불확실성 하 민첩 위성 스케줄링을 위한 하이브리드 평가 기반 유전 프로그래밍
본 논문은 불확실한 이익·자원·가시성을 고려한 민첩 지구관측 위성 스케줄링 문제(UAEOSSP)를 해결하기 위해, 정확 모드와 근사 모드를 동적으로 전환하는 하이브리드 평가(HE) 메커니즘을 온라인 스케줄링 알고리즘(OSA)에 통합한 HE‑GP 프레임워크를 제안한다. 실험 결과, HE‑GP는 기존 휴리스틱 및 단일 평가 기반 GPHH에 비해 평균 17.77 %의 학습 시간 절감과 전 시나리오에서 최고 평균 순위를 달성하였다.
저자: Junhua Xue, Yuning Chen, Mingyan Shao
본 논문은 급증하는 위성 데이터 수요와 민첩 위성(AEOS)의 복잡한 기동성을 고려한 스케줄링 문제를 다루며, 특히 이익, 자원 소비, 가시성 등 세 가지 핵심 요소를 확률적으로 모델링한 Uncertain Agile Earth Observation Satellite Scheduling Problem(UAEOSSP)을 정의한다. 기존 연구는 대부분 결정론적 가정을 두고 AEOSSP를 해결했으나, 실제 운용에서는 구름 커버, 급변하는 요청, 변동하는 데이터 전송률 등 다양한 불확실성이 존재한다. 이러한 현실을 반영하기 위해 저자는 각 요청 r_i에 대해 시나리오 집합 E를 도입하고, 시나리오별 실제 이익 p_i(env), 가시성 v_i(env), 데이터 쓰기율 c_i(env) 등을 사전에 알 수 있다고 가정한다. 목표는 모든 시나리오에 대한 기대 이익을 최대화하면서 메모리 용량, 가시성 제약, 연속 관측 시간, 자세 전이 시간 등을 만족하는 스케줄을 찾는 것이다. 수학적 모델은 이진 선택 변수 x_i(env)와 순서 변수 y_{i,j}(env), 시작·종료 시간 변수 등을 포함하며, 제약식(4)~(16)으로 구체화된다.
문제의 복합성으로 인해 정확한 최적화는 실용적이지 않으며, 메타휴리스틱과 휴리스틱이 주로 사용된다. 최근에는 해석 가능하고 경량인 정책을 자동으로 생성하는 Genetic Programming Hyper‑Heuristic(GPHH)가 주목받고 있다. GPHH는 정책을 트리 형태의 프로그램으로 표현하고, 이를 Online Scheduling Algorithm(OSA)에 적용해 시뮬레이션 기반 적합도를 평가한다. 그러나 평가 과정이 매우 비용 집약적이며, OSA 설계 자체가 평가 결과에 큰 영향을 미쳐 동일 정책이라도 다른 OSA에 의해 다른 적합도를 얻게 된다. 이는 ‘평가 의존적 로컬 옵티마’를 초래하고, 진화 효율을 저하시킨다.
이를 해결하기 위해 저자는 Hybrid Evaluation‑based Genetic Programming(HE‑GP)이라는 새로운 프레임워크를 제안한다. 핵심 아이디어는 OSA 내부에 Hybrid Evaluation(HE) 메커니즘을 삽입해 두 가지 평가 모드를 병행하는 것이다.
1. **Exact Mode**: 제약 검증 모듈을 통해 모든 시나리오에 대해 제약 위반 여부와 자원 사용량을 완전하게 확인한다. 이는 평가 정확도를 보장하지만 연산 비용이 높다.
2. **Approximate Mode**: 가시성 임계값, 평균 데이터 쓰기율, 기대 이익 대비 자원 비율 등 간단한 논리로 빠르게 후보 스케줄을 필터링한다. 연산 비용이 크게 감소하지만 정확도는 다소 떨어진다.
HE‑GP는 진화 과정에서 실시간으로 ‘진화 상태 정보’를 수집한다. 구체적으로, 현재 세대의 적합도 평균·분산, 적합도 변화율, 연산 시간 등을 모니터링하고, 사전에 정의된 전환 기준에 따라 두 모드 사이를 동적으로 전환한다. 예를 들어, 적합도 향상이 정체되면 근사 모드 비중을 늘려 탐색 폭을 넓히고, 급격한 향상이 감지되면 정확 모드로 전환해 해의 품질을 정밀 검증한다. 이러한 적응형 전환은 초기 탐색 단계에서 빠른 후보 생성, 후반부에서 정밀한 해 검증을 동시에 가능하게 하여 전체 연산량을 크게 절감한다.
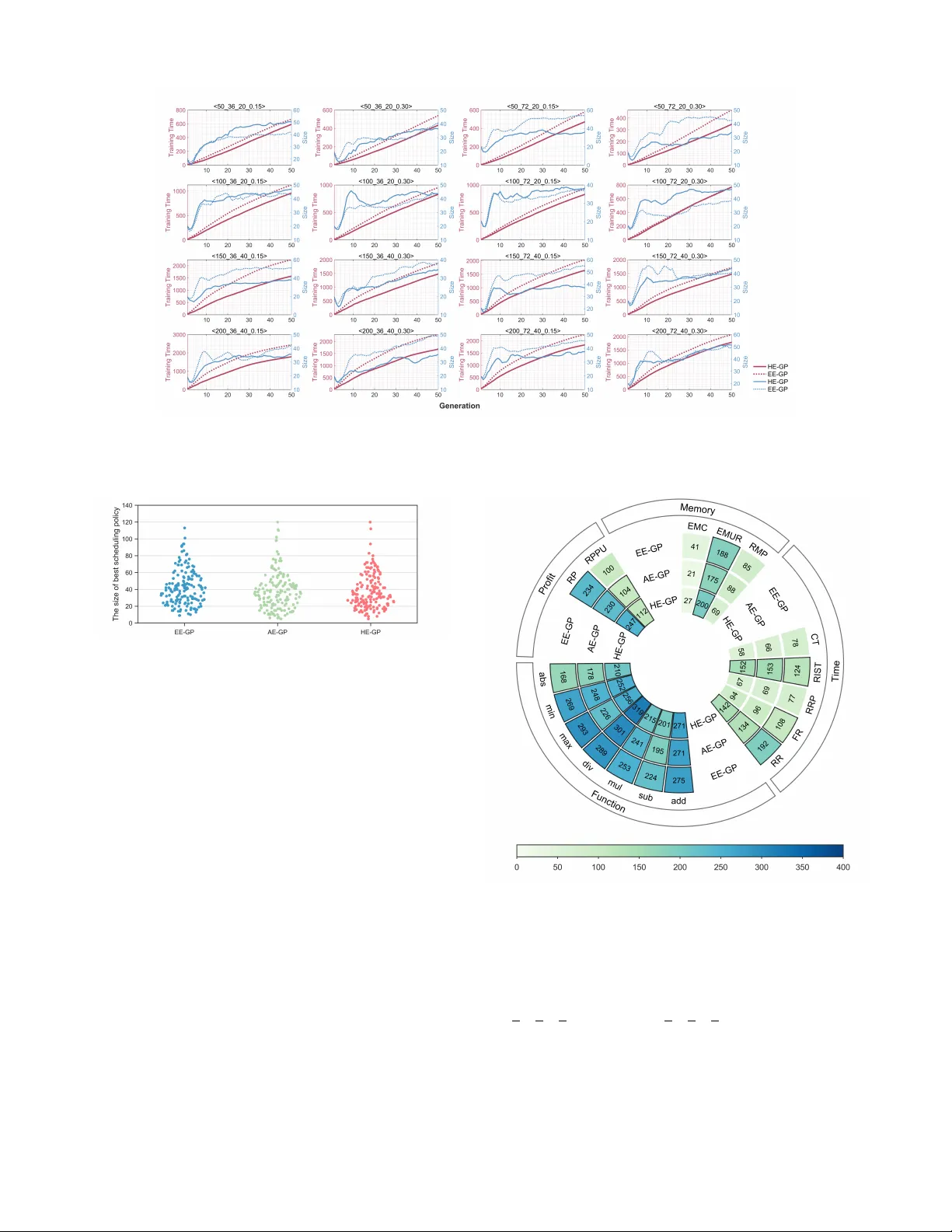
실험 설계는 16개의 다양한 시뮬레이션 인스턴스를 구축했으며, 각 인스턴스는 요청 수, 불확실성 수준, 메모리 용량 등 여러 파라미터를 달리했다. 비교 대상은 (1) 기존 수작업 휴리스틱, (2) 단일 평가 기반 GPHH(전부 Exact 혹은 전부 Approximate), (3) 제안된 HE‑GP이다. 주요 성능 지표는 평균 학습 시간, 기대 이익(평균 순위), 그리고 연산 비용이다. 결과는 다음과 같다.
- HE‑GP는 평균 학습 시간을 17.77 % 감소시켰으며, 이는 정확 모드만 사용한 GPHH 대비 유의미한 절감이다.
- 기대 이익 측면에서 HE‑GP는 모든 시나리오에서 최고 평균 순위를 기록했으며, 특히 불확실성이 높은 인스턴스에서 그 우위가 두드러졌다.
- 근사 모드만 사용한 GPHH는 연산 속도는 빠르지만 품질이 크게 저하되는 반면, HE‑GP는 품질 손실 없이 비용을 절감했다.
또한, 진화 과정 분석을 통해 최종 정책에 자주 등장하는 터미널과 함수들을 식별하였다. 주요 터미널은 현재 남은 메모리, 남은 가시성 윈도우 길이, 요청의 기대 이익 대비 자원 비율 등이며, 함수는 조건부 선택(if‑else), 가중치 조정, 우선순위 비교 등이었다. 이러한 피처는 향후 정책 설계 시 중요한 가이드라인이 될 수 있다.
결론적으로, HE‑GP는 평가 비용과 해의 질 사이의 트레이드오프를 동적으로 관리함으로써 불확실성 하 민첩 위성 스케줄링 문제에 실용적이고 해석 가능한 솔루션을 제공한다. 향후 연구에서는 다중 위성 협업, 실시간 온보드 구현, 그리고 강화학습과의 하이브리드 모델링 등을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기