlying database design. (2) MIST shows strong generalization across dierent LLM sizes and families. The eectiveness of MIST is consistent across all four evaluated LLMs, regardless of parameter scale or model family . For the Qwen family , MIST achieves branch coverage im- provements ranging from 31.2% to 69.2% on DuckDB, 31.5% to 54.2% on PostgreSQL, and 39.1% to 92.9% on SQLite. For Llama3.1- 8B, MIST achieves improv ements of 38.8%, 21.3%, and 52.1% on the three DBMSs, respectively . Notably , smaller models with MIST often outperform larger baseline models. For example, Qwen2.5-7B with MIST achieves 42.0% line cov erage on DuckDB, surpassing the base- line of Qwen2.5-32B (25.8%). This demonstrates that MIST is more critical than raw model capacity , making it practical for resour ce- constrained industrial environments where deploying large models may not be feasible. Answer to RQ1: MIST consistently improves code coverage across all three DBMSs and four LLMs, achieving average im- provements of 43.3% in line coverage , 32.3% in function coverage, and 46.4% in branch coverage compar ed to the baseline approach. The improvements demonstrate str ong generalization across dif- ferent DBMS architectures and LLM sizes. ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil Y ujia Chen, Yingli Zhou, Fangyuan Zhang, and Cuiyun Gao T able 1: Overall code coverage comparison between baseline and MIST . DuckDB PostgreSQL SQLite Model Approach Line Function Branch Line Function Branch Line Function Branch Fuzz4All 29.9% 29.7% 17.0% 23.1% 25.2% 16.2% 29.9% 38.9% 22.5% Qwen2.5-7B MIST 42.0% 38.2% 24.5% 30.3% 38.6% 21.3% 39.7% 46.1% 31.3% Fuzz4All 32.3% 31.7% 18.3% 24.2% 31.8% 16.9% 28.3% 36.6% 21.1% Llama3.1-8B MIST 43.2% 39.3% 25.4% 29.3% 37.7% 20.5% 39.9% 45.2% 32.1% Fuzz4All 26.4% 26.8% 14.6% 23.6% 31.3% 16.4% 21.6% 30.3% 15.6% Qwen2.5-14B MIST 42.2% 38.6% 24.7% 31.4% 39.9% 22.2% 38.1% 44.5% 30.1% Fuzz4All 25.8% 28.0% 18.6% 20.9% 28.4% 14.4% 26.5% 34.7% 19.8% Qwen2.5-32B MIST 41.8% 38.6% 24.4% 31.5% 40.1% 22.2% 36.5% 43.1% 29.0% T able 2: Module-level line coverage comparison b etween base- line and MIST . Model Approach Parser Optimizer Executor Storage DuckDB Qwen2.5 7B Fuzz4All 26.6% 51.6% 31.0% 20.0% MIST 43.2% 68.4% 42.2% 31.3% Llama3.1 8B Fuzz4All 30.1% 52.8% 35.1% 22.7% MIST 48.9% 69.3% 47.3% 32.9% Qwen2.5 14B Fuzz4All 24.2% 43.4% 22.9% 22.1% MIST 45.1% 67.0% 46.6% 31.8% Qwen2.5 32B Fuzz4All 23.7% 45.6% 26.4% 22.6% MIST 43.0% 66.9% 45.2% 31.8% PostgreSQL Qwen2.5 7B Fuzz4All 36.1% 50.8% 37.5% 31.8% MIST 41.0% 59.0% 43.1% 36.4% Llama3.1 8B Fuzz4All 32.9% 47.3% 33.5% 30.9% MIST 39.9% 57.4% 39.1% 36.3% Qwen2.5 14B Fuzz4All 32.2% 44.6% 30.6% 30.5% MIST 41.5% 62.6% 45.8% 38.1% Qwen2.5 32B Fuzz4All 29.6% 38.4% 25.3% 27.9% MIST 41.2% 63.4% 45.9% 38.1% 5.2 Module-Level Coverage of MIST (RQ2) Experimental Design. T o answer this research question, we ana- lyze the line coverage distribution across four critical DBMS mod- ules: Parser , Optimizer , Executor , and Storage . W e focus on DuckDB and PostgreSQL, as SQLite ’s monolithic architecture does not pro- vide clear module boundaries for ne-grained analysis. Results Analysis. T able 2 shows the module-level line coverage comparison between the baseline and MIST . Based on the results, we make the following observations. (1) MIST achieves substantial improvements across all four modules. For DuckDB, MIST improves Parser coverage by an av- erage of 73.2%, Optimizer coverage by 41.3%, Executor coverage by 61.4%, and Storage coverage by 46.5% across the four LLMs. For PostgreSQL, the impro vements are 25.8% in Parser , 35.8% in Opti- mizer , 40.7% in Executor , and 23.4% in Storage . These comprehensive improvements demonstrate that MIST eectively e xercises execu- tion paths across the entire DBMS pipeline, from front-end parsing to back-end storage operations. Notably , even the Storage module, which handles low-level data access and buer management, shows consistent gains of 46.5% and 23.4% for DuckDB and PostgreSQL, respectively , indicating that MIST’s test cases successfully trigger diverse storage access patterns. (2) The Optimizer mo dule achieves the highest absolute coverage across b oth DBMSs. Among the four mo dules, the Op- timizer consistently achieves the highest absolute coverage values with MIST . In DuckDB, MIST reaches an average of 67.9% Opti- mizer coverage, compar ed to 48.4% in the baseline. In PostgreSQL, MIST achieves 60.6% Optimizer coverage, up from 45.3% in the baseline. This is particularly b ecause the Optimizer is one of the most complex components in modern DBMSs, responsible for quer y plan generation, cost estimation, and selecting optimal execution strategies. The high coverage indicates that MIST’s feature-guided generation and MCTS-based mutation ee ctively trigger diverse optimization logic. For example, Llama3.1-8B with MIST achiev es 69.3% Optimizer coverage on DuckDB, demonstrating that even smaller mo dels can thoroughly exercise complex optimization paths when guided by MIST . (3) Dierent modules benet dierently from MIST , re- ecting their architectural characteristics. The magnitude of improvement varies across modules, with Parser and Executor show- ing larger relative gains in DuckDB (73.2% and 61.4%), while Post- greSQL shows more balanced improvements across all modules (23.4% to 40.7%). This dierence reects DuckDB’s specialized de- sign for analytical workloads, where Parser and Executor handle complex operations like window functions, CTEs, and vectorized execution. In contrast, PostgreSQL’s mature and extensively tested codebase shows mor e uniform improv ements, indicating that MIST discovers pre viously untested paths across all components rather than concentrating on specic modules. Answer to RQ2: MIST achie ves substantial impro vements across all DBMS modules, with the Optimizer mo dule showing the high- est absolute coverage (average 67.9% for DuckDB and 60.6% for PostgreSQL). LLM-Based T est Case Generation in DBMS through Monte Carlo Tree Search ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil T able 3: Ablation study results showing the impact of dierent components in MIST . Each row represents a dierent combination of synthetization strategy and mutation strategy . Synthetization Mutation DuckDB PostgreSQL SQLite Line Function Branch Line Function Branch Line Function Branch Simple Instruction % 29.9% 29.7% 17.0% 23.1% 25.2% 16.2% 29.9% 38.9% 22.5% Random Feature % 32.3% 31.7% 18.7% 25.2% 30.1% 16.9% 32.8% 41.7% 24.6% Hierarchical Feature (MIST) % 36.2% 34.7% 20.6% 27.4% 32.1% 17.8% 35.5% 43.2% 26.3% Hierarchical Feature (MIST) Simple Instruction 37.8% 35.7% 21.6% 28.3% 33.9% 18.1% 36.9% 44.2% 27.5% Hierarchical Feature (MIST) Random Rule 38.7% 36.7% 22.4% 28.8% 35.4% 19.5% 37.5% 44.8% 29.2% Hierarchical Feature (MIST) MCTS Rule (MIST) 42.0% 38.2% 24.5% 30.3% 38.6% 21.3% 39.7% 46.1% 31.3% 5.3 Ablation Study (RQ3) Experimental Design. T o answer this research question, we per- form ablation studies by evaluating dierent combinations of syn- thetization and mutation strategies using Qwen2.5-7B. For syntheti- zation, we compare three approaches: • Simple Instruction: Uses basic prompts without feature guidance. • Random Feature: Randomly selects features without hier- archical structure. • Hierarchical Feature: Uses our hierarchical feature tree with diversity-aware sampling. For mutation, we compare four approaches: • No Mutation: Skips the mutation stage. • Simple Instruction: Uses basic prompts for mutation. • Random Rule: Randomly applies mutation rules. • MCTS Rule: Uses our MCTS-based mutation engine. Results Analysis. Table 3 shows the coverage results of dier- ent component combinations. Based on the results, we make the following observations. (1) Hierarchical feature sele ction is the most eective syn- thetization strategy . Comparing the three synthetization strate- gies without mutation, Hierarchical Feature achieves branch cov- erage of 20.6% on DuckDB, 17.8% on PostgreSQL, and 26.3% on SQLite. This outperforms Random Feature by 10.2%, 5.3%, and 6.9%, respectively , and Simple Instruction by 21.2%, 9.9%, and 16.9%, re- spectively . The superior performance of Hierarchical Feature can be attributed to its ability to systematically sample features from the hierarchical tree while maintaining semantic coherence, ensuring that generated test cases exercise diverse DBMS functionalities. (2) MCTS-based mutation consistently outperforms al- ternative mutation strategies. Among the three mutation ap- proaches applied to Hierarchical Feature , MCTS Rule achieves branch coverage of 24.5% on DuckDB, 21.3% on PostgreSQL, and 31.3% on SQLite. This repr esents improvements of 13.4%, 17.7%, and 13.8% over Simple Instruction , and 9.4%, 9.2%, and 7.2% over Random Rule , respectively . The consistent superiority of MCTS Rule demonstrates that its tree search mechanism eectively balances exploration of new mutation paths and exploitation of high-coverage seeds. Ran- dom Rule p erforms better than Simple Instruction but still falls short of MCTS Rule , indicating that random selection cannot match the systematic search strategy provided by MCTS. (3) Removing either component leads to performance degra- dation, among which hierarchical feature selection has the greatest impact. The complete MIST framework (Hierarchical Feature and MCTS Rule) achie ves the highest cov erage across all DBMSs. Removing the mutation stage (Hierarchical Feature and No Mutation) reduces branch coverage by 18.9% on DuckDB, 19.7% on PostgreSQL, and 19.0% on SQLite. Replacing Hierarchical Feature with Simple Instruction while keeping MCTS Rule would r educe cov- erage by 44.1%, 31.5%, and 39.1% on the three DBMSs, respe ctively . These r esults demonstrate that both components are essential, with hierarchical feature selection being the more critical component. Answer to RQ3: Hierarchical feature selection outperforms base- lines by 5.3%-21.2%, while MCTS-based mutation further improv es coverage by 9.2%-17.7% ov er alternative mutation strategies. Re- moving either component leads to substantial performance degra- dation, with hierarchical feature selection having the greater impact, conrming the necessity of the complete framework. ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil Y ujia Chen, Yingli Zhou, Fangyuan Zhang, and Cuiyun Gao R 1. Insert Boundary Values R2 .Use CASE WHEN R3. NULL Handli ng F 1. PRIMARY KEY Constrain t F2. CREA TE INDEX F3. Aggregat ion Function F4. Subquery in SELECT CREATE TABLE users ( id INTEGER , name TEXT ); INSERT INTO users VALUES ( 1 , 'Alice' ); INSERT INTO users VALUES ( 2 , 'Bob’ ); INSERT INTO users VALUES ( 3 , ‘Coco’ ); INSERT INTO users VALUES ( 4 , ‘Diva’ ); SELECT * FROM users; Simple Synthesization Feature - Guided Synthesization 14.0 % Line 22 . 8% Function 9.0 % Branch 18. 2% Line 27 .3% Function 12.2 % Branch MCTS - Guided Mutation 19.4% Line 28 .3% Function 13.4 % Branch CREATE TABLE sales ( id INTEGER PRIMARY KEY , product TEXT NOT NULL , region TEXT , ..."omit"for"brevity"... ); CREATE INDEX idx_region ON sales(region); ..."omit"for"brevity"... INSERT INTO sales VALUES (...); ..."omit" for" brevity"... SELECT region , COUNT ( * ) as sale_count , ..."omit"for"brevity"..." FROM sales WHERE amount > ( SELECT AVG (amount) FROM sales) ..." omit"for"br evity"..." -- Same schema with PRIMARY KEY and INDEX …"omit"for"brevi ty"… INSERT INTO sales VALUES ( ..., NULL , 350 . 00 , ...); INSERT INTO sales VALUES ( ..., 'West' , - 50 . 00 , ...); …"omit"for"brevi ty"… …"omit"for"brevi ty"… CASE WHEN SUM (amount) > 2000 THEN 'High' …"omit"for"brevi ty"… ELSE 'None' END as performance_tier , …"omit"for"brevi ty"… WHERE region IS NOT NULL AND amount IS NOT NULL …"omit"for"brevi ty"… Figure 6: Case study on test case generation using Qwen2.5-7B on SQLite. 6 Discussion 6.1 Why does MIST work? The eectiveness of MIST lies in guiding LLM generation with hierarchical documentation structure and systematically exploring execution paths through MCTS-based mutation. As demonstrated in Figure 6, we pr esent a case study using Qwen2.5-7B on SQLite, comparing three approaches to SQL test case generation: simple synthesization, feature-guided synthesization, and MCTS-guided mutation. 6.1.1 Feature-guided synthetization for enriching the semantics of test cases with do cument knowledge. As shown in Figure 6, Simple Synthesization fails to provide sucient semantic richness. It relies solely on basic table structures and straightfor ward INSERT/SELECT statements, generating the minimal SQL that achie ves only 14.0% line coverage and 9.0% branch coverage . This represents the lower bound of what random generation can produce. In contrast, by organizing DBMS features into a hierarchical tree and performing path-based sampling, MIST systematically selects features that exer- cise deeper comp onents. The feature-guided approach incorporates PRIMARY KEY constraints (F1), CREA TE INDEX (F2), aggregation functions (F3), and subqueries (F4) into the generated SQL, result- ing in improvements of 30.0%, 19.7%, and 35.6% in terms of line coverage, function coverage, and branch coverage, respectively . This demonstrates that hierarchical feature selection eectively guides LLMs to generate semantically rich SQL that explor es wider execution paths. 6.1.2 Monte Carlo tree search-based mutation for exploring deep er execution paths to enhance coverage. MIST strategically mutates existing high-quality se eds using rules selecte d through MCTS, which ensures that mutation rules are systematically chosen to maximize coverage impr ovement potential rather than being ran- domly applied. Specically , the mutation introduces boundary value insertion (R1) with extreme values (NULL, -50.00), CASE WHEN branches (R2) with conditional logic, and N ULL handling (R3) with IS NOT NULL predicates. These mutations trigger edge case han- dling in arithmetic operations and storage management, activate dierent evaluation paths in the e xecutor , and exercise N ULL value processing logic. The MCTS-guided mutation achieves 19.4% line coverage, 28.3% function cov erage, and 13.4% branch coverage, rep- resenting additional improv ements of 6.6%, 3.7%, and 9.8% over feature-guided synthesis, respectively . The comparison across three approaches demonstrates that feature- guided synthesis and MCTS-based mutation address dierent as- pects of coverage improvement. Featur e selection provides seman- tic richness by guiding LLMs based on do cumentation knowledge, while MCTS-based mutation provides systematic edge case explo- ration when generation saturates, demonstrating the ee ctiveness of MIST in comprehensive DBMS testing. 6.2 Threats to V alidity W e identify three main threats to the validity of our study: Internal V alidity . The primary threat concerns coverage measure- ment accuracy . W e use compiler-based instrumentation (gcov/lcov ) to collect coverage data, which may introduce runtime overhead. T o mitigate this, we use dedicate d coverage-enabled builds sep- arate from production binaries and verify that instrumentation does not alter DBMS functional correctness. Another concern is the non-deterministic nature of LLM-based generation. T o mitigate this variability , we congure a xed temperature of 0.2 and use consistent random seeds across all experiments for reproducibility . The substantial and consistent co verage improvements obser ved across all four LLMs and three DBMSs demonstrate that MIST’s eectiveness remains stable despite this inherent randomness. External V alidity . Our evaluation focuses on three open-source DBMSs (DuckDB, PostgreSQL, SQLite) and two LLM families (Qwen and Llama), which may limit the generalizability to other systems. Howev er , these DBMSs represent diverse architectural designs and cover a broad spectrum of SQL diale cts. The consistent improve- ments across dierent model sizes (7B to 32B parameters) suggest that MIST is generalizable to similar systems and models. Construct V alidity . W e use code coverage (line, function, and branch) as the primary metric for evaluating test eectiveness. While coverage is a widely accepted pro xy for test quality , high cov- erage do es not guarantee the absence of bugs or complete functional correctness. W e acknowledge that our evaluation does not include LLM-Based T est Case Generation in DBMS through Monte Carlo Tree Search ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil explicit fault detection analysis, such as counting crashes or asser- tion failur es triggered by the generated test cases. Nevertheless, the substantially higher coverage achieved by MIST suggests that it exercises deep er execution paths and edge cases that are more likely to expose latent faults compared to the baseline appr oach. Future work could evaluate fault-nding eectiveness thr ough mutation testing or analysis of discovered bugs. 7 Related W ork 7.1 LLM-based T esting The advent of LLMs has introduced new paradigms for automate d software testing. Existing LLM-based testing approaches can be divided into two categories: direct generation and oine augmen- tation. For direct generation, Fuzz4All [ 41 ] leverages LLM-driven prompt generation and mutation to cr eate diverse test inputs for multiple programming languages. WhiteFox [ 44 ] applies a two- model approach for white-box compiler fuzzing, where one LLM an- alyzes compiler source code and another generates targeted test pro- grams. KernelGPT [ 45 ] enhances OS kernel fuzzing by prompting LLMs to synthesize system call spe cications from documentation. For oine augmentation, MetaMut [ 23 ] uses LLMs to automatically generate domain-specic mutators for compiler fuzzing, separating the costly LLM inference from high-throughput execution. Dierent from these approaches that focus on general-purpose programming languages, compilers, or operating systems, our work targets DBMS testing, where the challenge lies in adapting to proprietary SQL dialects and achieving high code cov erage with lightweight local models under industrial resource constraints. 7.2 T est Case Generation for DBMSs Existing metho ds for generating test cases for DBMSs can be di- vided into two categories: mutation-based and generation-base d testing. Mutation-base d approaches modify existing SQL state- ments to produce new test cases. Sedar [ 6 ] impr oves input diversity by transferring SQL se eds across DBMS diale cts. Grin [ 7 ] uses a grammar-free approach with a lightweight metadata graph to guide semantically-correct query mutations. Generation-based ap- proaches construct queries from scratch using predened rules. SQLsmith [ 34 ] generates random yet well-formed SQL queries by leveraging schema metadata. SQLancer [ 30 , 31 , 33 ] employs hand- crafted dialect-specic generators with sophisticated test oracles to dete ct logic bugs. Dierent from these traditional approaches that r ely on manual grammar engineering or random mutation, our work is the rst to leverage lightweight LLMs with hierarchical feature guidance and MCTS-based mutation guided by coverage feedback to systematically improve code coverage. 8 Conclusion In this paper , we propose MIST , a framework for generating high- quality SQL test cases using lightweight LLMs. By combining feature- guided generation with error feedback and MCTS-based mutation guided by coverage feedback, MIST addresses the challenges of limited model adaptability and insucient test diversity in indus- trial DBMS testing. Experiments on three widely-used DBMSs with four LLMs demonstrate that MIST greatly outp erforms baseline approaches across line, function, and branch coverage, while achiev- ing the highest coverage in critical modules such as the Optimizer . As a practical solution for resource-constrained industrial environ- ments, MIST contributes to more reliable and thoroughly tested database systems. In future work, we plan to extend MIST to addi- tional DBMSs and explore more sophisticated mutation strategies. References [1] Moritz Bley , T obias Scharnowski, Simon Wörner , Moritz Schloegel, and Thorsten Holz. 2025. Protocol- A ware Firmware Rehosting for Ee ctive Fuzzing of Embed- ded Network Stacks. arXiv preprint arXiv:2509.13740 (2025). [2] Nicolas Bruno, Surajit Chaudhuri, and Dilys Thomas. 2006. Generating queries with cardinality constraints for dbms testing. IEEE Transactions on Knowledge and Data Engine ering 18, 12 (2006), 1721–1725. [3] Rajiv Chopra. 2010. Database Management System (DBMS) A Practical Approach . S. Chand Publishing. [4] Ju Fan, Zihui Gu, Songyue Zhang, Yuxin Zhang, Zui Chen, Lei Cao, Guoliang Li, Samuel Madden, Xiaoyong Du, and Nan T ang. 2024. Combining small language models and large language models for zero-shot nl2sql. Proceedings of the VLDB Endowment 17, 11 (2024), 2750–2763. [5] Meihao Fan, Xiaoyue Han, Ju Fan, Chengliang Chai, Nan Tang, Guoliang Li, and Xiaoyong Du. 2024. Cost-eective in-context learning for entity resolution: A design space exploration. In 2024 IEEE 40th International Conference on Data Engineering (ICDE) . IEEE, 3696–3709. [6] Jingzhou Fu, Jie Liang, Zhiyong Wu, and Y u Jiang. 2024. Sedar: Obtaining High- Quality Seeds for DBMS Fuzzing via Cross-DBMS SQL Transfer . In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE . 146:1–146:12. [7] Jingzhou Fu, Jie Liang, Zhiyong Wu, Mingzhe W ang, and Yu Jiang. 2022. Grin : Grammar-Free DBMS Fuzzing. In 37th IEEE/ACM International Conference on Automated Software Engineering, ASE . 49:1–49:12. [8] Victor Giannakouris and Immanuel Trummer . 2025. 𝜆 -tune: Harnessing large language models for automated database system tuning. Procee dings of the ACM on Management of Data 3, 1 (2025), 1–26. [9] Aaron Grattaori, Abhimanyu Dubey , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur , Alan Schelten, Alex V aughan, et al . 2024. The llama 3 herd of models. arXiv preprint (2024). [10] Qiuhan Gu. 2023. Llm-based code generation method for golang compiler testing. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . 2201–2203. [11] Huggingface. 2025. Huggingface. https://huggingface.co/. [12] Sathvik Joel, Jie Wu, and Fatemeh Fard. 2024. A survey on llm-based co de generation for low-resource and domain-specic programming languages. ACM Transactions on Software Engineering and Methodology (2024). [13] Bilal K artal, Pablo Hernandez-Leal, and Matthew E T aylor . 2019. Action guidance with MCTS for deep reinfor cement learning. In Proce edings of the AAAI conference on articial intelligence and interactive digital entertainment , V ol. 15. 153–159. [14] Levente Kocsis and Csaba Szepesvári. 2006. Bandit based monte-carlo planning. In European conference on machine learning . Springer , 282–293. [15] W oosuk K won, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Ecient memory management for large language mo del serving with pagedattention. In Proceedings of the 29th symp osium on operating systems principles . 611–626. [16] Jiale Lao, Yibo W ang, Yufei Li, Jianping W ang, Yunjia Zhang, Zhiyuan Cheng, W anghu Chen, Mingjie Tang, and Jianguo W ang. 2024. Gptuner: A manual- reading database tuning system via gpt-guided bayesian optimization. Proceedings of the VLDB Endowment 17, 8 (2024), 1939–1952. [17] Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan T ang. 2024. The Dawn of Natural Language to SQL: Are W e Fully Ready? arXiv preprint arXiv:2406.01265 (2024). [18] Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Y ang, Binhua Li, Bowen Li, Bailin W ang, Bowen Qin, Ruiying Geng, Nan Huo, et al . 2023. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems 36 (2023), 42330–42357. [19] Lan Li, Liri Fang, and V etle I T orvik. 2024. AutoDCW orkow: LLM-based Data Cleaning W orkow Auto-Generation and Benchmark. arXiv preprint arXiv:2412.06724 (2024). [20] Fang Liu, Y ang Liu, Lin Shi, Houkun Huang, Ruifeng W ang, Zhen Y ang, Li Zhang, Zhongqi Li, and Yuchi Ma. 2024. Exploring and evaluating hallucinations in llm-powered code generation. arXiv preprint arXiv:2404.00971 (2024). [21] Eric Lo, Carsten Binnig, Donald Kossmann, M T amer Özsu, and Wing-Kai Hon. 2010. A framework for testing DBMS features. The VLDB Journal 19, 2 (2010), 203–230. ICSE-Companion ’26, April 12–18, 2026, Rio de Janeiro, Brazil Y ujia Chen, Yingli Zhou, Fangyuan Zhang, and Cuiyun Gao [22] Zan Ahmad Naeem, Mohammad Shahmeer Ahmad, Mohamed Eltabakh, Mourad Ouzzani, and Nan T ang. 2024. RetClean: Retrieval-Based Data Cleaning Using LLMs and Data Lakes. Procee dings of the VLDB Endowment 17, 12 (2024), 4421– 4424. [23] Xianfei Ou, Cong Li, Y anyan Jiang, and Chang Xu. 2024. The Mutators Reloaded: Fuzzing Compilers with Large Language Model Generated Mutation Operators. In Proceedings of the 29th ACM International Conference on A rchitectural Support for Programming Languages and Op erating Systems, V olume 4, ASPLOS . 298–312. [24] Mike O wens and Grant Allen. 2010. SQLite . Apress LP New Y ork. [25] M Tamer Özsu and Patrick Valduriez. 1996. Distributed and parallel database systems. ACM Computing Sur veys (CSUR) 28, 1 (1996), 125–128. [26] Lauren Pick, Amanda Xu, Ankush Desai, Sanjit A Seshia, and Aws Albarghouthi. 2025. Checking Obser vational Correctness of Database Systems. Proce edings of the A CM on Programming Languages 9, OOPSLA1 (2025), 1661–1688. [27] Yichen Qian, Yongyi He, Rong Zhu, Jintao Huang, Zhijian Ma, Haibin W ang, Y aohua Wang, Xiuyu Sun, Defu Lian, Bolin Ding, et al . 2024. UniDM: A Unied Framework for Data Manipulation with Large Language Models. Procee dings of Machine Learning and Systems 6 (2024), 465–482. [28] Qwen, :, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, Junyang Lin, Kai Dang, et al . 2024. Q wen2.5 T echnical Rep ort. arXiv preprint (2024). [29] Mark Raasveldt and Hannes Mühleisen. 2019. Duckdb: an emb eddable analytical database. In Proceedings of the 2019 international conference on management of data . 1981–1984. [30] Manuel Rigger and Zhendong Su. 2020. Detecting optimization bugs in database engines via non-optimizing reference engine construction. In ESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . ACM, 1140–1152. [31] Manuel Rigger and Zhendong Su. 2020. Finding bugs in database systems via query partitioning. Proc. A CM Program. Lang. 4, OOPSLA (2020), 211:1–211:30. [32] Manuel Rigger and Zhendong Su. 2020. T esting database engines via pivoted query synthesis. In 14th USENIX Symposium on Op erating Systems Design and Implementation (OSDI 20) . 667–682. [33] Manuel Rigger and Zhendong Su. 2020. T esting Database Engines via Pivoted Query Synthesis. In 14th USENIX Symposium on Operating Systems Design and Implementation, OSDI . 667–682. [34] Andreas Seltenreich. 2025. Sqlsmith. https://github.com/anse1/sqlsmith. [35] Vikramank Singh, Kapil Eknath V aidya, Vinayshekhar Bannihatti Kumar, Sopan Khosla, Murali Narayanaswamy , Rashmi Gangadharaiah, and Tim Kraska. 2024. Panda: Performance debugging for databases using LLM agents. (2024). [36] Michael Stonebraker and Lawrence A Rowe. 1986. The design of Postgres. ACM Sigmod Record 15, 2 (1986), 340–355. [37] Maciej Świechowski, Konrad Godlewski, Bartosz Sawicki, and Jacek Mańdziuk. 2023. Monte Carlo tree search: A review of r ecent modications and applications. A rticial Intelligence Review 56, 3 (2023), 2497–2562. [38] Jianxun Wang and Yixiang Chen. 2023. A review on code generation with llms: Application and evaluation. In 2023 IEEE International Conference on Medical A rticial Intelligence (Me dAI) . IEEE, 284–289. [39] Junjie W ang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song W ang, and Qing W ang. 2024. Software testing with large language mo dels: Sur vey , landscape, and vision. IEEE Transactions on Software Engineering 50, 4 (2024), 911–936. [40] Mingzhe W ang, Zh iyong Wu, Xinyi Xu, Jie Liang, Chijin Zhou, Huafeng Zhang, and Y u Jiang. 2021. Industry practice of coverage-guided enterprise-level DBMS fuzzing. In 2021 IEEE/ACM 43rd International Conference on Software Engine ering: Software Engine ering in Practice (ICSE-SEIP) . 328–337. [41] Chunqiu Ste ven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. 2024. Fuzz4All: Universal Fuzzing with Large Language Models. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE, Lisbon, Portugal . 126:1–126:13. [42] Y uanmin Xie, Zhenyang Xu, Y ongqiang Tian, Min Zhou, Xintong Zhou, and Chengnian Sun. 2025. Kitten: A Simple Y et Eective Baseline for Evaluating LLM- Based Compiler T esting Techniques. In Proce e dings of the 34th ACM SIGSOFT International Symposium on Software T esting and A nalysis . 21–25. [43] Zhiyi Xue, Liangguo Li, Senyue Tian, Xiaohong Chen, Pingping Li, Liangyu Chen, Tingting Jiang, and Min Zhang. 2024. Llm4n: Fully automating llm-p owered test case generation for ntech software acceptance testing. In Proce edings of the 33rd A CM SIGSOFT International Symposium on Software T esting and A nalysis . 1643–1655. [44] Chenyuan Yang, Yinlin Deng, Runyu Lu, Jiayi Yao , Jiawei Liu, Reyhaneh Jab- barvand, and Lingming Zhang. 2024. WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models. Proc. ACM Program. Lang. 8, OOPSLA2 (2024), 709–735. [45] Chenyuan Y ang, Zijie Zhao, and Lingming Zhang. 2025. KernelGPT: Enhanced Kernel Fuzzing via Large Language Models. In Proceedings of the 30th ACM International Conference on A rchitectural Support for Programming Languages and Operating Systems, V olume 2, ASPLOS . 560–573. [46] Y upeng Y ang, Y ongheng Chen, Rui Zhong, Jizhou Chen, and W enke Lee. 2024. T owards generic database management system fuzzing. In 33rd USENIX Security Symposium (USENIX Security 24) . 901–918. [47] Yihang Zheng, Bo Li, Zhenghao Lin, Yi Luo, Xuanhe Zhou, Chen Lin, Jinsong Su, Guoliang Li, and Shifu Li. 2024. Revolutionizing Database Q&A with Large Language Models: Comprehensive Benchmark and Evaluation. arXiv preprint arXiv:2409.04475 (2024). [48] Rui Zhong, Y ongheng Chen, Hong Hu, Hangfan Zhang, W enke Lee, and Dinghao Wu. 2020. Squirrel: T esting database management systems with language validity and coverage feedback. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security . 955–970. [49] Suyang Zhong and Manuel Rigger . 2025. Scaling A utomated Database System T esting. arXiv preprint arXiv:2503.21424 (2025). [50] Suyang Zhong and Manuel Rigger . 2025. T esting Database Systems with Large Language Model Synthesized Fragments. arXiv preprint arXiv:2505.02012 (2025). [51] Xuanhe Zhou, Guoliang Li, Chengliang Chai, and Jianhua Feng. 2021. A learne d query rewrite system using monte carlo tree search. Proceedings of the VLDB Endowment 15, 1 (2021), 46–58. [52] Xuanhe Zhou, Guoliang Li, Zhaoyan Sun, Zhiyuan Liu, W eize Chen, Jianming Wu, Jiesi Liu, Ruohang Feng, and Guoyang Zeng. 2024. D-bot: Database diagnosis system using large language models. Proceedings of the VLDB Endowment 17, 10 (2024), 2514–2527. Received 15 November 2025; revised 6 January 2026; accepted 6 Januar y 2026
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment