TabKD: Tabular Knowledge Distillation through Interaction Diversity of Learned Feature Bins
Data-free knowledge distillation enables model compression without original training data, critical for privacy-sensitive tabular domains. However, existing methods does not perform well on tabular data because they do not explicitly address feature …
Authors: Shovon Niverd Pereira, Krishna Khadka, Yu Lei
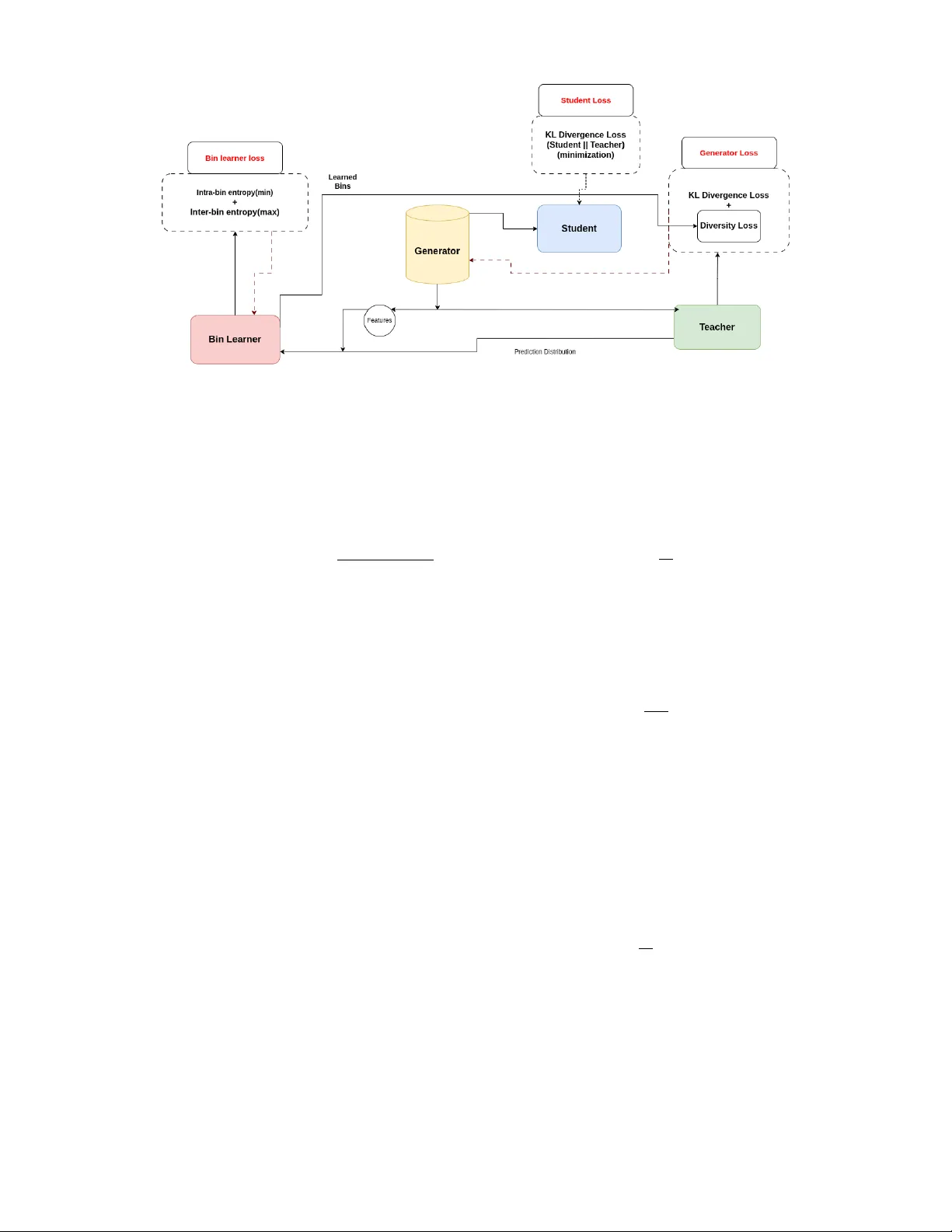
T abKD: T ab ular Knowledge Distillation thr ough Interaction Di versity of Lear ned F eatur e Bins Shovon Niverd Per eira , Krishna Khadka , Y u Lei The Uni versity of T exas at Arlington { snp3941, krishna.khadka } @mavs.uta.edu, ylei@cse.uta.edu, Abstract Data-free knowledge distillation enables model compression without original training data, criti- cal for pri v acy-sensiti v e tabular domains. How- ev er , existing methods does not perform well on tabular data because they do not explicitly address featur e interactions , the fundamental way tabular models encode predictiv e knowledge. W e iden- tify interaction diversity , systematic coverage of feature combinations, as an essential requirement for effecti v e tabular distillation. T o operational- ize this insight, we propose T abKD , which learns adaptiv e feature bins aligned with teacher decision boundaries, then generates synthetic queries that maximize pairwise interaction coverage. Across 4 benchmark datasets and 4 teacher architectures, T abKD achiev es highest student-teacher agreement in 14 out of 16 configurations, outperforming 5 state-of-the-art baselines. W e further show that in- teraction coverage strongly correlates with distilla- tion quality , validating our core hypothesis. Our work establishes interaction-focused exploration as a principled framew ork for tabular model extrac- tion. 1 Introduction In many real-world scenarios, organizations possess high- performing tabular models but cannot share the underly- ing training data. A hospital may deploy a diagnostic model trained on sensiti ve patient records; a bank may op- erate a credit scoring system built from proprietary trans- action histories. These models may be too lar ge for de- ployment on resource-constrained edge devices, requiring smaller compressed versions [Kang et al. , 2025]. T raining such compressed models typically requires the original train- ing data, which may be unavailable due to priv ac y regula- tions or proprietary concerns. Knowledge distillation [Hin- ton et al. , 2015] offers a solution by training a student model to mimic the teacher’ s outputs rather than learning from the original data. Howe v er , con ventional distillation still requires representati ve input samples to query the teacher . This constraint has moti v ated data-free kno wledge distilla- tion (DFKD), where the student learns solely from synthetic queries [Fang et al. , 2019; Chen et al. , 2019; Lopes et al. , 2017; T ruong et al. , 2021]. T abular models are fundamentally different from their vi- sion counterparts. While image classifiers detect local pat- terns through conv olutions, tabular models succeed by learn- ing which feature combinations predict outcomes. A credit risk model does not independently assess income or debt; it learns that the combination of these features signals risk, and neither feature alone suffices to predict the outcome. Unlike image data, where feature interactions are hierarchical and locally correlated, tab ular data relies on sharp, non-linear in- teractions across heterogeneous features with no predefined structure. This fundamental dif ference explains why exist- ing DFKD methods, designed for vision tasks, fail on tabular data for two reasons. First, state-of-the-art tab ular models are often gradient-free ensembles (XGBoost) that break adver - sarial generation schemes requiring backpropagation through the teacher . Second, vision methods rely on spatial inductiv e biases (conv olutions, locality) that hav e no analog in tabu- lar domains where features interact arbitrarily [Kang et al. , 2025]. Current DFKD methods use adversarial frame works where a generator creates “hard” samples that maximize student-teacher disagreement. While early work like StealML [T ram ` er et al. , 2016] laid the groundwork for black- box extraction, recent approaches hav e focused on tabular- specific challenges. DualCF [W ang et al. , 2022] uses coun- terfactual e xplanations for binary classification; Marich [Kar- makar and Basu, 2023] improv es query efficienc y through activ e sampling; T abExtractor [Jin et al. , 2025] handles fea- ture heterogeneity through entropy-guided generation. De- spite these advances, a fundamental bottleneck remains: ex- isting approaches frequently exhibit mode collapse, failing to explore the full decision manifold and resulting in students that miss critical decision rules. W e observe that ef fecti ve tabular extraction requires sys- tematically exploring the interaction space rather than in- dividual features. This insight is inspired by t -way com- binatorial testing [Kuhn et al. , 2013], a software engineer- ing strategy where co vering all t -way parameter interactions with minimal samples suf fices to expose system behaviors. The ke y observation is that significant beha viors of com- plex systems are rarely triggered by all parameters simul- taneously , b ut rather by interactions among a small subset. As in [Khadka et al. , 2024, 2026], the tabular model deci- sions similarly depend on interactions among small feature subsets. Consider a credit risk model that learns the rule ( age > 50 ∧ debt-to-income < 0 . 3) → lo w risk. Covering all pairwise feature interactions ensures the student observ es all such decision patterns. W e formalize this as interaction diversity : the system- atic co verage of feature combinations. T o operationalize this, we propose T abKD , which discretizes each feature into K learned bins aligned with the teacher’ s decision boundaries, reducing the infinite input space to a finite set of pairwise in- teractions that can be systematically cov ered. Our frame work operates in two stages. First, we learn adaptiv e bin bound- aries that partition each feature into semantically meaningful regions where teacher predictions are consistent. Second, we train a generator with an interaction div ersity loss that max- imizes entropy o ver pairwise bin combinations, pushing to- ward uniform cov erage rather than mode-collapsing into lim- ited regions. Random sampling may nev er query specific rare interactions, and entropy-based methods may locate de- cision boundaries but cannot certify which interactions ha v e been tested. T abKD provides both systematic coverage and boundary-aware sampling. Experiments across 4 benchmark datasets and 4 teacher architectures (neural networks, XGBoost, Random Forest, T abTransformer) demonstrate that T abKD achie v es highest student-teacher agreement in 14 of 16 configurations, out- performing 5 state-of-the-art baselines. W e further show that interaction co verage strongly correlates with distillation qual- ity , validating our core hypothesis. Our contributions are: 1. A ppr oach: W e propose T abKD, a data-free kno wledge distillation framework b uilt on the insight that interac- tion diversity , the systematic coverage of feature com- binations, is essential for effecti ve tabular distillation. T abKD operationalizes this through dynamic bin learn- ing aligned with teacher decision boundaries and a diver - sity loss that maximizes pairwise interaction cov erage. 2. Evaluation: W e perform comprehensiv e experiments across 4 datasets and 4 teacher architectures, demon- strating that T abKD achie ves highest agreement in 14 of 16 configurations ov er 5 baselines, and that interaction cov erage strongly correlates with distillation quality . 3. T ool: W e release our implementation as open-source tool. 1 2 Related W ork Model extraction and distillation research spans query-based methods using auxiliary data and data-free approaches using generators. While kno wledge distillation compresses a teach- ers knowledge into a smaller student, model extraction has in- tent of stealing a model through similar techniques. Both pre- dominantly dev eloped for vision domains and poorly suited to the heterogeneous feature interactions of tabular data. Re- lated works in this domain are discussed belo w . 1 Hosted anonymously for double-blind revie w at https:// anonymous.4open.science/r/int di v- 0413/README.md 2.1 Model Extraction Attacks Query-Based Extraction. Model extraction at- tacks [T ram ` er et al. , 2016] infer a victim model’ s behavior through black-box API queries. Early work focused on equation-solving approaches [T ram ` er et al. , 2016], requiring exponential queries for high-dimensional inputs. Acti ve learning strategies [Papernot et al. , 2017; Orekondy et al. , 2019] reduce query budgets by selecting informati v e samples based on uncertainty or gradient approximations. Howe v er , these methods assume access to auxiliary unlabeled data from public domain and do not provide any mechanism to assemble most meaningful sample set. Data-Free Extraction. Recent work on data-free ex- traction employs generativ e models to synthesize training data. DF AD [Fang et al. , 2019] uses adversarial training where a generator maximizes student-teacher disagreement. D AFL [Chen et al. , 2019] adds activ ation matching to pre- serve intermediate representations. These approaches excel in vision domains b ut fail on tab ular data due to hetero- geneous feature spaces and non-dif ferentiable teachers (tree ensembles). T abExtractor [Jin et al. , 2025] addresses non- differentiability through entropy maximization but lacks sys- tematic interaction cov erage, leading to mode collapse in high-dimensional feature spaces. 2.2 Knowledge Distillation Standard Distillation. Kno wledge distillation [Hinton et al. , 2015] transfers kno wledge from teacher to student via soft probability labels, preserving ”dark knowledge” about class relationships. V ariants e xplore attention transfer [Zagoruyko and Komodakis, 2016], intermediate representation match- ing [Romero, 2014], and relational knowledge [Park et al. , 2019]. All assume access to original training data or in- distribution samples. Data-Free Distillation. DFKD methods synthesize train- ing data through generati ve models. Zero-Shot KD [W ang, 2021] uses metadata and soft label smoothing. DeepIn ver- sion [Y in et al. , 2020] in v erts batch normalization statistics for vision models. CMI [F ang et al. , 2021] employs con- trastiv e learning for mode div ersity . These methods rely on vision-specific inductiv e biases (spatial locality , batch norm statistics) absent in tabular domains. 2.3 T abular Data Synthesis Generativ e models for tabular data face unique challenges due to mixed feature types and complex dependencies. Among exisiting works the most prominent few are, CTGAN [Xu et al. , 2019] uses mode-specific normalization and condi- tional generators. TV AE [Ishfaq et al. , 2018] employs v ari- ational autoencoders with tailored loss functions. How- ev er , these methods optimize data realism, not teacher fi- delity—generating plausible samples that may not expose student weaknesses or cov er decision boundaries. Gap in Prior W ork. No existing work addresses the funda- mental challenge of systematic interaction coverage in data- free tab ular model extraction. V ision-domain methods ig- nore heterogeneity and interactions; tabular synthesis meth- ods optimize realism ov er informativ eness; acti ve learning as- sumes auxiliary data. Our work fills this g ap with a principled interaction-focused framew ork. 3 Background 3.1 Data-free Kno wledge Distillation Standard KD assumes access to the original training dataset to gov ern the distillation process. Ho wev er , in many real- world scenarios inv olving pri v acy-sensiti v e information (e.g., medical records or biometric data), accessing the original data is prohibiti v e due to le gal constraints or proprietary con- cerns. This has gi ven rise to Data-Free Knowledge Distilla- tion (DFKD). In the absence of real data, DFKD methods typically em- ploy an adversarial frame work to synthesize training samples. The Generator aims to synthesize inputs that maximize the div er gence between the T eacher’ s and the Student’ s outputs (i.e., ”hard” samples), while the Student tries to minimize this div er gence. This adv ersarial game forces the Student to align its decision boundaries with the T eacher’ s, using the synthetic data as a proxy for the una v ailable real data. The student does not need to kno w the real data, it only needs to know ho w the teacher reacts to particular data point [Lopes et al. , 2017; Chen et al. , 2019; Fang et al. , 2019]. 3.2 T -way Combinatorial T esting T o address the fundamental challenge of ensuring suf ficient cov erage in feature space without infeasible exhaustiv e sam- pling, we draw upon concepts from Combinatorial T est- ing, introduced by [Kuhn et al. , 2013]. This methodology is grounded in the empirical ”interaction fault hypothesis, ” which suggests that significant behaviors in highly comple x systems are rarely triggered by unique interactions of all pa- rameters simultaneously , but rather by interactions among a relativ ely small number ( t ) of input parameters. Based on this hypothesis, t -way testing aims to generate a minimal, ef- ficient set of samples that guarantees coverage for e very pos- sible combination of values across any subset of t parame- ters. Formally represented by combinatorial designs known as Covering Arrays, this framework provides a rigorous math- ematical definition for structural co verage; when applied to generativ e modeling, it offers a principled metric for ensur - ing di v ersity , verifying that a generator explores the full com- binatorial landscape of features rather than mode-collapsing into limited regions. For example, suppose feature A has two bins: Bin 1 = [1–5] and Bin 2 = [6–10], and feature B has two bins: Bin 1 = [OLD] and Bin 2 = [NEW]. This creates four pairwise bin combinations that need to be cov ered: (A-Bin1, B-Bin1), (A-Bin1, B-Bin2), (A-Bin2, B-Bin1), and (A-Bin2, B-Bin2). T o achiev e full 2-way coverage, the generator must produce at least one concrete sample landing in each combi- nation. For instance, [2, OLD] cov ers (A-Bin1, B-Bin1), [3, NEW] covers (A-Bin1, B-Bin2), [6, OLD] cov ers (A-Bin2, B-Bin1), and [7, NEW] cov ers (A-Bin2, B-Bin2). 4 A pproach Effecti v e tabular distillation requires the student to see sam- ples cov ering all meaningful feature interactions, not just ran- dom points in the input space. Our approach operationalizes this insight in three stages: (1) learn bins aligned with teacher decision boundaries, (2) generate samples maximizing pair - wise bin coverage, and (3) train the student on these div erse, challenging samples. Problem Setup. Let T : R F → [0 , 1] C denote a pre- trained teacher mapping F -dimensional inputs to C class probabilities, and S : R F → [0 , 1] C a lightweight student. W e assume no access to original training data. 4.1 A pproach Ov erview T abKD consists of four components working together (Fig- ure 1): • Generator G ( z ) : Maps noise z ∼ N (0 , I ) to synthetic samples. T rained to maximize both interaction cov erage and student–teacher disagreement. • Bin Learner B ( x ) : Learns K adapti ve boundaries per feature, partitioning each into regions where teacher pre- dictions are consistent. Outputs soft membership v ectors m ∈ [0 , 1] K . • T eacher T ( x ) : T eacher is a tar get frozen pre-trained model providing ground-truth soft labels. • Student S ( x ) : Student model is a compact network trained to mimic the teacher . See section 5.3 T raining proceeds in three phases to ensure stable con ver- gence: 1. W armup: Pre-train student on uniform random sam- ples; populate replay buf fer(used later to pre vent catas- trophic forgetting during adv ersarial training). 2. Bin Learning: Train the bin learner to find decision- boundary-aligned discretizations; freeze upon con ver- gence. 3. Adversarial Distillation: Generator and student alter- nate, generator maximizes coverage and hardness; stu- dent minimizes div er gence from teacher . The staged approach pre v ents co-adaptation between gen- erator and bin learner , ensuring coverage reflects genuine fea- ture space e xploration. The following subsections detail each component. 4.2 Dynamic Bin Learning T o achiev e interaction diversity , we first need a meaningful discretization of each feature. Random or uniform bins waste cov erage on homogeneous re gions where the teacher’ s pre- dictions are constant. Instead, we learn bins aligned with the teacher’ s decision boundaries, ensuring each bin captures a semantically distinct prediction region. Intuition. The teacher’ s decision boundary implicitly par- titions each feature into regions of consistent predictions. Consider feature X 1 where the boundary crosses once, sep- arating values [1 – 5] (Class 0) from [6 – 10] (Class 1). These boundary crossings define natural bin boundaries. By learn- ing bins aligned with these transitions, we ensure that cov- ering all bin combinations means covering all behaviorally distinct regions. Figure 1: T abKD Framework. The bin learner partitions each feature into semantically meaningful regions based on teacher predictions. The generator then produces samples maximizing pairwise interaction coverage across these bins, while a hardness objective targets student weaknesses. The student learns from this div erse, challenging synthetic data. Learning Objective. W e train the bin learner to minimize intra-bin prediction variance (ensuring homogeneity within bins) while maximizing inter-bin prediction v ariance (ensur- ing bins capture different beha viors): L bin = λ intra · V ar intra ( M , P T ) + λ inter · 1 V ar inter ( M , P T ) (1) where M denotes soft bin memberships and P T the teacher’ s predictions. Soft membership is required to ensure the as- signment is differentiable, which a an discrete assignment cannot provide Frosst and Hinton [2017]. The variance is calculated as the spread of probability of samples inside each bin weighted with soft membership for each sample. Boundary-Focused Sampling. Learning meaningful bins requires samples near decision boundaries, where predictions transition between classes. During bin learning, we train a a generator to target these re gions: L (1) gen = λ div · L class-div ( S ( X gen )) + λ boundary · L entropy ( T ( X gen )) (2) where L class-div ensures class balance and L entropy targets high- uncertainty regions via entropy maximization. Why Staged T raining? Jointly optimizing bins and cov- erage causes instability: the generator fills bins faster than boundaries stabilize. Our staged approach, freezing bins be- fore adversarial training, pre vents this co-adaptation. With bins frozen, we can now define systematic co v erage. 4.3 Interaction Diversity Loss This is the core contribution of T abKD: a loss function that ensures systematic coverage of feature combinations. W ith frozen bins providing a meaningful discretization, we can now formalize what it means to “cov er” the interaction space. Formalization. For pairwise ( t = 2 ) cov erage, we con- sider all F 2 feature pairs. For each pair ( i, j ) , the joint bin assignment forms a K × K matrix. Ideally , generated sam- ples should uniformly populate all K 2 cells, ensuring every combination of feature i ’ s regions with feature j ’ s re gions is explored. W e compute the empirical joint distribution ov er bin com- binations: P ( k 1 , k 2 | i, j ) = 1 N X x m ( i ) k 1 ( x ) · m ( j ) k 2 ( x ) (3) where N is batch size and m ( i ) k ( x ) is the soft membership of sample x in bin k of feature i . Diversity Loss. Maximum entropy ov er this distribution corresponds to uniform coverage. Our di versity loss maxi- mizes this entropy: L div ersity = − 1 F 2 X i
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment