ResNet-50 with Class Reweighting and Anatomy-Guided Temporal Decoding for Gastrointestinal Video Analysis
We developed a multi-label gastrointestinal video analysis pipeline based on a ResNet-50 frame classifier followed by anatomy-guided temporal event decoding. The system predicts 17 labels, including 5 anatomy classes and 12 pathology classes, from fr…
Authors: Romil Imtiaz, Dimitris K. Iakovidis
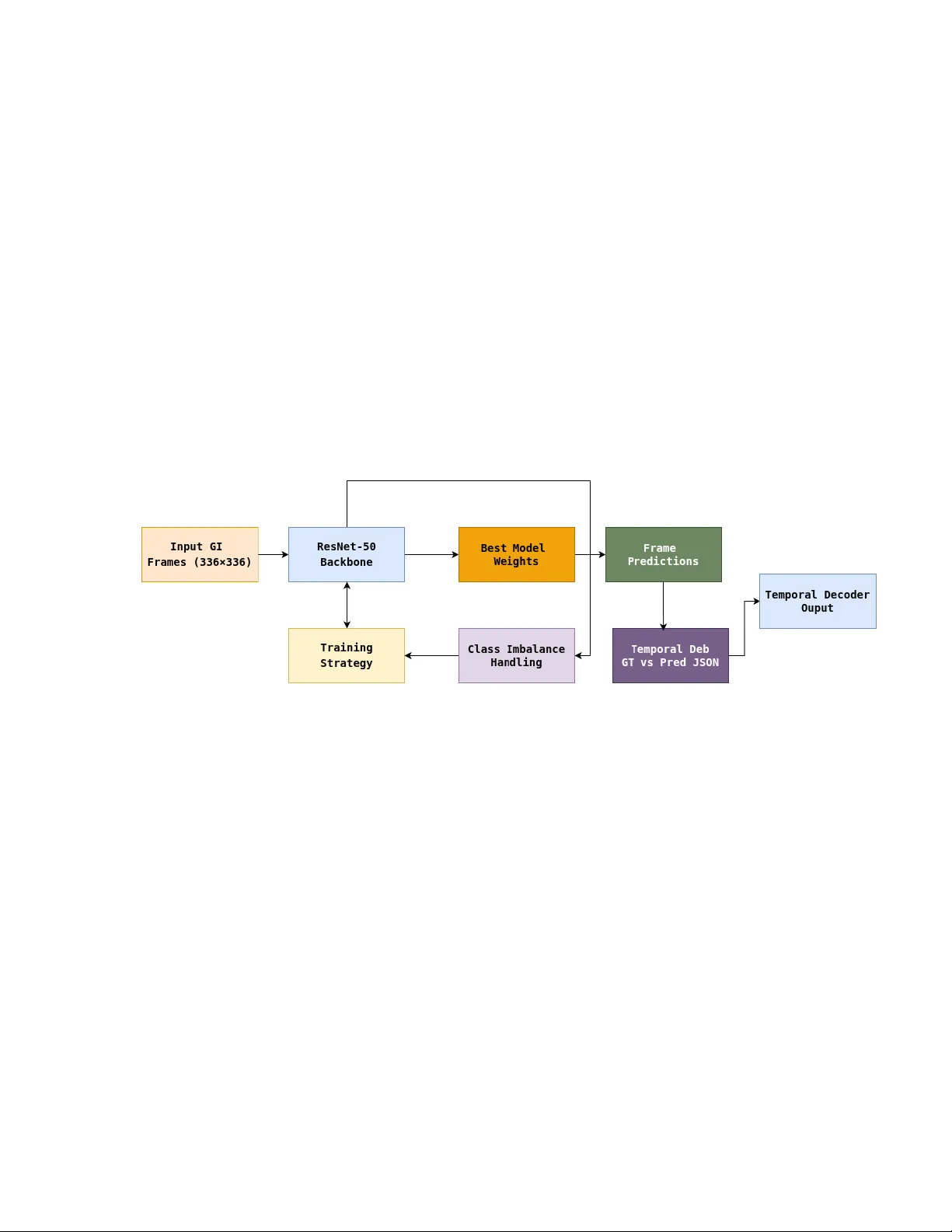
ResNet-50 with Class Rew eigh ting and Anatom y-Guided T emp oral Deco ding for Gastroin testinal Video Analysis Romil Im tiaz a , Dimitris K. Iak ovidis a a Departmen t of Computer Science and Biomedical Informatics, Univ ersity of Thessaly , P apasiop oulou 2–4, Lamia 35131, Greece Corresp onding Author Email: rimtiaz@uth.gr T eam Name: EndoInsight GitHub Rep ository Link: https://github.com/romilimtiaz/ResNet-50-for-GI-Events Abstract W e developed a multi-label gastrointestinal video an alysis pip eline based on a ResNet- 50 frame classifier follow ed by anatom y-guided temp oral even t deco ding. The system pre- dicts 17 lab els, including 5 anatomy classes and 12 pathology classes, from frames resized to 336 × 336. A ma jor c hallenge was severe class imbalance, particularly for rare pathol- ogy lab els. T o address this, w e used clipp ed class-wise p ositive w eighting in the training loss, which impro v ed rare-class learning while main taining stable optimization. A t the temp oral stage, we found that direct frame-to-ev ent con version produced fragmented mis- matc hes with the official ground truth. The final submission therefore combined GT-st yle framewise even t comp osition, anatomy vote smo othing, and anatom y-based pathology gating with a conserv ativ e h ysteresis deco der. This design improv ed the final temp oral mAP from 0.3801 to 0.4303 on the c hallenge test set. 1 Motiv ation Automatic understanding of gastroin testinal video is imp ortant for computer-assisted diagno- sis, lesion screening, and efficien t review of long clinical examinations. Ho wev er, rare abnormal findings are difficult to detect reliably b ecause they ma y app ear only briefly , coexist with c hang- ing anatom y , and b e represen ted b y v ery few training samples. W e participated in this challenge to study ho w far a robust frame-level visual mo del can b e pushed to ward temp orally consistent ev ent detection under a strict sequential ev aluation setting. In particular, the c hallenge is im- p ortan t b ecause it requires not only correct recognition of individual frames, but also correct lo calization of ev ent b oundaries o ver time. 2 Metho ds Our pip eline consisted of a frame-level classifier follo wed b y temp oral even t construction. Among the tested bac kb ones, ResNet-50 [1] provided the b est balance betw een stability , sp eed, and predictive p erformance, and was therefore selected as the core mo del. Eac h frame was re- sized to 336 × 336 and processed indep enden tly to predict the presence of 17 lab els. The lab el space con tained 5 anatom y classes (mouth, esophagus, stomach, small in testine, and colon) and 12 pathology classes. Let x i denote the i -th frame and y ic ∈ { 0 , 1 } the ground-truth lab el for class c . F or eac h class, the net work outputs a real-v alued score z ic b efore probabilit y normalization. This score is transformed in to a probability using the sigmoid function: p ic = σ ( z ic ) = 1 1 + e − z ic , (1) where p ic represen ts the predicted probabilit y that class c is presen t in frame i . A t the frame lev el, the mo del was trained using w eighted binary cross-entrop y [2]. F or class c , the loss was defined as L c = − 1 N N X i =1 [ w c y ic log( p ic ) + (1 − y ic ) log(1 − p ic )] , (2) where N is the num b er of training frames and w c is the p ositiv e class weigh t for class c . The total loss o ver all classes was L = C X c =1 L c , C = 17 . (3) 2.1 Ho w w as class im balance handled? Class imbalance was one of the main c hallenges in this w ork. The dataset con tained many more frames for common anatom y classes, whereas sev eral pathology classes had only a small n umber of positive samples. Without w eigh ting, the mo del quic kly became biased tow ard frequen t classes, and rare lab els sho wed very w eak learning signals. T o address this, we computed a positive class w eight for each class c based on the ratio of negativ e to p ositive samples: w c = N neg ,c N pos ,c , (4) where N pos ,c and N neg ,c denote the n umbers of p ositiv e and negativ e training samples for class c , resp ectiv ely . This increased the p enalty for mistakes on rare classes and encouraged the mo del to learn minorit y categories more effectiv ely . Because some classes w ere extremely rare, the raw w eights could b ecome excessiv ely large and destabilize optimization. Therefore, w e clipp ed the w eigh ts in to a safe in terv al: w c = min max( w c , w min ) , w max , (5) where w min = 1 . 0 and w max = 50 . 0 in our exp erimen ts. This clipping prev en ted explo ding gradien ts and reduced training instability . W e also explored fo cal-loss-st yle w eighting [3], written in our setting as L focal = − 1 N N X i =1 C X c =1 (1 − p ic ) γ [ w c y ic log( p ic ) + (1 − y ic ) log(1 − p ic )] . (6) Ho wev er, while fo cal loss sometimes impro v ed rare-class sensitivit y , it was not consisten tly sta- ble for extremely lo w-frequency labels. In practice, the clipp ed class-w eigh ting strategy w as one of the most imp ortant comp onen ts of the pip eline. Without weigh ting, rare pathology classes sho wed near-zero recall; with weigh ting, rare-class gradients increased and recall impro v ed; and with clipp ed w eighting, this impro vemen t w as ac hiev ed without causing unstable optimization. 2.2 T emp oral deco ding and ev en t construction A t the temp oral level, frame probabilities were con verted in to even t predictions. A baseline h ysteresis-style deco der was first used to map framewise scores into temp oral segments. How- ev er, temp oral debugging on the training set rev ealed a ma jor mismatch b etw een predictions and the official ev ent-lev el ground truth: the ground truth w as fragmented whenever the full activ e lab el set c hanged, whereas our initial predictions were fewer and longer. T o analyze this systematically , w e built a dedicated debugging pip eline that generated temp oral JSON files for b oth ground truth and predictions and rep orted per-video and p er-lab el segmen t coun ts. T o reduce this mismatch, we first comp osed final ev ents from framewise activ e lab els in the same st yle as the official ground truth. Sp ecifically , if the active lab el set at frame t is denoted b y S t , then a new temp oral ev en t is started whenev er S t = S t − 1 . 2.3 Anatom y v ote smo othing W e further stabilized anatom y predictions using a lo cal v oting windo w. F or a frame t , w e considered a neigh b orho o d W t = { t − r , . . . , t, . . . , t + r } , (7) where r is the window radius. Let ˆ a τ b e the predicted anatomy class at frame τ . The final anatom y lab el at frame t w as obtained b y ma jority voting: a t = arg max k X τ ∈W t 1 [ˆ a τ = k ] . (8) In our final setting, a window size of 1 was selected, whic h effectively av oided ov er-smo othing while still preserving true anatomical transitions. 