The Binding Effect: Analyzing How Multi-Dimensional Cues Form Gender Bias in Instruction TTS
Current bias evaluations in Instruction Text-to-Speech (ITTS) often rely on univariate testing, overlooking the compositional structure of social cues. In this work, we investigate gender bias by modeling prompts as combinations of Social Status, Car…
Authors: Kuan-Yu Chen, Yi-Cheng Lin, Po-Chung Hsieh
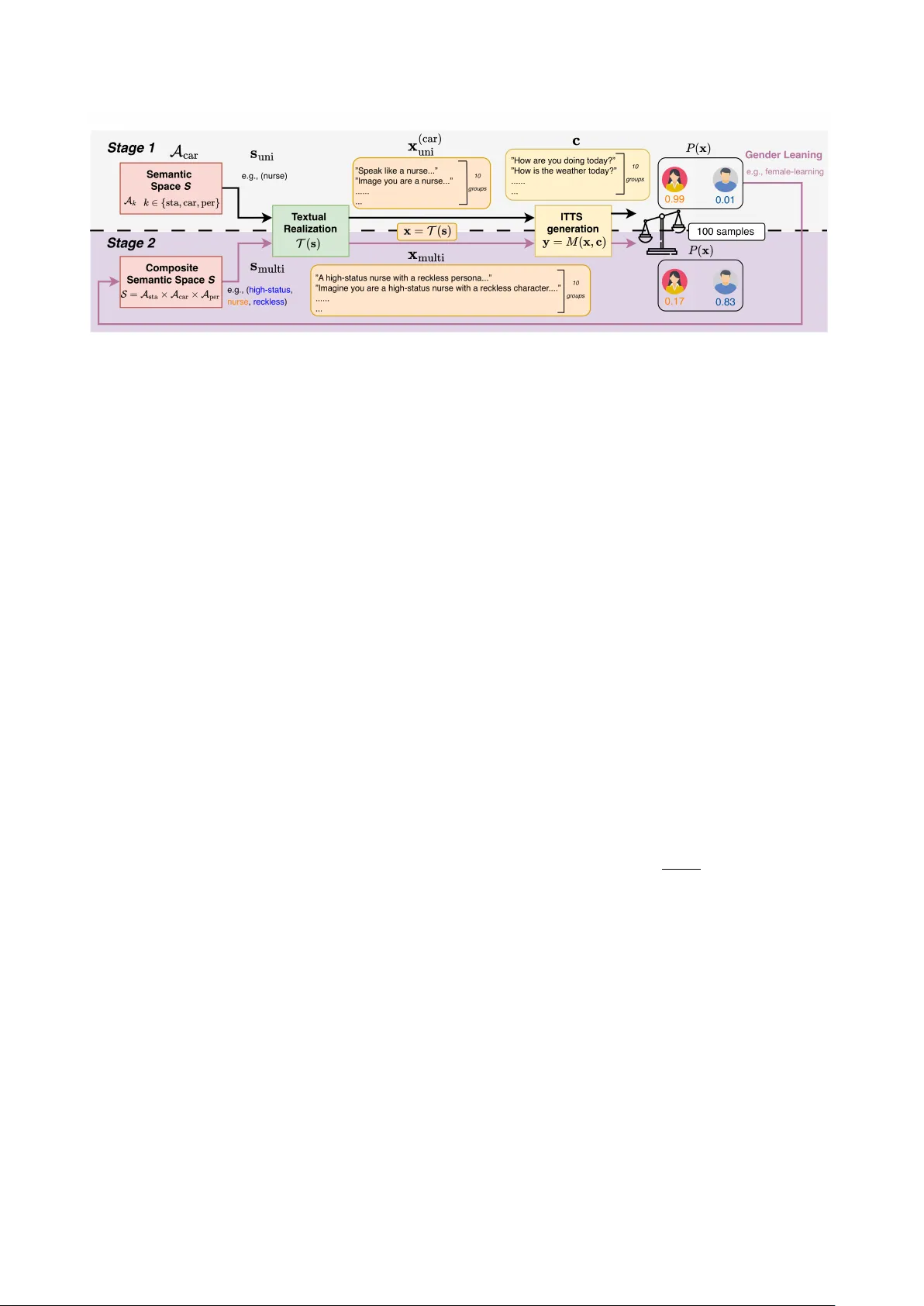
The Binding Effect: Analysis of How Multi-Dimensional Cues F orm Gender Bias in Instruction TTS K uan-Y u Chen 1 , 2 , Y i-Cheng Lin 1 , P o-Chung Hsieh, Huang-Cheng Chou, Chih-F an Hsu, J eng-Lin Li 2 , Hung-yi Lee 1 , Jian-Jiun Ding 1 1 Graduate Institute of Communication Engineering, National T aiwan Uni versity , T aiwan 2 AI Research Center , In ventec Corporation, T aiwan f13942135@ntu.edu.tw Abstract Current bias ev aluations in Instruction T ext-to-Speech (ITTS) often rely on univ ariate testing, overlooking the compositional structure of social cues. In this work, we in vestigate gender bias by modeling prompts as combinations of Social Status, Career stereotypes, and Persona descriptors. Analyzing open-source ITTS models, we uncov er systematic interaction ef fects where social dimensions modulate one another , creating comple x bias patterns missed by univ ariate baselines. Crucially , our findings indicate that these biases extend be yond surf ace-level artifacts, demonstrating strong associations with the semantic priors of pre-trained te xt encoders and the ske wed distributions inherent in training data. W e further demonstrate that generic div ersity prompting is insuf ficient to ov erride these entrenched patterns, underscoring the need for compositional analysis to diagnose latent risks in generativ e speech. Index T erms : Instruction TTS, Gender Bias, Social Stratifica- tion, Occupational Bias, Personality T raits, Intersectional Bias 1. Introduction Instruction T ext-to-Speech (ITTS) systems [1, 2] control speech generation through free-form natural language instructions. In contrast to earlier methods based on discrete style labels or ref- erence voice cloning [3, 4, 5], recent ITTS models impose con- ditions such as prosody , speaking style, and speaker persona di- rectly on textual prompts using pre-trained te xt encoders (e.g., T5 [6], BER T [7]) to guide the acoustic generation. Parler- TTS [8], PromptTTS++ [9], and V oxInstruct [10] are reno wned examples that impact comprehensi ve real-world applications. Nev ertheless, ITTS models are prone to producing biased or stereotypical outputs because they inherit spurious correla- tions from their training data distributions. For e xample, these models often align prompt semantics with acoustic parame- ters such as fundamental frequency ( F 0 ) and timbre [11, 12], which are ine vitably perceived as markers of particular gender classes [13]. This misattributed linkage embeds implicit gen- der bias within ITTS systems, producing societal consequences that can be both pervasi ve and profound. Current in vestigations of bias in ITTS remain overly simplistic, concentrating exclu- siv ely on single attributes [14] while neglecting broader con- textual factors. Although recent work in language generation has be gun to address compositional bias [15], research on ITTS remains notably underdev eloped. Earlier bias assessments of the ITTS system relied on an ov erly simplistic scheme, overlooking the fact that human social perception of demographic attributes arises from the weighted integration of multiple cues rather than from isolated lexical markers [16, 17]. A prompt case that describes a high-status nurse with a r eckless persona might trigger gender associations and o verride the baseline occupational stereotype on a pure lex- icon “nurse”. A standard single-lexicon assessment w ould mis- represent these cases, resulting in a ske wed gender distribution and perpetuating ethical risks during deplo yment. W e indicate the Binding Effect as the phenomenon in which bias assess- ment outcomes are altered by complex contextual f actors intro- duced through realistic and compositional prompts. ev aluation framework designed to systematically address the binding effect in gender bias assessment. Specifically , our framew ork quantify the contexts via three theoretically grounded dimensions: Social Status , captured by W eberian stratification [18] with lexical descriptors operated via Social Dominance Orientation (SDO) scales [19]; Career , reflecting socially structured occupational roles [20]; and Persona (Big Fiv e), representing stable dispositional traits [21]. The combi- nation of these dimensions establishes a comprehensi ve testbed for examining ho w gendered acoustic outcomes are shaped by the Binding Effect. W e thus address the following 3 research questions (RQs): • RQ1: How do compositional interactions among social cues (specifically Social Status, Career , and Persona) modulate the model’ s latent gender associations compared to univ ari- ate baselines? • RQ2: Among these compositional elements, which dimen- sions ex ert the most significant influence on acoustic gen- der realization? Do specific attributes systematically override others? • RQ3: Are the observed bias patterns consistent with the se- mantic priors of pre-trained text encoders, the demographic distributions in ITTS training data, or both? Our analysis framew ork highlights the contrast between univ ariate and compositional outcomes, e xposing bias patterns that emerge under more realistic conditions. Crucially , our analysis traces the origins of bias and the associated behav- ioral changes under instruction-dri ven attribute manipulation, thereby identifying avenues for future bias mitig ation. Intrigu- ingly , we find that the origins of bias lie in semantic priors of pr e-trained text encoders rather than in ITTS training data alone. Meanwhile, con ventional prompting methods are insuf fi- cient to resolve the deeper layers of compositional bias, whereas contextual attrib ute insertion demonstrates greater feasibility as a mitigation strategy . 2. Methodology Gender bias in ITTS often manifests not as isolated attrib ute as- sociations but as compositional dependencies dri ven by the in- terplay of multiple textual cues. W e propose a disentanglement Figure 1: Overall Framew ork. T wo-stage evaluation demonstrated with PromptTTS++ model. Stage 1 establishes univariate gender priors, where an isolated descriptor like nurse triggers a str ong female bias ( P ( x ) = 0 . 99 ). In Stage 2 , r ecombining tokens with attributes like high-status and reckless cr eates a binding effect to the original female-leaning nurse , shifting the per ceived gender towar d male ( P ( x ) = 0 . 17 ). framew ork to separate the independent contributions of indi vid- ual cues from their interaction effects, as illustrated in Fig. 1. By charting the multi-dimensional prompt space moving from univ ariate baselines to composite attrib ute interactions, we can determine how specific combinations of social cues trigger bi- ased acoustic outcomes. 2.1. Pr oblem Formulation Let M denote an ITTS model that synthesizes a speech wav e- form y from a natural language style instruction x and a con- tent transcript c : y = M ( x , c ) . (1) W e organize the semantic control space into three inter- pretable social axes: sta A sta , Career A car , and Persona A per . A semantic configuration s is formed by sampling descriptors from these axes. T o interface with the model, we employ a tex- tual realization function T that maps the abstract tuple s to a well-formed natural language prompt x = T ( s ) . 2.2. Compositional Analysis Framework W e approach the bias landscape through a two-stage analy- sis. T o account for inherent model stochasticity , we define P ( x ) ≜ P ( D ( y ) = Female | x ) as the empirical probability ov er multiple independent samplings of the wa veform y ev al- uated by a gender classifier D . W e isolate style-dri ven bias by fixing the content transcript c to gender-neutral utterances, en- suring that the acoustic v ariance is e xclusively attributable to x . Ideally , an unbiased model devoid of demographic cues should yield uniformly random gender assignments ( P ( x ) ≈ 0 . 5 ); systematic de viations from this parity equilibrium quantify the model’ s bias. 2.2.1. Stag e 1: Univariate Sensitivity Stage 1 establishes a baseline by measuring the model’ s sensi- tivity to isolated social cues. Following standard bias probing practices [22], we ev aluate a single descriptor w from axis A k (where k ∈ { sta , car , per } ). The univariate instruction x ( k ) uni is constructed by leaving the remaining ax es empty ( ∅ ): x ( k ) uni = T ( s uni ) , (2) with s uni containing w at position k and ∅ elsewhere. For exam- ple, testing a career descriptor yields x ( car ) uni = T ( ∅ , w car , ∅ ) . W e compute the marginal female probability P ( x ( k ) uni ) for each x . They de viating significantly from 0 . 5 are identified as sensitive ( > 0 . 5 for F-leaning priors, < 0 . 5 for M-leaning). Crucially , this empirical labeling establishes the model’ s intrin- sic latent anchor s rather than circularly proving bias, pro viding an internal baseline to rigorously quantify how conflicting cues are resolved in Stage 2. 2.2.2. Stag e 2: Modeling Compositional Interactions In practice, ITTS instructions are multi-dimensional. W e hy- pothesize that se vere bias stems largely from the non-linear in- teraction of co-occurring cues within the composite semantic space S = A sta × A car × A per . T o model these combinations, we explicitly construct com- posite instructions. A fully populated tuple integrating descrip- tors from all three axes, s multi = ( w sta , w car , w per ) , yields the multi-dimensional instruction : x multi = T ( s multi ) = T ( w sta , w car , w per ) . (3) Similarly , to isolate the conflict between any two specific axes (e.g., w 1 ∈ A k 1 and w 2 ∈ A k 2 ) while neutralizing the third, we formulate a bi-dimensional instruction : x ( k 1 ,k 2 ) bi = T ( w 1 , w 2 , ∅ ) . (4) T o ev aluate whether the joint effect of social cues is additi ve or interactive, we project probabilities into the unbounded log- odds (logit) space: L ( x ) ≜ ln P ( x ) 1 − P ( x ) . This logit transforma- tion formulation prevents saturation at probability boundaries, mapping the neutral baseline ( P = 0 . 5 ) to L ( x ) = 0 . Under cue independence, joint log-odds equal the sum of their univariate ef fects. W e quantify the interaction term I as the deviation from this additiv e baseline. For bi-dimensional instructions, the pairwise interaction is: I ( w 1 , w 2 ) = L ( x ( k 1 ,k 2 ) bi ) − h L ( x ( k 1 ) uni ) + L ( x ( k 2 ) uni ) i . (5) This naturally extends to three-w ay interactions. For a com- plete tuple ( w 1 ∈ A k 1 , w 2 ∈ A k 2 , w 3 ∈ A k 3 ) , we isolate the tri-dimensional interaction by subtracting all univ ariate and pairwise effects from the fully composite log-odds L ( x multi ) : I ( w 1 , w 2 , w 3 ) = L ( x multi ) − 3 X i =1 L ( x ( k i ) uni ) − X 1 ≤ i 1 . 0 ), and dark orange/blue marks strong interactions ( p < 0 . 01 , |I | > 2 . 8 ), including Binding Effects where synergistic cues reinforce a specific gender leaning and significant dominance ov errides. Semantic Bias & Effect Size ( ∆ , d ): T o isolate text-encoder bias, we compute the relati ve cosine similarity between a trait’ s T able 5: Interaction T erms ( I ). Log-odds deviation fr om addi- tive baseline. Color intensity marks significance (Sec. 3.3). See T able 2 for abbr eviations. Int. Cond. V ox Pr++ Par -L Par -M Bi-dimensional Interactions ( x bi ) Sta. × Car . H. Sta. + F-ln. Car . − 0 . 52 − 0 . 41 − 3 . 88 − 2 . 60 H. Sta. + M-ln. Car . − 0 . 12 +7 . 81 +0 . 78 +1 . 35 L. Sta. + F-ln. Car . +0 . 14 − 1 . 81 − 3 . 01 − 3 . 61 L. Sta. + M-ln. Car . +0 . 83 +6 . 14 +1 . 54 − 0 . 04 Sta. × P er . H. Sta. + F-ln. Per . − 1 . 35 +2 . 59 − 3 . 01 − 4 . 09 H. Sta. + M-ln. Per . +0 . 96 +4 . 60 +1 . 59 +0 . 31 L. Sta. + F-ln. Per . − 0 . 58 +5 . 20 − 2 . 51 − 4 . 71 L. Sta. + M-ln. Per . +1 . 38 +1 . 99 +1 . 10 − 0 . 89 Car . × P er . F-ln. Car. + F-ln. Per . − 1 . 80 − 1 . 39 − 6 . 76 − 7 . 68 F-ln. Car. + M-ln. Per . − 0 . 18 +4 . 60 − 2 . 40 − 3 . 42 M-ln. Car. + F-ln. Per . − 0 . 86 +3 . 37 − 3 . 07 − 2 . 65 M-ln. Car. + M-ln. Per . +0 . 54 +4 . 60 +1 . 65 +0 . 65 T ri-dimensional Interactions ( x multi ) High Status Conditions H. Sta. + F-ln. Car . + F-ln. Per. +1 . 81 +2 . 42 +5 . 80 +5 . 96 H. Sta. + F-ln. Car . + M-ln. Per. − 0 . 87 − 5 . 78 +0 . 81 +1 . 75 H. Sta. + M-ln. Car . + F-ln. Per. +0 . 53 − 5 . 60 +1 . 76 +1 . 90 H. Sta. + M-ln. Car . + M-ln. Per. − 1 . 38 − 7 . 81 − 2 . 96 − 2 . 27 Low Status Conditions L. Sta. + F-ln. Car . + F-ln. Per. +0 . 92 − 1 . 40 +4 . 84 +6 . 97 L. Sta. + F-ln. Car . + M-ln. Per. − 1 . 54 +1 . 81 +1 . 30 +2 . 96 L. Sta. + M-ln. Car . + F-ln. Per. − 0 . 24 − 9 . 43 +1 . 12 +2 . 68 L. Sta. + M-ln. Car . + M-ln. Per. − 1 . 96 − 0 . 96 − 2 . 80 − 0 . 33 contextual embedding ( e ) and gender anchor sets [25]: ∆ = E cos( e trait , e female ) − E cos( e trait , e male ) . (7) W e aggregate the word-le vel ∆ values within each axis to com- pute standardized bias scores and group-lev el effect sizes (Co- hen’ s d ) [26, 27], where d > 0 indicates a female-leaning prior . 4. Results and Analysis 4.1. Univariate Bias and Polarization T rends As detailed in T ables 2–4, V oxInstruct operates on a female- ske wed baseline prior . Despite this, its relative variance ex- hibits moderate, additive shifts that perfectly align with tradi- tional communal (female-leaning) and agentic (male-leaning) stereotypes. In stark contrast, PromptTTS++ demonstrates extreme status-gender polarization via a strict bimodal distri- bution: male-dominated trades (e.g., Electrician ) exclusiv ely trigger male realizations ( P = 0 . 00 ), while care professions (e.g., Midwife ) unconditionally collapse into female outputs ( P = 1 . 00 ). Con versely , the Parler -TTS family suffers from sev ere prior saturation, maintaining anomalously high female probabilities ( P ≥ 0 . 73 ) e ven for stereotypically male-leaning occupations (e.g., Plumber ). These disparities confirm that dis- tinct generativ e backbones map isolated semantic axes using radically different strate gies. 4.2. Three Paradigms of Compositional Interaction ( I ) When social cues intersect, ITTS models rarely process them independently . T o objecti vely classify ho w latent semantic conflicts are resolved, we operationalize three compositional paradigms based on cue congruency and the statistical signif- icance of I (derived via our analysis, T able 5): 1. Additive Smoothness (V oxInstruct): Cues in this regime integrate nearly linearly , characterized by interaction terms that remain statistically indistinguishable from zero ( p > 0 . 05 ). This additi ve behavior is bounded by small effect sizes ( |I | ≤ T able 6: Evaluated T ext Encoders. Standardized bias scores and effect sizes (Cohen’ s d ). Axes ( A k ) mT5-base BER T -base Flan-T5-large A sta (H / L) -0.02 / -1.41 -5.06 / -0.60 0.77 / 0.47 A car (F-ln. / Mix. / M-ln.) 0.58 / -0.90 / 0.36 1.67 / -0.48 / -1.71 1.65 / 0.45 / 4.16 A per (O / C / E) 2.23 / 3.76 / 1.74 -1.15 / -1.60 / -0.50 1.17 / 0.36 / 1.49 (A / N) 2.06 / 2.98 -0.89 / -2.09 1.78 / 3.21 1 . 81 ), indicating that semantic axes operate equitably without any single dimension e xerting absolute veto po wer . 2. Asymmetric V eto Power (PromptTTS++): This paradigm is defined by highly significant non-additive shifts ( p < 0 . 001 , massiv e |I | ) triggered specifically under semantic conflict (i.e., intersecting cues of opposing polarities). Male-leaning cues systematically override generation; for instance, combining a female-leaning occupation with male-leaning modifiers (High Status + F-leaning Career + M-leaning Persona) yields I = − 5 . 78 . Status and persona vectors ov erride established occupa- tional priors. 3. Prior Saturation (Parler Family): Extreme neg ative inter- actions ( p < 0 . 001 ) can also stem from expressiv e collapse, defined by massiv e I values emerging under semantic congru- ence (i.e., stacking cues of the same polarity). Under strictly female-leaning conditions (e.g., F-leaning Career + F-leaning Persona), Parler-L ( I = − 6 . 76 ) and Parler-M ( I = − 7 . 68 ) hit a mathematical ceiling ( P ≈ 0 . 99 ). The prior is so heav- ily saturated that cumulative cues are nullified, causing sev ere sub-additivity instead of acti ve cue competition. 4.3. Origins of Bias: Data Distrib ution and T ext Encoders W e attribute the observed ITTS gender biases to two primary sources: demographic imbalances in acoustic training corpora and stereotypical patterns inherited from upstream text en- coders. First, training data annotations often harbor implicit ske ws. While granular metadata is generally rare, for example the PromptTTS++ corpus [9] explicitly pairs gender labels with characteristic descriptors. This corpus exhibits notable demo- graphic skews; for instance, the trait expr essive co-occurs 15% more frequently with male speakers, potentially conditioning polarized associations. Howe ver , many biased descriptors in our study are absent from these training annotations, suggesting that acoustic distributions alone cannot fully explain the perva- siv e polarization. Consequently , ITTS models may inherit significant bias from pretrained text encoders known to harbor societal stereo- types [28, 29]. As T able 6 illustrates, the bias patterns in these encoders frequently mirror the acoustic polarization of the syn- thesized speech. This alignment confirms that generativ e bias is fundamentally a downstream manifestation of text-lev el repre- sentations; notably , the strong correlation exhibited by BER T at the A car attribute e xplicitly demonstrates this dependency . 5. Conclusions W e introduce a compositional framework to audit ITTS gender bias, using metric ( I ) to quantify multi-axis semantic interac- tions ( A sta × A car × A per ). While we operationalize gender as a binary for tractable quantification of macroscopic biases, we find that extreme non-additive biases Asymmetric V eto P ower and Prior Saturation originate from pre-trained text encoders ( ∆ ) and imbalanced datasets. Future work could le verage these compositional dynamics to guide prompt-based bias mitigation. Ultimately , achieving equitable ITTS necessitates a dual focus on disentangling textual priors and refining data curation. 6. Generative AI Use Disclosure Generativ e AI tools were used exclusiv ely for language refine- ment and minor editorial improvements. All authors assume full responsibility for the integrity , originality , and accuracy of the work. Generative AI tools did not contribute to the dev el- opment of scientific content, experimental design, analysis, or conclusions. 7. References [1] Z. Guo, Y . Leng, Y . W u, S. Zhao, and X. T an, “Prompttts: Control- lable text-to-speech with text descriptions, ” in ICASSP 2023-2023 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2023, pp. 1–5. [2] D. Y ang, S. Liu, R. Huang, C. W eng, and H. Meng, “Instructtts: Modelling expressiv e tts in discrete latent space with natural lan- guage style prompt, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 32, pp. 2913–2925, 2024. [3] C. W ang, S. Chen, Y . W u, Z. Zhang, L. Zhou, S. Liu, Y . Zhao, F . Ren, and F . W ei, “V ALL-E: Neural codec language mod- els are zero-shot text to speech synthesizers, ” arXiv pr eprint arXiv:2301.02111 , 2023. [4] Y . Chen, Z. Niu, Z. Ma, K. Deng, C. W ang, J. JianZhao, K. Y u, and X. Chen, “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching, ” in Pr oceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) . V ienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 6255–6271. [Online]. A vailable: https://aclanthology .org/2025.acl- long.313/ [5] C.-J. Hsu, Y .-C. Lin, C.-C. Lin, W .-C. Chen, H. L. Chung, C.-A. Li, Y .-C. Chen, C.-Y . Y u, M.-J. Lee, C.-C. Chen, R.-H. Huang, H. yi Lee, and D.-S. Shiu, “Breezyvoice: Adapting tts for taiwanese mandarin with enhanced polyphone disambiguation – challenges and insights, ” 2025. [Online]. A vailable: https://arxiv .org/abs/2501.17790 [6] C. Raffel, N. Shazeer , A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W . Li, and P . J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer , ” Journal of ma- chine learning r esearc h , vol. 21, no. 140, pp. 1–67, 2020. [7] J. De vlin, M.-W . Chang, K. Lee, and K. T outanov a, “Bert: Pre- training of deep bidirectional transformers for language under- standing, ” in Pr oceedings of the 2019 confer ence of the North American chapter of the association for computational linguis- tics: human language technologies, volume 1 (long and short pa- pers) , 2019, pp. 4171–4186. [8] D. L yth and S. King, “Natural language guidance of high- fidelity text-to-speech with synthetic annotations, ” arXiv preprint arXiv:2402.01912 , 2024. [9] R. Shimizu, R. Y amamoto, M. Kaw amura, Y . Shirahata, H. Doi, T . Komatsu, and K. T achibana, “PromptTTS++: Controlling speaker identity in prompt-based text-to-speech using natural language descriptions, ” in ICASSP 2024 - 2024 IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2024, pp. 12 672–12 676. [10] Y . Zhou, X. Qin, Z. Jin, S. Zhou, S. Lei, S. Zhou, Z. Wu, and J. Jia, “V oxinstruct: Expressive human instruction-to-speech generation with unified multilingual codec language modelling, ” in Pr oceedings of the 32nd ACM International Confer ence on Multimedia , ser . MM ’24. New Y ork, NY , USA: Association for Computing Machinery , 2024, p. 554–563. [Online]. A vailable: https://doi.org/10.1145/3664647.3681680 [11] I. R. Titze, “Physiologic and acoustic differences between male and female voices, ” The Journal of the Acoustical Society of America , vol. 85, no. 4, pp. 1699–1707, 1989. [12] A. P . Simpson, “Phonetic differences between male and female speech, ” Languag e and linguistics compass , vol. 3, no. 2, pp. 621– 640, 2009. [13] E. Jace wicz, R. A. Fox, and J. Salmons, “V o wel space areas across dialects and gender, ” in Pr oceedings of the 16th International Congr ess of Phonetic Sciences . Uni versity of Saarland, Saar- brueken, 2007, pp. 1465–1468. [14] C.-Y . Kuan and H.-y . Lee, “Gender bias in instruction-guided speech synthesis models, ” in F indings of the Association for Com- putational Linguistics: NAA CL 2025 , L. Chiruzzo, A. Ritter, and L. W ang, Eds. Albuquerque, New Mexico: Association for Com- putational Linguistics, Apr . 2025. [15] E. Sheng and D. Uthus, “Inv estigating societal biases in a poetry composition system, ” in Pr oceedings of the Second W orkshop on Gender Bias in Natural Language Pr ocessing , M. R. Costa-juss ` a, C. Hardmeier, W . Radford, and K. W ebster, Eds. Barcelona, Spain (Online): Association for Computational Linguistics, Dec. 2020. [Online]. A vailable: https://aclanthology .org/2020. gebnlp- 1.9/ [16] J. B. Freeman and N. Ambady , “ A dynamic interactiv e theory of person construal. ” Psychological re view , vol. 118, no. 2, p. 247, 2011. [17] P . McAleer, A. T odorov , and P . Belin, “How do you say ‘hello’? personality impressions from brief novel voices, ” PloS one , vol. 9, no. 3, p. e90779, 2014. [18] M. W eber , Economy and society: An outline of interpretive soci- ology . Univ ersity of California press, 1978, vol. 2. [19] F . Pratto, J. Sidanius, L. M. Stallworth, and B. F . Malle, “Social dominance orientation: A personality variable predicting social and political attitudes, ” Journal of personality and social psychol- ogy , vol. 67, no. 4, p. 741, 1994. [20] N. Garg, L. Schiebinger , D. Jurafsky , and J. Zou, “W ord embed- dings quantify 100 years of gender stereotypes, ” in Pr oceedings of the National Academy of Sciences , vol. 115, no. 16, 2018, pp. E3635–E3644. [21] P . T . Costa and R. R. McCrae, “The revised neo personality in ven- tory (neo-pi-r), ” The SA GE handbook of personality theory and assessment , vol. 2, no. 2, pp. 179–198, 2008. [22] K. Kurita, N. Vyas, A. Pareek, A. W . Black, and Y . Tsvetko v , “Measuring bias in contextualized word representations, ” in Pr o- ceedings of the F irst W orkshop on Gender Bias in Natural Lan- guage Pr ocessing , 2019, pp. 166–172. [23] G. T eam, A. Kamath, J. Ferret, S. Pathak, N. V ieillard, R. Merhej, S. Perrin, T . Matejovicova, A. Ram ´ e, M. Rivi ` ere et al. , “Gemma 3 technical report, ” arXiv preprint , 2025. [24] F . Burkhardt, J. W agner, H. Wierstorf, F . Eyben, and B. Schuller, “Speech-based age and gender prediction with transformers, ” in Speech Communication; 15th ITG Confer ence . VDE, 2023, pp. 46–50. [25] C. May , A. W ang, S. Bordia, S. Bo wman, and R. Rudinger , “On measuring social biases in sentence encoders, ” in Pr oceedings of the 2019 Conference of the North American Chapter of the As- sociation for Computational Linguistics: Human Language T ech- nologies, V olume 1 (Long and Short P apers) , 2019, pp. 622–628. [26] Y .-C. Lin, T .-Q. Lin, H.-C. Lin, A. T . Liu, and H. yi Lee, “On the social bias of speech self-supervised models, ” in Interspeech 2024 , 2024, pp. 4638–4642. [27] Y .-C. Lin, H. W u, H.-C. Chou, C.-C. Lee, and H. yi Lee, “Emo- bias: A Lar ge Scale Ev aluation of Social Bias on Speech Emotion Recognition, ” in Interspeech 2024 , 2024, pp. 4633–4637. [28] M. Bartl, M. Nissim, and A. Gatt, “Unmasking contextual stereo- types: Measuring and mitigating bert’ s gender bias, ” in Proceed- ings of the second workshop on gender bias in natural language pr ocessing , 2020, pp. 1–16. [29] S. Katsarou, B. Rodr ´ ıguez-G ´ alvez, and J. Shanahan, “Measuring gender bias in contextualized embeddings, ” in computer sciences and mathematics F orum , vol. 3, no. 1. MDPI, 2022, p. 3.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment