멀티모달 감정 인식을 위한 양방향 교차주의와 시계열 모델링
본 논문은 ABAW 10th Challenge의 Expression(EXPR) 과제에서 시각·음성 두 모달리티를 결합한 멀티모달 감정 인식 프레임워크를 제안한다. 사전 학습된 CLIP 이미지 인코더와 wav2vec2.0 오디오 인코더를 고정(frozen)한 채, 시각 특징에 Temporal Convolutional Network(TCN)으로 단기·장기 시계열 정보를 보강하고, 양방향 교차주의(bi‑directional cross‑attentio…
저자: Junhyeong Byeon, Jeongyeol Kim, Sejoon Lim
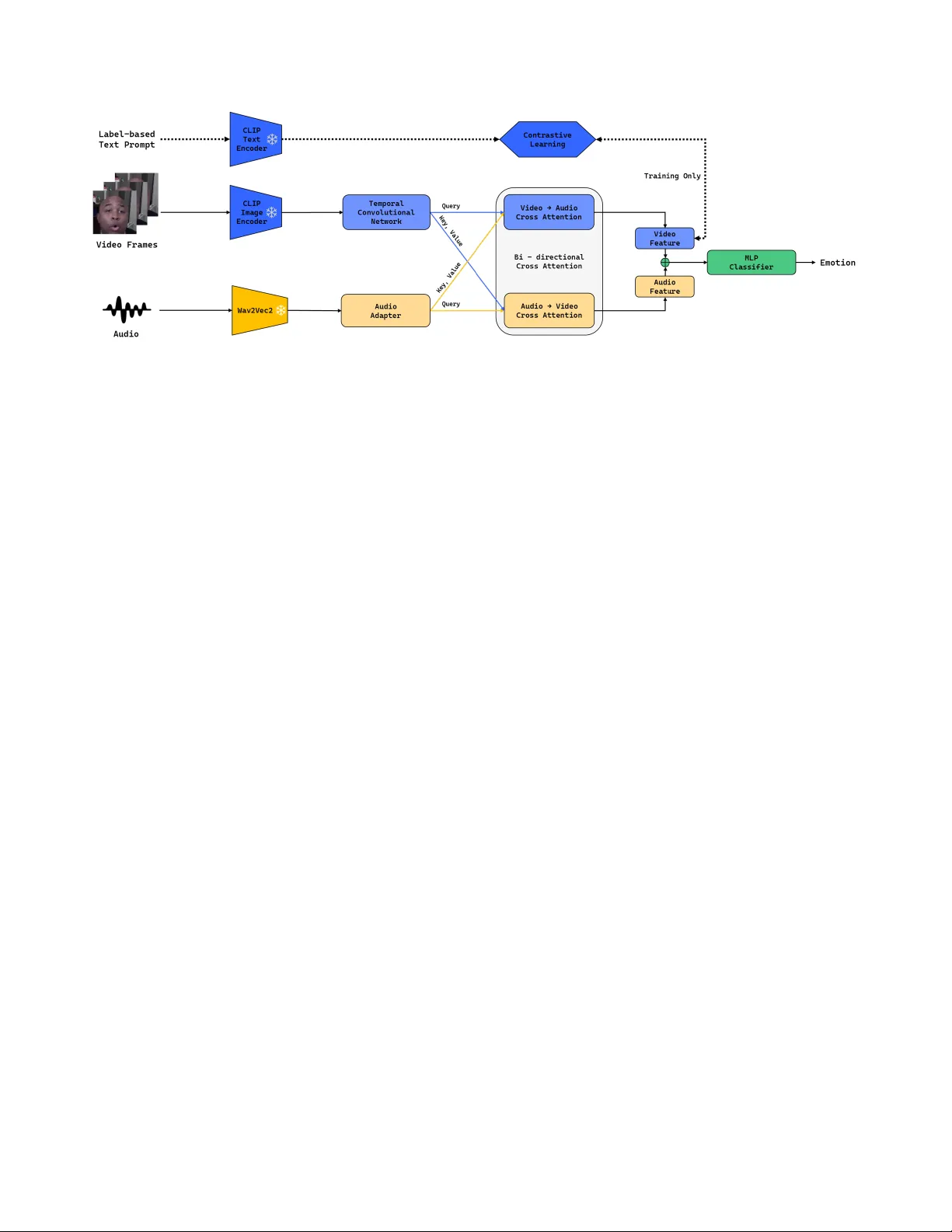
본 논문은 10차 Affective Behavior Analysis in‑the‑wild(ABAW) 챌린지의 Expression(EXPR) 트랙에서 인‑와일드 비디오의 감정을 정확히 인식하기 위한 멀티모달 프레임워크를 제안한다. 기존 연구들은 주로 단일 모달리티(얼굴 이미지 혹은 음성)에 의존하거나, 시각·음성 간 상호작용을 충분히 활용하지 못해 복합적인 감정 신호를 놓치는 문제가 있었다. 이를 해결하기 위해 저자들은 사전 학습된 대규모 모델인 CLIP(ViT‑B/32)와 wav2vec2.0을 각각 시각·음성 백본으로 채택하고, 두 백본을 고정(frozen)하여 학습 비용을 최소화하면서도 강력한 표현력을 확보하였다.
시각 스트림에서는 각 프레임을 CLIP 이미지 인코더로 512 차원 임베딩으로 변환한 뒤, Temporal Convolutional Network(TCN)를 적용한다. TCN은 6개의 dilated causal convolution 블록으로 구성돼, 점진적인 팽창을 통해 짧은 프레임부터 긴 프레임까지의 시계열 의존성을 포착한다. 이는 표정이 시간에 따라 변화하는 동적 특성을 효과적으로 모델링한다.
음성 스트림은 wav2vec2.0 Base 모델을 사용해 16 kHz 오디오를 768 차원 시퀀스로 인코딩하고, linear projection, LayerNorm, ReLU, Dropout으로 구성된 어댑터를 거쳐 512 차원으로 맞춘다. 이렇게 차원을 통일함으로써 이후 교차주의 단계에서 효율적인 상호작용이 가능하도록 설계하였다.
핵심적인 멀티모달 통합 방법으로는 양방향 교차주의(bi‑directional cross‑attention) 모듈을 도입한다. 시각 특징을 Query, 음성 특징을 Key·Value로 사용해 시각→음성 attention을 수행하고, 반대로 음성→시각 attention을 수행한다. 두 attention 결과는 Residual 연결과 LayerNorm을 거쳐 각각 H_V2A와 H_A2V를 만든다. 이 대칭적 상호작용은 한 모달리티가 다른 모달리티의 부족한 정보를 보완하도록 하며, 단순 concatenation보다 풍부한 교차 컨텍스트를 제공한다.
교차주의 후에는 평균 풀링을 통해 시계열 차원을 축소하고, 시각·음성 특징을 결합한 1024 차원 멀티모달 벡터를 얻는다. 이 벡터는 3개의 Linear 레이어와 ReLU, Dropout으로 구성된 MLP에 입력되어 8개의 감정 클래스에 대한 로짓을 출력한다.
또한, 라벨 기반 텍스트 프롬프트를 활용한 대비학습(contrastive learning) 기법을 도입한다. 각 감정 라벨을 “A face expressing
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기