Multimodal Emotion Recognition via Bi-directional Cross-Attention and Temporal Modeling
Expression recognition in in-the-wild video data remains challenging due to substantial variations in facial appearance, background conditions, audio noise, and the inherently dynamic nature of human affect. Relying on a single modality, such as faci…
Authors: Junhyeong Byeon, Jeongyeol Kim, Sejoon Lim
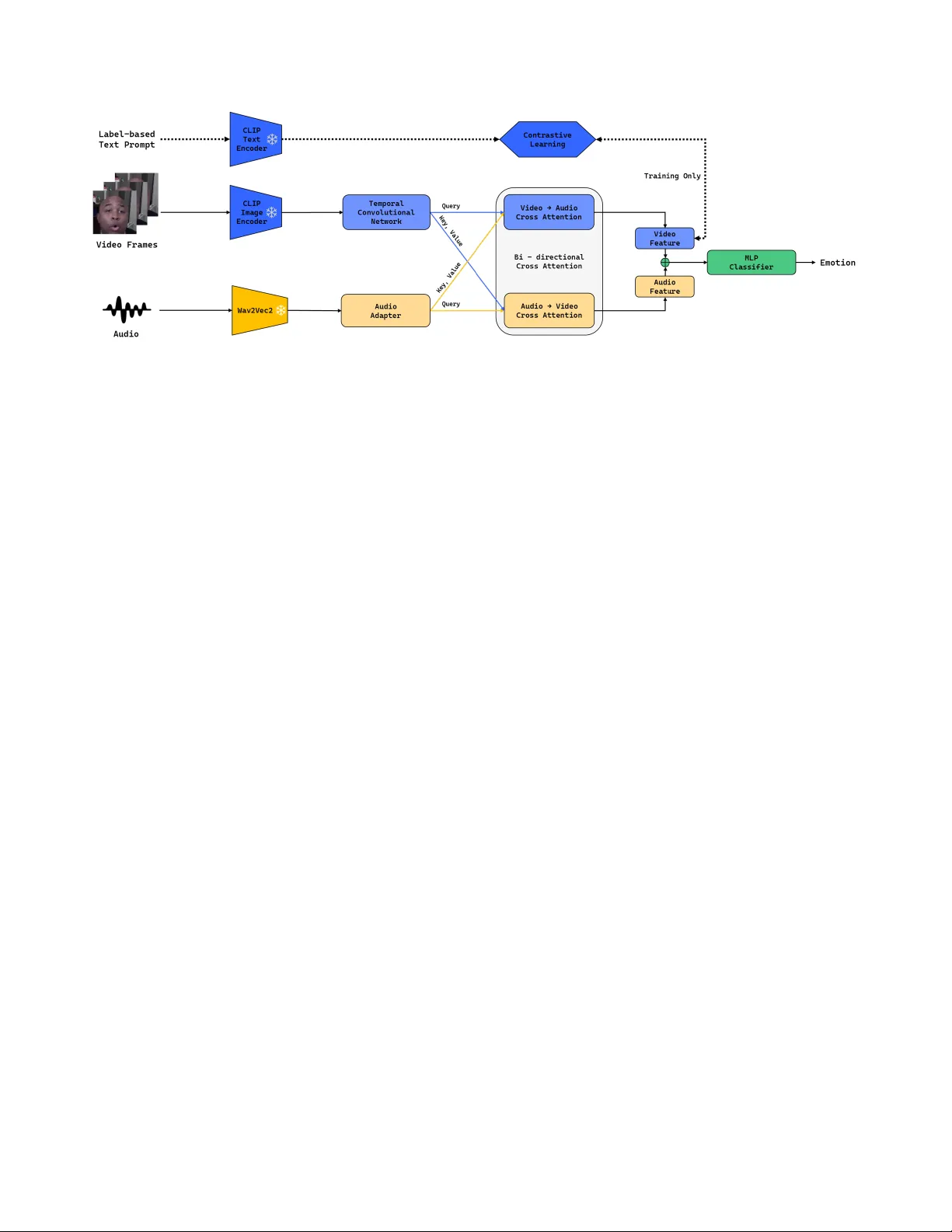
Multimodal Emotion Recognition via Bi-dir ectional Cr oss-Attention and T emporal Modeling Junhyeong Byeon Jeongyeol Kim Sejoon Lim * K ookmin Uni v ersity , Republic of K orea { junhyeong0519, kjy013125, lim } @kookmin.ac.kr Abstract Expr ession r ecognition in in-the-wild video data r emains challenging due to substantial variations in facial appear- ance, bac kgr ound conditions, audio noise, and the inher- ently dynamic nature of human affect. Relying on a sin- gle modality , such as facial expr essions or speech, is of- ten insuf ficient for capturing these comple x emotional cues. T o address this limitation, we pr opose a multimodal emo- tion r ecognition fr amework for the Expr ession (EXPR) task in the 10th Affective Behavior Analysis in-the-wild (AB A W) Challenge. Our fr amework b uilds on lar ge-scale pr e-trained models for visual and audio repr esentation learning and integr ates them in a unified multimodal arc hitectur e. T o better cap- tur e temporal patterns in facial expr ession sequences, we incorporate temporal visual modeling over video windows. W e further intr oduce a bi-dir ectional cr oss-attention fusion module that enables visual and audio featur es to interact in a symmetric manner , facilitating cr oss-modal contextu- alization and complementary emotion understanding. In addition, we employ a text-guided contrastive objective to encourag e semantically meaningful visual repr esentations thr ough alignment with emotion-related te xt prompts. Experimental r esults on the ABA W 10th EXPR bench- mark demonstrate the effectiveness of the pr oposed frame- work, achie ving a Macr o F1 score of 0.32 compared to the baseline score of 0.25, and highlight the benefit of combin- ing temporal visual modeling, audio repr esentation learn- ing, and cr oss-modal fusion for r obust emotion r ecognition in unconstrained r eal-world en vir onments. 1. Introduction Emotion recognition from in-the-wild videos is a funda- mental problem in affecti ve computing, with broad appli- cations in healthcare, education, and affect-a ware interac- tiv e systems. Howe ver , robust recognition in real-world * Corresponding author . settings remains challenging because affecti ve cues are of- ten degraded by head pose variation, illumination changes, occlusion, background noise, and other uncontrolled fac- tors [ 8 , 11 , 15 , 31 ]. T o address these challenges, recent studies ha v e increas- ingly explored multimodal frameworks that jointly lev er - age visual and audio signals [ 25 , 28 – 30 , 33 ]. The moti- vation is that the two modalities pro vide complementary af- fectiv e cues: facial expressions capture appearance-based emotional information, while speech contains prosodic and paralinguistic patterns that can help resolve visually am- biguous cases. In addition, large-scale pre-trained models hav e demonstrated strong representation power in both vi- sual and audio domains, making them promising founda- tions for multimodal emotion recognition [ 1 , 26 ]. Despite this progress, se veral challenges remain. First, many multimodal approaches do not fully exploit mutual in- teractions between visual and audio streams, limiting their ability to capture complementary cross-modal context [ 28 – 30 , 33 ]. Second, emotional expressions ev olve ov er time, and frame-le vel features alone are often insufficient for modeling the temporal dynamics required for robust pre- diction [ 2 , 22 – 24 , 34 , 37 ]. In this paper , we propose a multimodal framework for the Expression (EXPR) Recognition track of the 10th Affecti ve Behavior Analysis in-the-wild (AB A W) Chal- lenge [ 21 ]. Our method builds on frozen CLIP [ 26 ] and W av2V ec 2.0 [ 1 , 27 ] backbones for visual and audio fea- ture extraction, respecti vely , and improves their integra- tion in three ways. First, we apply a T emporal Con- volutional Network (TCN) to frame-le vel visual features to model short-term temporal dependencies in facial ex- pression sequences [ 2 , 22 ]. Second, we introduce a bi- directional cross-attention fusion module that allows visual and audio representations to refine each other through sym- metric cross-modal interaction. Third, we regularize the pooled visual representation with CLIP text embeddings via a te xt-guided contrasti ve objecti ve, encouraging seman- tically consistent representations for expression recogni- tion [ 26 , 35 , 37 ]. 1 The main contributions of this work are summarized as follows: 1. T emporal visual modeling with TCN: W e enhance frame-lev el visual features with a T emporal Conv olu- tional Network to capture temporal dependencies in fa- cial expression sequences. 2. Bi-directional cross-attention fusion: W e introduce a symmetric cross-attention mechanism that enables bidi- rectional interaction between visual and audio features for more effecti ve multimodal integration. 3. Label-based prompt supervision: W e conv ert expres- sion labels into natural language prompts and use the re- sulting CLIP text embeddings as an auxiliary supervi- sion signal for expression recognition. 2. Related W ork 2.1. F acial Expression Recognition Facial Expression Recognition (FER) is a core task in af fec- tiv e computing that aims to identify human emotional states from facial images and videos. Recent studies hav e sho wn that deep learning-based visual representations are ef fecti ve for recognizing discrete facial expressions [ 10 , 11 , 31 ]. As FER research has progressed, increasing attention has been giv en to af fecti ve behavior analysis in unconstrained real-world settings. Accordingly , recent studies have fo- cused on robust visual representation learning, temporal modeling for dynamic expressions, and multimodal fusion strategies for improved recognition performance. T o ad- dress these issues, large-scale in-the-wild datasets such as Aff-W ild and Aff-W ild2 were introduced, providing more realistic benchmarks for facial behavior analysis [ 7 , 11 , 31 ]. These datasets also supported studies on multiple af fectiv e tasks including expression recognition, v alence-arousal es- timation, and action unit detection [ 8 , 10 ]. Building upon these datasets, the AB A W challenge se- ries has e volved ov er the years and has played an impor- tant role in advancing af fecti ve behavior analysis under re- alistic in-the-wild conditions [ 4 , 9 , 12 , 14 , 17 , 18 , 20 , 21 ]. Related datasets, toolkits, and benchmarks hav e also been introduced to support broader beha vior analysis tasks in real-world scenarios [ 15 , 19 ]. In particular , the EXPR task in ABA W focuses on classifying facial expressions under challenging in-the-wild conditions, making it a representa- tiv e benchmark for robust expression recognition. Recent AB A W studies hav e explored various learning strategies, in- cluding multi-task learning, compound expression recogni- tion, and distribution-aware optimization, to improve per- formance on expression recognition and related af fecti ve tasks [ 5 , 6 , 13 , 16 ]. Despite these adv ances, facial expression recognition in the wild remains challenging due to subtle f acial v ariations, ambiguous e xpression boundaries, and sev ere environmen- tal noise. 2.2. V ision-Language Emotion Recognition Recent adv ances in vision-language representation learning hav e enabled models to align visual content with semantic information e xpressed in natural language. Among these approaches, CLIP showed that large-scale image-text pre- training can learn a shared embedding space in which visual and textual representations are semantically aligned [ 26 ]. Subsequent studies hav e explored prompt-based adapta- tion to transfer pre-trained vision-language models to do wn- stream tasks. In particular , conditional prompt learning ap- proaches such as CoCoOp [ 35 ] demonstrated that textual prompts can be optimized to better reflect task-specific se- mantic concepts. This is particularly relev ant to expression recognition, where each e xpression class can be associated with a linguistic description that pro vides additional seman- tic priors. Recent studies ha ve applied CLIP-based representations to expression recognition [ 37 ]. In the AB A W context, CLIP has also been explored as a visual feature extractor and in conjunction with rule-based emotion prompts [ 3 ]. These studies suggest that vision-language representations can provide useful semantic guidance for expression recog- nition under challenging in-the-wild conditions. 2.3. T emporal Modeling T emporal modeling has become increasingly important in expression analysis, since facial expressions e volv e ov er time through subtle movements and intensity changes. Static expression recognition methods can capture discrimi- nativ e spatial patterns from indi vidual images, b ut often f ail to reflect the process of e xpression formation and transition. This limitation has motiv ated the development of video- based and dynamic expression recognition approaches. Recent studies hav e increasingly adopted transformer- based architectures to capture both spatial and temporal information in dynamic expression recognition. Former- DFER [ 34 ] introduced separate modules for learning spa- tial and temporal representations, while Spatio-T emporal T ransformer (STT) jointly encoded spatial and temporal cues within a unified transformer framew ork [ 24 ]. NR- DFERNet [ 23 ] addressed the influence of noisy or less in- formativ e frames, highlighting the importance of both tem- poral continuity and frame quality in robust temporal mod- eling. Beyond transformer-based approaches, con volution- based methods hav e also been explored for temporal se- quence modeling. In particular, T emporal Conv olutional Networks (TCNs) model temporal dependencies efficiently through con v olutional operations with enlarged receptive fields and have sho wn strong performance in generic se- 2 quence modeling tasks [ 2 ]. TCNs hav e also been applied to video-based temporal understanding problems, further sug- gesting their applicability beyond recurrent modeling [ 22 ]. 2.4. Multimodal Fusion Multimodal learning has been widely studied for learn- ing shared representations from multiple information sources [ 25 ]. In emotion recognition, this perspecti ve is particularly important because af fecti ve cues are distrib uted across multiple modalities, including facial appearance and speech. Among these modalities, visual and audio information are particularly useful for emotion recognition. Facial expressions provide explicit visual evidence of affecti ve changes, while speech con veys additional emotional cues through tone, prosody , and temporal v ariation. T o obtain informativ e audio representations, recent studies ha ve ex- plored self-supervised speech representation learning. In particular , wa v2vec 2.0 [ 1 ] introduced an effecti ve frame- work for learning contextualized speech representations from raw audio, making it useful for downstream audio- based affecti ve analysis. The interaction between visual and audio modalities is a key factor in multimodal emotion recognition. Recent studies ha ve explored transformer-based fusion methods to model cross-modal dependencies more effecti vely than sim- ple feature concatenation [ 28 – 30 ]. By allowing one modal- ity to attend to another, these methods can capture comple- mentary af fective cues distributed across facial and vocal streams. Sev eral AB A W approaches ha ve explored multimodal framew orks that integrate multiple modalities, including vi- sual, audio, and in some cases linguistic information, for affecti ve beha vior analysis [ 32 , 33 , 36 ]. Ho we ver , ef fec- tiv ely integrating robust audio representation learning, vi- sual temporal modeling, and cross-modal interaction re- mains an open challenge in expression recognition. This motiv ates a frame work that integrates CLIP-based visual representation learning, wa v2vec 2.0-based audio represen- tation learning, visual temporal modeling, and transformer- based multimodal fusion for robust expression recognition. 3. A ppr oach In this section, we describe the proposed multimodal emo- tion recognition frame work for the EXPR task. Our model consists of fiv e components: (1) unimodal feature extrac- tion using pre-trained backbones, (2) temporal visual mod- eling and audio feature adaptation, (3) bi-directional cross- attention fusion, (4) temporal pooling and emotion classi- fication, and (5) label-based prompt supervision via con- trastiv e learning. 3.1. F eature Extraction and T ext Prompt Construc- tion T o obtain high-lev el semantic representations from ra w vi- sual and audio inputs, we employ large-scale pre-trained models as frozen backbone networks. • V isual Str eam. For the visual modality , we use the CLIP V iT -B/32 image encoder . Giv en an input frame sequence, each frame is independently encoded to produce a visual feature sequence X v ∈ R T v × D v , where D v = 512 . • A udio Stream. For the audio modality , an audio seg- ment synchronized with the input video window is re- sampled to 16 kHz and processed by the frozen W av2V ec 2.0 Base model, producing an audio feature sequence X a ∈ R T a × D a , where D a = 768 . • T ext Pr ompts. T o pro vide semantic supervision for emo- tion recognition, we generate a text prompt corresponding to the target emotion label using the template “A face ex- pr essing [Emotion]” . Each prompt p j is encoded by the frozen CLIP te xt encoder to produce a text embedding ˜ t j = E text ( p j ) . T o impro ve training stability and reduce ov erfitting on the downstream benchmark, both the CLIP and W av2V ec 2.0 backbones are kept frozen during training. 3.2. T emporal Modeling and A udio Featur e Adap- tation Facial expressions e volv e ov er time, and frame-lev el repre- sentations alone may not suf ficiently capture temporal dy- namics. Therefore, we further refine the unimodal features before multimodal fusion. • V isual TCN. T o model temporal dependencies in the vi- sual stream, we feed the frame-lev el visual features X v into a T emporal Conv olutional Network (TCN) composed of six stacked temporal blocks with dilated causal con vo- lutions. By progressi vely increasing the dilation factor across layers, the TCN expands the temporal receptiv e field and captures both short- and long-range f acial dy- namics. The final refined visual representation is denoted as F v ∈ R T v × 512 . • A udio Adapter . The audio features X a are projected into the same embedding dimension as the visual features us- ing an audio adapter , which consists of a linear projec- tion followed by Layer Normalization, ReLU activ ation, and Dropout. This produces the adapted audio representa- tion F a ∈ R T a × 512 . Matching the embedding dimensions facilitates effecti ve cross-modal interaction in the subse- quent fusion stage. 3.3. Bi-directional Cr oss-Attention Fusion T o effecti vely integrate visual and audio information, we employ a bi-directional cross-attention module with eight attention heads. Cross-modal attention is performed in both 3 Figure 1. Overall architecture of the proposed multimodal framew ork for the EXPR task. The model extracts visual and audio features, enhances them through temporal modeling and bi-directional cross-attention fusion, and predicts expression categories with auxiliary label- based prompt supervision during training. V ideo frames are encoded by a frozen CLIP image encoder followed by a temporal conv olutional network, while audio signals are processed by a frozen W av2V ec2 backbone and an audio adapter . The resulting representations are fused by bi-directional cross-attention, temporally pooled, and fed into an MLP classifier . During training, class-specific text prompts derived from expression labels are encoded by the CLIP te xt encoder and aligned with projected visual features via a contrastiv e objective. directions to enable mutual interaction between the two modalities. First, the visual features F v are used as queries, while the audio features F a are used as ke ys and values, yielding an audio-enhanced visual representation: H V 2 A = LN F v + MHA( F v , F a , F a ) . (1) Second, the audio features F a are used as queries, while the visual features F v are used as ke ys and values, yielding a visually enhanced audio representation: H A 2 V = LN F a + MHA( F a , F v , F v ) . (2) 3.4. T emporal P ooling and Emotion Classification After cross-attention fusion, the enhanced feature se- quences are aggregated using mean pooling along the tem- poral dimension. The pooled representations are concate- nated to form the multimodal feature vector z ∈ R 1024 . This representation is fed into a multi-layer perceptron (MLP) classifier consisting of three linear layers with ReLU activ ations and Dropout, producing the final logits for the eight emotion classes. 3.5. Label-Based Pr ompt Supervision via Con- trastive Lear ning In addition to the cross-entropy classification loss L cls , we use class-specific text prompts deriv ed from expression la- bels as an auxiliary supervision signal via a contrasti ve ob- jectiv e, encouraging label-aware visual representations. The temporally pooled visual representation after cross- modal fusion is projected into the CLIP embedding space and ℓ 2 -normalized to obtain v . Similarly , the text embed- dings are normalized as t j . Using scaled cosine similarity , we compute a bidirectional contrastive loss L con between matched video-text pairs within a mini-batch. Finally , the overall training objective combines the clas- sification loss and the contrastiv e loss: L = L cls + λ L con , (3) where we set λ = 0 . 1 in our implementation. 4. Experiments In this section, we ev aluate the proposed multimodal frame- work on the EXPR task of the ABA W 10th Challenge. W e first describe the implementation details and ev aluation metrics, and then examine how dif ferent temporal window sizes affect recognition performance, with comparisons to the official baseline. 4.1. Implementation and Evaluation Setup The proposed model w as implemented in PyT orch and trained on an NVIDIA R TX A5000 GPU. W e used frozen CLIP V iT -B/32 and W av2V ec 2.0 backbones for the visual and audio streams, respectively . All experiments were con- ducted with a fixed random seed of 42 for reproducibility . For optimization, we used AdamW with a learning rate of 1 × 10 − 5 and a cosine annealing scheduler . The model was trained for 30 epochs with a batch size of 64 and gradi- ent accumulation. T o alle viate class imbalance in the EXPR dataset, we employed a class-weighted cross-entropy loss for expression classification. In addition, text-guided con- trastiv e learning was used during training as an auxiliary supervision objectiv e. 4 4.2. Evaluation Metrics Follo wing the official protocol of the ABA W 10th EXPR Recognition Challenge, we report the following e valuation metric: • Macro F1-score: The official primary metric of the chal- lenge, computed by averaging the F1-scores of all eight expression classes equally . 4.3. Results on the V alidation Set T able 1 presents the v alidation performance of the proposed method under different temporal window sizes, together with the of ficial baseline. W e report results for four settings, namely 10, 15, 30, and 60 frames, to analyze the effect of temporal context. T able 1. Performance comparison on the EXPR challenge valida- tion set. Challenge Metric Method Result EXPR Macro F1 Baseline 0.2500 Ours (10 frames) 0.3265 Ours (15 frames) 0.3324 Ours (30 frames) 0.3670 Ours (60 frames) 0.3599 As shown in T able 1 , the proposed multimodal frame- work outperforms the official baseline across all temporal window sizes. Among the ev aluated settings, the 30-frame configuration achie ves the best performance, with a Macro F1-score of 0.3670. The results indicate that incorporat- ing temporal context is beneficial for expression recogni- tion, while increasing the temporal windo w beyond a cer- tain length does not necessarily lead to further improve- ment. Overall, these results show that the proposed frame work provides consistent performance gains over the baseline on the validation set. 4.4. Results on T est Set As sho wn in T able 2 , the 60-frame configuration achiev ed the best performance on the test set among the e v aluated settings. It also outperformed the baseline score of 0.25. 5. Conclusion In this paper , we presented a multimodal emotion recogni- tion frame work for the EXPR task of the AB A W 10th Chal- lenge. The proposed model combines CLIP-based visual representations and W av2V ec 2.0-based audio representa- tions within a unified architecture. T o better model tempo- ral and cross-modal information, we introduced a T emporal T able 2. Performance comparison on the EXPR challenge test set. Challenge Metric Method Result EXPR Macro F1 Baseline 0.25 Ours (10 frames) 0.28 Ours (15 frames) 0.30 Ours (30 frames) 0.31 Ours (60 frames) 0.32 Con volutional Network (TCN) for visual temporal model- ing and a bi-directional cross-attention module for multi- modal fusion. In addition, a text-guided contrastiv e objec- tiv e was incorporated to encourage semantically aligned vi- sual representations. Experimental results on the validation set demonstrated that the proposed frame work outperforms the of ficial base- line in terms of Macro F1-score. In particular , the 60-frame setting achie ved the best performance, indicating that incor- porating a broader temporal context is beneficial for robust expression recognition in unconstrained en vironments. For future work, we plan to explore more ef fecti ve temporal modeling strategies and stronger multimodal fusion mechanisms. W e also aim to inv estigate the use of additional modalities and more ef ficient architec- tures for robust emotion recognition in real-world scenar- ios. References [1] Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli. w av2v ec 2.0: A framework for self-supervised learning of speech representations, 2020. 1 , 3 [2] Shaojie Bai, J Zico Kolter , and Vladlen Koltun. An empirical ev aluation of generic conv olutional and recurrent networks for sequence modeling. arXiv pr eprint arXiv:1803.01271 , 2018. 1 , 3 [3] Josep Cabacas-Maso, Elena Ortega-Beltr ´ an, Ismael Benito- Altamirano, and Carles V entura. Enhancing facial expres- sion recognition through dual-direction attention mixed fea- ture networks and clip: Application to 8th abaw challenge, 2025. 2 [4] Dimitrios Kollias. Abaw: V alence-arousal estimation, e x- pression recognition, action unit detection & multi-task learning challenges. In Pr oceedings of the IEEE/CVF Con- fer ence on Computer V ision and P attern Recognition , pages 2328–2336, 2022. 2 [5] Dimitrios K ollias. Abaw: learning from synthetic data & multi-task learning challenges. In Eur opean Confer ence on Computer V ision , pages 157–172. Springer, 2022. 2 [6] Dimitrios Kollias. Multi-label compound expression recog- nition: C-expr database & network. In Proceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 5589–5598, 2023. 2 [7] Dimitrios K ollias and Stefanos Zafeiriou. Expression, af fect, 5 action unit recognition: Aff-wild2, multi-task learning and arcface. arXiv preprint , 2019. 2 [8] Dimitrios Kollias and Stef anos Zafeiriou. Af fect analysis in-the-wild: V alence-arousal, expressions, action units and a unified framework. arXiv preprint , 2021. 1 , 2 [9] Dimitrios K ollias and Stefanos Zafeiriou. Analysing affec- tiv e behavior in the second abaw2 competition. In Pr oceed- ings of the IEEE/CVF International Conference on Com- puter V ision , pages 3652–3660, 2021. 2 [10] Dimitrios Kollias, V iktoriia Sharmanska, and Stefanos Zafeiriou. Face behavior a la carte: Expressions, af- fect and action units in a single network. arXiv preprint arXiv:1910.11111 , 2019. 2 [11] Dimitrios Kollias, Panagiotis Tzirakis, Mihalis A Nicolaou, Athanasios P apaioannou, Guoying Zhao, Bj ¨ orn Schuller , Irene Kotsia, and Stefanos Zafeiriou. Deep affect prediction in-the-wild: Af f-wild database and challenge, deep architec- tures, and beyond. International Journal of Computer V ision , 127(6):907–929, 2019. 1 , 2 [12] Dimitrios K ollias, Attila Schulc, Elnar Hajiyev , and Stefanos Zafeiriou. Analysing affecti ve behavior in the first abaw 2020 competition. In 2020 15th IEEE International Confer- ence on Automatic F ace and Gestur e Recognition (FG 2020) , pages 637–643. IEEE, 2020. 2 [13] Dimitrios Kollias, V iktoriia Sharmanska, and Stefanos Zafeiriou. Distribution matching for heterogeneous multi- task learning: a large-scale face study . arXiv pr eprint arXiv:2105.03790 , 2021. 2 [14] Dimitrios Kollias, Panagiotis Tzirakis, Alice Baird, Alan Cowen, and Stefanos Zafeiriou. Abaw: V alence-arousal esti- mation, e xpression recognition, action unit detection & emo- tional reaction intensity estimation challenges. In Pr oceed- ings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pages 5889–5898, 2023. 2 [15] Dimitrios Kollias, Chunchang Shao, Odysseus Kaloidas, and Ioannis Patras. Behaviour4all: in-the-wild facial behaviour analysis toolkit. arXiv pr eprint arXiv:2409.17717 , 2024. 1 , 2 [16] Dimitrios Kollias, V iktoriia Sharmanska, and Stefanos Zafeiriou. Distribution matching for multi-task learning of classification tasks: a large-scale study on faces & beyond. In Pr oceedings of the AAAI Conference on Artificial Intelli- gence , pages 2813–2821, 2024. 2 [17] Dimitrios Kollias, Panagiotis Tzirakis, Alan Cowen, Ste- fanos Zafeiriou, Irene Kotsia, Alice Baird, Chris Gagne, Chunchang Shao, and Guanyu Hu. The 6th af fectiv e behav- ior analysis in-the-wild (abaw) competition. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P at- tern Recognition , pages 4587–4598, 2024. 2 [18] Dimitrios K ollias, Stefanos Zafeiriou, Irene Kotsia, Abhina v Dhall, Shre ya Ghosh, Chunchang Shao, and Guanyu Hu. 7th abaw competition: Multi-task learning and compound ex- pression recognition. In Eur opean Conference on Computer V ision , pages 31–45. Springer, 2024. 2 [19] Dimitrios Kollias, Damith C Senadeera, Jianian Zheng, Kaushal KK Y adav , Greg Slabaugh, Muhammad A wais, and Xiaoyun Y ang. Dvd: A comprehensiv e dataset for advanc- ing violence detection in real-world scenarios. arXiv preprint arXiv:2506.05372 , 2025. 2 [20] Dimitrios Kollias, Panagiotis Tzirakis, Alan Cowen, Ste- fanos Zafeiriou, Irene Kotsia, Eric Granger, Marco Peder- soli, Simon Bacon, Alice Baird, Chris Gagne, et al. Ad- vancements in affecti ve and beha vior analysis: The 8th aba w workshop and competition. In Pr oceedings of the Computer V ision and P attern Recognition Confer ence , pages 5572– 5583, 2025. 2 [21] Dimitrios Kollias, Stefanos Zafeiriou, Irene Kotsia, Greg Slabaugh, Damith Chamalke Senadeera, Jianian Zheng, Kaushal Kumar Keshlal Y adav , Chunchang Shao, and Guanyu Hu. From emotions to violence: Multimodal fine- grained behavior analysis at the 9th abaw . In Pr oceedings of the IEEE/CVF International Conference on Computer V i- sion , pages 1–12, 2025. 1 , 2 [22] Colin Lea, Rene V idal, Austin Reiter , and Gregory D Hager . T emporal con volutional networks: A unified approach to ac- tion segmentation. In Eur opean conference on computer vi- sion , pages 47–54. Springer , 2016. 1 , 3 [23] Hanting Li, Mingzhe Sui, Zhaoqing Zhu, and Feng Zhao. Nr- dfernet: Noise-robust network for dynamic facial expression recognition. arXiv pr eprint arXiv:2206.04975 , 2022. 2 [24] Fuyan Ma, Bin Sun, and Shutao Li. Spatio-temporal trans- former for dynamic facial expression recognition in the wild. arXiv pr eprint arXiv:2205.04749 , 2022. 1 , 2 [25] Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, Andrew Y Ng, et al. Multimodal deep learn- ing. In Icml , pages 689–696, 2011. 1 , 3 [26] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, P amela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. In International confer ence on machine learning , pages 8748–8763. PmLR, 2021. 1 , 2 [27] Steffen Schneider , Alexei Bae vski, Ronan Collobert, and Michael Auli. wav2v ec: Unsupervised pre-training for speech recognition. arXiv preprint , 2019. 1 [28] Minh T ran and Mohammad Sole ymani. A pre-trained audio- visual transformer for emotion recognition. In ICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 4698–4702. IEEE, 2022. 1 , 3 [29] Y ao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J Zico K olter , Louis-Philippe Morency , and Ruslan Salakhutdinov . Multimodal transformer for unaligned multimodal language sequences. In Proceedings of the 57th annual meeting of the association for computational linguistics , pages 6558–6569, 2019. [30] Shrav an V enkatraman, V igya Sharma, Santhosh Malarvan- nan, et al. Multimodal emotion recognition using audio- video transformer fusion with cross attention. arXiv pr eprint arXiv:2407.18552 , 2024. 1 , 3 [31] Stefanos Zafeiriou, Dimitrios K ollias, Mihalis A Nicolaou, Athanasios Papaioannou, Guoying Zhao, and Irene K otsia. 6 Aff-wild: V alence and arousal’in-the-wild’challenge. In Pr oceedings of the IEEE conference on computer vision and pattern r ecognition workshops , pages 34–41, 2017. 1 , 2 [32] Su Zhang, Ruyi An, Y i Ding, and Cuntai Guan. Continu- ous emotion recognition using visual-audio-linguistic infor- mation: A technical report for abaw3. In Pr oceedings of the IEEE/CVF conference on computer vision and pattern r ecognition , pages 2376–2381, 2022. 3 [33] W ei Zhang, Feng Qiu, Chen Liu, Lincheng Li, Heming Du, T iancheng Guo, and Xin Y u. Affecti ve behaviour analy- sis via integrating multi-modal knowledge. arXiv preprint arXiv:2403.10825 , 2024. 1 , 3 [34] Zengqun Zhao and Qingshan Liu. Former -dfer: Dynamic facial expression recognition transformer . In Pr oceedings of the 29th ACM international conference on multimedia , pages 1553–1561, 2021. 1 , 2 [35] Kaiyang Zhou, Jingkang Y ang, Chen Change Loy , and Ziwei Liu. Conditional prompt learning for vision-language mod- els. In Pr oceedings of the IEEE/CVF confer ence on com- puter vision and pattern reco gnition , pages 16816–16825, 2022. 1 , 2 [36] W eiwei Zhou, Jiada Lu, Zhaolong Xiong, and W eifeng W ang. Leveraging tcn and transformer for effectiv e visual- audio fusion in continuous emotion recognition. In Pr oceed- ings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pages 5756–5763, 2023. 3 [37] W eiwei Zhou, Chenkun Ling, and Zefeng Cai. Emotion recognition with clip and sequential learning. arXiv pr eprint arXiv:2503.09929 , 2025. 1 , 2 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment