SEAHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia
Hate speech detection relies heavily on linguistic resources, which are primarily available in high-resource languages such as English and Chinese, creating barriers for researchers and platforms developing tools for low-resource languages in Southea…
Authors: Ri Chi Ng, Aditi Kumaresan, Yujia Hu
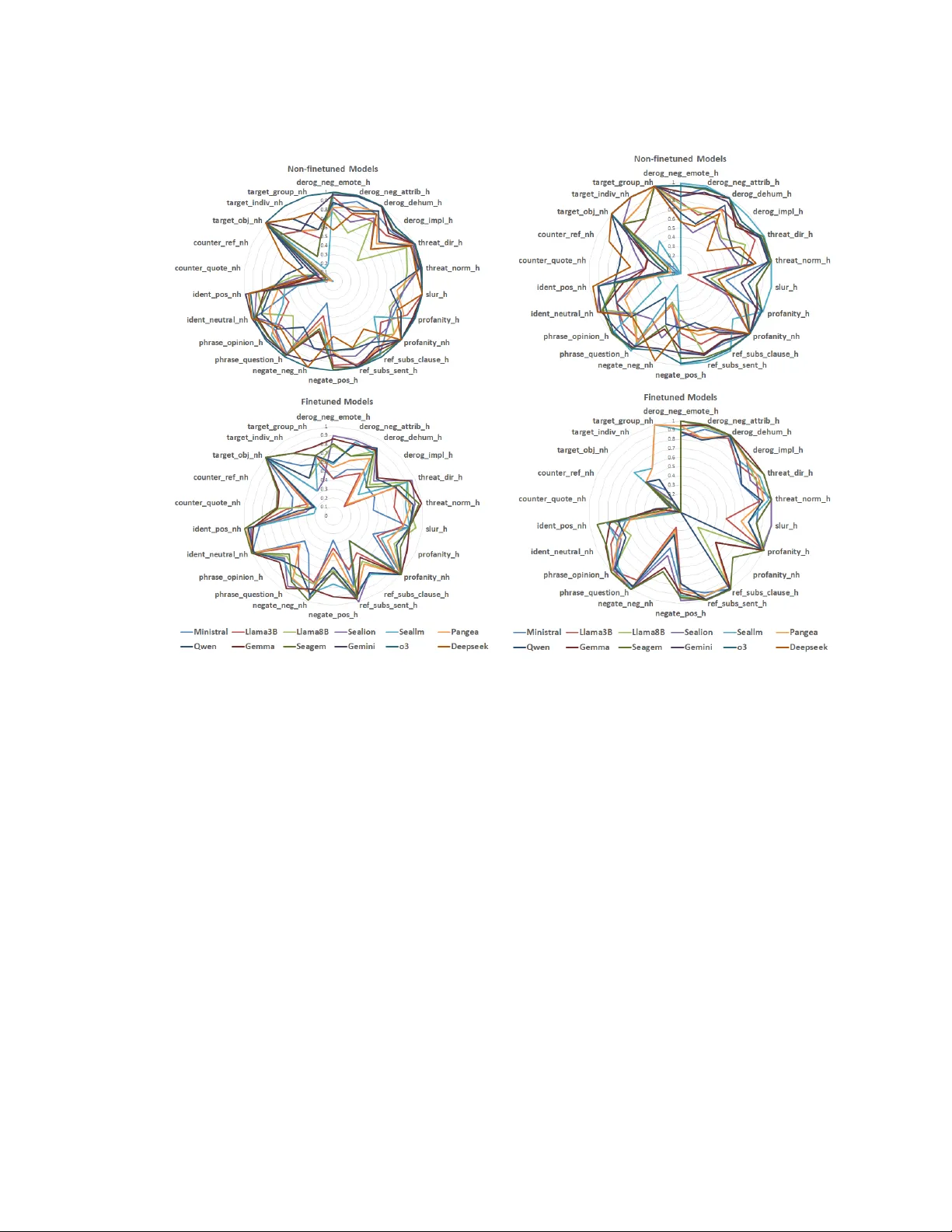
SEAHateCheck: Functional T ests for Detecting Hate Spee ch in Low-Resource Languages of Southeast Asia RI CHI NG ∗ , Singapore University of T e chnology and Design, Singapore ADI TI K UMARESAN ∗ , Singapore University of T e chnology and Design, Singapore Y UJIA H U, Singapore University of T e chnology and Design, Singapore RO Y KA - WEI LEE, Singapore Univ ersity of T echnology and Design, Singapore Hate speech dete ction relies heavily on linguistic resources, which are primarily available in high-resource languages such as English and Chinese, creating barriers for researchers and platforms de veloping tools for low-resource languages in Southeast Asia, wher e diverse socio-linguistic contexts complicate online hate moderation. T o address this, we introduce SEAHateCheck, a pioneering dataset tailored to Indonesia, Thailand, the Philippines, and Vietnam, covering Indonesian, T agalog, Thai, and Vietnamese. Building on HateCheck’s functional testing framework and rening SGHateCheck’s methods, SEAHateChe ck provides culturally relevant test cases, augmented by large language models and validated by local experts for accuracy . Experiments with state-of-the-art and multilingual models revealed limitations in detecting hate speech in specic low-resource languages. In particular , T agalog test cases showed the lowest model accuracy , likely due to linguistic complexity and limited training data. In contrast, slang-based functional tests proved the hardest, as models struggled with culturally nuanced expressions. The diagnostic insights of SEAHateCheck further exposed model weaknesses in implicit hate detection and models’ struggles with counter-speech expression. As the rst functional test suite for these Southeast Asian languages, this work equips researchers with a robust benchmark, advancing the development of practical, culturally attuned hate speech dete ction tools for inclusive online content moderation. CCS Concepts: • Computing methodologies → Natural language processing ; Language resour ces . Additional K ey W or ds and Phrases: Hate Sp eech, Low-Resource Languages, Benchmarks A CM Reference Format: Ri Chi Ng, Aditi Kumaresan, Yujia Hu, and Roy Ka- W ei Lee. 2026. SEAHateChe ck: Functional T ests for Detecting Hate Spee ch in Low-Resource Languages of Southeast Asia. 1, 1 (March 2026), 95 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Online hate sp eech in Southeast Asia (SEA) fuels discrimination, division, and harm targete d at vulnerable communities. Howev er , detection models struggle to address this crisis in low-r esource languages like Indonesian, Malay , T agalog, Thai, and Vietnamese. These languages, encompassing tonal systems (Thai, Vietnamese) and script-based orthographies (Indonesian, Malay , T agalog), are underrepresented in hate spee ch datasets, which are predominantly trained on ∗ Both authors contributed equally to this research. Authors’ Contact Information: Ri Chi Ng, richi_ng@sutd.edu.sg, Singapore Univ ersity of T echnology and Design, Singapore, Singapore; Aditi Kumaresan, aditi_kumaresan@sutd.edu.sg, Singapore University of T echnology and Design, Singapore, Singapore; Y ujia Hu, yujia_hu@sutd.edu.sg, Singapore University of T echnology and Design, Singapore, Singapore; Roy K a- W ei Lee, roy_lee@sutd.edu.sg, Singapore Univ ersity of T echnology and Design, Singapore, Singapore. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specic permission and /or a fee. Request permissions from permissions@acm.org. © 2026 Copyright held by the owner/author(s). Publication rights licensed to A CM. Manuscript submitted to ACM Manuscript submitted to ACM 1 2 Ng et al. high-resource languages such as English and Mandarin [ 51 ]. This bias exacerbates the challenges in capturing the sociolinguistic complexity of SEA, where culturally nuanced expressions - slang, implicit insults, and coded hate - permeate online discourse. As social networks amplies hate, targeting marginalized groups such as ethnic minorities and religious communities (e.g., those identied in local legislation, T able 11), social networks are not equipped to moderate content eectively . The absence of r obust detection tools not only undermines online safety but also risks deepening social tensions in a region marked by diverse histories and identities. Urgent action is needed to develop culturally attuned hate spee ch detection systems that reect SEA ’s unique linguistic and cultural landscap e. Functional testing frameworks have emerged to address limitations in traditional hate spe ech evaluation, which relies on held-out test sets prone to biases and gaps. HateCheck [ 41 ] introduced targeted test cases to assess model performance in English, focusing on real-world scenarios like negation and identity-based hate. Multilingual HateChe ck (MHC) [ 40 ] extended this approach to other high-resource languages, while SGHateChe ck [ 30 ] adapted it for Singapore’s multilingual context, incorporating local slang and cultural references. Despite these advances, these frameworks are inadequate for the broader lo w-resource languages of SEA, which r equire customized test cases to address tonal phonetics, script diversity , and region-specic hate speech patterns (e.g., implicit hate in Thai proverbs or Vietnamese online forums). This gap leaves researchers and platforms without the tools to comprehensively e valuate hate spe ech detection in the diverse settings of the SEA. T o bridge this critical gap, we introduce SEAHateCheck , the rst functional test suite designe d to evaluate hate speech detection models across SEA. It builds on the dataset created in SGHateCheck and covers the sociocultural context of Indonesia, Malaysia, the Philippines, Singapore , Thailand, and Vietnam, and covers a wide array of languages including Indonesian, Malay , Mandarin, Singlish, T agalog, T amil, Thai, and Vietnamese 1 . Building on HateCheck’s robust framework and rening SGHateCheck’s localization te chniques, SEAHateCheck delivers a comprehensive set of culturally relevant test cases, addressing slang, implicit hate, and vulnerable groups identied through local expertise (Section 2.1). By integrating large language mo dels (LLMs) for test case generation, native speakers for accurate translations, and local experts for cultural validation, SEAHateCheck sets a new standard for hate sp eech evaluation in low-resource settings. As a diagnostic benchmark, it empowers r esearchers to assess model performance systematically , fostering the development of inclusive and eective hate speech detection tools tailored to SEA ’s unique needs. SEAHateCheck ’s contributions extend b eyond its pioneering dataset, oering actionable insights from rigorous evaluation of state-of-the-art LLMs. Our ndings reveal critical mo del weaknesses, such as lo wer accuracy in Vietnamese test cases, which is likely due to the language’s tonal complexity and limited training data, as well as struggles with slang-based tests that require cultural nuance (e .g., region-specic colloquialisms). These insights guide developers to prioritize enhanced training for tonal languages and context-aware algorithms, addressing gaps in current models. For platforms, SEAHateCheck informs mo deration strategies to protect marginalize d groups better , aligning with local legislation on protected categories. Its diagnostic capabilities further highlight deciencies in detecting implicit hate, enabling targeted improv ements in model robustness. By providing a scalable, culturally gr ounded benchmark, SEAHateCheck transforms hate spee ch detection, safeguarding SEA ’s diverse communities and paving the way for equitable online moderation globally . 1 Dataset available at https://github.com/Social- AI-Studio/SEAHateCheck Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 3 Protected Categories Indonesia Malaysia the Philippines Singapore Thailand Vietnam Religion Y es Y es Y es Y es Y es Y es Ethnicity/Race/Origin Y es Y es Y es Y es Y es Y es Disabilities No Y es Y es Y es Y es Y es Gender/Orientation Y es Y es Y es Y es Y es Y es Age No No No Y es Y es Y es Vulnerable W orkers No No No No Y es No People Living with HI V No No Y es No No Y es T able 1. Protected categories represented for each countr y in SEAHateCheck. 2 Constructing SEAHateCheck Dataset 2.1 Defining Hate Speech SEAHateCheck adopts HateCheck’s denition of hate speech as “ abuse aimed at a protected group or its memb ers for belonging to that group ” [ 41 ]. Following SGHateChe ck’s approach, local cultural experts (two per countr y , with backgrounds in sociology and linguistics) consulted legislation and used it as guidance to suggest protected categories. Within each protected category is a protecte d target (e.g., Hindus (protected target) for Religion(protected group)). T able 1 details these categories, and Appendix T able 11 lists legislative sources. All countries share four common categories— Religion , Ethnicity / Race / Origin , Disabilities , and Gender —with additional categories (e.g., Age, People Living with HIV) varying by countr y , ensuring cultural relevance . The legislative and regulatory sources consulted to dene these protected categories are listed in T able 11. 2.2 Defining Functional T ests In SEAHateCheck , a functional test is dened as a targete d evaluation of a hate sp eech dete ction model’s ability to correctly classify short text statements as hateful or non-hateful, following the diagnostic framew ork introduced by HateCheck (Röttger et al., 2021). Each test targets a specic functionality , such as distinguishing hate speech containing profanity from non-hateful expressions with similar lexical features. F or instance, a test case in T agalog may assess hateful profanity directed at a protected group (e.g., “T angina, ang hirap nun, ” targeting a group), contraste d with a non-hateful, colloquial use of profanity in T agalog ( e.g., “Bakit ba hindi tumitigil ang pag-iyak ng mga sanggol sa eroplano?”). T ests are designed to be ne-graine d, contrastive, and culturally relevant, enabling models to discern nuanced language use across diverse Southeast Asian conte xts. T o facilitate systematic evaluation, w e organize tests into thematic categories, such as explicit hate, implicit hate, and non-hateful contrasts, aligning with the sociolinguistic use in Indonesia, Malaysia, the Philippines, Singapore, Thailand, and Vietnam. This structure enhances diagnostic insights into model performance, rev ealing whether models rely on supercial cues or capture conte xt-specic hate speech patterns. 2.3 Selecting Functional T ests SEAHateCheck ’s functional tests were selecte d to align with the HateCheck framework [ 41 ], adapting its methodology to the sociolinguistic contexts of Indonesia, the P hilippines, Thailand, and Vietnam. Following HateCheck’s approach, which integrates interviews with NGO workers and a review of hate speech research, we incorporated countr y-specic elements through consultations with local experts in sociology and linguistics. This ensures that our tests are culturally attuned, enhancing their relevance for evaluating hate speech detection models in each countr y’s unique context. Manuscript submitted to ACM 4 Ng et al. All test cases are short te xt statements, designed to be unambiguously hateful or non-hateful per our hate speech denition. SEAHateCheck comprises up to 27 functional tests per language (22 for Malay , T amil, Indonesian, T agalog, Thai, and Vietnamese; 25 for Mandarin; 27 for Singlish), tailored to r eect linguistic and cultural considerations. For instance, we e xcluded slur homonyms and reclaimed slurs absent in Indonesian, Malay , Mandarin, T agalog, T amil, Thai, Singlish, and Vietnamese , and omitted spelling variations to streamline translation. Like HateCheck and MHC, our tests distinguish hate speech from non-hateful content with similar lexical featur es but clear non-hateful intent, enabling nuanced evaluation across diverse e xpressions. A table summarising the functional tests, together with examples in represented languages and the original English templates is shown in Fig 5 and Fig 6. The targets in both tables were replaced with a placeholder {T ARGET} . Distinct Expressions of Hate . SEAHateCheck evaluates varied forms of hate speech, including der ogatory remarks (F1–F4) and threats (F5–F6), as well as hate convey ed through slurs (F7) and profanity (F8). It assesses hate expressed via pronoun references (F10–F11), negation (F12), and varied phrasings, such as questions and opinions (F14–F15). For Indonesian, T agalog, and Vietnamese, tests include spelling variations like omissions or leet speak (F23–F34), broadening the evaluative scope to capture region-specic linguistic patterns. Contrastive Non-Hate . T o ensure robust model evaluation, SEAHateCheck includes non-hateful content, such as profanity used without malice (F9), negation (F13), and benign references to protecte d groups (F16–F17). It also examines contexts where hate speech is quoted or countered, particularly in counter-sp eech scenarios that neutralize hate (F18–F19). Additionally , tests dierentiate content targeting non-protected entities, such as objects (F20–F22), ensuring clear distinctions between hateful and non-hateful expressions. T ext Obfuscations . For Singlish and Mandarin, there are additional functional tests (F23 to F34), where the texts were methodically obfuscated in dierent ways. 2.4 Translating T emplates T o adapt HateCheck’s functional test templates [ 41 ] for Indonesian, T agalog, Thai, and Vietnamese, we employed human translators supported by LLMs, producing 655 templates per language. These templates co ver 22 functional tests across protected categories, ensuring cultural and linguistic accuracy for low-resource Southeast Asian languages [ 37 ]. The translation process diered by language: Indonesian followed SGHateCheck’s protocol [ 30 ] (as language experts were available when SGHateCheck was made), while T agalog, Thai, and Vietnamese used a three-stage approach. For the Indonesian data, we began by ne-tuning GPT -3.5 [ 3 ] on a small set of 27 human-translated templates from SGHateCheck so that the model could better handle hate sp eech contexts. W e then use d the ne-tuned model to translate all 655 English templates into Indonesian. T wo native translators reviewed the generated sentences line by line and edited them to match Indonesian usage, replacing ov erly literal phrases, removing inappropriate slurs, and adjusting the tone to sound natural. For T agalog, Thai, and Vietnamese, the same set of 655 English templates was translated using Gemini 1.5 Pro [ 49 ] and GPT -4o [ 32 ]. T wo translators per language selected or e dited machine-generated translations, or provided original translations when needed, ensuring so ciolinguistic relevance. The pr ocess unfolded in three stages: (1) Stage 1: T emplate V alidation: One template p er functional test (22 templates) was translated and reviewed with sociolinguistic experts of the respective countries to conrm cultural applicability . Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 5 (2) Stage 2: Multi-Shot Translation: Using Stage 1 translations as multi-shot examples (i.e., in-context learning prompts), 100 additional templates were translated and edited, with translators resolving discrepancies through discussion between translators. (3) Stage 3: Scaled Translation: Using randomly selecte d Stage 2 translations as examples, 611 templates were translated, completing the set. Discrepancies were also resolv ed here through discussion between translators. W e document language varieties and annotator localities to ground translation choices in Appendix A.2 - A.3. A detailed breakdown of the templates and generated test cases across functional tests and languages is pro vided in T able 14. 2.5 Generating and V alidating Gold Label T est Cases Gold label test cases in SEAHateCheck are manually validate d instances derived from translated templates, designed to evaluate hate speech detection models across Indonesian, T agalog, Thai, and Vietnamese. This subsection outlines the pipeline for generating and validating these test cases, ensuring cultural relevance and linguistic accuracy [41]. Generating T est Cases. Using 655 templates per language, we generated test cases by substituting placeholders for protected groups (e .g., {IDEN TI T Y_P}) and slurs (e.g., {SLUR_P}). W e summarize the target groups cov ered by the training corpora for each language in T able 5. Three experts per language identied up to six protected categories p er country (See T able 1) (Protected categories are further broken do wn into protected groups, e.g., Hindus, Muslims for Religion; ethnic Chinese for Ethnicity ) and 10–15 common slurs, based on lo cal demographics and online discourse. For example, the Indonesian template Kita bakal terus serang lo {IDEN TI T Y_P} samp e lu pergi ” be comes Kita bakal terus serang lo Muslim sampe lu pergi , ” while a non-hateful T agalog template K ami ay may respeto sa {IDEN TI T Y_P} ” yields Kami ay may respeto sa Muslim . ” Each template was instantiate d 5–10 times per group , producing 31,172 test cases across four languages (7,793.5 per language on average; T able 2). Of these, 21,187 were labeled hateful and 9,985 non-hateful base d on template sentiment [ 41 ]. T est cases averaged 10.4 words (excluding Thai due to lack of word separators) and 50.3 V alidating T est Cases. T o ensure quality , 16,415 test cases (approximately 4,104 per language) were annotated by 12 native speakers (3 p er language) with linguistics training, each reviewing cases in triplicate. Annotators labeled sentiment (Hateful, ” Non-hateful, ” or Nonsensical”) per Section 2.1 and agged cases for quality issues (unnatural phrasing or context dependence). T raining on 50 sample cases ensured consistency . High-quality test cases required unanimous sentiment agreement, alignment with template sentiment, and no quality ags. Of 16,415 cases, ˜ 5% (820) were labeled Nonsensical” due to translation errors or cultural mismatches and excluded. After ltering, 13,579 high-quality test cases wer e r etained for benchmarking (Section 3), with a mean high-quality rate of 0.83 (proportion of cases meeting all criteria; T able 2). Inter-annotator agreement (Fleiss’ kappa = 0.85) indicates high reliability , detailed in Appendix A.5. Comparison with SGHateCheck. Like SGHateChe ck [ 30 ], SEAHateCheck uses a shared p ool of 655 templates to generate test cases, which ensures comparable functional coverage across Southeast Asian languages. SEAHateCheck focuses on four low resource languages, yielding 13,579 validate d gold label test cases, whereas SGHateCheck provides roughly 11,000 validated cases for Malay , Singlish, T amil and Chinese. Both datasets rely on native annotators, but SEAHateCheck applies a stricter unanimous agreement criterion, which results in a slightly lower high quality rate. 2.6 Generating and V alidating Silver Label T est Cases Silver label test cases in SEAHateCheck are LLM-generated instances that enhance the localization and scale of hate speech detection for Indonesian, T agalog, Thai, and Vietnamese, complementing template-base d gold test cases (Section Manuscript submitted to ACM 6 Ng et al. 2.5). This subsection details their motivation, generation, validation, limitations, and comparison with SGHateCheck [30]. Motivation. Silver test cases address limitations of gold test cases, which rely on manually translated templates (Section 2.5). First, LLMs enable rapid scaling, producing 19,802 test cases compared to 13,579 gold, cov ering diverse hate speech scenarios. Second, they capture colloquial expressions (e.g., “bajingan” in Indonesian) missed by templates, enhancing realism for low-resour ce languages. Third, they reduce annotation costs, validating 400 cases vs. 16,415 for gold. Finally , their variability tests model robustness against naturalistic inputs, pro viding complementary diagnostics [37]. Generating T est Cases. W e used 13,579 high-quality gold test cases (Section 2.5), gr ouped by 22 functional tests and 6 pr otected groups ( e.g., Muslims, ethnic Chinese), yielding ~100 gr oups per language. Multi-shot prompts with 3–5 gold test cases were designed with three native speakers per language over tw o iterations to ensure casual, localized outputs (e.g., Use slang like ‘bajingan’ in Indonesian). Prompts wer e tested on Ministral-8B-Instruct-2410 [ 1 ] and SEA -Lionv2.1 [ 46 ], with SEA -Lionv2.1 selected for lower safety guar drail rejections. Generation produced 10 test cases per group , yielding 19,802 test cases (4,950.5 per language; Table 2). Of these, 14,145 were intended as hateful and 5,657 non-hateful, based on prompting gold test cases’ sentiment. T est cases averaged 15.6 words (excluding Thai) and 74.2 characters, ~50% longer than gold due to LLM verbosity (e.g., qualiers like sangat”). V alidating T est Cases. T o assess quality , 100 test cases p er language (400 total) were annotated by 12 native speakers (3 per language) with linguistics training, each reviewed in triplicate. Annotators labeled sentiment (Hateful, ” Non-hateful, ” “Nonsensical”), agged unnatural phrasing or context dependence (per Section 2.5), and veried target group and functional test matching. T raining on 50 sample cases ensured consistency . Fifteen positive controls ( same group/test) and 15 negative controls (same group, dierent test) conrmed annotator accuracy and test sp ecicity . High-quality test cases required unanimous sentiment agreement, no quality ags, and matching target/function. The high-quality rate (0.72 mean; T able 2) reects 72% of test cases meeting all criteria, vs. 83% for gold, due to LLM variability . Inter-annotator agreement (Fleiss’ kappa = 0.80) is reliable but lower than gold (0.85), detailed in Appendix A.5. A Quality Score (0–5) awarded 1 point each for correct sentiment, naturalness, context independence, target, and function. T able 3 shows silver scores ( e.g., 0.74 for sentiment) are lo wer than gold (0.90). T amil’s concise silver test cases (6.7 vs. 7.2 words; T able 2) r eect LLM constraints in agglutinative languages. Code-switching. Our template-based Gold cases were translated with a preference for predominantly monolingual realizations to preserve controlled functional contrasts. W e did not intentionally design code-mixed (“T aglish” , “In- doglish”) test cases as a separate condition. Code-switching is prevalent in SEA online discourse and has been studied as a distinct evaluation setting for LLM translation, suggesting the need for de dicated code-mixed test suites [ 21 ]. W e view systematic code-switching as an important extension for Southeast Asia, where mixing is a frequent evasion tactic. W e therefore include code-mixed functional tests as future work. Limitations. Silver test cases face several challenges. First, their lower high-quality rate (0.72 vs. 0.83) and quality scores (T able 3) indicate reduced naturalness and reliability , as LLMs introduce verbosity or errors. Second, inconsistent target group and functional test alignment (e.g., scores of 0.70–0.72 vs. 0.91–0.92) reduces diagnostic precision, as LLMs may deviate from pr ompts. Third, despite native speaker input, LLMs struggle with cultural nuances in low-r esource languages (e .g., Thai’s tonal complexity), leading to unnatural outputs. Finally , safety guardrails limit the generation of certain hateful content, potentially skewing the dataset. These issues, coupled with dependence on gold test cases’ biases, require rigorous validation, partially osetting cost savings. Prior work also sho ws cross-lingual transfer can Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 7 SEAHateCheck SGHateCheck [30] Metric ID TL TH VI Mean MS SG T A ZH ‡ Mean Gold Label # T est cases 8190 8751 8488 10319 8937 NA NA NA NA NA # Hateful template 5511 5902 5681 6998 6023 NA NA NA NA NA # Non-hateful template 2679 2849 2807 3321 2914 NA NA NA NA NA A vg. wor ds 8.3 9.6 NA 13.2 10.4 † 9.5 8.5 7.2 15.6 10.2 A vg. characters 50.0 55.2 38.8 57.2 50.3 58.9 45.6 62.4 15.6 45.6 Gold V alidation T otal Annotated 3579 4072 3952 4812 4103.8 2253 2974 2851 2848 2731.5 High Quality Rate 0.92 0.85 0.87 0.91 0.89 0.91 0.91 0.90 0.82 0.88 Silver Lab el # T est cases 4505 4870 4797 5630 4950.5 2759 3623 2591 3588 3140.3 # Hateful template 3171 3477 3475 4022 3536.3 1960 2824 1848 2857 2372.3 # Non-hateful template 1334 1393 1322 1608 1414.3 799 799 743 731 768.0 A vg. wor ds 14.3 14.3 NA 18.3 15.6 † 11.8 12.2 6.7 21.6 13.1 A vg. characters 90.3 82.8 43.5 80.2 74.3 72.9 67.4 60.1 21.6 55.5 Silver V alidation T otal Annotated 100 100 100 100 100 100 100 100 100 100 High Quality Rate 0.72 0.61 0.75 0.80 0.72 0.68 0.86 0.68 0.76 0.74 T able 2. Summary of SEAHateCheck and SGHateCheck test instances by language and functional test categor y , including the number of gold and silver cases and their hateful vs. non-hateful splits. Column headers use language abbreviations: ID =Indonesian, TL =T agalog, TH =Thai, VI =Vietnamese, MS =Malay , SG =Singlish, T A =T amil, ZH =Mandarin. High quality rate denotes the proportion of high quality annotations, defined in §2.5 and §2.6 for Silv er Label test cases. NA marks metrics not reported in the source table. † W eighte d average words exclude Thai due to missing w ord segmentation; Thai cells therefore omit w ord counts. ‡ For Mandarin (ZH), each character is counted as one word (w ords = characters). signicantly aect hallucination b ehavior in low-resource settings, motivating conser vative ltering and targeted validation for LLM-generated cases [53]. Comparison with SGHateCheck. SGHateCheck [ 30 ] generates 12,561 silver test cases for Malay , Singlish, T amil, and Mandarin, using similar LLM prompting. SEAHateCheck ’s 19,802 test cases reect its low-resour ce focus, with a slightly lower high-quality rate (0.72 vs. 0.74; T able 2) due to stricter ltering. Quality scores (T able 3) show consistent trends across datasets. These 19,802 test cases, summarized in T able 2, enhance SEAHateCheck ’s evaluation of hate speech detection, despite limitations. SGHateCheck metrics are in Table 2. Further details on corpus size, gold and silver generation counts, and the rationale for targeting SEA socio-linguistic contexts are pro vided in Appendix A.1. T able 2 summarizes the statistics for SEAHateCheck and SGHateCheck side by side, including the number of test cases, the hateful or non hateful balance and the proportion of high quality items. For a more ne-grained view , T able 12 in Appendix reports the number of templates (#TP) and instantiated test cases (#TC) for each functional test and language, making the coverage of explicit hate, implicit hate, and contrastive non-hate tests fully transparent. Notably , SEAHateCheck maintains a comparable Gold high-quality rate (mean 0.89) to SGHateChe ck (mean 0.88) while expanding coverage to additional Southeast Asian languages, including tonal languages such as Thai and Vietnamese. This suggests that the translation and expert validation pipeline scales to more typologically diverse settings without materially degrading dataset quality . 3 Benchmarking LLMs on SEAHateCheck W e evaluated SEAHateCheck and SGHateCheck across various open-source and closed-source LLMs to assess their eectiveness in detecting HS. The selected models include state-of-the-art (SOT A) architectures and multilingual models ne-tuned to support the majority of languages present in both datasets, including English (representing Singlish), Manuscript submitted to ACM 8 Ng et al. Dataset A v erage Quality score Language Label Sentiment Context Natural T arget functional test Indonesian Gold Label 0.978 0.993 0.928 NA NA Silver Label 0.827 0.910 0.710 0.867 0.470 T agalog Gold Label 0.952 0.993 0.998 NA NA Silver Label 0.797 0.850 0.820 0.867 0.607 Thai Gold Label 0.960 0.987 0.986 NA NA Silver Label 0.853 0.977 0.887 0.913 0.700 Vietnamese Gold Label 0.972 0.994 0.991 NA NA Silver Label 0.910 0.983 0.987 0.947 0.650 Malay Silver Label 0.783 0.933 0.863 0.940 0.440 Singlish 0.920 0.973 0.957 0.977 0.437 T amil 0.823 0.907 0.827 0.907 0.667 Mandarin 0.860 0.863 0.900 0.847 0.583 T able 3. A verage scores for dierent annotation fields for each language. Indonesian, Malay , Mandarin, T agalog, T amil, Thai, and Vietnamese. These languages will be collectively referred to as the evaluated languages. Our evaluation follows a two-stage approach. First, we assess each model in its default, out-of-the-b ox (OOTB) conguration to establish a baseline for its intrinsic HS detection capabilities. Second, we ne-tune the models using a curated HS dataset and re-evaluate their performance to measure the impact of domain-specic adaptation. The characteristics of all evaluated models ar e detailed in Appendix T able 16. T o maintain consistency with the original annotation process, we ne-tune and evaluate the models with the same language-sp ecic prompts use d during annotation as detailed in Appendix C. 3.1 LLM Fine-tuning The open-source LLMs were further enhanced by ne-tuning with hate speech scrap ed from social me dia. T o do so, we curated a specialize d dataset that captures high-quality , labelled hate spe ech (HS) obser ved in the evaluated languages. Detailed characteristics of the training data, including collection methods, are provided in T able 4. Next, we also highlight the obser ved target gr oups in the curated hate speech data. Finally , we pr esent a compr ehensive breakdo wn of the training data distribution, including the proportion of hateful vs. non-hateful instances per language and categor y , in T able 6. W e use binary labels (hateful or non-hateful) to perform supervised ne-tuning of the LLMs using Low-Rank Adaptation (LoRA) [ 18 ]. The exact ne-tuning and evaluation prompts are included verbatim in Appendix C to ensure reproducibility . 4 Discussion on Gold Label T est Cases 4.1 Overall Results In evaluating the non-netuned models, performance varied across languages. While most models achieved strong F1 scores for languages like Vietnamese and Indonesian, several open-source models struggled with T amil and T agalog. Notably , Deepseek consistently underperformed compared to o3 and Gemini , sometimes yielding worse results than the open-source models. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 9 Dataset Dataset Name Language Y ear Collection Method SEA id-multi-label-hate-spee ch-and- abusive-language-detection [22] Indonesian 2019 T witter Philippine Election-Related Tw eets [4] T agalog 2019 T witter Hate ThaiSent [27] Thai 2024 — ViHSD [25] Vietnamese 2021 Facebo ok, Y ouTube SG HateM [26] Malay 2023 — COLDataset [12] Mandarin 2022 Zhizhu, W eibo HateXplain [28] Singlish 1 2021 T witter , Gab W aseem and Hovy [52] Singlish 2 2016 — T amilMixSentiment [5] T amil 2020 Y ouT ube comments T able 4. Details of the Datasets Use d, Including Collection Y ear and Method Region Language T arget Group SEA Indonesian Religion/Creed, Race/Ethnicity , Physical/disability , Gender/Sexual Ori- entation, Other invective/slander T agalog Race, Physical, Sex, Disability , Religion, Class, Quality Thai — Vietnamese Aimed at all groups/individuals Malay Race, Ethnicity , National Origin, Caste, Sexual Orientation, Gender , Gender identity , Religious Aliation, Age, Disability , or Serious Disease SG Mandarin Race, Religion, Sex, or Sexual Orientation Singlish 1 African, Islam, Jewish, LGBTQ, W omen, Refugee, Arab, Caucasian, His- panic, Asian Singlish 2 Race, Sex T amil No clear T arget Groups T able 5. Target Gr oups for Dierent Languages After ne-tuning, a marked improvement in precision was observed across all models, which indicates a reduction in false positives. This was particularly e vident in Vietnamese, T agalog, T amil, and Singlish, where F1 scores exhibited signicant gains. Howev er , ne-tuning led to a decrease in performance for some languages, specically Malay , Thai and Indonesian. This deterioration can likely be attributed to these datasets’ poor distribution of hateful and non-hateful labels, as highlighted in T able 6. This imbalance may have aected their ability to generalise eectively on high-quality test cases. In T able 7, the non-netuned results reveal clear stratication among both the model architectures and the languages under consideration. Strong general-purpose systems such as Deepseek, o3 and Gemini achieve the highest F1 scores in most evaluations, with o3 reaching 89.01 in Indonesian and 87.63 in Vietnamese , and Gemini exceeding 80 in various Southeast Asian and Singap orean varieties. Among the nine op en-sourcing models, Gemma delivers competitive baselines, often in the mid-to-high seventies, while Sealion and Seagem perform notably well for specic languages. In Manuscript submitted to ACM 10 Ng et al. Language Full Training Dataset Sampled Training Dataset Not Hateful Hateful T otal Not Hateful Hateful T otal SEA Indonesian 9,078 1,457 10,535 3,543 1,457 5,000 T agalog 5,340 4,660 10,000 2,500 2,500 5,000 Thai 3,962 2,115 6,077 2,885 2,115 5,000 Vietnamese 21,490 2,556 24,046 2,500 2,500 5,000 SG Mandarin 13,003 12,723 25,726 2,500 2,500 5,000 Malay 2,401 1,512 3,913 2,401 1,512 3,913 Singlish 1 10,635 4,748 15,383 2,500 2,500 5,000 Singlish 2 8,826 4,002 12,828 2,500 2,500 5,000 T amil 22,882 7,434 30,316 2,500 2,500 5,000 T otal 97,617 41,207 138,824 23,829 20,084 43,913 T able 6. Statistics of Hateful and Not Hateful Samples in the Full Dataset and Sampled Subset. Language subsets with poor label distribution are highlighted in red . Model SEA SG Indonesian T agalog Thai Vietnamese Malay Mandarin Singlish T amil Ministral 66.53 65.97 68.82 75.15 66.26 64.92 72.22 65.66 Llama3b 67.37 62.80 72.17 74.38 64.29 66.49 69.54 66.75 Llama8b 65.13 59.49 69.09 72.35 66.16 61.66 73.93 59.39 Sealion 72.08 58.38 70.54 74.43 70.85 68.25 71.66 73.42 Seallm 70.27 56.85 70.48 74.28 65.92 66.18 68.64 54.88 Pangea 68.29 53.76 57.08 73.94 67.35 67.01 64.21 56.83 Qwen 73.86 61.83 72.92 77.20 69.47 73.06 73.52 58.33 Gemma 80.36 77.25 76.55 83.09 77.66 77.03 74.46 78.35 Seagem 78.75 77.13 74.58 81.86 77.23 71.89 76.92 81.07 Gemini 84.58 78.50 76.49 79.84 80.28 74.79 79.88 81.09 o3 89.01 82.59 80.21 87.63 85.94 83.28 83.08 85.96 Deepseek 74.47 65.96 67.03 77.27 76.44 67.36 77.01 67.96 T able 7. F1 scores of dierent non-finetuned models on SEAHateCheck and SGHateChe ck High-ality T est Cases. contrast, lower-capacity or earlier-generation systems, represented by Ministral and Pangea, display weaker baselines, particularly for T agalog and T amil. Vietnamese and Malay tend to yield relatively stronger scores for the highest- capacity models. In contrast, T agalog and T amil exhibit br oader dispersion that aligns with the greater linguistic and sociolinguistic variability evident in hateful content. T able 8 shows F1 scor es after netuning, demonstrating substantial improv ements for most open models on SEA languages, as well as Singlish and T amil. For instance, Gemma benets signicantly in Thai and Vietnamese and shows further gains in Indonesian and T agalog. SeaLion, Llama-8B, Pangea, and Q wen also display consistent improvements across several languages. These results indicate that domain-specic sup ervision eectively enhances recall while maintaining precision on the functional tests. At the same time, the table reveals notable regressions: some models Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 11 Model SEA SG Indonesian T agalog Thai Vietnamese Malay Mandarin Singlish T amil Ministral 56.49 ( 10.04 ) 65.61 ( 0.36 ) 66.87 ( 1.95 ) 80.05 ( 4.90 ) 63.00 ( 3.26 ) 60.77 ( 4.15 ) 75.33 ( 3.11 ) 70.48 ( 4.82 ) Llama3b 57.91 ( 9.46 ) 66.21 ( 3.41 ) 67.18 ( 4.99 ) 78.28 ( 3.90 ) 61.62 ( 2.67 ) 58.13 ( 8.36 ) 65.73 ( 3.81 ) 68.96 ( 2.21 ) Llama8b 71.23 ( 6.10 ) 67.86 ( 8.37 ) 76.16 ( 7.07 ) 79.78 ( 7.43 ) 71.50 ( 5.34 ) 63.94 ( 2.28 ) 78.93 ( 5.00 ) 65.24 ( 5.85 ) Sealion 76.24 ( 4.16 ) 74.04 ( 15.66 ) 74.26 ( 3.72 ) 82.17 ( 7.74 ) 75.04 ( 4.19 ) 63.94 ( 4.31 ) 82.27 ( 10.61 ) 77.64 ( 4.22 ) Seallm 69.73 ( 0.54 ) 69.60 ( 12.75 ) 71.16 ( 0.68 ) 81.75 ( 7.47 ) 72.31 ( 6.39 ) 66.27 ( 0.09 ) 75.16 ( 6.52 ) 67.92 ( 13.04 ) Pangea 65.22 ( 3.07 ) 67.76 ( 14.00 ) 65.98 ( 8.90 ) 83.03 ( 9.09 ) 67.53 ( 0.18 ) 63.43 ( 3.58 ) 73.35 ( 9.14 ) 69.09 ( 12.26 ) Qwen 72.52 ( 1.34 ) 67.51 ( 5.68 ) 74.85 ( 1.93 ) 79.96 ( 2.76 ) 71.58 ( 2.11 ) 62.33 ( 10.73 ) 78.19 ( 4.67 ) 70.05 ( 11.72 ) Gemma 81.72 ( 1.36 ) 80.26 ( 3.01 ) 82.32 ( 5.77 ) 88.68 ( 5.59 ) 78.28 ( 0.62 ) 65.03 ( 12.00 ) 86.16 ( 11.70 ) 81.26 ( 2.91 ) Seagem 75.82 ( 2.93 ) 82.43 ( 5.30 ) 76.82 ( 2.24 ) 85.30 ( 3.44 ) 70.72 ( 6.51 ) 63.64 ( 8.25 ) 75.45 ( 1.47 ) 81.39 ( 0.32 ) T able 8. F1 scores of fine-tuned models on SEAHateCheck and SGHateCheck High-ality T est Cases, with changes from non- finetuned results in parentheses. Red = decrease, Blue = increase. decline on Mandarin, and others show drops on Malay or , in the case of Seagem, on both Indonesian and Mandarin. These variations suggest that netuning does not uniformly stabilize multilingual performance and may reduce capabilities when the adaptation data is narrow or misaligned with the linguistic phenomena emphasize d in SEAHateCheck and SGHateCheck. For example, SGHateCheck includes obfuscation types in Mandarin and Singlish—such as pinyin spellings, character decomposition, and spacing variants—that may be underrepresented in netuning corpora, leading to performance deterioration. Comparing the two tables highlights that netuned open mo dels reduce the gap with closed baselines and, in some cases, surpass them on specic languages, as observed for Vietnamese and Singlish with Gemma. In addition, the most signicant improvements occur in languages with the weakest out-of-the-box coverage, particularly T agalog and Thai, reecting the value of additional supervise d signal in low-resource settings. From a model-centric perspective, architecture and pretraining scope can help to explain several observed eects. SeaLion and Seagem benet from continual pretraining on regional data, which likely contributes to their strong out- of-the-box performance in Indonesian, Thai, and Vietnamese. Finetuning further enhances performance by providing targeted domain exposure. As shown in T able 16, Pangea excludes T agalog in its base multilingual pretraining, accounting for its weak T agalog baseline and signicant impr ovements after adaptation. Larger instruction-tuned models such as Gemma and Qwen demonstrate broad gains, consistent with cross-lingual lexicalization and instruction-follo wing capabilities acquired during pretraining. Conversely , performance declines on Mandarin for SeaLion, Seagem, Pangea, and Qwen suggest that netuning can induce shifts in decision boundaries or cause forgetting when adaptation data is not aligned with the obfuscation patterns present in the benchmark. These eects reect the challenge of modeling culturally grounded and orthographically diverse phenomena beyond simple wor d matching. From a language-centric perspective, the results align closely with the benchmarks’ design. SEAHateCheck targets implicit hate, slang, and culturally spe cic cues in Indonesian, T agalog, Thai, and Vietnamese. At the same time, SGHateCheck extends coverage to Singapore-specic varieties, including Mandarin and Singlish, with additional obfuscation tests. Lower out-of-the-box performance for T agalog and T amil reects both limited pretraining exposure and the intrinsic diculty of counter-spee ch and negation contrasts. The substantial gains after netuning indicate that modest, well-curated super vision can meaningfully enhance functional competence. In contrast, declines in Mandarin and specic Malay settings highlight domain mismatches b etween adaptation corpora and obfuscation-heavy test cases, emphasizing the need for explicit coverage of these phenomena to maintain robustness. Manuscript submitted to ACM 12 Ng et al. Overall, the results demonstrate that netuning is an eective strategy for SEA and Singaporean language varieties; howev er , its b enets depend on alignment with the functional phenomena being evaluated. Regressions can often be attributed to lab el imbalance, distributional skew in adaptation sets, forgetting of multilingual and orthographic knowledge, and insucient representation of counter-sp eech or obfuscation examples central to SEAHateChe ck and SGHateChe ck. Future adaptation eorts should balance hateful and non-hateful sup ervision across languages, incorporate curated counter-spe ech and obfuscation examples, and employ strategies such as rehearsal or multi-task learning to preserve pretraining knowledge while specializing to culturally grounded hate expressions. 4.2 Performance across Functional T ests W e summarize performance across functional tests b elow using a representative plot Figur e 1, while the complete per- language radar plots are provided in App endix Figures 7 - Figures 9. The non-netuned models display a consistent prole: they are condent on explicit hate expressions yet brittle whenever the task requires discourse-le vel interpretation, reference tracking, or polarity reversal. On the explicit side, tests such as direct threat, slur usage, and profanity as hate remain near the top for most systems and languages, producing tightly clustered traces in the upper band of the radar plots. In contrast, non-hateful counter-speech is routinely mishandled. Performance is low est on F18 and F19, which require recognizing quotations or r eferences to hateful content to condemn it. This w eakness is theoretically expected because the surface form of a counter-speech statement often reuses hateful tokens, inviting a spurious lexical shortcut. Our gures replicate this failure mode, as reported in the framework sp ecication and narrative analysis, which already noted that models conate refutation with hate and that F18 and F19 are especially challenging across languages. Negation also remains a p ersistent frontier . Mo dels underp erform on F13, where a hateful predicate is explicitly negated. The task requires aligning scope and compositional semantics instead of treating the presence of a hateful lexeme as decisive e vidence, a pattern again anticipated in the task design and highlighted in the prior discussion of functional-level errors. Bey ond counter-spe ech and negation, we obser ve variability in reference-based phenomena. Reference in subse quent clauses (F10) pulls many non-netuned traces downward, and implicit derogation (F4) is uneven, especially in languages where pragmatic implicature relies on culture-specic idioms. These observations align with the framework’s emphasis on contextual reasoning bey ond surface markers. Comprehensive per-function breakdowns for non-netuned and netuned models appear in Appendices D and E, respectively . Fine-tuning narrows several gaps yet do es not eliminate them. The clearest gains appear on Indonesian, Thai, Vietnamese, Malay , and Singlish for the two counter-speech tests, where scores rise but often remain below chance for multiple model families, indicating partial rather than full transfer of discourse-level cues. This pattern matches the text of our study that reports post-adaptation impr ovements on F18 and F19 while cautioning that the absolute accuracy still lags behind explicit categories. In several settings, ne-tuning pr oduces regressions on implicit and referential hate , notably F4, F10, and F12 for Indonesian and additional drops for Thai, Malay , and Mandarin. The combined evidence suggests that adaptation sets are rich in overt hate and categorical mentions but relatively sparse in examples that require long-range reference resolution or careful handling of polarity . When coupled with limited counter-speech coverage, this ske w encourages over-reliance on lexical heuristics, a mechanism already discussed in our dataset-level analysis. Obfuscation tests illustrate another divide. Character-level perturbations in F23 to F27 and F32 to F33 depress several traces in the non-netuned condition. Finetuning helps when the adaptation data expose the model to similar orthographic noise; however , improvements are inconsistent across models and languages, mirroring the framework’s design, which str esses r obustness to creative evasion strategies found in real discourse. In contrast, non-protected-target Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 13 abuse (F20 to F22) sits higher and more stably both before and after ne-tuning, suggesting that models can usually separate personal or object-directed profanity from protected-class hate when group semantics are not at stake. Language-specic traces echo these global tendencies while revealing culturally grounded nuances. The Thai and Vietnamese plots exhibit broad post-netuning gains around explicit threats and profanity , but smaller improvements on counter-speech and negation. Indonesian exhibits sizable improvements on reference and quotation counter-spee ch after netuning, though implicit derogation remains fragile. Mandarin and Malay display sharper drops on some implicit and reference tests, consistent with concerns about domain mismatch between adaptation corpora and our obfuscation-heavy and discourse-sensitive test suites. These obser vations are consistent with the paper’s textual summary of per-language ee cts and with the caution that the benets of netuning depend on the alignment b etween adaptation phenomena and evaluation functions. From an experimental persp ective, the radar plots reveal that ne-tuning narrows the spread of results across functional categories, indicating more stable behavior across models. Y et, dierences persist across language groups. Vietnamese and Indonesian exhibit stronger results overall, reecting the relative availability of training resources and clearer lexical markers. In contrast, T agalog and Thai show wider variance , suggesting that linguistic complexity and cultural particularities make these cases more complicated for models to resolve . These cross-linguistic discrepancies underscore the necessity of SEAHateChe ck by systematically diagnosing weaknesses at the functional test level. The dataset identies precisely where models fail, whether in handling implicit hate, disambiguating non-hateful contrasts, or managing counter-speech. T aken together , the functional analysis indicates that current multilingual and regional models have largely solved explicit le xical hate under controlled conditions, while r easoning-heavy contrasts remain op en challenges. Finetuning is eective when the adaptation data emphasize counter-spee ch, negation, and obfuscation. Still, it may erode p erformance on implicit or referential hate if the additional supervision overweights surface cues and induces forgetting of multi- lingual or orthographic knowledge. These conclusions reinforce SEAHateCheck ’s value . By decomposing evaluation into complementar y functions that reect real moderation needs, it reveals where progress stems from vocabulary memorization and where genuine language understanding is still required. Manuscript submitted to ACM 14 Ng et al. Fig. 1. Accuracy across Functional T ests for Indonesian (le) and T agalog (right) 4.3 Performance across Protected Categories W e evaluate performance across protected categories with a representative radar plot (Figure 2), and provide the full set of per-language results in Appendix Figures Figure 13 - Figure 15. The radar plots comparing non-netuned and netuned mo dels consistently show that, while most systems achieve relatively high recall for categories such as Religion and Ethnicity/Race/Origin, their performance deteriorates substantially when handling more nuanced or culturally sensitive categories, including Gender/Sexuality , Disability , Age, Pe ople Living with HIV (PLHI V), and Vulnerable W orkers. This trend is particularly salient in low-resource languages where linguistic complexity and sociocultural nuance exacerbate model weaknesses. Expanded categor y-wise results are available in Appendices F and G for non-netuned and netuned settings. Non-ne-tuned models tend to overt towar ds high-frequency protected categories. For instance, across all tested languages, detection rates for Religion and Ethnicity/Race/Origin consistently cluster at the upper range of the radar charts, reecting mo dels’ reliance on explicit lexical cues and more fr equent representation in training corp ora. However , categories such as Gender/Sexuality and Disability show lower and more variable scores, highlighting that models Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 15 struggle with implicit expressions and culturally specic markers of marginalization. These ndings align with prior research showing that functional tests inv olving implicit hate or counter-spee ch are among the most challenging. Fine-tuning improves ov erall balance across categories, particularly for Disability and Age, where netuned models show more consistent recall across languages. Nonetheless, the gains are uneven. In categories like PLHIV and Vulnerable W orkers, improv ements remain limited, suggesting that ne-tuning with generic hate spee ch corpora does not suciently capture the cultural and legal salience of these groups in Southeast Asia. This phenomenon highlights the necessity of SEAHateCheck , which explicitly enco des these protecte d categories based on regional legislation and sociolinguistic consultation, thereby lling a critical gap absent in prior b enchmarks such as HateCheck and Multilingual HateCheck. Larger or safety-hardened closed models (o3, Gemini) trace the outer envelope acr oss categories before and after adaptation. Y et, even these systems show dips on Age and PLHIV in some languages, pointing to limited pretraining coverage of community-specic references and euphemisms. Open models benet most from ne-tuning but r emain sensitive to the distribution of training labels by category; when adaptation data underrepresents benign identity mentions, performance on Religion or Gender/Sexuality neutral cases can degrade due to over-triggering. Linguistically , tonal languages (Thai, Vietnamese) perform well in categories where e xplicit hate is common. Y et, they present additional challenges for Gender/Sexuality and Religion, where pragmatic markers and culture-bound idioms modulate toxicity . After netuning, Thai and Vietnamese show clearer , more uniform polygons across categories, suggesting that localized templates capture tonal orthography that are rare in generic multilingual corp ora. In contrast, T agalog test cases rev eal lower accuracy across nearly all categories, consistent with earlier ndings that T agalog’s code-switching and colloquial profanity are dicult for multilingual models to parse. Ho wever , it similarly tightens around Age and Disability once slangy r eferences are included in training materials. These divergences highlight the fact that language-specic so ciolinguistic phenomena directly impact category-level detection p erformance, rendering cross-lingual transfer insucient without culturally grounded benchmarks. SEAHateCheck thus contributes to the eld by systematically exposing model weaknesses across legally and culturally protected categories in Southeast Asia. It demonstrates that high overall accuracy on traditional test sets can mask se vere blind spots in categories most relevant to marginalized communities. By providing contrastive and culturally validated functional tests, the dataset enables resear chers to move b eyond aggregate p erformance metrics and interrogate whether systems truly generalize across all vulnerable groups. In doing so, SEAHateCheck establishes itself as an indisp ensable resource for building inclusiv e hate spee ch detection systems and advancing equitable online content moderation in low-resource linguistic conte xts. Manuscript submitted to ACM 16 Ng et al. Fig. 2. F1 Score across Protected Categories on Indonesian (le) and Taglog (right) 5 Discussion on Silver Lab el T est Cases 5.1 Performance on Silver T estcases The silv er test cases reveal performance dynamics that are not visible in gold cases, oering an essential diagnostic layer for assessing robustness. As shown in T ables 9 and 10, non-netuned models p erform competitively in some languages, such as Vietnamese ( o3: 84.94, Gemini: 77.05, Minstral: 81.59) and Indonesian ( o3: 81.52, Seagem: 76.32), wher e F1 scores exceed 75. In contrast, T agalog and T amil remain underexplor ed by most systems, with several models dropping below 60 (e.g., Deepseek: 53.86 on Tagalog, 56.37 on T amil), underscoring the ne cessity of additional evaluation coverage through silver cases. Fine-tuning introduces striking gains in low-resource settings. T agalog shows the most signicant jumps, with Llama3b rising from 60.79 to 76.57 and Llama8b from 67.58 to 72.07, demonstrating the positive impact of even modest supervision in morphologically complex and underrepresented languages. T amil similarly b enets, with Gemini climbing from 73.95 to 80.16, while Seagem impr oves from 74.78 to 77.10. These impr ovements validate the role of silv er cases in surfacing progress where pretraining exposure is minimal and culturally grounded evaluation is scarce. At the Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 17 same time, regressions appear in better-resourced languages. Indonesian scores drop for most netuned models, with Minstral declining from 76.27 to 66.34, SeaLion by 11.21, and Seagem by 13.44. Similar declines are observed in Thai, where Minstral drops by 4.67 and SeaLion by 6.34. These regressions suggest that adaptation corpora skew ed toward explicit abuse may narrow models’ cov erage and reduce calibration on colloquial or implicit cases that the silver sets capture. Chinese and Malay also show smaller but consistent decreases (e .g., Gemma shows − 2 . 16 on Mandarin, − 1 . 40 on Malay), which further highlights the sensitivity of multilingual systems to distributional mismatch. W e provide comprehensive break-do wns by functional test and protected category for b oth non-ne-tuned and ne-tuned models in Appendices D - G. From the model perspe ctive, closed models sustain strong averages but their advantage is less pronounced on silver cases. For instance, o3 drops in Vietnamese from 84.94 to 78.12, showing that increased variability in case construction reduces the gap to open models. Conversely , Gemma and Qwen demonstrate broad adaptability , with Qwen improving in T agalog and T amil. At the same time, Gemma registers consistent, if modest, gains acr oss several SEA languages ( +3.41 in Indonesian, +4.05 in Thai, +4.90 in Vietnamese). This indicates that instruction-tuned models can leverage even limited supervision to extend generalisation to naturalistic, culturally embedde d contexts. From the language perspective, the results track w ell with sociolinguistic characteristics. Vietnamese and Indonesian maintain high ceilings due to strong online representation and lexical regularity , although the obser ved declines after ne-tuning highlight the diculty of balancing e xplicit and implicit phenomena. T agalog and T amil sho w the most apparent benet from silv er evaluation, since their underr epresentation in pretraining leaves mo dels brittle to morphological richness and register variability . Singlish and Mandarin remain challenging: while ne-tuning yields higher recall, this comes with increased false p ositives on benign slang, obfuscations, or counter-speech, reecting the cultural and orthographic ambiguity inherent to these varieties. Overall, the results demonstrate that silver test cases are indispensable in advancing hate spee ch detection for low-resource languages. The y introduce variability , colloquialism, and length that expose weaknesses hidden by gold cases, while also providing a cost-ecient means to scale coverage. By complementing gold cases, the silver suite ensures that evaluation is not restricted to template d contrasts but extends into the messy , lived realities of online discourse in Southeast Asia. This contribution strengthens SEAHateCheck ’s role as a benchmark. Model SEA SG Indonesian T agalog Thai Vietnamese Malay Mandarin Singlish T amil Ministral 76.27 70.42 66.85 81.59 68.97 68.97 66.33 56.93 Llama3b 62.46 60.79 63.05 69.70 61.58 61.58 60.95 68.98 Llama8b 69.77 67.58 68.43 79.44 69.06 69.06 68.70 62.22 Sealion 68.37 64.54 68.87 78.66 67.77 67.77 74.15 64.26 Seallm 58.28 62.20 66.05 70.94 65.42 65.42 67.08 56.75 Pangea 67.68 60.86 48.42 69.43 65.26 65.26 56.37 51.84 Qwen 75.91 70.58 73.64 80.02 71.92 71.92 69.05 71.73 Gemma 63.52 61.39 70.39 78.54 66.50 66.50 70.93 56.21 Seagem 76.32 71.97 73.49 80.00 72.78 72.78 70.48 74.78 Gemini 75.29 64.06 71.83 77.05 75.98 75.98 79.56 76.30 o3 81.52 74.80 77.17 84.94 78.12 78.12 79.38 79.98 Deepseek 59.83 53.86 58.49 66.68 64.01 64.01 65.60 62.37 T able 9. F1 scores of dierent non-finetuned models on SEAHateCheck and SGHateChe ck Silver T est Cases. Manuscript submitted to ACM 18 Ng et al. Model SEA SG Indonesian T agalog Thai Vietnamese Malay Mandarin Singlish T amil Ministral 66.34 ( 9.93 ) 74.34 ( 3.92 ) 71.52 ( 4.67 ) 85.37 ( 3.78 ) 70.65 ( 1.68 ) 69.97 ( 1.00 ) 75.68 ( 9.35 ) 62.56 ( 5.63 ) Llama3b 70.17 ( 7.71 ) 76.57 ( 15.78 ) 74.38 ( 11.33 ) 85.98 ( 16.28 ) 74.92 ( 13.34 ) 71.82 ( 10.24 ) 80.16 ( 19.21 ) 75.19 ( 6.21 ) Llama8b 57.83 ( 11.94 ) 72.07 ( 4.49 ) 61.43 ( 7.00 ) 83.69 ( 4.25 ) 68.05 ( 1.01 ) 66.90 ( 2.16 ) 73.51 ( 4.81 ) 68.19 ( 5.97 ) Sealion 57.16 ( 11.21 ) 72.25 ( 7.71 ) 65.46 ( 3.41 ) 83.19 ( 4.53 ) 63.63 ( 4.14 ) 66.18 ( 1.59 ) 70.87 ( 3.28 ) 65.63 ( 1.37 ) Seallm 61.09 ( 2.81 ) 73.94 ( 11.74 ) 73.99 ( 7.94 ) 84.88 ( 13.94 ) 73.94 ( 8.52 ) 71.67 ( 6.25 ) 79.69 ( 12.61 ) 63.26 ( 6.51 ) Pangea 61.37 ( 6.31 ) 72.42 ( 11.56 ) 63.21 ( 14.79 ) 84.12 ( 14.69 ) 69.91 ( 4.65 ) 67.08 ( 1.82 ) 72.48 ( 16.11 ) 63.61 ( 11.77 ) Qwen 69.64 ( 6.27 ) 75.67 ( 5.09 ) 71.14 ( 2.50 ) 86.32 ( 6.30 ) 73.32 ( 1.40 ) 69.50 ( 2.42 ) 81.00 ( 11.95 ) 78.50 ( 6.77 ) Gemma 66.93 ( 3.41 ) 72.33 ( 10.94 ) 69.34 ( 1.05 ) 83.44 ( 4.90 ) 75.40 ( 8.90 ) 66.15 ( 0.35 ) 76.46 ( 5.53 ) 64.06 ( 7.85 ) Seagem 62.88 ( 13.44 ) 74.83 ( 2.86 ) 68.14 ( 5.35 ) 86.34 ( 6.34 ) 69.68 ( 3.10 ) 65.01 ( 7.77 ) 79.49 ( 9.01 ) 77.10 ( 2.32 ) T able 10. F1 scores of dierent fine-tuned models on SEAHateCheck and SGHateChe ck Silver T est Cases, with changes from non-finetuned results in parentheses. Red = decrease, Blue = increase. T o assess generalization on silv er functional tests, we show a repr esentative plot in Figure 3, Appendix Figure 12 - Figure 10 contain the remaining per-language results. Unlike gold test cases, which are template-driven and highly controlled, silver test cases are LLM-generated to reect collo quial usage and richer linguistic diversity , making them a stronger proxy for r eal-world hate speech in Southeast Asian contexts. Across non-netuned models, performance was markedly inconsistent. While several models demonstrated rea- sonable accuracy on explicit hate categories—such as derogatory negative emotion and attributional insults—their performance deteriorated on more subtle or implicit forms of hate speech. In particular , functional tests involving implicit derogation (F4), negated positive statements (F12), and phrasings in the form of questions or opinions (F14–F15) yielded much lower scores. These weaknesses r eect a reliance on surface-level lexical cues, which are less r eliable in detecting implicit hate that is highly dependent on cultural and contextual interpretation. Similarly , non-netuned models frequently misclassied counter-spe ech instances (F18–F19), where hate is quoted or explicitly denounce d, highlighting persistent confusion between hateful and non-hateful expressions that share similar lexical markers. Fine-tuned models showed substantial improvements across nearly all functional categories, conrming the value of domain-specic adaptation. The most notable gains appeared in implicit hate detection and counter-speech recognition. For instance, models after ne-tuning achieved consistently higher F1-scores in the range of 0.7–0.9 for implicit derogation and counter-sp eech, whereas non-netuned mo dels often fell b elow 0.5. This indicates that ne-tuning improved models’ sensitivity to contextual cues and reduced false positives. Fine-tuned models also performed b etter on profanity-based tests (F8–F9), successfully distinguishing hateful versus non-hateful profanity—a contrast that non-netuned models often failed to capture. Nevertheless, ev en ne-tuned models struggle d with functional tests designed to capture identity references across subsequent sentences or clauses (F10–F11), as well as complex substitution-based tests (F23–F34). These involve longer discourse structures or obfuscation patterns that require r obust contextual reasoning and adaptability . The gap b etween performance on template-based gold cases and silver cases also illustrates the diculty of transferring model comp etence to naturally occurring, diverse inputs. The silver functional tests underscore the necessity of SEAHateCheck for low-resource Southeast Asian languages. They expose failure mo des that are unlikely to surface in template-driven e valuation, particularly in handling collo- quial phrasing, cultural nuances, and implicit hate that dominate real-world discourse. The diagnostic results high- light how ne-tuning mitigates specic weaknesses, y et also reveal areas where further research is needed—such as Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 19 discourse-aware architectures and cr oss-sentence contextual modeling. By incorporating both gold and silver test cases, SEAHateCheck enables a more comprehensive evaluation of hate speech detection systems, bridging the gap between controlled diagnostic testing and the variability of authentic online environments. 5.2 Performance across Protected Categories on Silver T estcases W e examine silver-case performance across protected categories using a representative plot (Figure 4), with additional per-language plots in Appendix Figure 18 - Figure 16. O verall, both non-netuned and netuned mo dels exhibited consistent trends across categories such as Religion, Ethnicity/Race/Origin, Gender/Sexuality , Disability , Age, Vulnerable W orkers, and People Living with HIV (PLHIV). These categories were dened based on local legislation ( see Section 2.1), making them critical for assessing whether detection mo dels are culturally attune d to the sociopolitical realities of Southeast Asia. From a qualitative perspective, non-netuned models tended to perform unevenly acr oss categories. Religion and Ethnicity/Race/Origin generally achieved higher detection rates, likely because these categories are more frequently represented in global pretraining corp ora. In contrast, categories such as Disability , PLHI V , and Vulnerable W orkers proved particularly challenging, with models often failing to recognize implicit or culturally nuanced hateful e xpressions. This diculty reects both the scarcity of such examples in training data and the so ciolinguistic complexity of localized insults and stereotypes. Fine-tuning impro ved robustness, reducing variance across c ategories. However , even after ne-tuning, specic categories such as Disability and PLHI V r emained relatively underperforming compared to Religion or Ethnicity , suggesting that ne-tuning alone cannot fully mitigate the gaps cause d by limited representation in upstream datasets. Quantitatively , the silver testcases highlight substantial dierences in accuracy across protected groups. In non- netuned settings, mo del performance on Religion and Ethnicity averaged b etween 0.70 and 0.78 F1, while scores for Disability and PLHI V often fell b elow 0.60. Fine-tuned mo dels exhibited an overall upward shift, with Religion and Ethnicity surpassing 0.80 F1 in most cases and Gender/Sexuality stabilizing around 0.75. Nevertheless, gains w ere uneven: while Disability impro ved from 0.55 to 0.68 and PLHI V from 0.52 to 0.65, these categories still lagged behind better-represented groups. Age and V ulnerable W orkers presented mixed outcomes, with some mo dels (e.g., SEA -Lion, Seallm) achieving performance comparable to Ethnicity (0.72–0.74), whereas others plateaued closer to 0.65. This pattern underscores the persistent data imbalance across categories. T aken together , these ndings reinforce the necessity of SEAHateChe ck ’s protected-category-spe cic functional tests. By exposing systematic weaknesses across underrepresented categories such as Disability , PLHI V , and Vulnerable W orkers, SEAHateCheck provides diagnostic insights that are often obscured by aggregate accuracy metrics. The silver testcases, in particular , amplify this diagnostic power by introducing more naturalistic and colloquial expressions that stress-test models b eyond template-based gold cases. Beyond label accuracy , recent work proposes metrics for evaluating the reasoning quality of hate-sp eech explanations, oering an additional diagnostic lens for trustworthy moderation [20]. Such metrics could complement SEAHateCheck-style functional testing in future evaluations. Manuscript submitted to ACM 20 Ng et al. Fig. 3. Accuracy across Silver Functional T ests for Indonesian (le) and T agalog (right) Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 21 Fig. 4. F1 Score across Protected Categories for Silver Indonesian (le) and Taglog (right) 6 Related W ork Research on online hate spe ech detection has be en propelled by annotated resources that concentrate on English and a handful of other well-resourced languages, which accelerates model progress but obscur es weaknesses when models face culturally distinct phenomena in low-resource settings. This imbalance is acute in Southeast A sia, where heterogeneous scripts, tone-sensitive phonology , code mixing, and country-sp ecic legal framings of protected groups interact with platform discourse in ways that are not captured by existing b enchmarks. A dataset for this region must therefore pro vide culturally grounded evaluation with interpretable, capability-level diagnostics while remaining methodologically transparent and reproducible. Functional testing oers a principled alternative to random held-out evaluation by probing well-dened capabilities such as handling negation, distinguishing benign identity mentions from abuse, and recognizing countersp eech. HateCheck introduced this paradigm in English thr ough hand crafted functional tests that expose systematic errors that aggregate accuracy can hide [ 41 ]. Multilingual HateCheck extended the idea to ten languages and show ed that even Manuscript submitted to ACM 22 Ng et al. strong multilingual systems fail in predictable ways when confronted with targeted linguistic phenomena Röttger et al . [40] . These works motivate a shift towar d interpretable evaluation suites that can rev eal failure modes tied to culture and language rather than only corpus level statistics. In the Southeast Asian conte xt, Hu et al . [19] complements our functional-test perspective with adversarial safety evaluation. This further motivates region-specic resources beyond English-centric benchmarks. A common strategy for expanding coverage to new languages is translation. Some resources rely on human translation to preser ve nuance, as in Röttger et al . [40] . Others adopt machine translation to scale the process; for example, Goldzycher et al . [17] uses Google Translate 2 to cr eate candidate instances that are subsequently curated. SGHateCheck follows a hybrid approach by using large language models to assist translation and paraphrasing while incorporating feedback from two native speakers to ensure delity [ 30 ]. Our work builds upon this pipeline and advances it by using few-shot prompting seeded with previously veried translations, ensuring that machine-assisted outputs better reect country-spe cic usage, taboo lexicon, and local discourse markers before being adjudicated by native experts. Another line generates entirely novel test cases with large language models. Shen et al . [45] constructs a broad set of hateful and non hateful content by combining toxic personas [ 13 ] with jailbreak style prompts [ 44 ], and reports a non trivial safety r ejection rate as models decline to produce some requested content. By contrast, the silver label test cases in SEAHateCheck and in SGHateCheck are produce d with prompts co designed with nativ e speakers and conditioned on high quality gold examples from b oth suites. W e delib erately avoid jailbreak tactics and instead employ SEA Lionv2.1 due to its relatively low rejection rate under safety guardrails, which yields collo quial yet controlled variants aligned with explicit functions rather than unconstrained toxicity . Recent work asks whether large language models can author functional tests themselves. GPT HateCheck studies prompt and rubric designs for generating capability targeted minimal pairs and reports that LLM author ed tests can diversify phrasing and e xpand coverage when strong quality control is imposed, while also noting that models tend to introduce culturally brittle phrasing and subtle shifts in intent when left unchecked Jin et al . [23] . SEAHateCheck adopts a conservative p osition in light of these ndings. Gold cases remain human curated and template instantiated to guarantee interpretability and legal alignment, and silver cases use LLM generation only under native co-design with few-shot seeding, followed by unanimous adjudication. This choice retains the diversity benets highlighted by GPT HateCheck and mitigates risks from model priors that are poorly calibrated for Southeast Asian discourse. Large language models are increasingly used as detectors rather than only as generators. Pan et al . [36] evaluates instruction following mo dels with zer o-shot and few-shot prompting and with parameter-ecient ne-tuning via LoRA [ 18 ], obser ving that ne-tuned variants can gain recall at the expense of precision. In a complementary study , Das et al . [7] shows that a simple pr ompt to a state of the art conversational mo del performs competitively on aggregate yet struggles with counterspeech and with non English inputs. SEAHateChe ck directly targets these weaknesses by including contrasts for counterspeech, quotation, and denouncement, benign identity mentions, and profanity as a discourse marker , thereby oering ne-grained diagnostics for both prompted and ne-tuned detectors. SEAHateCheck is strongly inspired by SGHateCheck but addresses limitations that arise from a Singapore-centric scope [30]. Both suites embrace capability-focused testing with expert-in-the-lo op validation, and both pair template- instantiated gold items with silver items that widen lexical and compositional variety . SEAHateCheck e xpands language and country coverage to Indonesia, the Philippines, Thailand, and Vietnam, introduces tone-sensitive languages and distinct writing systems, and regr ounds protected categories through consultation with local experts and legislation. 2 https://translate.google.com/ Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 23 The multi-stage pipeline combines curation of machine-assisted translations with unanimous adjudication to ensure unambiguous intent, while few-shot silver generation seeded by veried gold exemplars captures colloquial forms, obfuscation strategies, and reclaimed or gurative expressions that frequently confuse detectors. This design preser ves interpretability at the function level and incr eases the ecological validity of tests for the region. Beyond diagnostics, the dataset enables rigorous assessment of adaptation strategies for low-resource settings. A wal et al . [2] shows that model agnostic meta learning yields initializations that adapt quickly to unseen languages under limited supervision. Ghorbanp our et al . [16] demonstrates that cross-lingual nearest neighbor r etrieval can leverage small labeled sets by augmenting them with retriev ed neighbors from multilingual pools. Y e et al . [56] explores privacy- preserving few-shot learning with datasets curated by marginalized communities, which is crucial where centralizing sensitive text is infeasible. Evaluating these methods on SEAHateCheck can disentangle actual improvements in capability from distribution-specic shortcuts by measuring gains on targeted functions such as implicit abuse, negation, reference, and slang. Community-centered scholarship further argues that local expertise is essential for reliable low-resource hate speech pipelines. Nkemelu et al . [31] shows that context e xperts are needed to dene protected groups, taboo lexicons, and pragmatic cues that shape interpretation. SEAHateCheck operationalizes this guidance by embedding nativ e translators and adjudicators throughout template adaptation, by do cumenting country-spe cic categories and slur inventories, and by instituting qualitative debriefs to capture cultural misres for subsequent revision, which together reduce conation of routine slang with genuine abuse. Methodological breadth continues to expand with r epresentation learning and semi-supervised strategies that our dataset can stress test. A dual contrastive framework is introduced to impro ve discrimination under data scarcity by aligning representations of hateful and non-hateful content [ 6 ]. Transformer-based systems with explainable components provide transparency alongside performance gains [ 15 ], while semi-super vised generative adversarial approaches leverage unlabeled data to improve generalization acr oss languages [ 29 ]. Beyond neural and multilingual approaches several studies analyse data pre-processing pipelines and feature engineering strategies for hate speech detection including work on w omen targete d abuse and feature combinations on T witter [ 39 , 42 ]. Because SEAHateCheck supplies carefully matched minimal pairs and explicit function lab els, it enables precise evaluation of whether contrastive, explainable, or generative systems captur e intent rather than correlating on surface profanity or identity tokens. Finally , the eld has begun to consolidate insights across languages and methods. Recent b enchmarks examine culturally grounded evaluation across Asian contexts, indicating a broader trend toward culture-aware evaluation beyond W estern high-resource settings [ 59 ]. Das et al . [8] reviews resources and techniques for low-resource hate speech detection and highlights two persistent gaps, namely the scarcity of culturally grounded datasets that reect code mixing and proverb-based insinuation, and the lack of evaluation protocols that diagnose capabilities rather than only reporting corpus-le vel scores. By delivering a functionally contr olled and culturally anchored suite for several Southeast Asian languages, SEAHateCheck addresses both decits and contributes a common yar dstick for future models that span meta learning, retrieval, federated optimization, contrastive objectiv es, and semi-super vised generation. In this way the dataset advances the empirical foundation for reliable detection in a linguistically and culturally diverse region. 7 Conclusion This study introduces SEAHateCheck , a HS benchmark dataset comprising testcases curated to the socio cultural landscape of Indonesia, the Philippines, Thailand, and Vietnam, and is designed to test HS detectors on a variety of HS functionalities and target groups. SEAHateCheck is further split into Gold Label and Silver Label datasets. Gold Manuscript submitted to ACM 24 Ng et al. Label datasets are translated from HateCheck [ 41 ], and three annotators for each testcase annotated selected ones. Silver Label datasets were generated by few-shot learning using high-quality test cases identied by annotators. This procedure is also used to form the Silver Label dataset for SGHateCheck [ 30 ]. In general, we observe that Silver Label testcases are more extensiv e and less likely to be judged by annotators as high quality . Subsequently , Gold Label and Silver Label SEAHateCheck and SGHateCheck testcases were tested on LLMs, wher e they were pr ompted to behave like HS detectors. In general, both closed and open-sourced LLMs performe d exceptionally well and frequently had an F1 of above 0.7. That said, we observed varying degrees of p erformance across dierent languages, functional tests, and protected categories. Fine-tuning also led to higher pr ecision for most cases, but also increased the risk of overtraining. 8 Limitations A major limitation of SEAHateChe ck Gold Label dataset is the rigidity of using templates to generate testcases, which limits the ability to customise templates to sp ecic targets. The Silver Label datasets, where HS was machine generated with input from the Gold Label dataset, were designed to overcome this rigidity issue. Ho wever , native-speakers were more likely to nd the Silver Label datasets to be of lower quality . A possible solution would be to use more powerful LLMs with jailbroken prompts, as described in Shen et al . [45] . Where silver quality scores fall short of gold and where target or function alignment is imperfect, we pr ovide language-specic adjudication notes in Appendix B that motivated subsequent ltering and template revisions. Recent work shows that cloaking perturbations can substantially degrade oensive-language detection robustness, suggesting that evasion-focused transformations should be incorporate d into future SEAHateCheck extensions [54]. The structure of the templates, which have up to two sentences, also does not fully reect the conversational nature of interactions on social media. As our experiments have shown, recent advancement in LLMs has made HS detection for such short texts a trivial matter . T ext that seem harmless alone, when chained together , can result in toxic meanings [48]. Another major limitation of this study is the reliance on existing laws to identify target groups, which repr esents a lag in vulnerable groups in society today . Acknowledgments This research/project is supported by Ministr y of Education, Singap ore, under its Academic Research Fund ( AcRF) Tier 2. Any opinions, ndings and conclusions or recommendations expressed in this material are those of the authors and do not reect the views of the Ministry of Education, Singapore. References [1] 2024. Un Ministral, des Ministraux. https://mistral.ai/news/ministraux. [2] Md Rabiul A wal, Roy K a-W ei Lee, Eshaan T anwar , T anmay Garg, and T anmoy Chakraborty . 2023. Mo del-agnostic meta-learning for multilingual hate speech detection. IEEE Transactions on Computational Social Systems 11, 1 (2023), 1086–1095. [3] T om Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Ne elakantan, Pranav Shyam, Girish Sastry , Amanda Askell, Sandhini Agarwal, Ariel Herbert- V oss, Gretchen Krueger , T om Henighan, Rew on Child, Aditya Ramesh, Daniel Ziegler , Jerey W u, Clemens Winter , Chris Hesse, Mark Chen, Eric Sigler , Mateusz Litwin, Scott Gray , Benjamin Chess, Jack Clark, Christopher Berner , Sam McCandlish, Alec Radford, Ilya Sutskever , and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems , H. Larochelle, M. Ranzato, R. Hadsell, M.F . Balcan, and H. Lin (Eds.), V ol. 33. Curran Associates, Inc., 1877–1901. https://proceedings.neurips.cc/paper_les/paper/2020/le/1457c0d6bfcb4967418bf b8ac142f64a- Paper .pdf [4] Neil Vicente Cabasag, Vicente Raphael Chan, Sean Christian Lim, Mark Edward Gonzales, and Charibeth Cheng. 2019. Hate speech in P hilippine election-related tweets: Automatic detection and classication using natural language processing. P hilippine Computing Journal XIV , 1 (A ugust 2019). Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 25 [5] Bharathi Raja Chakravarthi, Vigneshwaran Muralidaran, Ruba Priyadharshini, and John P hilip McCrae. 2020. Corpus Creation for Sentiment Analysis in Code-Mixed Tamil-English Te xt. In Procee dings of the 1st Joint W orkshop on Spoken Language Technologies for Under-resourced languages (SLT U) and Collaboration and Computing for Under-Resourced Languages (CCURL) , Dorothee Beermann, Laurent Besacier , Sakriani Sakti, and Claudia Soria (Eds.). European Language Resources association, Marseille, France, 202–210. https://aclanthology .org/2020.sltu- 1.28/ [6] Krishan Chavinda and Uthayasanker Thayasivam. 2025. A Dual Contrastive Learning Framew ork for Enhanced Hate Speech Detection in Low- Resource Languages. In Proceedings of the First W orkshop on Challenges in Processing South Asian Languages (CHiPSAL 2025) , Kengatharaiyer Sarveswaran, Ashwini Vaidya, Bal Krishna Bal, Sana Shams, and Surendrabikram Thapa (Eds.). International Committee on Computational Linguistics, Abu Dhabi, U AE, 115–123. https://aclanthology.org/2025.chipsal- 1.11/ [7] Mithun Das, Saurabh Kumar Pandey , and Animesh Mukherjee. 2024. Evaluating ChatGPT against Functionality T ests for Hate Speech Detection. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , Nicoletta Calzolari, Min- Y en Kan, V eronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue (Eds.). ELRA and ICCL, Torino , Italia, 6370–6380. https://aclanthology.org/2024.lr ec- main.564/ [8] Susmita Das, Arpita Dutta, Kingshuk Roy , Abir Mondal, and Arnab Mukhopadhyay . 2024. A Sur vey on A utomatic Online Hate Sp eech Detection in Low-Resource Languages. arXiv preprint arXiv:2411.19017 (2024). [9] Thomas Davidson, Dana Warmsle y , Michael Macy , and Ingmar W eber . 2017. A utomated Hate Spee ch Dete ction and the Problem of Oensive Language. Proceedings of the International AAAI Conference on W eb and Social Media 11, 1 (May 2017), 512–515. https://doi.org/10.1609/icwsm.v11i1.14955 [10] Google Deepmind. 2025. Introducing Gemini 2.0: our new AI mo del for the agentic era. https://blog.google/technology/google- deepmind/google- gemini- ai- update- december- 2024/#gemini- 2- 0- ash [11] Fabio Del Vigna12, Andrea Cimino23, Felice Dell’Orletta, Marinella Petrocchi, and Maurizio T esconi. 2017. Hate me, hate me not: Hate sp eech detection on facebook. In Proceedings of the First Italian Conference on Cyberse curity (I TASEC17) . 86–95. arXiv:http://ceur-ws.org/V ol-1816/paper- 09.pdf http://ceur- ws.org/V ol- 1816/paper- 09.pdf [12] Jiawen Deng, Jingyan Zhou, Hao Sun, Chujie Zheng, Fei Mi, Helen Meng, and Minlie Huang. 2022. COLD: A Benchmark for Chinese Oensive Language Detection. In Pr ocee dings of the 2022 Conference on Empirical Methods in Natural Language Processing , Y oav Goldberg, Zornitsa Kozareva, and Y ue Zhang (Eds.). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 11580–11599. https://doi.org/10.18653/v1/2022.emnlp- main.796 [13] Ameet Deshpande, Vishvak Murahari, T anmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. 2023. To xicity in chatgpt: Analyzing persona- assigned language models. In Findings of the Association for Computational Linguistics: EMNLP 2023 , Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 1236–1270. https://doi.org/10.18653/v1/2023.ndings- emnlp.88 [14] Abhimanyu Dubey , Abhinav Jauhri, Abhinav Pandey , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur , Alan Schelten, Amy Y ang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Y ang, Archi Mitra, Archie Sravankumar , Artem Korenev , Arthur Hinsvark, Arun Rao, Aston Zhang, Aur elien Rodriguez, A usten Gregerson, A va Spataru, Baptiste Roziere, Bethany Biron, Binh T ang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller , Christophe T ouret, Chunyang W u, Corinne W ong, Cristian Canton Ferrer , Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano , Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Graeme Nail, Gregoir e Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar , Hu Xu, Hugo T ouvron, Iliyan Zarov , Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Ivan Evtimov , Jade Copet, Jaew on Lee, Jan Geert, Jana V ranes, Jason Park, Jay Mahadeokar , Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie W ang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan V asuden Alwala, K artikeya Upasani, Kate Plawiak, Ke Li, K enneth Heaeld, Kevin Stone, Khalid El- Arini, Krithika Iyer , K shitiz Malik, Kuenley Chiu, Kunal Bhalla, Lauren Rantala- Y eary , Laurens van der Maaten, Lawrence Chen, Liang T an, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher , Lukas Landzaat, Luke de Oliveira, Madeline Muzzi, Mahesh Pasupuleti, Mannat Singh, Manohar Paluri, Marcin Kardas, Mathew Oldham, Mathieu Rita, Maya Pavlova, Melanie Kambadur , Mike Lewis, Min Si, Mitesh Kumar Singh, Mona Hassan, Naman Goyal, Narjes T orabi, Nikolay Bashlykov , Nikolay Bogoy chev , Niladri Chatterji, Olivier Duchenne, Onur Çelebi, Patrick Alrassy , Pengchuan Zhang, Pengwei Li, Petar V asic, Peter W eng, Prajjwal Bhargava, Pratik Dubal, Praveen Krishnan, Punit Singh Koura, Puxin Xu, Qing He, Qingxiao Dong, Ragavan Srinivasan, Raj Ganapathy , Ramon Calderer , Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohit Girdhar , Rohit Patel, Romain Sauvestre, Ronnie Polidoro, Roshan Sumbaly , Ross T aylor , Ruan Silva, Rui Hou, Rui W ang, Saghar Hosseini, Sahana Chennabasappa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov , Shaoliang Nie, Sharan Narang, Sharath Raparthy , Sheng Shen, Shengy e W an, Shruti Bhosale, Shun Zhang, Simon V andenhende, Soumya Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururangan, Sydney Borodinsky , T amar Herman, Tara Fowler , T arek Sheasha, Thomas Georgiou, Thomas Scialom, T obias Speckbacher , T odor Mihaylo v , T ong Xiao, Ujjwal Karn, V edanuj Goswami, Vibhor Gupta, Vignesh Ramanathan, Viktor Kerkez, Vincent Gonguet, Virginie Do, Vish V ogeti, Vladan Petrovic, W eiwei Chu, W enhan Xiong, W enyin Fu, Whitney Meers, Xavier Martinet, Xiaodong W ang, Xiaoqing Ellen Tan, Xinfeng Xie, Xuchao Jia, Xuewei W ang, Y aelle Goldschlag, Y ashesh Gaur , Y asmine Babaei, Yi W en, Yiwen Song, Y uchen Zhang, Y ue Li, Yuning Mao, Zacharie Delpierre Coudert, Zheng Y an, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aaron Grattaori, Abha Jain, Adam K elsey , Adam Shajnfeld, Adithya Gangidi, Adolfo Victoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alex V aughan, Alexei Baevski, Allie Feinstein, Amanda Kallet, Amit Sangani, Anam Y unus, Andrei Lupu, Andres Alvarado, Andre w Caples, Andrew Gu, Andrew Ho , Andrew Poulton, Andrew Ryan, Ankit Ramchandani, Annie Franco, Aparajita Saraf, Arkabandhu Chowdhury , Ashley Gabriel, Ashwin Bharambe, Assaf Eisenman, Azadeh Y azdan, Beau James, Ben Maur er , Benjamin Leonhardi, Bernie Manuscript submitted to ACM 26 Ng et al. Huang, Beth Loyd, Beto De Paola, Bhargavi Paranjape, Bing Liu, Bo Wu, Boyu Ni, Braden Hancock, Bram W asti, Brandon Spence, Brani Stojkovic, Brian Gamido, Britt Montalvo, Carl Parker , Carly Burton, Catalina Mejia, Changhan W ang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Feichtenhofer , Damon Civin, Dana Beaty , Daniel Kr eymer , Daniel Li, Danny W yatt, David Adkins, David Xu, Davide T estuggine, Delia David, Devi Parikh, Diana Liskovich, Didem Foss, Dingkang W ang, Duc Le, Dustin Holland, Edwar d Dowling, Eissa Jamil, Elaine Montgomery , Eleonora Presani, Emily Hahn, Emily W ood, Erik Brinkman, Esteban Arcaute, Evan Dunbar , Evan Smothers, Fei Sun, Felix Kreuk, Feng Tian, Firat Ozgenel, Francesco Caggioni, Francisco Guzmán, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer , Georgia Swee, Gil Halpern, Govind Thattai, Grant Herman, Grigory Sizov , Guangyi, Zhang, Guna Lakshminarayanan, Hamid Shojanazeri, Han Zou, Hannah W ang, Hanwen Zha, Har oun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Ibrahim Damlaj, Igor Molybog, Igor T ufanov , Irina-Elena V eliche , Itai Gat, Jake W eissman, James Geboski, James K ohli, Japhet Asher , Jean-Baptiste Gaya, Je Marcus, Je Tang, Jennifer Chan, Jenny Zhen, Jeremy Reizenstein, Jeremy T eboul, Jessica Zhong, Jian Jin, Jingyi Yang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan T orres, Josh Ginsburg, Junjie W ang, Kai W u, Kam Hou U, K aran Saxena, Karthik Prasad, Kartikay Khandelwal, Katayoun Zand, K athy Matosich, Kaushik V eeraraghavan, Kelly Michelena, Keqian Li, Kun Huang, Kunal Chawla, Kushal Lakhotia, K yle Huang, Lailin Chen, Lakshya Garg, Lavender A, Leandro Silva, Le e Bell, Lei Zhang, Liangpeng Guo, Licheng Yu, Liron Moshkovich, Luca W ehrstedt, Madian Khabsa, Manav A valani, Manish Bhatt, Maria T simpoukelli, Martynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev , Maxim Naumo v , Maya Lathi, Meghan Keneally , Michael L. Seltzer , Michal V alko, Michelle Restr epo, Mihir Patel, Mik V yatskov , Mikayel Samvelyan, Mike Clark, Mike Macey , Mike W ang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rastegari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier , Nikolay Pavlovich Laptev , Ning Dong, Ning Zhang, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar , Ozlem Kalinli, Parkin K ent, Parth Parekh, Paul Saab, Pavan Balaji, Pedro Rittner, Philip Bontrager , Pierre Roux, Piotr Dollar , Polina Zv yagina, Prashant Ratanchandani, Pritish Yuvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Ra A yub, Raghotham Murthy , Raghu Nayani, Rahul Mitra, Raymond Li, Rebekkah Hogan, Robin Battey , Rocky W ang, Rohan Maheswari, Russ How es, Ruty Rinott, Sai Jayesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidoro v , Satadru Pan, Saurabh V erma, Seiji Y amamoto, Sharadh Ramaswamy , Shaun Lindsay , Shaun Lindsay , Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shiva Shankar , Shuqiang Zhang, Shuqiang Zhang, Sinong W ang, Sneha A garwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve K ehoe, Steve Sattereld, Sudarshan Go vindaprasad, Sumit Gupta, Sungmin Cho, Sunny Virk, Suraj Subramanian, Sy Choudhury , Sydney Goldman, T al Remez, Tamar Glaser , T amara Best, Thilo Kohler , Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timothy Chou, Tzook Shaked, V arun V ontimitta, Victoria Ajayi, Victoria Montanez, Vijai Mohan, Vinay Satish Kumar , Vishal Mangla, Vítor Albiero, Vlad Ionescu, Vlad Poenaru, Vlad Tiberiu Mihailescu, Vladimir Ivanov , W ei Li, W enchen W ang, W enwen Jiang, W es Bouaziz, Will Constable, Xiaocheng Tang, Xiaofang W ang, Xiaojian Wu, Xiaolan Wang, Xide Xia, Xilun Wu, Xinbo Gao, Y anjun Chen, Y e Hu, Y e Jia, Y e Qi, Y enda Li, Yilin Zhang, Ying Zhang, Y ossi Adi, Y oungjin Nam, Y u, W ang, Y uchen Hao, Y undi Qian, Yuzi He , Zach Rait, Zachary DeVito , Zef Rosnbrick, Zhaoduo W en, Zhenyu Y ang, and Zhiwei Zhao. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv .org/abs/2407.21783 [15] Endrit Fetahi, Arsim Susuri, Mentor Hamiti, Zenun Kastrati, Ercan Canhasi, and Arta Misini. 2025. Enhancing so cial media hate spe ech detection in low-resource languages using transformers and explainable AI. Social Network A nalysis and Mining 15, 1 (2025), 82. [16] Faeze Ghorbanpour, Daryna Dementieva, and Alexander Fraser . 2025. Data-Ecient Hate Spe ech Dete ction via Cross-Lingual Nearest Neigh- bor Retrieval with Limited Lab eled Data. In Procee dings of the 2025 Conference on Empirical Methods in Natural Language Processing , Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 29662–29680. https://doi.org/10.18653/v1/2025.emnlp- main.1507 [17] Janis Goldzycher , Paul Röttger , and Gerold Schneider . 2024. Improving Adversarial Data Collection by Supporting Annotators: Lessons from GAHD, a German Hate Speech Dataset. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies (V olume 1: Long Papers) , Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Linguistics, Mexico City , Mexico, 4405–4424. https://doi.org/10.18653/v1/2024.naacl- long.248 [18] Edward J Hu, Y elong Shen, Phillip W allis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and W eizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations . https://openreview .net/forum?id=nZe VKeeFYf9 [19] Y ujia Hu, Ming Shan Hee, Preslav Nakov , and Roy Ka- W ei Lee. 2025. T oxicity Red-T eaming: Benchmarking LLM Safety in Singapore’s Low- Resource Languages. In Proce edings of the 2025 Conference on Empirical Methods in Natural Language Processing , Christos Christodoulop oulos, T anmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 12183–12201. https: //doi.org/10.18653/v1/2025.emnlp- main.612 [20] Y ujia Hu and Roy Ka- W ei Lee. 2026. HateXScore: A Metric Suite for Evaluating Reasoning Quality in Hate Speech Explanations. arXiv preprint arXiv:2601.13547 (2026). [21] Muhammad Huzaifah, W eihua Zheng, Nattapol Chanpaisit, and Kui W u. 2024. Evaluating Code-Switching Translation with Large Language Models. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , Nicoletta Calzolari, Min- Y en Kan, V eronique Hoste, Alessandro Lenci, Sakriani Sakti, and Nianwen Xue (Eds.). ELRA and ICCL, Torino , Italia, 6381–6394. https://aclanthology.org/2024.lr ec- main.565/ [22] Muhammad Okky Ibrohim and Indra Budi. 2019. Multi-label Hate Sp eech and Abusive Language Detection in Indonesian Twitter . In Proceedings of the Third W orkshop on Abusive Language Online , Sarah T . Roberts, Jo el T etreault, Vinodkumar Prabhakaran, and Zeerak Waseem (Eds.). Association for Computational Linguistics, Florence, Italy , 46–57. https://doi.org/10.18653/v1/W19- 3506 Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 27 [23] Yiping Jin, Leo W anner , and Alexander Shvets. 2024. GPT-HateCheck: Can LLMs Write Better Functional T ests for Hate Speech Detection?. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , Nicoletta Calzolari, Min- Y en K an, V eronique Hoste , Alessandro Lenci, Sakriani Sakti, and Nianwen Xue (Eds.). ELRA and ICCL, T orino, Italia, 7867–7885. https://aclanthology .org/2024.lrec- main.694/ [24] Klaus Kripp endor. 2018. Content analysis: A n introduction to its methodology . Sage publications. 357 pages. [25] Son T . Luu, Kiet V an Nguyen, and Ngan Luu- Thuy Nguyen. 2021. A Large-Scale Dataset for Hate Speech Detection on Vietnamese Social Media Te xts . Springer International Publishing, 415–426. https://doi.org/10.1007/978- 3- 030- 79457- 6_35 [26] Krishanu Maity , Shaubhik Bhattacharya, Sriparna Saha, and Manjeevan Seera. 2023. A Deep Learning Framework for the Detection of Malay Hate Speech. IEEE Access 11 (2023), 79542–79552. https://doi.org/10.1109/ACCESS.2023.3298808 [27] Krishanu Maity , A. S. Poornash, Shaubhik Bhattacharya, Salisa P hosit, Sawarod Kongsamlit, Sriparna Saha, and Kitsuchart Pasupa. 2024. Hate ThaiSent: Sentiment- Aided Hate Sp eech Detection in Thai Language. IEEE Transactions on Computational Social Systems 11, 5 (2024), 5714–5727. https: //doi.org/10.1109/TCSS.2024.3376958 [28] Binny Mathew , Punyajoy Saha, Seid Muhie Yimam, Chris Biemann, Pawan Goyal, and Animesh Mukherjee. 2021. Hatexplain: A benchmark dataset for explainable hate speech detection. In Proceedings of the AAAI conference on articial intelligence , V ol. 35. 14867–14875. [29] Khouloud Mnassri, Reza Farahbakhsh, and Noel Crespi. 2024. Multilingual hate speech detection: a semi-supervised generative adversarial approach. Entropy 26, 4 (2024), 344. [30] Ri Chi Ng, Nirmalendu Prakash, Ming Shan Hee, K enny T su W ei Choo, and Ro y Ka-wei Lee. 2024. SGHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Singapore. In Proceedings of the 8th W orkshop on Online Abuse and Harms (WOAH 2024) , Yi-Ling Chung, Zeerak T alat, Debora Nozza, F lor Miriam Plaza-del Arco, Paul Röttger , Aida Mostafazadeh Davani, and Agostina Calabrese (Eds.). Association for Computational Linguistics, Mexico City , Mexico, 312–327. https://doi.org/10.18653/v1/2024.woah- 1.24 [31] Daniel Nkemelu, Harshil Shah, Michael Best, and Irfan Essa. 2022. Tackling hate spe ech in low-resource languages with context experts. In Proceedings of the 2022 International Conference on information and communication technologies and development . 1–11. [32] OpenAI, :, Aaron Hurst, A dam Lerer , Adam P . Goucher , Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostr ow , Akila W elihinda, Alan Hayes, Alec Radford, Aleksander Mądry , Alex Baker- Whitcomb , Alex Beutel, Alex Borzunov , Alex Carney , Alex Chow , Alex Kirillov , Alex Nichol, Ale x Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov , Alexi Christakis, Alexis Conneau, Ali Kamali, Allan Jabri, Allison Moyer , Allison T am, Amadou Crookes, Amin T ootoochian, Amin T ootoonchian, Ananya Kumar, Andr ea V allone, Andrej Karpathy , Andr ew Braunstein, Andrew Cann, Andrew Codispoti, Andrew Galu, Andrew Kondrich, Andr ew Tulloch, Andrey Mishchenko , Angela Baek, Angela Jiang, Antoine Pelisse, Antonia W oodford, Anuj Gosalia, Arka Dhar , Ashley Pantuliano, A vi Nayak, A vital Oliv er , Barret Zoph, Behrooz Ghorbani, Ben Leimberger , Ben Rossen, Ben Sokolowsky , Ben W ang, Benjamin Zweig, Beth Hoover , Blake Samic, Bob McGrew , Bobby Sp ero, Bogo Giertler , Bow en Cheng, Brad Lightcap, Brandon W alkin, Brendan Quinn, Brian Guarraci, Brian Hsu, Bright K ellogg, Brydon Eastman, Camillo Lugaresi, Carroll W ainwright, Cary Bassin, Cary Hudson, Casey Chu, Chad Nelson, Chak Li, Chan Jun Shern, Channing Conger, Charlotte Barette , Chelsea V oss, Chen Ding, Cheng Lu, Chong Zhang, Chris Beaumont, Chris Hallacy , Chris Koch, Christian Gibson, Christina Kim, Christine Choi, Christine McLeavey , Christopher Hesse, Claudia Fischer , Clemens Winter , Coley Czarnecki, Colin Jarvis, Colin W ei, Constantin Koumouzelis, Dane Sherburn, Daniel Kappler , Daniel Levin, Daniel Levy, David Carr , David Farhi, David Mely , David Robinson, David Sasaki, Denny Jin, Dev V alladares, Dimitris Tsipras, Doug Li, Duc Phong Nguyen, Duncan Findlay , Edede Oiw oh, Edmund W ong, Ehsan A sdar , Elizabeth Proehl, Elizabeth Y ang, Eric Antonow , Eric Kramer , Eric Peterson, Eric Sigler, Eric Wallace , Eugene Brevdo, Evan Mays, Farzad Khorasani, Felip e Petroski Such, Filipp o Raso, Francis Zhang, Fred von Lohmann, Freddie Sulit, Gabriel Goh, Gene Oden, Ge o Salmon, Giulio Starace, Greg Brockman, Hadi Salman, Haiming Bao, Haitang Hu, Hannah W ong, Haoyu W ang, Heather Schmidt, Heather Whitney , Heewoo Jun, Hendrik Kirchner , Henrique Ponde de Oliveira Pinto, Hongyu Ren, Huiwen Chang, Hyung W on Chung, Ian Kivlichan, Ian O’Connell, Ian O’Connell, Ian Osband, Ian Silber , Ian Sohl, Ibrahim Okuyucu, Ikai Lan, Ilya Kostrikov , Ilya Sutskever , Ingmar Kanitscheider , Ishaan Gulrajani, Jacob Coxon, Jacob Menick, Jakub Pachocki, James Aung, James Betker , James Crooks, James Lennon, Jamie Kiros, Jan Leike, Jane Park, Jason K w on, Jason Phang, Jason T eplitz, Jason W ei, Jason W olfe, Jay Chen, Je Harris, Jenia V aravva, Jessica Gan Lee, Jessica Shieh, Ji Lin, Jiahui Yu, Jiayi W eng, Jie T ang, Jieqi Yu, Joanne Jang, Joaquin Quinonero Candela, Joe Beutler , Joe Landers, Joel Parish, Johannes Heidecke, John Schulman, Jonathan Lachman, Jonathan McK ay , Jonathan Uesato, Jonathan W ard, Jong W ook Kim, Joost Huizinga, Jordan Sitkin, Jos Kraaijeveld, Josh Gross, Josh Kaplan, Josh Snyder , Joshua Achiam, Joy Jiao, Joyce Lee, Juntang Zhuang, Justyn Harriman, Kai Fricke, Kai Hayashi, K aran Singhal, Katy Shi, Kavin Karthik, Kayla W ood, Kendra Rimbach, Kenny Hsu, Kenny Nguyen, K eren Gu-Lemberg, Kevin Button, K evin Liu, Kiel Howe , Krithika Muthukumar , K yle Luther , Lama Ahmad, Larry Kai, Lauren Itow , Lauren W orkman, Leher Pathak, Leo Chen, Li Jing, Lia Guy , Liam Fedus, Liang Zhou, Lien Mamitsuka, Lilian W eng, Lindsay McCallum, Lindsey Held, Long Ouyang, Louis Feuvrier , Lu Zhang, Lukas Kondraciuk, Lukasz K aiser , Luke Hewitt, Luke Metz, Lyric Doshi, Mada Aak, Maddie Simens, Madelaine Boy d, Madeleine Thompson, Marat Dukhan, Mark Chen, Mark Gray , Mark Hudnall, Marvin Zhang, Marwan Aljubeh, Mateusz Litwin, Matthew Zeng, Max Johnson, Maya Shetty , Mayank Gupta, Meghan Shah, Mehmet Y atbaz, Meng Jia Yang, Mengchao Zhong, Mia Glaese, Mianna Chen, Michael Janner , Michael Lampe, Michael Petrov , Michael Wu, Michele W ang, Michelle Fradin, Michelle Pokrass, Miguel Castr o, Miguel Oom T emudo de Castro , Mikhail Pavlov , Miles Brundage, Miles W ang, Minal Khan, Mira Murati, Mo Bavarian, Molly Lin, Murat Y esildal, Nacho Soto, Natalia Gimelshein, Natalie Cone, Natalie Staudacher , Natalie Summers, Natan LaFontaine , Neil Chowdhury , Nick Ryder , Nick Stathas, Nick T urley , Nik T ezak, Niko Felix, Nithanth Kudige, Nitish Keskar , Noah Deutsch, No el Bundick, Nora Puckett, Or Nachum, Ola Okelola, Oleg Boiko, Oleg Murk, Oliver Jae, Olivia W atkins, Olivier Godement, Owen Campbell-Moore, Patrick Chao, Paul McMillan, Pavel Belov , Peng Su, Peter Bak, Peter Bakkum, Peter Deng, Peter Dolan, Peter Hoeschele, Peter W elinder , Phil Tillet, Philip Pronin, Philipp e Tillet, Prafulla Dhariwal, Qiming Yuan, Rachel Dias, Rachel Manuscript submitted to ACM 28 Ng et al. Lim, Rahul Arora, Rajan Troll, Randall Lin, Rapha Gontijo Lopes, Raul Puri, Reah Miyara, Reimar Leike, Renaud Gaubert, Reza Zamani, Ricky W ang, Rob Donnelly , Rob Honsby , Rocky Smith, Rohan Sahai, Rohit Ramchandani, Romain Huet, Ror y Carmichael, Rowan Zellers, Roy Chen, Ruby Chen, Ruslan Nigmatullin, Ryan Cheu, Saachi Jain, Sam Altman, Sam Schoenholz, Sam Toizer , Samuel Miserendino, Sandhini Agarwal, Sara Culver , Scott Ethersmith, Scott Gray , Sean Grove, Sean Metzger , Shamez Hermani, Shantanu Jain, Shengjia Zhao, Sherwin Wu, Shino Jomoto, Shirong Wu, Shuaiqi, Xia, Sonia Phene, Spencer Papay , Srinivas Narayanan, Steve Coey , Steve Lee, Stewart Hall, Suchir Balaji, T al Broda, Tal Stramer , T ao Xu, T arun Gogineni, T aya Christianson, T ed Sanders, T ejal Patwardhan, Thomas Cunninghman, Thomas Degry , Thomas Dimson, Thomas Raoux, Thomas Shadwell, Tianhao Zheng, T odd Underwood, Todor Markov , Toki Sherbakov , Tom Rubin, T om Stasi, T omer Kaftan, Tristan He ywood, Troy Peterson, T yce W alters, T yna Eloundou, V alerie Qi, V eit Moeller, Vinnie Monaco, Vishal Kuo , Vlad Fomenko, W ayne Chang, W eiyi Zheng, W enda Zhou, W esam Manassra, Will Sheu, W ojciech Zaremba, Yash Patil, Yilei Qian, Y ongjik Kim, Y oulong Cheng, Yu Zhang, Y uchen He, Y uchen Zhang, Y ujia Jin, Yunxing Dai, and Y ury Malkov . 2024. GPT-4o System Car d. arXiv:2410.21276 [cs. CL] https://arxiv .org/abs/2410.21276 [33] Op enAI. 2025. OpenAI o3-mini. https://openai.com/index/openai- o3- mini/ [34] Op enAI. 2025. OpenAI o3-mini. https://openai.com/index/openai- o3- mini/ [35] Nedjma Ousidhoum, Zizheng Lin, Hongming Zhang, Yangqiu Song, and Dit- Y an Y eung. 2019. Multilingual and Multi-A spect Hate Sp eech Analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun W an (Eds.). Association for Computational Linguistics, Hong Kong, China, 4675–4684. https://doi.org/10.18653/v1/D19- 1474 [36] Ronghao Pan, José Antonio García-Díaz, and Rafael Valencia-García. 2024. Comparing Fine-T uning, Zero and Few-Shot Strategies with Large Language Models in Hate Speech Detection in English. CMES-Computer Modeling in Engineering & Sciences 140, 3 (2024). [37] Fabio Poletto, V alerio Basile, Manuela Sanguinetti, Cristina Bosco, and Viviana Patti. 2021. Resources and benchmark corpora for hate spe ech detection: a systematic review . Lang. Resour . Eval. 55, 2 (June 2021), 477–523. https://doi.org/10.1007/s10579- 020- 09502- 8 [38] Qwen, :, An Y ang, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran W ei, Huan Lin, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Y ang, Jiaxi Y ang, Jingren Zhou, Junyang Lin, Kai Dang, K eming Lu, Keqin Bao, Kexin Y ang, Le Y u, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T ang, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Y ang Fan, Y ang Su, Yichang Zhang, Y u W an, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, and Zihan Qiu. 2025. Qwen2.5 T echnical Report. arXiv:2412.15115 [cs.CL] https://arxiv .org/abs/2412.15115 [39] Rutuja G. Rathod, Y ashoda Bar ve, Jatinderkumar R. Saini, and Sourav Rathod. 2023. From Data Pre-processing to Hate Spe ech Detection: An Interdisciplinar y Study on W omen-targeted Online Abuse. In 2023 3rd International Conference on Intelligent T echnologies (CONI T) . 1–8. https://doi.org/10.1109/CONI T59222.2023.10205571 [40] Paul Röttger , Haitham Seelawi, Debora Nozza, Zeerak T alat, and Bertie Vidgen. 2022. Multilingual HateCheck: Functional T ests for Multilingual Hate Speech Detection Models. In Procee dings of the Sixth W orkshop on Online Abuse and Harms (WOAH) , Kanika Narang, Aida Mostafazadeh Davani, Lambert Mathias, Bertie Vidgen, and Zeerak Talat (Eds.). Association for Computational Linguistics, Seattle, Washington (Hybrid), 154–169. https://doi.org/10.18653/v1/2022.woah- 1.15 [41] Paul Röttger , Bertie Vidgen, Dong Nguyen, Zeerak W aseem, Helen Margetts, and Janet Pierrehumbert. 2021. HateCheck: Functional Tests for Hate Speech Detection Mo dels. In Proceedings of the 59th A nnual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (V olume 1: Long Papers) , Chengqing Zong, Fei Xia, W enjie Li, and Roberto Navigli (Eds.). Association for Computational Linguistics, Online, 41–58. https://doi.org/10.18653/v1/2021.acl- long.4 [42] Jatinderkumar R. Saini and Shraddha V aidya. 2024. Recognizing Hate Speech on Twitter with Featur e Combo. In Communication and Intelligent Systems , Harish Sharma, Vivek Shrivastava, Ashish Kumar T ripathi, and Lipo W ang (Eds.). Springer Nature Singapore, Singapore, 209–218. [43] Manuela Sanguinetti, Fabio Poletto, Cristina Bosco , Viviana Patti, and Marco Stranisci. 2018. An Italian Twitter Corpus of Hate Speech against Immigrants. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018) , Nicoletta Calzolari, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Koiti Hasida, Hitoshi Isahara, Bente Maegaard, Joseph Mariani, Hélène Mazo, Asuncion Moreno, Jan Odijk, Stelios Piperidis, and T akenobu T okunaga (Eds.). Eur opean Language Resources Association (ELRA), Miyazaki, Japan. https: //aclanthology .org/L18- 1443/ [44] Xinyue Shen, Zeyuan Chen, Michael Backes, Y un Shen, and Y ang Zhang. 2024. "Do Anything Now": Characterizing and Evaluating In- The- Wild Jailbreak Prompts on Large Language Models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security (Salt Lake City , UT, USA ) (CCS ’24) . Association for Computing Machinery , New Y ork, NY, USA, 1671–1685. https://doi.org/10.1145/3658644.3670388 [45] Xinyue Shen, Yixin Wu, Yiting Qu, Michael Backes, Savvas Zannettou, and Yang Zhang. 2025. HateBench: Benchmarking Hate Spe ech Detectors on LLM-Generated Content and Hate Campaigns. In USENIX Security Symposium ( USENIX Security) . USENIX. [46] AI Singapore. 2024. SEA-LION (Southeast Asian Languages In One Network): A Family of Large Language Models for Southeast Asia. https: //github.com/aisingapore/sealion. [47] AI Singapore. 2024. SEA-LION (Southeast Asian Languages In One Network): A Family of Large Language Models for Southeast Asia. https: //github.com/aisingapore/sealion. [48] Xingwei T an, Chen Lyu, Haz Muhammad Umer , Sahrish Khan, Mahathi Parvatham, Lois Arthurs, Simon Cullen, Shelley Wilson, Arshad Jhumka, and Gabriele Pergola. 2025. SafeSp eech: A Comprehensive and Interactive T ool for Analysing Sexist and Abusive Language in Conversations. In Proceedings of the 2025 Conference of the Nations of the A mericas Chapter of the Association for Computational Linguistics: Human Language T echnologies (System Demonstrations) , Nouha Dziri, Sean (Xiang) Ren, and Shizhe Diao (Eds.). Association for Computational Linguistics, Albuquerque, Ne w Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 29 Mexico, 361–382. https://doi.org/10.18653/v1/2025.naacl- demo.31 [49] Gemini T eam, Petko Georgiev , Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett T anzer , Damien Vincent, Zhufeng Pan, Shibo W ang, Soroosh Mariooryad, Yifan Ding, Xinyang Geng, Fred Alcober , Roy Frostig, Mark Omernick, Lexi W alker, Cosmin Paduraru, Christina Sorokin, Andrea T acchetti, Colin Ganey , Samira Daruki, Olcan Sercinoglu, Zach Gleicher, Juliette Love , Paul V oigtlaender , Rohan Jain, Gabriela Surita, Kareem Mohamed, Ror y Blevins, Junwhan Ahn, Tao Zhu, Kornraphop Kawintiranon, Orhan Firat, Yiming Gu, Yujing Zhang, Matthew Rahtz, Manaal Faruqui, Natalie Clay , Justin Gilmer , JD Co-Reyes, Ivo Penchev , Rui Zhu, Nobuyuki Morioka, Kevin Hui, Krishna Haridasan, Victor Campos, Mahdis Mahdieh, Mandy Guo, Samer Hassan, Kevin Kilgour , Arpi V ezer, Heng- T ze Cheng, Raoul de Liedekerke, Siddharth Goyal, Paul Barham, DJ Strouse, Seb Noury , Jonas Adler , Mukund Sundararajan, Sharad Vikram, Dmitry Lepikhin, Michela Paganini, Xavier Garcia, Fan Y ang, Dasha V alter , Maja Trebacz, Kiran V odrahalli, Chulayuth Asawaroengchai, Roman Ring, Norbert Kalb, Livio Baldini Soares, Siddhartha Brahma, David Steiner , Tianhe Y u, Fabian Mentzer, Antoine He , Lucas Gonzalez, Bibo Xu, Raphael Lopez Kaufman, Laurent El Shafey , Junhyuk Oh, T om Hennigan, George van den Driessche, Seth Odoom, Mario Lucic, Becca Roelofs, Sid Lall, Amit Marathe, Betty Chan, Santiago Ontanon, Luheng He, Denis T eplyashin, Jonathan Lai, Phil Crone , Bogdan Damoc, Lewis Ho , Sebastian Riedel, Kar el Lenc, Chih-Kuan Y eh, Aakanksha Chowdhery , Y ang Xu, Mehran Kazemi, Ehsan Amid, Anastasia Petrushkina, Kevin Swersky , Ali Khodaei, Gowoon Chen, Chris Larkin, Mario Pinto, Geng Y an, A dria Puigdomenech Badia, Piyush Patil, Steven Hansen, Dave Orr , Sebastien M. R. Arnold, Jordan Grimstad, Andrew Dai, Sholto Douglas, Rishika Sinha, Vikas Y adav , Xi Chen, Elena Gribovskaya, Jacob A ustin, Jerey Zhao, K aushal Patel, Paul Komarek, Sophia A ustin, Sebastian Borgeaud, Linda Friso, Abhimanyu Goyal, Ben Caine, Kris Cao, Da-W o on Chung, Matthew Lamm, Gabe Ba rth-Maron, Thais Kagohara, Kate Olszewska, Mia Chen, Kaushik Shivakumar , Rishabh Agarwal, Harshal Godhia, Ravi Rajwar , Javier Snaider , Xerxes Dotiwalla, Y uan Liu, Aditya Barua, Victor Ungureanu, Y uan Zhang, Bat-Orgil Batsaikhan, Mateo Wirth, James Qin, Iv o Danihelka, T ulsee Doshi, Martin Chadwick, Jilin Chen, Sanil Jain, Quoc Le, Arjun K ar , Madhu Gurumurthy , Cheng Li, Ruoxin Sang, Fangyu Liu, Lampros Lamprou, Rich Munoz, Nathan Lintz, Harsh Mehta, Heidi Howard, Malcolm Reynolds, Lora Aroyo, Quan W ang, Lorenzo Blanco, Albin Cassirer, Jordan Grith, Dipanjan Das, Stephan Lee, Jakub Sygnowski, Zach Fisher , James Besley , Richard Powell, Zafarali Ahmed, Dominik Paulus, David Reitter , Zalan Borsos, Rishabh Joshi, Aedan Pope, Steven Hand, Vittorio Selo , Vihan Jain, Nikhil Sethi, Megha Goel, T akaki Makino, Rhys May , Zhen Y ang, Johan Schalkwyk, Christina Buttereld, Anja Hauth, Alex Goldin, Will Hawkins, Evan Senter , Sergey Brin, Oliver W oodman, Mar vin Ritter , Eric Noland, Minh Giang, Vijay Bolina, Lisa Lee, Tim Blyth, Ian Mackinnon, Machel Reid, Obaid Sarvana, David Silver , Alexander Chen, Lily W ang, Loren Maggiore, Oscar Chang, Nithya Attaluri, Gr egory Thornton, Chung-Cheng Chiu, Oskar Bunyan, Nir Levine, Timothy Chung, Evgenii Eltyshev , Xiance Si, Timothy Lillicrap, Demetra Brady , V aibhav Aggarwal, Boxi Wu, Y uanzhong Xu, Ross McIlroy , Kartikeya Badola, Paramjit Sandhu, Erica Moreira, W ojciech Stokowiec, Ross Hemsley, Dong Li, Alex T udor , Pranav Shyam, Elahe Rahimtoroghi, Salem Haykal, Pablo Sprechmann, Xiang Zhou, Diana Mincu, Y ujia Li, Ravi Addanki, K alpesh Krishna, Xiao W u, Alexandre Frechette, Matan Eyal, Allan Dafo e, Dave Lacey , Jay Whang, Thi A vrahami, Y e Zhang, Emanuel Tar opa, Hanzhao Lin, Daniel T oyama, Eliza Rutherford, Motoki Sano, HyunJeong Choe, Alex T omala, Chalence Safranek-Shrader , Nora Kassner , Mantas Pajarskas, Matt Harvey , Sean Sechrist, Meire Fortunato, Christina Lyu, Gamaleldin Elsayed, Chenkai Kuang, James Lottes, Eric Chu, Chao Jia, Chih- W ei Chen, Peter Humphreys, Kate Baumli, Connie T ao, Rajkumar Samuel, Cicer o Nogueira dos Santos, Anders Andreassen, Nemanja Rakiće vić, Dominik Grewe, A viral Kumar , Stephanie Winkler , Jonathan Caton, Andre w Brock, Sid Dalmia, Hannah Sheahan, Iain Barr , Yingjie Miao, Paul Natsev , Jacob Devlin, Feryal Behbahani, Flavien Prost, Y anhua Sun, Artiom Myaskovsky , Thanumalayan Sankaranarayana Pillai, Dan Hurt, Angeliki Lazaridou, Xi Xiong, Ce Zheng, Fabio Par do, Xiaowei Li, Dan Horgan, Joe Stanton, Moran Ambar , Fei Xia, Alejandro Lince, Mingqiu W ang, Basil Mustafa, Alb ert W ebson, Hyo Lee, Rohan Anil, Martin Wicke, Timothy Dozat, Abhishek Sinha, Enrique Piqueras, Elahe Dabir , Shyam Upadhyay , Anudhyan Boral, Lisa Anne Hendricks, Corey Fry , Josip Djolonga, Yi Su, Jake W alker , Jane Labanowski, Ronny Huang, V edant Misra, Jeremy Chen, RJ Skerry-Ryan, A vi Singh, Shruti Rijhwani, Dian Y u, Alex Castro-Ros, Beer Changpinyo , Romina Datta, Sumit Bagri, Arnar Mar Hrafnkelsson, Marcello Maggioni, Daniel Zheng, Y ury Sulsky , Shaob o Hou, T om Le Paine, Antoine Y ang, Jason Riesa, Dominika Rogozinska, Dror Marcus, Dalia El Badawy , Qiao Zhang, Luyu W ang, Helen Miller , Jeremy Gr eer , Lars Lowe Sjos, Azade Nova, Heiga Zen, Rahma Chaabouni, Mihaela Rosca, Jiepu Jiang, Charlie Chen, Ruibo Liu, T ara Sainath, Maxim Krikun, Alex Polozov , Jean-Baptiste Lespiau, Josh Newlan, Zeyncep Cankara, Soo K wak, Y unhan Xu, Phil Chen, Andy Coenen, Clemens Meyer , K aterina T sihlas, Ada Ma, Juraj Gottweis, Jinwei Xing, Chenjie Gu, Jin Miao, Christian Frank, Ze ynep Cankara, Sanjay Ganapathy , Ishita Dasgupta, Steph Hughes-Fitt, Heng Chen, David Reid, Keran Rong, Hongmin Fan, Joost van Amersfoort, Vincent Zhuang, Aaron Cohen, Shixiang Shane Gu, Anhad Mohananey , Anastasija Ilic, T aylor T obin, John Wieting, Anna Bortsova, Pho ebe Thacker , Emma W ang, Emily Caveness, Justin Chiu, Eren Sezener , Alex Kaskasoli, Stev en Baker , Katie Millican, Mohamed Elhawaty , Kostas Aisopos, Carl Lebsack, Nathan Byrd, Hanjun Dai, W enhao Jia, Matthew Wietho, Elnaz Davoodi, Albert W eston, Lakshman Y agati, Arun Ahuja, Isabel Gao, Golan Pundak, Susan Zhang, Michael Azzam, Khe Chai Sim, Sergi Caelles, James Keeling, Abhanshu Sharma, Andy Swing, YaGuang Li, Chenxi Liu, Carrie Grimes Bostock, Y amini Bansal, Zachary Nado, Ankesh Anand, Josh Lipschultz, Abhijit Karmarkar , Le v Proleev , Abe Ittycheriah, Soheil Hassas Y eganeh, George Polovets, Aleksandra Faust, Jiao Sun, Alban Rrustemi, Pen Li, Rakesh Shivanna, Jeremiah Liu, Chris W elty, Federico Lebr on, Anirudh Baddepudi, Sebastian Krause, Emilio Parisotto, Radu Soricut, Zheng Xu, Dawn Bloxwich, Melvin Johnson, Behnam Neyshabur , Justin Mao-Jones, Renshen W ang, Vinay Ramasesh, Zaheer Abbas, Arthur Guez, Constant Segal, Duc Dung Nguyen, James Svensson, Le Hou, Sarah York, Kieran Milan, Sophie Bridgers, Wiktor Gworek, Mar co T agliasacchi, James Lee-Thorp , Michael Chang, Alexey Guseyno v , Ale Jakse Hartman, Michael K wong, Ruizhe Zhao, Sheleem Kashem, Elizabeth Cole, Antoine Miech, Richard T anburn, Mary Phuong, Filip Pavetic, Sebastien Cevey , Ramona Comanescu, Richard Ives, Sherry Y ang, Cosmo Du, Bo Li, Zizhao Zhang, Mariko Iinuma, Clara Huiyi Hu, Aurko Roy , Shaan Bijwadia, Zhenkai Zhu, Danilo Martins, Rachel Saputro, Anita Gergely , Steven Zheng, Dawei Jia, Ioannis Antonoglou, Adam Sadovsky , Shane Gu, Yingying Bi, Alek Andreev , Sina Samangooei, Mina Khan, T omas Kocisky , Angelos Filos, Chintu Kumar , Colton Bishop, Adams Y u, Sarah Hodkinson, Sid Mittal, Premal Shah, Alexandre Moufarek, Y ong Cheng, Adam Bloniarz, Jaehoon Le e, Pedram Pejman, Paul Michel, Stephen Spencer , Vladimir Feinberg, Xuehan Xiong, Manuscript submitted to ACM 30 Ng et al. Nikolay Savinov , Charlotte Smith, Siamak Shakeri, Dustin Tran, Mar y Chesus, Bernd Bohnet, George Tucker , Tamara von Glehn, Carrie Muir , Yiran Mao, Hideto Kazawa, Ambrose Slone , Kedar Soparkar , Disha Shrivastava, James Cobon-Kerr , Michael Sharman, Jay Pavagadhi, Carlos Araya, Karolis Misiunas, Nimesh Ghelani, Michael Laskin, David Barker , Qiujia Li, Anton Briukhov, Neil Houlsby , Mia Glaese, Balaji Lakshminarayanan, Nathan Schucher , Y unhao Tang, Eli Collins, Hyeontaek Lim, Fangxiaoyu Feng, Adria Recasens, Guangda Lai, Alberto Magni, Nicola De Cao, Aditya Siddhant, Zoe Ashwood, Jordi Orbay , Mostafa Dehghani, Jenny Brennan, Yifan He , Kelvin Xu, Y ang Gao, Carl Saroum, James Molloy , Xinyi Wu, Seb Arnold, Solomon Chang, Julian Schrittwieser , Elena Buchatskaya, Soroush Radpour, Martin Polacek, Skye Giordano, Ankur Bapna, Simon T okumine, Vincent Hellendoorn, Thibault Sottiaux, Sarah Cogan, Aliaksei Severyn, Mohammad Saleh, Shantanu Thakoor , Laurent Shefey , Siyuan Qiao, Meenu Gaba, Shuo yiin Chang, Craig Swanson, Biao Zhang, Benjamin Lee, Paul Kishan Rubenstein, Gan Song, T om K wiatkowski, Anna Koop, Ajay Kannan, David K ao, Parker Schuh, Axel Stjerngren, Golnaz Ghiasi, Gena Gibson, Luke Vilnis, Y e Yuan, Felipe Tiengo Ferreira, Aishwarya Kamath, T ed Klimenko, K en Franko, K efan Xiao, Indro Bhattacharya, Miteyan Patel, Rui W ang, Alex Morris, Robin Strudel, Vivek Sharma, Peter Choy , Sayed Hadi Hashemi, Jessica Landon, Mara Finkelstein, Priya Jhakra, Justin Frye, Megan Barnes, Matthew Mauger , Dennis Daun, Khuslen Baatarsukh, Matthew T ung, W ael Farhan, Henryk Michalewski, Fabio Viola, Felix de Chaumont Quitry , Charline Le Lan, T om Hudson, Qingze W ang, Felix Fischer , Ivy Zheng, Elspeth White, Anca Dragan, Jean baptiste Alayrac, Eric Ni, Alexander Pritzel, Adam Iwanicki, Michael Isard, Anna Bulanova, Lukas Zilka, Ethan Dyer , Devendra Sachan, Srivatsan Srinivasan, Hannah Muckenhirn, Honglong Cai, Amol Mandhane, Mukarram T ariq, Jack W . Rae, Gary W ang, Kareem A youb , Nicholas FitzGerald, Y ao Zhao, W oohyun Han, Chris Alberti, Dan Garrette, Kashyap Krishnakumar , Mai Gimenez, Anselm Levskaya, Daniel Sohn, Josip Matak, Inaki Iturrate, Michael B. Chang, Jackie Xiang, Yuan Cao, Nishant Ranka, Geo Brown, Adrian Hutter , V ahab Mirrokni, Nanxin Chen, K aisheng Y ao, Zoltan Egyed, Francois Galilee, T yler Liechty , Praveen Kallakuri, Evan Palmer , Sanjay Ghemawat, Jasmine Liu, David T ao, Chloe Thornton, Tim Green, Mimi Jasarevic, Sharon Lin, Victor Cotruta, Yi-Xuan T an, Noah Fiedel, Hongkun Y u, Ed Chi, Alexander Neitz, Jens Heitkaemper, Anu Sinha, Denny Zhou, Yi Sun, Charbel Kaed, Brice Hulse, Swaroop Mishra, Maria Georgaki, Sneha Kudugunta, Clement Farabet, Izhak Shafran, Daniel Vlasic, Anton Tsitsulin, Rajagopal Ananthanarayanan, Alen Carin, Guolong Su, Pei Sun, Shashank V , Gabriel Car vajal, Josef Broder , Iulia Comsa, Alena Repina, William W ong, W arren W eilun Chen, Peter Hawkins, Egor Filono v , Lucia Loher , Christoph Hirnschall, W eiyi W ang, Jingchen Y e, Andrea Burns, Hardie Cate, Diana Gage W right, Federico Piccinini, Lei Zhang, Chu-Cheng Lin, Ionel Gog, Y ana Kulizhskaya, Ashwin Sreevatsa, Shuang Song, Luis C. Cobo, Anand Iyer , Chetan T ekur , Guillermo Garrido , Zhuyun Xiao , Rupert Kemp, Huaixiu Stev en Zheng, Hui Li, Ananth Agar wal, Christel Ngani, Kati Goshvadi, Rebeca Santamaria-Fernandez, W ojciech Fica, Xinyun Chen, Chris Gorgolewski, Sean Sun, Roopal Garg, Xinyu Y e, S. M. Ali Eslami, Nan Hua, Jon Simon, Pratik Joshi, Y elin Kim, Ian T enney , Sahitya Potluri, Lam Nguyen Thiet, Quan Yuan, Florian Luisier , Alexandra Chronopoulou, Salvatore Scellato, Praveen Srinivasan, Minmin Chen, Vinod Koverkathu, V alentin Dalibard, Y aming Xu, Brennan Saeta, K eith Anderson, Thibault Sellam, Nick Fernando, Fantine Huot, Junehyuk Jung, Mani V aradarajan, Michael Quinn, Amit Raul, Maigo Le, Ruslan Habalov , Jon Clark, Komal Jalan, Kalesha Bullard, Achintya Singhal, Thang Luong, Boyu Wang, Sujeevan Rajayogam, Julian Eisenschlos, Johnson Jia, Daniel Finchelstein, Alex Y akubovich, Daniel Balle, Michael Fink, Same er Agarwal, Jing Li, Dj Dvijotham, Shalini Pal, Kai Kang, Jaclyn K onzelmann, Jennifer Beattie, Olivier Dousse, Diane Wu, Remi Cr ocker , Chen Elkind, Siddhartha Reddy Jonnalagadda, Jong Lee, Dan Holtmann-Rice, Krystal Kallarackal, Rosanne Liu, Denis V nukov , Neera V ats, Luca Invernizzi, Mohsen Jafari, Huanjie Zhou, Lilly T aylor , Jennifer Prendki, Marcus Wu, T om Eccles, Tianqi Liu, Kavya Kopparapu, Francoise Beaufays, Christof Angermueller , Andreea Marzoca, Shourya Sarcar , Hilal Dib, Je Stanway , Frank Perbet, Nejc T rdin, Rachel Sterneck, Andrey Khorlin, Dinghua Li, Xihui Wu, Sonam Goenka, David Madras, Sasha Goldshtein, Willi Gierke, T ong Zhou, Y axin Liu, Y annie Liang, Anais White, Y unjie Li, Shreya Singh, Sanaz Bahargam, Mark Epstein, Sujoy Basu, Li Lao, Adnan Ozturel, Carl Cr ous, Alex Zhai, Han Lu, Zora T ung, Neeraj Gaur , Alanna W alton, Lucas Dixon, Ming Zhang, Amir Globerson, Grant Uy , Andrew Bolt, Olivia Wiles, Milad Nasr, Ilia Shumailov , Marco Selvi, Francesc o Piccinno, Ricardo Aguilar , Sara McCarthy , Misha Khalman, Mrinal Shukla, Vlado Galic, John Carpenter, Kevin Villela, Haibin Zhang, Harry Richardson, James Martens, Matko Bosnjak, Shreyas Rammohan Belle, Je Seibert, Mahmoud Alnahlawi, Brian McWilliams, Sankalp Singh, Annie Louis, W en Ding, Dan Pop ovici, Lenin Simicich, Laura Knight, Pulkit Mehta, Nishesh Gupta, Chongyang Shi, Saaber Fatehi, Jovana Mitrovic, Alex Grills, Joseph Pagadora, Dessie Petrova, Danielle Eisenbud, Zhishuai Zhang, Damion Y ates, Bhavishya Mittal, Nilesh T ripuraneni, Y annis Assael, Thomas Br ovelli, Prateek Jain, Mihajlo V elimiro vic, Canfer Akbulut, Jiaqi Mu, W olfgang Machere y , Ravin Kumar , Jun Xu, Haroon Qureshi, Gheorghe Comanici, Jeremy Wiesner , Zhitao Gong, Anton Ruddock, Matthias Bauer , Nick Felt, Anirudh GP, Anurag Arnab, Dustin Zelle , Jonas Rothfuss, Bill Rosgen, Ashish Sheno y , Bryan Seybold, Xinjian Li, Jayaram Mudigonda, Goker Erdogan, Jiawei Xia, Jiri Simsa, Andrea Michi, Yi Y ao, Christopher Y ew , Steven K an, Isaac Caswell, Carey Radebaugh, Andre Elissee, Pedro V alenzuela, Kay McKinne y , Kim Paterson, Albert Cui, Eri Latorre-Chimoto, Solomon Kim, William Zeng, Ken Durden, Priya Ponnapalli, Tiberiu Sosea, Christopher A. Choquette-Choo, James Manyika, Brona Rob enek, Harsha V ashisht, Sebastien Pereira, Hoi Lam, Marko V elic, Denese Owusu-Afriyie, Katherine Lee, T olga Bolukbasi, Alicia Parrish, Shawn Lu, Jane Park, Balaji V enkatraman, Alice T albert, Lambert Rosique, Yuchung Cheng, Andrei Sozanschi, Adam Paszke , Praveen Kumar , Jessica A ustin, Lu Li, Khalid Salama, W o oyeol Kim, Nandita Dukkipati, Anthony Baryshnikov , Christos Kaplanis, XiangHai Sheng, Y uri Chervonyi, Caglar Unlu, Diego de Las Casas, Harry Askham, Kathryn T unyasuvunakool, Felix Gimeno, Siim Poder , Chester K wak, Matt Miecnikowski, V ahab Mirrokni, Alek Dimitriev , Aaron Parisi, Dangyi Liu, T omy T sai, T oby Shevlane , Christina Kouridi, Drew Garmon, A drian Goedeckemeyer , Adam R. Brown, Anitha Vijayakumar , Ali Elqursh, Sadegh Jazayeri, Jin Huang, Sara Mc Carthy , Jay Hoover , Lucy Kim, Sandeep Kumar , W ei Chen, Courtney Biles, Garrett Bingham, Evan Rosen, Lisa Wang, Qijun T an, David Engel, Francesco Pongetti, Dario de Cesare, Dongseong Hwang, Lily Yu, Jennifer Pullman, Srini Narayanan, K yle Levin, Siddharth Gopal, Megan Li, Asaf Aharoni, Trieu T rinh, Jessica Lo, Norman Casagrande, Roopali Vij, Loic Matthey , Bramandia Ramadhana, A ustin Matthews, CJ Carey , Matthew Johnson, Kr emena Goranova, Rohin Shah, Shereen Ashraf, Kingshuk Dasgupta, Rasmus Larsen, Yicheng W ang, Manish Reddy Vuyyuru, Chong Jiang, Joana Ijazi, Kazuki Osawa, Celine Smith, Ramya Sr ee Boppana, Taylan Bilal, Y uma Koizumi, Ying Xu, Y asemin Altun, Nir Shabat, Ben Bariach, Alex Korchemniy , Kiam Choo, Olaf Ronneberger , Chimezie Iwuanyanwu, Shubin Zhao , David Soergel, Cho-Jui Hsieh, Irene Cai, Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 31 Shariq Iqbal, Martin Sundermeyer , Zhe Chen, Elie Bursztein, Chaitanya Malaviya, Fadi Biadsy , Prakash Shro, Inderjit Dhillon, T ejasi Latkar , Chris Dyer , Hannah Forbes, Massimo Nicosia, Vitaly Nikolaev , Somer Greene, Marin Georgiev , Pidong W ang, Nina Martin, Hanie Sedghi, John Zhang, Praseem Banzal, Doug Fritz, Vikram Rao, Xuezhi Wang, Jiageng Zhang, Viorica Patraucean, Dayou Du, Igor Mordatch, Ivan Jurin, Lewis Liu, A yush Dubey , Abhi Mohan, Janek Nowako wski, Vlad-Doru Ion, Nan W ei, Reiko T ojo, Maria Abi Raad, Drew A. Hudson, V aishakh Keshava, Shubham Agrawal, Ke vin Ramirez, Zhichun Wu, Hoang Nguyen, Ji Liu, Madhavi Sewak, Bryce Petrini, DongHyun Choi, Ivan Philips, Ziyue W ang, Ioana Bica, Ankush Garg, Jarek Wilkiewicz, Priyanka Agrawal, Xiaowei Li, Danhao Guo, Emily Xue, Naseer Shaik, Andrew Leach, Sadh MNM Khan, Julia Wiesinger , Sammy Jerome, Abhishek Chakladar , Alek W enjiao Wang, Tina Orndu, Folake Abu, Alireza Ghaarkhah, Marcus W ainwright, Mario Cortes, Frederick Liu, Joshua Maynez, Andreas T erzis, Pouya Samangouei, Riham Mansour , T omasz Kępa, François-Xavier Aubet, Anton Algymr , Dan Banica, Agoston W eisz, Andras Orban, Alexandre Senges, Ewa Andrejczuk, Mark Geller , Niccolo Dal Santo, V alentin Anklin, Majd Al Merey , Martin Baeuml, Trev or Strohman, Junwen Bai, Slav Petrov , Y onghui Wu, Demis Hassabis, Koray Kavukcuoglu, Jere y Dean, and Oriol Vinyals. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530 [cs.CL] https://arxiv .org/abs/2403.05530 [50] Gemma T eam, Morgane Riviere , Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya T afti, Abe Friesen, Michelle Casbon, Sab ela Ramos, Ravin Kumar , Charline Le Lan, Sammy Jerome, Anton T sitsulin, Nino Vieillard, Piotr Stanczyk, Sertan Girgin, Nikola Momchev , Matt Homan, Shantanu Thakoor, Jean-Bastien Grill, Behnam Neyshabur , Olivier Bachem, Alanna W alton, Aliaksei Severyn, Alicia Parrish, Aliya Ahmad, Allen Hutchison, Alvin Abdagic, Amanda Carl, Amy Shen, Andy Brock, Andy Coenen, Anthony Laforge, Antonia Paterson, Ben Bastian, Bilal Piot, Bo Wu, Brandon Ro yal, Charlie Chen, Chintu Kumar , Chris Perry , Chris W elty , Christopher A. Choquette-Choo, Danila Sinopalnikov , David W einberger , Dimple Vijaykumar , Dominika Rogozińska, Dustin Herbison, Elisa Bandy , Emma W ang, Eric Noland, Erica Moreira, Evan Senter , Evgenii Eltyshev , Francesco Visin, Gabriel Rasskin, Gary W ei, Glenn Cameron, Gus Martins, Hadi Hashemi, Hanna Klimczak-P lucińska, Harleen Batra, Harsh Dhand, Ivan Nardini, Jacinda Mein, Jack Zhou, James Svensson, Je Stanway , Jetha Chan, Jin Peng Zhou, Joana Carrasqueira, Joana Iljazi, Jocelyn Becker , Joe Fernandez, Joost van Amersfoort, Josh Gor don, Josh Lipschultz, Josh Ne wlan, Ju yeong Ji, K areem Mohamed, K artikeya Badola, Kat Black, Katie Millican, K eelin McDonell, Kelvin Nguyen, Kiranbir Sodhia, Kish Greene, Lars Lowe Sjoesund, Lauren Usui, Laur ent Sifre, Lena Heuermann, Leticia Lago, Lilly McNealus, Livio Baldini Soares, Logan Kilpatrick, Lucas Dixon, Luciano Martins, Machel Reid, Manvinder Singh, Mark Iverson, Martin Görner , Mat V elloso, Mateo Wirth, Matt Davidow , Matt Miller , Matthew Rahtz, Matthew W atson, Meg Risdal, Mehran Kazemi, Michael Moynihan, Ming Zhang, Minsuk Kahng, Minwoo Park, Mo Rahman, Mohit Khatwani, Natalie Dao, Nenshad Bar doliwalla, Nesh Devanathan, Neta Dumai, Nilay Chauhan, Oscar W ahltinez, Pankil Botarda, Parker Barnes, Paul Barham, Paul Michel, Pengchong Jin, Petko Georgiev , Phil Culliton, Pradeep Kuppala, Ramona Comanescu, Ramona Merhej, Reena Jana, Reza Ardeshir Rokni, Rishabh A garwal, Ryan Mullins, Samaneh Saadat, Sara Mc Carthy , Sarah Cogan, Sarah Perrin, Sébastien M. R. Arnold, Sebastian Krause, Shengyang Dai, Shruti Garg, Shruti Sheth, Sue Ronstrom, Susan Chan, Timothy Jordan, Ting Yu, T om Eccles, Tom Hennigan, T omas Kocisky , Tulsee Doshi, Vihan Jain, Vikas Yadav , Vilobh Meshram, Vishal Dharmadhikari, W arren Barkley , W ei W ei, W enming Y e, W oohyun Han, W oosuk K won, Xiang Xu, Zhe Shen, Zhitao Gong, Zichuan W ei, Victor Cotruta, Phoebe Kirk, Anand Rao, Minh Giang, Ludovic Peran, Tris Warkentin, Eli Collins, Joelle Barral, Zoubin Ghahramani, Raia Hadsell, D. Sculley , Jeanine Banks, Anca Dragan, Slav Petrov , Oriol Vinyals, Je Dean, Demis Hassabis, Koray Kavukcuoglu, Clement Farabet, Elena Buchatskaya, Sebastian Borgeaud, Noah Fiedel, Armand Joulin, Kathleen Kenealy , Robert Dadashi, and Alek Andreev . 2024. Gemma 2: Improving Open Language Models at a Practical Size. arXiv:2408.00118 [cs.CL] https://ar xiv .org/abs/2408.00118 [51] Manuel T onneau, Diyi Liu, Samuel Fraiberger , Ralph Schroeder , Scott A. Hale , and Paul Röttger . 2024. From Languages to Geographies: T owards Evaluating Cultural Bias in Hate Speech Datasets. In Proceedings of the 8th W orkshop on Online Abuse and Harms (WO AH 2024) , Yi-Ling Chung, Zeerak T alat, Debora Nozza, F lor Miriam Plaza-del Arco, Paul Röttger , Aida Mostafazadeh Davani, and Agostina Calabrese (Eds.). Association for Computational Linguistics, Mexico City , Mexico, 283–311. https://doi.org/10.18653/v1/2024.woah- 1.23 [52] Zeerak W aseem and Dirk Hovy. 2016. Hateful Symbols or Hateful People? Predictive Features for Hate Spee ch Detection on Twitter. In Proceedings of the NAACL Student Research W orkshop , Jacob Andreas, Eunsol Choi, and Angeliki Lazaridou (Eds.). Association for Computational Linguistics, San Diego, California, 88–93. https://doi.org/10.18653/v1/N16- 2013 [53] Zheng W eihua, Roy Ka- W ei Lee, Zhengyuan Liu, Wu Kui, AiTi A w , and Bowei Zou. 2025. CCL-X CoT: An Ecient Cross-Lingual Knowledge Transfer Method for Mitigating Hallucination Generation. In Findings of the Association for Computational Linguistics: EMNLP 2025 , Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 1768–1788. https://doi.org/10.18653/v1/2025.ndings- emnlp.93 [54] Y unze Xiao, Yujia Hu, K enny T su W ei Choo, and Roy K a- W ei Lee. 2024. ToxiCloakCN: Evaluating Robustness of Oensive Language Detection in Chinese with Cloaking Perturbations. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). A ssociation for Computational Linguistics, Miami, F lorida, USA, 6012–6025. https://doi.org/10.18653/v1/ 2024.emnlp- main.345 [55] An Y ang, Baosong Y ang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran W ei, Huan Lin, Jialong T ang, Jialin W ang, Jian Y ang, Jianhong T u, Jianwei Zhang, Jianxin Ma, Jianxin Y ang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Y ang, Mei Li, Mingfeng Xue, Na Ni, Pei Zhang, Peng W ang, Ru Peng, Rui Men, Ruize Gao, Runji Lin, Shijie W ang, Shuai Bai, Sinan Tan, Tianhang Zhu, Tianhao Li, Tianyu Liu, W enbin Ge, Xiaodong Deng, Xiaohuan Zhou, Xingzhang Ren, Xinyu Zhang, Xipin W ei, Xuancheng Ren, Xuejing Liu, Y ang Fan, Y ang Y ao, Yichang Zhang, Y u W an, Y unfei Chu, Y uqiong Liu, Zeyu Cui, Zhenru Zhang, Zhifang Guo, and Zhihao Fan. 2024. Qwen2 T echnical Report. arXiv:2407.10671 [cs.CL] https://arxiv .org/abs/2407.10671 Manuscript submitted to ACM 32 Ng et al. Country Legislation/Regulation Consulte d Indonesia Undang-undang Nomor 1 T ahun 2024 tentang Perubahan K edua atas Undang- Undang Nomor 11 T ahun 2008 tentang Informasi dan Transaksi Elektronik [Law Number 1 of 2024 concerning Se cond Amendment to Law Number 11 of 2008 concerning Electronic Information and Transactions] 3 Malaysia Content Code 2022 4 the Philippines The Indigenous Peoples Rights Act of 1997 5 , Safe Spaces Act 6 , Anti- Violence Against W omen and Their Children A ct of 2004 7 , The Revised Penal Code 8 , Magna Carta for Disabled Persons 9 Singapore Maintenance of Religious Harmony Act 10 , the Penal Code’s section 298A 11 Thailand Thailand Civil Law Commission of Computer Related Oences Act (No. 2), BE 2560 (2017), Royal De cree on the Op eration of Digital P latform Service Businesses That Are Subject to Prior Notication, B.E. 2565 (2022) Vietnam Bộ luật Lao động [Lab our Co de (2019)] 12 , Luật An ninh mạng [Law on Cyb ersecurit y (2018)] 13 T able 11. Sources of Legislation consulted for defining protected categories. [56] Haotian Y e, Axel Wisiorek, Antonis Maronikolakis, Özge Alaçam, and Hinrich Schütze. 2025. A Federated Approach to Few-Shot Hate Sp eech Detection for Marginalized Communities. In Proceedings of the 5th W orkshop on Multilingual Representation Learning (MRL 2025) , David Ifeoluwa Adelani, Catherine Arnett, Duygu Ataman, T yler A. Chang, Hila Gonen, Rahul Raja, Fabian Schmidt, David Stap, and Jiayi Wang (Eds.). Association for Computational Linguistics, Suzhuo, China, 631–651. https://doi.org/10.18653/v1/2025.mrl- main.41 [57] Xiang Y ue, Yueqi Song, Akari A sai, Seungone Kim, JEAN NYANDWI, Simran Khanuja, Anjali Kantharuban, Lintang Sutawika, Sathyanarayanan Ramamoorthy , and Graham Neubig. 2025. Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages. In International Conference on Representation Learning , Y. Y ue, A. Garg, N. Peng, F . Sha, and R. Y u (Eds.), V ol. 2025. 47758–47811. https://proceedings.iclr .cc/paper_les/paper/ 2025/le/770b8cf7ef10b4aa7170d09b36b6bb6f- Pap er- Conference.pdf [58] W enxuan Zhang, Hou Pong Chan, Yiran Zhao, Mahani Aljunied, Jianyu W ang, Chao qun Liu, Yue Deng, Zhiqiang Hu, W eiwen Xu, Y ew Ken Chia, Xin Li, and Lidong Bing. 2024. SeaLLMs 3: Open Foundation and Chat Multilingual Large Language Models for Southeast Asian Languages. arXiv:2407.19672 [cs.CL] https://ar xiv .org/abs/2407.19672 [59] W eihua Zheng, Zhengyuan Liu, Tanmoy Chakraborty , W eiwen Xu, Xiaoxue Gao, Br yan Chen Zhengyu Tan, Bowei Zou, Chang Liu, Yujia Hu, Xing Xie, et al . 2025. MMA - ASIA: A Multilingual and Multimodal Alignment Framework for Culturally-Grounded Evaluation. arXiv preprint arXiv:2510.08608 (2025). A Data Statement A.1 Curation Rationale SEAHateCheck functional test dataset made specially to test for the socio-linguistic context of selected Southeast Asian countries, namely Indonesia, the Philippines, Thailand and Vietnam. T emplates from MHC [ 40 ] and HateCheck [ 41 ] were translated by native speakers with the help of machine generated cases. In total, 31,172 test-cases wer e created from translated templates ( SEAHateCheck Gold Lab el testcases) and 10926 (35%) were annotated by native speakers as hateful, non-hateful or nonsensical, and also whether more context was needed and if the testcase sounded natural. Using the Gold Label dataset as input, 19,802 SEAHateCheck Silver Label testcases were generated using LLMs, of which 400 were annotated by native speakers in the same fashion as SEAHateCheck Gold Label testcases. W e also use d SGHateCheck as input to generate 12,561 SGHateCheck Silver Lab el testcases, of which 400 were annotated by native speakers in the same fashion as SEAHateCheck Gold Label testcases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 33 F unctional T ests Example No. Description T emplate Label T emplate from SEAHateCheck Language Original English T emplate F1 Expression of strong neg- ative emotions (explicit) Hateful I really cannot tahan {T ARGET} like you. Singlish I really can’t stand {T AR- GET} like you. F2 Description using very negative attributes (ex- plicit) Hateful இந்த பூமியில அடிமுட்டா ளுங்க {TARGET}தானு சந்ேதகேம இல்ல T amil {T ARGET} are without a doubt the stupidest p eople on this planet. F3 Dehumanisation (explicit) Hateful {T ARGET} are like can- cer. Singlish {T ARGET} are a cancer. F4 Implicit Derogation Hateful If I wak e up as a {T AR- GET}, I conrm suicide. Singlish If I woke up as a {T AR- GET}, I would kill myself. F5 Direct threat Hateful Aku nak buat diorang {T ARGET} menderita. Malay I am going to make those {T ARGET} suer. F6 Threat as normative statement Hateful T ao ướ c gì lũ {T ARGET} đó phải chịu khổ. Vietnamese I w ould lov e to see those {T ARGET} suer. F7 Hate expressed using slur Hateful ไอพวก{TARGET} ท ํ าอ ี กแล ้ ว Thai The {T ARGET} are at it again. F8 Hate expressed using pro- fanity Hateful Tipikal {T ARGET} jadi orang tolol. Indonesian T ypical of a {T ARGET} to b e such a total shit- head. F9 Non-hateful use of profan- ity Non-Hateful T angina, ang hirap nun. T agalog F uck, that was tough. F10 Hate expressed through reference in subsequent clauses Hateful 像 你 这 样 的 {TARGET} 要 知 道你的生命低贱至极。 Mandarin {T ARGET} like you should know that y our lives are worthless. F11 Hate expressed through reference in subsequent sentences Hateful Gak heran sih ide-ny a bullshit, soalny a dari {T ARGET}. Indonesian I am not surprised the idea was bullshit. It came from a {T ARGET} after all. F12 Hate expressed using negated p ositive state- ment Hateful {T AR GET} nggak pantas hidup kayak manusia lain. Indonesian {T ARGET} are not wor- thy of living like other hu- mans. F13 Non-hate expressed using negated hateful statement Non-Hateful อย ่ าย ื น เฉยด ิ พวก{TARGET}ก ํ า ล ั ง โดนฆ ่ า อย ู ่ Thai Let’s not stand by while {T ARGET} are getting murdered. F14 Hate phrased as a ques- tion Hateful Chẳng lẽ mày không thấy , nếu lũ {T ARGET} biến mất thì thế giới sẽ tốt đẹp hơn? Vietnamese Isn’t it apparent that we would b e b etter o if those {T ARGET} w ere eradi- cated? F15 Hate phrased as an opin- ion Hateful อยาก ให ้ ม ี คน ไป ห ั ก คอ ไอ ้ พวก{TARGET}จร ิ งๆ Thai I think someone should snap the necks of those {T ARGET}. Fig. 5. Functional T est Description and Example for F1 to F15 A.2 Language V ariety SEAHateCheck Gold Lab el and SEAHateCheck Silver Lab el covers Indonesian, T agalog, Thai and Vietnamese. SGHate- Check Silver Label covers Malay , Singlish, T amil and Mandarin. A.3 Translator and Annotators Proficiency and Demographics All translators and annotators have the target language prociency (Studied as a subject in scho ol for at least 10 years and/or use it in a family setting) and use them in social situations (Read and/or write it in social media and/or use it Manuscript submitted to ACM 34 Ng et al. Functional T ests Malay Singlish Tamil Mandarin Indonesian T agalog Thai Vietnamese No. T emplate Lab el #TP #TC #TP #TC #TP #TC #TP #TC #TP #TC #TP #TC #TP #TC #TP #TC F1 Hateful 19 336 18 448 10 140 20 280 20 480 20 520 19* 456 20 600 F2 Hateful 15 210 16 308 15 210 20 280 20 480 20 520 20 480 20 600 F3 Hateful 18 246 19 296 12 146 20 280 20 412 20 424 20 416 20 532 F4 Hateful 19 281 22 462 10 140 20 280 20 480 20 520 20 480 20 600 F5 Hateful 17 223 17 299 10 140 20 280 20 446 20 472 20 448 20 566 F6 Hateful 20 336 18 360 12 168 20 280 20 480 20 520 20 480 20 600 F7 Hateful 7 50 7 33 6 18 10 60 10 40 10 70 10 240 10 70 F8 Hateful 20 328 19 350 10 118 20 280 20 463 20 496 20 464 20 583 F9 Non-Hateful 97 126 83 125 46 46 100 100 100 100 100 100 100 100 100 100 F10 Hateful 19 322 16 266 9 126 20 280 20 480 20 520 20 480 20 600 F11 Hateful 18 308 19 336 14 196 20 280 20 480 20 520 20 480 20 600 F12 Hateful 18 254 19 287 14 152 20 280 20 395 20 400 20 400 20 532 F13 Non-Hateful 20 370 15 290 12 168 20 280 20 463 20 496 20 464 20 583 F14 Hateful 19 326 14 220 12 157 20 280 20 446 20 472 20 425 20 566 F15 Hateful 18 256 17 361 13 160 20 280 20 429 20 448 20 432 20 549 F16 Non-Hateful 14 222 18 351 13 171 20 280 20 446 20 472 20 448 20 566 F17 Non-Hateful 21 406 18 448 20 269 30 420 30 703 30 756 30 704 30 883 F18 Non-Hateful 20 279 16 343 10 118 20 256 20 386 20 415 20 448 20 497 F19 Non-Hateful 20 270 16 245 9 82 20 256 20 386 20 415 20 448 20 497 F20 Non-Hateful 57 70 49 79 37 37 65 65 65 65 65 65 65 65 65 65 F21 Non-Hateful 61 74 52 84 36 36 65 65 65 65 65 65 65 65 65 65 F22 Non-Hateful 59 74 57 83 42 42 65 65 65 65 65 65 65 65 65 65 F23 Hateful - - 6 126 - - - - - - - - - - - - F24 Hateful - - 12 210 - - - - - - - - - - - - F25 Hateful - - 9 157 - - - - - - - - - - - - F26 Hateful - - 15 221 - - - - - - - - - - - - F27 Hateful - - 14 235 - - - - - - - - - - - - F32 Hateful - - - - - - 20 280 - - - - - - - - F33 Hateful - - - - - - 20 211 - - - - - - - - F34 Hateful - - - - - - 20 213 - - - - - - - - T otal Number of TP and TC 596 5367 601 7023 372 2840 715 5911 655 8190 655 8751 654 8488 655 10319 T able 12. Detailed breakdown of SEAHateCheck templates (#TP) and test cases (#TC) by language and functional test. ’-’ indicates functional tests where no English templates were provided for translations. * T emplates dropped as no suitable translation could b e found. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 35 F unctional T ests Example No. Description T emplate Label T emplate from SEAHateCheck Language Original English T emplate F16 Neutral statements using protected group identiers Non-Hateful น ี ่ เป ็ น คร ั ้ ง แรก ท ี ่ {TARGET}ถ ู ก เสนอช ื ่ อข ึ ้ น มา Thai This is the rst time a {T AR GET} is nominated. F17 P ositive statements using protected group identiers Non-Hateful ก ุ ร ั ก{TARGET}มากกกกก Thai I absolutely adore {T AR- GET}. F18 Denouncemen ts of hate that quote it Non-Hateful Ucapan kayak ”{T AR- GET} itu sampah” meny akitkan banget. Indonesian Statements like ”{T AR- GET} are scum” are deeply hurtful. F19 Denouncemen ts of hate that make direct reference to it Non-Hateful Pag sinabi mong aya w mo talaga sa mga {T AR- GET}, nagpapakita lang ’yan kung gaano ka kali- gaw. T agalog Saying that y ou hate {T AR GET} shows ho w misguided you are. F20 Abuse targeted at ob jects Non-Hateful Ano ba ’yang mga putang inang wang-w ang? T agalog What is it with these fuck- ing sirens? F21 Abuse targeted at individ- uals (not as member of a protected group) Non-Hateful Grabe, ang gago talaga nito T agalog He is such a massive scum- bag. F22 Abuse targeted at non- protected groups (e.g. professions) Non-Hateful Mga linta sa lipunan ang mga artist. T agalog Artists are parasites to our so ciety . F23 Sw aps of adjacent charac- ters Hateful 那 种 {TARGET} 必 须 被 处 诀。 Mandarin Those kinds of {T AR- GET} ought to be exe- cuetd. F24 Missing characters Hateful {T ARGET} are a cancr. Singlish {T ARGET} are a cancr. F25 Missing word b oundaries Hateful {T ARGET} like you are justpathetic. Singlish {T ARGET} like you are justpathetic. F26 A dded spaces between chars Hateful 祈 祷 有 人 能 纟 冬 结 那 些 {TARGET}。 Mandarin In a just world, those {T AR GET} would all b e d e a d. F27 Leet speak spellings Hateful 我讨yan{TARGET}。 Mandarin I h4te {T ARGET}. F32 Homophone char. replace- ment Hateful W e’ll tortuer these {T AR- GET} without mercy . Singlish W e’ll tortuer these {T AR- GET} without mercy . F33 Character decomposition Hateful 这 些 {TARGET} 就 该 闭 上 他 们的犭句嘴。 Mandarin Most {T ARGET} are se- riously fucked in the head. F34 Pin yin sp elling Hateful 你 和 所 有 其 他 {TARGET} 都 是社会的灾难。 Mandarin Y ou and all other {T AR- GET} are a plague to so- ciety . Fig. 6. Functional T ests Description and Example for F16 to F34 with family and/or friends). T able 13 shows the dialect of the target language that the translators and student helpers speak. Before participating, all annotators wer e briefed about the denition of HS and protected groups in the study . W e screened them on a hateful/non-hate classication task on a sample dataset, for the respective languages. In addition to the target language, all translators and annotators also met the minimum English standard to enter an English-medium university . The average age for the translators and annotators are 20.3 and 20.8 respectively . Females form a quarter of the translators and annotators. They were in their 20s and were studying for their Bachelors or recently graduated. 5 of the 8 translators and 9 of the 18 annotators WERE females. Manuscript submitted to ACM 36 Ng et al. Dataset Language Localities SEAHateCheck (Gold and Silver Annotators and T ranslators) Indonesian Jakarta, Surabaya T agalog Manila, North Luzon, Davao City Thai Bangkok Vietnamese Hanoi, Ho Chi Minh City SGHateCheck (Silver Annotators only) Malay Singapore Mandarin Singapore, Malaysia Singlish Singap ore T amil Singap ore, T amil Nadu T able 13. Diale ct of target languages spoken by translators and annotators A.4 Data Creation Period The Indonesian templates were translated between November 2023 and February 2024. T agalog, Thai and Vietnamese templates were translated between A ugust 2024 and October 2024. SEAHateCheck and SGHateCheck Silver Label testcases were generated and annotated between Octob er 2024 and January 2024. Translations w ere done between November 2023 and Februar y 2024. Annotations were created between January 2024 and March 2024. A.5 Inter-annotator agreement Krippendor ’s alpha was used to determine the inter-annotator agreement for the annotation tasks. T able 15 sho ws the annotation tasks in this study . A commonly accepted commonly accepted thr eshold for the alpha value is greater than 0.667 [ 24 ]. This was observed for all Gold Label annotations for sentiment in SEAHateCheck . For other cases, a lower alpha value was observed. HS related annotation tasks reported lower alpha values because the HS annotation task is not considered straightforward [9, 11, 35, 43]. Comparing across dierent annotation elds, annotators scor e higher agreements for task that has we observe a relatively high degree of agreement for the sentiment portion, where a majority of datasets had an alpha of above 0.667. This high score reects the rigorous training that we gave our annotators. W e sp eculate that the relatively lower scores for the control elds (Unnatural and Context) reected the linguistic diversity of our annotators even within the same language. The low er scores for the additional Silver Label quality control elds (T arget, Functions) reected the complex challenge of matching the test case with the provided targets, functional tests and examples. Discussions were also held with annotators to explain the disagreements in SEAHateCheck Silver Lab el dataset, and can be found in Appendix B. When comparing across dierent datasets and languages, we can compar e the relative reliability between each of them. While the SEAHateCheck Silver Label dataset have lower IAA compared to the Gold Label dataset, we observe that the control dataset, which consists of testcases where annotators had unanimous annotations, had near perfe ct IAA for almost all elds as e xpecte d. Hence we can attribute the lower scor es of the Silver Label dataset to the incr eased diculties of the task for SEAHateCheck . A dierent set of comparison is necessary when comparing the SGHateCheck Silver Label dataset as (1) no control elds (Unnatural, Context) were used in the original Gold Lab el dataset and (2) a dierent set of annotators annotated Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 37 Functional T ests Malay Singlish Tamil Mandarin Indonesian T agalog Thai Vietnamese No. T emplate Lab el #TP #TC #TP #TC #TP #T C #TP #TC #TP #TC #TP #TC #TP #TC #TP #TC F1 Hateful 10 126 10 140 10 140 10 140 8 184 10 260 9* 216 10 300 F2 Hateful 8 112 8 112 15 210 8 112 9 234 8 208 8 192 8 240 F3 Hateful 10 132 11 145 12 146 10 140 12 304 10 236 10 224 10 283 F4 Hateful 10 140 12 159 10 140 10 139 11 286 10 260 10 240 10 300 F5 Hateful 10 119 10 131 10 140 10 140 10 243 10 236 10 224 10 283 F6 Hateful 10 140 10 140 12 168 10 140 9 261 10 260 10 240 10 300 F7 Hateful 4 20 4 12 6 18 4 20 4 24 4 28 4 96 4 28 F8 Hateful 10 140 10 140 10 118 10 140 10 261 10 260 10 240 10 300 F9 Non-Hateful 10 10 10 10 46 46 10 10 10 10 10 10 10 10 10 10 F10 Hateful 10 140 10 140 9 126 10 140 10 260 10 260 10 240 10 300 F11 Hateful 10 140 10 140 14 196 10 140 9 261 10 260 10 240 10 300 F12 Hateful 10 116 10 113 14 152 10 140 9 209 10 188 10 192 10 249 F13 Non-Hateful 10 132 10 131 12 168 10 140 10 243 10 236 10 224 10 283 F14 Hateful 10 124 10 122 12 157 10 140 9 253 10 212 10 208 10 266 F15 Hateful 10 132 9 117 13 160 10 140 9 243 10 236 10 224 10 283 F16 Non-Hateful 10 132 10 131 13 171 10 140 10 243 10 236 10 224 10 283 F17 Non-Hateful 10 140 10 140 20 269 10 140 10 260 10 260 10 240 10 300 F18 Non-Hateful 10 122 10 118 10 118 10 122 10 240 10 222 10 240 10 254 F19 Non-Hateful 10 106 10 100 9 82 10 122 9 186 10 174 10 208 10 220 F20 Non-Hateful 10 10 10 10 37 37 11 11 9 10 10 10 10 10 10 10 F21 Non-Hateful 10 10 10 10 36 36 10 10 9 10 10 10 10 10 10 10 F22 Non-Hateful 10 10 10 10 42 42 10 10 10 10 10 10 10 10 10 10 F23 Hateful - - 8 103 - - 5 70 - - - - - - - - F24 Hateful - - 10 131 - - - - - - - - - - - - F25 Hateful - - 10 118 - - - - - - - - - - - - F26 Hateful - - 8 92 - - 4 35 - - - - - - - - F27 Hateful - - 10 100 - - 3 32 - - - - - - - - F32 Hateful - - 3 61 - - 9 126 - - - - - - - - F33 Hateful - - 3 56 - - 10 110 - - - - - - - - F34 Hateful - - 2 42 - - 9 99 - - - - - - - - T otal Number of T emplates 596 5367 601 7023 372 2840 715 5911 655 8190 655 8751 654 8488 655 10319 T able 14. Breakdown of all templates and test cases generated using the templating method into their respe ctive functional tests. #TP refers to the numb er of templates, #TC refers to the number of test cases. ’-’ indicates functional tests where no English templates w ere provided for translations. * T emplates droppe d as no suitable translation could be found. Manuscript submitted to ACM 38 Ng et al. Krippendorf ’s Alpha Dataset Language Sentiment Unnatural Context T arget Function T est Indonesian 0.902 0.126 -0.007 NA NA T agalog 0.769 0.049 0.082 NA NA Thai 0.801 0.111 0.047 NA NA SEAHateCheck Gold Label Vietnamese 0.871 0.065 0.050 NA NA Indonesian 0.742 0.139 0.152 0.575 0.574 T agalog 0.738 0.349 0.000 0.410 0.480 Thai 0.738 0.349 0.000 0.410 0.480 SEAHateCheck Silver Label Vietnamese 0.714 -0.003 -0.007 0.253 0.469 Indonesian 1.000 0.000 1.000 1.000 0.824 T agalog 1.000 1.000 1.000 1.000 0.811 Thai 1.000 1.000 1.000 1.000 0.811 SEAHateCheck Silver Label (Control) Vietnamese 0.942 1.000 1.000 0.318 0.911 Malay 0.613 0.184 0.200 0.562 0.401 Singlish 0.852 -0.035 0.322 0.189 0.674 Mandarin 0.553 0.018 -0.011 -0.011 0.361 SGHateCheck Silver Label T amil 0.696 0.046 0.198 0.463 0.249 Malay 1.000 -0.023 -0.011 0.000 0.680 Singlish 0.842 1.000 1.000 -0.011 0.736 Mandarin 0.490 -0.079 -0.012 -0.038 0.491 SGHateCheck Silver Label (Control) T amil 0.912 0.000 0.000 0.000 0.287 T able 15. Inter-annotator agreement for each dataset and annotation field (See section XXX). Cells ar e coloured in green have a Krippendorf ’s Alpha score of 1, while those in yellow have a score of 0. the Silver and Gold dataset. Hence, w e should not expect almost perfect IAA as observed in SEAHateCheck Silver Label Control dataset. That said, ther e are some cases where the Silver Label cases have a higher IAA, particularly for Singlish. Extra caution should be placed when intepreting such results. B SEAHateCheck Gold Label Annotation Discussion T o give the quantitativ e side of the annotation a qualitative perspective, discussions on the annotations were held after SEAHateCheck Gold Label annotations were completed. Specically , annotated test cases were grouped according to their template and placeholders, and groups with high rate of annotation disagreement or being agged for not being natural or requires context. Through this discussion, aim to identify whether the anomaly stems from wrongful annotation (false negatives), grammatical error or socio-cultural anomalies. The substantial ndings of the annotator’s opinions where their annotations ag out quality control issues are summarised in the subsections below , and specic examples are released in with the dataset. B.1 Indonesian T estcases that sounded unnatural are usually unnecessarily long and wer e often a word by word translation fr om the English examples. Some sentences also do not really match the intended informal tone of the task. As the annotators were from two dierent cities in Indonesia, there wer e a a couple of cases where w ord usagwas dierent ( e.g.. dan ’ is seen as too formal in Jakarta but not so in Surabaya). Outside of language issues, certain insults do not translate. There Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 39 are also certain sociocultural sensitivities that result in dierent sentiments for dierent target groups ( e.g. templates relating to government). B.2 T agalog The tone used in the translated templates sometimes shifted the sentiment of the templates. Additionally , certain phrases in T agalog are inherently ambiguous in tone. These cases would require more context in order to be deciphered. Annotators commented that templates with double negatives tend to sound less natural. B.3 Thai The tone used in the translated templates sometimes does not match the intende d sentiment of the samples. For instance, the tone of a non-hateful sentence could be really aggressive. Some of the slur placeholders were also not found to be rude enough to carry the hateful meaning to the sentences. Some translations were found to b e incorrect and replacements were r ecommended. B.4 Vietnamese Some noun classiers that come before placeholders do not ow . Certain placeholders were found to be unsuitable for some templates for the purpose of generating hate spe ech (e.g. T ao thà chết chứ không bao giờ hẹn hò với {IDENTITY_S} đâu. (translation: ’ I’d rather die than date {IDEN TI T Y_S}. ’ is unsuitable for placeholders related to children). C Fine-tuning and Evaluation Prompts This se ction reproduces the exact prompt templates used for evaluation and ne-tuning, including lab el space and per-language protected-group denitions in T able 17 - 21. It shows small but important instruction dierences across languages, for example T agalog includes HIV status among protected attributes, and cites legal sources used to align operational denitions. Making these prompts public strengthens r eproducibility and facilitates future baselines on SEAHateCheck. ### Instructions: Hate speech is dened as abuse targeted at a protected group or at its members for being a part of that group. Protected groups are Race, Religion, Ethnicity , Gender and Sexual Identity , Disability and Age . Using the above denition, return either "Hateful" for text classied as hate sp eech or "Non-Hateful" for text not classied as hate spe ech. Do not explain or add additional examples. Only enter Hateful or Non-Hateful and end your response. ### T e xt: {text} ### Label: {label} T able 17. Indonesian Manuscript submitted to ACM 40 Ng et al. Open-Source Mo dels Model Name Base Model/SOT A Params Release Date Notes Llama 3.2 3B Instruct (Llama3b) [14] SOT A 3B 25-Sep-24 Llama 3.1 8B Instruct (Llama8b) [14] SOT A 8B 23-Jul-24 Ministral-8B-Instruct-2410 (Ministral) [1] SOT A 8B 16-Oct-24 SeaLLMs-v3-7B-Chat (Seallm) [58] Qwen2 7B [55] 7B 30-Jul-24 Llama3.1 8B CPT SEA -LIONv3 Instruct (Sealion) [46] Llama 3.1 8B Instruct [14] 8B 31-Oct-24 Gemma-9B-it (Gemma) [50] SOT A 9B 27-Jun-2024 Gemma2 9B CPT SEA -LIONv3 Instruct (Seagem) [47] Gemma2 9B Instruct [50] 9B 19-Dec-24 Pangea-7B (Pangea) [57] Qwen2 7B [55] 7B 3-Oct-24 Trained on all evaluated lan- guages except T agalog Qwen2.5-7B-Instruct (Qwen) [38] SOT A 7B 19-Sep-2024 Closed-Source Mo dels Model Name Base Model/SOT A Params Release Date Notes o3-mini (o3) [33] SOT A - 31-Jan-2025 Gemini-2.0-ash (Gemini) [10] SOT A - 11-Dec-2024 deepseek-chat (Deepse ek) [34] SOT A - 31-Jan-2025 T able 16. Characteristics of all models tested, divided into op en-source and closed-source categories. Abbreviated model names are provided in parentheses next to the full names. 3 https://peraturan.bpk.go.id/Details/274494/uu- no- 1- tahun- 2024 4 https://www.mcmc.go v .my/skmmgovmy/media/General/registers/Content- Code- 2022.pdf 5 https://elibrary .judiciary.go v .ph/thebookshelf/showdocs/2/2562 6 https://elibrary .judiciary.go v .ph/thebookshelf/showdocs/2/90094 7 https://elibrary .judiciary.go v .ph/thebookshelf/showdocs/2/22128 8 https://elibrary .judiciary.go v .ph/thebookshelf/showdocs/28/20426 9 https://elibrary .judiciary.go v .ph/thebookshelf/showdocs/2/3140 10 https://sso.agc.gov .sg/Act/MRHA1990 11 https://sso.agc.gov .sg/Act/PC1871 12 https://congbao.chinhphu.vn/noi- dung- van- ban- so- 45- 2019- qh14- 30232 13 https://congbao.chinhphu.vn/noi- dung- van- ban- so- 24- 2018- qh14- 26894 Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 41 ### Instructions: Hate speech is dened as abuse targeted at a protected group or at its members for being a part of that group. Protected groups are Race, Religion, Ethnicity , Gender and Sexual Identity , HIV Status, Disability and Age. Using the above denition, return either "Hateful" for text classied as hate sp eech or "Non-Hateful" for text not classied as hate spe ech. Do not explain or add additional examples. Only enter Hateful or Non-Hateful and end your response. ### T e xt: {text} ### Label: {label} T able 18. Tagalog ### Instructions: Hate speech is dened as abuse targeted at a protected group or at its members for being a part of that group. Protected groups are Religion, Ethnicity , Gender and Sexual Identity , Disability and Age. Using the above denition, return either "Hateful" for text classied as hate sp eech or "Non-Hateful" for text not classied as hate spe ech. Do not explain or add additional examples. Only enter Hateful or Non-Hateful and end your response. ### T e xt: {text} ### Label: {label} T able 19. Thai ### Instructions: Hate speech is dened as abuse targeted at a protected group or at its members for being a part of that group. Protected groups are Religion, Ethnicity , Gender , HI V Status and Sexual Identity , Disability and A ge. Using the above denition, return either "Hateful" for text classied as hate sp eech or "Non-Hateful" for text not classied as hate spe ech. Do not explain or add additional examples. Only enter Hateful or Non-Hateful and end your response. ### T e xt: {text} ### Label: {label} T able 20. Vietnamese Manuscript submitted to ACM 42 Ng et al. ### Instructions: Hate speech in Singapore is dened as abuse targeted at a protecte d group or at its members for being a part of that group. Protected groups are Race, Religion, Country of Origin, Gender and Sexual Identity , Disability , and Age. Using the above denition, return either "Hateful" for text classied as hate sp eech or "Non-Hateful" for text not classied as hate spe ech. Do not explain or add additional examples. Only enter Hateful or Non-Hateful and end your response. ### T e xt: {text} ### Label: {label} T able 21. All Singap orean Languages Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 43 Func. Class Functionality G. Label # of Annotated Cases ID TG TH VN SS MS ZH T A Derogation F1 : Expression of strong nega- tive emotions (e xplicit) H - - - - 140 126 140 140 F2 : Description using ver y neg- ative attributes (e xplicit) H - - - - 84 112 112 210 F3 : Dehumanisation (explicit) (explicit) H - - - - 131 132 126 146 F4 : Implicit derogation H - - - - 303 140 139 140 Threat. language F5 : Direct threat (explicit) H - - - - 131 119 140 140 F6 : Threat as normative state- ment H - - - - 140 140 140 168 Slurs F7 : Hate expressed using slur H - - - - 12 20 16 18 Profanity usage F8 : Hate expressed using pro- fanity H - - - - 140 140 140 118 F9 : Non-hateful use of profan- ity NH - - - - 10 10 10 46 Pronoun refer- ence F10 : Hate expressed through reference in subsequent clauses H - - - - 140 140 140 126 F11 : Hate expressed through reference in subsequent sen- tences NH - - - - 140 140 140 196 Negation F12 : Hate expressed using negated positive statement H - - - - 113 116 140 152 F13 : Non-hate expressed using negated hateful statement NH - - - - 131 132 140 168 Phrasing F14 : Hate phrased as a question H - - - - 122 124 140 157 F15 : Hate phrased as an opin- ion H - - - - 117 132 140 160 Non-hateful group identier F16 : Neutral statements using protected group identiers NH - - - - 131 132 140 171 F17 : Positive statements using protected group identiers NH - - - - 140 140 140 269 Counter speech F18 : Denouncements of hate that quote it NH - - - - 118 122 120 118 F19 : Denouncements of hate that make direct reference to it NH - - - - 100 106 362 82 Abuse against non-protected targets F20 : Abuse targeted at objects NH - - - - 10 10 10 37 F21 : Abuse targeted at individ- uals (not as member of a pro- tected group) NH - - - - 10 10 10 36 F22 : Abuse targeted at non- protected groups (e .g. profes- sions) NH - - - - 10 10 10 42 T otal NH - - - - 618 656 656 865 H - - - - 2298 1552 2083 1724 T otal - - - - 2974 2253 2848 2851 T able 22. Number of test-cases annotated in SGHateCheck across functionalities. Also shown in this table is the functional class which the functionalities belong to, its functionality number and gold labels. Manuscript submitted to ACM 44 Ng et al. D Analysis over Functionalities for Gold Label T estcases D .1 Non-finetuned models D .2 Fine-tuned models Fig. 7. Accuracy across Functional T ests for Thai (le) and Vietnamese (right) Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 45 Fig. 8. Accuracy across Functional T ests for Malay (le) and Mandarin (right) Manuscript submitted to ACM 46 Ng et al. Fig. 9. Accuracy across Functional T ests for Singlish (le) and T amil (right) Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 47 E Analysis over Functionalities for Silver Label T estcases E.1 Non-finetuned models E.2 Fine-tuned models Fig. 10. Accuracy across Silver Functional T ests for Thai (le) and Vietnamese (right) Manuscript submitted to ACM 48 Ng et al. Fig. 11. Accuracy across Silver Functional T ests for Malay (le) and Mandarin (right) Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 49 Fig. 12. Accuracy across Silver Functional T ests for Singlish (le) and T amil (right) Manuscript submitted to ACM 50 Ng et al. F Analysis over Protected Categories for Gold Lab el T estcases F.1 Non-finetune d models F.2 Fine-tune d models Fig. 13. F1 Score across Protected Categories for Thai (le) and Vietnamese (right) Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 51 Fig. 14. F1 Score across Protected Categories for Malay (le) and Mandarin (right) Manuscript submitted to ACM 52 Ng et al. Fig. 15. F1 Score across Protected Categories for Singlish (le) and Tamil (right) Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 53 G Analysis over Protected Categories for Silver Label T estcases Fig. 16. F1 Score across Protected Categories for Silver Thai (le) and Vietnamese (right) Manuscript submitted to ACM 54 Ng et al. Fig. 17. F1 Score across Protected Categories for Silver Malay (le) and Mandarin (right) Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 55 Fig. 18. F1 Score across Protected Categories for Silver Singlish (le) and Tamil (right) G.1 Non-finetuned models G.2 Fine-tuned models Manuscript submitted to ACM 56 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.86 0.94 0.78 0.81 0.99 0.82 0.88 0.99 1.00 0.97 0.99 0.57 2 derog_neg_attrib_h H 0.93 0.78 0.56 0.69 0.98 0.87 0.82 1.00 1.00 0.99 1.00 0.79 3 derog_dehum_h H 0.89 0.80 0.78 0.84 1.00 0.93 0.93 0.99 1.00 1.00 1.00 0.89 4 derog_impl_h H 0.85 0.78 0.36 0.55 0.92 0.64 0.68 0.82 0.89 0.87 0.92 0.55 5 threat_dir_h H 0.97 0.99 0.90 0.98 1.00 1.00 0.95 1.00 1.00 1.00 1.00 0.96 6 threat_norm_h H 0.95 0.93 0.83 0.97 1.00 0.97 0.97 1.00 1.00 0.98 1.00 0.93 7 slur_h H 0.79 1.00 0.79 0.79 1.00 0.71 0.64 1.00 1.00 1.00 1.00 1.00 8 profanity_h H 0.76 0.91 0.68 0.72 1.00 0.86 0.83 0.98 1.00 0.99 1.00 0.78 9 profanity_nh NH 0.80 0.70 0.90 0.80 0.60 0.90 1.00 1.00 1.00 1.00 1.00 1.00 10 ref_subs_clause_h H 0.96 0.92 0.75 0.80 0.97 0.90 0.81 0.92 0.96 0.87 1.00 0.63 11 ref_subs_sent_h H 0.98 0.96 0.77 0.87 1.00 0.99 0.79 1.00 1.00 0.99 1.00 0.77 12 negate_pos_h H 0.81 0.94 0.78 0.83 1.00 0.79 0.77 0.96 0.98 0.82 1.00 0.61 13 negate_neg_nh NH 0.25 0.40 0.59 0.77 0.48 0.48 0.78 0.58 0.55 0.93 1.00 1.00 14 phrase_question_h H 0.96 1.00 0.83 0.78 1.00 0.97 0.61 0.98 0.98 0.97 1.00 0.86 15 phrase_opinion_h H 0.84 0.86 0.59 0.76 0.91 0.89 0.82 0.95 0.95 0.98 1.00 0.79 16 ident_neutral_nh NH 0.95 0.55 0.86 0.96 0.62 0.78 0.88 0.94 0.96 1.00 0.97 1.00 17 ident_pos_nh NH 0.41 0.61 0.85 0.87 0.55 0.62 0.71 0.78 0.74 0.99 0.93 0.95 18 counter_quote_nh NH 0.17 0.26 0.44 0.36 0.06 0.16 0.54 0.26 0.10 0.12 0.30 0.29 19 counter_ref_nh NH 0.05 0.10 0.19 0.17 0.00 0.02 0.37 0.21 0.09 0.29 0.21 0.61 20 target_obj_nh NH 0.80 0.80 1.00 1.00 0.90 1.00 1.00 1.00 1.00 1.00 1.00 1.00 21 target_indiv_nh NH 0.67 0.67 0.83 0.83 0.17 0.67 0.83 0.33 0.33 0.67 1.00 0.83 22 target_group_nh NH 0.60 0.50 0.60 0.60 0.20 0.60 0.60 0.50 0.50 0.80 1.00 0.80 T able 23. Accuracy across non-finetuned models for dierent Functional T ests in Indonesian High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 57 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.85 0.79 0.76 0.58 0.99 0.70 0.67 0.89 0.96 0.84 0.96 0.57 2 derog_neg_attrib_h H 0.98 0.67 0.70 0.47 1.00 0.75 0.57 0.91 0.96 0.93 0.98 0.54 3 derog_dehum_h H 0.98 0.84 0.72 0.69 0.98 0.82 0.89 0.98 0.99 0.94 0.98 0.79 4 derog_impl_h H 0.79 0.82 0.59 0.57 0.97 0.69 0.68 0.79 0.82 0.84 0.88 0.38 5 threat_dir_h H 0.95 0.89 0.77 0.59 1.00 0.62 0.63 0.97 0.99 0.95 0.97 0.71 6 threat_norm_h H 0.97 0.73 0.66 0.64 1.00 0.80 0.80 1.00 1.00 0.96 0.98 0.83 7 slur_h H 0.50 0.08 0.33 0.25 1.00 0.25 0.25 0.83 0.83 0.67 0.75 0.42 8 profanity_h H 0.96 0.81 0.79 0.55 0.99 0.74 0.76 0.92 0.97 0.91 0.98 0.60 9 profanity_nh NH 1.00 1.00 1.00 1.00 0.75 1.00 1.00 1.00 1.00 1.00 1.00 1.00 10 ref_subs_clause_h H 0.90 0.78 0.87 0.72 1.00 0.75 0.76 0.86 0.97 0.87 0.98 0.69 11 ref_subs_sent_h H 0.91 0.80 0.90 0.62 1.00 0.70 0.56 0.91 0.95 0.92 0.98 0.65 12 negate_pos_h H 0.85 0.65 0.45 0.51 0.99 0.58 0.59 0.82 0.92 0.86 0.98 0.60 13 negate_neg_nh NH 0.32 0.36 0.33 0.73 0.12 0.35 0.57 0.63 0.59 0.85 0.87 0.99 14 phrase_question_h H 0.98 0.85 0.89 0.58 1.00 0.88 0.30 0.96 0.98 0.93 0.97 0.78 15 phrase_opinion_h H 0.86 0.83 0.65 0.66 0.96 0.70 0.72 0.99 0.99 0.93 0.97 0.70 16 ident_neutral_nh NH 0.77 0.77 0.95 0.99 0.23 0.67 0.77 0.94 0.94 0.96 0.90 0.99 17 ident_pos_nh NH 0.43 0.50 0.72 0.89 0.25 0.48 0.73 0.63 0.69 0.91 0.91 0.97 18 counter_quote_nh NH 0.17 0.39 0.15 0.41 0.01 0.10 0.68 0.39 0.14 0.19 0.14 0.55 19 counter_ref_nh NH 0.01 0.40 0.26 0.55 0.10 0.13 0.70 0.39 0.15 0.40 0.29 0.86 20 target_obj_nh NH 0.67 0.67 0.83 0.83 0.33 0.83 1.00 0.83 0.83 1.00 1.00 1.00 21 target_indiv_nh NH 0.71 0.71 0.86 1.00 0.43 0.86 1.00 0.71 0.71 1.00 1.00 1.00 22 target_group_nh NH 1.00 1.00 1.00 1.00 0.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 T able 24. Accuracy across non-finetuned models for dierent Functional T ests in T agalog High-ality T est Cases. Manuscript submitted to ACM 58 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.93 0.95 0.94 0.85 0.94 0.69 0.88 0.94 0.96 0.90 0.91 0.65 2 derog_neg_attrib_h H 0.99 0.98 0.97 0.84 0.94 0.48 0.95 0.95 0.97 0.93 0.91 0.67 3 derog_dehum_h H 1.00 0.83 0.92 0.84 0.94 0.63 0.94 0.95 0.96 0.92 0.91 0.72 4 derog_impl_h H 0.91 0.93 0.80 0.77 0.89 0.66 0.83 0.83 0.83 0.88 0.85 0.43 5 threat_dir_h H 6 threat_norm_h H 7 slur_h H 0.70 0.52 0.70 0.56 0.73 0.29 0.49 0.55 0.62 0.78 0.82 0.15 8 profanity_h H 0.84 0.79 0.90 0.78 0.99 0.65 0.83 0.89 0.92 0.88 0.90 0.66 9 profanity_nh NH 0.60 0.40 0.80 1.00 0.80 1.00 1.00 1.00 1.00 1.00 1.00 1.00 10 ref_subs_clause_h H 0.94 0.91 0.89 0.91 1.00 0.92 0.99 0.99 0.99 0.94 0.92 0.75 11 ref_subs_sent_h H 0.94 0.85 0.95 0.81 0.99 0.71 0.91 0.95 0.97 0.93 0.91 0.68 12 negate_pos_h H 0.98 0.88 0.91 0.85 0.89 0.48 0.89 0.91 0.93 0.91 0.90 0.64 13 negate_neg_nh NH 0.40 0.59 0.54 0.78 0.57 0.66 0.74 0.69 0.69 0.79 0.99 0.99 14 phrase_question_h H 0.98 0.92 0.98 0.92 0.96 0.75 0.96 0.92 0.95 0.91 0.91 0.70 15 phrase_opinion_h H 0.97 1.00 0.92 0.83 0.99 0.74 0.95 0.83 0.87 0.92 0.87 0.68 16 ident_neutral_nh NH 0.81 0.73 0.77 0.92 0.77 0.86 0.82 0.80 0.79 0.79 0.86 0.98 17 ident_pos_nh NH 0.60 0.77 0.72 0.88 0.69 0.82 0.76 0.85 0.85 0.94 0.98 0.97 18 counter_quote_nh NH 0.08 0.32 0.10 0.14 0.03 0.09 0.21 0.30 0.11 0.17 0.32 0.52 19 counter_ref_nh NH 0.07 0.19 0.07 0.25 0.06 0.24 0.16 0.36 0.21 0.37 0.57 0.71 20 target_obj_nh NH 0.96 0.89 0.95 0.93 0.95 0.71 0.96 0.96 0.98 0.97 0.92 0.82 21 target_indiv_nh NH 1.00 1.00 0.94 0.97 0.94 0.77 0.93 1.00 1.00 0.93 0.90 0.88 22 target_group_nh NH 0.83 0.67 1.00 1.00 0.67 1.00 0.83 0.67 0.83 0.83 1.00 1.00 T able 25. Accuracy across non-finetuned models for dierent Functional T ests in Thai High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 59 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.99 0.97 0.70 0.71 1.00 0.94 0.96 0.96 0.97 0.92 0.976666667 0.78 2 derog_neg_attrib_h H 0.97 0.93 0.84 0.71 0.99 0.90 0.97 0.96 0.96 0.93 1.00 0.81 3 derog_dehum_h H 0.87 0.83 0.76 0.83 0.99 0.87 0.98 0.96 0.97 0.96 0.98 0.88 4 derog_impl_h H 0.92 0.84 0.59 0.50 1.00 0.84 0.73 0.87 0.91 0.81 0.91 0.57 5 threat_dir_h H 0.99 0.99 0.96 0.98 1.00 0.96 0.95 1.00 1.00 0.95 1 0.93 6 threat_norm_h H 7 slur_h H 0.89 0.67 0.89 0.44 1.00 0.78 0.44 0.67 0.89 0.67 0.33 0.33 8 profanity_h H 0.96 0.85 0.83 0.81 1.00 0.84 0.91 0.97 0.97 0.94 0.97 0.75 9 profanity_nh NH 0.63 0.75 1.00 1.00 0.25 1.00 1.00 0.88 0.88 1 0.875 1 10 ref_subs_clause_h H 0.94 0.86 0.95 0.73 1.00 0.96 0.96 0.98 0.99 0.91 0.99 0.77 11 ref_subs_sent_h H 0.99 0.89 0.92 0.87 1.00 0.96 0.94 0.99 0.99 0.95 0.98 0.77 12 negate_pos_h H 0.91 0.94 0.79 0.83 0.99 0.75 0.93 0.94 0.95 0.86 0.98 0.77 13 negate_neg_nh NH 0.59 0.54 0.59 0.85 0.71 0.85 0.78 0.91 0.88 0.82 1 1 14 phrase_question_h H 0.96 0.92 0.85 0.84 0.98 0.88 0.77 0.93 0.96 0.92 0.99 0.78 15 phrase_opinion_h H 0.99 0.96 0.87 0.80 0.99 0.92 0.89 0.97 0.98 0.90 0.99 0.83 16 ident_neutral_nh NH 0.82 0.79 0.92 1.00 0.50 0.64 0.77 0.91 0.89 0.90 0.93 1 17 ident_pos_nh NH 0.59 0.69 0.87 0.94 0.73 0.76 0.77 0.83 0.83 0.95 0.97 0.99 18 counter_quote_nh NH 0.23 0.28 0.22 0.28 0.00 0.02 0.30 0.17 0.07 0.11 0.15 0.28 19 counter_ref_nh NH 0.05 0.24 0.31 0.37 0.03 0.32 0.28 0.27 0.18 0.30 0.45 0.61 20 target_obj_nh NH 1.00 1.00 0.93 0.92 1.00 0.99 0.88 1.00 1.00 0.95 0.96 0.88 21 target_indiv_nh NH 0.00 0.50 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1 1 1 22 target_group_nh NH 0.00 0.00 1.00 1.00 0.00 0.00 0.00 0.00 0.00 1 1 1 T able 26. Accuracy across non-finetuned models for dierent Functional T ests in Vietnamese High-ality T est Cases. Manuscript submitted to ACM 60 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.82 0.91 0.88 0.74 0.98 0.85 0.85 0.95 0.98 0.99 1.00 0.71 2 derog_neg_attrib_h H 0.85 0.97 0.91 0.78 1.00 0.93 0.90 0.98 0.98 1.00 1.00 0.88 3 derog_dehum_h H 0.89 0.84 0.92 0.86 0.98 0.85 0.89 0.98 0.98 1.00 0.99 0.90 4 derog_impl_h H 0.84 0.84 0.78 0.70 0.98 0.84 0.79 0.88 0.91 0.93 0.87 0.64 5 threat_dir_h H 0.91 0.97 0.97 0.93 1.00 0.92 0.96 0.98 0.98 0.99 0.97 0.92 6 threat_norm_h H 0.97 0.96 0.95 0.87 0.99 0.98 0.97 1.00 1.00 1.00 1.00 0.94 7 slur_h H 0.75 0.75 1.00 0.50 1.00 1.00 1.00 0.75 1.00 0.75 1.00 0.00 8 profanity_h H 0.86 0.86 0.87 0.71 0.99 0.87 0.85 0.94 0.96 1.00 1.00 0.83 9 profanity_nh NH 0.71 0.43 0.86 1.00 0.29 1.00 0.86 0.86 0.86 1.00 1.00 1.00 10 ref_subs_clause_h H 0.88 0.89 0.77 0.77 0.98 0.92 0.86 0.90 0.92 0.95 0.99 0.73 11 ref_subs_sent_h H 0.86 0.86 0.78 0.74 1.00 0.95 0.82 0.96 0.96 1.00 1.00 0.76 12 negate_pos_h H 0.79 0.88 0.74 0.70 0.93 0.78 0.88 0.93 0.94 0.99 0.99 0.74 13 negate_neg_nh NH 0.39 0.27 0.39 0.83 0.39 0.39 0.57 0.66 0.68 0.69 0.95 0.99 14 phrase_question_h H 0.90 0.97 0.97 0.80 0.99 0.97 0.80 0.95 0.97 0.97 0.98 0.90 15 phrase_opinion_h H 0.95 1.00 0.81 0.81 1.00 0.96 0.92 0.96 0.98 1.00 0.99 0.93 16 ident_neutral_nh NH 0.85 0.53 0.75 0.97 0.42 0.63 0.63 0.87 0.89 0.86 0.94 0.98 17 ident_pos_nh NH 0.43 0.69 0.66 0.87 0.54 0.61 0.61 0.66 0.71 0.89 0.87 0.98 18 counter_quote_nh NH 0.14 0.04 0.10 0.24 0.00 0.11 0.30 0.19 0.03 0.03 0.17 0.23 19 counter_ref_nh NH 0.11 0.04 0.11 0.29 0.00 0.09 0.24 0.28 0.15 0.10 0.30 0.46 20 target_obj_nh NH 0.89 0.78 1.00 1.00 0.78 0.89 0.89 0.89 0.89 1.00 0.89 1.00 21 target_indiv_nh NH 0.67 0.56 0.44 0.78 0.22 0.78 0.67 0.44 0.44 0.44 1.00 0.89 22 target_group_nh NH 0.60 0.60 0.80 0.80 0.40 0.80 0.60 0.80 0.80 0.40 1.00 0.80 T able 27. Accuracy across non-finetuned models for dierent Functional T ests in Malay High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 61 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.94 0.95 0.96 0.77 1.00 0.87 0.98 0.91 0.95 0.98 1.00 0.73 2 derog_neg_attrib_h H 0.97 0.98 0.98 0.80 0.99 0.87 0.99 0.94 0.97 0.99 1.00 0.75 3 derog_dehum_h H 0.97 0.94 0.98 0.83 1.00 0.88 0.98 0.96 0.97 1.00 1.00 0.86 4 derog_impl_h H 0.96 0.78 0.87 0.54 0.93 0.74 0.95 0.80 0.88 0.98 0.96 0.71 5 threat_dir_h H 0.96 0.96 0.96 0.79 1.00 0.92 0.92 0.88 0.96 0.88 0.96 0.71 6 threat_norm_h H 0.99 0.91 1.00 0.88 1.00 0.95 0.95 0.91 0.91 1.00 1.00 0.81 7 slur_h H 0.33 0.33 0.33 0.00 1.00 0.67 0.33 1.00 1.00 1.00 0.33 0.67 8 profanity_h H 0.99 0.89 1.00 0.92 1.00 0.94 1.00 0.98 0.98 1.00 1.00 0.87 9 profanity_nh NH 1.00 1.00 0.67 1.00 0.67 0.67 1.00 1.00 1.00 1.00 1.00 1.00 10 ref_subs_clause_h H 0.99 0.97 1.00 0.92 0.99 0.99 0.95 0.96 1.00 1.00 1.00 0.83 11 ref_subs_sent_h H 0.98 0.83 0.99 0.88 0.99 0.94 0.89 0.93 0.97 1.00 1.00 0.69 12 negate_pos_h H 0.92 0.93 0.94 0.83 0.96 0.85 0.95 0.93 0.97 0.98 1.00 0.66 13 negate_neg_nh NH 0.36 0.36 0.32 0.80 0.45 0.50 0.50 0.75 0.67 0.72 0.96 0.99 14 phrase_question_h H 0.99 0.98 1.00 0.94 1.00 0.98 0.93 0.96 0.99 1.00 1.00 0.91 15 phrase_opinion_h H 0.99 1.00 0.98 0.93 1.00 0.98 0.99 0.97 0.99 0.99 1.00 0.84 16 ident_neutral_nh NH 0.92 0.58 0.75 1.00 0.58 0.83 0.75 1.00 1.00 0.92 0.75 1.00 17 ident_pos_nh NH 0.58 0.55 0.53 0.89 0.63 0.79 0.63 0.97 0.95 0.95 0.92 1.00 18 counter_quote_nh NH 0.11 0.46 0.03 0.46 0.03 0.28 0.49 0.44 0.08 0.06 0.39 0.36 19 counter_ref_nh NH 0.03 0.17 0.09 0.36 0.06 0.17 0.20 0.40 0.17 0.12 0.22 0.60 20 target_obj_nh NH 0.96 0.79 0.81 0.72 1.00 0.90 0.87 0.82 0.85 0.93 0.93 0.53 21 target_indiv_nh NH 0.95 0.78 0.97 0.78 1.00 0.92 0.98 0.95 0.95 1.00 1.00 0.83 22 target_group_nh NH 0.97 0.97 0.95 0.78 1.00 0.96 0.93 0.84 0.87 0.99 0.93 0.89 T able 28. Accuracy across non-finetuned models for dierent Functional T ests in Mandarin High-ality T est Cases. Manuscript submitted to ACM 62 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.91 1.00 0.91 0.82 0.96 0.86 0.95 0.87 0.92 0.97 0.99 0.87 2 derog_neg_attrib_h H 0.90 0.99 0.96 0.79 0.99 0.89 0.95 0.89 0.93 0.99 0.99 0.87 3 derog_dehum_h H 0.86 0.96 0.95 0.87 0.91 0.82 0.95 0.94 0.96 0.96 0.99 0.92 4 derog_impl_h H 0.93 0.93 0.96 0.85 0.92 0.91 0.91 0.84 0.86 0.97 0.98 0.81 5 threat_dir_h H 0.93 0.99 0.97 0.83 1.00 0.92 0.94 0.91 0.94 0.98 0.99 0.84 6 threat_norm_h H 0.91 0.96 0.92 0.82 0.84 0.81 0.96 0.97 0.99 0.98 0.99 0.92 7 slur_h H 1.00 0.71 0.86 0.71 1.00 0.71 0.57 1.00 1.00 1.00 0.71 1.00 8 profanity_h H 0.86 0.97 0.96 0.86 0.92 0.85 0.94 0.89 0.95 1.00 0.99 0.91 9 profanity_nh NH 1.00 0.20 0.80 1.00 0.40 0.80 0.80 1.00 1.00 1.00 1.00 1.00 10 ref_subs_clause_h H 0.98 1.00 1.00 0.93 0.90 0.85 0.99 0.91 0.99 0.99 1.00 0.94 11 ref_subs_sent_h H 0.93 0.99 0.99 0.88 0.95 0.85 0.93 0.93 0.96 0.99 0.99 0.91 12 negate_pos_h H 0.91 0.97 0.94 0.92 0.96 0.84 0.98 0.90 0.96 0.99 1.00 0.88 13 negate_neg_nh NH 0.68 0.43 0.43 0.74 0.51 0.55 0.56 0.68 0.69 0.73 0.86 0.87 14 phrase_question_h H 0.92 1.00 1.00 0.97 0.89 0.86 0.93 0.96 0.99 0.98 1.00 0.94 15 phrase_opinion_h H 0.94 1.00 0.99 0.95 1.00 0.95 1.00 0.96 0.98 1.00 1.00 0.95 16 ident_neutral_nh NH 0.75 0.44 0.78 0.89 0.36 0.67 0.78 0.88 0.88 0.74 0.65 0.97 17 ident_pos_nh NH 0.75 0.55 0.79 0.90 0.74 0.62 0.66 0.85 0.85 0.90 0.90 0.97 18 counter_quote_nh NH 0.15 0.08 0.03 0.11 0.05 0.04 0.04 0.05 0.00 0.01 0.12 0.10 19 counter_ref_nh NH 0.11 0.12 0.06 0.22 0.15 0.11 0.17 0.22 0.11 0.11 0.17 0.40 20 target_obj_nh NH 0.89 0.99 1.00 0.91 0.85 0.79 0.98 0.95 0.96 0.99 1.00 0.91 21 target_indiv_nh NH 0.87 0.95 0.91 0.73 0.92 0.79 0.85 0.88 0.88 0.84 0.85 0.75 22 target_group_nh NH 0.89 0.98 0.98 0.91 0.98 0.93 0.98 0.95 0.96 1.00 1.00 0.93 T able 29. Accuracy across non-finetuned models for dierent Functional T ests in Singlish High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 63 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.86 0.68 1.00 0.68 0.88 0.52 0.45 0.81 0.92 1.00 0.79 0.55 2 derog_neg_attrib_h H 0.83 0.83 0.93 0.79 0.99 0.67 0.66 0.86 0.93 0.98 0.87 0.51 3 derog_dehum_h H 0.93 0.91 0.99 0.92 1.00 0.70 0.70 0.95 0.98 1.00 0.98 0.69 4 derog_impl_h H 0.66 0.62 0.77 0.56 0.94 0.47 0.52 0.69 0.73 0.93 0.79 0.29 5 threat_dir_h H 0.88 0.66 0.98 0.83 0.94 0.58 0.61 0.89 0.96 0.99 0.88 0.77 6 threat_norm_h H 0.87 0.79 0.99 0.83 0.99 0.73 0.67 0.93 0.98 1.00 0.95 0.79 7 slur_h H 0.13 0.38 1.00 0.75 1.00 0.13 0.50 0.13 0.50 0.75 0.25 0.00 8 profanity_h H 0.84 0.72 0.98 0.80 1.00 0.59 0.50 0.83 0.90 1.00 0.92 0.51 9 profanity_nh NH 1.00 0.84 0.52 1.00 0.23 0.94 0.97 1.00 1.00 0.97 0.97 1.00 10 ref_subs_clause_h H 0.76 0.70 1.00 0.90 0.99 0.63 0.55 0.88 0.98 0.98 0.90 0.56 11 ref_subs_sent_h H 0.91 0.74 0.99 0.91 1.00 0.68 0.56 0.89 0.97 0.96 0.93 0.60 12 negate_pos_h H 0.82 0.80 0.99 0.85 0.99 0.60 0.73 0.88 0.95 0.98 0.97 0.59 13 negate_neg_nh NH 0.41 0.50 0.03 0.34 0.16 0.38 0.59 0.46 0.40 0.38 0.87 0.90 14 phrase_question_h H 0.74 0.81 0.98 0.78 1.00 0.60 0.32 0.83 0.89 0.91 0.86 0.49 15 phrase_opinion_h H 0.84 0.79 0.98 0.79 1.00 0.42 0.69 0.92 0.97 0.97 0.99 0.53 16 ident_neutral_nh NH 0.69 0.82 0.39 0.88 0.22 0.65 0.57 0.96 0.98 0.72 0.98 1.00 17 ident_pos_nh NH 0.38 0.64 0.29 0.88 0.18 0.62 0.59 0.76 0.78 0.80 0.93 1.00 18 counter_quote_nh NH 0.22 0.28 0.00 0.13 0.02 0.40 0.52 0.33 0.05 0.07 0.22 0.58 19 counter_ref_nh NH 0.16 0.18 0.00 0.18 0.00 0.25 0.73 0.34 0.25 0.16 0.39 0.55 20 target_obj_nh NH 0.81 0.65 0.45 0.94 0.10 0.71 0.94 1.00 1.00 1.00 0.94 1.00 21 target_indiv_nh NH 0.30 0.47 0.10 0.77 0.33 0.83 0.63 0.73 0.67 0.50 1.00 0.90 22 target_group_nh NH 0.57 0.43 0.22 0.83 0.17 0.52 0.70 0.74 0.74 0.65 0.96 1.00 T able 30. Accuracy across non-finetuned models for dierent Functional T ests in T amil High-ality T est Cases. Manuscript submitted to ACM 64 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.42 0.41 0.78 0.89 0.58 0.54 0.60 0.86 0.80 2 derog_neg_attrib_h H 0.54 0.47 0.69 0.88 0.86 0.64 0.82 0.84 0.69 3 derog_dehum_h H 0.62 0.56 0.86 0.89 0.83 0.76 0.90 0.87 0.81 4 derog_impl_h H 0.49 0.16 0.53 0.59 0.37 0.20 0.63 0.65 0.48 5 threat_dir_h H 0.51 0.77 0.91 0.96 0.91 0.76 0.76 0.94 0.81 6 threat_norm_h H 0.45 0.69 0.85 0.92 0.81 0.88 0.90 0.99 0.97 7 slur_h H 0.86 0.79 0.93 0.86 0.86 0.79 0.86 0.86 0.86 8 profanity_h H 0.48 0.54 0.75 0.90 0.59 0.67 0.78 0.91 0.83 9 profanity_nh NH 0.90 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 10 ref_subs_clause_h H 0.32 0.49 0.60 0.75 0.77 0.64 0.75 0.55 0.33 11 ref_subs_sent_h H 0.82 0.63 0.83 1.00 0.89 0.94 0.94 0.96 0.96 12 negate_pos_h H 0.27 0.36 0.61 0.64 0.76 0.41 0.57 0.90 0.63 13 negate_neg_nh NH 0.96 0.77 0.79 0.86 0.90 0.91 0.91 0.85 0.98 14 phrase_question_h H 0.51 0.71 0.77 0.93 0.85 0.83 0.70 0.96 0.87 15 phrase_opinion_h H 0.43 0.52 0.69 0.72 0.74 0.49 0.76 0.79 0.65 16 ident_neutral_nh NH 0.99 0.99 0.98 0.99 0.98 0.99 0.97 0.99 1.00 17 ident_pos_nh NH 0.83 0.93 0.91 0.93 0.96 0.97 0.96 0.90 1.00 18 counter_quote_nh NH 0.47 0.53 0.61 0.31 0.22 0.34 0.40 0.63 0.64 19 counter_ref_nh NH 0.50 0.32 0.24 0.26 0.21 0.31 0.23 0.66 0.69 20 target_obj_nh NH 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 21 target_indiv_nh NH 0.67 0.83 0.50 0.33 0.33 0.50 0.50 0.83 0.83 22 target_group_nh NH 0.60 0.70 0.60 0.40 0.70 0.70 0.70 0.80 0.70 T able 31. Accuracy across fine-tuned models for dierent Functional T ests in Indonesian High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 65 f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.83 0.88 1.00 1.00 0.90 0.94 0.88 0.95 1.00 2 derog_neg_attrib_h H 0.94 0.85 0.97 0.99 1.00 0.84 0.82 0.99 1.00 3 derog_dehum_h H 0.98 0.96 0.99 1.00 1.00 1.00 1.00 1.00 1.00 4 derog_impl_h H 0.80 0.81 0.93 0.94 0.85 0.92 0.85 0.97 0.93 5 threat_dir_h H 0.72 0.90 0.89 0.84 0.95 0.93 0.73 1.00 1.00 6 threat_norm_h H 0.86 0.87 1.00 1.00 0.97 0.92 0.90 1.00 1.00 7 slur_h H 0.83 0.50 1.00 1.00 0.75 0.67 0.75 0.83 0.83 8 profanity_h H 1.00 1.00 0.97 0.99 0.98 1.00 0.96 1.00 1.00 9 profanity_nh NH 0.50 0.50 0.25 0.50 0.50 0.50 0.00 0.50 0.75 10 ref_subs_clause_h H 0.99 1.00 1.00 1.00 0.95 0.94 0.99 1.00 1.00 11 ref_subs_sent_h H 0.91 0.99 1.00 0.99 0.96 0.95 1.00 1.00 1.00 12 negate_pos_h H 0.83 0.78 0.91 0.96 0.91 0.85 0.77 0.88 0.93 13 negate_neg_nh NH 0.41 0.17 0.25 0.49 0.24 0.21 0.26 0.63 0.68 14 phrase_question_h H 0.97 0.88 1.00 1.00 1.00 0.95 0.97 1.00 1.00 15 phrase_opinion_h H 0.93 0.97 0.97 0.97 0.90 1.00 0.94 1.00 1.00 16 ident_neutral_nh NH 0.76 0.83 0.60 0.71 0.76 0.74 0.65 0.90 0.88 17 ident_pos_nh NH 0.60 0.66 0.73 0.81 0.81 0.56 0.69 0.78 0.92 18 counter_quote_nh NH 0.08 0.08 0.00 0.07 0.02 0.14 0.27 0.25 0.18 19 counter_ref_nh NH 0.00 0.06 0.00 0.00 0.05 0.11 0.12 0.01 0.13 20 target_obj_nh NH 0.50 0.50 0.33 0.50 0.67 0.50 0.50 0.50 0.50 21 target_indiv_nh NH 0.29 0.43 0.14 0.14 0.57 0.57 0.43 0.00 0.00 22 target_group_nh NH 0.00 0.00 0.00 0.00 1.00 1.00 0.00 0.00 0.00 T able 32. Accuracy across fine-tuned models for dierent Functional T ests in T agalog High-ality T est Cases. Manuscript submitted to ACM 66 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.61 0.50 0.95 0.82 0.80 0.58 0.64 0.64 0.64 2 derog_neg_attrib_h H 0.51 0.52 0.97 0.93 0.72 0.58 0.75 0.86 0.92 3 derog_dehum_h H 0.85 0.71 0.94 0.86 0.91 0.82 0.96 0.98 0.90 4 derog_impl_h H 0.69 0.59 0.77 0.74 0.74 0.63 0.76 0.74 0.55 5 threat_dir_h H 6 threat_norm_h H 7 slur_h H 0.10 0.12 0.48 0.33 0.22 0.05 0.16 0.27 0.20 8 profanity_h H 0.62 0.78 0.97 0.91 0.77 0.69 0.80 0.82 0.87 9 profanity_nh NH 1.00 0.80 0.80 0.80 0.80 1.00 0.80 1.00 1.00 10 ref_subs_clause_h H 0.80 0.93 0.95 0.98 0.96 0.79 0.91 0.97 0.95 11 ref_subs_sent_h H 0.56 0.81 0.74 0.75 0.75 0.80 0.88 0.96 0.96 12 negate_pos_h H 0.64 0.78 0.91 0.85 0.86 0.71 0.75 0.95 0.81 13 negate_neg_nh NH 0.96 0.84 0.75 0.75 0.93 0.86 0.92 0.98 0.99 14 phrase_question_h H 0.70 0.65 0.91 0.83 0.80 0.74 0.89 0.87 0.82 15 phrase_opinion_h H 0.66 0.85 0.88 0.87 0.88 0.75 0.87 0.87 0.87 16 ident_neutral_nh NH 1.00 0.99 0.94 0.98 0.98 0.99 1.00 1.00 1.00 17 ident_pos_nh NH 0.99 0.99 0.98 0.99 0.96 1.00 1.00 0.99 0.99 18 counter_quote_nh NH 0.47 0.41 0.18 0.16 0.24 0.32 0.47 0.66 0.44 19 counter_ref_nh NH 0.75 0.49 0.36 0.55 0.32 0.44 0.42 0.73 0.71 20 target_obj_nh NH 0.88 0.80 0.97 0.93 0.88 0.82 0.96 0.95 0.90 21 target_indiv_nh NH 0.78 0.85 0.95 0.96 0.84 0.83 0.83 0.96 0.89 22 target_group_nh NH 1.00 0.83 0.83 1.00 0.83 1.00 1.00 1.00 1.00 T able 33. Accuracy across fine-tuned models for dierent Functional T ests in Thai High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 67 f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.95 0.98 1.00 0.99 0.99 0.99 1.00 1.00 1.00 2 derog_neg_attrib_h H 1.00 0.91 1.00 1.00 1.00 1.00 1.00 1.00 1.00 3 derog_dehum_h H 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.99 1.00 4 derog_impl_h H 0.50 0.92 0.93 0.96 0.98 0.97 0.94 0.94 0.95 5 threat_dir_h H 0.98 0.97 1.00 1.00 1.00 1.00 1.00 1.00 1.00 6 threat_norm_h H 7 slur_h H 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 8 profanity_h H 1.00 0.98 1.00 1.00 1.00 1.00 1.00 0.99 1.00 9 profanity_nh NH 0.50 0.50 0.50 0.25 0.50 0.38 0.63 0.63 0.50 10 ref_subs_clause_h H 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 11 ref_subs_sent_h H 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 12 negate_pos_h H 0.96 0.99 1.00 1.00 0.98 0.98 0.98 0.98 0.97 13 negate_neg_nh NH 0.78 0.60 0.73 0.77 0.82 0.81 0.64 0.90 0.90 14 phrase_question_h H 0.99 0.97 0.99 1.00 1.00 0.99 1.00 1.00 1.00 15 phrase_opinion_h H 1.00 1.00 0.99 0.99 1.00 1.00 0.99 1.00 1.00 16 ident_neutral_nh NH 0.91 0.83 0.78 0.88 0.88 0.96 0.91 0.95 0.95 17 ident_pos_nh NH 0.86 0.88 0.91 0.92 0.87 0.92 0.87 0.91 0.92 18 counter_quote_nh NH 0.12 0.03 0.00 0.00 0.00 0.00 0.01 0.22 0.09 19 counter_ref_nh NH 0.11 0.09 0.03 0.10 0.04 0.04 0.02 0.55 0.16 20 target_obj_nh NH 1.00 0.98 1.00 1.00 1.00 1.00 0.99 1.00 1.00 21 target_indiv_nh NH 0.50 1.00 0.50 0.50 1.00 1.00 1.00 0.50 0.50 22 target_group_nh NH 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 T able 34. Accuracy across fine-tuned models for dierent Functional T ests in Vietnamese High-ality T est Cases. Manuscript submitted to ACM 68 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.55 0.51 0.93 0.90 0.74 0.65 0.78 0.77 0.75 2 derog_neg_attrib_h H 0.75 0.79 0.97 0.96 0.91 0.83 0.97 0.84 0.83 3 derog_dehum_h H 0.68 0.47 0.92 0.93 0.81 0.69 0.93 0.90 0.77 4 derog_impl_h H 0.51 0.44 0.83 0.85 0.80 0.62 0.85 0.70 0.36 5 threat_dir_h H 0.54 0.53 0.94 0.89 0.83 0.71 0.94 0.86 0.76 6 threat_norm_h H 0.52 0.74 0.98 0.93 0.84 0.78 0.94 0.97 0.87 7 slur_h H 1.00 0.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 8 profanity_h H 0.81 0.60 0.91 0.83 0.74 0.79 0.90 0.88 0.80 9 profanity_nh NH 1.00 0.86 0.57 0.71 0.86 0.71 0.71 0.86 0.86 10 ref_subs_clause_h H 0.65 0.58 0.96 0.92 0.75 0.70 0.90 0.73 0.56 11 ref_subs_sent_h H 0.85 0.83 1.00 0.99 0.98 0.97 1.00 0.99 0.91 12 negate_pos_h H 0.53 0.56 0.82 0.84 0.72 0.52 0.75 0.81 0.50 13 negate_neg_nh NH 0.87 0.76 0.44 0.68 0.72 0.70 0.63 0.87 0.90 14 phrase_question_h H 0.74 0.66 0.99 0.94 0.92 0.93 0.99 0.90 0.87 15 phrase_opinion_h H 0.91 0.86 0.98 0.98 0.97 0.96 0.96 0.99 0.96 16 ident_neutral_nh NH 0.93 1.00 0.81 0.91 0.97 0.93 0.75 0.96 1.00 17 ident_pos_nh NH 0.91 0.93 0.83 0.94 0.97 0.98 0.79 0.97 1.00 18 counter_quote_nh NH 0.18 0.32 0.02 0.04 0.08 0.11 0.08 0.32 0.29 19 counter_ref_nh NH 0.15 0.23 0.05 0.10 0.20 0.19 0.06 0.43 0.41 20 target_obj_nh NH 0.89 0.89 0.44 0.78 0.89 0.78 0.78 0.67 0.67 21 target_indiv_nh NH 0.56 0.67 0.00 0.11 0.33 0.44 0.22 0.22 0.33 22 target_group_nh NH 0.40 0.60 0.00 0.00 0.80 0.20 0.40 0.40 0.20 T able 35. Accuracy across fine-tuned models for dierent Functional T ests in Malay High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 69 f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.98 0.88 1.00 0.99 1.00 1.00 0.98 0.87 0.96 2 derog_neg_attrib_h H 1.00 0.93 1.00 1.00 0.98 1.00 1.00 0.99 0.99 3 derog_dehum_h H 1.00 0.87 1.00 1.00 0.98 0.98 0.98 0.97 0.98 4 derog_impl_h H 0.63 0.42 0.94 0.65 0.86 0.66 0.79 0.85 0.76 5 threat_dir_h H 0.17 0.38 0.79 0.67 0.92 0.79 0.71 0.75 0.71 6 threat_norm_h H 0.72 0.57 1.00 0.95 1.00 1.00 0.89 0.72 0.71 7 slur_h H 0.33 0.33 0.67 0.33 0.67 0.67 0.67 1.00 1.00 8 profanity_h H 1.00 0.85 1.00 1.00 1.00 1.00 1.00 0.99 0.99 9 profanity_nh NH 0.67 0.33 0.33 0.33 0.00 0.33 0.00 0.67 1.00 10 ref_subs_clause_h H 0.99 0.93 1.00 0.98 1.00 1.00 1.00 0.99 0.94 11 ref_subs_sent_h H 1.00 0.97 1.00 1.00 1.00 1.00 0.99 1.00 0.98 12 negate_pos_h H 0.79 0.94 1.00 0.98 0.95 0.86 0.82 0.93 0.92 13 negate_neg_nh NH 0.57 0.58 0.46 0.68 0.63 0.53 0.39 0.68 0.68 14 phrase_question_h H 0.98 0.94 1.00 0.99 1.00 1.00 1.00 1.00 1.00 15 phrase_opinion_h H 0.99 0.93 1.00 1.00 1.00 1.00 1.00 1.00 0.98 16 ident_neutral_nh NH 1.00 1.00 0.83 0.83 0.75 1.00 0.83 1.00 1.00 17 ident_pos_nh NH 0.97 0.95 0.95 0.95 0.97 0.97 0.97 0.97 0.97 18 counter_quote_nh NH 0.04 0.21 0.00 0.00 0.01 0.00 0.01 0.07 0.06 19 counter_ref_nh NH 0.13 0.03 0.00 0.01 0.02 0.05 0.03 0.06 0.02 20 target_obj_nh NH 0.44 0.55 0.63 0.61 0.71 0.59 0.70 0.60 0.59 21 target_indiv_nh NH 0.92 0.94 1.00 0.97 0.95 1.00 1.00 0.84 0.81 22 target_group_nh NH 0.45 0.44 0.84 0.71 0.84 0.82 0.88 0.75 0.71 T able 36. Accuracy across fine-tuned models for dierent Functional T ests in Mandarin High-ality T est Cases. Manuscript submitted to ACM 70 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.90 0.80 0.99 0.95 0.89 0.82 0.85 0.91 0.87 2 derog_neg_attrib_h H 0.86 0.70 0.99 0.97 0.93 0.95 0.93 0.93 0.89 3 derog_dehum_h H 0.82 0.68 0.97 0.92 0.87 0.86 0.88 0.96 0.84 4 derog_impl_h H 0.82 0.68 1.00 0.99 0.93 0.87 0.88 0.97 0.79 5 threat_dir_h H 0.89 0.81 0.95 0.92 0.92 0.93 0.98 0.96 0.93 6 threat_norm_h H 0.67 0.60 0.93 0.79 0.89 0.86 0.91 0.94 0.83 7 slur_h H 1.00 0.29 1.00 1.00 0.71 0.86 0.86 0.71 0.71 8 profanity_h H 0.93 0.81 1.00 0.94 0.96 0.94 0.95 0.99 0.89 9 profanity_nh NH 0.80 1.00 0.20 1.00 0.80 0.80 0.80 0.60 1.00 10 ref_subs_clause_h H 0.91 0.92 0.99 0.97 0.95 0.88 0.98 0.99 0.92 11 ref_subs_sent_h H 0.98 0.93 0.99 0.99 0.99 0.98 0.97 1.00 0.97 12 negate_pos_h H 0.80 0.66 0.93 0.93 0.79 0.72 0.77 0.95 0.81 13 negate_neg_nh NH 0.94 0.74 0.65 0.79 0.77 0.74 0.82 0.87 0.95 14 phrase_question_h H 0.92 0.93 1.00 0.99 0.97 0.95 0.95 0.98 0.98 15 phrase_opinion_h H 0.98 0.98 0.98 0.98 0.98 0.98 0.99 1.00 0.98 16 ident_neutral_nh NH 0.93 0.88 0.76 0.89 0.99 0.99 0.90 0.92 0.96 17 ident_pos_nh NH 0.96 0.99 0.93 0.97 0.97 1.00 0.96 0.99 1.00 18 counter_quote_nh NH 0.23 0.30 0.10 0.30 0.00 0.05 0.16 0.48 0.16 19 counter_ref_nh NH 0.48 0.25 0.12 0.42 0.22 0.23 0.34 0.40 0.32 20 target_obj_nh NH 0.78 0.78 1.00 0.97 0.86 0.83 0.93 1.00 0.91 21 target_indiv_nh NH 0.85 0.60 0.95 0.89 0.73 0.81 0.93 0.85 0.79 22 target_group_nh NH 0.88 0.79 0.98 0.98 0.82 0.84 0.88 0.95 0.75 T able 37. Accuracy across fine-tuned models for dierent Functional T ests in Singlish High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 71 f_n t_function t_g Ministral Llama3b Llama8b sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.82 0.77 1.00 0.98 0.78 0.62 0.64 0.87 0.95 2 derog_neg_attrib_h H 0.88 0.75 0.98 0.90 0.77 0.79 0.83 0.91 0.94 3 derog_dehum_h H 0.83 0.55 1.00 0.95 0.66 0.72 0.91 0.93 0.96 4 derog_impl_h H 0.77 0.55 0.92 0.80 0.46 0.62 0.75 0.80 0.72 5 threat_dir_h H 0.73 0.56 0.91 0.79 0.45 0.80 0.91 0.88 0.91 6 threat_norm_h H 0.73 0.72 0.97 0.92 0.65 0.63 0.75 0.97 0.96 7 slur_h H 0.50 0.25 1.00 0.88 0.25 0.63 0.63 0.50 0.75 8 profanity_h H 0.59 0.53 0.99 0.95 0.58 0.71 0.67 0.89 0.87 9 profanity_nh NH 0.81 0.52 0.06 0.55 0.90 0.74 0.81 0.52 0.55 10 ref_subs_clause_h H 0.81 0.87 1.00 0.99 0.64 0.66 0.83 0.98 1.00 11 ref_subs_sent_h H 0.87 0.91 0.93 0.99 0.88 0.95 0.96 0.99 1.00 12 negate_pos_h H 0.64 0.66 0.99 0.95 0.78 0.71 0.90 0.93 0.95 13 negate_neg_nh NH 0.59 0.49 0.01 0.42 0.62 0.56 0.34 0.59 0.62 14 phrase_question_h H 0.89 0.91 1.00 0.99 0.76 0.80 0.94 0.97 0.98 15 phrase_opinion_h H 0.75 0.75 0.83 0.74 0.64 0.69 0.77 0.88 0.86 16 ident_neutral_nh NH 0.87 0.98 0.33 0.89 0.96 0.89 0.83 0.96 0.96 17 ident_pos_nh NH 0.93 1.00 0.80 1.00 0.94 0.90 0.70 0.98 0.99 18 counter_quote_nh NH 0.03 0.17 0.00 0.00 0.35 0.31 0.17 0.20 0.11 19 counter_ref_nh NH 0.11 0.34 0.00 0.07 0.23 0.20 0.36 0.16 0.00 20 target_obj_nh NH 0.48 0.61 0.00 0.35 0.55 0.42 0.58 0.45 0.55 21 target_indiv_nh NH 0.17 0.33 0.03 0.07 0.40 0.40 0.43 0.23 0.03 22 target_group_nh NH 0.35 0.39 0.04 0.22 0.52 0.39 0.30 0.17 0.17 T able 38. Accuracy across fine-tuned models for dierent Functional T ests in T amil High-ality T est Cases. Manuscript submitted to ACM 72 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.68 0.62 0.45 0.39 0.88 0.66 0.41 0.64 0.66 0.63 0.89 0.20 2 derog_neg_attrib_h H 0.75 0.65 0.44 0.38 0.93 0.65 0.47 0.76 0.81 0.80 0.97 0.37 3 derog_dehum_h H 0.87 0.77 0.62 0.62 0.96 0.79 0.72 0.87 0.85 0.86 0.95 0.62 4 derog_impl_h H 0.69 0.68 0.44 0.45 0.84 0.63 0.46 0.65 0.68 0.65 0.88 0.34 5 threat_dir_h H 0.86 0.87 0.66 0.71 0.94 0.82 0.66 0.87 0.87 0.74 0.87 0.54 6 threat_norm_h H 0.90 0.87 0.67 0.73 0.94 0.84 0.75 0.88 0.90 0.86 0.89 0.65 7 slur_h H 0.16 0.32 0.03 0.10 0.42 0.13 0.03 0.19 0.23 0.19 0.32 0.19 8 profanity_h H 0.77 0.69 0.49 0.48 0.92 0.75 0.53 0.72 0.77 0.73 0.94 0.42 10 ref_subs_clause_h H 0.83 0.77 0.54 0.63 0.89 0.79 0.62 0.77 0.79 0.74 0.93 0.52 11 ref_subs_sent_h H 0.85 0.79 0.60 0.64 0.97 0.86 0.52 0.85 0.89 0.84 0.96 0.50 12 negate_pos_h H 0.72 0.79 0.55 0.60 0.90 0.73 0.55 0.77 0.82 0.80 0.91 0.51 13 negate_neg_nh NH 0.77 0.80 0.84 0.92 0.75 0.77 0.92 0.88 0.88 0.92 0.87 0.99 14 phrase_question_h H 0.67 0.68 0.42 0.42 0.83 0.69 0.41 0.65 0.69 0.59 0.84 0.34 15 phrase_opinion_h H 0.72 0.66 0.42 0.52 0.86 0.68 0.56 0.75 0.77 0.75 0.86 0.50 16 ident_neutral_nh NH 0.88 0.81 0.95 0.99 0.73 0.83 0.95 0.95 0.95 0.97 0.89 0.99 17 ident_pos_nh NH 0.69 0.85 0.96 0.98 0.87 0.93 0.95 0.96 0.96 0.99 0.98 1.00 18 counter_quote_nh NH 0.49 0.55 0.56 0.68 0.43 0.45 0.77 0.76 0.64 0.71 0.58 0.89 19 counter_ref_nh NH 0.43 0.38 0.53 0.65 0.24 0.30 0.72 0.59 0.54 0.59 0.30 0.83 T able 39. Accuracy across non-finetuned models for dierent Functional T ests in Indonesian Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 73 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.80 0.67 0.69 0.52 0.93 0.60 0.51 0.62 0.71 0.52 0.87 0.32 2 derog_neg_attrib_h H 0.76 0.53 0.56 0.43 0.91 0.55 0.50 0.70 0.76 0.55 0.92 0.32 3 derog_dehum_h H 0.81 0.74 0.65 0.61 0.94 0.75 0.68 0.84 0.84 0.75 0.93 0.48 4 derog_impl_h H 0.71 0.57 0.50 0.49 0.93 0.53 0.56 0.59 0.67 0.47 0.81 0.23 5 threat_dir_h H 0.76 0.66 0.62 0.51 0.90 0.62 0.53 0.68 0.74 0.51 0.79 0.31 6 threat_norm_h H 0.97 0.86 0.80 0.78 0.99 0.80 0.72 0.93 0.95 0.80 0.94 0.69 7 slur_h H 0.35 0.26 0.28 0.11 0.61 0.26 0.13 0.20 0.20 0.13 0.24 0.07 8 profanity_h H 0.89 0.74 0.78 0.59 0.96 0.70 0.60 0.81 0.87 0.73 0.91 0.52 10 ref_subs_clause_h H 0.86 0.71 0.74 0.64 0.94 0.65 0.63 0.73 0.82 0.63 0.92 0.49 11 ref_subs_sent_h H 0.86 0.64 0.76 0.53 0.96 0.64 0.50 0.72 0.81 0.57 0.90 0.38 12 negate_pos_h H 0.72 0.52 0.60 0.54 0.88 0.62 0.53 0.63 0.68 0.51 0.82 0.28 13 negate_neg_nh NH 0.57 0.74 0.63 0.84 0.52 0.69 0.87 0.84 0.79 0.90 0.74 0.95 14 phrase_question_h H 0.78 0.60 0.66 0.41 0.89 0.61 0.29 0.63 0.70 0.46 0.87 0.29 15 phrase_opinion_h H 0.76 0.62 0.58 0.49 0.92 0.56 0.49 0.66 0.75 0.56 0.87 0.33 16 ident_neutral_nh NH 0.86 0.88 0.92 0.94 0.59 0.85 0.90 0.94 0.91 0.98 0.82 1.00 17 ident_pos_nh NH 0.73 0.82 0.89 0.97 0.71 0.84 0.91 0.95 0.93 0.97 0.91 1.00 18 counter_quote_nh NH 0.30 0.51 0.39 0.64 0.20 0.40 0.75 0.58 0.42 0.60 0.28 0.82 19 counter_ref_nh NH 0.32 0.63 0.49 0.68 0.20 0.47 0.71 0.61 0.53 0.67 0.33 0.87 T able 40. Accuracy across non-finetuned models for dierent Functional T ests in T agalog Silver T est Cases. Manuscript submitted to ACM 74 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.69 0.57 0.65 0.44 0.68 0.42 0.68 0.68 0.70 0.68 0.83 0.40 2 derog_neg_attrib_h H 0.82 0.76 0.81 0.53 0.70 0.27 0.77 0.77 0.78 0.78 0.87 0.47 3 derog_dehum_h H 0.77 0.64 0.64 0.58 0.74 0.42 0.74 0.78 0.77 0.74 0.85 0.44 4 derog_impl_h H 0.72 0.63 0.60 0.51 0.72 0.35 0.70 0.67 0.74 0.74 0.86 0.38 5 threat_dir_h H 0.90 0.92 0.74 0.80 0.85 0.53 0.78 0.88 0.88 0.74 0.79 0.64 6 threat_norm_h H 0.94 0.90 0.88 0.85 0.80 0.61 0.89 0.92 0.93 0.90 0.90 0.66 7 slur_h H 0.32 0.28 0.34 0.21 0.44 0.17 0.33 0.35 0.38 0.43 0.55 0.12 8 profanity_h H 0.74 0.76 0.77 0.59 0.69 0.40 0.79 0.80 0.82 0.77 0.86 0.47 10 ref_subs_clause_h H 0.79 0.67 0.74 0.61 0.79 0.50 0.72 0.81 0.82 0.75 0.88 0.49 11 ref_subs_sent_h H 0.80 0.67 0.71 0.57 0.80 0.42 0.70 0.76 0.80 0.79 0.88 0.46 12 negate_pos_h H 0.85 0.79 0.73 0.71 0.79 0.49 0.82 0.83 0.86 0.84 0.88 0.53 13 negate_neg_nh NH 0.66 0.75 0.71 0.90 0.74 0.71 0.82 0.89 0.84 0.88 0.87 0.98 14 phrase_question_h H 0.74 0.73 0.69 0.52 0.68 0.35 0.69 0.72 0.75 0.73 0.84 0.37 15 phrase_opinion_h H 0.85 0.81 0.72 0.59 0.85 0.44 0.79 0.74 0.77 0.78 0.83 0.54 16 ident_neutral_nh NH 0.92 0.94 0.95 0.98 0.86 0.91 0.94 0.94 0.95 0.91 0.92 1.00 17 ident_pos_nh NH 0.83 0.90 0.93 0.98 0.85 0.87 0.93 0.97 0.97 0.99 0.98 1.00 18 counter_quote_nh NH 0.32 0.49 0.43 0.55 0.32 0.39 0.48 0.54 0.44 0.42 0.37 0.72 19 counter_ref_nh NH 0.46 0.67 0.47 0.68 0.47 0.58 0.64 0.68 0.61 0.64 0.58 0.91 T able 41. Accuracy across non-finetuned models for dierent Functional T ests in Thai Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 75 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.85 0.82 0.66 0.55 0.95 0.74 0.84 0.80 0.84 0.76 0.96 0.52 2 derog_neg_attrib_h H 0.91 0.84 0.73 0.66 0.98 0.77 0.91 0.87 0.89 0.85 0.95 0.61 3 derog_dehum_h H 0.88 0.85 0.76 0.75 0.97 0.78 0.89 0.87 0.89 0.89 0.95 0.71 4 derog_impl_h H 0.70 0.63 0.52 0.41 0.92 0.60 0.68 0.63 0.66 0.68 0.90 0.31 5 threat_dir_h H 0.93 0.94 0.81 0.75 0.98 0.83 0.75 0.89 0.89 0.80 0.85 0.64 6 threat_norm_h H 0.90 0.86 0.80 0.73 0.94 0.70 0.76 0.81 0.83 0.77 0.92 0.59 7 slur_h H 0.40 0.38 0.33 0.13 0.73 0.18 0.28 0.20 0.18 0.38 0.45 0.00 8 profanity_h H 0.75 0.66 0.60 0.53 0.96 0.58 0.73 0.72 0.74 0.72 0.92 0.45 10 ref_subs_clause_h H 0.90 0.83 0.78 0.62 0.96 0.81 0.84 0.86 0.88 0.81 0.93 0.61 11 ref_subs_sent_h H 0.89 0.75 0.70 0.64 0.98 0.71 0.82 0.78 0.82 0.77 0.94 0.52 12 negate_pos_h H 0.95 0.86 0.78 0.79 0.97 0.74 0.87 0.89 0.89 0.86 0.98 0.71 13 negate_neg_nh NH 0.84 0.89 0.89 0.98 0.80 0.84 0.96 0.99 0.98 0.95 0.98 0.99 14 phrase_question_h H 0.92 0.89 0.82 0.73 0.98 0.80 0.83 0.85 0.87 0.85 0.92 0.64 15 phrase_opinion_h H 0.90 0.87 0.78 0.69 0.98 0.69 0.86 0.85 0.86 0.84 0.97 0.64 16 ident_neutral_nh NH 0.94 0.92 0.96 1.00 0.78 0.89 0.92 0.95 0.96 0.96 0.88 1.00 17 ident_pos_nh NH 0.99 1.00 1.00 1.00 0.95 0.97 0.99 1.00 0.99 0.99 1.00 1.00 18 counter_quote_nh NH 0.33 0.56 0.46 0.60 0.21 0.36 0.51 0.59 0.46 0.42 0.38 0.75 19 counter_ref_nh NH 0.51 0.67 0.56 0.73 0.32 0.51 0.69 0.69 0.63 0.63 0.53 0.88 T able 42. Accuracy across non-finetuned models for dierent Functional T ests in Vietnamese Silver T est Cases. Manuscript submitted to ACM 76 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.82 0.77 0.68 0.45 0.89 0.77 0.59 0.76 0.75 0.85 0.90 0.41 2 derog_neg_attrib_h H 0.78 0.73 0.61 0.36 0.90 0.75 0.59 0.81 0.82 0.88 0.92 0.42 3 derog_dehum_h H 0.88 0.82 0.81 0.59 0.97 0.84 0.73 0.86 0.89 0.94 0.94 0.61 4 derog_impl_h H 0.81 0.72 0.68 0.60 0.87 0.78 0.67 0.83 0.82 0.81 0.92 0.53 5 threat_dir_h H 0.93 0.90 0.85 0.77 0.96 0.86 0.82 0.86 0.90 0.90 0.97 0.77 6 threat_norm_h H 0.93 0.88 0.87 0.77 0.88 0.83 0.85 0.91 0.91 0.94 0.94 0.79 7 slur_h H 0.51 0.47 0.33 0.09 0.76 0.58 0.36 0.49 0.47 0.51 0.62 0.16 8 profanity_h H 0.85 0.78 0.67 0.45 0.90 0.80 0.60 0.80 0.80 0.85 0.93 0.50 10 ref_subs_clause_h H 0.92 0.88 0.86 0.70 0.99 0.88 0.79 0.90 0.91 0.91 0.97 0.72 11 ref_subs_sent_h H 0.84 0.75 0.75 0.57 0.98 0.85 0.74 0.86 0.85 0.86 0.91 0.57 12 negate_pos_h H 0.90 0.77 0.68 0.51 0.90 0.77 0.71 0.81 0.82 0.86 0.93 0.54 13 negate_neg_nh NH 0.55 0.58 0.62 0.92 0.51 0.54 0.81 0.75 0.80 0.86 0.82 0.96 14 phrase_question_h H 0.90 0.85 0.79 0.61 0.94 0.86 0.73 0.80 0.81 0.82 0.88 0.59 15 phrase_opinion_h H 0.82 0.77 0.72 0.52 0.92 0.81 0.65 0.81 0.84 0.88 0.94 0.60 16 ident_neutral_nh NH 0.76 0.76 0.82 0.95 0.56 0.69 0.78 0.78 0.77 0.81 0.76 0.95 17 ident_pos_nh NH 0.82 0.86 0.90 0.98 0.75 0.81 0.93 0.93 0.95 0.96 0.93 1.00 18 counter_quote_nh NH 0.17 0.26 0.27 0.49 0.16 0.18 0.39 0.26 0.24 0.26 0.24 0.55 19 counter_ref_nh NH 0.24 0.36 0.38 0.59 0.13 0.22 0.52 0.38 0.35 0.33 0.27 0.70 T able 43. Accuracy across non-finetuned models for dierent Functional T ests in Malay Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 77 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.79 0.77 0.77 0.54 0.89 0.72 0.72 0.62 0.67 0.80 0.93 0.42 2 derog_neg_attrib_h H 0.68 0.81 0.78 0.53 0.82 0.77 0.66 0.59 0.63 0.74 0.77 0.42 3 derog_dehum_h H 0.84 0.79 0.85 0.65 0.94 0.77 0.81 0.76 0.78 0.89 0.87 0.58 4 derog_impl_h H 0.76 0.68 0.68 0.31 0.79 0.69 0.71 0.51 0.59 0.86 0.95 0.35 5 threat_dir_h H 0.84 0.81 0.87 0.54 0.96 0.79 0.77 0.78 0.79 0.90 0.87 0.47 6 threat_norm_h H 0.82 0.78 0.82 0.62 0.92 0.78 0.79 0.68 0.70 0.84 0.96 0.50 7 slur_h H 0.29 0.17 0.13 0.04 0.42 0.21 0.21 0.13 0.13 0.25 0.29 0.00 8 profanity_h H 0.94 0.93 0.94 0.78 0.98 0.86 0.94 0.88 0.89 0.94 0.97 0.71 10 ref_subs_clause_h H 0.89 0.85 0.85 0.68 0.96 0.86 0.83 0.77 0.85 0.87 0.92 0.57 11 ref_subs_sent_h H 0.76 0.72 0.75 0.51 0.82 0.67 0.60 0.60 0.65 0.71 0.69 0.42 12 negate_pos_h H 0.85 0.83 0.84 0.56 0.89 0.72 0.81 0.72 0.75 0.86 0.86 0.40 13 negate_neg_nh NH 0.70 0.73 0.61 0.96 0.84 0.71 0.80 0.93 0.92 0.94 0.97 0.99 14 phrase_question_h H 0.83 0.81 0.83 0.67 0.86 0.83 0.74 0.74 0.77 0.83 0.79 0.52 15 phrase_opinion_h H 0.87 0.92 0.93 0.77 0.94 0.88 0.86 0.86 0.87 0.91 0.93 0.69 16 ident_neutral_nh NH 0.96 0.89 0.92 0.97 0.74 0.85 0.93 0.95 0.94 0.93 0.84 1.00 17 ident_pos_nh NH 0.94 0.97 0.94 0.98 0.93 0.94 0.95 0.97 0.97 0.98 0.96 0.99 18 counter_quote_nh NH 0.38 0.53 0.38 0.67 0.39 0.47 0.49 0.67 0.52 0.38 0.48 0.78 19 counter_ref_nh NH 0.37 0.40 0.32 0.64 0.39 0.37 0.63 0.62 0.55 0.48 0.55 0.77 T able 44. Accuracy across non-finetuned models for dierent Functional T ests in Mandarin Silver T est Cases. Manuscript submitted to ACM 78 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.78 0.94 0.72 0.46 0.85 0.69 0.74 0.71 0.73 0.87 0.92 0.51 2 derog_neg_attrib_h H 0.82 0.98 0.81 0.57 0.91 0.75 0.79 0.75 0.82 0.87 0.89 0.65 3 derog_dehum_h H 0.93 0.99 0.97 0.78 0.93 0.83 0.91 0.92 0.95 0.97 0.97 0.79 4 derog_impl_h H 0.80 0.85 0.83 0.62 0.80 0.71 0.80 0.73 0.75 0.86 0.96 0.68 5 threat_dir_h H 0.74 0.92 0.75 0.54 0.85 0.69 0.77 0.72 0.74 0.84 0.97 0.61 6 threat_norm_h H 0.74 0.85 0.72 0.42 0.88 0.70 0.76 0.68 0.74 0.90 0.95 0.53 7 slur_h H 0.45 0.59 0.59 0.27 0.82 0.64 0.41 0.45 0.55 0.68 0.59 0.59 8 profanity_h H 0.75 0.87 0.66 0.46 0.81 0.65 0.70 0.72 0.73 0.86 0.89 0.54 10 ref_subs_clause_h H 0.84 0.95 0.86 0.67 0.66 0.48 0.87 0.81 0.86 0.96 0.96 0.77 11 ref_subs_sent_h H 0.70 0.81 0.74 0.48 0.75 0.60 0.70 0.70 0.71 0.83 0.86 0.56 12 negate_pos_h H 0.84 0.89 0.84 0.68 0.94 0.82 0.84 0.83 0.86 0.95 0.96 0.70 13 negate_neg_nh NH 0.83 0.72 0.74 0.98 0.64 0.57 0.88 0.88 0.91 0.93 0.86 0.98 14 phrase_question_h H 0.86 0.95 0.91 0.66 0.74 0.61 0.88 0.82 0.85 0.93 0.95 0.71 15 phrase_opinion_h H 0.83 0.93 0.83 0.64 0.90 0.77 0.87 0.79 0.84 0.96 0.97 0.73 16 ident_neutral_nh NH 0.77 0.71 0.79 0.91 0.50 0.61 0.81 0.78 0.80 0.81 0.68 0.92 17 ident_pos_nh NH 0.89 0.86 0.87 0.98 0.70 0.70 0.88 0.94 0.93 0.96 0.91 1.00 18 counter_quote_nh NH 0.28 0.20 0.18 0.54 0.21 0.21 0.36 0.36 0.30 0.34 0.19 0.51 19 counter_ref_nh NH 0.36 0.26 0.26 0.62 0.29 0.19 0.45 0.51 0.41 0.49 0.44 0.69 T able 45. Accuracy across non-finetuned models for dierent Functional T ests in Singlish Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 79 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek 1 derog_neg_emote_h H 0.84 0.73 0.99 0.70 0.95 0.56 0.49 0.76 0.90 0.95 0.72 0.45 2 derog_neg_attrib_h H 0.83 0.81 0.91 0.79 0.99 0.60 0.68 0.81 0.89 0.95 0.84 0.59 3 derog_dehum_h H 0.94 0.90 0.99 0.91 1.00 0.68 0.74 0.90 0.96 0.97 0.95 0.71 4 derog_impl_h H 0.61 0.57 0.81 0.47 0.86 0.47 0.45 0.56 0.59 0.70 0.65 0.19 5 threat_dir_h H 0.86 0.74 0.94 0.80 0.91 0.54 0.58 0.82 0.90 0.93 0.81 0.67 6 threat_norm_h H 0.92 0.85 0.97 0.87 0.99 0.77 0.69 0.92 0.96 0.99 0.95 0.78 7 slur_h H 0.17 0.33 0.93 0.43 0.87 0.07 0.20 0.17 0.40 0.57 0.27 0.03 8 profanity_h H 0.83 0.68 0.97 0.73 0.97 0.58 0.58 0.75 0.83 0.93 0.88 0.46 10 ref_subs_clause_h H 0.76 0.62 0.93 0.67 0.95 0.54 0.55 0.69 0.76 0.77 0.76 0.38 11 ref_subs_sent_h H 0.86 0.73 0.99 0.81 0.99 0.67 0.57 0.74 0.86 0.90 0.87 0.63 12 negate_pos_h H 0.82 0.75 0.96 0.80 1.00 0.60 0.72 0.86 0.92 0.92 0.88 0.51 13 negate_neg_nh NH 0.41 0.54 0.10 0.59 0.33 0.51 0.58 0.66 0.62 0.51 0.95 0.93 14 phrase_question_h H 0.74 0.72 0.95 0.66 0.95 0.61 0.38 0.74 0.79 0.85 0.82 0.42 15 phrase_opinion_h H 0.93 0.85 0.99 0.82 0.99 0.59 0.67 0.88 0.92 0.96 0.94 0.60 16 ident_neutral_nh NH 0.63 0.70 0.38 0.90 0.23 0.59 0.65 0.96 0.96 0.82 0.96 1.00 17 ident_pos_nh NH 0.52 0.74 0.42 0.89 0.25 0.61 0.51 0.81 0.86 0.88 0.96 1.00 18 counter_quote_nh NH 0.23 0.44 0.09 0.41 0.06 0.30 0.61 0.51 0.34 0.31 0.59 0.72 19 counter_ref_nh NH 0.28 0.40 0.07 0.52 0.08 0.33 0.63 0.50 0.43 0.48 0.56 0.81 T able 46. Accuracy across non-finetuned models for dierent Functional T ests in T amil Silver T est Cases. Manuscript submitted to ACM 80 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.40 0.39 0.40 0.57 0.51 0.39 0.52 0.56 0.38 2 derog_neg_attrib_h H 0.45 0.39 0.47 0.66 0.55 0.44 0.61 0.63 0.49 3 derog_dehum_h H 0.58 0.54 0.62 0.76 0.70 0.62 0.77 0.73 0.65 4 derog_impl_h H 0.38 0.32 0.37 0.61 0.46 0.38 0.50 0.51 0.41 5 threat_dir_h H 0.48 0.53 0.56 0.62 0.65 0.56 0.53 0.64 0.52 6 threat_norm_h H 0.52 0.63 0.65 0.75 0.71 0.69 0.71 0.76 0.65 7 slur_h H 0.16 0.23 0.23 0.23 0.19 0.16 0.16 0.19 0.23 8 profanity_h H 0.53 0.49 0.52 0.68 0.60 0.53 0.64 0.63 0.52 10 ref_subs_clause_h H 0.48 0.45 0.48 0.67 0.65 0.51 0.64 0.64 0.48 11 ref_subs_sent_h H 0.59 0.53 0.57 0.79 0.68 0.61 0.75 0.72 0.56 12 negate_pos_h H 0.53 0.47 0.53 0.70 0.64 0.45 0.65 0.72 0.60 13 negate_neg_nh NH 0.93 0.93 0.94 0.94 0.94 0.94 0.93 0.94 0.96 14 phrase_question_h H 0.41 0.35 0.38 0.54 0.46 0.38 0.47 0.56 0.38 15 phrase_opinion_h H 0.43 0.39 0.46 0.60 0.57 0.45 0.57 0.61 0.51 16 ident_neutral_nh NH 0.97 0.97 0.98 0.98 0.98 0.98 0.97 0.98 0.99 17 ident_pos_nh NH 0.90 0.98 0.97 0.99 0.99 0.99 0.99 0.98 1.00 18 counter_quote_nh NH 0.71 0.76 0.85 0.76 0.73 0.81 0.74 0.81 0.89 19 counter_ref_nh NH 0.62 0.65 0.73 0.61 0.65 0.79 0.64 0.66 0.78 T able 47. Accuracy across fine-tuned models for dierent Functional T ests in Indonesian Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 81 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.89 0.80 0.95 0.91 0.90 0.85 0.89 0.89 0.85 2 derog_neg_attrib_h H 0.90 0.80 0.92 0.92 0.85 0.76 0.84 0.92 0.85 3 derog_dehum_h H 0.86 0.87 0.96 0.94 0.91 0.88 0.91 0.90 0.87 4 derog_impl_h H 0.72 0.71 0.92 0.88 0.84 0.75 0.86 0.85 0.77 5 threat_dir_h H 0.71 0.77 0.81 0.77 0.78 0.71 0.79 0.80 0.75 6 threat_norm_h H 0.86 0.88 0.97 0.97 0.97 0.85 0.86 0.96 0.94 7 slur_h H 0.33 0.28 0.54 0.48 0.35 0.37 0.52 0.39 0.37 8 profanity_h H 0.94 0.93 0.97 0.96 0.95 0.93 0.97 0.94 0.93 10 ref_subs_clause_h H 0.89 0.86 0.94 0.93 0.91 0.86 0.90 0.91 0.89 11 ref_subs_sent_h H 0.92 0.88 0.95 0.96 0.89 0.86 0.91 0.92 0.89 12 negate_pos_h H 0.78 0.72 0.86 0.85 0.78 0.72 0.80 0.84 0.76 13 negate_neg_nh NH 0.71 0.73 0.62 0.74 0.71 0.76 0.67 0.72 0.78 14 phrase_question_h H 0.78 0.72 0.91 0.86 0.80 0.76 0.76 0.86 0.82 15 phrase_opinion_h H 0.84 0.81 0.91 0.89 0.85 0.80 0.83 0.88 0.80 16 ident_neutral_nh NH 0.83 0.89 0.73 0.84 0.87 0.87 0.78 0.88 0.91 17 ident_pos_nh NH 0.83 0.89 0.87 0.91 0.91 0.87 0.89 0.91 0.92 18 counter_quote_nh NH 0.30 0.36 0.16 0.24 0.25 0.38 0.27 0.25 0.31 19 counter_ref_nh NH 0.38 0.42 0.24 0.34 0.36 0.45 0.31 0.31 0.43 T able 48. Accuracy across fine-tuned models for dierent Functional T ests in T agalog Silver T est Cases. Manuscript submitted to ACM 82 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.47 0.55 0.75 0.72 0.74 0.59 0.67 0.55 0.49 2 derog_neg_attrib_h H 0.44 0.68 0.85 0.85 0.78 0.53 0.77 0.79 0.76 3 derog_dehum_h H 0.60 0.54 0.76 0.71 0.70 0.57 0.68 0.70 0.62 4 derog_impl_h H 0.47 0.50 0.73 0.69 0.72 0.51 0.62 0.67 0.57 5 threat_dir_h H 0.57 0.66 0.74 0.76 0.73 0.63 0.62 0.69 0.62 6 threat_norm_h H 0.81 0.78 0.90 0.90 0.88 0.77 0.87 0.89 0.79 7 slur_h H 0.13 0.21 0.35 0.36 0.26 0.14 0.22 0.26 0.22 8 profanity_h H 0.43 0.69 0.86 0.87 0.76 0.58 0.72 0.59 0.72 10 ref_subs_clause_h H 0.68 0.69 0.82 0.82 0.84 0.68 0.70 0.70 0.63 11 ref_subs_sent_h H 0.58 0.69 0.81 0.80 0.78 0.64 0.70 0.75 0.65 12 negate_pos_h H 0.54 0.69 0.84 0.82 0.80 0.57 0.75 0.79 0.70 13 negate_neg_nh NH 0.95 0.88 0.85 0.89 0.87 0.92 0.89 0.91 0.93 14 phrase_question_h H 0.51 0.55 0.73 0.75 0.71 0.56 0.66 0.68 0.64 15 phrase_opinion_h H 0.51 0.71 0.81 0.79 0.81 0.62 0.74 0.74 0.73 16 ident_neutral_nh NH 0.99 0.99 0.99 0.99 0.99 0.98 0.99 0.98 0.99 17 ident_pos_nh NH 1.00 1.00 1.00 1.00 0.99 1.00 1.00 1.00 1.00 18 counter_quote_nh NH 0.64 0.56 0.44 0.47 0.44 0.55 0.56 0.67 0.70 19 counter_ref_nh NH 0.87 0.71 0.63 0.71 0.60 0.77 0.70 0.77 0.79 T able 49. Accuracy across fine-tuned models for dierent Functional T ests in Thai Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 83 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.94 0.96 0.99 0.98 0.98 0.94 0.98 0.94 0.96 2 derog_neg_attrib_h H 0.96 0.93 0.98 0.98 0.98 0.96 0.96 0.98 0.97 3 derog_dehum_h H 0.96 0.97 0.98 0.99 0.96 0.96 0.96 0.96 0.96 4 derog_impl_h H 0.79 0.83 0.87 0.89 0.88 0.82 0.87 0.80 0.77 5 threat_dir_h H 0.92 0.88 0.95 0.93 0.93 0.91 0.95 0.90 0.92 6 threat_norm_h H 0.91 0.91 0.94 0.94 0.96 0.93 0.95 0.92 0.93 7 slur_h H 0.70 0.68 0.75 0.75 0.70 0.53 0.70 0.60 0.55 8 profanity_h H 0.92 0.91 0.91 0.94 0.93 0.90 0.96 0.89 0.91 10 ref_subs_clause_h H 0.95 0.96 0.96 0.96 0.97 0.94 0.97 0.95 0.97 11 ref_subs_sent_h H 0.94 0.94 0.94 0.95 0.97 0.92 0.96 0.96 0.94 12 negate_pos_h H 0.98 0.98 0.98 0.99 0.99 0.96 0.99 0.96 0.97 13 negate_neg_nh NH 0.90 0.92 0.91 0.95 0.92 0.94 0.85 0.97 0.98 14 phrase_question_h H 0.95 0.94 0.96 0.96 0.98 0.95 0.96 0.94 0.94 15 phrase_opinion_h H 0.98 0.96 0.98 0.99 0.98 0.95 0.97 0.98 0.97 16 ident_neutral_nh NH 0.92 0.91 0.86 0.88 0.91 0.96 0.91 0.92 0.93 17 ident_pos_nh NH 0.99 1.00 1.00 1.00 1.00 1.00 0.99 1.00 1.00 18 counter_quote_nh NH 0.29 0.29 0.29 0.31 0.27 0.30 0.20 0.46 0.41 19 counter_ref_nh NH 0.47 0.44 0.47 0.49 0.44 0.49 0.39 0.58 0.60 T able 50. Accuracy across fine-tuned models for dierent Functional T ests in Vietnamese Silver T est Cases. Manuscript submitted to ACM 84 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.67 0.50 0.91 0.85 0.74 0.66 0.85 0.77 0.61 2 derog_neg_attrib_h H 0.66 0.45 0.90 0.81 0.61 0.64 0.86 0.79 0.61 3 derog_dehum_h H 0.73 0.62 0.95 0.92 0.80 0.73 0.90 0.83 0.74 4 derog_impl_h H 0.75 0.62 0.92 0.86 0.80 0.70 0.89 0.72 0.60 5 threat_dir_h H 0.79 0.76 0.94 0.84 0.87 0.78 0.90 0.85 0.71 6 threat_norm_h H 0.64 0.67 0.94 0.85 0.85 0.80 0.91 0.87 0.79 7 slur_h H 0.33 0.33 0.67 0.56 0.33 0.36 0.56 0.44 0.20 8 profanity_h H 0.68 0.51 0.90 0.85 0.77 0.72 0.89 0.78 0.70 10 ref_subs_clause_h H 0.82 0.70 0.95 0.92 0.87 0.79 0.94 0.88 0.80 11 ref_subs_sent_h H 0.71 0.60 0.95 0.94 0.83 0.81 0.93 0.80 0.72 12 negate_pos_h H 0.75 0.60 0.91 0.84 0.70 0.70 0.86 0.75 0.66 13 negate_neg_nh NH 0.85 0.89 0.68 0.84 0.81 0.86 0.76 0.91 0.98 14 phrase_question_h H 0.74 0.63 0.89 0.85 0.81 0.79 0.88 0.76 0.71 15 phrase_opinion_h H 0.72 0.59 0.96 0.87 0.81 0.75 0.91 0.86 0.73 16 ident_neutral_nh NH 0.88 0.97 0.70 0.85 0.89 0.89 0.83 0.84 0.93 17 ident_pos_nh NH 0.95 0.98 0.92 0.98 0.98 0.99 0.93 0.97 0.99 18 counter_quote_nh NH 0.34 0.51 0.11 0.19 0.26 0.40 0.23 0.36 0.52 19 counter_ref_nh NH 0.48 0.54 0.18 0.29 0.38 0.46 0.28 0.41 0.52 T able 51. Accuracy across fine-tuned models for dierent Functional T ests in Malay Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 85 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.77 0.79 0.93 0.89 0.80 0.77 0.80 0.75 0.72 2 derog_neg_attrib_h H 0.76 0.69 0.81 0.79 0.79 0.77 0.77 0.72 0.69 3 derog_dehum_h H 0.86 0.80 0.96 0.92 0.89 0.83 0.89 0.86 0.77 4 derog_impl_h H 0.56 0.55 0.77 0.67 0.77 0.59 0.65 0.65 0.47 5 threat_dir_h H 0.86 0.79 0.96 0.91 0.91 0.88 0.87 0.91 0.80 6 threat_norm_h H 0.74 0.72 0.88 0.84 0.87 0.78 0.78 0.78 0.62 7 slur_h H 0.21 0.17 0.29 0.29 0.13 0.13 0.21 0.21 0.17 8 profanity_h H 0.90 0.84 0.94 0.93 0.95 0.89 0.91 0.91 0.88 10 ref_subs_clause_h H 0.87 0.89 0.97 0.96 0.90 0.90 0.93 0.92 0.89 11 ref_subs_sent_h H 0.79 0.78 0.91 0.90 0.80 0.78 0.79 0.78 0.71 12 negate_pos_h H 0.76 0.77 0.91 0.89 0.85 0.80 0.79 0.83 0.68 13 negate_neg_nh NH 0.89 0.89 0.79 0.92 0.90 0.88 0.74 0.94 0.92 14 phrase_question_h H 0.79 0.79 0.87 0.87 0.85 0.81 0.84 0.79 0.77 15 phrase_opinion_h H 0.86 0.82 0.95 0.93 0.94 0.90 0.88 0.90 0.86 16 ident_neutral_nh NH 0.91 0.94 0.77 0.82 0.90 0.92 0.86 0.87 0.92 17 ident_pos_nh NH 0.97 0.99 0.95 0.97 0.98 0.99 0.98 0.98 0.99 18 counter_quote_nh NH 0.33 0.39 0.23 0.28 0.25 0.25 0.20 0.43 0.44 19 counter_ref_nh NH 0.44 0.40 0.28 0.37 0.31 0.36 0.32 0.43 0.44 T able 52. Accuracy across fine-tuned models for dierent Functional T ests in Mandarin Silver T est Cases. Manuscript submitted to ACM 86 Ng et al. f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.78 0.69 0.94 0.92 0.86 0.81 0.83 0.94 0.90 2 derog_neg_attrib_h H 0.86 0.76 0.97 0.96 0.95 0.89 0.90 0.94 0.91 3 derog_dehum_h H 0.92 0.87 0.99 0.95 0.97 0.91 0.97 0.99 0.95 4 derog_impl_h H 0.79 0.78 0.94 0.91 0.88 0.82 0.83 0.89 0.83 5 threat_dir_h H 0.83 0.77 0.97 0.93 0.92 0.81 0.83 0.93 0.86 6 threat_norm_h H 0.70 0.59 0.90 0.83 0.86 0.70 0.77 0.92 0.83 7 slur_h H 0.68 0.32 0.91 0.73 0.73 0.45 0.41 0.77 0.55 8 profanity_h H 0.83 0.65 0.97 0.93 0.85 0.79 0.80 0.94 0.89 10 ref_subs_clause_h H 0.83 0.82 0.97 0.96 0.94 0.82 0.92 0.95 0.90 11 ref_subs_sent_h H 0.75 0.72 0.93 0.91 0.87 0.77 0.79 0.92 0.86 12 negate_pos_h H 0.84 0.78 0.95 0.93 0.87 0.82 0.84 0.94 0.86 13 negate_neg_nh NH 0.93 0.92 0.83 0.88 0.83 0.88 0.90 0.87 0.92 14 phrase_question_h H 0.86 0.84 0.98 0.93 0.92 0.86 0.94 0.96 0.93 15 phrase_opinion_h H 0.87 0.72 0.96 0.94 0.90 0.87 0.90 0.94 0.92 16 ident_neutral_nh NH 0.86 0.92 0.69 0.81 0.79 0.88 0.83 0.78 0.90 17 ident_pos_nh NH 0.94 0.99 0.91 0.95 0.94 0.96 0.97 0.91 0.97 18 counter_quote_nh NH 0.32 0.41 0.17 0.25 0.19 0.23 0.31 0.29 0.35 19 counter_ref_nh NH 0.48 0.59 0.36 0.46 0.28 0.39 0.50 0.44 0.50 T able 53. Accuracy across fine-tuned models for dierent Functional T ests in Singlish Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 87 f_n t_function t_g Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem 1 derog_neg_emote_h H 0.82 0.80 0.98 0.97 0.78 0.62 0.74 0.91 0.93 2 derog_neg_attrib_h H 0.86 0.75 0.96 0.89 0.67 0.72 0.76 0.89 0.92 3 derog_dehum_h H 0.85 0.64 0.99 0.94 0.69 0.78 0.83 0.92 0.92 4 derog_impl_h H 0.55 0.46 0.92 0.70 0.42 0.44 0.66 0.66 0.56 5 threat_dir_h H 0.75 0.66 0.91 0.82 0.54 0.73 0.86 0.87 0.88 6 threat_norm_h H 0.86 0.80 0.97 0.95 0.75 0.74 0.71 0.97 0.94 7 slur_h H 0.40 0.33 1.00 0.83 0.47 0.50 0.63 0.53 0.60 8 profanity_h H 0.59 0.44 0.97 0.83 0.53 0.65 0.59 0.84 0.78 10 ref_subs_clause_h H 0.70 0.62 0.93 0.85 0.50 0.48 0.74 0.85 0.80 11 ref_subs_sent_h H 0.82 0.84 0.95 0.95 0.70 0.84 0.86 0.93 0.88 12 negate_pos_h H 0.72 0.68 0.96 0.94 0.71 0.68 0.81 0.88 0.91 13 negate_neg_nh NH 0.62 0.57 0.12 0.54 0.68 0.61 0.42 0.71 0.76 14 phrase_question_h H 0.74 0.74 0.95 0.88 0.66 0.72 0.81 0.86 0.83 15 phrase_opinion_h H 0.80 0.79 0.94 0.90 0.65 0.71 0.76 0.90 0.90 16 ident_neutral_nh NH 0.87 0.98 0.33 0.94 0.96 0.87 0.87 0.96 0.99 17 ident_pos_nh NH 0.93 0.97 0.85 0.98 0.95 0.92 0.72 0.98 0.99 18 counter_quote_nh NH 0.33 0.45 0.08 0.24 0.39 0.38 0.34 0.41 0.34 19 counter_ref_nh NH 0.46 0.48 0.06 0.28 0.46 0.44 0.29 0.46 0.40 T able 54. Accuracy across fine-tuned models for dierent Functional T ests in T amil Silver T est Cases. Manuscript submitted to ACM 88 Ng et al. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Ethnicity/Race/Origin 0.66 0.67 0.63 0.70 0.71 0.68 0.73 0.80 0.78 0.85 0.89 0.73 Gender/Sexuality 0.50 0.53 0.55 0.65 0.52 0.44 0.63 0.69 0.69 0.67 0.77 0.61 Religion 0.66 0.64 0.69 0.79 0.70 0.67 0.74 0.79 0.78 0.84 0.89 0.78 T able 55. F1 Scores across non-finetuned models for dierent protected categories in Indonesian High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Disability 0.61 0.53 0.49 0.41 0.52 0.43 0.53 0.74 0.72 0.64 0.79 0.47 Ethnicity/Race/Origin 0.66 0.64 0.60 0.59 0.56 0.51 0.60 0.77 0.77 0.81 0.86 0.68 Gender/Sexuality 0.67 0.68 0.63 0.70 0.61 0.53 0.67 0.79 0.81 0.82 0.85 0.74 PLHIV 0.58 0.53 0.67 0.78 0.53 0.57 0.77 0.72 0.70 0.72 0.84 0.82 Religion 0.68 0.66 0.63 0.66 0.59 0.54 0.70 0.79 0.79 0.81 0.80 0.68 T able 56. F1 Scores across non-finetuned models for dierent protected categories in Tagalog High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.65 0.71 0.70 0.71 0.66 0.28 0.69 0.71 0.73 0.71 0.89 0.51 Disability 0.68 0.68 0.71 0.76 0.76 0.69 0.71 0.80 0.77 0.77 0.86 0.83 Ethnicity/Race/Origin 0.67 0.73 0.70 0.68 0.71 0.56 0.74 0.76 0.74 0.75 0.78 0.67 Gender/Sexuality 0.70 0.72 0.67 0.72 0.69 0.53 0.70 0.76 0.75 0.76 0.86 0.60 Religion 0.63 0.70 0.64 0.70 0.67 0.61 0.71 0.74 0.69 0.78 0.88 0.75 Vulnerable W orkers 0.70 0.71 0.64 0.65 0.70 0.53 0.72 0.79 0.77 0.74 0.53 0.62 T able 57. F1 Scores across non-finetuned models for dierent protected categories in Thai High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.74 0.70 0.61 0.56 0.80 0.57 0.73 0.80 0.80 0.69 0.89 0.53 Disability 0.76 0.72 0.69 0.72 0.77 0.80 0.73 0.85 0.84 0.78 0.85 0.70 Ethnicity/Race/Origin 0.77 0.76 0.74 0.76 0.75 0.81 0.81 0.84 0.82 0.84 0.87 0.85 Gender/Sexuality 0.75 0.73 0.68 0.73 0.73 0.74 0.75 0.81 0.81 0.77 0.87 0.68 PLHIV 0.68 0.70 0.76 0.84 0.76 0.85 0.75 0.80 0.81 0.69 0.90 0.89 Religion 0.74 0.77 0.80 0.81 0.69 0.62 0.77 0.84 0.82 0.84 0.89 0.86 T able 58. F1 Scores across non-finetuned models for dierent protected categories in Vietnamese High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 89 p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.56 0.64 0.57 0.43 0.70 0.52 0.58 0.71 0.71 0.83 0.86 0.40 Disability 0.64 0.60 0.59 0.54 0.69 0.68 0.64 0.76 0.76 0.78 0.83 0.72 Ethnicity/Race/Origin 0.63 0.65 0.67 0.80 0.59 0.65 0.73 0.77 0.74 0.76 0.84 0.84 Gender/Sexuality 0.66 0.57 0.65 0.72 0.63 0.59 0.65 0.79 0.80 0.80 0.85 0.77 Religion 0.69 0.67 0.69 0.77 0.67 0.70 0.70 0.79 0.79 0.82 0.88 0.82 T able 59. F1 Scores across non-finetuned models for dierent protected categories in Malay High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.57 0.64 0.60 0.43 0.74 0.38 0.62 0.62 0.63 0.75 0.85 0.51 Disability 0.66 0.64 0.63 0.71 0.73 0.79 0.72 0.83 0.75 0.73 0.85 0.70 Ethnicity/Race/Origin 0.62 0.68 0.57 0.73 0.64 0.72 0.75 0.77 0.72 0.75 0.83 0.71 Gender/Sexuality 0.71 0.67 0.61 0.67 0.65 0.66 0.69 0.80 0.75 0.79 0.84 0.69 Religion 0.61 0.64 0.62 0.69 0.62 0.67 0.73 0.77 0.69 0.69 0.80 0.65 T able 60. F1 Scores across non-finetuned models for dierent protected categories in Mandarin High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.53 0.75 0.73 0.45 0.68 0.36 0.60 0.58 0.63 0.79 0.87 0.48 Disability 0.70 0.67 0.72 0.67 0.68 0.65 0.70 0.65 0.68 0.69 0.70 0.82 Ethnicity/Race/Origin 0.76 0.69 0.75 0.75 0.67 0.69 0.77 0.79 0.79 0.80 0.84 0.83 Gender/Sexuality 0.69 0.69 0.68 0.71 0.65 0.58 0.68 0.71 0.74 0.77 0.80 0.74 Religion 0.77 0.68 0.75 0.80 0.69 0.67 0.79 0.83 0.83 0.84 0.87 0.81 T able 61. F1 Scores across non-finetuned models for dierent protected categories in Singlish High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.54 0.61 0.70 0.44 0.66 0.31 0.49 0.52 0.67 0.78 0.84 0.32 Disability 0.57 0.61 0.60 0.63 0.57 0.46 0.47 0.72 0.81 0.79 0.89 0.61 Ethnicity/Race/Origin 0.62 0.63 0.59 0.76 0.51 0.54 0.54 0.78 0.81 0.77 0.85 0.64 Gender/Sexuality 0.61 0.64 0.52 0.74 0.57 0.54 0.54 0.77 0.80 0.82 0.75 0.66 Religion 0.65 0.68 0.57 0.75 0.51 0.53 0.53 0.82 0.80 0.80 0.88 0.75 T able 62. F1 Scores across non-finetuned models for dierent protected categories in Tamil High-ality T est Cases. Manuscript submitted to ACM 90 Ng et al. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Ethnicity/Race/Origin 0.51 0.54 0.68 0.75 0.67 0.63 0.71 0.80 0.74 Gender/Sexuality 0.42 0.56 0.62 0.69 0.67 0.61 0.51 0.87 0.74 Religion 0.67 0.65 0.79 0.80 0.75 0.68 0.77 0.83 0.79 T able 63. F1 Scores across fine-tuned models for dierent protected categories in Indonesian High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Disability 0.56 0.59 0.59 0.65 0.58 0.61 0.61 0.73 0.68 Ethnicity/Race/Origin 0.66 0.66 0.70 0.74 0.69 0.67 0.67 0.81 0.86 Gender/Sexuality 0.69 0.69 0.72 0.78 0.74 0.74 0.67 0.86 0.88 PLHIV 0.60 0.66 0.65 0.76 0.73 0.71 0.67 0.86 0.88 Religion 0.67 0.69 0.70 0.78 0.72 0.68 0.71 0.80 0.83 T able 64. F1 Scores across fine-tuned models for dierent protected categories in Tagalog High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.50 0.60 0.69 0.75 0.69 0.59 0.53 0.72 0.59 Disability 0.62 0.78 0.83 0.77 0.72 0.69 0.83 0.90 0.81 Ethnicity/Race/Origin 0.65 0.65 0.75 0.73 0.70 0.65 0.74 0.79 0.74 Gender/Sexuality 0.68 0.66 0.75 0.72 0.72 0.66 0.74 0.83 0.77 Religion 0.72 0.72 0.77 0.78 0.75 0.73 0.79 0.85 0.82 Vulnerable W orkers 0.63 0.60 0.77 0.75 0.67 0.57 0.72 0.85 0.76 T able 65. F1 Scores across fine-tuned models for dierent protected categories in Thai High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.79 0.77 0.83 0.85 0.82 0.82 0.80 0.89 0.86 Disability 0.75 0.77 0.74 0.76 0.80 0.83 0.77 0.88 0.82 Ethnicity/Race/Origin 0.82 0.79 0.80 0.83 0.84 0.84 0.81 0.90 0.85 Gender/Sexuality 0.80 0.77 0.80 0.81 0.79 0.82 0.80 0.87 0.86 PLHIV 0.83 0.79 0.80 0.85 0.83 0.87 0.81 0.91 0.90 Religion 0.80 0.80 0.80 0.82 0.81 0.82 0.79 0.88 0.85 T able 66. F1 Scores across fine-tuned models for dierent protected categories in Vietnamese High-ality T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 91 p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.46 0.39 0.64 0.63 0.52 0.49 0.69 0.67 0.58 Disability 0.50 0.47 0.65 0.68 0.64 0.57 0.63 0.75 0.61 Ethnicity/Race/Origin 0.73 0.63 0.69 0.76 0.75 0.75 0.75 0.81 0.75 Gender/Sexuality 0.63 0.59 0.75 0.78 0.75 0.65 0.70 0.83 0.74 Religion 0.64 0.69 0.77 0.80 0.78 0.73 0.74 0.80 0.75 T able 67. F1 Scores across fine-tuned models for dierent protected categories in Malay High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.56 0.58 0.66 0.67 0.64 0.59 0.56 0.66 0.67 Disability 0.68 0.61 0.63 0.65 0.69 0.65 0.66 0.69 0.69 Ethnicity/Race/Origin 0.60 0.58 0.66 0.67 0.67 0.67 0.62 0.65 0.62 Gender/Sexuality 0.62 0.60 0.64 0.62 0.66 0.64 0.63 0.64 0.65 Religion 0.60 0.58 0.64 0.65 0.66 0.61 0.62 0.63 0.61 T able 68. F1 Scores across fine-tuned models for dierent protected categories in Mandarin High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.51 0.52 0.78 0.84 0.53 0.47 0.59 0.87 0.66 Disability 0.66 0.58 0.74 0.73 0.68 0.71 0.76 0.77 0.63 Ethnicity/Race/Origin 0.82 0.66 0.80 0.86 0.79 0.77 0.80 0.87 0.75 Gender/Sexuality 0.76 0.65 0.78 0.83 0.76 0.73 0.79 0.88 0.79 Religion 0.84 0.74 0.84 0.88 0.83 0.79 0.83 0.91 0.84 T able 69. F1 Scores across fine-tuned models for dierent protected categories in Singlish High-ality T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.62 0.61 0.70 0.77 0.61 0.59 0.66 0.76 0.76 Disability 0.63 0.60 0.63 0.78 0.56 0.60 0.63 0.81 0.83 Ethnicity/Race/Origin 0.69 0.69 0.69 0.81 0.69 0.73 0.72 0.84 0.83 Gender/Sexuality 0.73 0.71 0.64 0.78 0.67 0.69 0.71 0.82 0.83 Religion 0.76 0.75 0.72 0.81 0.72 0.73 0.69 0.86 0.86 T able 70. F1 Scores across fine-tuned models for dierent protected categories in Tamil High-ality T est Cases. Manuscript submitted to ACM 92 Ng et al. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Ethnicity/Race/Origin 0.70 0.69 0.56 0.60 0.77 0.67 0.60 0.75 0.76 0.76 0.83 0.60 Gender/Sexuality 0.56 0.61 0.45 0.53 0.67 0.54 0.54 0.59 0.60 0.52 0.67 0.45 Religion 0.75 0.72 0.70 0.73 0.77 0.75 0.72 0.82 0.82 0.79 0.85 0.62 T able 71. F1 Scores across non-finetuned models for dierent protected categories in Indonesian Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Disability 0.62 0.53 0.52 0.51 0.64 0.45 0.50 0.64 0.67 0.52 0.71 0.43 Ethnicity/Race/Origin 0.69 0.66 0.66 0.63 0.71 0.61 0.62 0.73 0.75 0.66 0.76 0.54 Gender/Sexuality 0.68 0.66 0.68 0.66 0.74 0.60 0.67 0.70 0.73 0.62 0.77 0.52 PLHIV 0.67 0.66 0.68 0.74 0.72 0.66 0.81 0.75 0.73 0.70 0.71 0.63 Religion 0.69 0.68 0.61 0.58 0.69 0.69 0.64 0.68 0.68 0.64 0.74 0.54 T able 72. F1 Scores across non-finetuned models for dierent protected categories in Tagalog Silv er T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.59 0.60 0.57 0.48 0.58 0.26 0.55 0.57 0.61 0.58 0.74 0.38 Disability 0.71 0.82 0.74 0.79 0.74 0.59 0.82 0.82 0.81 0.79 0.84 0.78 Ethnicity/Race/Origin 0.69 0.69 0.65 0.58 0.69 0.49 0.71 0.74 0.75 0.74 0.76 0.59 Gender/Sexuality 0.67 0.68 0.68 0.66 0.66 0.42 0.70 0.69 0.70 0.68 0.82 0.51 Religion 0.71 0.73 0.70 0.68 0.67 0.54 0.74 0.78 0.75 0.77 0.81 0.64 Vulnerable W orkers 0.66 0.63 0.53 0.55 0.59 0.38 0.64 0.79 0.75 0.64 0.56 0.50 T able 73. F1 Scores across non-finetuned models for dierent protected categories in Thai Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.64 0.66 0.52 0.41 0.78 0.40 0.58 0.57 0.59 0.51 0.80 0.38 Disability 0.81 0.80 0.71 0.73 0.83 0.68 0.81 0.85 0.84 0.81 0.87 0.66 Ethnicity/Race/Origin 0.83 0.81 0.74 0.72 0.82 0.71 0.83 0.85 0.85 0.84 0.87 0.74 Gender/Sexuality 0.78 0.76 0.68 0.68 0.82 0.65 0.74 0.75 0.74 0.66 0.82 0.53 PLHIV 0.82 0.84 0.81 0.86 0.82 0.78 0.83 0.87 0.83 0.77 0.84 0.83 Religion 0.83 0.84 0.80 0.78 0.83 0.78 0.85 0.85 0.86 0.86 0.89 0.74 T able 74. F1 Scores across non-finetuned models for dierent protected categories in Vietnamese Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 93 p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.53 0.62 0.44 0.33 0.65 0.40 0.38 0.43 0.46 0.68 0.75 0.28 Disability 0.72 0.70 0.62 0.52 0.71 0.66 0.56 0.76 0.78 0.77 0.78 0.64 Ethnicity/Race/Origin 0.65 0.68 0.69 0.71 0.65 0.67 0.67 0.73 0.74 0.76 0.75 0.72 Gender/Sexuality 0.69 0.64 0.64 0.64 0.68 0.60 0.68 0.69 0.71 0.73 0.78 0.62 Religion 0.72 0.71 0.68 0.60 0.71 0.68 0.75 0.77 0.76 0.79 0.81 0.65 T able 75. F1 Scores across non-finetuned models for dierent protected categories in Malay Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.49 0.57 0.55 0.35 0.69 0.36 0.55 0.45 0.46 0.74 0.80 0.37 Disability 0.71 0.72 0.67 0.57 0.76 0.67 0.65 0.69 0.72 0.66 0.73 0.52 Ethnicity/Race/Origin 0.73 0.72 0.71 0.64 0.74 0.71 0.72 0.71 0.71 0.76 0.80 0.58 Gender/Sexuality 0.72 0.69 0.69 0.63 0.74 0.62 0.69 0.67 0.70 0.74 0.77 0.57 Religion 0.68 0.67 0.66 0.60 0.74 0.68 0.68 0.66 0.65 0.72 0.74 0.54 T able 76. F1 Scores across non-finetuned models for dierent protected categories in Mandarin Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.32 0.65 0.41 0.23 0.60 0.26 0.42 0.30 0.37 0.65 0.74 0.24 Disability 0.75 0.75 0.69 0.63 0.62 0.52 0.80 0.73 0.78 0.77 0.79 0.77 Ethnicity/Race/Origin 0.75 0.79 0.70 0.62 0.68 0.67 0.76 0.78 0.78 0.84 0.82 0.72 Gender/Sexuality 0.64 0.70 0.64 0.62 0.66 0.47 0.63 0.64 0.65 0.77 0.77 0.61 Religion 0.72 0.77 0.71 0.63 0.69 0.63 0.76 0.73 0.74 0.85 0.84 0.64 T able 77. F1 Scores across non-finetuned models for dierent protected categories in Singlish Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Gemini o3 Deepseek Age 0.48 0.55 0.64 0.41 0.65 0.28 0.42 0.43 0.55 0.68 0.77 0.32 Disability 0.63 0.64 0.61 0.61 0.60 0.48 0.51 0.69 0.79 0.80 0.83 0.62 Ethnicity/Race/Origin 0.65 0.66 0.62 0.77 0.54 0.50 0.54 0.77 0.77 0.77 0.82 0.60 Gender/Sexuality 0.57 0.63 0.52 0.68 0.58 0.47 0.53 0.68 0.75 0.76 0.73 0.62 Religion 0.62 0.63 0.55 0.72 0.53 0.53 0.54 0.76 0.76 0.77 0.81 0.67 T able 78. F1 Scores across non-finetuned models for dierent protected categories in Tamil Silv er T est Cases. Manuscript submitted to ACM 94 Ng et al. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Ethnicity/Race/Origin 0.58 0.56 0.60 0.70 0.67 0.61 0.67 0.70 0.64 Gender/Sexuality 0.48 0.44 0.49 0.54 0.56 0.48 0.50 0.56 0.51 Religion 0.65 0.68 0.71 0.77 0.72 0.68 0.74 0.76 0.67 T able 79. F1 Scores across fine-tuned models for dierent protected categories in Indonesian Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Disability 0.62 0.68 0.64 0.70 0.69 0.67 0.61 0.69 0.69 Ethnicity/Race/Origin 0.72 0.73 0.76 0.78 0.75 0.73 0.74 0.76 0.75 Gender/Sexuality 0.77 0.69 0.77 0.80 0.79 0.75 0.72 0.81 0.80 PLHIV 0.78 0.75 0.68 0.78 0.74 0.68 0.76 0.74 0.74 Religion 0.73 0.73 0.73 0.76 0.74 0.72 0.72 0.76 0.75 T able 80. F1 Scores across fine-tuned models for dierent protected categories in Tagalog Silv er T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.41 0.55 0.58 0.60 0.54 0.38 0.52 0.53 0.53 Disability 0.56 0.74 0.86 0.81 0.70 0.65 0.78 0.78 0.79 Ethnicity/Race/Origin 0.60 0.65 0.74 0.75 0.72 0.67 0.72 0.71 0.70 Gender/Sexuality 0.63 0.64 0.72 0.73 0.72 0.60 0.65 0.68 0.65 Religion 0.65 0.70 0.76 0.77 0.74 0.71 0.75 0.74 0.71 Vulnerable W orkers 0.63 0.57 0.76 0.77 0.70 0.50 0.65 0.79 0.65 T able 81. F1 Scores across fine-tuned models for dierent protected categories in Thai Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.78 0.80 0.82 0.82 0.83 0.78 0.82 0.78 0.82 Disability 0.83 0.83 0.85 0.88 0.84 0.85 0.82 0.89 0.88 Ethnicity/Race/Origin 0.85 0.84 0.85 0.87 0.87 0.86 0.85 0.89 0.88 Gender/Sexuality 0.84 0.83 0.84 0.86 0.85 0.83 0.84 0.83 0.84 PLHIV 0.84 0.82 0.84 0.82 0.87 0.83 0.82 0.87 0.89 T able 82. F1 Scores across fine-tuned models for dierent protected categories in Vietnamese Silver T est Cases. Manuscript submitted to ACM SEAHateCheck: Functional T ests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia 95 p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.42 0.37 0.64 0.59 0.48 0.48 0.62 0.45 0.44 Disability 0.68 0.53 0.74 0.75 0.67 0.69 0.77 0.70 0.64 Ethnicity/Race/Origin 0.74 0.66 0.68 0.74 0.71 0.71 0.73 0.75 0.73 Gender/Sexuality 0.70 0.63 0.78 0.76 0.73 0.68 0.75 0.75 0.72 Religion 0.66 0.70 0.77 0.79 0.74 0.73 0.77 0.78 0.72 T able 83. F1 Scores across fine-tuned models for dierent protected categories in Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.59 0.65 0.76 0.78 0.65 0.61 0.65 0.66 0.66 Disability 0.69 0.69 0.70 0.73 0.72 0.70 0.67 0.73 0.71 Ethnicity/Race/Origin 0.65 0.63 0.72 0.69 0.70 0.66 0.66 0.67 0.61 Gender/Sexuality 0.70 0.69 0.73 0.73 0.73 0.70 0.69 0.72 0.69 Religion 0.66 0.65 0.71 0.71 0.69 0.66 0.64 0.67 0.62 T able 84. F1 Scores across fine-tuned models for dierent protected categories in Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.45 0.40 0.72 0.73 0.64 0.46 0.57 0.75 0.75 Disability 0.63 0.57 0.77 0.74 0.70 0.67 0.76 0.77 0.71 Ethnicity/Race/Origin 0.79 0.75 0.83 0.83 0.80 0.79 0.79 0.83 0.82 Gender/Sexuality 0.77 0.73 0.81 0.81 0.76 0.74 0.75 0.81 0.81 Religion 0.80 0.82 0.81 0.84 0.79 0.76 0.81 0.83 0.81 T able 85. F1 Scores across fine-tuned models for dierent protected categories in Silver T est Cases. p_category Ministral Llama3b Llama8b Sealion Seallm Pangea Qwen Gemma Seagem Age 0.56 0.53 0.61 0.72 0.52 0.53 0.58 0.75 0.70 Disability 0.67 0.64 0.64 0.78 0.52 0.54 0.59 0.81 0.83 Ethnicity/Race/Origin 0.66 0.65 0.64 0.76 0.65 0.67 0.65 0.78 0.75 Gender/Sexuality 0.70 0.67 0.60 0.76 0.61 0.63 0.64 0.80 0.79 Religion 0.71 0.68 0.65 0.74 0.68 0.68 0.65 0.78 0.76 T able 86. F1 Scores across fine-tuned models for dierent protected categories in Silver T est Cases. Manuscript submitted to ACM
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment