LLM 기반 DBMS 테스트 케이스 생성: 몬테카를로 트리 탐색으로 커버리지 향상
본 논문은 경량 LLM을 활용해 다양한 DBMS 방언에 맞는 고품질 SQL 테스트 케이스를 자동 생성하고, 몬테카를로 트리 탐색(MCTS) 기반 변이 기법으로 코드 커버리지를 크게 향상시키는 MIST 프레임워크를 제안한다. 실험 결과, 라인·함수·분기 커버리지가 평균 43.3%, 32.3%, 46.4%씩 개선되었으며, Optimizer 모듈에서 69.3%의 최고 라인 커버리지를 달성했다.
저자: Yujia Chen, Yingli Zhou, Fangyuan Zhang
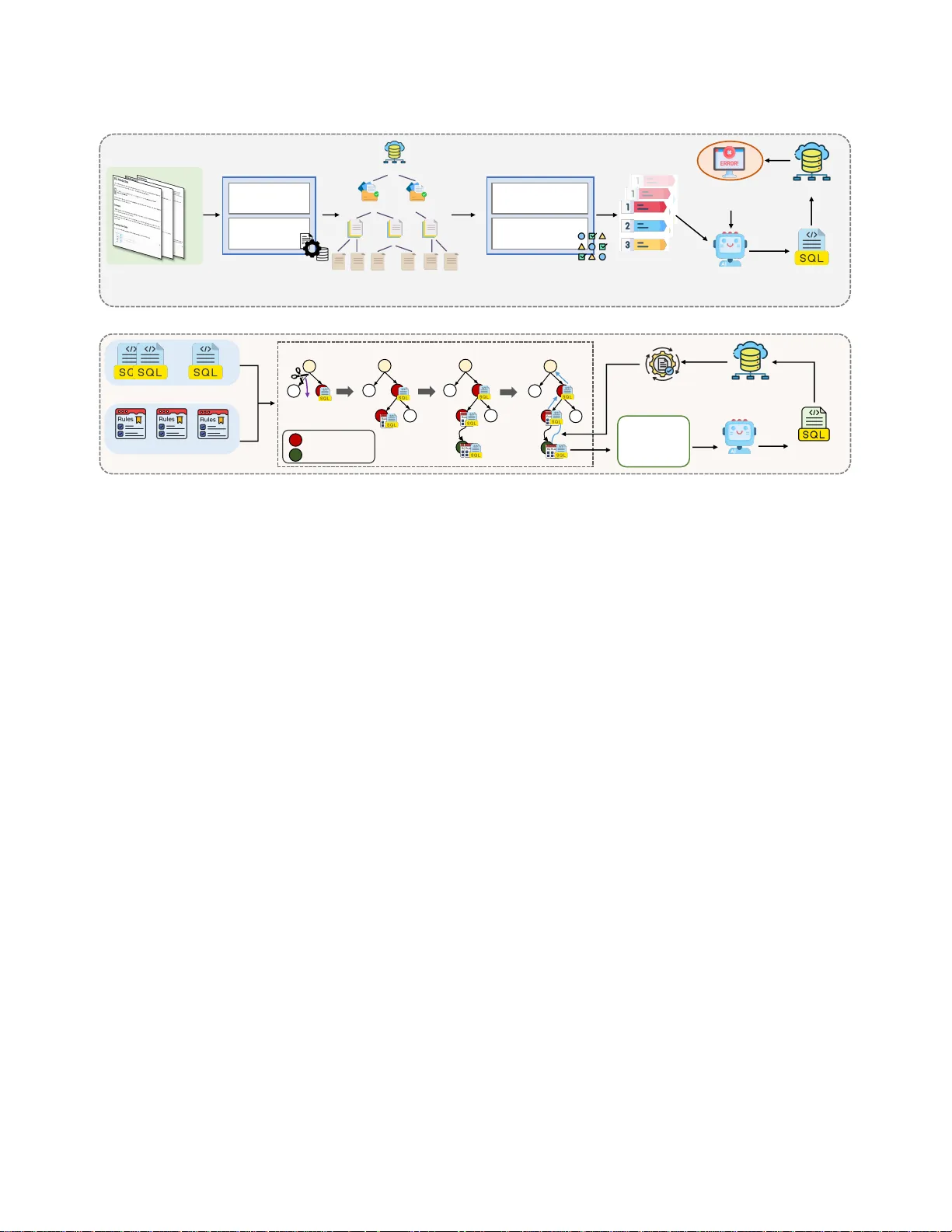
본 논문은 데이터베이스 관리 시스템(DBMS)의 신뢰성을 확보하기 위한 테스트 케이스 자동 생성 문제에 주목한다. 기존의 퍼징 기반 도구(BuzzBee, SQLsmith, SQLancer 등)는 특정 DBMS에 최적화돼 있지만, 서로 다른 방언을 가진 상용 DBMS에 적용하려면 문법 규칙을 새로 작성해야 하는 높은 인력 비용이 발생한다. 최근 대규모 언어 모델(LLM)이 텍스트‑투‑SQL, 데이터 정제, DBMS 튜닝 등 다양한 데이터 관리 작업에서 성공을 거두면서, DBMS 테스트에도 활용 가능성이 제기되었다. 그러나 산업 현장에서는 보안·프라이버시 이유로 70B 이하의 경량 모델을 로컬에 배포해야 하며, 이러한 모델은 복잡한 방언 구문을 정확히 생성하지 못하고, 생성된 쿼리들이 의미적으로 유사해 커버리지가 빠르게 정체되는 두 가지 핵심 문제에 직면한다.
이를 해결하기 위해 저자들은 MIST(LLM‑based test case generation framework for DBMS through Monte Carlo Tree Search)라는 두 단계 프레임워크를 설계했다. 첫 단계인 Feature‑Guided Error‑Driven Test Case Synthetization에서는 목표 DBMS의 공식 문서를 파싱해 Feature Tree를 만든다. 트리는 DBMS → 기능 그룹 → 구체적 기능 토픽으로 계층화되며, 각 기능은 이름, 설명, 대표 구문을 포함한다. 예를 들어 DuckDB의 문자열 연결 연산자 ‘||’와 PostgreSQL의 CONCAT 함수를 별도 노드로 구분한다. 이렇게 구축된 트리는 무작위 경로 샘플링을 통해 기능 조합을 선택하고, 선택된 기능들을 프롬프트에 삽입해 LLM이 SQL을 생성하도록 유도한다. 생성 과정에서 발생한 구문·의미 오류는 Error Memory에 저장돼 다음 프롬프트에 피드백으로 제공된다. 이 피드백 루프는 경량 LLM이 방언 특화 제약을 학습하게 하여, 초기에는 오류가 많았지만 반복 수행될수록 syntactic validity와 semantic diversity가 크게 향상된다.
두 번째 단계인 Monte Carlo Tree Search‑Based Test Case Mutation은 초기 생성 단계에서 커버리지가 정체될 때 작동한다. 기존에 생성된 테스트 케이스를 Seed Pool로 두고, 사전에 정의된 변이 규칙(DDL 변형, DML 변형, DQL 변형)을 적용한다. 변이 적용 과정은 MCTS 알고리즘에 의해 제어되며, 각 노드는 “현재 시드 + 적용된 변이 집합”이라는 상태를 나타낸다. MCTS는 선택(Selection), 확장(Expansion), 시뮬레이션(Simulation), 역전파(Backpropagation) 네 단계로 진행되며, 선택 단계에서는 Upper Confidence Bound(UCB) 공식을 사용해 탐색‑활용 균형을 맞춘다. 시뮬레이션 단계에서는 변이된 쿼리를 실제 DBMS에 실행해 라인·함수·분기 커버리지를 측정하고, 이를 보상값으로 사용한다. 보상값은 역전파를 통해 트리 전체에 전파돼, 높은 보상을 얻은 변이 조합이 다음 탐색에서 더 자주 선택된다. 변이 규칙은 스키마 변형(컬럼 추가·삭제·타입 변경), 데이터 변형(값 교체·NULL 삽입·중복 제거), 쿼리 연산 변형(조인 유형 교체·집계 함수 교체·서브쿼리 삽입) 등으로 구성돼 있어, 복잡한 실행 경로(예: 다중 조인, 서브쿼리, 옵티마이저 플랜 선택)를 탐색하도록 설계되었다.
실험은 DuckDB, PostgreSQL, SQLite 세 개의 오픈소스 DBMS와 Qwen2.5‑7B, Qwen2.5‑14B, Qwen2.5‑32B, Llama3.1‑8B 네 종류의 경량 LLM을 조합해 수행되었다. Baseline은 기존 LLM‑only 생성 방식이며, MIST는 두 단계 모두 적용한다. 결과는 다음과 같다. (1) 라인 커버리지는 DuckDB에서 69.3%, PostgreSQL에서 63.4%, SQLite에서 58.7%까지 상승했다. (2) 함수·분기 커버리지는 평균 32.3%·46.4% 향상되었다. (3) 특히 Optimizer 모듈에서 큰 폭의 개선이 관찰됐으며, 이는 변이 단계가 복잡한 쿼리 플랜을 유도해 옵티마이저 내부 경로를 넓게 탐색했기 때문이다. (4) 경량 LLM만 사용했음에도 불구하고, 대형 모델 대비 비슷하거나 높은 커버리지를 달성했으며, 보안·프라이버시 요구가 있는 기업 환경에 적합함을 입증했다.
논문의 주요 기여는 다음과 같다. 첫째, 경량 LLM만으로도 다양한 DBMS 방언에 맞는 고품질 테스트 케이스를 자동 생성할 수 있는 프레임워크를 제시했다. 둘째, 계층적 Feature Tree와 Error‑Driven 피드백을 결합해 LLM의 syntactic validity와 semantic diversity를 동시에 향상시켰다. 셋째, MCTS 기반 변이 엔진을 도입해 초기 생성 단계에서 정체된 커버리지를 효과적으로 탈피하고, 깊은 실행 경로를 탐색했다. 넷째, 세 개의 DBMS와 네 종류의 LLM에 대한 광범위한 실험을 통해 MIST가 기존 방법 대비 18.5%~92.9% 높은 커버리지를 달성함을 실증했다.
한계점으로는 Feature Tree 구축에 수작업이 필요하고, 새로운 DBMS 버전이나 방언이 추가될 경우 재구축 비용이 발생한다는 점이다. 또한, 변이 규칙이 사전에 정의돼 있어, 완전히 새로운 쿼리 패턴을 자동으로 발견하는 데는 한계가 있다. MCTS 탐색 비용도 시드와 변이 규칙 수에 비례해 증가하므로, 대규모 테스트 환경에서는 효율적인 병렬화와 탐색 깊이 제한이 필요하다. 향후 연구에서는 자동화된 Feature Extraction, 동적 변이 규칙 학습, 강화학습 기반 탐색 전략을 결합해 비용 효율성을 높이고, CI/CD 파이프라인에 실시간으로 통합하는 방안을 모색한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기