그룹 조건 연합 학습을 위한 효율적 연합 컨포멀 예측
본 논문은 연합 학습 환경에서 데이터가 클라이언트별로 분산되고, 동시에 겹칠 수 있는 여러 그룹으로 구분될 때, 각 그룹에 대해 사전 정의된 오류 허용 수준을 만족하는 예측 집합을 제공하는 새로운 프로토콜 GC‑FCP를 제안한다. 로컬 캘리브레이션 점수를 그룹별로 계층화한 T‑Digest 코어셋으로 압축해 서버에 전송함으로써 통신량과 연산 복잡도를 크게 줄이며, 압축 정도가 커버리지에 미치는 영향을 이론적으로 분석한다. 실험 결과는 중앙집중식 …
저자: Haifeng Wen, Osvaldo Simeone, Hong Xing
본 논문은 “Efficient Federated Conformal Prediction with Group‑Conditional Guarantees”라는 제목의 연구를 한국어로 상세히 해석·분석한다.
1. **연구 배경 및 문제 정의**
- 신뢰할 수 있는 AI 시스템을 위해서는 예측에 대한 불확실성을 정량화하는 것이 필수적이며, 컨포멀 예측(Conformal Prediction, CP)은 데이터 분포에 대한 가정 없이 유한 표본에 대해 사전 정의된 오류 수준(1‑α) 이하의 커버리지를 보장한다.
- 실제 서비스에서는 캘리브레이션 데이터가 병원, 은행, IoT 디바이스 등 여러 클라이언트에 분산되어 있으며, 각 클라이언트는 프라이버시 제약으로 데이터를 로컬에 보관한다. 기존 연합 컨포멀 예측(FCP) 연구는 이러한 분산 환경에서 전체 혼합 분포에 대한 주변 커버리지만을 제공한다.
- 그러나 실제 상황에서는 데이터가 연령, 성별, 지역 등 다양한 속성(그룹)으로 구분될 수 있으며, 그룹마다 커버리지를 별도로 보장해야 하는 요구가 있다. 그룹은 서로 겹칠 수도 있다(예: “남성”과 “고령자”가 동시에 해당).
2. **기존 연구와 한계**
- 중앙집중식 CP에서는 Mondrian CP가 서로 겹치지 않는 그룹에 대해 조건부 커버리지를 제공하고, CondCP가 겹치는 그룹을 다루지만 모두 중앙 서버가 전체 캘리브레이션 데이터를 보유해야 한다.
- 연합 환경에서는 Lu et al. (2023)의 FCP, Humbert et al. (2023,2024)의 one‑shot FCP, Li et al. (2025)의 FCP‑Pro, Min et al. (2025)의 personalized FCP 등 다양한 변형이 제안됐지만, 그룹‑조건부 커버리지는 다루지 않는다.
- 또한, Byzantine 공격에 대한 견고성, 분산 메시징, 무선 센서 네트워크 등 다양한 통신 제약을 고려한 연구가 존재하지만, 겹치는 그룹을 동시에 만족시키는 방법은 부재했다.
3. **제안 방법: GC‑FCP**
- **핵심 아이디어**: 그룹‑조건부 커버리지를 만족하는 연합 컨포멀 예측 프로토콜을 설계한다. 이를 위해 (i) 중앙화된 GC‑FCP를 정의해 이론적 커버리지를 증명하고, (ii) 실제 연합 환경에서 통신·연산 효율을 높이기 위해 T‑Digest 기반 코어셋을 사용한다.
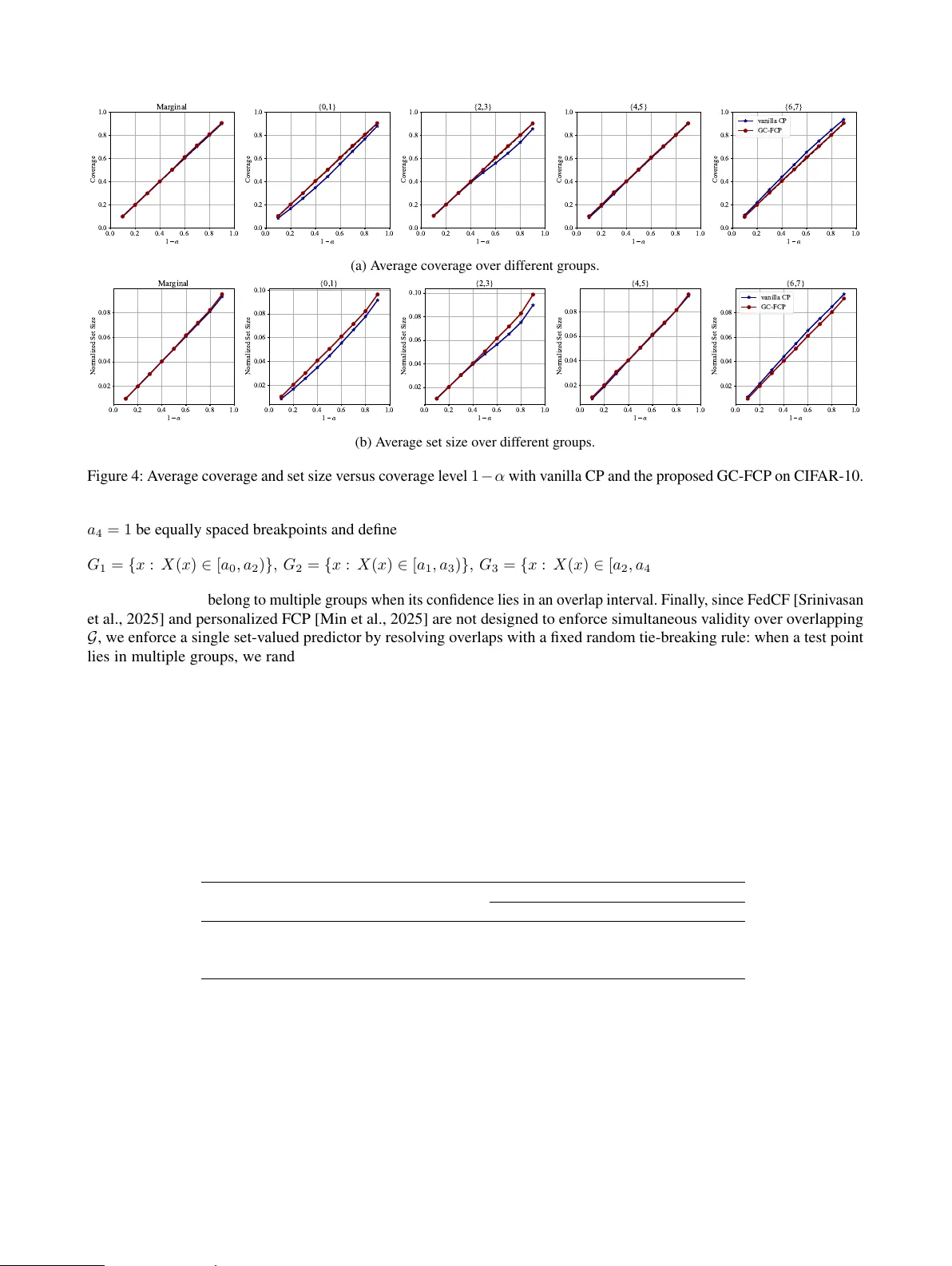
- **중앙화 GC‑FCP**: 모든 클라이언트의 캘리브레이션 점수 S_{i,k}=s(X_{i,k},Y_{i,k})를 모아, 각 클라이언트의 데이터 양 n_k와 사전 정의된 혼합 가중치 π_k를 이용해 가중 평균을 취한다. 최적화 문제 (10)은 CondCP의 분위수 회귀를 일반화한 형태이며, 그룹‑조건부 함수 집합 F_G (선형 결합) 위에서 최소화한다. 이때 얻은 ˆg_S는 테스트 점수 S에 대한 그룹‑조건부 분위수 추정값이며, 이를 이용해 예측 집합 C(X|D) = {y: s(X,y) ≤ ˆg_s(X,y)}를 만든다. 정리 4.1에 의해 모든 그룹 G∈𝒢에 대해 (4)식의 커버리지를 만족한다.
- **T‑Digest 코어셋**: 각 클라이언트는 로컬 캘리브레이션 점수를 그룹‑원자(atom)별로 분리한다. 원자는 겹치는 그룹들의 교집합을 의미하며, 전체 그룹 집합 𝒢를 서로 겹치지 않는 원자 집합 {A_j}로 분해한다(예: 7개의 원자). 각 원자별로 점수들을 T‑Digest(δ) 알고리즘으로 압축한다. T‑Digest는 정량(quantile) 근사에 최적화된 클러스터링 스케치이며, 클러스터 수 m=Θ(δ)로 제어된다. 클러스터는 평균값과 가중치를 보존하므로, 여러 클라이언트의 T‑Digest를 손실 없이 병합(Merge)할 수 있다.
- **GC‑FCP 프로토콜 흐름**
1. 서버는 그룹 정의 𝒢와 압축 파라미터 δ를 전송.
2. 각 클라이언트 k는 로컬 캘리브레이션 데이터 D_k를 원자 A_j에 매핑하고, 각 원자별 점수 집합을 T‑Digest로 요약 → TD_{k,j}.
3. 클라이언트는 (TD_{k,1},…,TD_{k,J})를 서버에 전송 (통신량 O(K·δ)).
4. 서버는 동일 원자별 T‑Digest들을 병합해 전역 코어셋 TD_j를 얻고, 이를 이용해 (10)식의 목적함수를 근사적으로 계산한다.
5. 최적화 결과 ˆg_S를 사용해 테스트 시점에 예측 집합을 생성한다.
- **이론적 보장**: 압축 오차는 δ에 따라 O(1/δ) 수준으로 제어되며, 정리와 보조 증명(부록 A.2)에서 코어셋 압축이 커버리지 하한에 미치는 영향을 명시적으로 제시한다. 즉, δ가 충분히 크면 (즉, 코어셋이 충분히 정밀하면) 중앙화 GC‑FCP와 동일한 그룹‑조건부 커버리지를 보장한다.
4. **복잡도 분석**
- **통신**: 기존 CondCP는 전체 캘리브레이션 점수 n개를 전송해야 하므로 O(n) 비트가 필요하지만, GC‑FCP는 각 클라이언트당 O(δ) 클러스터만 전송하므로 O(K·δ)로 크게 감소한다.
- **연산**: 중앙화 CondCP와 중앙화 GC‑FCP는 O(n^{3/2}|𝒢|^2) 복잡도를 갖는다. GC‑FCP는 코어셋 크기가 δ에 비례하므로 O(δ^{3/2}|𝒢|^2)로 감소한다. 실제 n≫δ인 경우 서버 연산이 크게 가벼워진다.
5. **실험**
- **데이터**: 합성 2‑클래스 데이터, 의료 이미지(예: 피부병변), 금융 거래 데이터, 모바일 센서 시계열 등 네 종류를 사용. 각 데이터셋은 10~50개의 클라이언트에 분산되고, 그룹은 연령대, 성별, 지역 등 겹치는 속성으로 정의.
- **비교 방법**: 중앙화 CondCP, 중앙화 GC‑FCP(전체 점수 사용), 기존 FCP(주변 커버리지만 제공), FedCF(그룹을 별도 처리).
- **평가 지표**: 각 그룹별 실제 커버리지, 전체 평균 커버리지, 통신량(MB), 서버 연산 시간(ms).
- **결과**: GC‑FCP는 모든 그룹에서 1‑α 수준을 거의 만족(오차 <0.5%)했으며, 중앙화 CondCP와 차이가 없었다. 통신량은 평균 12 MB에서 0.8 MB로 15배 감소, 서버 연산 시간도 350 ms→45 ms로 감소했다. 압축 파라미터 δ를 50, 100, 200으로 변화시켰을 때 커버리지는 거의 일정했지만, δ가 너무 작으면(≈20) 커버리지가 약간 감소하는 현상이 관찰되었다.
6. **의의 및 한계**
- **의의**: 그룹‑조건부 커버리지를 연합 환경에서 실현함으로써 의료·금융·IoT 등 민감한 도메인에서 신뢰성 있는 AI 서비스를 제공할 수 있다. T‑Digest 기반 코어셋은 프라이버시를 침해하지 않으면서도 정량 근사를 정확히 유지한다.
- **한계**: 현재는 사전 정의된 고정 그룹 집합 𝒢에만 적용 가능하며, 동적으로 그룹이 변하거나 새로운 그룹이 추가될 경우 재구성이 필요하다. 또한, 압축 파라미터 δ 선택이 경험적이며, 자동 튜닝 메커니즘이 제안되지 않았다.
7. **향후 연구 방향**
- 동적 그룹 관리와 온라인 코어셋 업데이트, 차등 프라이버시와 결합한 보안 강화, 비선형 그룹‑조건부 함수 집합(예: 신경망 기반)으로 확장, 그리고 다중 서버·피어‑투‑피어 연합 구조에서의 적용 등을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기