Counteractive RL: Rethinking Core Principles for Efficient and Scalable Deep Reinforcement Learning
Following the pivotal success of learning strategies to win at tasks, solely by interacting with an environment without any supervision, agents have gained the ability to make sequential decisions in complex MDPs. Yet, reinforcement learning policies…
Authors: Ezgi Korkmaz
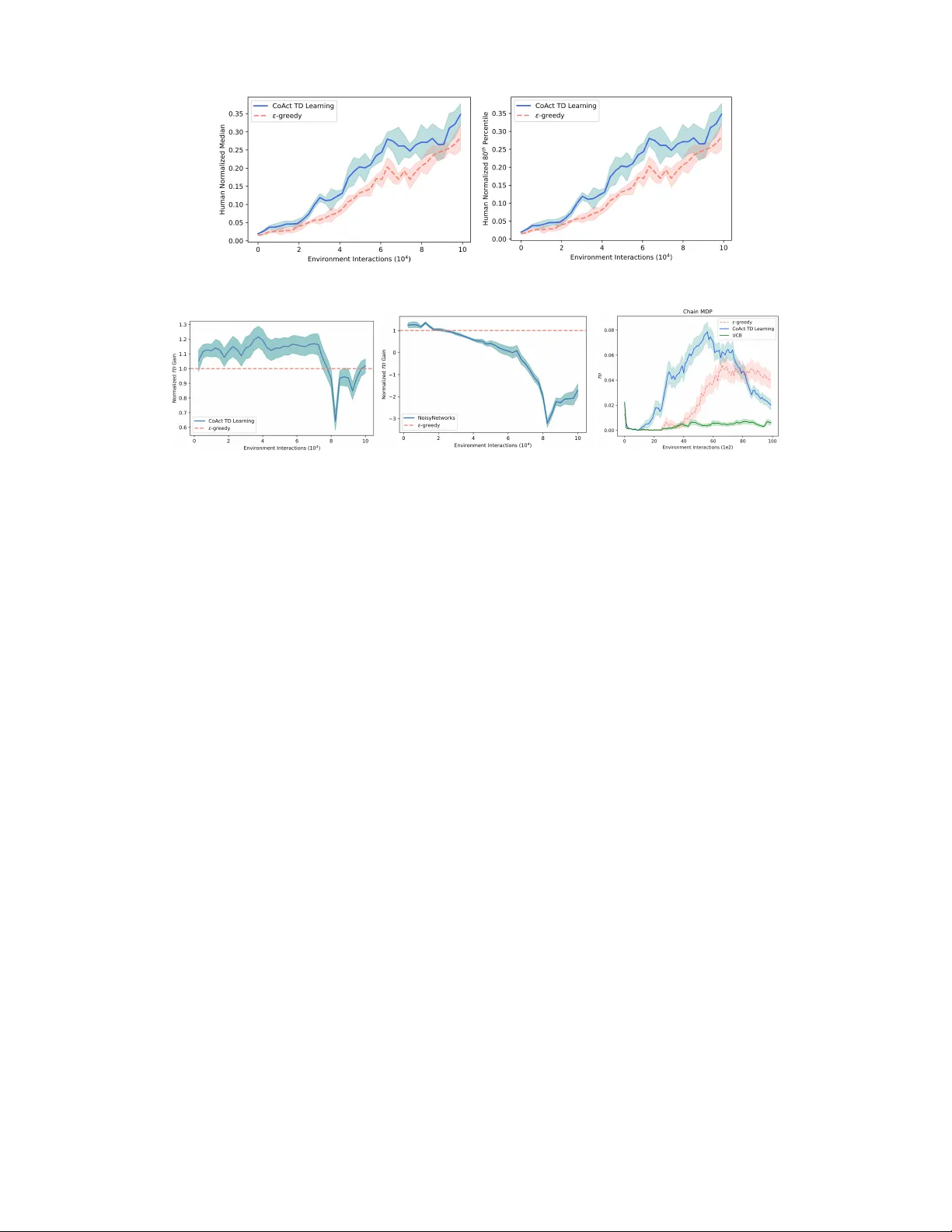
Counteractiv e RL: Rethinking Cor e Principles f or Efficient and Scalable Deep Reinf or cement Lear ning Ezgi Korkmaz Abstract Follo wing the pi votal success of learning strate gies to win at tasks, solely by inter- acting with an environment without an y supervision, agents have gained the ability to make sequential decisions in comple x MDPs. Y et, reinforcement learning poli- cies f ace e xponentially gro wing state spaces in high dimensional MDPs resulting in a dichotomy between computational complexity and polic y success. In our paper we focus on the agent’ s interaction with the en vironment in a high-dimensional MDP during the learning phase and we introduce a theoretically-founded novel paradigm based on experiences obtained through counteractiv e actions. Our anal- ysis and method provide a theoretical basis for ef ficient, ef fectiv e, scalable and accelerated learning, and further comes with zero additional computational com- plexity while leading to significant acceleration in training. W e conduct extensi ve experiments in the Arcade Learning En vironment with high-dimensional state representation MDPs. The experimental results further v erify our theoretical anal- ysis, and our method achieves significant performance increase with substantial sample-efficienc y in high-dimensional en vironments. 1 Introduction Utilization of deep neural networks as function approximators enabled learning functioning policies in high-dimensional state representation MDPs [Mnih et al., 2015]. Following this initial work, the current line of research trains deep reinforcement learning policies to solve highly complex problems from game solving [Hasselt et al., 2016, Schrittwieser et al., 2020] to mathematical and scientific reasoning of lar ge language models [Guo et al., 2025]. Y et, there are still remaining unsolved problems restricting the current capabilities of reinforcement learning in exponentially growing state spaces. One of the main intrinsic open problems in deep reinforcement learning research is sample complexity and experience collection in high-dimensional state representation MDPs. While prior work e xtensiv ely studied the polic y’ s interaction with the en vironment in bandits and tab ular reinforcement learning, and proposed various algorithms and techniques optimal to the tabular form or the bandit context [Fiechter, 1994, K earns and Singh, 2002, Brafman and T ennenholtz, 2002, Kakade, 2003, Lu and Roy, 2019], experience collection in deep reinforcement learning remains an open challenging problem while practitioners repeatedly emplo y quite simple yet effecti ve techniques (i.e. ϵ -greedy) [Whitehead and Ballard, 1991, Flennerhag et al., 2022, Hasselt et al., 2016, W ang et al., 2016, Hamrick et al., 2020, Kapturo wski et al., 2023, K orkmaz, 2024, Schmied et al., 2025, Krishnamurthy et al., 2024]. Despite the prov able optimality of the techniques designed for the tab ular or bandit setting, they generally rely strongly on the assumptions of tabular reinforcement learning, and in particular on the ability to record tables of statistical estimates for ev ery state-action pair which have size growing with the number of states times the number of actions. Hence, these assumptions are far from what is being faced in the deep reinforcement learning setting where states and actions can be parametrized by high-dimensional representations. Thus, in high-dimensional complex MDPs, for which deep Correspondence to Ezgi K orkmaz: ezgikorkmazmail@gmail.com 39th Conference on Neural Information Processing Systems (NeurIPS 2025) Spotlight Presentation . neural networks are used as function approximators, the ef ficiency and the optimality of the methods proposed for tabular settings do not transfer well to deep reinforcement learning [Kakade, 2003]. Hence, in deep reinforcement learning research still, nai ve and standard techniques (e.g. ϵ -greedy) are preferred o ver both the optimal tab ular techniques and over the particular recent e xperience collection techniques targeting only high scores for particular games [Mnih et al., 2015, Hasselt et al., 2016, W ang et al., 2016, Bellemare et al., 2017, Dabney et al., 2018, Flennerhag et al., 2022, Korkmaz, 2024, Kapturowski et al., 2023]. Sample efficiency still remains to be one of the main challenging problems restricting research progress in reinforcement learning. The magnitude of the number of samples required to learn and adapt continuously is one of the main limiting factors pre venting current state-of-the-art deep reinforcement learning algorithms from being deployed in many di verse settings from large language model reasoning to the physical world, but most importantly one of the main challenges that needs to be dealt with on the way to building neural policies that can generalize and adapt continuously in non-stationary en vironments. Hence, gi ven these limitations in our paper we aim to seek answers for the following questions: • How can we construct policies that have the ability to collect novel experiences in high- dimensional complex MDPs without any additional computational comple xity? • What is the natural theor etical motivation that can be used to design a zer o-cost experience collection strate gy while achieving high sample ef ficiency? T o be able to answer these questions, in our paper we focus on en vironment interactions in deep reinforcement learning and make the follo wing contributions: Contributions. W e introduce a fundamental theoretically well-motiv ated paradigm for reinforce- ment learning based on state-action value function minimization, which we call counteracti ve temporal difference learning. Our approach centers on solely reconstituting and conceptually shifting the core principles of learning and as a result increases the information gained from the en vironment interac- tions of the polic y in a gi ven MDP without adding computational complexity . W e first pro vide the theoretical analysis in Section 3, explaining why and ho w minimization will result in higher temporal difference. W e then as a first step demonstrate the efficac y of counteracti ve temporal difference learning in a motiv ating example, i.e. the canonical chain MDP setup, in Section 4. The results in the chain MDP verify the theoretical analysis provided in Section 3 that counteracti ve temporal dif ference learning increases temporal difference obtained from the experiences. Furthermore, we conduct an extensi ve study in the Arcade Learning En vironment 100K benchmark with the state-of-the-art algorithms and demonstrate that our temporal difference learning algorithm CoAct TD learning improv es performance by 248% across the entire benchmark compared to the baseline algorithm. W e demonstrate the ef ficacy of our proposed CoAct TD Learning algorithm in terms of sample-ef ficiency . Our method based on maximizing nov el experiences via minimizing the state-action value function reaches approximately to the same performance lev el as model-based deep reinforcement learning algorithms, without building and learning any model of the en vironment. Finally , we sho w that CoAct TD learning is a fundamental impro vement over canonical methods, it is modular and a plug-and-play method, and any algorithm that uses temporal difference learning can be immediately and simply switched to CoAct TD learning. 2 Background and Pr eliminaries The reinforcement learning problem is formalized as a Markov Decision Process (MDP) [Puterman, 1994] M = ⟨S , A , r , γ , ρ 0 , T ⟩ that contains a continuous set of states s ∈ S , a set of actions a ∈ A , a probability transition function T ( s, a, s ′ ) on S × A × S , discount factor γ , a reward function r ( s, a ) : S × A → R with initial state distribution ρ 0 . A policy π ( s, a ) : S × A → [0 , 1] in an MDP assigns a probability distribution o ver actions for each state s ∈ S . The main goal in reinforcement learning is to learn an optimal policy π that maximizes the discounted expected cumulati ve re wards R = E a t ∼ π ( s t , · ) ,s t +1 ∼T ( s t ,a t , · ) P t γ t r ( s t , a t ) . In Q -learning [W atkins, 1989] the learned policy is parameterized by a state-action value function Q : S × A → R , which represents the value of taking action a in state s . The optimal state-action v alue function is learnt via iterativ e Bellman update Q ( s t , a t ) ← Q ( s t , a t ) + α [ r ( s t , a t ) + γ max a Q ( s t +1 , a ) − Q ( s t , a t )] 2 where max a Q ( s t +1 , a ) = V ( s t +1 ) . Let a ∗ be the action maximizing the state-action value function, a ∗ ( s ) = arg max a Q ( s, a ) , in state s . Once the Q -function is learnt the policy is determined via taking action a ∗ ( s ) . T emporal difference learning [Sutton, 1988] improves the estimates of the state-action values in each iteration via the Bellman Operator [Bellman, 1957] (Ω ∗ Q )( s, a ) = E s ′ ∼T ( s,a, · ) [ r ( s, a ) + γ max a ′ Q ( s ′ , a ′ )] . For distributional reinforcement learning, QRDQN is an algorithm that is based on quantile regression [K oenker and Hallock, 2001, K oenker, 2005] temporal difference learning Ω Z ( s, a ) = r ( s, a ) + γ Z ( s ′ , arg max a ′ E z ∼Z ( s ′ ,a ′ ) [ z ]) and Z ( s, a ) : = 1 N N X i =1 δ θ i ( s,a ) where Z θ ∈ Z Q maps state-action pairs to a probability distrib ution ov er values. In deep reinforce- ment learning, the state space or the action space is large enough that it is not possible to learn and store the state-action values in a tab ular form. Thus, the Q -function is approximated via deep neural networks. In deep double- Q learning, two Q -networks are used to decouple the Q -network deciding which action to take and the Q -network to e valuate the action taken θ t +1 = θ t + α ( r ( s t , a t ) + γ Q ( s t +1 , arg max a Q ( s t +1 , a ; θ t ); ˆ θ t ) − Q ( s t , a t ; θ t )) ∇ θ t Q ( s t , a t ; θ t ) . Current deep reinforcement learning algorithms use ϵ -greedy during training [W ang et al., 2016, Mnih et al., 2015, Hasselt et al., 2016, Hamrick et al., 2020, Flennerhag et al., 2022, Kapturo wski et al., 2023, Krishnamurthy et al., 2024, Schmied et al., 2025, K orkmaz, 2026]. In particular , the ϵ -greedy [Whitehead and Ballard, 1991] algorithm takes an action a k ∼ U ( A ) with probability ϵ in a giv en state s , i.e. π ( s, a k ) = ϵ |A| , and takes an action a ∗ = arg max a Q ( s, a ) with probability 1 − ϵ , i.e. π ( s, arg max a Q ( s, a )) = 1 − ϵ + ϵ |A| While a family of algorithms hav e been proposed based on counting state visitations (i.e. the number of times action a has been taken in state s by time step t ) with prov able optimal regret bounds using the principal of optimism in the face of uncertainty in the tabular MDP setting, yet incorporating these count-based methods in high-dimensional state representation MDPs requires substantial complexity including training additional deep neural networks to estimate counts or other uncertainty metrics. As a result, many state-of-the-art deep reinforcement learning algorithms still use simple, randomized experience collection methods based on sampling a uniformly random action with probability ϵ [Mnih et al., 2015, Hasselt et al., 2016, W ang et al., 2016, Hamrick et al., 2020, Flennerhag et al., 2022, K orkmaz, 2023, Kapturo wski et al., 2023]. In our experiments, while pro viding comparison against canonical methods, we also compare our method against computationally complicated and expensi ve techniques such as noisy-networks that is based on the injection of random noise with additional layers in the deep neural network [Hessel et al., 2018] in Section 5, and count based methods in Section 4 and Section 6. W e further highlight that our method is a fundamental theoretically motiv ated impro vement of temporal dif ference learning. Thus, an y algorithm that is based on temporal dif ference learning can immediately be switched to CoAct TD learning. 3 Maximizing T emporal Differ ence with Counteractive Actions Seeking experiences that contain high information has long been the focus of reinforcement learning [Schmidhuber, 1991, 1999, Moore and Atkeson, 1993] and more particularly the experiences that correspond to higher temporal difference [Moore and Atkeson, 1993]. In this section we will provide the theoretical analysis for our proposed algorithm counteracti ve TD learning. Section 5 further provides the experimental results verifying the theoretical predictions. In deep reinforcement learning the state-action v alue function is initialized with random weights [Mnih et al., 2015, 2016, Hasselt et al., 2016, W ang et al., 2016, Schaul et al., 2016, Oh et al., 2020, Schrittwieser et al., 2020, Hubert et al., 2021]. During a large portion of the training prior to con vergence, the Q -function behav es as a random function rather than providing an accurate representation of the optimal state-action values while interacting with ne w experiences in high-dimensional MDPs as the learning continues. In particular , in high-dimensional environments in a significant portion of the training the Q -function, on av erage, assigns approximately similar v alues to states that are similar , and has little correlation with the immediate rew ards. Hence, let us formalize these facts on the state-action value function in the following definitions. 3 Definition 3.1 ( η -uninformed ) . Let η > 0 . A Q -function parameterized by weights θ ∼ Θ is η -uninformed if for any state s ∈ S with a min = arg min a Q θ ( s, a ) we hav e | E θ ∼ Θ [ r ( s t , a min )] − E a ∼U ( A ) [ r ( s t , a )] | < η . Definition 3.2 ( δ -smooth ) . Let δ > 0 . A Q -function parameterized by weights θ ∼ Θ is δ -smooth if for any state s ∈ S and action ˆ a = ˆ a ( s, θ ) with s ′ ∼ T ( s, ˆ a, · ) we hav e | E θ ∼ Θ [max a Q θ ( s, a )] − E s ′ ∼T ( s, ˆ a, · ) ,θ ∼ Θ [max a Q θ ( s ′ , a )] | < δ where the expectation is over both the random initialization of the Q -function weights, and the random transition to state s ′ ∼ T ( s, ˆ a, · ) . Definition 3.3 ( Disadvantage Gap ) . For a state-action value function Q θ the disadv antage gap in a state s ∈ S is giv en by D ( s ) = E a ∼U ( A ) ,θ ∼ Θ [ Q θ ( s, a ) − Q θ ( s, a min )] where a min = arg min a Q θ ( s, a ) . The follo wing theorem captures the intuition that choosing counteracti ve actions, i.e. the action minimizing the state-action value function, will achie ve an abov e-av erage temporal difference. Theorem 3.4 ( Counter active Actions Incr ease T emporal Differ ence ) . Let η , δ > 0 and suppose that Q θ ( s, a ) is η -uninformed and δ -smooth. Let s t ∈ S be a state, and let a min be the action minimizing the state-action value in a given state s t , a min = arg min a Q θ ( s t , a ) . Let s min t +1 ∼ T ( s t , a min , · ) . Then for an action a t ∼ U ( A ) with s t +1 ∼ T ( s t , a t , · ) we have E s min t +1 ∼T ( s t ,a min , · ) ,θ ∼ Θ [ r ( s t , a min ) + γ max a Q θ ( s min t +1 , a ) − Q θ ( s t , a min )] > E a t ∼U , ( A ) s t +1 ∼T ( s t ,a t , · ) ,θ ∼ Θ [ r ( s t , a t ) + γ max a Q θ ( s t +1 , a ) − Q θ ( s t , a t )] + D ( s t ) − 2 δ − η Pr oof. Since Q θ ( s, a ) is δ -smooth we hav e E s min t +1 ∼T ( s t ,a min , · ) ,θ ∼ Θ [ γ max a Q θ ( s min t +1 , a ) − Q θ ( s t , a min )] > γ E θ ∼ Θ [max a Q θ ( s t , a )] − δ − E θ ∼ Θ [ Q θ ( s t , a min )] > γ E s t +1 ∼T ( s t ,a t , · ) ,θ ∼ Θ [max a Q θ ( s t +1 , a )] − 2 δ − E θ ∼ Θ [ Q θ ( s t , a min )] ≥ E a t ∼U ( A ) ,s t +1 ∼T ( s t ,a t , · ) ,θ ∼ Θ [ γ max a Q θ ( s t +1 , a ) − Q θ ( s t , a t )] + D ( s t ) − 2 δ where the last line follows from Definition 3.3. Further , because Q θ ( s, a ) is η -uninformed, E θ ∼ Θ [ r ( s t , a min )] > E a t ∼U ( A ) [ r ( s t , a t )] − η . Combining with the pre vious inequality completes the proof. Theorem 3.4 shows that counteractiv e actions, i.e. actions that minimize the state-action value function, in fact increase temporal dif ference. Now we will pro ve that counteracti ve actions achie ve an increase in temporal difference further in the case where action selection and ev aluation in the temporal difference are computed with two dif ferent sets of weights θ and ˆ θ as in double Q -learning. Definition 3.5 ( δ -smoothness for Double- Q ) . Let δ > 0 . A pair of Q -functions parameterized by weights θ ∼ Θ and ˆ θ ∼ Θ are δ -smooth if for any state s ∈ S and action ˆ a = ˆ a ( s, θ ) ∈ A with s ′ ∼ T ( s, ˆ a, · ) , we hav e E θ, ˆ θ ∼ Θ s ′ ∼T ( s, ˆ a, · ) Q ˆ θ ( s, arg max a Q θ ( s, a )) − E θ, ˆ θ ∼ Θ s ′ ∼T ( s, ˆ a, · ) Q ˆ θ ( s ′ , arg max a Q θ ( s ′ , a )) < δ where the expectation is o ver both the random initialization of the Q -function weights θ and ˆ θ , and the random transition to state s ′ ∼ T ( s, ˆ a, · ) . No w we will prove that counteracti ve actions, i.e. actions that minimize the state-action value instead of maximizing, will lead to increase in temporal difference in the case of two Q -functions, i.e. Q θ and Q ˆ θ , that are alternativ ely used to take an action and ev aluate the v alue of the action. 4 Theorem 3.6. Let η , δ > 0 and suppose that Q θ and Q ˆ θ ar e η -uniformed and δ -smooth. Let s t ∈ S be a state, and let a min = arg min a Q θ ( s t , a ) . Let s min t +1 ∼ T ( s t , a min , · ) . Then for an action a t ∼ U ( A ) with s t +1 ∼ T ( s t , a t , · ) we have E s t +1 ∼T ( s,a, · ) ,θ ∼ Θ , ˆ θ ∼ Θ [ r ( s t , a min ) + γ Q ˆ θ ( s min t +1 , arg max a Q θ ( s min t +1 , a )) − Q θ ( s t , a min )] > E a t ∼U ( A ) ,s t +1 ∼T ( s,a, · ) ,θ ∼ Θ , ˆ θ ∼ Θ [ r ( s t , a t ) + γ Q ˆ θ ( s t +1 , arg max a Q θ ( s t +1 , a )) − Q θ ( s t , a t )] + D ( s t ) − 2 δ − η Pr oof. Since Q θ and Q ˆ θ are δ -smooth we have E s min t +1 ∼T ( s t ,a min , · ) ,θ ∼ Θ , ˆ θ ∼ Θ [+ γ Q ˆ θ ( s min t +1 , arg max a Q θ ( s min t +1 , a )) − Q θ ( s t , a min )] > E s min t +1 ∼T ( s t ,a min , · ) ,θ ∼ Θ , ˆ θ ∼ Θ [+ γ Q ˆ θ ( s t , arg max a Q θ ( s t , a )) − Q θ ( s t , a min )] − δ > E s t +1 ∼T ( s t ,a t , · ) ,θ ∼ Θ , ˆ θ ∼ Θ [+ γ Q ˆ θ ( s t +1 , arg max a Q θ ( s t +1 , a )) − Q θ ( s t , a min )] − 2 δ ≥ E s t +1 ∼T ( s t ,a t , · ) ,θ ∼ Θ , ˆ θ ∼ Θ [+ γ Q ˆ θ ( s t +1 , arg max a Q θ ( s t +1 , a )) − Q θ ( s t , a t )] + D ( s t ) − 2 δ where the last line follo ws from Definition 3.3. Further , because Q θ and Q ˆ θ are η -uniformed, E θ ∼ Θ , ˆ θ ∼ Θ [ r ( s t , a min )] > E a t ∼U ( A ) [ r ( s t , a t )] − η . Combining with the previous inequality completes the proof. Core Counterintuition: How could minimizing the state-action value function accelerate learning? At first, the results in Theorem 3.4 and 3.6 might appear counterintuitiv e. Y et, understanding this counterintuitiv e fact relies on first understanding the intrinsic dif ference between the randomly initialized state-action v alue function, i.e. Q θ , and the optimal state-action v alue function, i.e. Q ∗ . In particular, from the perspecti ve of the function Q ∗ , the action a min Q θ ( s ) = arg min a Q θ ( s, a ) is a uniform random action. Ho wev er , from the perspective of the function Q θ , the action a min is meaningful, in that it will lead to a higher TD-error update than an y other action; hence the realization of the intrinsic difference between a min Q θ ( s ) and a min Q ∗ ( s ) with regard to Q θ and Q ∗ provides a v aluable insight on ho w counteractiv e actions do in fact increase temporal dif ference. In fact, Theorem 3.4 and 3.6 precisely provide the formalization that the temporal diff erence achie ved by taking the minimum action is lar ger than that of a random action by an amount equal to the disadv antage gap D ( s ) . Experimental results reported in Section 5 further verify the theoretical analysis. No w we will formalize this intuition for initialization and prove that the distrib ution of the minimum value action in a giv en state is uniform by itself, but is constant once it is conditioned on the weights θ . Proposition 3.7 ( Marginal and Conditional Distrib ution of Counteractive Actions ) . Let θ be the random initial weights for the Q -function. F or any state s ∈ S let a min ( s ) = arg min a ′ ∈A Q θ ( s, a ′ ) . Then for any a ∈ A , P θ ∼ Θ [arg min a ′ ∈A Q θ ( s, a ′ ) = a ] = 1 |A| i.e. the distribution P θ ∼ Θ [ a min ( s )] is uniform. Simultaneously , the conditional distribution P θ ∼ Θ [ a min ( s ) | θ ] is constant. The proof is pro vided in the supplementary material. Proposition 3.7 shows that in states in which the Q -function has not recei ved suf ficient updates, taking the minimum action is almost equiv alent to taking a random action with respect to its contrib ution to the re wards obtained. Howe ver , while the action chosen early on in training is almost uniformly random when only considering the current state, it is at the same time still completely determined by the current value of the weights θ , as is the temporal dif ference. Thus while the mar ginal distribution on actions tak en is uniform, the temporal dif ference when taking counteracti ve actions, i.e. the minimum action, is quite different than from the case where an independently random action is chosen. In particular , in expectation ov er the random initialization θ ∼ Θ , the temporal dif ference is higher when taking the minimum v alue action than that of a random action as demonstrated in Section 3. The main objecti ve of our approach is to increase the information gained from each en vironment interaction, and we sho w that this can be achie ved via actions that minimize the state-action value 5 Algorithm 1 CoAct TD Learning: Counteracti ve T emporal Difference Learning Input: In MDP M with γ ∈ (0 , 1] , s ∈ S , a ∈ A with Q θ ( s, a ) function parametrized by θ , ϵ dithering parameter , B e xperience replay buf fer , N is the training learning steps. Populating Experience Replay Buffer: for s t in e do Sample κ ∼ U (0 , 1) if κ < ϵ then a min = arg min a Q ( s t , a ) s min t +1 ∼ T ( s t , a min , · ) B ← ( r ( s t , a min ) , s t , s min t +1 , a min ) else a max = arg max a Q ( s t , a ) s t +1 ∼ T ( s t , a max , · ) B ← ( r ( s t , a max ) , s t , s t +1 , a max ) end if end for Learning: for n in N do Sample from replay buf fer: ⟨ s t , a t , r ( s t , a t ) , s t +1 ⟩ ∼ B Thus, T D receiv es update with probability ϵ T D = r ( s t , a min ) + γ max a Q ( s min t +1 , a ) − Q ( s t , a min ) T D receiv es update with probability 1 − ϵ : T D = r ( s t , a max ) + γ max a Q ( s t +1 , a ) − Q ( s t , a max ) Gradient step with ∇L ( T D ) end for function. While minimization of the Q -function may initially be reg arded as counterintuiti ve, Section 3 provides the e xact theoretical justification on how taking actions that minimize the state-action value function results in higher temporal difference for the corresponding state transitions, and Section 5 provides experimental results that verify the theoretical analysis. Our method is a fundamental theoretically well-moti vated impro vement on temporal difference learning. Thus, any algorithm in reinforcement learning that is built upon temporal dif ference learning can be simply switched to CoAct TD learning. Algorithm 1 summarizes our proposed algorithm CoAct TD Learning based on minimizing the state-action v alue function as described in detail in Section 3. Note that populating the experience replay buf fer and learning are happening simultaneously with dif ferent rates. TD receiv es an update with probability ϵ solely due to the experience collection. CoAct TD is modular: It is a plug-and-play method with any canonical baseline algorithm. 4 Motivating Example T o truly understand the intuition behind our counterintuitive foundational method, we consider a motiv ating example: the chain MDP . In particular, the chain MDP which consists of a chain of n states s ∈ S = { 1 , 2 , · · · n } each with four actions. Each state i has one action that transitions the agent up the chain by one step to state i + 1 , one action that transitions the agent to state 2 , one action that transitions the agent to state 3 , and one action which resets the agent to state 1 at the beginning of the chain. All transitions hav e rew ard zero, except for the last transition returning the agent to the beginning from the n -th state. Thus, when started from the first state in the chain, the agent must learn a policy that takes n − 2 consecutiv e steps up the chain, and then one final step to reset and get the rew ard. For the chain MDP , we compare standard approaches in temporal dif ference learning in tabular Q -learning with our method CoAct TD Learning based on minimization of the state-action values. In particular we compare our method CoAct TD Learning with both the ϵ -greedy action selection method, and the upper confidence bound (UCB) method. In more detail, in the UCB method the number of training steps t , and the number of times N t ( s, a ) that each action a has been taken in state s by step t are recorded. Furthermore, the action a ∈ A selection is determined as follows: a UCB = arg max a ∈A Q ( s, a ) + 2 s log t N t ( s, a ) . In a given state s if N ( s, a ) = 0 for any action a , then an action is sampled uniformly at random from the set of actions a ′ with N ( s, a ′ ) = 0 . For the e xperiments reported in our paper the length of the chain is set to n = 10 . The Q -function is initialized by independently sampling each state-action value from a normal distribution with µ = 0 and σ = 0 . 1 . In each iteration we train the agent using Q -learning for 100 steps, and then ev aluate the rew ard obtained by the argmax policy using the current Q -function for 100 steps. Note that the maximum achiev able reward in 100 steps is 11. 6 Figure 1: Human normalized scores median and 80 th percentile o ver all g ames in the Arcade Learning En vironment (ALE) 100K benchmark for CoAct TD Learning and the canonical temporal dif ference learning with ϵ -greedy for QRDQN. Left: Median. Right: 80 th Percentile. Figure 2: Learning curv es in the chain MDP with our proposed algorithm CoAct TD Learning, the canonical algorithm ϵ -greedy and the UCB algorithm with variations in ϵ . Figure 2 reports the learning curves for each method with v arying ϵ ∈ [0 . 15 , 0 . 25] with step size 0 . 025 . The results in Figure 2 demonstrate that our method conv erges faster to the optimal policy than either of the standard approaches. 5 Experimental Results The experiments are conducted in the Arcade Learning En vironment (ALE). W e conduct empirical analysis with multiple baseline algorithms including Deep Double-Q Network [Hasselt et al., 2016] initially proposed in [v an Hasselt, 2010] trained with prioritized experience replay [Schaul et al., 2016] without the dueling architecture with its original version [Hasselt et al., 2016], and the QRDQN algorithm that is also described in Section 2. The experiments are conducted both in the 100K Arcade Learning En vironment benchmark, and the canonical version with 200 million frame training [Mnih et al., 2015, W ang et al., 2016]. Note that the 100K Arcade Learning Environment benchmark is an established baseline proposed to measure sample efficienc y in deep reinforcement learning research, and contains 26 different Arcade Learning En vironment games. The policies are e valuated after 100000 en vironment interactions. All of the polices in the experiments are trained ov er 5 random seeds. The hyperparameters, the architecture details, and additional experimental results are reported in the supplementary material. All of the results in the paper are reported with the standard error of the mean. The human normalized scores are computed as, HN = ( Score agent − Score random ) / ( Score human − Score random ) . Figure 1 reports results of human normalized median scores and 80 th percentile ov er all of the games of the Arcade Learning Environment (ALE) in the lo w-data regime for QRDQN, while Figure 5 reports results for double Q-learning. The results reported in Figure 1 once more demonstrate that the performance obtained by the CoAct TD Learning algorithm is approximately double the performance achiev ed by the canonical experience collection techniques. F or completeness we also report sev eral results with 200 million frame training (i.e. 50 million en vironment interactions). Furthermore, we also compare our proposed CoAct TD Learning algorithm with NoisyNetworks as referred to in Sec- tion 2. T able 1 reports results of human normalized median scores, 20 th percentile, and 80 th percentile for the Arcade Learning En vironment 100K benchmark. T able 1 further demonstrates that the CoAct TD Learning algorithm achiev es significantly better performance results compared to NoisyNetworks. Primarily , note that NoisyNetworks includes adding layers in the Q-network to increase exploration. Howe ver , this increases the number of parameters that hav e been added in the training process; thus, introducing substantial additional cost. Figure 4 demonstrates the learning curves for our proposed algorithm CoAct TD Learning and the original v ersion of the DDQN algorithm with ϵ -greedy training. In the large data re gime we observe that while in some MDPs our proposed method CoAct TD Learn- 7 Figure 3: T emporal difference for our proposed algorithm CoAct TD Learning and the canonical ϵ -greedy algorithm in the Arcade Learning En vironment 100K benchmark. Dashed lines report the temporal dif ference for the ϵ -greedy algorithm and solid lines report the temporal dif ference for the CoAct TD Learning algorithm. Colors indicate games. Figure 4: The learning curves for our proposed method CoAct TD Learning algorithm and canonical temporal dif ference learning in the Arcade Learning En vironment with 200 million frame training. Left: JamesBond. MiddleLeft: Gravitar . MiddleRight: Surround. Right: T ennis. ing that focuses on experience collection with no vel temporal dif ference boosting via counteractive actions conv erges faster , in other MDPs CoAct TD Learning simply con ver ges to a better policy . T able 1: Human normalized scores median, 20 th and 80 th percentile across all of the games in the Arcade Learning En vironment 100K benchmark for CoAct TD Learning, ϵ - greedy and NoisyNetworks with DDQN. Method CoAct TD ϵ -greedy NoisyNetworks Median 0.0927 ± 0.0050 0.0377 ± 0.0031 0.0457 ± 0.0035 20 th Percentile 0.0145 ± 0.0003 0.0056 ± 0.0017 0.0102 ± 0.0018 80 th Percentile 0.3762 ± 0.0137 0.2942 ± 0.0233 0.1913 ± 0.0144 T able 1 demonstrates that our pro- posed CoAct TD Learning algo- rithm improves on the performance of the canonical algorithm ϵ -greedy by 248% and NoisyNetworks by 204%. The results reported in both of the sample regimes demonstrate that CoAct TD learning results in faster con ver gence rate and signifi- cantly impro ves sample-efficiency in deep reinforcement learning. The large scale experimental analysis verifies the theoretical predictions of Section 3, and further discovers that the CoAct TD Learning algorithm achieves substantial sample-ef ficiency with zero-additional cost across many algorithms and different sample-comple xity regimes over canonical baseline alternati ves. 6 In vestigating the T emporal Differ ence In Section 3 we provided the theoretical analysis and justification for collecting experiences with counteractiv e actions, i.e. the minimum Q -value action, in which counteractiv e actions increase the temporal dif ference. Increasing temporal dif ference of the experiences results in no vel transitions, and hence accelerates learning [Andre et al., 1997]. The theoretical analysis from Theorem 3.4 and Theorem 3.6 sho ws that taking the minimum value action results in an increase in the temporal difference. In this section, we further inv estigate the temporal difference and provide empirical measurements of the TD. T o measure the change in the temporal dif ference when taking the minimum action v ersus the a verage action, we compare the temporal difference obtained by CoAct TD Learning with that obtained by sev eral other canonical methods. In more detail, during training, for each batch Λ of transitions of the form ( s t , a t , s t +1 ) we record, the temporal difference T D E ( s t ,a t ,s t +1 ) ∼ Λ T D ( s t , a t , s t +1 ) = E ( s t ,a t ,s t +1 ) ∼ Λ [ r ( s t , a t ) + γ max a Q θ ( s t +1 , a ) − Q θ ( s t , a t )] . The results reported in Figure 3 and Figure 6 further confirm the theoretical predictions made via Definition 3.2, Theorem 3.6 and Theorem 3.4. In addition to the results for indi vidual games reported in Figure 3, we compute a normalized measure of the gain in temporal difference achieved when using CoAct TD Learning and plot the median across games. W e define the normalized T D gain to be, Normalized T D Gain = 1 + ( T D method − T D ϵ -greedy ) / ( |T D ϵ -greedy | ) , where T D method and T D ϵ -greedy are the temporal difference for any given learning method and ϵ -greedy respecti vely . The leftmost and middle plot of Figure 6 report the median across all games of the normalized T D gain results for CoAct TD Learning and NoisyNetw orks in the Arcade Learning En vironment 100K benchmark. Note that, consistent with the predictions of Theorem 3.4, the median normalized 8 Figure 5: Human normalized scores median and 80 th percentile o ver all g ames in the Arcade Learning En vironment (ALE) 100K benchmark in DDQN for CoAct TD Learning algorithm and the canonical temporal difference learning with ϵ -greedy . Left:Median. Right: 80 th Percentile. Figure 6: Left and Middle: Normalized temporal difference T D gain median across all games in the Arcade Learning En vironment 100K benchmark for CoAct TD Learning and NoisyNetworks. Right: T emporal dif ference T D when exploring chain MDP with Upper Confidence Bound (UCB) method, ϵ -greedy and our proposed algorithm CoAct TD Learning. temporal difference gain for CoAct TD Learning is up to 25 percent lar ger than that of ϵ -greedy . The results for NoisyNetworks demonstrate that alternate experience collection methods lack this positiv e bias relative to the uniform random action. Further note that to guarantee that e very action has non-zero probability of being chosen in every possible state for guaranteeing con vergence of Q -learning, one can additionally introduce noise, and achie ve higher temporal dif ference by CoAct TD learning. Albeit, across all of the experiments introduction of the noise was not necessary , as there is suf ficient noise in the training process that satisfies the property for con vergence. Hence, across all the benchmarks CoAct-TD Learning results in consistently and substantially better performance. CoAct TD Learning is e xtremely modular , only requir es two lines of additional code and can be used as a dr op-in replacement f or any baseline algorithm that uses the canonical methods. The fact that, as demonstrated in T able 1, CoAct TD Learning significantly outperforms noisy networks in the lo w-data regime is further e vidence of the advantage the positi ve bias in temporal difference confers. The rightmost plot of Figure 6 reports T D for the motiv ating example of the chain MDP . As in the large-scale experiments, prior to con ver gence CoAct TD Learning exhibits a notably larger temporal difference relati ve to the canonical baseline methods, thus CoAct TD Learning achiev es accelerated learning across domains from tabular MDPs to lar ge-scale. 7 Conclusion In our study we focus on the follo wing questions: (i) Is it possible to maximize sample ef ficiency in deep r einforcement learning without additional computational complexity by solely rethinking the cor e principles of learning?, (ii) What is the foundation and theor etical motivation of the learning paradigm we intr oduce that r esults in one of the most computationally efficient ways to explor e in deep r einforcement learning? and, (iii) How would the theoretically well-motivated appr oach transfer to high-dimensional complex MDPs? T o be able to answer these questions we propose a nov el, theoretically moti vated method with zero additional computational cost based on counteracti ve actions that minimize the state-action value function in deep reinforcement learning. W e demonstrate theoretically that our method CoAct TD Learning based on minimization of the state-action v alue results in higher temporal difference, and thus creates nov el transitions with more unique experience collection. F ollowing the theoretical motiv ation we initially demonstrate in a motiv ating example in the chain MDP setup that our proposed method CoAct TD Learning results in achie ving higher sample-efficienc y . Then, we expand this intuition and conduct large scale experiments in the Arcade Learning En vironment, and demonstrate that our proposed method CoAct TD Learning increases the performance on the Arcade Learning En vironment 100K benchmark by 248% . 9 References D. Andre, N. Friedman, and R. P arr . Generalized prioritized sweeping. Confer ence in Advances in Neural Information Pr ocessing Systems, NeurIPS , 1997. M. G. Bellemare, W . Dabney , and R. Munos. A distributional perspecti ve on reinforcement learning. In Pr oceedings of the 34th International Confer ence on Machine Learning , ICML , volume 70 of Pr oceedings of Machine Learning Resear ch , pages 449–458. PMLR, 2017. R. E. Bellman. Dynamic programming. In Princeton, NJ: Princeton University Pr ess , 1957. R. I. Brafman and M. T ennenholtz. R-max-a general polynomial time algorithm for near-optimal reinforcement learning. Journal of Mac hine Learning Resear ch , 2002. W . Dabney , M. Rowland, M. G. Bellemare, and R. Munos. Distributional reinforcement learning with quantile regression. In S. A. McIlraith and K. Q. W einberger , editors, Pr oceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, F ebruary 2-7, 2018 , pages 2892–2901. AAAI Press, 2018. C.-N. Fiechter . Ef ficient reinforcement learning. In Pr oceedings of the Seventh Annual ACM Confer ence on Computational Learning Theory COLT , 1994. S. Flennerhag, Y . Schroecker , T . Zahavy , H. van Hasselt, D. Silver , and S. Singh. Bootstrapped meta-learning. 10th International Confer ence on Learning Repr esentations, ICLR , 2022. D. Guo, D. Y ang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P . W ang, X. Bi, X. Zhang, X. Y u, Y . W u, Z. F . W u, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. W ang, B. W u, B. Feng, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F . Lin, F . Dai, F . Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. W ang, H. Ding, H. Xin, H. Gao, H. Qu, H. Li, J. Guo, J. Li, J. W ang, J. Chen, J. Y uan, J. Qiu, J. Li, J. L. Cai, J. Ni, J. Liang, J. Chen, K. Dong, K. Hu, K. Gao, K. Guan, K. Huang, K. Y u, L. W ang, L. Zhang, L. Zhao, L. W ang, L. Zhang, L. Xu, L. Xia, M. Zhang, M. Zhang, M. T ang, M. Li, M. W ang, M. Li, N. T ian, P . Huang, P . Zhang, Q. W ang, Q. Chen, Q. Du, R. Ge, R. Zhang, R. Pan, R. W ang, R. J. Chen, R. L. Jin, R. Chen, S. Lu, S. Zhou, S. Chen, S. Y e, S. W ang, S. Y u, S. Zhou, S. P an, and S. S. Li. Deepseek-r1 incenti vizes reasoning in llms through reinforcement learning. Natur e , 2025. J. Hamrick, V . Bapst, A. SanchezGonzalez, T . Pfaf f, T . W eber , L. Buesing, and P . Battaglia. Com- bining q-learning and search with amortized value estimates. In 8th International Conference on Learning Repr esentations, ICLR , 2020. H. v . Hasselt, A. Guez, and D. Silver . Deep reinforcement learning with double q-learning. Association for the Advancement of Artificial Intelligence (AAAI) , 2016. M. Hessel, J. Modayil, H. V an Hasselt, T . Schaul, G. Ostrovski, W . Dabney , D. Horgan, B. Piot, M. Azar , and D. Silver . Rainbow: Combining improvements in deep reinforcement learning. In Thirty-second AAAI confer ence on artificial intelligence , 2018. T . Hubert, J. Schrittwieser , I. Antonoglou, M. Barekatain, S. Schmitt, and D. Silv er . Learning and planning in complex action spaces. In Pr oceedings of the 38th International Confer ence on Machine Learning , ICML , volume 139 of Pr oceedings of Machine Learning Resear ch , pages 4476–4486. PMLR, 2021. S. Kakade. On the sample complexity of reinforcement learning. In PhD Thesis: University Colle ge London , 2003. S. Kapturowski, V . Campos, R. Jiang, N. Rakice vic, H. van Hasselt, C. Blundell, and A. P . Ba- dia. Human-le vel atari 200x faster . In The Eleventh International Confer ence on Learning Repr esentations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenRevie w .net, 2023. URL https://openreview.net/pdf?id=JtC6yOHRoJJ . M. K earns and S. Singh. Near-optimal reinforcement learning in polynomial time. Machine Learning , 2002. 10 R. K oenker . Quantile regression. Cambridge Univer sity Pr ess , 2005. R. K oenker and K. F . Hallock. Quantile regression. Journal of Economic P erspectives , 2001. E. K orkmaz. Adversarial robust deep reinforcement learning requires redefining robustness. In Thirty-Seventh AAAI Confer ence on Artificial Intelligence, AAAI , pages 8369–8377. AAAI Press, 2023. E. Korkmaz. Understanding and Diagnosing Deep Reinforcement Learning. In International Confer ence on Machine Learning , ICML 2024 , 2024. E. K orkmaz. Principled analysis of deep reinforcement learning design and e valuation paradigms. In AAAI Confer ence on Artificial Intelligence, AAAI , 2026. A. Krishnamurthy , K. Harris, D. J. Foster , C. Zhang, and A. Slivkins. Can large language models explore in-conte xt? In Advances in Neur al Information Pr ocessing Systems 38: Annual Confer- ence on Neural Information Pr ocessing Systems 2024, NeurIPS 2024, V ancouver , BC, Canada, December 10 - 15, 2024 , 2024. X. Lu and B. V . Roy . Information-theoretic confidence bounds for reinforcement learning. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , pages 2458–2466, 2019. V . Mnih, K. Kavukcuoglu, D. Silv er , A. A. Rusu, J. V eness, a. G. Bellemare, A. Grav es, M. Riedmiller , A. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, Antonoglou, H. King, D. K umaran, D. W ierstra, S. Legg, and D. Hassabis. Human-lev el control through deep reinforcement learning. Natur e , 518:529–533, 2015. V . Mnih, A. P . Badia, M. Mirza, A. Graves, T . P . Lillicrap, T . Harley , D. Silver , and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In Pr oceedings of the 33nd International Confer ence on Machine Learning , ICML 2016 , volume 48, pages 1928–1937, 2016. A. W . Moore and C. G. Atkeson. Prioritized sweeping: Reinforcement learning with less data and less time. Machine Learning , 13:103–130, 1993. J. Oh, M. Hessel, W . M. Czarnecki, Z. Xu, H. van Hasselt, S. Singh, and D. Silver . Discov ering rein- forcement learning algorithms. In Advances in Neural Information Pr ocessing Systems (NeurIPS) , 2020. M. L. Puterman. Markov decision processes: Discrete stochastic dynamic programming. J ohn W iley and Sons, Inc , 1994. T . Schaul, J. Quan, I. Antonogloua, and D. Silver . Prioritized experience replay . International Confer ence on Learning Repr esentations (ICLR) , 2016. J. Schmidhuber . A possibility for implementing curiosity and boredom in model-building neural controllers. 1991. J. Schmidhuber . Artificial curiosity based on disco vering nov el algorithmic predictability through coev olution. In Pr oceedings of the 1999 Congress on Evolutionary Computation, CEC 1999, W ashington, DC, USA J uly 6-9, 1999 , pages 1612–1618. IEEE, 1999. doi: 10.1109/CEC.1999. 785467. URL https://doi.org/10.1109/CEC.1999.785467 . T . Schmied, J. Bornschein, J. Grau-Moya, M. W ulfmeier , and R. Pascan. Llms are greedy agents: Effects of rl fine-tuning on decision-making abilities. 2025. J. Schrittwieser , I. Antonoglou, T . Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T . Graepel, T . P . Lillicrap, and D. Silver . Mastering atari, go, chess and shogi by planning with a learned model. Natur e , 588, 2020. R. Sutton. Learning to predict by the methods of temporal differences. In Machine Learning , 1988. H. van Hasselt. Double q-learning. In Advances in Neural Information Pr ocessing Systems 23: 24th Annual Confer ence on Neural Information Pr ocessing Systems 2010. , pages 2613–2621. Curran Associates, Inc., 2010. 11 Z. W ang, T . Schaul, M. Hessel, H. V an Hasselt, M. Lanctot, and N. De Freitas. Dueling network architectures for deep reinforcement learning. Internation Confer ence on Machine Learning ICML. , page 1995–2003, 2016. C. W atkins. Learning from delayed rewards. In PhD thesis, Cambridge . King’ s College, 1989. S. Whitehead and D. Ballard. Learning to percie ve and act by trial and error . In Machine Learning , 1991. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment