생성 심리측정에서 프롬프트 설계가 척도 개발에 미치는 영향
본 연구는 Monte Carlo 시뮬레이션을 통해 네 가지 프롬프트 설계(제로‑샷, 퍼‑샷, 페르소나, 적응형)가 AI‑GENIE 파이프라인에서 생성된 빅 파이브 항목의 품질에 미치는 영향을 평가한다. 모델 온도와 세 종류의 최신 GPT 모델을 변인으로 설정하고, 네트워크 심리계량(EGA, UV‑A, bootEGA)으로 구조 타당도와 중복성을 측정하였다. 적응형 프롬프트가 가장 높은 구조 타당도와 낮은 의미 중복을 보였으며, 특히 최신 고용량 …
저자: Lara Lee Russell-Lasal, ra, Hudson Golino
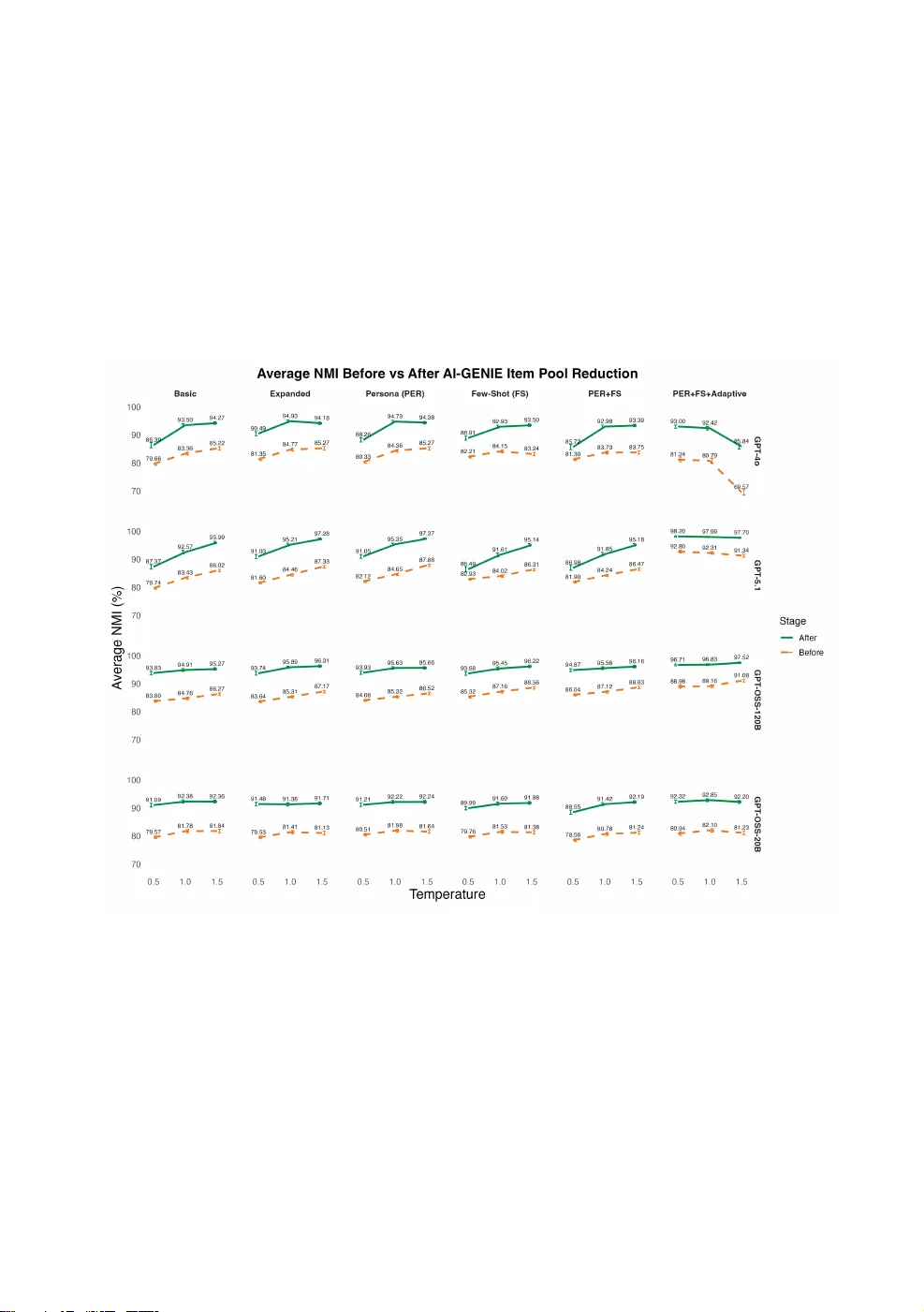
본 논문은 최근 급부상하고 있는 ‘생성 심리측정(Generative Psychometrics)’이라는 패러다임 하에, 대규모 언어 모델(LLM)로부터 자동으로 생성된 항목을 심리척도로 전환하는 과정에서 프롬프트 설계가 차지하는 역할을 체계적으로 탐구한다. 연구자는 AI‑GENIE(Automatic Item Generation with Network‑Integrated Evaluation)라는 파이프라인을 기반으로, 빅 파이브 다섯 요인(외향성, 친화성, 성실성, 신경성, 개방성)을 목표로 하는 아이템 풀을 네 가지 프롬프트 전략—(1) 기본 제로‑샷, (2) 확장 제로‑샷, (3) 퍼‑샷, (4) 페르소나, (5) 적응형—에 따라 생성하였다. 각 전략은 프롬프트의 구성 요소(과제 지시, 맥락 제공, 출력 형식 명시, 입력 데이터 제공)의 활성화 정도와 예시 제공 여부에 차이가 있다. 제로‑샷은 최소한의 지시만 제공해 모델이 자체적으로 형식을 유추하도록 하며, 확장 제로‑샷은 정의와 형식 요구사항을 추가한다. 퍼‑샷은 실제 예시를 삽입해 모델의 인‑컨텍스트 학습을 촉진하고, 페르소나 프롬프트는 모델에게 전문가 역할을 부여해 도메인 일관성을 강화한다. 가장 복잡한 적응형 프롬프트는 생성‑평가‑수정 루프를 도입해, 이전에 생성된 항목을 피드백으로 제공하고 중복을 명시적으로 차단한다.
시뮬레이션은 세 가지 최신 GPT 모델(GPT‑3.5‑turbo, GPT‑4, GPT‑4o)과 온도 파라미터(0.2, 0.5, 0.8)를 조합해 36가지 조건을 만들고, 각 조건마다 1,000개 이상의 항목을 10번 반복 생성해 평균적인 품질 지표를 산출했다. 생성된 텍스트는 OpenAI text‑embedding‑3‑small 모델을 이용해 고차원 의미 임베딩으로 변환한 뒤, TMFG와 EBIC‑glasso를 활용해 네트워크를 구축하고 Exploratory Graph Analysis(EGA)로 요인 구조를 추정했다. 구조 타당도는 추정된 군집과 사전 정의된 요인 라벨 간의 Normalized Mutual Information(NMI)으로 측정했으며, 의미 중복은 항목 간 코사인 유사도 평균으로 정의했다. 이후 AI‑GENIE 파이프라인의 핵심 단계인 Unique Variable Analysis(UVA)와 bootstrap EGA를 순차적으로 적용해 중복을 제거하고 구조 타당도를 재평가하였다.
주요 결과는 다음과 같다. 첫째, 적응형 프롬프트가 모든 모델과 온도 설정에서 가장 높은 초기 NMI(0.72~0.85)와 가장 낮은 중복도(평균 0.12)를 달성했다. 특히 최신 고용량 모델(GPT‑4, GPT‑4o)과 결합될 때 효과가 극대화되었으며, 온도 변화에 대한 민감도도 크게 완화되었다. 둘째, 제로‑샷(특히 기본형)은 초기 NMI가 0.58 수준에 머물렀고, 중복도는 0.31로 높아 구조 타당도 회복이 제한적이었다. 확장 제로‑샷과 퍼‑샷은 중간 정도의 성과를 보였으며, 페르소나 프롬프트는 도메인 일관성은 향상했지만 중복 억제에서는 적응형에 미치지 못했다. 셋째, GPT‑4o는 온도 0.8에서 적응형 프롬프트의 중복 억제 효과가 급격히 감소해 NMI가 0.73으로 떨어지는 예외를 보였으며, 이는 고온에서 모델이 자체적인 샘플링 변동성을 더 크게 반영한다는 점을 시사한다. 넷째, AI‑GENIE 자체의 구조 타당도 향상 효과는 초기 아이템 풀의 품질에 역비례했으며, 고품질 풀에서는 추가 개선 폭이 작아지는 경향을 보였다. 즉, 프롬프트 설계가 초기 품질을 좌우하고, AI‑GENIE는 그 품질을 보완·정제하는 역할을 수행한다는 결론에 도달했다.
논의에서는 적응형 프롬프트가 LLM의 ‘자기‑반복’ 현상을 효과적으로 차단하고, 모델 용량이 클수록 복잡한 프롬프트를 더 잘 해석한다는 최신 이론과 일치한다는 점을 강조한다. 또한, 온도와 모델 특성 간의 상호작용을 고려한 프롬프트 설계가 향후 자동 척도 개발 파이프라인의 표준이 될 수 있음을 제안한다. 제한점으로는 시뮬레이션이 실제 응답 데이터를 사용하지 않았으며, 인간 전문가 평가와의 비교가 부족하다는 점을 들었다. 향후 연구에서는 실제 피험자 데이터를 통한 검증, 다양한 심리구조(예: 다차원 감정 모델) 적용, 그리고 프롬프트 자동 최적화 알고리즘 개발을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기