IndexRAG: Bridging Facts for Cross-Document Reasoning at Index Time
Multi-hop question answering (QA) requires reasoning across multiple documents, yet existing retrieval-augmented generation (RAG) approaches address this either through graph-based methods requiring additional online processing or iterative multi-ste…
Authors: Zhenghua Bao, Yi Shi
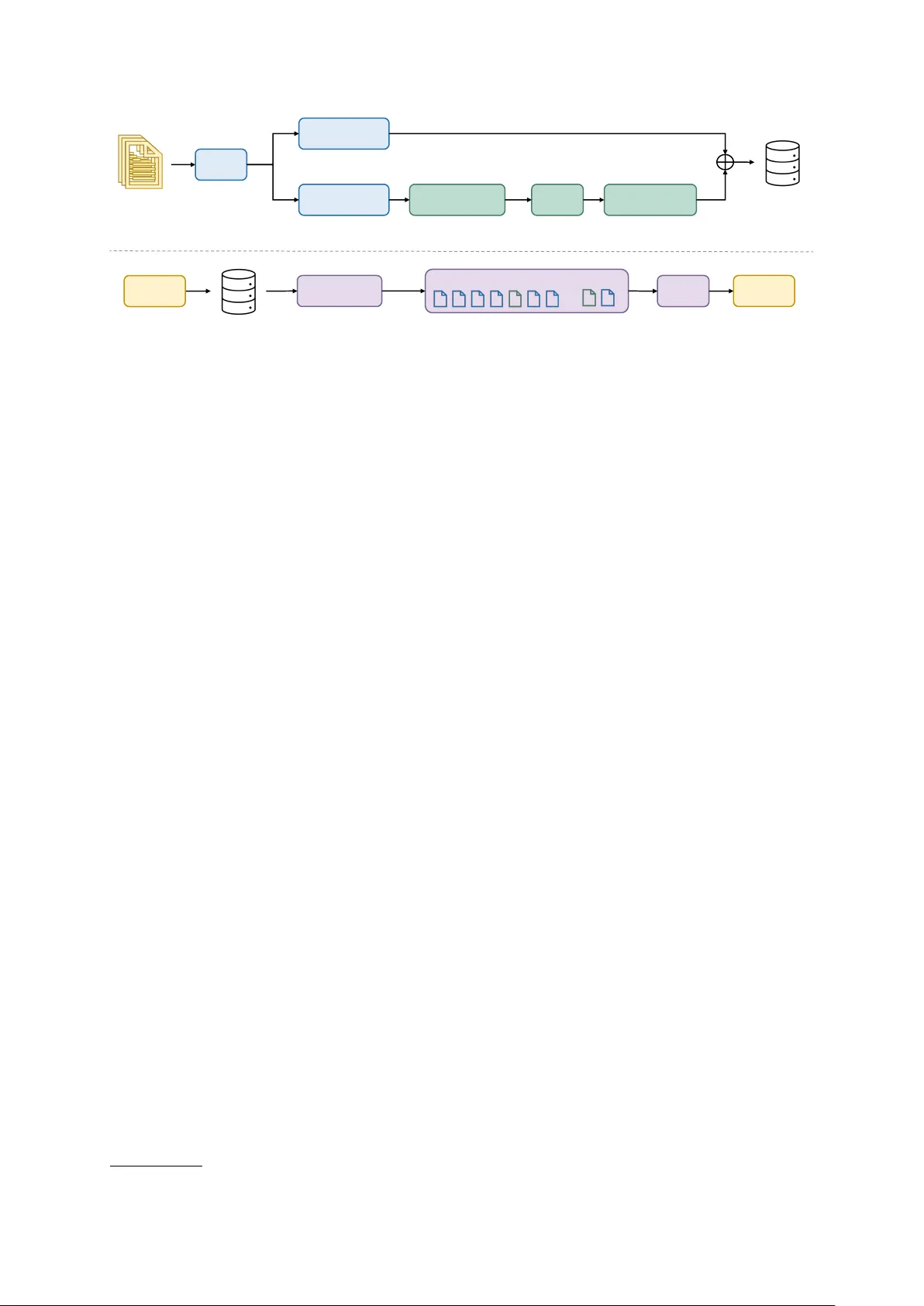
IndexRA G: Bridging F acts f or Cr oss-Document Reasoning at Index Time Zhenghua Bao Continuum AI Shanghai, China zhenghua.bao@continuum-ai.dev Y i Shi Continuum AI San Francisco, CA, USA yi.shi@continuum-ai.dev Abstract Multi-hop question answering (QA) requires reasoning across multiple documents, yet ex- isting retriev al-augmented generation (RA G) approaches address this either through graph- based methods requiring additional online pro- cessing or iterative multi-step reasoning. W e present Inde xRA G, a no vel approach that shifts cross-document reasoning from online infer- ence to of fline indexing. IndexRA G identifies bridge entities shared across documents and generates bridging facts as independently re- triev able units, requiring no additional training or fine-tuning. Experiments on three widely- used multi-hop QA benchmarks (HotpotQA, 2W ikiMultiHopQA, MuSiQue) show that In- dexRA G improves F1 o ver Nai ve RA G by 4.6 points on av erage, while requiring only single- pass retrie v al and a single LLM call at inference time. When combined with IRCoT , IndexRA G outperforms all graph-based baselines on av er- age, including HippoRA G and FastGraphRA G, while relying solely on flat retriev al. Our code will be released upon acceptance. 1 Introduction Large language models (LLMs), b uilt on the T rans- former architecture ( V aswani et al. , 2017 ), hav e achie ved remarkable performance across a wide range of tasks, from language ( Brown et al. , 2020 ) to vision ( Doso vitskiy et al. , 2020 ; Radford et al. , 2021 ). Ho wev er , their reliance on static para- metric kno wledge limits their ability to incorpo- rate domain-specific or up-to-date information, of- ten leading to hallucinations ( Huang et al. , 2025 ). Retrie val-Augmented Generation (RA G) mitigates this by grounding generation in an external kno wl- edge base, allo wing the model to retrie ve rele v ant context before responding ( Le wis et al. , 2020 ). While ef fectiv e for single-hop questions, con- ventional RA G pipelines retriev e passages inde- pendently and struggle when answering a question LLM Query Where was the director of film Aylwin born? Result Henry Edwards Bridging fact Henry Edwards, director of Aylwin, was born in Weston-super-Mare. Chunk A Aylwin directed by H. Edwards LLM Query Where was the director of film Aylwin born? Naive RAG IndexRAG (ours) Chunk A Aylwin directed by H. Edwards Chunk B Henry Edwards appeared in 30 films Chunk C Henry Edwards born in Weston- super-Mare Result Weston-super-Mare Chunk C Henry Edwards born in Weston- super-Mare NOT RETRIEVED Docs Chunks Docs Docs Naive RAG flat retrieval at inferenc e GraphRAG graph traversal at inference IndexRAG (Ours) flat retrieval at inference Bridging facts Reasoning a) Offline Indexing Entity & Relation Fixed Chunking Knowledge Graph AKUs b) Online Inference Figure 1: (a) Comparison of different RA G approaches during of fline indexing. IndexRA G shifts reasoning to index time, generating bridging facts stored alongside AKUs in a unified vector store. (b) Example from 2W iki- MultiHopQA ( Ho et al. , 2020 ). The query “Where was the director of the film A ylwin born?” requires two- hop reasoning. W ith nai ve RA G, Chunk C containing the director’ s birthplace is not retrieved, causing the LLM to output the director’ s name instead. With In- dexRA G, a bridging fact connecting the film to the director’ s birthplace is directly retriev ed, enabling the correct answer . See Section 5.2.1 for detailed analysis. requires synthesizing information across multiple documents. Multi-hop QA requires reasoning over multiple pieces of evidence spread across dif ferent documents to reach the correct answer ( Y ang et al. , 2018 ; Ho et al. , 2020 ; T riv edi et al. , 2022 ). Graph- based RA G systems ( Edge et al. , 2024 ; Gutiérrez et al. , 2024 ; Y ou et al. , 2025 ) address this by con- structing knowledge graphs that e xplicitly repre- sent inter-document relationships. Howe v er , these methods often require multi-step online processing, such as query-time entity e xtraction, graph trav er- sal, and multiple LLM calls, which increases infer - ence cost and latency . Iterativ e approaches such as IRCoT ( T ri vedi et al. , 2023 ) decompose comple x queries through multiple rounds of retriev al and generation, resulting in higher inference cost and 1 Single-pass Cross-doc Single LLM T raining- Index-time retrie val reasoning call free reasoning Nai ve RA G ✓ × ✓ ✓ × HippoRA G × ✓ × ✓ × IRCoT × ✓ × ✓ × IndexRA G (Ours) ✓ ✓ ✓ ✓ ✓ T able 1: Qualitati ve comparison of dif ferent RA G approaches. IndexRA G is the only method that achie v es cross- document reasoning with single-pass retriev al and a single LLM call at inference time. slo wer response times. T o address these limitations, we propose In- dexRA G, a no vel approach that shifts cross- document reasoning from online inference to of- fline indexing. W e observe that cross-document reasoning patterns are lar gely query-independent, as the connections between documents are deter- mined by their content rather than any specific query . This makes it possible to precompute these reasoning connections at indexing time, transform- ing per-query reasoning into an offline step. W e refer to this paradigm as inde x-time r easoning . Dur- ing indexing, we extract atomic kno wledge units (AKUs) and entities from each document, and identify entities that appear across multiple docu- ments. W e then prompt an LLM to generate bridg- ing facts that capture cross-document reasoning by linking related evidence from dif ferent sources. Both AKUs and bridging facts are stored in a uni- fied v ector store. At inference time, a single re- trie val pass and a single LLM call suf fice, without graph tra versal, query decomposition, or iterati v e retrie val-generation loops. Our main contributions are as follo ws: • W e propose IndexRA G , a novel approach that shifts cross-document reasoning from online inference to of fline indexing. • W e introduce bridging facts , a new type of retrie val unit that encodes cross-document rea- soning as independently retriev able entries in a flat vector store, along with a balanced con- text selection mechanism to control their pro- portion at retrie val time. • W e propose a training-free frame work that is agnostic to the underlying retriev al strategy and compatible with iterati v e methods such as IRCoT , requiring no fine-tuning of the embed- ding model or LLM. • Experiments on three multi-hop QA bench- marks sho w that IndexRA G outperforms all single-LLM-call baselines on average, and fur - ther surpasses multi-call methods including HippoRA G when combined with IRCoT . 2 Related W ork 2.1 Retriev al-A ugmented Generation T o mitigate hallucinations arising from the static parametric knowledge of LLMs, RA G augments generation with external retrie val ( Lewis et al. , 2020 ). In a typical RA G pipeline, documents are encoded into a vector store, and rele v ant passages are retrie ved based on embedding similarity at in- ference time. Recent research has focused on im- proving retrie v al representations. Karpukhin et al. ( 2020 ) replace sparse retrie val with learned dense representations, while Gao et al. ( 2023 ) prompt the LLM to generate a hypothetical answer and use it as the retrie v al query to better align with target passages. Other work in vestigates ho w doc- uments should be segmented for indexing. Chen et al. ( 2024 ) sho w that finer -grained units such as propositions yield stronger retriev al than fixed-size chunks. While propositions decompose individual passages into finer units, they do not capture rea- soning across documents. RAPTOR ( Sarthi et al. , 2024 ) recursiv ely summarizes passages into a hier- archical tree structure for retrie val. These methods primarily focus on improving ho w indi vidual passages are represented or orga- nized. In contrast, our work focuses on the implicit reasoning connections across documents, generat- ing ne w retrie val units that make cross-document inferences explicitly retrie v able. 2.2 Multi-hop Reasoning in RA G Standard RA G retrieves passages independently , struggling with questions that require reasoning across multiple documents ( Y ang et al. , 2018 ; Ho 2 LLM AKUs ( a 1 , a 2 , …, a n ) Entities ( e 1 , e 2 , …, e n ) Stage 2: Cross-Document Bridging Fac t Generation Flat Retrieval Balanced Context Selection (max k b ) … Entity GroupBy ( freq ≥ 2 ) LLM Bridging Facts ( b 1 , b 2 , …, b m ) Stage 1: AKU & Entity Extraction a) Offline Indexing LLM A n s w e r a Query q b) Online Inference Answer a Documents ( d 1 , d 2 , …, d n ) V ector Stor e Figure 2: Overvie w of IndexRA G. (a) Of fline Indexing: In Stage 1, the LLM extracts AKUs and associated entities from each document. In Stage 2, documents sharing the same entity are identified and used to generate bridging facts. The resulting AKUs and bridging facts are encoded and stored in a unified vector store. (b) Online Inference: the user query q is encoded and used to retrieve rele v ant context. After applying balanced context selection with k b , the selected context (a mix of AKUs and bridging facts) is fed to the LLM to generate the answer a . et al. , 2020 ; T ri vedi et al. , 2022 ). T wo main direc- tions hav e emerged to address this limitation. The first incorporates graph structures into RA G. GraphRA G ( Edge et al. , 2024 ) constructs an entity graph from the corpus, applies community detec- tion, and generates summaries for each community to support global reasoning. FastGraphRA G 1 is another graph-based approach that prioritizes in- ference efficienc y . HippoRA G ( Gutiérrez et al. , 2024 ) dra ws inspiration from the human hippocam- pal memory system, using a knowledge graph as a long-term memory inde x to connect related pas- sages, with Personalized PageRank for graph-based retrie val. MS-RA G ( Y ou et al. , 2025 ) maintains separate vector stores for entities, relations, and chunks, using vector search for entity extraction, but still requires graph tra versal at inference time. Although these methods improve multi-hop per- formance, they require additional inference-time processing, such as entity extraction, graph tra ver - sal, or reranking, beyond standard v ector search. The second direction uses iterati ve retrie v al. IR- CoT ( T riv edi et al. , 2023 ) interleaves chain-of- thought reasoning with retrie v al, using intermedi- ate reasoning steps to formulate new queries across multiple rounds. This improv es recall of relev ant e vidence but introduces repeated retrie val and gen- eration cycles that increase inference latenc y . In contrast, IndexRA G shifts cross-document reasoning to indexing time, making implicit con- nections retriev able through standard vector search without additional inference-time ov erhead. 1 https://github.com/circlemind- ai/ fast- graphrag 3 Method 3.1 Overview IndexRA G follows a two-phase pipeline: offline indexing and online inference. During of fline in- dexing, we first extract atomic kno wledge units (AKUs) and entities from each document ( Stage 1 ), then generate bridging facts that capture cross- document reasoning by linking documents through shared entities ( Stage 2 ). Both AKUs and bridging facts are encoded and stored in a unified vector store, making cross-document reasoning directly accessible through standard vector search. During online inference, we perform single-pass retrie val with balanced conte xt selection and prompt the LLM for answer generation. The ov erall pipeline is illustrated in Figure 2 and detailed belo w . 3.2 Offline Indexing 3.2.1 Stage 1: AKU and Entity Extraction Gi ven a corpus of n documents D = { d 1 , d 2 , . . . , d n } , we prompt an LLM to extract a set of atomic f acts, structured as question-answer pairs, and associated entities from each document d i . W e retain only the answers, mer ging them into a single text unit per document as the minimal retrie vable unit. W e refer to this unit as an atomic knowledge unit (AKU), denoted a i . The LLM simultaneously extracts a set of entities E i = { e ( i ) 1 , e ( i ) 2 , . . . } . Each AKU a i is then encoded by a dense embedding model f and stored in a flat v ector store V . Empirically , the choice of extraction method in Stage 1 does not significantly af fect overall pipeline performance (Section 5.3.1 ). 3 3.2.2 Stage 2: Bridging Fact Generation The key observ ation motiv ating this stage is that documents sharing common entities often contain complementary information. While each document alone may only pro vide partial e vidence, their com- bination can yield reasoning conclusions not explic- itly stated in any single source. By making these implicit connections explicit and retriev able, Stage 2 enables cross-document reasoning without any additional inference-time processing. Bridge Entity Identification. W e aggre gate all entities from Stage 1 and identify bridge entities that appear across multiple documents: E bridge = ( e ∈ n [ i =1 E i 2 ≤ df ( e ) ≤ τ ) (1) where df ( e ) = |{ d i ∈ D : e ∈ E i }| is the docu- ment frequency of entity e , and τ is an upper-bound threshold. The lower bound ensures that bridge en- tities connect at least tw o documents, while the upper bound τ excludes overly generic entities (e.g., common nouns or high-frequency terms) that would produce tri vial bridging facts. Bridging F act Generation. For each bridge en- tity e ∈ E bridge , let D e = { d i ∈ D : e ∈ E i } be the set of documents mentioning e . W e collect the subset of facts in each AKU a i that mention en- tity e , denoted a i [ e ] , identified via string matching against the entity list from Stage 1. W e then prompt the LLM to generate bridging facts: B e = LLM ( e, { a i [ e ] : d i ∈ D e } ) (2) where B e is the resulting set of bridging facts. W e limit the number of source documents to 5 and facts per document to 8 to manage input length. Unlike cross-document summaries, which com- press existing content into shorter passages, bridg- ing f acts are constructed to directly answer implicit cross-document questions. For example, gi ven Doc A stating “ A ylwin is directed by Henry Ed- wards” and Doc B stating “Henry Edwards was born in W eston-super-Mare”, Inde xRA G generates the bridging fact “The director of the film A ylwin was born in W eston-super-Mare”. Unlike either source document, this fact directly encodes the two- hop reasoning chain and is semantically aligned with queries like “Where was the director of A yl- win born?”, making it retriev able via standard vec- tor search ev en though neither source document alone is suf ficient to answer the query . All bridging facts B = S e ∈E bridge B e are indi- vidually encoded by f and stored alongside the AKUs in V . When a ne w document d new is added, only Stage 1 for d new and Stage 2 for af fected bridge entities need to be re-e xecuted. This in- cludes both existing bridge entities that appear in d new ( E new ∩ E bridge ) and ne wly formed bridge enti- ties whose document frequency reaches 2 after the addition. The rest of the index remains unchanged. 3.3 Online Inference Gi ven a query q , we encode it with the same embed- ding model f and retriev e the top- k entries from V by cosine similarity , where v j ∈ V is either an AKU or a bridging fact. Balanced Context Selection. The retrieved top- k set typically contains a mix of AKUs and bridg- ing facts. Howe ver , because bridging facts are considerably shorter than AKUs on av erage (166 vs. 634 characters in our experiments), they tend to dominate the top- k , crowding out the longer , information-dense AKUs. T o control this, let R = { r 1 , r 2 , . . . } be all en- tries in V sorted by descending similarity to q , where each r j is either an AKU ( r j ∈ A ) or a bridging fact ( r j ∈ B ). W e greedily b uild the con- text C by iterating o ver R in order . Each entry is included if it is an AKU or if the number of bridg- ing facts already in C is belo w k b , until | C | = k . The procedure is summarized in Appendix B . The selected context C is concatenated in sim- ilarity order and provided to the LLM for answer generation (see Figure 2 b), without any additional inference-time ov erhead. 4 Experimental Setup 4.1 Datasets W e ev aluate on three widely-used multi-hop QA datasets: HotpotQA ( Y ang et al. , 2018 ), 2Wiki- MultiHopQA ( Ho et al. , 2020 ), and MuSiQue ( T ri vedi et al. , 2022 ). HotpotQA contains 113k questions requiring rea- soning ov er multiple Wikipedia passages. 2Wiki- MultiHopQA provides multi-hop questions across dif ferent types (comparison, bridge comparison, compositional, and inference) with structured rea- soning paths. MuSiQue consists of 25k 2-4 hop questions composed from single-hop sub-questions, and is generally considered the most challenging among the three. Follo wing prior w ork ( Press et al. , 2023 ; T riv edi et al. , 2023 ; Gutiérrez et al. , 2024 ), 4 Dataset Questions Passages HotpotQA 1,000 9,827 2W ikiMultiHopQA 1,000 6,262 MuSiQue 1,000 9,723 T able 2: Dataset statistics for the 1,000 question subsets used in our experiments. we sample 1,000 questions from each validation set and collect all associated passages (supporting and distractor) as the retriev al corpus. Dataset statistics are summarized in T able 2 . 4.2 Implementation Details W e use GPT -4o-mini 2 as the LLM for all stages and all methods, including baselines, to ensure a fair comparison. All text is encoded using Ope- nAI’ s te xt-embedding-3-small 3 , and we use F AISS ( Douze et al. , 2025 ) for vector indexing. Prompt templates for all stages and answer generation are provided in Appendix D . Offline Indexing. In Stage 1, we pass each full document to the LLM for AKU and entity e xtrac- tion. In Stage 2, we set the entity frequency thresh- old τ = 10 , with a maximum of 5 source docu- ments and 8 facts per document for each bridge en- tity . The offline pipeline requires one LLM call per document for Stage 1 and one LLM call per bridge entity for Stage 2, with the total Stage 2 cost pro- portional to |E bridge | . Entities with no meaningful cross-document connection are discarded, account- ing for the non-empty rates in T able 3 . For baseline methods that require chunking (Naiv e RA G, RAP- TOR, etc.), we split documents into passages of approximately 100 words following ( Chen et al. , 2024 ) with 80 characters of ov erlap. Online Infer ence. All methods retrie ve 20 can- didates and select the top k = 10 for answer gener- ation. For Inde xRA G, balanced context selection with k b = 3 is additionally applied to control the proportion of bridging facts in the selected context. Unless otherwise specified, k b = 3 is used in all IndexRA G experiments. Since all ev aluated datasets e xpect short-form answers (typically a fe w words), we set the gener - ation temperature to 0 and max tokens to 50. For IRCoT e xperiments, we follow Tri v edi et al. ( 2023 ) 2 https://openai.com/index/ gpt- 4o- mini- advancing- cost- efficient- intelligence/ 3 https://developers.openai.com/api/docs/ models/text- embedding- 3- small HotpotQA 2Wiki MuSiQue Bridge entities 6,400 4,817 6,471 Bridging facts 8,000 6,821 8,010 Non-empty rate 80% 88% 79% T able 3: Bridging fact generation statistics. with 3 reasoning steps and top-20 retrie v al per step. When combined with IndexRA G, bridging facts are included in the retriev al corpus and balanced context selection is applied at the final answer gen- eration step, with k b = 3 . 4.3 Baselines W e compare IndexRA G against baselines span- ning fi ve cate gories: (1) Sparse retriev al: BM25 ( Robertson and W alker , 1994 ), (2) Dense retrie val: Nai ve RA G with fixed-size chunking using the same embedding model, (3) Iterati ve A pproach: IRCoT ( T riv edi et al. , 2023 ), (4) Graph-based: FastGraphRA G 4 and HippoRA G ( Gutiérrez et al. , 2024 ), and (5) Hierar chical: RAPTOR ( Sarthi et al. , 2024 ). W e adopt FastGraphRA G as a repre- sentati ve graph-based baseline due to its improved ef ficiency over GraphRA G ( Edge et al. , 2024 ) while maintaining competiti ve performance. Hip- poRA G requires an additional LLM call for query- time entity extraction and graph-based retrie val via Personalized P ageRank. Note that IRCoT was orig- inally e valuated with BM25. T o demonstrate the generality of Stage 2, we also report IRCoT com- bined with bridging facts. 4.4 Evaluation Metrics W e ev aluate using three metrics: Exact Match (EM), Accuracy (Acc), and F1 score, all computed after answer normalization following Rajpurkar et al. ( 2016 ). In addition, we report average re- trie val latency and the number of LLM calls at inference time to assess ef ficiency . Formal defini- tions are provided in Appendix A . 5 Results 5.1 Quantitative Results 5.1.1 Multi-hop QA Perf ormance T able 4 presents the main results across the three multi-hop QA benchmarks. W e report F1 score as the primary metric as it captures partial credit for partially correct answers. 4 https://github.com/circlemind- ai/ fast- graphrag 5 HotpotQA 2WikiMultiHopQA MuSiQue A verage EM Acc F1 EM Acc F1 EM Acc F1 EM Acc F1 BM25 47.2 51.2 60.3 31.6 32.5 35.9 9.8 10.7 19.2 29.5 31.5 38.5 Naiv e RA G 50.2 54.0 63.6 42.2 44.5 47.7 19.0 20.4 29.9 37.1 39.6 47.1 FastGraphRA G 50.0 53.8 63.5 49.5 54.8 57.4 17.5 18.8 27.2 39.0 42.5 49.4 RAPTOR 50.2 54.1 63.6 42.3 44.2 47.8 19.3 20.3 29.7 37.3 39.5 47.0 IndexRA G 54.1 59.3 68.9 44.8 50.3 51.7 22.4 24.4 34.4 40.3 44.7 51.7 HippoRA G 56.5 60.7 70.5 50.2 55.7 57.2 23.8 25.5 34.7 43.5 47.3 54.1 IRCoT 49.8 54.9 62.5 39.7 41.3 43.1 11.1 12.3 19.3 33.5 36.2 41.6 IRCoT + IndexRA G 54.5 59.7 68.7 53.4 61.2 61.2 24.6 26.5 35.0 44.2 49.1 55.0 T able 4: Multi-hop QA performance (%) on three multi-hop QA benchmarks. IndexRA G uses k b = 3 . Best single-call results per dataset are in bold . Best multi-call results are in bold gray . Methods requiring multiple LLM calls at inference time are greyed out. Single-call methods. Among methods requir - ing only a single LLM call at inference time, In- dexRA G achie ves the highest a verage scores across all three metrics. Inde xRA G obtains an average F1 of 51.7, improving o ver Nai ve RA G (+4.6), BM25 (+13.2), FastGraphRA G (+2.3), and RAP- TOR (+4.7). On HotpotQA and MuSiQue, In- dexRA G ranks first across all metrics, with par- ticularly strong gains on MuSiQue (34.4 vs. 29.9 for Nai ve RA G), where all baselines achie v e their lo west scores across the three datasets. On 2Wiki- MultiHopQA, FastGraphRA G achiev es the best single-call performance (57.4). This dataset is dom- inated by comparison and bridge comparison ques- tions (44%), which require parallel entity lookups that naturally align with explicit graph structures. IndexRA G’ s bridging facts are generated along se- quential reasoning paths and provide limited bene- fit for these question types, as further analyzed in Section 5.3.3 . Despite this, IndexRA G achie ves the best av erage F1 among all single-call methods. Multi-call methods. When combined with IR- CoT , IndexRA G achie ves the best results among all methods including multi-call ones. IRCoT + IndexRA G reaches an av erage of 55.0, surpassing HippoRA G (54.1) and standalone IRCoT (41.6). Adding bridging facts to IRCoT impro ves perfor- mance by 13.4 points ov er IRCoT alone on aver - age, with the largest gain on 2W ikiMultiHopQA (+18.1), suggesting that bridging facts provide cross-document context that iterative reasoning alone cannot capture. HippoRA G achiev es the highest single-dataset score on HotpotQA (70.5), but requires an additional LLM call for query-time entity extraction, resulting in significantly higher retrie val latenc y , as detailed in Section 5.1.2 . Method EM Time(s) Calls Nai ve RA G 19.0 0.29 1.0 FastGraphRA G 17.5 2.55 1.0 RAPTOR 19.3 0.47 1.0 IndexRA G 22.4 0.30 1.0 HippoRA G 23.8 3.13 2.0 IRCoT + IndexRA G 24.6 1.08 3.2 T able 5: Quality-efficiency comparison (%) on MuSiQue. Gray ro ws indicate multi-call methods. 5.1.2 Quality-Efficiency Comparison T able 5 presents the quality-efficienc y trade-of f on MuSiQue. Among single-call methods, IndexRA G achie ves the best EM (22.4) with a retrie val latency of 0.30 seconds, nearly identical to Naiv e RA G (0.29s) while improving EM by 3.4 points. Fast- GraphRA G, despite requiring only a single LLM call, requires 2.55 seconds per query , 8.5 × slo wer than IndexRA G while achieving lo wer EM (17.5). Among multi-call methods, HippoRA G achie ves a slightly higher EM of 23.8 but at the cost of two LLM calls and a retrie v al latency of 3.13 seconds, ov er 10 × that of IndexRA G. IRCoT + IndexRA G achie ves the best EM of 24.6 with a retrie val latency of 1.08 seconds, still 3 × faster than HippoRA G de- spite av eraging 3.2 LLM calls per query . These results sho w that IndexRA G effecti vely shifts computational cost from inference to inde x- ing, achieving strong performance with minimal online ov erhead. 5.2 Qualitative Results 5.2.1 Case Study T o illustrate ho w bridging facts improv e multi-hop retrie val, we examine a concrete example from 2W ikiMultiHopQA (T able 6 ). The query “Where was the director of the film A yl win born?” requires tw o-hop reasoning: (1) 6 Query: Where was the director of the film A ylwin born? Gold Answer: W eston-super-Mare Naive RA G Retriev ed [1] A ylwin is a 1920 British silent drama film directed by Henry Edwards... [2] Jim W ynorski (born August 14, 1950) is an American screenwriter ... [3] Frank Launder (28 January 1906 – 23 February 1997) was a British writer , film director ... Generated ✗ Henry Edwards IndexRA G Retriev ed [1] A ylwin is a 1920 British silent drama film directed by Henry Edwards... (AKU) [2] Henry Edwards directed both A ylwin and In the Soup, sho wcasing his career ... (bridging fact) [3] Henry Edw ards, born on 18 September 1882 in W eston-super-Mare... (bridging fact) Generated ✓ W eston-super-Mare T able 6: Case study from 2W ikiMultiHopQA. Naiv e RA G retriev es the correct film passage but fails to retriev e the passage containing the director’ s biographical information within its top- k results, producing an incorrect answer (“Henry Edwards”). IndexRA G retrie ves two bridging facts within its top- k that directly connect the film to the director’ s career and birthplace, producing the correct answer (“W eston-super-Mare”). The key bridging fact is highlighted in green . For bre vity , only the top-3 results are shown. identifying the director of the film A ylwin as Henry Edwards, and (2) determining his birthplace. The rele vant information is spread across two docu- ments, requiring cross-document reasoning to con- nect the film to the director’ s biographical details. For both methods, we present the top-3 retrie ved results. Naiv e RA G retrie ves the correct film pas- sage as its top-ranked result, which identifies Henry Edwards as the director of A ylwin. Howe v er , the remaining two passages contain unrelated directors. The passage containing Edwards’ birthplace exists in the vector store b ut falls outside the top- k , caus- ing the LLM to output the director’ s name rather than his birthplace. IndexRA G retrieves the same film passage as its top-ranked result. Howe ver , the remaining two slots are filled by bridging facts generated during of fline indexing: one connecting Edwards to his directing career and another linking him to his birthplace in W eston-super -Mare. W ith this cross- document context directly a v ailable, the LLM cor- rectly answers the query . This example demonstrates that bridging facts do not merely summarize existing content b ut cre- ate ne w retrie vable units that connect information across document boundaries, making pre viously unreachable evidence directly accessible through standard vector search. 5.3 Ablation Study 5.3.1 Effect of Each Stage Stage 1: Extraction Method. T able 7 compares three Stage 1 strategies on HotpotQA without bridg- ing facts. Naive chunking yields the lo west perfor- mance with an F1 of 63.6. Summarization provides Method EM Acc F1 Chunking 50.2 54.0 63.6 Summary 51.7 55.4 66.0 QA extraction 53.2 57.4 67.2 T able 7: Stage 1 extraction method comparison (%) on HotpotQA without bridging facts. Configuration EM Acc F1 Nai ve RA G 19.0 20.4 29.9 + Stage 2 22.3 24.4 34.4 QA Extraction 18.1 20.1 30.1 + Stage 2 22.4 24.4 34.4 T able 8: Stage 2 independence verification (%) on MuSiQue. a modest improv ement (+2.4) over nai ve chunking by compressing each document before indexing. QA extraction achiev es the best results across all metrics, with an F1 improvement of 3.6 ov er chunk- ing and 1.2 ov er summarization, suggesting that structuring document content as question-answer pairs produces denser and more query-aligned re- trie val units, as each AKU directly encodes a piece of answerable information rather than raw docu- ment text. QA extraction is therefore adopted as our Stage 1 strategy in all subsequent e xperiments. Stage 2: Independence from Stage 1. T able 8 verifies that Stage 2 is independent of the Stage 1 extraction method. On MuSiQue, adding bridg- ing facts to Nai v e RA G (EM 19.0 → 22.3) yields nearly identical gains to adding bridging facts to QA extraction (EM 18.1 → 22.4), confirming that the bridging fact module is general-purpose and 7 Dataset Datastore Recall@10 EM HotpotQA QA extraction 66.4 53.2 + Bridging 57.5 54.1 2W iki QA extraction 50.5 41.7 + Bridging 46.7 44.8 MuSiQue QA extraction 62.0 18.1 + Bridging 52.8 22.4 T able 9: Recall@10 vs EM (%) with and without bridg- ing facts. Comp. Bridge. Composit. Infer . 0 50 100 78 . 2 63 . 3 17 . 2 20 . 6 79 . 6 63 . 5 22 . 9 24 . 3 EM (%) w/o bridging facts w/ bridging facts Figure 3: Fine-grained EM (%) on 2W ikiMultiHopQA by question type. Results are shown with and without bridging facts. improv es performance re gardless of ho w the under - lying documents are indexed. This independence is practically important, as it allo ws Stage 2 to be applied on top of an y e xisting RA G system without modifying the underlying indexing pipeline. 5.3.2 Recall vs. End-to-End Perf ormance T able 9 examines the relationship between passage recall and QA performance when bridging facts are added to the vector store. Across all three datasets, adding bridging f acts consistently reduces Recall@10 yet improv es EM, with the largest EM gain on MuSiQue (+4.3), follo wed by 2W ikiMul- tiHopQA (+3.1) and HotpotQA (+0.9), suggest- ing bridging facts are most beneficial for harder datasets requiring more cross-document reasoning. The recall drops because bridging facts compete with original passages for retriev al slots. Since bridging facts are newly generated by the LLM, they do not correspond to any original passage and therefore contribute no gain to passage-le vel re- call. Despite this, the consistent EM improv ement across all three datasets suggests that the cross- document reasoning encoded in bridging facts is more v aluable for answering multi-hop questions than the original passages they replace. 5.3.3 Perf ormance Acr oss Question T ypes T o further understand IndexRA G’ s performance on 2W ikiMultiHopQA, we break do wn results by question type. Figure 3 sho ws results across four question types (comparison, bridge comparison, compositional, and inference). The largest gains from bridging f acts appear on compositional (+5.7) and inference (+3.7) questions, both of which re- quire combining evidence from separate documents to derive an answer . This aligns with the design of bridging facts, which e xplicitly encode cross- document connections. Comparison questions also benefit from bridging facts (+1.4), as they often require retrie ving infor- mation of two entities from different documents. Bridge comparison questions show minimal im- prov ement (+0.2). These questions require parallel two-hop reasoning: each hop independently identi- fies a piece of information (e.g., birthdate) of a dif- ferent entity before comparing them. For instance, “Which film has the director born later, X or Y?” re- quires resolving the director and birthdate for both X and Y separately . Since our bridging facts are generated along sequential reasoning paths, they tend to cov er only one of the two parallel paths, providing limited benefit for this question type. These results suggest that bridging f acts are most ef fectiv e for question types that require synthesiz- ing evidence across documents, such as compo- sitional and inference questions. The relati vely smaller gains on comparison and bridge compar- ison questions, which together account for 44% of the dataset, partially explain IndexRA G’ s lo wer ov erall performance on 2WikiMultiHopQA com- pared to other benchmarks. 6 Conclusion W e present IndexRA G , a novel approach that shifts cross-document reasoning from online inference to offline indexing. During indexing, IndexRA G generates bridging facts that capture entity-lev el connections across documents, stored alongside original passages in a unified vector store. At infer- ence time, a single retriev al pass and a single LLM call suf fice to produce the final answer . Extensiv e experiments on three multi-hop QA benchmarks sho w that IndexRA G achieves the best av erage F1 among single-LLM-call methods, outperforming the strongest baseline by 2.3 F1 points. Future work could explore question-type-a ware bridging fact generation to handle di verse reasoning patterns. 8 Limitations While IndexRA G demonstrates strong perfor- mance, se veral limitations remain. First, bridg- ing fact quality depends on the LLM used during of fline indexing, and noisy or hallucinated facts may introduce irrele v ant retriev al units and hurt performance. Second, bridge entities are currently extracted by the LLM directly , which may miss entities or introduce noise. Using a dedicated NER model could potentially impro ve extraction preci- sion. Third, ev aluation is limited to English multi- hop QA benchmarks, and generalization to other languages or domains remains unexplored. References T om Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry , Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information pr ocessing systems , 33:1877–1901. T ong Chen, Hongwei W ang, Sihao Chen, W enhao Y u, Kaixin Ma, Xinran Zhao, Hongming Zhang, and Dong Y u. 2024. Dense x retriev al: What retriev al granularity should we use? In Pr oceedings of the 2024 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 15159–15177. Alex ey Dosovitskiy , Lucas Be yer , Alexander K olesnikov , Dirk W eissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer , Georg Heigold, Sylvain Gelly , and 1 others. 2020. An image is worth 16x16 words: T ransformers for image recognition at scale. arXiv pr eprint arXiv:2010.11929 . Matthijs Douze, Alexandr Guzhv a, Chengqi Deng, Jeff Johnson, Gergely Szilvasy , Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2025. The faiss library . IEEE T ransactions on Big Data . Darren Edge, Ha T rinh, Ne wman Cheng, Joshua Bradley , Alex Chao, Apurva Mody , Steven Truitt, Dasha Metropolitansky , Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization. arXiv pr eprint arXiv:2404.16130 . Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023. Precise zero-shot dense retriev al without rel- ev ance labels. In Pr oceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (V olume 1: Long P apers) , pages 1762–1777. Bernal J Gutiérrez, Y iheng Shu, Y u Gu, Michihiro Y a- sunaga, and Y u Su. 2024. Hipporag: Neurobiologi- cally inspired long-term memory for lar ge language models. Advances in neural information pr ocessing systems , 37:59532–59569. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugaw ara, and Akiko Aiza wa. 2020. Constructing a multi-hop qa dataset for comprehensiv e e valuation of reasoning steps. In Pr oceedings of the 28th International Con- fer ence on Computational Linguistics , pages 6609– 6625. Lei Huang, W eijiang Y u, W eitao Ma, W eihong Zhong, Zhangyin Feng, Haotian W ang, Qianglong Chen, W eihua Peng, Xiaocheng Feng, Bing Qin, and 1 oth- ers. 2025. A survey on hallucination in large lan- guage models: Principles, taxonomy , challenges, and open questions. ACM T ransactions on Information Systems , 43(2):1–55. Vladimir Karpukhin, Barlas Oguz, Sew on Min, Patrick Lewis, Ledell W u, Serge y Edunov , Danqi Chen, and W en-tau Y ih. 2020. Dense passage retrie v al for open- domain question answering. In Proceedings of the 2020 confer ence on empirical methods in natural language pr ocessing (EMNLP) , pages 6769–6781. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler , Mike Lewis, W en-tau Y ih, T im Rock- täschel, and 1 others. 2020. Retrie val-augmented gen- eration for knowledge-intensi v e nlp tasks. Advances in neural information pr ocessing systems , 33:9459– 9474. Ofir Press, Muru Zhang, Sew on Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. 2023. Measuring and narro wing the compositionality gap in language models. In F indings of the Association for Computa- tional Linguistics: EMNLP 2023 , pages 5687–5711. Alec Radford, Jong W ook Kim, Chris Hallacy , Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try , Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In International confer ence on machine learning , pages 8748–8763. PmLR. Pranav Rajpurkar , Jian Zhang, Konstantin Lop yrev , and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Pr oceedings of the 2016 conference on empirical methods in natural language pr ocessing , pages 2383–2392. Stephen E Robertson and Ste ve W alker . 1994. Some simple effecti ve approximations to the 2-poisson model for probabilistic weighted retriev al. In SI- GIR’94: Pr oceedings of the Seventeenth Annual In- ternational ACM-SIGIR Conference on Resear ch and Development in Information Retrieval, or ganised by Dublin City University , pages 232–241. Springer . Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. Raptor: Recursive abstracti ve processing for tree-organized retrie v al. In The T welfth International Confer ence on Learning Repr esentations . 9 Harsh T riv edi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Musique: Multi- hop questions via single-hop question composition. T r ansactions of the Association for Computational Linguistics , 10:539–554. Harsh T riv edi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. Interlea ving retriev al with chain-of-thought reasoning for kno wledge- intensiv e multi-step questions. In Pr oceedings of the 61st annual meeting of the association for com- putational linguistics (volume 1: long papers) , pages 10014–10037. Ashish V aswani, Noam Shazeer, Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information pr ocessing systems , 30. Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, W illiam Cohen, Ruslan Salakhutdino v , and Christo- pher D Manning. 2018. Hotpotqa: A dataset for div erse, explainable multi-hop question answering. In Pr oceedings of the 2018 confer ence on empiri- cal methods in natural language pr ocessing , pages 2369–2380. Xiaozhou Y ou, Y ahui Luo, and Lihong Gu. 2025. Ms- rag: Simple and effecti ve multi-semantic retrieval- augmented generation. In Pr oceedings of the 2025 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 22620–22636. A Evaluation Metrics Let ˆ a and a ∗ denote the normalized prediction and gold answer , and let T ( · ) denote the token set of a string. Exact Match (EM) measures whether the prediction is identical to the gold answer: EM = ( 1 if ˆ a = a ∗ 0 otherwise (3) Accuracy (Acc) measures whether the gold an- swer appears as a substring of the prediction: Acc = ( 1 if a ∗ ⊆ ˆ a 0 otherwise (4) F1 computes the token-le v el harmonic mean of precision and recall: P = | T (ˆ a ) ∩ T ( a ∗ ) | | T (ˆ a ) | , R = | T (ˆ a ) ∩ T ( a ∗ ) | | T ( a ∗ ) | (5) F 1 = 2 P R P + R (6) B Balanced Context Selection Algorithm 1 presents the full procedure for bal- anced context selection, which controls the propor- tion of bridging facts in the retrie ved conte xt. Algorithm 1 Balanced Context Selection 1: C ← ∅ , n b ← 0 2: for r j in R do 3: if | C | = k then 4: br eak 5: end if 6: if r j ∈ A or n b < k b then 7: C ← C ∪ { r j } 8: if r j ∈ B then 9: n b ← n b + 1 10: end if 11: end if 12: end for 13: retur n C C Effect of Balanced Context Selection The parameter k b controls the maximum number of bridging facts included in the retrieved conte xt. T a- ble 10 sho ws results for k b ∈ { 0 , 1 , 2 , 3 , 5 } , where k b = 0 corresponds to retriev al without bridging facts. Performance peaks at k b = 2 on HotpotQA 10 k b HotpotQA 2Wiki MuSiQue 0 (no bridging) 53.2 41.7 18.1 1 52.7 43.3 21.6 2 54.1 43.2 22.4 3 53.9 44.8 22.4 5 52.9 44.4 22.3 T able 10: Balanced retrie val ablation (EM, %). and MuSiQue (with MuSiQue tying at k b = 2 and k b = 3 ), and at k b = 3 on 2W ikiMultiHopQA, then declines as k b increases further . This is because bridging facts are shorter than AKUs on av erage (166 vs. 634 characters), so including too many bridging facts displaces original context, which contains more informativ e content. W e observe that datasets requiring more cross-document rea- soning, such as MuSiQue, tolerate a higher k b . D Prompt T emplates W e present all prompt templates used in our ex- periments. Figure 4 sho ws the Stage 1 AKU extraction prompt, which instructs the LLM to extract f actual information from a document as atomic question-answer pairs. Figure 5 shows the summary-based Stage 1 baseline. The LLM is asked to produce a comprehensi ve summary of each document. For Stage 2, Figure 6 provides documents sharing a common entity and prompts the LLM to generate cross-document bridging facts in JSON format. Figure 7 is the answer generation prompt shared across all methods, requiring the LLM to output concise, exact answers without e x- planation. Figure 8 presents the IRCoT reasoning prompt, which elicits step-by-step chain-of-thought reasoning and guides the LLM to suggest follow- up search queries when additional information is needed. 11 Y ou are an expert information extractor specializing in con verting unstructured documents into clear , atomic question-answer pairs. Extract ALL factual information from the follo wing document as question-answer pairs. Each pair must answer exactly one question, be self-contained, and be verifiable from the source content. Extract questions for facts, descriptions, properties, relationships, and ev ents. For each entity mentioned, also extract questions about its relationships to other entities. Document: {text} Return only a valid JSON object without an y other text. Figure 4: Prompt template f or Stage 1 AKU extraction. Giv en the following document, write a comprehensive summary that captures all key facts, entities, relationships, and details. Be thorough and do not omit important information. Document: {text} Summary: Figure 5: Prompt template f or the Stage 1 summary strategy . Giv en the follo wing information about “{entity}” from multiple source documents, generate bridging facts that connect information across these documents. {doc_sections} Requirements: - Each bridging fact must combine information from 2+ documents - Be factually accurate — only connect information that is logically related - Each fact should be self-contained and understandable without context - Do not generate speculativ e connections - If documents share the entity name but are about unrelated topics, return empty Return a JSON array of strings. If no meaningful connections exist, return []. Figure 6: Prompt template f or Stage 2 bridging fact generation. Y ou are a precise question answering assistant. Answer with ONL Y the exact information requested, with no explanations or extra words. If the answer is a name, giv e only the name. If the answer is a number , giv e only the number . If the answer is yes/no, giv e only yes or no. Context: {context} Question: {question} Figure 7: Prompt template f or answer generation (used by all methods). Y ou are a reasoning assistant that helps answer multi-hop questions step by step. Question: {question} Retrieved Inf ormation: {context} Reasoning so far: {cot_so_far} Write ONE brief reasoning sentence that mak es progress tow ard answering the question. If more information is needed, suggest a specific search query . Format y our r esponse as: Reasoning: 〈 one sentence of reasoning 〉 Search: 〈 next search query , or DONE if ready to answer 〉 Figure 8: Prompt template f or IRCoT chain-of-thought r easoning, following T ri vedi et al. ( 2023 ). 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment