Are Large Language Models Truly Smarter Than Humans?
Public leaderboards increasingly suggest that large language models (LLMs) surpass human experts on benchmarks spanning academic knowledge, law, and programming. Yet most benchmarks are fully public, their questions widely mirrored across the interne…
Authors: Eshwar Reddy M, Sourav Karmakar
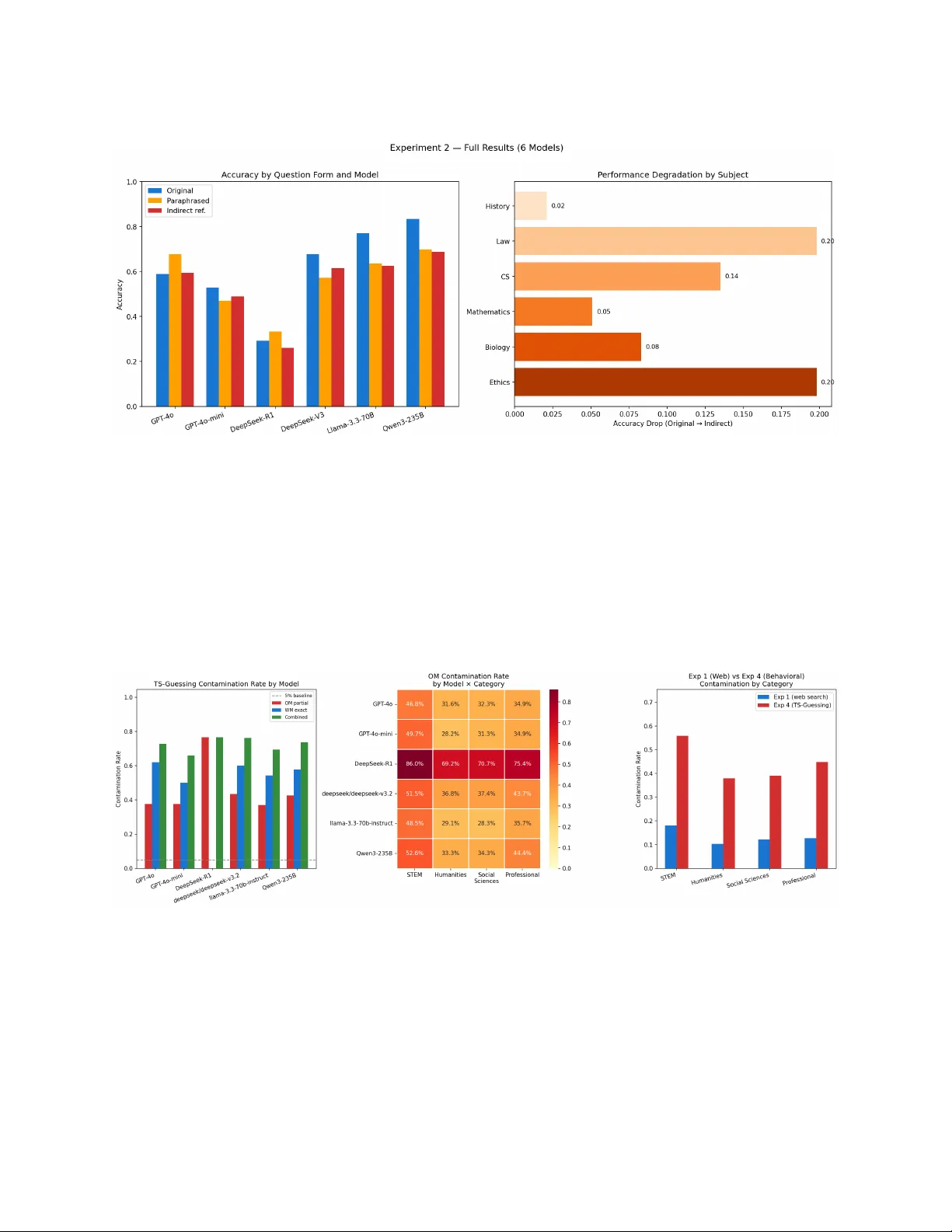
Are Large Language Mo dels T ruly Smarter Than Humans? Benc hmark Con tamination, Surface-P attern Reliance, and Beha vioral Memorization Across Six F ron tier Mo dels Esh w ar Reddy M Applied AI Scien tist, Health V ectors malireddy.eshwar@gmail.com Soura v Karmak ar Senior AI Scien tist, In tuit India souravkarmakar29@gmail.com Marc h 2026 Abstract Public leaderb oards increasingly suggest that large language mo dels (LLMs) surpass human exp erts on b enchmarks spanning academic knowledge, law, and programming. Y et most b enc h- marks are fully public, their questions widely mirrored across the in ternet, creating systematic risk that mo dels w ere trained on the very data used to ev aluate them. This paper presen ts three original, complementary experiments that together form a rigorous multi-method con- tamination audit of six frontier LLMs—GPT-4o, GPT-4o-mini, DeepSeek-R1, DeepSeek-V3, Llama-3.3-70B, and Qwen3-235B—conducted entirely using public APIs and op en b enchmarks. Exp erimen t 1 applies a lexical contamination detection pip eline to 513 sampled MMLU test questions across all 57 sub ject categories, finding an o verall con tamination rate of 13.8% (18.1% in STEM, up to 66.7% in Philosoph y) and estimated p erformance gains (EPG) of +0.030– +0.054 accuracy p oin ts by category . Exp erimen t 2 applies a paraphrase and indirect-reference diagnostic to 100 MMLU questions across six sub jects and all six models, finding that mo del accuracy drops b y an a verage of 7.0 p ercentage p oints when surface wording c hanges to indi- rect reference—rising to 19.8 pp in b oth La w and Ethics, precisely the domains most heavily con taminated in Exp erimen t 1. Exp erimen t 3 applies TS-Guessing behavioral prob es (Option Mask and W ord Mask) to all 513 sampled questions and all six mo dels, finding that 72.5% of questions trigger memorization signals far ab o ve chance baselines, with DeepSeek-R1 displaying an anomalous distributed memorization signature (76.6% partial reconstruction, 0% v erbatim recall) that directly explains its uniquely brittle accuracy pattern in Exp erimen t 2. Across all three exp erimen ts, STEM is consistently the most contaminated category and the methods con verge on the same sub ject-category ranking, pro viding indep enden t con vergen t evidence that con tamination is perv asiv e, structurally non-uniform, and not adequately captured b y an y single detection approac h alone. Con tents 1 In tro duction 1 2 Bac kground: Benc hmarks, Con tamination, and Intelligence 1 2.1 Benc hmarks and ev aluation culture . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1 2.2 Mec hanisms of ev aluation data con tamination . . . . . . . . . . . . . . . . . . . . . . 2 2.3 In telligence, generalization, and memorization . . . . . . . . . . . . . . . . . . . . . . 2 3 Prior Empirical W ork on Con tamination 2 3.1 Retriev al-based detection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 3.2 Output-distribution metho ds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 3.3 Impact metrics and contamination-free b enc hmarks . . . . . . . . . . . . . . . . . . . 2 4 Exp erimen t 1: Lexical Contamination Detection in MMLU 3 4.1 Metho dology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 4.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 5 Exp erimen t 2: Paraphrase and Indirect-Reference Diagnostic 4 5.1 Motiv ation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 5.2 Metho dology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 5.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 5.4 Mo del-specific patterns . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 5.5 Con v ergence with Exp erimen t 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 6 Exp erimen t 3: TS-Guessing Behavioral Con tamination Prob e 6 6.1 Motiv ation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 6.2 Metho dology . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 6.3 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 6.4 The DeepSeek-R1 anomaly explained . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 6.5 Con v ergen t v alidity across all three exp eriments . . . . . . . . . . . . . . . . . . . . . 8 7 Syn thesis: What the Three Exp erimen ts Sho w T ogether 9 8 Hallucination and the Limits of Benc hmark In telligence 9 8.1 Theoretical context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 8.2 In teraction with con tamination . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 9 What Benc hmarks Really Measure 10 10 Normativ e and Policy Implications 10 10.1 Disclosure obligations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 10.2 Implications for legal and medical practice . . . . . . . . . . . . . . . . . . . . . . . . 11 10.3 Regulatory ev aluation standards . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 11 F uture Directions 11 12 Conclusion 11 1 In tro duction Public b enchmarks and leaderb oards ha v e become the primary currency of progress in large lan- guage mo dels. New systems are announced with headline claims such as “mo del X outp erforms most humans on the bar exam” or “mo del Y surpasses human exp erts on MMLU,” shaping p er- ceptions among researchers, policymakers, in v estors, and the broader public [ 9 ]. These claims typ- ically rest on p erformance on static, op en-access benchmarks whose complete test sets—including question–answ er pairs and often detailed solutions—hav e been a v ailable online for years. As training corpora for LLMs ha ve expanded to include v ast slices of the in ternet, it has b ecome increasingly plausible that b enc hmark items, or close v arian ts of them, are present in pretraining data. If the mo del has effectiv ely “seen the exam” during training, a high score does not demonstrate the same kind of general intelligence that a human’s first-time p erformance would. Instead, it reflects a mixture of memorization, pattern completion, and interpolation within a highly familiar distribution. This pap er addresses the central question through three original, m utually reinforcing exp er- imen ts on six fron tier mo dels, using only public APIs and open b enc hmarks, making the entire ev aluation pipeline independently repro ducible. Con tributions • Exp erimen t 1 (Section 4 ): A full lexical contamination scan of MMLU across all 57 sub jects (513 questions), yielding an o verall contamination rate of 13.8% and sub ject-lev el rates as high as 66.7% (Philosoph y). Estimated performance gains from con tamination range from +0.030 to +0.054 accuracy points by category . • Exp erimen t 2 (Section 5 ): A paraphrase and indirect-reference diagnostic on 100 MMLU ques- tions across six sub jects and all six mo dels, quantifying accuracy degradation under surface- form c hange. Av erage drop of 7.0 pp on indirect-reference v ariants across all mo dels, with La w ( − 19.8 pp) and Ethics ( − 19.8 pp) showing the largest degradation—directly matc hing their high Exp erimen t 1 contamination rates. • Exp erimen t 3 (Section 6 ): A TS-Guessing behavioral con tamination probe on all 513 sampled questions and all six mo dels, finding a 72.5% av erage com bined flagging rate and revealing a distinctiv e DeepSeek-R1 distributed memorization signature (76.6% partial reconstruction, 0% exact recall) that explains its anomalous Experiment 2 profile. • A structured synthesis showing that all three methods con verge on the same category-level con- tamination ranking, pro viding multi-method indep enden t evidence for the p erv asiv eness and structure of LLM b enc hmark contamination. 2 Bac kground: Benc hmarks, Contamination, and In telligence 2.1 Benc hmarks and ev aluation culture Mo dern LLM b enc hmarks cov er a wide sp ectrum of tasks. Massiv e Multitask Language Under- standing (MMLU) [ 9 ] aggregates thousands of m ultiple-c hoice questions across dozens of academic and professional sub jects. Co de b enc hmarks suc h as HumanEv al [ 10 ] present short programming problems with unit tests, while T ruthfulQA [ 11 ] probes susceptibility to common misconceptions. Man y commercial and op en-source mo del releases rep ort p erformance on such b enchmarks along- side comparisons to h uman baselines, often suggesting the mo del matc hes or exceeds a v erage college 1 graduates or domain experts. Leaderb oards amplify this culture, incen tivizing score improv ements o v er methodological transparency . 2.2 Mec hanisms of ev aluation data con tamination Ev aluation data contamination o ccurs when b enc hmark examples—or their paraphrases, transla- tions, or deriv ative discussions—app ear in training data. Common mec hanisms include: (a) dir e ct inclusion of b enchmark repository files scraped in to pretraining corpora; (b) indir e ct inclusion via blog p osts, teaching materials, and solution write-ups that preserv e problem structure; (c) fine- tuning c ontamination through instruction-tuning datasets that incorp orate b enc hmark-lik e Q&A; and (d) delib er ate b enchmaxxing , where practitioners inten tionally include b enc hmark items to maximize leaderb oard scores. Critically , con tamination is not limited to exact string matc hes. Ev en when n-gram dedupli- cation is applied, models may b e exposed to paraphrased or near-duplicate v ersions that preserve underlying problem structure while modifying surface form—a key motiv ation for the b eha vioral detection metho ds in Exp erimen ts 2 and 3. 2.3 In telligence, generalization, and memorization In cognitiv e science and machine learning, intelligence is linked to generalization: applying finite learned exp erience to structurally no vel situations. Memorization can pro duce impressive interpola- tion on similar tasks, but differs from the robust, causal reasoning that c haracterizes expert h uman p erformance in la w, medicine, and science [ 8 ]. Ev aluations that fail to separate memorization from generalization risk o v erstating what these systems can safely do in deplo yment. 3 Prior Empirical W ork on Con tamination 3.1 Retriev al-based detection One line of w ork inv estigates contamination using retriev al-based and b eha vioral methods [ 1 ]. F or op en mo dels, search pip elines find b enc hmark items in training data. F or closed-source mo dels, b eha vioral T estset Slot Guessing (TS-Guessing) proto cols mask elements of b enc hmark questions and chec k whether mo dels reconstruct them—the basis for our Exp erimen t 3. Empirical results sho w that leading commercial models reconstruct missing MMLU options at rates far ab ov e c hance, indicating prior exposure. 3.2 Output-distribution metho ds A second line detects con tamination from mo del outputs alone [ 2 ]. Con taminated items pro duce “p eak ed” output distributions: a memorizing mo del assigns very high probability to the correct con tin uation. Con tamination Detection via output Distribution (CDD) uses this signal; the Mem- orization Generalization Index (MGI) separates memorization-driven from generalization-driven p erformance. 3.3 Impact metrics and contamination-free b enc hmarks The Con tamination Threshold Analysis Metho d (ConT AM) [ 3 ] in tro duces the Estimated Perfor- mance Gain (EPG) metric, applied directly in Exp erimen t 1. MMLU-CF [ 5 ] reconstructs MMLU with strict decontamination; absolute scores drop and mo del rankings c hange. MMLU-Pro [ 4 ] adds 2 T able 1: F amilies of con tamination detection metho ds and the exp erimen t in this pap er that instan tiates each. Metho d family Primary signal Data needed This paper Retriev al-based (n-gram) W eb o verlap with question text Public searc h API Exp. 1 Impact-based (ConT AM/EPG) Accuracy on clean vs. flagged items Con tamination labels Exp. 1 P araphrase diagnostic Accuracy drop under sur- face c hange Mo del API only Exp. 2 Beha vioral (TS-Guessing) Reconstruction of masked elemen ts Mo del API only Exp. 3 T able 2: MMLU contamination rates by sub ject category (Exp erimen t 1). Detection: T a vily w eb searc h, ≥ 30% 8-gram ov erlap AND correct answer presen t. EPG = Estimated P erformance Gain (ConT AM, Singh et al. 2024). N = 513 questions, 9 per sub ject. Category N Con tam. (%) Rep orted Acc. EPG Humanities 117 10.3 0.72 +0.030 Professional 126 12.7 0.78 +0.040 STEM 171 18.1 0.74 +0.054 So cial Sciences 99 12.1 0.76 +0.037 All 513 13.8 0.74 + 0.040 reasoning-in tensiv e questions and similarly reduces reported scores. These results motiv ate our Ex- p erimen t 2 paraphrase diagnostic: if p erformance is inflated by surface familiarity , accuracy should degrade as surface form div erges from training text. 4 Exp erimen t 1: Lexical Contamination Detection in MMLU 4.1 Metho dology W e sampled 9 questions per sub ject from the MMLU test split across all 57 sub jects (513 questions, random seed 42). F or eac h question w e issued a T avily web searc h query (first 150 c haracters) and collected top-5 result snippets. A question was flagged contaminated if: (a) the fraction of the question’s 8-grams (low ercased, punctuation-stripp ed) found in the combined snipp ets exceeded 0.30; and (b) the correct answer text app eared verbatim in the snipp ets. The dual condition guards against false p ositiv es from tangen tially related pages. EPG w as computed as acc × rate × 0 . 4 follo wing the ConT AM metho dology [ 3 ]. 4.2 Results T able 2 reports contamination rates and EPG by category . The o v erall con tamination rate w as 13.8% . A further 40.7% of questions sho w ed an y lexical o v erlap with w eb con tent, and 25.3% had the correct answ er present in searc h results. STEM sub jects show ed the highest con tamination (18.1%), follow ed b y Professional (12.7%), So cial Sciences (12.1%), and Humanities (10.3%). The most contaminated individual sub jects— Philosoph y (66.7%), Anatom y (55.6%), Electrical Engineering, Mark eting, and Conceptual Physics 3 T able 3: T op 15 most contaminated MMLU sub jects (Exp erimen t 1). Av erage o v erlap = mean 8-gram ov erlap score across all 9 questions in the sub ject. Sub ject N Con tam. (%) Avg. ov erlap Philosoph y 9 66.7 0.667 Anatom y 9 55.6 0.508 Electrical Engineering 9 44.4 0.543 Mark eting 9 44.4 0.444 Conceptual Ph ysics 9 44.4 0.716 Professional Accoun ting 9 44.4 0.433 High Sc hool Geography 9 33.3 0.712 College Ph ysics 9 33.3 0.672 Computer Securit y 9 33.3 0.472 Medical Genetics 9 33.3 0.506 Elemen tary Mathematics 9 33.3 0.409 Moral Disputes 9 22.2 0.536 Public Relations 9 22.2 0.168 High Sc hool Statistics 9 22.2 0.517 High Sc hool Micro economics 9 22.2 0.694 (all 44.4%)—are precisely those with the densest online cov erage in lecture notes, textb ooks, and practice-set solutions. EPG estimates indicate that remo ving contaminated items would reduce rep orted STEM accuracy b y approximately 5.4 percentage points, substan tially closing the claimed gap b etw een fron tier models and human exp ert p erformance. Tw o cav eats apply . First, our t w o-condition threshold is conserv ativ e: true contamination rates ma y b e higher if paraphrased questions or near-duplicates are counted. Second, T avily do es not comprehensiv ely mirror pretraining corpora, so this metho d is b est interpreted as a lower b ound on w eb exposure. Exp erimen t 3 addresses the complemen tary question of in ternal model memorization without reliance on external w eb indices. 5 Exp erimen t 2: P araphrase and Indirect-Reference Diagnostic 5.1 Motiv ation Exp erimen t 1 establishes that MMLU questions are widely av ailable online. But web presence is not proof that a mo del has memorized those questions. Exp erimen t 2 operationalizes memorization through its b ehavioral signature: if models rely on surface-form familiarity rather than underlying domain kno wledge, their accuracy should fall when question w ording c hanges while the underlying kno wledge requirement stays constan t. 5.2 Metho dology W e sampled 100 MMLU questions across six sub jects: High Sc ho ol US History , Professional Law, College Computer Science, High School Mathematics, High Sc ho ol Biology , and Moral Scenarios ( ≈ 17 per sub ject). Sub jects were selected deliberately to span all four MMLU categories (STEM: CS, Mathematics, Biology; Humanities: History , Ethics; Professional: Law) and to include b oth high-c ontamination sub jects (La w, CS, Ethics — among the most con taminated in Exp erimen t 1) and low-c ontamination sub jects (History , Mathematics — among the least contaminated), enabling a contamination-stratified analysis of whether surface-form sensitivit y correlates with w eb exposure. 4 T able 4: Accuracy on original, paraphrased, and indirect-reference question forms (Experiment 2). Drop P = paraphrased − original; Drop I = indirect − original. A purely reasoning-based mo del w ould show zero drop. All six mo dels are included. Mo del Original P araphrased Drop P Indirect Drop I GPT-4o 0.588 0.677 +0.089 0.594 +0.006 GPT-4o-mini 0.529 0.469 − 0.060 0.490 − 0.039 DeepSeek-R1 0.292 0.333 +0.041 0.260 − 0.032 DeepSeek-V3 0.677 0.573 − 0.104 0.615 − 0.062 Llama-3.3-70B 0.771 0.635 − 0.136 0.625 − 0.146 Qw en3-235B 0.833 0.698 − 0.135 0.688 − 0.146 Av erage 0.615 0.564 − 0.051 0.545 − 0.070 T able 5: Accuracy drop (original → indirect) by sub ject, av eraged across all six models (Exp eri- men t 2). La w and Ethics show the largest drops, directly matc hing their high con tamination rates in Exp eriment 1. Sub ject Original Indirect Drop History 0.823 0.802 − 0.021 La w 0.635 0.437 − 0.198 CS 0.677 0.541 − 0.135 Mathematics 0.416 0.365 − 0.051 Biology 0.792 0.708 − 0.083 Ethics 0.615 0.416 − 0.198 Av erage 0.660 0.545 − 0.115 Questions within each sub ject were sampled randomly (seed 42, same as Exp erimen t 1) from the MMLU test split, excluding the 9 questions already used in Exp eriment 1 to prev en t ov erlap. F or eac h question, GPT-4o generated t w o v ariants: (a) a p ar aphr ase d version (entirely different w ording, identical kno wledge requiremen t and correct answer) and (b) an indir e ct-r efer enc e v ersion (k ey sub ject entities describ ed via an associated property or ev en t rather than named directly). All six mo dels w ere ev aluated on all three forms at temp erature 0. 5.3 Results T able 4 rep orts accuracy by question form and mo del. Across all six mo dels, a v erage accuracy dropp ed from 0.615 on original questions to 0.545 on indirect-reference v ariants—a drop of 7.0 p ercen tage p oin ts . The paraphrased form was in termediate (av erage 0.564, drop of 5.1 pp), consisten t with the h yp othesis that accuracy degrades as surface form diverges from familiar training text. 5.4 Mo del-sp ecific patterns GPT-4o shows a near-zero indirect drop (+0.006), suggesting its p erformance is robust to surface- form change at this accuracy lev el (Original 0.588 → Indirect 0.594). Llama-3.3-70B and Qw en3- 235B b oth show the largest drops ( − 0.146 each), with Qwen achieving the highest baseline accuracy (0.833) yet losing 14.6 pp under indirect referencing—the clearest signal of surface-pattern reliance in the experiment. 5 DeepSeek-R1 (highligh ted) remains a notable anomaly: its original accuracy of 0.292 is far b elo w all other mo dels, y et its indirect-reference drop is among the smallest ( − 0.032). This com bination—lo w baseline, near-zero sensitivity to surface c hange—is inconsistent with simple surface memorization and inconsisten t with robust reasoning. Exp erimen t 3 reveals the underlying explanation. 5.5 Con v ergence with Exp erimen t 1 The sub ject-level pattern in T able 5 directly mirrors the con tamination findings of Exp erimen t 1. La w ( − 19.8 pp drop) falls in the Professional category (12.7% con taminated in Exp 1; Profes- sional Accounting at 44.4%). Ethics ( − 19.8 pp) falls in Humanities (Philosoph y 66.7%, Moral Disputes 22.2%). By con trast, History ( − 2.1 pp) and Mathematics ( − 5.1 pp) are the least surface-sensitiv e and among the least contaminated in their categories. This alignment b et w een external web detection and b eha vioral accuracy degradation under surface-form c hange constitutes con v ergen t m ulti-metho d evidence for the same underlying phenomenon. 6 Exp erimen t 3: TS-Guessing Behavioral Con tamination Prob e 6.1 Motiv ation Exp erimen ts 1 and 2 detect contamination from the outside—w eb presence and accuracy degrada- tion. Exp erimen t 3 probes con tamination internal ly , directly testing whether models ha v e stored b enc hmark question conten t, without requiring an y external data source or accuracy comparison. This makes it the only metho d in this pap er applicable to all closed-source mo dels on equal fo oting and fully independent of the web indices used in Exp erimen t 1. 6.2 Metho dology W e implemented the TS-Guessing proto col of Deng et al. [ 1 ] across b oth sub-tasks for all 513 sampled MMLU questions × all 6 models (6,156 prob es p er task): T ask A – Option Mask (OM): One wrong answ er choice is replaced with [MASK] . The model is sho wn the complete question, all answ er c hoices including the mask, and is told whic h answ er is correct. It is then ask ed to write the original text of the masked wrong option. A model with no prior exposure has no principled basis to reconstruct the sp ecific w ording of an incorrect option (exact-matc h random baseline ≈ 0%). W e rep ort b oth exact-matc h rate and partial-match rate ( ≥ 50% token ov erlap), using partial-match as the primary metric. T ask B – W ord Mask (WM): One conten t w ord (the longest non-stopw ord token of ≥ 5 c haracters) is blanked from the question stem. The mo del fills in the single missing word. The random exact-match baseline is ≈ 0.002% giv en v o cabulary size. W e rep ort exact-matc h rate. A question is flagged con taminated if OM partial ≥ 0 . 50 or WM exact = 1. 6.3 Results T able 6 rep orts contamination rates by mo del. The av erage com bined flagging rate across all six mo dels w as 72.5% —far ab o v e b oth random baselines—constituting strong b eha vioral evidence that the v ast ma jority of sampled MMLU questions are internally memorized by frontier LLMs. 6 Figure 1: Exp erimen t 2 results (all six mo dels). Left: Accuracy b y question form and mo del. Blue = original, orange = paraphrased, red = indirect reference. Most mo dels show accuracy degradation as surface form div erges from training text; DeepSeek-R1 is a notable anomaly (low baseline, minimal drop) explained b y Exp erimen t 3. Righ t: Average accuracy drop (original → indirect) b y sub ject across all six mo dels. La w ( − 0.20) and Ethics ( − 0.20) sho w the largest drops, directly corresp onding to the highest Exp erimen t 1 con tamination rates in the Professional and Humanities categories. Figure 2: Exp erimen t 3 results. Left: TS-Guessing con tamination rates b y mo del. Red = OM partial ( ≥ 50% ov erlap); blue = WM exact; green = combined. All mo dels far exceed the 5% random baseline (dashed). DeepSeek-R1 sho ws the highest OM-partial rate (76.6%) with zero WM-exact recall—the distributed memorization signature. Centre: OM partial con tamination rate b y mo del × MMLU category (heatmap). STEM is consisten tly the most con taminated category across all mo dels; DeepSeek-R1 reaches 86% in STEM. Righ t: Contamination rate by category comparing Exp erimen t 1 (w eb-searc h lexical, blue) vs. Experiment 3 (TS-Guessing b eha vioral, red). Both metho ds indep enden tly rank STEM highest, pro viding con v ergen t multi-method evidence. 7 T able 6: TS-Guessing contamination rates b y model (Exp erimen t 3). OM exact : wrong option reconstructed verbatim. OM partial : ≥ 50% tok en o verlap (primary metric). WM exact : masked question w ord reconstructed exactly . Combined : flagged b y either task. Random baselines: OM exact ≈ 0%, OM partial ≈ 5%, WM exact ≈ 0%. N = 513 questions per mo del. Mo del OM exact OM partial ( ≥ 50%) WM exact Combined GPT-4o 15.6% 37.6% 62.1% 72.9% GPT-4o-mini 15.0% 37.6% 50.0% 66.1% DeepSeek-R1 0.0% 76.6% 0.0% 76.6% DeepSeek-V3 19.9% 43.5% 60.0% 76.4% Llama-3.3-70B 13.1% 37.0% 54.3% 69.6% Qw en3-235B 21.4% 42.7% 57.8% 73.7% Av erage 14.2% 45.8% 47.4% 72.5% T able 7: Contamination rate b y MMLU sub ject category: Experiment 1 (web-searc h lexical) vs. Exp erimen t 3 (TS-Guessing b eha vioral, OM partial av eraged across all mo dels). Both metho ds indep enden tly rank STEM as the most con taminated category . Category Exp 1 (w eb) Exp 3 (TS-Guessing) Difference STEM 18.1% 55.9% +37.8% Professional 12.7% 44.8% +32.1% So cial Sciences 12.1% 39.1% +27.0% Humanities 10.3% 38.0% +27.7% 6.4 The DeepSeek-R1 anomaly explained The most striking pattern in T able 6 is DeepSeek-R1’s profile: OM partial = 76.6% (highest of all six mo dels) paired with OM exact = 0.0% and WM exact = 0.0% . This means DeepSeek- R1 reconstructs roughly three-quarters of wrong answ er options with substan tial but non-v erbatim o v erlap, while failing to repro duce an y answ er option or question w ord exactly . This is the signature of distribute d memorization : the mo del has s tored the conceptual and seman tic structure of MMLU questions—kno wing what wrong options should b e ab out —without retaining exact surface phrasing. This finding directly resolves the DeepSeek-R1 anomaly from Exp eriment 2. Its low original accuracy (0.292) com bined with near-zero indirect-reference drop ( − 0.031) is precisely what dis- tributed memorization predicts. The mo del recognizes conceptual conten t w ell enough to score at mo derate levels when question phrasing is familiar, but cannot reconstruct exact text, and it do es not degrade further under indirect reference b ecause it was never relying on verbatim sur- face matc hing in the first place. Three indep enden t measurements—OM partial rate (Exp 3), low original accuracy (Exp 2), and minimal surface sensitivity (Exp 2)—con v erge on one explanation: DeepSeek-R1 has enco ded MMLU in a compressed conceptual form that breaks down on genuinely no v el ev aluation material. 6.5 Con v ergent v alidit y across all three exp erimen ts T able 7 sho ws that Exp erimen t 1 (external w eb detection) and Experiment 3 (internal b eha vioral probing) indep enden tly rank STEM as the most con taminated category , follo w ed b y Professional, So cial Sciences, and Humanities. Combined with Exp erimen t 2’s sub ject-level result that CS and La w sho w the largest accuracy drops under surface-form c hange—b oth STEM and Professional 8 domain sub jects respectively—all three exp eriments con v erge on the same structural conclusion. The absolute rates differ substan tially betw een methods (Exp 1: 18.1% vs. Exp 3: 55.9% for STEM). This gap is informativ e: approximately 38 percentage points of STEM memorization are b eha viorally detectable but externally in visible, confirming that w eb-searc h-only con tamination detection is a significant underestimate for closed-source models whose pretraining corpora extend far b eyond what public w eb indices capture. 7 Syn thesis: What the Three Exp erimen ts Sho w T ogether The three experiments form an in terlo cking argumen t. Exp erimen t 1 establishes external exp osur e : b enc hmark questions appear online in forms consistent with pretraining data ingestion, with STEM most affected. Exp erimen t 2 prob es the b ehavior al c onse quenc e of that exp osur e : accuracy degrades when surface form changes, most sharply in the highest-con tamination domains. Experiment 3 pro vides direct internal evidenc e of stored conten t: what Exp erimen t 1 detects externally and Exp erimen t 2 detects through accuracy degradation is also presen t inside the mo dels as reco v erable memorized structure. Three broader conclusions emerge from this triangulation. Con tamination is p erv asiv e and structurally non-uniform. MMLU con tamination is not confined to a handful of unlucky sub jects. It p erv ades all categories, reac hes 66.7% in the most affected individual sub ject, and is detectable by all three independent metho ds. All metho ds agree on the category ranking: STEM > Professional > So cial Sciences > Humanities. This consistency rules out method-sp ecific artifacts as an explanation. Mo dels differ qualitatively in how they memorize. Fiv e of the six mo dels sho w the stan- dard memorization profile: v erbatim and near-v erbatim recall of both question words and answ er options, alongside accuracy that is sensitive to surface-form c hanges. DeepSeek-R1 sho ws the opp o- site: high partial reconstruction with zero verbatim recall, and accuracy nearly inv ariant to surface c hanges despite a low absolute baseline. This distinction has practical consequences—verbatim memorization is mitigated b y paraphrase; distributed memorization requires gen uinely no v el ev al- uation material to detect. Standard b enc hmark practice cannot separate kno wledge from familiarit y . The com- bined evidence establishes that a substantial fraction of MMLU p erformance reflects recognition of memorized conten t rather than transferable domain knowledge. The fraction is non-trivial (13.8% b y conserv ative w eb detection, 72.5% by b eha vioral probing) and v aries by sub ject in w a ys that correlate with online exp osure. Until ev aluation practice conv erges on decon taminated, withheld b enc hmarks ev aluated under controlled surface-form v ariation, claims of human-lev el or sup erh u- man AI performance on standard benchmarks cannot be tak en at face v alue. 8 Hallucination and the Limits of Benchmark In telligence 8.1 Theoretical context Theoretical work argues that hallucinations are structurally unav oidable in large language mo d- els [ 7 ]. No finite-parameter mo del can correctly approximate all computable functions; there will alw a ys b e inputs on whic h the learned approximation div erges from the target. This reframes 9 hallucination not as a bug to b e patc hed but as a structural limitation—one that becomes particu- larly consequen tial when con tamination-inflated benchmark scores create o v erconfiden t deplo yment decisions. 8.2 In teraction with contamination Con tamination and hallucination interact in a wa y that mak es con taminated b enc hmark p erfor- mance esp ecially misleading. On contaminated b enc hmarks, mo dels app ear highly accurate b ecause they are pattern-matc hing to memorized con ten t. When mov ed to nov el or real-w orld tasks, the same mo dels may hallucinate frequently , b ecause high benchmark scores reflect stored patterns rather than grounded domain understanding [ 6 ]. In la w, mo dels frequently hallucinate incorrect case holdings or fabricate citations with high confidence and fluent prose [ 8 ]. In medicine, mo dels ma y inv ent nonexistent drug in teractions or misstate clinical guideline thresholds. The Experiment 2 sub ject-lev el results are directly consisten t with this: La w and Ethics—domains where professional errors ha v e direct consequences—sho w the largest accuracy drops under surface-form change (19.8 pp each), precisely the conditions that appro ximate real-world deploymen t where exact benchmark question w ording is absent. 9 What Benc hmarks Really Measure The evidence across three exp eriments supp orts a h ybrid view of curren t LLM b enc hmark perfor- mance. Scores reflect a mixture of: (a) lar ge-sc ale memorization of question text, answ er options, and surrounding online discussion; (b) statistic al gener alization within the tr aining distribution , en- abling correct in terp olation b et w een seen examples; and (c) variable surfac e-p attern r elianc e , with sensitivit y to surface-form changes that correlates with contamination level. The exam metaphor is instructive. Human exams are designed under the assumption that test items are completely unseen. When an LLM is ev aluated on a b enc hmark it has ingested, the situation is closer to a student sitting an exam after receiving—in some cases—the complete question set itself. A decon taminated, withheld b enc hmark with surface-form v ariation testing is the appropriate analogue of a genuine no v el exam. Common ev aluation pitfalls include: rep orting ra w accuracy on publicly a v ailable benchmarks without contamination analysis; generalizing from narrow b enc hmark domains to broad o ccupa- tional comp etence; treating single-n um b er accuracy scores as representativ e of robustness across prompt formulations; and equating a v erage accuracy with fitness for high-stak es deploymen t where calibration and failure mo de matter as muc h as mean performance. 10 Normativ e and Policy Implications 10.1 Disclosure obligations If b enchmark scores are materially influenced b y prior exp osure to test items, model pro viders ar- guably hav e an obligation to d isclose this. The three-exp eriment pip eline in this paper demonstrates that con tamination analyses are feasible with public infrastructure and mo dest API costs. T rans- paren t rep orting of con tamination analyses alongside p erformance claims would allo w do wnstream users—emplo y ers, policymakers, judges, and researc hers—to calibrate expectations appropriately . 10 10.2 Implications for legal and medical practice In legal practice, b enc hmark scores are sometimes inv oked in supp ort of claims ab out mo del reli- abilit y . Courts and regulators should treat such claims with caution: a mo del performing well on con taminated la w questions ma y still hallucinate case la w, misin terpret statutes, or fail to recognize jurisdictional conflicts [ 8 ]. The 19.8 percentage-point accuracy drop under indirect referencing for La w questions (Experiment 2) indicates that legal reasoning p erformance on MMLU substantially reflects familiarit y with sp ecific question phrasings rather than transferable legal analysis. The same concern applies in medicine, where ov erreliance on b enc hmark scores may lead to deploymen t of systems with brittle, memorization-driv en p erformance in high-stakes clinical con texts. 10.3 Regulatory ev aluation standards Con tamination-a w are ev aluation is an essen tial component of rigorous AI regulation. Regulatory guidance for high-stak es AI systems should require: ev aluation on decontaminated or propri- etary b enc hmarks not included in training data; b eha vioral contamination analyses (TS-Guessing or equiv alent); robustness testing across prompt formulations including paraphrase and indirect- reference v arian ts; and standardized disclosure of ev aluation metho dology . The three-exp erimen t framew ork presented here pro vides a replicable, lo w-cost template for suc h audits. 11 F uture Directions Sev eral extensions follow directly from this work. A prop erly p o wered priv ate b enc hmark comparison— with at least 100–200 carefully difficult y-calibrated questions p er domain, authored after mo del training cutoffs and verified offline—would complement the b eha vioral evidence here with a di- rect accuracy measuremen t on gen uinely no v el material. Domain-matched difficulty calibration is essen tial and could be established by piloting questions on a human cohort before LLM ev aluation. The TS-Guessing protocol should b e extended to sentence-lev el reconstructions and multi- hop comp ositional prob es, pro viding a richer profile of what mo dels store and in what form. The DeepSeek-R1 anomaly—distributed memorization without verbatim recall—deserves dedicated in v estigation: understanding whether this pattern is architectural (c hain-of-though t pretraining depth), corpus-related, or a delib erate training design choice has significan t implications for con- tamination mitigation strategy . The con vergence b et w een Exp erimen ts 1 and 3 on category ordering invites a systematic study of whic h w eb-presence features best predict b eha vioral memorization, p oten tially enabling ligh tw eigh t con tamination screening without requiring full API ev aluation of all models. Finally , the interaction b et w een con tamination and hallucination deserves direct causal study using con trolled synthetic benchmarks where memorization exposure can b e precisely manipulated, allo wing clean estimation of how m uch con tamination con tributes to both inflated scores and do wn- stream hallucination frequency . 12 Conclusion Returning to the motiv ating question—are LLMs truly smarter than h umans, or did they simply see the exam?—the evidence from three independent experiments points to the same answer: the question cannot b e definitively resolved with current b enc hmark practice, and the av ailable evidence giv es substantial reason for skepticism. 11 Exp erimen t 1 establishes that 13.8% of MMLU questions are con taminated under a conserv ative t w o-condition detection rule, rising to 18.1% in STEM and 66.7% in the most affected individual sub ject. Experiment 2 sho ws that surface-form changes reduce model accuracy b y an a v erage of 7.0 p ercen tage p oin ts across all six models, with the sharp est degradation in the highest-con tamination domains (Law: − 19.8 pp, Ethics: − 19.8 pp)—direct b eha vioral evidence that a meaningful p or- tion of MMLU performance reflects surface-pattern familiarit y rather than transferable knowledge. Exp erimen t 3 finds that 72.5% of MMLU questions trigger memorization signals far ab ov e random c hance across six fron tier mo dels, with DeepSeek-R1 displa ying a distinctive distributed memoriza- tion signature that explains its anomalous Experiment 2 profile. All three exp erimen ts agree on the category-level ordering of contamination severit y: STEM > Professional > So cial Sciences > Humanities. This conv ergence across three metho dologically indep enden t approac hes—external w eb detection, accuracy degradation under surface-form pertur- bation, and internal reconstruction probing—constitutes the strongest a v ailable multi-method evi- dence that MMLU contamination is a real, structural, and practically consequen tial phenomenon. The three-experiment framework presented here is fully replicable with public infrastructure at mo dest cost and should be adopted as a standard audit proto col. Claims of human-lev el or sup er- h uman AI p erformance deriv ed from contaminated public b enc hmarks deserve the same scrutin y w e w ould apply to an y scien tific claim where the ev aluation procedure is kno wn to be compromised. References [1] Y. Deng, W. Zhang, W. Chen, and Q. Gu. In vestigating data con tamination in mo dern b enc h- marks for large language models. In Pr o c e e dings of the 2024 Confer enc e of the North A meric an Chapter of the Asso ciation for Computational Linguistics (NAACL) , pages 8698–8711, 2024. [2] H. Dong, Y. F u, X. Ma, Z. Geng, X. Meng, and X. Jia. Generalization or memorization: Data contamination and trust w orth y ev aluation for large language mo dels. arXiv pr eprint arXiv:2402.15938 , 2024. [3] A. K. Singh, M. Y. Ko cyigit, A. Poulton, D. Esiobu, M. S. Aslan, M. Artetxe, and M. Kam- badur. Ev aluation data con tamination in LLMs: ho w do we measure it and when do es it matter? arXiv pr eprint arXiv:2411.03923 , 2024. [4] W. Zhao, Z. Shang, Y. Liu, L. W ang, and J. Liu. MMLU-Pro: a more robust and challenging m ulti-task language understanding b enc hmark. arXiv pr eprint arXiv:2406.01574 , 2024. [5] Q. Zhao, Y. Huang, T. Lv, L. Cui, F. W ei, Q. Sun, Y. Xin, S. Mao, X. Zhang, Q. Yin, and S. Li. MMLU-CF: a con tamination-free multi-task language understanding b enc hmark. arXiv pr eprint arXiv:2412.15194 , 2024. [6] Z. Ji, N. Lee, R. F riesk e, T. Y u, D. Su, Y. Xu, E. Ishii, Y. Bang, A. Madotto, and P . F ung. Surv ey of hallucination in natural language generation. A CM Computing Surveys , 55(12):1–38, 2023. [7] F. Xu, J. Shi, and E. Choi. Hallucination is inevitable: an innate limitation of large language mo dels. arXiv pr eprint arXiv:2401.11817 , 2024. [8] J. H. Choi, K. E. Hic kman, A. Monahan, and D. Sc h w arcz. ChatGPT go es to la w sc ho ol. Journal of L e gal Educ ation , 71(3):387–400, 2023. 12 [9] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeik a, D. Song, and J. Steinhardt. Measuring massiv e multitask language understanding. In Pr o c e e dings of the International Confer enc e on L e arning R epr esentations (ICLR) , 2021. [10] M. Chen, J. Tw orek, H. Jun, Q. Y uan, H. Ponde, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Bro ckman, et al. Ev aluating large language mo dels trained on co de. arXiv pr eprint arXiv:2107.03374 , 2021. [11] S. Lin, J. Hilton, and O. Ev ans. T ruthfulQA: measuring ho w mo dels mimic human falsehoo ds. In Pr o c e e dings of the 60th Annual Me eting of the Asso ciation for Computational Linguistics (A CL) , pages 3214–3252, 2022. [12] L. Gao, S. Biderman, S. Blac k, L. Golding, T. Hoppe, C. F oster, J. Phang, H. He, A. Thite, N. Nab eshima, S. Presser, and C. Leahy . The Pile: an 800GB dataset of div erse text for language mo deling. arXiv pr eprint arXiv:2101.00027 , 2020. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment