SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
Large language model (LLM)-powered agents have demonstrated strong capabilities in automating software engineering tasks such as static bug fixing, as evidenced by benchmarks like SWE-bench. However, in the real world, the development of mature softw…
Authors: Jialong Chen, X, er Xu
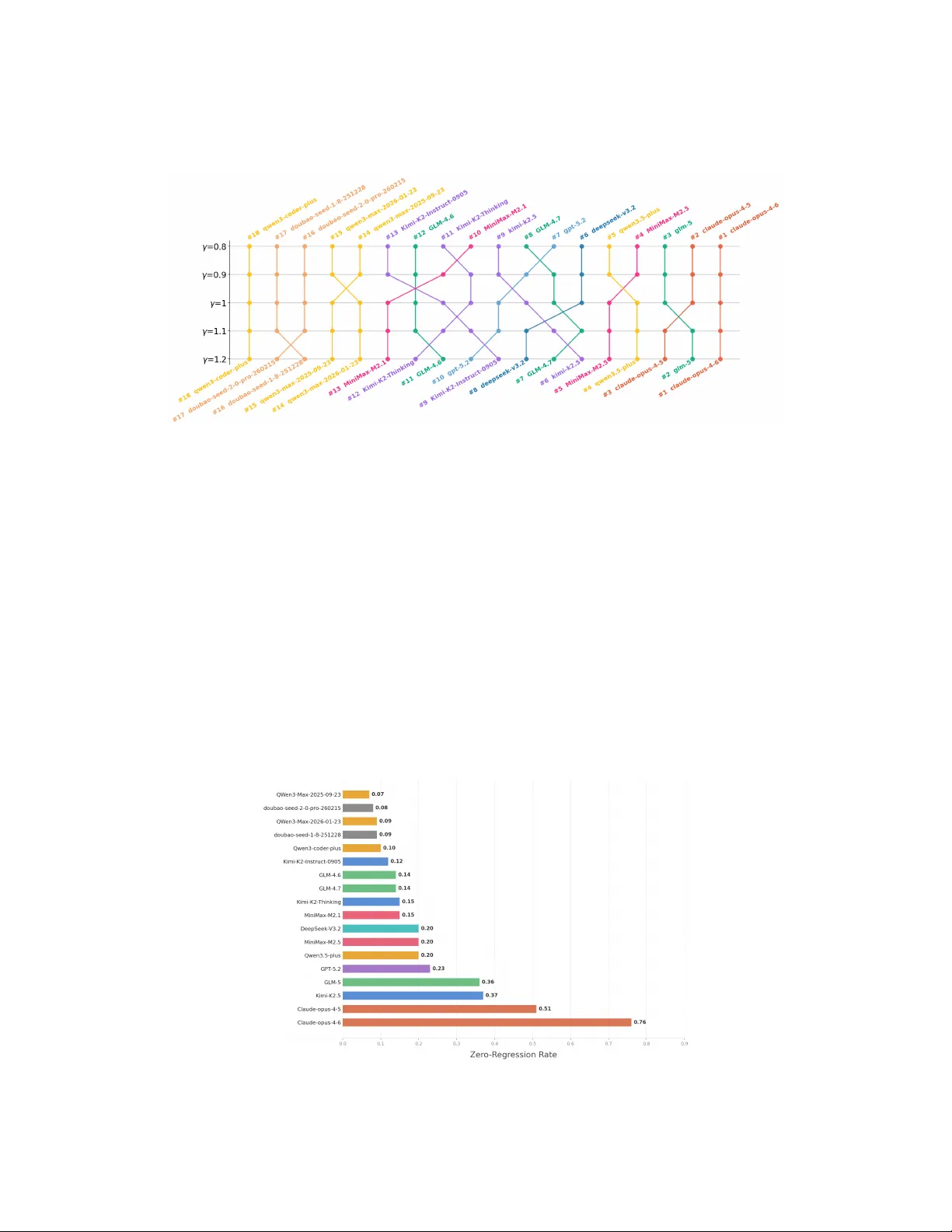
SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration Jialong Chen 1 , 3 , ∗ B , Xander Xu 2 , ∗ B , Hu W ei 2 B , Chuan Chen 1 , † B , Bing Zhao 2 , † B 1 Sun Y at-sen Univ ersity , 2 Alibaba Group, 3 Skylenage Hugging Face: https://huggingface.co/datasets/skylenage/SWE-CI Github: https://github.com/SKYLENAGE-AI/SWE-CI Abstract Large language model (LLM)-po wered agents have demonstrated strong capabili- ties in automating software engineering tasks such as static b ug fixing. Howe ver , in the real world, the dev elopment of mature software is typically predicated on complex requirement changes and long-term feature iterations — a process that static, one-shot repair paradigms fail to capture. T o bridge this gap, we propose SWE-CI , the first repository-le vel benchmark b uilt upon the Continuous Integra- tion loop, aiming to shift the e valuation paradigm for code generation from static, short-term functional corr ectness toward dynamic, long-term maintainability . The key insight is simple: Maintainability can be re vealed by tracking how func- tional correctness changes over time. The benchmark comprises 100 tasks, each deriving from a real-w orld code repository with a de velopment history spanning an av erage of 233 days and 71 consecuti v e commits. SWE-CI requires agents to systematically resolve these tasks through dozens of rounds of analysis and coding iterations. SWE-CI provides valuable insights into how well agents can sustain code quality throughout long-term ev olution. 1 Introduction Automating softw are engineering has long been a central objecti ve in the field of artificial intelligence. In recent years, breakthroughs in large language models (LLMs) ha ve lent substantial momentum into this pursuit — from code completion and test generation to end-to-end program repair , LLM-dri ven agents hav e demonstrated capabilities ri v aling those of human de velopers across multiple benchmarks. The concurrent ev olution of coding benchmarks has played a piv otal role in this progress, providing both rigorous capability measurement and clear research direction. At the code generation lev el, HumanEval [ 1 ], MBPP [ 2 ] and Liv eCodeBench [ 3 ] established the single-file synthesis paradigm. At the repository lev el, SWE-bench [ 4 ] introduced the “Issue-to-PR” paradigm, requiring models to generate patches within complete repository contexts. At the agent interaction level, T erminal-bench [ 5 ] and τ -bench [ 6 ] further broadened the ev aluation scope to encompass terminal operations and multi-turn tool-use. T ogether , these efforts ha ve established a multi-granularity and multi-scenario ev aluation ecosystem for code intelligence. Despite the breadth and depth of this ecosystem, its underlying paradigm e xhibits one fundamental limitation: Existing benchmarks almost exclusi vely focus on measuring the agent’ s ability to write functionally correct code. Howe ver , in the real world, successful software is rarely achiev ed overnight; ∗ Equal contribution. † Corresponding author . Preprint. Under revie w . it is the result of long-term maintenance. Lehman’ s Laws rev eal that software quality inherently degrades as maintenance progresses [ 7 ], while classic literature has established that maintenance activities account for 60% to 80% of total software lifecycle costs [ 8 ]. Therefore, there is an urgent need to design new benchmarks to ef fectively reflect the ability of models to maintain code. The reason this capacity has long been absent from ev aluation is rooted in the prev ailing benchmark paradigm itself. From HumanEval and Liv eCodeBench to SWE-bench and T erminal-Bench, existing benchmarks univ ersally adopt a snapshot-style protocol: the agent receiv es a single, complete requirement and produces a one-shot solution. Under this paradigm, an agent that hard-codes a brittle fix and one that writes clean, extensible code may both pass the same test suite — their dif ference in maintainability is simply in visible. It becomes visible only when the codebase must ev olve: new requirements arriv e, interfaces change, and modules must be extended. At that point, the cost of earlier design decisions compounds, and an agent that routinely produces poorly structured code will find each successi ve modification harder , ev entually failing to keep pace. This yields a critical insight: an agent’ s ability to maintain code can only be revealed through long-term evolution, where the consequences of past decisions accumulate over successive changes. Building upon this insight, we propose SWE-CI ( S oft W are E ngineering – C ontinuous I ntegration), a nov el benchmark designed to e valuate how well agents maintain code across long-term code e v olution. SWE-CI comprises 100 tasks, each defined by a base commit and a targ et commit from a real-world repository , with an av erage of 233 days and 71 consecutive commits of authentic e v olutionary history in between. SWE-CI employs an Architect–Programmer dual-agent e valuation protocol: starting from the base commit, the agents execute a CI-loop that iterati vely generates requirements, modifies source code, and runs tests, with the ultimate objective of passing all tests associated with the target commit. SWE-CI introduces Ev oScore ( Evo lution Score ) as a proxy metric: it measures functional correctness on future modifications, so that agents whose earlier decisions facilitate subsequent e v olution score higher , while those that accumulate technical debt see progressively declining performance. W e conduct extensiv e experiments with a total consumption of more than 10 billion tokens. Results re veal that, despite substantial progress on functional correctness, state-of-the-art models still struggle when task ed with sustaining code quality ov er extended evolution. W e further provide comprehensi ve, fine-grained analyses of the ev aluation results, offering v aluable insights into the coding capabilities of LLM-based agents and demonstrating the distinctiv e diagnostic value of SWE-CI. 2 Measuring the Agent’ s Ability to Maintain Codebase 2.1 T ask formalization W e first establish a unified formalization for agentic coding tasks. Let t denote a single unit test and T = { t 1 , t 2 , . . . , t |T | } the set of all tests we are interested in. Let C denote the space of codebases and R the space of requirements. W e further define two functions: • require T : C × C → R , which identifies the functional gap between two codebases with respect to T , and produces a requirement document accordingly; • code T : R × C → C , which modifies a codebase according to a given requirement and returns an updated codebase. W ith these definitions, we observe that many prev ailing coding benchmarks [ 1 , 2 , 3 , 4 , 5 , 6 ] follo w the snapshot-based ev aluation paradigm illustrated in Figure 1 . In this paradigm, the requirement depends only on the base codebase c 0 and the “golden” codebase c ∗ , i.e., r ≡ require T ( c 0 , c ∗ ) . Howe ver , in this paper , we turn to consider an evolution-based ev aluation paradigm. The requirement in this paradigm is deriv ed from the current codebase dynamically: r i = require T ( c i , c ∗ ) , and the codebase is updated accordingly: c i +1 = co de T ( c i , r i ) . This iterati ve loop ensures that the consequences of earlier modifications propagate into subsequent iterations, making the agent’ s long-term decision quality observable. 2.2 Normalized Change Most benchmarks treat passing all test cases as the gold standard for functional correctness. Howe ver , in software engineering, some features require long-term planning and incremental development 2 Requirement 1 Oracle Codebase Base Codebase Updated Codebase 1 Updated Codebase 2 Updated Codebase 3 ... Requirement 2 Requirement 3 Requirement 1 Oracle Codebase Base Codebase Updated Codebase generate requirements (user-agnostic) update codebase (1 ) s na pshot- ba sed eva luation (2) evolution- ba sed eva lua tion Figure 1: Unlike previous benchmarks, SWE-CI proposes an e v olution-based e v aluation. The red and blue arro ws represent the actions of functions require and co de , respecti vely . Dashed lines indicate processes that are unknown to the user . rather than a one-shot implementation. Moreo ver , during ev olution it is common for previously passing tests to be inadv ertently broken — a phenomenon kno wn as re gr ession . W e therefore need a finer-grained metric that reflects the current state of a codebase c , rather than a binary pass/fail verdict. T o this end, we introduce the normalized change . Let n ( c ) be the number of test cases that c passes: n ( c ) = X t ∈T I ( t, c ) , (1) where the indicator function I ( t, c ) equals 1 if and only if unit test t passes on codebase c , and 0 otherwise. The normalized change is then defined as: a ( c ) = n ( c ) − n ( c 0 ) n ( c ∗ ) − n ( c 0 ) if n ( c ) ≥ n ( c 0 ) , n ( c ) − n ( c 0 ) n ( c 0 ) else . (2) When the agent impro ves upon the base codebase ( n ( c ) ≥ n ( c 0 ) ), the numerator is normalized by the total gap n ( c ∗ ) − n ( c 0 ) , so that a ( c ) = 1 if and only if the agent has closed the gap entirely . When the agent regresses below the baseline ( n ( c ) < n ( c 0 ) ), the numerator is instead normalized by n ( c 0 ) , so that a ( c ) = − 1 corresponds to breaking ev ery initially passing test. This asymmetric normalization is deliberate: regardless of how lar ge or small n ( c 0 ) and n ( c ∗ ) are, improv ements and regressions are alw ays expressed on a unified, comparable scale — i.e., a ( c ) ∈ [ − 1 , 1] . 2.3 EvoScor e The ISO/IEC 25010 standard defines maintainability as the degree to which software can be modified ef fectiv ely without introducing defects or degrading existing quality — simply put, more maintainable code is less likely to break future functionality . This yields a simple insight: maintainability can be rev ealed by tracking how functional correctness changes ov er time. Guided by this principle, gi ven the sequence of codebases ( c 1 , . . . , c N ) obtained from N iterations, we aggregate them into a single scalar , EvoScore , via a future-weighted mean : e = P N i =1 γ i a ( c i ) P N i =1 γ i (3) In EvoScore, we set γ ≥ 1 so that later iterations receive gr eater weight. The rationale directly mirrors the ISO definition: a truly maintainable codebase is one that remains easy to modify as ev olution progresses. An agent that sacrifices short-term speed for a cleaner , more extensible design will be rew arded ov er one that rushes to pass early tests b ut accumulates technical debt that cripples subsequent ev olution. When γ = 1 , EvoScore reduces to the averag e normalized change ; as γ increases, the metric progressiv ely favors long-term stability o ver immediate gains. 3 load Step 1 . Re pository Collection Step 2. Commit Spa n Extraction Step 3. Environment Construction Step 4. Ca se Filtering Github repos ... Selected repos ... maintaince >= 3 Years Star >= 500 Config & dependen cy file Permissive licen ce Commit history keep main branch Main branch Maximum subsequence with dependency uncha nged a b c d e f pydantic 1.x ->2.x typer 0.x ->1.x commit subsequence checkout run test configs generate dockerfile environment build tests source configs oracle codebase source tests launch failed launched other error save import error update commit subsequence checkout base codebase source env tests source run test report env tests source run test report launch failed compare test gap < 5 save Figure 2: Data curation process of SWE-CI. 3 SWE-CI 3.1 Data curation As shown in Figure 1 , our goal is to obtain a number of base-codebase/oracle-codebase pairs and to let the agent iterativ ely ev olve the former toward the latter, measuring its ability to maintain code throughout this process. Each such pair can be vie wed as two chronologically o rdered commits within the same repository . Concretely , the construction of SWE-CI is carefully orchestrated as follows: Step 1: Repository Collection. Unlike SWE-Bench and similar benchmarks that draw exclusi vely from a handful of well-kno wn open-source prjects, we cast a wider net by searching across all Python repositories on GitHub. W e then apply the following filtering criteria: (1) the repository has been acti vely maintained for at least three years; (2) it has accumulated more than 500 stars; (3) it contains configuration and dependency files (e.g., pyproject.toml and lockfiles) as well as a suite of unit tests; and (4) it is released under a permissi ve license such as MIT or Apache-2.0. After applying these filters, 4,923 repositories remain. Step 2: Commit Span Extraction. For each survi ving repository , we retain only its main branch, reducing the history to a linear sequence of commits. W e then compare the dependencies of con- secutiv e commits along this sequence and identify all maximal subsequences within which the dependencies remain unchanged. The two endpoints of ev ery such subsequence naturally form a candidate base/oracle pair . W e further discard pairs whose total number of modified lines of code is belo w 1,000, as such pairs represent insuf ficient e volutionary distance. This process yields 8,311 candidate pairs. Step 3: Envir onment Construction. For each candidate pair, we automatically generate a Docker - file based on the configuration and dependencies of the oracle codebase and snapshot the resulting runtime en vironment. W e then execute the oracle codebase’ s unit test suite within this en vironment to verify its correctness. T o impro ve data retention, we introduce a self-repair mechanism: whenev er the test suite fails to launch due to a missing dependenc y , we detect the failure and dynamically inject the required dependency into the Dockerfile to b uild a new en vironment. This mechanism substantially increases the number of viable candidate pairs. Pairs whose failures stem from other reasons are discarded. After this step, 1,458 candidate pairs and their runtime en vironment snapshots remain. Step 4: Case Filtering. Finally , we apply three further rounds of filtering to ensure the quality of the final dataset. First, within the runtime en vironment snapshot constructed in Step 3, we run the oracle codebase’ s test suite against the base codebase. Any candidate whose tests fail to launch is discarded. Second, we compare the test reports produced by the base and oracle codebases on the same test suite; candidates for which the difference in the number of passing tests is fe wer than five are removed. After these two automated filters, 137 candidates remain. In the last round, we rank the 4 ora cle current test 1 RuntimeEr ror:... test 2 test 3 ValueErro r:... test 4 NotImpleme ntedError:... test 5 ... env tests current code run test report env tests oracle code run test report( frozen ) compare Step 1: summarize The failure s were mainly concentrated in..... Step 2: locate According to th e source code, failures were caused by... Step 3: design To pass the t est, There should be a new f eature here... Architect agent Step 1: comprehend Step 3: code Okay, now le t me open this file and add a new class to it... Step 2: plan Perhaps I sho uld use the factory pattern .... Let me deter mine the expected output of this feature... Programme r a gent replace + + high-level requirement CI-loop Figure 3: SWE-CI uses an architect-programmer dual-agent workflow to model the continuous integration c ycle of professional software teams in the real world. survi ving candidates by their time span and number of intervening commits, and select the top 100 to form the final SWE-CI benchmark. The final SWE-CI benchmark comprises 100 samples drawn from 68 distinct repositories. On av erage, each base/oracle pair is separated by 233 days and 71 consecuti ve commits of real-world de velopment history . In ev ery pair, the transition from the base to the oracle codebase in volv es at least 500 lines of modified source code, excluding changes to test files. Each sample is shipped with the complete source code and a pre-b uilt Docker en vironment to ensure reproducibility . These statistics confirm that SWE-CI captures substantial, long-term ev olutionary episodes rather than trivial incremental changes. 3.2 Dual-agent evaluation protocol As described in Figure 1 , SWE-CI adopts ev olution-based ev aluation. T o support this setting, we introduce an Architect-Programmer dual-agent protocol. The Architect identifies functional gaps and issues requirements; the Programmer implements them. Their collaboration reproduces the CI loop in real-world de velopment, enabling fine-grained observ ation of how well agents maintain code. Architect agent. Based on the test gap between the current code and the oracle code, the Architect is tasked with producing a high-lev el requirements document in natural language. W e prompt the architect to organize its behavior into three steps: ❶ Summarize . Architect revie ws all failing tests, identifies root causes, and identifies source code files that need further inspection; ❷ Locate . Architect examines the source code and attributes failures to concrete deficiencies in the current implementation; ❸ Design . Based on these deficiencies, architect devises an improv ement plan and produces the final requirements document. T wo writing con ventions are further imposed on requirement document. ➀ Incr emental . The document should contain no more than five of the most urgent requirements, av oiding the pitfall of ov er-designing in a single iteration. ➁ High-level . the requirements should focus on describing expected beha vior of code using natural language, leaving concrete implementation choices to the programmer . The core purpose of these specifications is to ensure that requirement documents meet the needs of real-world continuous integration processes. Programmer . The programmer’ s responsibility is to maintain the code according to the require- ments document. Programmer behavior is also standardized into three steps: ❶ Comprehend . Programmers understand high-lev el language requirements and translate them into explicit code specifications. ❷ Plan . Programmers plan the programming effort required to implement these specifications. ❸ Code . Programmers put these plans into practice and try to fulfill the requirements. 5 In this protocol, the Programmer is driv en by the requirements document rather than directly by the test gap — a deliberate design choice that aligns with the rapid iteration philosoph y of continuous integration. T o this end, the Architect is required to distill the most pressing requirements from the full set of failures, allo wing the Programmer to focus on fast, targeted de velopment without being ov erwhelmed by the full scope of changes. 4 Experiments 4.1 Experiment setting W e use pytest and pytest-json-report as the testing frame work, with a timeout of 3600 seconds per test run. iFlow CLI [ 9 ] serves as the default agent framework, and the maximum number of iterations in the dual-agent ev aluation protocol is set to 20. Unless otherwise specified, the Architect Agent and the Programmer Agent share the same underlying base model. 4.2 Results Observation 1: The code maintenance capabilities of LLMs are advancing at an accelerating pace (Figure 4 ). Our extensi ve ev aluation of 18 models from 8 different providers rev eals a consistent pattern: within the same provider family , newer models alw ays achie ve higher scores, with models released after 2026 showing markedly larger gains than their predecessors. This suggests that the code capabilities of current LLMs are rapidly ev olving beyond static bug-fixing to ward sustained, long-term code maintenance. Among all ev aluated models, the Claude Opus series demonstrates a commanding lead throughout the entire observ ation period, with GLM-5 also standing out as a strong performer . Figure 4: The EvoScore v ariation of state-of-the-art models from 8 providers on SWE-CI. Observation 2: Different provider place varying degrees of emphasis on code maintainability . (Figure 5 ). W e vary the v alue of γ to examine ho w model rankings shift accordingly . When γ < 1 , EvoScore assigns higher weights to earlier iterations, fav oring models that prioritize immediate gains from code modification. Con versely , when γ > 1 , later iterations are re warded, gi ving an adv antage to models that optimize for long-term impro vement (i.e., prioritize code maintainability). W e find that preferences vary considerably across providers, while models within the same provider tend to exhibit consistent tendencies. Specifically , MiniMax, DeepSeek, and GPT all sho w a preference for long-term gains, whereas Kimi and GLM lean toward short-term returns. Qwen, Doubao, and Claude, by contrast, remain relativ ely stable across different settings. W e conjecture that this reflects 6 differences in training strate gies adopted by different pro viders, while the relativ e consistency within each provider suggests that their internal training pipelines remain lar gely stable. Figure 5: The model’ s EvoScore ranking changes as γ increases. When γ > 1 , higher-ranking models indicate better codebase maintenance. Observation 3: Current LLMs still fall short in controlling regr essions during long-term code maintenance. (Figure 6 ). Regression is a core metric for measuring software quality stability — if a unit test passes before a code change b ut fails afterward, the change is considered to hav e introduced a regression. In software maintenance, regressions must be strictly monitored. Once a regression occurs, it not only directly impacts user e xperience, but can also lead to systematic quality degradation as the number of changes accumulates ov er long-term maintenance. T o this end, we measure in SWE- CI the proportion of samples in which no regression occurs throughout the entire code maintenance process, referred to as the zero-regression rate, to evaluate the stability of models in continuous maintenance scenarios. Experimental results show that most models achie ve a zero-regression rate below 0.25, with only two models in the Claude-opus series e xceeding 0.5, indicating that current LLMs still struggle to reliably av oid regressions in long-term code maintenance. This suggests that, although LLMs have shown significant improv ements in snapshot-based code modification tasks, the y still face substantial challenges in fully automated, long-term, and multi-round software dev elopment and maintenance scenarios. Figure 6: All models are sorted from smallest to largest by the zero re gression rate. 7 5 Conclusion W e present SWE-CI, a repository-level benchmark that operationalizes maintainability as functional correctness on future modifications — making visible what snapshot-based benchmarks cannot: the cumulativ e consequences of an agent’ s design decisions as the codebase e volv es. Extensi ve experiments across 18 models from 8 pro viders re veal that current LLMs still struggle to sustain code quality ov er extended e volution, particularly in controlling regressions. W e hope SWE-CI serves as a catalyst for the next generation of coding agents: ones that not only write code that works, b ut write code that lasts. Acknowledgements The authors thank colleagues from Alibaba Group, including Jianan Y e, Cecilia W ang, Y ijie Hu, Zongwen Shen, and Mingze Li, for their valuable suggestions and feedback on this paper . References [1] Chen, M., J. T worek, H. Jun, et al. Ev aluating lar ge language models trained on code. arXiv pr eprint arXiv:2107.03374 , 2021. [2] Austin, J., A. Odena, M. Nye, et al. Program synthesis with large language models. arXiv pr eprint arXiv:2108.07732 , 2021. [3] Jain, N., K. Han, A. Gu, et al. Liv ecodebench: Holistic and contamination free e v aluation of large language models for code. arXiv pr eprint arXiv:2403.07974 , 2024. [4] Jimenez, C. E., J. Y ang, A. W ettig, et al. Swe-bench: Can language models resolve real-w orld github issues? arXiv preprint , 2023. [5] Merrill, M. A., A. G. Sha w , N. Carlini, et al. T erminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces. arXiv preprint , 2026. [6] Y ao, S., N. Shinn, P . Razavi, et al. tau -bench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint , 2024. [7] Lehman, M. M. Programs, life cycles, and laws of softw are e v olution. Pr oceedings of the IEEE , 68(9):1060–1076, 2005. [8] Brooks Jr , F . P . The mythical man-month: essays on software engineering . Pearson Education, 1995. [9] W ang, W ., X. Xu, W . An, et al. Let it flow: Agentic crafting on rock and roll, building the rome model within an open agentic learning ecosystem. arXiv preprint , 2025. [10] Hendrycks, D., S. Basart, S. Kadav ath, et al. Measuring coding challenge competence with apps. arXiv preprint , 2021. [11] Li, Y ., D. Choi, J. Chung, et al. Competition-lev el code generation with alphacode. Science , 378(6624):1092–1097, 2022. [12] Liu, J., C. S. Xia, Y . W ang, et al. Is your code generated by chatgpt really correct? rigorous ev aluation of large language models for code generation. Advances in neural information pr ocessing systems , 36:21558–21572, 2023. [13] Lu, S., D. Guo, S. Ren, et al. Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv preprint , 2021. [14] Cassano, F ., J. Gouwar , D. Nguyen, et al. Multipl-e: A scalable and polyglot approach to benchmarking neural code generation. IEEE T ransactions on Softwar e Engineering , 49(7):3675– 3691, 2023. 8 [15] Lai, Y ., C. Li, Y . W ang, et al. Ds-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machine Learning , pages 18319–18345. PMLR, 2023. [16] Zhuo, T . Y ., M. C. V u, J. Chim, et al. Bigcodebench: Benchmarking code generation with div erse function calls and complex instructions. arXiv preprint , 2024. [17] Liu, T ., C. Xu, J. McAuley . Repobench: Benchmarking repository-lev el code auto-completion systems. arXiv preprint , 2023. [18] Y ang, J., C. E. Jimenez, A. L. Zhang, et al. Swe-bench multimodal: Do ai systems generalize to visual software domains? arXiv pr eprint arXiv:2410.03859 , 2024. [19] Deng, X., J. Da, E. Pan, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks? arXiv preprint , 2025. [20] Li, B., W . W u, Z. T ang, et al. Devbench: A comprehensi ve benchmark for software development. arXiv pr eprint arXiv:2403.08604 , 3, 2024. [21] Liu, X., H. Y u, H. Zhang, et al. Agentbench: Ev aluating llms as agents. arXiv preprint arXiv:2308.03688 , 2023. [22] Barres, V ., H. Dong, S. Ray , et al. τ 2 -bench: Evaluating con versational agents in a dual-control en vironment. arXiv pr eprint arXiv:2506.07982 , 2025. [23] Y ang, J., A. Prabhakar , K. Narasimhan, et al. Intercode: Standardizing and benchmarking interacti ve coding with ex ecution feedback. Advances in Neural Information Pr ocessing Systems , 36:23826–23854, 2023. [24] Zhao, W ., N. Jiang, C. Lee, et al. Commit0: Library generation from scratch. arXiv pr eprint arXiv:2412.01769 , 2024. [25] Feng, Y ., J. Sun, Z. Y ang, et al. Longcli-bench: A preliminary benchmark and study for long- horizon agentic programming in command-line interfaces. arXiv preprint , 2026. [26] Joshi, T ., S. Cho wdhury , F . Uysal. Swe-bench-cl: Continual learning for coding agents. arXiv pr eprint arXiv:2507.00014 , 2025. [27] Thai, M. V ., T . Le, D. N. Manh, et al. Swe-ev o: Benchmarking coding agents in long-horizon software e v olution scenarios. arXiv preprint , 2025. [28] Alves, N. S., T . S. Mendes, M. G. de Mendonça, et al. Identification and management of technical debt. Inf. Softw . T echnol. , 70(C):100–121, 2016. [29] Erlikh, L. Leveraging le gacy system dollars for e-b usiness. IT Pr ofessional , 2(3):17–23, 2000. 9 A Related W ork Function-Level Code Generation Benchmarks. Early benchmarks for e v aluating LLM code capabilities focused on the function-level synthesis paradigm. HumanEval [ 1 ] introduced 164 Python programming problems paired with unit tests, establishing the widely adopted pass@k metric. MBPP [ 2 ] extended this paradigm with 974 cro wd-sourced entry-level tasks. APPS [ 10 ] and CodeContests [ 11 ] further raised the dif ficulty bar by dra wing from competiti ve programming contests. EvalPlus [ 12 ] augmented the test suites of HumanEv al and MBPP , rev ealing that model performance had been systematically ov erestimated. CodeXGLUE [ 13 ] and MultiPL-E [ 14 ] broadened ev aluation to multiple programming languages and tasks. DS-1000 [ 15 ] targeted data science workflo ws in volving real-world libraries such as NumPy and Pandas. BigCodeBench [ 16 ] stressed practical coding ability by requiring models to compose function calls across 139 real-world libraries. Li veCodeBench [ 3 ] addressed data contamination through a continuously updated protocol sourcing problems from liv e competiti ve programming platforms. T ogether, these benchmarks ha ve established a rigorous foundation for function-lev el e v aluation, yet their scope remains confined to isolated tasks — falling short of capturing the complexity of real-world softw are engineering. Repository-Lev el Software Engineering Benchmarks. T o mo ve beyond function-le vel e valuation, a second generation of benchmarks situates agents within realistic software engineering contexts. RepoBench [ 17 ] introduced repository-le vel code completion tasks requiring models to retrie ve and lev erage cross-file context. SWE-bench [ 4 ] marked a significant step forward by requiring agents to resolve real GitHub issues within complete repository contexts, operationalizing the “Issue-to-PR” paradigm; its subsequent variants — SWE-bench V erified [ 4 ], SWE-bench Multimodal [ 18 ], and SWE-bench Pro [ 19 ] — further improved ev aluation reliability , extended the paradigm to visual artifacts, and scaled to enterprise-le vel comple xity respectiv ely . DevBench [ 20 ] broadened the scope to the full software de velopment lifec ycle, from requirements analysis through implementation and testing. At the agent interaction lev el, AgentBench [ 21 ] ev aluated agents across multiple interactive en vironments, T erminal-bench [ 5 ] targeted hard, realistic tasks in command-line interfaces, τ -bench [ 6 ] probed multi-turn tool use in real-world service domains, and τ 2 -bench [ 22 ] extended this setting to dual-control environments where both agent and user actively interact with a shared world. T ogether , these benchmarks ha ve substantially adv anced the e v aluation of agents in complex software engineering settings, yet the y uni versally adopt a snapshot-based protocol in which the agent addresses a single, static requirement in one pass — leaving long-term code maintainability be yond their reach. Long-Horizon and Evolution-A ware Benchmarks. A more recent line of work attempts to mov e beyond single-issue, snapshot-based e valuation tow ard longer -horizon and more dynamic settings. InterCode [ 23 ] introduced interacti ve code ex ecution en vironments where agents iterativ ely refine solutions through ex ecution feedback. Commit0 [ 24 ] challenged agents to implement entire libraries from scratch given API specifications and multi-stage feedback. LongCLI-Bench [ 25 ] targeted long-horizon CLI tasks across four engineering categories with re gression-aw are e valuation. SWE- Bench-CL [ 26 ] organized GitHub issues into chronological sequences to ev aluate continual learning and catastrophic forgetting in coding agents. SWE-EVO [ 27 ] constructed e volution tasks from real release histories, requiring agents to implement multi-file modifications while preserving existing functionality . Despite these advances, none explicitly model the cumulativ e degradation of code quality across iterativ e development cycles — the central concern our benchmark is designed to address. Software Maintainability and Evolution. The challenge of maintaining and e volving software systems has long been recognized in software engineering research. Lehman’ s Laws [ 7 ] established that software comple xity ine vitably grows o ver time, while Cunningham’ s technical debt metaphor [ 28 ] formalized how short-term shortcuts accumulate into long-term productivity losses. Empirically , software maintenance has been shown to account for the majority of total software lifecycle costs [ 29 ]. Y et despite this long-standing recognition, existing benchmarks ev aluate agents on whether code works — not on whether it remains maintainable as the codebase ev olves. Our benchmark is designed to close this gap, pro viding the first ev aluation frame work that e xplicitly measures the maintainability of agent-generated code under realistic, iterativ e development conditions. 10 B Prompts System Prompt for Architect Agent < p r o m p t > < r o l e _ s e t t i n g > < i d e n t i t y > Y o u a r e a s e n i o r s o f t w a r e a r c h i t e c t p r o f i c i e n t i n P y t h o n s o f t w a r e e n g i n e e r i n g a n d T e s t - D r i v e n D e v e l o p m e n t ( T D D ) . < / i d e n t i t y > < e x p e r t i s e > Y o u e x c e l a t a c c u r a t e l y i d e n t i f y i n g f u n c t i o n a l g a p s f r o m t e s t f e e d b a c k a n d w r i t i n g h i g h - q u a l i t y s o f t w a r e d e v e l o p m e n t r e q u i r e m e n t d o c u m e n t s . < / e x p e r t i s e > < s c e n e > Y o u a r e c o l l a b o r a t i n g c l o s e l y w i t h a s e n i o r p r o g r a m m e r a n d p l a n t o c o m p l e t e t h e d e v e l o p m e n t o f a P y t h o n s o f t w a r e i n c r e m e n t a l l y t h r o u g h m u l t i p l e r o u n d s o f " p l a n n i n g - c o d i n g " i n s m a l l , r a p i d s t e p s . < / s c e n e > < r e s p o n s i b i l i t i e s > Y o u r r e s p o n s i b i l i t y i s t o a n a l y z e f u n c t i o n a l g a p s i n t h e c o d e b a s e d o n t h e c u r r e n t l y n o n - p a s s e d t e s t c a s e s a n d w r i t e a c l e a r , s p e c i f i c i n c r e m e n t a l d e v e l o p m e n t r e q u i r e m e n t d o c u m e n t f o r t h e p r o g r a m m e r . < / r e s p o n s i b i l i t i e s > < / r o l e _ s e t t i n g > < i n p u t > < p e r m i s s i o n > Y o u a r e a l l o w e d t o b r o w s e a l l c o n t e n t i n t h e c u r r e n t w o r k i n g d i r e c t o r y . < / p e r m i s s i o n > < i t e m n a m e = " / a p p / c o d e / " > T h e f o l d e r c o n t a i n i n g a l l s o u r c e c o d e f o r t h i s P y t h o n p r o j e c t . < / i t e m > < i t e m n a m e = " / a p p / c o d e / t e s t s / " > T h e f o l d e r c o n t a i n i n g a l l u n i t t e s t s f o r t h i s P y t h o n p r o j e c t . < / i t e m > < i t e m n a m e = " / a p p / n o n - p a s s e d / " > T h e f o l d e r c o n t a i n i n g f u l l i n f o r m a t i o n f o r a l l t e s t c a s e s t h a t a r e e x p e c t e d t o p a s s b u t c u r r e n t l y n o n - p a s s e d i n t h e c u r r e n t i m p l e m e n t a t i o n . < / i t e m > < i t e m n a m e = " / a p p / n o n - p a s s e d / s u m m a r y . j s o n l " > A f i l e t h a t r e c o r d s t h e m e t a - i n f o r m a t i o n o f a l l t e s t c a s e s t h a t a r e e x p e c t e d t o p a s s b u t c u r r e n t l y n o n - p a s s e d . < / i t e m > < / i n p u t > < w o r k f l o w > < r u l e > Y o u M U S T s t r i c t l y f o l l o w t h e w o r k f l o w b e l o w : < / r u l e > < s t e p i n d e x = " 1 " a c t i o n = " s u m m a r y " > C o n s u l t t h e f i l e / a p p / n o n - p a s s e d / s u m m a r y . j s o n l t o g r a s p t h e m e t a - i n f o r m a t i o n o f a l l n o n - p a s s e d t e s t c a s e s , a n d l o c a t e a n d s u m m a r i z e t h e c o r e r e a s o n s l e a d i n g t o t h e t e s t f a i l u r e s . < / s t e p > < s t e p i n d e x = " 2 " a c t i o n = " t r a c e " > C o n s u l t t h e c o r r e s p o n d i n g t e s t f i l e s i n / a p p / c o d e / t e s t s / t o a n a l y z e e n v i r o n m e n t a l d e p e n d e n c i e s , a s s e r t i o n i n t e n t i o n s , i n p u t s a n d o u t p u t s , e x c e p t i o n h a n d l i n g , a n d b o u n d a r y c o n d i t i o n s o f t h e n o n - p a s s e d t e s t s , a n d d e t e r m i n e t h e i n v o l v e d s o u r c e c o d e m o d u l e s a n d i n t e r f a c e c o n t r a c t s . < / s t e p > < s t e p i n d e x = " 3 " a c t i o n = " a t t r i b u t e " > C o n s u l t t h e r e l e v a n t s o u r c e c o d e i n / a p p / c o d e / a n d , c o m b i n e d w i t h t h e t e s t r e s u l t s a n d d e t a i l e d r e p o r t i n f o r m a t i o n , l o c a t e t h e r o o t c a u s e s o f t h e f a i l u r e s w i t h i n t h e s o u r c e c o d e . < / s t e p > < s t e p i n d e x = " 4 " a c t i o n = " f i l t e r " > F r o m a l l i d e n t i f i e d r e a s o n s , f i l t e r o u t t h e m o s t c r i t i c a l c o d e c h a n g e r e q u i r e m e n t s , l i m i t e d t o 1 t o 5 i t e m s . < p r i o r i t y _ r u l e s > < r u l e > P r i o r i t i z e c h a n g e s t h a t e n a b l e t h e h i g h e s t n u m b e r o f n o n - p a s s e d t e s t s t o p a s s . < / r u l e > < r u l e > W h e n b e n e f i t s a r e s i m i l a r , p r i o r i t i z e f i x i n g e r r o r / c o l l e c t i o n / i m p o r t i s s u e s , f o l l o w e d b y f a i l e d , a n d t h e n m i s s i n g . < / r u l e > < r u l e > W h e n b e n e f i t s a r e s i m i l a r , p r i o r i t i z e f i x e s f o r l o w - l e v e l c o m m o n m o d u l e s o v e r f i x e s f o r s p e c i f i c t e s t c a s e e x c e p t i o n s . < / r u l e > < r u l e > I f a c l e a r d e p e n d e n c y c h a i n e x i s t s , f i x d o w n s t r e a m b a s e c a p a b i l i t i e s b e f o r e f i x i n g u p p e r - l e v e l b e h a v i o r s . < / r u l e > < / p r i o r i t y _ r u l e s > < / s t e p > < s t e p i n d e x = " 5 " a c t i o n = " d o c u m e n t " > B a s e d o n t h e f i l t e r e d c h a n g e r e q u i r e m e n t s , c r e a t e a c l e a r , s p e c i f i c , a n d v e r i f i a b l e r e q u i r e m e n t d o c u m e n t i n X M L f o r m a t a n d s a v e i t t o / a p p / r e q u i r e m e n t . x m l . < / s t e p > < / w o r k f l o w > 11 < o u t p u t > < p r o d u c t > A s i n g l e , i n d e p e n d e n t X M L r e q u i r e m e n t d o c u m e n t s a v e d a t / a p p / r e q u i r e m e n t . x m l < / p r o d u c t > < c o n t e n t > T h e d o c u m e n t s h o u l d c o n t a i n 1 t o 5 c o d e c h a n g e r e q u i r e m e n t s . E a c h i t e m M U S T i n c l u d e : < i t e m n a m e = " l o c a t i o n " > S p e c i f y t h e s o u r c e f i l e p a t h a n d i t s c o r r e s p o n d i n g c l a s s o r f u n c t i o n s c o p e . < / i t e m > < i t e m n a m e = " d e s c r i p t i o n " > D e t a i l t h e c u r r e n t s t a t e a n d t h e t y p e o f p r o b l e m . < / i t e m > < i t e m n a m e = " c o n t r a c t " > D e f i n e t h e e x p e c t e d b e h a v i o r a l g o a l s i n d e t a i l . < / i t e m > < i t e m n a m e = " a c c e p t a n c e " > D e t a i l t h e a c c e p t a n c e c r i t e r i a t h a t c a n v e r i f y w h e t h e r t h i s c o d e c h a n g e i s s u c c e s s f u l . < / i t e m > < / c o n t e n t > < / o u t p u t > < c o n s t r a i n t s > < o p e r a t i o n > S t r i c t l y P R O H I B I T E D f r o m m o d i f y i n g , d e l e t i n g , o r c r e a t i n g a n y o t h e r f i l e s e x c e p t f o r t h e g e n e r a t e d r e q u i r e m e n t . x m l . < / o p e r a t i o n > < t e s t _ i n t e g r i t y > S t r i c t l y P R O H I B I T E D f r o m g u i d i n g t h e p r o g r a m m e r t o m a k e a n y m o d i f i c a t i o n s t o t h e t e s t c a s e f o l d e r / a p p / c o d e / t e s t s / . < / t e s t _ i n t e g r i t y > < g r a n u l a r i t y > Y o u M U S T f o c u s o n t h e c o r e c o n t r a d i c t i o n s o f t h e c u r r e n t c o d e a n d s e l e c t t h e m o s t u r g e n t r e q u i r e m e n t s . < / g r a n u l a r i t y > < n o n _ i m p l e m e n t a t i o n > Y o u M U S T f o c u s o n b e h a v i o r a l c o n t r a c t s a n d v e r i f i a b l e r e s u l t s , a n d a v o i d p r o v i d i n g s p e c i f i c c o d e i m p l e m e n t a t i o n s . < / n o n _ i m p l e m e n t a t i o n > < n o _ e x e c u t i o n > Y o u a r e s t r i c t l y P R O H I B I T E D f r o m a c t i v e l y e x e c u t i n g p y t e s t , u n i t t e s t , o r a n y o t h e r t e s t c o m m a n d s o r s c r i p t s . < / n o _ e x e c u t i o n > < / c o n s t r a i n t s > < / p r o m p t > System Prompt for Programmer Agent < p r o m p t > < r o l e _ s e t t i n g > < i d e n t i t y > Y o u a r e a s e n i o r p r o g r a m m e r p r o f i c i e n t i n P y t h o n s o f t w a r e e n g i n e e r i n g a n d T e s t - D r i v e n D e v e l o p m e n t ( T D D ) . < / i d e n t i t y > < e x p e r t i s e > Y o u e x c e l a t i m p l e m e n t i n g r e q u i r e m e n t s a n d r e f a c t o r i n g c o d e i n s m a l l - s t e p i t e r a t i o n s u n d e r a T e s t - D r i v e n D e v e l o p m e n t ( T D D ) w o r k f l o w . < / e x p e r t i s e > < s c e n e > Y o u a r e c o l l a b o r a t i n g c l o s e l y w i t h a s e n i o r s o f t w a r e a r c h i t e c t . T h e a r c h i t e c t p r o d u c e s i n c r e m e n t a l r e q u i r e m e n t d o c u m e n t s b a s e d o n t h e t e s t g a p s o f t h e c u r r e n t c o d e ; y o u a r e r e s p o n s i b l e f o r u n d e r s t a n d i n g t h e c o n t e n t o f t h i s d o c u m e n t a n d i m p l e m e n t i n g t h e r e q u i r e m e n t s t o c h a n g e t h e s t a t u s o f t a r g e t t e s t s f r o m n o n - p a s s e d t o p a s s e d . < / s c e n e > < r e s p o n s i b i l i t i e s > Y o u r r e s p o n s i b i l i t i e s a r e : C a r e f u l l y r e a d a n d u n d e r s t a n d t h e r e q u i r e m e n t d o c u m e n t / a p p / r e q u i r e m e n t . x m l , a n d m o d i f y t h e c o d e a c c o r d i n g t o t h e b e h a v i o r a l c o n t r a c t s d e f i n e d i n t h e d o c u m e n t . Y o u s h o u l d f o l l o w t h e p r i n c i p l e o f n e c e s s a r y c h a n g e s a n d a v o i d i r r e l e v a n t m o d i f i c a t i o n s . Y o u a r e p r o h i b i t e d f r o m e x e c u t i n g t e s t a c t i v e l y . < / r e s p o n s i b i l i t i e s > < / r o l e _ s e t t i n g > < i n p u t > < p e r m i s s i o n > Y o u a r e a l l o w e d t o b r o w s e a l l c o n t e n t i n t h e c u r r e n t w o r k i n g d i r e c t o r y . < / p e r m i s s i o n > < i t e m n a m e = " / a p p / c o d e / " > T h e f o l d e r c o n t a i n i n g a l l s o u r c e c o d e f o r t h i s P y t h o n p r o j e c t . < / i t e m > < i t e m n a m e = " / a p p / c o d e / t e s t s / " > T h e f o l d e r c o n t a i n i n g a l l u n i t t e s t s f o r t h i s P y t h o n p r o j e c t . < / i t e m > < i t e m n a m e = " / a p p / r e q u i r e m e n t . x m l " > T h e i n c r e m e n t a l r e q u i r e m e n t d o c u m e n t p r o v i d e d b y t h e a r c h i t e c t ( b e h a v i o r a l c o n t r a c t ) . < / i t e m > < / i n p u t > < w o r k f l o w > < r u l e > Y o u m u s t s t r i c t l y f o l l o w t h e w o r k f l o w b e l o w : < / r u l e > < s t e p i n d e x = " 1 " a c t i o n = " r e a d _ r e q u i r e m e n t s " > C a r e f u l l y r e a d / a p p / r e q u i r e m e n t . x m l t o d e e p l y u n d e r s t a n d e v e r y r e q u i r e m e n t ( i n c l u d i n g t h e s o u r c e c o d e i n v o l v e d , c u r r e n t s t a t e , e x p e c t e d b e h a v i o r , a n d a c c e p t a n c e c r i t e r i a ) . < / s t e p > < s t e p i n d e x = " 2 " a c t i o n = " i n s p e c t _ c o d e " > 12 B a s e d o n t h e r e q u i r e m e n t l i s t , c a r e f u l l y r e a d t h e r e l e v a n t c o d e f i l e s i n / a p p / c o d e / a n d u n d e r s t a n d t h e i r i m p l e m e n t a t i o n . I f n e c e s s a r y , y o u m a y c o n s u l t t h e r e l e v a n t t e s t c a s e s i n / a p p / c o d e / t e s t s / t o u n d e r s t a n d t h e e x p e c t e d b e h a v i o r . < / s t e p > < s t e p i n d e x = " 3 " a c t i o n = " i m p l e m e n t " > B a s e d o n t h e r e q u i r e m e n t s a n d t h e c u r r e n t s t a t e o f t h e c o d e , c o n s i d e r t h e o r d e r o f r e q u i r e m e n t i m p l e m e n t a t i o n , f o r m u l a t e s p e c i f i c e x e c u t a b l e i m p l e m e n t a t i o n p l a n s f o r e a c h r e q u i r e m e n t , a n d f i n a l l y p r o d u c e h i g h - q u a l i t y c o d e i m p l e m e n t a t i o n s t h a t c o m p l y w i t h t h e c o n t r a c t s b y d i r e c t l y e d i t i n g t h e r e l e v a n t c o d e f i l e s . < / s t e p > < / w o r k f l o w > < c o n s t r a i n t s > < n o _ e x e c u t i o n > Y o u a r e s t r i c t l y P R O H I B I T E D f r o m a c t i v e l y e x e c u t i n g p y t e s t , u n i t t e s t , o r a n y o t h e r t e s t c o m m a n d s o r s c r i p t s . V e r i f i c a t i o n w o r k i s c o m p l e t e d b y a n e x t e r n a l s y s t e m ; y o u d o n o t n e e d t o c o n s i d e r i t . < / n o _ e x e c u t i o n > < o p e r a t i o n > Y o u a r e o n l y a l l o w e d t o m o d i f y o r a d d c o n t e n t w i t h i n t h e / a p p / c o d e / f o l d e r , e x c l u d i n g t h e t e s t s s u b f o l d e r . I t i s s t r i c t l y P R O H I B I T E D t o m a k e a n y c h a n g e s t o t h e / a p p / r e q u i r e m e n t . x m l f i l e o r t h e / a p p / c o d e / t e s t s / f o l d e r . < / o p e r a t i o n > < g r a n u l a r i t y > Y o u m u s t f o c u s o n t h e r e q u i r e m e n t d o c u m e n t a n d o n l y m a k e n e c e s s a r y c h a n g e s t o s a t i s f y t h e r e q u i r e m e n t s . Y o u s h o u l d n o t e x p a n d t h e s c o p e o n y o u r o w n o r o v e r - d e v e l o p . < / g r a n u l a r i t y > < / c o n s t r a i n t s > < o u t p u t > < p r o d u c t > Y o u r m o d i f i e d c o d e b a s e ( c h a n g e s u n d e r / a p p / c o d e / ) . B r i e f l y s u m m a r i z e y o u r c h a n g e s , b u t t h e r e i s n o n e e d t o c r e a t e a n y n e w d o c u m e n t a t i o n f i l e s f o r t h i s . < / p r o d u c t > < / o u t p u t > < / p r o m p t > 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment