Prompt Engineering for Scale Development in Generative Psychometrics
This Monte Carlo simulation examines how prompt engineering strategies shape the quality of large language model (LLM)--generated personality assessment items within the AI-GENIE framework for generative psychometrics. Item pools targeting the Big Fi…
Authors: Lara Lee Russell-Lasal, ra, Hudson Golino
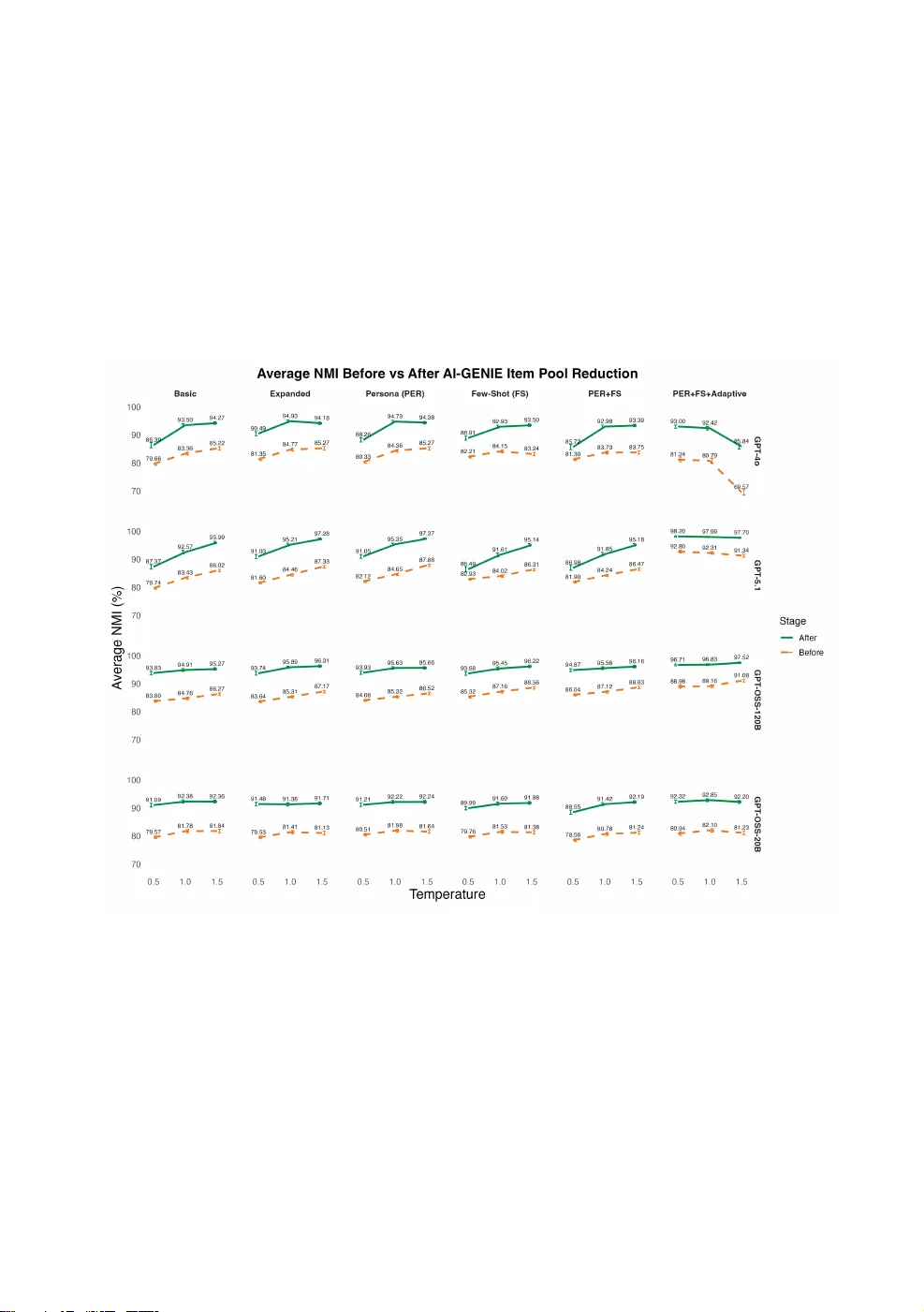
Promp t Engineering for Sc ale Development in Gener ativ e Psy chometrics Lara L. Russell-Lasalandra * and Hu dson Golino * Uni versity of Virginia, Charlottesvill e, V A, US A *Corresponding author. Email: llr7cb@virginia.edu ; hfg9s@virginia.edu Abstr act This Monte Carlo simulation examines how prompt engineering strategies shape the qualit y of large language model (LLM)–generated personalit y a ssessment items within the AI-GEN IE framework for generativ e psychometrics. Item pools targeting the Big Fiv e traits were generated using multiple prompting designs (zero-shot, few-shot, persona-based, an d adaptiv e), model temperatures, and LLMs, then evaluated and redu ced using net w ork psychometric methods. A cross all conditi ons, AI-GENI E reliably improv ed structural validit y follo wing redu ction, with the magnitude of its incremental contributio n inv ersely rel ated to the qualit y of the incoming item pool. Prompt design exerted a subst antial influence on both pre- and po st-reducti on item qualit y. A daptiv e prompting consistently outperf ormed no n-adaptiv e strategies by sharply reducing semantic redundancy, elevating pre-reductio n structural validit y, and preserving substantially larger item pool, particularly when paired with newer, higher-capacit y models. These gains were robust acro ss temperature settings for most models, indi cating that adaptive pro mpting mitigates common trade-offs bet w een creativit y and psychometric coherence. An exception was observ ed for the GPT-4o model at high temperatures, suggesting model-specific sensitivity to adaptive constraints at elevated stochasti cit y. Overall, the findings demonstrate that adaptiv e prompting is the strongest approach in this context, and that its benefits scale with model capabilit y, motivating continued in vestigati on of model–prompt interacti ons in generati ve psycho metric pipelines. Keywords: Psychological scale dev elopment, l arge language models, net w ork psychometrics, Exploratory Graph Analysis, Uni que V ariable Analysis, generativ e psychometrics, prompt engineering, AI-GENIE 1. Introduction Generativ e artificial intelligence (AI) is increasingly reshaping f oun datio n al practices in psychometrics (Garrido et al., 2025 ). L arge language models (LLMs) are no w routinely used in psychological scal e dev elopment to a utomatically content analyze items (Fyffe et al., 2024 ), create embeddings to be u sed for dimensi onalit y recov ery prior to data collection (Garri do et al., 2025 ), generate entire item pools (Götz et al., 2024 ; Hern an dez & Nie, 2023 ; P. L ee et al., 2023 ), and execute the post-gen eratio n checks [e.g., content review, bias assessment, and revisio n; P. L ee et al. ( 2025 )]. W e’ve ev en seen best-practice reco mmendati ons det ailing the respo nsible use of AI within this precise context (see Brickman et al., 2025 ; Sal ah et al., 2025 ). What is more, these LLM-authored items have already been shown to be adequately comparable to expert-a uthored items in some contexts (Hommel et al., 2022 ), and surpass them in others (Martin Ko wal et al., 2025 ). 2 Lara L. Russell-Lasalandra These devel opments reflect a broader methodological shift tow ard treating l anguage itself as a scal able source of psychological informatio n. That is, langu age can be analyzed, filtered, and structured ev en before human response dat a are collected. This emerging set of practices has led to what has been termed Gen erativ e Psychometrics (Ru ssell-Lasal andra et al., 2024 ), a research paradigm that integrates LLM-ba sed generati on with quantitative psychometric evaluatio n t o support faster, more scal able, an d more reproducibl e measurement devel opment. Item content is no lo nger treated as a fixed human-authored input, but a s a probabilistic o utput that can be generated in large quantities and ev alu ated algorithmically. W ithin this fi eld, a new methodol ogy operatio nalizing psychometrics and LLMs has been proposed: Automatic Item Generation with Net w ork-Integrated Evaluati on ( AI-GENIE ; R ussell-Lasal an dra et al., 2024 ), which uses LLMs to generate l arge pools of candi date items and then applies n et w ork psychometric methods to evaluate an d reduce these pools. Although modern LLMs are capable of producing highly fluent and expert-like text without retraining (Brown et al., 2020 ; Carlini et al., 2021 ; Raffel et al., 2023 ), psychometric scale devel opment requires more than surface-level plausibility. The central challenge is generating items that accurately refl ect the intended construct while maint aining adequate structural validit y and minimi zing redundancy. AI-GENI E addresses this challenge by offering a scalable pipeline that not only generates items but also (deterministically) evaluates them in silic o using psychometri c approaches, improving the effici ency an d feasibilit y of assessment dev elopment. Despite these advances, a critical methodological questio n remains l argely unexplored in this emerging field: how do different pr ompt eng ineering strategies influen ce the qualit y of item pools enter- ing generativ e psychometri c pipelines? Prompt engineering, i.e., the art of effectively communicating with an advanced model to obtain high-qualit y, desirable output, has become a central compo nent of harnessing the full potenti al of AI systems across appli cations (OpenAI, 2024b ; R ussell-Lasal an dra et al., 2024 ). More formally, it can be defined as the systematic design and optimiz ati on of input prompts to guide LLM responses, ensuring accuracy, relevan ce, and coherence in the generated output (Chen et al., 2025a ). P rompt engineering is no w widely recognized as a key element of LLM output qualit y (Ekin, 2023 ; Fatawi et al., 2024 ; White, 2023 ). What began as an empirical practice ha s evolv ed into a stru ctured research domain, with milestones ranging fro m early structured inputs to modern techni ques su ch a s chain-of-thought and self-consisten cy prompting, all within the broader framework of in-context learning (Chen et al., 2025a ). A ccordingly, several resources no w provi de practical gui dance f or crafting effectiv e prompts (Ekin, 2023 ; Giray, 2023 ; see OpenAI, 2024b ). The rel evance of a w ell-articulated prompt cannot be ov erstated, as prompt qu alit y plays a central role in the consistency an d viabilit y of generated outputs (Jin et al., 2022 ; White, 2023 ). W ithin the context of psychological a ssessment, prior work has sho wn that prompt variatio n influences generated content (Dauphin & Si efert, 2025 ; de W inter et al., 2024 ) and can potentially alter the psychometric properties of resulting items, inclu ding aspects of validity (P. L ee et al., 2025 ; Marengo et al., 2025 ). Ho wev er, existing w ork in generativ e psychometrics has l argely treated prompting a s a fixed or secon dary design choice. No study has systematically examin ed how diff erent prompting strategies affect redundancy, structural v alidit y, and item-reducti on outcomes within a psychometri cally groun ded generativ e framework. The present research theref ore inv estigates whether, and to what extent, diff erent prompting strategies impro ve item generati on outco mes within the AI-GEN I E framew ork (Ru ssell-Lasal andra et al., 2024 ), addressing a key gap in the gen erative psycho metrics literature: how pro mpting choi ces affect the qualit y of both the initial item pool and the final, automatically filtered an d selected set of items. Specifically, this study examin es whether new er, l arger language models benefit more fro m advanced pro mpt-engineering methods than earlier models, an d ho w this relationship is modulated by the temperature parameter. Fin ally, the efficacy of these strategies is evaluated across multipl e 3 GPT models to assess how model characteristi cs interact with different prompting approaches. 1.1 Prompt Engineering and In-Context L earning The “prompt” is yo ur interface bet ween y our human intent and the model’s understanding. Because LLMs generate responses by predicting text conditi oned on the prompt, even small changes in phrasing, structure, or contextual framing can meaningfully alter the content, st yle, an d reliabilit y of the output (Amatriain, 2024 ). Prompt engineering theref ore provides a mechanism f or “ eliciting” and “steering” the model to wards o ne’s objectiv e, influencing both what the model generates an d ho w consistently it does so across repeated trials. On its surface, prompt engineering ma y appear to be simply a valuable techni cal skill , perhaps on e that is particularly promising for researchers and educators in higher educatio n (D. L ee & Palmer, 2025 ). How ever, as AI has advanced into the black-box, excepti onally large and deep models we kno w today, prompting has increasingly become more than just a craft learned through trial and error. Instead, it has developed into an emerging research paradigm (S chulhoff et al., 2025 ), with growing interest in systemati c strategies that improv e performan ce, reduce hallucinations, increase controllabilit y, and support reprodu cibilit y (Huang et al., 2025 ; Y. Liu et al., 2024 ). Prompt engineering has ev en begun to take on the characteristi cs of a formal professio n, as organiz atio ns inv est in training employees to properly prompt LLM-based systems (J oshi, 2025 ). Ho wev er, prompt engineering is o nly part of the equ ati on. The model’s abilit y to demonstrate in-context learning (ICL), or its abilit y t o adapt to new ta sks from inputted exampl es witho ut model-parameter tuning (Brown et al., 2020 ), pl a ys a central role in the efficacy of prompting strategies. That is, model-prompt interaction eff ects impact output qualit y (Chen et al., 2025b ; Han et al., 2025 ; Meht a & Gupt a, 2025 ). For example, when W ei, W ang, et al. ( 2022 ) introduced the chain-of-thought prompting strategy (i.e., an ICL approach that provi des the model with a series of reasoning steps), they f ound that this prompting techni que was particularly effectiv e only o nce models reach suffici ent scale. R ecent theoretical work reveals on ce models exceed a critical capacit y, they exhibit qu alita- tiv ely stronger in-context adapt ati on, including greater stabilit y, reduced sensitivit y to sampling temperature, and the abilit y to internali ze complex, set-lev el constraints from prompts (Mehta & Gupta, 2025 ). As a result, advanced pro mpting strategies disproportio n ately ben efit new er, larger models, while older models remain more sensitiv e to stochasticit y and pro mpt variatio n. Therefore, generativ e models will be increasingly responsi ve to advanced prompt design as model capabilities impro ve. As such, these empirical compariso ns will report the model and prompt interacti on rather than per-model performan ce alone. 1.2 Prompting T echniques The present stu dy evaluates f our widely u sed approaches: (1) zero-shot prompting, using both a basic and an expanded simulation co ndition; (2) few-shot pro mpting; (3) persona-based prompting; and (4) adaptiv e prompting. Each technique can be un derstood as a distinct wa y of structuring the four core components of an effectiv e prompt: clear t ask instructi ons, relevant contextual informati on, specificati on of the desired output format, and provisi on of any necessary input dat a (Chen et al., 2025a ; Russell-Lasalandra et al., 2024 ). The techniqu es vary systematically in ho w many of these compon ents they activate and ho w explicitly they do so. The most minimal prompt engineering scheme is z ero-shot prompting, in which the model receiv es ta sk instructi ons alon e (e.g., “Generate items measuring conscienti ousness”) with no examples or contextual scaffolding (Bro wn et al., 2020 ). This strategy is attractive because of its simplicit y and scalabilit y, but it pl aces the f ull burden of inferring the desired format, specifi cit y, and constru ct boun daries o n the model itself (Kojima et al., 2022 ). The expanded zero-shot conditi on used in the present simulation partially relaxes this constraint by supplying a construct definitio n and a small set 4 Lara L. Russell-Lasalandra of item-format requirements, thereby acti vating the context an d output-format co mpon ents of the prompt stru cture while still withhol ding examples. This design allo ws for a graded test of how much informati on, short of exemplars, is needed to impro ve o utput qu alit y. Few-shot prompting exten ds this logic by embedding a small set of examples directly into the prompt (e.g., sample items of the desired style and psychometri c qualit y), which anchors o utputs to a t arget register and implicitly communicates the expected format (Brown et al., 2020 ). The techniqu e draw s on the same in-context learning mechanism that underli es much of modern LLM behavi or: exposure to even a han df ul of demonstrati ons can meaningf ully impro v e t ask perf ormance without any modificati on to model parameters (Chen et al., 2025a ; X. Liu et al., 2023 ). In prompting research, these examples f un ctio n as what might loosely be called embedded training signal, but not in the traditional sense of a large curated corpus: as a compact set of positiv e examples that constrain the space of possibl e outputs. R esearch on o ne-shot versus few-shot designs suggests that a singl e example may suffice for simpler ta sks or highly capable models, while multiple examples provi de additio n al guidan ce for more compl ex t asks or less capable on es (Brown et al., 2020 ). This technique is clo sely related to “prompt programming” approaches that treat prompts as stru ctured inputs capable of controlling an d stabili zing model beha vior (R eynolds & McDon ell, 2021 ). P ersona prompting introduces a role or identit y frame (e.g., “Y ou are an expert psychometrician dev eloping a perso n alit y assessment”) to bias the model t o ward domain-consistent l anguage, decisi on rules, and tone (A. Liu et al., 2024 ). Conceptually, persona prompting f uncti ons as a high-lev el behavi oral prior that shapes what the model atten ds to an d ho w it interprets task demands (Olea et al., 2024 ; T ouvro n et al., 2023 ). Assigning a role to the model has been sho wn to impro ve accuracy o n some kno wledge-intensiv e benchmarks rel ativ e to role-free prompts (Kong et al., 2024 ), though the benefits are in consistent and depen d on factors such as the persona cho sen and its alignment with the task domain (Zheng et al., 2024 ). This technique is wi dely used in applied settings, including psychological perso n alit y assessment (De Paoli, 2023 ; Jiang et al., 2024 ), because it ten ds to increase coherence an d domain alignment, ev en when the requested output remains purely textual. The most sophisti cated technique in the present simulatio n is adaptive pro mpting. Spliethö v er et al. ( 2025 ) introduce adapti ve prompting as a method that selects the most eff ective pro mpt compositi on for each input instance from a predefined pool, using a learned predictor to i dentif y the best co nfiguration for that specifi c example. The present simulation adopts a related but operatio nally distinct f orm of adaptivit y, grounded in the iterati ve refin ement paradigm (Lightman et al., 2023 ): the model is dyn ami cally provi ded with its own previ ously generated items and explicitly instructed to av oid duplicati on (e.g., “Do NOT repeat or rephra se anything in this list. . . ”). This design instantiates a generate-evaluate-revise cycle analogous to the prompt chaining l ogic described in the broader prompt engineering literature (Chen et al., 2025a ; R ussell-Lasal an dra et al., 2024 ), in which each gen eratio n step is con ditio ned o n the outputs of prior steps an d t argeted feedback. The approach is especially relevant to l arge-scal e item generati on because LLMs often exhibit degenerative repetitio n, where l ater outputs conv erge tow ard semantically similar phra sing in the absence of external constraints. A gro wing literature on iterativ e refinement, including self-reflectio n, self- revisio n, and feedback-co nditi oned prompting, demo nstrates that repeatedly con ditio ning the model on its pri or outputs and explicit corrective signals can substanti ally impro ve uniqueness and reliabilit y without any retraining (Krishn a et al., 2024 ; Sun et al., 2024 ). 1.3 AI-GENIE While prompt engin eering strategies can substantially influence LLM-generated text, their practical value f or psychological measurement depends on ho w these strategies transl ate into high-qualit y items. More specifically, qualit y item pools should ha ve little redun dancy an d high structural vali dit y. The present study theref ore embeds prompt engineering strategi es within the AI-G EN I E pipeline (R ussell-Lasal an dra et al., 2024 ), which provi des a deterministic, n et w ork-based mechanism to 5 evaluate these different pro mpting approaches and LLMs. Before diving into the present simul ati on, we provide an ov erview of the AI-GEN I E methodology which co nsists of these steps: • Generate an d Embed an Initial Item Pool • P erform an Initial Exploratory Graph Analysis (EGA) t o Set a Baseline • R un Uniqu e V ariable Analysis (UV A) Iterativ ely to Redu ce Redun dancy • R un Bootstrap EGA (bootEGA) Iteratively f or Structural V alidatio n • P erform a Final EGA to Assess R educti on Qualit y 1.3.1 Generate and Embed an Initial Item Pool The process begins by generating an initial set of candi date items, which is the focu s of the cur- rent simulation. Next, AI-GENI E embeds each item using a language-model embedding system (specifically OpenAI’s text-embedding-3-small (OpenAI, 2024c )), conv erting each item into a high- dimensio n al semantic v ector (that is, embeddings “translate” human l anguage into quantitative input for psychometric modeling). These embeddings allo w the pipeline to operati onali ze relatio nships among items based on meaning similarit y, enabling the constructi on of a net w ork. 1.3.2 Perf orm an Initial Exploratory Graph Analysis (EGA) to Set a Baseline W ith the embedded item net w ork in hand, the pipeline performs an initial Exploratory Graph Analysis (EGA; Golino and Epskamp, 2017 ) to estimate the pool’s dimensional structure as a baseline before any redu ction steps. EGA is a net w ork psychometric method f or estimating the dimensional structure of a set of variables by modeling them as a net w ork (as opposed to a traditional f actor model). It first estimates a net work (e.g., using T riangul ated Maximally Filtered Graph (TMFG; Massara et al., 2016 ) and Extended Ba yesian Informatio n Criterio n Glasso (EBICgla sso; Foygel and Drton, 2010 ; F riedman et al., 2008 )) where n odes are items and edges represent st atisti cal or semantic relationships among them. Then, it applies a communit y detection algorithm (such as W alktrap (P ons and Lat apy, 2005 )) to identif y clusters of densely conn ected nodes, which are interpreted as l atent dimensions or f actors. Because the clusters emerge from patterns of connecti vit y, EGA pro vides an empiri cally driv en wa y to disco v er how many dimensi ons exist and which items bel ong to each dimensio n. The resulting dimensional soluti on can be evaluated using N ormali zed Mutual Informati on (NMI; Dano n et al., 2005 ). NMI is a metric for quantif ying ho w similar t wo diff erent clusterings of the same set of items are, with scores closer to 0 indicating lo w accuracy, or tot al dissimilarit y, and scores closer to 1 in dicating perfect accuracy. In this context, it’s used to evaluate ho w w ell the communities recov ered by EGA match the kn own, “tru e” item gro upings in simulatio n (e.g., whether items intended to measure N euroticism actually cluster together). 1.3.3 Run Unique Variable Analysis (UV A) Iteratively to Reduce Redundancy AI-GENI E then reduces the pool in two iterativ e phases designed to remo ve redun dant and unstable items. First, Uni que V ariable An alysis (UV A; Christensen et al., 2023 ) detects redundancy using w eighted topological o verlap (wTO; Zhang and Horvath, 2005 ) within a Gaussian graphical model framew ork. In a net w ork view, redundant items will look like they share nearly the same pattern of conn ectio ns (neighbors an d edge strengths). That is, t w o redundant items will ha ve high wTO if they conn ect to the same other items with similar edge strengths. UV A identifi es sets of items that exceed a redundan cy cutoff (a wTO threshold). Fro m each redundant pair or set, o nly the item with lo west ov erall ov erl ap with the rest of the pool (i.e., the most unique representative of that set) is retained. The remaining items in that redundant clu ster are remo ved beca use they contribute little uniqu e co verage. Redun dant items are remov ed iteratively until n o further redundant pairs or sets remain. 6 Lara L. Russell-Lasalandra 1.3.4 Run Bootstrap EGA (bootEGA) Iterativ ely for Structural Validation After redundancy remov al, the pipeline uses bootstrap EGA (bootEGA; Christensen and Golino, 2021 ) to assess structural stabilit y. BootEGA is an extensi on of EGA that ev alu ates the stabilit y and replicabilit y of an estimated dimensio nal structure. BootEGA then tracks ho w consistently each item is assigned t o the same dimensi on across resamples. Items that frequently “w ander” between dimensio ns accross the bootstrap (lo w a ssignment consisten cy) are interpreted as poor qu alit y items that destabili ze the n et w ork structure, whil e items that remain in the same cluster are consi dered stronger and more reliable. Items that f all belo w a st abilit y threshold are remov ed from the item pool. Then, this process is repeated until all remaining items show high stabilit y. 1.3.5 Perf orm a Final EGA to Assess Reduction Quality In the final step of the AI-GENI E pipeline, an EGA net w ork is computed on the reduced item pool so the NMI can be recal cul ated and compared to the baseline calculated pre-reducti on. This step is a post-pruning structural check t o confirm that the reduced item pool reco vers the inten ded dimensio ns better than the original pool. That is, after a su ccessf ul AI-GENI E reductio n, the NMI is higher than the initial NMI, indi cating that the pruning remov ed less st able or highly redundant items while impro ving the recov ery of the t arget structure. 2. Methodology The present stu dy used a Mo nte Carlo simulation t o evaluate ho w prompting strategies influence the psychometri c qu alit y of AI-generated personalit y assessment items within the AI-GENI E framew ork. Each uniqu e combination of experimental conditi ons was replicated 100 times, yi elding a large set of indepen dent item pools and reductio n outcomes. E ach repli cate had at least 60 AI-authored items. Experimental f actors inclu ded: • Four language models (GPT-4o, GPT-5.1, GPT-OSS-20B, and GPT-O SS-120B) • Three LLM model temperatures (0.5, 1, 1.5) • Fiv e personalit y traits corresponding to J ohn and Sriv ast a va’s 1999 Big Fiv e model (Openness, Conscienti ousness, Extra versi on, Agreeableness, Neuroticism). These are the OCE AN personalit y traits. • Six prompt designs (Basi c, Expanded, Few S hot, Perso n a, P ersona + Few Shot, P ersona + Few Shot + A daptiv e). • T wo EGA n et work estimatio n models 1 (TMFG, EBICglasso) The first experimental f actor is the LLM model used to gen erate the items. T wo of the models are open-source (GPT-O SS 120B and 20B (OpenAI, 2025a )), an d t wo of the models are proprietary (GPT-4o (OpenAI, 2024a ) and GPT-5.1 (OpenAI, 2025b )). The second experimental f actor is the model’s temperature setting. T emperature is a hyperparameter of an LLM that, very gen erally, sets the lev el of creativit y on e should expect from the output (see exceptio n; P eeperkorn et al. ( 2024 )). By increasing the temperature, an LLM w ould be more likely t o select at ypi cal tokens, indu cing a uniqu e response. Conv ersely, low er temperatures produce more predicabl e responses. The third experimental f actor is the OCE AN perso nalit y trait. Therefore, w e will be creating item pools that target each of the Big Five (J ohn & Srivastava, 1999 ) perso n alit y traits. Th Big Five model was selected because we used this model in our simul atio n that demonstrates the efficacy of AI-GENI E (Russell-Lasalandra et al., 2024 ). A dditio nally, relying on the Big Fi ve is deliberate 1 For every generated item pool within each replicatio n, the AI-GEN IE reduction pipeline was executed under t wo alternative EGA model specifications. These EGA conditions did not inv olve regenerating new items; rather, the same generated item pool was embedded on ce and then passed through AI-GENI E under each EGA model to evaluate whether downstream stru ctural validation an d reduction results diff ered as a function of the network estimatio n method. 7 because it is heavily represented in psychological research (and likely LLM training dat a), so it f un ctio ns as a rigorous first test of whether AI-GEN I E can match expert-dev eloped measures under fav orable, w ell-understood conditio ns. Once a pattern is observed, f urther research can test the robustness of the findings in the context of l ess established constructs, where training-data cov erage and theory are w eaker. Several attributes associated with the targeted OCEAN personalit y traits were pro vided to the model. Including these trait attributes helps ensure that the items generated were not unidimensi onal and that they targeted several important a spects of the giv en trait. The attributes for each trait w ere as follo ws: 1. Openness : creativ e, perceptu al, curi ous, and philo sophical 2. C onscientiousness : organized, responsible, disciplined, an d prudent 3. N eur oticism : anxiou s, depressed, insecure, and emoti onal 4. A greeableness : cooperative, compassi onate, trust w orthy, and humble 5. Extr aversion : frien dly, positiv e, assertive, an d energeti c The f ourth experimental factor is the pro mpt design used to generate the items. The basic prompt was a zero-shot design that plainly instructed the model to generate items that targeted each of the pro vided trait attributes. For example, the basic prompt used t o generate ‘ extra v ersio n’ items was as foll ows: Generate n ov el items that assess the perso nalit y trait ’extrav ersion’ from the ’Big Fiv e’ personalit y model. Extrav ersion has the f ollowing attributes of interest: friendly, posi- tiv e, a ssertiv e, and energeti c. For E A CH attribute, write EXA CTL Y TW O (2) single- sentence, first-perso n items each reflecting O NL Y that given attribute. Do NOT add any attributes or lea ve any out." At this point, the reader may be w ondering why w e would ask the model to produce only t w o items per attribute when a t arget of 60 total items is desired. When using an Applicatio n Programming Interface (API) to access these models, there are token limitations which prev ent the model from outputting all 60 items in a single AP I call. Therefore, to gen erate 60 items, the prompt had to be parsed many times per sample. The expande d prompt elaborated on the instructio ns a bit f urther: Ensure that each item is extremely high-qualit y, psychometrically robu st, and co ncise. Each item should be no vel, so be creativ e; aim for breadth across these attributes. Items should be polished an d ready for immediate practical use. The f ew shot prompt f urther appended a list of examples for the model to emualte in terms of qualit y and structure. These items were pulled from J ohn and Sriv a stava’s 1999 assessment v erbatim: • I am someo ne who is compassionate, has a soft heart. • I am someo ne who st arts arguments with others. • I am someo ne who is dependable, steady. • I am someo ne who has difficult y getting started on t asks. • I am someo ne who has an assertive personalit y. • I am someo ne who rarely feels excited or eager. • I am someo ne who is moody, has up and do wn mood swings. • I am someo ne who st a ys optimistic after experiencing a setback. • I am someo ne who is inv entive, finds cl ever wa ys to do things. • I am someo ne who av oids intellectual, phil osophical discu ssio ns. 8 Lara L. Russell-Lasalandra T o prevent the model from recycling the content of these examples, the model w as also instructed to refrain from regurgitating J ohn and Srivastava’s 1999 i deas: Here are some EXAMPLE items that y ou must emulate in terms of Q U ALITY an d item STR UCTURE only, but do NOT reuse any of these examples’ content. The content of the items y ou generate mu st be entirely uniqu e. The persona prompt added an appropriate system role to the expande d prompt. A system role is a secon dary prompt that primes the model with an expert persona to improv e its output. For example, our system rol e for the extra versi on trait was as follo ws: Y ou are an expert psychometri ci an an d test dev eloper specializing in personalit y assess- ment. Y our ta sk is to create high-qualit y, psychometrically robust items for a personalit y inv entory measuring ’extrav ersion’ from the ’Big Fiv e’ model of personalit y. The persona + few shot prompting con dition simply added this system role to the f ew shot prompt. Likewise, the persona + f ew shot + adaptive prompt approach added the adaptive co mponent. Typically, we ran the prompt 8-15 times to build sample of at least 60 items tot al. The adaptive compo nent inclu ded a running list of the items that the model had already generated in all of these previous outputs. For example, this adaptiv e compon ent woul d tell the model the foll o wing: Do NOT repeat, rephrase, or reuse the content of ANY items from this list of items y ou’v e already generated for ’extra versio n’: 1. pr eviousl y g enerate d extr aversion item #1. 2. pr eviousl y g enerate d extr aversion item #2. 3. pr eviousl y g enerate d extr aversion item #3. and so on. . . See T able 1 f or a visual breakdown of which pro mpt compon ent was included in each of the six prompting con ditions f or this simul ati on. Lastly, a basic instructi on on the required formatting was appended to the end of every sin- gle prompt so the output could be adequately parsed. For extrav ersion items, for example, these instructi ons were as f ollo ws: R eturn output STRICTL Y a s a JSO N array of objects, each with keys attribute and statement, e.g.: ["attribute":"frien dly", "statement": "Y our item here.", ...] This JSO N formatting is EXTREMEL Y important. Do NOT in clude any explanatio ns, commen- tary, or markdown. O utput only the JS ON. The "attribute" key should ONL Y ha ve these EXA CT valu es: friendly, po sitiv e, assertiv e, and en ergetic. 3. Results Figure 1 provides an ov erview of average NMI before and after AI-GENI E reducti on across all models, temperatures, and prompting conditio ns. Sev eral patterns are immedi ately apparent: AI- GENI E reli ably impro v es NMI across virtually all con ditio ns (the blue post-reducti on line consistently exceeds the orange pre-redu ction lin e); adaptiv e prompting substantially raises the pre-reducti on NMI floor f or the new est models; and GPT-4o at temperature 1.5 under adaptiv e prompting is the sole con dition where po st-reducti on NMI falls below the n on-adaptive baselin e, motivating cl oser examination of that model’s beha vior. The adaptiv e prompting strategy, especially when paired with newer models, prov ed to be especially pow erf ul. A daptiv e prompting produced large, systematic impro vements in the qualit y of 9 Figure 1. A verage NMI before and after AI-GENI E reduction across prompting conditi ons, models, and temperatures. AI-GENI E reliably improv ed NMI across virtually all conditi ons. A daptiv e prompting substantially raised the pre-reduction NMI floor for the newest models, with GPT-4o at temperature 1.5 as the sol e conditi on where post-reductio n NMI fell below the non-adapti ve baseline. 10 Lara L. Russell-Lasalandra T able 1. Compon ents Included in Each P rompting Design BA S EXP FS PER PER+FS PER+FS+A Essential Instructi ons ✓ ✓ ✓ ✓ ✓ ✓ More Detailed Instructio ns – ✓ ✓ ✓ ✓ ✓ A system role pro mpt – – – ✓ – ✓ A list of item examples – – ✓ – ✓ ✓ A list of items generated thus far – – – – – ✓ N ote. The prompt compo nents used to constru ct the fin al prompt giv en to the model f or each con dition. The ba si c (BA S) prompt co nditi on only receiv ed minimal instructi ons, whereas the expanded (EXP) prompt con dition receiv ed more det ailed instructi ons in addition to the minimal instructio ns. The other con ditions built upon the expanded prompt co nditi on f urther by adding compon ents like a model persona and item exampl es. item pools across multipl e outcome measures. How ever, the magnitude of impro vement ov er the basic prompt baseline depen ded strongly on model capabilit y and temperature sensiti vit y. Most strikingly, the adaptive con dition drastically reduced initial item pool redundancy by roughly 93.7%. W e observed similarly large proportional decreases of of 88.5%, 83.3%, and 53.4%, for GPT- 4o, GPT-OSS-120B, and GPT-OSS-20B respectively. For almost all experiment al con ditio ns, these reducti ons in redundancy were accompanied by gains in the final structural validity. Relativ e to the basic prompt, the final NMI increased by an average of 10.8%, 5.4%, and 1.7% for GPT-5.1 at temperatures 0.5, 1.0, an d 1.5, respectiv ely, yielding n ear-ceiling final NMI values. Attenuated baseline impro vements were observed for GPT-OSS-120B (1.9-2.9% across temperatures), and GPT-OSS-20B sho wed modest gains (0-1.2%). A daptiv e prompting also subst antially increased the number of items ret ained after AI-GENI E filtering, particularly for the new est models (e.g., GPT-5.1 had an av erage fin al sample siz e of 56–57 items under adaptive prompting and only 16–29 items under the basic prompt). GPT-4o represents a notable exception to the otherwise consistent pattern of adaptiv e gains. A lthough adaptive pro mpting reduced UV A remov als for GPT-4o, impro vements in the final NMI were not monotoni c across temperatures. At the highest temperature, adaptive prompting resulted in an 8.5% decrease relative to the basic prompt. This finding suggests an unu sual, model-specific sensitivity to adaptive prompting at higher temperatures. 3.1 Redundancy Analysis Using UV A W e first examined how prompt design influen ced redundan cy in the initial item pools, operationalized as the number of items remo ved during the UV A step of AI-GENI E. A cross all models and temperatures, the adaptive prompting con dition produced substantially few er UV A remo vals than the basic pro mpt and all other n on-adaptive pro mpt designs (Figure 2 ). This effect was especially pron ounced for the n ewest LLM, GPT-5.1. A veraged acro ss temperature settings, GPT-5.1 remov ed approximately 35.9 items under the basic prompt, compared to o nly 2.3 items under adaptiv e prompting, an absolute reducti on of 33.6 items on a verage, correspo nding to a 93.7% decrease in redundan cy. Import antly, this redu ction was robust across temperature lev els, with redundan cy remo vals remaining a small han df ul of items. A similar qualit ativ e pattern was observed f or GPT-4o and GPT-OSS-120B. GPT-4o exhibited an av erage reducti on from 23.1 items remo ved un der the basic prompt to 2.7 items un der adaptiv e 11 Figure 2. The av erage number of items remo ved during the UV A step of AI-GENI E relative t o the basic prompt con dition. The redundancy reductio n is most notable for the adaptive prompting conditi on, which shows substantial gains ov er the baseline. prompting (an 88.5% reductio n), while GPT-OSS-120B decreased from 30.6 to 5.1 items (an 83.3% reducti on). The smaller GPT-OSS-20B model show ed a more modest benefit, with adaptive prompting redu cing av erage UV A removals from 17.1 t o 8.0 items (a 53.4% reducti on). No n-adaptiv e prompting strategi es, Expanded , F ew-Shot , P ersona , and P ersona + F ew-Shot , pro- duced comparativ ely small and inco nsistent changes rel ativ e to the basic prompt. In sev eral cases, these no n-adaptiv e designs yielded equal or greater redundan cy than the basic conditi on, underscoring that redundan cy reducti on was not a general co nsequence of adding pro mpt complexity, but rather a distinctiv e effect of the adaptiv e component specifi cally. The absolute scale of this redundancy is notable: under the basic prompt at the lo west temperature, GPT-5.1 flagged an a verage of 41.0 items per pool as redun dant (approximately 68% of all gen erated items) underscoring ju st how severe degenerativ e repetition can be in the absence of adapti v e constraints (Figure 3 ). 3.2 Pre-Reduction Quality Check Using NMI Consistent with the redun dancy results, adaptiv e prompting produced the largest impro vements in initial NMI for the new est models (Figure 4 ). Recall that the initial NMI (or accuracy) quantifies ho w well the EGA model reco vered the kn o wn communities (i.e., Big Fiv e P ersonalit y traits) before any pruning is don e. For GPT-5.1, adaptive prompting increased the initial NMI relative to the basic prompt by 13.1%, 8.9%, an d 5.3% at temperatures 0.5, 1.0, and 1.5, respectively, yielding initial NMI values exceeding 91% across all temperatures. These gains were substantially l arger than those observ ed for any non-adaptiv e prompting strategy, which t ypically impro ved initial NMI by only 1–3% ov er the baseline. A similar but attenuated pattern was observed for GPT-OSS-120B, where adaptiv e prompting impro ved the initial NMI by approximately 4–5% across temperatures. GPT-OSS-20B 12 Lara L. Russell-Lasalandra Figure 3. A verage number of items remov ed at the UV A redundancy step across prompting conditio ns, models, and temperatures. A daptive prompting (P ER+FS+A daptiv e) produced dramatically few er remov als than all other conditio ns, with reducti ons most pro noun ced for the newest models. 13 Figure 4. The average NMI before AI-GEN I E reduction rel ativ e to the basic prompt conditio n. A daptiv e prompting produced impro vements in accuracy ov er the baseline for GPT-5.1 and GPT-OSS-120B. On the other hand, GPT-OSS-20B show s very modest gains whil e GPT-4o’s high and default temperature models sho w a dip in the initial NMI. sho wed only minimal impro vements in initial NMI un der adaptiv e prompting (generally less than 1.5%), indi cating that the benefits of adaptiv e prompting scale with model capacit y. 3.3 Post -Reduction Quality Check Using NMI As can be seen in Figure 5 , our results sho w that prompt design also influen ced structural v alidit y after AI-GEN I E reducti on. Whereas the initial NMI reflects the structure prior to AI-GEN I E filtering, the final NMI reflects the combined eff ects of prompt design and the AI-GENI E pipeline, capturing ho w well the redu ced item sets recov er the intended dimensio ns. A cross models and temperatures, adaptiv e prompting produced the strongest post-redu ctio n outcomes. This effect was most pro nounced f or GPT-5.1, which achiev ed almost perfect reco very under the adapti ve co nditio n. Relativ e to the basic prompt, adaptiv e prompting increased the final NMI by 10.8%, 5.4%, and 1.7% at temperatures 0.5, 1.0, and 1.5, respectively, yi elding a v erage final NMI values of approximately 98% across all temperatures. These gains subst antially exceeded those observ ed for non-adapti ve prompting strategi es, which t ypically produ ced improv ements of only 1–4% o ver baselin e. GPT-OSS-120B exhibited a similar but attenuated pattern. U nder adaptive prompting, final NMI increased by approximately 1.9% to 2.9% rel ativ e to the basic prompt across temperatures, resulting in final NMI values bet ween 96% and 97.5% (T able 2 ). While smaller in magnitude than the gains observ ed for GPT-5.1, these impro vements w ere consistent across temperatures and in dicate that adaptiv e prompting enhances post-redu ction structural vali dit y for large open-source models as w ell. GPT-OSS-20B show ed modest improv ements in the fin al NMI under adaptiv e prompting, with gains generally bel o w 1.5% and a verage final NMI valu es near 92–93%. This pattern mirrors the limited improv ements observed in pre-redu ctio n structure and redun dancy reductio n for this model, 14 Lara L. Russell-Lasalandra Figure 5. The av erage NMI after AI-GEN IE implementation relative to the basic prompt conditi on. A daptive prompting produced impro vements in accuracy ov er the baseline for GPT-5.1, GPT-OSS-120B, and GPT-OSS-20B. Ho wever, GPT- 4o’s high temperature model provi ded a notable exception as adaptiv e prompting sho wed a dip in the final NMI. reinforcing the co nclusio n that the benefits of adaptiv e prompting scale with model capabilit y. GPT-4o again deviated from the general pattern. A lthough adaptive pro mpting impro ved final NMI at low er temperatures (e.g., 6.6% at temperature 0.5), performance deteriorated sharply at the highest temperature. At temperature 1.5, adaptive pro mpting resulted in a final NMI of 85.8%, representing an 8.4% decrease relativ e to the basic prompt. This reversal co ntra sts with the stable or mon otonic gains observ ed for the other models and un derscores a model-specific sensitivit y to adaptiv e constraints at higher levels of sampling st ochasticit y. 3.4 AI-GENIE’ s Incremental Contribution Across Pr ompting Conditions A complementary perspecti ve on these results is pro vided by examining the magnitude of im- pro vement delivered by AI-GENI E itself, that is, the gain from pre- to post-redu ctio n NMI across prompting conditi ons (Figure 6 ). For GPT-5.1 under no n-adaptive conditio ns, AI-GENI E im- pro ved NMI by approximately 7.5-10%, reflecting the pipeline’s capacit y to substanti ally refine lo wer-qualit y initial pools. Under adapti ve prompting, this gain narro ws to approximately 5-6%. This apparent atten uation is not evi dence of redu ced pipeline effectiv eness; rather, it reflects a ceil- ing dyn ami c. A daptiv e prompting produces initi al item pools with pre-reducti on NMIs already exceeding 91%, lea ving less structural room f or the pipeline to impro ve. This pattern confirms that adaptiv e prompting and AI-GENI E are complementary rather than redundant: the former elev ates the qualit y of what enters the pipeline, while the latter pro vides deterministi c refinement of whatev er it receiv es. Notably, for GPT-OSS-20B, where adapti ve prompting’s effect o n initial qu alit y w as minimal, AI-GENI E’s incremental gain remains st able acro ss all prompting con ditio ns, consistent with the interpretation that the pipeline’s co ntribution is largest when incoming qualit y is lo west. 15 Figure 6. A verage improvement in NMI delivered by AI-GEN I E (pre- to post-reduction) across prompting conditions, models, and temperatures. 16 Lara L. Russell-Lasalandra T able 2. Mean Final NMI After AI-GENI E R educti on BASI C EXP ANDED PERS ONA FEW SH OT PER+FS PER+FS+A Grand Mean gpt-4o T emp 0.5 86.39 90.49 88.26 88.90 85.72 93.00 88.79 T emp 1 93.49 94.93 94.79 92.93 92.98 92.42 93.59 T emp 1.5 94.28 94.18 94.38 93.50 93.39 85.84 92.60 Mean 91.39 93.20 92.48 91.78 90.70 90.42 gpt-5.1 T emp 0.5 87.37 91.01 91.06 86.50 87.01 98.20 90.19 T emp 1 92.55 95.21 95.35 91.60 91.85 97.99 94.09 T emp 1.5 95.99 97.28 97.37 95.14 95.18 97.70 96.44 Mean 91.97 94.50 94.59 91.08 91.35 97.96 gpt-oss-120b T emp 0.5 93.83 93.74 93.94 93.68 94.87 96.71 94.46 T emp 1 94.91 95.89 95.63 95.45 95.55 96.83 95.71 T emp 1.5 95.27 96.31 95.66 96.22 96.16 97.52 96.19 Mean 94.67 95.31 95.08 95.12 95.53 97.02 gpt-oss-20b T emp 0.5 91.08 91.48 91.22 89.99 88.55 92.32 90.77 T emp 1 92.38 91.38 92.22 91.60 91.42 92.85 91.98 T emp 1.5 92.36 91.71 92.24 91.88 92.19 92.20 92.10 Mean 91.94 91.52 91.89 91.15 90.72 92.46 Grand Mean 92.49 93.63 93.51 92.28 92.07 94.47 N ote. The average final NMI aftter AI-GENI E reductio n. The highest final NMIs were recorded for the GPT-5.1 model under the adaptiv e prompting conditi on. How ever, the most modest NMIs w ere recorded for the same adaptive prompting con dition when paired with the older GPT-4o model. 3.5 Item P ool Size aer R eduction Consistent with the preceding results, adaptive prompting yielded markedly higher item retentio n f or the most capable models. For GPT-5.1, adaptive pro mpting resulted in an av erage of approximately 56–57 retained items across all temperature settings, co mpared to 16-29 items under the Basic prompt (Figure 7 ). This represents a more than t wof old increase in retained items while simult aneou sly achieving n ear-ceiling post-redu ctio n structural v alidit y. A similar pattern was observed f or GPT- OSS-120B, where adaptiv e prompting retained approximately 51-52 items, compared to only 25-32 items under the basic co nditio n. GPT-OSS-20B exhibited more modest retention gains un der adaptiv e prompting, with the final item pool size increasing by approximately 6 to 14 items relative to the basic prompt, depen ding on temperature. This pattern mirrors the smaller improv ements observed f or redundancy reducti on and final NMI in this model, suggesting that adaptive prompting yields diminishing returns f or lo wer-capacit y architectures. For GPT-4o, adaptive prompting increased item retention at low er temperatures (e.g., fin al item pool siz e of roughly 46-49 items under adaptive prompting versus 20-33 items under basic prompting at temperatures 0.5 an d 1.0), but this advantage diminished at the highest temperature. At temperature 1.5, adaptive pro mpting yielded slightly f ew er retained items than the ba si c prompt, paralleling the decline in final NMI observ ed for this con dition. 17 Figure 7. A v erage item pool size after AI-GENI E implementatio n relativ e to the basic prompt conditi on. A daptive pro mpting retained the largest number of items for all co nditio ns except GPT-4o’s highest temperature model. 3.6 Summary of Findings These findings suggest that adapti ve prompting is the dominant driv er of qualit y improv ements in generativ e psychometric item dev elopment, with effects that scale strongly with model capabilit y. For the new est model, GPT-5.1, adaptiv e prompting produced dramati c reductions in redun dancy and large impro vements in both pre and po st-reduction communit y detecti on accuracy acro ss all temperature settings, while simultaneously retaining substanti ally larger item pools after reducti on. GPT-OSS-120B exhibited the same qualitative pattern with smaller but consistent gains, whereas GPT-OSS-20B sho wed more modest impro vements. In contrast, non-adaptiv e prompting strategies yielded comparatively small, in consistent, or n egligible benefits rel ativ e to the ba sic prompt. GPT-4o pro ved to be somewhat of an exception to the otherwise impressive gains noticed when using adaptiv e prompting. Altho ugh adaptive pro mpting reduced redundan cy for this model, its structural performan ce was highly sensitiv e to temperature, with marked declin es in both initial and final NMI at the highest temperature. Overall, these findings indi cate that adaptive prompting substantially enhances the efficien cy and structural qualit y of AI-generated item pools when paired with sufficiently capable language models, motivating closer examination of model–prompt interactio ns and the mechanisms underlying these eff ects. 4. Discussion The present study inv estigated how prompt engin eering strategies interact with model capabilit y to shape the qualit y of AI-generated assessment items within the AI-GENI E framew ork. A cross a large Monte Carl o simulation, w e fo und that adaptive prompting emerged as the do minant prompting approach, yielding dramati c reducti ons in redundan cy and subst antially greater item retentio n when paired with sufficiently capable LLMs. The older and smaller OSS model sho w ed some benefits, and GPT-4o exhibited a distinctive pattern of temperature sensitivit y that diverged from the general trend. 18 Lara L. Russell-Lasalandra 4.1 Adaptive Prompting and ICL With R espect to Model Age and Size A central contributi on of this w ork is demonstrating that the benefits of adaptive prompting scale sharply with model capabilit y. For GPT-5.1, adaptive pro mpting reduced redundan cy by ov er 90%, produced near-perfect post-reducti on NMIs, and retained substantially larger item pools. These gains w ere robust across temperature settings, indi cating that the model was abl e to internalize and respect complex, cumulative constraints provi ded through adaptive prompting. By contrast, GPT-OSS- 120B sho wed similar but smaller gains, an d GPT-OSS-20B exhibited only modest impro vements across outco mes. This pattern aligns with the noti on that larger and new er models are better able to treat prompts as a form of ta sk-specifi c adaptation rather than as isol ated instructi ons (Dong et al., 2024 ; W ei, T ay, et al., 2022 ). Empirical stu dies demonstrate that advanced prompting strategi es often yield substanti al gains only once models reach sufficient scale (Mehta & Gupta, 2025 ; W ei, W ang, et al., 2022 ). Mechanistic and theoretical work f urther suggests that large transformer models can implement learning-like updates within their forward pass, enabling them to infer and apply abstract rules from context alo ne (V on Oswal d et al., 2023 ; see also P. Liu et al., 2023 ). From this perspecti ve, adapti v e prompting may functio n as a structured training signal, one that new er models can exploit more effectiv ely because they possess the represent ati onal capacit y to internaliz e set-lev el constraints (e.g., “ do n ot rephrase prior items”). The most immediate effect of adaptive prompting was its impact on redundancy, as reflected by the dramatic redu ctio n in items fl agged by the UV A step of AI-GEN I E. For GPT-5.1, adaptiv e prompting redu ced UV A remov als to less than 3 items on a verage acro ss temperatures, indi cating that the generated item pools w ere already diverse an d almost entirely n on-redun dant bef ore any pruning occurred. Importantly, no n-adaptive prompting strategies did not consistently produce similar effects, and in so me cases increased redundan cy relative to the basi c prompt. A dditionally, adapti v e prompting substantially increased the number of usable items retained after reducti on for the n ewest models. GPT-5.1 and GPT-OSS-120B retained roughly twice as many items under adapti v e prompting as un der the basic prompt, without sacrifi cing structural vali dit y. Thus, researchers can generate larger, higher-qualit y initial pools that ultimately ret ain more items. These findings un derscore that prompt complexity alone is insuffi cient. What matters is whether the model can dynami cally incorporate feedback about its prior outputs and adjust subsequent generati ons accordingly. A daptiv e prompting directly t argets the f ailure mode most relevant to large-scale item generati on, semantic repetiti on, and appears to do so in a wa y that only sufficiently capable models can reliably explo it. 4.2 Limitations A primary limitation of the present simulation is that it f ocuses exclusiv ely o n the Big Fiv e perso nalit y traits. These constructs are un usually well-defin ed, broad, and widely represented in both psycholog- ical literature and general publi c discourse, which likely increases the probabilit y that modern LLMs hav e learned rich semantic represent atio ns of them. As a result, the observed effectiv eness of advanced prompting strategies may not generalize to constru cts underrepresented in the literature. Altho ugh it should be noted that preliminary findings suggest that AI-GENI E w orks well for emerging constru cts (R ussell-Lasal an dra et al., 2024 ). A lso, the present simulation is fully in silico and does n ot incorporate human expert evaluatio n. While this design is co nsistent with the goal of auto mating early-st age item dev elopment, human review remains a cornerst one of psychol ogical measurement, particularly for ensuring that items represent the inten ded construct, a vo id ambiguit y or do uble-barreled wording, and adhere to ethi cal standards. A dditionally, these con clusions are anchored to a specific set of model families and v ersio ns. LLMs are not fixed entiti es. They are periodically updated thro ugh alignment changes, instruction 19 tuning, and saf et y filters, and these updates can meaningfully alter performance characteristi cs such as repetition, creativity, specificit y, and adheren ce to constraints. C onsequ ently, newer models ma y shift the relative advantage of one prompting strategy ov er another, especially in t asks like item generati on where subtle phrasing diff erences can hav e downstream consequ ences. 4.3 Final Thoughts Prompt engineering can meaningfully shape the raw materi al of item pools, while AI-GENI E offers a deterministic, psychometrically grounded mechanism f or transforming that material into stru cturally vali d, no nredundant, an d stable measures. Critically, the simulation sho ws that adaptiv e prompting is the standout methodological lev er, simultaneously boosting structural validit y to near-ceiling lev els when used with the new est models and dampening the t ypical sensitivit y to temperature settings. This simul ati on demo nstrates a scalable path to ward fa ster, more reprodu cible, and more cost-effi cient measurement dev elopment. AI-generated scale development is almost cert ainly on the hori zon as a mainstream practice, but this paper makes a crucial contributio n by showing that its rise does not hav e to resemble a methodological “wild west.” Rather than treating LLM-based item generation as an inherently unruly or unsci entific shortcut, the work demonstrates ho w rigorous psychometri c guardrails can be built directly into the w orkflow through stru ctured, reproducible pipelines like AI-GENI E. This precedent matters. If AI is go ing to reshape measurement dev elopment, it can do so within a framew ork of trans- parency, repli cabilit y, and high standards, where prompt engin eering becomes a disciplined method- ological l ever and psycho metric vali dation remains the n on-n egotiable backbon e. In that sense, the paper does not simply anti cipate the future. It helps define the norms that shoul d gov ern it. Acknowledgement s The authors di d not preregister the stu dy. Competing Inter est s The authors report there are n o competing interests to declare. Author Contributions L ara L. Ru ssell-Lasal andra: Conceptualization, Data Curation, Formal Anal- ysis, Inv estigatio n, Methodology, V alidati on, V isu alization, W riting – Original Draft, W riting – R eview & Editing; Hudson Golino: Conceptualization, Data Curation, Inv estigation, Methodol ogy, R esources, V alidatio n, W riting – Original Draft, W riting – R eview & Editing, Supervisio n. Refer ences Amatriain, X. (2024). Prompt design and engineering: Introdu ctio n and advanced methods. Brickman, J., Gupta, M., & Oltmanns, J. R. (2025). Large language models for psychol ogical assessment: A comprehensi ve ov erview. Adv ances in Methods and Pr actices in P sychological Science , 8 (3), 25152459251343582. https://doi.org/10. 1177/25152459251343582 Brown, T. B., Mann, B., R y der, N., Subbi ah, M., Kaplan, J., Dhariw al, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., K rueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., W u, J., W inter, C., . . . Amodei, D. (2020). Language models are few-shot learners. Carlini, N., T ramèr, F., W allace, E., Jagielski, M., Herbert-V oss, A., Lee, K., R oberts, A., Brown, T., Song, D., Erlingsson, Ú., Oprea, A., & Raffel, C. (2021). Extracting training data from large l anguage models. 30th USENIX Se curity S ymposium (USENIX Security 21) , 2633–2650. https://www.usenix.org/conferen ce/usenixsecurit y21/presentation/ carlini- extracting Chen, B., Zhang, Z., Langrené, N., & Zhu, S. (2025a). Unleashing the potential of pro mpt engineering f or large language models. P atterns , 6 (6). Chen, B., Zhang, Z., Langrené, N., & Z hu, S. (2025b). U nleashing the potential of prompt engineering f or large langu age models. P atterns , 6 (6), 101260. https://doi.org/https://do i.org/10.1016/j.patter.2025.101260 Christensen, A. P., Garrido, L. E., & Golino, H. (2023). Uni que variable analysis: A net work psycho metrics method to detect local dependence. Multivariate Behavior al Research , 58 (6), 1165–1182. https : / /doi . org/ 10 . 1080/ 00273171 . 2023. 2194606 20 Lara L. Ru ssell-Lasal andra Christensen, A. P., & Golino, H. (2021). Estimating the st abilit y of psychological dimensi ons via bootstrap exploratory graph analysis: A monte carlo simulatio n and tutorial. P sych , 3 (3), 479–500. https://doi.org/10.3390/psych3030032 Danon, L., Diaz-Guilera, A., Du ch, J., & Arena s, A. (2005). Comparing community stru cture i dentificatio n. Journal of Statistical Mechanics: Theory and Experiment , 2005 , P09008. https://doi.org/10.1088/1742- 5468/2005/09/P09008 Dauphin, B., & Siefert, C. (2025). Fro m llama to l anguage: Prompt-engin eering allo ws general-purpose artifi cial intelligence to rate narratives like expert psychol ogists. F r ontiers in Artificial Intelligence , 8 , 1398885. De Paoli, S. (2023). Improv ed prompting and process for writing user personas with llms, using qualitative interviews: Capturing behavi our and personalit y traits of users. arXiv preprint . de W inter, J. C., Driessen, T., & Dodou, D. (2024). The use of chatgpt f or personalit y research: A dministering questionnaires using generated personas. P ersonality and Individual Dierences , 228 , 112729. https: // doi.org /https :// doi.org /10 . 1016/j.paid.2024.112729 Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., W u, Z., Chang, B., et al. (2024). A survey on in-context learning. Pr oceeding s of the 2024 conf erence on empirical methods in natur al languag e processing , 1107–1128. Ekin, S. (2023). Prompt engin eering for chatgpt: A qui ck guide to techni ques, tips, and best practices. A uthorea Preprints . Fatawi, I., Asy’ari, M., Hunaepi, H., Samsuri, T., & Bil ad, M. R. (2024). Empo wering language models through advanced prompt engineering: A comprehensiv e bibliometric review. Indonesian Journal of Science and T echnology , 9 (2), 441–462. Foygel, R., & Drton, M. (2010). Extended bayesian informatio n criteria for gaussian graphical models. Adv ances in neural inf ormation processing systems , 23 . Friedman, J., Hastie, T., & Tibshirani, R. (2008). Sparse inv erse covariance estimati on with the graphical lasso. Biostatistics , 9 (3), 432–441. Fyffe, S., Lee, P., & Kaplan, S. (2024). “transforming” personalit y scale dev elopment: Illustrating the potential of st ate-of- the-art natural langu age processing. Org anizational Research Methods , 27 (2), 265–300. https: //doi.org /10.1177 / 10944281231155771 Garrido, L. E., Russell-Lasalandra, L., & Golino, H. (2025). Estimating dimensional structure in generative psycho metrics: Comparing pca and n et w ork methods using large language model item embeddings. Giray, L. (2023). Prompt engineering with chatgpt: A guide for academi c writers. Annals of biomedical eng ineering , 51 (12), 2629–2633. Golino, H. F., & Epskamp, S. (2017). Exploratory graph an alysis: A new approach f or estimating the n umber of dimensions in psychological research. PLoS ONE , 12 (6), e0174035. https://doi.org/10.1371/journal.pon e.0174035 Götz, F. M., Maertens, R., Loomba, S., & V an Der Linden, S. (2024). Let the algorithm speak: How to use n eural net works for aut omatic item gen eratio n in psychological scale dev elopment. P sychological Methods , 29 (3), 494. Han, B., Mathrani, A., & Susnjak, T. (2025). Evaluating prompting strategies and large langu age models in systematic literature review screening: R elevance and task-stage cla ssificati on. arXiv preprint . Hernandez, I., & Nie, W. (2023). The ai-ip: Minimizing the guesswork of personalit y scale item development through artificial intelligence. P ersonnel P sychology , 76 (4), 1011–1035. Hommel, B. E., W ollang, F. - J. M., Koto va, V., Zacher, H., & Schmukl e, S. C. (2022). T ransformer-based deep neural language modeling for co nstruct-specific a utomatic item generatio n. psychometrika , 87 (2), 749–772. Huang, L., Y u, W., Ma, W., Zhong, W., Feng, Z., W ang, H., Chen, Q., P eng, W., Feng, X., Qin, B., & Liu, T. (2025). A survey o n hallucination in large language models: Principles, t axon omy, challenges, an d open questions. A CM T r ansactions on Information S ystems , 43 (2), 1–55. https://doi.org/10.1145/3703155 Jiang, H., Z hang, X., Cao, X., Breazeal, C., Roy, D., & Kabbara, J. (2024). Personallm: Inv estigating the abilit y of l arge language models to express personalit y traits. F inding s of the association f or computational linguistics: N AA CL 2024 , 3605–3627. Jin, W., Cheng, Y., Shen, Y., Chen, W., & R en, X. (2022). A good prompt is w orth millio ns of parameters: Low-resource prompt-based learning for vision-language models. Procee dings of the 60th annual meeting of the association f or computational ling uistics (volume 1: long papers) , 2763–2775. J ohn, O. P., & Srivastava, S. (1999). The big five trait t axon omy: History, measurement, and theoretical perspectives. In L. A. P ervin & O. P. John (Eds.), Handbo ok of personality: Theory and research (2nd, pp. 102–138). Guilf ord Press. J oshi, S. (2025). Retraining us w orkforce in the age of agentic gen ai: R ole of prompt engineering an d up-skilling initiatives. International Journal of Adv anced Research in Science, C ommunication and T echnology (IJ ARSCT) , 5 (1). Kojima, T., Gu, S. S., Rei d, M., Matsuo, Y., & Iwasawa, Y. (2022). Large language models are z ero-shot reason ers. Adv ances in neur al information pr ocessing systems , 35 , 22199–22213. Kong, A., Zhao, S., Chen, H., Li, Q., Qin, Y., Sun, R., Z hou, X., W ang, E., & Dong, X. (2024). Better zero-shot reasoning with role-play prompting. Procee dings of the 2024 C onference of the N orth American Chapter of the Association for C omputational Linguistics: H uman Language T echnologies (V olume 1: Long Papers) , 4099–4113. Krishn a, S., Agarwal, C., & Lakkaraju, H. (2024). U nderstanding the effects of iterativ e prompting on truthfulness. https: Lee, D., & Palmer, E. (2025). Prompt engineering in higher education: A systematic review to help inform curricula. International Journal of Educational T echnology in Hig her Education , 22 (1), 7. 21 Lee, P., Fyffe, S., Son, M., Jia, Z., & Y ao, Z. (2023). A paradigm shift from “human writing” to “machine generation” in personalit y test dev elopment: An applicatio n of st ate-of-the-art natural language processing. Journal of Business and P sychology , 38 (1), 163–190. Lee, P., Son, M., & Jia, Z. (2025). Ai-pow ered automatic item gen eration f or psychological tests: A conceptual framework f or an llm-based multi-agent aig system. Journal of Business and P sychology , 1–29. Lightman, H., Kosaraju, V., Burda, Y., Edw ards, H., Baker, B., L ee, T., Leike, J., Schulman, J., Sutskever, I., & Cobbe, K. (2023). Let’s verif y step by step. Liu, A., Diab, M., & F ried, D. (2024). Ev aluating large language model biases in persona-steered generatio n. abs/2405.20253 Liu, P., Y uan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2023). Pre-train, prompt, and predict: A systemati c survey of prompting methods in natural language processing. ACM c omputing surveys , 55 (9), 1–35. Liu, X., W ang, J., Sun, J., Y uan, X., Dong, G., Di, P., W ang, W., & W ang, D. (2023). Prompting frameworks for large language models: A survey. arXiv preprint . Liu, Y., Deng, G., Xu, Z., Li, Y., Zheng, Y., Zhang, Y., Z hao, L., Zhang, T., W ang, K., & Liu, Y. (2024). Jailbreaking chatgpt via prompt engineering: An empirical stu dy. Marengo, A., Karaoğlan Yılmaz, F. G., Yılmaz, R., & Ceylan, M. (2025). Development and v alidation of generativ e artificial intelligence attitude scal e for students. F r ontiers in Computer Science . https://do i.org/10.3389/fcomp.2025.1528455 Martin Kowal, J., Hurley Bryant, K., Segall, D., & Kantrowitz, T. (2025). Harnessing generative ai for assessment item devel opment: Comparing ai-generated and human-authored items. International Journal of Sele ction and Assessment , 33 (3), e70021. Massara, G. P., Di Matteo, T., & Aste, T. (2016). Net w ork filtering for big data: T riangul ated maximally filtered graph. Journal of complex N etworks , 5 (2), 161–178. Mehta, S., & Gupta, I. (2025). S caling laws and in-context learning: A unified theoretical framework. arXiv preprint arXiv:2511.06232 . Olea, C., T ucker, H., Phelan, J., Pattison, C., Zhang, S., Lieb, M., S chmi dt, D., & White, J. (2024). Evaluating persona prompting f or questio n answering tasks. Procee ding s of th e 10th international conf erence on artificial intelligence and soft computing , S ydney, Austr alia . OpenAI. (2024a). Openai gpt-4o api. https://platform.openai.com/docs/models/gpt- 4o OpenAI. (2024b). Prompt engin eering [A ccessed: 2026-03-05]. OpenAI. (2024c, January). N ew embedding models and api updates [A ccessed: 2024-06-06]. https://platform.openai.com/ docs/guides/embeddings OpenAI. (2025a, A ugust). Gpt-oss-120b & gpt-oss-20b model card [A ccessed: 2025-1-08]. OpenAI. (2025b, No vember). Gpt 5.1 model card [A ccessed: 2026-1-08]. P eeperkorn, M., Kouw enhov en, T., Brown, D., & Jordano us, A. (2024). Is temperature the creativit y parameter of large language models? arXiv preprint . P ons, P., & Lat apy, M. (2005). Computing communiti es in large net w orks using random walks. International S ymposium on C omputer and Information Sciences , 284–293. Raffel, C., S haz eer, N., R oberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., & Liu, P. J. (2023). Exploring the limits of transfer learning with a unifi ed text-to-text transformer. R eynolds, L., & McDonell, K. (2021). Prompt programming for l arge langu age models: Beyond the few-shot paradigm. Extended abstr acts of the 2021 CHI conf erence on human f actors in computing systems , 1–7. Russell-Lasalandra, L. L., Christensen, A. P., & Golino, H. (2024). Generativ e psychometrics via ai-genie: Auto matic item generatio n and validati on via network-integrated evaluatio n. PsyArXiv Pr eprints . Salah, M., Abdelfattah, F., Al Halbusi, H., Jassem, S., Mohammed, M., Ismail, M. M., & Al Balghouni, A. (2025). Can generativ e ai craft scale items? a mixed-method study on ai’s capabilit y to adapt and create new scales with recommendati ons for best practices. Social Sciences & Humanities Open , 12 , 101698. https : / / doi . org / https : //doi.org/10.1016/j.ssaho.2025.101698 Schulhoff, S., Ilie, M., Balepur, N., Kahadze, K., Liu, A., Si, C., Li, Y., Gupta, A., Han, H., S chulhoff, S., Dulepet, P. S., V idyadhara, S., Ki, D., Agrawal, S., Pham, C., Kroiz, G., Li, F., T ao, H., Srivastava, A., . . . R esnik, P. (2025). The prompt report: A systemati c survey of pro mpt engineering techniqu es. Spliethö ver, M., Knebler, T., Fumagalli, F., Muschalik, M., Hammer, B., Hüllermeier, E., & W achsmuth, H. (2025). A daptiv e prompting: A d-hoc prompt co mposition f or social bias detection. Sun, J., Luo, Y., Gong, Y., Lin, C., Shen, Y., Guo, J., & Duan, N. (2024, June). Enhancing chain-of-thoughts prompting with iterative bootstrapping in large l anguage models. In K. Duh, H. Gomez, & S. Bethard (Eds.), F indings of the association f or computational ling uistics: N aacl 2024 (pp. 4074–4101). Association f or Computational Linguistics. https://doi.org/10.18653/v1/2024.findings- naacl.257 T ouvron, H., Martin, L., Sto ne, K., A lbert, P., Almahairi, A., Babaei, Y., Bashlyko v, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023). Llama 2: Open foun dation an d fine-tuned chat models. arXiv preprint . V on Oswald, J., N iklasson, E., Randazzo, E., Sacramento, J., Mordvintsev, A., Zhmoginov, A., & V ladymyrov, M. (2023). T ransformers learn in-context by gradi ent descent. International Conf erence on Machine Learning , 35151–35174. W ei, J., T ay, Y., Bo mmasani, R., Raffel, C., Zoph, B., Borgeau d, S., Y ogat ama, D., Bosma, M., Zhou, D., Metzl er, D., et al. (2022). Emergent abilities of large language models. arXiv preprint . 22 Lara L. Russell-Lasalandra W ei, J., W ang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., L e, Q. V., Z hou, D., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Adv ances in neural inf ormation processing systems , 35 , 24824– 24837. White, J. (2023). A prompt pattern catalog to enhance prompt engin eering with chatgpt. arXiv preprint . Zhang, B., & Horvath, S. (2005). A general framework for weighted gene co-expression net w ork an alysis. Statistical Applications in Genetics and Molecular Biology , 4 (1). https://doi.org/10.2202/1544- 6115.1128 Zheng, M., Pei, J., Logeswaran, L., Lee, M., & Jurgens, D. (2024). When” a helpf ul assistant” is not really helpful: Personas in system pro mpts do not improv e perf ormances of large language models. F indings of the A ssociation f or C omputational Linguistics: EMNLP 2024 , 15126–15154.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment