반사실 예시 검색으로 시각 인컨텍스트 학습 강화
CIRCLES는 속성‑가이드된 합성 이미지 검색을 이용해 반사실(대조) 예시를 추출하고, 이를 기존의 유사도 기반 예시와 결합해 시각‑언어 모델의 인컨텍스트 학습 성능을 크게 향상시킨다. 특히 작은 모델이나 데이터가 부족한 상황에서 인과 관계를 명시적으로 드러내는 데 효과적이다.
저자: Guangzhi Xiong, Sanchit Sinha, Zhenghao He
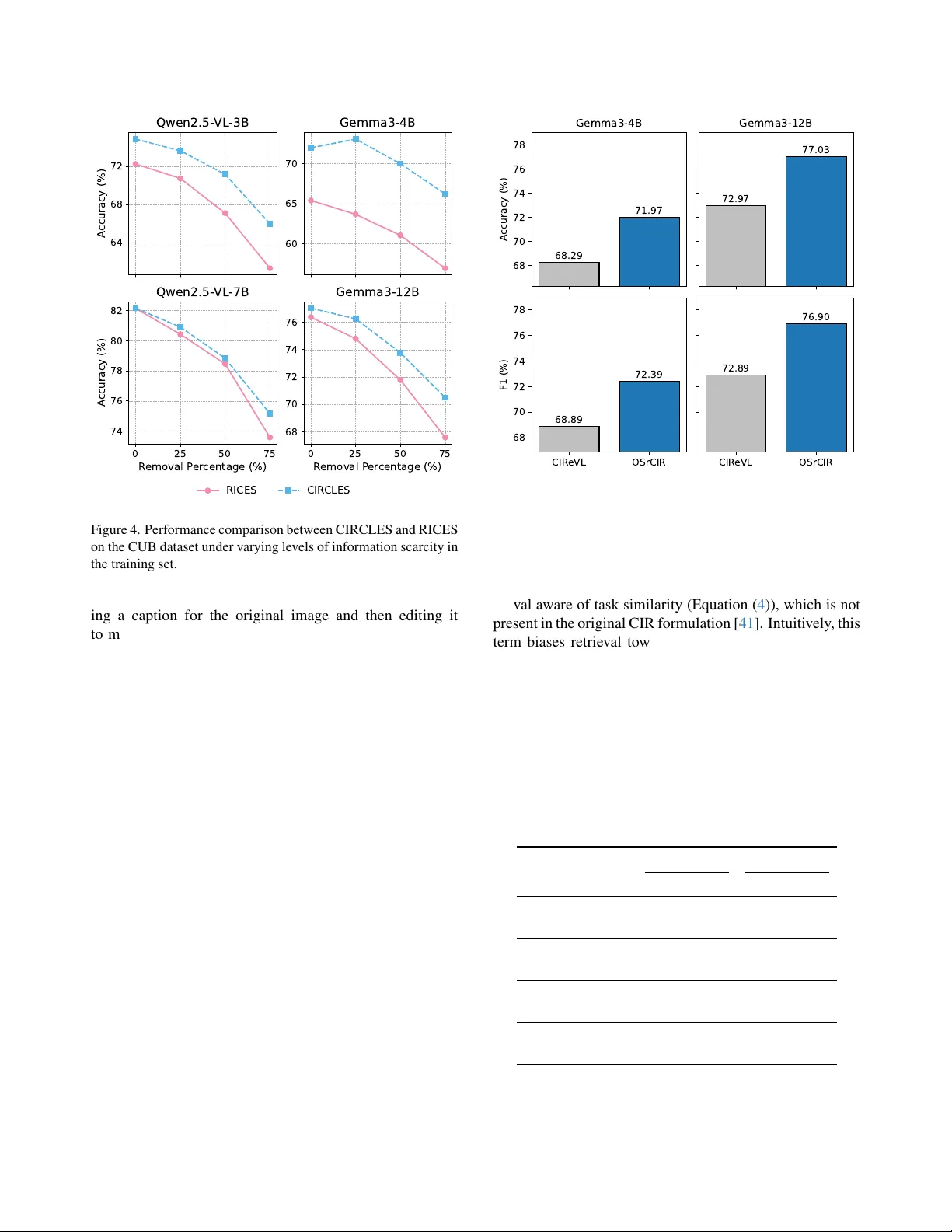
본 논문은 시각‑언어 모델(VLM)이 미세한 시각 속성 구분과 인과 관계 추론에 어려움을 겪는 현상을 지적하고, 이를 보완하기 위한 새로운 인컨텍스트 학습(ICL) 프레임워크인 **CIRCLES (Composed Image Retrieval for Causal Learning Example Selection)** 를 제안한다. 기존 ICL 방법은 RICES, MUIER, MMICES와 같이 질의 이미지와 가장 유사한 이웃을 검색해 데모 예시로 제공한다. 이러한 패시브 검색은 질문과 정답 사이의 실제 인과 메커니즘을 반영하지 못하고, 상관관계에만 의존하게 된다. 결과적으로 모델은 스푸리어스한 패턴을 학습하고, 데이터가 부족하거나 도메인 이동이 발생했을 때 성능이 급격히 저하된다.
CIRCLES는 두 가지 검색 전략을 결합한다. 첫 번째는 **속성‑가이드된 합성 이미지 검색(CIR)** 으로, 질의 이미지와 질문을 입력으로 VLM에게 핵심 속성‑값 쌍을 추출하도록 프롬프트한다. 예를 들어 “가슴 색상=회색”과 같은 속성을 식별한다. 각 속성에 대해 가능한 대체값을 선정하고, VLM에게 “속성 a_i 를 v′_i 로 바꾼 가상의 캡션”을 생성하도록 한다. 이 가상 캡션은 ‘do(a_i=v′_i)’라는 인과적 개입을 의미한다. 이후 모든 후보 이미지에 대해 (1) 이미지‑캡션 유사도 s_img_j = z_I_j^T · f_T(c_do)와 (2) 질문‑질문 유사도 s_txt_j = z_Q_q^T · z_Q_j 를 계산하고, 두 점수를 합산한 S_j = s_img_j + s_txt_j 로 순위를 매긴다. 상위 k 개의 이미지를 **인과적 예시 집합(R_causal)** 로 선택한다.
두 번째 단계는 전통적인 **이미지‑이미지 유사도 기반 검색**이다. 질의 이미지와 가장 시각적으로 유사한 이미지들을 **상관적 예시 집합(R_corr)** 로 선정한다. 이는 모델이 일반적인 시각 패턴이나 배경 정보를 보강하도록 돕는다.
두 집합을 합쳐 최종 컨텍스트 R = R_causal ∪ R_corr 를 구성하고, VLM Φ에 (I_q, Q_q, R) 를 입력해 답을 생성한다. 이렇게 하면 모델은 표면적인 상관관계와 인과적 변화를 동시에 관찰하게 되어, 보다 견고하고 해석 가능한 추론을 수행한다.
실험은 네 개의 벤치마크(CUB, Flowers, OK‑VQA, VizWiz)를 사용했으며, Gemma‑3‑B, Gemma‑12‑B, Qwen2.5‑VL‑3B/‑7B 등 다양한 규모의 VLM에 적용했다. 결과는 다음과 같다. (1) 모든 데이터셋에서 CIRCLES가 기존 베이스라인보다 평균 4~7%p(Acc/EM) 높은 성능을 기록했다. (2) 특히 작은 모델(Gemma‑3‑B, Qwen2.5‑VL‑3B)에서 인과적 예시가 큰 효과를 발휘했다. (3) 정보가 제한된 ‘정보 희소성’ 실험에서도 CIRCLES는 유사도 기반 검색만 사용할 때보다 현저히 높은 정확도를 유지했다. (4) 정성 분석에서는 CIRCLES가 추출한 예시가 속성 변화를 명확히 드러내며, 모델이 “배꼽 무늬가 바뀌면 종이 바뀐다”는 인과 관계를 학습하는 모습을 시각화했다.
논문의 주요 기여는 다음과 같다. ① 인컨텍스트 학습에 반사실 예시를 체계적으로 도입한 프레임워크 제시. ② 속성‑가이드된 합성 이미지 검색을 통해 인과적 변수를 효율적으로 근사하는 방법 개발. ③ 다양한 모델·데이터셋에서 일관된 성능 향상을 입증한 광범위한 실험. ④ 저데이터·소형 모델 환경에서 특히 유용함을 강조한 분석.
한계점으로는 (1) 속성 집합을 사전 정의하거나 VLM이 속성을 정확히 추출하지 못할 경우 성능 저하 가능성, (2) 대규모 이미지 풀에서 실시간 CIR을 수행하는 계산 비용이 아직 높다는 점을 들 수 있다. 향후 연구는 자동 속성 탐색, 효율적인 인덱싱, 그리고 완전한 인과 그래프 학습과의 연계를 통해 CIRCLES를 확장하는 방향이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기