MemPO: Self-Memory Policy Optimization for Long-Horizon Agents
Long-horizon agents face the challenge of growing context size during interaction with environment, which degrades the performance and stability. Existing methods typically introduce the external memory module and look up the relevant information fro…
Authors: Ruoran Li, Xinghua Zhang, Haiyang Yu
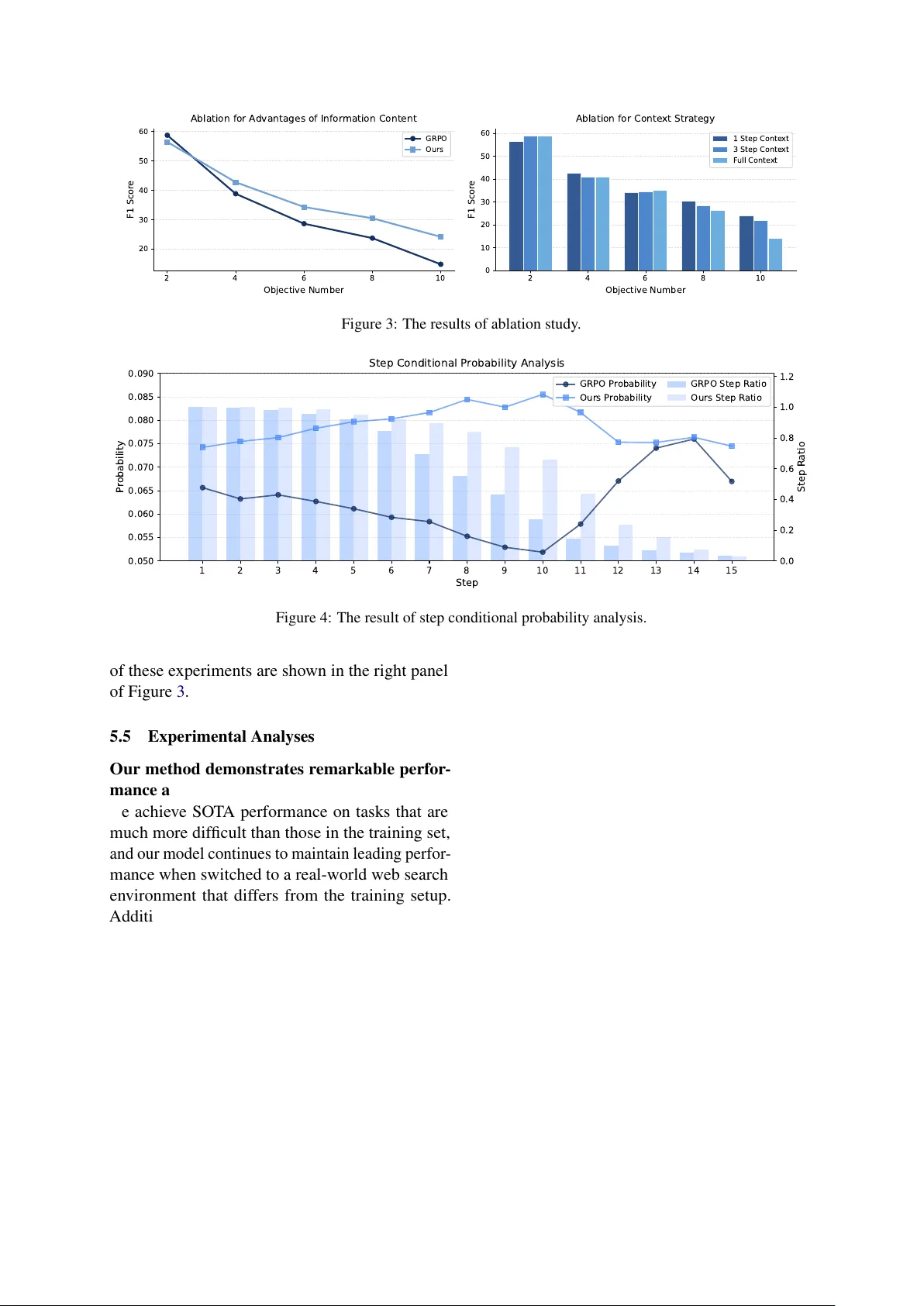
MemPO: Self-Memory P olicy Optimization f or Long-Horizon Agents Ruoran Li 1 , Xinghua Zhang 2 , Haiyang Y u 2 , Shitong Duan 2 , Xiang Li 2 , W enxin Xiang 1 , Chonghua Liao 1 , Xudong Guo 2 , Y ongbin Li 2* , Jinli Suo 1* , 1 Tsinghua Uni versity 2 T ongyi Lab, Alibaba Group, lrr24@mails.tsinghua.edu.cn, zhangxinghua.zxh@alibaba-inc.com, shuide.lyb@alibaba-inc.com, jlsuo@tsinghua.edu.cn Abstract Long-horizon agents face the challenge of growing context size during interaction with en vironment, which degrades the performance and stability . Existing methods typically intro- duce the external memory module and look up the relev ant information from the stored memory , which prev ents the model itself from proactiv ely managing its memory content and aligning with the agent’ s overarching task ob- jectiv es. T o address these limitations, we pro- pose the self-memory policy optimization al- gorithm ( MemPO ), which enables the agent (policy model) to autonomously summarize and manage their memory during interaction with en vironment. By improving the credit assignment mechanism based on memory ef- fectiv eness, the policy model can selecti vely retain crucial information, significantly reduc- ing token consumption while preserving task performance. Extensiv e experiments and anal- yses confirm that MemPO achiev es absolute F1 score gains of 25.98 ov er the base model and 7.1 ov er the pre vious SO T A baseline, while reducing token usage by 67.58% and 73.12%. The code is released at https://github.com/ TheNewBeeKing/MemPO 1 Introduction As lar ge language models (LLMs) continue to e volv e, LLM agents are becoming increasingly pro- ficient in addressing more complex problems. In areas such as deep research ( Zhang et al. , 2025 ; Zheng et al. , 2025 ), data analysis ( Hong et al. , 2025 ), and vibe coding ( Zhang et al. , 2024 ; Islam et al. , 2024 ; Ho et al. , 2025 ), they ha v e showcased remarkable performance. Long-horizon decision- making has always been one of the core capabilities for agents to solve comple x user queries. Currently , the dominant method for the agent- en vironment interaction is ReAct paradigm ( Y ao et al. , 2022 ). The feedback from the en vironment is attached to the previous interaction history and is used as a prompt, which then determines the next course of action. Howe v er , this approach causes the context to gro w linearly with each round of inter- action, resulting in longer conte xts when tackling more complex problems, and presenting se veral challenges. Firstly , current LLMs have relativ ely limited context windo w sizes, which impose an ex- plicit upper bound on the number of interactions. Secondly , long conte xts lead to e xcessi v ely high to- ken costs, which impedes the widespread adoption of agent systems in practical scenarios. Further- more, excessi vely long conte xts can lead to the “lost in the middle” phenomenon ( Liu et al. , 2023 ), which degrades the model’ s ability , thereby reduc- ing the ov erall performance of the agent. T o address this challenge, a gro wing body of research is focusing on agent memory , with the aim of providing LLMs with historical interaction records to reduce the need for the entire context. Currently , the mainstream solution in volv es design- ing a memory module as an external kno wledge database to maintain the agent’ s interaction history . When the memory module is accessed, relev ant historical information is retrie ved and integrated into the prompt ( Bor geaud et al. , 2022 ; Gao et al. , 2024 ; Lewis et al. , 2020 ) based on the retriev al- augmented generation technique (RA G). Ho we v er , the offline memory context compression method lacks the capacity for joint optimization oriented to ward the agent task execution, making it dif ficult to ef fecti vely align with the agent’ s overarching task objectives. As a result, the model’ s memory retrie v al remains passiv e, rather than lev eraging its o wn capabilities to proactiv ely select and organize information, and the latter would facilitate more ef fecti ve task completion. T o this end, we formalize the agent interac- tion paradigm as autonomously refining and or- ganizing historical information, while simultane- ously reasoning and in v oking tools with three ac- tions , , and . In this 1 𝑰 𝟏 𝑴 𝟏 𝑻 𝟏 𝑪 𝟏 A ge nt 𝑸 𝑴 Me m or y : 𝑻 T hi nk : 𝑪 T oo l Cal l : 𝑰 Inf orm ati on : To ol Cal l To ol Res po ns e E n v i ron men t 𝑰 𝒕 𝑴 𝒕 𝑻 𝒕 𝑪 𝒕 𝑰 𝒕 − 𝟏 𝑴 𝒕 − 𝟏 𝑻 𝒕 − 𝟏 𝑪 𝒕 − 𝟏 … … Q ue s ti on : 𝑸 St e p 1 St e p t Figure 1: The self-memory inference process of our method, which only uses the previous step interaction for next step input with action. paradigm, the agent itself proacti v ely compresses and reor ganizes long - horizon historical informa- tion for the ne xt step of interaction, making mem- ory management an intrinsic part of its capabilities, as sho wn in Figure 1 . T o further enhance this abil- ity , we propose self-memory policy optimization ( MemPO ), which incorporates the trajectory-le vel and memory-le vel information into adv antage esti- mation to optimize the action for agent with task-objecti ve awareness. Concretely , the tokens output by the agent are assigned trajectory-lev el adv antages, and in each step of the interaction, the tokens of the action additionally take into account memory-lev el advantages, effecti v ely al- le viating the credit assignment problem in long- horizon, multi-turn interactions. In terms of dense re wards for action in each step, the condi- tional probability of the answer given con- tent is designed to measure the quality of the action. Our contrib utions are as follo ws: • W e render memory management an intrinsic part of the agent’ s own capabilities that differs from external memory modules, achieving joint optimization of long-horizon memory , reasoning, and tool in v ocation. • W e propose MemPO , a self-memory policy optimization algorithm, which ef fecti vely ad- dresses credit assignment and steers the action toward retaining the most relev ant in- formation for solving the task. • Extensi ve experiments on fi ve long-horizon benchmarks confirm the ef ficac y of MemPO with 25.98% and 7.1% absolute F1 gains over the base model and pre vious SO T A, 67.58% and 73.12% reductions in token usage. 2 Related W orks 2.1 Memory f or LLM agents In recent years, researchers ha ve introduced e xter - nal memory systems to address the limitations of LLM context windo ws ( Xu et al. , 2025 ; Chhikara et al. , 2025 ; Zheng et al. , 2024 ; Packer et al. , 2024 ; Zhong et al. , 2023 ). MemGPT ( Packer et al. , 2024 ) proposes an operating-system-inspired vir- tual memory management frame work that emplo ys multiple memory hierarchies to manage contex- tual information. Mem0 ( Chhikara et al. , 2025 ) enhances memory capacity through dynamic ex- traction, consolidation, and retrie v al of conv ersa- tional information. Despite their effecti v eness in specific domains, most of these approaches rely on fixed workflo ws and limited optimization fle xibility . They typically fail to support flexible cross-stage joint optimization, which constrains the adaptabil- ity and scalability of the ov erall system. 2.2 RA G in Memory System RA G has emer ged as a po werful approach for en- hancing LLM by incorporating external knowledge sources to improv e model performance ( Borgeaud et al. , 2022 ; Gao et al. , 2024 ; Le wis et al. , 2020 ). In existing memory systems, the retrie v al of rele v ant memory fragments is predominantly implemented based on RA G. While this approach can efficiently surface relev ant information in certain scenarios, its major limitation lies in the lack of flexibility and end-to-end joint optimization. Specifically , retrie val relies solely on embedding similarity be- tween the query and chunks, which does not nec- essarily yield information that is most useful for solving the target problem. 2.3 RL f or LLM Agents The recent success of reinforcement learning meth- ods in LLMs has established RL as a central tool to enhance LLM-based agents to solve increasingly complex tasks ( Jin et al. , 2025 ; Chen et al. , 2025 ; Zheng et al. , 2025 ). Howe ver , relativ ely fe w stud- ies hav e e xplored applying RL to the optimization of agent memory . Existing approaches exhibit no- table limitations. For example, MEM1 ( Zhou et al. , 2025 ) integrates memory into the reasoning pro- cess and applies RL optimization for policy model. Ho wev er , it does not explicitly design objecti ves for memory optimization, which can lead to sub- optimal memory representations. In contrast, our method introduces a dedicated credit assignment 2 mechanism for memory re wards, encouraging the model to retain information that is most relev ant for solving the target task. 3 Preliminaries 3.1 T ask Formulation Gi ven a question-answer pair ( q , a g t ) , when an LLM-based agent is tasked with solving the ques- tion q , it interacts with the external environment through multiple rounds of reasoning and tool in- vocation to acquire the information required for problem solving. If the agent completes the task after T steps, a full trajectory can be denoted as τ = { s 1 , s 2 , . . . , s T } . Each state s t is further decomposed into { s mem t , s think t , s call t , s resp t } . Specifically , s mem t represents the model-generated summary of effecti v e infor- mation from pre vious outputs s . s think t corresponds to the model’ s reasoning process and is wrapped by . s call t denotes the in v ocation of external tools by the model, which is represented as . s resp t captures the information returned by the tool and is enclosed by . Once the agent has gathered suf ficient information to answer the question q , it produces a predicted answer a pred , wrapped by . 3.2 Group Relati ve RL In reinforcement learning for LLM, a class of group-based methods, e xemplified by Group Rel- ati ve Policy Optimization (GRPO) ( Shao et al. , 2024 ), abandon per-trajectory v alue function mod- eling and instead performs relativ e comparison within a batch of candidate trajectories. Concretely , for a gi ven task input q , the policy π θ old generates N complete trajectories { τ 1 , τ 2 , . . . , τ N } in one shot, and each trajectory is assigned a scalar return R ( τ i ) that measures the ov erall quality of the gener - ated outcome. The algorithm then relies solely on statistics within this group to construct advantages, without explicitly learning a v alue netw ork: A ( τ i ) = GroupAgg { R ( τ j ) } N j =1 , i , (1) where GroupAgg( · ) is the aggre gation operator based on normalization, or pairwise comparison. The design bypasses the instabilities of value function estimation and reduces it to modeling rel- ati ve preferences among a set of candidate answers. In large-scale LLM training, group-based methods can reduce the memory ov erhead of e xtra networks, making them an efficient alternati ve for RL train- ing. 3.3 Beha vior Cloning T o enable the model to better follow the action for- mat, we first adopt GPT -4.1 ( OpenAI et al. , 2024 ) to perform inference on the publicly a v ailable train- ing dataset from the work of ( T ang et al. , 2025 ), filter out trajectory with incorrect answers, and finally generate approximately 10K trajectories fol- lo wing the predefined action format in § 3.1 . Based on these trajectory data, we fine-tune the LLM and provide a promising starting point for self-memory policy optimization. 4 Self-Memory Policy Optimization As mentioned abov e, memory is introduced to ad- dress long contexts of agents by removing irrele- v ant information and retaining key details. V anilla GRPO computes rew ards based on answer correct- ness and uses trajectory-lev el advantages, where tokens within the same trajectory share the same re ward. It provides the sparse rew ards and limited guidance for memory generation, as the correct- ness of the final answer can not directly reflect the quality of each action during the interaction. T o address this, we propose MemPO , a self- memory polic y optimization algorithm. W e de- sign a novel advantage computation method that, in addition to trajectory-le vel advantages, ev alu- ates the information content of memory within at each step and computes an ad- ditional adv antage, ensuring memory remains con- cise while preserving important information. 4.1 Advantages of Global T rajectory W e first ev aluate the trajectory format and the accu- racy of the final answer to provide a coarse-grained assessment of the ov erall trajectory quality . Sup- pose that for a single training sample, we perform N rollout and assign an overall score to each result- ing trajectory , denoted as a group: G T = { ( τ 1 , R T ( τ 1 )) , ( τ 2 , R T ( τ 2 )) , . . . , ( τ N , R T ( τ N )) } . (2) where τ i denotes a trajectory , and R T ( τ i ) repre- sents the trajectory-level rew ard. In our method, the re ward consists of ev aluations of both the out- put format and the correctness of predicted answer . 3 Ro ll ou t T raj ecto ry R ew ards A d van tag es Self - Memory Poli cy Opt imi z at ion T oo l s A gen t Re spon se In v oca tio n Agent - Environm ent Interac tion Figure 2: Overvie w of MemPO. At step t of any trajectory τ i , the context is represented as { s mem t , s think t , s call t , s resp t } . The memory rew ard R M is calculated using conditional probabilities and contributes to the advantage A M . The final adv antage is the sum of A M and the trajectory-level advantage A T . During inference, only the previous step’ s content is used as context, discarding earlier information. Concretely , the rew ard is set to 1 if and only if the predicted answer is correct and output format is proper; otherwise, it is set to 0. T o assess the global relativ e quality of each tra- jectory within the group, we adopt the adv antage calculation strategy from GRPO ( Shao et al. , 2024 ), which normalizes the total re ward using the mean and standard de viation computed ov er the group: A T ( τ i ) = R T ( τ i ) − mean { R T ( τ j ) } N j =1 std { R T ( τ j ) } N j =1 . (3) 4.2 Advantages of Inf ormativ e Memory According to the probabilistic formulation of LLMs, the output of model is characterized as conditional probabilities gi ven the preceding con- text, i.e., π θ ( s t | q , s action) generated at each interaction step, which reflects the quality of ef fecti ve information retained in memory: R M τ i ( s mem t ) = P [ s ans | τ i ( s mem t )] − ϵ, 1 ≤ i ≤ N , 1 ≤ t ≤ T . (4) where τ i ( s mem t ) denotes the memory content within action in step t of trajectory τ i , and s ans = { a 1 , a 2 , . . . , a L } represents the correct an- swer string, where a l denotes the l -th token of the answer . The ϵ represents P [ s ans | τ i ( s action), its adv an- tage is giv en by the sum of the trajectory-le vel adv antage and the memory-le vel advantage; oth- erwise, only the trajectory-lev el advantage A T is used. In this way , tokens belonging to memory recei ve richer and more explicit feedback signals, which more effecti v ely guide the rollout process for memory generation. 4.4 Policy Optimization and Infer ence Optimization. The policy optimization objecti v e is to maximize J ( θ ) , written as: J ( θ ) = E " 1 N N X i =1 1 | τ i | | τ i | X k =1 min γ i,k A i,k , clip( γ i,k , 1 − ϵ, 1 + ϵ ) A i,k − β D KL ( π θ ∥ π ref ) # . (10) where γ i,k is the importance sampling ratio: π θ ( τ i,k | q , τ i, ) 54.57 42.95 38.31 28.60 29.78 22.60 18.97 13.65 11.01 7.84 30.53 23.13 4.39 0.81 MemPO (Ours) 56.47 46.15 42.75 31.90 34.32 26.93 30.48 23.70 24.15 18.16 37.63 29.37 1.18 0.18 Online W eb Sear ch Qwen2.5 (ReAct) 45.71 33.60 16.83 11.80 12.12 9.07 9.66 6.80 7.25 4.68 18.31 13.19 3.14 0.34 ReSearch 51.17 39.20 29.92 21.10 25.21 18.73 17.09 12.50 10.37 7.44 26.75 19.79 2.17 0.40 MEM1 50.56 39.60 30.43 22.00 21.67 16.20 19.48 14.30 18.06 12.12 28.04 20.84 0.96 0.14 MemPO (Ours) 57.40 45.20 41.42 30.20 37.92 28.60 34.30 25.80 22.92 16.32 38.79 29.22 0.86 0.12 the memory component from the trajectories to use them for fine-tuning the baseline model, which was trained using GRPO and does not include memory , ensuring fairness in the comparison. In the RL phase, we follo wed MEM1 and used the 2-objective task synthesized from HotpotQA and NQ as part of the training set. And we ran- domly sampled a subset from both datasets as an- other part of training set. The rollout group size N for group-based RL methods is set to 16, with a batch size of 128 and a learning rate of 1e-6. The maximum number of interaction rounds is set to 16. During training, we use the local wiki search engine as the search tool. 5.4 Experimental Results Multi-objective task. The results of each baseline on the multi-objective task are shown in T able 1 . W e selected tasks with 4, 6, 8, and 10 objectives as progressively harder task groups and recorded F1 and EM for the answers from each baseline as precision metrics. Among the baselines, MEM1, A-MEM, and our method use truncated contexts, meaning the model only has access to the pre vi- ous step of interactions, while the other baselines use the complete context. Additionally , we also recorded the total number of tokens required to solve a single problem (TT) and the peak token consumption per step (PT) during the model’ s e x e- cution. The more detailed results are presented in Appendix T able 2 . Conditional probability analysis. T o in v esti- gate the impact of our reward design on the model, we performed a statistical analysis of the true val- ues of P [ s ans | s mem ] during inference on the 10- objecti ve task. W e compared the results of models trained with v anilla GRPO and our method. Specif- ically , let the dataset size be M , and denote the memory component at step t of the m -th trajec- tory as τ m ( s mem t ) , with the corresponding ground truth answer string being τ m ( s ans ) . Figure 5 shows the grouped results of P [ τ m ( s ans ) | τ m ( s mem t )] , where the x-axis represents the group values of the conditional probability , and the y-axis shows the proportion of memory samples in that range rela- ti ve to the total memory samples. This distribution illustrates the conditional probability distribution of the memory produced by the model. The line graph’ s y-axis represents the average accurac y of trajectories whose memory falls within each group, providing insight into the relationship between ac- curacy and the conditional probability . Figure 4 displays the aggregated results of P [ τ m ( s ans ) | τ m ( s mem t )] by step. The x-axis repre- sents the step t of the memory , and the y-axis of the line graph sho ws the av erage conditional probabil- ity of the memory at step t across all M trajectories. This provides insight into ho w conditional proba- bility e volv es with the step. The histogram sho ws the proportion of memories at each step relativ e to the total number of trajectories. Ablation study . T o validate the ef fecti veness of our design, we compared the performance of the memory-enabled model trained with vanilla GRPO and our model, keeping all other conditions identical. The only dif ference between the two models is the inclusion of a reward specifically for memory . The results are shown in the left panel of Figure 3 . Additionally , we e v aluated our method under dif ferent context retention settings: full con- text, retaining 1 or 3 interaction rounds. The results 6 2 4 6 8 10 Objective Number 20 30 40 50 60 F1 Scor e Ablation for A dvantages of Infor mation Content GRPO Ours 2 4 6 8 10 Objective Number 0 10 20 30 40 50 60 F1 Scor e Ablation for Conte xt Strategy 1 Step Conte xt 3 Step Conte xt F ull Conte xt Figure 3: The results of ablation study . 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Step R atio 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Step 0.050 0.055 0.060 0.065 0.070 0.075 0.080 0.085 0.090 P r obability Step Conditional P r obability Analysis GRPO P r obability Ours P r obability GRPO Step R atio Ours Step R atio Figure 4: The result of step conditional probability analysis. of these experiments are sho wn in the right panel of Figure 3 . 5.5 Experimental Analyses Our method demonstrates remarkable perfor - mance and generalization. As shown in T able 1 , we achie ve SOT A performance on tasks that are much more difficult than those in the training set, and our model continues to maintain leading perfor - mance when switched to a real-w orld web search en vironment that differs from the training setup. Additionally , as presented in T able 1 , our model achie ves SO T A performance while minimizing to- ken consumption, thereby achie ving the highest performance with the least resource usage. Fur- thermore, as seen in Figure 3 , whether using full context, retaining 1 or 3 interaction rounds for in- ference, our method’ s performance remains con- sistently stable, sho wcasing strong generalization capabilities. The memory mechanism significantly reduces token consumption. As sho wn in Appendix T a- ble 2 , token consumption for tasks solved by MEM1, A-MEM, and our method, which all in- corporate the memory mechanism, is noticeably lo wer than that of other baselines. T aking Re- Search as an example and comparing it with our method, when the task is relatively simple, such as a 2-objectiv e task, the token consumption is only slightly higher than ours. Howe v er , as the com- plexity of the task increases, the gap between the two methods becomes more pronounced. By the time the task reaches 10 objecti ves, the number of tokens required by our method to solv e a problem is approximately 1/3 of ReSearch’ s, with the token peak being 1/5. This is comparable to ReSearch’ s token consumption on a 4-objectiv e task. More- ov er , our method not only uses truncated contexts but also provides effecti ve guidance on the memory content, resulting in even more compact contexts compared to other memory-related methods. As a result, token consumption in our method is the lo west among all baselines. The ability of memory to pr ovide str ongly rel- ev ant informa tion is crucial for task success. In the baseline methods, A-MEM generates memory based on a RAG approach. As mentioned in the introduction, the memory obtained by this method is not necessarily the most relev ant for solving the task and contains a significant amount of redun- 7 0.00 0.05 0.10 0.15 0.20 0.25 Gr oup R atio 0.008 0.024 0.040 0.056 0.072 0.088 0.104 0.120 0.136 0.152 Gr ouped P r obability 0.10 0.15 0.20 0.25 0.30 0.35 0.40 A CC Scor e Gr ouped Conditional P r obability Analysis GRPO A CC Ours A CC GRPO Gr oup R atio Ours Gr oup R atio Figure 5: The result of grouped conditional probability analysis. dancy . As a result, while A-MEM reduces token consumption compared to ReAct, its performance does not sho w a significant improv ement. On the other hand, MEM1 generates memory by combin- ing the model’ s summary with reasoning, creating a stronger link between memory generation and the task-solving process. This allo ws MEM1 to sho w a considerable improv ement on long-horizon tasks. Furthermore, our method explicitly guides the model to retain the context that most strongly contributes to solving the problem, outperforming other memory-related baselines in all datasets. The number of context steps impacts perfor - mance on long-horizon tasks. As sho wn in the right panel of Figure 3 , we present the results of inference using complete conte xt, truncated in 1 step and in 3 steps. Overall, the performance dif- ferences between these methods fluctuate within an acceptable range, with the trend showing that the more context steps used, the better the perfor - mance on short-horizon tasks, but the weaker the performance on long-horizon tasks. This ef fect is particularly noticeable on long-horizon tasks. W e belie ve that this aligns with the phenomenon of attention dilution caused by long contexts, which leads to performance degradation. Our reward design positively contributes to impro ving the effective inf ormation content. Fig- ure 3 presents a performance comparison between v anilla GRPO and our method. The results show that our re ward design leads to an improv ement in the model’ s performance. W e also quantitativ ely analyzed the information content of the memory in the trajectories of both vanilla GRPO and our method. The bar graph in Figure 5 indicates that, compared to the baseline, our method’ s probability distribution is more ske wed to w ard higher v alues, which contributes to greater precision of responses, as confirmed by the line graph. Additionally , the line graph in Figure 4 shows that, for the first 10 steps of 10-objecti ve task, the mean probability of our method increases as the steps progress, whereas the baseline shows a de- creasing trend. W e believe this reflects the more ef- fecti ve organization of memory by our method com- pared to the baseline. After 10 steps, our method’ s probability starts to decrease, which is reasonable gi ven that the typical number of search steps in a 10-objecti ve task is around 10. If the task is not completed by this point, it suggests that some infor - mation is dif ficult to find and is still being searched for . In contrast, the baseline experiences more dif- ficulty in the first 10 steps, and as seen in the bar chart, only 20% of the search examples continue after the 10th step. W e hypothesize that the few re- maining e xamples that did not abandon exploration likely achiev ed relativ ely higher accuracy , which explains the continued increase in probability after the 10th step. Overall, both the final performance and the prob- ability analysis validate that our rew ard design is ef fecti ve and aligns with e xpectations. 6 Conclusion Our method optimizes memory management for agents by introducing a novel reward design that retains only relev ant information, improving task performance and reducing computational costs. By integrating memory , reasoning, and tool in v oca- tion via reinforcement learning, we achiev e supe- rior performance, especially on long-horizon tasks, with efficient tok en consumption. Future work will focus on optimizing memory re ward design and enhancing the scalability of self-memory method in more applications. 8 Limitations Although our method sho ws promising perfor- mance, one potential limitation is that, due to vary- ing tool in vocation at dif ferent steps, the informa- tion content in memory naturally dif fers and the states are not completely equi v alent across all steps in all rollout trajectories, which may introduce bias when calculating group-based adv antages. While we alleviate this issue by introducing ϵ in Equa- tion 4 , more refined solutions may reduce this bias in more complex en vironments, and understand- ing the generalization to di v erse real - world settings needs further in v estigation. References Sebastian Borgeaud, Arthur Mensch, Jordan Hof fmann, T re vor Cai, Eliza Rutherford, Katie Millican, George Bm V an Den Driessche, Jean-Baptiste Lespiau, Bog- dan Damoc, Aidan Clark, Die go De Las Casas, Aure- lia Guy , Jacob Menick, Roman Ring, T om Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer , and 9 others. 2022. Improving Language Models by Retrieving from T rillions of T okens . In Pr oceedings of the 39th International Confer ence on Machine Learning , pages 2206–2240. PMLR. ISSN: 2640-3498. Mingyang Chen, Linzhuang Sun, T ianpeng Li, Haoze Sun, Y ijie Zhou, Chenzheng Zhu, Haofen W ang, Jeff Z. Pan, W en Zhang, Huajun Chen, Fan Y ang, Zenan Zhou, and W eipeng Chen. 2025. ReSearch: Learning to Reason with Search for LLMs via Rein- forcement Learning . Preprint , arXi v:2503.19470. Prateek Chhikara, Dev Khant, Saket Aryan, T aranjeet Singh, and Deshraj Y adav . 2025. Mem0: Building Production-Ready AI Agents with Scalable Long- T erm Memory . Preprint , arXi v:2504.19413. Y unfan Gao, Y un Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Y uxi Bi, Y i Dai, Jiawei Sun, Meng W ang, and Haofen W ang. 2024. Retrie v al-Augmented Gen- eration for Lar ge Language Models: A Surv ey . arXiv pr eprint . ArXiv:2312.10997 [cs]. Chia-T ung Ho, Haoxing Ren, and Brucek Khailany . 2025. V erilogcoder: Autonomous verilog coding agents with graph-based planning and abstract syntax tree (ast)-based wav eform tracing tool . In Proceed- ings of the AAAI Confer ence on Artificial Intellig ence , volume 39, pages 300–307. Issue: 1. Xanh Ho, Anh-Khoa Duong Nguyen, Saku Suga wara, and Akiko Aizawa. 2020. Constructing A Multi- hop QA Dataset for Comprehensiv e Evaluation of Reasoning Steps . arXiv pr eprint . [cs]. Sirui Hong, Y izhang Lin, Bang Liu, Bangbang Liu, Bin- hao W u, Ceyao Zhang, Dan yang Li, Jiaqi Chen, Jiayi Zhang, and Jinlin W ang. 2025. Data interpreter: An llm agent for data science . In F indings of the Asso- ciation for Computational Linguistics: ACL 2025 , pages 19796–19821. Md Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan P arvez. 2024. MapCoder: Multi-Agent Code Generation for Competiti v e Problem Solving . arXiv pr eprint . ArXiv:2405.11403 [cs]. Bowen Jin, Hansi Zeng, Zhenrui Y ue, Jinsung Y oon, Sercan Arik, Dong W ang, Hamed Zamani, and Jiawei Han. 2025. Search-R1: Training LLMs to Reason and Lev erage Search Engines with Reinforcement Learning . Preprint , arXi v:2503.09516. Mandar Joshi, Eunsol Choi, Daniel S. W eld, and Luke Zettlemoyer . 2017. T ri viaQA: A Large Scale Dis- tantly Supervised Challenge Dataset for Reading Comprehension . arXiv preprint . ArXi v:1705.03551 [cs]. Kiseung Kim and Jay-Y oon Lee. 2024. RE-RAG: Im- proving Open-Domain QA Performance and Inter- pretability with Relev ance Estimator in Retriev al- Augmented Generation . In Proceedings of the 2024 Confer ence on Empirical Methods in Natural Language Pr ocessing , pages 22149–22161, Miami, Florida, USA. Association for Computational Lin- guistics. Satyapriya Krishna, Kalpesh Krishna, Anhad Mo- hananey , Ste ven Schw arcz, Adam Stambler , Shyam Upadhyay , and Manaal Faruqui. 2025. Fact, Fetch, and Reason: A Unified Ev aluation of Retriev al-Augmented Generation . arXiv preprint . ArXiv:2409.12941 [cs] v ersion: 3. T om Kwiatko wski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur P arikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Ken- ton Lee, Kristina T outanova, Llion Jones, Matthew Kelce y , Ming-W ei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Sla v Petro v . 2019. Natural Questions: A Benchmark for Question Answering Research . T r ansactions of the Association for Com- putational Linguistics , 7:453–466. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler , Mike Lewis, W en-tau Y ih, Tim Rock- täschel, Sebastian Riedel, and Douwe Kiela. 2020. Retriev al-Augmented Generation for Knowledge- Intensiv e NLP T asks . In Advances in Neural Infor- mation Pr ocessing Systems , v olume 33, pages 9459– 9474. Curran Associates, Inc. Nelson F . Liu, K e vin Lin, John He witt, Ashwin P aran- jape, Michele Be vilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the Middle: How Lan- guage Models Use Long Contexts . arXiv pr eprint . ArXiv:2307.03172 [cs]. Alex Mallen, Akari Asai, V ictor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. 9 When Not to Trust Language Models: In v estigat- ing Effecti v eness of Parametric and Non-P arametric Memories . arXiv preprint . ArXi v:2212.10511 [cs]. Grégoire Mialon, Clémentine Fourrier , Craig Swift, Thomas W olf, Y ann LeCun, and Thomas Scialom. 2023. GAIA: a benchmark for General AI Assistants . arXiv pr eprint . ArXiv:2311.12983 [cs]. OpenAI, Josh Achiam, Ste v en Adler , Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Alt- man, Shyamal Anadkat, Red A vila, Igor Babuschkin, Suchir Balaji, V alerie Balcom, Paul Baltescu, Haim- ing Bao, Mohammad Bav arian, Jeff Belgum, and 262 others. 2024. GPT-4 T echnical Report . arXiv pr eprint . ArXiv:2303.08774 [cs]. Charles Pack er , Sarah W ooders, K evin Lin, V ivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2024. MemGPT: T ow ards LLMs as Operating Sys- tems . Preprint , arXi v:2310.08560. Ofir Press, Muru Zhang, Sew on Min, Ludwig Schmidt, Noah Smith, and Mike Le wis. 2023. Measuring and Narrowing the Compositionality Gap in Language Models . In F indings of the Association for Computa- tional Linguistics: EMNLP 2023 , pages 5687–5711, Singapore. Association for Computational Linguis- tics. Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Hao wei Zhang, Mingchuan Zhang, Y . K. Li, Y . W u, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathemat- ical Reasoning in Open Language Models . Preprint , Qiaoyu T ang, Hao Xiang, Le Y u, Bowen Y u, Y aojie Lu, Xianpei Han, Le Sun, W enJuan Zhang, Pengbo W ang, Shixuan Liu, Zhenru Zhang, Jianhong Tu, Hongyu Lin, and Junyang Lin. 2025. Beyond T urn Limits: T raining Deep Search Agents with Dynamic Context W indo w . arXiv pr eprint . ArXiv:2510.08276 [cs]. Harsh T ri vedi, Niranjan Balasubramanian, T ushar Khot, and Ashish Sabharwal. 2022. MuSiQue: Multi- hop Questions via Single-hop Question Composition . arXiv pr eprint . ArXiv:2108.00573 [cs]. Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser , and Illia Polosukhin. 2017. Attention is All you Need . In Advances in Neural Information Pro- cessing Systems , volume 30. Curran Associates, Inc. Guoqing W ang, Sunhao Dai, Guangze Y e, Zeyu Gan, W ei Y ao, Y ong Deng, Xiaofeng W u, and Zhen- zhe Y ing. 2025. Information Gain-based Pol- icy Optimization: A Simple and Effecti v e Ap- proach for Multi-T urn LLM Agents . arXiv pr eprint . ArXiv:2510.14967 [cs]. Jialong W u, W enbiao Y in, Y ong Jiang, Zhenglin W ang, Zekun Xi, Runnan Fang, Linhai Zhang, Y ulan He, Deyu Zhou, Pengjun Xie, and Fei Huang. 2025. W ebW alker: Benchmarking LLMs in W eb Tra v er- sal . arXiv preprint . ArXi v:2501.07572 [cs]. W ujiang Xu, Kai Mei, Hang Gao, Juntao T an, Zu- jie Liang, and Y ongfeng Zhang. 2025. A-MEM: Agentic Memory for LLM Agents . Pr eprint , Zhilin Y ang, Peng Qi, Saizheng Zhang, Y oshua Bengio, W illiam Cohen, Ruslan Salakhutdino v , and Christo- pher D. Manning. 2018. HotpotQA: A Dataset for Di verse, Explainable Multi-hop Question Answering . In Pr oceedings of the 2018 Conference on Empiri- cal Methods in Natural Languag e Pr ocessing , pages 2369–2380, Brussels, Belgium. Association for Com- putational Linguistics. Shunyu Y ao, Jeffre y Zhao, Dian Y u, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Y uan Cao. 2022. React: Synergizing reasoning and acting in language models . In The eleventh international confer ence on learning r epr esentations . Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. 2024. CodeAgent: Enhancing Code Genera- tion with T ool-Integrated Agent Systems for Real- W orld Repo-le v el Coding Challenges . arXiv pr eprint . ArXiv:2401.07339 [cs]. W enlin Zhang, Xiaopeng Li, Y ingyi Zhang, Pengyue Jia, Y ichao W ang, Huifeng Guo, Y ong Liu, and Xiangyu Zhao. 2025. Deep Research: A Survey of Autonomous Research Agents . arXiv preprint . ArXiv:2508.12752 [cs]. Longtao Zheng, Rundong W ang, Xinrun W ang, and Bo An. 2024. Synapse: Trajectory-as-Exemplar Prompting with Memory for Computer Control . Pr eprint , arXi v:2306.07863. Y uxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, L yumanshan Y e, Pengrui Lu, and Pengfei Liu. 2025. DeepResearcher: Scaling Deep Research via Re- inforcement Learning in Real-world En vironments . arXiv pr eprint . ArXiv:2504.03160 [cs]. W anjun Zhong, Lianghong Guo, Qiqi Gao, He Y e, and Y anlin W ang. 2023. MemoryBank: Enhancing Large Language Models with Long-T erm Memory . Pr eprint , arXi v:2305.10250. Zijian Zhou, Ao Qu, Zhaoxuan W u, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low , and Paul Pu Liang. 2025. MEM1: Learning to Synergize Memory and Rea- soning for Efficient Long-Horizon Agents . Pr eprint , A A ppendix A.1 Single-Objective T asks T o assess the effecti v eness of our approach on single-objecti ve settings, we conduct experiments on se ven question answering benchmarks: 2W iki- MultiHopQA, HotpotQA, Bamboogle, Musique, 10 Natural Questions (NQ), Tri viaQA, and PopQA ( Ho et al. , 2020 ; Y ang et al. , 2018 ; Press et al. , 2023 ; T ri v edi et al. , 2022 ; Kwiatk o wski et al. , 2019 ; Joshi et al. , 2017 ; Mallen et al. , 2023 ). These datasets span di verse domains and are widely used in prior agent-oriented research. For datasets with more than 1k samples, we randomly sample 1k samples for e v aluation. Datasets. The following are details of these datasets: • Natural Questions (NQ) : a QA dataset whose questions are deri ved from real anonymized and aggre gated queries issued to the Google Search engine. • T riviaQA : a large-scale dataset with composi- tional questions that often require non-tri vial reasoning. • PopQA : 14K questions focusing on long-tail factual kno wledge. • Bamboogle : a manually constructed multi- hop QA benchmark in which questions are designed to be dif ficult to answer with a single search engine call. • Musique : a 25K-question multi-hop QA dataset requiring e vidence composition across multiple facts. • HotpotQA : a W ikipedia-based multi-hop dataset where answering requires retrieving and reasoning ov er multiple supporting docu- ments. • 2WikiMultiHopQA : a multi-hop QA dataset combining structured and unstructured evi- dence, explicitly constructed to necessitate multi-hop reasoning. Results. As shown in T able 3 and T able 4 , our method achiev es strong performance across all benchmarks. On se v eral datasets (e.g., T ri viaQA), it surpasses all baselines and reaches SOT A per- formance, while substantially reducing token con- sumption. These results suggest that our method can significantly improve performance on long- horizon tasks while maintaining competiti veness on short-horizon tasks, matching or ev en exceed- ing agent models trained specifically for single- objecti ve settings. A.2 Deep Research T asks W e further e v aluate our approach on three deep research benchmarks: GAIA ( Mialon et al. , 2023 ), Frames ( Krishna et al. , 2025 ), and W ebW alkerQA ( W u et al. , 2025 ). In contrast to the above datasets, deep research questions are often constructed from real web search results, and thus are fully out-of- domain (OOD) relativ e to our training setting. This e v aluation tests whether our method generalizes to complex OOD tasks. T o reduce ev aluation cost, for the larger benchmarks (Frames and W ebW alk- erQA), we randomly sample 250 instances. Datasets. • GAIA : a collection of 165 tasks spanning three difficulty le v els (53 Le vel-1, 86 Le vel-2, and 26 Le vel-3), designed to measure tool use and multi-step reasoning. • Frames : measures multi-perspecti v e reason- ing and role-conditioned information synthe- sis, requiring consistent integration of evi- dence across dif ferent contextual frames. • W ebW alkerQA : ev aluates complex, multi- turn web interaction, consisting of 680 real- world queries across four domains and over 1,373 webpages. Results. As reported in T able 5 , in terms of a v- erage accuracy , our method achieves performance comparable to DeepResearcher while significantly reducing token usage. Notably , DeepResearcher is trained specifically in real web search en viron- ments. Moreover , on longer-horizon tasks with higher token demands (e.g., GAIA), our method de- li vers relati v ely strong performance. Overall, these findings indicate that our approach generalizes well to out-of-domain settings while still demonstrating solid capability on long-horizon reasoning tasks. 11 T able 2: The token consumption for multi-objecti ve tasks of baselines. T ext with bold means SO T A. Local Wiki Sear ch Model 2-objective 4-objective 6-objective 8-objective 10-objective A vg TT PT TT PT TT PT TT PT TT PT TT PT Qwen2.5 (ReAct) 1.90 0.38 2.80 0.51 3.97 0.63 4.89 0.76 4.66 0.77 3.64 0.61 Research 0.45 0.26 1.58 0.52 3.18 0.76 4.63 0.91 6.62 1.11 3.29 0.71 DeepResearcher 0.96 0.31 2.60 0.61 4.13 0.79 5.48 0.93 8.26 1.19 4.29 0.77 A-MEM 1.14 0.34 2.16 0.38 2.61 0.38 3.49 0.41 3.69 0.40 2.62 0.38 MEM1 0.50 0.16 0.88 0.18 1.31 0.20 1.81 0.22 2.40 0.24 1.38 0.20 GRPO (no mem) 0.45 0.26 2.29 0.62 3.91 0.84 6.32 1.07 8.96 1.28 4.39 0.81 Ours 0.32 0.14 0.80 0.17 1.22 0.19 1.61 0.20 1.94 0.21 1.18 0.18 Online W eb Search Qwen2.5 (ReAct) 0.24 0.13 4.53 0.36 2.63 0.34 3.21 0.40 5.08 0.48 3.14 0.34 Research 0.27 0.14 1.04 0.29 1.94 0.41 3.13 0.52 4.48 0.62 2.17 0.40 MEM1 0.31 0.10 0.57 0.12 0.89 0.14 1.30 0.16 1.74 0.19 0.96 0.14 Ours 0.19 0.08 0.56 0.11 0.85 0.12 1.17 0.14 1.53 0.15 0.86 0.12 T able 3: The results of multi-hop QA datasets.They are the first part of single-objecti v e QA datasets. Multi-hop QA Model 2W ikiMultihopQA Bamboogle HotpotQA Musique A vg F1 EM TT PT F1 EM TT PT F1 EM TT PT F1 EM TT PT F1 EM TT PT qwen2.5 (ReAct) 45.21 35.90 1.12 0.29 43.70 32.80 0.95 0.24 47.12 34.30 1.07 0.26 23.86 14.40 2.06 0.37 39.97 29.35 1.30 0.29 ReSearch 50.07 41.90 0.55 0.28 53.61 40.80 0.41 0.24 50.26 33.90 0.40 0.23 29.63 17.80 0.58 0.29 45.89 33.60 0.48 0.26 DeepResearcher 51.44 43.90 1.24 0.34 48.48 37.60 1.22 0.30 51.96 38.40 1.01 0.29 26.55 17.00 2.54 0.44 44.61 34.23 1.50 0.34 GRPO (no mem) 62.35 53.80 0.93 0.32 53.18 40.80 0.79 0.28 57.29 42.30 0.62 0.27 33.78 21.50 0.86 0.33 51.65 39.60 0.80 0.30 Ours 59.17 50.20 0.37 0.15 52.90 36.80 0.29 0.14 57.64 42.90 0.34 0.15 33.48 22.10 0.39 0.15 50.80 38.00 0.35 0.15 T able 4: The results of single-hop QA datasets.They are the second part of single-objecti v e QA datasets. Single-hop QA Model NQ PopQA T ri viaQA A vg F1 EM TT PT F1 EM TT PT F1 EM TT PT F1 EM TT PT qwen2.5 (ReAct) 49.18 36.30 1.87 0.30 47.77 40.50 1.43 0.26 62.73 52.60 1.02 0.22 53.23 43.13 1.44 0.26 ReSearch 52.49 38.00 0.23 0.16 52.41 43.80 0.23 0.16 62.04 50.10 0.24 0.17 55.65 43.97 0.23 0.16 DeepResearcher 50.15 39.50 1.19 0.25 47.90 40.80 0.60 0.22 61.89 52.30 0.95 0.23 53.32 44.20 0.91 0.23 GRPO (no mem) 56.04 43.90 0.63 0.23 53.77 46.50 1.00 0.26 64.57 54.50 0.52 0.23 58.13 48.30 0.72 0.24 Ours 57.46 46.10 0.22 0.14 53.53 46.70 0.25 0.14 67.83 57.10 0.25 0.14 59.61 49.97 0.24 0.14 T able 5: The results of deep research datasets. Deep Research Model GAIA Frames W ebW alker A vg F1 EM TT PT F1 EM TT PT F1 EM TT PT F1 EM TT PT qwen2.5 (ReAct) 14.28 8.74 1.54 0.22 29.37 20.00 0.61 0.15 29.93 8.50 0.42 0.14 24.52 12.41 0.86 0.17 ReSearch 16.00 8.74 0.41 0.17 35.04 22.40 0.37 0.16 33.02 7.29 0.25 0.13 28.02 12.81 0.34 0.15 DeepResearcher 22.44 16.50 4.94 0.33 37.69 24.40 0.44 0.17 32.10 9.31 1.16 0.19 30.75 16.74 2.18 0.23 Ours 25.07 17.48 0.62 0.12 37.56 24.00 0.33 0.10 31.85 8.91 0.29 0.09 31.49 16.79 0.41 0.10 12 T able 6: T raining prompt text. Prompt: Y ou will answer multiple comple x questions using iterativ e reasoning and web search. Y our task is to: 1. Perform reasoning within ... . 2. Then choose one of the follo wing actions: - If any question remains unanswered, issue a single query for one question inside ... . - If all questions are answered, provide the final answers separated by semicolons within answer1; answer2; ... . The answers must be concise, usually short phrases or words, and av oid an y explanations. Important: - Must strictly follo w one of these two structures: \n...\n \n\n...\n or \n...\n \n\n...\n . - Do not search multiple queries or questions simultaneously . Don’t gi v e up searching for information until you find clear information that provides the answer . 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment