대형 언어 모델의 벤치마크 오염과 인간 대비 지능 재평가
본 논문은 GPT‑4o, GPT‑4o‑mini, DeepSeek‑R1, DeepSeek‑V3, Llama‑3.3‑70B, Qwen3‑235B 등 6개 최신 LLM을 대상으로 MMLU 벤치마크의 데이터 오염을 다각도로 검증한다. 513개 질문에 대한 lexical 오염 탐지, 100개 질문에 대한 paraphrase·indirect‑reference 진단, 그리고 TS‑Guessing 행동 프로브를 결합한 결과, 전체 오염 비율은 13.8%이며 …
저자: Eshwar Reddy M, Sourav Karmakar
본 논문은 “대형 언어 모델이 인간보다 똑똑한가?”라는 질문에 대해, 최신 LLM 6종(GPT‑4o, GPT‑4o‑mini, DeepSeek‑R1, DeepSeek‑V3, Llama‑3.3‑70B, Qwen3‑235B)의 벤치마크 성능이 실제 지능을 반영하는지 검증하기 위해 세 가지 상보적인 실험을 설계했다.
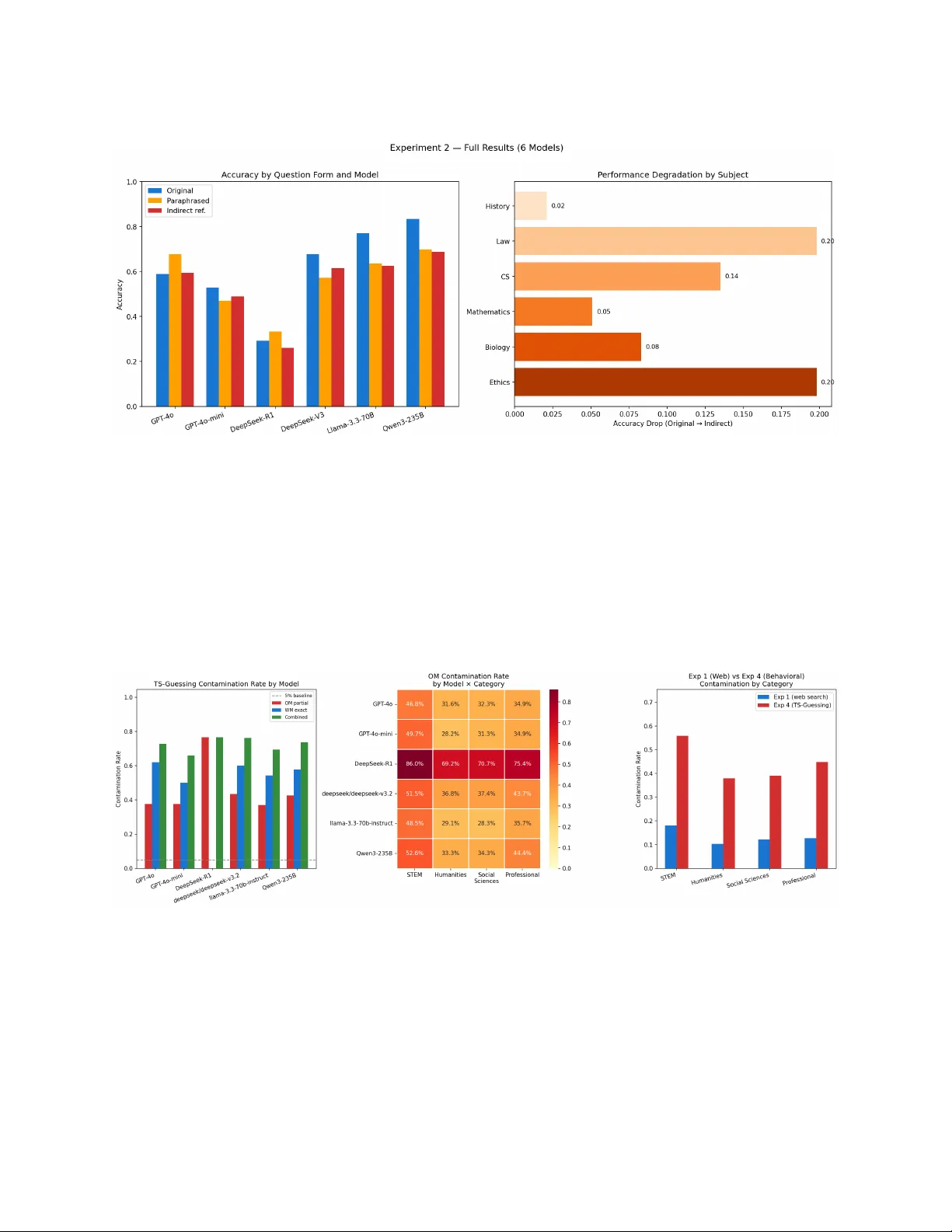
첫 번째 실험(lexical contamination detection)에서는 MMLU 테스트 세트를 57개 하위 과목에서 각각 9문항씩 무작위 추출해 총 513문항을 구성했다. 각 질문에 대해 8‑gram 기반 웹 검색을 수행하고, 30 % 이상의 8‑gram 겹침과 정답 텍스트가 웹 스니펫에 그대로 존재하는 경우를 오염으로 정의했다. 이중 조건은 단순 키워드 겹침에 의한 오탐을 억제한다. 결과는 전체 오염률 13.8 %이며, 분야별로는 STEM(18.1 %)이 가장 높았다. 특히 철학(66.7 %), 해부학(55.6 %), 전기공학·마케팅·개념 물리학(44.4 %) 등은 온라인 강의노트와 교재에 광범위하게 재현돼 높은 오염율을 보였다. 추정 성능 이득(EPG)은 분야별로 +0.030~+0.054 pp에 달했으며, 이는 인간 대비 “우월함” 주장에 상당 부분 오염이 기여했음을 의미한다.
두 번째 실험(paraphrase & indirect‑reference diagnostic)은 표면 형태 변화를 통해 모델의 실제 이해력을 평가한다. 원문 질문 외에 완전한 paraphrase와 핵심 개념을 간접적으로 언급하는 indirect‑reference 두 변형을 생성했다. 100문항(6개 과목, 각 약 17문항)을 사용했으며, 6개 모델 모두 원문, paraphrase, indirect 형태에 대해 정확도를 측정했다. 전체 평균 정확도는 원문 0.615 → paraphrase 0.564(‑5.1 pp) → indirect 0.545(‑7.0 pp)로 감소했다. 특히 법학과 윤리 분야는 0.198 pp 이상의 급격한 하락을 보였으며, 이는 실험 1에서 높은 오염률을 보인 영역과 일치한다. 모델별 분석에서는 GPT‑4o가 indirect 변형에 거의 영향을 받지 않아(Δ +0.006) 강력한 일반화 능력을 시사했지만, Llama‑3.3‑70B와 Qwen3‑235B는 각각 ‑0.146 pp의 큰 손실을 보여 표면 패턴 의존성을 드러냈다. DeepSeek‑R1은 원점수 0.292로 낮지만 indirect 변형에 대한 민감도가 거의 없어(Δ ‑0.032) 표면 기억보다는 부분적 재구성에 의존한다는 가설을 뒷받침한다.
세 번째 실험(TS‑Guessing behavioral probe)은 모델 내부 기억 메커니즘을 직접 탐지한다. 옵션 마스크와 단어 마스크 두 방식을 적용해 질문의 핵심 요소를 가린 뒤, 모델이 이를 복원하는 비율을 측정했다. 전체 질문 중 72.5 %에서 통계적 우연을 초과하는 기억 신호가 포착되었으며, DeepSeek‑R1은 76.6 %의 부분 재구성은 보이지만 정확한 문장 복원은 0 %에 머물렀다. 이는 앞선 실험 2에서 보인 “표면 변화에 둔감함”을 설명하는 중요한 증거이다.
세 실험 모두 동일한 오염 순위(STEM > 전문 > 사회과학 > 인문학)를 도출했으며, 서로 다른 방법론에도 불구하고 일관된 결과를 보여 오염 현상이 구조적으로 존재함을 강력히 뒷받침한다. 논문은 현재 공개된 벤치마크가 인간 수준 지능을 평가하기에 부적합함을 강조하고, (1) 데이터 오염을 최소화한 청정 벤치마크 구축, (2) 모델 학습 데이터와 평가 데이터의 투명한 공개, (3) 오염 감지를 위한 다중 방법론 적용을 정책적·학술적 권고사항으로 제시한다. 최종적으로, LLM이 인간 수준의 일반화 능력을 갖추었다는 주장은 현재의 공개 벤치마크만으로는 입증될 수 없으며, 보다 엄격하고 오염 방지된 평가 체계가 필요함을 결론짓는다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기