오프라인 탐색 인식 파인튜닝으로 수학적 추론 강화
본 논문은 SFT 단계에서 탐색성을 고양시키는 오프라인 탐색‑인식(OXA) 파인튜닝을 제안한다. 낮은 신뢰도의 정답 데이터를 강화하고, 높은 신뢰도의 오류 데이터를 억제함으로써 초기 정책 엔트로피를 높이고, 이후 RLVR 학습에서 지속적인 성능 향상을 달성한다. Qwen2.5‑1.5B‑Math 모델에 적용한 결과 Pass@1이 평균 +6점, Pass@k가 +5점 상승하였다.
저자: Yongyu Mu, Jiali Zeng, F
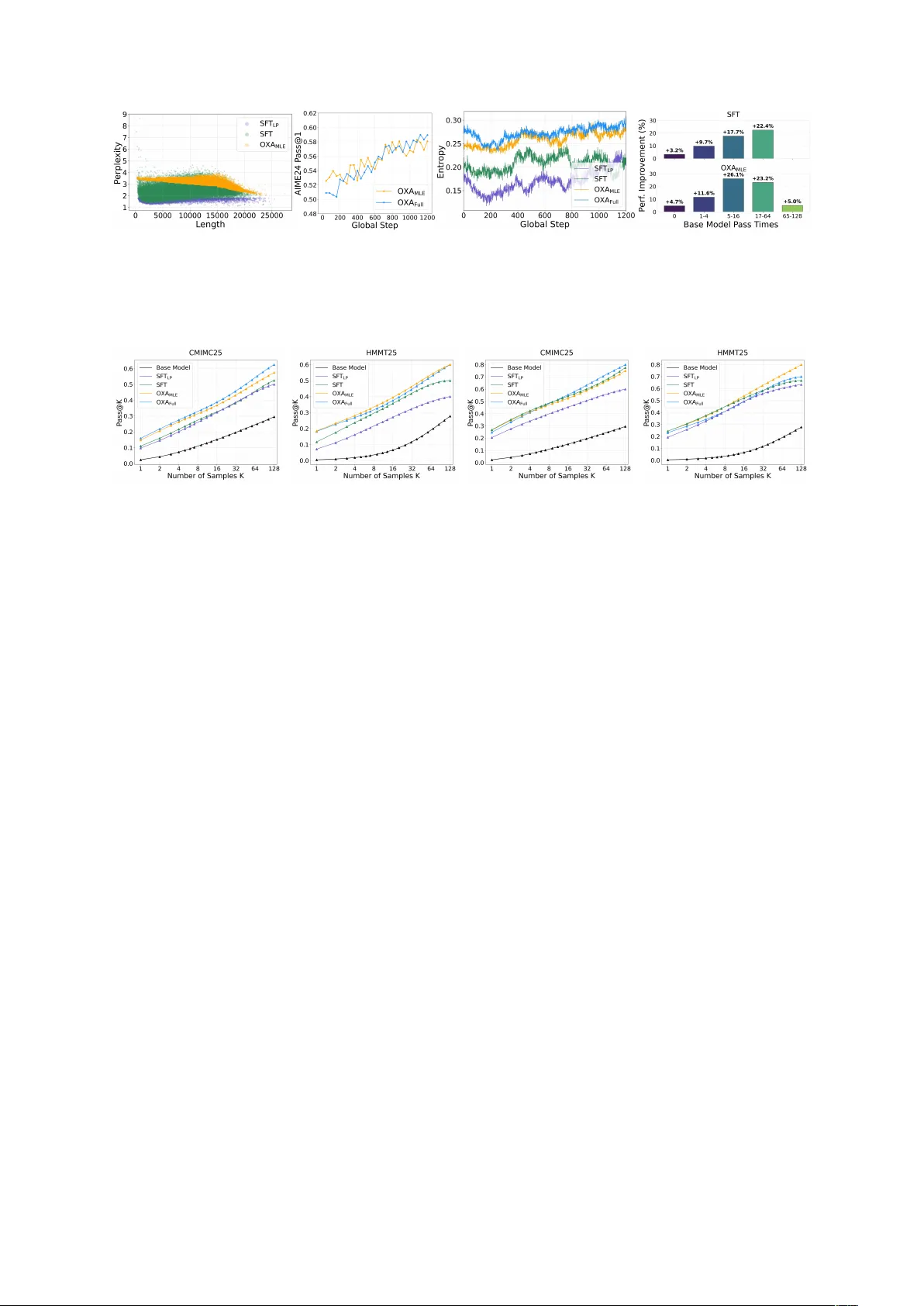
본 논문은 대규모 언어 모델(LLM)의 장기 수학적 추론 능력을 향상시키기 위해, 기존의 두 단계 학습 파이프라인인 Supervised Fine‑Tuning(SFT)과 Reinforcement Learning from Verifiable Rewards(RLVR)를 재구성한다. 기존 연구는 주로 RLVR 단계에서 정책 엔트로피를 유지하거나 증가시키는 정규화·샘플링 기법에 집중했으며, SFT 단계는 교사 모델의 지식을 단순히 전이하는 데에만 초점을 맞추었다. 그러나 저자들은 SFT가 모델의 초기 확률 분포, 즉 정책 엔트로피를 결정짓는 핵심 단계임을 강조한다. 엔트로피가 낮아지면 모델은 고확률 토큰에 과도하게 집중해 탐색 공간이 급격히 축소되고, 이는 RLVR이 새로운 추론 경로를 발견하는 능력을 저해한다.
이를 해결하기 위해 제안된 Offline eXploration‑Aware(OXA) 파인튜닝은 두 가지 상반된 목표를 동시에 최적화한다. 첫 번째 목표는 낮은 신뢰도(높은 Perplexity)를 가진 정답 경로를 MLE 손실로 강화하는 것이다. 교사 모델이 검증한 올바른 체인‑오브‑생각을 저확률 영역에서 끌어올려 모델이 이전에 놓쳤던 추론 패턴을 내부화하도록 한다. 이를 위해 Gaussian‑Guided PPL Sampling 알고리즘을 설계했으며, 데이터셋을 PPL 기준으로 binning하고, 목표 Gaussian 분포(μ, σ)에 따라 샘플을 선택한다. 동일 PPL 구간 내에서는 길이가 긴 복합 추론을 우선순위로 두어, 모델이 다단계 논증을 학습하도록 유도한다.
두 번째 목표는 높은 신뢰도이지만 검증에 실패한 오류 경로를 Unlikelihood 손실로 억제하는 것이다. 사전 학습된 LLM이 생성한 오류 샘플을 PPL 기준으로 선정하고, 토큰‑레벨에서 1‑p(s_t|s_
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기