Offline Exploration-Aware Fine-Tuning for Long-Chain Mathematical Reasoning
Through encouraging self-exploration, reinforcement learning from verifiable rewards (RLVR) has significantly advanced the mathematical reasoning capabilities of large language models. As the starting point for RLVR, the capacity of supervised fine-t…
Authors: Yongyu Mu, Jiali Zeng, F
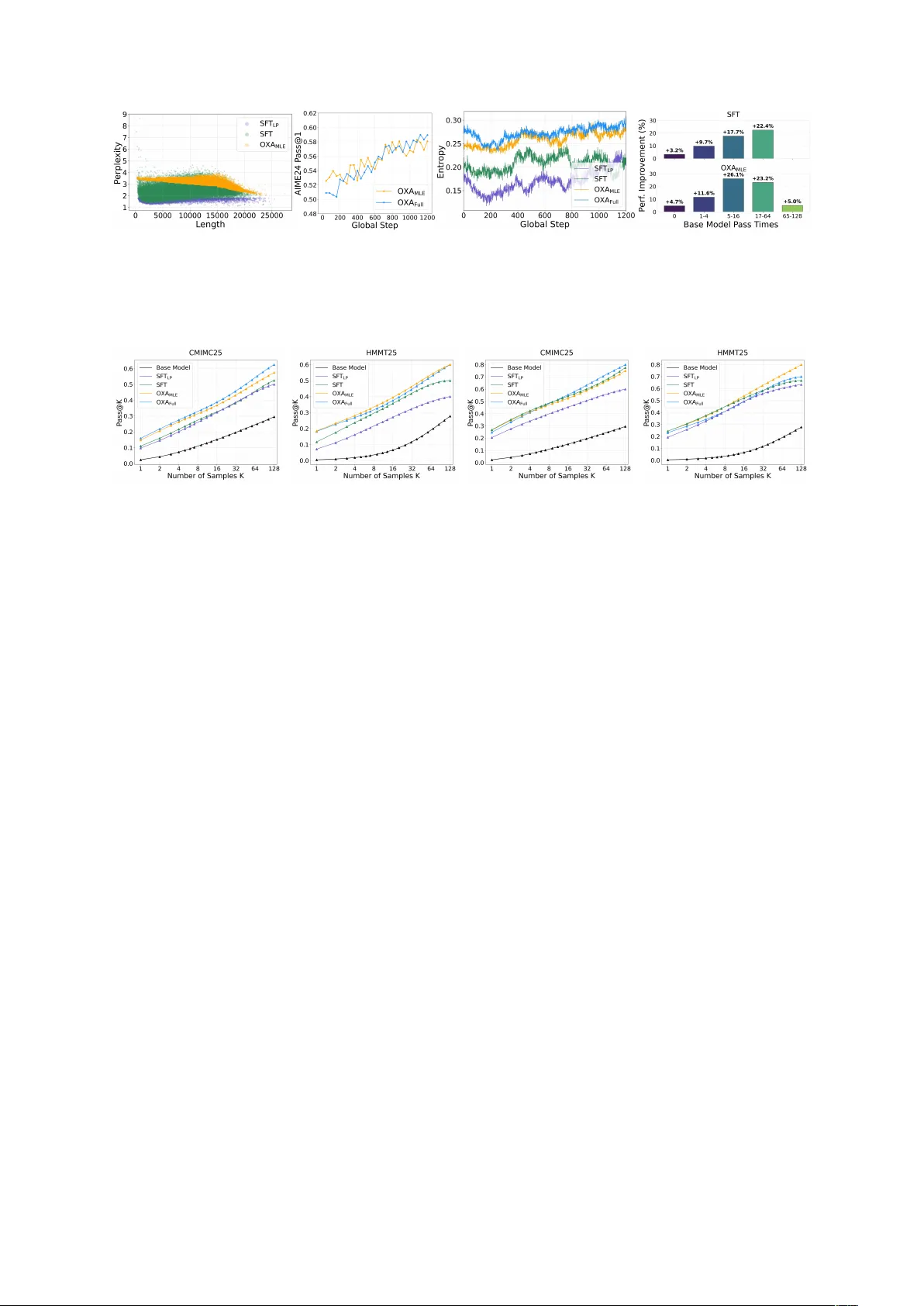
Offline Exploration-A war e Fine-T uning f or Long-Chain Mathematical Reasoning Y ongyu Mu 1 * , Jiali Zeng 2 , F andong Meng 2 and Jingbo Zhu 1 , T ong Xiao 1 † 1 NLP Lab, School of Computer Science and Engineering, Northeastern Uni versity , Shenyang, China 2 Pattern Recognition Center , W eChat AI, T encent Inc, China lixiaoyumu9@gmail.com {lemonzeng,fandongmeng}@tencent.com {xiaotong,zhujingbo}@mail.neu.edu.cn Abstract Through encouraging self-exploration, rein- forcement learning from verifiable rew ards (RL VR) has significantly adv anced the math- ematical reasoning capabilities of large lan- guage models. As the starting point for RL VR, the capacity of supervised fine-tuning (SFT) to memorize ne w chain-of-thought trajecto- ries provides a crucial initialization that shapes the subsequent exploration landscape. How- ev er , e xisting research primarily focuses on facilitating exploration during RL VR train- ing, leaving exploration-a ware SFT under- explored. T o bridge this gap, we propose O ffline e X ploration- A w are (O XA) fine-tuning. Specifically , O XA optimizes tw o objectives: promoting lo w-confidence verified teacher- distillation data to internalize previously un- captured reasoning patterns, and suppressing high-confidence incorrect self-distillation data to redistrib ute probability mass of incorrect pat- terns tow ard potentially correct candidates. Ex- perimental results across 6 benchmarks show that O XA consistently improves mathematical reasoning performance, especially achie ving an av erage gain of +6 Pass@1 and +5 Pass@ k points compared to conv entional SFT on the Qwen2.5-1.5B-Math . Crucially , O XA ele v ates initial policy entropy , and performance gains persist throughout extensi ve RL VR training, demonstrating the long-term value of O XA. 1 Introduction The mathematical reasoning capabilities of large language models (LLMs) ha v e witnessed a break- through by scaling up inference computation for long-chain reasoning. Building upon pre-trained LLMs, a common strategy to achiev e state-of- the-art performance in volv es a two-stage training pipeline ( DeepSeek-AI , 2025 ; Y ang et al. , 2025a ): (1) Supervised fine-tuning (SFT), which distills * W ork was done when Y ongyu Mu was interning at Pattern Recognition Center , W eChat AI, T encent Inc. † Corresponding author . kno wledge from teacher models to acti vate initial reasoning capabilities and learn long-chain output formats; and (2) Reinforcement learning from veri- fiable rew ards (RL VR), which further boosts perfor - mance by encouraging self-e xploration and learn- ing from model-generated samples. In reinforcement learning, maintaining suffi- cient policy entropy to pre vent premature con ver- gence and encourage exploration is fundamental ( W illiams and Peng , 1991 ; Williams , 1992 ; Eysen- bach and Levine , 2021 ). In the context of RL VR, thorough exploration is particularly critical, as it allo ws the model to discov er diverse reasoning paths and unlock greater potential. T o this end, existing research has attempted to manipulate pol- icy entropy through objecti ve-lev el regularizations ( Zhang et al. , 2025b ; Cheng et al. , 2025 ; Jiang et al. , 2025 ), fine-grained update and sampling controls ( Liao et al. , 2025 ; Cui et al . , 2025 ), and semantic- le vel abstractions ( Cao et al. , 2025 ). Ho we ver , these ef forts primarily focus on f acilitating explo- ration during the RL VR process, ov erlooking the role of the SFT stage. As the starting point for RL VR, SFT provides a crucial initialization that shapes the subsequent exploration landscape. Moreov er , recent studies re veal that while RL VR excels at optimizing known paths, it struggles to ex- pand the model’ s fundamental reasoning space. In contrast, SFT is highly ef fecti v e at enabling models to internalize ne w reasoning pathw ays ( Y ue et al. , 2025 ; Kim et al. , 2025 ; Chu et al. , 2025 ). This suggests that by enriching the model’ s exploration space with div erse reasoning pathways, intuiti v ely , SFT can facilitate e xploration in the RL VR process. Despite this potential, current long-chain reason- ing SFT research focuses exclusiv ely on activ ating reasoning capabilities ( Liu et al. , 2025 ; Guha et al. , 2025 ) or data pruning for efficienc y ( Muennighof f et al. , 2025 ; Y ang et al. , 2025b ). This work ad- dresses the question: How can we tr ain explor ation- engaged models for RL VR via fine-tuning? 1 W e en vision that an ideal initialization for RL VR should exhibit two key characteristics: superior initial r easoning accur acy and high initial pol- icy entr opy . T o achie ve this, we propose O ffline e X ploration- A ware (O XA) fine-tuning, an algo- rithm designed to train on strate gically selected of fline reasoning trajectories. T o counteract the entropy collapse illustrated in Figure 1 , O XA rein- forces lo w-probability trajectories while weak ening high-probability ones to preserve the smoothness of the predictive distrib ution. Specifically , O XA op- timizes two objecti v es: pr omoting low-confidence verified teacher -distillation data and suppr ess- ing high-confidence incorr ect self-distillation data . The former internalizes previously uncaptured rea- soning trajectories, while the latter redistributes probability mass of incorrect paths toward poten- tially correct candidates. Since these objectives are decoupled, we introduce tw o v ariants: a base ver - sion of O XA utilizing only the first objectiv e and the full OXA frame work. While the base version accounts for the primary performance gains, the full framework syner gizes superior performance with robust e xploration potential. W e ev aluate O XA by applying the SFT -then- RL VR paradigm to 4 LLMs ranging from 1.5B to 7B parameters. Experimental results across 6 typical mathematical benchmarks sho w that O XA consistently enhances reasoning capabilities. No- tably , it achiev es an a v erage improvement of +6 Pass@1 and +5 Pass@ k points compared to con- ventional SFT on the 1.5B LLM. Comprehensi ve analysis further demonstrates that O XA not only improv es performance on challenging problems but also significantly expands the reasoning out- put space, achie ving high initial policy entropy . Crucially , these gains persist throughout exten- si ve RL VR training and are orthogonal to exist- ing RL VR-enhancement methods, yielding consis- tent additiv e improvements. § GitHub: https: //github.com/takagi97/OXA- Fine- tuning 2 Related W ork T raining long-chain reasoning LLMs. There are primarily three trajectories for training long- chain reasoning LLMs. Initial ef forts face the scarcity of supervised data with annotated reason- ing steps. They le verage RL VR to directly train pre-trained LLMs to explore self-disco vered rea- soning paths to ward correct answers ( DeepSeek-AI , 2025 ; T eam et al. , 2025 ). This base-model training process is termed Zero-RL. Ho wev er , these models often suffer from poor readability and lower per- formance ceilings ( DeepSeek-AI , 2025 ). A second paradigm in v olves two stages: first distilling kno wl- edge from teacher models (e.g., Zero-RL models) into pre-trained LLMs via SFT for a cold start, then follo wed by RL VR. Other works extend this by integrating supervised signals from teachers into RL VR to learn superior reasoning trajectories ( Y an et al. , 2025 ; Xu et al. , 2025 ; Lv et al. , 2025 ; Zhang et al. , 2025a ). In this work, we follo w the SFT - then-RL VR paradigm, widely validated by vari- ous open-source LLMs ( DeepSeek-AI , 2025 ; Y ang et al. , 2025a ; Xia et al. , 2025 ). Analysis of SFT and RL VR. Although both SFT and RL VR can train long-chain reasoning models, recent works re veal that their learning mechanisms dif fer . RL VR e xhibits a generalization pattern: con- strained by self-generated training samples, it im- prov es accurac y by increasing the probability of correct answers, but fails to expand capability by sampling correct answers outside the model’ s out- put space ( Y ue et al. , 2025 ; Mu et al. , 2025 ). In con- trast, SFT tends to memorize training data. By in- troducing ne w kno wledge during distillation, SFT can enhance the model’ s capabilities on dif ficult problems ( Kim et al. , 2025 ; Chu et al. , 2025 ). Policy entropy in RL VR. Rooted in informa- tion theory , entropy provides a principled mecha- nism to manage the exploitation-e xploration trade- of f. Higher policy entrop y indicates that the model is more likely to explore diverse reasoning paths, thereby enhancing performance. T o maintain high entropy during early training, v arious efforts ha ve been made, including restricting the update of high- cov ariance tokens ( Cui et al. , 2025 ), adjusting entropy regularization coefficients ( Zhang et al. , 2025b ), tuning rollout temperature ( Liao et al. , 2025 ), adding extra entropy terms to advantage calculations ( Cheng et al. , 2025 ), lev eraging cumu- lati ve entropy regulation ( Jiang et al. , 2025 ), and ele v ating entropy control from the token to the se- mantic le vel ( Cao et al. , 2025 ). Ho wever , pre vious works predominantly manipulate RL VR training dynamics but o v erlook SFT , leaving an open ques- tion: How can we encourage models to explor e mor e r easoning trajectories via SFT? Long-chain reasoning SFT . Recent SFT re- search tar geting long-chain reasoning generally fol- lo ws two directions. The first focuses on eliciting 2 Entropy collapse Counteracting entropy collapse Probability Mass Output Space Probability Mass Output Space Probability Mass Output Space Probability Mass Output Space Action pr obability High Reinforced W eakened Low During training Action pr obability High Reinforced W eakened Low During training Figure 1: Conceptual illustration of entropy collapse versus counteracting entrop y collapse. reasoning capabilities in pretrained LLMs. Some studies expand reasoning paths by multi-sample distillation from teacher models ( Liu et al. , 2025 ; Guha et al. , 2025 ), while others employ curriculum learning or decompose complex structures ( W en et al. , 2025 ; An et al. , 2025 ; Luo et al. , 2025 ). The second direction focuses on data pruning to en- hance training efficiency ( Muennighoff et al. , 2025 ; Y ang et al. , 2025b ). While our method also in volv es data selection, it is distinct in its objecti ve: rather than optimizing for training ef ficiency , O XA aims to cultiv ate exploration-engaged models that pro- vide a superior initialization for subsequent RL VR. 3 Methodology In the SFT -then-RL VR training paradigm, SFT models serve as the critical foundation for subse- quent reinforcement learning. W e hypothesize that an ideal SFT model should e xhibit superior initial reasoning capabilities while simultaneously foster- ing e xploration-engaged beha vior to unlock greater RL potential. Specifically , we aim to achie ve two objecti ves: • Achieving higher initial perf ormance: Pro- viding a robust backbone that maintains or am- plifies the performance superiority established during SFT throughout the RL VR process. • Maintaining higher policy entropy: Broad- ening the reasoning output space and facilitat- ing sampling di verse reasoning trajectories. T o this end, we propose O f fline e X ploration- A w are (O XA) fine-tuning, an algorithm designed to train on strategically selected offline reasoning trajec- tories. Specifically , inspired by counteracting en- tropy collapse, O XA optimizes the model by pro- moting low-confidence correct answers and sup- pressing high-confidence errors. The former in- creases the likelihood of generating pre viously un- captured reasoning trajectories, particularly those near the distribution boundaries, while the latter re- distributes probability mass of incorrect reasoning paths toward other potentially correct candidates. Ultimately , O XA yields a model that combines enhanced performance with high initial policy en- tropy . As a purely SFT -based approach, O XA of fers two distinct adv antages: First, it enhances the ex- ploration capability without changing the RL VR frame work, thereby preserving training stability while delivering consistent performance gains. Sec- ond, empirical results demonstrate that O XA is orthogonal to RL VR-enhancement methods, pro- viding additi ve impro vements. 3.1 Dissecting Entropy Dynamics Policy entrop y , quantifying the smoothness of the predicti ve distrib ution of model π θ , is defined as: H ( π θ ) = − |V | X i =1 p i log p i , (1) where p i represents the probability of the i -th token in the vocabulary V of size |V | . In the context of training long-chain mathematical reasoning LLMs, entropy serves as a direct proxy for the diversity of reasoning paths the model can sample. A higher policy entropy indicates a more uniform distribu- tion of probability mass, enabling the model to ex- plore more candidate outputs. Con versely , a lo wer entropy characterizes a sharp distribution where the 3 model’ s confidence is excessi vely concentrated on a limited set of tok ens, thereby restricting its e xplo- ration space and limiting the variety of generated reasoning trajectories. Entropy collapse. When a model is trained to con vergence, the entrop y generally decreases. As illustrated in the upper one of Figure 1 , this phenomenon stems from the model being highly aligned with the empirical distribution of the train- ing data, including reinforcing the distribution peaks while suppressing the troughs. Counteracting entropy collapse. T o mitigate en- tropy collapse, a straightforward strategy is to in- versely influence the distribution dynamics: pro- moting the probability mass at the distribution troughs while suppressing ov er-confident peaks, which is depicted in the lo wer one of Figure 1 . 3.2 Offline Exploration-A ware Fine-tuning A higher policy entropy is preferred for exploration- engaged models. Ho we ver , directly reinforcing the probability at the trough and weakening that at the peak can se verely destabilize the model. O XA provides a solution that selecti v ely promotes lo w- confidence truths and suppresses high-confidence errors. All reasoning instruction data for this pro- cess is curated of fline. 3.2.1 Promote Lo w-Confidence T ruths This objectiv e aims to reinforce the model’ s proba- bility mass in low-confidence regions by training on verified teacher -distilled data via the maximum likelihood estimation (MLE) criterion. Through this process, the model internalizes pre viously un- captured reasoning trajectories, thereby effecti vely expanding its reasoning space. Data. Based on the teacher -distilled dataset, we first employ the rule-based verifier used during RL VR training to filter the data, retaining only correct reasoning paths. W e then use perplexity (PPL) to quantify the model’ s confidence in a spe- cific reasoning route. For a reasoning trajectory S = { s 1 , s 2 , . . . , s K } , the PPL is defined as: PPL ( S ) = exp − 1 K K X t =1 log p ( s t | s ..., then summarize it and present the final answer within \boxed — for e xample: reasoning process here \boxedanswer here. ” For RL VR train- ing, we use DeepSeek-Distill-Qwen2.5-7B to perform 8-sample generation per query . W e se- lect 10 , 000 trajectories with pass rates between 0 . 2 and 0 . 8 , effecti vely filtering out tasks that are either tri vial or excessi vely difficult. T raining details. F or SFT , the Qwen2.5-1.5B- Math model is trained with a cutof f len of 32 , 768 , a learning rate of 2 . 5 × 10 − 4 , and 6 . 0 epochs. W e use a warmup ratio of 0 . 03 , weight decay of 0 . 1 , and Adam optimizer with β 1 = 0 . 9 , β 2 = 0 . 95 , using a global batch size of 128 . For other mod- els, we adjust only the learning rates: 5 . 0 × 10 − 5 for Qwen2.5-7B-Math, and 2 . 0 × 10 − 4 for both LLaMA3.2-3B and Qwen3-1.7B . Reinforce- ment learning parameters are kept uniform: train batch size is 64 , max response length is 16 , 384 , actor learning rate is 2 . 0 × 10 − 6 , KL coef ficient is 0 . 001 , with 8 rollouts per query at a tempera- ture of 0 . 85 . In our data scaling e xperiments with Qwen2.5-7B-Math , we increase the global batch size to 384 and the learning rate to 1 . 5 × 10 − 4 to ensure the total number of optimization updates remains consistent with our baseline experiments. W e use LLaMA-Factory ( Zheng et al. , 2024b ) and Verl ( Sheng et al. , 2025 ) for fine-tuning and rein- forcement learning, respecti vely . A.4 Compute Overhead Discussion Compared to con ventional SFT , the additional com- putational ov erhead of O XA primarily stems from two components: PPL estimation for data selection and model decoding during self-distillation. Efficiency of PPL estimation. While O XA intro- duces a PPL calculation step, this process is highly ef ficient in practice. Since PPL estimation is per- formed through a single forward pass, the negati ve log-likelihoods of all tokens in a sequence are com- puted simultaneously in parallel. This allows the selection process to scale efficiently with sequence 12 (a) (b) (c) (d) Figure 6: Impact of data perplexity ranges on reasoning performance. (a)-(b) Performance on AIME24 of 1.5B models fine-tuned on various PPL intervals. (c)-(d) Corresponding results for 7B models across different PPL ranges. length, av oiding the sequential bottlenecks typical of autoregressi ve generation. Self-distillation and mitigation. The primary source of extra compute relati v e to vanilla SFT is the generation of high-confidence error trajec- tories via self-distillation. Howe v er , the cost of this phase is significantly mitigated by modern inference-time optimizations. In our pipeline, we le verage high-throughput inference frameworks such as vLLM ( Kw on et al. , 2023 ) and SGLang ( Zheng et al. , 2024a ), coupled with model quanti- zation techniques. These adv ancements ensure that the generation of self-distilled data is both rapid and cost-effecti ve, making O XA a practical choice for large-scale training. A.5 Comparison O XA Fine-T uning with Direct Pr efer ence Optimization While both O XA and direct preference optimiza- tion (DPO) ( Rafailo v et al. , 2023 ) promote desir- able samples and suppress undesirable ones, they dif fer fundamentally in two ke y aspects: Data structur e and coupling . DPO is inherently a pairwise framework, requiring each training in- stance to consist of a triplet: a single query as- sociated with both a “chosen” (desirable) and a “rejected” (undesirable) response. This constraint limits the utilization of unpaired data. In contrast, the data requirements for O XA are entirely decou- pled. O XA permits queries to be associated with only a desirable or only an undesirable response, significantly lo wering the barrier for data collec- tion. Furthermore, this decoupling allo ws for flexi- ble control over the mixing ratio of desirable and undesirable samples within each training batch, a hyperparameter that can be tuned to balance explo- ration and exploitation. Optimization mechanism. The training dynam- ics of the tw o methods are distinct. DPO employs a contrasti ve loss, which primarily focuses on maxi- mizing the relati v e log-probability gap between the chosen and rejected responses. Con versely , O XA treats promotion and suppression as tw o indepen- dent objecti ves: the NLL loss focuses on internal- izing correct reasoning patterns, while the unlike- lihood loss directly minimizes the probability of incorrect paths. There is no intrinsic mathematical linkage between these two objecti ves in O XA, al- lo wing the model to learn from each type of signal independently without the need for a direct com- parison between two specific trajectories for e very query . 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment