맞춤형 낙상 감지를 위한 선택적 피드백 균형 및 대조학습 프레임워크
본 논문은 낙상 감지 모델을 개인별로 최적화하기 위해, 비낙상(ADL) 피드백이 과다하게 축적되는 문제를 반영형 클러스터링과 대조학습(contrastive learning)으로 해결한다. 세 가지 재학습 전략(TFS, TL, FSL)을 비교 실험했으며, 10명의 참가자 실험에서 TFS가 기존 모델 대비 최대 25%, FSL이 7% 향상된 성능을 보였다.
저자: Awatif Yasmin, Tarek Mahmud, Sana Alamgeer
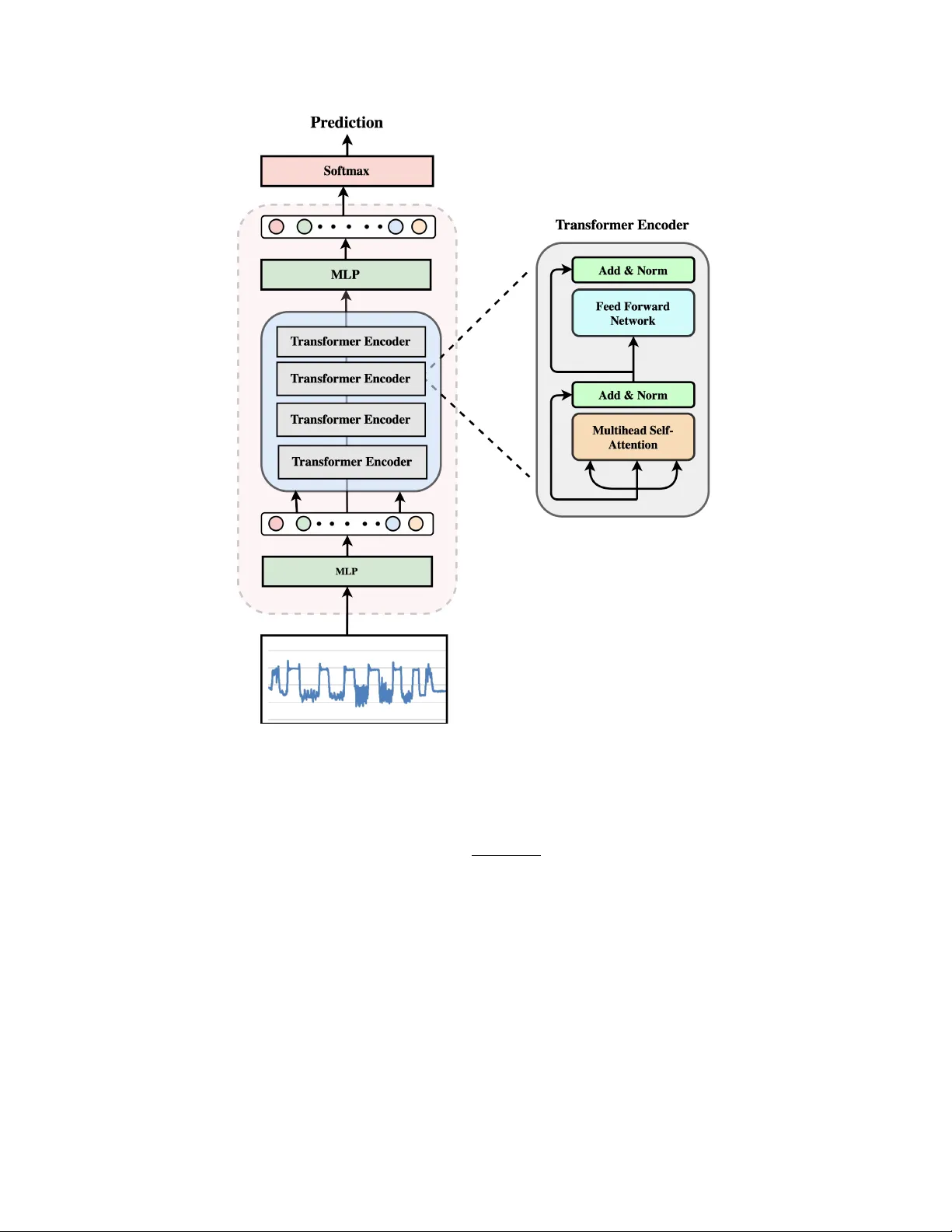
본 논문은 개인 맞춤형 낙상 감지 모델의 정확성을 향상시키기 위해, 실제 사용 환경에서 발생하는 데이터 불균형 문제를 해결하는 새로운 프레임워크를 제안한다. 낙상 감지는 고령자와 같은 취약 계층의 안전을 보장하는 핵심 기술이지만, 실제 현장에서 수집되는 데이터는 대부분 일상 활동(Activities of Daily Living, ADL)이며, 실제 낙상 사례는 극히 드물다. 이러한 상황에서 기존의 일반화된 모델을 그대로 재학습하면 ADL 데이터가 과다하게 축적되어 모델이 비낙상 패턴에 편향되고, 결과적으로 낙상 감지 민감도(Recall)가 크게 저하되는 문제가 발생한다.
저자는 이러한 문제를 인식하고, 두 가지 핵심 기술을 결합한 선택적 피드백 균형 메커니즘을 설계하였다. 첫 번째는 반지도학습(semi‑supervised) 클러스터링이다. 스마트워치에 탑재된 사전 학습된 Transformer 기반 낙상 탐지 모델(M₀)을 운영하면서 발생한 사용자 피드백(실제 낙상 TP와 오탐 FP)을 클라우드에 저장한다. 이 피드백 샘플들은 동일 데이터셋으로 사전 학습된 Siamese Neural Network(SNN)를 통해 임베딩 공간에 매핑되고, K‑means 혹은 DBSCAN과 같은 클러스터링 알고리즘으로 그룹화된다. 클러스터링 단계에서는 비낙상 샘플 내에서도 다양한 행동 유형을 구분해 과도한 특정 ADL(예: 걷기, 앉기) 편향을 방지한다.
두 번째는 대조학습(contrastive learning) 기반의 그래디언트 기여도 평가이다. 각 클러스터 내 샘플에 대해 현재 모델 파라미터에 대한 손실 함수의 그래디언트를 계산하고, 그 크기를 기준으로 상위 x개의 샘플을 선택한다. 이 과정은 “가장 학습에 기여하는” 샘플을 추출함으로써, 데이터 양이 제한된 상황에서도 효율적인 모델 업데이트를 가능하게 한다. 선택된 샘플은 원본 학습 데이터와 결합되어 개인화 모델(Mᵢ) 재학습에 사용된다.
재학습 전략은 세 가지로 구분된다. ① Training from Scratch(TFS): 선택된 데이터만을 사용해 모델을 처음부터 학습한다. 이는 데이터 품질이 높을 경우 가장 큰 성능 향상을 기대할 수 있다. ② Transfer Learning(TL): 사전 학습된 M₀의 가중치를 초기값으로 두고, 선택된 데이터로 미세조정한다. 기존 지식을 활용하지만, 불균형 데이터가 여전히 존재하면 과적합 위험이 있다. ③ Few‑Shot Learning(FSL): 메타러닝 기반 프로토타입 네트워크를 활용해 소량의 샘플만으로 빠르게 적응한다. 실시간 적용 가능성이 높으며, 제한된 피드백에서도 일정 수준의 향상을 제공한다.
실험은 SmartFallMM 데이터셋을 기반으로 진행되었다. 초기 모델 M₀는 30명의 피험자(총 1,950 트라이얼) 데이터를 사용해 Transformer(4 encoder layers, 4 multi‑head attention, embedding size 128)로 학습되었으며, leave‑one‑subject‑out 교차 검증을 통해 일반화 성능을 확보했다. 이후 10명의 참가자를 대상으로 18시간 동안 스마트워치를 착용하게 하여 실시간 피드백을 수집하였다. 피드백 데이터는 평균 120개의 TP와 1,800개의 FP로 구성되었으며, 이는 전형적인 불균형 비율을 반영한다.
클러스터링 및 그래디언트 기반 샘플 선택 후, 세 가지 재학습 전략을 적용한 결과는 다음과 같다. TFS는 기존 베이스라인 대비 최고 25%의 F1‑score 향상을 기록했으며, 특히 Recall이 0.81에서 0.95로 크게 개선되었다. FSL은 7% 정도의 향상을 보였으며, 데이터 양이 적을 때도 안정적인 성능을 유지했다. TL은 중간 정도의 향상을 보였지만, ADL 비중이 20%를 초과하는 경우 Recall이 급격히 감소하는 현상이 관찰되었다. 이러한 결과는 선택적 샘플링이 비낙상 클래스 내 다양성을 확보하고, 중요한 FP 샘플을 효과적으로 활용함으로써 모델의 민감도를 회복시킨다는 점을 실증한다.
논문의 주요 기여는 다음과 같다. 첫째, 반지도학습과 대조학습을 결합해 피드백 데이터의 품질을 자동으로 평가·선택함으로써 데이터 불균형 문제를 근본적으로 완화한다. 둘째, 선택적 재학습이 개인화 모델의 Recall을 크게 향상시켜 실제 낙상 감지 시스템에서의 실용성을 높인다. 셋째, 전체 파이프라인이 클라우드 기반으로 구현되어, 사용자 별 데이터 라벨링 부담 없이 자동화된 개인화가 가능하도록 설계되었다.
하지만 몇 가지 한계도 존재한다. 현재 SNN은 고정된 사전 학습 모델에 의존하므로, 새로운 센서 종류(예: 관절 각도, 심박수)나 환경 변화에 대한 적응성이 제한적이다. 또한 클러스터링 파라미터(클러스터 수, 거리 임계값) 설정이 데이터 특성에 민감해, 자동 튜닝 메커니즘이 필요하다. 향후 연구에서는 온라인 클러스터링, 도메인 적응, 그리고 멀티모달 센서 융합을 통해 더욱 견고하고 확장 가능한 개인화 프레임워크를 구축할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기