An Efficient Heterogeneous Co-Design for Fine-Tuning on a Single GPU
Fine-tuning Large Language Models (LLMs) has become essential for domain adaptation, but its memory-intensive property exceeds the capabilities of most GPUs. To address this challenge and democratize LLM fine-tuning, we present SlideFormer, a novel s…
Authors: Ruijia Yang, Zeyi Wen
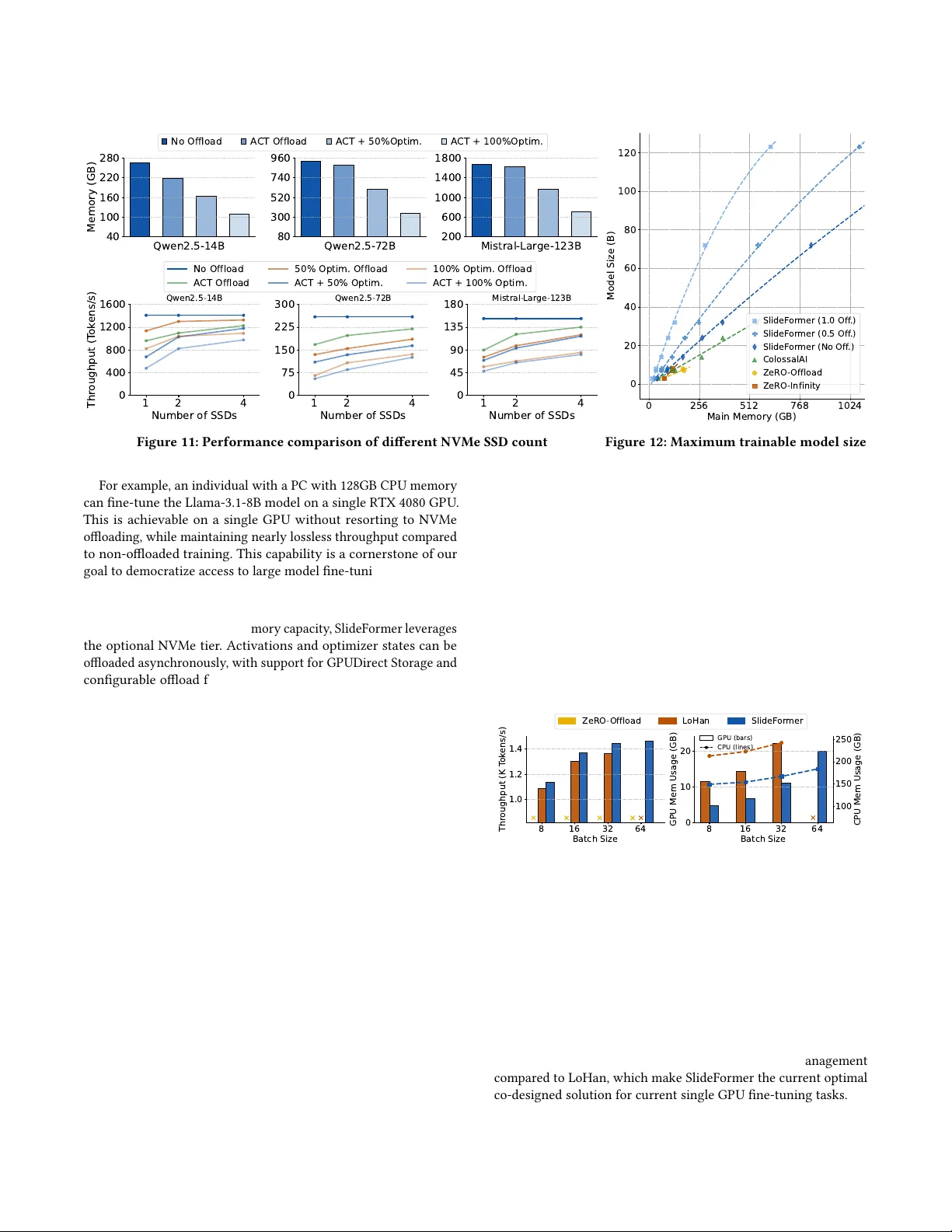
An Eicient Heterogeneous Co-Design for Fine- T uning on a Single GP U Ruijia Y ang Hong Kong Univ ersity of Science and T e chnology (Guangzhou) Guangzhou, China ryang379@connect.hkust- gz.edu.cn Zeyi W en ∗ Hong Kong Univ ersity of Science and T e chnology (Guangzhou) Guangzhou, China wenzeyi@hkust- gz.edu.cn Abstract Fine-tuning Large Language Models (LLMs) has become essential for domain adaptation, but its memor y-intensive property exceeds the capabilities of most GP Us. T o address this challenge and de- mocratize LLM ne-tuning, we present SlideFormer , a novel system designed for single-GP U environments. Our innovations are: (1) A lightweight asynchronous engine that treats the GP U as a slid- ing window and overlaps GP U computation with CP U updates and multi-tier I/O . (2) A highly ecient heterogeneous memory management scheme signicantly reduces p eak memory usage. (3) Optimized Triton kernels to solv e key bottlenecks and integrated advanced I/O. This collaborative design enables ne-tuning of the latest 123B+ models on a single RTX 4090, supporting up to 8 × larger batch sizes and 6 × larger models. In evaluations, SlideFormer achieves 1.40 × to 6.27 × higher throughput while roughly halving CP U/GP U memory usage compared to baselines, sustaining >95% peak performance on both N VIDIA and AMD GP Us. Ke ywords LLM ne-tuning, single-GP U training, heterogeneous memory man- agement, ooading 1 Introduction Large Language Mo dels (LLMs) have revolutionized natural lan- guage processing with their remarkable capabilities across diverse tasks [ 20 , 26 ], and ne-tuning open-source pre-trained models [ 1 , 2 , 25 ] on specic datasets is often preferred ov er training from scratch to achieve specialized performance [ 34 ]. Howev er , as the models continue to grow in size , their ne-tuning memor y requirements increase linearly . For example, ne-tuning an 8B model with mixed precision training [ 21 ] requires ov er 128 GB of GP U memory , far exceeding the VRAM of most high-end GP Us (e.g., 24-96 GB). This memory bottleneck prevents the democratization of LLM ne-tuning, posing a signicant barrier for individuals and small labs without access to GP U clusters or cloud resources. For single- GP U scenarios, a paradox arises: modern GP Us such as RTX 4090 possess ample computational power to ne-tune an 8B model, yet existing methods cannot eciently handle the b ottleneck, creating an urgent nee d for single-GP U solutions that break the VRAM wall. A key trend motivating our work is the increasingly divergent growth trajectories b etween CP U and GP U memory , as shown in gure 1. Consumer systems now utilize DDR5 memory with doubled capacity (up to 256 GB) and faster I/O (PCIe and NVMe), whereas the maximum VRAM on GP Us has seen modest increases, ∗ Corresponding author: wenzeyi@hkust-gz.edu.cn from 24 GB (RTX 3090) in 2020 to 32 GB (RTX 5090) by 2025. This widening gap makes ooading attractive, turning single-GP U ne- tuning into a heterogeneous system design problem: How can we holistically co-design a system to le verage the entire platform (GP U, CP U, RAM, NVMe) to overcome the VRAM bottleneck? 2018 2020 2023 2025 0 50 100 150 200 250 Memory Capacity (GB) The W idening Gap R TX 2080T i R TX 3090 R TX 4090 R TX 5090 V100 A100 H100 H200 64GB (DDR4) 128GB (DDR5) 192GB (DDR5) 256GB (DDR5) Consumer System R AM Data Center GPU VR AM Consumer GPU VR AM Figure 1: The widening gap between CP U and GP U memory . V arious methods have been propose d to address the memory constraints in LLM ne-tuning. Distributed techniques such as Pipeline Parallelism [ 11 , 22 ], T ensor Parallelism [ 30 ], and Data Par- allelism [ 16 , 27 ] are generally unsuitable for single-GP U scenarios. Parameter-ecient ne-tuning [ 19 ] methods such as LoRA [ 10 ] have been proven insucient to match the performance of full parameter ne-tuning in many cases [ 31 ]. Among existing ooad- ing systems, ZeRO-Ooad [ 29 ] and ZeRO-Innity [ 28 ] are widely recognized. Ho wever , their designs ar e primarily for multi-GP U set- tings and fail to eectively pipeline computation with transfers and CP U updates, leaving signicant room for performance improve- ment in single-GP U scenarios. Although some works [ 12 , 17 , 32 ] have explored this overlap potential, they are incompatible with recent LLMs and lack ne-grained optimizations for memory and eciency , which are critical for practical usability . T o address the challenge, we pr esent SlideFormer , a novel frame- work optimized for single-GP U ne-tuning through holistic hetero- geneous co-design. Our work makes the following contributions: • A Lightweight Asynchronous Engine: W e propose a Layer- Sliding architecture that maintains a small, activ e window on the GP U, orchestrated by a multi-pipeline engine built on a lightweight thread-based mechanism, which eciently overlaps GP U computa- tion with CP U updates and I/O across hierarchies. • Ecient Heterogeneous Memory Management: A queue of pre-allocated GP U cache units eliminates fragmentation and reallocation, while host-side shared buers for gradients and type conversion reduce peak CP U memor y by over 25%. In concert with our pipeline, this co-design enables ne-tuning with signicantly less GP U and CP U memory than prior work. Y ang and W en • Integrated Advanced I/O and Optimized Kernels: W e extend the memory hierar chy to NVMe and pioneer the integration of GP UDirect Storage[ 4 ] for ooading, bypassing the CP U. W e also integrate a suite of fuse d Triton kernels for computations, resolving critical memory bottlene cks overlooked by previous systems. The holistic co-design translates directly to state-of-the-art p er- formance and scalability , enabling ne-tuning >123B models on a single RTX 4090. For a high-end PC equipped with 256 GB CP U memory , mo dels up to 24B can b e ne-tuned at over 95% p eak GP U performance on both NVIDIA and AMD GP Us. Compared to existing frameworks, SlideFormer achie ves a 1.40 × to 6.27 × im- provement in thr oughput, reduces GP U memor y consumption by over 50%, lo wers CP U memory usage by approximately 40%, and supports 8x larger batch sizes and 6 × larger model sizes. Our work is implemente d based on Py T orch [ 16 ] and Trans- formers [ 35 ] libraries, ensuring compatibility with the latest model architectures ( e.g., Llama, Qwen). W e expect SlideFormer to democ- ratize LLM ne-tuning, enabling individuals and researchers with limited resources to leverage the pow er of large models. 2 Background 2.1 Memory Challenges in LLM Fine- T uning Fine-tuning adapts a pre-trained LLM to a target domain with far fewer steps and data than pre-training; yet it remains memor y- bound at scale. For a model with 𝑁 parameters and 𝑛 layers, hidden size ℎ , sequence length 𝑠 , and batch size 𝑏 , memory demand comes from: parameters, gradients, optimizer states, and activations. Static footprints. Parameters are typically stored in FP16/BF16 ( 2 𝑁 bytes), while gradients contribute another 2 𝑁 in FP16/BF16 . The Adam [ 13 ] optimizer is commonly used; it adds two FP32 states per parameter (momentum/variance, 8 𝑁 ), making optimizer states the largest static term. Besides, mixed-precision training [ 21 ] requires the optimizer to maintain an FP32 master copy ( 4 𝑁 ) of parameters for stability . Forward activations scale with O ( 𝑛 · ℎ · 𝑠 · 𝑏 ) and must be available for the backward pass unless recomputed. A succinct approximation is: 𝑀 𝑒𝑚 𝑟 𝑒 𝑞 = 2 𝑁 | {z } Params + 2 𝑁 | {z } Grads + 4 𝑁 + 8 𝑁 | {z } Optimizer States + O ( 𝑛 · ℎ · 𝑠 · 𝑏 ) | {z } Activations (1) Single-GP U tension. Distribute d parallelism techniques [ 11 , 16 , 22 , 27 , 30 ] amortize memory across multiple devices but are infea- sible on a single GP U. A single high-end GP U has ample compute to ne-tune multi-billion-parameter mo dels; yet the footprint in Eq. (1) frequently exceeds VRAM, forming the central bottleneck. Common mitigations. Gradient checkpointing [ 3 ] trades 30% extra compute for > 80% activation savings; PEFT (e.g., Adapter [ 8 ], LoRA [ 10 ]) updates a small subset of w eights but underperforms compared to full-parameter ne-tuning on domain-critical tasks [ 18 , 19 , 34 , 36 ]; Kernel optimizations (e.g., FlashAttention [ 6 ], xForm- ers [ 14 ], Liger [ 9 ]) reduce transient allocations and improve through- put. These te chniques are complementary , but not sucient to resolve the VRAM wall in single-GP U full-parameter ne-tuning. 2.2 Existing O loading T echniques A key trend driving us is the incr easingly divergent growth trajecto- ries between CP U and GP U memor y , as shown in Figure 1. Recent PCs and workstations with abundant CP U memory (e.g., up to 256 GB DDR5) and high-spee d N VMe storage enable memory-ecient LLM ne-tuning through strategic ooading. Coupled with faster PCIe interconnects, stronger CP U performance, and technologies like GP UDirect Storage [ 4 ], this motivates a pipeline-aware ooad- ing design that jointly orchestrates the GP U, CP U, and N VMe rather than treating VRAM as the only limiting resource . Several repr esentative frameworks hav e been developed to this end. ZeRO-Ooad [ 29 ] pioneers ooading the optimizer and gra- dients to the CP U. Then ZeRO-Innity [ 28 ] extends it to a multi- tiered memory system, dynamically ooading components to both CP U and N VMe. Other notable systems, such as T ransformer En- gine [ 24 ] and NeMo [ 23 ], provide a layer-wise approach for acti- vation ooading, and ColossalAI [ 15 ]’s gemini [ 7 ] introduces a dynamic chunk-based hetero-memory management. Besides, sev- eral r esearch prototypes have explored similar concepts [ 12 , 17 , 32 ]. 2.3 Limitations of Existing Solutions While mainstream frameworks excel in distributed and multi-GP U settings, their design is not holistically co-designed for single- GP U scenarios. For instance, ZeRO-Ooad and ZeRO-Innity in- herit considerable overhead from their distributed-rst architecture; mechanisms intended for multi-GPU communication remain activ e on a single device, introducing additional memory fo otprint and latency . This, combined with underutilize d CP U memor y pools, creates signicant overhead, as obser ved in Section 4.3. Similarly , ColossalAI’s chunk-wise memory management, while eectively utilizing memory for larger models, is suboptimal for single-GP U eciency . Critically , their design is synchronous at the up date stage, leaving the GP U idle while waiting for the CP U update to nish. Academic prototypes that r ecognize this overlap potential still suer from critical design aws. Stronghold [ 32 ] was an early at- tempt but relied on an outdated version of Megatron [ 30 ] and did not fully recognize or optimize for single-GP U environments. Lo- Han [ 17 ], a recent work, employs a multiprocess-based engine for asynchronous updates, which incurs IPC ov erhead, rather than a thread-based approach. Furthermore, LoHan utilizes on-demand memory management, which is prone to runtime fragmentation, and operates at a Param Group granularity without analyzing how to set its size. Its design choices are architecturally distinct from SlideFormer’s pre-allocated and layer-granular design. These lim- itations, combine d with incomplete optimizations (e.g., ignoring the CrossEntropyLoss bottleneck) and limited model support (e.g., only GPT -2), necessitate a new , holistically designed system. 3 System Design The design goal of SlideFormer is to break the memory wall of single-GP U ne-tuning through a holistic system-level co-design, while achieving state-of-the-art eciency . W e propose a unied architecture where computation scheduling, memory management, and I/O are jointly optimized. As illustrate d in Figure 2, our system is built on three pillars: (1) a Layer-Sliding Architecture powered by a lightweight asynchronous engine , (2) a Pre-allocated Hetero- geneous Memory system to eliminate overhead, (3) an Integrated I/O and Compute stack utilizing GP UDirect and fused kernels. An Eicient Heterogeneous Co-Design for Fine- Tuning on a Single GP U Checkpointing Manager GPU Lay er Optimizer 𝐿 compute 𝐴 𝑂𝑆 𝐴 𝐴 𝐿 𝐿 d2h h2d 𝐿 𝐿 𝐿 Async Stream BF16 Grad BF16 Param Model FP32 Pa rams and shared Buffers … 𝐿 … 𝐿 𝑂𝑆 𝑂𝑆 Layer Sliding Async Updat e GPU Direct CPU NVMe Update Thread Stream Transfer Thread G S l i d e F o r m e r O v e r v i e w (Convert on CPU) L: Layer G: Gradient A: Activation OS: Optimizer State d2h: Device to Host h2d: Host to Device Figure 2: Overview of SlideFormer . 3.1 The Layer-Sliding Architecture Asynchronous Parameter Updating: As illustrated in Figur e 3, we adopt a layer-granular appr oach to pipeline the backward and update with ooading. Once the backward computation for layer 𝐿 𝑖 nishes on the GP U, its gradients 𝐺 𝑖 are asynchronously trans- ferred to host memory (d2h). In parallel, the CP U applies the opti- mizer to update 𝑃 𝑖 using the host-resident optimizer states. While the CP U updates 𝑃 𝑖 , the GP U continues computing the backward pass for 𝐿 𝑖 − 1 and prefetches the parameters for 𝐿 𝑖 − 2 (h2d). This schedule eliminates the heterogeneous resource idle issue in ZeRO- Ooad [ 29 ] by overlapping GP U-bound compute with CP U-b ound updates and cross-tier transfers. FWD Par am Update Grad Off load Backward FWD Perfo rmance Improvement 40% ZeRO-Offload SlideFormer d2h_stream CPU GPU d2h_stream CPU GPU Backward Grad Off load Par am Update IDLE D i f f e r e n c e Figure 3: Backward ov erlaps with parameter updates. Rationale for Layer Granularity: The cornerstone of e- ciency lies in our layer-granular strategy for memory management and computation scheduling, which restructures the ne-tuning process to maximize Hetero-hardware utilization. Layer is the small- est constitutional repeating unit in LLMs. Non-repeating units, such as the param-group used in ZeRO-Ooad or LoHan [ 17 ], intr oduce complex management for various-sized components and require manual conguration. Critically , a multi-layer window is coun- terproductive in memory-constrained environments, as layers are computed serially , consuming scarce VRAM that could be used to increase the batch/model size while oering negligible b enets. As shown in Figure 4, the critical batch size required to achieve eective overlap remains remarkably stable across dierent layer sizes (from 77M-3B to 878M-72B). Because all backward pipeline latencies ( 𝑇 𝑏 𝑤𝑑 , 𝑇 𝑔𝑟 𝑎𝑑 _ 𝑑 2 ℎ , 𝑇 𝑢 𝑝𝑑 𝑎𝑡 𝑒 ) scale proportionally with granu- larity , the overlap condition mainly depends on the batch size. A single layer is sucient to saturate modern GP U, as e videnced by the high GP U utilization in T able 1 and Figure 8. 3B 7B 14B 32B 72B Qwen2.5 Model Size (Billion P arameters) 10 15 20 25 Batch Size R TX 4090 A100 80GB Figure 4: Critical batch size for achieving full backward over- lap with updates ( 𝑇 𝑏 𝑤𝑑 ≥ 𝑇 𝑔𝑟 𝑎𝑑 _ 𝑑 2 ℎ + 𝑇 𝑢 𝑝𝑑 𝑎𝑡 𝑒 ). Thread-Based Lightweight Engine: The backb one of Slide- Former’s eciency is its extensive use of asynchronous operations to overlap data transfers and CP U computations with the GP U workload. Unlike LoHan, which r elies on a multi-process optimizer introducing IPC overhead, SlideFormer implements a lightw eight thread-based engine through dedicated: (i) CUDA Streams [ 5 ] : Sep- arate streams are employed for asynchronous h2d/d2h transfers and concurrent GP U computation. (ii) CP U Threads : T wo thread executors, one for transfers between h2d/d2h and the other for Layer- Adam to update parameters, prevent potential blocking I/O or CP U-intensive tasks from stalling the main ne-tuning thread. CPU Compute GPU Compute Bwd L Update L d2h_stream h2d_stream G A Backward L G A Backward L Update L P P P Overlapped Figure 5: Computation-communication overlap during back- ward propagation in GP U-CP U tier pipeline. Condition for Eective Overlap: The eciency of our asyn- chronous engine hinges on latency hiding, where the following conditions should be met: (i) In forward pass, lossless overlap oc- curs when the computation time for the current layer is greater than or equal to the parameter prefetch time for the next layer , i.e., 𝑇 𝑐𝑜 𝑚𝑝𝑢 𝑡 𝑒 _ 𝑓 𝑤𝑑 ≥ 𝑇 𝑝 𝑎𝑟 𝑎𝑚 _ ℎ 2 𝑑 . (ii) In the backward pass, as illus- trated in Figure 5, lossless overlap occurs when 𝑇 𝑐𝑜 𝑚𝑝𝑢 𝑡 𝑒 _ 𝑏 𝑤𝑑 ≥ 𝑇 𝑔𝑟 𝑎𝑑 _ 𝑑 2 ℎ + 𝑇 𝑢 𝑝𝑑 𝑎𝑡 𝑒 . When N VMe ooading is enabled, the transfer overhead of the optimizer states makes 𝑇 𝑢 𝑝𝑑 𝑎𝑡 𝑒 the main perfor- mance bottleneck. T o quantify the degree of backward overlap , we introduce the hiding factor ( 𝜂 = 𝑇 bwd / ( 𝑇 d2h + 𝑇 update ) ), where 𝜂 ≥ 1 indicates zero-overhead ooading. T able 1 presents the timeline breakdown for ne-tuning Qwen2.5-14B, conrming that our archi- tecture achieves eective overlap acr oss various hardware. Unlike sequential methods such as ZeRO-Ooad that would completely stall the GP U, SlideFormer maintains a robust performance advan- tage even on imbalanced hardware where full overlap ( 𝜂 < 1 ) is infeasible, using extremely pow erful or memory-limited GP Us. 3.2 Ecient Heterogeneous Memory Co-Design Previous works [ 17 , 29 , 32 ] often overlooked the evaluation and optimization of heterogeneous memory fo otprints, but we hope to Y ang and W en T able 1: Prole timelines of backward stage for SlideFormer during the ne-tuning of Qwen2.5-14B. (All time in ms) Batch Size 𝑇 𝑏 𝑤𝑑 𝑇 𝑑 2 ℎ 𝑇 𝑢 𝑝𝑑 𝑎𝑡 𝑒 Factor ( 𝜂 ) GP U Util. (%) RTX 4090 24GB (PC) 16 170 22 175 0.66 93.1 32 340 25 195 1.55 96.9 64 660 25 195 3.00 98.4 A100 80GB (Server) 32 225 24 152 1.28 97.2 64 450 25 151 2.56 98.8 128 910 25 153 5.11 99.3 co-design an extremely ecient, xed footprint, and fragment free memory management system base d on a layer sliding architecture. Pre-allocated GP U Cache Unit Queue: Rather than ke eping the entire model in GPU memory , SlideFormer maintains a window of active layers, which is exactly a queue of pre-allocated GP U cache units, each sized to hold a layer’s parameters and gradients. During training, layers (i.e., parameters) se quentially slide into this cache queue to perform computations, after which the used units are released for new layers. Only during the backward pass, the gradients of each layer ar e ooaded to CP U memory . Unlike the on-demand allocation used by StrongHold [ 32 ] and LoHan [ 17 ], this unit reuse design ensures a xed GP U memory footprint and avoids reallocation, reducing overhead and fragmentation. Optimized CP U Memor y Layout with Shared Buers: On the CP U side , FP32 parameter master copies of each lay er are stored in a attened, pinned tensor ( cpu_params_flat ) for ecient h2d transfers. T o optimize memor y usage, we emplo y shared buers for intermediate data. Gradients ooaded from the GP U are stored in a layer-shared, pinned BF16/FP16 tensor ( cpu_grad_flat ), which reduces the gradient footprint on CP U memory ( 2 𝑁 bytes) to 1 / 𝑛𝑢𝑚 _ 𝑙 𝑎𝑦𝑒𝑟 𝑠 . Similarly , a layer-shared buer is dedicated to con- vert FP32 parameters to BF16/FP16 before h2d transfer , thus avoid- ing additional transfer/memor y costs of typ e conversion on the GP U and storing 2 𝑁 bytes of BF16/FP16 parameters in CP U memory . On the GP U side, parameters and gradients maintain BF16/FP16 precision, following the mixed precision training [21] scheme. Sliding Activation : T o further alleviate GP U memory pressure from activations, we employ a sliding checkpointing mechanism modied from standard gradient checkpointing [ 3 , 16 ]. After each layer’s forward pass, activations are asynchr onously ooaded to the CP U memory or N VMe and prefetched to the GP U memory for recomputation before the backward pass of that lay er , ensuring that VRAM required for activations is limited to only a small window . W e pre-allocate pinned tensors in CP U memor y or les on SSDs for storing activations before the ne-tuning begins. Layer- Adam Optimizer : A self-developed variant of Deep- Speed’s CP U-A dam, it stores the optimizer states of each layer in a attened tensor in the host memory . When the gradients of the layer are ooaded to the CP U, the optimizer updates the layer’s param- eters separately . Additionally , the optimizer states can be further ooaded to the N VMe tier , and an asynchronous ooad-prefetch mechanism is established to reduce latency . 3.3 Integrated I/O and Compute Co-Design The nal pillar of our co-design optimizes the data movement paths and intra-layer computation to eliminate remaining bottlenecks that pure scheduling cannot address. GP UDirect Storage and NVMe Tiering: T o support models exceeding CP U RAM capacity , SlideFormer extends the memor y hi- erarchy to NVMe storage. Crucially , we pioneer to integrate GP UDi- rect Storage (GDS) [ 4 ] for LLM ne-tuning ooad. GDS establishes a direct data path between N VMe and GP U, bypassing the CP U bounce buer . This "zero-copy" mechanism signicantly reduces CP U utilization and PCIe bus contention, leaving CP U resources for asynchronous engine and parameter updates. W e support of- oading activations and optimizer states to this N VMe tier . Why Not O load Parameters. Although ooading parame- ters to N VMe storage could achieve lower memory usage and larger models, we deliberately avoid it due to diminishing returns: (i) Per- formance Degradation: Parameter transfers (h2d/d2h) are critical for overlapping with GPU computation (c.f. Section 3.1). Moving parameters to NVMe would shift the transfer bottleneck from PCIe to NVMe sp eed, severely hindering overall thr oughput. (ii) Simpli- ed Data Paths: As shown in Figure 2, SlideFormer ensures that any given data type moves only between two memory tiers. Intro- ducing NVMe as a third tier for parameters would complicate the data transfer path and add unnecessary overhead. 2 4 8 16 32 64 128 Batch Size 10 20 30 40 50 P eak Memory (GB) 22.2% 53.3% 72.5% 83.2% 88.9% tor ch LCE 2 4 8 16 32 64 128 Batch Size 0.0 0.5 1.0 1.5 2.0 Ex ecution T ime (s) tor ch LCE Figure 6: Memory usage and execution time comparison be- tween torch standard method and LCE for Llama3.1-8B. Optimized T riton K ernels: While our pipelines optimize inter- layer data movement, we integrate optimized Triton [ 33 ] kernels to accelerate intra-layer computational eciency . Beyond FlashAt- tention [ 6 ], we employ ecient T riton kernels for operations like RoPE, RMSNorm, and SwiGLU, collectively reducing peak memory usage and improving throughput. Among these, the most criti- cal optimization is the fuse d LinearCrossEntropy kernel for the output layer and loss computation, which addresses a major and often overlooked memory b ottleneck. For recent models with large vocabularies like Llama-3.1, the intermediate logits tensor ( 𝐵 × 𝑆 × 𝑉 ) can consume more VRAM than all preceding activa- tions combined. LoHan [ 17 ] sidesteps this issue in evaluation by replacing the standard loss with MSE, which is impractical for real- world tasks. SlideFormer solves this directly by integrating a Fused LinearCrossEntropy (LCE) kernel. This kernel fuses the projection and loss calculation, computing gradients in small chunks to avoid materializing the full logits tensor . As shown in Figure 6, this re- duces the memory footprint of the output layer by over 80% without sacricing accuracy or speed, unlocking the ability to train with models and batch sizes essential for pipeline saturation. An Eicient Heterogeneous Co-Design for Fine- Tuning on a Single GP U 4 8 16 32 64 0 900 1800 2700 Thr oughput (T ok ens/s) ZeRO -Infinity ColossalAI ZeRO - Offload SlideF or mer 4 8 16 32 64 Batch Size 0 64 128 192 Memory (G) Figure 7: Throughput and CP U memor y com- parison between SlideFormer and baselines for Llama-3.1-8B ne-tuning on RTX4090. 3B 7B 14B 32B 72B 0 32 64 96 128 Thr oughput (TFL OPS) P eak w/o Offload ColossalAI ZeRO -Infinity ZeRO - Offload SlideF or mer 3B 7B 14B 32B 72B Model Size (B) 0 256 512 768 Memory (G) Figure 8: Throughput and CP U memor y com- parison between SlideFormer and baselines for various sizes of Qwen2.5 on RTX4090. 4 8 16 32 64 Batch Size 8 12 16 20 GPU Allocated Memory (GB) ColossalAI ZeRO - Offload SlideF or mer Figure 9: GP U memory vs. batch size on various frame- works for Llama-3.1-8B. 4 Evaluation In this section, we conduct a comprehensive evaluation of our design to demonstrate its performance and eciency . 4.1 Experimental Setup W e evaluate SlideFormer on two typ es of platforms: a high-end PC (NVIDIA RTX 4090 24GB or AMD RX 7900XT 20GB, AMD Ryzen 9 9950X, 256GB DDR5) and a ser ver (NVIDIA A100 80GB, dual Intel Xeon Gold 6338N, 1024GB DDR4). All experiments use PyT orch 2.7.0 and CUDA 12.5 with a xed se quence length of 1024. For performance benchmarking, we use a synthetic dataset to ensure a consistent computational load (with a stable eective length). W e compare SlideFormer against leading ooading baselines: ZeRO-Ooad [ 29 ], ZeRO-Innity [ 28 ], ColossalAI [ 15 ], and Lo- Han [ 17 ]. T o ensure a fair comparison, all frameworks use the latest versions with identical training congs, including activation check- pointing and optimized kernels where applicable. W e evaluate a range of modern LLMs, including Llama-3.1 (8B) [ 1 ], Qwen-2.5 (3B-72B) [ 25 ], and Mistral (24B-123B) [ 2 ]. Performance is measured by Throughput (tokens/s and TFLOPS), peak Memory Usage (GP U and CP U), and trainable model size (B). 3B 7B 8B 14B 0 20 40 60 Thr oughput (TFL OPS) AMD RX7900X T 20G 7B 14B 32B 72B 0 50 100 150 Thr oughput (TFL OPS) NVIDIA A100 80G P eak w/o Offload B S=16 B S=32 B S=64 B S=128 B S=256 Figure 10: The ne-tuning throughput of Q wen2.5 in various sizes on AMD RX7900XT and NVIDIA A100. 4.2 Throughput Scalability SlideFormer demonstrates superior throughput scalability across both increasing batch sizes and model sizes, consistently outper- forming leading ooading systems. Scalability with Batch Size. As shown in Figure 7, SlideFormer outperforms all baselines across every batch size, achieving through- put improvements of 1.39 × , 2.82 × , 6.34 × over baselines on Llama- 3.1-8B. The results also illustrate our pip eline ’s dynamics: at smaller batch sizes, the step time r emains constant, as the backward compu- tation is insucient to fully mask the update latency . However , as the batch size incr eases to 32, the system shifts to a compute-bound regime where the transfer and update latencies are eectively hid- den. This, along with Figure 10, conrms our design’s ability to leverage larger batch sizes for higher computational throughput. Scalability with Model Size. Figure 8 sho w that SlideFormer not only delivers higher thr oughput than baselines at equivalent sizes but also dramatically extends the boundaries of trainable mod- els on a single GP U. While ZeRO-Ooad and ZeRO-Innity fail to run models of 14B parameters or larger , SlideFormer success- fully ne-tunes models exceeding 72B parameters. Crucially , Slide- Former’s performance consistently reaches 90% to 95% of the peak non-ooading ne-tuning TFLOPS. This high utilization is robust across platforms, with Figure 10 conrming similar high eciency (ov er 95% peak performance) on both AMD RX7900XT and N VIDIA A100 GP Us, underscoring SlideFormer’s broad applicability . 4.3 Heterogeneous Memor y Usage SlideFormer’s ecient control ov er memor y across the hierarchy is what enables maximum scalability and batch sizes. CP U Memor y Eciency . The lower panels of Figure 7 and Figure 8 illustrate that SlideFormer maintains the lowest CP U mem- ory footprint across all scenarios, reducing usage by approximately 40% compared to the fastest baseline. This signicant saving is a direct result of our optimized host memory layout, which utilizes layer-shared buers for gradients and type conversion, eliminating redundant memory copies and peak consumption. GP U Memory Eciency . Figure 9 plots the GP U memory footprint against batch size, showing that SlideFormer consistently uses the least VRAM, achieving a reduction of over 50% compared to ZeRO-Ooad. This is attributed to our pre-allocated cache queue and the integrated Fused LCE kernel, which together alleviate the primary memor y bottleneck in ne-tuning, making it feasible to train large models on consumer-grade hardware. Y ang and W en Qwen2.5-14B 40 100 160 220 280 Memory (GB) Qwen2.5-72B 80 300 520 740 960 Mistral-Lar ge-123B 200 600 1000 1400 1800 No Offload A CT Offload A CT + 50%Optim. A CT + 100%Optim. 1 2 4 Number of SSDs 0 400 800 1200 1600 Thr oughput (T ok ens/s) Qwen2.5-14B 1 2 4 Number of SSDs 0 75 150 225 300 Qwen2.5-72B 1 2 4 Number of SSDs 0 45 90 135 180 Mistral-Lar ge-123B No Offload A CT Offload 50% Optim. Offload A CT + 50% Optim. 100% Optim. Offload A CT + 100% Optim. Figure 11: Performance comparison of dierent NVMe SSD count 0 256 512 768 1024 Main Memory (GB) 0 20 40 60 80 100 120 Model Size (B) SlideF or mer (1.0 Off .) SlideF or mer (0.5 Off .) SlideF or mer (No Off .) ColossalAI ZeRO - Offload ZeRO -Infinity Figure 12: Maximum trainable model size For example, an individual with a PC with 128GB CP U memory can ne-tune the Llama-3.1-8B model on a single RTX 4080 GP U. This is achievable on a single GP U without resorting to NVMe ooading, while maintaining nearly lossless throughput compar e d to non-ooaded training. This capability is a cornerstone of our goal to democratize access to large model ne-tuning. 4.4 Analysis of NVMe O loading For models exceeding CP U memor y capacity , SlideFormer leverages the optional NVMe tier . Activations and optimizer states can be ooaded asynchronously , with support for GP UDirect Storage and congurable ooad fractions (50% or 100%) for optimizer states. Figure 11 illustrates the trade-o between the CP U memory savings achieved through various ooading strategies and the correspond- ing impact on throughput: First, performance scales near-linearly with the number of NVMe drives, as I/O bandwidth becomes the primary b ottleneck. Second, by enabling all ooading options, Slide- Former can reduce CP U memory consumption by 60-80%, with a corresponding throughput degradation contained within 30-50%. Third, the optimal ooading strategy is mo del-size dependent. For smaller models like Qwen2.5-14B, activations constitute a larger portion of the ooaded data. Ooading them provides signicant memory savings but incurs a notable performance p enalty as it im- pacts both the forward and backward passes. In this case, ooading optimizer states alone yields a better performance-to-memory trade- o. Conversely , for larger models where optimizer states dominate the memory footprint, ooading them rst is most eective, and the additional, marginal impact of ooading activations becomes negligible. W e therefore r e commend ooading activations only for the largest models or under severe CP U memory constraints. 4.5 Maximum Trainable Model Size Figure 12 presents a comparison of the maximum model sizes that can be ne-tuned using SlideFormer versus baseline frameworks, and each point is derived from actual tests conducted on listed pre- trained models. The experimental results demonstrate that, unlike other baselines which are constrained by GPU memor y and thus limited in max trainable model size (e.g., Zero-ooad supports up to 8B parameters, and ColossalAI supports up to 32B parameters), SlideFormer signicantly extends the upper limit of ne-tunable model sizes. By shifting the primary memory constraint to CP U memory , SlideFormer enables the ne-tuning of models exceeding 123B parameters on a single GP U. For a high-end PC equippe d with 256GB of CP U memor y , enabling N VMe ooading allows ne-tuning models up to 90B parameters and can ne-tune models within 24B without throughput loss, as shown in Figure 8. 4.6 Compared to Related W orks 8 16 32 64 Batch Size 1.0 1.2 1.4 Thr oughput (K T ok ens/s) 8 16 32 64 Batch Size 0 10 20 GPU Mem Usage (GB) GPU (bars) CPU (lines) 100 150 200 250 CPU Mem Usage (GB) ZeRO - Offload L oHan SlideF or mer Figure 13: Throughput and memory comparison b etween SlideFormer and LoHan for GPT2-13B on RTX4090. In recent r esearch, LoHan [ 17 ] is one of comparable to our work. Howev er , it only supports GPT -2 and uses a non-standard loss function (MSE) during evaluation to sidestep the associated GP U memory overhead. Figure 13 shows that under a standard GPT - 2 Fine-tuning task, SlideFormer achieves superior performance, delivering higher throughput and consuming < 50% of the GP U memory and saving 30% in CP U memory usage. ZeRO-Ooad failed to run due to exceeding GP U memory . This result fundamentally validates our better architecture design and memor y management compared to LoHan, which make SlideFormer the current optimal co-designed solution for current single GP U ne-tuning tasks. An Eicient Heterogeneous Co-Design for Fine- Tuning on a Single GP U 5 Conclusion In this paper , we present SlideFormer , a novel system that imple- ments a holistic heterogeneous co-design, which signicantly en- hances the eciency of full-parameter LLM ne-tuning on a sin- gle GP U. SlideFormer achiev es 1.40-6.27 × throughput gains while substantially halving CP U/GP U memor y usage. It enables train- ing 6 × larger models and handling 8 × larger batch sizes, demon- strating high compatibility (over 95% p eak performance on both NVIDIA&AMD GP Us) with the latest LLMs. The primary signif- icance of SlideFormer is its democratization of LLM ne-tuning, empowering individual researchers and smaller organizations. References [1] et al. Aaron Grattaori. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv .org/abs/2407.21783 [2] Mistral AI. 2024. Mistral-Large-Instruct-2411. https://huggingface.co/mistralai/ Mistral- Large- Instruct- 2411. [3] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174 (2016). [4] NVIDIA Corporation. 2021. NVIDIA GP UDirect Storage: Benchmarking and Conguration Guide. https://docs.nvidia.com/gpudirect- storage/. [5] NVIDIA Corporation. 2025. CUDA Runtime API: Stream Management. https: //docs.nvidia.com/cuda/cuda- runtime- api/group__CUDART__STREAM.html. [6] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashat- tention: Fast and memory-ecient exact attention with io-awareness. Advances in neural information processing systems 35 (2022), 16344–16359. [7] Jiarui Fang and Yang You. 2022. Meet Gemini: The Heterogeneous Memory Manager of Colossal- AI. https://colossalai.org/docs/advanced_tutorials/meet_ gemini/. [8] Neil Houlsby , Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-ecient transfer learning for NLP. In International conference on machine learning . PMLR, 2790–2799. [9] Pin-Lun Hsu, Yun Dai, Vignesh K othapalli, Qingquan Song, Shao T ang, Siyu Zhu, Steven Shimizu, Shivam Sahni, Hao wen Ning, and Y anning Chen. 2024. Liger Kernel: Ecient Triton Kernels for LLM Training. arXiv preprint (2024). arXiv:2410.10989 [cs.LG] https://arxiv .org/abs/2410.10989 [10] Edward J Hu, Y elong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Y uanzhi Li, Shean W ang, Lu W ang, W eizhu Chen, et al . 2022. Lora: Low-rank adaptation of large language models. ICLR 1, 2 (2022), 3. [11] Y anping Huang, Y oulong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Y onghui Wu, et al . 2019. Gpipe: Ecient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems 32 (2019). [12] Hongsun Jang, Jaeyong Song, Jaewon Jung, Jaeyoung Park, Y oungsok Kim, and Jinho Lee. 2024. Smart-innity: Fast large language model training using near- storage processing on a real system. In 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA) . IEEE, 345–360. [13] Diederik P Kingma and Jimmy Ba. 2014. Adam: A metho d for stochastic opti- mization. arXiv preprint arXiv:1412.6980 (2014). [14] Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, W enhan Xiong, Vittorio Caggiano, Sean Naren, Min Xu, Jieru Hu, Marta Tintore, Susan Zhang, Patrick Labatut, Daniel Haziza, Luca W ehrstedt, Jeremy Reizenstein, and Grigory Sizov . 2022. xFormers: A modular and hackable Transformer modelling library . https: //github.com/facebookresearch/xformers. [15] Shenggui Li, Hongxin Liu, Zhengda Bian, Jiarui Fang, Haichen Huang, Yuliang Liu, Boxiang W ang, and Y ang Y ou. 2023. Colossal- AI: A Unied Deep Learning System For Large-Scale Parallel Training. In Proce edings of the 52nd International Conference on Parallel Processing (Salt Lake City, U T , USA) (ICPP ’23) . Association for Computing Machinery , New Y ork, N Y, USA, 766–775. doi:10.1145/3605573. 3605613 [16] Shen Li, Y anli Zhao, Rohan V arma, Omkar Salpekar, Pieter Noordhuis, T eng Li, Adam Paszke, Je Smith, Brian V aughan, Pritam Damania, et al . 2020. Pytorch distributed: Experiences on accelerating data parallel training. arXiv preprint arXiv:2006.15704 (2020). [17] Changyue Liao, Mo Sun, Zihan Y ang, Jun Xie, Kaiqi Chen, Binhang Y uan, Fei Wu, and Zeke W ang. 2024. LoHan: Low-Cost High-Performance Framework to Fine- Tune 100B Model on a Consumer GP U. arXiv:2403.06504 [cs.DC] https: //arxiv .org/abs/2403.06504 [18] Qijun Luo, Heng xu Y u, and Xiao Li. 2024. BAdam: A Memory Ecient Full Parameter Optimization Method for Large Language Models. In Advances in Neural Information Processing Systems , A. Glob erson, L. Mackey , D . Belgrave, A. Fan, U. Paquet, J. T omczak, and C. Zhang (Eds.), V ol. 37. Curran Associates, Inc., 24926–24958. https://proceedings.neurips.cc/paper_les/paper/2024/le/ 2c570b0f9938c7a58a612e5b00af9cc0- Paper- Conference.pdf [19] Sourab Mangrulkar , Sylvain Gugger , Lysandre Debut, Y ounes Belkada, Sayak Paul, and Benjamin Bossan. 2022. PEFT: State-of-the-art Parameter-Ecient Fine- Tuning methods. https://github.com/huggingface/peft. [20] Ben Mann, N Ryder , M Subbiah, J Kaplan, P Dhariwal, A Ne elakantan, P Shyam, G Sastry , A Askell, S Agarwal, et al . 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 1 (2020), 3. [21] Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh V enkatesh, et al . 2017. Mixed precision training. arXiv preprint (2017). [22] Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur , Gregory R Ganger , Phillip B Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized pipeline parallelism for DNN training. In Proce edings of the 27th ACM symposium on operating systems principles . 1–15. [23] NVIDIA. [n. d.]. N VIDIA/NeMo: A Scalable Generative AI Framework Built for Researchers and Developers W orking on Large Language Models, Multimo dal, and Speech AI (A utomatic Spee ch Recognition and Te xt-to-Speech). https: //github.com/NVIDIA/NeMo. Accessed: May 15, 2025, n.d.. [24] NVIDIA. 2024. Transformer Engine: A Library for Accelerating Transformer Models on NVIDIA GP Us. https://github.com/NVIDIA/TransformerEngine. V er- sion 2.1.0, accessed on 2025-04-23. [25] Qwen, :, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, K eqin Bao, Kexin Y ang, Le Y u, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T ang, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Y ang Fan, Y ang Su, Yichang Zhang, Y u W an, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. 2025. Qwen2.5 T echnical Report. arXiv:2412.15115 [cs.CL] https://arxiv .org/abs/2412.15115 [26] Alec Radford, Jerey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever , et al . 2019. Language mo dels are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9. [27] Samyam Rajbhandari, Je Rasley , Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. In SC20: Inter- national Conference for High Performance Computing, Networking, Storage and A nalysis . IEEE, 1–16. [28] Samyam Rajbhandari, Olatunji Ruwase, Je Rasley , Shaden Smith, and Yuxiong He. 2021. Zero-innity: Breaking the gpu memory wall for extreme scale deep learning. In Proce e dings of the international conference for high performance computing, networking, storage and analysis . 1–14. [29] Jie Ren, Samyam Rajbhandari, Reza Y azdani Aminabadi, Olatunji Ruwase, Shuangyan Y ang, Minjia Zhang, Dong Li, and Y uxiong He. 2021. Zero-ooad: Democratizing Billion-Scale Model Training. In 2021 USENIX Annual T e chnical Conference ( USENIX A TC 21) . 551–564. [30] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley , Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language mo dels using model parallelism. arXiv preprint arXiv:1909.08053 (2019). [31] Reece Shuttlew orth, Jacob Andreas, Antonio T orralba, and Pratyusha Sharma. 2025. LoRA vs Full Fine-tuning: An Illusion of Equivalence. arXiv:2410.21228 [cs.LG] https://arxiv .org/abs/2410.21228 [32] Xiaoyang Sun, W ei W ang, Shenghao Qiu, Renyu Y ang, Songfang Huang, Jie Xu, and Zheng W ang. 2022. Stronghold: fast and aordable billion-scale deep learning model training. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis . IEEE, 1–17. [33] Philippe Tillet, H. T . Kung, and David Cox. 2019. Triton: an intermediate lan- guage and compiler for tiled neural network computations. In Proce edings of the 3rd ACM SIGPLAN International W orkshop on Machine Learning and Program- ming Languages (Phoenix, AZ, USA) (MAPL 2019) . Association for Computing Machinery , New Y ork, N Y, USA, 10–19. doi:10.1145/3315508.3329973 [34] Jason W ei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, A dams W ei Y u, Brian Lester , Nan Du, Andrew M Dai, and Quoc V Le . 2021. Finetune d language models are zero-shot learners. arXiv preprint arXiv:2109.01652 (2021). [35] Thomas W olf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement De- langue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer , Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, T even Le Scao, Sylvain Gugger , Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the- Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations . Association for Computational Lin- guistics, Online, 38–45. https://ww w .aclweb.org/anthology/2020.emnlp- demos.6 [36] Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang W ang, Anima Anandkumar , and Yuandong Tian. 2024. Galore: Memory-ecient llm training by gradient low-rank projection. arXiv preprint arXiv:2403.03507 (2024).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment