다중 가설 기반 엔터티 교정 프레임워크
RECOVER는 음성 인식 결과에서 드물거나 도메인 특화된 엔터티가 누락·오인식되는 문제를 해결하기 위해, 동일 ASR 모델에서 온 다중 가설을 증거로 활용하고, LLM을 도구로 사용해 엔터티만을 제한적으로 교정하는 에이전트 기반 시스템이다. 네 가지 가설 융합 전략을 비교한 결과, LLM‑Select 방식이 전체 WER를 유지하면서 엔터티 오류를 8 %‑46 % 감소시키고, 재현율을 최대 22 포인트 끌어올렸다.
저자: Abhishek Kumar, Aashraya Sachdeva
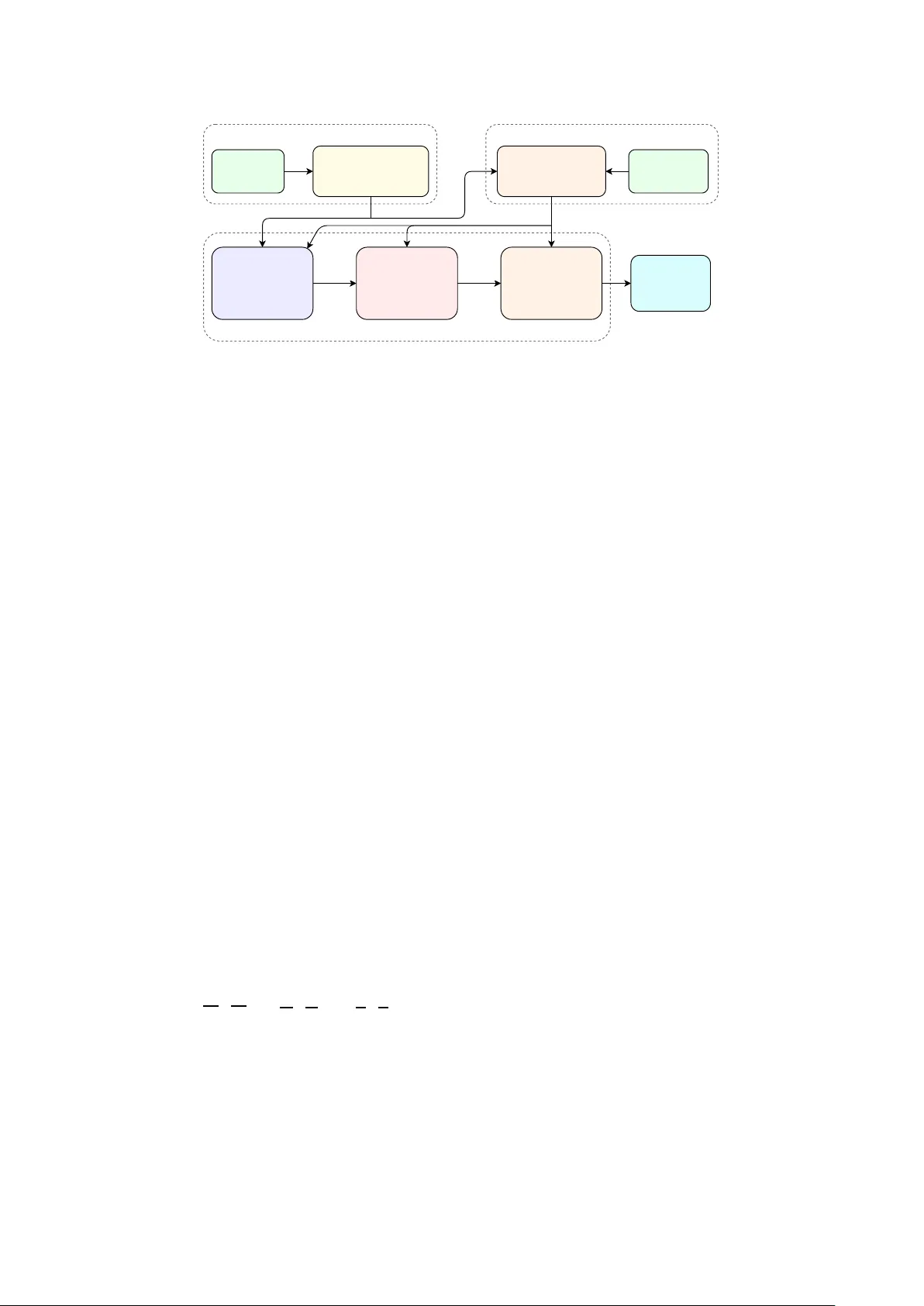
본 논문은 자동 음성 인식(ASR) 시스템이 금융, 의료, 항공통신 등 전문 분야에서 자주 등장하는 드물거나 도메인 특화된 엔터티를 제대로 인식하지 못하는 문제를 해결하고자 한다. 기존 연구는 디코딩 단계에서 컨텍스트 바이어싱이나 대체 철자 모델을 적용했지만, 이는 ASR 내부 구조에 접근할 수 있는 경우에만 유효하고, 실제 서비스에서는 블랙박스 형태의 상용 ASR을 사용하기 때문에 적용이 어려웠다. 또한, 사후 교정 방식은 1‑Best 가설에만 의존할 경우 엔터티가 완전히 사라진 상황에서 복구가 불가능하다는 한계가 있다.
이를 극복하기 위해 저자들은 ‘RECOVER’라는 에이전트 기반 교정 프레임워크를 제안한다. 핵심 아이디어는 동일 ASR 모델에서 온 다중 가설을 증거로 활용하고, LLM을 도구(tool) 형태로 사용해 엔터티 교정만을 제한적으로 수행하도록 하는 것이다. 프레임워크는 크게 세 단계로 구성된다.
1️⃣ **다중 가설 생성**: Whisper‑small 모델을 온도 샘플링(0.0 ~ 0.8)으로 다섯 개의 서로 다른 전사 가설을 만든다. 온도 조절을 통해 모델이 다양한 토큰 시퀀스를 출력하도록 유도함으로써, 한 가설에서 누락된 엔터티가 다른 가설에 존재할 가능성을 높인다.
2️⃣ **동적 엔터티 후보 추출**: 전체 엔터티 리스트(최대 6 198개)와 각 가설을 비교해 정확 일치, 퍼지 유사도(레벤슈타인 기반), 음성학적 프리픽스(음성 키) 세 가지 점수를 가중합한다. 가중치는 각각 1.0, 1.2, 0.6으로 설정했으며, 이를 통해 상위 K (=200) 후보만을 선별한다. 이렇게 하면 LLM 프롬프트에 불필요한 후보가 포함되지 않아 효율성과 정확도가 동시에 향상된다.
3️⃣ **에이전트 오케스트레이션**: Agno 프레임워크 위에 구축된 에이전트가 세 개의 도구를 순차적으로 호출한다.
- **Tool 1 – Fuse Hypotheses**: 네 가지 가설 융합 전략을 제공한다. 1‑Best는 단일 가설을 그대로 사용하고, Entity‑Aware Select는 엔터티 후보와의 일치 횟수가 가장 많은 가설을 선택한다. ROVER Ensemble은 피벗 가설을 기준으로 전역 정렬 후 다수결 토큰 병합을 수행한다. LLM‑Select는 모든 가설과 후보 리스트를 LLM에 전달해 최적 가설과 동시에 교정 제안을 받는다.
- **Tool 2 – Propose Corrections**: LLM(GPT‑4o 또는 GPT‑4o‑mini)에게 “엔터티 교정만 허용, 교정 후보는 반드시 엔터티 리스트에 존재”라는 엄격한 프롬프트를 제공한다. LLM은 JSON 형태로 교정 위치, 원본·대체 문자열, 엔터티 유형, 신뢰도, 교정 이유를 반환한다.
- **Tool 3 – Verify & Apply**: LLM이 제안한 교정을 다중 검증한다. (1) 교체 문자열이 엔터티 리스트에 존재하는지, (2) 대소문자만 변한 경우는 무시, (3) 오프셋 오류 시 자동 재조정, (4) 원본과 교체 문자열의 레벤슈타인 유사도가 사전 정의된 임계값 이상인지, (5) 교정이 겹치지 않는지 확인 후 왼쪽‑우측 순서대로 적용한다.
**실험 설정**: 다섯 개 데이터셋—Earnings‑21(재무), ATCO2(항공통신), Eka‑Medical(의료), Common Voice(일반 음성), ContextASR‑Bench(대화)—에서 Whisper‑small(temperature = 0) 기반 1‑Best를 베이스라인으로 삼았다. 전체 WER와 엔터티 전용 WER(E‑WER), 엔터티 정밀도·재현율·F1을 평가 지표로 사용했다.
**주요 결과**:
- 모든 도메인에서 LLM 기반 교정(특히 1‑Best 전략)만으로도 E‑WER를 평균 20 % ~ 45 % 감소시켰다.
- 다중 가설을 활용한 전략 중 LLM‑Select가 전체 WER를 거의 유지하면서도 E‑WER를 가장 크게 낮추었으며, 엔터티 재현율을 8 ~ 22 포인트 향상시켰다.
- ROVER Ensemble은 일부 도메인(ATCO2)에서 전체 WER가 상승했지만, 엔터티 회복 측면에서는 경쟁력 있었다.
- GPT‑4o‑mini를 사용한 LLM‑Select는 성능이 다소 낮았지만, 여전히 2 % ~ 16 % 수준의 E‑WER 감소를 보여 LLM 규모가 교정 품질에 영향을 미침을 확인했다.
**분석 및 시사점**:
- **다중 가설 증거**는 엔터티가 한 가설에서 누락되더라도 다른 가설에서 복구할 수 있는 중요한 정보원이다. 온도 샘플링을 통한 다양성 확보가 핵심이다.
- **동적 후보 필터링**은 LLM 프롬프트 길이 제한을 극복하고, 불필요한 후보가 교정에 방해되지 않게 한다.
- **제한된 LLM 편집**은 일반 LLM이 야기할 수 있는 hallucination을 효과적으로 억제한다. 엔터티 리스트와 레벤슈타인 유사도 검증을 통해 무분별한 교정을 차단한다.
- **에이전트‑도구 구조**는 각 단계의 책임을 명확히 분리함으로써 시스템 확장성과 디버깅을 용이하게 만든다. 향후 다른 도메인이나 다른 LLM으로 교체해도 구조적 변경 없이 적용 가능하다.
**한계와 미래 연구**: 현재는 Whisper‑small과 온도 샘플링에 의존하고 있어, 다른 ASR 모델이나 더 큰 N에 대한 일반화 검증이 필요하다. 또한 후보 추출 단계에서 가중치를 고정했는데, 도메인별 최적화나 학습 기반 가중치 조정이 성능을 더욱 끌어올릴 수 있다. 마지막으로, 현재는 엔터티 교정에만 초점을 맞추었지만, 문법·구문 교정까지 확장한다면 전체 WER 감소에도 기여할 수 있을 것이다.
**결론**: RECOVER는 다중 가설을 증거로 활용하고, LLM을 도구화해 엔터티 교정을 엄격히 제한함으로써 블랙박스 ASR 시스템에서도 엔터티 오류를 효과적으로 복구한다. 네 가지 융합 전략을 비교한 결과, LLM‑Select가 가장 일관된 성능을 보였으며, 전체 시스템은 다양한 도메인에서 8 %‑46 %의 E‑WER 감소와 최대 22 포인트의 재현율 향상을 달성했다. 이는 실무에서 도메인 특화 엔터티 인식 정확도를 크게 높일 수 있는 실용적인 솔루션으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기