탭형 지식 증류 상호작용 다양성 기반 특성 구간 학습
TabKD는 데이터 없이 탭형 모델을 압축하기 위해 특성들을 교사 모델의 결정 경계에 맞춰 적응형 구간으로 나눈 뒤, 구간 조합을 균등하게 탐색하는 합성 샘플을 생성한다. 쌍별 상호작용 다양성 손실을 통해 모든 특성 쌍의 구간 조합을 고르게 커버함으로써 학생 모델이 교사의 복잡한 규칙을 빠짐없이 학습하도록 한다. 4개 데이터셋·4개 교사 아키텍처 실험에서 16가지 설정 중 14가지에서 최고 성능을 기록했다.
저자: Shovon Niverd Pereira, Krishna Khadka, Yu Lei
**1. 연구 배경 및 문제 정의**
프라이버시·규제 문제로 원본 데이터에 접근할 수 없는 상황에서 모델 압축을 위해 데이터‑프리 지식 증류(DFKD)가 주목받고 있다. 그러나 기존 DFKD 연구는 대부분 이미지·비전 분야에 초점을 맞추어, 공간적 인덕티브 바이어스와 연속적인 입력 분포를 전제로 설계되었다. 탭형 데이터는 이와 달리 이산·연속형 특성이 혼합된 고차원 공간이며, 예측은 특정 특성들의 비선형 조합에 의해 결정된다. 특히 XGBoost·Random Forest와 같은 트리 기반 교사는 미분이 불가능해 역전파 기반 적대적 샘플 생성이 적용되지 않는다. 이러한 차이점 때문에 기존 DFKD 방법은 탭형 모델에서 모드 붕괴와 결정 경계 미탐색 문제를 겪으며, 학생 모델이 교사의 핵심 규칙을 놓치는 현상이 빈번히 발생한다.
**2. 핵심 아이디어: 상호작용 다양성**
저자들은 탭형 모델의 핵심이 “특성 간 상호작용”이라는 점에 착안한다. 소프트웨어 테스트 분야의 t‑way combinatorial testing 개념을 차용해, 모든 특성 쌍에 대해 가능한 구간 조합을 최소한 한 번씩 탐색하면 대부분의 중요한 행동을 드러낼 수 있다고 가정한다. 이를 “상호작용 다양성(Interaction Diversity)”이라 정의하고, 이를 정량화·최적화하는 프레임워크를 설계한다.
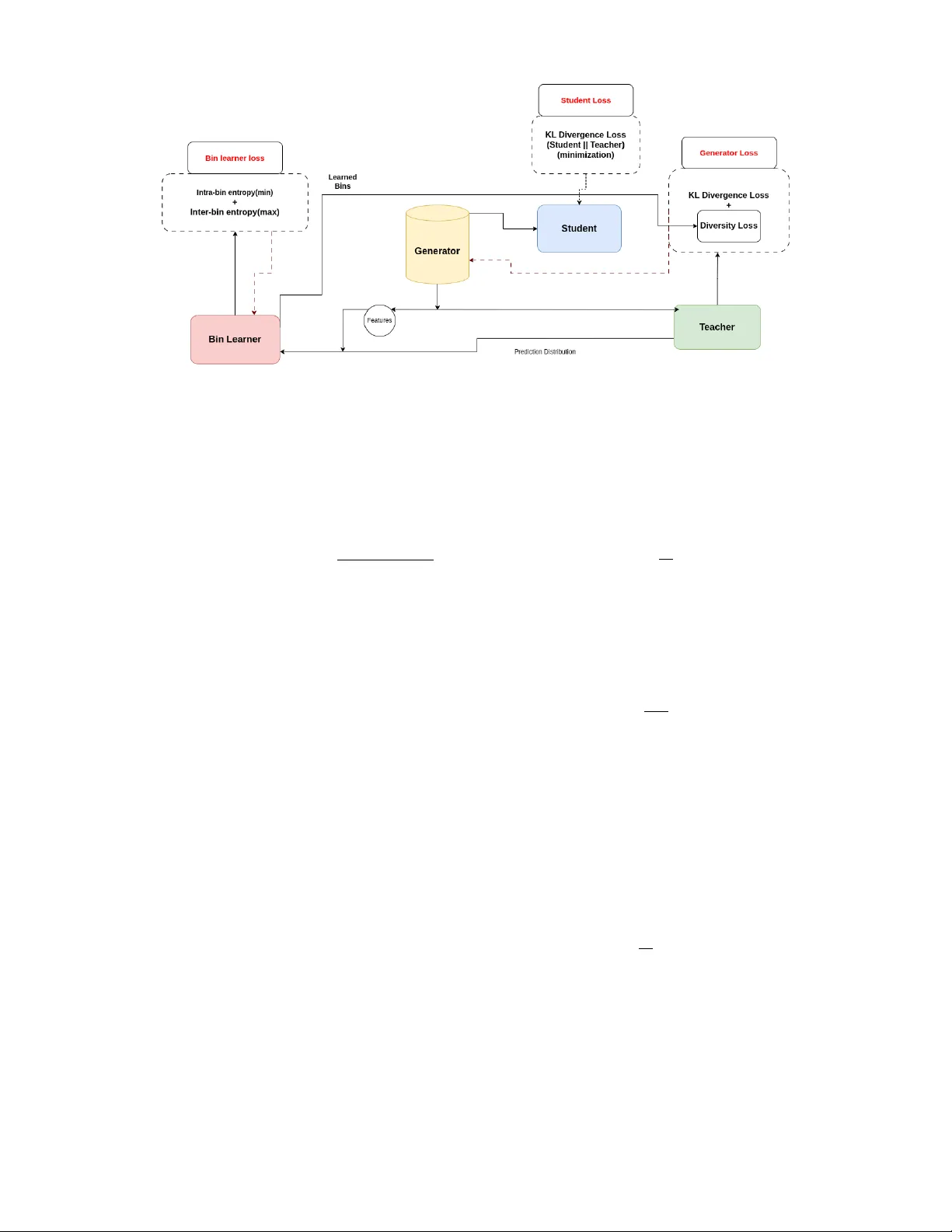
**3. TabKD 프레임워크 구성**
TabKD는 네 가지 모듈로 구성된다.
- **Bin Learner B**: 각 특성을 K개의 적응형 구간으로 분할한다. 구간 경계는 교사의 예측이 크게 변하는 지점에 맞추어 학습되며, intra‑variance(구간 내부 예측 분산 최소)와 inter‑variance(구간 간 예측 분산 최대)를 동시에 최적화한다. 소프트 멤버십 m(i)k(x)를 사용해 미분 가능하게 만든다.
- **Generator G**: 노이즈 z를 입력받아 합성 샘플 x̂=G(z)를 생성한다. 학습 목표는 (1) 구간 조합을 균등하게 커버하는 다양성 손실 L_diversity와 (2) 학생‑교사 불일치를 최대화하는 hardness loss를 동시에 최소화하는 것이다.
- **Teacher T**: 사전 학습된 고성능 교사 모델(MLP, XGBoost, Random Forest, TabTransformer)으로, 합성 샘플에 대한 소프트 라벨을 제공한다.
- **Student S**: 경량 모델로, 교사의 소프트 라벨을 KL‑divergence 최소화 방식으로 학습한다.
**4. 학습 절차**
1) **워밍업**: 무작위 샘플로 학생을 사전 학습시켜 초기 파라미터를 안정화한다.
2) **Bin Learning**: 별도 생성기를 이용해 경계 근처 샘플을 생성하고, 위에서 정의한 L_bin을 최소화해 구간을 학습한다. 구간이 수렴하면 고정한다.
3) **Adversarial Distillation**: 고정된 구간을 기반으로 생성기가 L_diversity와 hardness loss를 동시에 최적화한다. 학생은 교사의 소프트 라벨을 모방하며, 생성기와 학생이 교대로 업데이트된다.
**5. 상호작용 다양성 손실 상세**
각 특성 쌍 (i, j)마다 K×K 형태의 공동 구간 분포 P(k₁,k₂|i,j)를 추정한다.
P(k₁,k₂|i,j)= (1/N) Σ_x m(i)k₁(x)·m(j)k₂(x)
여기서 N은 배치 크기이며, m(i)k(x)·m(j)k₂(x)는 샘플이 해당 구간 조합에 속할 확률이다.
다양성 손실은 모든 쌍에 대해 엔트로피의 평균을 최대화한다:
L_diversity = - (1/ C(F,2)) Σ_{i2) 확장은 계산 비용이 급증한다. 효율적인 고차원 커버리지 설계가 필요하다.
- Bin Learner는 K값을 사전에 지정해야 하는데, 자동화된 K 선택 혹은 비균등 구간 크기 학습이 향후 과제로 남는다.
- 생성기의 샘플 품질이 실제 데이터와 크게 다를 경우, 학생이 과도한 “hard” 샘플에만 노출될 위험이 있다. 이를 완화하기 위한 realism regularization이 검토될 수 있다.
**8. 결론**
TabKD는 교사의 결정 경계에 정렬된 적응형 구간 학습과 구간 기반 쌍별 상호작용 다양성 최적화를 결합함으로써, 데이터‑프리 환경에서도 탭형 모델의 핵심 규칙을 효과적으로 전달한다. 단계적 학습 설계는 생성기와 구간 학습기의 공동 적응으로 인한 불안정을 방지하고, 실험을 통해 제안된 상호작용 다양성 지표가 증류 성능을 예측함을 확인했다. 이 연구는 프라이버시‑민감한 탭형 데이터에서 모델 압축·배포를 위한 새로운 패러다임을 제시하며, 향후 고차원 상호작용 커버리지와 자동 구간 탐색 연구에 기반이 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기