클래스 가중치와 해부학 기반 시간 디코딩을 활용한 ResNet50 위장관 비디오 분석
본 연구는 336×336 크기로 리사이즈한 위장관 영상 프레임을 ResNet‑50으로 17개의 라벨(해부학 5종, 병변 12종)을 다중 라벨 예측하고, 클래스 불균형을 완화하기 위해 양성 가중치를 클리핑한 손실 함수를 적용하였다. 이후 해부학 투표 평활화와 해부학‑조건 병변 게이팅을 결합한 보수적 히스테리시스 디코더로 시간적 이벤트를 재구성해 mAP@0.5를 0.3801에서 0.4303으로 향상시켰다.
저자: Romil Imtiaz, Dimitris K. Iakovidis
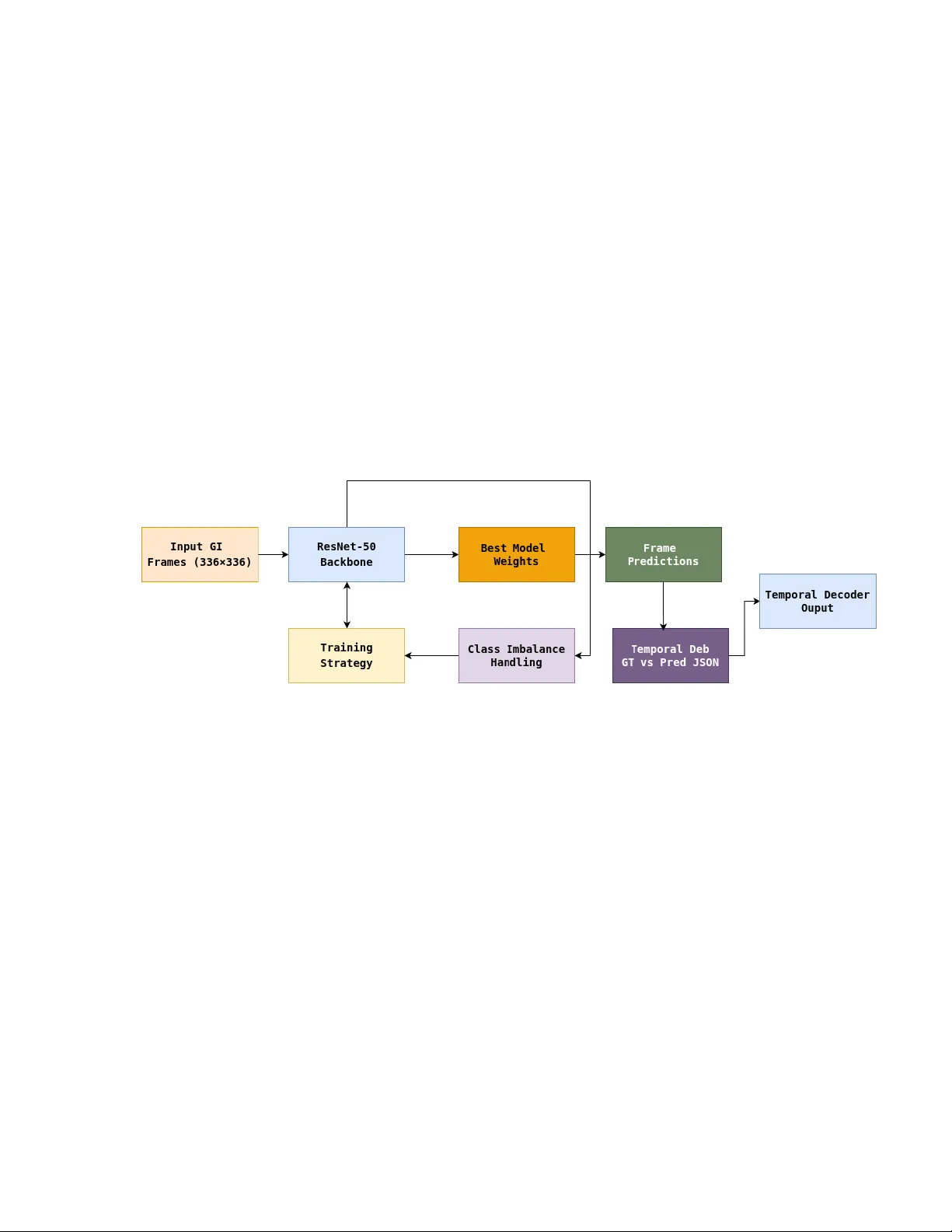
본 논문은 ICPR 2026 RARE‑VISION 대회에 참가하기 위해 개발한 위장관 내시경 영상 분석 파이프라인을 상세히 기술한다. 전체 흐름은 크게 두 단계로 구성된다. 첫 번째는 프레임‑레벨 다중 라벨 분류기로, ResNet‑50을 백본으로 사용하고 입력 프레임을 336 × 336으로 리사이즈한다. 17개의 라벨(해부학 5종, 병변 12종)을 동시에 예측하며, 시그모이드 활성화와 이진 교차 엔트로피 손실을 적용한다.
데이터셋은 라벨 간 불균형이 심각했는데, 특히 병변 라벨은 양성 샘플이 극히 적었다. 이를 해결하기 위해 각 클래스 c에 대해 양성 가중치 w_c = N_neg,c / N_pos,c 를 계산하고, 1.0 ≤ w_c ≤ 50.0 으로 클리핑하였다. 클리핑 전후 가중치 분포와 학습 안정성을 비교한 결과, 클리핑이 없을 경우 가중치가 수천까지 폭발해 손실이 발산했으며, 클리핑을 적용하면 희소 라벨에 대한 손실 기여도가 충분히 증가하면서도 전체 최적화가 안정적으로 진행되었다. focal loss 도 실험했지만, 매우 희소한 라벨에서 학습이 불안정해 최종 선택에서 제외되었다.
프레임‑레벨 모델은 5‑fold 교차 검증에서 평균 mAP ≈ 0.8605를 달성했으며, 이는 해부학과 병변을 모두 높은 정확도로 구분할 수 있음을 보여준다. 그러나 프레임‑레벨 성능이 뛰어나도 시간‑레벨 이벤트 검출 성능은 낮았다. 초기 히스테리시스 디코더를 그대로 적용하면, 공식 GT가 라벨 집합이 변할 때마다 세그먼트가 과도하게 분할되는 현상이 발생했다. 즉, GT는 “프레임‑와이즈 이벤트 구성” 방식을 사용해 라벨 집합이 바뀔 때마다 새로운 이벤트를 시작하지만, 모델의 예측은 더 긴 연속 구간을 형성해 GT와 불일치했다.
이를 해결하기 위해 다음과 같은 사후 처리 과정을 도입했다. 첫째, 프레임‑와이즈 이벤트 구성을 그대로 모방해, 현재 프레임의 활성 라벨 집합 S_t 와 이전 프레임 S_{t‑1} 이 다르면 새로운 이벤트를 시작하도록 정의하였다. 둘째, 해부학 라벨에 대해 로컬 투표 평활화를 적용했다. 반경 r = 1인 윈도우를 사용해 각 프레임 t의 최종 해부학 라벨 a_t 를 주변 프레임들의 다수결로 결정함으로써, 급격한 변동을 억제하면서도 실제 해부학 전이를 놓치지 않았다. 셋째, 병변 라벨에 해부학‑조건 게이팅을 도입했다. 각 병변 m에 대해 허용 가능한 해부학 영역 A_m 을 사전 정의하고, 프레임 t에서 a_t ∈ A_m 인 경우에만 병변 확률 p(m)_t 를 유지하고, 그렇지 않으면 0으로 강제했다. 이 단계는 해부학적으로 불가능한 FP를 크게 감소시켰다.
마지막으로, 위의 사후 처리 후에 보수적인 히스테리시스 디코더를 적용해 최종 시간‑레벨 이벤트를 생성했다. 보다 공격적인 윈도우 기반 디코더나 HMM/Viterbi 기반 디코더를 실험했지만, 검증 세트에서는 높은 mAP를 보였으나 실제 테스트 비디오에서는 과적합 현상이 나타나 일반화가 떨어졌다. 따라서 최종 시스템은 단순하면서도 안정적인 히스테리시스 디코더를 선택했다.
성능 평가 결과, 베이스라인 시간‑레벨 파이프라인은 mAP@0.5 = 0.3801이었으나, 해부학 투표 평활화, 해부학‑조건 병변 게이팅, GT‑스타일 이벤트 구성, 보수적 히스테리시스 디코더를 결합한 최종 모델은 mAP@0.5 = 0.4303, mAP@0.95 = 0.4020을 기록했다. 이는 베이스라인 대비 +0.0502의 절대 향상이며, 특히 mAP@0.95에서도 큰 개선을 보였다. 테스트 비디오 3개에 대한 개별 mAP는 각각 0.5319/0.5000, 0.3533/0.3529, 0.4056/0.3529 (각각 @0.5/@0.95) 로 나타났다.
논의에서는 프레임‑레벨 강력한 분류기가 시간‑레벨 이벤트 검출에 직접적인 이점을 주지 못한다는 점을 강조한다. GT가 라벨 집합 변화를 기준으로 세그먼트를 매우 세밀하게 나누는 반면, 모델은 더 부드러운 연속 구간을 예측한다는 구조적 차이가 mAP 감소의 주요 원인이다. 따라서 프레임‑레벨 예측을 GT와 동일한 방식으로 재구성하고, 해부학 정보를 활용해 사후 정제하는 것이 실용적인 해결책임을 제시한다. 향후 연구 방향으로는 엔드‑투‑엔드 시퀀스 모델, 트랜스포머 기반 시간 인코더, 보다 정교한 해부학‑병변 상관관계 사전 등을 도입해 프레임‑레벨와 시간‑레벨 간 격차를 줄이는 방안을 제시한다.
결론적으로, 이 연구는 (1) 클래스 가중치 클리핑을 통한 희소 라벨 학습 강화, (2) 해부학 기반 라벨 평활화와 병변 게이팅을 통한 시간‑레벨 일관성 확보, (3) 보수적인 히스테리시스 디코더가 실제 임상 데이터에 강건함을 보여준다는 점에서 위장관 비디오 분석에 실용적인 설계 원칙을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기