Efficient Federated Conformal Prediction with Group-Conditional Guarantees
Deploying trustworthy AI systems requires principled uncertainty quantification. Conformal prediction (CP) is a widely used framework for constructing prediction sets with distribution-free coverage guarantees. In many practical settings, including h…
Authors: Haifeng Wen, Osvaldo Simeone, Hong Xing
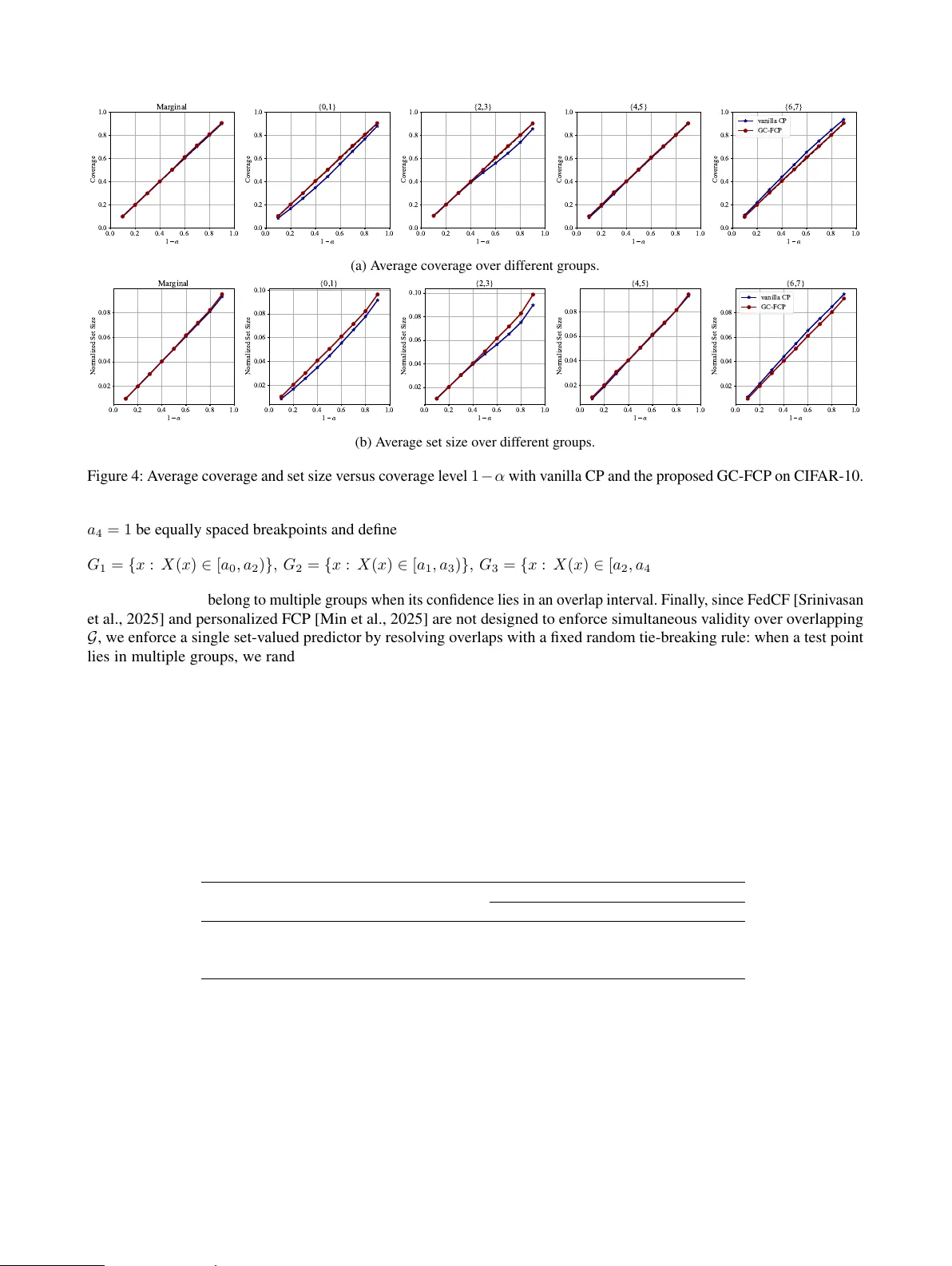
Efficient F ederated Conf ormal Pr ediction with Group-Conditional Guarantees Haifeng W en 1 Osvaldo Simeone 2 Hong Xing 1,3 1 IoT Thrust, The Hong K ong Univ ersity of Science and T echnology (Guangzhou), Guangzhou, China 2 Institute for Intelligent Networked Systems (INSI), Northeastern Uni versity London, London, UK 3 Department of ECE, The Hong K ong Univ ersity of Science and T echnology , HK SAR Abstract Deploying trustworthy AI systems requires prin- cipled uncertainty quantification. Conformal pre- diction (CP) is a widely used framework for con- structing prediction sets with distribution-free cov- erage guarantees. In many practical settings, in- cluding healthcare, finance, and mobile sensing, the calibration data required for CP are distributed across multiple clients, each with its own local data distribution. In this federated setting, data can often be partitioned into, potentially o verlapping, groups, which may reflect client-specific strata or cross-cutting attributes such as demographic or se- mantic categories. W e propose gr oup-conditional federated conformal prediction (GC-FCP), a nov el protocol that provides group-conditional cov erage guarantees. GC-FCP constructs mergeable, group- stratified coresets from local calibration scores, en- abling clients to communicate compact weighted summaries that support efficient aggre gation and calibration at the server . Experiments on synthetic and real-world datasets validate the performance of GC-FCP compared to centralized calibration baselines. 1 INTR ODUCTION Deploying trustworthy AI systems critically depends on uncertainty quantification to enable reliability control at deployment time. Gi ven a pretrained model, conformal pr e- diction (CP) post-processes the model’ s outputs to construct prediction sets with finite-sample, distribution-free cover - age guarantees. The calibration of the prediction set is carried out offline by leveraging held-out calibration data [V ovk et al., 2005, Angelopoulos and Bates, 2021, Barber et al., 2021, Simeone and Romano, 2025]. In many practi- cal deployments, howe ver , calibration data are inherently distributed and subject to priv acy constraints, so that each client must retain its data on-site, e.g., hospitals, banks, or Internet-of-Things devices [McMahan et al., 2017]. F ederated conformal pr ediction (FCP) [Lu et al., 2023] addresses the outlined distributed setting with the goal of preserving marginal co verage with respect to a distrib ution obtained by mixing local data distributions. Pursuing a sim- ilar marginal coverage guarantee, Humbert et al. [2023] and Humbert et al. [2024] proposed one-shot FCP schemes based on a quantile-of-quantiles estimator . Beyond calibra- tion targeting the mixture distribution, FCP-Pro [Li et al., 2025] and personalized FCP [Min et al., 2025] address the heterogeneity of local data distrib utions by training ad- ditional models during the calibration process, providing marginal coverage on local distributions or on the distri- bution of a new client. T o address robustness, Kang et al. [2024] studied Byzantine clients that may report arbitrary statistics. Considering more general connectivity constraints underlying communications, decentralized calibration via message passing ov er arbitrary graphs was proposed by [W en et al., 2025], and distributed remote calibration proto- cols were studied in [Zhu et al., 2025] for wireless sensor networks. The state of the art on federated calibration summarized abov e did not target group-conditional coverage guaran- tees. In federated settings, data can often be partitioned into, potentially ov erlapping, groups, which may reflect client-specific strata or cross-cutting attributes such as de- mographic or semantic categories (see Fig. 1). For central- ized settings, Mondrian CP [V ovk et al., 2003] addresses group-conditional cov erage ov er disjoint groups of cov ari- ates, while CondCP [Gibbs et al., 2025] allows for o verlap- ping groups by reframing conditional co verage as simulta- neous cov erage ov er a class of cov ariate shifts. Kandinsky CP [Bairaktari et al., 2025] extended Mondrian CP and CondCP to groups that depend on both co v ariates and labels. Other related research directions for centralized scenarios include localized cov erage guarantees [Guan, 2023]; learn- ing improv ed conformity scores to reduce conditional mis- clien t client … client calibra tion data serv er CP ca libra ted set pr ediction input { le op ard , ti ger , cat } wildl ife ca nine s m a rg ina l co v erag e g r o up - co ndition a l co v erag e: co ndition ed o n le opar d {ti ger , ca t} cat {o wl, ca t } le opar d { le opar d, ti g er , c a t } cat {ca t} Figure 1: Left : In a federated system with heterogeneous clients, each client k holds local calibration data D k and communicates ov er a bandwidth-limited channel to a central server . The server aggregates these summaries to perform conformal calibration (CP) and outputs a set-valued predictor C ( · | D ) . Right : GC-FCP targets group-conditional coverage for potentially ov erlapping groups G = { G 1 , G 2 , G 3 } , ensuring the inequality P ( Y ∈ C ( X | D ) | X ∈ G ) ≥ 1 − α for all groups G ∈ G , whereas methods that only guarantee marginal coverage P ( Y ∈ C ( X | D )) ≥ 1 − α , such as FCP [Lu et al., 2023], may still under-co ver within specific groups. cov erage [Xie et al., 2024]; as well as analyses of sample- conditional validity for split conformal methods [Duchi, 2025]. All this prior art on group-conditional CP has focused on centralized settings. T o address this knowledge gap, in this paper , we propose a communication- and computation- ef ficient federated extension of CondCP [Gibbs et al., 2025], namely gr oup-conditional federated conformal pr ediction (GC-FCP) , which enables ef ficient server-side prediction- set construction by communicating only compact summaries sketched from group-stratified local calibration scores, while preserving the information needed for group-conditional cal- ibration. Unlike FedCF [Srini vasan et al., 2025], GC-FCP does not treat dif ferent groups separately , seeking simulta- neous cov erage across all groups. The main contributions are summarized as follo ws: • W e first propose centralized GC-FCP , an extension of CondCP [Gibbs et al., 2025] that achie ves group- conditional cov erage guarantees under the mixture of the local data distribution. • W e de velop GC-FCP , an ef ficient federated protocol that accelerates communication and computation by compressing group-stratified calibration scores into mergeable T -Digest [Dunning and Ertl, 2019] coresets. • W e establish group-conditional coverage bounds for GC-FCP , making explicit ho w the coreset compression lev el affects the achiev ed coverage. • W e validate the proposed methods on synthetic and real-world benchmarks, demonstrating that GC-FCP attains group-conditional reliability while substantially reducing computational ov erhead. 2 PR OBLEM SETTING As illustrated in Fig. 1, we study a federated calibration setting that follo ws reference [Lu et al., 2023]. Accord- ingly , we consider a network consisting of K clients that communicate with a central server . In this setup, each client k ∈ { 1 , . . . , K } ≜ [ K ] has access to a local cali- bration dataset D k = { ( X i,k , Y i,k ) } n k i =1 , with data points ( X i,k , Y i,k ) drawn i.i.d. from a client-specific distribution P k ov er X × Y . W e define a global calibration dataset as the union D = S K k =1 D k , with n = P K k =1 n k . As in [Lu et al., 2023], the goal is to calibrate a shared pre-trained model f : X 7→ Y through communication with the central server . Calibration is ev aluated on test data ( X n +1 , Y n +1 ) drawn from the mixture P = K X k =1 π k P k , (1) for some arbitrary and known mixture weights π k ≥ 0 with P K k =1 π k = 1 . In practice, the weights { π k } K k =1 dictate the relativ e relev ance of the data of each client k for the calibration of model f . Calibration aims at obtaining a set predictor C ( · | D ) : X → 2 Y . (2) using the distributed calibration data via clients-to-server communication. Prior work [Lu et al., 2023] imposed the constraint that the prediction set (2) satisfies the marginal cov erage condition P ( Y n +1 ∈ C ( X n +1 | D )) ≥ 1 − α (3) with respect to the mixture distribution (1) . In contrast, as explained ne xt, we impose a more flexible conditional cov- erage condition based on grouping. Let G ⊆ 2 X be a finite collection of groups in the cov ariate space X and S G ∈G = X . Importantly , the groups are gen- erally ov erlapping, i.e., there exist groups G i , G j ∈ G such that G i T G j = ∅ (see Fig. 1). Groups may or may not rep- resent client-specific partitions. In fact, some groups G may correspond to data cate gories that are more representativ e of the distribution P k of a giv en client k . Howe ver , it may also be that groups refer to cate gories that apply equally across all clients. W e consider the set G to be arbitrary and giv en. Giv en a target mis-cov erage lev el α ∈ (0 , 1) , calibration aims to construct set prediction C ( · | D ) such that, for e very group G ∈ G , the following group-conditional coverage requirement holds: P ( Y n +1 ∈ C ( X n +1 | D ) | X n +1 ∈ G ) ≥ 1 − α, (4) where the probability in (4) is taken ov er the calibration data in D and the test data ( X n +1 , Y n +1 ) . For condition (4) to be meaningful, we assume that all groups G ∈ G satisfy the inequality P ( X n +1 ∈ G ) > 0 under the mixture distribution (1) . Note that this does not require that the inequality P k ( X ∈ G ) > 0 holds for ev ery client k . Rather , it only requires that at least one component with probability π k > 0 places positiv e mass on the group G . If the groups G were disjoint, the conditional coverage re- quirement (4) could be obtained by combining FCP [Lu et al., 2023] and Mondrian CP [V ovk et al., 2003]. Ac- cordingly , one applies the FCP protocol separately for each group G ∈ G . Ho wev er , ensuring the conditions (4) become dif ficult when groups o verlap, and we address this challenge in this paper . 3 PRELIMINARIES T o start, consider , for reference, a centralized split- conformal setting in which a serv er has access to i.i.d. cal- ibration data { ( X i , Y i ) } n i =1 and a test covariate X n +1 . In this section, we revie w CondCP [Gibbs et al., 2025], which addresses the problem of satisfying the constraints (4) in such a centralized setting. Let s : X × Y 7→ R be a score function derived from a predictive model f , and define the calibration scores S i = s ( X i , Y i ) with i = 1 , . . . , n . Furthermore, let ℓ α ( θ , S ) denote the pinball loss at lev el 1 − α : ℓ α ( θ , S ) = ( (1 − α )( S − θ ) , S ≥ θ , α ( θ − S ) , S < θ . (5) Giv en the set of groups G (possibly overlapping), define the group-membership map Φ : X → { 0 , 1 } |G | as Φ( x ) = 1 { x ∈ G } G ∈G ∈ { 0 , 1 } |G | , (6) which encodes membership of element x ∈ X belonging to each group of G as a binary indicator vector (where T able 1: Communication load and computational complex- ity . Method Comm. Comp. CondCP & Centralized GC-FCP O ( n ) O n 3 / 2 |G | 2 GC-FCP O ( K δ ) O δ 3 / 2 |G | 2 1 { true } = 1 and 1 { false } = 0 ). Then, CondCP defines the set of functions F G = n x 7→ β ⊤ Φ( x ) : β ∈ R |G | o , (7) which corresponds to arbitrary linear combinations for the group indicators. Specifically , for any input test score S ∈ R , CondCP solves the augmented quantile r e gr ession problem: ˆ g S = arg min g ∈F G ( 1 n + 1 n X i =1 ℓ α g ( X i ) , S i + 1 n + 1 ℓ α g ( X n +1 ) , S . (8) Note that the solution ˆ g S is a function in class (7) . By the properties of the pinball loss, the solution ˆ g S repre- sents a cov ariate ( X n +1 )-dependent version of the (1 − α ) - empirical quantile of the augmented calibration scores { S i } n i =1 ∪ { S } [Gibbs et al., 2025]. The prediction set is then defined as the set of all labels y ∈ Y whose score s ( X n +1 , y ) is no larger than the corresponding empirical quantile ˆ g s ( X n +1 ,y ) ( X n +1 ) , i.e., C ( X n +1 | D ) = y ∈ Y : s ( X n +1 , y ) ≤ ˆ g s ( X n +1 ,y ) ( X n +1 ) . (9) The prediction set (9) is constructed by addressing an equiv a- lent formulation of the con vex problem (8) via dual methods (see Appendix D for details). Under the assumption of i.i.d. calibration and test data, the set C ( X n +1 | D ) in (9) satisfies group-conditional cov erage (4). Communication overhead: Solving problem (8) at the server would require collecting all calibration scores and their group-membership features, yielding a communication ov erhead O ( n ) . Computational overhead: Solving problem (8) requires computational complexity of order O ( n 3 / 2 |G | 2 ) using stan- dard con ve x problem solvers [Renegar, 1988, Nestero v and Nemirovskii, 1994]. 4 GR OUP-CONDITIONAL FEDERA TED CONFORMAL PREDICTION (GC-FCP) This section introduces gr oup-conditional federated confor- mal pr ediction (GC-FCP), a federated calibration procedure designed to achie ve group-conditional co verage (4) ov er a prescribed, generally overlapping, collection of groups G under any mixture distrib ution (1) . In GC-FCP , each client computes calibration scores locally and communicates to the server only a compact, group-stratified summary , while the server efficiently constructs the CP set for each test point without accessing raw client-le vel calibration scores. 4.1 FEDERA TED A UGMENTED QU ANTILE REGRESSION T o start, consider an ideal setting in which the entire cal- ibration dataset D , which includes the datasets D k from all clients k ∈ [ K ] , is av ailable at the central server . As- sume also no computational limitations at the server . Even in this simplified setup, as explained in the previous section, CondCP would fail to guarantee the conditional cov erage requirements (4) , since the data points in dataset D are not i.i.d. with respect to the mixture distribution (1) . W e address this challenge in this section by proposing centr alized GC- FCP , a centralized calibration scheme that guarantees the desired condition (4). As in Section 3, let s : X × Y 7→ R be a score function deriv ed from the shared predictive model f . W e denote the calibration scores at client k as S i,k = s ( X i,k , Y i,k ) with i ∈ { 1 , . . . , n k } and k ∈ [ K ] . Furthermore, given a test point ( X n +1 , Y n +1 ) ∼ P , we denote its score by S n +1 = s ( X n +1 , Y n +1 ) . For a test cov ariate X n +1 and an input score v alue S ∈ R , centralized GC-FCP solves the following federated aug- mented quantile regression estimator as a generalization of the CondCP problem (8): ˆ g S = argmin g ∈F G K X k =1 π k n k + 1 n k X i =1 ℓ α ( g ( X i,k ) , S i,k ) + ℓ α ( g ( X n +1 ) , S ) , (10) where the function set F G is defined in (7) . The objective in problem (10) incorporates the scores of all K clients, with each k -th term weighted by the factor π k / ( n k + 1) , thus matching the structure of the target mixture distribution (1) . Using this definition, centralized GC-FCP obtains the prediction set as in (9). Theorem 4.1 (Group-conditional cov erage for centralized GC-FCP) . F or every group G ∈ G , the set (9) with the empirical quantile (10) pr oduced by centralized GC-FCP satisfies the conditional covera ge condition (4) . Pr oof: See Appendix A.1. As summarized in T able 1, the centralized GC-FCP shares the same communication and computational ov erheads as CondCP . 4.2 GR OUP-CONDITIONAL FEDERA TED CONFORMAL PREDICTION The previous subsection focused on a centralized version of GC-FCP , which solves problem (10) using the calibra- tion scores pooled from all clients. T o mitigate the commu- nication and computational overhead associated with this approach, we now introduce GC-FCP , a nov el distributed protocol that replaces the full calibration dataset with small group-stratified coresets. As summarized in T able 1, this protocol reduces the communication load and enables a more efficient serv er-side optimization (whenev er n ≫ δ ). GC-FCP starts by applying a coreset construction based on T -Digest [Dunning and Ertl, 2019], which is a sketching algorithm for computing approximations of quantiles, and is elaborated in the sequel. The sketches produced by T - Digest are then used to solve the optimization problem (10) at the central server . While T -Digest was also used by FCP [Lu et al., 2023], GC-FCP must additionally account for the structure of the groups in the set G , producing stratified structures (see Fig. 2). 4.2.1 T -Digest Let { ( R i , w i ) } ℓ i =1 be weighted real-valued samples with R i ∈ R and weights w i > 0 , and define the total weight as W = P ℓ i =1 w i . The associated weighted em- pirical cumulative distribution function (CDF) is F ( t ) = 1 W P ℓ i =1 w i 1 { R i ≤ t } , with generalized empirical quan- tile function Q ( u ) = inf { t : F ( t ) ≥ u } for u ∈ [0 , 1] . T -Digest: A T -Digest [Dunning and Ertl, 2019] produces an ordered collection of m < ℓ clusters R c ⊆ { 1 , . . . , ℓ } , i.e., if c 1 < c 2 , R i ≤ R j for any i ∈ R c 1 and j ∈ R c 2 . Cluster R c is described by a cluster representativ e ¯ R c and an aggregate weight W c . Each cluster R c includes a subset of samples { R i } ℓ i =1 with total weight W c = P i ∈R c w i , and the weighted cluster means ¯ R c = 1 W c P i ∈R c w i R i . In summary , T -Digest returns the weights and the cluster means as TD = ( ¯ R c , W c ) m c =1 . (11) It is worth noting that T -Digest enforces the ordering ¯ R 1 ≤ ¯ R 2 ≤ · · · ≤ ¯ R m , producing ordered cluster means. T o this end, it orders the original set { R i } ℓ i =1 such that we hav e R 1 ≤ R 2 ≤ · · · ≤ R ℓ . Clusters are then constructed greedily as follo ws. T o elaborate, let V c = P c i =1 W i with V 0 = 0 , and define the empirical left and right quantile boundaries of cluster c ∈ { 1 , . . . , m } as q L c = V c − 1 W and q R c = V c W . (12) Samples R 1 , R 2 , . . . , R ℓ are aggregated in an increasing order into the current cluster R c as long as adding the next 1 2 3 4 5 6 7 Figure 2: Illustration of the atom partitions applied by GC-FCP . Gi ven the set of overlapping groups G = { G 1 , G 2 , G 3 } , the resulting 7 non-empty atoms A = { A 1 , . . . , A 7 } are shown on the right, together with the corresponding group-membership vector (6). sample preserves the constraint r q R c − r q L c ≤ 1 , c = 1 , . . . , m. (13) with scale function r ( q ) = δ 2 π arcsin(2 q − 1) . (14) for some parameter δ > 0 that controls the le vel of compres- sion. Intuitiv ely , the condition (13) enforces finer resolution near the tails of the empirical distribution of the scalars { R i } ℓ i =1 , while permitting larger clusters near the median. By this construction, the number of retained clusters scales as m = Θ( δ ) [Dunning and Ertl, 2019]. From the digest TD = ( ¯ R c , W c ) m c =1 , the approximate quantile function for u ∈ [0 , 1] is giv en by b Q ( u ) = inf { t : b F ( t ) ≥ u } , (15) where b F ( t ) = 1 W m X c =1 W c 1 { ¯ R c ≤ t } . (16) is an estimate of the empirical CDF F ( t ) . The quality of this estimate will be analyzed in Section 5. Merging T -Digests: A key property of T -Digest is that digests can be merged and then re-compressed such that the number of retained clusters remains Θ( δ ) [Dunning and Ertl, 2019]. Let TD ( j ) = { ( ¯ R ( j ) c , W ( j ) c ) } m j c =1 be digests obtained from disjoint datasets indexed by j = 1 , . . . , J . T o merge them, one applies the same procedure discussed above to the pooled samples S J j =1 TD ( j ) . W e denote the merged digest as Merge( TD (1) , . . . , TD ( J ) ) . 4.2.2 GC-FCP In order to address the group-conditional constraint (4) , GC- FCP first stratifies the data at the clients into disjoint atoms based on unique group membership patterns. Independent T -Digests are then constructed per atom, and used at the server as coresets to approximate the solution of the quantile regression problem (10). Atoms construction: As illustrated in Fig. 2, GC-FCP first partitions the input domain X into a collection A = { A } A ∈A of atoms, which are defined as S A ∈A A = X and A T A ′ = ∅ , for any pair A, A ′ ∈ A . The collection A corresponds to the smallest-cardinality partition of the set X such that all the sets G can be recovered via union operations on its atoms. F ormally , for each subset of groups, S ⊆ G , define A ( S ) = \ G ∈S G ! \ \ G ∈G \S G c (17) as the intersection of all groups in subset S and the com- plement of all groups not in subset S . The construction A = { A ( S ) } S ⊆G yields the collection of atoms [Kallen- berg, 2002]. By construction, each atom A corresponds to all points x ∈ X with the same membership vector Φ( x ) . Accordingly , for any x ∈ A , we can write Φ A = Φ( x ) . An example is illustrated in Fig. 2. Local-score partition and digest: W e now partition the set of local scores at client k ∈ [ K ] into |A| subsets D k,A , one per atom A as D k,A = { s ( X, Y ) : X ∈ A, ( X, Y ) ∈ D k } . (18) Each client k ∈ [ K ] , for each atom A , builds a separate digest TD k,A using the scores D k,A and equal weights w = π k / ( n k + 1) . Follo wing Section 4.2, the resulting digest TD k,A consists of a set of means and weights with m k,A = Θ( δ ) clusters TD k,A = ¯ S k,A,c , W k,A,c m k,A c =1 , (19) where ¯ S k,A,c = 1 W k,A,c P i ∈S k,A,c π k n k +1 S i is the weighted mean of the scores in cluster S k,A,c , and W k,A,c = |S k,A,c | π k n k +1 is the aggregated weight. Next, client k ∈ [ K ] transmits the digest TD k,A along with all A ∈ A to the server . For each atom A ∈ A , the server merges the recei ved digests { TD k,A } K k =1 to obtain a global digest TD A = Merge TD 1 ,A , . . . , TD K,A = ¯ S A,c , W A,c m A c =1 , (20) with m A = Θ( δ ) clusters, where Merge( · ) denotes the merge operation on { TD k,A } K k =1 . As a result, the union ov er the digests of all atoms yields the final coreset: e D = A, ¯ S , W : ¯ S , W ∈ TD A , A ∈ A (21) Algorithm 1 GC-FCP Input: Clients’ calibration sets {D k } K k =1 ; groups G ; score s ( · , · ) ; mis-coverage lev el α ; mixture weights π k ; T - Digest compression parameter δ . ▷ Client side (in parallel): for de vice k ∈ { 1 , . . . , K } do Construct T -Digest TD k,A for each atom A ∈ A using D k,A . T ransmit T -Digests { TD k,A } A ∈A to the central server . end for ▷ Server side: Merge { TD k,A } k ∈ [ K ] for each atom A ∈ A via (20). Solve (22) and compute the prediction set (23). Output: C ( · | e D ) with size | e D | = Θ( |A| δ ) . Note that each entry ( A, ¯ S , W ) of the coreset includes the identifier of the atom A , the mean score ¯ S , and the corresponding weight W . Set construction: Giv en a test score S , GC-FCP solves problem (10) using the coreset e D instead of the original pooled data D , i.e., ˜ β ( S ) = argmin β ∈ R |G | X ( A, ¯ S ,W ) ∈ e D W ℓ α β ⊤ Φ A , ¯ S + K X k =1 π k n k + 1 ! ℓ α β ⊤ Φ( X n +1 ) , S . (22) Finally , the prediction set is constructed as C ( X n +1 | e D ) = y ∈ Y : s ( X n +1 , y ) ≤ ˜ g s ( X n +1 ,y ) ( X n +1 ) . (23) where ˜ g S ( x ) = ˜ β ( S ) ⊤ Φ( x ) . The proposed GC-FCP is summarized in Algorithm 1. Communication ov erhead: Solving problem (22) at the server requires collecting all digests { TD k,A } , yielding a to- tal communication load of GC-FCP of order O ( K δ ) , instead of the o verhead of order O ( n ) of CondCP and centralized GC-FCP . Computational overhead: Solving the dual of prob- lem (22) requires computational complexity of order O ( | e D | 3 / 2 |G | 2 ) = O ( δ 3 / 2 |G | 2 ) by standard con vex problem solvers [Rene gar, 1988, Nesterov and Nemiro vskii, 1994], instead of the order O ( n 3 / 2 |G | 2 ) of CondCP and centralized GC-FCP . 5 CO VERA GE GU ARANTEES OF GC-FCP The key property of GC-FCP is its ability to provide group- conditional coverage guarantees (4) for the prediction set. Deri ving finite-sample group-conditional guarantees for GC- FCP is technically challenging, since one must simultane- ously account for the non-exchangeability of the samples in the coreset and for the approximation error introduced by sketching via the local digest. T o this end, we first ana- lyze the quantile estimation accuracy of T -Digest, and then provide a group-conditional co verage bound for GC-FCP . 5.1 Q U ANTILE A CCURA CY OF T -DIGEST W e start by deri ving a relationship between the compression parameter δ used in the scale function (14) by T -Digest for compression, which dictates the number of clusters m = Θ( δ ) , and the accuracy of the approximate quantile (15). Lemma 5.1 (Uniform bound of T -Digest) . Defining as F ( t ) the true CDF of original samples, the CDF estimate (16) pr oduced by T -Digest satisfies the uniform accuracy bound sup t ∈ R F ( t ) − b F ( t ) ≤ sin π δ ≤ π δ . (24) Mor eover , for all u ∈ [0 , 1] , the quantile estimate 16 satisfies the inequality | F ( b Q ( u )) − u | ≤ π / δ. Pr oof. See Appendix B.1. 5.2 GR OUP-CONDITIONAL CO VERA GE GU ARANTEES OF GC-FCP Based on properties of T -Digest presented in Lemma 5.1, we can no w prov e the group-conditional cov erage guarantees of GC-FCP . Theorem 5.1 (Group-conditional coverage guarantees for GC-FCP) . F or each gr oup G ∈ G , the pr ediction set C ( X n +1 | e D ) pr oduced by GC-FCP satisfies the inequality P ( Y n +1 ∈ C ( X n +1 | e D ) | X n +1 ∈ G ) ≥ 1 − α − π δ . (25) Pr oof: See Appendix B.2. While Theorem 5.1 assumes that problems (22) are solved exactly , the next result accounts for suboptimality induced by numerically solving problem (22). An upper bound of the group-conditional coverage of GC- FCP can be found in Appendix C. 6 EXPERIMENTS W e e valuate GC-FCP on ( i ) a synthetic regression bench- mark [Romano et al., 2019]; ( ii ) CIF AR-10 image classifi- cation [Krizhevsk y and Hinton, 2009]; and ( iii ) PathMNIST medical image classification [Y ang et al., 2023]. Across all experiments, we compare the proposed scheme, GC- FCP , to the following benchmarks: ( i ) vanilla centralized CP , which provides the marginal guarantee (3) ; ( ii ) FedCP [Lu et al., 2023], which also satisfies (3) ; ( iii ) centralized CondCP [Gibbs et al., 2025]; and ( iv ) centralized GC-FCP , which is described in Section 4.1. CondCP and centralized GC-FCP are only ev aluated on the small-scale synthetic dataset and CIF AR-10 due to their prohibitiv e computa- tional complexity (see T able 1). Further comparisons with FedCF [Sriniv asan et al., 2025] and personalized FCP [Min et al., 2025] can be found in Appendix E.2. For each group G ∈ G , we estimate group- conditional co verage on a test set T as d co v( G ) = 1/ |T G | P ( x,y ) ∈T G 1 { y ∈ C ( x | D ) } , where T G = { ( x, y ) ∈ T : x ∈ G } , and report the empirical cov erage d co v( G ) for all groups G ∈ G . For classifi- cation, we also report the average prediction set size (1 / |T | ) P ( x,y ) ∈T |C ( x | D ) | . Computational complexity is ev aluated by the average w all-clock time required for each method to construct a prediction set on the same platform. 6.1 SYNTHETIC REGRESSION For the synthetic re gression task, we consider K = 4 clients with heterogeneous covariate distributions P X,k giv en by truncated normal distributions on the interval [0 , 5] with mean µ k = 0 . 5 + 4( k − 1) K − 1 and variance σ k = 0 . 5 + 0 . 1( k − 1) . Follo wing [Romano et al., 2020], we generate responses as Y k ∼ P ois(sin 2 ( X ) + 0 . 1) + 0 . 03 X ϵ 1 + 25 1 { U < 0 . 01 } ϵ 2 + N (0 , 0 . 01 k 2 ) , (26) with independent variables ϵ 1 , ϵ 2 ∼ N (0 , 1) and U ∼ Unif ([0 , 1]) . W e train a centralized linear regression model f ( · ) on a separate training dataset generated in the same way , and use the score s ( x, y ) = | y − f ( x ) | . Groups are gi ven by ov erlapping intervals G = { [0 , 2] , [1 , 3] , [2 , 4] , [3 , 5] } . The miscov erage lev el α is set to α = 0 . 1 . Other parameters are summarized in T able 3 in Appendix E.1. Fig. 3 (a)-(b) visualizes representati ve prediction sets, while Fig. 3 reports the mis-coverage rate across the four ov er- lapping interval groups. Centralized CP and FedCP apply a single global threshold and therefore exhibit une ven group- wise miscoverage rates. In particular , some groups are under- cov ered (mis-coverage abov e α ), reflecting shifts in the conditional score distribution across cov ariate regions. In contrast, CondCP , centralized GC-FCP , and GC-FCP yield substantially more uniform group-wise mis-co verage near the target le vel α across all groups (Fig. 3(c)) by adapting the threshold ov er the cov ariate space (Fig. 3(b)). 6.2 CIF AR-10 EXPERIMENTS W e now adopt a pre-trained ResNet56 model f ( · ) for the CIF AR-10 image classification task with score function s ( x, y ) = 1 − [ f ( x )] y , where y denotes the y -th entry of the softmax result [Sadinle et al., 2019]. W e consider K = 5 clients with a non-i.i.d. label partition, so that each client holds 10 /K disjoint classes. W e set uniform mixture weights π k = 1 /K , and total calibration size n = P k n k = 5000 . Groups are defined by overlapping predicted label classes ˆ y ( x ) = arg max y [ f ( x )] y : G 1 = { x : ˆ y ( x ) ∈ { 0 , 1 , 2 , 3 }} , G 2 = { x : ˆ y ( x ) ∈ { 2 , 3 , 4 , 5 }} , G 3 = { x : ˆ y ( x ) ∈ { 4 , 5 , 6 , 7 }} , and G 4 = { x : ˆ y ( x ) ∈ { 6 , 7 , 8 , 9 }} . W e set the miscoverage le vel α = 0 . 1 and use a pre-trained ResNet56 to serve the model f ( · ) to construct the score function s ( x, y ) = 1 − [ f ( x )] y [Sadinle et al., 2019]. The report results represent the average after 50 Monte Carlo simulations, each with 5000 test points. T able 2 reports marginal coverage, group-conditional co ver - age (with a verage set size in brackets), and computational speedup (“Comp. speedup”), with the latter being normal- ized with respect to the complexity of centralized CondCP . Centralized CP and FedCP attain the same marginal cov- erage near 0 . 9 , but their group-conditional co verage v aries substantially across groups (e.g., below 0 . 9 for groups G 1 and G 2 ), indicating that marginal calibration does not con- trol errors uniformly across overlapping groups. Central- ized CondCP and centralized GC-FCP achiev e near-uniform group-conditional cov erage across all groups, matching the intended behavior of augmented quantile calibration under grouping conditions. GC-FCP closely tracks the centralized group-conditional performance while substantially impro ving computational ef ficiency . The computational gains are pronounced: depend- ing on δ , GC-FCP yields from 3 . 96 × to 34 . 36 × per-test- point speedup relativ e to centralized CondCP , illustrating the accuracy–ef ficiency trade-of f governed by the digest com- pression parameter . The value of the compression parameter affects co verage. For instance, with aggressi ve compression ( δ = 25 ), some groups are slightly under -covered (e.g., G 2 ), in a manner consistent with Theorem 5.1. 6.3 MEDICAL D A T ASET EXPERIMENTS Finally , we e valuate GC-FCP on P athMNIST from MedM- NIST (9 tissue classes) with images resized to 3 × 28 × 28 [Y ang et al., 2023]. W e consider K = 5 clients, each hold- ing samples from 2 disjoint classes, except the last client holds 1 class. W e train a centralized CNN f ( · ) on the train- ing split. W e randomly shuffle the mixture v alidation and test data, split it into calibration and conformal test datasets equally , and allocate calibration samples to clients as in the CIF AR-10 experiments. Groups are defined by predicted- label classes: G 1 = { x : ˆ y ( x ) ∈ { 0 , 1 , 2 }} , G 2 = { x : 1 2 3 4 1 2 3 4 (a ) (b) (c ) Figure 3: V isualization of prediction sets for the synthetic regression task for (a) centralized CP and FedCP [Lu et al., 2023], as well as for (b) centralized CondCP , centralized GC-FCP , and GC-FCP . (c) Per-group miscov erage rate. T able 2: Coverage, set size, and computational load comparisons on CIF AR-10 [Krizhevsk y and Hinton, 2009]. Methods Marginal coverage Coverage (set size) Comp. speedup G 1 G 2 G 3 G 4 Centralized CP 0.901 0.879 ↓ (0.91) 0.855 ↓ (0.90) 0.906 (0.93) 0.936 (0.95) N/A Centralized CondCP 0.903 0.901 (0.96) 0.901 (0.98) 0.902 (0.94) 0.901 (0.91) 1 × Centralized GC-FCP 0.906 0.903 (0.96) 0.903 (0.99) 0.905 (0.94) 0.905 (0.92) 1.01 × FedCP 0.902 0.880 ↓ (0.92) 0.856 ↓ (0.90) 0.906 (0.93) 0.936 (0.95) N/A GC-FCP ( δ = 25 ) 0.911 0.896 ↓ (0.95) 0.887 ↓ (0.96) 0.919 (0.95) 0.931 (0.95) 34.36 × GC-FCP ( δ = 250 ) 0.906 0.903 (0.96) 0.902 (0.98) 0.905 (0.94) 0.906 (0.92) 19.73 × GC-FCP ( δ = 2500 ) 0.906 0.903 (0.96) 0.903 (0.99) 0.905 (0.94) 0.905 (0.92) 3.96 × ˆ y ( x ) ∈ { 1 , 2 , 3 }} , G 3 = { x : ˆ y ( x ) ∈ { 2 , 3 , 4 }} , G 4 = { x : ˆ y ( x ) ∈ { 3 , 4 , 5 }} , G 5 = { x : ˆ y ( x ) ∈ { 4 , 5 , 6 , 7 , 8 }} . Other parameters remain the same as CIF AR-10 experiments. T able 4 in Appendix E.1 shows that Centralized CP and FedCP achiev e marginal co verage near 0 . 9 , but can de viate noticeably at the group le vel (e.g., lo wer cov erage on G 3 ). GC-FCP with moderate compression ( δ = 250 or δ = 2500 ) attains group-conditional coverage close to the target for all groups, while maintaining small average set sizes (near one label on average). In contrast, overly aggressiv e compres- sion ( δ = 25 ) degrades calibration. Overall, these results corroborate that GC-FCP achie ves group-conditional relia- bility in heterogeneous federated classification tasks, with accuracy controlled by the digest compression parameter δ . 7 CONCLUSION W e have introduced Gr oup-Conditional F ederated Confor - mal Pr ediction (GC-FCP) , a principled framework for con- structing prediction sets with group-conditional guarantees in heterogeneous federated settings. GC-FCP leverages T - Digest to compress stratified calibration scores into a small mergeable coreset. Under mild assumptions, we established group-conditional coverage guarantees for GC-FCP , and empirical results on synthetic regression and image clas- sification benchmarks corroborated these findings while demonstrating substantial computational speedups. Future work includes extending the framew ork to richer conditional structures beyond finite group f amilies, as well as in vestigating robustness to more complex settings such as decentralized calibration [W en et al., 2025], adversarial behavior [Kang et al., 2024], and online CP [Angelopoulos et al., 2024, Gasparin and Ramdas, 2024]. References Anastasios N Angelopoulos and Stephen Bates. A gen- tle introduction to conformal prediction and distribution- free uncertainty quantification. arXiv preprint arXiv:2107.07511 , 2021. Anastasios Nikolas Angelopoulos, Rina Barber, and Stephen Bates. Online conformal prediction with decaying step sizes. In Pr oceedings of the 41st International Confer ence on Machine Learning , v olume 235, pages 1616–1630, Jul. 2024. K onstantina Bairaktari, Jiayun W u, and Stev en W u. Kandin- sky conformal prediction: Beyond class- and covariate- conditional cov erage. In Pr oceedings of the 42nd Inter - national Confer ence on Machine Learning , volume 267 of Pr oceedings of Machine Learning Researc h , pages 2581–2602, 13–19 Jul 2025. Rina Foygel Barber , Emmanuel J. Candès, Aaditya Ram- das, and Ryan J. Tibshirani. Predictive inference with the jackknife+. The Annals of Statistics , 49(1):486–507, 2021. John Duchi. Sample-conditional coverage in split-conformal prediction. In The Thirty-ninth Annual Conference on Neural Information Pr ocessing Systems , 2025. T ed Dunning and Otmar Ertl. Computing extremely accurate quantiles using t-digests. arXiv pr eprint arXiv:1902.04023 , 2019. Matteo Gasparin and Aaditya Ramdas. Conformal online model aggregation. arXiv pr eprint arXiv:2403.15527 , 2024. Isaac Gibbs, John J Cherian, and Emmanuel J Candès. Con- formal prediction with conditional guarantees. Journal of the Royal Statistical Society Series B: Statistical Method- ology , page qkaf008, 2025. Leying Guan. Localized conformal prediction: A gen- eralized inference frame work for conformal prediction. Biometrika , 110(1):33–50, 2023. Pierre Humbert, Batiste Le Bars, Aurélien Bellet, and Syl- vain Arlot. One-shot federated conformal prediction. In Pr oceedings of the 40th International Confer ence on Ma- chine Learning , volume 202, pages 14153–14177, Jul. 2023. Pierre Humbert, Batiste Le Bars, Aurélien Bellet, and Syl- vain Arlot. Marginal and training-conditional guaran- tees in one-shot federated conformal prediction. arXiv pr eprint arXiv:2405.12567 , 2024. Olav Kallenberg. F oundations of Modern Pr obability . Springer , New Y ork, 2 edition, 2002. Mintong Kang, Zhen Lin, Jimeng Sun, Cao Xiao, and Bo Li. Certifiably Byzantine-robust federated conformal predic- tion. In Pr oceedings of the 41st International Conference on Machine Learning , v olume 235, pages 23022–23057, Jul. 2024. Alex Krizhevsky and Geoffre y Hinton. Learning mul- tiple layers of features from tiny images. T echni- cal report, University of T oronto, T oronto, Canada, 2009. URL https://www.cs.toronto.edu/ ~kriz/learning- features- 2009- TR.pdf . Guorui Li, Y anhui Zhang, Y ing W ang, and Cong W ang. Fcp- pro: Federated conformal prediction algorithm based on prototype similarity . P attern Recognition , page 112514, 2025. Charles Lu, Y aodong Y u, Sai Praneeth Karimireddy , Michael Jordan, and Ramesh Raskar . Federated confor- mal predictors for distributed uncertainty quantifica tion. In Pr oceedings of the 40th International Confer ence on Machine Learning , v olume 202, pages 22942–22964, Jul. 2023. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication- efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics , pages 1273– 1282. PMLR, 2017. Y injie Min, Chuchen Zhang, Liuhua Peng, and Changliang Zou. Personalized federated conformal prediction with lo- calization. In The Thirty-ninth Annual Confer ence on Neu- ral Information Pr ocessing Systems , 2025. URL https: //openreview.net/forum?id=QQUhGPST45 . Y urii Nesterov and Arkadii Nemirovskii. Interior -P oint P olynomial Algorithms in Conve x Pr ogramming . Society for Industrial and Applied Mathematics (SIAM), Philadel- phia, P A, 1994. doi: 10.1137/1.9781611970791. James Renegar . A polynomial-time algorithm, based on Newton’ s method, for linear programming. Mathemat- ical Pr ogr amming , 40(1):59–93, 1988. doi: 10.1007/ BF01580724. Y ani v Romano, Ev an Patterson, and Emmanuel Candès. Conformalized quantile regression. In Advances in Neu- ral Information Pr ocessing Systems , volume 32, 2019. Y aniv Romano, Matteo Sesia, and Emmanuel Candes. Clas- sification with valid and adapti ve cov erage. Advances in Neural Information Pr ocessing Systems , 33:3581–3591, 2020. Mauricio Sadinle, Jing Lei, and Larry W asserman. Least ambiguous set-v alued classifiers with bounded error lev- els. Journal of the American Statistical Association , 114 (525):223–234, 2019. Osvaldo Simeone and Y aniv Romano. Uncertainty-aware data-efficient ai: An information-theoretic perspectiv e. arXiv pr eprint arXiv:2512.05267 , 2025. Anutam Srini vasan, Aditya T V adlamani, Amin Meghrazi, and Srini vasan P arthasarathy . Fedcf: Fair federated con- formal prediction. arXiv preprint , 2025. Vladimir V ovk, Da vid Lindsay , Ilia Nouretdinov , and Alex Gammerman. Mondrian confidence machine. T echnical Report , 2003. Vladimir V ovk, Ale xander Gammerman, and Glenn Shafer . Algorithmic learning in a random world , volume 29. Springer , 2005. Haifeng W en, Hong Xing, and Osvaldo Simeone. Dis- tributed conformal prediction via message passing. In F orty-second International Confer ence on Machine Learning , 2025. URL https://openreview.net/ forum?id=R7sAZDq0M9 . Ran Xie, Rina Barber , and Emmanuel Candes. Boosted conformal prediction interv als. Advances in Neural Infor- mation Pr ocessing Systems , 37:71868–71899, 2024. Jiancheng Y ang, Rui Shi, Donglai W ei, Zequan Liu, Lin Zhao, Bilian K e, Hanspeter Pfister, and Bingbing Ni. Medmnist v2-a large-scale lightweight bench- mark for 2d and 3d biomedical image classifica- tion. Scientific Data , 10(1):41, 2023. doi: 10.1038/ s41597- 022- 01891- 7. URL https://doi.org/10. 1038/s41597- 022- 01891- 7 . Meiyi Zhu, Matteo Zecchin, Sangwoo Park, Caili Guo, Chunyan Feng, Petar Popovski, and Osvaldo Simeone. Conformal distributed remote inference in sensor net- works under reliability and communication constraints. IEEE T ransactions on Signal Pr ocessing , 73:1485–15 00, 2025. doi: 10.1109/TSP .2025.3549222. Efficient F ederated Conf ormal Pr ediction with Group-Conditional Guarantees (Supplementary Material) Haifeng W en 1 Osvaldo Simeone 2 Hong Xing 1,3 1 IoT Thrust, The Hong K ong Univ ersity of Science and T echnology (Guangzhou), Guangzhou, China 2 Institute for Intelligent Networked Systems (INSI), Northeastern Uni versity London, London, UK 3 Department of ECE, The Hong K ong Univ ersity of Science and T echnology , HK SAR A PR OOF OF SECTION 4 A.1 PR OOF OF THEOREM 4.1 Pr oof. First assume there are no ties, i.e., S i,k = ˆ g S n +1 ( X i,k ) for all i ∈ [ n k ] , k ∈ [ K ] , and S n +1 = ˆ g S n +1 ( X n +1 ) . The tie case is handled at the end of the proof. Recall that g ( x ) = β ⊤ Φ( x ) with β ∈ R |G | and Φ( · ) defined in (6) , then the optimal function ˆ g S n +1 ( · ) solved by (10) reduces to a real-v alue vector gi ven by β ∗ = argmin β ∈ R |G | K X k =1 π k n k + 1 n k +1 X i =1 ℓ α X G ∈G β G 1 { X i,k ∈ G } , S i,k , (27) where we denote S n k +1 ,k = S n +1 for simplicity . Under the no-ties assumption, the first-order optimality condition implies that for ev ery group G ∈ G , K X k =1 π k n k + 1 n k +1 X i =1 1 { X i,k ∈ G } 1 { S i,k < θ ∗ i,k } − (1 − α ) = 0 , ∀ G ∈ G (28) where θ ∗ i,k = P G ∈G β ∗ G 1 { X i,k ∈ G } . Let E k be the ev ent that ( X n +1 , Y n +1 ) is drawn from P k . Conditioned on E k , the ( n k + 1) scores { S i,k } n k +1 i =1 are exchangeable. Let E be the ev ent that, for ev ery k ∈ [ K ] , there exists a permutation σ k such that S σ k (1) ,k , . . . , S σ k ( n k +1) ,k = s 1 ,k , . . . , s n k +1 ,k , (40) where ( s 1 ,k , . . . , s n k +1 ,k ) denotes the realized values of ( S 1 ,k , . . . , S n k +1 ,k ) . Then, we hav e, for all G ∈ G , P ( Y n +1 ∈ C ( X n +1 | D ) | X n +1 ∈ G, E ) = P ( S n +1 ≤ θ ∗ n +1 , X n +1 ∈ G | E ) P ( X n +1 ∈ G | E ) = P K k =1 π k P ( S n +1 ≤ θ ∗ n +1 , X n +1 ∈ G | E , E k ) P K k =1 π k P ( X n +1 ∈ G | E , E k ) ( a ) = P K k =1 π k n k +1 P n k +1 i =1 1 { S i,k ≤ θ ∗ i,k } 1 { X i,k ∈ G } P K k =1 π k n k +1 P n k +1 i =1 1 { X i,k ∈ G } ( b ) = (1 − α ) P K k =1 π k n k +1 P n k +1 i =1 1 { X i,k ∈ G } P K k =1 π k n k +1 P n k +1 i =1 1 { X i,k ∈ G } = 1 − α, (29) where ( a ) follows e xchangeability on client k under the ev ent E k and ( b ) follows the first-order condition. This result implies marginal co verage under G = X . If the assumption S i = ˆ g S ( X i ) does not hold, we hav e P ( Y n +1 ∈ C ( X n +1 | D ) | X n +1 ∈ G, E ) ≥ 1 − α. The proof technique is similar to [Gibbs et al., 2025] and Appendix B.2 and is omitted here. By the to wer rule, we obtain the desired result. B PR OOFS FOR SECTION 5 B.1 RESUL TS ON T -DIGEST This section provides additional results on T -Digest and proves Lemma 5.1. T o begin, we state the following f act that holds in our digest construction described in Section 4.2. B.1.1 Important Lemmas Lemma B.1 (CDF error controlled by maximal cluster mass) . Let { ( R i , w i ) } ℓ i =1 be weighted samples with total weight W and empirical CDF F . Let TD = { ( ¯ R c , W c ) } m c =1 be a digest with induced CDF b F ( t ) = 1 W P m c =1 W c 1 { ¯ R c ≤ t } . Define the maximal normalized cluster mass ρ max = max 1 ≤ c ≤ m W c W . (30) Then, sup t ∈ R F ( t ) − b F ( t ) ≤ ρ max . (31) Pr oof. Let {R c } m c =1 be the partition for the digest defined in Section 4.2, and define L c = min i ∈R c R i and U c = max i ∈R c R i . Fix t ∈ R and consider any cluster c . If t < L c , then cluster c contributes zero to both F ( t ) and b F ( t ) . If t ≥ U c , cluster c contributes W c /W to both F ( t ) and b F ( t ) . If t ∈ [ L c , U c ) , discrepancy arises from the cluster c only because max i ∈R c R i ≤ min i ∈R c ′ R i for any c ′ > c , which yields F ( t ) − b F ( t ) ≤ W c W . (32) Therefore, the abov e sum is bounded by ρ max . T aking the supremum over t completes the proof. Lemma B.2 (Arcsine scale implies ρ max ≤ sin( π/δ ) ) . Suppose the digest is constructed with the scale r ( q ) = δ 2 π arcsin(2 q − 1) under the condition of (13) . Then ρ max = max 1 ≤ c ≤ m W c W ≤ sin π δ ≤ π δ . (33) Pr oof. For each cluster c , let its empirical left/right quantile boundaries be q L c = V c − 1 /W and q R c = V c /W , where V c = P c i =1 W i (with V 0 = 0 ). Then q R c − q L c = W c /W . The well-formedness constraint giv es r ( q R c ) − r ( q L c ) ≤ 1 ⇐ ⇒ arcsin(2 q R c − 1) − arcsin(2 q L c − 1) ≤ 2 π δ . (34) Let u L = 2 q L c − 1 and u R = 2 q R c − 1 , so that u L , u R ∈ [ − 1 , 1] and q R c − q L c = ( u R − u L ) / 2 . Under the constraint arcsin( u R ) − arcsin( u L ) ≤ 2 π /δ , the difference u R − u L is maximized by taking symmetry around zero: arcsin( u R ) = π /δ and arcsin( u L ) = − π /δ , hence u R = sin( π /δ ) and u L = − sin( π /δ ) . Therefore u R − u L ≤ 2 sin π δ = ⇒ q R c − q L c = u R − u L 2 ≤ sin π δ , (35) which is exactly W c /W ≤ sin( π /δ ) . T aking the maximum over c yields the claim. Lemma B.3 (From ∥ F − b F ∥ ∞ to rank-accurate quantiles) . Let F , b F be CDFs on R and define the gener alized quantile function b Q ( u ) = inf { t : b F ( t ) ≥ u } . If sup t ∈ R | F ( t ) − b F ( t ) | ≤ ϵ , then for all u ∈ [0 , 1] , F ( b Q ( u )) ∈ [ u − ϵ, u + ϵ ] . (36) In particular , when F is an empirical CDF with total weight W , b Q ( u ) has empirical rank within ( u ± ϵ ) W . Pr oof. Fix u ∈ [0 , 1] and let t ⋆ = b Q ( u ) . By definition, b F ( t ⋆ ) ≥ u and for any t < t ⋆ , b F ( t ) < u . Using sup t | F ( t ) − b F ( t ) | ≤ ϵ giv es F ( t ⋆ ) ≥ b F ( t ⋆ ) − ϵ ≥ u − ϵ . For the upper bound, for any η > 0 we have b F ( t ⋆ − η ) < u , hence F ( t ⋆ − η ) ≤ b F ( t ⋆ − η ) + ϵ < u + ϵ . Letting η → 0 and using right-continuity of F yields F ( t ⋆ ) ≤ u + ϵ . B.1.2 Pr oof of Lemma 5.1 Pr oof. By Lemma B.1, sup t | F ( t ) − b F ( t ) | ≤ ρ max . (37) By Lemma B.2, ρ max ≤ sin( π /δ ) , hence sup t | F ( t ) − b F ( t ) | ≤ sin( π /δ ) =: ϵ . The bound sin( π /δ ) ≤ π /δ yields the second inequality . Finally , Lemma B.3 implies that b Q is ϵ -accurate in the quantile/rank sense. B.2 PR OOF OF THEOREM 5.1 W e begin with the following corollary that controls the error of T -Digest for each atom. Corollary B.1 (Atom-wise sketch accurac y) . Let p A be its weighted empirical CDF and let b p A be the step-CDF induced by the mer ged digest TD A . Then, under the ar csine scale (14) , sup t ∈ R p A ( t ) − b p A ( t ) ≤ ϵ = π δ . (38) Equivalently , the quantile query induced by TD A is ϵ -accurate in the sense of Section 4.3. Pr oof. This is a direct application of Lemma 5.1 to the weighted sample set D A . Step 1: First-order condition. The subgradient of (22) on ˆ β with respect to β is giv en by ( X A ∈A m A X c =1 W A,c v A,c Φ A + w test v test Φ( X n +1 ) v A,c = α if ¯ S A,c < ˆ β T Φ A , − (1 − α ) if ¯ S A,c > ˆ β T Φ A , t A,c if ¯ S A,c = ˆ β T Φ A , v test = α if S < ˆ β T Φ( X n +1 ) , − (1 − α ) if S > ˆ β T Φ( X n +1 ) , t test if S = ˆ β T Φ( X n +1 ) , (39) where w test = P K k =1 λ k with λ k = π k / ( n k + 1) and t A,c , t test ∈ [ α − 1 , α ] . The first-order condition for optimality implies that for each group G ∈ G , there exist t A,c ∈ [ α − 1 , α ] (for clusters with ties) and t test ∈ [ α − 1 , α ] (if the test point has a tie) such that X A : A ⊆ G m A X c =1 W A,c v A,c + w test v test 1 { X n +1 ∈ G } = 0 , where the v A,c and v test are as defined abov e. Step 2: Empirical CDF and T -Digest approximate. The atoms { A } partition X disjointly , with membership vectors Φ A . The true empirical CDF per atom is p A ( t ) = W − 1 A X i : X i ∈ A λ k ( i ) 1 { S i ≤ t } , where W A = P i : X i ∈ A λ k ( i ) , λ k ( i ) = π k ( i ) / ( n k ( i ) + 1) , and k ( i ) is the index of the client that the sample X i belongs to, for i ∈ [ n ] . The coreset per atom yields ˆ p A ( t ) = W − 1 A m A X c =1 W A,c 1 { ¯ S A,c ≤ t } , with sup t | p A ( t ) − ˆ p A ( t ) | ≤ ϵ by Corollary B.1. Step 3: Coverage. W ith ( X n +1 , Y n +1 ) ∼ P K k =1 π k P k , as in the proof of FCP [Lu et al., 2023], let E k be the e vent that ( X n +1 , Y n +1 ) is drawn from P k . For each k ∈ [ K ] , let Π n k +1 denote the set of all permutations of { 1 , . . . , n k + 1 } , and define the ev ent E = ∀ k ∈ [ K ] , ∃ σ k ∈ Π n k +1 s.t. S σ k (1) ,k , . . . , S σ k ( n k +1) ,k = s 1 ,k , . . . , s n k +1 ,k , (40) where ( s 1 ,k , . . . , s n k +1 ,k ) denotes the realized values of ( S 1 ,k , . . . , S n k +1 ,k ) . Then, we hav e, for all G ∈ G , P ( Y n +1 ∈ C ( X n +1 | e D ) | X n +1 ∈ G, E ) = E E k h P ( S n +1 ≤ ˆ β T S n +1 Φ( X n +1 ) | X n +1 ∈ G, E , E k ) i = N D , where N = X A : A ⊆ G W A p A ( ˆ θ A ) + w test 1 { S n +1 ≤ ˆ θ n +1 } 1 { X n +1 ∈ G } , D = X A : A ⊆ G W A + w test 1 { X n +1 ∈ G } with ˆ θ A = ˆ β T S n +1 Φ A and ˆ θ n +1 = ˆ β T S n +1 Φ( X n +1 ) Analogously , define the GC-FCP approximate numerator and denominator as ˆ N = X A : A ⊆ G W A ˆ p A ( ˆ θ A ) + w test 1 { S n +1 ≤ ˆ θ n +1 } 1 { X n +1 ∈ G } , ˆ D = D . By Corollary B.1, we hav e N ≥ X A : A ⊆ G W A ( ˆ p A ( ˆ θ A ) − ϵ ) + w test 1 { S n +1 ≤ ˆ θ n +1 } 1 { X n +1 ∈ G } = ˆ N − ϵ X A : A ⊆ G W A . By the first-order condition, for the component corresponding to G , there exist t A,c , t test ∈ [ α − 1 , α ] such that α X A : A ⊆ G X c : ¯ S A,c < ˆ θ A W A,c − (1 − α ) X A : A ⊆ G X c : ¯ S A,c > ˆ θ A W A,c + X A : A ⊆ G X c : ¯ S A,c = ˆ θ A W A,c t A,c + w test v test 1 { X n +1 ∈ G } = 0 = ⇒ X A : A ⊆ G m A X c =1 W A,c 1 n ¯ S A,c < ˆ θ A o + w test 1 n S n +1 < ˆ θ n +1 o 1 { X n +1 ∈ G } + (1 − α ) T 0 = (1 − α ) D − T , where T 0 = X A : A ⊆ G m A X c =1 W A,c 1 n ¯ S A,c = ˆ θ A o + w test 1 n S n +1 = ˆ θ n +1 o 1 { X n +1 ∈ G } T = X A : A ⊆ G m A X c =1 W A,c t A,c 1 n ¯ S A,c = ˆ θ A o + w test t test 1 { S n +1 = ˆ θ n +1 } 1 { X n +1 ∈ G } . By the definition of ˆ p A ( t ) and ˆ N , we hav e ˆ N − α T 0 = (1 − α ) D − T Because t A,c , t test ∈ [ α − 1 , α ] , α T 0 − T ≥ 0 , yielding ˆ N ≥ (1 − α ) D . This yields P( Y n +1 ∈ C ( X n +1 | e D ) | X n +1 ∈ G, E ) = N D ≥ ˆ N − ϵ P A : A ⊆ G W A D ≥ (1 − α ) D − ϵ P A : A ⊆ G W A D ≥ 1 − α − ϵ, where the last inequality is due to P A : A ⊆ G W A < D . T aking expectation on both sides w .r .t. E yields the desired result. C GR OUP-CONDITIONAL CO VERA GE UPPER BOUND OF GC-FCP Theorem C.1 (Upper bound coverage in the case of perfect quantile regression) . Assume that the conditional scor e distribution S | X is continuous and fix any confidence level η ∈ (0 , 1) . Then, with pr obability at least 1 − η / 2 over the calibration data, for e very gr oup G ∈ G , GC-FCP satisfies P ( Y n +1 ∈ C ( X n +1 | e D ) | X n +1 ∈ G ) ≤ 1 − α + π δ + ∆ G , (41) wher e the additive term ∆ G = |G | max n π δ , P K k =1 π k n k +1 o P k π k n k n k +1 p k,G − q log(2 K/η ) 2 n k , (42) with p k,G = P X,k ( X ∈ G ) being the pr obability that a covariate X drawn fr om client k belongs to gr oup G . Pr oof: See Appendix C.1. Theorem C.1 shows that GC-FCP cannot be arbitrarily conserv ativ e. The group-wise cov erage lies in a narrow band around 1 − α , with band width controlled explicitly by the additiv e term ∆ G , which consists of the mis-coverage gap ϵ , calibration sizes n k , and the mixture-weighted group mass p k,G . For instance, when the mixture-weighted group mass P k π k p k,G is small, the denominator shrinks, and ∆ G grows, which suggests that an efficient prediction set for low-support groups requires more calibration samples. C.1 PR OOF OF THEOREM C.1 For an y G ∈ G , where |G | = d , we begin with P( Y n +1 ∈ C ( X n +1 | e D ) | X n +1 ∈ G, E ) = N D ≤ ˆ N + ϵ P A : A ⊆ G W A D ≤ ˆ N D + ϵ Record that t A,c , t test ∈ [ α − 1 , α ] , which yields T ≥ ( α − 1) T 0 , ˆ N = (1 − α ) D − T + α T 0 = ⇒ ˆ N ≤ (1 − α ) D + T 0 Hence, P( Y n +1 ∈ C ( X n +1 | e D ) | X n +1 ∈ G, E ) ≤ 1 − α + ϵ + T 0 D Now our tar get is to upper bound T 0 = X A : A ⊆ G m A X c =1 W A,c 1 n ¯ S A,c = ˆ θ A o + w test 1 n S n +1 = ˆ θ n +1 o 1 { X n +1 ∈ G } under the assumption that the distribution of S | X is continuous. T o bound this term, we first simplify the notation by relabeling the pseudo-points with the test point with i = 1 , . . . , m, m + 1 , where m = P A ∈A m A = O ( δ |A| ) is the total number of clusters and ¯ S m +1 = S n +1 . Claim 1. Under the conditions of Theorem C.1, with probability 1, we hav e X A : A ⊆ G m A X c =1 1 n ¯ S A,c = ˆ θ A o + 1 n S n +1 = ˆ θ n +1 o ≤ d. Pr oof. See Appendix C.2 By Claim 1, with probability 1, we hav e T 0 D ≤ d · max max A,c : A ⊆ G,c ∈ [ m A ] W A,c , w test 1 { X n +1 ∈ G } P A : A ⊆ G W A + w test 1 { X n +1 ∈ G } Next, we bound RHS using the properties of T -Digest. Record that w test = P K k =1 λ k = P K k =1 π k n k +1 . Claim 2. Assume that GC-FCP uses the scale function r ( q ) = δ 2 π arcsin(2 q − 1) for q ∈ [0 , 1] , where q is the normalized cumulativ e weight, i.e., quantile. Then, we have max A,c W A,c ≤ W A sin π δ ≤ sin π δ ≤ π δ . Pr oof. This is a direct result of Lemma B.2 and W A ≤ 1 . Claim 3. Assume that the mixture weights π k > 0 , with p k,G = P X,k ( X ∈ G ) > 0 , for any η > 0 , with probability larger than 1 − η / 2 , we have X A : A ⊆ G W A ≥ X k π k n k n k + 1 p k,G − s log(2 K /η ) 2 n k . (43) Pr oof. See Appendix C.3. Combining Claims 1, 2, and 3, we hav e T 0 D ≤ d max n π δ , P K k =1 π k n k +1 o P k π k n k n k +1 p k,G − q log(2 K/η ) 2 n k Record that P( Y n +1 ∈ C ( X n +1 | e D ) | X n +1 ∈ G, E ) ≤ 1 − α + ϵ + T 0 D , combing the bound of T 0 /D and taking expectation o ver E yield the desired result. C.2 PR OOF OF CLAIM 1 Pr oof. Let L denote the set of all pseudo-points, consisting of the clusters across all atoms and the test point. Specifically , L = { ( A, c ) : A ∈ A , c ∈ [ m A ] } ∪ { test } , with |L| = m + 1 , where m = P A ∈A m A = O ( δ |A| ) is the total number of clusters at merged T -Digests. For each l ∈ L , define the feature Ψ l = Φ A if l = ( A, c ) is a cluster in atom A , or Ψ l = Φ( X n +1 ) if l = test, and the score T l = ¯ S A,c if l = ( A, c ) , or T l = S n +1 if l = test. The optimizer ˆ β S n +1 is the solution to the weighted quantile regression problem (22) with S = S n +1 . A tie at pseudo-point l occurs if T l = ˆ β T S n +1 Ψ l . Let D aug = { X i,k } i ∈ [ n k ] ,k ∈ [ K ] ∪ { X n +1 } . As in [Gibbs et al., 2025], we calculate the probability P X l ∈L 1 n T l = ˆ β T S Ψ l o > d | D aug ! The e vent n P l ∈L 1 n T l = ˆ β T S Ψ l o > d o implies that there exists a subset I ⊆ L with |I | = d + 1 such that T l = ˆ β T S Ψ l for all l ∈ I . Therefore, P X l ∈L 1 n T l = ˆ β T S Ψ l o > d | D aug ! ≤ X I ⊆L , |I | = d +1 P ∃ β ∈ R d s.t. T l = β T Ψ l ∀ l ∈ I D aug For a fixed I , the event is that the vector ( T l ) l ∈I ∈ span { (Ψ T l ) l ∈I } , where span { (Ψ T l ) l ∈I } is the image of the map β 7→ (Ψ T l β ) l ∈I , which is a linear subspace of R d +1 with dimension at most d . Under the continuity assumption, the conditional distribution of ( S i,k ) i,k ∪ { S n +1 } giv en the X ’ s is absolutely continuous with respect to Lebesgue measure on R n +1 . The mapping from the original scores S i,k (and S n +1 ) to the coreset scores { T l } l ∈L is piecewise affine. For each atom A , the score space R n A is partitioned into finitely many open cones R π index ed by permutations π ∈ S n A , where R π = { s ∈ R n A : s π (1) < · · · < s π ( n A ) } , where boundaries hav e measure zero. W ithin each R π , the sorted scores s ( π ) determine fixed quantile positions q l based on permuted weights, leading to fixed cluster assignments via the deterministic T -Digest merge rules. Thus, each ¯ S A,c is an af fine function of s ( π ) (weighted av erage ov er fixed indices), and hence af fine in s . The full map to ( T l ) l ∈I is therefore piecewise af fine across atoms and the test score, preserving measure-zero sets under the continuous distribution of S | X . Since the subspace has Lebesgue measure zero in R d +1 , its pre-image under the af fine map also has measure zero. For a fixed I , we hav e P ∃ β ∈ R d s.t. T l = β T Ψ l ∀ l ∈ I D aug = 0 . Since there are at most m +1 d +1 many such I , the union bound yields P X l ∈L 1 n T l = ˆ β T S Ψ l o > d | D aug ! = 0 Because X A : A ⊆ G m A X c =1 1 n ¯ S A,c = ˆ θ A o + 1 n S n +1 = ˆ θ n +1 o > d ⊆ ( X l ∈L 1 n T l = ˆ β T S Ψ l o > d ) , we hav e P X A : A ⊆ G m A X c =1 1 n ¯ S A,c = ˆ θ A o + 1 n S n +1 = ˆ θ n +1 o > d | D aug ≤ P X l ∈L 1 n T l = ˆ β T S Ψ l o > d | D aug ! = 0 . Marginalizing D aug yields the desired result. C.3 PR OOF OF CLAIM 3 Pr oof. The calibration weight in G is P A : A ⊆ G W A = P k λ k · # { i : X i,k ∈ G } , where λ k = π k / ( n k + 1) . Let Z k = # { i : X i,k ∈ G } , then P A : A ⊆ G W A = P k λ k Z k , and Z k ∼ Bin( n k , p k,G ) , with p k,G = P X,k ( X ∈ G ) and the expected weight is E X A : A ⊆ G W A = X k λ k n k p k,G = X k π k n k n k + 1 p k,G . By Hoeffding’ s inequality , for each k , P ( Z k ≤ n k p k,G − t k ) ≤ exp − 2 t 2 k n k , for t k > 0 . Set t k = p ( n k / 2) log(2 K /η ) with an y η > 0 , we hav e P( Z k ≤ n k p k,G − t k ) ≤ η 2 K . By union bound ov er k , with probability larger than 1 − η / 2 , X k λ k Z k ≥ X k λ k ( n k p k,G − t k ) = X k π k n k n k + 1 p k,G − s log(2 K /η ) 2 n k . W e have, with probability lar ger than 1 − η / 2 , X A : A ⊆ G W A = X k λ k Z k ≥ X k π k n k n k + 1 p k,G − s log(2 K /η ) 2 n k . D DU AL CONSTRUCTION FOR (9) UNDER THE OBJECTIVE (10) Reformulate the primal: Let λ k = π k / ( n k + 1) . The primal objectiv e of (10) is rewritten as: K X k =1 λ k n k X i =1 ℓ α ( g ( X i,k ) , S i,k ) + K X k =1 λ k ! ℓ α ( g ( X n +1 ) , S ) . The pinball loss is gi ven by ℓ α ( u, s ) = (1 − α )( s − u ) + + α ( u − s ) + , where ( a ) + = max { a, 0 } . T o reformulate the primal problem (10), we first introduce the following claim to re write the pinball loss as an optimization problem. Claim 4 (Pinball Loss Reformulation) . Fix any scalar residual r = s − u . Consider the following problem min p,q ≥ 0 (1 − α ) p + α q s.t. r = p − q . (44) Then, the optimal value of (44) equals ℓ α ( u, s ) . Pr oof. Since r = p − q , we ha ve p = r + q . T ogether with p ≥ 0 and q ≥ 0 , feasible pairs satisfy q ≥ max {− r , 0 } = ( − r ) + and then p = r + q ≥ 0 . Substitute p = r + q into the objective: (1 − α ) p + α q = (1 − α )( r + q ) + αq = (1 − α ) r + q . Thus, minimizing ov er feasible q is equiv alent to min q ≥ ( − r ) + (1 − α ) r + q , whose minimum is attained at q ∗ = ( − r ) + , giving v alue (1 − α ) r + ( − r ) + . If r ≥ 0 , then ( − r ) + = 0 , so the value is (1 − α ) r = (1 − α )( s − u ) . If r < 0 , then ( − r ) + = − r , so the value is (1 − α ) r − r = − α r = α ( u − s ) . Therefore, the optimal value is e xactly (1 − α )( s − u ) + + α ( u − s ) + = ℓ α ( u, s ) . By Claim 4, we introduce auxiliary p i,k , q i,k ≥ 0 for each calibration point ( i, k ) and p test k , q test k ≥ 0 for each virtual test copy per client k and re write the problem (10) as (P0) : min g ∈F G ,p,q K X k =1 n k X i =1 λ k ((1 − α ) p i,k + αq i,k ) + K X k =1 λ k (1 − α ) p test k + αq test k , s.t. S i,k − g ( X i,k ) = p i,k − q i,k , S − g ( X n +1 ) = p test k − q test k , ∀ i ∈ [ n k ] , ∀ k ∈ [ K ] p i,k , q i,k , p test k , q test k ≥ 0 , ∀ i ∈ [ n k ] , ∀ k ∈ [ K ] (45) Dual problem: Introduce dual variables η i,k for calibration constraints and η test k for each test copy . Using standard calculations, the dual problem is giv en by the following linear programming (LP) problem: (P1) : max { η i,k } , { η test k } K X k =1 n k X i =1 η i,k S i,k + S K X k =1 η test k (46) s.t. − λ k α ≤ η i,k ≤ λ k (1 − α ) , ∀ i ∈ [ n k ] , ∀ k ∈ [ K ] , (47) − λ k α ≤ η test k ≤ λ k (1 − α ) , ∀ k ∈ [ K ] , (48) K X k =1 n k X i =1 η i,k Φ( X i,k ) + K X k =1 η test k Φ( X n +1 ) = 0 . (49) where Φ( x ) = 1 { x ∈ G } G ∈G ∈ { 0 , 1 } |G | . The last constraint is to enforce the linearity of g ( x ) = β T Φ( x ) , which arises mathematically from the stationary condition with respect to the primal weights β . Set construction via KKT conditions: In [Gibbs et al., 2025, Section 4], the conformal prediction set is constructed using the dual solution η S (for input score S ) and KKT conditions. The optimal ˆ g S ( X n +1 ) satisfies: η n +1 S = 1 − α if S > ˆ g S ( X n +1 ) , η n +1 S = − α if S < ˆ g S ( X n +1 ) , and η n +1 S ∈ [ − α, 1 − α ] if S = ˆ g S ( X n +1 ) . Similarly , let η test S = P K k =1 η test k,S be the sum of dual variables o ver test copies (since the test is duplicated). The set is: ˆ C dual ( X n +1 ) = ( y : η test s ( X n +1 ,y ) ≤ K X k =1 λ k ! (1 − α ) ) , using the weighted upper bound. Binary search: W e compute ˆ C dual ( X n +1 ) using the following two-step procedure. First, using Algorithm 1 of [Gibbs et al., 2025], we binary search for the largest value of S ∗ such that η n +1 S ∗ < 1 − α . Second, we output all y such that s ( X n +1 , y ) ≤ S ∗ [Gibbs et al., 2025, Theorem 4]. T able 3: Experimental setup for synthetic regression. Parameter V alue T -Digest parameter δ δ = 250 Local calibration sizes n k n 1 = 1000 , n k = 333 for k > 1 Mixture weights π k π k = 1 /K for all k Miscov erage lev el α α = 0 . 1 Model f ( · ) linear regression Score s ( x, y ) | y − f ( x ) | T est points n test 200 Monte Carlo runs 100 T able 4: Coverage and set size comparisons on P athMNIST [Y ang et al., 2023]. Methods Marginal coverage Coverage (set size) G 1 G 2 G 3 G 4 G 5 Centralized CP 0.901 0.888 ↓ (1.00) 0.885 ↓ (1.00) 0.879 ↓ (1.00) 0.935 (1.00) 0.895 ↓ (1.00) FedCP 0.905 0.892 ↓ (1.01) 0.889 ↓ (1.01) 0.883 ↓ (1.02) 0.937 (1.01) 0.900 (1.02) GC-FCP ( δ = 25 ) 0.876 ↓ 0.891 ↓ (1.12) 0.890 ↓ (1.14) 0.880 ↓ (1.15) 0.895 ↓ (1.07) 0.853 ↓ (1.01) GC-FCP ( δ = 250 ) 0.908 0.913 (1.07) 0.910 (1.08) 0.911 (1.11) 0.911 (0.98) 0.898 ↓ (1.03) GC-FCP ( δ = 2500 ) 0.909 0.913 (1.07) 0.910 (1.08) 0.910 (1.11) 0.912 (0.98) 0.900 (1.03) E ADDITIONAL EXPERIMENT AL RESUL TS E.1 EXPERIMENT AL SETTINGS AND RESUL TS OF SECTION 6 Other parameters for the synthetic regression can be found in T able 3. The experimental results of P athMNIST are summarized in T able 4. Figure 4 reports the empirical group-wise cov erage and the av erage set size over confidence le vel α on CIF AR-10. V anilla CP achie ves competiti ve mar ginal coverage but e xhibits group-wise miscalibration under non-i.i.d. client partitions. GC-FCP reduces these discrepancies, pushing group-wise co verage closer to the target across G ∈ G . This impro vement comes with a moderate increase in set size, reflecting the standard trade-off when enforcing conditional v alidity over ov erlapping groups. Figure 5 reports the empirical group-wise cov erage and the av erage set size ov er confidence le vel α on PathMNIST . As expected, v anilla CP exhibits nonuniform conditional cov erage across groups and different v alues of α . GC-FCP improv es stability across groups while keeping prediction sets competitiv e, highlighting its practical value in pri vac y-constrained settings. E.2 COMP ARISON WITH PERSONALIZED FCP AND FEDCF In this section, we compare the proposed GC-FCP with personalized FCP [Min et al., 2025] and FedCF [Srini vasan et al., 2025] on CIF AR-10 [Krizhe vsky and Hinton, 2009] using a fixed pretrained ResNet-56 classifier p θ ( · | x ) and the standard classification nonconformity score S ( x, y ) = 1 − p θ ( y | x ) . W e split the CIF AR-10 test set uniformly at random into a calibration pool and an e valuation pool independently in each Monte Carlo repetition. The calibration pool is partitioned into K = 5 source clients by a disjoint partition of the true labels: each sample ( x, y ) is assigned to client k if y belongs to the corresponding label subset as in Sec. 6.2, yielding client-specific calibration sets {D k } K k =1 . In addition, we construct a synthetic ( K + 1) -th tar get client by sampling 2000 samples with replacement from the same calibration pool. All test points are drawn from the synthetic target client in the same way . FedCF [Srinivasan et al., 2025] and GC-FCP calibrate using the calibration data from the K source clients together with the synthetic target calibration client, whereas personalized FCP [Min et al., 2025] lev erages the source-client data to train additional distribution-estimation models and calibrates for the target client accordingly . For grouping, we consider the model confidence X ( x ) = max c ∈{ 0 ,..., 9 } p θ ( c | x ) and define an overlapping family of confidence-based groups G = { G 1 , . . . , G 4 } on the restricted confidence range [0 . 5 , 1] . Let 0 . 5 = a 0 < a 1 < a 2 < a 3 < (a) A verage co verage ov er different groups. (b) A verage set size o ver dif ferent groups. Figure 4: A verage coverage and set size versus coverage level 1 − α with vanilla CP and the proposed GC-FCP on CIF AR-10. a 4 = 1 be equally spaced breakpoints and define G 1 = { x : X ( x ) ∈ [ a 0 , a 2 ) } , G 2 = { x : X ( x ) ∈ [ a 1 , a 3 ) } , G 3 = { x : X ( x ) ∈ [ a 2 , a 4 ) } , G 4 = { x : X ( x ) ∈ [ a 3 , a 4 ] } , so that a point may belong to multiple groups when its confidence lies in an overlap interval. Finally , since FedCF [Srini vasan et al., 2025] and personalized FCP [Min et al., 2025] are not designed to enforce simultaneous v alidity over o verlapping G , we enforce a single set-v alued predictor by resolving o verlaps with a fix ed random tie-breaking rule: when a test point lies in multiple groups, we randomly select one eligible group and construct the prediction set using the corresponding group-specific calibration. The report results represent the av erage after 100 Monte Carlo simulations, each with 2000 test points drawn from the tar get client. T able 5 shows that GC-FCP achiev es coverage across all overlapping groups. In contrast, personalized FCP and FedCF exhibit under-cov erage for some groups despite providing marginal coverage, because both methods are group-wise procedures that treat each group independently and thus only admit guarantees when groups form a disjoint partition, which breaks under overlap. Consequently , the inability of these baselines to coordinate calibration across ov erlapping groups results in systematic group-conditional violations, whereas GC-FCP’ s joint optimization ov er the overlapping family preserves group-conditional v alidity . T able 5: Coverage comparisons on CIF AR-10 [Krizhevsk y and Hinton, 2009]. Methods Marginal cov erage Coverage G 1 G 2 G 3 G 4 Personalized FCP 0.898 0.893 ↓ 0.890 ↓ 0.626 ↓ 0.913 FedCF 0.898 0.801 ↓ 0.824 ↓ 0.792 ↓ 0.905 GC-FCP ( δ = 250 ) 0.899 0.922 0.930 0.925 0.901 (a) A verage co verage ov er different groups. (b) A verage set size o ver dif ferent groups. Figure 5: A verage coverage and set size versus coverage level 1 − α with vanilla CP and the proposed GC-FCP on PathMNIST .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment