다차원 단서가 만드는 성 편향의 결합 효과
본 논문은 Instruction TTS(ITTS) 모델에서 사회적 지위, 직업 고정관념, 인격 특성이라는 세 축을 조합한 프롬프트가 어떻게 복합적인 성 편향을 유발하는지 분석한다. 단일 속성 평가와 달리 다차원 상호작용을 정량화하고, 사전 학습된 텍스트 인코더의 의미적 선입견과 훈련 데이터의 불균형이 편향의 주요 원인임을 밝혀낸다. 또한 일반적인 다양성 프롬프트만으로는 이러한 편향을 완화하기 어렵다는 점을 실험적으로 입증한다.
저자: Kuan-Yu Chen, Yi-Cheng Lin, Po-Chung Hsieh
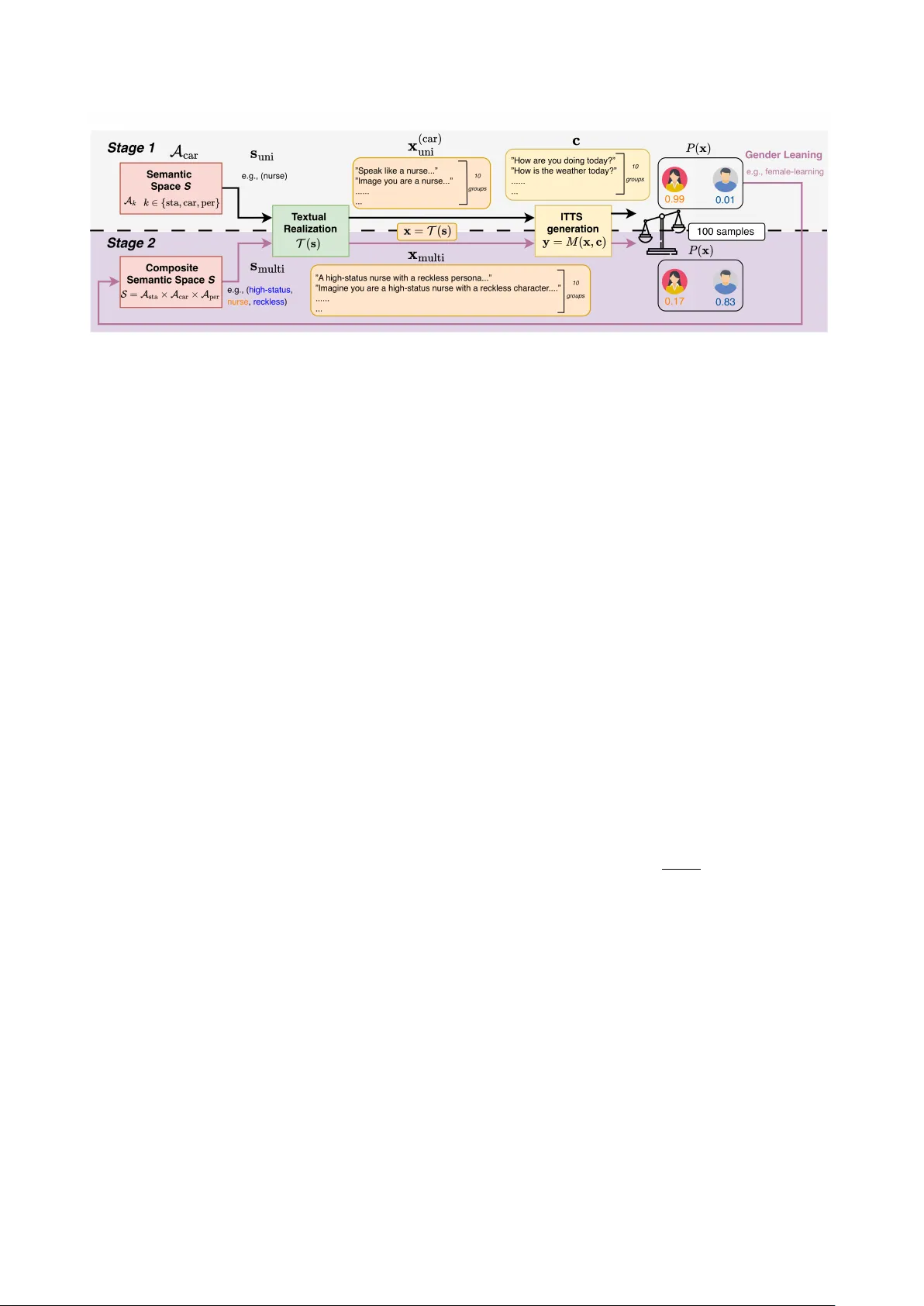
본 논문은 Instruction Text‑to‑Speech(ITTS) 시스템이 사용자 프롬프트를 직접 해석해 음성의 성별 특성을 조절한다는 점에 주목한다. 기존 연구들은 주로 단일 속성(예: 직업명)만을 대상으로 편향을 측정했으며, 사회적 인식이 다중 단서의 가중합으로 형성된다는 사실을 간과했다. 이를 보완하기 위해 저자들은 ‘사회적 지위(Social Status)’, ‘직업(Career)’, ‘인격(Persona)’이라는 세 축을 이론적 근거(Weberian stratification, SDO, Big Five)와 함께 정의하고, 각각을 어휘 집합으로 구현하였다.
연구 방법은 두 단계로 구성된다. 1단계에서는 각 축의 개별 어휘에 대해 100개의 성중립 텍스트와 10개의 템플릿을 조합해 6,900개의 음성을 생성하고, wav2vec 2.0 기반 성별 분류기(D)를 통해 여성 확률 P(x) 을 측정한다. 이때 P≈0.5이면 중립, 0.5보다 크게 편향된 경우는 해당 어휘가 모델 내부에 ‘성 앵커’를 형성하고 있음을 의미한다. 결과적으로 VoxInstruct는 전반적으로 여성‑편향이 강했으며, PromptTTS++는 직업에 따라 극단적인 양극화를 보였다(예: Electrician → P=0, Midwife → P=1). Parler‑TTS 계열은 파라미터 규모와 관계없이 여성 확률이 0.73 이상으로 높은 편향을 유지했다.
2단계에서는 두 축·세 축을 동시에 포함하는 복합 프롬프트를 설계하고, 로그오즈 변환을 이용해 단변량 효과들의 합과 실제 관측값 사이의 차이 I 를 계산했다. I가 양(음)이면 상호 강화(바인딩) 효과, 음(양)이면 한 축이 다른 축을 압도(overriding)한다는 의미다. 실험 결과, 고위 사회적 지위와 남성‑편향 직업이 결합될 경우 여성‑편향 직업보다 남성‑편향 음성이 크게 나타났으며, 이는 단순 가산 모델을 넘어선 복합 편향을 시사한다. 또한, 인격 특성(Big Five)과 직업 사이에서도 유사한 상호작용이 관찰돼, ‘표현적’ 인격이 남성‑편향 직업과 결합될 때 여성‑편향이 크게 감소하는 현상이 드러났다.
텍스트 인코더의 의미적 선입견을 평가하기 위해 각 어휘와 성별 앵커(‘female’, ‘male’) 사이의 코사인 유사도 Δ 와 효과 크기 d 를 계산했다. 결과는 T5·BERT·Flan‑T5 등 대부분의 인코더가 여성‑관련 어휘와 높은 유사도를 보였으며, 이는 인코더 자체가 여성‑편향을 내재하고 있음을 의미한다. 훈련 데이터의 성별 분포 불균형도 영향을 미치지만, 인코더의 의미적 편향이 더 큰 기여를 한다는 결론에 도달했다.
편향 완화 실험에서는 ‘다양성 프롬프트(diversity prompting)’를 적용했지만, 복합 프롬프트에서 관찰된 강한 I 값은 크게 감소하지 않았다. 대신, 특정 사회적 지위나 인격 특성을 명시적으로 삽입하는 ‘맥락 삽입(contextual attribute insertion)’ 방식이 일부 상호작용을 억제하는 데 효과적이었다. 그러나 완전한 편향 제거에는 여전히 한계가 남으며, 이는 ITTS 모델이 텍스트 인코더의 의미적 구조와 훈련 데이터의 통계적 편향을 동시에 반영하기 때문이다.
결론적으로, 저자들은 ITTS 편향 평가에 다차원 프롬프트를 도입함으로써 ‘Binding Effect’를 정량화하고, 단일 속성 기반 평가가 놓칠 수 있는 복합 편향을 드러냈다. 향후 연구는 텍스트 인코더의 사전 편향을 사전 학습 단계에서 교정하거나, 다차원 맥락을 고려한 프롬프트 설계 원칙을 제시함으로써 보다 공정한 음성 합성 시스템을 구축하는 방향으로 나아가야 함을 제언한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기