Personalized Fall Detection by Balancing Data with Selective Feedback Using Contrastive Learning
Personalized fall detection models can significantly improve accuracy by adapting to individual motion patterns, yet their effectiveness is often limited by the scarcity of real-world fall data and the dominance of non-fall feedback samples. This imb…
Authors: Awatif Yasmin, Tarek Mahmud, Sana Alamgeer
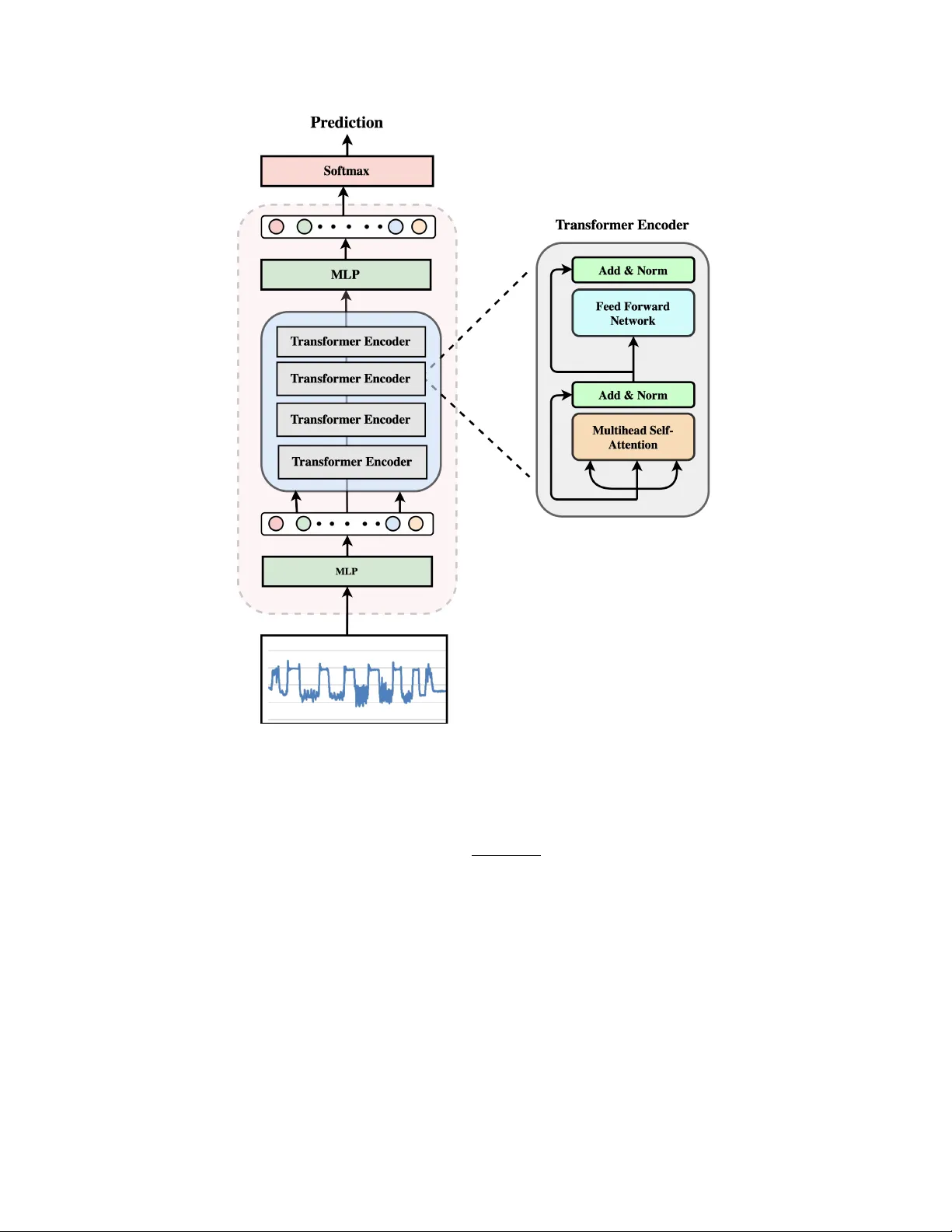
P E R S O N A L I Z E D F A L L D E T E C T I O N B Y B A L A N C I N G D A T A W I T H S E L E C T I V E F E E D B A C K U S I N G C O N T R A S T I V E L E A R N I N G A watif Y asmin T exas State Univ ersity nuc4@txstate.edu T arek Mahmud T exas A&M Univ ersity - Kingsville tarek.mahmud@tamuk.edu Sana Alamgeer T exas State Univ ersity sana.alamgeer@txstate.edu Anne H. H. Ngu T exas State Univ ersity angu@txstate.edu March 19, 2026 A B S T R AC T Personalized f all detection models can significantly impro ve accuracy by adapting to indi vidual mo- tion patterns, yet their effecti veness is often limited by the scarcity of real-world f all data and the dominance of non-fall feedback samples. This imbalance biases the model toward routine acti vities and weakens its sensitivity to true fall ev ents. T o address this challenge, we propose a personalization framew ork that combines semi-supervised clustering with contrastive learning to identify and bal- ance the most informative user feedback samples. The frame work is ev aluated under three retraining strategies, including T raining from Scratch (TFS), T ransfer Learning (TL), and Few-Shot Learning (FSL), to assess adaptability across learning paradigms. Real-time experiments with ten participants show that the TFS approach achieves the highest performance, with up to a 25% improvement ov er the baseline, while FSL achiev es the second-highest performance with a 7% improvement, demon- strating the effecti veness of selecti ve personalization for real-world deplo yment. K eywords Fall Detection, Personalization, T ransformer 1 Introduction Personalization has become a cornerstone of modern intelligent systems, playing a crucial role in enhancing user experiences and system performance across a wide range of domains, from content recommendation engines (like those used in Y ouT ube) to adaptive smart homes [13, 27] and autonomous vehicles [11, 15, 28]. Personalization allows systems to tailor their beha vior to indi vidual users’ unique preferences, beha viors, and contexts [21]. This user- centric approach is particularly valuable in applications where variability in user characteristics or en vironments can significantly affect the system’ s effecti veness. By learning and adapting to individual patterns o ver time, personalized models can offer impro ved accuracy , applicability , and usability compared to generalized, one-size-fits-all solutions. In the healthcare domain, personalization is especially critical, as physiological, beha vioral, and en vironmental factors vary greatly from user to user [19]. A personalized fall detection system is beneficial for monitoring elderly individuals living independently , as timely and accurate detection is essential to ensure rapid assistance. Traditional f all detection systems often rely on generalized models that fail to account for individual differences in mov ement patterns. As a result, these systems will result in high false alarms or miss actual fall e vents, and result in low user acceptance. T o build an accurate and practical personalized fall detection model, it is essential to collect motion-based activity data from the target user . Se veral recent works propose personalization strategies [6, 21, 7, 5] for human activity recognition and fall detection that rely on user metadata, domain adaptation, labeled retraining, and multi-sensor setups, respectiv ely , which are not feasible due to their dependence on external data, continuous data assumptions, and complex infrastructure. Additionally , fall events are usually rare, making it difficult to gather fall-specific data A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 during normal usage. When a user wears a sensor-embedded de vice for fall detection, the majority of the data collected typically consists of Acti vities of Daily Li ving (ADLs), with little to no fall instances. Retraining the model using only this ADL data creates a highly imbalanced dataset, which biases the model toward recognizing ADLs and reduces its sensitivity to f alls. The issue becomes more severe with each round of personalization when additional ADL samples are added without corresponding fall data, where only a fe w types of ADL samples dominate (i.e., walking, sitting, etc.). T o mitigate this imbalance, we employ semi-supervised clustering with contrastiv e learning to selectiv ely choose and balance the training data to train a personalized model, ensuring that the personalized models are trained on representativ e and ev enly distributed data. This approach also helps maintain a higher recall compared to the one- size-fits-all fall detection model. W e ev aluated the effecti veness of our approach using the SmartFallMM dataset [30]. W e trained the initial fall detection model using T ransformer ( M O ), which serves as the baseline for all participants. Subsequently , each user’ s feedback data was gathered for 18 hours while the user wore the smartwatch on his/her left wrist and interacted with the system in the home environment. During this time, the initial model M O was running in the background. When a fall was predicted by the system, users confirm whether it was a true positiv e or a false alarm, enabling the system to label and store the feedback data. This data was then used to retrain the M O for each individual, resulting in personalized models ( M P i , where i ∈ { 1 , 2 , . . . , N } and N is the total number of participants). Our experimental results showed that all the personalized models M P i trained with selectiv ely chosen ADL data achiev ed better precision and recall than the initial common model M O as well as the models trained with combined feedback data from all users. The primary contributions of this w ork are summarized as follo ws: • Balanced Data for Personalization: W e use a semi-supervised contrastiv e learning to carefully select ADL data for re-training. This approach not only addresses the ov erall class imbalance between fall and non-fall activities but also ensures div ersity within the non-fall class itself. By avoiding over -representation of any single activity (e.g., walking or sitting), we create a more balanced and representativ e training set, which improv es the quality and generalizability of the personalized model, M P i . • Improved Recall in Personalized Models: Our method sho ws a significant improvement in recall compared to the model trained with combined feedback data from all users. This means the personalized models trained with our selectiv e feedback data, M P i , are better at detecting fall events without increasing false positiv es, which is important for real-world scenarios. • Practical Personalization Process: The proposed framework simplifies and scales the process of personal- ization by embedding semi-supervised learning in the pipeline. By automatically selecting training samples using semi-supervised clustering and similarity metrics, we eliminate the need for manual labeling of ADL feedback data for re-training. 2 Background Personalization is a strategy to optimize machine learning models for individual users or specific user groups, particu- larly in scenarios where generalized, one-size-fits-all models fail to achie ve high accuracy [6]. This approach becomes essential in domains in volving biometric and behavioral data, such as human activity recognition, voice-prints, gait cycles, and hand mov ement patterns, including orientation and grasp, where the inherent variability across individuals makes it dif ficult for models to generalize ef fecti vely . In such systems, a typical pipeline, as sho wn in figure 1, begins with the user i interacting with a de vice or environment equipped with sensors, such as smartphones, smartwatches, cameras, or ambient embedded systems within smart homes. During initial usage, the system collects demographic metadata and a limited set of real-time sensor data to serve as a calibration phase. Pre-trained fall detection model ( M O ) makes early predictions based on this data. Concurrently , the system continuously stores the sensed time series data and predicted labels on a cloud-based server . Once a suf ficient volume of data has been collected from a particular user or group based on a defined metric, a personalized model ( M P i corresponding to the i -th user) is trained. This updated model is then stored in a cloud infrastructure and deployed back to the device when the user activ ates the App next, offering improved accuracy tailored to that user’ s specific behavioral patterns. As more user data is collected, the repeated process of retraining helps the model become more precise with a reduced number of false positi ves without sacrificing the recall. In practical fall detection scenarios, as users continuously interact with the system, the model predominantly recei ves feedback data, which is mostly ADL. During personalized retraining, we combine the original training dataset with the user’ s ne wly collected feedback data. Over time, this naiv e approach progressively increases the data imbalance tow ard ADLs, inadvertently introducing bias into the model. W e used a subset of the SmartFallMM [30] dataset as the 2 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 User (i) Label, Store T rain, Update Personalized Model (M Pi ) System Pre-trained ML Model (M O ) Cloud based Storage Data Figure 1: Personalization pipeline initial training data, which includes fall and ADL samples from 30 participants (a total of 1,950 trials). T o personalize the model for each user , we merged their collected feedback data with this dataset and trained a new model tailored to that individual. Figure 2 illustrates this effect for a particular i -th user . Initially , retraining the model with just three hours of the user’ s ADL data yielded a recall of 0.81. Howe ver , with each subsequent retraining session (each adding an additional three hours of ADL data), the recall steadily decreased. By the sixth retraining cycle, recall dropped below 0.50, demonstrating a notable reduction in the model’ s capacity to accurately detect falls. On the other hand, precision impro ved incrementally with additional ADL data. This indicates that while the model generates fe wer false positiv es over time, it simultaneously loses ef fecti veness in identifying actual fall e vents. Our systematic analysis shows that incorporating more than 20% feedback data during personalization results in a noticeable recall drop on the SmartFallMM dataset, indicating increased bias toward ADL patterns. This highlights the risk of ov erfitting to ADLs when fall data are scarce. T o address this issue, we in vestigate strategies that maintain recall across successiv e personalization rounds. 3 Related W ork Personalization remains a key challenge in human activity recognition due to large inter-user variability and limited labeled data. Recent work addresses this through adaptive modeling , which customizes acti vity recognition for each individual by learning user-specific motion patterns and incorporating user feedback, unsupervised or self-supervised learning , which learns representations from unlabeled data, and active learning , which strategically selects informativ e samples for labeling. Adaptive Modeling Lingmei and W eisong [26] introduced a subject-adaptiv e thresholding mechanism using a waist-worn sensor and a weighted combination of user-specific and group-lev el thresholds. While this approach bet- ter captures individual variability , it relies heavily on heuristic rules and hand-crafted features. V allabh et al. [32] proposed a personalized fall detector using smartphone accelerometer data and angle-based outlier detection with- out explicit fall data, but its unbounded retraining risks overfitting and drift, and its signal magnitude vector-based 3 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 Figure 2: Reducing recall over time (SMV)segmentation is sensitiv e to noisy , low-fidelity sensors. Brian et al. [31] similarly used subject-specific non-fall distributions and a fixed threshold from external fall data, refined by user feedback, but their method assumes stable sensor quality and lacks online adaptation, limiting robustness in dynamic en vironments. Ferrari et al. [6] improved accuracy by exploiting user similarity based on physical traits and sensor signals, yet their approach is less suitable for fall detection, where metadata are often unav ailable, and fall events are rare and highly indi vidual. Ngu et al. [24] proposed a real-time personalized system using an LSTM-based model deplo yed on wrist-worn smartwatches, le veraging user feedback for periodic retraining from scratch. They trim feedback segments around acceleration spikes to reduce noise, but this trimming is purely temporal and does not account for semantic informativ eness, so it cannot distinguish high-quality from redundant samples. Diraco et al. [5] highlighted the importance of personalization and conte xt in smart li ving en vironments, b ut their w ork focuses on multi-sensor-based systems rather than single-device wearables. Mhalla et al. [21] introduced a domain adaptation frame work that personalizes models without labeled data. Howe ver , the method assumes a smooth domain shift and continuous data streams, conditions that rarely hold in sporadic, e vent-dri ven fall detection. Our approach is tailored for fall detection on resource-constrained wearables, operating without additional user metadata or external sensors. Unsupervised and Self-super vised Learning Unsupervised and self-supervised techniques hav e been increasingly used to reduce dependence on labeled data. For example, Li et al. [18] proposed a self-supervised framework that enhances skeleton-based action recognition through feature enrichment and fidelity preservation. Qin et al. [25] in- troduced a progressi ve semantic learning approach that incrementally refines ambiguous action representations in an unsupervised manner . On the other hand, Xu et al. [33] addressed a core limitation in contrastiv e learning, excessiv e intra-class variance, by introducing a fuzzy threshold mechanism to better distinguish between positive and negati ve samples based on similarity distributions using multi-perspectiv e skeleton data. These methods excel on vision-based skeleton data but are less suited to wearable sensor-based fall detection, where irregular sampling, high noise, and extreme class imbalance dominate. They also lack mechanisms for temporal distortions, rare-e vent modeling, and online personalization. Active Learning Acti ve learning methods aim to maximize model performance while minimizing labeling costs by strategically selecting the most informativ e unlabeled samples for annotation. For example, Hasan and Roy-Cho wdhury [10] employed entropy-based active learning with conditional random fields to select informative samples for video-based activity recognition. Bi et al. [3] combined uncertainty , diversity , and representati veness 4 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 criteria to select informativ e samples and identify new acti vity classes. Kazllarof and Kotsiantis [12] applied ac- tiv e learning with least confidence sampling to time series feature extraction across spectral, statistical, and temporal domains. More recently , Arrotta et al. [1] introduced SelfAct, which combines self-supervised learning with an unsu- pervised acti ve learning strategy based on cluster density , selecting representativ e samples from clusters of embeddings generated by a pre-trained model. Our framew ork addresses a related but distinct challenge. Activ e learning assumes control ov er which samples to present for labeling, which is impractical in real-world fall detection, where alerts occur naturally during daily ac- tivities, and users can only confirm or reject them as they happen. Rather than selecting which samples to label, we operate on already-labeled user feedback (TP/FP confirmations) and focus on selecting which confirmed samples to incorporate during retraining. This is necessary because feedback data is inherently imbalanced, i.e., false positiv es from routine ADLs vastly outnumber true fall ev ents, biasing the model toward non-fall patterns and reducing fall sensitivity . Our clustering-based gradient selection addresses this by identifying diverse, informati ve e xamples from the feedback pool to balance class representation. 4 Methodology Figure 3 presents an overvie w of the personalization pipeline for each user . The pipeline begins with the feedback data collected from the user while using a fall detection model. For this, we used a pretrained transformer model ( M O ) trained with a subset of the SmartFallMM dataset [30], deployed on a smartwatch for fall detection. Whenever the model triggers fall alerts as users go about their daily acti vities, the system prompts the user to provide feedback by confirming whether the alert was a true positiv e (TP), an actual fall, or a false positi ve (FP), an ADL incorrectly classified as a fall. All confirmed FP and TP are automatically archiv ed to the cloud. False positiv es are especially useful for helping the model learn to distinguish between fall-like ADLs and actual falls. True positi ves are equally important, as they represent real fall patterns specific to each user . These labeled samples (both FP and TP) are stacked and clustered using a pretrained Siamese Neural Network (SNN), a general-purpose model trained in adv ance using the same subset of the SmartFallMM dataset as the initial transformer model M O . The SNN is stored in the cloud and reused across all users to consistently group similar feedback samples. Finally , to build a compact and representativ e training set, we compute the gradient for each sample and select the top x samples from each cluster based on their contribution to model learning. These selected instances, representing di verse and challenging examples, are then combined with the original training data used by M O to retrain a personalized fall detection model M P i . 4.1 F eedback Data Collection W e deployed a fall detection model ( M O ) on a smartwatch-based fall detection application (details omitted for anonymity) and recruited ten participants to use the App at home to collect feedback data. 4.1.1 F all Detection Model The initial fall detection model, M O was obtained by training a Transformer model [9] with a subset of the Smart- FallMM dataset. Our implementation used a Transformer architecture, illustrated in figure 4, comprising 4 encoder layers and 4 multi-head attention heads, with an attention embedding size of 128 and a dropout rate of 0.25. The final representation was passed through a multi-layer perceptron (MLP) with 1, 8, and 16 layer sizes. W e applied a sigmoid activ ation function at the output and trained the model using binary cross-entropy loss. T raining was con- ducted ov er 100 epochs using the Adam optimizer , with a batch size of 64 and a learning rate of 0.001. T o promote subject-independent generalization, we adopted a leav e-one-subject-out cross-v alidation strategy for e valuation. 4.1.2 Data Collection via User Interaction Once the smartwatch is paired with a smartphone, data sensing is acti vated through the phone’ s App interface. After activ ation, all interactions with the users occur through the smartw atch. The App continuously senses 128 accelerom- eter data points from the wrist’ s motion before making a fall prediction. Each data point w as sampled at an interval of 32 ms. If a fall is detected, the watch will prompt the user for confirmation. A “NO” response is recorded as a false positiv e (FP), while a “YES” response is follo wed by an additional prompt asking if help is needed. Confirmed falls, whether help is requested or not, are sa ved as true positives (TP). This labeled feedback data is periodically uploaded to the cloud server and will be used to train the personalized model M P i for each user . 5 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 Data Prepr ocessing Clustering with Pretrained SNN Gradient based Data Selection (b) SNN architectur e Contrastive Loss Distance Layer Dense Layer 2 Dense Layer 1 Output Layer Input Layer Clusters Merge Dataset and Re-training (a) Feedback Data Collection Balanced Feedback Data Figure 3: (a) Overview of the pipeline for training personalized models ( M P i ) & (b) SNN architecture In our experimental studies, each user will use the system for three hours per day ov er six days. During this time, the user’ s only task is to provide feedback by confirming whether any fall alert triggered by the model is a true positiv e or a false positi ve. At the end of the sixth day , the sa ved feedback data is downloaded from the cloud and clustered. This enables the identification of different clusters of ADL activities and selection of informativ e samples to personalize the model for each user . 4.2 Data Prepr ocessing W e start the personalization process by se gmenting each feedback sample using a sliding window approach with over - lap. Through experimentation, a window size of 128 data points with a 10-point overlap provided optimal results for distinguishing falls from ADLs. With the smartwatch sampling rate of 32 ms, each window represents approximately 4 s of activity . For each windo w , we compute similarity scores using three complementary measures: Pearson’ s Linear Correlation Coefficient (PLCC) [2], Dynamic Time W arping (DTW) [35], and Cosine Similarity [23]. These metrics jointly capture aligned temporal trends, temporal misalignments, and complex feature-space relationships, enabling robust and discriminati ve clustering of user feedback data. PLCC quantifies the linear relationship between two sequences, identifying patterns that move together over time, ev en if their scales differ . It is defined as: r x,y = P n i =1 ( x i − x )( y i − y ) p P n i =1 ( x i − x ) 2 × p P n i =1 ( y i − y ) 2 where x i and y i are data points, and x and y are their means. DTW measures the optimal alignment between two sequences that may differ in speed or duration—useful in fall scenarios where timing varies. It is computed as: D T W ( i, j ) = d ( x i , y j ) + min D T W ( i − 1 , j ) , D T W ( i, j − 1) , D T W ( i − 1 , j − 1) where d ( x i , y j ) is the distance between points. 6 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 Figure 4: Transformer architecture Cosine Similarity ev aluates the angle between two vectors, ignoring magnitude, making it suitable for deep feature comparisons: cos( θ ) = x · y ∥ x ∥ × ∥ y ∥ 4.3 Clustering with Pretrained SNN W e first trained a Siamese Neural Network (SNN) [29] on the SmartFallMM dataset [30] and used the pretrained model to cluster feedback data based on similarity to labeled ADL patterns. SNNs are well-suited for this task because they learn pairwise similarity and perform ef fectively with limited labeled data, making them particularly useful when few samples are a vailable per class [29]. By producing discriminative embeddings, the SNN enables semi-supervised clustering and identification of high-confidence unlabeled ADL samples. The SNN architecture used for clustering consists of three main components: a base network, a distance layer , and a contrastiv e loss function, as illustrated in Figure 3(b). 1. Base Network: The base network serves as a shared feature extractor that transforms each input vector into a fixed-length embedding. Both inputs pass through identical networks with shared weights to ensure consistent feature extraction. The architecture includes four layers: 7 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 • Input Layer: Feature vector of shape (9,), representing similarity metrics (cosine similarity , PLCC, DTW) between accelerometer axes (x, y , z). • Dense Layer 1: 128 neurons with ReLU acti vation. • Dense Layer 2: 64 neurons with ReLU acti vation. • Output Layer: 32 neurons with linear acti vation, producing the embedding v ector . 2. Distance Layer: This layer computes the similarity between two embeddings from the base network using the Euclidean (L2) distance: Distance = ∥ Embedding A − Embedding B ∥ 2 A smaller distance indicates higher similarity , while a larger distance indicates lower similarity . 3. Contrastive Loss: Training is guided by the contrastive loss function [8], which minimizes distances for similar pairs ( y = 1 ) and maximizes them for dissimilar pairs ( y = 0 ) up to a margin: L = y · ( distance ) 2 + (1 − y ) · max(0 , margin − distance ) 2 where y ∈ { 0 , 1 } and the margin is a tunable parameter (e.g., 1.0). The SNN w as trained using data from 30 participants in the SmartF allMM dataset [30] for 100 epochs. This approach allows the model to embed input signals in a discriminati ve feature space, effecti vely grouping similar motion patterns into clusters for use in the selectiv e feedback process. 4.3.1 Clustering Once the pretrained SNN model is obtained, each feedback instance x i ∈ X is passed through it to generate its embedding, forming a lo w-dimensional feature space in which similar motion patterns are grouped for clustering and subsequent selectiv e data selection. After that, the DBSCAN clustering algorithm [14] is emplo yed on the embeddings to group them into clusters as: C = { C 1 , C 2 , . . . , C K } = DBSCAN ( f SNN ( X )) (1) where f SNN ( · ) denotes the SNN model, and C represents the resulting set of clusters. Since the SNN has learned to place similar items close together , the clusters correspond to the true classes. Unlike K -means clustering, DBSCAN automatically determines the appropriate number of clusters based on data density , ensuring that clusters are formed only when sufficient similar samples e xist, and thereby preventing the creation of artificial or redundant groups. 4.4 Gradient-based Data Selection After obtaining the C clusters, we calculate the gradient for each window of data within each cluster C j to identify the windows exhibiting the most significant temporal changes. Since the data points within a window are uniformly spaced in time, we compute the av erage gradient by taking the mean of the consecutiv e differences between points. The gradient for a window w i ∈ C j with n points is computed as [16]: g i = 1 n − 1 n − 1 X z =1 y ( i ) z +1 − y ( i ) z (2) where y ( i ) z represents the signal v alue at the z -th time step of the i -th window . A higher g i value indicates greater tem- poral variation within the windo w , reflecting more dynamic motion patterns such as falls or abrupt limb mov ements. Once the gradient values are computed, we select the windows with the highest g i values, as they contribute most to model learning. Empirical ev aluation on the SmartFallMM dataset showed that using about one-fifth of the data achiev es an optimal trade-of f between accuracy and ef ficiency . Accordingly , x = 0 . 2 × | X | |C | samples are allocated per cluster to provide suf ficient representation of user-specific motion patterns without redundancy . Clusters with fe wer than x samples include all av ailable data, with the remaining quota filled from other clusters, while those with more than x samples apply gradient-based selection to retain only the most informativ e windo ws, yielding a balanced and div erse personalized dataset. 4.5 Merge Dataset F or Retraining and Evaluation The selected feedback samples D sel = S |C | j =1 S j , where S j = T op x ( { g i | x i ∈ C j } ) , are then mer ged with the original SmartFallMM dataset D orig to create a retraining dataset D merged = D orig ∪ D sel . T o assess the effecti veness of the 8 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 proposed selectiv e personalization approach, we ev aluated it under three standard retraining strategies: Training from Scratch (TFS), T ransfer Learning (TL), and Few-Shot Learning (FSL), yielding personalized models M P i . These strategies are employed to examine whether the selecti vely merged dataset D merged improv es model performance across different retraining paradigms. T o train and ev aluate personalized models ( M P i ), each participant’ s feedback data were split using an 80–20 within- subject partition. For each participant, the base model ( M 0 ) was retrained using 80% of the feedback data combined with the original training subset ( D orig ) of SmartFallMM, producing a participant-specific model. The remaining 20% of feedback data were merged with the test subset, containing both fall and ADL events, for ev aluation. This split balances effecti ve retraining and reliable e valuation without overfitting. As a result, each participant yields three personalized models corresponding to TFS, TL, and FSL, producing a total of 30 personalized models for ten participants. 5 Experimental Design W e used the Transformer model described in Section 4.1.1 as our initial model ( M O ). This model was first trained on a subset of the SmartFallMM dataset [30] and then deployed to collect user feedback data during real-world use. The collected feedback from each participant was later used to retrain the model, follo wing three strate gies: T raining From Scratch (TFS), T ransfer Learning (TL), and Fe w-Shot Learning (FSL). 5.1 Initial Model T raining and Feedback Data Collection The initial T ransformer model ( M 0 ) was trained on the SmartFallMM dataset [30], which contains motion data from 30 participants performing 13 activities, including five simulated falls and eight ADLs. The trained model( M 0 ) was deployed on W earOS smartwatches paired with Android phones. T en participants used the system for six days, during which accelerometer data were continuously collected and segmented into 128-sample windows for real-time fall detection. Users provided feedback on detected falls, which was stored in Couchbase to create personalized datasets of confirmed fall and non-fall events. These datasets were subsequently used to retrain personalized models under identical experimental conditions. All models were implemented in T ensorFlow and trained on a Dell Precision 7820 workstation with an NVIDIA GeForce GTX 1080 GPU. Each experiment was repeated three times, and results were av eraged for consistency . Hyperparameters such as learning rate, batch size, embedding dimension, and attention head count were empirically tuned for each approach, and all models were trained and e valuated using identical dataset splits and computational settings to ensure fair comparison. 5.2 Retraining A pproaches After six days of use, the collected feedback data were retriev ed and mer ged with the original SmartFallMM subset to create personalized datasets for each participant. These datasets were used to retrain models using TFS, TL, and FSL, with all experiments conducted under identical hardware and computational conditions for f air comparison. 5.2.1 T raining from Scratch In this approach, the personalized models M P i for each user i are obtained by retraining the M O model using each participant’ s combined dataset D merged , which included both the SmartFallMM subset and their individual selectiv e feedback data. This process allowed the model to completely relearn from both general and user-specific data dis- tributions without relying on pretrained parameters, producing M T F S personalized model. This approach required the longest training time and the greatest computational cost, as all model parameters were optimized from initializa- tion. While highly effecti ve in terms of performance, the high runtime makes this method less practical for on-de vice retraining or frequent updates. 5.2.2 T ransfer Learning For the T ransfer Learning (TL) approach, we applied the fine-tuning method described by Maray et al. [20], adapting it to the Transformer -based architecture illustrated in Figure 4. The lower encoder layers, responsible for extracting fundamental motion features, were frozen to retain general motion dynamics learned from the initial training. The upper layers and the classification head were then retrained using each participant’ s selective feedback data. The model parameters were optimized using the Adam optimizer with categorical cross-entropy loss, and h yperparameters 9 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 Figure 5: Precision and recall over time for models trained with selecti ve data vs. all feedback data such as learning rate, embedding dimension, and number of attention heads were empirically tuned on D merged dataset, producing M T L personalized model. 5.2.3 F ew Shot Learning The Few Shot Learning (FSL) approach was implemented following the method of Zhou et al. [17], designed to enable rapid personalization with limited feedback data. The model shared the same Transformer -based backbone as the TL model, consisting of an input embedding layer, positional encodings, stacked T ransformer encoder blocks, and a fully connected classification head. The lo wer layers were kept frozen to preserve general temporal representations, while only the upper layers and the classifier were fine-tuned using a small set of feedback samples. Unlike the TFS and TL strategies, which retrain or fine-tune the model using the entire mer ged dataset D merged , the FSL model uses only a small subset, resulting in a few-shot-based personalized model M F S . 10 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 T able 1: Real-time ev aluation results of 10 participants using all 3 approaches of retraining vs M O (bold values indicate the highest F1 score achiev ed across models for a given participant) Participant ( i ) Baseline P ersonalized Models ( M P i ) M O M T F S M T L M F S Participant 1 0.69 0.89 0.72 0.79 Participant 2 0.71 0.9 0.69 0.78 Participant 3 0.76 0.92 0.67 0.8 Participant 4 0.68 0.93 0.7 0.76 Participant 5 0.73 0.94 0.75 0.74 Participant 6 0.76 0.88 0.68 0.77 Participant 7 0.75 0.88 0.65 0.81 Participant 8 0.75 0.94 0.71 0.76 Participant 9 0.71 0.93 0.77 0.82 Participant 10 0.74 0.92 0.73 0.79 A verage 0.73 0.91 0.71 0.78 6 Results and Analysis 6.1 Model Perf ormance 6.1.1 Offline Perf ormance Figure 5 sho ws the av erage result from 10 participants using the test set that was built from 20% of that user’ s feed- back data with the TFS retraining strategy . W e can see how precision and recall ev olve for different personalization strategies: using selectiv ely chosen data versus all feedback data. For precision (top panel), both strategies maintain consistently high values over time. The all-data approach yields slightly higher precision but at the cost of bias, i.e., by including many repetitiv e ADL samples, the model becomes ov erly conservati ve, reducing false positiv es but missing true falls. In contrast, the selective-data method, though marginally lo wer in precision, achieves a better balance by preserving sensiti vity to both ADL and fall ev ents. For recall (bottom panel), the difference is more pronounced. Recall with selecti ve data increases steadily from about 0.80 to 0.88, while in the all-data condition, it declines sharply from 0.80 to 0.41 as feedback accumulates. The unfiltered data led to ov erfitting on ADL and poor fall sensitivity . A veraged across participants, the selective-data strategy reached an F1-score of 0.88 (compared to 0.82 for M T F S and 0.48 for the all-data case), confirming that curated, high-gradient samples yield more generalizable and reliable models for personalized fall detection. 6.1.2 Real Time P erformance T able 1 summarizes the F1-scores achie ved by each participant for the baseline T ransformer ( M O ) and three retraining strategies: T raining from Scratch ( M T F S ), Transfer Learning ( M T L ), and Few-Shot Learning ( M F S ). Selective retraining consistently improves performance across all participants. The baseline model ( M O ) achiev ed an av erage F1-score of 0.73, while retraining from scratch ( M T F S ) yielded the best performance with an av erage F1-score of 0.91, representing an improv ement of approximately 25%. Few-shot learning ( M F S ) al so performed well, achie ving an av erage F1-score of 0.78 and offering a fav orable balance between accuracy and efficienc y . In contrast, transfer learning ( M T L ) underperformed with an av erage F1-score of 0.71, indicating limited adaptability to user-specific motion patterns. For example, Participant 4’ s F1-score improv ed from 0.68 ( M O ) to 0.93 ( M T F S ), while Participant 7’ s increased from 0.75 to 0.88. Overall, these results confirm that selectiv e data personalization enhances model robustness, with TFS achie ving the highest accuracy and FSL providing a practical trade-off between performance and computational ef ficiency . 6.2 Perf ormance of SNN T o ensure the accuracy of SNN for our clustering of ADL data, we compare the performance of the proposed SNN across four different datasets. T able 2 summarizes the accuracy of the SNN across four benchmark datasets: Smart- FallMM, HAR, CZU-MHAD, and K-Fall. Accuracy was determined by assigning each cluster to the class with the most representativ e samples. The model demonstrates strong generalization ability across a range of human activity recognition and fall detection tasks, with accuracy v alues ranging from 85% to 94%. 11 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 T able 2: Accuracy of SNN on Dif ferent Datasets Dataset Accuracy SmartFallMM 91% HAR 94% CZU-MHAD 85% K-Fall 86% W alking W aving hands W ashing hands Sitting standing Sweeping W earing a jack et Drinking water Pick up object Activity 82 84 86 88 90 92 Accuracy (%) Figure 6: Clustering accuracy for each activity The highest performance is observed on the HAR [22] dataset, where the model achie ves an accuracy of 94%. This dataset contains clean, structured smartphone sensor data of routine human acti vities performed in controlled settings. On the SmartFallMM dataset, which is the primary dataset used for model dev elopment and ev aluation, the model achiev es an accuracy of 91%. This dataset is characterized by real-world, unconstrained acti vity data collected in div erse conditions. The model also performs well on the CZU-MHAD [4] dataset with an accuracy of 85%. This dataset includes multi- modal motion data captured from multiple users performing a broader set of actions. The K-Fall dataset [34] achieved a strong clustering accuracy of 86%, which is especially notable because it does not include wrist-based sensor data. Unlike other datasets, which are collected from a smartwatch on the wrist, K-Fall uses a sensor placed on the lower back. This means the motion patterns are quite dif ferent. The SNN model achie ves consistently high performance across all datasets, demonstrating its adaptability to dif ferent sensors and acti vities. These results confirm the proposed method’ s potential to be used as a semi-supervised clustering method for feedback data. In addition to model-level e valuation, we assessed the accuracy of the clustering mechanism used for selective data sampling only on SmartFallMM. This component identifies high-gradient, informativ e segments from user feedback, enabling efficient and rob ust retraining by emphasizing representative motion patterns. Figure 6 shows that clustering accuracy varies slightly across ADLs, with an ov erall average of 91%. Activities with distinct and consistent motion patterns, such as W earing a jacket and Sitting and standing, achieved the highest accu- 12 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 T able 3: Comparing the performance of SNN with different inputs Input for SNN Precision Recall F1-Score Similarity metrics 0.92 0.9 0.91 Basic statistical features (min, max, mean, std) 0.75 0.55 0.63 Raw time-series data 0.63 0.72 0.67 T able 4: Model performance across different amounts of feedback data while personalizing T raining Data F1-Score Initial dataset + 5% feedback data 0.80 Initial dataset + 10% feedback data 0.85 Initial dataset + 15% feedback data 0.88 Initial dataset + 20% feedback data 0.91 Initial dataset + 25% feedback data 0.89 racies (92% and 91%, respectively), while W aving hands and Pick up object both reached 90%, indicating effecti ve separation of upper-limb acti vities. Con versely , acti vities inv olving smaller or more repetiti ve wrist movements, such as W ashing hands (87%) and Drink- ing water (85%), e xhibited comparati vely lo wer clustering accuracies. This reduction can be attrib uted to ov erlapping motion characteristics and limited dynamic v ariation, which make these acti vities more challenging to distinguish in the feature space. Despite these minor variations, the clustering accuracy across all activities remained consistently abov e 85%, indicating the reliability and stability of the clustering method. Overall, the results depicted in Figure 6 confirm that the SNN-based clustering framework effecti vely identifies rep- resentativ e and informati ve motion segments for selecti ve retraining. By achieving an a verage clustering accuracy of 89%, the process ensures that feedback-driv en fine-tuning concentrates on the most meaningful data samples. 6.3 Ablation Study 6.3.1 Similarity Metrics vs. Basic Statistical Features T o assess the choice of similarity metrics, we conducted an ablation study . T able 3 presents the performance of three different personalization strategies regarding precision, recall, and F1-score. For this ev aluation, we ran the full personalization pipeline using a dif ferent instance of the SNN for each experiment to ensure robustness and consistency in the results. The method utilizing all 3 similarity metrics, such as cosine similarity , PLCC, and DTW , achieves the highest ov erall performance, with a precision of 0.92, a recall of 0.9, and an F1-score of 0.91. In contrast, substituting these similarity metrics with basic statistical features (minimum, maximum, mean, and stan- dard deviation) results in significantly lower performance. The F1-score drops to 0.63, with a significant decline in recall (0.55), suggesting that simple descriptiv e statistics did not sufficiently capture the complex patterns necessary for accurate fall detection. Similarly , using the raw time-series data without engineered similarity or statistical features leads to a slightly better recall (0.72) than the statistical feature method. Still, the o verall F1-score remains low at 0.67 due to a notable drop in precision (0.63). This underscores the importance of carefully selecting features that reflect meaningful relationships in time-series data for effecti ve personalization. 6.3.2 Gradient based vs Random Data Selection T o ev aluate the effect of gradient-based (GB) selection, we compared the full pipeline using GB sampling with random selection. After clustering, random selection of 20% samples per cluster achiev ed an av erage F1-score of 0.85 (0.80- 0.91 across runs), whereas GB selection, which prioritizes high-gradient windows, improved the a verage F1-score to 0.91, demonstrating its effecti veness in identifying informati ve feedback samples. W e further examined the impact of feedback size on personalization. As shown in T able 4, performance increased from an F1-score of 0.80 at 5% feedback to 0.91 at 20%, before slightly declining to 0.89 at 25% due to increased redundancy and reduced data div ersity . Overall, selecting approximately 20% of feedback data using GB sampling provides the best trade-of f between accuracy and computational efficienc y . 13 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 6.4 Discussion The experimental results demonstrate a clear trade-of f between model performance and computational efficiency in the proposed personalization framework. T raining models from scratch using user -specific feedback data produced the highest o verall accurac y , achieving an average F1 score of 0.88. This performance impro vement highlights the benefit of fully retraining the model with user-tailored motion data, which allo ws it to learn the unique temporal and kinematic characteristics of individual movement patterns. Howe ver , this approach comes at a significant computational cost. T raining from scratch requires a longer runtime, higher memory consumption, and repeated optimization ov er a large parameter space, which limits its feasibility for real-time or on-device personalization. In contrast, the transfer learning and few-shot learning approaches demonstrated much shorter personalization run- times, making them more suitable for deployment on resource-constrained devices such as smartwatches or mobile platforms. In both cases, the lower layers of the T ransformer encoder were reused to preserve general motion repre- sentations, while only the higher layers were fine-tuned on user feedback data. This strategy significantly reduced the computational burden and time required for model adaptation while maintaining reasonable accuracy . Specifically , the few-shot learning model achiev ed an a verage F1 score of 0.71 in its baseline form and 0.76 after applying the selec- tiv e data strategy , outperforming the transfer learning models in both scenarios. These findings indicate that few-shot learning provides an effecti ve balance between accuracy and computational efficiency , allowing rapid personalization without requiring extensi ve retraining. Although the fully retrained models currently yield the best accuracy , their high computational cost and longer re- training ti me mak e them less practical for continuous real-w orld adaptation. The results suggest that fe w-shot learning offers the most promising direction for scalable, low-latency personalization. W ith further fine-tuning and optimization such as adjusting the learning rate schedule, freezing strategies, or the number of attention heads, few-shot learning could potentially approach the accuracy of full retraining while retaining its lightweight computational profile. Future work will focus on refining the few-shot pipeline to close this performance gap and to enable dynamic, on-device adaptation that operates efficiently under real-w orld constraints. 7 Conclusion This study proposed a selectiv e data-driv en framew ork for personalization for time series data (fall detection) that in- tegrates clustering with contrasti ve learning and gradient-based selection. The selectiv e data strategy enables ef ficient use of limited feedback, allowing the model to focus on the most representati ve motion patterns while reducing redun- dancy and computational cost. Experimental ev aluation demonstrated that incorporating selectively chosen feedback samples improves personalization performance across multiple retraining approaches, leading to more reliable and user-adapti ve detection. Overall, the proposed approach provides a scalable and ef ficient solution for real-time, on-device fall detection. Build- ing on these findings, future work will explore few-shot learning for continual personalization with minimal human supervision. References [1] Luca Arrotta, Gabriele Civitarese, Samuele V alente, and Claudio Bettini. Selfact: Personalized activity recogni- tion based on self-supervised and activ e learning, 2023. [2] Jacob Benesty , Jingdong Chen, Y iteng Huang, and Israel Cohen. Pearson correlation coef ficient. In Noise Reduction in Speech Pr ocessing , pages 37–40. Springer , 2009. [3] Haixia Bi, Miquel Perello-Nieto, Raul Santos-Rodriguez, and Peter Flach. Human activity recognition based on dynamic activ e learning. IEEE Journal of Biomedical and Health Informatics , 25(4):922–934, 2021. [4] Xin Chao, Zhenjie Hou, and Y ujian Mo. Czu-mhad: a multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors. IEEE Sensors Journal , 22(7):7034–7042, 2022. [5] Giov anni Diraco, Gabriele Rescio, Andrea Caroppo, Andrea Manni, and Alessandro Leone. Human action recognition in smart living services and applications: context awareness, data availability , personalization, and priv acy . Sensors , 23(13):6040, 2023. [6] Anna Ferrari, Daniela Micucci, Marco Mobilio, and Paolo Napoletano. On the personalization of classification models for human activity recognition. IEEE Access , 8:32066–32079, 2020. [7] Anna Ferrari, Daniela Micucci, Marco Mobilio, and Paolo Napoletano. Deep learning and model personalization in sensor-based human acti vity recognition. Journal of Reliable Intellig ent En vironments , 9(1):27–39, 2023. 14 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 [8] Jeff Z. HaoChen, Colin W ei, Adrien Gaidon, and T engyu Ma. Prov able guarantees for self-supervised deep learning with spectral contrasti ve loss. In M. Ranzato, A. Beygelzimer , Y . Dauphin, P .S. Liang, and J. W ortman V aughan, editors, Advances in Neural Information Pr ocessing Systems , volume 34, pages 5000–5011. Curran Associates, Inc., 2021. [9] Syed T ousiful Haque, Minakshi Debnath, A watif Y asmin, T arek Mahmud, and Anne Hee Hiong Ngu. Experi- mental study of long short-term memory and transformer models for fall detection on smartwatches. Sensors , 24, 2024. [10] Mahmudul Hasan and Amit K. Roy-Chowdhury . Context aware acti ve learning of acti vity recognition models. In 2015 IEEE International Confer ence on Computer V ision (ICCV) , pages 4543–4551, 2015. [11] Ruya Karagulle, Necmiye Ozay , Nikos Aréchiga, Jonathan Decastro, and Andrew Best. Incorporating logic in online preference learning for safe personalization of autonomous vehicles. In Proceedings of the 27th ACM International Confer ence on Hybrid Systems: Computation and Contr ol , pages 1–11, 2024. [12] V angjel Kazllarof and Sotiris Kotsiantis. Human activity recognition using time series feature extraction and activ e learning. In Pr oceedings of the 12th Hellenic Confer ence on Artificial Intellig ence , SETN ’22, Ne w Y ork, NY , USA, 2022. Association for Computing Machinery . [13] Alireza Keyanf ar , Liyana Meh, and Reihaneh Rabbani. Using adaptive smart solutions to create user-centric living environments responsi ve to the psychological needs and preferences of home users. Journal of Housing and the Built En vironment , 39(3):1563–1581, 2024. [14] Kamran Khan, Saif Ur Rehman, Kamran Aziz, Simon Fong, and Sababady Sarasvady . Dbscan: Past, present and future. In The fifth international confer ence on the applications of digital information and web technolo gies (ICADIWT 2014) , pages 232–238. IEEE, 2014. [15] Saydulu Kolasani. Connected cars and autonomous vehicles: personalizing owner/customer experiences and innov ation using ai, iot, blockchain, and big data. International numeric journal of mac hine learning and r obots , 8(8):1–17, 2024. [16] Samory Kpotufe, Abdeslam Boularias, Thomas Schultz, and Kyoungok Kim. Gradients weights impro ve regres- sion and classification. Journal of Machine Learning Resear ch , 17(22):1–34, 2016. [17] Chenglin Li, Di Niu, Bei Jiang, Xiao Zuo, and Jianming Y ang. Meta-har: Federated representation learning for human activity recognition. In Pr oceedings of the W eb Conference 2021 , WWW ’21, page 912–922, New Y ork, NY , USA, 2021. Association for Computing Machinery . [18] Chuankun Li, Shuai Li, Y anbo Gao, and et al. Unsupervised feature enrichment and fidelity preserv ation learning framew ork for skeleton-based action recognition. IEEE , 2025. [19] Y u-Hao Li, Y u-Lin Li, Mu-Y ang W ei, and Guang-Y u Li. Innovation and challenges of artificial intelligence technology in personalized healthcare. Scientific reports , 14(1):18994, 2024. [20] Nader Maray , Anne Hee Ngu, Jianyuan Ni, Minakshi Debnath, and Lu W ang. Transfer learning on small datasets for improv ed fall detection. Sensors , 23(3), 2023. [21] Ala Mhalla and Jean-Marie Fa vreau. Domain adaptation frame work for personalized human acti vity recognition models. Multimedia T ools and Applications , 83(25):66775–66797, 2024. [22] Santiago Morales García, Carlos Henao Baena, and Andres Calvo Salcedo. Human acti vities recognition using semi-supervised svm and hidden markov models. T ecnoLógicas , 26(56), 2023. [23] Nguyen Ngoc-Hieu, Nguyen Hung-Quang, The-Anh T a, Thanh Nguyen-T ang, Khoa D Doan, and Hoang Thanh- T ung. A cosine similarity-based method for out-of-distribution detection. arXiv pr eprint arXiv:2306.14920 , 2023. [24] Anne Hee Ngu, V angelis Metsis, Shuan Coyne, Priyanka Srini vas, T arek Salad, Uddin Mahmud, and Kyong Hee Chee. Personalized watch-based fall detection using a collaborativ e edge-cloud frame work. International Journal of Neural Systems , 32(12):2250048, 2022. [25] Hao Qin, Luyuan Chen, Ming K ong, Zhuoran Zhao, Xianzhou Zeng, Mengxu Lu, and Qiang Zhu. Progressive semantic learning for unsupervised skeleton-based action recognition. Machine Learning , 114(3):1–20, 2025. [26] Lingmei Ren and W eisong Shi. Chameleon: personalised and adaptiv e fall detection of elderly people in home- based en vironments. Int. J. Sen. Netw . , 20(3):163–176, March 2016. [27] Danial Safaei, Ali Sobhani, and Ali Akbar Kiaei. Deeplt: personalized lighting facilitates by trajectory prediction of recognized residents in the smart home. International J ournal of Information T echnology , 16(5):2987–2999, 2024. 15 A P R E P R I N T - M A R C H 1 9 , 2 0 2 6 [28] Mariah L. Schrum, Emily Sumner , Matthew C. Gombolay , and Andrew Best. Mav eric: A data-dri ven approach to personalized autonomous driving. IEEE T ransactions on Robotics , 40:1952–1965, 2024. [29] Mohamed Shalaby , Nahla A Belal, and Y asser Omar . Data clustering improves siamese neural networks classi- fication of parkinson’ s disease. Comple xity , 2021(1):3112771, 2021. [30] SmartfallMM. Smartfallmm dataset. https://github.com/txst- cs- smartfall/SmartFallMM- Dataset. git . [31] Brian Sulliv an, Rakesh Kharidia, Rakesh Batra, Milind Dandekar , Arindam Ghosh, Debasish Ghosh, Saurabh Ghosh, Ankur Jain, Ankur Khandelwal, Anuj K umar , et al. Systems and methods for providing a virtual assistant interface for enterprise applications. U.S. Patent US12027035B2, 2020. https://patents.google.com/ patent/US12027035B2/en . [32] Pranesh V allabh, Nazanin Malekian, Reza Malekian, and Ting-Mei Li. Personalized fall detection monitoring system based on learning from the user mov ements. CoRR , abs/2012.11195, 2020. [33] Hengsheng Xu, Jianqi Zhong, Deliang Lian, Hanxu Hou, and W enming Cao. Positi ve sample mining: Fuzzy threshold-based contrastiv e learning for enhanced unsupervised skeleton-based action recognition. IEEE T rans- actions on Artificial Intelligence , 2025. [34] Xiaoqun Y u, Jaehyuk Jang, and Shuping Xiong. A large-scale open motion dataset (kfall) and benchmark al- gorithms for detecting pre-impact fall of the elderly using wearable inertial sensors. F rontier s in Aging Neur o- science , 13:692865, 2021. [35] Ahmet T uran Özdemir . An analysis on sensor locations of the human body for wearable fall detection devices: Principles and practice. Sensors , 16(8), 2016. 16
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment