인덱스 시점 다중문서 추론을 위한 브리징 팩트
IndexRAG는 문서 인덱싱 단계에서 공유 엔터티를 찾아 교차 문서 추론을 위한 “브리징 팩트”를 생성하고, 이를 기존의 원자 지식 단위(AKU)와 함께 벡터스토어에 저장한다. 추론 시에는 단일 패스 검색과 하나의 LLM 호출만으로 답을 도출해, 기존 그래프 기반·반복적 방법에 비해 비용과 지연을 크게 낮추면서 HotpotQA, 2WikiMultiHopQA, MuSiQue에서 평균 4.6 F1 포인트 향상을 달성한다.
저자: Zhenghua Bao, Yi Shi
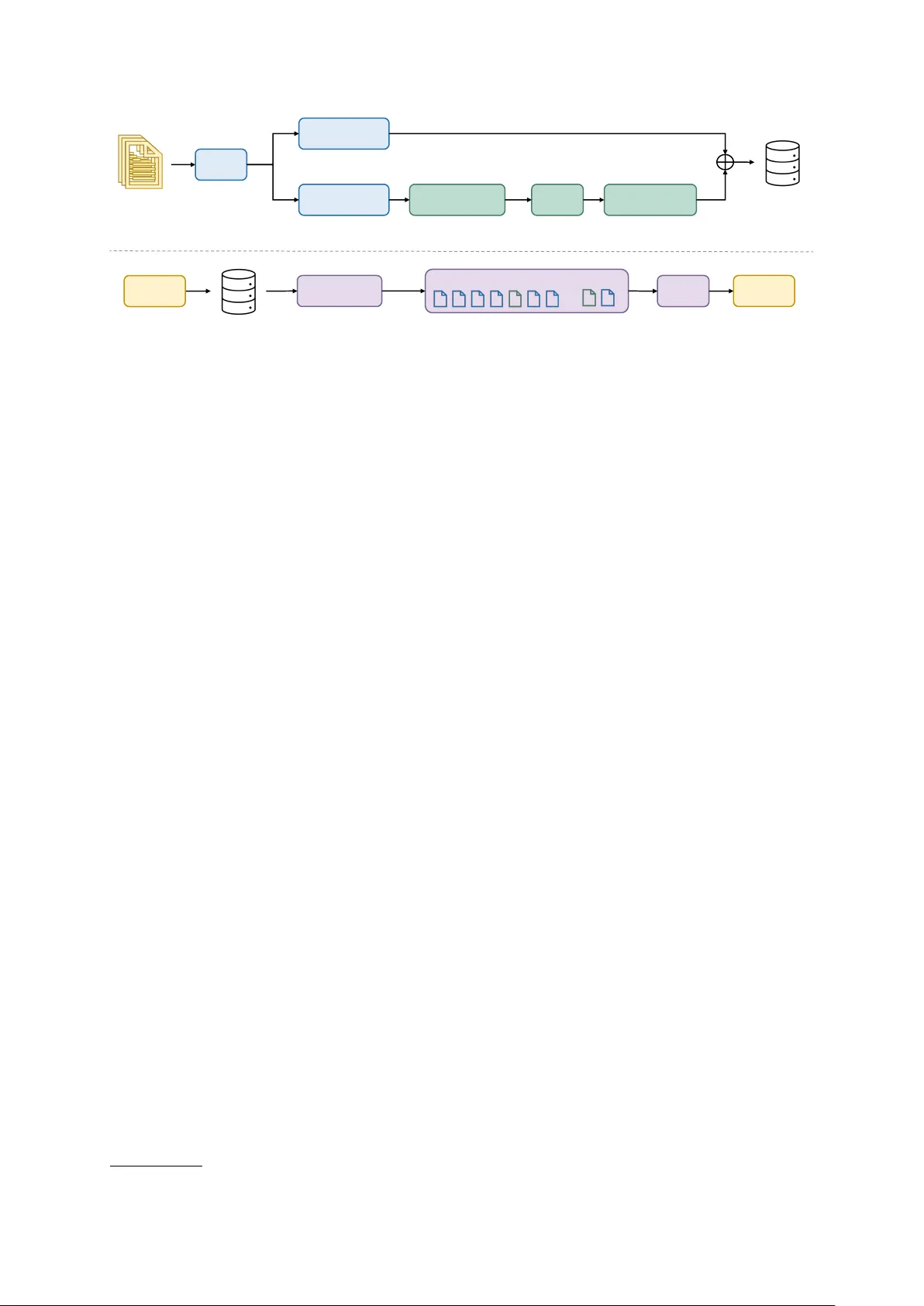
본 논문은 멀티홉 질문응답(Multi‑hop QA)에서 필수적인 “문서 간 추론”을 기존의 질의 시점 연산이 아닌 인덱스 시점에 미리 수행하는 새로운 프레임워크인 IndexRAG를 제안한다. 기존 Retrieval‑Augmented Generation(RAG) 방식은 각 문서를 독립적인 청크로 임베딩하고 질의와의 유사도만으로 검색한다. 따라서 두 개 이상의 문서에 흩어져 있는 증거를 결합해야 하는 질문에 대해 필요한 중간 엔터티가 포함된 청크가 검색되지 않으면 답변이 부정확하거나 완전히 실패한다. 이를 보완하기 위해 그래프 기반 RAG(예: HippoRAG, FastGraphRAG)는 엔터티 추출·그래프 구축·페이지랭크 등 추가 연산을 질의 시점에 수행한다. 그러나 이러한 방법은 연산 비용·지연이 크게 증가하고, 복잡한 파이프라인 관리가 필요하다.
IndexRAG는 이러한 문제를 “브리징 팩트(bridging fact)”라는 새로운 검색 단위로 해결한다. 인덱싱 단계는 두 단계로 구성된다. 1) AKU(Atomic Knowledge Unit)와 엔터티 추출: 각 문서를 LLM에 입력해 질문‑답변 형태의 원자 지식 단위와 해당 문서에 등장하는 엔터티 집합을 추출한다. 추출된 답변만을 하나의 텍스트 블록으로 결합해 AKU라 부르고, 이를 dense embedding 모델(f)으로 인코딩해 평면 벡터스토어 V에 저장한다. 2) 브리징 팩트 생성: 전체 문서에서 두 개 이상 문서에 공통으로 등장하는 엔터티를 “브리지 엔터티”로 선정한다(문서 빈도 ≥ 2, ≤ τ). 각 브리지 엔터티에 대해 해당 엔터티가 포함된 AKU들을 모아 LLM에 제공하고, “엔터티 A와 B가 연결된다 → B와 C가 연결된다”와 같은 다중 홉 추론을 한 문장으로 요약하도록 프롬프트한다. 이렇게 생성된 브리징 팩트는 원본 AKU보다 짧고 질의와 의미적으로 직접 정렬되므로, 질의 임베딩과의 코사인 유사도 검색에서 높은 순위를 차지한다. 브리징 팩트와 AKU는 동일한 임베딩 모델으로 인코딩돼 하나의 통합 벡터스토어에 저장된다.
추론 단계에서는 질의를 동일한 임베딩 모델로 변환하고, V에서 top‑k(예: 20) 후보를 검색한다. 브리징 팩트는 짧아 상위 k에 과다히 포함될 위험이 있기 때문에, “균형 컨텍스트 선택” 알고리즘을 적용한다. 후보 리스트를 순차적으로 살피면서 AKU는 무조건 포함하고, 브리징 팩트는 사전에 정한 상한(kb, 기본값 = 3) 이하만 포함한다. 이렇게 구성된 컨텍스트 C는 유사도 순으로 연결돼 하나의 프롬프트에 삽입되고, LLM은 추가 호출 없이 최종 답변을 생성한다.
실험은 HotpotQA, 2WikiMultiHopQA, MuSiQue 세 가지 멀티홉 QA 벤치마크에서 수행되었다. 각 데이터셋에서 1,000개의 검증 질문을 샘플링해 전체 문서를 인덱싱하고, GPT‑4o‑mini를 LLM·임베딩 모델(text‑embedding‑3‑small)로 사용했다. IndexRAG는 Naive RAG 대비 평균 4.6 F1 포인트 향상을 보였으며, 특히 IRCoT와 결합했을 때 HippoRAG·FastGraphRAG 등 최신 그래프 기반 모델을 전반적으로 앞섰다. 비용 측면에서도 단일 검색·단일 LLM 호출 구조이므로 추론 지연이 크게 감소한다. 새로운 문서가 추가될 경우 해당 문서와 연관된 브리지 엔터티만 재처리하면 되므로 인덱스 유지 비용도 효율적이다.
핵심 기여는 다음과 같다. ① 인덱스 시점에 교차 문서 추론을 미리 수행해 질의 시점 연산을 최소화한다. ② “브리징 팩트”라는 새로운 검색 단위를 도입해 다중 홉 추론을 한 문장 형태로 직접 검색 가능하게 만든다. ③ 균형 컨텍스트 선택 메커니즘으로 짧은 브리징 팩트가 AKU를 압도하지 않도록 조절한다. ④ LLM 기반 생성만으로 동작하며, 별도 파인튜닝이나 그래프 구축 없이 기존 RAG 파이프라인에 쉽게 통합할 수 있다.
결과적으로 IndexRAG는 기존 RAG의 단순성, 그래프 기반 방법의 정확성, 그리고 반복적 체인‑오브‑생각(Chain‑of‑Thought) 방식의 풍부한 증거 활용을 각각 장점으로 흡수하면서, 인덱싱 단계에만 추가 비용을 두고 추론 단계는 최소화한다는 점에서 차세대 멀티홉 QA 시스템 설계에 중요한 방향성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기