긴 시간 에이전트를 위한 자기 기억 정책 최적화 MemPO
MemPO는 LLM 기반 에이전트가 외부 메모리 모듈에 의존하지 않고, 자체적으로 <mem> 액션을 통해 기억을 요약·압축하도록 학습시키는 알고리즘이다. 트래젝터리 수준 보상에 더해 메모리 내용의 조건부 확률을 이용한 메모리‑레벨 어드밴티지를 도입해 신용 할당 문제를 완화하고, 토큰 사용량을 70% 이상 절감하면서 F1 점수를 25% 이상 향상시킨다.
저자: Ruoran Li, Xinghua Zhang, Haiyang Yu
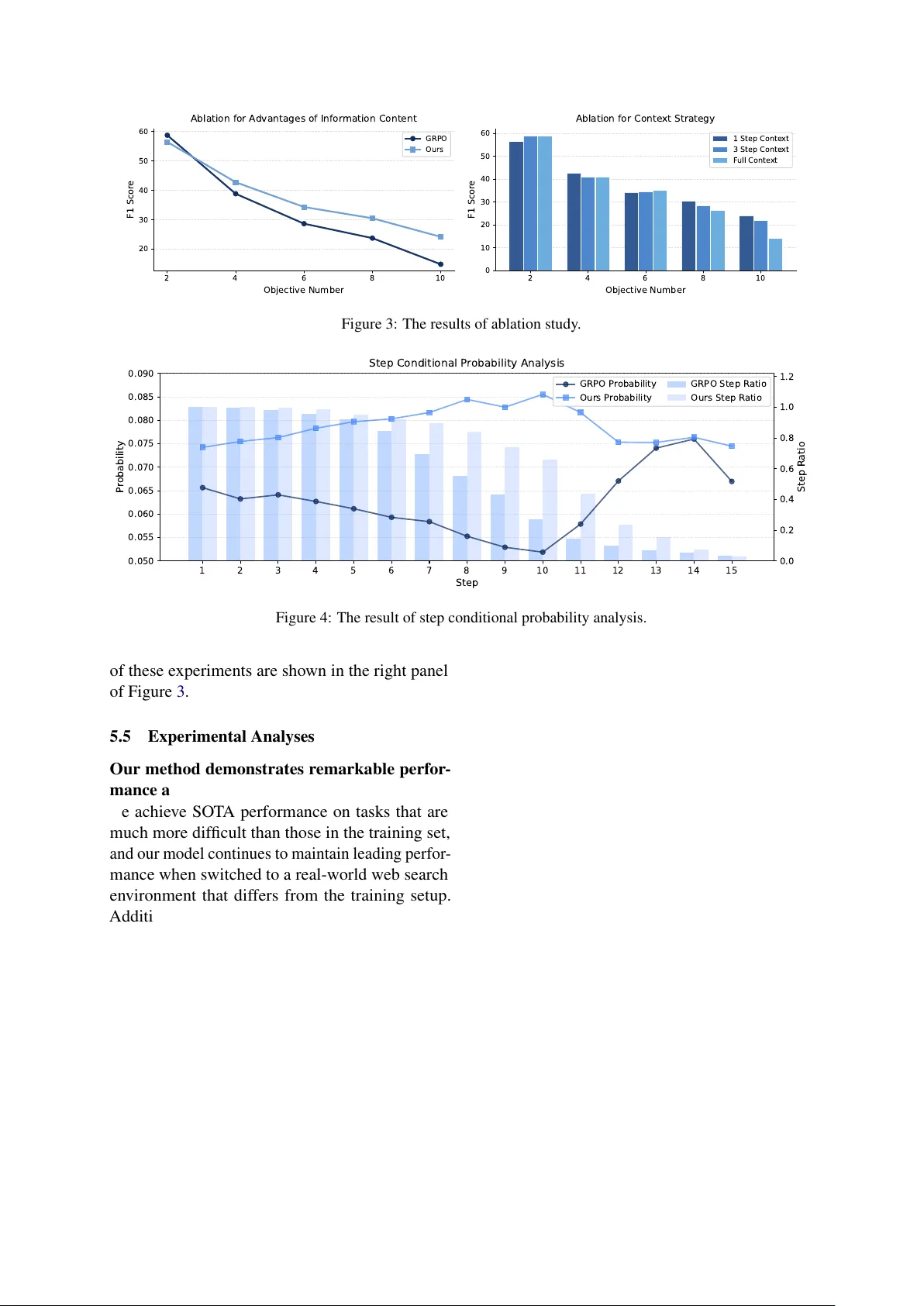
본 논문은 대형 언어 모델(LLM) 기반 에이전트가 장기 상호작용을 수행할 때 발생하는 컨텍스트 폭증 문제를 해결하고자 한다. 기존 연구는 외부 메모리 모듈을 도입해 과거 대화·행동 기록을 저장하고, RAG(Retrieval‑Augmented Generation) 방식으로 관련 조각을 검색해 프롬프트에 삽입하는 방식을 주로 사용한다. 이러한 접근은 메모리 검색이 모델 자체의 목표와 동기화되지 않아, 에이전트가 “필요한 정보를 스스로 선택·정리”하는 능력을 충분히 발휘하지 못한다는 한계가 있다. 또한, 컨텍스트가 선형적으로 증가함에 따라 LLM의 제한된 윈도우 크기와 토큰 비용 문제가 심화되고, “중간에 길을 잃는다(lost in the middle)” 현상으로 성능이 저하된다.
이를 극복하기 위해 저자들은 MemPO(Self‑Memory Policy Optimization)라는 새로운 알고리즘을 제안한다. MemPO는 에이전트가 자체적으로 액션을 통해 이전 단계의 핵심 정보를 요약·압축하도록 학습한다. 구체적으로, 에이전트는 , , 세 가지 액션을 사용해 각각 기억 요약, 사고, 도구 호출을 수행한다. 기억 요약은 s_mem_t 라는 토큰 시퀀스로 표현되며, 이는 … 태그로 감싸진다.
핵심 기술은 두 단계의 어드밴티지 계산이다. 첫 번째는 기존 GRPO와 동일하게 트래젝터리‑레벨 보상 R_T를 그룹 내 평균·표준편차로 정규화해 A_T를 얻는다. 두 번째는 메모리‑레벨 보상 R_M을 도입한다. R_M은 현재 단계에서 생성된 메모리 s_mem_t가 정답 토큰 시퀀스 a_ans를 생성할 조건부 확률 P
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기