A Hybrid Conditional Diffusion-DeepONet Framework for High-Fidelity Stress Prediction in Hyperelastic Materials
Predicting stress fields in hyperelastic materials with complex microstructures remains challenging for traditional deep learning surrogates, which struggle to capture both sharp stress concentrations and the wide dynamic range of stress magnitudes. …
Authors: Purna Vindhya Kota, Meer Mehran Rashid, Somdatta Goswami
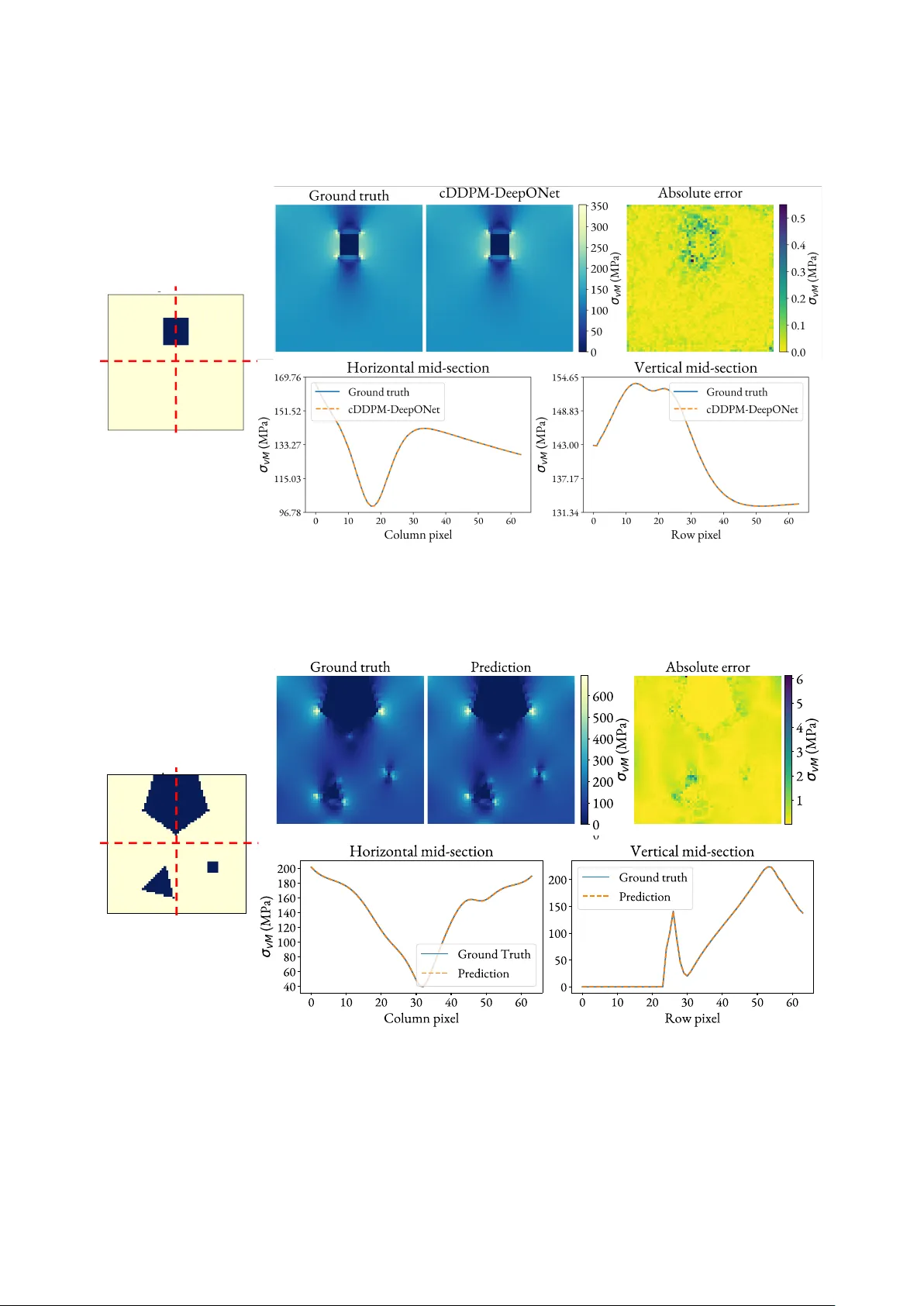
A Hybrid Conditional Diffusion-DeepONet F ramew ork for High-Fidelit y Stress Prediction in Hyp erelastic Materials Purna Vindh ya Kota a, ∗ , Meer Mehran Rashid a , Somdatta Gosw ami a , Lori Graham-Brady a a Dep artment of Civil and Systems Engineering, Johns Hopkins University, 3400 N. Charles Str e et, Baltimor e, 21218, MD, USA Abstract Predicting stress fields in h yp erelastic materials with complex microstructural features remains chal- lenging for traditional deep learning surrogates, whic h struggle to s im ultaneously capture sharp stress con- cen trations and the wide dynamic range of stress magnitudes. Con volutional arc hitectures such as UNet tend to ov ersmo oth high-frequency gradients, while neural op erators lik e DeepONet suffer from sp ectral bias and underpredict lo calized extremes. Conv ersely , diffusion mo dels can reco ver fine-scale structure but often introduce low-frequency amplitude drift, degrading physical scaling. T o address these limitations, we prop ose a h ybrid surrogate framework, cDDPM–DeepONet, that decouples stress morphology from stress magnitude. A conditional denoising diffusion probabilistic mo del (cDDPM), built on a UNet bac kb one, generates high-fidelity normalized von Mises stress fields conditioned on geometry and loading. In parallel, a mo dified DeepONet predicts the corresp onding global scaling parameters (minimum and maxim um v on Mises stress), enabling accurate reconstruction of full-resolution physical stress maps. This separation of roles allows the diffusion mo del to fo cus on broadband spatial structure while the op erator netw ork corrects global amplitude, ov ercoming sp ectral and scaling biases present in existing surrogates. W e ev aluate the framew ork on tw o nonlinear hyperelastic datasets in volving single and m ultiple p olygonal voids. Across all metrics, the cDDPM-DeepONet hybrid model outp erforms UNet, DeepONet, and standalone cDDPM base- lines by one to tw o orders of magnitude. Sp ectral analysis further shows that the prop osed mo del achiev es close agreemen t with finite elemen t reference solutions across the full w av en umber spectrum, preserving both lo w-frequency global behavior and high-frequency stress concen trations. Overall, the cDDPM–DeepONet ar- c hitecture offers a robust, generalizable, and physically consistent surrogate for stress prediction in complex h yp erelastic media. Keywor ds: DDPM, DeepONet, Hyp er-elastic materials, Neural Op erators, Diffusion Mo dels 1. In tro duction Accurate prediction of stress fields in nonlinear elastic materials is a cen tral problem in computational mec hanics, with relev ance to the design of heterogeneous microstructures, p orous solids, arc hitected ma- terials, and fracture and failure analysis. T raditional finite element analyses (FEA) provide high-fidelity solutions but b ecome prohibitiv ely exp ensive when large num b ers of geometries, load cases, or parameter v ariations must be ev aluated. These constrain ts hav e motiv ated the developmen t of machine-learning sur- rogates capable of approximating stress distributions at a fraction of the cost. Y et, despite rapid progress in scien tific mac hine learning, constructing surrogates that sim ultaneously capture sharp lo cal stress con- cen trations, broad spatial v ariability , and the large dynamic range characteristic of hyperelastic resp onses remains c hallenging. ∗ Corresponding author Email addr ess: pkota2@jh.edu (Purna Vindhy a Kota) Pr eprint submitte d to Elsevier Mar ch 20, 2026 Deep learning (DL) mo dels hav e found imp ortan t applications in computational mec hanics by enabling rapid, high-fidelity syn thesis of mechanical resp onse fields from compact descriptions. Once trained, the DL mo del can infer the full solution field at a sp eed several orders of magnitude faster than traditional n umerical metho ds [ 1 – 3 ], which is b eneficial in situations where many ev aluations are needed with c hanging inputs. This is esp ecially imp ortan t when dealing with a large design parameter space in generative design and top ology optimization [ 4 , 5 ]. The application of DL has demonstrated tremendous p oten tial in p erforming efficien t micro-scale analysis and has catalyzed transformations in material property prediction [ 6 – 15 ]. Key successes in computational mechanics in volv e the prediction of homogenized or effective material proper- ties [ 16 – 20 ], the reconstruction and c haracterization of material microstructures [ 21 – 24 ], and, critically for design and failure analysis, the prediction of lo cal stress and strain fields [ 25 – 29 ]. Con volutional enco der–deco der netw orks suc h as UNet [ 30 ] ha ve b een w idely adopted for field-to-field prediction [ 31 ]. Their hierarc hical, m ultiresolution design facilitates the extraction of local and global spatial features, enabling accurate reconstruction of smo oth stress fields. As a result, UNet-based mo dels ha ve been sho wn to provide computationally efficient surrogates for finite elemen t simulations across a range of solid mec hanics applications [ 28 , 32 – 38 ]. Ho wev er, their inherent spatial smo othing and finite receptive field limit their ability to reconstruct high-frequency stress features, particularly the steep gradien ts that arise near voids, inclusions, or geometric singularities. Neural op erators suc h as DeepONet and F ourier Neural Op erators offer an app ealing alternative b y learning mappings b et ween function spaces rather than relying solely on local con volutions. These models learn the mapping b et w een function spaces and ha ve been applied to v arious problems in solid mechanics, including the iden tification of material properties [ 39 – 41 ] and the prediction of mec hanical resp onse of materials [ 42 – 44 ]. While these arc hitectures excel at representing smo oth, low-frequency components, they exhibit w ell-do cumen ted sp ectral bias [ 45 , 46 ] and tend to under- predict lo calized p eaks, esp ecially in problems where the stress field contains sharp, geometry-dep enden t v ariations. Moreo ver, producing high-resolution images requires ev aluation on dense grids, whic h reduces efficiency when the target is an image-v alued field rather than a small set of functionals. Generative models, and diffusion models in particular, hav e recen tly emerged as p o w erful to ols for producing high-fidelity spatial fields [ 47 , 48 ]. Denoising Diffusion Probabilistic Mo dels (DDPMs) [ 49 – 51 ] address these issues by iterativ e recov ery of complex, m ultimo dal data distribution and sampling from it. Their applications are rapidly expanding in computational mec hanics, encompassing the modeling of fracture phenomena [ 52 , 53 ], prediction of mechanical resp onse fields [ 54 – 56 ], and in v erse design of microstructures [ 57 – 59 ]. When conditioned on geometric information, diffusion mo dels can reconstruct intricate stress morphologies with far greater fidelity than conv olution-based regressors. Conditioning on input parameters fo cuses the reverse pro cess on the relev ant manifold of solutions [ 60 – 63 ], which reduces v ariance and impro ves sample quality . Ho wev er, diffusion netw orks in tro duce a complementary limitation: they often drift in high-frequency amplitude, producing normalized stress fields with correct morphology but incorrect global scaling. F or mec hanics problems where absolute stress magnitude carries physical meaning e.g. , material yielding, failure initiation, or safety-factor ev aluation, this amplitude drift leads to unacceptable errors. These limitations highligh t a fundamen tal issue: mo dels that reconstruct fine-scale features tend to distort global scaling, while mo dels that capture global structure struggle with high-frequency stress concentrations. This motiv ates a decomp osition strategy that treats these tw o asp ects of the stress field separately . In this w ork, we prop ose a h ybrid surrogate framework to learn the von Mises stress maps of materials, b y explicitly decoupling the stress morphology from the stress magnitude (see Figure 1 for an ov erview of the arc hitecture). A conditional DDPM (cDDPM) model, built up on a UNet backbone, is trained to generate high-resolution normalized von Mises stress fields conditioned on geometry and loading. In parallel, a DeepONet predicts the tw o global scaling parameters: the minim um and maxim um v on Mises stress asso ciated with each sample. The physical stress field is then reconstructed by rescaling the diffusion- generated normalized field. This separation of roles leverages the strengths of each mo del: the diffusion model captures complex, spatial structure, while the DeepONet provides an accurate global amplitude prediction free from sp ectral bias. The UNet backbone preserv es spatial resolution without introducing prohibitive memory growth, since the op erator head handles global calibration rather than full-field syn thesis. The DeepONet comp onent generalizes across parametric v ariations. The cDDPM focuses on spatial frequency con tent rather than absolute magnitude, whic h reduces the n umber of time steps required to ac hieve accurate 2 Lear ning the s cale Lear ning the scaled stress map 𝜎 !" , $%& 𝜎 !" , $'( Geometry Loa d DeepONet Encoder Rever se P roce ss Conditional DDPM Noise 𝝈 𝒗𝑴 Min - Max Nor malization For war d Pr o ce ss Inputs UNet 𝜎 !" (MPa) Figure 1: Description of the denoising diffusion framework for stress map prediction conditioned by the geometry and loading. The scaled stress maps are learned by the UNet in the conditional DDPM, and the minimum & maximum von Mises stresses are learned by the DeepONet. A CNN-based enco der is used for feature represen tation and is used to condition the UNet. The learned scaling and stress maps are com bined to get the final stress maps. fields and impro ves data efficiency compared to unconditional generation. W e ev aluate the prop osed cDDPM–DeepONet framework on tw o hyperelastic material datasets inv olv- ing heterogeneous domains with single and multiple polygonal voids sub jected to tensile loading. Across b oth datasets, the hybrid architecture is compared to t wo baselines, UNet and standalone diffusion mo del (cDDPM), sho wing that the h ybrid mo del ac hiev es substantial improv emen ts ov er these individual archi- tectures. In addition to reductions of one to tw o orders of magnitude in error metrics, spectral analysis demonstrates that the prop osed mo del accurately repro duces b oth high- and low-frequency comp onents of the stress field, addressing biases inheren t to each constituent mo del. F urthermore, the framework exhibits strong generalization to unseen geometries and loading scenarios, underscoring its robustness and practical v alue. Ov erall, this work demonstrates that com bining generative diffusion models with neural op erators pro- vides an effective pathw ay tow ard high-fidelity , generalizable surrogates for hyperelastic material stress prediction. The decoupling strategy in tro duced here op ens a broader av en ue for hybrid physical–generativ e mo dels capable of capturing multiscale phenomena in solid mechanics and beyond. The man uscript is arranged as follows: Section 2 presents the prop osed cDDPM–DeepONet framework, detailing its architecture and training strategy . Section 3 describ es the data generation pro cess and hypere- lastic sim ulation setup. Section 4 ev aluates the h ybrid surrogate across m ultiple quan titativ e and qualitativ e metrics. Finally , Section 5 concludes with a summary of findings and directions for future work. 2. Metho dology This section presents the theoretical foundations of DDPMs and DeepONet and describ es the arc hitecture of the prop osed hybrid framework. 2.1. UNet-b ase d denoising diffusion pr ob abilistic mo del Denoising Diffusion Probabilistic Mo dels are laten t-v ariable generative mo dels that learn to recov er samples from a target data distribution by iteratively inv erting a Marko vian noise corruption pro cess [ 50 ]. 3 They consist of t w o complementary stages: (1) a forw ard diffusion pro cess, in which Gaussian noise is progressiv ely added to the data until its structure is nearly destro yed, and (2) a reverse denoising pro cess, implemen ted by a neural netw ork, whic h learns to inv ert the diffusion steps by predicting and removing the injected noise. By learning this reverse Mark ov c hain, the mo del approximates the underlying data distribution. As a result, new samples can b e generated b y starting from pure Gaussian noise and iterativ ely applying the learned denoising steps [ 51 , 64 ]. This framew ork pro vides a stable generative mechanism capable of capturing complex, m ultimo dal data distributions and pro ducing high-fidelity spatial fields. 2.1.1. F orwar d diffusion pr o c ess Let x (0) i ∈ R d denote the i -th training sample of an N × N image drawn from the empirical data distribution q ( x (0) ). The forward diffusion process defines a Marko v chain indexed b y discrete time steps t = 1 , . . . , T , in whic h the data sample x (0) i is progressiv ely corrupted by the addition of Gaussian noise. The resulting joint distribution o ver the forward tra jectory factorizes as q ( x (0: T ) i ) = q ( x (0) i ) Q T t =1 q ( x ( t ) i | x ( t − 1) i ). As t increases, the distribution q ( x ( t ) ) approac hes a standard normal distribution N ( 0 , I ), where 0 ∈ R d is the zero v ector and I ∈ R d × d is the identit y matrix. Eac h transition adds Gaussian noise with a time- dep enden t signal scaling h yp erparameter α ( t ) ∈ (0 , 1): q ( x ( t ) i | x ( t − 1) i ) = N x ( t ) i ; p α ( t ) x ( t − 1) i , (1 − α ( t ) ) I . (1) A typical scheduler satisfies 1 > α (1) > α (2) > · · · > α ( T ) > 0, ensuring that the data becomes progressively noisy . When α ( T ) is sufficiently small, the terminal distribution q ( x ( T ) i ) b ecomes n umerically indistinguish- able from N ( 0 , I ). T o ensure smo othness and stability in noise addition during the diffusion pro cess, we emplo y a cosine noise scheduling mechanism [ 51 ], defined by ¯ α ( t ) = f ( t ) f (0) , f ( t ) = cos 2 t/T + b 1 + b · π 2 , (2) where b is a small offset preven ting rapid noise growth near t = 0. The cum ulative pro duct, ¯ α ( t ) = Q t s =1 α ( s ) , represen ts the total signal preserv ed after t diffusion steps. Because the forw ard pro cess is Gaussian and Mark ovian, we can marginalize Eq. ( 1 ) to obtain the closed-form conditional distribution at any time t : q ( x ( t ) i | x (0) i ) = N x ( t ) i ; p ¯ α ( t ) x (0) i , (1 − ¯ α ( t ) ) I . (3) Using the reparameterization tric k [ 65 ], samples can b e generated explicitly via x ( t ) i = p ¯ α ( t ) x (0) i + p 1 − ¯ α ( t ) ϵ , ϵ ∼ N ( 0 , I ) . (4) 2.1.2. R everse denoising pr o c ess During inference, the goal is to inv ert the forward diffusion pro cess and recov er samples from the em- pirical data distribution, starting from Gaussian noise. Because the true rev erse transitions q ( x ( t − 1) i | x ( t ) i ) are intractable, DDPMs approximate them using a parameterized Gaussian model. The original data dis- tribution can b e reformulated using a conditional distribution constructed from the transition distribution p θ ( x ( t − 1) i | x ( t ) i ), parametrized b y θ , as p θ ( x (0: T ) i ) = p ( x ( T ) i ) T Y t =1 p θ ( x ( t − 1) i | x ( t ) i ) , (5) where p ( x ( T ) i ) = N ( 0 , I ) is the standard Gaussian prior and θ denotes neural-netw ork parameters. The conditionals, p θ ( x ( t − 1) i | x ( t ) i ), can b e appro ximated as Gaussians from the Gauss-Mark o v theory [ 50 ]. Hence, eac h reverse distribution is mo deled as p θ ( x ( t − 1) i | x ( t ) i ) = N x ( t − 1) i ; µ θ ( x ( t ) i , t ) , σ 2 θ ( t ) I , (6) 4 where µ θ ( x ( t ) i , t ) and σ 2 θ ( t ) are the mean and v ariance. It is conv enien t to parameterize the mean in terms of the predicted noise. Let ϵ θ ( x ( t ) i , t ) denote the neural netw ork’s estimate of the forward noise ϵ in Eq. ( 4 ). The mean and v ariance are functions of ϵ θ ( x ( t ) i , t ) as µ θ ( x ( t ) i , t ) = 1 √ α ( t ) x ( t ) i − 1 − α ( t ) √ 1 − ¯ α ( t ) ϵ θ ( x ( t ) i , t ) , σ 2 θ ( t ) = 1 − ¯ α ( t − 1) 1 − ¯ α ( t ) (1 − α ( t ) ) , (7) In this work, ϵ θ is learned using a UNet-based architecture. The mo del is trained by minimizing a simplified ob jective equiv alent to maximizing the v ariational low er b ound on the data likelihoo d. T o learn the actual data distribution using the ab ov e mo del, the v ariational low er-bound on the negative log likelihoo d can b e appro ximated by the loss function, defined as: L DD P M ( θ ) = E p h − log p θ ( x (0: T ) ) q ( x (1: T ) | x (0) ) i . (8) Optimizing the lik eliho o d is akin to estimating the mean in the reverse pro cedure. With reparame- terization, the loss function is reduced to a simpler form. The resulting DDPM loss after simplification is L DDPM ( θ ) = E x (0) ∼ q E t ∼U { 1 ,...,T } E ϵ ∼N ( 0 , I ) ϵ − ϵ θ ( x ( t ) i , t ) 2 2 , (9) where x ( t ) i is constructed from x (0) i and ϵ using Eq. ( 4 ). This loss forces ϵ θ to predict the forw ard-pro cess noise accurately , which is equiv alent to learning the mean of the reverse Gaussian transition. A detailed description of the deriv ation of the loss function is discussed in App endix A . F urther details can b e found in [ 50 , 51 , 64 ]. 2.1.3. Conditional diffusion denoising pr ob abilistic mo del The unconditional DDPM described in Sections 2.1.1 and 2.1.2 generates samples consisten t with the o verall training distribution, but it does not enforce dep endence on problem-sp ecific inputs suc h as geometry , material parameters, or loading. F or stress field prediction, the generated field m ust b e consistent with the ph ysical parameters asso ciated with each data sample. T o incorp orate this, we adopt a conditional diffusion mo del [ 60 ] in which the reverse denoising pro cess is guided by a feature vector represen ting the relev an t ph ysical information. The physical parameters, y , are mapp ed to an em bedding vector ζ emb = g ( y ) using an em b edding net work g ( · ) during training. This em b edding remains fixed across all diffusion steps and pro vides con text to the denoising net work. The forward (noising) pro cess remains iden tical to the unconditional form ulation b ecause the diffusion corruption is indep enden t of y , with the transition distribution mo difying to ˆ q ( x ( t ) i | x ( t − 1) i , ζ emb ) := q ( x ( t ) i | x ( t − 1) i ). In the conditional reverse pro cess, the neural netw ork receives ( x ( t ) i , t, ζ emb ) as input and predicts the noise comp onen t to b e remov ed. W e mo del the conditional rev erse transition distribution as: p θ ( x ( t − 1) i | x ( t ) i , ζ emb ) = N x ( t − 1) i ; µ θ ( x ( t ) i , ζ emb , t ) , σ 2 θ ( t ) I , (10) Starting from the final noise sample x ( T ) i , the mo del iteratively remo ves noise to gradually restore the original stress field distribution, giv en by x ( t − 1) i = 1 √ α ( t ) x ( t ) i − 1 − α ( t ) √ 1 − ¯ α ( t ) ˆ ϵ θ ( x ( t ) i , ζ emb , t ) + σ q ( t ) ξ , (11) where ξ ∼ N ( 0 , I ) is standard Gaussian noise. Here, ˆ ϵ θ ( · ) is the conditional noise-prediction netw ork that replaces its unconditional counterpart, ϵ θ , in Section 2.1.2 . T o learn the conditional distribution, w e maximize the v ariational lo wer b ound on the data lik eliho od, analogous to the unconditional case. T raining pro ceeds by minimizing the cDDPM ob jective: L cDDPM ( θ ) = E x (0) ∼ q E t ∼U { 1 ,...,T } E ϵ ∼N ( 0 , I ) ϵ − ˆ ϵ θ ( x ( t ) , ζ emb , t ) 2 2 , (12) 5 2.2. De epONet Classical neural net works learn mappings b etw een finite-dimensional input–output pairs. In contrast, man y problems in computational mec hanics require learning mappings betw een functions , suc h as geometry- dep enden t boundary conditions, spatially v arying material parameters, or load fields. Neural op erators generalize sup ervised learning to this setting by approximating maps b et w een infinite-dimensional Banach spaces. Among these, the DeepONet, in tro duced by Lu et al. [ 66 ], pro vides an efficient architecture for learning nonlinear op erators from data. Let U ∈ A denote an input function enco ding the geometry and loading configuration of a sample (e.g., discretized geometry indicator fields and load magnitudes). Let ϕ ( U ) ∈ Φ denote the corresp onding von Mises stress field arising from a nonlinear hyperelastic response. Assuming that eac h input field U uniquely determines a stress solution ϕ ( U ) that satisfies the gov erning finite-strain hyperelasticity equilibrium equa- tions and b oundary conditions, the underlying solution op erator is G : A → Φ . (13) In this work, DeepONet is not required to reconstruct the full stress field. Instead, we adopt a reduced form ulation in whic h the op erator predicts only the sample-specific glob al sc aling p ar ameters —the mini- m um and maxim um von Mises stresses asso ciated with the given domain geometry and prescrib ed loading, b oundary conditions. These sample sp ecific extrema are subsequen tly used to rescale the normalized stress fields pro duced by the diffusion mo del. Accordingly , we define the reduced op erator F : A → min s ∈ Ω ϕ ( U )( s ) , max s ∈ Ω ϕ ( U )( s ) , (14) whic h maps each input function U to tw o scalar quantities representing the global stress range. 2.3. cDDPM-De epONet hybrid mo del The prop osed hybrid mo del architecture describ ed in Figure 1 integrates a cDDPM with a DeepONet to predict the full-field v on Mises stress maps of hyperelastic materials sub ject to tensile loading. The conditional diffusion mo del reconstructs the normalized spatial stress morphology . Its bac kb one is a UNet equipp ed with residual blo c ks and a global attention mechanism to capture b oth lo calized concentra- tion phenomena and long-range spatial dep endencies. Conditioning on geometry and loading is introduced through an em b edding vector ζ em b constructed by a CNN enco der acting on a t wo-c hannel input, with one c hannel containing the material geometry and the other channel containing an image represen tation of the load condition, with a colored ro w that indicates the magnitude of loading. This em be dding is fused with the diffusion timestep embedding through a bilinear transformation, and the resulting context vector is injected at each resolution level of the UNet. In this manner, the reverse denoising pro cess remains anchored to the input configuration throughout all diffusion time steps. The DeepONet consists of t wo subnetw orks: • Branc h net w ork : enco des the input function U , discretized on a fixed N × X grid. Because U ∈ R N × N × 2 is high dimensional, the branch net work is implemen ted using a UNet-based encoder to efficien tly capture geometric and loading features. • T runk netw ork : enco des output query co ordinates s . Since the outputs here are global extrema rather than spatial fields, the trunk net work acts as a basis encoder and is implemented as a m ultilay er p erceptron netw ork. F ollo wing an inner pro duct op eration b et w een the output of the branch net and trunk net, the resulting high-dimensional feature maps are passed to a final pro jection lay er. This lay er maps the features to a scalar output in R 2 , whic h corresp onds to the predicted minimum and maximum v alues in the domain. The parameters of the op erator netw ork are identified by minimizing an L 1 loss b etw een the predicted and true extrema. 6 Inputs to the network v on Mises stress map Multiple - vo id dataset Single - voi d dataset Figure 2: Datasets used for ev aluation: The first dataset con tains single void and loading v alues as input to predict the von Mises stress maps. The second dataset comprises geometries with multiple voids, which, along with loading v alues, are used to estimate the stress. During inference, the tw o comp onen ts of the hybrid architecture are applied in parallel. F or a given geometry–loading pair, the cDDPM generates a normalized stress map, while the DeepONet provides the corresp onding global minimum and maxim um stresses. The true von Mises field is then obtained by linearly rescaling the normalized outputs using these predicted extrema. Notably , the cDDPM and the DeepONet are trained indep enden tly , with the former learning to reconstruct normalized stress maps and the latter learning to predict global stress range parameters. During inference, they are combined, but no further learning or iterativ e feedback b etw een them is necessary . 3. Datasets T o asse ss the mo del’s performance on nonlinear material behavior, w e generate datasets following the pro cedure of [ 55 ]. All samples are sim ulated using a Neo-Hookean hyperelastic constitutiv e mo del, which in tro duces geometric and material nonlinearities b ey ond the linear-elastic regime. This setting pro vides a more stringent test of the surrogate’s ability to learn complex stress–response relationships. The uniaxial tension problem is solved using the nonlinear finite element solver FEniCS [ 67 – 69 ]. Figure 2 illustrates the mapping from inputs to the resulting von Mises stress fields for the datasets describ ed in Sections 3.1 and 3.2 . 3.1. Single-void hyp er elastic dataset The first dataset consists of t w o-dimensional domains Ω ⊂ R 2 con taining a single polygonal void. The p olygon has n sides, where n ∈ { 3 , 4 , 5 , 6 , 7 , 8 } , and its size, orientation, and lo cation are sampled to ensure geometric v ariability . The material behavior is mo deled by a compressible Neo-Ho ok ean constitutiv e law [ 70 ]. Let F = ∇ u denote the deformation gradien t, where u is the displacement field. The strain-energy density is W ( F ) = µ 2 ∥ F ∥ 2 − 3 − 2 ln det F , (15) 7 where µ is the shear mo dulus and ∥ F ∥ denotes the F rob enius norm. The voids are mo deled using a binary mask M to define the material distribution within the square domain. F or each sample, the v oid geometry is sampled randomly , and the mask is defined suc h that M ( x ) = 1 in the material domain and M ( x ) = 0 at v oid locations. This mask is applied to the material prop erties, such that the effective Y oung’s mo dulus is E ef f ( x ) = M ( x ) E , representing zero stiffness within the v oids. The finite element mesh is generated explicitly for the regions where M ( x ) = 1. The b ottom b oundary is sub ject to a fixed displacemen t u x ( x, y = 0) = u y ( x, y = 0) = 0, and the top boundary is sub ject to a uniform tensile traction τ x ( x, y max ) = 0 and τ y ( x, y max ) = L , where the load magnitude L is sampled uniformly from [100 , 700] kN. The vertical b oundaries are traction-free, i.e., τ x (0 , y ) = τ y (0 , y ) = τ x ( x max , y ) = τ y ( x max , y ) = 0. The full stress tensor throughout the domain is computed using FEniCS on a uniform grid, from which the v on Mises stress, σ vM ( x ), is ev aluated. While w e recognize that using a square grid for the finite element (FE) mesh can cause inaccuracies in predicting stresses esp ecially near the edges of the v oid, the fo cus of this work is not on optimizing the mesh or the FE method itself. Instead, the goal is to dev elop a deep learning arc hitecture that can successfully learn to repro duce the sp ecific FE results it is trained on. This scalar field serves as the ground truth output for training and v alidating the surrogate mo dels. In this w ork, 19 , 900 samples w ere generated for training and 3 , 317 for testing. This dataset was sampled from [ 55 ] and can b e accessed here . 3.2. Multiple-void hyp er elastic dataset T o reflect the microstructural complexit y of real heterogeneous materials, w e constructed a multiple- v oid h yp erelastic dataset in which the t wo-dimensional domain discussed in the previous section contains sev eral polygonal voids and is sub ject to the same boundary conditions as described in Section 3.1 , except the magnitudes of the applied tensile load are sampled uniformly from the interv al [100 , 400] kN. The void shapes range from triangles to heptagons (3–7 sides) and v ary in orien tation (0 ◦ , 45 ◦ , and 90 ◦ ), size, and spatial lo cation within the domain. The presence of multiple defects in eac h sample in tro duces rich mechanical in teractions, including inter-v oid stress coupling, comp eting stress-concentration zones, and non trivial load- redistribution pathw ays. As a result, the resulting stress fields exhibit significantly higher v ariability than in the single-v oid setting, providing a challenging b enchmark for ev aluating the p erformance of the prop osed h ybrid mo del. In this dataset, 20 , 000 samples were generated for training and 3 , 000 for testing. These sim ulations form the ground truth dataset for training, and testing of the proposed mo del. Both datasets are a v ailable at INSER T LINK T o quantify the complexit y of the stress distributions, we define tw o levels of statistical reduction. First, for each individual sample i , we calculate the spatial mean stress µ σ vM ,i and the maximum stress σ v M,max,i o ver the H × W grid. W e then ev aluate the following ensem ble statistics across the entire dataset of N samples to capture the sample-to-sample v ariability: Mean of Means: E [ µ σ vM ] = 1 N N X i =1 µ σ vM ,i Mean of Maxima: E [ σ v M,max ] = 1 N N X i =1 σ v M,max,i Std of Means: Std( µ σ vM ) = v u u t 1 N N X i =1 ( µ σ vM ,i − E [ µ σ vM ]) 2 Std of Maxima: Std( σ v M,max ) = v u u t 1 N N X i =1 ( σ v M,max,i − E [ σ v M,max ]) 2 As suggested by the metrics in T able 1 , the datasets p ossess a non-trivial lev el of complexity . The high v alues for Std( µ σ vM ) and Std( σ v M,max ) indicate that the mo del must navigate significan t shifts in both global stress in tensity and lo cal p eak concentrations from one sample to the next. This v ariabilit y is a primary factor making these datasets a challenging b enc hmark, as it requires the mo del to b e robust against large fluctuations in b oth av erage field intensit y and local singular p eaks. 8 T able 1: Statistical Analysis of von Mises Stress ( σ vM ) Distributions. Dataset E [ µ σ vM ] Std( µ σ vM ) E [ σ v M,max ] Std( σ v M,max ) Single-v oid 404.335 180.43 3364.41 2842.95 Multiple-v oid 394.56 162.32 3047.62 1795.37 4. Results and discussion T o critically assess the p erformance of the prop osed hybrid mo del, its predictions are systematically compared against those obtained from a baseline UNet mo del [ 28 ] and the standalone cDDPM architecture describ ed in Section 2.1 . All surrogates are trained using an L 1 loss; how ev er, to rigorously ev aluate p erformance, we emplo y a comprehensive suite of error and structural similarit y metrics, summarized in T able 2 . These ev aluations span multiple complemen tary criteria that quantify p oin t-wise accuracy , dynamic- range preserv ation, and fidelity of lo cal physical structure. The ro ot mean squared error (RMSE) measure absolute and large-magnitude deviations b etw een predicted and true von Mises stress fields, whereas the relativ e mean absolute error (RelMAE) normalizes MAE by the stress range to account for scale v ariabilit y across the dataset. The p eak absolute error (P AE) assesses the accuracy of global extrema, while the p eak- to-v alley (PV) error quantifies the accuracy of the predicted global stress range. Finally , the lo calized stress gradien t (LSG) quan tifies discrepancies in stress gradien ts near v oid boundaries, where ph ysical accuracy is most critical. Because the von Mises stresses in the datasets span several orders of magnitude, accurate reco very of b oth global scaling and lo calized concentration zones are essen tial. Metric Definition Mean absolute error 1 N P x,y | σ vM − ˆ σ vM | Ro ot mean square error q 1 N P x,y ( σ vM − ˆ σ vM ) 2 Relativ e mean absolute error MAE max σ vM − min σ vM P eak absolute error | max Ω σ vM − max Ω ˆ σ vM | Lo calized stress gradien t 1 N P x,y |∇ σ vM − ∇ ˆ σ vM | P eak-to-v alley error | ∆( σ vM ) − ∆( ˆ σ vM ) | T able 2: Mathematical definitions of quan titative metrics used to ev aluate prediction accuracy and spatial fidelity of surrogates. Here, σ vM := σ vM ( x, y ) and ˆ σ vM := ˆ σ vM ( x, y ) denote the ground truth and predicted stress fields, and N = | Ω | is the total num b er of spatial p oin ts. The magnitude of gradient is defined as ∇ σ = p ( ∂ σ /∂ x ) 2 + ( ∂ σ/∂ y ) 2 , and ∆( σ vM ) = | max Ω σ vM − min Ω σ vM | denotes the peak-to-valley range. The quan titative results reported in T able 3 , ev aluated using the definitions in T able 2 , demonstrate that the prop osed cDDPM–DeepONet hybrid mo del consistently outp erforms the UNet and cDDPM baselines across all error measures and for b oth datasets. F or the single-void dataset, the cDDPM–DeepONet mo del reduces MAE by 99.29% relative to the UNet and b y 84.59% relative to the cDDPM, while for the multiple- v oid dataset the corresp onding MAE reductions are 86.77% and 46.84%, resp ectiv ely . Similar reductions are observed in the RMSE, where the squared error term indicates that the hybrid mo del not only improv es a verage point wise accuracy but also significantly reduces large lo cal deviations that baselines fail to capture. Consequen tly , the RelMAE v alues remain b elo w 1% for the hybrid mo del in b oth datasets, confirming that p oin t wise errors are negligible relative to the sample-wise stress range. Giv en that the mean maximum target von Mises stresses are 2313 . 34 MPa in the single-void dataset and 2087 . 67 MPa for the multiple-v oid dataset, the cDDPM-DeepONet hybrid mo del reconstructs these maxim um stress v alues with 2 . 07% and 0 . 28% error for eac h dataset, resp ectiv ely , demonstrating substantial impro vemen ts in P AE and accurately capturing the dynamic range. P eak-based errors exhibit a consistent reduction pattern, with the hybrid mo del decreasing Peak Abso- lute Error by 97.36% relative to the UNet and 82.24% relative to the cDDPM in the single-v oid dataset, 9 and by 99.30% and 98.28%, resp ectiv ely , in the multiple-v oid dataset, ensuring accurate recov ery of the dynamic range across v arying geometric complexities. The PV error reveals a similar pattern in the single- v oid dataset, where the hybrid mo del more closely recov ers the global stress range than either baseline. Finally , gradien t-based accuracy , quan tified b y LSG, distinguishes the models most clearly: the UNet ex- hibits the largest gradient errors consisten t with spatial smo othing, the cDDPM provides partial mitigation, and the h ybrid mo del achiev es the lo west gradient discrepancies, corresp onding to an order-of-magnitude impro vemen t relativ e to the UNet and several-fold improv emen t relative to the cDDPM. Ov erall, the com bination of diffusion-based field reconstruction with operator-based amplitude prediction yields a surrogate that accurately recov ers b oth the global stress magnitude and lo calized features. The p erformance gains exceed tw o orders of magnitude in most metrics. Dataset Mo del MAE RMSE RelMAE P AE LSG PV Single-v oid UNet [ 28 ] 194.85 350.65 0.0147 1809.21 41.95 1398.73 cDDPM 28.36 84.32 0.0282 269.07 11.30 338.45 cDDPM-DeepONet 4.12 5.91 0 . 0017 47.79 0.73 47.78 Multiple-v oid UNet [ 28 ] 166.99 235.25 0.1086 838.51 39.04 826.24 cDDPM 41.56 74.03 0.0169 338.50 13.07 266.92 cDDPM-DeepONet 23.52 45.16 0.0021 5.83 3.67 38.19 T able 3: Quantitativ e comparison of error metrics for the UNet, cDDPM, and cDDPM-DeepONet hybrid mo dels on the single- void and multiple-v oid datasets. The hybrid framework yields the low est error v alues across all rep orted metrics, including point-wise accuracy (MAE, RMSE, RelMAE), global extrema prediction (P AE, PV), and gradient fidelity (LSG). 4.1. Pr e dicte d str ess fields While aggregate metrics shown in T able 3 provide a sense of the ov erall p erformance of each mo del, it is also important to visualize the predictions of the spatially v arying stress maps, the stress distribu- tion fidelit y , and the robustness of the p erformance across complex test cases. Figure 3 presen ts a direct qualitativ e comparison of the ground-truth FEM stress field with predictions from the UNet, cDDPM, and h ybrid mo dels for a representativ e test sample of the single-void and m ultiple-void hyperelastic datasets. The UNet struggles to capture the lo cal pattern of the stress distribution and exhibits smo othing artifacts, failing to resolve the stresses at the b oundaries of the voids. The cDDPM captures sharp er features b etter but o vershoots the stress magnitudes and high-frequency artifacts around the v oid, distorting physical stress ranges. In contrast, the cDDPM-DeepONet hybrid mo del preserves b oth the amplitude and lo calization of stress concentrations near void b oundaries, aligning closely with the FEM ground truth. These differences underscore the h ybrid model’s superior capabilit y to capture sharp transitions and spatial detail, comple- men ting the quan titativ e impro vemen ts rep orted earlier. Similar trends are observ ed in the multiple-v oid case, where the hybrid mo del consistently resolv es in teracting stress fields while maintaining correct mag- nitude and spatial coherence. Figures 4 and 5 further examine the representativ e stress field predictions from the cDDPM-DeepONet h ybrid model, for represen tativ e samples from the single-v oid and m ultiple-v oid datasets, resp ectiv ely . The absolute error plots indicate that the lo calized errors are 0 . 16% and 0 . 88% of the p eak stress magnitude in Figures 4 and 5 , resp ectively . The one-dimensional cross sections of the stress distribution show the strong agreemen t b etw een the hybrid mo del predictions and the ground truth, ev en when the section crosses an interface, as in Figure 5 . Although these figures illustrate individual samples, comparable agreement is observed across the full dataset, indicating consistent generalization across test geometries. While spatial stress maps provide insight into individual predictions, they are less effective for assessing consistency across a large n um b er of test samples. T o assess prediction consistency across the full test dataset, Figure 6 sho ws the empirical distribution of mean von Mises stresses across all test samples of 10 Ground truth UNet cDDPM cDDPM-DeepONet 0 50 100 150 200 250 300 350 250 0 250 500 750 1000 1250 1500 1750 50 100 150 200 250 300 350 0 50 100 150 200 250 300 350 v M ( M P a ) (a) Single-void dataset Ground truth UNet cDDPM cDDPM-DeepONet 0 100 200 300 400 500 600 0 500 1000 1500 2000 2500 0 100 200 300 400 500 600 700 0 100 200 300 400 500 600 v M ( M P a ) (b) Multiple-void dataset Figure 3: Comparison of ground truth FEM stress maps, UNet, cDDPM and cDDPM-DeepONet predictions for single-void ( 3a ) and multiple-v oid ( 3b ) hyperelastic datasets. b oth datasets. The hybrid mo del’s histogram aligns closely with the FEM reference in b oth datasets, accurately recov ering both the mo dal mean stress v alues and the long high-stress tails. This indicates that the model captures b oth a verage-case and extreme stress scenarios. The UNet predictions exhibit a narro wer distribution with attenuated tails, reflecting systematic underestimation of the sample-to- sample v ariability in the mean stress. The cDDPM baseline displa ys wider support than UNet but deviates from the true distribution’s central p eak, suggesting some amplitude distortion. These differences highlight distinct inductiv e biases across architectures and reflect the hybrid mo del’s sup erior distributional fidelit y . 4.2. Sp e ctr al char acterization T o assess the sp ectral fidelity of predicted stress fields, w e conduct a sp ectral analysis using 1D isotropic energy sp ectra and 2D F ourier magnitude maps. These diagnostics prob e not only how well mo dels capture spatial v ariabilit y but also how they represent energy across physically relev an t wa v enum ber bands. This is particularly imp ortan t for applications suc h as fatigue prediction, crack initiation, and m ultiscale sim ulation pip elines where errors in lo cal gradients or high-frequency conten t can propagate do wnstream. F or a discretized von Mises stress field σ v M ( x i , y j ) : i, j = 1 , . . . , N , the 2D sp ectrum is obtained by applying the discrete F ourier transform, b σ v M ( k x,m , k y ,n ) = F [ σ v M ( x i , y j )]. Here, k x,m and k y ,n denote the discrete wa v enum bers in the x and y directions, resp ectiv ely , and m, n = 1 , . . . , N , where N is the n umber of w av en umbers in each direction. The maximum resolv able wa ven um b er in each direction is determined by the Nyquist frequency , whic h for a spatial discretization with grid spacing ∆ x is given by k x,M = π ∆ x . W e compute the magnitude sp ectrum as S 2D ( k x,m , k y ,n ) = log (1 + | b σ v M,c ( k x,m , k y ,n ) | ) . (16) where, b σ v M,c ( k x,m , k y ,n ) = b σ v M ( k x,m + N 2 ) mo d N , ( k y ,n + N 2 ) mo d N . This cen tering improv es visual in terpretability by placing low-frequency comp onen ts at the center of the plot. The logarithmic transfor- mation in Eq. 16 is applied to enhance con trast b et ween low- and high-magnitude mo des and to ensure n umerical stability , particularly when sp ectral magnitudes span several orders of magnitude. 11 Figure 4: Randomly selected sample from the single-v oid dataset: Comparison of cDDPM-DeepONet predictions and FEM stress maps. The stress maps in the upp er row compare the hybrid mo del’s predictions with the ground-truth FEM results, showing excellent visual correlation and very low absolute error. The line plots illustrate the accurate pixel-wise matching of model outputs and FE along sp ecific horizontal and vertical cross-sections. Figure 5: Randomly selected sample from the m ultiple-void dataset: Comparison of predicted and FEM stress maps. The FEM ground truth and cDDPM-DeepONet hybrid predicted stress maps show strong visual agreement, esp ecially in the regions of high stress concentration induce d by the inclusions. The absolute error map confirms this accuracy , showing consistently low error v alues across the domain. The horizontal and vertical mid-section plots provide quantitativ e v alidation, showing that the hybrid mo del’s predicted stress profile closely matches the ground truth across the respective cross-sections. 12 200 400 600 800 1000 1200 M e a n v M ( M P a ) 0.000 0.002 0.004 0.006 0.008 0.010 0.012 0.014 Probability density Ground truth UNet cDDPM cDDPM-DeepONet (a) Single-void dataset 0 200 400 600 800 1000 1200 1400 1600 M e a n v M ( M P a ) 0.000 0.002 0.004 0.006 0.008 0.010 0.012 Probability density Ground truth UNet cDDPM cDDPM-DeepONet (b) Multiple-void dataset Figure 6: Probability density of the mean von Mises stress across test samples for tw o datasets, comparing predicted stress fields from different mo dels against ground truth data. F ull 2D log-sp ectrum maps, computed using Eq. 16 and av eraged ov er all the test samples, are provided in Figures 7a and 8a for the single- and m ultiple-v oid datasets, adding a differen t w ay to visualize the relativ e strengths and weaknesses of the mo dels presented here. The brigh t central region corresp onds to lo w-frequency , smo othly v arying comp onen ts of the stress field, whereas increased intensit y a wa y from the cen ter reflects higher-frequency conten t asso ciated with sharp stress gradients and fine geometric features near the v oids. The presence of directional streaks in these maps indicates anisotropic spectral contributions in tro duced b y v oid shap es, applied loading configurations and their magnitudes. The ground truth FEM sp ectra exhibit a relatively broad spectral fo otprint, reflecting the ric h sp ectral density of the underlying stress resp onse. While the h ybrid mo del closely mirrors this texture, including faint peripheral structure and balanced energy spread, the UNet collapses muc h of the energy into a central lo w frequency core, suggesting excessive smo othing and low-pass filtering b eha vior. The cDDPM mo del partially restores high- frequency detail but lacks consistent amplitude normalization, resulting in ov erall sp ectral mismatch. This supp orts the design of the hybrid mo del; it lev erages the denoising diffusion pro cess to recov er fine texture in greater detail while anchoring amplitude via DeepONet scaling. These observ ations are reinforced b y the corresp onding sp ectral error maps in Figures 7b and 8b , which plot the absolute difference b et w een the 2D log-sp ectrum maps of the predictions of the surrogates with that of the ground truth. The UNet exhibits large, structured errors at mid- and high-frequency regions, particularly along principal axes, indicating a failure to recov er anisotropic fine-scale features. The cDDPM substantially reduces these errors but retains directionally aligned residuals, consistent with imp erfect amplitude calibration across frequency bands. In con trast, the cDDPM-DeepONet h ybrid model yields uniformly lo w spectral error across the frequency plane in b oth the single- and multiple-v oid datasets. T o help visualize fine differences b et w een the mo dels, the 1D isotropic sp ectrum is calculated by aggre- gating the 2D sp ectral data in to radial wa ven um b er bins. The energy densit y at a giv en radial w av en um b er k r is defined as E ( k r ) = D | b σ v M,c ( k x,m , k y ,n ) | 2 E k r < √ k 2 x,m + k 2 y,n ≤ k r +∆ k r , (17) where ⟨ · ⟩ denotes av eraging ov er all sp ectral co efficien ts within an annular band of width ∆ k r . The radial w av en umber range spans from 0 up to the isotropic Nyquist limit, k r , max = √ 2 π , giv en a spatial discretization of ∆ x = ∆ y = 1. Figures 9a and 10a plot the mean of E ( k r ) o v er the test samples of the single- and m ultiple-v oid datasets, resp ectiv ely . Figures 9b and 10b plot the corollary relative error betw een the predicted and the ground truth relative energy densities. The cDDPM–DeepONet hybrid mo del achiev es the closest agreement with the FEM sp ectrum across all k r in b oth datasets. In particular, the h ybrid mo del av oids the low-frequency amplitude mismatc h observed in the UNet and maintains energy densit y in the high-frequency tail, where the UNet spectrum notably decays due to smoothing. While the standalone cDDPM recov ers these high- 13 Ground truth UNet cDDPM cDDPM-DeepONet 7 8 9 10 11 12 13 14 S 2 D (a) Mean 2D log-magnitude sp ectrum UNet cDDPM cDDPM DeepONet 0.0 0.5 1.0 | S m o d e l 2 D S g r o u n d t r u t h 2 D | (b) Mean sp ectral error relative to FEM Figure 7: Single-void dataset. (a) Mean 2D log-magnitude F ourier sp ectrum of the von Mises stress fields, av eraged over all test samples. The bright central region corresp onds to dominant lo w-frequency comp onen ts asso ciated with smo oth v ariations in the stress field, while increased in tensity aw ay from the center indicates higher-frequency con tent generated b y sharp gradien ts near the v oid boundary . This visualization provides a frequency-domain reference for assessing ho w surrogate models reproduce the spatial features presen t in the FEM solutions. (b) Mean spectral error relative to the FEM solution, highlighting frequency- dependent discrepancies in surrogate mo del predictions. frequency mo des b etter than the UNet, it exhibits a p ersistent amplitude offset across all w av en umbers, indicated b y the elev ated flat error profile in the relative error plots. How ev er, lik e the UNet, it lac ks consisten t amplitude normalization, leading to a mismatc h at lo wer wa ven um b ers. The abov e conclusions are quan titatively supported by the log–linear area metric ( A c ) in T able 4 , whic h compares the area betw een the isotropic sp ectra of the surrogates and ground truth: A c = Z log 10 E pred ( k r ) − log 10 E true ( k r ) dk r . (18) As rep orted in T able 4 , the hybrid mo del attains the low est sp ectral discrepancy scores, with A c = 4 . 4189 for the single-v oid dataset and A c = 4 . 43 for the m ultiple-v oid dataset. In comparison, the UNet yields considerably higher v alues, exceeding 5 . 2 in b oth cases. The standalone cDDPM sho ws intermediate p erformance with A c v alues of appro ximately 4 . 54, quantifying the cost of its amplitude drift. Notably , the h ybrid mo del’s sp ectral error remains stable ( A c ≈ 4 . 4) across b oth datasets despite the increased geometric complexit y of the multiple-v oid case, demonstrating robust generalization in the frequency domain. The sp ectral tools discussed here (1D E ( k r ), relativ e E ( k r ) error, and 2D FFT magnitude) are useful diagnostics to distinguish b et w een model behaviors. In con trast to scalar metrics that aggregate p erformance in to a single v alue, these sp ectral diagnostics isolate sp ecific failure mo des, rev ealing whether a mo del 14 Ground truth UNet cDDPM cDDPM-DeepONet 8 9 10 11 12 13 14 S 2 D (a) Mean 2D log-magnitude sp ectrum UNet cDDPM cDDPM DeepONet 0.0 0.2 0.4 0.6 0.8 | S m o d e l 2 D S g r o u n d t r u t h 2 D | (b) Mean sp ectral error relative to FEM Figure 8: Multiple-v oid dataset. (a) Mean 2D log-magnitude F ourier sp ectrum of the von Mises stress fields, av eraged ov er all test samples. The central p eak reflects the dominant low-frequency components of the stress resp onse, while the broader spread of intensit y aw ay from the center indicates the presence of additional high-frequency features caused by interactions among m ultiple-voids. This frequency-domain representation highlights the increased geometric complexity of the dataset and provides a reference for ev aluating surrogate mo del performance. (b) Mean spectral error relative to the FEM solution, highlighting frequency-dep endent discrepancies in surrogate mo del predictions. suffers from low-frequency global bias, excessive smo othing of sharp gradients, or the loss of fine-scale stress features. As such, these sp ectral analyses are not merely diagnostic but guide architectural c hoices and training strategies for surrogate mo deling of stress and other spatially v arying b eha viors. Dataset Model Area Betw een Curves (log–linear scale) Single-v oid UNet [ 28 ] 5.2572 cDDPM 4.5372 cDDPM-DeepONet 4 . 4198 Multiple-v oid UNet [ 28 ] 5.3313 cDDPM 4.5451 cDDPM-DeepONet 4 . 4166 T able 4: Area b etw een the log–log energy spectra of the predicted and ground-truth stress fields, computed as describ ed in Eq. 18 Low er v alues indicate b etter sp ectral agreement across all wa v enum ber scales for b oth single-void and multiple-v oid hyperelastic datasets. 15 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 k r 1 0 1 6 1 0 1 2 1 0 8 1 0 4 1 0 0 1 0 4 1 0 8 E ( k r ) Ground truth UNet cDDPM cDDPM DeepONet 1 2 3 1 0 7 1 0 8 High-frequency detail (a) Ensemble-a v eraged 1D isotropic energy spectrum for FEM and surrogate mo dels. 0 1 2 3 4 k r 1 0 1 1 0 2 1 0 5 1 0 8 1 0 1 1 1 0 1 4 1 0 1 7 | E m o d e l ( k r ) E g r o u n d t r u t h ( k r ) E g r o u n d t r u t h ( k r ) | UNet cDDPM cDDPM DeepONet (b) Relative spectral error across wa ven um b ers. Figure 9: Single-v oid dataset: Comparison of sp ectral characteristics. 9a shows the ensem ble-av eraged 1D isotropic energy spectra, demonstrating how accurately each surrogate repro duces the multiscale frequency conten t of the FEM reference. 9b presents the corresponding relative sp ectral error across wa ven umbers, highlighting scale-dep enden t deviations in the predicted stress fields. T ogether, these plots quantify the mo dels’ ability to recov er b oth lo w- and high-frequency comp onents of the stress resp onse. 4.3. T r aining and optimization In setting the training data size and key mo del hyperparameters, we p erformed a series of parametric studies to ensure con vergence and accuracy . One important h yp erparameter is the num b er of time steps T used in the cDDPM (both in the standalone cDDPM and the hybrid cDDPM-DeepONet mo del). Figure 11 rep orts the sensitivit y of error metrics with resp ect to T for the single-void dataset. The p erformance of all these metrics ec ho each other. Increasing T improv es accuracy by enabling a smo other progression from the Gaussian prior N ( 0 , I ) to the data distribution p ( x ). How ev er, improv emen ts diminish beyond T = 100, reflecting the diffusion b ehavior, in whic h low-frequency mo des are reco vered early , and high-frequency details con verge gradually [ 71 ]. Similar trends ha ve b een observ ed in prior stress-field diffusion mo dels [ 55 ]. T o ev aluate the data efficiency of our models, we perform ablation exp erimen ts by systematically v arying the fraction of training data used for b oth datasets. F or the single-void dataset, we use 33%, 40%, 50%, 66%, and 100% of the a v ailable 19 , 900 training data p oints; for the multiple-v oid dataset, w e use 25%, 50%, 75%, and 100% of the av ailable 20 , 000 training data p oin ts. As seen in Figure 12 , the RMSE exhibits a sharp decline with increasing dataset size, but the gains saturate b eyond a certain threshold. In the single-v oid dataset, improv ement in performance of the mo del plateaus after using around 66.7% of the training set (13 , 267 samples), b ey ond which additional data offers marginal impro vemen ts. In the multiple- v oid dataset, we observ e a similar trend —training with 50% of the dataset (10 , 000 samples) ac hieves p erformance comparable to that of the full dataset, in the interest of the training time. T ogether, these observ ations indicate that neither the diffusion process nor the DeepONet op erator in the hybrid mo del exhibits dep endence on large T or v ery large datasets. Instead, the hybrid mo del demon- strates p erformance saturation at practical op erating p oints. This highlights the mo del’s sample efficiency and inference tractability . W e attribute this to the enco der-driven conditioning mechanism describ ed in Section 2.3 , which narrows the p osterior v ariance in the reverse diffusion pro cess and concen trates samples near deterministic reconstructions. This aligns with recent w ork on classifier guidance and distillation in diffusion mo dels [ 60 , 72 ], which demonstrates that accurate generation can b e achiev ed with as few as 100 steps. 5. Conclusion In this w ork, we introduced a h ybrid surrogate mo deling framew ork that com bines conditional denois- ing diffusion mo dels with neural op erators to predict stress fields in hyperelastic materials with complex 16 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 k r 1 0 2 3 1 0 1 9 1 0 1 5 1 0 1 1 1 0 7 1 0 3 1 0 1 E ( k r ) Ground truth UNet cDDPM cDDPM DeepONet 1 2 3 1 0 0 1 0 1 1 0 2 High-frequency detail (a) Ensemble-a v eraged 1D isotropic energy spectrum for FEM and surrogate mo dels 0 1 2 3 4 k r 1 0 2 1 0 1 1 0 4 1 0 7 1 0 1 0 1 0 1 3 1 0 1 6 | E m o d e l ( k r ) E g r o u n d t r u t h ( k r ) E g r o u n d t r u t h ( k r ) | UNet cDDPM cDDPM DeepONet (b) Relative spectral error across wa ven um b ers Figure 10: Multiple-void dataset: Sp ectral comparison of predicted and FEM stress fields. 10a rep orts the ensemble-a veraged isotropic sp ectra, reflecting how well each surrogate captures the broader range of spatial frequencies introduced by multiple interacting voids. 10b shows the corresp onding relative sp ectral error, indicating the scales at which discrepancies are most pronounced. T ogether, these results illustrate each model’s ability to reproduce the richer sp ectral characteristics of the multiple-v oid dataset. microstructural features. By decoupling the representation of stress morphology from stress magnitude, the proposed cDDPM–DeepONet architecture addresses fundamental limitations inheren t to existing deep- learning surrogates. This decoupling strategy effectively reconciles the trade-offs inherent to standard deep learning surrogates. While standalone diffusion mo dels excel at generating broadband spatial structure, they often suffer from lo w-frequency amplitude drift. Con versely , neural op erators capture global scaling but t yp- ically struggle to resolve high-frequency stress concentrations due to sp ectral bias. Our framework lev erages the complemen tary strengths of b oth mo del classes: the cDDPM reconstructs normalized stress distribu- tions with fine-scale accuracy , and DeepONet pro vides physically consisten t global scaling parameters that restore correct stress magnitudes. Extensiv e n umerical exp eriments on single-void and m ulti-void h yp erelastic datasets demonstrate that the hybrid mo del deliv ers substantial accuracy gains o ver UNet, DeepONet, and standalone diffusion base- lines. The cDDPM-DeepONet hybrid significan tly reduces the smo othing artifacts common in conv olutional arc hitectures, ensuring the preserv ation of sharp stress transitions near geometric discon tinuities. F ur- thermore, spectral analysis confirms that the mo del maintains fidelity across the full frequency sp ectrum, mitigating b oth the high-frequency attenuation observed in standard regression mo dels and the amplitude instabilit y c haracteristic of pure generativ e approac hes. The mo del further generalizes w ell to unseen geome- tries, underscoring its robustness and p oten tial for deploymen t in design and simulation w orkflows requiring large-scale exploration of geometric v ariations. Bey ond the demonstrated b enefits for h yp erelastic stress prediction, the decoupling strategy proposed here offers a general paradigm for combining generative mo dels with operator-learning architectures in computational mec hanics. By assigning complemen tary comp onen ts of the solution to distinct netw ork mo dules, hybrid surrogates can o vercome structural biases that p ersist even in adv anced architectures. F uture extensions of this work include applications to three -dimensional R VEs, rate-dependent or history- dep enden t materials, sto c hastic microstructures, and m ultiscale constitutive mo deling. The integration of ph ysical constraints or differen tiable solvers within the diffusion pro cess also presen ts promising av enues for impro ving stability and interpretabilit y . Ov erall, the cDDPM–DeepONet framew ork pro vides a flexible and accurate surrogate mo deling approac h capable of capturing the ric h m ultiscale b eha vior of nonlinear elastic solids. Its ability to com bine generativ e fidelit y with op erator-based ph ysical scaling signals a broader opportunity for hybrid architectures to adv ance data-driv en mo deling in solid mec hanics and b ey ond. 17 1 0 1 1 0 2 1 0 3 1 . 5 × 1 0 3 Number of time steps 1 0 3 1 0 2 1 0 1 1 0 0 Error metric MAE RMSE RelMAE PAE LSG PV Figure 11: Single-v oid dataset: V ariation of error metrics with num b er of diffusion time steps ( T ). on the single-void dataset. MSE, MAE, LSG, and P AE all improv e rapidly up to T = 100, with diminishing returns b eyond. The contrast illustrates that while global stress ranges are recov ered quickly , finer structural accuracy contin ues to b enefit from additional time steps. 33.3 40.0 50.0 66.7 100.0 Percentage of total dataset used for training 27.5 30.0 32.5 35.0 37.5 40.0 42.5 45.0 47.5 RMSE (a) Single-void dataset 25.0 33.3 50.0 100.0 Percentage of total dataset used for training 45 50 55 60 65 RMSE (b) Multiple-void dataset Figure 12: RMSE vs. percentage of av ailable training data used for the cDDPM–DeepONet framework. Performance saturates near 66.7% for the single-void and 50% for the multiple-v oid datasets, indicating strong sample efficiency . 18 App endix A. Detailed Deriv ation of the Diffusion Loss While Section 2.1 outlines the forward and rev erse pro cesses, the training ob jectiv e is derived from the Evidence Low er Bound (ELBO). This app endix details the decomp osition of the ELBO and the deriv ation of the p osterior distribution required to arrive at the simplified loss function in Eq. 9 . A.1. ELBO De c omp osition The goal is to maximize the log-lik eliho od of the data p θ ( x (0) ). Since the marginal lik eliho od is in- tractable, w e optimize the v ariational lo wer b ound: log p θ ( x (0) ) ≥ E q log p θ ( x (0: T ) ) q ( x (1: T ) | x (0) ) . (A.1) By le v eraging the Marko v prop ert y of the forward and reverse chains, this b ound can b e decomp osed into a sum of KL-div ergence terms: L VLB = E q h D K L q ( x ( T ) | x (0) ) ∥ p ( x ( T ) ) | {z } L T + T X t =2 D K L q ( x ( t − 1) | x ( t ) , x (0) ) ∥ p θ ( x ( t − 1) | x ( t ) ) | {z } L t − 1 − log p θ ( x (0) | x (1) ) | {z } L 0 i . (A.2) The term L T is constan t (as q is fixed and p is a Gaussian prior), and L 0 is a reconstruction term. The core training signal comes from the L t − 1 terms, which align the learned rev erse transition p θ with the tractable forw ard p osterior q ( x ( t − 1) | x ( t ) , x (0) ). A.2. T r actable F orwar d Posterior Unlik e the reverse transition, the forward p osterior conditioned on x (0) is tractable and Gaussian. Using Ba yes’ rule: q ( x ( t − 1) | x ( t ) , x (0) ) = q ( x ( t ) | x ( t − 1) ) q ( x ( t − 1) | x (0) ) q ( x ( t ) | x (0) ) . (A.3) Giv en the Gaussian forms defined in Eq. (1) and Eq. (3), the p osterior is derived as N ( x ( t − 1) ; ˜ µ t , ˜ β t I ), where the mean ˜ µ t is: ˜ µ t ( x ( t ) , x (0) ) = √ α ( t − 1) β ( t ) 1 − α ( t ) x (0) + √ α ( t ) (1 − α ( t − 1) ) 1 − α ( t ) x ( t ) . (A.4) This form ulation dep ends on x (0) , which is unkno wn during sampling. Ho wev er, during training, we can express x (0) in terms of x ( t ) and the added noise ϵ using the reparameterization trick x (0) = x ( t ) − √ 1 − α ( t ) ϵ √ α ( t ) . Substituting this in to Eq. A.4 simplifies the p osterior mean to: ˜ µ t ( x ( t ) , x (0) ) = 1 √ α ( t ) x ( t ) − 1 − α ( t ) p 1 − α ( t ) ϵ ! . (A.5) 19 A.3. Par ameterization and L oss F unction The reverse transition p θ ( x ( t − 1) | x ( t ) ) is mo deled as N ( x ( t − 1) ; µ θ , σ 2 t I ). T o minimize the KL divergence term L t − 1 , the model mean µ θ aims to predict ˜ µ t . W e therefore parameterize µ θ to match the functional form of the p osterior mean: µ θ ( x ( t ) , t ) = 1 √ α ( t ) x ( t ) − 1 − α ( t ) p 1 − α ( t ) ˆ ϵ θ ( x ( t ) , t ) ! . (A.6) The KL div ergence b et ween t w o Gaussians with fixed v ariances is prop ortional to the squared Euclidean distance b etw een their means. Substituting the definitions of ˜ µ t and µ θ , the ob jective simplifies to minimizing the error b et w een the true noise ϵ and the predicted noise ˆ ϵ θ : L simple = E t, x (0) ,ϵ h ∥ ϵ − ˆ ϵ θ ( x ( t ) , t ) ∥ 2 i . (A.7) Declaration of generativ e AI and AI-assisted technologies in the writing process During the preparation of this w ork, the authors used the ChatGPT 5 Thinking mo del in order to impro v e the readabilit y and language of the In tro duction section of the man uscript. After using this to ol/service, the authors reviewed and edited the conten t as needed and tak e full resp onsibility for the con tent of the published article. References [1] J. He, D. Abueidda, R. Abu Al-Rub, S. Koric, I. Jasiuk, A deep learning energy-based method for classical elastoplasticit y , International Journal of Plasticity 162 (2023) 103531. doi:https://doi.org/10.1016/j.ijplas.2023.103531 . URL https://www.sciencedirect.com/science/article/pii/S0749641923000177 [2] S. Koric, A. Viswan tah, D. W. Abueidda, N. A. Sobh, K. Khan, Deep learning op erator netw ork for plastic deformation with v ariable loads and material prop erties, Engineering with Computers 40 (2) (2024) 917–929. [3] J. He, S. Kush waha, D. Abueidda, I. Jasiuk, Exploring the structure-property relations of thin-w alled, 2d extruded lattices using neural networks , Computers & Structures 277-278 (2023) 106940. doi:https://doi.org/10.1016/j.compstruc. 2022.106940 . URL https://www.sciencedirect.com/science/article/pii/S0045794922002000 [4] J.-H. Bastek, D. M. Kochmann, In verse design of nonlinear mec hanical metamaterials via video denoising diffusion models, Nature Machine Intelligence 5 (12) (2023) 1466–1475. [5] Z. Y ang, C.-H. Y u, K. Guo, M. J. Buehler, End-to-end deep learning method to predict complete strain and stress tensors for complex hierarchical comp osite microstructures , Journal of the Mechanics and Physics of Solids 154 (2021) 104506. doi:https://doi.org/10.1016/j.jmps.2021.104506 . URL https://www.sciencedirect.com/science/article/pii/S0022509621001721 [6] S. Y e, B. Li, Q. Li, H.-P . Zhao, X.-Q. F eng, Deep neural netw ork metho d for predicting the mechanical prop erties of composites, Applied Physics Letters 115 (16) (2019). [7] J. W ei, X. Chu, X.-Y. Sun, K. Xu, H.-X. Deng, J. Chen, Z. W ei, M. Lei, Mac hine learning in materials science, InfoMat 1 (3) (2019) 338–358. [8] K. T. Butler, D. W. Davies, H. Cart wright, O. Isayev, A. W alsh, Machine learning for molecular and materials science, Nature 559 (7715) (2018) 547–555. [9] V. V enturi, H. L. Pa rks, Z. Ahmad, V. Viswanathan, Machine learning enabled discovery of application dep enden t design principles for tw o-dimensional materials, Machine Learning: Science and T echnology 1 (3) (2020) 035015. [10] S. Y. Lee, J. Lee, J. S. Lee, S. Lee, Deep learning-based prediction and interpretabilit y of physical phenomena for metaporous materials, Materials T oday Physics 30 (2023) 100946. [11] K. Guo, Z. Y ang, C.-H. Y u, M. J. Buehler, Artificial intelligence and machine learning in design of mechanical materials, Materials Horizons 8 (4) (2021) 1153–1172. [12] Z. Y ang, Y. C. Y abansu, D. Jha, W.-k. Liao, A. N. Choudhary , S. R. Kalidindi, A. Agra wal, Establishing structure- property localization linkages for elastic deformation of three-dimensional high contrast comp osites using deep learning approaches, Acta Materialia 166 (2019) 335–345. [13] W. Chen, A. Iyer, R. Bostanabad, Data centric design: A new approach to design of microstructural material systems, Engineering 10 (2022) 89–98. [14] G. A. Sengodan, Prediction of tw o-phase comp osite microstructure prop erties through deep learning of reduced dimensional structure-response data, Comp osites Part B: Engineering 225 (2021) 109282. 20 [15] D.-W. Kim, J. H. Lim, S. Lee, Prediction and v alidation of the transverse mec hanical behavior of unidirectional comp osites considering in terfacial deb onding through conv olutional neural net works, Comp osites P art B: Engineering 225 (2021) 109314. [16] M. Pathan, S. Ponn usami, J. Pathan, R. Pitisongsaw at, B. Erice, N. Petrinic, V. T agarielli, Predictions of the mechanical properties of unidirectional fibre comp osites by supervised machine learning, Scientific Reports 9 (1) (2019) 1–10. doi: 10.1038/s41598- 019- 50144- w . [17] Z. Y ang, Y. C. Y abansu, R. Al-Bahrani, W. keng Liao, A. N. Choudhary , S. R. Kalidindi, A. Agraw al, Deep learning approaches for mining structure-prop ert y link ages in high contrast comp osites from simulation datasets , Computational Materials Science 151 (2018) 278–287. doi:https://doi.org/10.1016/j.commatsci.2018.05.014 . URL https://www.sciencedirect.com/science/article/pii/S0927025618303215 [18] C. Rao, Y. Liu, Three-dimensional conv olutional neural net work (3d-cnn) for heterogeneous material homogenization , Computational Materials Science 184 (2020) 109850. doi:https://doi.org/10.1016/j.commatsci.2020.109850 . URL https://www.sciencedirect.com/science/article/pii/S0927025620303414 [19] K. W ang, W. Sun, A multiscale m ulti-p ermeabilit y p oroplasticity mo del linked by recursive homogenizations and deep learning , Computer Methods in Applied Mec hanics and Engineering 334 (2018) 337–380. doi:https://doi.org/10.1016/ j.cma.2018.01.036 . URL https://www.sciencedirect.com/science/article/pii/S0045782518300380 [20] S. Saha, Z. Gan, L. Cheng, J. Gao, O. L. Kafk a, X. Xie, H. Li, M. T a jdari, H. A. Kim, W. K. Liu, Hierarchical deep learning neural net work (hidenn): An artificial intelligence (ai) framework for computational science and engineering , Computer Metho ds in Applied Mechanics and Engineering 373 (2021) 113452. doi:10.1016/j.cma.2020.113452 . URL https://www.sciencedirect.com/science/article/pii/S004578252030637X [21] A. Bhaduri, A. Gupta, A. Olivier, L. Graham-Brady , An efficient optimization based microstructure reconstruction ap- proach with multiple loss functions, Computational Materials Science 199 (2021) 110709. [22] A. M. C. Carneiro, A. F. C. Alves, R. C. P . Co elho, J. S. Cardoso, F. M. A. Pires, A simple machine learning-based framework for faster multi-scale simulations of path-indep endent materials at large strains, Finite El emen ts in Analysis & Design 222 (2023) 103956. doi:10.1016/j.finel.2023.103956 . [23] L. F. Li, C. Q. Chen, Equilibrium-based conv olutional neural netw orks for constitutive mo deling of hyperelastic materials, Journal of the Mechanics and Physics of Solids 164 (2022) 104931. doi:10.1016/j.jmps.2022.104931 . [24] L. Liang, M. Liu, C. Martin, W. Sun, A deep learning approach to estimate stress distribution: a fast and accurate surrogate of finite-elemen t analysis, Journal of The Roy al Society In terface 15 (138) (2018) 20170844. doi:10.1098/rsif.2017.0844 . [25] Z. Nie, H. Jiang, L. B. Kara, Stress field prediction in cantilev ered structures using conv olutional neural networks , Journal of Computing and Information Science in Engineering 20 (1) (2020) 011002. doi:10.1115/1.4044097 . URL https://doi.org/10.1115/1.4044097 [26] Y. Sun, I. Hanhan, M. D. Sangid, G. Lin, Predicting mechanical properties from microstructure images in fib er-reinforced polymers using conv olutional neural networks , Journal of Comp osites Science 8 (10) (2024). URL https://www.mdpi.com/2504- 477X/8/10/387 [27] M. M. Rashid, T. Pittie, S. Chakrab orty , N. A. Krishnan, Learning the stress-strain fields in digital comp osites using fourier neural op erator , iScience 25 (11) (2022) 105452. doi:https://doi.org/10.1016/j.isci.2022.105452 . URL https://www.sciencedirect.com/science/article/pii/S2589004222017242 [28] A. Bhaduri, A. Gupta, L. Graham-Brady , Stress field prediction in fib er-reinforced composite materials using a deep learning approach, Comp osites Part B: Engineering 238 (2022) 109879. [29] M. M. Rashid, S. Chakraborty , N. A. Krishnan, Revealing the predictive p ow er of neural op erators for strain evolution in digital comp osites, Journal of the Mechanics and Physics of Solids 181 (2023) 105444. [30] O. Ronneb erger, P . Fischer, T. Bro x, U-net: Conv olutional netw orks for biomedical image segmentation, in: Medical Image Computing and Computer-Assisted Interv en tion (MICCAI) 2015, V ol. 9351 of LNCS, Springer, 2015, pp. 234–241. doi:10.1007/978- 3- 319- 24574- 4\_28 . [31] I. Saha, A. Gupta, L. Graham-Brady , Prediction of local elasto-plastic stress and strain fields in a t wo-phase composite microstructure using a deep conv olutional neural netw ork , Computer Metho ds in Applied Mechanics and Engineering 421 (2024) 116816. doi:https://doi.org/10.1016/j.cma.2024.116816 . URL https://www.sciencedirect.com/science/article/pii/S0045782524000720 [32] A. Mendizabal, P . M´ arquez-Neila, S. Cotin, Simulation of hyperelastic materials in real-time using deep learning, Medical Image Analysis 59 (2020) 101569. doi:10.1016/j.media.2019.101569 . [33] A. Bhaduri, D. Brandyb erry , M. D. Shields, P . Geubelle, L. Graham-Brady , On the usefulness of gradient information in surrogate mo deling: Application to uncertaint y propagation in comp osite material mo dels, Probabilistic Engineering Mechanics 60 (2020) 103024. [34] F. E. Bock, R. C. Aydin, C. J. Cyron, N. Hub er, S. R. Kalidindi, B. Klusemann, A review of the application of machine learning and data mining approaches in contin uum materials mechanics, F rontiers in Materials 6 (2019) 110. [35] A. Stoll, P . Benner, Mac hine learning for material characterization with an application for predicting mechanical prop erties, GAMM-Mitteilungen 44 (1) (2021) e202100003. [36] N. Ko v achki, B. Liu, X. Sun, H. Zhou, K. Bhattachary a, M. Ortiz, A. Stuart, Multiscale mo deling of materials: Computing, data science, uncertaint y and goal-oriented optimization, Mechanics of Materials 165 (2022) 104156. [37] Z. Zhang, G. X. Gu, Finite-ele men t-based deep-learning mo del for deformation b ehavior of digital materials, Adv anced Theory and Simulations 3 (7) (2020) 2000031. [38] P . Zhang, Z.-Y. Yin, A nov el deep learning-based mo delling strategy from image of particles to mechanical properties for granular materials with CNN and BiLSTM, Computer Methods in Applied Mechanics and Engineering 382 (2021) 113858. 21 doi:10.1016/j.cma.2021.113858 . [39] S. Rezaei, R. N. Asl, S. F aroughi, M. Asgharzadeh, A. Harandi, R. N. Ko opas, G. Laschet, S. Reese, M. Ap el, A finite op erator learning tec hnique for mapping the elastic prop erties of microstructures to their mechanical deformations , International Journal for Numerical Methods in Engineering 126 (1) (2025) e7637. arXiv:https://onlinelibrary.wiley. com/doi/pdf/10.1002/nme.7637 , doi:https://doi.org/10.1002/nme.7637 . URL https://onlinelibrary.wiley.com/doi/abs/10.1002/nme.7637 [40] Z. Li, N. Kov achki, K. Azizzadenesheli, B. Liu, K. Bhattachary a, A. Stuart, A. Anandkumar, F ourier neural operator for parametric partial differential equations (2021). . URL [41] Z. Li, D. Z. Huang, B. Liu, A. Anandkumar, F ourier neural operator with learned deformations for p des on general geometries , Journal of Machine Learning Research 24 (388) (2023) 1–26. URL http://jmlr.org/papers/v24/23- 0064.html [42] J. He, S. Koric, S. Kushw aha, J. Park, D. Abueidda, I. Jasiuk, Nov el deep onet architecture to predict stresses in elasto- plastic structures with v ariable complex geometries and loads, Computer Metho ds in Applied Mechanics and Engineering 409 (2023) 116277. doi:10.1016/j.cma.2023.116277 . [43] M. Mozaffar, R. Bostanabad, W. Chen, K. Ehmann, J. Cao, M. A. Bessa, Deep learning predicts path-dependent plasticit y , Proceedings of the National Academy of Sciences 116 (52) (2019) 26414–26420. arXiv:https://www.pnas.org/doi/pdf/ 10.1073/pnas.1911815116 , doi:10.1073/pnas.1911815116 . URL https://www.pnas.org/doi/abs/10.1073/pnas.1911815116 [44] M. Shin, M. Seo, H. Choi, J. Jung, K. Y o on, Lo cal stress fields prediction using global displacement through fourier neural operators, Journal of Computational Design and Engineering 12 (5) (2025) 21–40. [45] N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprech t, Y. Bengio, A. Courville, On the spectral bias of neural netw orks, in: In ternational conference on machine learning, PMLR, 2019, pp. 5301–5310. [46] Z.-Q. J. Xu, Y. Zhang, T. Luo, Y. Xiao, Z. Ma, F requency principle: F ourier analysis sheds light on deep neural networks, arXiv preprint arXiv:1901.06523 (2019). [47] A. Creswell, T. White, V. Dumoulin, K. Arulkumaran, B. Sengupta, A. A. Bharath, Generative adversarial netw orks: An ov erview, IEEE signal pro cessing magazine 35 (1) (2018) 53–65. [48] J. Song, C. M eng, S. Ermon, Denoising diffusion implicit mo dels, arXiv preprint arXiv:2010.02502 (2020). [49] J. Sohl-Dickstein, E. W eiss, N. Maheswaranathan, S. Ganguli, Deep unsup ervised learning using nonequilibrium thermo- dynamics , in: F. Bach, D. Blei (Eds.), Pro ceedings of the 32nd International Conference on Machine Learning, V ol. 37 of Proceedings of Machine Learning Research, PMLR, Lille, F rance, 2015, pp. 2256–2265. URL https://proceedings.mlr.press/v37/sohl- dickstein15.html [50] J. Ho, A. Jain, P . Abb eel, Denoising diffusion probabilistic mo dels, Advances in neural information pro cessing systems 33 (2020) 6840–6851. [51] A. Q. Nichol, P . Dhariwal, Improv ed denoising diffusion probabilistic models, in: International conference on machine learning, PMLR, 2021, pp. 8162–8171. [52] M. J. Buehler, Mo deling atomistic dynamic fracture mechanisms using a progressive transformer diffusion mo del , Jour- nal of Applied Mechanics 89 (12) (2022) 121009. arXiv:https://asmedigitalcollection.asme.org/appliedmechanics/ article- pdf/89/12/121009/6925738/jam_89_12_121009.pdf , doi:10.1115/1.4055730 . URL https://doi.org/10.1115/1.4055730 [53] M. J. Buehler, Predicting mec hanical fields near cracks using a progressive transformer diffusion mo del and exploration of generalization capacity , Journal of Materials Research 38 (5) (2023) 1317–1331. doi:10.1557/s43578- 023- 00892- 3 . URL https://doi.org/10.1557/s43578- 023- 00892- 3 [54] Z. Gao, C. Zh u, C. W ang, Y. Sh u, S. Liu, J. Miao, L. Y ang, Adv anced deep learning framework for m ulti-scale prediction of mechanical properties from microstructural features in p olycrystalline materials , Computer Methods in Applied Mec hanics and Engineering 438 (2025) 117844. doi:https://doi.org/10.1016/j.cma.2025.117844 . URL https://www.sciencedirect.com/science/article/pii/S0045782525001161 [55] Y. Jadhav, J. Berthel, C. Hu, R. Panat, J. Beuth, A. B. F arimani, Stressd: 2d stress estimation using denoising diffusion model, Computer Metho ds in Applied Mechanics and Engineering 416 (2023) 116343. [56] H. Jiang, Z. Nie, R. Y eo, A. B. F arimani, L. B. Kara, Stressgan: A generativ e deep learning mo del for two-dimensional stress distribution prediction, Journal of Applied Mechanics 88 (5) (2021) 051005. [57] N. N. Vlassis, W. Sun, Denoising diffusion algorithm for inv erse design of microstructures with fine-tuned nonlinear material properties , Computer Metho ds in Applied Mechanics and Engineering 413 (2023) 116126. doi:https://doi. org/10.1016/j.cma.2023.116126 . URL https://www.sciencedirect.com/science/article/pii/S0045782523002505 [58] E. Herron, X. Y. Lee, A. Balu, B. S. S. Pokuri, B. Ganapath ysubramanian, S. Sark ar, A. Krishnamurth y , Generativ e design of material microstructures for organic solar cells using diffusion mo dels (2022). URL https://openreview.net/forum?id=f9Lk1G9q- G- [59] A. J. Lew, M. J. Buehler, Single-shot forw ard and in verse hierarc hical arc hitected materials design for nonlinear mechanical properties using an atten tion-diffusion model , Materials T oday 64 (2023) 10–20. doi:https://doi.org/10.1016/j.mattod. 2023.03.007 . URL https://www.sciencedirect.com/science/article/pii/S136970212300069X [60] P . Dhariwal, A. Nic hol, Diffusion mo dels b eat gans on image syn thesis, Adv ances in neural information pro cessing systems 34 (2021) 8780–8794. [61] H. Chang, H. Zhang, L. Jiang, C. Liu, W. T. F reeman, Maskgit: Masked generative image transformer, in: Pro ceedings 22 of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11315–11325. [62] H. Chang, H. Zhang, J. Barb er, A. Maschinot, J. Lezama, L. Jiang, M.-H. Y ang, K. Murphy , W. T. F reeman, M. Ru- binstein, et al., Muse: T ext-to-image generation via masked generative transformers, arXiv preprint (2023). [63] F. Bao, C. Li, J. Sun, J. Zhu, Why are conditional generative mo dels b etter than unconditional ones?, arXiv preprint arXiv:2212.00362 (2022). [64] H. Cao, C. T an, Z. Gao, Y. Xu, G. Chen, P .-A. Heng, S. Z. Li, A survey on generative diffusion models, IEEE transactions on knowledge and data engineering 36 (7) (2024) 2814–2830. [65] D. P . Kingma, T. Salimans, M. W elling, V ariational dropout and the lo cal reparameterization trick, Adv ances in neural information pro cessing systems 28 (2015). [66] L. Lu, P . Jin, G. E. Karniadakis, Learning nonlinear operators via deep onet based on the univ ersal appro ximation theorem of op erators, Nature Machine Intelligence 3 (2021) 218–229. doi:10.1038/s42256- 021- 00302- 5 . [67] A. Logg, K. B. Ølgaard, M. E. Rognes, G. N. W ells, Ffc: the fenics form compiler , in: A. Logg, K.-A. Mardal, G. W ells (Eds.), Automated Solution of Differential Equations by the Finite Element Metho d: The FEniCS Book, Springer Berlin Heidelberg, Berlin, Heidelb erg, 2012, pp. 227–238. doi:10.1007/978- 3- 642- 23099- 8_11 . URL https://doi.org/10.1007/978- 3- 642- 23099- 8_11 [68] M. W. Scroggs, J. S. Dokken, C. N. Ric hardson, G. N. W ells, Construction of arbitrary order finite element degree- of-freedom maps on p olygonal and polyhedral cell meshes, ACM T ransactions on Mathematical Softw are 48 (2) (2022) 18:1–18:23. doi:10.1145/3524456 . [69] M. S. Alnaes, A. Logg, K. B. Ølgaard, M. E. Rognes, G. N. W ells, Unified form language: A domain-sp ecific language for weak formulations of partial differential equations, A CM T ransactions on Mathematical Soft ware 40 (2014). doi: 10.1145/2566630 . [70] G. A. Holzapfel, Nonlinear Solid Mechanics: A Contin uum Approach for Engineering Science , Meccanica 37 (4) (2002) 489–490. doi:10.1023/A:1020843529530 . URL https://doi.org/10.1023/A:1020843529530 [71] R. Benita, M. Elad, J. Keshet, Sp ectral analysis of diffusion mo dels with application to schedule design, arXiv preprint arXiv:2502.00180 (2025). [72] C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, M. Norouzi, Image sup er-resolution via iterative refinement, IEEE transactions on pattern analysis and machine intelligence 45 (4) (2022) 4713–4726. 23
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment