RECOVER: Robust Entity Correction via agentic Orchestration of hypothesis Variants for Evidence-based Recovery
Entity recognition in Automatic Speech Recognition (ASR) is challenging for rare and domain-specific terms. In domains such as finance, medicine, and air traffic control, these errors are costly. If the entities are entirely absent from the ASR outpu…
Authors: Abhishek Kumar, Aashraya Sachdeva
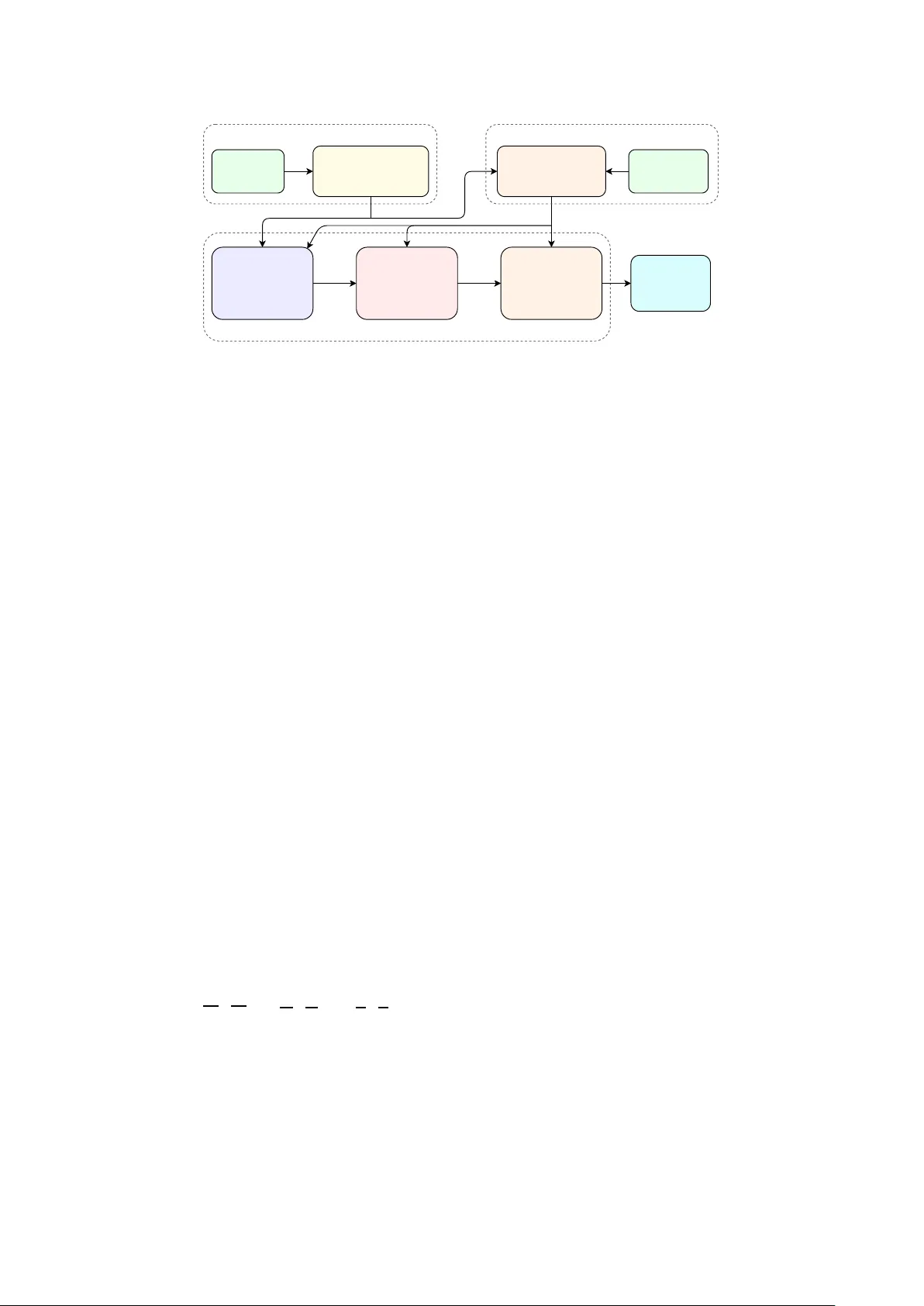
RECO VER: Rob ust Entity Corr ection via agentic Orchestration of h ypothesis V ariants f or Evidence-based Recov ery Abhishek K umar , Aashraya Sachde va Observe.AI, India { abhishek.kumar, aashraya.sachdeva } @observe.ai Abstract Entity recognition in Automatic Speech Recognition (ASR) is challenging for rare and domain-specific terms. In domains such as finance, medicine, and air traffic control, these errors are costly . If the entities are entirely absent from the ASR out- put, post-ASR correction becomes difficult. T o address this, we introduce RECO VER, an agentic correction frame work that serves as a tool-using agent. It leverages multiple hypotheses as evidence from ASR, retrieves relev ant entities, and applies Large Language Model (LLM) correction under constraints. The hypotheses are used using dif ferent strategies, namely , 1-Best, Entity-A ware Select, Recognizer Output V oting Error Reduction (R O VER) Ensemble, and LLM-Select. Evaluated across fiv e diverse datasets, it achieves 8-46% relati ve reduc- tions in entity-phrase word error rate (E-WER) and increases recall by up to 22 percentage points. The LLM-Select achieves the best ov erall performance in entity correction while main- taining ov erall WER. Index T erms : speech recognition, entity correction, whisper , Agentic AI, Large Language Models 1. Introduction Modern end-to-end ASR systems such as Whisper [1], wa v2vec 2.0 [2], and Conformer-based models [3, 4] achiev e impressiv e word error rates (WER) on general benchmarks. Howe v er , their performance degrades on entity phrases, i.e. proper nouns, brand names, and domain-specific terminology , that are rare or absent from training data [5, 6]. In domains like finance, air-traf fic control (A TC), and medicine, entity er- rors are costly and often can come as small but critical near- misses (e.g., cytiba → cytiva , oscar kill papa r omeo mike → oscar kilo papa r omeo mike , linear zolid → linezolid ). Addressing such entity errors via contextual biasing at decode time has been a primary research focus. Some of the recent advancements include neural transducers with deep biasing [7, 8] and alternate-spelling models to capture out- of-vocab ulary (OO V) terms [9]. T rie-based decoding passes hav e also been e xplored to unify global and near-context bi- asing [10, 11]. While these approaches are ef fectiv e, they typ- ically ha ve access to decoder internals or bias-aware decoding, which is often una v ailable when using production ASR systems as black boxes. Alternativ ely , post-ASR error correction using LLM of- fers a more flexible text-based approach. Recent works have shown that LLMs can reduce WER by lev eraging the con- text [12, 13, 14, 15], but they are prone to hallucinations or over- correction without strict constraints [16]. T o improve entity ac- curacy , other works hav e used contextual descriptions [17] or cross-lingual evidence [18]. Howe v er , all these methods face a fundamental e vidence limitation that if an entity is deleted or heavily corrupted in the 1-best ASR output, the LLM often lacks the signal to recov er the term. T o bridge this evidence gap, many w orks hav e turned to N- best hypotheses to utilize alternati ve candidates [19, 20]. While R O VER (Recognizer Output V oting Error Reduction) [21] tra- ditionally combines outputs from different ASR systems, mod- ern approaches use N-best reranking via LLMs to select the most probable transcription [22, 23, 24]. Motivated by this, we exploit multi-h ypothesis div ersity from a single ASR model (Whisper-small) via temperature sampling. These variations help spot complementary errors more ef fecti vely and support corrections. Finally , we frame post-ASR entity correction as an agentic framew ork. Recently , agentic reasoning (e.g., ReAct) and tool- use hav e matured [25, 26]. But their application in speech has largely been limited to con v ersational or dialogue tasks [27, 28] rather than robust post-ASR entity reco very . These observations motivate a post-ASR correction frame- work that works with an ASR system by leveraging multi- hypothesis evidence when av ailable, and applies constrained edits to entity phrases with deterministic guardrails. W e present RECO VER, an agentic correction frame work that uses a strictly constrained LLM editor to make entity corrections. Our contri- butions are: • Multi-hypothesis div ersity: W e show that generating multi- ple hypotheses from an ASR using the same audio produces complementary errors that can be exploited for entity correc- tion. In our experiments, we obtain these via temperature sampling with Whisper-small, but the framework is agnostic to the method used to generate hypotheses. • Agentic architecture: The pipeline is decomposed into three agent tools (Fuse Hypotheses, Propose Corrections, V erify & Apply) which are orchestrated by an agent. • Four correction strategies: 1-Best (single h ypothesis), Entity- A ware Select, RO VER Ensemble, and LLM-Select share a common pipeline b ut dif fer in ho w hypotheses are fused (by deterministic hypothesis selection, or token-level merge, or selection using the LLM). • Constrained LLM editing: The LLM proposes find or re- place edits, b ut is restricted to the entities present in the entity phrase list. Every proposed replacement is verified by multi- ple validations. W e conduct comprehensive e valuations across fiv e div erse datasets spanning financial, A TC, medical, general speech, and dialogue domains using different correction methods. W e demonstrate 8-46% relativ e entity-phrase WER (E-WER) re- duction and consistent gains across domains. Audio Whisper-small T ∈ {0.0, 0.2, 0.4, 0.6, 0.8} N =5 transcript hypotheses Entity phrases Candidate Retrieval exact + fuzzy + phonetic scoring → T op- K entities T ool 1: Fuse Hypotheses Entity scoring + 1-Best / Entity-Aware Select / ROVER Ensemble / LLM-Select T ool 2: Propose Corrections LLM + T op- K entity candidates → find/replace T ool 3: V erify & Apply Guardrail validation & Non-overlapping application Corrected T ranscript + Correction log fused text proposals Agentic Orchestration Multi-Hypothesis Generation Dynamic Entity Candidate Retrieval N variants T op- K Figure 1: End-to-end system overview . Audio is decoded at five temperatur es using Whisper -small, pr oducing five transcript hypotheses. Entity phrases are scor ed against the hypotheses using exact, fuzzy , and phonetic matching and the top- K candidates ( K =200 ) are selected. The agentic or chestr ates thr ee tools in sequence: T ool 1 (Fuse Hypotheses), T ool 2 (Pr opose Corrections via a constrained LLM pr ompt), and T ool 3 (V erify & Apply with deterministic guardr ails), pr oducing the corr ected transcript. 2. Proposed Appr oach ASR systems often misrecognise entity phrases and rare or out- of-vocab ulary tokens that are underrepresented in the training data. Giv en a list of kno wn entity phrases and one or more ASR hypotheses, our goal is to correct entity-lev el errors in the tran- script while leaving the rest of the text intact. T o address this, we propose a frame work as in Figure 1: Multi-Hypothesis Gen- eration to produce transcript hypotheses, Dynamic Entity Can- didate Retrie val to select the top- K entity candidates ( K =200 ), and three agent tools: T ool 1 (Fuse Hypotheses), T ool 2 (Pro- pose Corrections), and T ool 3 (V erify & Apply). The pipeline is implemented as a tool-using agent in Agno [26] with three specialised tools. 2.1. Multi-Hypothesis Generation The framew ork accepts N ASR hypotheses for each audio seg- ment. The hypotheses can be obtained using any method, such as temperature sampling from a single ASR model, beam search with diverse decoding, or an ensemble of dif ferent ASR sys- tems. The key requirement is that, when N > 1 , the hypothe- ses contain complementary errors so that entity tokens missed or corrupted in one hypothesis may be correctly transcribed in another . In our experiments (Section 3), we generate five hy- potheses via temperature sampling with Whisper-small. 2.2. Dynamic Entity Candidate Retrieval Entity phrase lists can be large (up to 6,198 phrases in our ex- periments). Sending all phrases in the LLM prompt is wasteful and may degrade quality . W e therefore dynamically retriev e the top- K most relev ant candidates per segment using a three- signal scoring function applied to ev ery phrase b in the list: score ( b ) = n exact · w e | {z } exact token hits + f best · w f | {z } fuzzy similarity + p hit · w p | {z } phonetic prefix (1) where n exact counts how many words of b appear as exact to- kens across all transcript hypotheses (the variants are concate- nated to build a unified token set), f best ∈ [0 , 1] is the best nor- malised Le venshtein similarity between any word of b and any token from any hypothesis (restricted to tokens within ± 3 char- acters), and p hit ∈ { 0 , 1 } is 1 if the phonetic key of b shares a 5-character prefix with any token’ s phonetic key from any hy- pothesis. The weights w e =1 . 0 , w f =1 . 2 , w p =0 . 6 are set em- pirically . Here, exact matches are the most trustworthy . On the other hand, fuzzy similarity is weighted slightly higher per unit because it is the primary mechanism for recovering corrupted entities (e.g., sitiva → cytiva ), and phonetic matching serves as a supplementary signal. Since we take the top- K candidates (a sufficiently lar ge pool), the final ranking is robust to moderate changes in weights. Phrases are sorted by score, and the top- K are passed to the LLM. W e use K =200 in all experiments. 2.3. Agentic Orchestration The agent orchestrates the three tools inside the dashed bound- ary in Figure 1. Giv en the ASR hypotheses and the retriev ed top- K entity candidates, it (i) analyses and fuses hypotheses into a single transcript, (ii) queries the LLM to propose entity- only find/replace edits, and (iii) verifies and applies only the edits that pass deterministic guardrails. T ool 1 (Fuse Hypotheses) takes the N input hypotheses and produces a single transcript. As part of fusion, it uses the top- K entity candidates (selected by the candidate retriev al step, which scored phrases against all hypotheses combined) to count how many of these candidates appear as exact substrings in each in- dividual hypothesis. These per-v ariant entity-hit counts (“entity scoring” step) dri v e variant selection in Entity-A ware Select and piv ot selection in R O VER Ensemble. For 1-Best, entity count- ing is trivially skipped (only one hypothesis). T ool 1 supports four fusion strategies: • 1-Best: It passes the single greedy hypothesis ( N =1 ) through unchanged. • Entity-A ware Select: It chooses the h ypothesis with the max- imum number of exact entity-candidate substring matches, with transcript length as a weak tie-breaker (since longer tran- scripts correlate with fewer deletions). • RO VER Ensemble: It chooses an entity-aware piv ot (same heuristic as Entity-A ware Select), align each remaining hy- pothesis to the pi vot using Needleman–W unsch global align- ment [29], and take a majority-vote token merge (ties fav our the pi vot and insertions are accepted only if supported by ≥ 3 of 5 hypotheses). • LLM-Select: It dele gates selection to the LLM by providing all N hypotheses and the top- K entity candidates. The LLM chooses the best base v ariant and can propose entity-only cor- rections in the same call. T ool 2 (Propose Corrections) proposes entity-only find or replace edits using an LLM prompt which enforces strict rules that replacements must be exactly one of the entity-list phrases, no generic word rewrites (grammar , punctuation, filler words, casing), and near-miss correction is encouraged (e.g., citeva → cytiva ). The output is a valid JSON containing character offsets, the original and replacement spans, entity type, confidence, and a short reason. W ith T ool 3 (V erify & Apply), ev ery LLM-proposed re- placement passes through multiple deterministic checks: (1) the replacement must exist in the entity phrase list, (2) case-only changes are discarded, (3) if the LLM-provided character off- sets are wrong, the system relocates the find span and recom- putes them, (4) the normalised Lev enshtein similarity between the original span and the replacement must be high enough to prev ent unrelated substitutions (e.g., citeva → cytiva passes, but star → cytiva is rejected), and (5) replacements are applied left- to-right, skipping any that o verlap with an earlier edit. 3. Experimental Setup 3.1. Datasets W e ev aluate on fi v e datasets spanning div erse domains (T a- ble 1). Earnings-21 [6] comprises 44 real earnings conference calls. Since each call is about 1 hour long, we segment these calls into ∼ 1-minute audio clips resulting in 2,086 segments. The entity list of 1,013 phrases covers organisation names, person names, financial terms, and product names. From the A TCO2 [30, 31] corpora, we use the 1-hour test set (A TCO2- test-set-1h). W e use 446 callsign entities, as other entity types (commands, v alues) contained mostly general phrases. Eka- Medical 1 [32] is a medical ASR ev aluation dataset with 3,619 utterances and 6,198 medical entity phrases covering diseases, symptoms, medications, and procedures. Common V oice [33] Corpus-22 English test set has 16,401 utterances. Since Com- mon V oice lacks an entity list, we extract named entities us- ing a BER T -based NER model follo wing the approach of Thor - becke et al. [10], yielding 3,098 entity phrases. ContextASR- Bench [34] provides contextual ASR evaluation data. W e use the English ContextASR-Dialogue test set (5,273 samples) with 3,704 movie-name entities pro vided in the dataset. 3.2. ASR system and LLM All audio is decoded by Whisper-small [1] via faster-whisper 2 for faster implementation at five temperatures T ∈{ 0 . 0 , 0 . 2 , 0 . 4 , 0 . 6 , 0 . 8 } . Our main correc- tion experiments use GPT -4o [35]. W e also report an ablation with GPT -4o-mini (LLM-Select only) since LLM-Select has the best performance among the four fusion strategies. 3.3. Evaluation All W E R values are computed using SCLITE [21]. Entity- phrase WER (E-WER) is computed only over reference to- kens belonging to entity phrases. Relativ e E-WER reduction (R WERR) is ( E-WER base − E-WER sys ) / E-WER base × 100% . W e also report entity precision (P), recall (R), and F1. Using these metrics, we compare the baseline (Whisper greedy de- 1 https://huggingface.co/datasets/ekacare/ eka- medical- asr- evaluation- dataset 2 https://github.com/SYSTRAN/faster- whisper T able 1: Dataset statistics. Se gments is the number of indepen- dently pr ocessed transcript units. Entity Refer ence T okens is the total number of wor ds in r efer ence belonging to entity phrases (used for E - W E R computation). Audio hours is the approxi- mate total duration of the e valuated audio. Dataset Segments Audio hours (approx.) Entities Entity Reference T okens Entity types Earnings-21 2,086 38.8 1,013 6,535 Persons, Or gs, Products A TCO2 560 1.1 446 4,771 Callsigns Eka-Medical 3,619 8.4 6,198 42,449 Medical terms Common V oice 16,401 27.1 3,098 7,889 Deri ved Named Entities ContextASR-Bench 5,273 221.9 3,704 92,381 Movie names coding at T =0 , no correction) against four fusion strate gies (1-Best, Entity-A ware Select, R O VER Ensemble, and LLM- Select) while using GPT -4o. W e also present an ablation using GPT -4o-mini on the best-performing LLM-Select strategy . 4. Results and Discussion T able 2 reports overall W E R, entity-phrase WER ( E - W E R ) (with R WERR beneath), and entity F1 (with Precision / Recall beneath) for all fi ve datasets. W ith constrained LLM editing effecti v e across all domains, even the 1-Best strategy achiev es 33.2% R WERR on Earnings-21, 41.2% on Common V oice, 20.4% on Medical, and 12.7% on ContextASR-Bench. This confirms that an LLM (GPT -4o) with entity-list guardrails is a strong post-ASR corrector . Among multi-hypothesis meth- ods, LLM-Select is the most consistent strategy , achieving the best or near -best E - W E R on four of fi ve datasets . This strategy also preserves or improves the overall W E R . On Earnings-21, it reaches 33.4%, within 1.1 pp of Entity-A ware Select (34.5%). On ContextASR-Bench, R O VER Ensemble achieves the high- est R WERR (20.8%) but at the cost of increased ov erall W E R . W e also conduct an ablation study with GPT -4o-mini using the best performing LLM-Select method in T able 2. With R WERR lying in the range of 2.2–15.7%, the entity gains are small but consistent. This indicates that a stronger LLM reasoning has improv ed entity recov ery under strict constraints. Both Entity- A ware Select and R O VER Ensemble can degrade ov erall W E R on noisy domains such as A TCO2 (48.63% → 64–66%) because multi-hypothesis fusion introduces insertion noise. LLM-Select av oids this by selecting the best single v ariant rather than merg- ing tokens. The dominant gain across all datasets comes from entity recall: +11.6 pp on Earnings-21, +8.2 pp on A TCO2, +6.2 pp on Medical, +21.5 pp on Common V oice, and +0.9 pp on ContextASR-Bench, confirming that the baseline’ s main weak- ness is entity deletion and substitution. In A TCO2, with calls being noisy , long callsigns are sometimes dropped al- most entirely (e.g., helicopter hotel bravo zulu whiske y juli- ett rendered as missing tokens), while Medical sho ws fre- quent near-miss substitutions for drug names (e.g., amlodip- ine as amplodifin / amnodipine ) and ContextASR movie titles exhibit phonetic confusions (e.g., chr onicles → c hr onic holes ). The modest ContextASR-Bench gain reflects its already-high baseline recall (94.51%). Precision is largely preserved (e.g., 96.76% → 96.73% on Medical) or trades off modestly (7–9 pp on Earnings-21 and Common V oice), but in ev ery case the re- call gains outweigh the precision loss, yielding net F1 improv e- ments of +0.3 to +10.7 pp. Common V oice sho ws the lar gest F1 gain (+10.7 pp) with its NER-deriv ed entities. The results also sho w some patterns shaped by domain, au- dio quality , and entity characteristics. On Earnings-21, having financial entities, all methods perform similarly (R WERR 33– 35%), with Entity-A ware Select performing marginally best. For context, Huang et al. [8] report that a contextualized T able 2: Results acr oss five datasets (all values in %) with RECO VER using GPT -4o (all corr ection strate gies) and GPT -4o-mini (LLM- select only). Below eac h E - W E R : R WERR = relative E - W E R r eduction vs. baseline. Below eac h F1: (P / R) = entity pr ecision / recall. Best W E R ( ↓ ), E - W E R ( ↓ ), and F1 ( ↑ ) per dataset are highlighted. Earnings-21 A TCO2 Eka-Medical Common V oice ContextASR-Bench LLM System W E R E - W E R F1 W ER E- W E R F1 W E R E - W ER F1 W E R E - W E R F1 WE R E- W E R F1 – Baseline 13.59 23.81 (–) 80.02 (93.25 / 70.07) 48.63 51.50 (–) 54.76 (70.77 / 44.66) 17.23 19.63 (–) 86.56 (96.76 / 78.31) 15.02 25.57 (–) 73.40 (96.39 / 59.26) 9.40 4.82 (–) 94.89 (95.26 / 94.51) GPT -4o 1-Best 13.51 15.90 (33.2) 84.54 (88.74 / 80.71) 47.18 46.68 (9.4) 60.79 (73.41 / 51.88) 14.57 15.62 (20.4) 89.29 (95.45 / 83.88) 14.82 15.05 (41.2) 81.06 (82.63 / 79.57) 9.42 4.21 (12.7) 94.82 (94.49 / 95.14) Entity-A ware Select 14.34 15.59 ( 34.5 ) 83.83 (86.17 / 81.62) 65.53 46.82 (9.1) 56.32 (56.92 / 55.74) 19.31 16.22 (17.4) 88.85 (94.50 / 83.84) 18.72 15.35 (40.0) 79.98 (80.43 / 79.53) 10.54 4.36 (9.6) 94.33 (93.78 / 94.89) RO VER Ensemble 13.88 15.90 (33.2) 83.89 (87.57 / 80.50) 64.43 47.39 (8.0) 55.81 (57.46 / 54.25) 19.39 16.24 (17.3) 88.78 (94.77 / 83.50) 18.17 15.69 (38.6) 80.09 (81.66 / 78.58) 9.77 3.82 ( 20.8 ) 94.81 (94.08 / 95.54) LLM-Select 13.55 15.85 (33.4) 85.60 (91.15 / 80.69) 44.51 44.06 ( 14.5 ) 62.11 (75.37 / 52.82) 13.93 15.09 ( 23.1 ) 90.21 (96.73 / 84.52) 14.45 13.88 ( 45.7 ) 84.13 (87.74 / 80.79) 9.30 3.97 (17.8) 95.17 (94.95 / 95.40) GPT -4o-mini LLM-Select 14.07 20.93 (12.1) 82.19 (91.90 / 74.33) 50.73 50.35 (2.2) 54.49 (67.69 / 45.60) 17.04 18.28 (6.9) 87.64 (96.31 / 80.41) 15.88 21.56 (15.7) 76.96 (91.48 / 66.43) 9.75 4.51 (6.6) 94.65 (94.44 / 94.86) T able 3: Entity-level alignment counts for baseline vs. LLM- Select: Corr ect (C), Substitution (S), Deletion (D), Insertion (I). Dataset System C S D I Earnings-21 Baseline 4,994 1,248 293 15 LLM-Select 5,511 781 243 12 ∆ +517 –467 –50 –3 A TCO2 Baseline 2,433 1,694 644 119 LLM-Select 2,742 1,470 559 73 ∆ +309 –224 –85 –46 Eka-Medical Baseline 35,258 6,324 867 1,140 LLM-Select 36,989 4,627 833 946 ∆ +1,731 –1,697 –34 –194 Common V oice Baseline 5,939 1,811 139 67 LLM-Select 6,830 952 107 36 ∆ +891 –859 –32 –31 ContextASR-Bench Baseline 88,056 3,352 973 132 LLM-Select 88,838 2,815 728 122 ∆ +782 –537 –245 –10 AED with biasing on Earnings-21 improv es phrase-level recall from 58.66 to 79.11 (+20.45 pp) and F1 from 71.50 to 79.88 with overall WER change being minimal (14.96 → 15.12). Al- though this is not directly comparable (different ASR model and a decode-time contextualization setting), our black-box post-ASR pipeline attains a similar recall on Earnings-21 (70.07 → 80.69, +10.62 pp) while keeping overall W E R essen- tially unchanged (13.59 → 13.55). On A TCO2, ha ving A TC call- signs, LLM-Select (14.5%) significantly outperforms RO VER Ensemble (8.0%) and Entity-A ware Select (9.1%). A TCO2 is extremely noisy and have more insertion errors with R O VER Ensemble or Entity-A ware Select methods. On Eka-Medical, LLM-Select again leads (23.1% vs. 17.3–17.4% for the oth- ers) and also improv es o verall W E R by 3.3 pp. Common V oice shows the largest gains (38.6–45.7% R WERR), which is dri ven by a high baseline E - W E R (25.57%) and large entity list (3,098 phrases), and correcting NER-deriv ed entity near-misses (e.g., max black institute → max planck institute ). On ContextASR- Bench, the baseline E - W E R is already low (4.82%), but all methods achie ve meaningful reductions. RO VER Ensemble performs best with 20.8% R WERR, and is followed by LLM- Select at 17.8%. LLM-Select also improves ov erall W E R from 9.40% to 9.30%. It achieves the highest F1 (95.17%), and con- firms that corrections are precise ev en in a lo w-error scenario. T able 3 presents the entity-lev el SCLITE alignment counts for the baseline and LLM-Select method across all five datasets. Substitution reduction is the dominant correction mechanism, accounting for 63–93% of the total error reduction. This sho ws that the constrained LLM correction primarily resolves en- tity near -misses (e.g., saitiva → cytiva , left hansa → lufthansa , chr onic holes → chr onicles ). On Eka-Medical, the substitution drop ( ∆ =–1,697) is the largest absolute change. This aligns with its high baseline entity error rate. On Common V oice, the relativ e substitution reduction is the steepest (1,811 → 952, –47%), consistent with the highest R WERR (45.7%) in T able 2. Insertions remain low or decrease in all cases, indicating that the system is effecti v e in prev enting spurious additions. An important practical concern is whether entity correc- tion degrades o verall W E R. T able 2 shows that selection-based strategies, 1-Best and LLM-Select, preserve or improve over - all W E R (Medical: 17.23% → 13.93%, ContextASR-Bench: 9.40% → 9.30%), while changes on Earnings-21 and Common V oice remain within ± 0.6 pp. On the other hand, merge-based fusion can increase overall W E R on noisy domains. This can happen due to an increase in insertions or substitutions in non-entity regions. On A TCO2, RO VER Ensemble reduces E - W E R from 51.50% to 47.39% (R WERR 8.0%) but raises W E R from 48.63% to 64.43% (+15.8 pp) as insertions grow . On ContextASR-Bench, Entity-A ware Select yields a minor E - W E R reduction (4.82% → 4.36%, R WERR 9.6%) but increases W E R by +1.14 pp (9.40% → 10.54%) due to insertions. Such insertion noise can appear in non-entity regions in outputs un- der R O VER Ensemble or Entity-A ware Select. These cases mo- tiv ate the use of selection-based strategies (1-Best, LLM-Select) when preserving ov erall transcript quality is important. 5. Conclusions W e ha v e presented RECO VER, an agentic post-ASR entity cor - rection frame work that combines multi-hypothesis ASR decod- ing with constrained LLM editing and deterministic guardrails. Evaluated across five di verse domains, the framework achie ves 8–46% relative entity-W E R reduction, with entity recall as the primary driver (gains of up to 22 pp), confirming that deletion and substitution of entity phrases are the dominant ASR failure modes. Even a single greedy hypothesis benefits substantially from constrained LLM editing, while multi-hypothesis diver - sity provides further domain-dependent gains: LLM-Select is the most consistent strate gy ov erall, Entity-A ware Select excels on well-defined financial entities, and R O VER Ensemble of fers strong deletion recovery at the cost of some overall W E R degra- dation. The three-tool agentic architecture cleanly separates analysis & fusion, correction, and verification, enabling mod- ular ablation and ensuring that LLM hallucinations are rejected before application. Future work will explore adapti ve per-se gment strategy se- lection based on inter-hypothesis agreement, integration with word-le vel ASR confidence scores, comparison with more LLMs, and extension to multi-agent architectures. 6. References [1] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLeav ey , and I. Sutskev er , “Robust speech recognition via lar ge-scale weak supervision, ” in International confer ence on machine learning . PMLR, 2023, pp. 28 492–28 518. [2] A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations, ” Advances in neural information processing systems , vol. 33, pp. 12 449–12 460, 2020. [3] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar , Y . Zhang, J. Y u, W . Han, S. W ang, Z. Zhang, Y . Wu et al. , “Conformer: Convolution- augmented transformer for speech recognition, ” arXiv preprint arXiv:2005.08100 , 2020. [4] M. Burchi and V . V ielzeuf, “Ef ficient conformer: Progressive downsampling and grouped attention for automatic speech recog- nition, ” in 2021 IEEE Automatic Speech Recognition and Under- standing W orkshop (ASR U) . IEEE, 2021, pp. 8–15. [5] T . N. Sainath, R. P ang, D. Rybach, Y . He, R. Prabha v alkar , W . Li, M. V isontai, Q. Liang, T . Strohman, Y . Wu et al. , “T wo-pass end- to-end speech recognition, ” arXiv preprint , 2019. [6] M. Del Rio, N. Delw orth, R. W esterman, M. Huang, N. Bhandari, J. Palakapilly , Q. McNamara, J. Dong, P . Zelasko, and M. Jett ´ e, “Earnings-21: A practical benchmark for asr in the wild, ” arXiv pr eprint arXiv:2104.11348 , 2021. [7] M. Jain, G. Keren, J. Mahadeokar , G. Zweig, F . Metze, and Y . Saraf, “Contextual rnn-t for open domain asr , ” arXiv preprint arXiv:2006.03411 , 2020. [8] K. Huang, A. Zhang, Z. Y ang, P . Guo, B. Mu, T . Xu, and L. Xie, “Contextualized end-to-end speech recognition with contextual phrase prediction network, ” arXiv preprint , 2023. [9] J. D. Fox and N. Delworth, “Improving contextual recognition of rare words with an alternate spelling prediction model, ” arXiv pr eprint arXiv:2209.01250 , 2022. [10] I. Thorbecke, E. V illatoro-T ello, J. P . Zuluaga, S. Kumar , S. Bur- disso, P . Rangappa, A. Carofilis, S. Madikeri, P . Motlicek, K. Pan- dia et al. , “Unifying global and near-conte xt biasing in a single trie pass, ” in International Conference on T ext, Speech, and Dialogue . Springer , 2025, pp. 170–181. [11] D. Le, M. Jain, G. Keren, S. Kim, Y . Shi, J. Mahadeokar , J. Chan, Y . Shangguan, C. Fuegen, O. Kalinli et al. , “Contextual- ized streaming end-to-end speech recognition with trie-based deep biasing and shallow fusion, ” arXiv preprint , 2021. [12] S. Dutta, S. Jain, A. Maheshwari, S. Pal, G. Ramakrishnan, and P . Jyothi, “Error correction in asr using sequence-to-sequence models, ” arXiv preprint , 2022. [13] R. Ma, M. Qian, M. Gales, and K. Knill, “ Asr error correction us- ing large language models, ” IEEE T ransactions on Audio, Speec h and Language Pr ocessing , 2025. [14] Z. Min and J. W ang, “Exploring the integration of large language models into automatic speech recognition systems: An empirical study , ” in International Conference on Neural Information Pro- cessing . Springer , 2023, pp. 69–84. [15] C.-H. H. Y ang, Y . Gu, Y .-C. Liu, S. Ghosh, I. Bulyko, and A. Stolcke, “Generati ve speech recognition error correction with large language models and task-activating prompting, ” in 2023 IEEE Automatic Speech Recognition and Understanding W ork- shop (ASR U) . IEEE, 2023, pp. 1–8. [16] P . Manakul, A. Liusie, and M. Gales, “Selfcheckgpt: Zero- resource black-box hallucination detection for generati ve large language models, ” in Pr oceedings of the 2023 conference on em- pirical methods in natural language processing , 2023, pp. 9004– 9017. [17] J. Suh, I. Na, and W . Jung, “Improving domain-specific asr with llm-generated conte xtual descriptions, ” arXiv pr eprint arXiv:2407.17874 , 2024. [18] S. Li, C. Chen, C. Y . Kwok, C. Chu, E. S. Chng, and H. Kawai, “In vestigating asr error correction with large language model and multilingual 1-best hypotheses, ” in Pr oc. Interspeech , v ol. 2024, 2024, pp. 1315–1319. [19] H. W ang, J. Chen, M. Laali, J. King, K. Durda, W . M. Campbell, and Y . Liu, “Lev eraging asr n-best in deep entity retriev al, ” 2021. [20] R. Ma, M. J. Gales, K. M. Knill, and M. Qian, “N-best t5: Ro- bust asr error correction using multiple input hypotheses and con- strained decoding space, ” arXiv preprint , 2023. [21] J. G. Fiscus, “ A post-processing system to yield reduced word er- ror rates: Recognizer output voting error reduction (rover), ” in 1997 IEEE W orkshop on Automatic Speech Recognition and Un- derstanding Pr oceedings . IEEE, 1997, pp. 347–354. [22] A. Xu, T . Feng, S. H. Kim, S. Bishop, C. Lord, and S. Narayanan, “Large language models based asr error correction for child con- versations, ” arXiv pr eprint arXiv:2505.16212 , 2025. [23] J. Pu, T .-S. Nguyen, and S. St ¨ uker , “Multi-stage large lan- guage model correction for speech recognition, ” arXiv preprint arXiv:2310.11532 , 2023. [24] F . Azmi and R. T ong, “Llm-enhanced spok en named entity recog- nition leveraging asr n-best hypotheses, ” in 2025 International Confer ence on Asian Languag e Pr ocessing (IALP) . IEEE, 2025, pp. 153–158. [25] S. Y ao, J. Zhao, D. Y u, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in lan- guage models, ” in The ele venth international confer ence on learn- ing r epr esentations , 2022. [26] H. Derouiche, Z. Brahmi, and H. Mazeni, “ Agentic ai frame- works: Architectures, protocols, and design challenges, ” arXiv pr eprint arXiv:2508.10146 , 2025. [27] Y . Chen, X. Y ue, C. Zhang, X. Gao, R. T . T an, and H. Li, “V oicebench: Benchmarking llm-based voice assistants, ” arXiv pr eprint arXiv:2410.17196 , 2024. [28] D. Jain, H. Shukla, G. Rajeev , A. Kulkarni, C. Khatri, and S. Agar- wal, “V oiceagentbench: Are voice assistants ready for agentic tasks?” arXiv preprint , 2025. [29] S. B. Needleman and C. D. W unsch, “ A general method applicable to the search for similarities in the amino acid sequence of two proteins, ” Journal of molecular biology , vol. 48, no. 3, pp. 443– 453, 1970. [30] J. Zuluaga-Gomez, A. Prasad, I. Nigmatulina, S. Sarfjoo, P . Motlicek, M. Kleinert, H. Helmke, O. Ohneiser , and Q. Zhan, “ Atco2 corpus: A large-scale dataset for research on automatic speech recognition and natural language understanding of air traf- fic control communications, ” arXiv pr eprint arXiv:2211.04054 , 2022. [31] J. Zuluag a-Gomez, P . Motlicek, Q. Zhan, K. V esely , and R. Braun, “ Automatic speech recognition benchmark for air-traffic commu- nications, ” in Proc. Inter speech , 2020, pp. 2297–2301. [32] S. Kumar , P . Shivaprakash, A. Manoharan, A. Kurariya, D. Mukherjee, L. Shukla, A. Mukherjee, P . Chand, and P . Murthy , “ Asr under the stethoscope: Evaluating biases in clin- ical speech recognition across indian languages, ” arXiv preprint arXiv:2512.10967 , 2025. [33] R. Ardila, M. Branber, K. Davis, M. Henretty , M. K ohler , J. Meyer, R. Morais, L. Saunders, F . M. T yers, and G. W eber, “Common v oice: A massively-multilingual speech corpus, ” in Pr oceedings of the T welfth Language Resources and Evaluation Confer ence , 2020, pp. 4218–4222. [34] M. W ang et al. , “Contextasr-bench: A massive contextual speech recognition benchmark, ” arXiv preprint , 2025. [35] A. Hurst, A. Lerer , A. P . Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow , A. W elihinda, A. Hayes, A. Radford et al. , “Gpt-4o system card, ” arXiv preprint , 2024.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment