Efficient Policy Learning with Hybrid Evaluation-Based Genetic Programming for Uncertain Agile Earth Observation Satellite Scheduling
The Uncertain Agile Earth Observation Satellite Scheduling Problem (UAEOSSP) is a novel combinatorial optimization problem and a practical engineering challenge that aligns with the current demands of space technology development. It incorporates unc…
Authors: Junhua Xue, Yuning Chen, Mingyan Shao
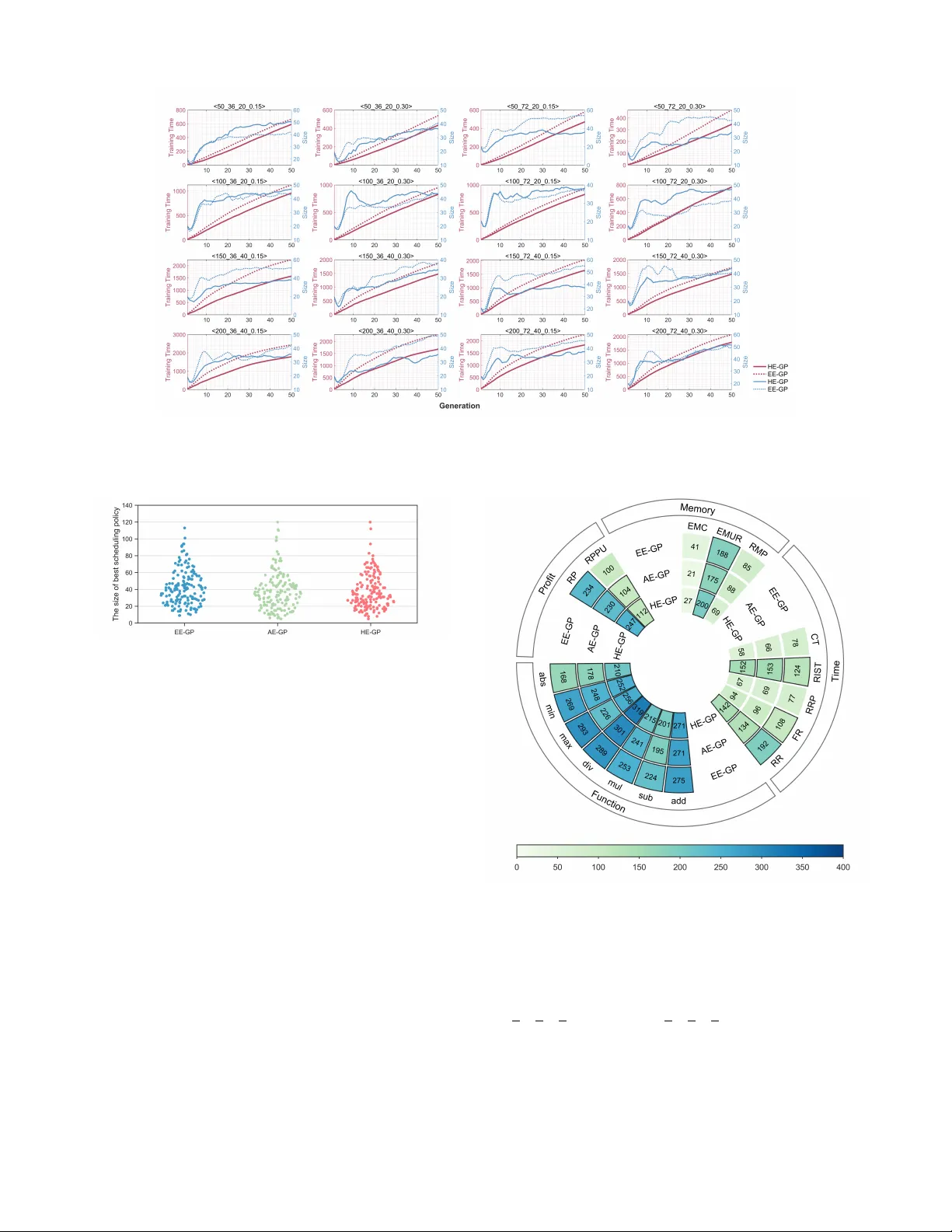
1 Ef ficient Polic y Learning with Hybrid Ev aluation-Based Genetic Programming for Uncertain Agile Earth Observ ation Satellite Scheduling Junhua Xue , Y uning Chen , Mingyan Shao , Y angming Zhou , Qinghua W u, and Y ingwu Chen Abstract —The Uncertain Agile Earth Observation Satellite Scheduling Problem (U AEOSSP) is a novel combinatorial op- timization pr oblem and a practical engineering challenge that aligns with the current demands of space technology develop- ment. It incorporates uncertainties in pr ofit, resource consump- tion, and visibility , which may render pr e-planned schedules suboptimal or even infeasible. Genetic Programming Hyper- Heuristic (GPHH) shows pr omise for evolving interpretable scheduling policies; howev er , their simulation-based evaluation incurs high computational costs. Moreo ver , the design of the constructive method, denoted as Online Scheduling Algorithm (OSA), directly affects fitness assessment, resulting in evaluation- dependent local optima within the policy space. T o address these issues, this paper proposes a Hybrid Evaluation-based Genetic Programming (HE-GP) for effectively solving U AEOSSP . A Hybrid Evaluation (HE) mechanism is integrated into the policy-driven OSA, combining exact and approximate filtering modes: exact mode ensures evaluation accuracy through elabo- rately designed constraint verification modules, while approxi- mate mode reduces computational ov erhead via simplified logic. HE-GP dynamically switches between evaluation models based on r eal-time evolutionary state inf ormation. Experiments on 16 simulated instance sets demonstrate that HE-GP significantly outperforms handcrafted heuristics and single-ev aluation based GPHH, achieving substantial reductions in computational cost while maintaining excellent scheduling performance acr oss di- verse scenarios. Specifically , the a verage training time of HE-GP was reduced by 17.77% compared to GP employing exclusively exact evaluation, while the optimal policy generated by HE-GP achieved the highest av erage ranks across all scenarios. Index T erms —Agile earth observation satellite scheduling problem, uncertainty , genetic programming hyper -heuristic, markov decision process, h ybrid evaluation I . I N T R O D U C T I O N E AR TH observation satellites (EOSs) are spaceborne plat- forms engineered to fulfill a wide range of observa- tion requirements across disciplines such as agriculture and economics, making the EOS scheduling problem (EOSSP) a longstanding focus in optimization research [1].W ith the rapid advancement of satellite technologies and the escalating demand for satellite imagery across various applications, the optimization of scheduling processes for Agile EOSs (AEOSs) has attracted increasing attention. The AEOSs feature three degrees of freedom in attitude control (roll, pitch, and yaw), and their enhanced maneuverability enables them to handle ov erlapping observation requests and complex operations [2]. Compared to EOSSP , AEOSSP’ s search space is considerably larger , with theoretically innumerable observation windows (O Ws) within visible time windo ws (VTWs) for each request [3]. Contemporary research primarily concentrates on satellite scheduling challenges that incorporate considerations of agile maneuverability [4]. The integration of artificial intelligence and cyber -physical systems has dri ven a gro wing demand for autonomous satel- lite scheduling, particularly under the constraints of limited onboard computational resources [5]. Autonomous scheduling requires satellites to dynamically adjust schedules based on real-time state information while ef fectively managing en- vironmental uncertainties. Ho wev er, most existing AEOSSP studies tend to oversimplify real-world operational conditions, frequently adopting static and deterministic problem formula- tions. These con ventional static models and their associated so- lution methodologies present inherent limitations in effecti vely supporting the dev elopment of autonomous scheduling, as AEOSs inherently encounter v arious resource-related and task- related uncertainties during scheduling [6]. While recent re- search has considered single-source uncertainties such as cloud cov er impacts [7]–[9] and the dynamic arriv al of observation requests [3], systematic in vestigations into multi-uncertainty integration remain insufficient. T o bridge this critical gap and better align theoretical research with practical requirements, this study introduces the Uncertain AEOSSP (U AEOSSP) [10]. The U AEOSSP explicitly characterizes profit, resource consumption, and visibility as stochastic v ariables, thereby providing a more accurate depiction of the operational en- vironment. Consequently , it holds substantial theoretical and practical significance for advancing autonomous scheduling capabilities. Markov Decision Processes (MDPs) pro vide a robust frame- work for uncertain sequential decision-making, enabling dy- namic schedule generation based on real-time state informa- tion and supporting autonomous satellite operations [11]–[13]. They simulate the on-board autonomous decision-making pro- cess of satellites, where irrev ersible decisions are made based on real-time state information. Scheduling policies play a crucial role in methodologies that employ the MDP framework for modeling autonomous scheduling. Handcrafted schedul- ing policies, such as priority-based sequential construction procedures [14], have demonstrated some efficacy , but their performance is highly scenario-dependent and contingent upon specific optimization objectives. Moreover , designing ef fectiv e policies tailored to specific scenarios requires substantial time and domain e xpertise. Recent de velopments in Machine Learn- 2 ing (ML) technologies have prompted numerous studies to utilize ML methodologies to generate scheduling policies [11], [15]–[18]. These approaches deri ve optimization policies from historical datasets and data-driv en patterns. Howe ver , most existing satellites are equipped solely with CPU hardware, whereas complex models, such as deep neural networks, require high-performance GPU resources [19]. Additionally , these network models suf fer from the “black box” problem, which limits transparency and interpretability and hinders their direct application in satellite scheduling scenarios that impose stringent engineering reliability requirements [20]. Genetic Programming Hyper-Heuristic (GPHH) has emerged as a promising approach to address the challenges associated with interpretability in scheduling optimization [21]. As a population-based ev olutionary approach, GPHH ev olves heuristic policies via genetic operations rather than generating specific schedules directly [22]. Unlike deep neural network models, the ev olved policies can be expressed as transparent and interpretable mathematical formulations, thereby enhancing user comprehension and trust. The efficac y of such mathematically represented policies has been demonstrated across a v ariety of real-world scheduling problems [20]. Furthermore, prior studies hav e successfully applied GPHH to develop robust policies for uncertain scheduling [23]–[25]. T o date, some scholars have employed GPHH to address the AEOSSP while incorporating uncertainty considerations: W ei et al. proposed a knowledge- transfer based GP for multi-objective dynamic AEOSSP [3]. Chen et al. were the first to apply GPHH to solve the AEOSSP under conditions inv olving multiple uncertainties [10]. Although GPHH has demonstrated remarkable performance in studying AEOSSP under uncertainty [3], [10], it still exhibits certain limitations that warrant further inv estigation. Currently , there is a paucity of research analyzing the design and impact of ev aluation models, despite their indispensable and critical role within GPHH. The ev aluation of GP individ- uals is intrinsically linked to constructi ve methods [11], with the design of these methods directly influencing the fitness ev aluation of identical policies. This relationship causes the distribution of local optima within the policy space to depend on the construction method employed. While prior studies hav e predominantly focused on the ef fects of enhancements to genetic operators [26], [27], modifications to ev aluation can steer distinct ev olutionary trajectories and potentially improv e the algorithm’ s search ef ficacy . In addition, GPHH is distinguished by high computational requirements, largely attributable to the time-intensi ve e valuation process [28]. Some research has sought to mitigate these computational costs by constraining policy comple xity through multi-objective opti- mization methods [29], [30]. Howe ver , this approach either re- stricts the potential effecti veness of ev olved policies or lacks a comprehensiv e and systematic inv estigation specifically aimed at enhancing ev aluation ef ficiency within the context of the problem. Therefore, achieving an optimal balance between reducing the computationally expensiv e ev aluation ov erhead and preserving strong algorithmic performance remains a significant and unresolved challenge in applying GPHH to the U AEOSSP . Building on the abov e considerations, this study introduces an innov ativ e Hybrid Ev aluation-based Genetic Programming (HE-GP) approach designed to address the U AEOSSP ef- fectiv ely . The HE-GP framework utilizes a con ventional GP architecture for population ev olution while incorporating a nov el Hybrid Evaluation (HE) mechanism within a policy- driv en Online Scheduling Algorithm (OSA). This HE mecha- nism integrates both exact and approximate filtering strategies: the exact filtering mode ensures accuracy through meticu- lously designed constraint verification modules, whereas the approximate filtering mode reduces computational demands by employing simplified logical procedures. Unlike ev aluation models that rely on a single mode, the HE-OSA dynamically alternates between filtering modes based on the real-time ev olutionary status of the GP population, thereby achieving an optimal balance between computational efficienc y and search effecti veness. The principal contributions of this paper are summarized as follows: • A HE-GP was dev eloped to address the U AEOSSP by integrating a nov el-designed HE mechanism within the policy-based OSA. This integration enabled efficient pol- icy e valuation through adapti ve switching between exact and approximate filtering modes, thereby enhancing both the algorithm’ s ef ficiency and its search performance. • The HE-GP and its ev olved scheduling policies were ev aluated across different configurations, verifying the effecti veness and superiority of the proposed HE mech- anism in reducing computational cost and improving solution quality . • In-depth analysis was conducted on the impact of the HE mechanism on algorithm e volutionary characteristics and the composition of e volv ed scheduling policies, identify- ing key feature terminals for optimal policy design and providing valuable theoretical references for subsequent research on GPHH and AEOS autonomous scheduling. The remainder of this paper is organized as follows. Section II delineates the problem description and mathematical formu- lation of the UAEOSSP , and also revie ws related work perti- nent to this study . Section III introduces the basic framework of GPHH for solving the UAEOSSP , with an emphasis on the policy-based OSA. Section IV details the implementation of the HE mechanism. Section V describes the generation of experimental instance sets and the configuration of algorithmic parameters. Section VI presents a comparativ e analysis of manually designed heuristics, HE-GP , and GP employing a single e valuation model across 16 simulated instance sets, fol- lowed by a detailed discussion. Finally , Section VII concludes the paper and outlines directions for future research. I I . B AC K G RO U N D A. Uncertain Agile Earth Observation Satellite Scheduling Pr oblem The AEOSSP is an oversubscribed planning and scheduling challenge focused on producing feasible, practical plans for satellites in orbit. This study introduced a stochastic variant of 3 AEOSSP that accounts for uncertainty in problem parameters. Howe ver , de veloping scheduling plans in practical manage- ment conte xts often entails significant complexity , as the y must integrate intricate operational considerations, including regula- tory constraints and specific user requests [2]. T o facilitate the analysis of U AEOSSP , some reasonable simplifications and assumptions are proposed as follows: • The satellite’ s av ailable resources and the VTWs for all requests are known a priori. • Only point targets are considered in the requests. • AEOS operates in a uniform-speed ground imaging mode, and its memory consumption is directly proportional to the imaging duration. • AEOS is equipped with a single imaging payload and can observe only one request at a time. • Cloud cover affects imaging quality , which in turn af fects the profit per request. Since the uncertainty in profit has been incorporated into U AEOSSP , the current model does not account for the impact of partial cloud cov er . The U AEOSSP in volves a set of candidate observation requests R . For each request r i ∈ R , there exists a corre- sponding VTW [ ws r i , w e r i ] . Each request is characterized by its required imaging duration du r i and an expected profit p r i . This paper focuses on the planning and scheduling of a single satellite in orbit with a maximum onboard memory capacity denoted by mmc . At any t within the [ w s r i , w e r i ] , the satellite assumes a unique attitude att t,r i that enables the observation of r i . The satellite executes dif ferent requests through attitude maneuvers. Each r i requires a continuous observation duration du r i for complete imaging. During the observation period of r i , the satellite’ s attitude angle varies ov er time. Upon completion of imaging r i , the corresponding profit is obtained. Considering uncertainties during scheduling, the actual profit, resource consumption, and visibility associated with r i may vary under different en vironmental conditions. Let E denote the set of scenarios representing the same situation under varying en vironmental conditions. For a given env ∈ E , the actual profit p r i ( env ) and visibility v is r i ( env ) of r i are assumed to be known in adv ance. Ho wev er , the actual data write rate cr r i ( env ) during imaging of r i is environment- dependent and cannot be predetermined, introducing uncer- tainty into the resource consumption of r i . The variable x r i ( env ) indicates whether r i is observed in scenario env , and y r i ,r j ( env ) represents the sequencing order between r i and r j . The decision variables are shown as (1) and (2). In a feasible schedule (i.e., solution), the [ os r i , oe r i ] of each selected r i must also be determined. x r i ( env ) = ( 1 , if r i is selected 0 , otherwise (1) y r i ,r j ( env ) = 1 , if r j is selected immediately after request r i 0 , otherwise (2) The objective function aims to maximize the e xpected total profit in an uncertain scheduling scenario and is formulated as shown in (3). max P | R | i =1 x r i ( env ) · p r i ( env ) | E | (3) Here, the numerator denotes the total actual profit across all en vironments, while the denominator is the total number of en vironments. Constraint (4) ensures that the total memory consumption does not exceed the maximum memory capacity mmc . | R | X i =1 ( x r i ( env ) · cr r i ( env ) · du r i ) ≤ mmc (4) Constraint (5) stipulates that if r i is in visible, it cannot be scheduled for observation. x r i ( env ) = 0 , ∀ vis r i ( env ) = 0 (5) Constraint (6) requires that, for any observed r i , the O W must lie entirely within [ w s r i , w e r i ] . w s r i ≤ os r i ( env ) < oe r i ( env ) ≤ we r i , ∀ x r i ( env ) = 1 (6) Constraint (7) specifies that the duration for each observed r i must equal du r i to ensure complete imaging. oe r i ( env ) − os r i ( env ) = du r i , ∀ x r i ( env ) = 1 (7) Constraint (8) ensures that the attitude transition time be- tween two consecuti ve observ ations does not exceed the time interval between their O Ws. The transition angle ∆ g between the two attitudes is calculated based on the differences in pitch ( γ ), roll ( η ), and yaw ( ϑ ) angles, as shown in (9). Furthermore, the transition time can be modeled as a piece wise linear function, as described in (10) [2], [18]. oe r i ( env ) + T r ans att oe r i ,r i , att oe r j ,r j ≤ oe r j ( env ) , ∀ y r i ,r j ( env ) = 1 (8) ∆ g ( att oe r i ,r i ,att oe r j ,r j ) = | γ ( att oe r i ,r i ) − γ ( att oe r j ,r j ) | + | η ( att oe r i ,r i ) − η ( att oe r j ,r j ) | + | ϑ ( att oe r i ,r i ) − ϑ ( att oe r j ,r j ) | (9) T r ans (∆ g ) = a 1 + ∆ g v 1 , ∆ g ≤ θ 11 a 2 + ∆ g v 2 , θ 20 ≤ ∆ g ≤ θ 21 . . . a n + ∆ g v n , θ n 0 ≤ ∆ g ≤ θ n 1 (10) Here, a , v , and θ are satellite-specific parameters associated with the function T ran ( · ) . Constraint (11) prohibits an y r i from having a sequential relationship with itself. y r i ,r i ( env ) = 0 , (11) T o address the issue of representing the first and last re- quests in the observation sequence within the decision variable y ( env ) , dummy requests are introduced as per [31]. The 4 corresponding constraints on the dummy requests are specified as (12). x r 0 ( env ) = x r | R | +1 ( env ) = 1 (12) Constraints (13) represents that if r i is observed, it must hav e exactly one successor and one predecessor request. x r i ( env ) = | R | X j =1 y r i ,r j ( env ) = | R | X i =1 y r i ,r j ( env ) , ∀ x r i ( env ) = 1 (13) Constraint (14) ensures that if r j is observed immediately after r i , both requests must be included in the schedule. x r i ( env ) = 1 ∧ x r j ( env ) = 1 , ∀ y r i ,r j ( env ) = 1 (14) The DFJ constraint proposed by Dantzig et al. in 1954 is an effecti ve method of av oiding subloops on the path [32], which can be expressed by (15). X r i ∈ S X r j ∈ S y r i ,r j ( env ) ≤ | S | − 1 , ∀ S ⊆ { 1 , 2 , · · · , | R |} , S = ∅ (15) Constraint (16) is the domain of decision v ariables, which is shown as (16). x r i ( env ) ∈ { 0 , 1 } , y r i ,r j ( env ) ∈ { 0 , 1 } , os r i ( env ) ∈ R + , oe r i ( env ) ∈ R + (16) B. Related W ork The AEOSSP has arisen from adv ances in satellite technol- ogy , notably the increased maneuverability of agile satellites, and has been shown to be NP-hard [33]. Since e xact methods are only suitable for small-scale instances, heuristic [34], [35] and metaheuristic [2], [36] approaches hav e predominantly been employed to address AEOSSP . Most studies focus on static and deterministic AEOSSP models, which oversimplify real-world conditions. Simultaneously , the associated solution methodologies encounter significant challenges when address- ing stochastic v ariations in the en vironment [10]. The growing demand for autonomous scheduling capabilities imposes more stringent requirements on contemporary research in the field of AEOSSP [5], with a primary focus on enabling satellites to effecti vely manage the uncertainties inherent in the scheduling process. Incorporating uncertainty fundamentally enhances the rel- ev ance of research on AEOSSP to the requirements of aerospace engineering. In recent years, the inv estigation of AEOSSP models and solution methodologies that incorpo- rate uncertainty has garnered significant scholarly attention. Sev eral studies hav e examined the impact of cloud cov er uncertainty on satellite observations [7]–[9]. The dynamic nature of demand arri vals and cancellations, a practical chal- lenge in satellite scheduling, has also emerged as a prominent research area [3], [37], [38]. Furthermore, some research has addressed uncertainties related to resource consumption [39] and emergency e vents [40] within the context of satellite scheduling. Nev ertheless, existing studies predominantly focus on single uncertainty , with limited integration of multiple uncertainties. T o more effecti vely address the AEOSSP amid uncertain- ties, considerable research has focused on scheduling method- ologies with rapid-response capabilities. These methodologies are primarily categorized into rescheduling and policy-based scheduling approaches. Rescheduling approaches predomi- nantly focus on managing unforeseen occurrences, such as the arriv al of new demand, and may in volv e either creating an entirely ne w schedule or modifying the existing solu- tions [41], [42]. The drawback of rescheduling approaches lies in their strong dependence on the initial plan and in- cur high computational costs, leading to slo w responses to frequently occurring uncertainties. Policy-based approaches provide scheduling policies that facilitate the generation of schedules rather than directly optimizing them. These policies can guide constructive methods to produce solutions, often deriv ed from handcrafted heuristic rules [14] or ML algorithms [18], [43]. Although the network-based policies provide AEOS with enhanced autonomous scheduling functionalities, their applicability is constrained by limited interpretability , often characterized as a “black box” [20], [23]. In many engineering fields, especially in the aerospace sector , maintaining users’ trust and confidence in machine systems is of paramount importance. Therefore, it is essential to dev elop autonomous scheduling capabilities for satellites that incorporate policies ensuring both operational effecti veness and interpretability , thereby providing reliable support [13]. T o ensure the interpretability of the scheduling policies, GPHH has been e xtensiv ely applied to scheduling optimization ov er the past decade. It can generate interpretable policies with mathematical or logical e xpressions [44]. Recent de velopments in GPHH have primarily focused on designing algorithmic architectures and operators to improv e both the efficienc y of the e volutionary process and the quality of the resulting ev olved policies. Partial techniques are listed as follo ws: multi-objectiv e ev aluation to regulate policy complexity [13], [30], [45]; transfer learning to enhance the initial population’ s performance [3], [26]; ensemble learning to increase decision robustness [46], [47]; and niching to maintain population div ersity [27], [48]. Howe ver , to our kno wledge, there remains a notable lack of systematic research focused on ev aluation, despite its indispensable role in the e volutionary process of GPHH. Evaluation is a crucial aspect of GPHH that warrants further in vestigation. In scheduling optimization, training time is often prolonged due to inef ficient e valuation processes [28]. Moreover , dif ferent e valuation models can steer the ev olutionary process in distinct directions, as variations in the e valuation model may produce different schedules for the same polic y . Firstly , the inef ficiency in the ev aluation process directly impedes the training speed. Therefore, minimizing runtime is crucial for the practical implementation of GPHH [49]. Existing studies mainly accelerate e valuation from three 5 perspectiv es: fitness inheritance and imitation methods esti- mate a GP indi vidual’ s fitness based on related individuals rather than performing full ev aluations [50], [51]; multi-fidelity fitness approximation methods can balance fidelity and compu- tational expense by employing multi-fidelity simulations and surrogate models to expedite the search for optimal solutions, ultimately yielding acceptable results [28], [52], [53]; and parallel and distributed computing techniques ha ve been uti- lized to alle viate computational burdens [54]. Besides parallel and distrib uted computing techniques, other methods mainly employ approximate ev aluation for GP indi viduals to mitigate the high computational cost associated with exact ev aluation. Approximate ev aluation models are widely utilized, and they simplify the ev aluation process by leveraging exact ev aluation models to generate approximate results, thereby accelerating training [55]. Nonetheless, discrepancies exist between ap- proximate and exact models, so the algorithm’ s performance is highly contingent upon the design of the approximate model [28]. The fitness values derived from approximate e valuation differ from those obtained through e xact ev aluation, potentially causing inconsistencies in the identification of local and global optima. Currently , there is still limited research addressing the trade-offs and integration between approximate and pre- cise ev aluations. Most existing studies primarily concentrate on incorporating approximate models to accelerate training, provided that the reduction in result quality remains within acceptable bounds. In summary , we introduce an AEOSSP model that better reflects real-world conditions by incorporating multiple un- certainties, and we solve it using the GPHH method. Gi ven the high computational cost of GPHH and its dependence on ev aluations, this study innovati vely designs a technique that integrates both e xact and approximate ev aluations to achiev e a better balance between computational ef ficiency and ev olutionary quality . I I I . G E N E T I C P R O G R A M M I N G H Y P E R - H E U R I S T I C F O R UA E O S S P This section introduces a basic GPHH frame work for solv- ing UAEOSSP , and the specific designs of each component are provided. A. The Overall F ramework of GPHH Algorithm 1 illustrates the architecture of the GPHH used to solve the U AEOSSP . Initially , a population of N GP individu- als, each representing a scheduling policy , is randomly gener - ated. The e valuation utilizes a constructiv e method grounded in MDP , allowing the satellite to progressively generate a schedule in accordance with the scheduling policy . Based on GP individuals’ fitness values, the GP population undergoes iterativ e refinement using genetic operators to continuously improv e the effecti veness of scheduling policies. Once the stopping criteria are met, the evolutionary process terminates and returns the highest-performing scheduling policy . Specif- ically , the constructiv e method employed for ev aluation must be suitable for the U AEOSSP , thereby pro viding an objective Algorithm 1 The Overall Frame work of GPHH Input: The number of individuals in the GP population N , the Maximum number of iterations T , a training dataset tr ainS et Output: The optimal policy sp ∗ 1: pop ← Init ( N ) ; \\ Initialize a GP population. (See Section III-B) 2: bestGen ← ∅ , bestF it ← −∞ ; 3: for t ← 1 to T do 4: f its ← Evaluation ( pop, trainS et ) ; \\ Evaluate the current population using training instances. (See Section III-C) 5: \\ Genetic Operators is applied to generate offspring. (See Section III-D) 6: pop ′ ← Selection ( pop, f its ) ; 7: pop ′ ← Crossover ( pop ′ ) ; 8: pop ′ ← Mutation ( pop ′ ) ; 9: pop ← Reproduction ( pop, pop ′ ) ; 10: Update sp ∗ in pop ; 11: end for 12: retur n sp ∗ ; and ef fectiv e basis. For an y scheduling scenarios, this polic y- driv en, timeline-based MDP should be capable of producing feasible schedules, ensuring that all constraints are satisfied. B. Individual Repr esentation and Initialization GP individuals represent heuristic scheduling policies that guide decision-making. Each GP individual is encoded as a tree structure comprising function nodes and terminal nodes, which can be translated into a mathematical expression. For instance, the scheduling policy illustrated in Fig. 1 can be expressed as | RP − RR | +max( C T , 5 . 20) . W ithin the dynamic decision-making process, the scheduling policy is applied prior to each decision to compute heuristic values for candidate requests, which serve as the basis for selecting the optimal request r ∗ . The initial population is generated using Koza’ s half-and-half method [56], in which individuals are created with equal probability via either the full or grow method. Fig. 1. An example of the tree representation of a scheduling policy . C. A Constructive Method for F itness Evaluation The policy-dri ven, timeline-based MDP model proposed herein is named the Online Scheduling Algorithm (OSA). OSA must be capable of generating feasible schedules based on GP indi viduals (i.e., scheduling strategies) within specific en vironmental contexts to e valuate their effecti veness. For 6 the AEOSSP with time-dependent transition time, some re- searchers have modeled it as an MDP [3], [11], [17]. Gi ven that the U AEOSSP incorporates unpredictable information, decision points are not predetermined [57]. Furthermore, the uncertainty associated with specific parameters results in in- determinate state transitions, thereby rendering the U AEOSSP effecti vely a partially observ able MDP [58]. A request that is still feasible is defined as a candidate request. Each candidate request has an earliest start time of O W , and can be observed from this time until the end of its VTW . In the MDP of the U AEOSSP , the action is to select a candidate request according to the scheduling policy sp at each step, determine its earliest O W , and ex ecute the observ ation at that time to reach the next state. Each request has a corresponding actual profit, which serves as the rew ard the satellite receiv es after completing each action. The objecti ve of this paper is to identify a scheduling policy that performs robustly on av erage across div erse environmental conditions. Accordingly , the fitness of sp is defined as the mean total profit obtained ov er multiple scenarios, as formalized in (17). F it ( sp ) = P env ∈ E O S A ( sp, env ) | E | (17) Here, O S A ( sp, env ) represents the total profit obtained by policy sp in the scheduling scenario under en vironment env , and E denotes a set of distinct environments. Algorithm 2 provides the specific implementation process for OSA. During the e xecution of OSA, the satellite’ s state is classified as either acti ve (working) or inactiv e (idle). The satellite is deemed idle immediately following initialization or upon completion of a prior observation. Decision points arise exclusi vely when the satellite is idle, at which juncture the scheduling policy must determine the optimal action based on the current information. Once a decision is made under the sp , the satellite transitions to the acti ve state. A new decision point is triggered each time the satellite re-enters the idle state. Initially , all requests are incorporated into the candidate request pool U . Prior to each decision, the feasibility of requests within U is verified, and their earliest O W start times are computed. The heuristic v alue of each r i ∈ U is calculated using sp , and the one with the optimal heuristic value is selected for execution. Scheduling terminates and returns the schedule and total profit if U = ∅ or if the onboard memory is insufficient. Otherwise, the satellite iterati vely recalculates heuristic values for candidate requests and makes decisions accordingly . Notably , the proposed OSA exhibits inherent adaptability to dynamic scenarios. Newly arriving requests can be directly appended to U , while canceled requests can be remov ed, follo wed by appropriate schedule adjustments. This renders the constructiv e method is readily extendable to dynamic scheduling problems. The principal computational challenge associated with the OSA arises from state updates and policy-based decision- making. The computational complexity inherent in policy- based decision-making is directly proportional to the size of the policy , with more complex policies demanding increased computational resources. Therefore, expediting state update procedures represents a crucial objectiv e for improving the Algorithm 2 The Online Scheduling Algorithm for Solving U AEOSSP Input: A scheduling policy ss ( · ) , a request set R , a schedul- ing scenario env , the maximum memory capacity mmc , the actual profit p ( · ) , the actual write code rate cr ( · ) , the imaging duration dur ( · ) Output: A feasible schedule sol = { ( u, os u , oe u ) } , fitness of the giv en policy f it 1: sol ← ∅ , f it ← 0 , t ← 0 ; 2: U ← R ; \\ U is the pool of unobserved requests 3: while U = ∅ do 4: U ′ , O S u ← F ilter ( U, t, sol ) ; \\ Update U to ensure the feasibility of candidate requests, and the OW start time for each is calculated. (See Section IV) 5: u ∗ ← arg max u ∈ U ′ { ss ( u, F ) } ; \\ u ∗ is the selected request with optimal heuristic value 6: mmc ← mmc − dur ( u ∗ ) × cr ( u ∗ ) ; 7: if mmc < 0 then 8: break; \\ The scheduling terminates due to insufficient memory capacity . 9: end if 10: t ← O S u ( u ∗ ) + dur ( u ∗ ) ; 11: sol ← sol ∪ { u ∗ , O S u ( u ∗ ) , t } , f it ← f it + p ( u ∗ ) ; 12: U ← U ′ \ u ∗ ; 13: end while 14: retur n sol , f it ; ov erall ef ficiency of the OSA. The principal innov ation of this study is the introduction of a HE-based OSA (HE- OSA), which facilitates rapid filtering of the U and efficient computation of the earliest O Ws for r i ∈ U . HE-OSA encompasses both exact and approximate e valuation models, each utilizing two distinct filtering modes: exact filtering and approximate filtering. The methodologies for approximate and exact filtering are described in Sections IV -B and IV -A, respectiv ely . In contrast to emplo ying a single filtering mode or allocating iterations to each mode through a two-stage process, this study proposes an adaptiv e switching mechanism that lev erages evolutionary state information, as detailed in Section IV -C. The objectiv e of U AEOSSP requires multiple training in- stances for ev aluation. Howe ver , directly assessing GP individ- uals on the entire training set incurs prohibitive computational costs. T o mitigate this expense, a mini-batch rotation mecha- nism [59] is employed, wherein each iteration ev aluates fitness using only one mini-batch. A round-robin sampling strategy is adopted to sequentially select mini-batches, ensuring system- atic and balanced utilization of training instances throughout the ev olutionary process. D. Genetic Operators The genetic operators of the EH-GP include selection, crossov er, mutation, and population reproduction: 1) Selection : The tournament selection operator with a tournament size of T siz e is employed. T siz e individuals are randomly sampled without replacement from the parent pop- 7 ulation, and the individual with the optimal fitness is selected to enter the offspring population. 2) Crossov er : The single-point crossover operator is uti- lized. T wo indi viduals are randomly selected from the off- spring population, and crossover points are chosen from their non-leaf nodes. The subtrees rooted at these crossover points are exchanged to generate two new offspring individuals, which replace the original selected indi viduals. 3) Mutation : The uniform mutation operator is applied to introduce genetic di versity into the population. GP individuals are selected for mutation with a preset mutation probability . For the selected indi vidual, a random node is chosen from its tree structure, and a ne w subtree generated by the half-and-half method replaces the selected node. 4) Reproduction : At the end of each iteration, the parent population and the newly generated offspring population are combined. The tournament selection is reimplemented on the combined population to screen indi viduals with excellent fitness, which constitute the next-generation population, and maintain the same scale of the GP population during e volution. I V . H Y B R I D E V A L U A T I O N M E C H A N I S M Building upon the frame work outlined in Section III, this section proposes a hybrid ev aluation (HE) mechanism de- signed to enhance the performance of the OSA used for ev alu- ation. The HE mechanism of fers a nov el e valuation strate gy for GP indi viduals, enabling adapti ve switching between e xact and approximate e valuation models. Dif ferent ev aluation models correspond to distinct filtering modes, which also account for differences among e valuation models under HE-GP . OSA is a constructiv e-based MDP model, which is also widely used for ev aluation in scheduling optimization [3], [15], [16]. During the autonomous scheduling process, state updates and polic y-based decision-making are indispensable (see Section III-C). The decision logic employed is determin- istic, meticulously calculating heuristic values for all candidate requests based on a given scheduling policy and selecting the optimal one. The filtering in the state updates is also heuristic due to the di versity of OWs. Beyond ensuring that any schedule meets the constraints, the agility of AEOS extends the VTWs, making the OW for each candidate request non-unique. The state update requires removing unobserv- able requests from U and recalculating the O W for each r i ∈ U . Therefore, the distinction between different filtering modes lies in the selection of O Ws for candidate requests. In contrast to vehicle routing planning problems, where path information between request points can be predetermined [60], the transition time between an y two requests cannot be predetermined. Consequently , the O Ws of candidate requests are neither fixed nor rapidly computable, as illustrated in Fig. 2. The frequent necessity to verify constraints and update OWs imposes substantial computational overhead during ev aluation, directly affecting training efficienc y . Hence, developing ef- ficient procedures for removing infeasible requests from U and updating O Ws is essential to mitigate costly e valuation ov erhead. Prior studies hav e typically selected the earliest O W r i that meets the constraints to observe r i [31], [38]. This approach Fig. 2. An example of the AEOS attitude transition is provided. The duration necessary for the attitude transition between two identical candidate requests exhibits variability . can be considered a form of exact filtering, which determines whether to remov e candidate requests based on the occurrence of the earliest OW . Howe ver , this commonly used filtering mode design in the past still has certain shortcomings: 1) The frequent computation of earliest O Ws significantly increases the computational load, whereas pruning tech- niques can effecti vely pre vent unnecessary resource ex- penditure. For example, the maximum transition time mT r ans can be pre-estimated based on VTW informa- tion, thereby avoiding updates for candidate requests with later O W start times. 2) The exact determination of O Ws depends on heuristic strategies that do not guarantee optimal solutions when combined with specific scheduling policies. Dif ferent O W selection heuristics can produce varying performance out- comes for the same policies and may guide the algorithm tow ard different local optima. Therefore, incorporating a hybrid e valuation mechanism can promote the exploration of di verse local optima, thereby improving the global search capability . Based on the abov e considerations, the main contribution of the proposed HE mechanism is the improvement of the traditional ev aluation approach, which relies on a fixed e xact model. It introduces a more efficient approximate filtering mode and possesses the capability to adapti vely switch be- tween filtering modes based on the current ev olutionary state information. The two meticulously designed modes incor- porate multiple check modules to verify the feasibility of candidate requests. The ke y difference between the exact ev aluation model and the approximate e valuation model lies in how U is updated. A. Exact F iltering Mode Fig. IV -A illustrates the flowchart of exact filtering mode utilized in the HE mechanism. The exact filtering mode employed in the exact ev aluation model comprises four check modules, each tasked with con- ducting specific constraint checks or making pruning deci- sions. These four modules are described as follo ws: (1) Pruning Judgment Check w s r i ≥ t now + mT r ans (18) 8 Fig. 3. Flowchart of the exact filtering mode. Here, w s r i denotes the start time of the VTW for request r i , t now is the current time, and mT r ans represents the maximum transition time, which depends solely on the satellite’ s ma- neuvering capabilities and the spatial distribution of requests. Candidate requests in U are sorted by ws r i . Satisfaction of this condition implies that all subsequent requests in U do not require recomputation of OWs. (2) Complete Imaging Check w e r i < t now + dur r i (19) Here, w e r i is the end time of the VTW for request r i , and dur r i is the required observ ation duration. If this inequality holds, request r i cannot be fully imaged, enabling rapid exclusion of requests that cannot be completely observed in a single operation. Giv en that satellites typically execute requests in a jump-observ ation mode, many candidate requests between adjacent observations are unobservable; this module efficiently identifies and remov es them. (3) Memory Check dur r i × cr > mmc now (20) Here, cr is the write code rate during imaging and mmc now denotes the current av ailable memory . If this condition is met, request r i violates memory constraints and is discarded. (4) Exact Earliest Observation Window Check The existence of a feasible O W is a necessary condition for the ex ecutability of a candidate request. This check employs a two-stage binary search algorithm to precisely compute the earliest O W for candidate requests. If no OW satisfies the constraints for a given request, it is remov ed from U . The proposed two-stage binary search algorithm is de- signed to efficiently and accurately calculate the earliest O W [ os r i , oe r i ] . The theoretical foundation of this search algorithm is based on the time-delay monotonicity property of AEOS attitude transitions [31]. Specifically , if an earliest O W exists for a request, there exists a unique time point at which the Algorithm 3 The two-stage binary search algorithm Input: the current moment t , a request id i , the current attitude angles attN ow , the start time of VTW ws , the end time of VTW w e , the time required for imaging dur , the desired precision pr e Output: the earliest start time of O W est 1: est ← − 1 ; \\ If the returned est = − 1 , it indicates that r i does not have a feasible O W . 2: lp ← w s ( i ) , rp ← w e ( i ) ; 3: while l p ≤ r p do 4: mid ← ( l p + r p ) / 2 ; 5: if mid + dur ( i ) ≤ we ( i ) then 6: attN ex ← GetAttitude ( i, mid ) ; \\ Get the satellite attitude angle required to observ e r i at time mid 7: if mid ≥ t + Trans ( attN ow , attN ex ) then 8: r p ← mid − pr e ; 9: est ← mid ; 10: else 11: lp ← mid + pr e ; 12: end if 13: else 14: r p ← mid − pr e ; 15: end if 16: end while 17: retur n est ; satellite completes the attitude transition at os r i . Algorithm 3 delineates the procedure for identifying the earliest OW start time of candidate request r i . Initially , the left pointer lp is set to w s r i and the right pointer r p to w e r i . The first stage identifies the right endpoint r ′ such that any time within the interval [ l , r ′ ] guarantees complete observation of request r i . The second stage locates the earliest os r i , ensuring that the earliest OW complies with all constraints. If the pointers l and r coincide, this point corresponds to the earliest os r i ; otherwise, the satellite cannot observe request r i . Giv en that the width of the VTW for r i is w w r i , the time comple xity of the search algorithm is O (log ww r i ) , representing a substantial improvement ov er the brute-force search complexity of O ( ww r i ) . B. Appr oximate F iltering Mode Fig. IV -B illustrates the flowchart of approximate filtering mode in volved in the HE mechanism. Obviously , the approximate filtering mode does not include the memory check module, while a novel verification module is employed to compute OWs. The specific design of this module is as follows: (5) A pproximate Earliest Observation Window Check In the context of UAEOSSP , the VTWs of requests are deterministic and known a priori. Regardless of the order of the requests, the maximum transition time mtt ( r i , r j ) for each request pair ( r i , r j ) can be preprocessed. This v alue is calculated based on the maximum angular difference within the VTWs of the two requests, as follo ws: 9 Fig. 4. Flowchart of the approximate filtering mode. mtt ( r i , r j ) = mtt ( r j , r i ) = T r an max t r i ,t r j n ∇ g att r i ,t r i , att r j ,t r j o , ∀ t r i ∈ [ w s r i , w e r i ] , ∀ t r j ∈ w s r j , w e r j (21) After completing the preceding request r pre , the O W start time os r i for request r i is updated as: os r i = max ( w s r i , t now + maxT r an ( r pre , r i )) , ∀ r i ∈ U (22) If the updated O W start time satisfies the following inequal- ity: os r i + dur r i ≤ w e r i (23) then request r i is retained; otherwise, it is remov ed from U due to constraint violation. Giv en that any mtt ( r i , r j ) can be preprocessed in advance, the time complexity of the verification module is O (1) . This represents a significant improvement compared to the O (log ww r i ) time complexity required to calculate the exact earliest O W . C. Adaptive Switching Methodology T o quantify the e volutionary status of the algorithm, two indicators are introduced: the ev olutionary stage factor f ac es and the population di versity factor f ac pd . f ac es measures ev olutionary progress based on the current generation g rel- ativ e to the total number of generations G . f ac pd assesses population div ersity by e valuating the uniqueness of fitness values within the population. Define a mapping N b : µ → N that counts the occurrences of elements, where N b ( x ) denotes the frequency of element x in set b . For the population pop with corresponding fitness set f its , let the deduplicated fitness set be d f its = { f ∈ f its | N f its ( f ) ≥ 1 } . The two factors are computed as follows: f ac es = g G , f ac pd = | d f its | | f its | (24) The HE mechanism relies on the two aforementioned factors to regulate the likelihood of employing either exact or ap- proximate filtering modes. Fundamentally , its rationale is that as the evolutionary process progresses or population diversity decreases, the need for exact ev aluation increases. During the initial phases of evolution, the focus is on global exploration by generating div erse strategies aimed at co vering potentially optimal regions. At this stage, the primary ev aluation criterion prioritizes ef ficiency over accuracy . Con versely , in the middle to later stages of e volution, as the population’ s ov erall fitness improv es, the algorithm should shift toward local exploitation. This inv olves the exact ev aluation of high-quality policies to more effecti vely dif ferentiate their fitness values. When population diversity declines, meaning that most individuals hav e similar fitness v alues, e xact e valuation model should be employed to provide accurate fitness feedback. The fitness val- ues of GP individuals serve as phenotypic indicators reflecting similarity among individuals. Accordingly , the probability of employing the exact filtering mode, denoted P exact , is defined as follows: P exact = φ es × f actor es + φ pd × (1 − f actor pd ) (25) where φ es and φ pd are weighting coefficients satisfying φ es + φ pd = 1 . Let ρ be a random variable uniformly distributed over [0 , 1] . The e volutionary indicator function is then defined as follo ws: I ( g ) = ( 1 , if ρ < P exact 0 , otherwise (26) For any scheduling policy sp , the fitness ev aluation function is modified as follows: F it ( sp, g ) = 1 | E | X env ∈ E O S A ( sp, env, I ( g )) (27) The online scheduling function O S A ( · ) is specified by: O S A ( sp, env, I ) = ( O S A appro ( sp, env ) , if I = 0 O S A exact ( sp, env ) , if I = 1 (28) Here, O S A appro ( · ) and O S A exact ( · ) denote the approximate and exact ev aluation models, respectiv ely . The ev aluation function can be further expressed as follows: F it ( sp, g ) = 1 | E | X env ∈ E [(1 − I ( g )) · O S A appro ( sp, env ) + I ( g ) · OS A exact ( sp, env )] (29) 10 V . E X P E R I M E N TA L D E S I G N Instance generation was conducted on a laptop equipped with a 13th-generation Intel Core i9-13980HX processor oper - ating at 2.20 GHz and 15.6 GB of RAM. The satellite schedul- ing simulations and instance generation were performed using MA TLAB R2020b with the Satellite T oolkit (STK) version 12. All algorithms were developed in Python and ex ecuted on a workstation with a 32-core Intel Xeon Gold 6459C processor . A. Instance Generation This study addresses the UAEOSSP , in which request profit, visibility , and imaging data write rate are modeled as stochastic variables. An instance set comprises problem instances that share identical deterministic parameters b ut dif fer in realiza- tions of random variables, representing varying en vironmental conditions. Due to the lack of established benchmarks, the STK is used to simulate 16 distinct AEOSSP scenarios. For each scenario, random parameters are sampled from specified distributions to generate corresponding U AEOSSP instances, with a scheduling horizon spanning from 00:00:00 to 24:00:00 UTC on September 1, 2024. The satellite configurations utilized in the scenarios are based on prior works [31], [38]. The satellite’ s spatial position is characterized by six classical orbital elements: semi-major axis ( a ), eccentricity ( e ), inclination ( i ), argument of perigee ( ω ), right ascension of the ascending node ( RAAN ), and mean anomaly ( m ). T able I presents the initial orbital parameters of the AEOS. Attitude constraints restrict the pitch and roll angles within the interval [ − 27 ◦ , 27 ◦ ] . The imaging data write rate is fixed at 3.5 GB/s. Parameters governing the attitude transition time function T ran () are configured as detailed in T able II. T ABLE I T H E O RB I TAL PAR A M E TE R S O F T H E A E O S Parameter α ( m ) e ( ◦ ) i ( ◦ ) ω ( ◦ ) RAAN ( ◦ ) m ( ◦ ) V alue 6878137 0 . 00 0 . 00 0 . 00 360 . 00 360 . 00 T ABLE II T H E PAR A M ET E R S O F T H E F U NC T I O N T r an () Segment α i v i θ i 0 θ i 1 1 5 1 0 15 2 10 2 15 40 3 16 2.5 40 90 4 22 3 90 - The number of requests ranges from 50 to 200 in increments of 50, consistent with prior single-satellite scheduling studies [15], [16]. mmc is set to 2048 GB for small-scale scenarios (50 or 100 requests) and 4096 GB for larger instances (150 or 200 requests). Unlike pre vious studies that randomly generate coordinates within geographic regions [2], this study employs a ground-track-based method to ensure all requests possess valid visibility windows. The scheduling time interval [0 , S T ] uses S T ∈ { 3600 , 7200 } seconds, where request coordinates are generated by randomly selecting points along the satellite trajectory within [0 , S T ] and applying perturbations in the range [ − 2 ◦ , 2 ◦ ] . The imaging duration dur r i follows a normal distribution N (25 , 9) , and the request profit is modeled as N (2 × dur r i , 100) , following [31], [38]. Uncertain parameters are modeled using probability distri- butions. Follo wing [59], request profit and write code rate are modeled using gamma distributions Gm ( α, β ) , which are commonly employed for non-negativ e random variables. The expected v alue and v ariance are α/β and α/β 2 , respectiv ely . For fixed expected values (corresponding to deterministic AEOSSP parameters), varying α produces different distribu- tion shapes. Fig. 5 illustrates the probability density functions for a fixed expectation of 20 with v arying α . Notably , as α → ∞ , the gamma distribution conv erges to a Gaussian distribution. In this study , α p = 30 and α cr = 350 are used to simulate realistic v ariations in profit and write code rate, with α cr reflecting the relati vely stable write code rate observed during satellite operations. Request visibility uncertainty is modeled using cloud coverage probability p cc ∈ { 0 . 15 , 0 . 30 } . Each scheduling scenario generates 50 test instances and 100 training instances. GP ev olution utilizes only the training set, while performance is assessed on the test set. Concurrently , the exact ev aluation model is employed throughout the testing phase to assess scheduling performance, thereby guaranteeing fairness. Fig. 5. Probability density function curves are presented with a fixed mean of 20 and varying v alues of the parameter α . α takes values from 20 to 100 in increments of 20. It is evident that the larger the α , the steeper the curve. Based on the described instance design, 16 scheduling scenarios were constructed. Instance sets are named to reflect their parameter configurations; for example, the instance set “50 36 20 0.15” denotes a scenario with 50 requests, a request distribution time range of [0 , 3600] seconds, a max- imum onboard memory of 2048 GB, and a cloud coverage probability of 0.15. B. P arameter Settings T able III enumerates the feature terminals employed, cat- egorized into profit, memory , and time groups, collectiv ely constituting the terminal set for the HE-GP . T o mitigate unit inconsistencies among features, all terminals are normalized to the interv al [0 , 1] prior to input into the scheduling policy . The function set comprises { + , − , × , ÷ , max , min , abs } , with all functions safeguarded against computational errors. Specif- ically , di vision is implemented as protected division, returning 1 when the denominator is zero. 11 T ABLE III T H E T ER M I NA L S E T D E V EL O P ED F O R U AE O S S P C O N S IS T S O F T H R E E D I S T IN C T C A T E G O RI E S O F F E A T U RE S . Category T erminal Description Profit RP Real profit. This feature is normalized using the min-max scaling method prior to application [61]. RP P U Real profit per unit of time. This feature is normalized via min-max scaling method. Memory E M C Expected memory consumption. This feature is normalized via min-max scaling method. E M U R Expected memory usage ratio. This feature is computed as the expected memory consumption divided by the remaining onboard memory . RM P Remaining memory percentage. This feature is calculated as the current remaining memory divided by the mmc . T ime C T Current time. This feature is calculated by di viding the current time by the total scheduling duration (i.e., S T ). RI S T Request imaging start time. This feature is defined by the following equation: RI S T r i = os r i − t now + c T − t now + c t now is the current time; T is the total scheduling time; os r i is the earliest observable time of the request r i ; c is a small constant. RRP Remaining request percentage. This feature is obtained as the number of candidate requests di vided by the total number of requests. F R Full ranking. All requests are ordered by the start time of their VTWs from earliest to latest. The feature is computed as the rank of the request divided by the total number of requests. RR Relativ e Ranking. Considering the rank of requests within the candidate pool U , candidate requests in U are similarly sorted by the start time of their VTWs. This feature is calculated as the rank of the request divided by the total number of candidate requests. Other C Constant. The v alues are generated from a uniform random distribution over the interval [ − 1 , 1] . The GP parameters utilized are detailed in T able IV and align with those commonly adopted in recent related research [3], [24]. Operator selection and population reproduction em- ploy binary tournament selection. During training, a mini- batch rotation mechanism is used: the 100 training instances per scenario are partitioned into 20 mini-batches, each con- taining 5 instances. T ABLE IV T H E G P PA R AM E T E R S E TT I N GS F O R H E - G P . Parameter V alue Parameter V alue Population size 200 T ournament size 2 Number of iterations 50 Maximum depth 8 Crossover probability 0.80 Initial minimum depth 2 Mutation probability 0.15 Initial maximum depth 6 Furthermore, the hyperparameters f ac es and f ac pd are also in volv ed in the ev aluation process. An increased value of f ac es causes the algorithm to prioritize selection based on the degree of ev olution, resulting in a higher likelihood of utilizing approximate e valuation model during the early stages of e volution. The sensiti vity analysis of these two parameters is detailed in Section VI-A; therefore, specific values are not assigned at this stage. V I . R E S U LT S A N D D I S C U S S I O N T o assess the effecti veness of the proposed HE-GP al- gorithm in addressing the U AEOSSP , this section presents comparativ e experiments in volving 16 scheduling scenario instances. The benchmark methods include two categories of handcrafted heuristic algorithms. Additionally , two GP-based methods utilizing a single e valuation model are incorporated: the GP algorithm based on exact e valuation (EE-GP) and the GP algorithm based on approximate ev aluation (AE-GP). Each of the three GP-based approaches was independently executed 10 times across all 16 scheduling scenarios. Three ev aluation metrics are introduced: Relativ e Percent- age Deviation (RPD), which intuitiv ely assesses solution qual- ity by quantifying the deviation of each solution from the optimal solution [62], as shown in (30); Relativ e Gap (RG), which measures the relati ve dif ference between two values, as shown in (31); and A verage Rank, which represents the av erage rank of performance across all scenarios. RP D (%) = C best − C method C best × 100% (30) RG (%) = C A − C B C A × 100% (31) Here, C best denotes the best value obtained among all algo- rithms, and C method represents the value achie ved by a specific algorithm (for instance, C A corresponds to the v alue obtained by algorithm A ). A. P arameter Sensitivity Analysis The novel HE mechanism modulates the preference for various filtering modes through two hyperparameters, f ac es and f ac pd , which are constrained such that their sum equals one. T o assess the effects of these parameters on the per- formance of HE-GP , a sensiti vity analysis was conducted across 16 scheduling scenarios. The HE-GP with varying parameter settings is denoted as HE-GP ( f ac es , f ac pd ) , with both parameters ranging from 0 to 1 in increments of 0.1. Each parameter configuration was independently ex ecuted ten times. Fig. 6 presents a heatmap illustrating the frequency with which each ( f ac es , f ac pd ) setting surpasses alternati ve set- tings in a verage performance across 16 scenarios, along with its mean ranking within these scenarios. The W ilcoxon rank- sum test confirmed that there are no significant differences in the results across v arious ( f ac es , f ac pd ) at a 95% confidence lev el. The results indicate no significant dif ferences among the 12 parameter settings. Additionally , no single parameter setting consistently outperforms the others in most scenarios. Based on the av erage rank and heatmap, HE-GP demonstrates en- hanced performance when the weights assigned to the two factors are approximately balanced. These findings underscore the efficac y of the HE mechanism’ s design, which adapti vely adjusts the e valuation model based on the evolutionary stage and population div ersity . Fig. 6. Heatmap of the frequency with which HE-GP outperforms other settings across 16 scenarios under v arious ( f ac es , f ac pd ) settings. A larger square indicates that the parameter setting corresponding to the row outper- forms others in a greater number of scenarios on av erage. The av erage rank represents the mean rank across 16 scenarios for each setting. In general, the parameter settings (0 . 4 , 0 . 6) , (0 . 5 , 0 . 5) , and (0 . 6 , 0 . 4) demonstrate superior a verage performance compared to other settings. Notably , (0 . 6 , 0 . 4) achie ves the highest av erage rank of 4.25 and outperforms other parameter settings in the majority of ev aluated scenarios. Therefore, subsequent experiments will employ the parameter pair (0 . 8 , 0 . 2) to further in vestigate HE-GP’ s performance characteristics. B. Scheduling P erformance The benchmark algorithms considered in this study com- prise Look-Ahead Heuristics (LAHs) [63] and Manually De- signed Heuristics (MDHs) [59]. LAHs operate by selecting a request from a set of anticipated future requests at each deci- sion point, guided by a greedy selection rule. The effecti veness of LAHs depends on both the length of the look-ahead horizon and the specific rule used. For instance, with a look-ahead step size of three, the algorithm selects one request from the next three (or fe wer) forthcoming requests at each decision step. Notably , when the look-ahead step size is set to one, LAHs consistently select the nearest observ able request. In contrast, MDHs are scheduling policies dev eloped from experiential knowledge, are highly interpretable, and can be seamlessly integrated with the proposed OSA to produce schedules. A comprehensiv e overvie w of both LAHs and MDHs is provided as follows: • LAH1 : Employs a look-ahead length of 1, thereby con- sidering only the candidate request nearest to the satellite at each step. • LAH2 : Selects the request with the highest actual profit among look-ahead requests, with the look-ahead length varying between 2 and 20. • LAH3 : Chooses the request with the highest ratio of actual profit to imaging time among look-ahead requests, with the look-ahead length ranging from 2 to 20. • MDH1 : Computes the v alue density of candidate requests as follows, prioritizing requests with higher values: M D H 1( r i ) = p r i ( env ) dur r i + T r ans ( att r pre ,t r pre , att os r i ,r i ) Here, the previously fulfilled request and its associated observation end time are denoted as r pre and t r pre , respectiv ely . The attitude information at that specific time is represented as att r pre ,t r pre . • MDH2 : Calculates the interval time from the current moment to the start of observation for each candidate request using: M D H 2( r i ) = max { T r ans att r pre ,t r pre , att os r i ,r i , os r i − t pre } At each decision point, the candidate request with the minimal interval time is selected. This approach is anal- ogous to the nearest-node selection strategy in the T rav- elling Salesman Problem. • MDH3 : Applies MDH1 when mmc now is less than half of mmc ; otherwise, MDH2 is used. In addition to the aforementioned handcrafted heuristic al- gorithms, two variants of HE-GP were introduced to facilitate a comparati ve performance analysis. The first v ariant, Exact Evaluation-based GPHH (EE-GP), employs exact ev aluation methods, whereas the second, Approximate Ev aluation-based GPHH (AE-GP), uses approximate e valuation methods. The efficac y of these novel design algorithms was assessed using their best and average performance metrics from 10 indepen- dent experimental runs. Each HE-GP v ariant and the com- parison algorithms were executed on 16 distinct U AEOSSP instance sets, with results systematically recorded. Note that the U AEOSSP dataset is partitioned into a training set of 100 instances and a test set of 50; this comparison focuses exclusi vely on algorithmic performance on the test set. T able V summarizes the performance outcomes of the vari- ous algorithms. Overall, HE-GP achie ved the highest a verage ranking of 1.4375 and identified the optimal policy in 9 scenarios. The AE-GP , which relies solely on the approximate ev aluation model, demonstrated inferior overall performance relativ e to the other two GP-based approaches, and its av- erage performance across all scenarios is worse than HE- GP . Nonetheless, all three GP-based methods surpassed the handcrafted heuristic algorithms across 16 scenarios. Specif- ically , HE-GP achieved average performance improv ements of 4.857% and 12.011% over the best results of the LAHs and MDHSs, respecti vely . Furthermore, the W ilcoxon rank- sum test was employed to assess the statistical significance 13 T ABLE V A V E R AG E P E RF O R M AN C E ( S T A N DA R D D E VI ATI O N ) ( R PD ) , W I T H B O LD I N DI C A T I N G T H E O P T IM A L A V E R AG E P E RF O R M AN C E I N T H E C O R RE S P O ND I N G S C EN A RI O . W I N /D R AW / L O S E S HO W S T H E P E R F OR M A N CE O F T H E C O M P A R I SO N A LG O R I TH M C O M P A R E D T O H E - G P . A V E R AG E R A NK G IV E S T H E A V E R AG E R A N KI N G O F E AC H AL G O R IT H M ’ S A V E R AG E P E R FO R M AN C E A CR OS S D IFF E R EN T S CE NA R I O S . Scenario LAHs-Best MDHs-Best EE-GP AE-GP HE-GP 50 36 20 0.15 1333.94(-)(4.03%) 1283.52(-)(8.12%) 1384.90(15.59)(0.20%) 1383.12(17.25)(0.33%) 1387.74(12.25)(0.00%) 50 36 20 0.30 1206.97(-)(11.94%) 1293.89(-)(4.42%) 1336.81(14.71)(1.07%) 1334.78(9.45)(1.22%) 1351.09(8.07)(0.00%) 50 72 20 0.15 1353.01(-)(3.96%) 1253.45(-)(12.22%) 1394.88(17.48)(0.84%) 1398.63(15.98)(0.57%) 1406.58(14.32)(0.00%) 50 72 20 0.30 1212.65(-)(12.46%) 1273.00(-)(7.13%) 1363.76(16.98)(0.00%) 1359.69(13.01)(0.30%) 1361.16(14.82)(0.19%) 100 36 20 0.15 1492.58(-)(3.74%) 1301.99(-)(18.92%) 1548.36(21.11)(0.00%) 1542.15(21.09)(0.40%) 1547.80(9.25)(0.04%) 100 36 20 0.30 1471.70(-)(2.11%) 1286.54(-)(16.80%) 1492.52(13.59)(0.68%) 1495.56(15.09)(0.48%) 1502.75(24.94)(0.00%) 100 72 20 0.15 1499.17(-)(4.11%) 1270.18(-)(22.87%) 1560.74(17.01)(0.00%) 1543.39(29.71)(1.12%) 1558.49(13.03)(0.14%) 100 72 20 0.30 1478.57(-)(2.14%) 1252.04(-)(20.62%) 1499.77(26.25)(0.70%) 1496.70(25.14)(0.90%) 1510.23(22.59)(0.00%) 150 36 40 0.15 2646.37(-)(6.87%) 2631.33(-)(7.48%) 2827.78(24.36)(0.01%) 2767.12(74.62)(2.21%) 2828.19(38.85)(0.00%) 150 36 40 0.30 2647.44(-)(3.93%) 2571.17(-)(7.02%) 2751.63(13.94)(0.00%) 2662.42(46.69)(3.35%) 2731.55(25.98)(0.73%) 150 72 40 0.15 2743.25(-)(4.25%) 2456.76(-)(16.41%) 2845.46(48.67)(0.51%) 2836.35(41.64)(0.82%) 2859.87(34.19)(0.00%) 150 72 40 0.30 2636.81(-)(5.23%) 2417.71(-)(14.76%) 2763.08(56.68)(0.42%) 2766.40(36.60)(0.30%) 2774.66(34.56)(0.00%) 200 36 40 0.15 2880.63(-)(4.34%) 2809.14(-)(6.99%) 3000.01(45.43)(0.19%) 2927.36(42.83)(2.67%) 3005.64(23.70)(0.00%) 200 36 40 0.30 2851.83(-)(2.42%) 2721.55(-)(7.33%) 2921.01(34.26)(0.00%) 2844.34(73.92)(2.69%) 2919.43(30.54)(0.05%) 200 72 40 0.15 2874.93(-)(5.46%) 2594.81(-)(16.84%) 3031.89(29.21)(0.00%) 3003.36(44.82)(0.95%) 3018.35(23.59)(0.45%) 200 72 40 0.30 2857.73(-)(2.55%) 2568.64(-)(14.09%) 2930.58(37.31)(0.00%) 2882.61(73.74)(1.66%) 2926.25(41.33)(0.15%) W in/Draw/Lose 0/0/16 0/0/16 7/0/9 0/0/16 N/A A verage Rank 4.0625 4.8750 1.7500 2.8750 1.4375 of performance dif ferences among the algorithms. The results indicate that, with 95% confidence, the HE-GP demonstrates significantly superior average performance compared to hand- crafted heuristic algorithms across 16 scenarios, except for LAH2 and LAH3. Simultaneously , although no substantial differences are observed among the GP-based methods, HE- GP unexpectedly demonstrates superior performance in the av erage ranking metric and outperforms EE-GP in most sce- narios. The HE mechanism proposed in this study aims to re- duce ev aluation overhead while improving the algorithm’ s search efficiency by adapti vely switching between exact and approximate ev aluation models. These models employ distinct filtering modes, which may result in v ariations in the schedules generated by an identical policy , thus affecting the policy’ s fitness. This design essentially perturbs the ev olutionary search process by introducing ev aluation noise, which can enhance exploration capabilities during the early stages of the algorithm or when population diversity is low . This study in vestigates this phenomenon by analyzing the ev olutionary process of GP- based methods. Fig. 7 displays the performance of the optimal policies obtained by the three GP-based methods on the test set throughout the e volutionary process. All methods utilize the exact ev aluation model for testing to ensure a fair compar- ison. The e volutionary trajectories indicate that HE-GP is more adept at escaping local optima during ev olution (except < 150 72 40 0.15 > , < 200 36 40 0.15 > ), as evidenced by continuous improv ements in the best policy rather than stag- nation. For instance, in scenario < 100 36 20 0.30 > , both EE-GP and AE-GP exhibit premature con vergence, with no enhancement in the best policy ov er an extended period. In contrast, HE-GP achie ves improvements through perturbations induced by the HE mechanism. Overall, HE-GP shows su- perior performance in scenarios of small and medium scale. From the perspective of ev olutionary potential, the frequencies with which HE-GP , EE-GP , and AE-GP exhibited the most significant advancements in Fig. 7 correspond to a ratio of 12 : 4 : 0 . Additionally , the highest counts of iterations showing improvements in optimal performance follow a ratio of 8 : 6 : 2 . These observ ations suggest that, in certain cases, once EE-GP and AE-GP become trapped in local optima, es- caping solely through traditional genetic operations appears to be challenging. For instance, in scenario < 100 72 20 0.15 > , AE-GP sho ws no improv ement in optimal performance from generation 13 to 50, whereas HE-GP continuously finds better policies and ev entually surpasses EE-GP . C. T raining T ime The findings in Section VI-B confirm that HE-GP is compa- rable to EE-GP and ev en surpasses it based on certain metrics. T o verify the positive impact of the HE mechanism on the algorithm, we compared the training times of the two methods, with training time serving as a ke y indicator of ef ficiency . T able VI presents a comparative analysis of training and ev aluation times between EE-GP and HE-GP . Compared to EE-GP , HE-GP achiev es an average reduction of 17.77% in training time and 17.78% in ev aluation time across 16 scenar - ios. These findings clearly demonstrate that the approximate ev aluation model and adapti ve switching mechanism intro- duced by HE substantially decrease e valuation costs. Notably , both EE-GP and HE-GP allocate over 99% of their total runtime to ev aluation, indicating that ev aluation ef ficiency is the predominant factor influencing overall algorithm runtime. Furthermore, the ev aluation overhead is proportional to the number of requests: an increase in requests results in more decision points within the timeline-based decision process and a higher volume of requests requiring updates at each decision step, including feasibility checks, determination of OWs, and calculation of heuristic values. Fig. 8 presents line graphs depicting the cumulati ve train- ing time and the av erage size throughout the ev olutionary 14 Fig. 7. The optimal performance of the evolutionary process in GP-based methods across 16 scenarios. The random seed is set to 1. T ABLE VI C O MPA R IS O N O F T R A I NI N G T I M E A ND E V A L UA T I O N T I ME B ET W E E N E E -G P A N D H E - G P . G A P I S T HE P ER C E N T AG E R E D U CT I O N O F H E - GP C OM PA RE D T O E E - G P . E V A L UA T I O N T I ME R A T I O = E V A L UA T I O N T IM E / T R AI N I N G T IM E . Scenario A verage Training T ime (seconds) A verage Evaluation Time (seconds) Evaluation Ratio (%) EE-GP HE-GP Gap (%) EE-GP HE-GP Gap (%) EE-GP HE-GP 50 36 20 0.15 668.56 591.30 11.56 666.58 589.45 11.57 99.70 99.69 50 36 20 0.30 540.47 435.26 19.47 538.50 433.51 19.50 99.63 99.60 50 72 20 0.15 581.64 472.21 18.81 579.55 470.38 18.84 99.64 99.61 50 72 20 0.30 467.50 346.26 25.93 465.50 344.45 26.00 99.57 99.48 100 36 20 0.15 1125.24 961.38 14.56 1123.74 959.92 14.58 99.87 99.85 100 36 20 0.30 952.20 831.19 12.71 950.64 829.66 12.73 99.84 99.81 100 72 20 0.15 933.28 829.53 11.12 931.78 828.08 11.13 99.84 99.82 100 72 20 0.30 770.55 768.87 0.22 768.93 767.35 0.20 99.79 99.80 150 36 40 0.15 2242.68 1573.54 29.84 2241.21 1572.34 29.84 99.93 99.92 150 36 40 0.30 1867.37 1481.23 20.68 1865.80 1479.87 20.68 99.91 99.91 150 72 40 0.15 2037.04 1644.73 19.26 2035.47 1643.21 19.27 99.92 99.91 150 72 40 0.30 1718.74 1475.19 14.17 1717.01 1473.49 14.18 99.90 99.88 200 36 40 0.15 2439.90 1788.97 26.68 2439.10 1788.19 26.69 99.97 99.96 200 36 40 0.30 2291.57 1683.05 26.55 2290.65 1682.18 26.56 99.96 99.95 200 72 40 0.15 2257.89 1836.10 18.68 2256.94 1835.22 18.68 99.96 99.95 200 72 40 0.30 2079.62 1786.79 14.08 2078.60 1785.77 14.09 99.95 99.94 A verage - - 17.77 - - 17.78 99.84 99.82 processes of EE-GP and HE-GP . In certain scenarios, the av erage size of HE-GP exceeds that of EE-GP for the majority of iterations (e.g., < 50 36 20 0.15 > , < 100 36 20 0.30 > ). It suggests that the improvement in ev aluation efficienc y is not due to simplifying the policy used to accelerate heuristic value computation. In < 100 72 20 0.30 > , the average size of HE-GP during the iteration process is significantly lar ger than that of EE-GP , which explains why the reduction in training time for HE-GP compared to EE-GP in this scenario is minimal. When the average sizes of the two algorithms are similar , HE-GP exhibits a shorter training time. Collectively , the e xperimental findings corroborate that the HE mechanism effecti vely improves training efficiency . Meanwhile, the com- parable av erage sizes suggest that HE-GP and EE-GP exhibit a similar extent of coverage within the policy space, further substantiating the superior performance of HE-GP analyzed in Section VI-B. D. Component Analysis This study in vestigates three GP-based methods (i.e., EE- GP , AE-GP , and HE-GP) and their ev olved scheduling policies by analyzing feature frequencies and the mathematical signif- icance of the resulting tree-based policies. Fig. 9 presents the sizes of the optimal policies generated by these methods across 10 independent runs on 16 scenarios. Despite dif ferences in their ev aluation approaches, the distribution of policy sizes is similar across the three methods, with most policies ranging from 20 to 60 nodes and relativ ely few outside this range. This suggests that modifications to the ev aluation process do not significantly affect the policy structure. 15 Fig. 8. Line chart of cumulati ve training time and average size of EE-GP and HE-GP in the 16 scenarios. A verage size refers to the mean size of all policies in GP population. Fig. 9. The size of the optimal scheduling policy for all running results of GP- based methods on 16 scenarios (with 10 independent runs for each scenario) Although assessing the importance of terminal nodes solely based on their frequency is imprecise, due to potential con- founding ef fects from redundant structures (e.g., the expres- sion “ X − X ” artificially inflates the frequenc y of terminal X [13]), frequency analysis can nonetheless provide a partial indication of the algorithm’ s preference for certain terminals. Fig. 10 sho ws the frequency distribution of terminals, includ- ing both features and functions, within the optimal scheduling policies obtained from 10 independent runs across 16 scenar- ios. Notably , the frequency of feature terminals is remarkably similar across the three GP-based methods. Among these, Profit- RP , Memory- E M U R , and T ime- R I S T / RR exhibit relativ ely high frequencies. In particular , RP appears most frequently , underscoring its critical role in shaping policy logic. Additionally , E M U R , R I S T , RR , and RP P U are significant contrib utors to optimal policies. Conv ersely , E M C , which represents expected memory consumption, occurs least frequently , possibly because it is less intuitiv e and less influ- ential than E M U R (expected memory usage ratio). Scheduling policies serve as priority functions that guide decision-making and are encoded as tree-structured genotypes, which can be represented as mathematical expressions. Ana- lyzing these e xpressions facilitates a deeper understanding of the underlying decision-making logic. T wo robust scheduling Fig. 10. The frequency of feature terminals and functions in the optimal scheduling policies among all the running results of GP-based methods on 16 scenarios (with 10 independent runs for each scenario). The darker the color , the higher the frequency . policies, denoted S P 1 and S P 2 , derived from HE-GP in < 50 36 20 0.15 > and < 50 36 20 0.30 > , respectiv ely , are presented below: S P 1 = max ( E M U R , || R R || ) + max( E M U R, E M U R ) ÷ ( RP ÷ (0 . 5239 + RP )) (32) S P 2 = RR + min ( |− 0 . 8010 | , E M U R ÷ RP ) + ( RRP + F R ) (33) 16 In (32), E M U R exhibits a positiv e correlation with the priority assigned to candidate requests, whereas RP shows a negati ve correlation. This relationship also holds in (33). In (33), ranking information makes a significant role, incorporat- ing both absolute ranking ( F R ) and relativ e ranking ( RR ). A negati ve correlation exists between reward and heuristic value in both (32) and (33). This counterintuitive finding suggests that HE-GP can identify policies that are challenging to discern based on expert experience but prove effecti ve in scheduling scenarios. Nonetheless, the structures within (32) contain redundancies, ex emplified by expressions like max( E M U R , E M U R ) , which can be simplified to E M U R . The simplified expressions for S P 1 are shown in (34): S P ′ 1 = max ( E M U R , R R ) + E M U R ÷ ( RP ÷ (0 . 5239 + R P )) (34) V I I . C O N C L U S I O N This research in vestigates the U AEOSSP , a more realistic extension of the con ventional AEOSSP , by incorporating un- certainties related to profit, resource consumption, and visibil- ity . The problem is formulated as a stochastic programming model to effecti vely represent the uncertain en vironmental conditions characteristic. Inspired by recent advancements in GPHH for scheduling optimization, this study applies GPHH to solve the U AEOSSP . T o mitigate the computational b urden associated with ev aluation and enhance algorithmic perfor- mance, a nov el HE mechanism was developed and integrated into GPHH. This HE mechanism accelerates the filtering of candidate requests within the MDP employed for ev aluation by implementing a rigorously designed constraint-checking procedure. T wo ev aluation models are incorporated into the HE mechanism: an exact ev aluation model and an approx- imate ev aluation model, with the latter further improving computational efficiency based on the former . Moreov er, the HE mechanism adopts an adaptive switching technique that dynamically alternates between the two models in response to the ev olutionary state information. Extensiv e e xperimental ev aluations were conducted across 16 scheduling scenarios, comparing HE-GP with LAHs, MDHs, EE-GP , and AE-GP . Analyzing the average perfor - mance of the ev olved scheduling policies, HE-GP achieved an av erage rank of 1.4375, the highest among all algorithms considered. HE-GP outperformed the GP utilizing a single ev aluation model in more than half of the scenarios and sur- passed handcrafted algorithms in all scenarios. Moreover , HE- GP achie ved an average reduction of 17.77% in training time compared to EE-GP , which relies solely on the exact e valuation model. The findings rev eal that the HE mechanism not only speeds up training ef ficiency but also effecti vely alleviates ev olutionary stagnation, as evidenced by HE-GP exhibiting better continuous optimization capability and greater optimiza- tion magnitude compared to EE-GP and AE-GP . Component analyses of the ev olved scheduling policies confirmed their interpretability , while feature frequency analyses identified ke y terminals (e.g., profit-related and memory-related features) that contribute substantially to the optimal policies. These analyses validated the interpretability of the ev olved policies and provided v aluable insights to inform future research in this field. Notwithstanding these promising results, this study acknowledges several limitations. First, the current implemen- tation is limited to single-AEOS scheduling; future research could extend the research to include constellations of multiple AEOSs. Second, the hyperparameters of the HE mechanism require further optimization through systematic tuning, and the robustness of the ev olved policies should be assessed under a wider range of en vironmental conditions. Third, existing GP-based methods ine vitably produce scheduling policies that include redundant structures, which not only reduce decision- making efficienc y but also hinder user understanding. In summary , the proposed HE-GP constitutes a notable advancement in addressing the U AEOSSP . The interpretability of the deriv ed scheduling policies renders them especially appropriate for practical implementation in aerospace contexts, where reliability and transparency are critical. This study not only advances the domain of satellite scheduling but also provides valuable insights into the dev elopment of effecti ve ev aluation frame works for GP-based optimization methods. R E F E R E N C E S [1] B. Ferrari, J.-F . Cordeau, M. Delorme, M. Iori, and R. Orosei, “Satellite scheduling problems: A survey of applications in earth and outer space observation, ” Computers & Operations Resear ch , vol. 173, p. 106875, Jan. 2025. [2] X. Liu, G. Laporte, Y . Chen, and R. He, “ An adaptiv e large neighborhood search metaheuristic for agile satellite scheduling with time-dependent transition time, ” Computers & Operations Researc h , vol. 86, pp. 41–53, Oct. 2017. [3] L. W ei, M. Chen, L. Xing, Q. W an, Y . Song, Y . Chen, and Y . Chen, “Knowledge-transfer based genetic programming algorithm for multi- objectiv e dynamic agile earth observation satellite scheduling problem, ” Swarm and Evolutionary Computation , vol. 85, p. 101460, Mar . 2024. [4] X. W ang, G. W u, L. Xing, and W . Pedrycz, “ Agile earth observation satellite scheduling ov er 20 years: Formulations, methods, and future directions, ” IEEE Systems Journal , vol. 15, no. 3, pp. 3881–3892, Sep. 2021. [5] K. Thangav el, R. Sabatini, A. Gardi, K. Ranasinghe, S. Hilton, P . Ser- vidia, and D. Spiller , “ Artificial intelligence for trusted autonomous satel- lite operations, ” Pr ogress in Aer ospace Sciences , vol. 144, p. 100960, Jan. 2024. [6] D. Ouelhadj and S. Petrovic, “ A survey of dynamic scheduling in manufacturing systems, ” Journal of Scheduling , vol. 12, no. 4, pp. 417– 431, Aug. 2009. [7] X. W ang, G. Song, R. Leus, and C. Han, “Rob ust earth observation satel- lite scheduling with uncertainty of cloud coverage, ” IEEE T ransactions on Aer ospace and Electr onic Systems , v ol. 56, no. 3, pp. 2450–2461, Jun. 2020. [8] C. Han, Y . Gu, G. Wu, and X. W ang, “Simulated annealing-based heuristic for multiple agile satellites scheduling under cloud coverage uncertainty , ” IEEE T ransactions on Systems, Man, and Cybernetics: Systems , vol. 53, no. 5, pp. 2863–2874, May 2023. [9] W . Jianjiang, H. Xuejun, and H. Chuan, “Reacti ve scheduling of multiple eoss under cloud uncertainties: Model and algorithms, ” Journal of Systems Engineering and Electronics , vol. 32, no. 1, pp. 163–177, Feb . 2021. [10] Y . Chen, J. Xue, W . Gu, and M. Shao, “ An effecti ve genetic program- ming hyper-heuristic for uncertain agile satellite scheduling, ” in 2025 11th International Confer ence on Big Data and Information Analytics (BigDIA) . Nha Trang, V ietnam: IEEE, Nov . 2025, pp. 311–318. [11] M. Chen, Y . Du, K. T ang, L. Xing, Y . Chen, and Y . Chen, “Learning to construct a solution for the agile satellite scheduling problem with time-dependent transition times, ” IEEE T ransactions on Systems, Man, and Cybernetics: Systems , vol. 54, no. 10, pp. 5949–5963, Oct. 2024. [12] D. Eddy and M. Kochenderfer , “Marko v decision processes for multi- objectiv e satellite task planning, ” in 2020 IEEE Aer ospace Conference . Big Sky , MT , USA: IEEE, Mar. 2020, pp. 1–12. 17 [13] S. W ang, Y . Mei, and M. Zhang, “T owards interpretable routing policy: A two stage multi-objective genetic programming approach with feature selection for uncertain capacitated arc routing problem, ” 2020 IEEE Symposium Series on Computational Intelligence (ssci) , pp. 2399–2406, 2020. [14] R. Xu, H. Chen, X. Liang, and H. W ang, “Priority-based constructive algorithms for scheduling agile earth observation satellites with total priority maximization, ” Expert Systems with Applications , v ol. 51, pp. 195–206, Jun. 2016. [15] J. Chun, W . Y ang, X. Liu, G. Wu, L. He, and L. Xing, “Deep reinforcement learning for the agile earth observ ation satellite scheduling problem, ” Mathematics , vol. 11, no. 19, p. 4059, Sep. 2023. [16] M. W ang, Z. Zhou, Z. Chang, E. Chen, and R. Li, “Deep reinforcement learning for agile earth observation satellites scheduling problem with variable image duration, ” Applied Soft Computing , vol. 169, p. 112575, Jan. 2025. [17] L. W ei, Y . Chen, M. Chen, and Y . Chen, “Deep reinforcement learning and parameter transfer based approach for the multi-objectiv e agile earth observation satellite scheduling problem, ” Applied Soft Computing , v ol. 110, p. 107607, 2021. [18] M. Chen, Y . Chen, Y . Chen, and W . Qi, “Deep reinforcement learning for agile satellite scheduling problem, ” in 2019 IEEE Symposium Series on Computational Intelligence (SSCI) . Xiamen, China: IEEE, Dec. 2019, pp. 126–132. [19] H. Liu, H. Liu, Y . Kuang, J. W ang, and B. Li, “Deep symbolic optimization for combinatorial optimization: Accelerating node selection by discovering potential heuristics, ” Jun. 2024. [20] Y . Mei, Q. Chen, A. Lensen, B. Xue, and M. Zhang, “Explainable artifi- cial intelligence by genetic programming: A survey , ” IEEE Tr ansactions on Evolutionary Computation , vol. 27, no. 3, pp. 621–641, Jun. 2023. [21] E. Burke, M. Hyde, G. Kendall, G. Ochoa, E. ¨ Ozcan, and R. Qu, “ A survey of hyper-heuristics, ” School of Computer Science and Informa- tion T echnology Univ ersity of Nottingham Jubilee Campus, T ech. Rep. No. NOTTCS-TR-SUB-0906241418-2747, Jan. 2009. [22] E. Burke, G. Kendall, J. New all, E. Hart, P . Ross, and S. Schulenburg, “Hyper-heuristics: An emerging direction in modern search technology , ” in Handbook of Metaheuristics , F . Glover and G. A. Kochenberger , Eds. Boston, MA: Springer US, 2003, pp. 457–474. [23] S. W ang, Y . Mei, and M. Zhang, “Explaining genetic programming- ev olved routing policies for uncertain capacitated arc routing problems, ” IEEE T ransactions on Evolutionary Computation , v ol. 28, no. 4, pp. 918–932, Aug. 2024. [24] Z. Sun, Y . Mei, F . Zhang, H. Huang, C. Gu, and M. Zhang, “Multi- tree genetic programming hyper-heuristic for dynamic flexible workflow scheduling in multi-clouds, ” IEEE T ransactions on Services Computing , vol. 17, no. 5, pp. 2687–2703, Sep. 2024. [25] C. Zhang, J. Y ang, and N. W ang, “Multitree genetic programming with rule reconstruction for dynamic task scheduling in integrated cloud–edge satellite–terrestrial networks, ” IEEE Internet of Things Journal , v ol. 12, no. 12, pp. 21 429–21 442, Jun. 2025. [26] M. Ansari Ardeh, Y . Mei, and M. Zhang, “Genetic programming with knowledge transfer and guided search for uncertain capacitated arc routing problem, ” IEEE Tr ansactions on Evolutionary Computation , vol. 26, no. 4, pp. 765–779, Aug. 2022. [27] S. W ang, Y . Mei, M. Zhang, and X. Y ao, “Genetic programming with niching for uncertain capacitated arc routing problem, ” IEEE T ransactions on Evolutionary Computation , vol. 26, no. 1, pp. 73–87, Feb . 2022. [28] F . Zhang, S. Nguyen, and M. Zhang, “Collaborative multifidelity-based surrogate models for genetic programming in dynamic flexible job shop scheduling, ” IEEE T ransactions on Cybernetics , v ol. 52, no. 8, pp. 8142– 8156, 2022. [29] S. W ang, Y . Mei, and M. Zhang, “ A multi-objectiv e genetic program- ming approach with self-adaptiv e α dominance to uncertain capacitated arc routing problem, ” in 2021 IEEE Congr ess on Evolutionary Compu- tation (Cec) . Krak ´ ow , Poland: IEEE, Jun. 2021, pp. 636–643. [30] ——, “T wo-stage multi-objective genetic programming with archive for uncertain capacitated arc routing problem, ” in Pr oceedings of the Genetic and Evolutionary Computation Conference . Lille France: ACM, Jun. 2021, pp. 287–295. [31] X. Chu, Y . Chen, and Y . T an, “ An anytime branch and bound algorithm for agile earth observation satellite onboard scheduling, ” Advances in Space Researc h , vol. 60, no. 9, pp. 2077–2090, Nov . 2017. [32] G. Dantzig, R. Fulkerson, and S. Johnson, “Solution of a large-scale trav eling-salesman problem, ” Journal of the Operations Researc h Soci- ety of America , vol. 2, no. 4, pp. 393–410, 1954. [33] M. Lema ˆ ıtre, G. V erfaillie, F . Jouhaud, J.-M. Lachiver , and N. Bataille, “Selecting and scheduling observations of agile satellites, ” Aer ospace Science and T echnology , vol. 6, no. 5, pp. 367–381, Sep. 2002. [34] G. Peng, R. Dewil, C. V erbeeck, A. Gunawan, L. Xing, and P . V ansteen- wegen, “ Agile earth observation satellite scheduling: An orienteering problem with time-dependent profits and trav el times, ” Computers & Operations Resear ch , vol. 111, pp. 84–98, Nov . 2019. [35] R. Kandepi, H. Saini, R. K. George, S. Konduri, and R. Karidhal, “ Agile earth observ ation satellite constellations scheduling for large area target imaging using heuristic search, ” Acta Astr onautica , vol. 219, pp. 670– 677, Jun. 2024. [36] G. Peng, G. Song, Y . He, J. Y u, S. Xiang, L. Xing, and P . V ansteenwegen, “Solving the agile earth observ ation satellite scheduling problem with time-dependent transition times, ” IEEE T ransactions on Systems, Man, and Cybernetics: Systems , vol. 52, no. 3, pp. 1614–1625, Mar . 2022. [37] H. Chen, S. Peng, C. Du, and J. Li, Earth Observation Satellites: T ask Planning and Scheduling . Singapore: Springer Nature Singapore, 2023. [38] X. Chu, Y . Chen, and L. Xing, “ A branch and bound algorithm for agile earth observation satellite scheduling, ” Discrete Dynamics in Nature and Society , vol. 2017, pp. 1–15, 2017. [39] A. Maillard, “Flexible scheduling for an agile earth-observing satelllite, ” in Proceedings of the 24th International Confer ence on Artificial Intel- ligence , ser . IJCAI’15. Buenos Aires, Argentina: AAAI Press, 2015, pp. 4379–4380. [40] W . Y ang, L. He, X. Liu, and Y . Chen, “Onboard coordination and scheduling of multiple autonomous satellites in an uncertain en viron- ment, ” Advances in Space Researc h , vol. 68, no. 11, pp. 4505–4524, Dec. 2021. [41] S. Liu, Y . Chen, L. Xing, and X. Guo, “T ime-dependent autonomous task planning of agile imaging satellites, ” Journal of Intelligent & Fuzzy Systems , vol. 31, no. 3, pp. 1365–1375, Sep. 2016. [42] X. Zhu, J. W ang, X. Qin, J. W ang, Z. Liu, and E. Demeule- meester , “Fault-tolerant scheduling for real-time tasks on multiple earth- observation satellites, ” IEEE Tr ansactions on P arallel and Distributed Systems , vol. 26, no. 11, pp. 3012–3026, Nov . 2015. [43] K. Li, T . Zhang, and R. W ang, “Deep reinforcement learning for multiobjectiv e optimization, ” IEEE T ransactions on Cybernetics , vol. 51, no. 6, pp. 3103–3114, Jun. 2021. [44] M. T aleby Ahvanooey , Q. Li, M. W u, and S. W ang, “ A survey of genetic programming and its applications, ” KSII T ransactions on Internet and Information Systems , vol. V ol.13, pp. 1765–1793, Apr. 2019. [45] S. W ang, Y . Mei, and M. Zhang, “ A multi-objectiv e genetic program- ming algorithm with α dominance and archiv e for uncertain capacitated arc routing problem, ” IEEE T ransactions on Evolutionary Computation , vol. 27, no. 6, pp. 1633–1647, Dec. 2023. [46] ——, “Novel ensemble genetic programming hyper-heuristics for un- certain capacitated arc routing problem, ” in Pr oceedings of the Genetic and Evolutionary Computation Confer ence . Prague Czech Republic: A CM, Jul. 2019, pp. 1093–1101. [47] S. W ang, Y . Mei, J. Park, and M. Zhang, “Evolving ensembles of routing policies using genetic programming for uncertain capacitated arc routing problem, ” in 2019 IEEE Symposium Series on Computational Intelligence (Ssci) . Xiamen, China: IEEE, Dec. 2019, pp. 1628–1635. [48] Y . Zakaria, Y . Zakaria, A. BahaaElDin, and M. Hadhoud, “Niching- based feature selection with multi-tr ee genetic programming for dynamic flexible job shop scheduling, ” in Studies in Computational Intelligence . Cham: Springer International Publishing, 2021, pp. 3–27. [49] Z.-H. Zhan, L. Shi, K. C. T an, and J. Zhang, “ A survey on evolu- tionary computation for complex continuous optimization, ” Artificial Intelligence Review , vol. 55, no. 1, pp. 59–110, Jan. 2022. [50] C. Sun, J. Zeng, J. Pan, S. Xue, and Y . Jin, “ A new fitness estimation strategy for particle swarm optimization, ” Information Sciences , vol. 221, pp. 355–370, 2013. [51] J.-H. Chen, D. E. Goldberg, S.-Y . Ho, and K. Sastry , “Fitness inheritance in multi-objective optimization, ” in Pr oceedings of the 4th Annual Confer ence on Genetic and Evolutionary Computation , ser. GECCO’02. San Francisco, CA, USA: Morg an Kaufmann Publishers Inc., 2002, pp. 319–326. [52] C. Sun, Y . Jin, R. Cheng, J. Ding, and J. Zeng, “Surrogate-assisted co- operativ e swarm optimization of high-dimensional expensiv e problems, ” IEEE T ransactions on Evolutionary Computation , v ol. 21, no. 4, pp. 644–660, Aug. 2017. [53] H. W ang, Y . Jin, and J. Doherty , “ A generic test suite for ev olutionary multifidelity optimization, ” IEEE T ransactions on Evolutionary Compu- tation , vol. 22, no. 6, pp. 836–850, Dec. 2018. [54] X.-F . Liu, Z.-H. Zhan, J.-H. Lin, and J. Zhang, “Parallel dif ferential ev olution based on distributed cloud computing resources for power 18 electronic circuit optimization, ” in Proceedings of the 2016 on Genetic and Evolutionary Computation Conference Companion , ser. GECCO ’16 Companion. Ne w Y ork, NY , USA: Association for Computing Machinery , 2016, pp. 117–118. [55] T . Hildebrandt and J. Branke, “On using surrogates with genetic pro- gramming, ” Evolutionary Computation , vol. 23, no. 3, pp. 343–367, Sep. 2015. [56] J. R. Koza, “Genetic programming as a means for programming com- puters by natural selection, ” Statistics and Computing , vol. 4, no. 2, pp. 87–112, Jun. 1994. [57] F . Zhang, Y . Chen, and Y . Chen, “Evolving constructiv e heuristics for agile earth observing satellite scheduling problem with genetic programming, ” in 2018 IEEE Congress on Evolutionary Computation (CEC) , Jul. 2018, pp. 1–7. [58] Y . He, L. Xing, Y . Chen, W . Pedrycz, L. W ang, and G. W u, “ A generic markov decision process model and reinforcement learning method for scheduling agile earth observation satellites, ” IEEE T ransactions on Systems, Man, and Cybernetics: Systems , vol. 52, no. 3, pp. 1463–1474, Mar . 2022. [59] Y . Liu, Y . Mei, M. Zhang, and Z. Zhang, “ Automated heuristic design using genetic programming hyper-heuristic for uncertain capacitated arc routing problem, ” in Pr oceedings of the Genetic and Evolutionary Computation Confer ence . Berlin Germany: A CM, Jul. 2017, pp. 290– 297. [60] B. Golden, X. W ang, and E. W asil, The Evolution of the V ehicle Routing Pr oblem: A Surve y of VRP Resear ch and Practice fr om 2005 to 2022 , ser . Synthesis Lectures on Operations Research and Applications. Cham: Springer Nature Switzerland, 2023. [61] P . J. Muhammad Ali, “Investigating the impact of min-max data nor- malization on the regression performance of k-nearest neighbor with different similarity measurements, ” Ar o-the Scientific Journal of K oya University , vol. 10, no. 1, pp. 85–91, Jun. 2022. [62] X. Lin, Y . Chen, J. Xue, B. Zhang, Y . Chen, and C. Chen, “Parallel machine scheduling with job family , release time, and mold availability constraints: Model and two solution approaches, ” Memetic Computing , vol. 16, no. 3, pp. 355–371, Sep. 2024. [63] K. Sun, G. Bai, Y . Chen, R. He, and L. Xing, “ Action planning for agile earth-observing satellite mission planning problem, ” Journal of National University of Defense T echnology , vol. 34, no. 6, pp. 141–147, 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment