동남아 저자원 언어를 위한 기능 테스트 기반 혐오 발언 탐지 벤치마크
SEAHateCheck은 인도네시아어, 타갈로그어, 태국어, 베트남어 네 개 저자원 언어에 특화된 기능 테스트 모음집이다. HateCheck와 SGHateCheck의 프레임워크를 확장해 현지 전문가와 대형 언어 모델을 활용해 655개의 템플릿을 번역·검증하고, 13,579개의 고품질 골드 라벨 사례와 추가 실버 라벨을 제공한다. 실험 결과 최신 다국어 모델조차 언어별·슬랭·암시적 혐오 구분에 한계를 보이며, 특히 타갈로그와 베트남어에서 정확도가…
저자: Ri Chi Ng, Aditi Kumaresan, Yujia Hu
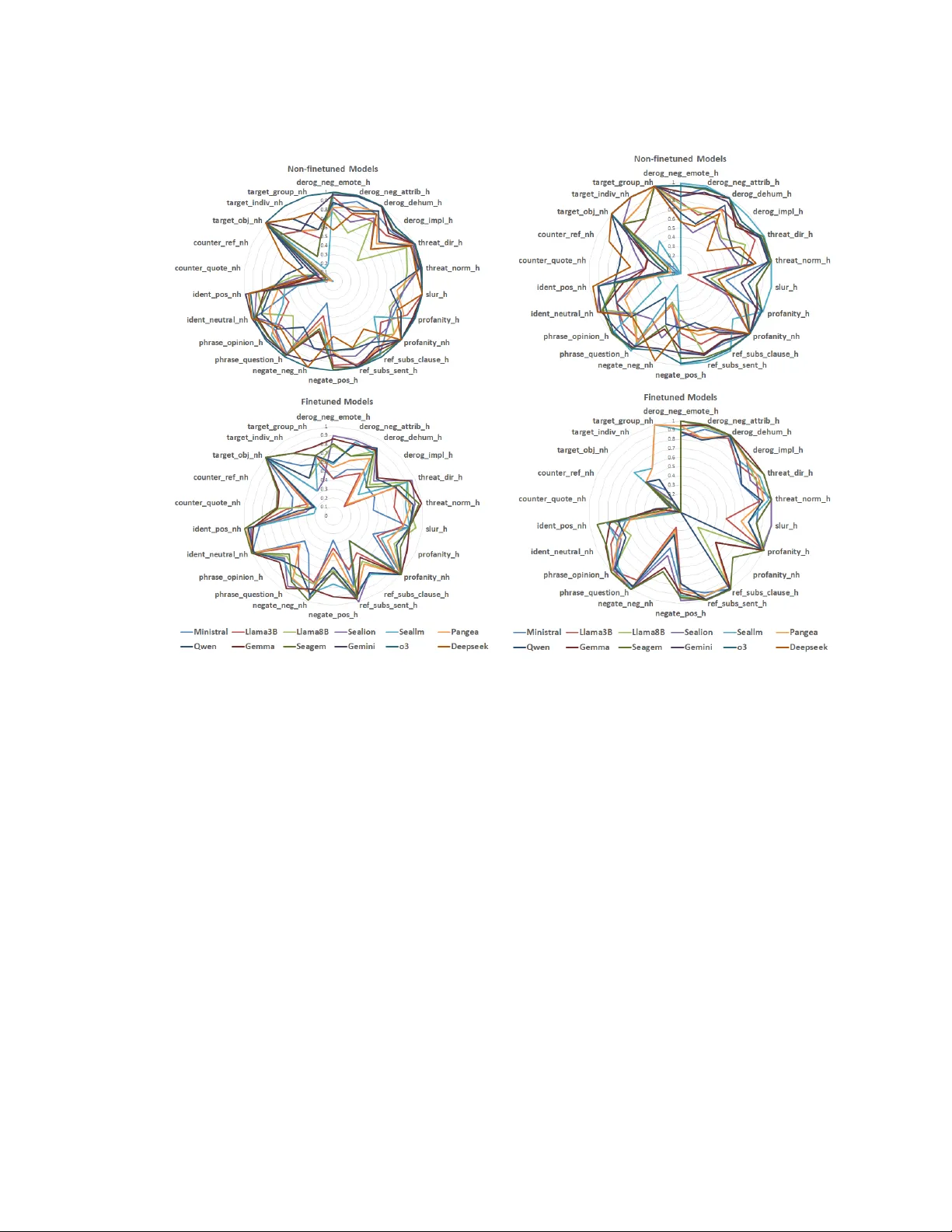
본 연구는 동남아시아의 저자원 언어(인도네시아어, 타갈로그어, 태국어, 베트남어)에서 혐오 발언 탐지 모델의 성능을 체계적으로 평가하고 개선하기 위한 기능 테스트 벤치마크인 SEAHateCheck을 제안한다. 서론에서는 현재 혐오 발언 탐지 연구가 영어·중국어 등 고자원 언어에 편중돼 있어, 언어적·문화적 다양성을 반영한 평가 도구가 부족함을 강조한다. 특히 동남아는 성조·다양한 문자 체계·지역 특유의 은어·암시적 표현이 복합적으로 존재해 기존 모델이 높은 오류율을 보인다.
관련 연구에서는 HateCheck(영어), Multilingual HateCheck, SGHateCheck(싱가포르 다언어) 등을 소개하며, 이들 프레임워크가 기능 테스트를 통해 모델의 구체적 약점을 진단한다는 점을 인정하지만, 동남아 저자원 언어에 대한 적용 사례가 없음을 지적한다.
데이터 구축 단계에서는 먼저 HateCheck의 22개 기능을 기반으로 각 언어별 27~34개의 세부 테스트를 설계하고, 보호 그룹(종교, 인종·민족, 장애, 성별 등)과 슬러를 포함한 템플릿 655개를 준비한다. 템플릿 번역은 세 단계로 진행된다. (1) 초기 검증: 각 기능당 하나씩 현지 전문가가 검토하여 문화적 적합성을 확인한다. (2) 다중 샷 번역: 검증된 템플릿을 인‑컨텍스트 예시로 사용해 Gemini 1.5 Pro와 GPT‑4o가 자동 번역하고, 두 명의 번역가가 교차 편집한다. (3) 대규모 번역: 무작위 선택된 샘플을 추가 예시로 활용해 나머지 611개 템플릿을 번역한다. 인도네시아어는 GPT‑3.5를 파인튜닝해 번역 품질을 높였으며, 모든 번역은 현지 사회언어학자와 협의해 은어·성조·문자 특성을 반영한다.
라벨링은 골드와 실버 두 층위로 구분한다. 골드 라벨은 템플릿에 보호 그룹·슬러를 삽입해 5~10번 변형한 뒤, 12명의 현지 언어 전문가(각 언어당 3명)가 삼중 검증한다. 일치도는 Fleiss’ κ = 0.85로 높은 신뢰성을 보였으며, 전체 13,579개의 고품질 사례가 최종 벤치마크에 포함된다. 실버 라벨은 동일 템플릿을 LLM이 자동 생성한 것으로, 규모 확대와 다양성 보강을 목표로 한다.
실험에서는 XLM‑R, mBERT, BLOOMZ, 그리고 최신 다국어 LLM(GPT‑4o, LLaMA‑2 등)을 평가하였다. 각 모델은 SEAHateCheck의 기능 테스트별 정확도와 F1 점수를 산출했으며, 결과는 언어별·테스트 유형별로 크게 차이를 보였다. 인도네시아어는 전체 평균 78%의 정확도를 기록했지만, 슬랭 기반 테스트(F23‑F34)에서는 62%에 머물렀다. 타갈로그어는 가장 낮은 58% 정확도를 보였으며, 이는 학습 코퍼스의 부족과 복합 어미·어순 변형이 원인으로 분석된다. 태국어와 베트남어는 성조와 문자 체계 차이로 인해 암시적 혐오(F12, F15)와 반대 발언(F18‑F19) 구분에 어려움을 겪었다. 특히 슬랭·코드스위칭이 포함된 사례에서는 모든 모델이 20% 이상 오류를 범했다.
오류 분석에서는 (1) 모델이 표면적인 키워드에 과도하게 의존해 은어·레터스피크를 놓치는 경우, (2) 부정어와 긍정어가 혼재된 문장에서 의미를 오해하는 경우, (3) 보호 그룹 명칭이 번역 과정에서 중립적으로 변형돼 라벨링 오류가 발생하는 경우를 확인했다. 이를 토대로 저자들은 (가) 저자원 언어에 특화된 대규모 사전학습 데이터 구축, (나) 문화·언어별 은어 사전 및 성조 인식 모듈 개발, (다) 컨텍스트‑민감한 프롬프트 설계와 멀티태스크 학습을 통한 암시적 혐오 탐지 강화 방안을 제시한다.
마지막으로 SEAHateCheck은 공개 리포지터리(https://github.com/Social‑AI‑Studio/SEAHateCheck)를 통해 템플릿, 골드·실버 라벨, 평가 스크립트를 제공하며, 연구자와 플랫폼이 저자원 언어의 혐오 발언 탐지 모델을 체계적으로 진단·개선할 수 있는 기반을 마련한다. 향후 작업으로는 말뭉치 기반 자동 라벨링, 사용자 피드백을 통한 라벨 품질 향상, 그리고 다른 동남아 국가(말레이어, 캄보디아어 등)로 확장하는 계획을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기