Retrieving Counterfactuals Improves Visual In-Context Learning
Vision-language models (VLMs) have achieved impressive performance across a wide range of multimodal reasoning tasks, but they often struggle to disentangle fine-grained visual attributes and reason about underlying causal relationships. In-context l…
Authors: Guangzhi Xiong, Sanchit Sinha, Zhenghao He
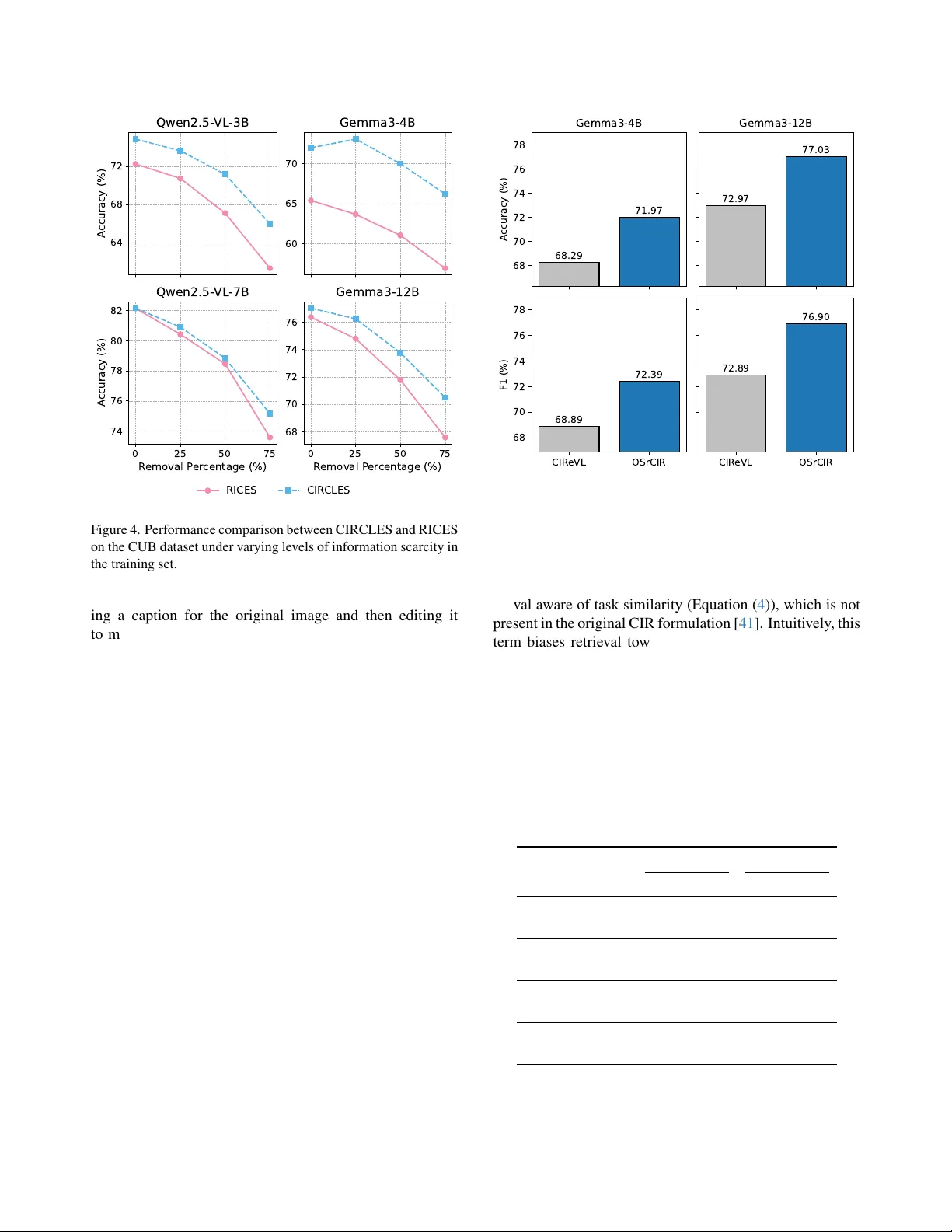
Retrieving Counterfactuals Impr ov es V isual In-Context Learning Guangzhi Xiong Sanchit Sinha Zhenghao He Aidong Zhang Uni versity of V ir ginia Abstract V ision-language models (VLMs) have achieved impr essive performance acr oss a wide range of multimodal r easoning tasks, but the y often struggle to disentangle fine-grained vi- sual attributes and r eason about underlying causal relation- ships. In-context learning (ICL) offers a promising avenue for VLMs to adapt to new tasks, but its ef fectiveness criti- cally depends on the selection of demonstr ation e xamples. Existing r etrieval-augmented appr oaches typically r ely on passive similarity-based retrie val, whic h tends to select cor- r elated but non-causal examples, amplifying spurious as- sociations and limiting model r obustness. W e intr oduce CIRCLES (Composed Image Retrieval for Causal Learn- ing Example Selection), a novel frame work that actively constructs demonstration sets by retrie ving counterfactual- style examples thr ough targ eted, attrib ute-guided composed image retrie val. By incorporating counterfactual-style e x- amples, CIRCLES enables VLMs to implicitly r eason about the causal r elations between attributes and outcomes, mov- ing beyond superficial corr elations and fostering mor e r o- bust and gr ounded r easoning. Compr ehensive experiments on four diverse datasets demonstr ate that CIRCLES consis- tently outperforms e xisting methods acr oss multiple arc hi- tectur es, especially on small-scale models, with pr onounced gains under information scar city . Furthermor e, CIRCLES r etrieves more diverse and causally informative examples, pr oviding qualitative insights into how models levera ge in- context demonstrations for impr oved reasoning . Our code is available at https : / / github . com / gzxiong / CIRCLES . 1. Introduction V ision-language models (VLMs) have recently demon- strated remarkable generalization across a wide spectrum of visual reasoning tasks, achieving impressi ve results on tasks such as visual question answering [ 4 , 16 , 47 ], im- age captioning [ 8 , 50 ], and multimodal classification [ 1 , 14 , 38 ]. This progress is largely attrib uted to their rich multimodal representations learned through large-scale pre- training. Howe ver , in practice, VLMs often struggle with fine-grained and attribute-sensitiv e visual reasoning, set- tings prev alent in real-world vision applications [ 11 , 19 , 24 ]. T o address these challenges, in-context learning (ICL) has emerged as a powerful paradigm, enabling VLMs to rapidly adapt to ne w tasks by conditioning on a small set of demonstration examples provided at test time [ 3 , 43 , 51 ]. Recent work in visual ICL has highlighted the crucial role of retriev al-based selection strategies for constructing effec- tiv e demonstration sets [ 9 , 12 , 28 ]. Standard approaches, such as RICES (Retriev al-based In-Context Example Se- lection) [ 3 , 48 ], assemble in-context examples by identi- fying the nearest neighbors to the query image within the embedding space. Follo w-up works such as MUIER [ 32 ] and MMICES [ 13 ] augment this process by lev eraging mul- timodal similarity metrics that jointly consider both visual and te xtual features, enhancing the relev ance of retrieved examples to the query . Despite these advances, such similarity-oriented selec- tion can lead to systematic errors when critical attrib utes are entangled with irrele vant co-occurrences. Because these retriev al baselines do not explicitly control or intervene on causal fact ors, models prompted with their selected demon- strations often learn to mimic surface correlations rather than identify the attributes that truly determine the answer . This limitation becomes more pronounced under informa- tion scarcity or distribution shifts, where relying solely on correlated neighbors offers little guidance on how chang- ing specific attributes af fects the outcome. These obser- vations motiv ate approaches that go beyond similarity and instead curate demonstration sets that expose disentangled, attribute-le vel v ariations. T o address the limitations abo ve, we introduce CIR- CLES (Composed Image Retriev al for Causal Learning Ex- ample Selection), a ne w frame work for visual in-context learning that explicitly incorporates counterfactual reason- ing signals into the example selection process. Unlike prior work that selects examples only by image similarity , CIR- CLES constructs demonstration sets by e xplicitly collecting attribute-le vel counterfactual-style examples via composed image retriev al (CIR), and combining them with standard similarity-based examples to create an informati ve context. belly pattern to solid Golden-winged Warbler Standard Image Retrieval Pine Warbler breast color to grey Composed Image Retrieval Causal Understanding Correlational Understanding Figure 1. Illustration of how composed image retriev al provides additional causal understanding. As illustrated in Figure 1 , standard similarity-based re- triev al provides examples that are visually close to the query but may share irrelev ant or confounding attributes. In con- trast, by retrieving and composing images that reflect con- trolled interventions on key attributes (e.g., changing the belly pattern to solid while keeping other attributes as simi- lar as possible), CIR identifies examples that isolate the ef- fect of each attribute on the answer (e.g., similar images with a solid belly pattern are labeled as Pine W arbler), pro- viding more causally informativ e demonstrations for ICL. By composing causally informativ e examples with similarity-based demonstrations, CIRCLES constructs demonstration sets that better re veal the underlying fac- tors dri ving the correct answer, enabling VLMs to learn disentangled, robust, and interpretable reasoning strategies. Our experiments on four benchmark datasets demonstrate that CIRCLES consistently outperforms existing ICL meth- ods across a range of VLM architectures, with pronounced improv ements on small-scale VLMs where models’ inter- nal knowledge is limited. CIRCLES is especially effecti ve under challenging conditions such as information scarcity , where the performance gap widens as rele vant data becomes limited. Qualitative analysis further sho ws that CIRCLES retriev es more di verse and informative examples that clar - ify critical attributes, providing insights into the ICL pro- cess. Our main contributions are as follo ws: • W e propose CIRCLES, a nov el ICL framework that en- riches demonstration sets by retrieving counterfactual examples, moving beyond standard similarity-based re- triev al. • Empirical ev aluations on multiple image classification and visual question answering datasets demonstrate con- sistent improv ements over e xisting ICL methods. • Additional analyses highlight the strength of CIRCLES in low-data regimes and explore optimal practices for con- structing informativ e demonstration sets. 2. Related W ork 2.1. Multimodal Reasoning V ision-language models (VLMs) ha ve rapidly adv anced vi- sual tasks such as visual question answering (VQA), im- age captioning, and multimodal classification by integrat- ing po werful visual encoders with large language models [ 3 , 25 , 27 ]. Despite these gains, se veral studies hav e high- lighted the limitations of VLMs in compositional and causal reasoning, rev ealing that state-of-the-art systems often rely on dataset priors or spurious correlations, rather than truly understanding fine-grained attributes or relational structure [ 2 , 22 , 39 ]. For instance, models can achie ve high a ver- age scores but struggle when asked to reason about the ef- fect of specific attribute changes or to generalize to out- of-distribution queries [ 21 ]. These observ ations motiv ate methods that structure inference-time evidence around at- tributes and relations rather than surf ace similarity . 2.2. V isual In-Context Learning In-context learning (ICL) enables VLMs to adapt at infer - ence time via conditioning on a small set of demonstration examples [ 3 , 10 , 43 ], but the ef fectiveness of this process is highly dependent on the structure of the demonstration set [ 28 , 31 , 37 ]. Recent research has shown the sensitivity of VLMs to the order, div ersity , and retrie val strategies used to assemble demonstrations [ 12 , 20 , 26 , 49 ], demonstrating that naive similarity-based selection can lead to inconsistent performance, sensitivity to confounders, and susceptibility to spurious correlations [ 7 , 18 , 52 ]. These findings motiv ate moving beyond nearest-neighbor similarity to ward example sets that are deliberately diverse and task-aligned. Our ap- proach complements this literature by explicitly introducing counterfactual examples into the demonstration pool, thus enriching the reasoning signal av ailable to the model. 2.3. Composed Image Retriev al Composed image retriev al (CIR) is a closely related area that focuses on retrieving images matching complex, com- positionally specified queries, typically combining a refer- ence image and a manipulation text [ 15 , 40 ]. Existing CIR techniques are optimized for retrie val accuracy rather than downstream reasoning or ICL composition [ 5 , 44 ]. Datasets such as FashionIQ [ 46 ] and CIRR [ 29 ] ha ve adv anced re- search on controlled attrib ute modifications, but these works treat CIR as an end task. Our use of CIR diver ges from this paradigm: instead of retrieving a single modified image, we lev erage CIR to construct a set of counterfactually informa- tiv e demonstrations for in-context learning. By integrating attribute-guided text modifications with VLM-dri ven cap- tioning, our method operationalizes CIR as a tool for coun- terfactual intervention, re vealing which attributes meaning- fully influence downstream predictions. Causal Understanding via Composed Image Retrieval T ext Encoder Q Q Q Q Key Attribute Correlational Understanding via Standard Image Retrieval Retrieval-Augmented Inference User Inputs In-context Examples Answer Prediction Image Encoder Modified Caption Figure 2. Overvie w of the CIRCLES framework. Gi ven a query image I q and question Q q , the top branch illustrates correlational understanding via standard image retriev al, while the bottom branch depicts causal understanding using attribute-guided composed image retriev al with counterfactual captions from the VLM Φ . Blue/orange rounded rectangles represent image/text embeddings. R corr and R causal denote the retriev ed in-context examples for answer prediction. 3. Methodology In this section, we introduce the CIRCLES (Composed Image Retriev al for Causal Learning Example Selection) framew ork, designed to enhance visual in-context learn- ing for vision-language models (VLMs). CIRCLES does not aim to perform formal causal identification. Instead, it leverages composed image retrie val (CIR) to approxi- mate interv entions on ke y attributes and to facilitate im- plicit in-context reasoning through contrasti ve retrie ved ex- amples. W e begin by formalizing the problem and estab- lishing notation. W e then detail the CIRCLES pipeline, which consists of three main components: (1) causal under - standing through attribute-guided CIR, (2) correlational un- derstanding via standard image retrieval , and (3) retriev al- augmented inference. 3.1. T ask F ormulation and Notation Let K = { ( I j , Q j , A j ) } N j =1 denote a visual question an- swering corpus, where I j is an image, Q j a natural lan- guage question, and A j the answer . Giv en a query ( I q , Q q ) , a VLM Φ produces an answer A q conditioned on the query and an optional retriev ed context R ⊆ K . W e use a frozen CLIP model E = ( f I , f T ) with image encoder f I and text encoder f T to obtain L2-normalized embeddings. For each candidate in the training corpus, we precompute embeddings z I j = f I ( I j ) and z Q j = f T ( Q j ) . At test time, we compute z I q = f I ( I q ) and z Q q = f T ( Q q ) for the query . An overvie w of our CIRCLES framework is illustrated in Figure 2 . 3.2. Causal Understanding via Attribute-Guided Composed Image Retriev al T o collect demonstrations for causal understanding, CIR- CLES identifies semantically meaningful attributes and re- triev es counterfactual examples through a two-stage pro- cess. Key Attribute Identification. Gi ven ( I q , Q q ) , we prompt the VLM Φ to extract decisive attribute-value pairs for an- swering Q q (e.g., the attribute “breast color” has the value “grey” in Figure 1 ). Let the set of attributes be A = { a 1 , . . . , a m } , (1) with corresponding values on I q as v = ( v 1 , . . . , v m ) , v i = a i ( I q ) . (2) Each attrib ute a i has a finite v alue set V i (e.g., possible col- ors for “breast color”). These attributes form the basis for counterfactual intervention. Counterfactual Example Retriev al. T o isolate the influ- ence of each attribute on the answer , we consider coun- terfactual variants of the query image by changing one at- tribute a i from its original value v i to an alternati ve v ′ i ∈ V i \ { v i } while keeping all other attrib utes fixed. Direct identification of such counterfactuals in real datasets is gen- erally infeasible. Therefore, for each attribute a i and can- didate counterfactual value v ′ i , we prompt the VLM to gen- erate a counterfactual caption c do ( a i = v ′ i ) which describes I q under the atomic interv ention do ( a i = v ′ i ) [ 35 ] with only attribute a i set to v ′ i and all a k = i unchanged. For each candidate example ( I j , Q j , A j ) in K , we com- pute the image-caption similarity score s img j = z I ⊤ j f T ( c do ( a i = v ′ i ) ) , (3) which measures the visual faithfulness of I j to the counter- factual scenario described by c do ( a i = v ′ i ) . Howe ver , relying solely on image-caption similarity can result in retrie ving examples that visually align with the counterfactual but are not semantically relev ant to the origi- nal query , particularly when attrib ute changes alter the con- text in unintended ways. T o address this, we introduce an additional question-question similarity score s txt j = z Q ⊤ q z Q j , (4) which serves as a semantic constraint to ensure that re- triev ed examples not only match the counterfactual at- tributes b ut also remain closely related to the original ques- tion context. The score for each candidate is computed as S j = s img j + s txt j . (5) By combining both visual faithfulness and semantic rele- vance, this scoring function identifies training examples that best approximate the intended counterfactual scenario for the giv en query . All candidates are ranked according to S j , and the top- k causal examples are selected to form the set R comp i ( v i → v ′ i ) = T opK j ( S j ) , (6) where T opK j returns the top examples by the scores. Aggregating across attributes and sampled counterfactuals yields the causal retriev al pool: R causal = m [ i =1 R comp i ( v i → ˜ v ′ i ) , (7) where ˜ v ′ i is one alternativ e v alue sampled from V i \ { v i } for efficienc y , especially when V i is large. In practice, we implement this sampling by prompting the VLM to suggest a plausible alternativ e value for each attrib ute. 3.3. Correlational Understanding via Standard Im- age Retriev al T o complement causal understanding gi ven by the coun- terfactual e xamples, CIRCLES incorporates a correlation- oriented retriev al stage that provides broader contextual in- formation. Here, we retrieve images that are most similar to the query image in the embedding space, without enforcing any attribute-based interv ention or counterfactual modifica- tion. This approach helps the model leverage common vi- sual or semantic patterns present in the dataset, supporting recognition and grounding ev en when explicit causal factors are absent. For query image I q , we compute the image-image simi- larity score for all candidates in K as s corr j = z I ⊤ q z I j , (8) and select the top- k corr most similar examples to form the correlation retriev al set R corr = T opK j ( s corr j ) . (9) While advanced retriev al methods exist [ 13 , 32 ], we adopt this standard image-only retrie val for its efficiency and gen- erality , which matches the standard RICES-style baseline [ 3 , 48 ] and cleanly isolates the added value of the pro- posed causal understanding module. Our experiments in Appendix E further illustrate that image-only retriev al is sufficient when the task is dominated by visual similarity (e.g., classification), while incorporating task text into re- triev al becomes important as question semantics become more div erse (e.g., visual question answering). 3.4. Retriev al-A ugmented In-Context Learning The causal and correlational retriev al results are integrated into a unified context for model inference. The final re- triev ed context is constructed as R = R causal ∪ R corr , (10) which is used as context for answer generation: A q = Φ( I q , Q q , R ) . (11) By exposing the model to both correlated and counterfac- tual instances, CIRCLES encourages reasoning that goes beyond surface-le vel associations and provides deeper in- sights into the in-context learning process. 4. Experiments 4.1. Experimental Settings Datasets. F or ev aluation, we consider a div erse set of datasets: CUB [ 45 ] and Flo wers [ 34 ] for fine-grained image classification, OK-VQA [ 33 ] for open-ended visual ques- tion answering, and V izW iz [ 17 ] for real-w orld visual ques- tion answering under challenging conditions. For CUB and Flowers, we report classification accuracy (Acc) and weighted F1 scores. For OK-VQA and V izW iz, we use ex- act match (EM) and word-le vel F1 metrics. These datasets enable a comprehensiv e assessment of visual reasoning ca- pabilities across various domains. T able 1. Performance comparison between CIRCLES and baseline methods across different models and datasets. A verage scores are computed by treating accuracy (Acc) as EM for classification tasks and averaging EM and F1 across all datasets. The best results for each model and dataset are highlighted in bold. Model Method CUB Flowers OK-VQA V izWiz A verage Acc F1 Acc F1 EM F1 EM F1 EM F1 Gemma3 -4B None 10.56 8.19 46.76 46.50 19.12 26.70 39.85 57.26 29.07 34.66 Random 9.98 8.10 37.01 39.51 24.81 30.74 51.84 67.08 30.91 36.36 RICES 65.40 67.62 86.70 87.43 26.65 32.72 56.08 70.40 58.71 64.54 MUIER 65.21 67.42 86.39 87.28 26.87 32.82 56.59 70.75 58.77 64.57 MMICES 13.95 10.98 38.09 38.20 26.24 32.41 52.72 68.21 32.75 37.45 CIRCLES 71.97 72.39 93.32 93.49 31.27 36.89 57.61 71.35 63.54 68.53 Gemma3 -12B None 30.34 25.02 67.51 64.33 25.47 33.89 56.82 71.26 45.04 48.62 Random 29.27 25.82 71.28 71.56 33.59 39.56 70.13 80.54 51.07 54.37 RICES 76.37 76.25 96.44 96.29 36.86 42.61 73.98 83.43 70.91 74.65 MUIER 76.51 76.39 96.42 96.28 36.58 42.30 73.72 83.04 70.81 74.50 MMICES 36.37 31.61 71.36 69.13 35.12 40.85 71.50 81.56 53.59 55.79 CIRCLES 77.03 76.90 97.77 97.75 37.75 43.23 74.30 82.35 71.71 75.06 Qwen2.5 -VL-3B None 7.09 5.97 22.57 24.04 42.29 46.12 75.83 78.58 36.95 38.68 Random 15.81 15.63 41.76 44.57 41.54 45.30 74.48 77.40 43.40 45.73 RICES 72.26 73.88 93.06 92.84 42.57 46.26 70.80 73.37 69.67 71.59 MUIER 72.25 73.87 93.06 92.83 41.66 45.82 71.61 74.74 69.64 71.81 MMICES 17.26 15.38 33.84 35.47 39.32 42.95 73.23 76.21 40.91 42.50 CIRCLES 74.89 76.34 94.70 94.77 43.24 47.27 72.93 75.33 71.44 73.43 Qwen2.5 -VL-7B None 14.83 11.79 43.47 42.14 33.31 38.33 68.70 73.30 40.08 41.39 Random 26.27 24.42 47.15 49.74 41.66 46.20 76.11 78.34 47.80 49.67 RICES 82.15 81.91 98.83 98.85 43.66 48.32 73.79 76.13 74.61 76.30 MUIER 82.14 81.90 98.93 98.95 44.29 48.76 74.67 77.08 75.01 76.67 MMICES 34.57 29.72 49.15 47.62 43.40 47.66 70.69 72.77 49.45 49.44 CIRCLES 82.17 82.13 98.99 99.04 43.54 48.53 77.63 82.36 75.58 78.02 Baselines. W e compare CIRCLES against sev eral in- context learning baselines: None : zero-shot prompting without in-context examples. Random : in-context learn- ing with randomly sampled examples. RICES [ 3 , 48 ]: re- triev al based on nearest neighbors using image-image sim- ilarity . MUIER [ 32 ]: multimodal retriev al leveraging both image-image and image-text similarities for example se- lection. MMICES [ 13 ]: a two-stage multimodal selec- tor that first retrieves candidates by image-image similar - ity and then re-ranks them using text-image similarity for improv ed query alignment. All methods are implemented with Gemma3 (4B/12B) [ 42 ] and Qwen2.5-VL (3B/7B) [ 6 ] backbones. CLIP (V iT -g/14) [ 36 ] is used as the image/text encoder for retriev al, and the in-context example budget is set to 32 for all methods, where CIRCLES has 16 images in R causal and 16 in R corr . More implementation details are provided in Appendix A . 4.2. Perf ormance Comparison T able 1 presents a comprehensive ev aluation of CIRCLES and baseline methods across multiple datasets and vision- language models (VLMs). The results show that all VLMs benefit from in-context learning, achieving 6.33% to 118.58% relativ e EM improv ements over the zero-shot baseline (None). Additionally , retriev al-based methods (RICES, MUIER, MMICES, CIRCLES) consistently out- perform random selection, with up to 105.56% relative im- prov ement, highlighting the importance of selecting rele- vant e xamples for effecti ve in-context learning. Moreov er, CIRCLES consistently surpasses other exam- ple selection baselines across nearly all datasets and back- bone configurations, achieving av erage relativ e EM im- prov ements ranging from 0.76% to 94.02%. This high- lights the effectiv eness of composed image retriev al (CIR) in CIRCLES, which complements the similarity-based re- triev al with causal understanding. The performance gains are especially pronounced for smaller backbone models such as Gemma3-4B and Qwen2.5-VL-3B, indicating that CIRCLES pro vides substantial contextual support when the model’ s internal knowledge is limited. Comparing performance improvements across datasets, we find that CIRCLES yields especially pronounced gains on fine-grained classification tasks (CUB, Flowers), where Magnolia W arbler Myrtle W arbler Myrtle W arbler Myrtle W arbler Intervention on "black head markings" Blue-winged W arbler White-eyed Vireo Intervention on "white wing patches" Myrtle W arbler Golden-winged W arbler IR CIR Query Image CIRCLES RICES Myrtle W arbler Magnolia W arbler Figure 3. Qualitative comparison of in-context examples retriev ed by RICES and CIRCLES for a CUB test image ( Magnolia W arbler ). T op: standard image retrieval (IR) neighbors used by RICES, leading to incorrect predictions. Bottom: counterfactual examples from composed image retriev al (CIR) in CIRCLES, highlighting key attrib ute changes and guiding the model to the correct label. distinguishing subtle attribute differences is critical for ac- curate predictions. This underscores the value of CIR in scenarios requiring nuanced visual reasoning. While im- prov ements on visual question answering tasks (OK-VQA, V izW iz) are more modest, CIRCLES consistently achiev es leading results, demonstrating its ef fecti veness and versatil- ity across div erse vision-language challenges. 4.3. Qualitative Analysis of CIRCLES Figure 3 provides a qualitative comparison of in-context ex- amples retrieved by RICES (images via standard image re- triev al) and CIRCLES (images via both standard and com- posed image retriev al) for a test sample from the CUB dataset. The query image is a Magnolia W arbler , whose la- bel is largely determined by ke y attributes like “black head markings” and “white wing patches”. RICES, which op- erates purely in the visual similarity space, retriev es a se- quence of images that are globally similar to the query (top row). Because these retrie ved examples overrepresent Myr - tle W arblers, the in-context prompt encourages the model tow ard the incorrect Myrtle W arbler prediction. In contrast, CIRCLES e xplicitly constructs counterfac- tual examples with CIR that intervene on semantically meaningful attributes (bottom ro w), retrieving images that closely resemble the query but differ in tar geted features such as the presence or absence of “black head markings. ” This approach retriev es counterfactual examples that clearly demonstrate how changes in key attributes result in different bird species labels. By illustrating class transitions across these counterfactuals, CIRCLES provides the VLM with explicit cues about which attrib utes are decisiv e, enabling accurate predictions and offering a more interpretable per- spectiv e on the in-context learning process. 4.4. CIRCLES under Inf ormation Scarcity CIRCLES complements standard image retriev al (IR) with CIR to provide div erse and informative in-context exam- ples, which should be particularly beneficial when the train- ing set contains limited information rele vant to the query . T o validate this hypothesis, we assess the robustness of CIRCLES and RICES under v arying degrees of information scarcity in the training set. Specifically , we simulate differ- ent levels of information scarcity by randomly removing a certain percentage of samples from the training set (rang- ing from 0% to 75%) and ev aluate the performance of each method on the CUB dataset using dif ferent backbone mod- els. The attribute set used in CIRCLES is fixed across all lev els of information scarcity to ensure a fair comparison. As shown in Figure 4 , both RICES and CIRCLES ex- perience performance de gradation as more training samples are removed. Howe ver , CIRCLES consistently outperforms RICES across all le vels of information scarcity . Notably , as the percentage of removed training samples increases, CIRCLES’ s performance advantage ov er RICES becomes more pronounced. In small-scale VLMs such as Gemma3- 4B, the relativ e improvement of CIRCLES over RICES in- creases from 10.05% to 16.28% when the removal percent- age is increased from 0% to 75%. For larger models such as Gemma3-12B, the relative improvements are smaller but still show a consistent upward trend, rising from 0.86% with the full training set to 4.31% when 75% of the samples are remov ed. Since CIRCLES shares the same standard image re- triev al component as RICES, these results indicate that the CIR component in CIRCLES ef fectiv ely mitigates the chal- lenges posed by limited rele vant information in the training set, enhancing the robustness of in-context learning under information scarcity . 4.5. Impact of CIR Implementation on CIRCLES T o assess the impact of dif ferent CIR methods on CIRCLES performance, we compare two representative training-free CIR implementations: CIReVL [ 23 ] and OSrCIR [ 41 ]. CIReVL generates counterfactual captions by first produc- 64 68 72 A ccuracy (%) Qwen2.5- VL -3B 60 65 70 Gemma3-4B 0 25 50 75 R emoval P er centage (%) 74 76 78 80 82 A ccuracy (%) Qwen2.5- VL -7B 0 25 50 75 R emoval P er centage (%) 68 70 72 74 76 Gemma3-12B RICES CIR CLES Figure 4. Performance comparison between CIRCLES and RICES on the CUB dataset under v arying le vels of information scarcity in the training set. ing a caption for the original image and then editing it to modify target attributes, which can sometimes result in generic or less contextually grounded descriptions. In con- trast, OSrCIR directly synthesizes captions conditioned on both the query image and manipulation text, enabling more flexible and fine-grained descriptions of attribute changes and their interactions. This approach allo ws OSrCIR to capture subtle attribute variations and complex dependen- cies, producing counterfactuals that are more informati ve and relev ant for in-context learning. In our implementa- tion of CIRCLES, we adopt OSrCIR due to its demonstrated superiority in generating high-quality composed image re- triev als [ 41 ]. Figure 5 compares CIRCLES instantiated with CIReVL and OSrCIR on the CUB dataset using Gemma3-4B and Gemma3-12B backbones. As sho wn, CIRCLES with CIR implemented by OSrCIR consistently outperforms CIReVL on both backbone VLMs, achie ving relativ e accuracy im- prov ements ranging from 5.39% to 5.56% and relative F1 improv ements from 5.08% to 5.50%. These results align with the CIR performance comparison reported in [ 41 ], where OSrCIR demonstrated superior retriev al accuracy ov er CIReVL. Overall, the quality of the CIR method di- rectly impacts the effecti veness of CIRCLES, as more ac- curate and contextually relev ant composed image retriev als yield better counterfactual examples for in-context learning. As discussed in Section 3 , we further augment CIR with 68 70 72 74 76 78 A ccuracy (%) 68.29 71.97 Gemma3-4B 72.97 77.03 Gemma3-12B CIR eVL OSrCIR 68 70 72 74 76 78 F1 (%) 68.89 72.39 CIR eVL OSrCIR 72.89 76.90 Figure 5. Comparison of CIRCLES performance using CIR im- plemented by CIReVL and OSrCIR on the CUB dataset with Gemma3 (4B/12B) backbones. a question-question similarity component to make the re- triev al aware of task similarity (Equation ( 4 )), which is not present in the original CIR formulation [ 41 ]. Intuitively , this term biases retriev al toward examples that not only share visual content but also require similar reasoning skills or knowledge types. Because CUB and Flo wers hav e identi- cal questions for all samples, this similarity will not have an effect. Therefore, we e valuate the impact of our proposed enhancement on OK-VQA and V izW iz, where questions are more div erse. T able 2. Performance comparison of CIRCLES on OK-VQA and V izWiz with (w/) and without (w/o) the question-question similar- ity component in CIR. Model Setting OK-VQA V izWiz EM F1 EM F1 Gemma -4B w/o 27.72 33.64 57.40 71.65 w/ 31.27 36.89 57.61 71.35 Gemma -12B w/o 33.02 39.07 74.37 83.20 w/ 37.75 43.23 74.30 82.35 Qwen -3B w/o 41.12 45.33 73.28 75.94 w/ 43.24 47.27 72.93 75.33 Qwen -7B w/o 40.80 46.22 77.29 81.72 w/ 43.54 48.53 77.63 82.36 T able 2 compares CIRCLES performance with and with- 4 6 8 10 12 14 16 #CIR 55 60 65 70 A ccuracy (%) #IR = 4 #IR = 8 #IR = 16 #IR = 32 (a) 4 8 16 #CIR 1 2 4 #A ttributes 53.40 62.62 68.47 57.63 61.91 66.17 59.58 64.91 62.27 #IR = 4 4 8 16 #CIR 61.70 67.28 70.31 66.95 66.24 67.24 68.50 68.57 66.10 #IR = 8 4 8 16 #CIR 68.24 67.33 71.97 70.88 65.53 70.90 70.94 69.40 70.35 #IR = 16 55.0 57.5 60.0 62.5 65.0 67.5 70.0 A ccuracy (%) (b) Figure 6. Retrie val budget analysis on CUB with Gemma3-4B. (a) CIRCLES accuracy vs. number of composed images retrie ved (#CIR) under different standard retrievals (#IR). (b) Accuracy as a function of the number of intervened attributes (#Attributes) and composed images (#CIR). out the question-question similarity term. On OK-VQA, we observe consistent impro vements across all backbone mod- els, with relativ e EM gains of +5.16% to 14.32% and F1 gains of +4.28% to 10.65%. This demonstrates that explic- itly matching questions enables retrie val of demonstrations with similar reasoning requirements, which is particularly beneficial for knowledge-intensi ve, open-ended queries. On V izW iz, the impro vements are more modest, likely due to the highly div erse and often noisy user-generated questions and challenging images, where textual similarity is a weaker signal and visual cues are more influential. Ne vertheless, the addition of the similarity term does not cause signifi- cant performance degradation, suggesting it is a robust de- fault that can yield substantial gains when task structures are more regular , as in OK-VQA. 4.6. Retriev al Budget Analysis W e further analyze how to best allocate the in-context ex- ample budget between standard image retriev al (IR) and composed image retriev al (CIR) in CIRCLES. Figure 6a shows classification accurac y as a function of the number of composed images retriev ed (#CIR) for dif ferent settings of standard retriev als (#IR). Increasing #CIR consistently im- prov es accuracy across all #IR configurations, highlighting the benefit of CIR for providing targeted and informati ve context. Importantly , adding composed images yields sub- stantial gains, e ven when the total number of retriev ed ex- amples is lo wer than using only standard retriev al (grey line: #CIR=0, #IR=32). This indicates that CIR enables more ef- ficient use of the retriev al budget, as composed examples focus the model on key attribute-lev el changes and support causal reasoning. Overall, these results demonstrate that combining CIR and IR leads to more informative in-context examples and impro ved model performance. While Figure 6a examines the effect of v arying the num- ber of composed images (#CIR) when only a single attribute is intervened on (#Attributes = 1), we further analyze how accuracy changes as both #Attributes and #CIR are v ar- ied. Figure 6b presents a heatmap of CIRCLES accurac y on CUB across dif ferent hyperparameter settings. When the retrie val budget is limited (e.g., #CIR = 4), distribut- ing interventions across more attributes per query yields better performance than focusing retriev als on a single at- tribute. As the budget increases (e.g., #CIR = 16), allocat- ing more compositions to fewer attributes becomes advan- tageous. This suggests that the optimal allocation of the in-context example budget shifts from breadth (intervening on more attributes) to depth (focusing on fewer attributes) as #CIR grows. In practice, these results indicate that un- der tight budgets, spreading compositions across attributes maximizes co verage, while with larger budgets, concentrat- ing CIR on a smaller subset of attrib utes provides more pre- cise and informati ve interventions, because imperfect CIR methods may not alw ays rank the most relev ant images at the top. Further discussions on ef ficiency and additional de- sign ablations are provided in Appendices B , D , and E . 5. Conclusion W e proposed CIRCLES, a retriev al-augmented ICL method that introduces counterfactual demonstrations through attribute-guided composed image retrie val, enabling VLMs to reason beyond surface similarity and better capture the causal structure underlying visual tasks. By integrating compositional interventions with con ventional similarity- based retriev al, CIRCLES offers a principled mechanism for enriching demonstration sets with examples that ex- pose disentangled attribute-le vel variations. Our experi- ments highlight not only consistent quantitati ve gains b ut also qualitativ e improv ements in the div ersity and causal informativ eness of retrieved examples, particularly un- der information-scarce regimes where traditional retriev al methods degrade most sharply . These findings suggest that counterfactual retrie val is a practical and effecti ve approach for enhancing visual in-context learning in VLMs. Acknowledgments This work is supported in part by the US Na- tional Science Foundation (NSF) and the National In- stitute of Health (NIH) under grants IIS-2106913, IIS- 2538206, IIS-2529378, CCF-2217071, CNS-2213700, and R01LM014012-01A1. Any recommendations expressed in this material are those of the authors and do not necessarily reflect the views of NIH or NSF . References [1] Abdelrahman Abdelhamed, Mahmoud Afifi, and Alec Go. What do you see? enhancing zero-shot image classification with multimodal large language models, 2025. 1 [2] Aishwarya Agraw al, Dhruv Batra, Devi Parikh, and Anirud- dha Kembha vi. Don’t just assume; look and answer: Over- coming priors for visual question answering. In Pr oceed- ings of the IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , 2018. 2 [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr , Y ana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Re ynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, T engda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob L Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sa- hand Sharifzadeh, Mikoł aj Bi ´ nko wski, Ricardo Barreira, Oriol V inyals, Andrew Zisserman, and Kar ´ en Simonyan. Flamingo: a visual language model for few-shot learning. In Advances in Neural Information Pr ocessing Systems , pages 23716–23736. Curran Associates, Inc., 2022. 1 , 2 , 4 , 5 [4] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: V isual question answering. In Pr oceedings of the IEEE International Confer ence on Computer V ision (ICCV) , 2015. 1 [5] Muhammad Umer Anwaar , Egor Labintce v , and Martin Kle- insteuber . Compositional learning of image-text query for image retriev al. In Proceedings of the IEEE/CVF W inter Confer ence on Applications of Computer V ision (W ACV) , pages 1140–1149, 2021. 2 [6] Shuai Bai, K eqin Chen, Xuejing Liu, Jialin W ang, W enbin Ge, Sibo Song, Kai Dang, Peng W ang, Shijie W ang, Jun T ang, Humen Zhong, Y uanzhi Zhu, Mingkun Y ang, Zhao- hai Li, Jianqiang W an, Pengfei W ang, W ei Ding, Zheren Fu, Y iheng Xu, Jiabo Y e, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Y ang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025. 5 , 1 [7] Ivana Balazevic, David Steiner, Nikhil Parthasarathy , Relja Arandjelovi ´ c, and Olivier Henaff. T owards in-context scene understanding. In Advances in Neural Information Pr ocess- ing Systems , pages 63758–63778. Curran Associates, Inc., 2023. 2 [8] Davide Bucciarelli, Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Personalizing mul- timodal large language models for image captioning: An experimental analysis. In Computer V ision – ECCV 2024 W orkshops , pages 351–368, Cham, 2025. Springer Nature Switzerland. 1 [9] Cheng Chen, Y unpeng Zhai, Y ifan Zhao, Jin yang Gao, Bolin Ding, and Jia Li. Prov oking multi-modal few-shot lvlm via exploration-e xploitation in-context learning. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P at- tern Recognition (CVPR) , pages 3826–3835, 2025. 1 [10] Huiyi Chen, Jiawei Peng, Kaihua T ang, Xin Geng, and Xu Y ang. Enhancing multimodal in-context learning for image classification through coreset optimization. In Proceedings of the 33rd ACM International Conference on Multimedia , pages 5130–5139, 2025. 2 [11] Meiqi Chen, Bo Peng, Y an Zhang, and Chaochao Lu. CELLO: Causal e valuation of large vision-language models. In Pr oceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing , pages 22353–22374, Miami, Florida, USA, 2024. Association for Computational Linguistics. 1 [12] Shuo Chen, Zhen Han, Bailan He, Mark Buckley , Philip T orr , V olker T resp, and Jindong Gu. Understanding and im- proving in-context learning on vision-language models. In ICLR 2024 W orkshop on Mathematical and Empirical Un- derstanding of F oundation Models , 2024. 1 , 2 [13] Shuo Chen, Zhen Han, Bailan He, Jianzhe Liu, Mark Buck- ley , Y ao Qin, Philip T orr , V olk er T resp, and Jindong Gu. Can multimodal large language models truly perform multimodal in-context learning? In 2025 IEEE/CVF W inter Confer ence on Applications of Computer V ision (W ACV) , pages 6000– 6010, 2025. 1 , 4 , 5 [14] A vi Cooper, K eizo Kato, Chia-Hsien Shih, Hiroaki Y amane, Kasper V inken, K entaro T akemoto, T aro Sunagaw a, Hao- W ei Y eh, Jin Y amanaka, Ian Mason, and Xavier Boix. Re- thinking vlms and llms for image classification. Scientific Reports , 15(1):19692, 2025. 1 [15] Longye Du, Shuaiyu Deng, Y ing Li, Jun Li, and Qi T ian. A surve y on composed image retriev al. ACM T rans. Multime- dia Comput. Commun. Appl. , 21(7), 2025. 2 [16] Y ifan Du, Junyi Li, T ianyi T ang, W ayne Xin Zhao, and Ji- Rong W en. Zero-shot visual question answering with lan- guage model feedback. In F indings of the Association for Computational Linguistics: A CL 2023 , pages 9268–9281, T oronto, Canada, 2023. Association for Computational Lin- guistics. 1 [17] Danna Gurari, Qing Li, Abigale J. Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jef frey P . Bigham. V izwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2018. 4 [18] Hrayr Harutyunyan, Raf ayel Darbinyan, Samvel Kara- petyan, and Hrant Khachatrian. In-context learning in pres- ence of spurious correlations. In ICML 2024 W orkshop on In-Context Learning , 2024. 2 [19] Cheng-Y u Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kem- bhavi, and Ranjay Krishna. Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality . In Ad- vances in Neural Information Pr ocessing Systems , pages 31096–31116. Curran Associates, Inc., 2023. 1 [20] Brandon Huang, Chancharik Mitra, Assaf Arbelle, Leonid Karlinsky , T rev or Darrell, and Roei Herzig. Multimodal task vectors enable many-shot multimodal in-context learning. In Advances in Neural Information Pr ocessing Systems , pages 22124–22153. Curran Associates, Inc., 2024. 2 [21] Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and composi- tional question answering. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2019. 2 [22] Justin Johnson, Bharath Hariharan, Laurens v an der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elemen- tary visual reasoning. In Proceedings of the IEEE Confer- ence on Computer V ision and P attern Recognition (CVPR) , 2017. 2 [23] Shyamgopal Karthik, Karsten Roth, Massimiliano Mancini, and Zeynep Akata. V ision-by-language for training-free compositional image retriev al. In The T welfth International Confer ence on Learning Representations , 2024. 6 [24] Jeonghwan Kim and Heng Ji. Finer: In vestigating and en- hancing fine-grained visual concept recognition in large vi- sion language models. In Proceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Pr ocessing , pages 6187–6207, Miami, Florida, USA, 2024. Association for Computational Linguistics. 1 [25] Junnan Li, Dongxu Li, Silvio Sav arese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In Pr o- ceedings of the 40th International Confer ence on Machine Learning , pages 19730–19742. PMLR, 2023. 2 [26] Li Li, Jiawei Peng, Huiyi Chen, Chongyang Gao, and Xu Y ang. Ho w to configure good in-context sequence for vi- sual question answering. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pages 26710–26720, 2024. 2 [27] Haotian Liu, Chunyuan Li, Qingyang W u, and Y ong Jae Lee. V isual instruction tuning. In Advances in Neural Information Pr ocessing Systems , pages 34892–34916. Curran Associates, Inc., 2023. 2 [28] Jiachang Liu, Dinghan Shen, Y izhe Zhang, W illiam B Dolan, Lawrence Carin, and W eizhu Chen. What makes good in- context examples for gpt-3? In Proceedings of Deep Learn- ing Inside Out (DeeLIO 2022): The 3r d workshop on knowl- edge extraction and integr ation for deep learning architec- tur es , pages 100–114, 2022. 1 , 2 [29] Zheyuan Liu, Cristian Rodriguez-Opazo, Damien T eney , and Stephen Gould. Image retriev al on real-life images with pre-trained vision-and-language models. In Proceedings of the IEEE/CVF International Confer ence on Computer V ision (ICCV) , pages 2125–2134, 2021. 2 [30] Pan Lu, Swaroop Mishra, T anglin Xia, Liang Qiu, Kai- W ei Chang, Song-Chun Zhu, Oyvind T afjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reason- ing via thought chains for science question answering. In Advances in Neural Information Pr ocessing Systems , pages 2507–2521. Curran Associates, Inc., 2022. 5 [31] Y ao Lu, Max Bart olo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitiv- ity . In Proceedings of the 60th Annual Meeting of the Asso- ciation for Computational Linguistics (V olume 1: Long P a- pers) , pages 8086–8098, Dublin, Ireland, 2022. Association for Computational Linguistics. 2 [32] Y ang Luo, Zangwei Zheng, Zirui Zhu, and Y ang Y ou. Ho w does the textual information affect the retriev al of multi- modal in-context learning? In Pr oceedings of the 2024 Con- fer ence on Empirical Methods in Natural Language Process- ing , pages 5321–5335, Miami, Florida, USA, 2024. Associ- ation for Computational Linguistics. 1 , 4 , 5 [33] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external kno wledge. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2019. 4 [34] Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification ov er a large number of classes. In 2008 Sixth Indian Confer ence on Computer V ision, Graphics & Image Pr ocessing , pages 722–729, 2008. 4 [35] Judea Pearl. Causality . Cambridge University Press, 2 edi- tion, 2009. 4 [36] Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger , and Ilya Sutske ver . Learning transferable visual models from natural language supervision. In Pr oceedings of the 38th International Confer ence on Machine Learning , pages 8748–8763. PMLR, 2021. 5 , 1 [37] Ohad Rubin, Jonathan Herzig, and Jonathan Berant. Learn- ing to retrieve prompts for in-context learning. In Proceed- ings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies , pages 2655–2671, Seattle, United States, 2022. Association for Computational Linguistics. 2 [38] Oindrila Saha, Grant V an Horn, and Subhransu Maji. Im- prov ed zero-shot classification by adapting vlms with text descriptions. In Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition (CVPR) , pages 17542–17552, 2024. 1 [39] Sanchit Sinha, Guangzhi Xiong, and Aidong Zhang. COCO- tree: Compositional hierarchical concept trees for enhanced reasoning in vision-language models. In Proceedings of the 2025 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 2695–2711, Suzhou, China, 2025. Association for Computational Linguistics. 2 [40] Xuemeng Song, Haoqiang Lin, Haokun W en, Bohan Hou, Mingzhu Xu, and Liqiang Nie. A comprehensive survey on composed image retriev al. ACM T rans. Inf. Syst. , 44(1), 2025. 2 [41] Y uanmin T ang, Jue Zhang, Xiaoting Qin, Jing Y u, Gaopeng Gou, Gang Xiong, Qingwei Lin, Saravan Rajmohan, Dong- mei Zhang, and Qi W u. Reason-before-retrieve: One-stage reflectiv e chain-of-thoughts for training-free zero-shot com- posed image retrie val. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pages 14400–14410, 2025. 6 , 7 , 2 , 5 [42] Gemma T eam, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino V ieillard, Ramona Merhej, Sarah Perrin, T a- tiana Matejovicov a, Alexandre Ram ´ e, Morgane Rivi ` ere, Louis Rouillard, Thomas Mesnard, Geoffre y Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Cas- bon, Etienne Pot, Iv o Penche v , Ga ¨ el Liu, Francesco V isin, Kathleen Kenealy , Lucas Beyer , Xiaohai Zhai, Anton Tsit- sulin, Robert Busa-Fekete, Alex Feng, Noveen Sachdev a, Benjamin Coleman, Y i Gao, Basil Mustafa, Iain Barr , Emilio Parisotto, David Tian, Matan Eyal, Colin Cherry , Jan-Thorsten Peter , Danila Sinopalnikov , Surya Bhupatiraju, Rishabh Agarwal, Mehran Kazemi, Dan Malkin, Ravin Ku- mar , David V ilar, Idan Brusilo vsky , Jiaming Luo, Andreas Steiner , Abe Friesen, Abhanshu Sharma, Abheesht Sharma, Adi Mayra v Gilady , Adrian Goedeckeme yer, Alaa Saade, Alex Feng, Alexander Kolesnik ov , Alexei Bendebury , Alvin Abdagic, Amit V adi, Andr ´ as Gy ¨ orgy , Andr ´ e Susano Pinto, Anil Das, Ankur Bapna, Antoine Miech, Antoine Y ang, An- tonia P aterson, Ashish Shenoy , A yan Chakrabarti, Bilal Piot, Bo W u, Bobak Shahriari, Bryce Petrini, Charlie Chen, Char - line Le Lan, Christopher A. Choquette-Choo, CJ Care y , Cor- mac Brick, Daniel Deutsch, Danielle Eisenbud, Dee Cat- tle, Derek Cheng, Dimitris Paparas, Di vyashree Shi vaku- mar Sreepathihalli, Doug Reid, Dustin T ran, Dustin Zelle, Eric Noland, Erwin Huizenga, Eugene Kharitonov , Frederick Liu, Gagik Amirkhanyan, Glenn Cameron, Hadi Hashemi, Hanna Klimczak-Pluci ´ nska, Harman Singh, Harsh Mehta, Harshal T ushar Lehri, Hussein Hazimeh, Ian Ballantyne, Idan Szpektor, Ivan Nardini, Jean Pouget-Abadie, Jetha Chan, Joe Stanton, John W ieting, Jonathan Lai, Jordi Or- bay , Joseph Fernandez, Josh Newlan, Ju yeong Ji, Jyotin- der Singh, Kat Black, Kathy Y u, Ke vin Hui, Kiran V odra- halli, Klaus Greff, Linhai Qiu, Marcella V alentine, Marina Coelho, Marvin Ritter, Matt Hoffman, Matthew W atson, Mayank Chaturvedi, Michael Moynihan, Min Ma, Nabila Babar , Natasha Noy , Nathan Byrd, Nick Roy , Nikola Mom- chev , Nilay Chauhan, Noveen Sachdev a, Oskar Bun yan, Pankil Botarda, Paul Caron, Paul Kishan Rubenstein, Phil Culliton, Philipp Schmid, Pier Giuseppe Sessa, Pingmei Xu, Piotr Stanczyk, Pouya T afti, Rakesh Shiv anna, Renjie W u, Renke P an, Reza Rokni, Rob W illoughby , Rohith V allu, Ryan Mullins, Sammy Jerome, Sara Smoot, Sertan Girgin, Shariq Iqbal, Shashir Reddy , Shruti Sheth, Siim P ˜ oder , Sijal Bhatnagar , Sindhu Raghuram Panyam, Siv an Eiger , Susan Zhang, Tianqi Liu, T revor Y acovone, T yler Liechty , Uday Kalra, Utku Evci, V edant Misra, V incent Roseberry , Vlad Feinberg, Vlad K olesnikov , W oohyun Han, W oosuk Kwon, Xi Chen, Y inlam Chow , Y uvein Zhu, Zichuan W ei, Zoltan Egyed, V ictor Cotruta, Minh Giang, Phoebe Kirk, Anand Rao, Kat Black, Nabila Babar, Jessica Lo, Erica Moreira, Luiz Gusta vo Martins, Omar Sanse viero, Lucas Gonzalez, Zach Gleicher , Tris W arkentin, V ahab Mirrokni, Evan Sen- ter , Eli Collins, Joelle Barral, Zoubin Ghahramani, Raia Hadsell, Y ossi Matias, D. Sculley , Slav Petrov , Noah Fiedel, Noam Shazeer, Oriol V inyals, Jef f Dean, Demis Hassabis, K oray Kavukcuoglu, Clement Farabet, Elena Buchatskaya, Jean-Baptiste Alayrac, Rohan Anil, Dmitry , Lepikhin, Se- bastian Borgeaud, Olivier Bachem, Armand Joulin, Alek Andreev , Cassidy Hardin, Robert Dadashi, and L ´ eonard Hussenot. Gemma 3 technical report, 2025. 5 , 1 [43] Maria Tsimpoukelli, Jacob L Menick, Serkan Cabi, S. M. Ali Eslami, Oriol V inyals, and Felix Hill. Multimodal fe w-shot learning with frozen language models. In Advances in Neu- ral Information Pr ocessing Systems , pages 200–212. Curran Associates, Inc., 2021. 1 , 2 [44] Nam V o, Lu Jiang, Chen Sun, Ke vin Murphy , Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrie val - an empirical odyssey . In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , 2019. 2 [45] Catherine W ah, Steve Branson, Peter W elinder, Pietro Per- ona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011. 4 [46] Hui W u, Y upeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Ste ven Rennie, Kristen Grauman, and Rogerio Feris. Fashion iq: A new dataset to wards retrieving images by natural language feedback. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition (CVPR) , pages 11307–11317, 2021. 2 [47] Qi W u, Damien T eney , Peng W ang, Chunhua Shen, Anthony Dick, and Anton v an den Hengel. V isual question answering: A surve y of methods and datasets. Computer V ision and Im- age Understanding , 163:21–40, 2017. Language in V ision. 1 [48] Zhengyuan Y ang, Zhe Gan, Jianfeng W ang, Xiaowei Hu, Y umao Lu, Zicheng Liu, and Lijuan W ang. An empirical study of gpt-3 for few-shot knowledge-based vqa. In Pr o- ceedings of the AAAI conference on artificial intelligence , pages 3081–3089, 2022. 1 , 4 , 5 [49] Ellen Y i-Ge, Jiechao Gao, W ei Han, and W ei Zhu. DR UM: Learning demonstration retriev er for large MUlti-modal models. In Proceedings of the 63r d Annual Meeting of the Association for Computational Linguistics (V olume 4: Stu- dent Resear ch W orkshop) , pages 1051–1063, V ienna, Aus- tria, 2025. Association for Computational Linguistics. 2 [50] Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Ja- son Corso, and Jianfeng Gao. Unified vision-language pre- training for image captioning and vqa. In Pr oceedings of the AAAI confer ence on artificial intelligence , pages 13041– 13049, 2020. 1 [51] Y ucheng Zhou, Xiang Li, Qianning W ang, and Jianbing Shen. V isual in-context learning for lar ge vision-language models. In F indings of the Association for Computational Linguistics: A CL 2024 , pages 15890–15902, Bangkok, Thai- land, 2024. Association for Computational Linguistics. 1 [52] Y uhang Zhou, Paiheng Xu, Xiaoyu Liu, Bang An, W ei Ai, and Furong Huang. Explore spurious correlations at the con- cept level in language models for text classification. In Pr o- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 478–492, Bangkok, Thailand, 2024. Association for Compu- tational Linguistics. 2 Retrieving Counterfactuals Impr ov es V isual In-Context Learning Supplementary Material A. Implementation Details A.1. Baseline Implementations Backbone vision-language models. All baselines and CIRCLES are instantiated with the same backbone vision- language models (VLMs) to ensure a fair comparison. W e use Gemma3 [ 42 ] with 4B and 12B parameters (denoted as Gemma3-4B and Gemma3-12B) and Qwen2.5-VL [ 6 ] with 3B and 7B parameters (denoted as Qwen2.5-VL-3B and Qwen2.5-VL-7B) from the HuggingFace platform. For all models, we run inference with BFloat16 precision using the vLLM library . Retrieval backbone. For all retriev al-based baselines, in- cluding RICES, MUIER, MMICES, and CIRCLES, we use CLIP V iT -g/14 (”laion/CLIP-V iT -g-14-laion2B-s12B- b42K”) [ 36 ] as the shared image-text encoder . Unless other- wise specified, all visual and textual features are extracted from the CLIP image/text encoder and L2-normalized be- fore similarity computation. Prompting setup. W e use a unified prompting template across all methods for each task. For each instance, the prompt includes the query image and question, followed by in-context demonstrations selected by the respectiv e method. The input query is repeated at the end of the prompt for clarity . All methods and VLMs use a decod- ing temperature of 0.0 for deterministic generation, and the maximum output length is set to 512 tokens for all ex- periments. For VQA tasks (OK-VQA and V izWiz), in- context demonstrations consist of the original question- answer pairs. For classification tasks (CUB and Flo wers), we use fixed question templates and the corresponding class labels as in-context examples. Specifically , the question template for CUB is “What is the category of the bird in this image?”, and for Flowers, “What is the category of the flower in this image?”. Baselines. W e implement the following baselines: • None (zero-shot): The backbone VLM receiv es only the task description and query example, without any in- context demonstrations. • Random : In-context demonstrations are uniformly sam- pled from the training set for each query , without re- triev al. • RICES [ 3 , 48 ]: For each query , CLIP image embeddings are computed and the top- K nearest neighbors in the vi- sual feature space are retrieved by cosine similarity . Re- triev ed e xamples are sorted by similarity and added to the prompt. • MUIER [ 32 ]: Follo wing the original paper , we use a multimodal similarity score combining image-image and image-text similarities, with the same CLIP backbone as RICES. The image-text similarity is computed between the query image and each candidate example’ s question text. Candidates are ranked by the multimodal score, and the top- K are selected as demonstrations. • MMICES [ 13 ]: MMICES is implemented as a two-stage selector . First, 1024 candidate demonstrations are re- triev ed using image-image similarity . Second, these can- didates are re-ranked by a text-image similarity score measuring how well each candidate’ s image matches the query’ s question. The top- K re-ranked examples are used as in-context demonstrations. All baselines are ev aluated with a fixed in-context bud- get of K = 32 demonstrations per query , unless otherwise specified in ablations. Demonstrations are selected from the training set of each dataset. A.2. Implementation of CIRCLES CIRCLES augments standard image retriev al (IR) with composed image retriev al (CIR) to construct richer and more causally informati ve in-context examples. For each query , CIRCLES first retrie ves visually similar neighbors (IR) using CLIP , and then inv okes a training-free CIR module to generate counterfactual examples via language- guided attribute interventions. The final in-conte xt set is composed of both IR and CIR examples, constrained by a fixed total b udget of 32 examples unless otherwise stated. Attribute Extraction. For each query , we prompt the backbone VLM to identify the most prominent attributes visible in the image that are relev ant to the given question. The VLM outputs a ranked list of attributes, ordered from most to least important for answering the query . This ap- proach does not rely on explicit attribute labels or fixed vo- cabularies; instead, attribute phrases are generated dynami- cally by the VLM based on the image and question context. Standard image retriev al (IR). The IR component in CIRCLES is identical to RICES: CLIP image embeddings are computed for all training images and the query image, and we retriev e the top- K I R neighbors by cosine similarity . For a full in-context budget of 32 e xamples, we set K I R =16 and allocate the remaining budget to CIR (e.g., K C I R =16). Composed image retrieval (CIR) with OSrCIR. W e implement CIR using OSrCIR [ 41 ], a training-free frame- work that synthesizes captions conditioned on the query im- age and attribute-manipulation text. For each selected at- tribute of a query image, we prompt the VLM to generate a counterfactual caption describing the image with the de- sired attrib ute change. This composed caption is encoded with CLIP and used to retrie ve images from the training set whose visual embeddings best match the description. As detailed in Section 3 , candidates are ranked by the sum of image-image and te xt-text similarity scores, both normal- ized to the range [0 , 1] via L2-normalization. The top K C I R candidates are selected as CIR examples and combined with IR examples to form the final in-conte xt set. The detailed prompts used in our implementation are provided in Appendix G . B. Discussions on Efficiency Compared to retriev al-only in-context learning baselines such as RICES, MUIER, and MMICES, CIRCLES intro- duces additional computation at inference time due to at- tribute extraction and composed image retrie val. For each query , we first in voke the VLM once to identify salient attributes, and then issue one VLM call per selected at- tribute to generate a counterfactual caption describing the desired manipulation. These calls are in addition to the fi- nal answer-generation call, which is shared by all methods. In contrast, standard retriev al baselines perform only CLIP- based retrie val follo wed by a single VLM call for answer generation. Although CIRCLES introduces additional VLM calls for attribute extraction and composed retriev al, these calls use short prompts, and the dominant cost still comes from the final in-context inference step with 32 demonstrations. T o quantify this overhead, T able 3 reports the average number of tokens processed per question for RICES and CIRCLES across datasets. Overall, CIRCLES adds only about 10% token overhead relati ve to RICES, while providing consis- tently better performance in the main experiments. T able 3. A verage token usage per question for RICES and CIR- CLES. The additional VLM calls in CIRCLES introduce only a modest ov erhead (around 10%). Model Method CUB Flowers OK-VQA V izWiz Gemma3 -4B RICES 11.1k 10.0k 9.4k 10.2k CIRCLES 12.2k 11.2k 10.6k 11.4k Qwen2.5 -VL-3B RICES 9.9k 15.8k 12.8k 33.3k CIRCLES 10.9k 17.2k 14.1k 35.9k T o further compare CIRCLES with baseline methods under the same VLM call budget, we test a compute- matched variant of RICES, denoted RICES*, which per - forms multiple answer generations ( K = 3 ) followed by self-consistency . As shown in T able 4 , CIRCLES con- sistently outperforms RICES* across datasets and model scales. This suggests that the improv ements of CIRCLES are not explained solely by additional generations, but by the quality of the attribute-guided retrieved demonstrations. T able 4. Compute-matched comparison between CIRCLES and RICES*. RICES* uses multiple generations ( K = 3 ) with self- consistency under the same inference-time call b udget. Model Method CUB Flowers OK-VQA V izWiz Gemma3 -4B RICES* 64.73 86.60 26.34 56.17 CIRCLES 71.97 93.32 31.27 57.61 Gemma3 -12B RICES* 75.70 96.02 36.64 74.09 CIRCLES 77.03 97.77 37.75 74.30 Finally , we view CIRCLES as a first, training-free instantiation of counterfactual retrie val rather than an efficienc y-optimized endpoint. Our current implementa- tion relies on an LLM to generate counterfactual captions, which are then encoded with CLIP and used for composed retriev al. As composed image retriev al models and multi- modal embedding architectures mature, one could instead directly embed joint (image, manipulation text) queries, or precompute attribute-a ware embeddings, thereby reduc- ing or e ven eliminating the need for multiple online LLM calls. Such designs would bring the computational profile of counterfactual retrie val closer to that of standard similarity- based retrie val, while retaining the robustness and causal benefits demonstrated by CIRCLES. C. Robustness and Sensiti vity Our main experiments use deterministic decoding with tem- perature 0.0. T o assess robustness under stochastic gener- ation, we additionally ev aluate RICES and CIRCLES with Gemma3-4B using temperature 1.0 and repeat decoding fiv e times. T able 5 reports the mean and standard de viation across the benchmark datasets. T able 5. Rob ustness under stochastic decoding for Gemma3-4B. W e set temperature = 1.0, repeat decoding five times, and report mean ± standard deviation. Method CUB Flowers OK-VQA V izWiz RICES 64.42 ± 0.32 86.42 ± 0.24 26.08 ± 0.23 55.69 ± 0.07 CIRCLES 70.30 ± 0.28 92.87 ± 0.13 30.54 ± 0.21 57.04 ± 0.23 CIRCLES consistently outperforms RICES under stochastic decoding on all four datasets. Moreover , the Query Image Nest Nearby Small Size Small Size + Images from Standard IR Acadian Flycatcher Least Flycatcher + Images from Standard IR + Images from Standard IR Least Flycatcher Figure 7. Qualitati ve examples of CIRCLES. T op: failure due to a non-discriminativ e extracted attribute. Middle: failure due to weak composed retrie val. Bottom: success case with better matched composed examples. Red denotes unhelpful retrie ved e xamples or incorrect predictions, and green denotes helpful retriev ed examples or the correct prediction. standard deviations are small relati ve to the performance gaps between the two methods, suggesting that the gains from CIRCLES are stable across repeated stochastic runs rather than driv en by fav orable sampling variation. Figure 7 shows two representati ve failure modes of CIR- CLES and one successful case. In the top row , the extracted attribute ( nest nearby ) is visually plausible but not discrim- inativ e, so the composed examples provide little useful sig- nal beyond standard IR. In the middle row , the extracted attribute ( small size ) is relev ant, but the composed retriev al is only weakly aligned with the target, limiting its benefit for prediction. In the bottom row , the same attribute yields better matched composed examples and leads to the cor- rect answer . These cases suggest that the ef fectiveness of CIRCLES depends on both reliable attribute extraction and high-quality attribute-conditioned retriev al, which we view as promising directions for future improv ement. D. Effect of Attrib ute Quality and Counterfac- tual Retriev al W e first inv estigate how the quality of attrib ute information affects the performance of CIRCLES. On CUB, in addition to the attributes extracted by the backbone VLM, we have access to class-specific attribute frequency tables provided by the dataset. For each attrib ute, we compute a discrimi- nativ eness score as the gap between its frequency within a giv en class and its highest frequency across all other classes, and rank attributes for each class by this score. Then, for a query image, we form a sample-specific attrib ute list by tak- ing the top-ranked attributes for its class and pruning those that are not annotated as present in the image. This pro vides a set of clean, image-le vel attribute descriptions that we feed to CIRCLES in place of VLM-extracted attributes. As shown in T able 6 , using these ground-truth attributes yields consistent improv ements ov er VLM-extracted attrib utes for both Gemma3-4B and Gemma3-12B, confirming that accu- rate attribute identification is beneficial for composed image retriev al and, consequently , for in-context learning. At the same time, the gains are relativ ely modest, suggesting that the backbone VLM is already able to recov er attributes that are close to the dataset oracle. T able 6. Effect of replacing VLM-extracted attributes with ground-truth attribute annotations on CUB. Attribute Source Gemma3-4B Gemma3-12B Acc F1 Acc F1 LLM 71.97 72.39 77.03 76.90 Dataset 72.44 72.82 77.65 77.46 Next, we explore whether it is the e xplicit use of at- tributes or the counterfactual retriev al itself that dri ves the gains of CIRCLES. T o disentangle these factors, we com- pare three settings on all four benchmarks: (1) standard im- age retriev al only (IR), which corresponds to the RICES- style baseline; (2) IR with attribute information but with- out CIR (IR+Attr), where we retriev e images using IR and append the extracted attrib utes as additional textual con- text without composing counterfactual queries; and (3) IR with full CIR (IR+CIR), which is our proposed CIRCLES setting where attributes are used to generate counterfactual captions and retriev e manipulated visual examples. The results for Gemma3-4B are summarized in T able 7 . W e observe that providing attrib ute information alone (IR+Attr) substantially improv es performance ov er IR on fine-grained classification tasks such as CUB and Flo w- ers, where attribute recognition is central to the task. In contrast, on open-ended VQA benchmarks like OK-VQA T able 7. Ablation of CIR versus attribute-only prompting on Gemma3-4B. IR denotes standard image retriev al; Attr denotes adding textual attributes without CIR. Setting CUB Flowers OK-VQA V izWiz Acc F1 Acc F1 EM F1 EM F1 IR 65.40 67.62 86.70 87.43 26.65 32.72 56.08 70.40 IR + Attr 71.99 71.91 92.91 93.53 26.16 32.63 53.83 68.82 IR + CIR 71.97 72.39 93.32 93.49 31.27 36.89 57.61 71.35 and V izW iz, simply adding attrib utes without counterfac- tual retrieval slightly degrades performance, likely because the added textual descriptions can bias the model to ward spurious cues without offering new visual evidence. In all cases, enabling CIR on top of IR and attributes (IR+CIR) yields the best performance, with clear gains over both IR and IR+Attr across all datasets. This suggests that attributes are most effecti ve when the y are grounded through counter- factual visual examples, which help the model better inter- pret and utilize fine-grained attribute cues in div erse down- stream tasks. E. More Ablations on CIRCLES Designs While Section 4.5 ablates se veral design choices within the CIR module itself, here we further probe the overall CIR- CLES frame work by examining (i) dif ferent implementa- tions of the underlying image retriev al (IR) component and (ii) the relativ e contributions of IR and CIR. Alternativ e IR similarity functions. In the main exper - iments, we implement IR using image-image similarity in CLIP space, following the RICES design. T o under- stand whether richer similarity measures can further help CIRCLES, we consider two additional variants inspired by prior work. First, we augment image-image similarity with image-text similarity as in MUIER, where we also match the query image against the question text associated with each candidate example. Second, we combine image-image similarity with the text-text similarity used in our CIR im- plementation to capture task similarity between questions. Since CUB and Flo wers are classification tasks with an identical question template for all test images, text-based similarity is uninformati ve there. W e therefore restrict these IR ablations to OK-VQA and V izW iz. Results in T able 8 sho w that simply adding image- text similarity does not improve performance, and in fact slightly degrades results on OK-VQA, mirroring the small gap between RICES and MUIER observed in T able 1 . In contrast, incorporating text-text similarity on top of image- image similarity yields small but consistent gains on both datasets, especially on V izWiz. This suggests that, for open- ended VQA, capturing task similarity at the text lev el is ben- T able 8. CIRCLES with different implementations of the image retriev al component (Gemma3-4B). Similarity OK-VQA V izWiz EM F1 EM F1 image-image 31.27 36.89 57.61 71.35 image-image + image-text 30.14 35.67 57.81 71.63 image-image + text-te xt 31.37 36.74 59.09 72.64 eficial, while the simple image-image retriev al used in our main CIRCLES configuration is already a strong baseline. IR versus CIR versus IR+CIR. W e also disentangle the effects of IR and CIR by comparing three variants: (1) IR only , which corresponds to a standard retrie val-based ICL setup using only retrie ved images and their labels; (2) CIR only , where we discard the original retriev ed examples and retain only the counterfactual examples produced by CIR; and (3) IR + CIR (full CIRCLES), which includes both the original retrie ved examples and their counterfactual coun- terparts in the in-context prompt. The results on Gemma3- 4B are summarized in T able 9 . On fine-grained classification benchmarks (CUB and Flowers), CIR only lags far behind IR only , indicating that counterfactual examples alone are not sufficient to capture the subtle visual prototypes needed for class recognition. In contrast, on OK-VQA and V izWiz, CIR only achiev es performance comparable to IR only , slightly improving EM and F1 on OK-VQA while being close on V izW iz. Across all four datasets, ho wever , the combined IR + CIR v ariant consistently yields the best performance, sometimes by a large margin (e.g., +6-7 accuracy points over IR only on CUB and Flowers). These trends highlight that IR and CIR play complementary roles: IR provides realistic, prototypi- cal examples that anchor the model’ s understanding of the task, while CIR introduces targeted counterfactual varia- tions that clarify the role of ke y attributes and reduce spuri- ous correlations. T ogether , they enable CIRCLES to le ver- age both factual and counterf actual experience for more ro- bust in-conte xt learning. T able 9. Ablation of IR and CIR in CIRCLES, tested on Gemma3-4B. Setting CUB Flowers OK-VQA V izWiz Acc F1 Acc F1 EM F1 EM F1 IR only 65.40 67.62 86.70 87.43 26.65 32.72 56.08 70.40 CIR only 25.16 26.14 60.24 65.85 29.81 35.52 54.06 68.29 IR + CIR 71.97 72.39 93.32 93.49 31.27 36.89 57.61 71.35 F. Additional Results on Benchmarks and Model Scaling Results on ScienceQA. T o further examine the generality of CIRCLES beyond image classification and visual ques- tion answering tasks, we additionally ev aluate CIRCLES on ScienceQA [ 30 ], a more challenging multimodal reasoning benchmark. Follo wing the same in-context learning proto- col used in the main paper , we construct the demonstration pool from the ScienceQA v alidation split and report perfor - mance on the test split. T able 10 sho ws that CIRCLES con- sistently outperforms all compared example selection base- lines on ScienceQA. The gains are modest b ut consistent across both model sizes. T able 10. T est accuracy (%) on ScienceQA. In-context examples are retrie ved from the v alidation split. The experiments are run on the Qwen2.5-VL model family . Size Random RICES MUIER CIRCLES 3B 78.33 80.12 80.66 80.71 7B 85.18 88.05 87.90 88.35 Scaling to Larger Models: Gemma3-27B. T o examine whether the gains of CIRCLES persist at a larger model scale, we additionally ev aluate Gemma3-27B, a larger model in the Gemma3 family , on the same four benchmarks used in the main paper . T able 11 sho ws that CIRCLES con- tinues to outperform RICES across all datasets, indicating that the benefit of attribute-conditioned, contrasti ve retriev al is not limited to smaller or mid-sized backbones. T able 11. Performance comparison on Gemma3-27B. Method CUB Flowers OKVQA V izWiz RICES 69.76 93.98 38.66 67.24 CIRCLES 72.21 97.51 39.14 68.72 G. Prompt T emplates W e provide the detailed prompt templates used for each dataset in this section. Figure 8 shows the template used to extract key visual attributes that are relev ant for answer- ing the question. Giv en an input image and question, the VLM is instructed to list a small set of concise attributes, which are then used as the basis for constructing counter- factual manipulations. Figure 9 contains the template used to generate counterfactual captions with targeted attrib ute changes. The system prompt in Figure 9 follows the one used in OSrCIR [ 41 ]. Figures 10 – 12 show the templates used for VLM in- ference under different in-conte xt learning settings: Fig- ure 10 corresponds to the setting without in-context exam- ples (“None” in T able 1 ); Figure 11 illustrates the base- line prompt used for in-context learning methods such as RICES; and Figure 12 presents the full CIRCLES prompt, which augments the standard retriev ed demonstrations with the counterfactual examples produced by CIR. Across all of these templates, the value of {{Task Type}} is set to “Image Classification” for CUB and Flowers, and to “V isual Question Answering” for OK-VQA and V izW iz, so that the VLM is explicitly informed of the task format. For the classification datasets (CUB and Flowers), we additionally enforce a closed set of answer options to align with the standard ev aluation protocol. Concretely , for these datasets, we append the sentence “Y ou need to choose one of the following options: {{Options}} ” immedi- ately after the first sentence describing the task type, where {{Options}} is replaced by the list of candidate class names for the giv en example. For OK-VQA and V izW iz, which are ev aluated in an open-ended manner, we do not provide such options and instead allow the model to freely generate answers conditioned on the image, question, and in-context demonstrations. Prompt template for attribute e xtraction Identify the key attributes of the following image that are most rele vant to answering the question. {{Image}} Question: {{Question}} Please list the top {{num_attributes}} key attributes as short phrases in a section named ‘### Attributes’, one per line, ordered from most to least important. Figure 8. Prompt template for attribute extraction. Prompt template for generating counterfactual caption {{System Prompt by OSrCIR}} {{Image}} Manipulation T ext: Change the attrib ute {{Attribute}} to a dif ferent plausible v alue. Ensure the modified caption is concise and contains no more than 77 tokens. Figure 9. Prompt template for generating counterfactual caption based on the query image and identified key attrib ute. Prompt template for VLM inference used by None Y our task is to perform {{Task Type}} . {{Image}} Question: {{Question}} Please provide your response by directly outputting the answer . Figure 10. Prompt template for VLM inference used by None (zero-shot learning). Prompt template for VLM inference used by Random/RICES/MUIER/MMICES Y our task is to perform {{Task Type}} . {{Image}} Question: {{Question}} Here are {{K_IR}} in-context e xamples to help you answer the question: {{Retrieved Image}} Question: {{Retrieved Question}} Answer: {{Retrieved Answer}} {{Retrieved Image}} ...... Here is the original question again. {{Image}} Question: {{Question}} Please provide your response by directly outputting the answer . Figure 11. Prompt template for VLM inference used by Random, RICES, MUIER, and MMICES. Prompt template for VLM inference used by CIRCLES Y our task is to perform {{Task Type}} . {{Image}} Question: {{Question}} Here are {{K_IR}} in-context e xamples to help you answer the question: {{Retrieved Image}} Question: {{Retrieved Question}} Answer: {{Retrieved Answer}} {{Retrieved Image}} ...... Examples retriev ed based on the target image description after changing {{Attribute}} (caption: {{Caption}} ): {{Retrieved Image}} Question: {{Retrieved Question}} Answer: {{Retrieved Answer}} {{Retrieved Image}} ...... Here is the original question again. {{Image}} Question: {{Question}} Please provide your response by directly outputting the answer . Figure 12. Prompt template for VLM inference used by CIRCLES.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment