연속 통합 기반 LLM 코드 유지보수 능력 평가 벤치마크 SWE‑CI
SWE‑CI는 실제 오픈소스 저장소의 장기 커밋 히스토리를 활용해, LLM 기반 에이전트가 지속적인 코드 유지보수와 기능 확장을 얼마나 잘 수행하는지를 측정한다. 100개의 과제는 평균 233일·71개의 커밋을 포함하며, 요구사항‑코드‑테스트의 CI 루프를 반복 수행한다. EvoScore와 Normalized Change라는 새로운 메트릭을 도입해 장기적인 유지보수성을 정량화한다.
저자: Jialong Chen, X, er Xu
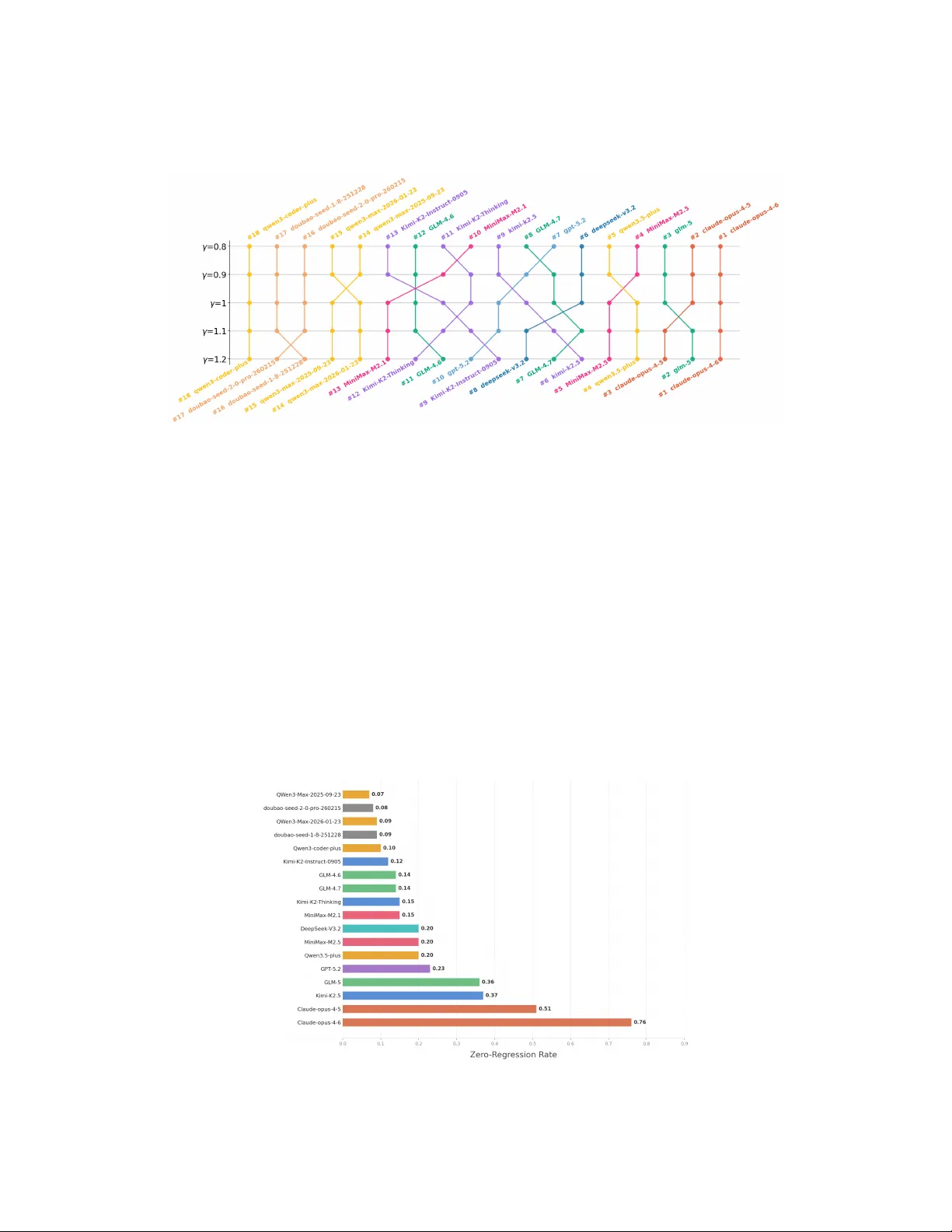
본 논문은 대형 언어 모델(LLM) 기반 에이전트가 실제 소프트웨어 개발에서 요구되는 **장기 유지보수 능력**을 평가하기 위한 새로운 벤치마크 SWE‑CI를 제안한다. 기존의 SWE‑bench, HumanEval, MBPP 등은 단일 요구사항에 대한 정답을 찾는 “스냅샷‑기반” 평가에 머물러, 코드가 시간이 흐름에 따라 어떻게 변하고 유지보수 비용이 누적되는지를 측정하지 못한다. 이를 보완하고자 저자들은 **연속 통합(CI) 루프**를 모사한 평가 프레임워크를 설계하였다.
SWE‑CI는 100개의 과제로 구성되며, 각 과제는 실제 오픈소스 저장소에서 추출한 베이스 커밋과 오라클 커밋을 쌍으로 만든다. 평균 233일·71개의 연속 커밋을 포함해, 최소 1,000줄 이상의 코드 변경을 포함한다. 데이터 수집 단계에서는 별 ≥ 500, 유지기간 ≥ 3년, 의존성·테스트 파일을 갖춘 Python 프로젝트를 4,923개 선별하고, 메인 브랜치의 의존성 불변 구간을 찾아 서브시퀀스를 추출했다. Docker 환경 자동 구축·의존성 보강(self‑repair) 과정을 통해 실행 가능한 후보를 확보하고, 테스트 차이 ≥ 5와 실행 오류 없는 경우만 남겨 최종 100개의 고품질 과제를 선정하였다.
평가 프로토콜은 **Architect‑Programmer 듀얼 에이전트** 모델을 사용한다. Architect는 현재 코드와 목표 코드 사이의 테스트 격차를 분석해, “요약‑위치‑설계” 3단계로 구성된 고수준 요구사항 문서를 만든다. 요구사항은 증분(최대 5개)·고수준 형태로 제한해, Programmer가 구현에 집중하도록 설계되었다. Programmer는 “이해‑계획‑코드” 3단계로 요구사항을 실제 패치에 반영한다. 각 라운드마다 pytest 기반 테스트를 실행하고, 통과한 테스트 수 n(c)를 기반으로 **Normalized Change** a(c)를 계산한다. a(c)는 베이스와 오라클 사이의 전체 테스트 격차를 정규화해
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기