2.4 Anatom y-based pathology gating W e also introduced an anatomy-guided gating mec hanism for pathology predictions. The idea is that some abnormalities are anatomically plausible only in specific regions. Let p ( m ) t denote the pathology probabilit y for class m at frame t , and let A m denote the set of anatomies where pathology m is allo w ed according to our anatomy-gating prior. The gated pathology probabilit y w as defined as ˜ p ( m ) t = ( p ( m ) t , if a t ∈ A m , 0 , otherwise . (9) This step suppressed anatomically implausible pathology predictions and reduced false positives in regions where the target abnormality should not o ccur. 2.5 Final temp oral deco der After anatom y vote smoothing and pathology gating, the final pathology sequence w as deco ded using the default h ysteresis-based temp oral deco der. Compared with more aggressive support- windo w deco ding, the conserv ativ e deco der generalized b etter on unseen data and ga ve the b est final test result. W e also tested an HMM/Viterbi-based deco der [4] with temp erature scaling [5], but the final c hosen system remained the simpler and more stable anatom y-guided h ysteresis pip eline. Figure 1: Ove rall flo wc hart of the prop osed ResNet-50-based temporal even t detection pipeline. Figure 1 illustrates the o v erall w orkflow of the prop osed metho d. First, gastroin testinal video frames are resized to 336 × 336 and passed through a ResNet-50 backbone for frame- lev el prediction. During training, the mo del is optimized using a dedicated training strategy together with class-imbalance handling, whic h is one of the k ey comp onents of the pip eline. The best-p erforming mo del w eights are then used to generate frame-level predictions. T o b et- ter understand the gap b etw een frame-level and temp oral p erformance, a temporal debugging stage is introduced by comparing ground-truth and predicted JSON ev ents. Finally , a tem- p oral deco der con verts the frame-lev el outputs into sequen tial ev ent predictions in the official c hallenge format. 3 Results A t the frame level, the ResNet-50 backbone achiev ed a strong p erformance of approximately 0.8605 mAP in 5-fold ev aluation, confirming that the model learned discriminativ e visual features for b oth anatomy and pathology classes. Our initial baseline temp oral pip eline achiev ed an ov erall temp oral mAP of 0.3801 . After in tro ducing anatomy vote smo othing, anatom y-based pathology gating, and GT-style framewise ev ent comp osition while k eeping the default hysteresis deco der, the final temp oral performance impro ved to: • Ov erall mAP @ 0.5 = 0.4303 • Ov erall mAP @ 0.95 = 0.4020 This corresp onds to a net impro v ement of +0.0502 mAP o v er the temp oral baseline. F or the final c hallenge-style temp oral ev aluation on the three test videos, the obtained p er-video results w ere: • ukdd navi 00051: mAP@0.5 = 0.5319 , mAP@0.95 = 0.5000 • ukdd navi 00068: mAP@0.5 = 0.3533 , mAP@0.95 = 0.3529 • ukdd navi 00076: mAP@0.5 = 0.4056 , mAP@0.95 = 0.3529 A summary of the temp oral results is giv en in T able 1 . T able 1: Summary of temp oral results. Ev aluation mAP@0.5 mAP@0.95 Baseline temp oral pip eline 0.3801 – T raining temporal analysis 0.7236 0.6780 T est video ukdd navi 00051 0.5319 0.5000 T est video ukdd navi 00068 0.3533 0.3529 T est video ukdd navi 00076 0.4056 0.3529 Final o verall test temp oral 0.4303 0.4020 These results show that frame-lev el recognition w as substan tially stronger than ev ent-lev el lo calization, but also confirm that ana tomically informed temporal refinemen t improv ed p erfor- mance. In particular, anatom y-based pathology gating reduced anatomically implausible false p ositiv es, while the lo cal anatom y voting strategy stabilized region labels without blurring true transitions. 4 Discussion The main lesson from this c hallenge w as that strong frame-lev el classification do es not directly translate in to strong temp oral even t detection. Our debugging exp erimen ts sho wed that the official ground truth w as highly fragmented according to the full activ e lab el set, whereas early predictions w ere smoother and con tained fewer segmen ts. This mismatc h significantly reduced temp oral IoU matc hing ev en when the frame-lev el predictions w ere visually reasonable. W e also observ ed that more aggressive temp oral deco ders could impro ve training-set tempo- ral mAP , but these gains did not consisten tly transfer to unseen videos. In contrast, the combi- nation of GT-st yle ev ent comp osition, anatom y v ote smo othing, and anatomy-based pathology gating improv ed the final test p erformance while preserving stable deco ding b eha vior. The most robust final system was therefore a stable frame classifier combined with anatomically informed temp oral refinemen t rather than a highly aggressiv e temp oral model. F uture impro v ements could include end-to-end temp oral training, sequence-a w are arc hi- tectures, or more adv anced anatomical priors. How ev er, within the a v ailable time budget, the most effective strategy w as to combine a strong frame classifier with carefully designed temporal ev ent construction. 5 Summary T eam EndoInsigh t utilized ResNet-50 [1] as the main AI mo del. A k ey comp onent of the prop osed pip eline was the use of clipp ed class-wise p ositive weigh ting to address severe class im balance, particularly for rare pathology classes. In the temp oral stage, anatom y v ote smo othing , anatom y-based pathology gating , and GT-st yle framewise even t com- p osition improv ed the consistency of even t prediction and reduced anatomically implausible detections. The team impro v ed the baseline temporal mAP from 0.3801 to a final o verall mAP@0.5 of 0.4303 , with an o verall mAP@0.95 of 0.4020 . 6 Ac kno wledgmen ts This w ork has b een funded by the Europ ean Union Marie Curie Sklo dowsk a Action (MSCA), gran t agreemen t No. 101169012, pro ject In telli-Ingest ( h ttps://www.intelli-ingest.com/ ). As participan ts in the ICPR 2026 RARE-VISION Comp etition, we fully comply with the comp etition’s rules as outlined in [6]. Our AI mo del dev elopment is based exclusiv ely on the datasets in the comp etition. The mAP v alues are rep orted using the test dataset and sanity c heck er released in the comp etition. References [1] Kaiming He, Xiangyu Zhang, Shao qing Ren, and Jian Sun. Deep residual learning for image recognition. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition , pages 770–778, 2016. [2] Ian Go o dfellow, Y oshua Bengio, and Aaron Courville. De ep L e arning . MIT Press, 2016. URL https://www.deeplearningbook.org/ . [3] Tsung-Yi Lin, Priya Goy al, Ross Girshic k, Kaiming He, and Piotr Doll´ ar. F o cal loss for dense ob ject detection. In Pr o c e e dings of the IEEE International Confer enc e on Computer Vision , pages 2980–2988, 2017. [4] La wrence R. Rabiner. A tutorial on hidden marko v mo dels and selected applications in sp eec h recognition. Pr o c e e dings of the IEEE , 77(2):257–286, 1989. [5] Ch uan Guo, Geoff Pleiss, Y u Sun, and Kilian Q. W ein b erger. On calibration of mo dern neural netw orks. In Pr o c e e dings of the 34th International Confer enc e on Machine L e arning , v olume 70, pages 1321–1330, 2017. [6] Anni La wniczak, Manas Dhir, Maxime Le Flo ch, P alak Handa, and Anastasios Koulaouzidis. ICPR 2026 RARE-VISION Comp etition Do cument and Flyer. 12 2025. doi: 10.6084/m9.figshare.30884858.v3. URL https://figshare.com/articles/ preprint/ICPR_2026_RARE- VISION_Competition_Document_and_Flyer/30884858 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment