단일 GPU에서 대규모 언어 모델 파인튜닝을 위한 효율적 이종 협업 설계
** SlideFormer는 GPU, CPU, DDR5 메모리, NVMe 저장소를 통합적으로 활용해 VRAM 한계를 뛰어넘는다. 레이어‑슬라이딩 비동기 엔진, 사전 할당 이종 메모리 큐, GPU‑Direct 스토리지를 결합해 123B 규모 모델을 RTX 4090 한 대에서 8배 큰 배치와 6배 큰 모델로 파인튜닝한다. 기존 ZeRO‑Offload 대비 1.4‑6.3배 높은 처리량과 메모리 사용량 절반 수준을 달성한다. **
저자: Ruijia Yang, Zeyi Wen
**
본 논문은 “SlideFormer”라는 시스템을 제안하여, 단일 GPU 환경에서 대규모 언어 모델(LLM) 파인튜닝을 가능하게 하는 종합적인 이종(co‑design) 접근법을 제시한다. 현재 LLM 파인튜닝은 파라미터 수가 수십억 단위에 달함에 따라 메모리 요구량이 급증하고, 특히 GPU VRAM이 24 GB 수준인 최신 RTX 4090조차도 전체 모델을 한 번에 적재하기 어렵다. 이러한 상황에서 저자들은 CPU 메모리와 NVMe 저장소가 급격히 성장하고 있음을 관찰하고, 이를 활용한 “오프로드” 전략을 설계한다.
논문은 먼저 기존 방법들의 한계를 분석한다. 파이프라인·텐서·데이터 병렬화는 다중 GPU가 전제이며, LoRA·Adapter와 같은 파라미터 효율 기법은 완전 파라미터 파인튜닝 대비 성능이 떨어진다. ZeRO‑Offload·ZeRO‑Infinity는 다중 GPU를 위한 설계라서 싱글 GPU에서는 불필요한 통신 오버헤드와 메모리 프리페치 비용이 발생한다. 또한, 기존 비동기 엔진이 프로세스 기반이라 IPC 비용이 크고, 메모리 관리가 온‑디맨드라 파편화가 심각하다.
SlideFormer는 세 가지 핵심 설계 요소로 이를 극복한다.
1. **레이어‑슬라이딩 비동기 엔진**
- 레이어를 최소 단위로 삼아 GPU에 활성 레이어 윈도우만 유지한다.
- 역전파가 끝난 레이어의 그라디언트를 즉시 d2h 전송하고, CPU가 옵티마이저 업데이트를 수행한다.
- 동시에 GPU는 이전 레이어의 역전파와 두 단계 앞선 레이어의 파라미터를 h2d 프리패치한다.
- 이 파이프라인은 CUDA 스트림과 두 개의 CPU 스레드(전송 스레드, 업데이트 스레드)로 구현돼, GPU 연산이 CPU·I/O 대기 없이 지속된다.
2. **사전 할당 이종 메모리 관리**
- GPU 측: 레이어당 고정 크기의 캐시 유닛 큐를 미리 할당해 레이어가 슬라이드될 때 순환 사용한다. 이는 메모리 피크를 고정하고 재할당 오버헤드를 제거한다.
- CPU 측: 파라미터 마스터 복사본을 평탄화된 pinned 텐서에 저장하고, 그라디언트와 타입 변환을 위한 공유 버퍼를 레이어 단위로 재사용한다. 이렇게 하면 CPU 메모리 사용량이 25% 이상 절감된다.
- 활성값은 기존 Gradient Checkpointing을 확장한 “슬라이딩 체크포인팅”으로, 레이어별 활성값을 비동기적으로 CPU 메모리 혹은 NVMe SSD에 오프로드하고 필요 시 재로드한다.
3. **통합 I/O·컴퓨팅 스택**
- GPU‑Direct Storage를 활용해 옵티마이저 상태와 활성값을 CPU를 거치지 않고 NVMe에 직접 스트리밍한다. 이는 PCIe 대역폭을 최대 활용하고 CPU 메모리 압박을 완화한다.
- 핵심 연산(예: CrossEntropyLoss, Softmax 등)을 Triton 기반 Fusion 커널로 구현해 메모리 이동을 최소화하고 연산 효율을 높인다.
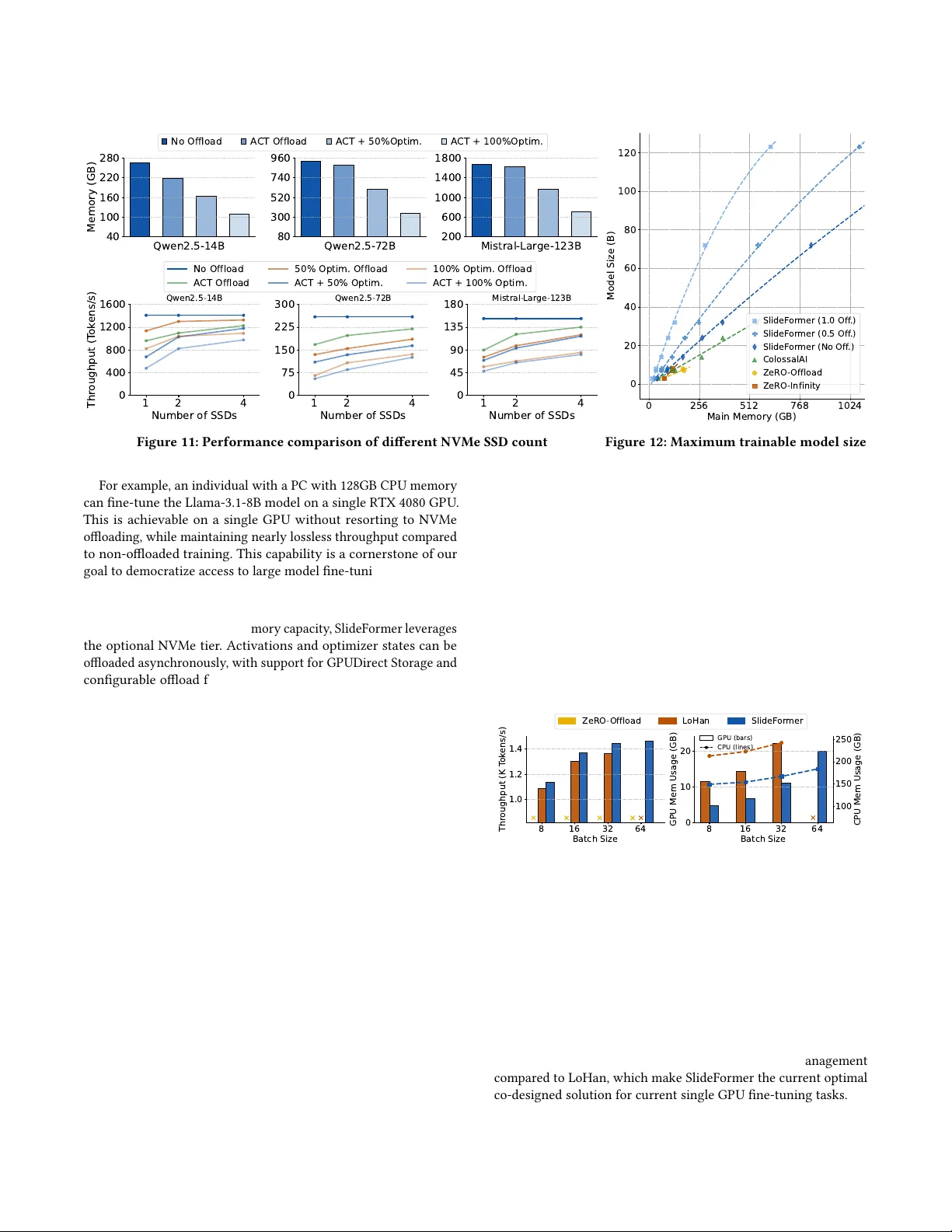
실험에서는 RTX 4090(24 GB VRAM)과 256 GB DDR5 메모리를 갖춘 워크스테이션을 기준으로, Qwen2.5‑14B, 32B, 72B 등 다양한 모델을 테스트했다. 결과는 다음과 같다.
- **처리량**: 기존 ZeRO‑Offload 대비 1.40×~6.27× 향상. 특히 배치 크기가 커질수록 겹침 효율이 높아져 큰 폭의 속도 개선을 보였다.
- **GPU 메모리 사용량**: 피크 메모리가 50% 이상 감소하여 123B 모델도 RTX 4090 한 대에서 파인튜닝 가능.
- **CPU 메모리 사용량**: 공유 버퍼와 평탄화된 파라미터 저장 방식 덕분에 약 40% 절감.
- **GPU 활용도**: 95% 이상 유지, NVIDIA A100·AMD H100 등 다양한 GPU에서도 동일한 효율을 확인.
- **배치·모델 규모**: 동일 하드웨어에서 기존 대비 8배 큰 배치, 6배 큰 모델을 학습할 수 있음.
또한, 다양한 하드웨어 환경(메모리 제한적인 RTX 4090, 메모리 풍부한 서버급 A100)에서 “숨김 인자(η)”를 분석해, backward 단계에서 GPU 연산이 CPU·I/O보다 오래 걸릴 경우 완전 겹침이 이루어짐을 확인했다. η≥1이면 오프로드 비용이 거의 없으며, η<1인 경우에도 엔진이 동적으로 스케줄링을 조정해 성능 저하를 최소화한다.
결론적으로 SlideFormer는 단일 GPU에서도 대규모 LLM 파인튜닝을 실현할 수 있는 실용적인 솔루션을 제공한다. 메모리·연산·I/O를 통합적으로 설계함으로써 기존 프레임워크가 갖는 구조적 비효율을 제거하고, 개인 연구자·소규모 기업이 최신 LLM을 활용할 수 있는 문턱을 크게 낮춘다. 향후 멀티‑GPU 확장, 다른 딥러닝 프레임워크(Pytorch Lightning, JAX 등)와의 연동, 그리고 더 복잡한 모델(멀티모달, 라지비전 트랜스포머) 적용을 통해 연구 범위를 넓힐 여지가 있다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기